PROFESSIONAL JAVA FOR WEB APPLICATIONS (2014)
Part III Persisting Data with JPA and Hibernate ORM
· CHAPTER 19: Introducing Java Persistence API and Hibernate ORM
· CHAPTER 20: Mapping Entities to Tables with JPA Annotations
· CHAPTER 21: Using JPA in Spring Framework Repositories
· CHAPTER 22: Eliminating Boilerplate Repositories with Spring Data JPA
· CHAPTER 23: Searching for Data with JPA and Hibernate Search
· CHAPTER 24: Creating Advanced Mappings and Custom Data Types
Chapter 19 Introducing Java Persistence API and Hibernate ORM
IN THIS CHAPTER
· Understanding data persistence
· What is an Object-Relational Mapper?
· Understanding Hibernate ORM
· How to prepare a relational database
· How to use the Maven dependencies in this Part
WROX.COM CODE DOWNLOADS FOR THIS CHAPTER
There are no code downloads for this chapter.
NEW MAVEN DEPENDENCIES FOR THIS CHAPTER
There are no new Maven dependencies for this chapter. Continue to use the Maven dependencies introduced in all previous chapters.
WHAT IS DATA PERSISTENCE?
With few exceptions, every application needs persistence in some form or another. But what exactly is persistence? Put simply, persistence is making some form of data last across multiple executions of an application. In that sense, logging is a form of persistence because it persists diagnostic information about program execution so that you can analyze it while or after the application executes. Indeed, you can persist logging information to a flat file, an XML file, a JSON file, a database, or any number of other media, as is the case with all other forms of persistence.
Generally, however, persistence does not refer to logging. Instead, it refers to the saving of entities within the application to some storage media. Entities can be anything — people, users, tickets, forum posts, shopping carts, store orders, products, news articles, and more. The list goes on, and this entire book is not long enough to enumerate them all. In software development, an entity contains data but usually no logic of significance. Entities are passed between units of a program and encapsulate properties that the program uses.
In the Spring Framework applications you built in Part II of this book, your controllers created entities and handed them off to services to apply business rules, and then those services handed the entities off to repositories that stored the entities in memory using maps. Likewise, when your controllers received requests for one or more entities, they passed those requests on to the services that retrieved the stored entities from the repositories. In Java entities are POJOs; in C# entities are POCOs. Other languages have equivalent jargon for these data types.
An in-memory persistence map, however, is not sufficient in the real world. The data does not exist on every node in the cluster, and it disappears when the application shuts down. When considering how to persist data, you have many options and no one option is the “magic bullet.” Every option is right for certain use cases. Nevertheless, there are some storage media that are more common or popular than others, for better or worse.
Flat-File Entity Storage
A natural approach to entity persistence is to use the native file systems that the operating system provides. A likely scenario involves directories for each entity type, with each file in a directory representing a distinct entity named for that entity’s surrogate key(SK). An SK is a unique identifier for an entity that enables you to individually locate it within the storage medium. As a filename, the SK acts as a sort of index so that the entity can be located quickly.
Data stored within a flat file can take many formats. It can be persisted as a Java serialized object (or serialized object of some other language) or represented using key-value pairs, XML, or JSON. The Java serialized form enables extremely efficient storage and retrieval but eliminates portability entirely. Only other Java applications can access the entity.
Either way, in general, flat file storage is extremely slow and difficult to manage compared to its alternatives. Each entity CRUD operation results in the opening of a file handle, immediate writing of data to the filesystem, and then closing of the file handle. The overhead from this is enormous and especially hinders entity location operations that involve more than just the surrogate key, such as searching on the properties of an entity. For this reason, flat-file entity storage is useful only for the smallest and most basic cases, such as application settings.
Structured File Storage
Structured file storage is similar to flat-file storage in many ways. It uses the operating system’s file system to store application data in files, and CRUD operations often result in the repeated opening and closing of file handles. However, instead of relying on directories and individual files to store entities, structured file storage systems often create large files that store many entities in one file using a predetermined structure that the program can understand. Instead of one directory per entity type, you often have one file per entity type. This has the advantage that search operations are much more efficient; they can be performed against a single file instead of many hundreds or thousands of files. However, individual lookups by surrogate key can suffer from such an arrangement. Often it is necessary to create a smaller index file of some type that makes it easier to identify the location of records within the larger data file.
If this sounds a lot like a relational database to you, you are correct. Many relational databases work in a very similar manner. Btrieve, one of the earliest databases of the sort, stored entities in files like this using the Indexed Sequential Access Method (ISAM) format. There are many differences between relational databases and structured file storage systems, however, namely that structured file storage tends to be proprietary and happen directly within the application code, whereas relational databases are based on a somewhat-portable standard and usually run within another application. More important, structured file storage is usually ignorant of the relationships between entities. The capability to relate different entities is a hallmark of relational databases. In this sense, Btrieve was a structured file storage system and not a relational database; however, it did have a concept of transactions common in today’s relational databases.
Relational Database Systems
If you’re reading this book, you probably already know about relational database management systems (RDBMSs). In fact, you’re going to have to know about them to read this and the next five chapters. Relational databases store entities as records in tables, and each table stores exactly one type of entity (though a complex entity may include data from multiple tables). These tables consist of a strict schema that defines the names, types, and sizes of the various fields or columns. You cannot store records in a table with columns that don’t already exist, and you can also not store records in a table with null values for columns that are NOT NULL. Typically, a table contains a single primary key column (or, sometimes, several columns forming a composite primary key) that acts as the entity’s surrogate key. You interact with relational databases using the ANSI standard Structured Query Language (SQL), a language designed to manipulate table schema and data content in a universal way.
Unfortunately, there are no relational databases that abide by the ANSI standard fully, and most also define their own proprietary extensions that aren’t supported by other databases. For example, Oracle calls its SQL implementation PL/SQL, whereas Microsoft SQL Server uses Transact-SQL or T-SQL. This makes it difficult to create all but the most basic SQL statements that work across all databases, and nearly impossible to form CREATE TABLE or ALTER TABLE statements that work on more than one database.
NOTE It is a matter of great contention whether SQL is pronounced “sequel” or “es-kyu-el.” This author prefers the pronunciation “sequel” for two important reasons. First, it’s historically correct. When it was first developed in the 1970s, SQL was originally called Structured English Query Language (SEQUEL for short). However, SEQUEL was already trademarked, so it was shortened to SQL. Second, “sequel” is simply easier to say. Because you’re reading this book and not listening to it, you can pronounce it however you like.
