PROFESSIONAL JAVA FOR WEB APPLICATIONS (2014)
Part III Persisting Data with JPA and Hibernate ORM
Chapter 23 Searching for Data with JPA and Hibernate Search
IN THIS CHAPTER
· Searching basics
· How to locate objects with advanced criteria
· Using full-text indexes with JPA
· Using Apache Lucene and Hibernate Search to index your data
WROX.COM CODE DOWNLOADS FOR THIS CHAPTER
You can find the wrox.com code downloads for this chapter at http://www.wrox.com/go/projavaforwebapps on the Download Code tab. The code for this chapter is divided into the following major examples:
· Advanced-Criteria
· Customer-Support-v17 Project
· Search-Engine Project
NEW MAVEN DEPENDENCY FOR THIS CHAPTER
In addition to the Maven dependencies introduced in previous chapters, you also need the following Maven dependency only for the section that covers Apache Lucene, Hibernate Search, and the Search-Engine project.
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-search-orm</artifactId>
<version>4.5.0.Final</version>
<scope>compile</scope>
</dependency>
AN INTRODUCTION TO SEARCHING
Searching through data takes many different forms. You might use a tool like grep, find, Agent Ransack, Spotlight, or Windows Search to locate a file on your hard drive. You could look for matching filenames or matching file contents. Perhaps most familiar to you, searching might involve opening your web browser and using a popular search tool such as Google to find content on the Internet. Or maybe you have a Gmail account and you use the search bar at the top of a Gmail page to find e-mails and create filters from search patterns.
If you like to shop online, you probably have a favorite store, and it’s likely you have used its search tool to find products that interest you. As a developer, undoubtedly you have used a search tool in your IDE to find specific files or classes, keywords in a project, or code in a code file. You might have used the GitHub search to find code in an Open Source repository and then used your browser’s search tool to locate specific keywords on a page. Perhaps you have a social networking profile and use its search tool to locate people you know or find topics you are interested in. And, of course, who could forget the tried-and-true (and least accurate) method of searching: manually looking through paper documents in your filing cabinet or microfiche in a library to find the data you are looking for.
In all these different approaches to searching, two undeniable truths emerge: Indexed searching is faster than non-indexed searching, and creating indexes makes creating content take longer.
WAIT — INDEXES OR INDICES?
The intersection of language and computer jargon often results in some interesting disputes. For example, do you use computer mice or computer mouses? (This author uses computer mouses.) The word “index” in plural form has traditionally been “indices,” but this has changed somewhat in recent years. Some people learn the phrase, “Books have indexes; math has indices.” Because mathematical indices also have important meanings in computer science, many people prefer the word “indexes” when referring to a technological but non-mathematical index in the plural form. This book uses the word “indexes” as well.
Understanding the Importance of Indexes
Take the filing cabinet as an example. You could throw all your documents in the first available spot in the filing cabinet as soon as you get them. This would be very fast and with the drawers closed would take on the appearance of being very organized. But finding that one bill six months after you got it will prove to be a time-consuming task.
Alternatively, you could create folders in your filing cabinet to organize all the bills together — all your insurance paperwork together, all your research on a particular topic together, and so on. Suddenly, finding that bill is much easier. Instead of looking through the entire filing cabinet (or, worse, cabinets) until you find the bill, you can open the drawer you know it’s in, reach into the Bills folder, and sift through the handful of similar documents until you find the right one. The downside is that inserting the bill into the filing cabinet takes longer. You can’t just open a drawer, throw it in, and walk away. You have to find the right drawer for the document type, locate the appropriate folder, create a new folder if the appropriate one doesn’t exist, and then insert the document.
Indexing your documents also involves a certain amount of occasional reorganization. If a certain drawer or folder gets too full, you might make smaller, less narrow categories and reclassify some or all of your documents. The point that should be abundantly clear by now is that keeping your documents organized isn’t free. It’s not even cheap and can consume considerable time. The same is true of indexes containing digital information. The question that you must always ask yourself is, “Is the price worth the benefit?”
Compare searching for a document using grep versus using Mac OS X’s Spotlight feature. If you grep a small folder’s contents, it will likely return results fairly quickly. So will Spotlight. But what about an entire hard disk containing hundreds of thousands of files? Grep could take several minutes or even hours to return results, whereas Spotlight still takes mere seconds. The difference is in the approach. Grep must open and read every document every time it searches whereas Spotlight keeps an index of file contents and uses that index instead. The cost is in disk performance: Every time you save a file, Spotlight must update the index. Every few days or hours (depending on how active your computer is) Spotlight cranks up the CPU to reorganize its indexes. Much of the time you never notice it, but sometimes your machine briefly slows down. Is this expense worth the immeasurable increase in searching speed? For most users, it absolutely is.
An index is any kind of structure that makes finding data easier. Indexes take many forms depending on what’s doing the indexing. Many relational databases make heavy use of B-tree indexes, which store ordered data very well. Text-heavy data stores that need to search based on how closely the content matches a search query often use full-text indexes. Google’s search uses a closely guarded indexing algorithm that most people know little about. All these indexes, for their purposes, have a benefit (faster searching) and a cost. For most indexes that cost is slower saving of data. For search engines like Google that cover content created by third parties, the cost is the expense of operating “crawlers” that index the data after it is updated.
So how do you know whether an index is worth the cost? That’s a complicated question whose answer could fill many, many chapters. Generally speaking, the cost of an index is directly related to the ratio of writes to reads. A system that performs significantly more reads than writes can afford more indexes and more complicated indexes than a system that performs more writes than reads. Sometimes this ratio varies for different parts of a system. For example, a database table holding news articles is updated far less often than a database table holding comments on those news articles. Therefore, the news article table can have more indexes and more complicated indexes than the comments table for approximately the same cost. The value of that index is then related to the cost versus the ratio of reads that use the index to reads that don’t use the index.
Determining how and where to create indexes is a learned art and often involves painstaking analysis of query types and ratios, bottlenecks, and the output of profiling tools. But generally speaking, if you want to search any large amount of data in a reasonable amount of time, you will need one or more indexes. Without any indexes your search will be unbearably slow and probably affect the performance of other areas of your application. What kind of indexing technology you use largely depends on your storage medium, computer language, and programming methodologies.
Taking Three Different Approaches
This chapter explores three different approaches to searching and indexing:
· Simple indexes with complex queries
· Full-text searching using database vendor indexes
· Full-text searching using Apache Lucene and Hibernate Search
This is by no means an exhaustive analysis, but it does cover some of the most common techniques adopted by other Java, JPA, and relational database programmers. All these approaches integrate with the Java Persistence API in some way or another, but you can use them all outside of a JPA environment as well. After you have learned about these three different techniques, you should be at a good jumping-off point for integrating any other searching and indexing technologies you may want to use into your applications.