In Java, you interact with relational databases using Java Database Connectivity (JDBC). You obtain a java.sql.Connection to a relational database, either using the java.sql.DriverManager or from some kind of java.sql.DataSource like a connection pool, and then you execute statements against that Connection. For simple statements that contain no parameters, you use the java.sql.Statement, and for complex statements that contain one or more parameters, you use java.sql.PreparedStatement. There is even ajava.sql.CallableStatement for executing stored procedures and functions. These interfaces provide the capability to execute SQL statements against a database to query or manipulate data. Saving entities to and retrieving entities from a database involves mapping column names to POJO properties. This is the challenge that you tackle in this part of the book.
Object-Oriented Databases
Object-oriented database management systems (OODBMSs), often just called object databases, are an attempt to solve the natural disconnect between object-oriented entities and relational databases. They use the same model of representing data that object-oriented programming languages do.
One principal of object databases is to store this data in such a manner that SQL can still be used to manipulate and retrieve objects. Unfortunately, this causes a number of problems due to object inheritance. Another approach involves storing JSON or XML within text columns in a database and using proprietary SQL extensions to query within that data, but the capability of indexing this data for efficient retrieval is minimal. The key problem with object databases is the attempt to maintain a strict schema. It is primarily for this reason that object databases have never really caught on, despite their having been around since the 1980s.
Schema-less Database Systems
A schema-less database is, naturally, a database that lacks a strict schema. The term NoSQL, coined in 1998, is typically used to describe such databases. NoSQL databases are a relatively new phenomenon, having become popular only in the last 5 to 10 years. NoSQL databases solve a lot of problems not easily solved in relational databases, such as flexible fields and object inheritance. There are a number of different types of NoSQL databases, the most common of which are document-oriented databases.
Even though it lacks a strict structure, a document database encodes data in a consistent and well-known format, such as XML or JSON (or BSON, the compact, binary version of JSON). A document is roughly synonymous with a record in a relational database, and a collection is roughly synonymous with a table. Documents in a collection, though they must not adhere to a particular schema, are generally similar to each other. When two documents in a collection contain a property with the same name, best practices dictate that those properties are the same type and have the same semantic meaning.
Most document databases tend to have extremely fast insertion times, sometimes orders of magnitude better than relational databases. They are sometimes not quite as fast for indexed lookups as relational databases, but they can store data on much larger scales than can relational databases. Some document databases can store many hundreds of gigabytes or even terabytes of data without sacrificing insertion performance. This makes document databases ideal for storing logging- and auditing-related data. Some of the more popular document databases include MongoDB, Apache CouchDB, and Couchbase Server.
Another popular type of NoSQL database is a key-value store. It is much like it sounds, storing key-value pairs in a very flat manner. This can be likened to a Java Map<String, String>, though some key-value stores are multivalue and can store data more like aMap<String, List<String>>. Some popular key-value stores include Apache Cassandra, Freebase, Amazon DynamoDB, memcache, Redis, Apache River, Couchbase, and MongoDB. (Yes, some document databases double as key-value stores.)
Graph databases are NoSQL databases that focus on object relationships. In a graph database objects have attributes (properties), objects have relationships to other objects, and those relationships have attributes. Data is stored and represented as a graph, with relationships between entities existing naturally, not in the contrived manner created with foreign keys. This makes it easy, for example, to solve the degrees of separation problem, finding relationships between entities that might not have been realized at insertion time. Perhaps the most popular graph database is Neo4j. Though Neo4j is written in Java and despite its name, it can work on any platform. It is, however, very well suited for Java applications.
NoSQL databases do not operate on any type of standard like ANSI SQL. As such, there is no common way (like JDBC) to access any two NoSQL databases. This, of course, is a natural downside to using NoSQL databases, but there is an upside as well. Each NoSQL database comes with its own client library, and most of these client libraries can take Java objects and store them directly in the database in whatever format the database requires. This eliminates the task of mapping POJOs to “tables” and properties to “columns,” and thus makes NoSQL an attractive alternative to relational databases for entity storage. Because the approach to every NoSQL database is different, and because NoSQL client libraries obviate the need for object-relational mappers, this book does not cover them further.
WHAT IS AN OBJECT-RELATIONAL MAPPER?
To date, relational databases are the most common databases in use. You can find them backing nearly all major enterprise software, storing everything from entities to application settings to auditing records. However, storing object-oriented entities in a relational database is often not a simple feat and requires a great deal of repetitive code and conversion between data types. Object-relational mappers, or O/RMs, were created to solve this problem. An O/RM persists entities in and retrieves entities from relational databases without the programmer having to write SQL statements and translate entity properties to statement parameters and result set columns to entity properties.
This chapter and the next five cover object-relational mappers and how to use them to persist entities in your application. Before you can truly recognize how an O/RM can help, you need to understand the problem.
Understanding the Problem of Persisting Entities
To understand the scale of the code necessary to persist and retrieve persisted entities, consider the following repository method, which retrieves a product record from the database and copies its data to a hypothetical Product object.
public Product getProduct(long id) throws SQLException
{
try(Connection connection = this.getConnection();
PreparedStatement s = connection.prepareStatement(
"SELECT * FROM dbo.Product WHERE productId = ?"
))
{
s.setLong(1, id);
try(ResultSet r = s.executeQuery())
{
if(!r.next())
return null;
Product product = new Product(id);
product.setName(r.getNString("Name"));
product.setDescription(r.getNString("Description"));
product.setDatePosted(r.getObject("DatePosted", Instant.class));
product.setPurchases(r.getLong("Purchases"));
product.setPrice(r.getDouble("Price"));
product.setBulkPrice(r.getDouble("BulkPrice"));
product.setMinimumUnits(r.getInt("MinimumUnits"));
product.setSku(r.getNString("Sku"));
product.setEditorsReview(r.getNString("EditorsReview"));
return product;
}
}
}
As you well know, there are some things missing from this picture. For one, this method has no error handling, which in reality is needed. Also, store products generally have many more properties than this — the code here is very conservative. This method could easily be many times the length that it is. Then there’s creating a new Product:
public void addProduct(Product product) throws SQLException
{
try(Connection connection = this.getConnection();
PreparedStatement s = connection.prepareStatement(
"INSERT INTO dbo.PRODUCT (Name, Description, DatePosted," +
"Purchases, Price, BulkPrice, MinimumUnits, Sku," +
"EditorsReview) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)",
new String[] { "ProductId" }
))
{
s.setNString(1, product.getName());
s.setNString(2, product.getDescription());
s.setObject(3, product.getDatePosted(), JDBCType.TIMESTAMP);
s.setLong(4, product.getPurchases());
s.setDouble(5, product.getPrice());
s.setDouble(6, product.getBulkPrice());
s.setInt(7, product.getMinimumUnits());
s.setNString(8, product.getSku());
s.setNString(9, product.getEditorsReview());
if(s.executeUpdate() != 1)
throw new SaveException("Failed to insert record.");
try(ResultSet r = s.getGeneratedKeys())
{
if(!r.next())
throw new SaveException("Failed to retrieve product ID.");
product.setProductId(r.getLong("ProductId"));
}
}
}
And, of course, you must also provide methods for updating and deleting products. (Though, arguably, the delete method is vastly easier to implement.)