USING ADVANCED CRITERIA TO LOCATE OBJECTS
Perhaps the most obvious solution initially, is that you can use the criteria API to find objects in many different ways. Like all the solutions presented in this chapter, it is the best choice for some situations and a bad choice for other situations. One place in which it excels is in building dynamic queries. In a dynamic query, a user provides expected values for one or more fields, possibly indicates whether all or any of the criteria should be met, and submits the search. This isn’t something as simple as the user typing in a person’s first and last names to find a Person object in the application. You don’t need the criteria API for that; you can simply create a Spring Data query method named findByFirstNameAndLastName to satisfy this requirement.
In a dynamic query, you don’t know at compile time what fields the user wants to search on, so you can’t write even the most complex query method to power the search. From the user side, a dynamic query might look something like Figure 23-1. There’s no official name for this; it’s just another type of search. You may call it something different. This book, consistently calls it a dynamic query.
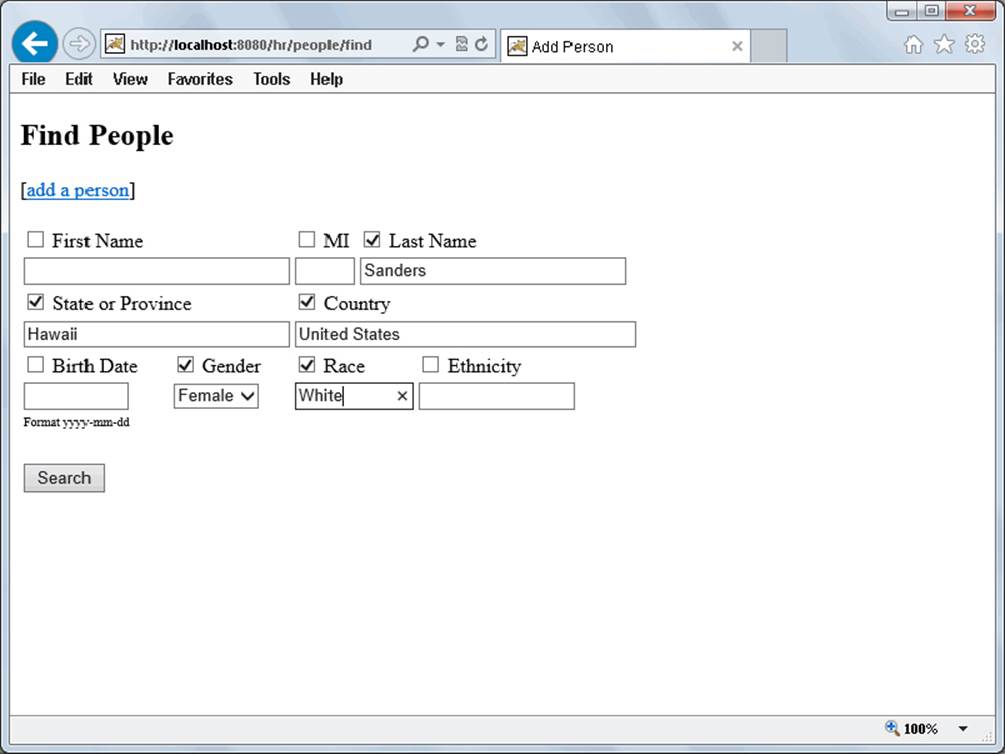
FIGURE 23-1
In this search screen, you can include as few or as many of the fields in your query as you want. The query currently entered should find all white females with the last name of Sanders living in Hawaii, United States. The criteria are implicitly grouped with the ANDlogical operator, but fields without the check box checked are not included in the query. You cannot perform this search with a static query known at compile time. This is a dynamic query, and the best way to approach it is with the criteria API.
Creating Complex Criteria Queries
Continuing with the example search screen in Figure 23-1, assume your application has the following Person entity with appropriate mutator and accessor methods. You can follow along with this section in the Advanced-Criteria project available for download on thewrox.com code download site.
@Entity
@Table(name = "Person")
public class Person
{
private long id;
private String firstName;
private String middleInitial;
private String lastName;
private String state;
private String country;
private Date birthDate;
private Gender gender;
private String race;
private String ethnicity;
// mutators and accessors
}
Representing Search Criteria in an API
You can’t use the JPA criteria API to create search criteria and pass them down through the layers of your application. This API requires an EntityManager instance and access to your domain layer, which shouldn’t be accessible from your user interface layer. You need some way to convey the search query from the user interface to the repository. Because this is likely not the only entity that you want to search in this manner, you need to reuse this mechanism across your application, so it can’t be Person-specific.
public class Criterion
{
private final String propertyName;
private final Operator operator;
private final Object compareTo;
public Criterion(String propertyName, Operator operator, Object compareTo)
{ ... }
// accessors
public static enum Operator
{
EQ, NEQ, LT, LTE, GT, GTE, LIKE, NOT_LIKE, IN, NOT_IN, NULL, NOT_NULL
}
}
public interface SearchCriteria extends List<Criterion>
{
}
The API is simple: A search involves a list of one or more Criterion instances. Each Criterion represents a comparison between a property on an entity and a value, using the Operator enum to determine how to perform that comparison. For now, it permits only theAND-ing of criteria because that’s all you need for this search and it’s easier to implement. If you want to add an AND/OR toggle or add AND/OR groupings, you can create extra features in the SearchCriteria interface to do that. (This is a task you can do on your own.)
Adding a Custom Search Method
Your repository needs a custom search method that can accept a SearchCriteria argument. It should also accept a Pageable and return a Page<Person> so that search results can be retrieved in pages. However, you don’t want to rewrite this method for every repository, so you need to make it generic. This requires some of the clever trickery you used in Chapter 21 to get the type arguments for a generic class.
First, create an interface to reflect what you want the searchable repository to do. Your Person repository interface should extend this interface to indicate that people are searchable.
public interface SearchableRepository<T>
{
Page<T> search(SearchCriteria criteria, Pageable pageable);
}
public interface PersonRepository extends JpaRepository<Person, Long>,
SearchableRepository<Person>
{
}
All searchable repositories can share a common implementation of the search method you create, so it makes sense to implement a common base class for your custom repository implementations. The code in search needs to know the Class for T, but you could also have other common base classes that need this information. So create a base class for abstracting the type argument and a base class for searching.
abstract class AbstractDomainClassAwareRepository<T>
{
protected final Class<T> domainClass;
@SuppressWarnings("unchecked")
protected AbstractDomainClassAwareRepository()
{
Type genericSuperclass = this.getClass().getGenericSuperclass();
while(!(genericSuperclass instanceof ParameterizedType))
{
if(!(genericSuperclass instanceof Class))
throw new IllegalStateException("Unable to determine type " +
"arguments because generic superclass neither " +
"parameterized type nor class.");
if(genericSuperclass == AbstractDomainClassAwareRepository.class)
throw new IllegalStateException("Unable to determine type " +
"arguments because no parameterized generic superclass " +
"found.");
genericSuperclass = ((Class)genericSuperclass).getGenericSuperclass();
}
ParameterizedType type = (ParameterizedType)genericSuperclass;
Type[] arguments = type.getActualTypeArguments();
this.domainClass = (Class<T>)arguments[0];
}
}
abstract class AbstractSearchableJpaRepository<T>
extends AbstractDomainClassAwareRepository<T>
implements SearchableRepository<T>
{
@PersistenceContext protected EntityManager entityManager;
@Override
public Page<T> search(SearchCriteria criteria, Pageable pageable)
{
return null;
}
}
Right now the search method is stubbed out, but you’ll fill it in in a minute. You added SearchableRepository<Person> to the PersonRepository interface, but Spring Data still doesn’t know how to find the search method implementation. To solve this, you need aPersonRepositoryImpl class. Notice that this class implements only SearchableRepository<Person> (by way of extending AbstractSearchableJpaRepository<Person>). It does not implement PersonRepository because Spring Data JPA does that for you.
public class PersonRepositoryImpl extends
AbstractSearchableJpaRepository<Person>
{
}
Creating Queries from Search Input
Now you still need to complete the search method implementation. It needs to do several things:
· Convert the SearchCriteria into a JPA CriteriaQuery<Long> to count the number of matching records.
· Convert the SearchCriteria into a JPA CriteriaQuery<T> to retrieve actual entities.
· Order the records properly using the Sort information in the Pageable parameter.
· Apply the Pageable limits to the query to retrieve the correct page.
· Convert the query results to a Page<T> with a fully initialized list of entities.
As you start to think about all the options in the Criterion.Operator enum, you should quickly realize how much code this consumes. Because you have to convert the SearchCriteria twice, that conversion should be in a separate method. However, even this method would contain 12 if statements or 12 case statements (one for each Operator) — not the most object-oriented approach. Why perform such onerous logic when the Operator enum is naturally polymorphic?
As it turns out, you can represent each Criterion with a javax.persistence.criteria.Predicate (not to be confused with Java 8’s java.unit.function.Predicate). In a general sense (and in the case of both Predicate interfaces), a predicate is just a boolean expression. In the sense of the JPA and Java 8 interfaces, a Predicate is a boolean expression that you can evaluate at some later point. Each Operator constant can precisely evaluate to a Predicate using the Criterion, Root, and CriteriaBuiler as input. The Operator enum in Listing 23-1defines an abstract toPredicate method, implemented in each constant.
LISTING 23-1: Criterion.java
public class Criterion
{
// previously printed code
public static enum Operator
{
EQ {
@Override
public Predicate toPredicate(Criterion c, Root<?>r, CriteriaBuilder b)
{
return b.equal(r.get(c.getPropertyName()), c.getCompareTo());
}
}, NEQ {
@Override
public Predicate toPredicate(Criterion c, Root<?>r, CriteriaBuilder b)
{
return b.notEqual(r.get(c.getPropertyName()), c.getCompareTo());
}
}, LT {
@Override @SuppressWarnings("unchecked")
public Predicate toPredicate(Criterion c, Root<?>r, CriteriaBuilder b)
{
return b.lessThan(
r.<Comparable>get(c.getPropertyName()), getComparable(c)
);
}
}, LTE {
@Override @SuppressWarnings("unchecked")
public Predicate toPredicate(Criterion c, Root<?>r, CriteriaBuilder b)
{
return b.lessThanOrEqualTo(
r.<Comparable>get(c.getPropertyName()), getComparable(c)
);
}
}, GT {
@Override @SuppressWarnings("unchecked")
public Predicate toPredicate(Criterion c, Root<?>r, CriteriaBuilder b)
{
return b.greaterThan(
r.<Comparable>get(c.getPropertyName()), getComparable(c)
);
}
}, GTE {
@Override @SuppressWarnings("unchecked")
public Predicate toPredicate(Criterion c, Root<?>r, CriteriaBuilder b)
{
return b.greaterThanOrEqualTo(
r.<Comparable>get(c.getPropertyName()), getComparable(c)
);
}
}, LIKE {
@Override
public Predicate toPredicate(Criterion c, Root<?>r, CriteriaBuilder b)
{
return b.like(
r.get(c.getPropertyName()), getString(c)
);
}
}, NOT_LIKE {
@Override
public Predicate toPredicate(Criterion c, Root<?>r, CriteriaBuilder b)
{
return b.notLike(
r.get(c.getPropertyName()), getString(c)
);
}
}, IN {
@Override
public Predicate toPredicate(Criterion c, Root<?>r, CriteriaBuilder b)
{
Object o = c.getCompareTo();
if(o == null)
return r.get(c.getPropertyName()).in();
if(o instanceof Collection)
return r.get(c.getPropertyName()).in((Collection) o);
throw new IllegalArgumentException(c.getPropertyName());
}
}, NOT_IN {
@Override
public Predicate toPredicate(Criterion c, Root<?>r, CriteriaBuilder b)
{
Object o = c.getCompareTo();
if(o == null)
return b.not(r.get(c.getPropertyName()).in());
if(o instanceof Collection)
return b.not(r.get(c.getPropertyName()).in((Collection) o));
throw new IllegalArgumentException(c.getPropertyName());
}
}, NULL {
@Override
public Predicate toPredicate(Criterion c, Root<?>r, CriteriaBuilder b)
{
return r.get(c.getPropertyName()).isNull();
}
}, NOT_NULL {
@Override
public Predicate toPredicate(Criterion c, Root<?>r, CriteriaBuilder b)
{
return r.get(c.getPropertyName()).isNotNull();
}
};
public abstract Predicate toPredicate(Criterion c, Root<?> r,
CriteriaBuilder b);
@SuppressWarnings("unchecked")
private static Comparable<?> getComparable(Criterion c) {
Object o = c.getCompareTo();
if(o != null && !(o instanceof Comparable))
throw new IllegalArgumentException(c.getPropertyName());
return (Comparable<?>)o;
}
private static String getString(Criterion c) {
if(!(c.getCompareTo() instanceof String))
throw new IllegalArgumentException(c.getPropertyName());
return (String)c.getCompareTo();
}
}
}
Using the toPredicate method, the code to convert the SearchCriteria into a CriteriaQuery is much simpler:
...