These methods may not seem awful on their own, but consider a more complex product entity, and then start thinking about product reviews, shopping carts, orders, shipping, searching, users, store administration, discounts and coupons, merchants (if you allow your users to sell their own products), payments, refunds, and more. An online store could easily have many dozens or even hundreds of different entities, each with code very similar to this, each requiring a lot of SQL and use of Statements and ResultSets.
No doubt, before you were done with it you would likely begin to write your own set of utilities to make this task easier. Likely this utility would involve some form of reflection so that it could handle any entity type. So if this tool were already written for you, and already tested extensively by a community of users, wouldn’t that be easier?
O/RMs Make Entity Persistence Easier
A good O/RM can greatly simplify this long, tedious code that’s vulnerable to typos and hard to unit test effectively. O/RMs use reflection to analyze entities and line up their properties to the columns of the relational database tables they are stored in. Using an O/RM, the previous code becomes something more like this:
public Product getProduct(long id)
{
return this.getCurrentTransaction().get(Product.class, id);
}
public void addProduct(Product product)
{
this.getCurrentTransaction().persist(product);
}
Even better, adding methods to update and delete products is just as easy, and far easier than using straight JDBC:
public void updateProduct(Product product)
{
this.getCurrentTransaction().update(product);
}
public void deleteProduct(Product product)
{
this.getCurrentTransaction().delete(product);
}
As you can see, this code is much more palatable. In fact, if you’re clever you could even make it generic to an extent so that you could write this code in an abstract class and use it for any class. Of course, that’s not all there is to it. An O/RM can’t just “know” what tables and columns to map an entity or entities to, nor can it always know how the data types should line up. (Although, often it can figure out a great deal of this information on its own.) When using an O/RM, you must create formal mapping instructions telling the O/RM how to map your entities. This can take many different forms depending on which O/RM you use, which is kind of a problem. After you create dozens or hundreds of entity mappings using the proprietary format of a particular O/RM, it becomes extremely difficult to switch to another O/RM at any given point in the future. There could be all kinds of reasons to switch to another O/RM: Perhaps you need a feature that a different O/RM offers, or you discovered that the O/RM you use doesn’t perform well and you want one that performs better. Either way, significant work would be required to switch to a different O/RM.
There are some other consequences of using O/RMs that some consider problematic. For one, the high level of abstraction that comes with using an O/RM can make it hard to understand what happens behind the scenes. What happens when you call the persistmethod to persist an entity to the database? You know that the entity gets inserted into the table, but is that enough? Should you know more?
Many argue yes, and to an extent they are right. It’s important to understand how an O/RM works to some degree because, if it’s generating poor SQL statements, it could result in bad application performance. But there’s certainly no reason to understand the exact inner workings of an O/RM. You can always perform load testing against an O/RM to ensure its performance is adequate, and you can set up statement logging on your database server to analyze the statements it generates for acceptable quality.
In addition, O/RMs are often cited as a reason for poor database design decisions, and perhaps that’s correct. But does it matter? Well, that depends. First, if you use your database for some means other than merely as persistence storage (for example, as a data warehouse), of course design matters. However, if your database’s only purpose is storing the data for your application, it is a means to an end, nothing more. As long as it works and works well, it’s not necessarily bad that the database tables aren’t pretty. Of course, both of these statements ignore a simple fact: You create the database. It’s true that many O/RMs can generate table schema automatically based on your mapping instructions, but this should never be used in a production environment. You should always create the tables and columns yourself. If your database is poorly designed, it is your doing, not the fault of the O/RM.
In the end, only you can make the decision about whether an O/RM is applicable to your use cases, but in most cases the benefits far outweigh the drawbacks.
JPA Provides a Standard O/RM API
One of the earliest O/RMs was TopLink, developed for Smalltalk in the early 1990s. Its developers, The Object People (hence the “Top” in TopLink), released TopLink for Java in 1998, and in 2002 Oracle Corporation purchased TopLink for Oracle Fusion Middleware. Over the course of many years and code donations to Sun Microsystems and eventually Eclipse Foundation, TopLink became EclipseLink. (However, TopLink still exists today as an Oracle product.) In addition to mapping objects to relational databases, TopLink and EclipseLink can also map objects to XML documents.
Another O/RM, iBATIS, started in 2002 and continued as an Apache Software Foundation project until 2010, when it was retired and replaced with MyBatis at Google Code. iBATIS was written for Java, .NET, and Ruby, and MyBatis for Java and .NET. Hibernate ORM, perhaps one of the most popular Java O/RMs, started in 2001 and has evolved significantly. Its Hibernate Query Language (HQL) closely resembles SQL but is used for querying entities instead of tables. NHibernate is a .NET port of Hibernate ORM, bringing similar features to the .NET platform.
The problem with having so many different O/RMs is flexibility. An application written to use Hibernate, for example, cannot easily be changed to use EclipseLink or MyBatis without significant refactoring of the domain layer. The Java Persistence API was created to solve this problem and provide a standard API for Java object persistence in relational databases using O/RM technology. Programming solely against the Java Persistence API allows you to switch out O/RM implementations with minimal effort when the need arises.
JPA 1.0 was standardized in 2006 under JSR 220 as part of the Java EE 5 umbrella. It unified the Java Data Objects (JDO) API and the EJB 2.0 Container Managed Persistence (CMP) API and included many features inspired by or based on TopLink and Hibernate ORM. It also defined the Java Persistence Query Language (JPQL), a query language nearly identical to HQL. It had some drawbacks, however:
· It lacked a standard way to lookup objects based on complex criteria without using JPQL. Because many developers preferred a pure Java approach without a query language, they often used provider-specific features such as Hibernate’s Criteria.