public Page<T> search(SearchCriteria criteria, Pageable pageable)
{
CriteriaBuilder builder = this.entityManager.getCriteriaBuilder();
CriteriaQuery<Long> countCriteria = builder.createQuery(Long.class);
Root<T> countRoot = countCriteria.from(this.domainClass);
long total = this.entityManager.createQuery(
countCriteria.select(builder.count(countRoot))
.where(toPredicates(criteria, countRoot, builder))
).getSingleResult();
CriteriaQuery<T> pageCriteria = builder.createQuery(this.domainClass);
Root<T> pageRoot = pageCriteria.from(this.domainClass);
List<T> list = this.entityManager.createQuery(
pageCriteria.select(pageRoot)
.where(toPredicates(criteria, pageRoot, builder))
.orderBy(toOrders(pageable.getSort(), pageRoot, builder))
).setFirstResult(pageable.getOffset())
.setMaxResults(pageable.getPageSize())
.getResultList();
return new PageImpl<>(new ArrayList<>(list), pageable, total);
}
private static Predicate[] toPredicates(SearchCriteria criteria, Root<?> root,
CriteriaBuilder builder)
{
Predicate[] predicates = new Predicate[criteria.size()];
int i = 0;
for(Criterion c : criteria)
predicates[i++] = c.getOperator().toPredicate(c, root, builder);
return predicates;
}
...
This code executes the five steps previously enumerated. The toOrders method invocation (in bold) is a static import from org.springframework.data.jpa.repository.query.QueryUtils that turns a Spring Data Sort into JPA ordering instructions. The search method returns a new org.springframework.data.domain.PageImpl with the Pageable information, total record count, and list of results. Remember that the list returned by the JPA provider may be lazy-loaded and thus won’t populate until iterated. This is why the code wraps the list in a new ArrayList.
NOTE The unfortunate part about the search method is the need to convert the SearchCriteria to a CriteriaQuery twice. Some JPA implementations let you reuse the Root object for multiple queries, in which case you could avoid this additional step. However, the JPA specification is unclear on this; therefore, such use is not portable.
The Advanced-Criteria project contains a MainController, a /WEB-INF/jsp/view/people/add.jsp, and a /WEB-INF/jsp/view/people/find.jsp that comprise the user interface for creating and searching people. MainController uses PersonService, and DefaultPersonService usesPersonRepository. The details are unimportant because they don’t contain anything you haven’t seen already in this book. However, you should know that the current user interface is limited — it only supports AND-ing all criteria together, and it only supports the EQoperator. Feel free to extend the user interface yourself further to support other operators, such as LT, GT, LIKE, and so on. In doing so, you will quickly realize that creating useful dynamic querying is an enormous task.
To test the existing, limited user interface:
1. Be sure to run create.sql in MySQL Workbench and create the following DataSource resource in Tomcat’s context.xml configuration file.
2. <Resource name="jdbc/AdvancedCriteria" type="javax.sql.DataSource"
3. maxActive="20" maxIdle="5" maxWait="10000"
4. username="tomcatUser" password="password1234"
5. driverClassName="com.mysql.jdbc.Driver"
6. defaultTransactionIsolation="READ_COMMITTED"
url="jdbc:mysql://localhost/AdvancedCriteria" />
7. Compile the project and start Tomcat from your IDE, then go to http://localhost:8080/hr/people/add in your favorite browser. Add several people with different names, genders, birth dates, races, and locations to your database using this screen.
8. Once you have added enough people to perform a useful test of searching, go to http://localhost:8080/hr/people/find. You should see a screen like the previous Figure 23-1. Try different search queries to see how they change the results you see. To test paging, you will need to perform a search that matches more than 10 people.
Using OR in Your Queries
By now you should recognize that the criteria API is exceptionally powerful. So powerful, in fact, that it can even be dangerous — giving your users unfettered access to create queries on any columns can have disastrous performance consequences. But so far all you have done is specified a lot of simple-expression Predicates in the where method. All these Predicates are AND-ed together, which of course isn’t enough for all situations. Suppose you know a person’s birthdate and the name “Cooper,” but you don’t know whether that’s the first or last name. You would need to OR the first and last name Predicates, and then AND the result of that and the birthdate Predicate. So how do you accomplish this with the criteria API?
As you should know from everyday programming experience, when you AND or OR two or more boolean expressions, the result itself is a boolean expression. Likewise, using the criteria API you can AND or OR two or more Predicates to create another Predicate. The wheremethod is an implicit AND if you supply multiple Predicates, but you can explicitly AND or OR Predicates together, as well. Returning to the person named “Cooper,” you could accomplish this with the following code where n is the name “Cooper” and b is the birthdate:
criteria.select(root)
.where(
builder.or(
builder.equal(root.get("lastName"), n),
builder.equal(root.get("firstName"), n)
),
builder.equal(root.get("birthDate"), b)
);
The or method here accepts multiple Predicates and returns a Predicate with those Predicates OR-ed. The where method, again, acts as an implicit AND of the OR-ed predicates and the birth date predicates. If you prefer to explicitly AND criteria, you could rewrite the same query like this:
criteria.select(root)
.where(
builder.and(
builder.or(
builder.equal(root.get("lastName"), n),
builder.equal(root.get("firstName"), n)
),
builder.equal(root.get("birthDate"), b)
)
);
Using the or and and methods, which you can nest as deeply as you need to mimic levels of parenthesis in code or SQL, you can execute some fairly complex queries. Most of the time you don’t need queries like this for standard searching situations, but this level of complexity will likely come in handy in batch situations and background jobs.
pageCriteria.select(pageRoot)
.where(
builder.or(
builder.and(
builder.equal(expr),
builder.equal(expr),
pageRoot.get("property").in(expr)
),
builder.or(
builder.lessThan(expr),
builder.greaterThanOrEqualTo(expr)
)
),
builder.and(
builder.equal(expr),
builder.greaterThan(expr)
)
);
Creating Useful Indexes to Improve Performance
As you read earlier, any time you search through data you’re going to need one or more indexes. But it’s important to understand up front that you can’t index for every scenario. The more you index a database table, the more it slows down for inserts, updates, and deletes. Your exact goal will vary between every application, and a detailed discussion on the intricacies of database indexing is an entire book on its own. Every database system is different, and no guidelines work for everything. Generally speaking, however, you should aim for having 95 percent of queries contain at least the first column in at least one index, and a majority of queries contain two or more columns in at least one index. (“Contain” here means in the WHERE clause.) You should prioritize your most heavily run queries over the less common ones. This might mean running a trace program against your database to capture statistics on which queries run how often. Depending on which database server you use, you likely have tools available to analyze queries and get a glimpse of which indexes are needed, if any.