· One of the core principles of JPA is the ability to transform the limited set of SQL data types to Java data types such as the primitives and their wrappers, Strings, Enums, Dates, Calendars, and more. JPA specified a limited set of data type transformations that all implementations must support but unfortunately provided no way to define custom converters to handle other data types. Some implementations support additional data types (for example, Hibernate ORM supports all the Joda Time types), but relying on that ties you to a particular implementation. Implementations also often provided a way to specify your own custom data types, but that still ties you to a particular implementation.
· JPA 1.0 lacked support for collections of entities within other entities, multiple levels of nested entities, and ordered lists.
JSR 317 standardized JPA 2.0 in 2009 as part of Java EE 6 and added better support for collections of entities, nested entities, and ordered lists. It also added support for automatically generating database schema based on the defined entities and integrating with the Bean Validation API. Perhaps most important, it added a standard criteria API that enables pure Java entity lookup without the use of JPQL. Unfortunately, it still lacked support for custom data type conversion, causing many developers to continue relying on proprietary implementation features such as Hibernate’s UserType. JPA 2.1 finally satisfied this need for custom data types. Part of Java EE 7, JPA 2.1 was standardized with JSR 338 in 2013. In addition to custom data types, it included enhancements to JPQL, support for stored procedures, and improvements to the JPA 2.0 criteria API to support bulk update and delete operations.
Sun’s GlassFish application server contained the reference implementation of JPA 1.0, based on the code donated from Oracle’s TopLink. After JPA 1.0 Sun donated the code to Eclipse, and TopLink became EclipseLink. Despite Hibernate’s overwhelming popularity, EclipseLink was chosen as the reference implementation for JPA 2.0 and 2.1. BatooJPA, DataNucleus, EclipseLink, Hibernate ORM, ObjectDB, Apache OpenJPA, IBM WebSphere, and Versant JPA are just some of the JPA 2.0 providers. As of this writing, only EclipseLink, DataNucleus, and Hibernate have released JPA 2.1 implementations.
NOTE JPA implementations use JDBC for executing SQL statements, but you will never have to deal with this detail. You will always use the Java Persistence API, never the JDBC API directly.
Why Hibernate ORM?
In this book you use Hibernate ORM as the JPA implementation for your sample projects. This may seem curious, as Hibernate is neither the original Java O/RM nor the JPA reference implementation — both of those titles belong to EclipseLink. However, Hibernate is a very mature and stable project with a large support community and thousands of how-to articles online. You can easily get help with Hibernate when you need to, but the global knowledge base for EclipseLink is simply not as extensive. (Hibernate is also what this author knows best.)
Hibernate ORM also supports lazy loading of collections without having to manipulate the bytecode of your entities. EclipseLink, on the other hand, must weave bytecode decorations into your entities to achieve this, and that can be tricky to configure. The good news is that you do not have to use Hibernate just because this book does. You will be working with the Java Persistence API, so you can easily switch to a different JPA implementation whenever you like.
A BRIEF LOOK AT HIBERNATE ORM
The next several chapters focus on using the Java Persistence API for persisting entities in your applications. You will not use the implementation provider (Hibernate ORM) API directly. In fact, the provider libraries you use in this book have a runtime scope in the Maven file, preventing you from using them directly. However, there are times when using the provider API is necessary, as discussed in the previous section. Though continued improvements to the JPA standard make this less and less likely, you need to understand the libraries you use. As such, this section introduces you to Hibernate ORM and how it works outside of the scope of JPA.
Using Hibernate Mapping Files
Recall from the previous section that, before you can persist an entity using an O/RM, you must first define a mapping of that entity’s fields to the corresponding relational database columns. When you use JPA for this, you always use annotations to map an entity. Between Hibernate ORM 3.0 and 3.5 you could use proprietary Hibernate annotations modeled after the JPA annotations to map an entity through the separate Hibernate Annotations project. Since Hibernate ORM 3.5, the proprietary annotations have been bundled with the Hibernate core library, and Hibernate has also supported the JPA annotations. Prior to Hibernate 3.0, however, you were required to use XML mapping files using the Hibernate Mapping XML schema. These files have the extension .hbm.xml and contain instructions that tell Hibernate how to save entities to and retrieve entities from a relational database. You can still use XML mappings today if you prefer, but only if you use Hibernate ORM directly, without JPA.
Hibernate XML mapping files always contain the <hibernate-mapping> root element. Within that, one or more <class> elements indicate mappings given class names and the tables they map to. Though it is possible to include multiple mappings within a single mapping file by using multiple <class> elements, the best practice is to use one file per entity, with the file named after the class. For example, the mapping file for the Product class would be Product.hbm.xml. It is also best practice to include the mapping files alongside your entity classes in the package structure (in the resources directory), so the mapping file for com.wrox.entities.Product would be com/wrox/entities/Product.hbm.xml.
Within a <class> element, the <id> element specifies a single-column, single-field surrogate key, whereas the mutually exclusive <composite-id> element specifies a multi-column, multi-field surrogate key. One or more <property> elements map class fields to database columns. For most use cases the mapping can be completely represented using attributes of <property>, but for more complex use cases, you may need to use the nested <column> element.
NOTE You may have noticed this section referring to mapping entity “fields” to database columns. In this case the word “field” refers to a JavaBean property (an instance field with an accessor and a mutator). In both JPA and Hibernate ORM, all mapped fields must be JavaBean properties by default. (However, you can specify different behavior.) The field name is determined by removing the “get” or “is” prefix from the getter and converting the first character to lowercase. (The field name is not determined by examining the backing instance field.) Contrary to what it may sound like when called “field,” JPA and Hibernate entity fields do not need backing instance fields. A matching getter and setter are sufficient to qualify as an entity field.
If you continue with the product example, creating a mapping for the Product class is pretty simple:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name="com.wrox.entities.Product" table="Product" schema="dbo">
<id name="productId" column="ProductId" type="long" unsaved-value="0">
<generator class="identity" />
</id>
<property name="name" column="Name" type="string" length="60" />
<property name="description" column="Description" type="string"
length="255" />
<property name="datePosted" column="DatePosted"
type="java.time.Instant" />
<property name="purchases" column="Purchases" type="long" />
<property name="price" column="Price" type="double" />
<property name="bulkPrice" column="BulkPrice" type="double" />
<property name="minimumUnits" column="MinimumUnits" type="int" />
<property name="sku" column="Sku" type="string" length="12" />
<property name="editorsReview" column="EditorsReview" type="string"
length="2000" />
</class>
</hibernate-mapping>
Most of this should be fairly self-explanatory. The productId field is mapped to the ProductId column and uses identity generation (IDENTITY columns in Microsoft SQL Server, AUTO_INCREMENT columns in MySQL, and so on). The other properties are all simple fields mapped to simple columns. You could also create <map>, <list>, and <set> properties, and use elements like <one-to-many> and <many-to-one> to associate entities with each other. There are dozens of pages’ worth of mapping examples and instructions in the Hibernate ORM 4.3 user manual. Because you use only JPA mappings in this book, no further examples are covered here.