Remember that a LIKE comparison can use an index unless it starts with a wildcard — when this happens, it will trigger a scan. Scanning is bad (very slow), so when you know you’ll be performing a LIKE comparison starting with a wildcard, try to include at least one other criterion that can always use an index. For example, you could require the user to specify a date range or automatically limit the results to those created or updated within the last year.
OR-ed criteria can utilize indexes but not as efficiently as AND-ed criteria in most cases. So if you have to OR something, try to include an indexed AND as well, if possible.
Keep in mind that a query must contain the first column in an index before it can use any other columns in that index. So if you have an expensive query with one column in the WHERE clause and no indexes start with that column, you’re going to have a problem. It does you no good for an index to have that column as the second or third column in the index.
Finally, unique constraints are your friend. They are the fastest indexes other than the primary key. (In some databases like Oracle, you must explicitly create the index to match the constraint.) If you’re creating a User table and you think, “I’ll enforce username uniqueness in the code,” take a step back. The unique constraint doesn’t just enforce uniqueness — it also gives you a very efficient means for locating records that you are very likely to look up using that one column (otherwise, why would you care about uniqueness?). Enforce uniqueness in the code, for sure — that’s a best practice. But add the unique constraint, too.
TAKING ADVANTAGE OF FULL-TEXT INDEXES WITH JPA
Though different trends exist in different industries and types of applications, these days most users prefer entering a search query into a single text box for searching data. You have several ways to approach this use case, but full-text searches are a very common solution. In a full-text search, a search engine analyzes every single word in every single document in the database and comes up with matches that contain relevance scores. Different search engines calculate relevance in different ways, but generally speaking it involves measuring how closely a result matches a search query and how close the search terms are to each other in a particular result. A result that contains an exact phrase matching the search will have a higher relevance score than a result that merely contains all the words but not together.
Such a search can be far more expensive than simple LIKE comparisons, but specialized full-text indexes can make the task much more efficient. These indexes store every word that exists in the indexed data along with how many times each word appears (the most common words are weighted less important than the least common words) and which records it appears in, among other statistics and analysis. When a full-text search is performed, the database can quickly find matches using the index and then calculate the relevance of the results. This technique is so much more efficient than a brute-force full-text search that most databases require you to have a full-text index before you are allowed to perform a full-text search.
In this section you explore how to create full-text indexes in MySQL, how to use those indexes in a JPA repository, and how to make full-text searching more portable with other relational databases. You add full-text searching to the Customer Support project that you have been working on throughout the book, enabling your users and employees to easily search through your support tickets. You can follow along with the text in the Customer-Support-v17 project, available for download from the wrox.com code download site.
Creating Full-Text Indexes in MySQL Tables
MySQL, like most databases, requires a full-text index if you want to perform full-text searches. It has supported full-text indexes for more than 10 years as part of the MyISAM database engine, but during most of that time only MyISAM tables could house full-text indexes. This meant that you could create a transactional table (InnoDB), or a full-text-capable table (MyISAM), but you couldn’t create a table that was both transactional and full-text-capable. However, as of MySQL 5.6.4 you can now create full-text indexes in InnoDB tables, a feature thousands of users have been awaiting for years. This, finally, enables you to have fully ACID-compliant tables that also support full-text searching. This change in MySQL is not without its caveats, so you should keep these things in mind:
· MyISAM and InnoDB are different engines within the MySQL umbrella, so naturally their full-text implementations and algorithms are not identical. This is not to say that one is better than the other, but keep this in mind when switching from MyISAM to InnoDB. However, using full-text searching and indexing in MyISAM and InnoDB is syntactically identical.
· The InnoDB full-text engine is still very young. (Only 12 patch versions, 5.6.5 through 5.6.16, have been released since full-text support was added.) As such, it is bound to have bugs that have not yet been identified and fixed. Don’t let this stop you from using it, though! The community needs your help finding and reporting issues.
· Although MyISAM has 543 default stopwords (words that are filtered out from the index due to their commonness), InnoDB has only 36 default stopwords. Some people have complained for some time that MyISAM has too many stopwords, and this was addressed in InnoDB (without breaking backward compatibility for MyISAM users). The MySQL documentation provides instructions for adding to and removing from the stopword list for both engines.
· The relevance scores calculated by the InnoDB engine are completely different from those calculated by the MyISAM engine, so you cannot compare scores from a query run against a MyISAM table with scores from a query run against an InnoDB table. That wouldn’t be a good practice, anyway.
· The MyISAM ft_min_word_length configuration setting and the InnoDB innodb_ft_min_token_size configuration setting serve essentially the same purpose but default to different values. If you previously used MyISAM full-text search, you may want to alter theinnodb_ft_min_token_size setting to one that works well for you.
· Several critical InnoDB full-text bugs have been fixed lately. Make sure you are running at least MySQL 5.6.16, 5.7.3, or better!
If you are familiar with creating full-text indexes on MyISAM tables, the task is no different on InnoDB, except that you can add only one full-text index at a time. A table can have multiple full-text indexes, but for some reason they must be added in separate statements. For purposes of the Customer Support application, which you have been working on since Part I, you want ticket subjects, ticket bodies, and comment bodies to be indexed. Open MySQL Workbench and run the following statements, which create the necessary full-text indexes.
USE CustomerSupport;
ALTER TABLE Ticket ADD FULLTEXT INDEX Ticket_Search (Subject, Body);
ALTER TABLE TicketComment ADD FULLTEXT INDEX TicketComment_Search (Body);
If you have not used the Customer Support application in previous chapters, you should run the entire create.sql script provided with the downloaded project and create the appropriate DataSource resource in Tomcat’s context.xml configuration file.
NOTE When you create these full-text indexes, MySQL will issue a warning with the message, “124 InnoDB rebuilding table to add column FTS_DOC_ID.” Do not let this concern you; it is normal. MySQL adds a hidden column to full-text indexed InnoDB tables to uniquely identify each indexed record. You will never see this column, and it will not interfere with normal use of the table. If a table has multiple full-text indexes, MySQL adds only this one hidden column, and all indexes for that table share it.