Understanding the Session API
The primary unit for performing work within Hibernate ORM is the org.hibernate.Session interface. A Hibernate Session is nothing like an HttpSession or a WebSocket Session. Hibernate Sessions represent the life of a transaction from start to finish. Depending on how your application is architected, that might be less than a second or several minutes; and in a web application, it could be one of several transactions in a request, a transaction lasting an entire request, or a transaction spanning multiple requests. A Session, which is not thread-safe and must be used only in one thread at a time, is responsible for managing the state of entities.
When an entity is retrieved from the database, it is attached to the Session and remains part of the Session until the Session (and its transaction) ends. This way, certain properties of an entity can be loaded in a lazy manner, as long as they are accessed during the life of the Session. Likewise, when an entity is added or updated, those changes are also attached to the Session, and when an entity is deleted from the database, it is removed from the Session. As you’ll learn later, this is very similar to how JPA’s EntityManager works.
Finding an entity by its surrogate key is simple using the get method on a Session instance:
return (Product)session.get(Product.class, id);
If the specified product does not exist, get simply returns null. To add a new entity, pass it to the save method.
session.save(product);
This method returns the generated ID of the entity being added; though you don’t usually need to use the returned value. After calling this method, the ID property of the entity you passed in to the method will have been updated with the generated ID. An alternative to save is persist, which also adds a new entity. The key difference is that persist is safer: It will never result in an INSERT if the transaction has already closed, whereas save will result in an extra-transaction insert. As such, persist is usually the preferred method. However, the INSERT triggered by persist isn’t guaranteed to execute until flush time, so persist does not return the generated ID, and the entity’s ID property may or may not have been set when persist completes. If you need the ID right away, you shouldflush the Session after saving the entity:
session.persist(product);
session.flush();
Flushing a Session simply causes any pending statements to execute immediately; it does not end the transaction. As such, you may call flush as many times as you need during the life of a Session. Closing a Session or committing its transaction automatically flushes the Session. The reasoning behind flushing Sessions lies in how Hibernate queues statements. In a transaction involving more than one action, the actions might not actually execute in the order you specify. At flush time, all actions since the last flush are executed in the following order:
· All entity insertions in the order you added them
· All entity updates in the order you updated them
· All collection deletions in the order you deleted them
· All collection element insertions, updates, and deletions in the order you executed them
· All collection insertions in the order you added them
· All entity deletions in the order you deleted them
As such, if you need to guarantee that an action or actions execute before some other action or actions, you must call flush between them. The only exception is save, which always executes an INSERT immediately regardless of flushing. (But remember, persist is subject to flushing.)
WARNING Flushing affects only the writing of Session changes to the database. The changes you make to a Session are reflected immediately in memory. Be careful with this behavior because it can be the source of many mix-ups.
Updating an entity is a little tricky to understand. You could use the update method, as in the following snippet:
session.update(product);
However, this works only if the entity has not already been attached to the Session (if you did not use get, save, or persist for this entity during the transaction). If the entity has already been attached, update throws an exception. Because of this it’s almost always best to use the merge method, which works whether the entity has or hasn’t already been attached to the Session:
session.merge(product);
Deleting an entity is quite straightforward:
session.delete(product);
Entity eviction is an interesting concept in Hibernate. Calling the evict method causes the entity to be detached from the Session, but it does not result in any changes to the database like deleting the entity.
session.evict(product);
If you want to evict all the entities attached to a session, you can call the clear method. Note that evict cancels any pending changes for the evicted entity that have not already been flushed. Likewise, clear cancels all pending changes on all entities in the Session(including insertions and deletions) that have not already been flushed.
Getting a single entity using its surrogate key is certainly not the only type of query you will ever need to perform. You will want to look up single entities and collections of entities using multiple criteria. You can use either the org.hibernate.Criteria API or theorg.hibernate.Query API to perform both of these tasks. The following two return statements result in the exact same single entity:
return (Product)session.createCriteria(Product.class)
.add(Restrictions.eq("sku", sku))
.uniqueResult();
return (Product)session.createQuery("FROM Product p WHERE p.sku = :sku")
.setString("sku", sku)
.uniqueResult();
Note that Product in the HQL query refers to the entity name, not the table name, and in both places sku refers to the sku property of the entity, not the Sku field in the database table. Likewise, both of the following return statements result in a List of Products posted less than a year ago whose names start with “java”:
return (List<Product>)session.createCriteria(Product.class)
.add(Restrictions.gt("datePosted",
Instant.now().minus(365L, ChronoUnit.DAYS)))
.add(Restrictions.ilike("name", "java", MatchMode.START))
.addOrder()
.list();
return (List<Product>)session.createQuery("FROM Product p WHERE
datePosted > :oneYearAgo AND name ILIKE :nameLike ORDER BY name")
.setParameter("oneYearAgo",
Instant.now().minus(365L, ChronoUnit.DAYS))
.setString("nameLike", "java%")
.list();
There are many other things that you can do with the Session API, but these basic tasks should meet many of your needs.
Getting a Session from the SessionFactory
Sessions don’t just appear out of nowhere. A Session is associated with a JDBC database connection, and something must create the connection or retrieve it from a DataSource, instantiate the Session implementation, and attach the Session to the connection, all before it can be used. It’s also necessary to “look up” an existing Session if one is already in progress for the current context instead of creating a new Session every time you need to perform an action. The org.hibernate.SessionFactory interface exists for just this purpose. It contains several methods for building Sessions, opening Sessions, and retrieving the “current” Session. For example, to open a new Session, you can call the openSession method:
Session session = sessionFactory.openSession();
This opens a Session with all the default settings (DataSource, interceptors, and so on) configured for the SessionFactory. Sometimes, however, it’s necessary to override those settings. You might need to use a connection to a different database for some special purpose:
Session session = sessionFactory.withOptions()
.connection(connection).openSession();
Or perhaps you need to intercept all SQL statements to modify them in some way. For example, your mappings may specify something like schema="@SCHEMA@", and at run time you replace that with a value from a setting, parameter, or other variable:
Session session = sessionFactory.withOptions()
.interceptor(new EmptyInterceptor() {
@Override
public String onPrepareStatement(String sql)
{
return sql.replace("@SCHEMA@", schema);
}
})
.openSession();
Hibernate ORM also has a concept of stateless sessions, represented by org.hibernate.StatelessSession. Particularly well-suited for bulk data operations, a StatelessSession can do many of the same things that a Session can, but it does not hold on to attached entities like a Session does. You can open a default StatelessSession with openStatelessSession and a custom StatelessSession using withStatelessOptions.