Creating and Using a Searchable Repository
As before, you need to customize your repositories to make them searchable. This starts with a slightly different SearchableRepository than you used in the previous section. You also need a way to return not just the Ticket, but also its relevance to the result. This requires the use of a custom JPA result set mapping, something you have not done yet but will do in this section. For the purposes of returning the entity and the relevance, the new SearchResult class serves as a wrapper for both.
public class SearchResult<T>
{
private final T entity;
private final double relevance;
public SearchResult(T entity, double relevance)
{
this.entity = entity;
this.relevance = relevance;
}
// accessors
}
public interface SearchableRepository<T>
{
Page<SearchResult<T>> search(String query, boolean useBooleanMode,
Pageable pageable);
}
public interface TicketRepository extends JpaRepository<TicketEntity, Long>,
SearchableRepository<TicketEntity>
{
}
Searching with Native Queries and Custom Mappings
JPA doesn’t support full-text searching natively. There is no provision in the criteria API or JPQL for performing full-text searches. However, JPA does enable you to perform native queries. Native queries are executed directly in the database instead of being interpreted by the JPA provider like JPQL queries. As such, you must write native queries in the SQL syntax supported by your database vendor, not in JPQL syntax. You can use a native query to execute a full-text search on a database. Unfortunately, native queries are not TypedQuerys, but you can still provide the domain Class when creating them, so the provider still knows how to translate the result set into the correct entities.
In addition to this, you need to retrieve both the TicketEntity and a custom column, search relevance, from the database using just one query. This means that you can’t use a standard query with just the domain Class. Instead, you need to define a custom result set mapping that tells JPA what to do with the extra columns. This is achieved by marking the TicketEntity class with the @javax.persistence.SqlResultSetMapping annotation.
@Entity
@Table(name = "Ticket")
@SqlResultSetMapping(
name = "searchResultMapping.ticket",
entities = { @EntityResult(entityClass = TicketEntity.class) },
columns = { @ColumnResult(name = "_ft_scoreColumn", type = Double.class) }
)
public class TicketEntity implements Serializable
{
...
}
A custom result set mapping is named, and you reference that name when creating a query that should use the mapping. You can then use one or more of the entities, columns, and classes attributes to specify how the result set should map. Using entities, you can specify one or more managed JPA entities that should be mapped from the result. (So you could, for example, return multiple different entities using one query.) The columns attribute enables you to map individual columns to scalar values. In this case,_ft_scoreColumn maps to a Double. Finally, the classes attribute is an array of @javax.persistence.ConstructorResult annotations. Using this, you can map multiple scalar columns to the constructor of any class, and that class is constructed and returned using those columns.
@SqlResultSetMapping does not replace the mapping instructions for the entity it appears on. In fact, it doesn’t even have to appear on an entity that it maps — it just has to appear on some entity somewhere so that the JPA provider can discover the custom result set mapping. If you don’t want to use the annotation for this purpose, you can use XML mappings instead. The following XML is identical to the previous use of @SqlResultSetMapping:
<?xml version="1.0" encoding="UTF-8"?>
<entity-mappings xmlns="http://xmlns.jcp.org/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence/orm
http://xmlns.jcp.org/xml/ns/persistence/orm_2_1.xsd"
version="2.1">
<sql-result-set-mapping name="searchResultMapping.ticket">
<entity-result entity-class="com.wrox.site.entities.TicketEntity" />
<column-result name="_ft_scoreColumn" class="java.lang.Double" />
</sql-result-set-mapping>
</entity-mappings>
Normally you would place this XML in /META-INF/orm.xml. However, you can specify a different classpath location for this file using <mapping-file> in persistence.xml. You can also use Spring Framework’s LocalContainerEntityManagerFactoryBean to specify a different classpath location:
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactoryBean()
{
...
factory.setJpaPropertyMap(properties);
factory.setMappingResources("com/wrox/config/mappings.xml");
return factory;
}
The TicketRepositoryImpl implements the custom search method for searching tickets in the database. Notice that there is no AbstractSearchableJpaRepository as in the Advanced-Criteria project. Although you could make full-text searching a generic affair, it involves a lot of code and is extremely complicated. A generic repository needs to be aware of the table and schema for each entity, as well as the columns indexed in the full-text index. In addition, the query for searching the tickets isn’t your ordinary full-text search query. If it were, it would look something like this:
SELECT *, MATCH(Subject, Body) AGAINST('search phrase') AS _ft_scoreColumn
FROM Ticket
WHERE MATCH(Subject, Body) AGAINST('search phrase')
ORDER BY _ft_scoreColumn DESC, TicketId DESC;
In this case, however, the user wants to find matching tickets and tickets with matching comments, which requires a much more complicated query.
public class TicketRepositoryImpl implements SearchableRepository<TicketEntity>
{
@PersistenceContext EntityManager entityManager;
@Override
public Page<SearchResult<TicketEntity>> search(String query,
boolean useBooleanMode,
Pageable pageable)
{
String mode = useBooleanMode ?
"IN BOOLEAN MODE" : "IN NATURAL LANGUAGE MODE";
String matchTicket = "MATCH(t.Subject, t.Body) AGAINST(?1 " + mode + ")";
String matchComment = "MATCH(c.Body) AGAINST(?1 " + mode + ")";
long total = ((Number)this.entityManager.createNativeQuery(
"SELECT COUNT(DISTINCT t.TicketId) FROM Ticket t " +
"LEFT OUTER JOIN TicketComment c ON c.TicketId = " +
"t.TicketId WHERE " + matchTicket + " OR " + matchComment
).setParameter(1, query).getSingleResult()).longValue();
@SuppressWarnings("unchecked")
List<Object[]> results = this.entityManager.createNativeQuery(
"SELECT DISTINCT t.*, (" + matchTicket + " + " + matchComment +
") AS _ft_scoreColumn " +
"FROM Ticket t LEFT OUTER JOIN TicketComment c " +
"ON c.TicketId = t.TicketId " +
"WHERE " + matchTicket + " OR " + matchComment + " " +
"ORDER BY _ft_scoreColumn DESC, TicketId DESC",
"searchResultMapping.ticket"
).setParameter(1, query)
.setFirstResult(pageable.getOffset())
.setMaxResults(pageable.getPageSize())
.getResultList();
List<SearchResult<TicketEntity>> list = new ArrayList<>();
results.forEach(o -> list.add(
new SearchResult<>((TicketEntity)o[0], (Double)o[1])
));
return new PageImpl<>(list, pageable, total);
}
}
As you can see, the TicketRepositoryImpl handles not only searching, but also paging the results properly. The first query counts the matching tickets and tickets with matching comments, whereas the second query returns the appropriate tickets. The second query adds the relevance score of the ticket and the comments together so that tickets that match and also have comments that match have an increased score; then it sorts by that score descending. This also ensures that tickets that don’t match, but which have comments that match, are included at the appropriate location in the sort. For pagination to work properly, the order of results must be deterministic. Because it is possible for two records to share the same relevance, you should always add a backup sort. Sorting by the primary key descending is a great option, as newer results are typically more relevant to most users.
NOTE Don’t worry that the same MATCH criteria appear in both the SELECT and the WHERE clauses in the query. The MySQL query optimizer recognizes this and knows to evaluate them only once.
The list of results must be cast and unchecked warnings suppressed due to the lack of a TypedQuery. Because you use a custom result set mapping (notice how the second query references the searchResultMapping.ticket named result set mapping), the query returns a list of Object arrays. The Object arrays are the length of the number of mappings specified in the @SqlResultSetMapping annotation. Because you have two mappings (one for the TicketEntity entity and one for the Double scalar value), the Object arrays in the result Listeach contain two elements. The lambda expression in bold populates the result list with SearchResults created from those Object arrays.
Adding Search to the User Interface
You need to add a search method to the TicketService, which is a straightforward task. The bulk of the work is not significantly different from the getAllTickets and getComments methods.
public interface TicketService
{
...
Page<SearchResult<Ticket>> search(
@NotBlank(message = "{validate.ticketService.search.query}")
String query,
boolean useBooleanMode,
@NotNull(message = "{validate.ticketService.search.page}")
Pageable pageable
);
...
}
public class DefaultTicketService implements TicketService
{
...
@Override
@Transactional
public Page<SearchResult<Ticket>> search(String query, boolean useBooleanMode,
Pageable pageable)
{
List<SearchResult<Ticket>> list = new ArrayList<>();
Page<SearchResult<TicketEntity>> entities =
this.ticketRepository.search(query, useBooleanMode, pageable);
entities.forEach(r -> list.add(
new SearchResult<>(this.convert(r.getEntity()), r.getRelevance())
));
return new PageImpl<>(list, pageable, entities.getTotalElements());
}
...
}
NOTE The search method implementation must create a new set of SearchResult objects, which is unfortunate and reinforces the need to get rid of the DTO process and figure out how to persist the Ticket directly, mapping the Instant field and the attachments automatically. Don’t give up. You learn about this in the next chapter!
Adding search to the controller is equally easy. You just need a simple method for displaying the empty search form and another simple method for processing it. You also need the new SearchForm command object, which is just a POJO.
public class TicketController
{
...
@RequestMapping(value = "search")
public String search(Map<String, Object> model)
{
model.put("searchPerformed", false);
model.put("searchForm", new SearchForm());
return "ticket/search";
}
@RequestMapping(value = "search", params = "query")
public String search(Map<String, Object> model, @Valid SearchForm form,
Errors errors, Pageable pageable)
{
if(errors.hasErrors())
model.put("searchPerformed", false);
else
{
model.put("searchPerformed", true);
model.put("results", this.ticketService.search(
form.getQuery(), form.isUseBooleanMode(), pageable
));
}
return "ticket/search";
}
...
}
The view, /WEB-INF/jsp/view/ticket/search.jsp, is long but straightforward, so it isn’t printed here. It has a trivial form for providing a query and enabling Boolean search operators, paging just like you saw in the previous chapter, and listing just like in /WEB-INF/jsp/view/ticket/list.jsp. There’s also a new link to the search page in /WEB-INF/tags/template/basic.tag. The view displays each result’s relevance in its raw form, which isn’t very meaningful to most users. Making this value meaningful is an exercise left up to you.
Now you can give it a try! Compile the project and start Tomcat from your IDE. Log in to the support application at http://localhost:8080/support/ and make sure you have several tickets with different content so that your search doesn’t return everything. Then click the search link, enter a search phrase, and submit the form. Be sure to try searching for things that you know will return no results, too. You’re now searching records!
Making Full-Text Searching Portable
As written now, the search method in TicketRepositoryImpl is strictly MySQL-specific. It won’t work in any other relational database. So how do you make this method portable? Well, quite simply, you can’t — at least not completely. Not every relational database supports full-text searching, so you can never make this feature completely portable. Such is the case with many JPA features, however, like identity-generated IDs (which Oracle doesn’t support, for example). It is possible to have general portability, supporting all databases that support full-text searching.
Achieving this is no simple task. General things — such as executing the queries and handling pagination — could happen in a generic sense. But you would need a different implementation for generating the native SQL queries for each supported relational database. You would then have to either detect the underlying database somehow or require configuration of some type. (Not unreasonable — you almost always have to configure the Hibernate ORM dialect.) So before you go to this trouble, you have to ask yourself whether you actually need it. Realistically, you will usually work only with a single relational database in a particular application. If you switch or add another database, you can add support for its full-text searching as needed.
Alternatively, you could use the open source project JPA Native Full-Text Search (Maven artifact net.nicholaswilliams.java.jpa.search:fulltext-core). Its goal is to provide a generic, self-configuring JPA full-text integration that works across multiple databases and can support all your entities without you having to write any queries. However, it is still a very young project and needs contributors to support all the different SQL dialects and test all its features.
INDEXING ANY DATA WITH APACHE LUCENE AND HIBERNATE SEARCH
As you have seen so far, full-text search is an extremely powerful tool that can be indispensable to you and your users. However, it’s not always an option available to you. Perhaps you use a relational database that doesn’t support full-text searching, such as HyperSQL. Or maybe you use a combination of databases and want the search to be consistent across all of them. Perhaps you even use other storage options, such as XML or JSON files, or a NoSQL database that doesn’t support full-text search. It could even be that you simply don’t like the way the full-text search works in your database but don’t have the option of switching. Thankfully, there is no rule that you must use the full-text search tools provided by your database vendor. There are plenty of other options that can meet your searching needs. One of those is Apache Lucene.
Apache Lucene is an umbrella project, encompassing several open source search software projects. One of those is Lucene Core. Lucene Core is a Java-based search engine that also provides advanced tools, such as spell checking, hit highlighting, and advanced search analysis. It is arguably much more advanced and feature-rich than full-text search provided by most databases, and powers the search on sites such as Twitter, Apple, and Wikipedia.
Apache Solr is a search server powered by Lucene Core. It provides high-performance HTTP, XML, JSON, Ruby, and Python APIs, caching, replication, and a graphical server administration interface. You can use Lucene Core with or without Solr using its client Java API. Even better, using the Hibernate project Hibernate Search, you can integrate Lucene Core and JPA/Hibernate so that searches against the Lucene Core search engine return your JPA entities from wherever they are stored. You can use Hibernate Search with the Hibernate ORM API directly or with JPA, but only if Hibernate is your JPA provider. If you use some other JPA provider (such as OpenJPA or EclipseLink), you need to use the Lucene API directly.
For the rest of this chapter, you can follow along in the Search-Engine project, available for download from the wrox.com code download site. Wherever you see the term Lucene, you can assume it refers to Apache Lucene Core. Likewise, anywhere you see Solr refers to Apache Solr.