Perhaps one of the most important features of a SessionFactory is its capability to hold and retrieve the “current” Session. (No such ability exists for StatelessSessions due to their stateless nature.) But what exactly is the “current” Session? Unlike Sessions,SessionFactorys are thread-safe, so the “current” Session is not simply the last one opened with openSession. Rather, the meaning of “current” is defined by the supplied implementation of org.hibernate.context.spi.CurrentSessionContext. The most common implementation is org.hibernate.context.internal.ThreadLocalSessionContext, which stores the current session in a java.lang.ThreadLocal. Any calls to getCurrentSession retrieve the session previously opened within the current thread, if any.
Session session = sessionFactory.openSession();
...
Session session = sessionFactory.getCurrentSession();
Creating a SessionFactory with Spring Framework
SessionFactorys can be tricky to configure, and in a web application it is extremely important that resources are properly cleaned up at the end of each request. Failing to do so could result in memory leaks or (worse) data leaks across applications. As with so many other things, Spring Framework makes creating a SessionFactory easier and manages the creation and closure of Sessions and transactions on your behalf so that you don’t have to worry about that repetitive code everywhere in your application. When configuring Hibernate ORM in Spring, you use one of two Spring classes to create a SessionFactory.
If you configure Spring using XML, it’s easiest to define an org.springframework.orm.hibernate4.LocalSessionFactoryBean bean, a special type of Spring bean that creates and returns a SessionFactory. LocalSessionFactoryBean also implementsorg.springframework.dao.support.PersistenceExceptionTranslator, so it can serve as a translator that converts Hibernate ORM exceptions to Spring Framework generic persistence exceptions.
When using Java configuration, however, the org.springframework.orm.hibernate4.LocalSessionFactoryBuilder is a simpler approach. It extends org.hibernate.cfg.Configuration to provide some shortcuts for configuring a SessionFactory in your Spring Framework application. This approach is shown in the following Java configuration snippet:
...
@EnableTransactionManagement
public class RootContextConfiguration
implements AsyncConfigurer, SchedulingConfigurer
{
...
@Bean
public PersistenceExceptionTranslator persistenceExceptionTranslator()
{
return new HibernateExceptionTranslator();
}
@Bean
public HibernateTransactionManager transactionManager()
{
HibernateTransactionManager manager = new HibernateTransactionManager();
manager.setSessionFactory(this.sessionFactory());
return manager;
}
@Bean
public SessionFactory sessionFactory()
{
LocalSessionFactoryBuilder builder = new
LocalSessionFactoryBuilder(this.dataSource());
builder.scanPackages("com.wrox.entities");
builder.setProperty("hibernate.default_schema", "dbo");
builder.setProperty("hibernate.dialect",
MySQL5InnoDBDialect.class.getCanonicalName());
return builder.buildSessionFactory();
}
...
}
With this configuration, Spring Framework can automatically create a Session prior to an @org.springframework.transaction.annotation.Transactional service or a repository method being invoked and close the Session after that method returns. If a @Transactionalmethod calls other @Transactional methods, the current Session and transaction remain in effect. Then, you need to have only an @Injected SessionFactory in your repositories and call getCurrentSession whenever you need to use the Session. You learn more about@EnableTransactionManagement and @Transactional in Chapter 21.
PREPARING A RELATIONAL DATABASE
To complete and use the examples and sample projects in the rest of this book, you need to have access to a relational database for storing persisted entities. You could use a 100 percent Java embedded database like HyperSQL, but that would defeat the purpose of replacing the in-memory repositories you have been using so far in this book. Instead, the examples will be more effective if you use a separate, standalone relational database like MySQL, PostgreSQL, or Microsoft SQL Server.
The examples in this book assume you have access to a relational database; if you do not, you need to install one. In addition, the examples are written for and tested against a MySQL server because it is the most popular, free database system available. However, there is no reason why you shouldn’t be able to use any relational database to complete the examples. Most of the code works completely independently of any particular database (that is, after all, part of the point of an ORM), but you need to do a bit of independent thinking when using the configuration code show throughout the examples. For example, whenever you see something database-specific like the MySQL5InnoDBDialect class used in the previous section, you need to figure out the appropriate replacement for your database of choice. You also need to translate the MySQL database, table, and index creation statements to the appropriate statements for your database of choice.
In addition to showing you how to install a JDBC driver and create connection resources in Tomcat, this section also helps you install a local MySQL server in case you do not already have access to a database you would like to use. If you plan on using some other database you should still read this section! It contains important information that also applies to your database vendor.
Installing MySQL and MySQL Workbench
To install MySQL Database, follow these steps:
1. Go to the MySQL download website and download the MySQL Community Server and MySQL Workbench products.
2. For MySQL Community Server, select the appropriate platform (Mac OS X, Windows, SuSE, and so on) and download the correct installer or archive for your platform version.
3. Follow the installation instructions for your operating system to install MySQL Community Server on your computer. The installer should guide you through the process.
4. If presented with a Setup Type screen, you can usually just choose Developer Default, as shown in Figure 19-1. This installs everything you need to develop with MySQL, including extensions for Microsoft Excel if you’re on a Windows system. If you want to install only certain features, choose the Custom setup type, and select the features you want to install on the screen, as shown in Figure 19-2.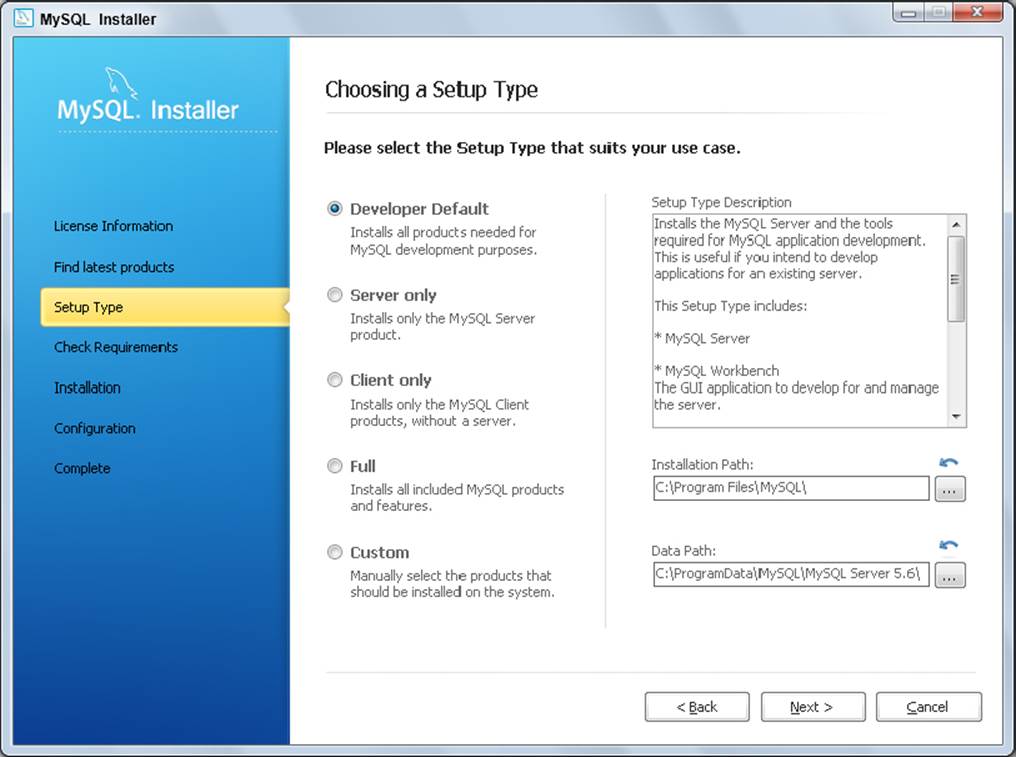
FIGURE 19-1
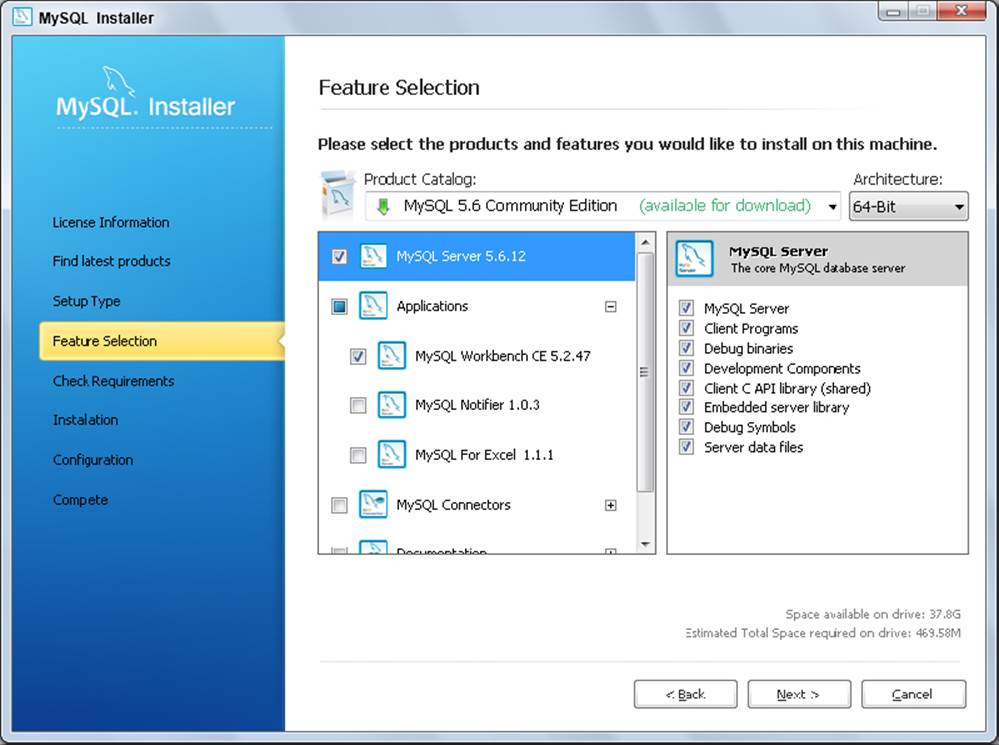
FIGURE 19-2
NOTE Many Linux distributions offer MySQL in their package management systems, and it may be easier for you to install MySQL using that approach. However you install it, you must use MySQL 5.6.12 or newer — earlier versions do not support some of the features used in the following chapters. When downloading from the MySQL site, you do not have to create an account or log in. You can click the “No thanks, just start my download” link to skip this process.
MySQL Workbench is a database browser and management tool similar to Microsoft SQL Server Management Studio and Oracle SQL Developer. Some of the examples and screen shots in this book tell you to execute queries against your MySQL database and show you what the results should look like in Workbench. You can, of course, use whatever tool you prefer to perform these tasks. If you ran an installer for the MySQL server and that installer included Workbench, you do not need to do anything further to install Workbench. Otherwise, to download and install Workbench, you should select the appropriate platform and download the correct installer or binary for your platform version. Installing Workbench is a simpler process than installing MySQL Community Server, and Workbench is typically not found in standard package management repositories.
For the most part, your MySQL Community Server should be ready to go after installation. It requires no extra configuration to get started for development purposes; however, in its default configuration it is not optimized for performance and it is not secure. The default configuration should be sufficient to use the examples and perform the tasks detailed in this book. You will, however, need to create a username and password that your applications can use to access databases through JDBC.
NOTE The details of managing a MySQL Community Server are outside the scope of this book, but the MySQL website has plenty of resources that help you configure it to meet your needs.
To create this username and password, open MySQL Workbench and connect to your local MySQL installation. You will need to enter the root username and password to log in; if you did not set up a root password during installation, the root password is blank by default.
![]() In the query editor, enter the following statements and click the execute icon to execute them:
In the query editor, enter the following statements and click the execute icon to execute them:
GRANT ALL PRIVILEGES ON *.* TO 'tomcatUser'@'localhost'
IDENTIFIED BY 'password1234';
GRANT ALL PRIVILEGES ON *.* TO 'tomcatUser'@'127.0.0.1'
IDENTIFIED BY 'password1234';
GRANT ALL PRIVILEGES ON *.* TO 'tomcatUser'@'::1' IDENTIFIED BY 'password1234';
FLUSH PRIVILEGES;
This creates a user that you can connect with from your Tomcat server on the same machine. Of course, this user is granted far too many privileges. On a production machine, you would want to limit its permissions to a single database, and perhaps allow only data manipulation and prohibit schema manipulation. For the purposes of a developer machine, this is sufficient.
Installing the MySQL JDBC Driver
MySQL, like most other relational database vendors, supplies a JDBC driver for connecting to MySQL databases from Java. You need to download this driver (a JAR file) and place it in your Tomcat installation so that you can use it from your applications. This may strike you as odd because other JAR files you use are simply packaged with your applications in /WEB-INF/lib. You must never do this with a JDBC driver for two reasons:
· Most important, doing so can cause a memory leak. JDBC drivers automatically register themselves with the java.sql.DriverManager, which is part of the Java SE core libraries. If your application includes a JDBC driver in /WEB-INF/lib, the DriverManager holds on to the driver classes forever, even if your application is undeployed. The application server then cannot fully undeploy your application, resulting in a memory leak.
· It’s a best practice to have the application server manage your JDBC DataSources. Application servers have built-in systems for managing connection pools, improving the performance of database connections in your applications. For the application server to be able to manage these connections, you must load the JDBC driver in the application server class loader instead of the web application class loader.
Installing the MySQL JDBC driver in Tomcat is extremely easy. On the MySQL download website mentioned previously, locate the Connector/J product. This is the JDBC driver. It is platform-independent, so all you need to do is download the ZIP or TAR archive (whichever is easiest for you to use on your computer). Extract the JAR file from the archive, and copy it to C:\Program Files\Apache Software Foundation\Tomcat 8.0\lib (or the equivalent directory for your Tomcat installation).
That’s all there is to it. The next time Tomcat starts, the MySQL JDBC driver becomes available to all web applications.
WARNING As of the time of this writing, the MySQL JDBC driver is mostly compatible with JDBC 4.1, which was part of Java 7. Java 8 includes JDBC 4.2. The only significant changes in JDBC 4.2 are the addition of the Java 8 Date and Time types for SQL DATE, TIME, and DATETIME types. Because the MySQL Driver is not yet compatible with JDBC 4.2, you cannot use the Java 8 Date and Time types directly with JDBC statements and result sets — yet. JDBC vendors usually release new versions of their drivers 6 months to several years after a new Java/JDBC version is released, or it may not. By the time you read this, the MySQL driver may already be JDBC 4.2-compliant. Make sure you download the latest version and consult the Connector/J documentation to see if it is JDBC 4.2-compliant. This cautionary note also applies to any other JDBC drivers you may use.
Creating a Connection Resource in Tomcat
Creating a pooled connection DataSource in Tomcat is quite straightforward and takes only a few minutes. Any time you use a new database for an example or sample project, this book instructs you to create a Tomcat connection resource. You will likely want to refer back to this section from time to time to remember how to do that. Instead of creating a brand new resource every time and having dozens of resources by the end of the book, it is also acceptable to simply create one resource and change it every time you need to.
1. To create a connection resource, open C:\Program Files\Apache Software Foundation\Tomcat 8.0\conf\context.xml (or the equivalent in your Tomcat installation) in your favorite text editor.
2. Add the following <Resource> element between the beginning and end <Context> elements:
3. <Resource name="jdbc/DataSourceName" type="javax.sql.DataSource"
4. maxActive="20" maxIdle="5" maxWait="10000"
5. username="mysqluser" password="mysqlpassword"
6. driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/databaseName" />
7. For each example you must replace jdbc/DataSourceName with the appropriate data source name (which should always start with jdbc/) and databaseName with the correct database name. mysqluser and mysqlpassword should be replaced with the user (tomcatUser) and password (password1234) that you previously created for Tomcat to access MySQL. You can reuse this username and password for all the examples in this book.
This <Resource> definition causes Tomcat to expose the connection pool DataSource as a JNDI resource so that it can be looked up via JNDI by any application.
A NOTE ABOUT MAVEN DEPENDENCIES
The Maven dependencies you use in this part of the book aren’t quite as straightforward as you may be used to. Most of the Java EE dependencies you have used up to this point are the actual Java EE specification libraries from the Maven Central Repository, such as javax.servlet:javax.servlet-api:3.1.0 and javax.websocket:javax.websocket-api:1.0. However, other Java EE components have different licenses that prohibit binary distribution in Maven Central.
The legal absurdities that result in this are beyond the scope of this book, but suffice it to say that there is no “official” javax.persistence (Java Persistence API) artifact in Maven Central for JPA 2.0 or 2.1. You may also come across similar situations for other Java EE components in the future. However, the implementation providers for these APIs publish identical, unofficial API artifacts in Maven Central and it is safe to use those. The best practice is to use the API published by the reference implementation in these cases because it is the most likely to be 100 percent correct. When you see the following Maven dependency in the next chapter, know that this is the Java Persistence API 2.1 artifact provided by the reference implementation EclipseLink. It is compatible with any JPA implementation, including Hibernate ORM.
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId>javax.persistence</artifactId>
<version>2.1.0</version>
<scope>compile</scope>
</dependency>
Hibernate ORM also publishes an org.hibernate.javax.persistence:hibernate-jpa-2.1-api:1.0.0 artifact for JPA 2.1, and you can use it if you prefer. The only alternative to using provider-published artifacts is to manually download the official JARs from the Java website, but that does not work well with Maven projects and is really not necessary. Fortunately, this is the exception and not the norm for Java EE components.
SUMMARY
This brief preparatory chapter introduced you to Object-Relational Mappers (O/RMs) and the Java Persistence API (JPA). It explained the history and evolution of both and explained the advantages of using JPA instead of a proprietary O/RM API. You also got a brief introduction to using Hibernate ORM outside of JPA. However, in the rest of this book, you use only the JPA classes and interfaces. You learned that you must have access to a relational database for the rest of the book and were given instructions for installing and setting up MySQL for this purpose. Finally, you learned how to install a JDBC driver in Tomcat and configure a Tomcat connection pool DataSource.
In upcoming chapters, you use JPA to persist all sorts of entities to relational databases. You also learn about the different techniques that you can employ to map entities to database tables and explore adding, updating, deleting, reading, and searching entities in various manners.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.