WARNING This book is presenting Apache Lucene only as an alternative to the other searching approaches detailed in this chapter. Lucene is a huge project with many facets, and it is outside the scope of this book to serve as a definitive guide on Lucene’s features or configuration. You get only a cursory look at the search engine and using it with Hibernate Search, and you should not use it in a production environment without considerably more research and understanding of how it works.
Understanding Lucene Full-Text Indexing
Lucene works in a simple CRUD fashion, much like the Java Persistence API and Hibernate ORM. Although you persist entities in JPA, you persist Lucene documents using Lucene’s API. These documents are not the same as the documents you persist in NoSQL document databases. A Lucene document contains only a document identifier and the data you want to be indexed. This document ID must somehow tie to the full entity from which it comes so that you can relate these pieces of data on retrieval. The common practice is to simply use the primary key of the entity as the document ID for the Lucene document.
In this sense, Lucene is very much an advanced full-text index to supplement your database’s capabilities. More important, its indexing and matching analysis capabilities are far beyond what most full-text indexes offer. It can identify words that sound alike, such as “through” and “thru” or “cat” and “kat,” and causes searches for one to match the other. It can also recognize related words and words with the same roots. For example, a search for “run” could also match “ran” and “running,” whereas a search for “there” might also match “their” and “they’re.”
Synonyms are another one of its strengths, where a search for “hop” can match results with “hop,” “jump,” and “leap” in the index. One of Lucene’s extremely useful features is its capability to spell-check queries and indexed data (when enabled), enabling it to suggest matches for misspelled queries and find results that might have misspelled matches in them. It does all this while sporting impressive performance statistics, which you can read about on its website.
Another great feature of Lucene is that you can configure its indexing to happen asynchronously. This means that your create, update, and delete actions are not slowed down by the full-text indexing process. This is a very useful capability that modern relational databases simply cannot offer with their full-text indexing.
When you use Apache Lucene on its own, you index data (and remove deleted data from the index) by calling the Lucene Java API. This applies whether you use Lucene within the same Java process (similar to an in-memory database) or use Solr as a Lucene search server. This book does not cover the Lucene API. Instead, you use Hibernate Search, which provides a simpler interface for indexing and searching JPA and Hibernate ORM entities. Hibernate ORM and Hibernate Search automatically index your entities in Lucene when you add and update them through JPA, and retrieve your persisted entities through JPA when you search for them in Lucene.
Annotating Entities with Indexing Metadata
Instead of manually configuring Lucene for indexing all your entities and managing the Lucene API each time you add or update an entity, you can annotate the entities you want indexed with Hibernate Search annotations so that Hibernate Search does all this for you. Just think of Lucene as the JDBC API and Hibernate Search as the O/RM for Lucene. The Search-Engine project represents an extremely primitive forum where users can post messages. It doesn’t have any reply capabilities. The User entity is obviously a simple entity. It contains only an ID and a username.
@Entity
@Table(name = "UserPrincipal")
public class User
{
private long id;
private String username;
@Id
@Column(name = "UserId")
@GeneratedValue(strategy = GenerationType.IDENTITY)
public long getId() { ... }
public void setId(long id) { ... }
@Basic
@Field
public String getUsername() { ... }
public void setUsername(String username) { ... }
}
This entity is just a standard JPA entity. In this case, you don’t actually need to perform full-text searches on the user entity, but you do need the ability to search for forum postings by the usernames of the users who created them. So how does that work? Take a look at the ForumPost entity.
@Entity
@Table(name = "Post")
@Indexed
public class ForumPost
{
private long id;
private User user;
private String title;
private String body;
private String keywords;
@Id
@DocumentId
@Column(name = "PostId")
@GeneratedValue(strategy = GenerationType.IDENTITY)
public long getId() { ... }
public void setId(long id) { ... }
@ManyToOne(fetch = FetchType.EAGER, optional = false)
@JoinColumn(name = "UserId")
@IndexedEmbedded
public User getUser() { ... }
public void setUser(User user) { ... }
@Basic
@Field
public String getTitle() { ... }
public void setTitle(String title) { ... }
@Lob
@Field
public String getBody() { ... }
public void setBody(String body) { ... }
@Basic
@Field(boost = @Boost(2.0F))
public String getKeywords() { ... }
public void setKeywords(String keywords) { ... }
}
ForumPost uses two JPA annotations that you haven’t learned about yet: @ManyToOne and @JoinColumn. You explore them more in the next chapter, but for now they are necessary to demonstrate Hibernate Search’s capabilities. This entity is also an@org.hibernate.search.annotations.Indexed entity. The @Indexed annotation indicates that this entity is eligible for full-text indexing. Hibernate Search automatically creates or updates the document for this entity whenever you add or save it. The@org.hibernate.search.annotations.DocumentId annotation tells Hibernate Search which property is the document ID. It is placed on the id property solely for demonstration purposes; if you leave it off, Hibernate Search automatically falls back to the property annotated @Id.
@org.hibernate.search.annotations.IndexedEmbedded is an annotation of interest. It tells Hibernate Search that the property is itself an entity with indexed fields that should be indexed as part of this document. This way, you can include the user property in your searches and find postings based on the users that made them.
The @org.hibernate.search.annotations.Field annotation is used on both the User and ForumPost entities. It marks a property as one that should be full-text indexed and eligible for searching, and it has many different attributes that can affect the way the property is indexed and stored. Understanding how to use these attributes requires the in-depth understanding of Lucene that this book does not include. In many cases the default values are very safe to go with. In the ForumPost entity, the keywords property is literally given an extra boost with the @org.hibernate.search.annotations.Boost annotation and the boost attribute. This specifies a factor by which the relevance score derived from the keywords property should be increased. In this case, the property contains user-specified keywords that the author feels best indicate the content of the posting. Therefore, it makes sense that keywords should have greater weight in the scores.
The create.sql file in the Search-Engine project creates the SearchEngine database and the necessary tables for these entities. It also populates the User table with several users. You should open MySQL Workbench and execute this script to create the database, and then create the following DataSource resource in Tomcat’s context.xml configuration file:
<Resource name="jdbc/SearchEngine" type="javax.sql.DataSource"
maxActive="20" maxIdle="5" maxWait="10000"
username="tomcatUser" password="password1234"
driverClassName="com.mysql.jdbc.Driver"
defaultTransactionIsolation="READ_COMMITTED"
url="jdbc:mysql://localhost/SearchEngine" />
Using Hibernate Search with JPA
When you have entities that are index-ready, you must configure Hibernate Search for indexing and use the Hibernate Search and Apache Lucene APIs to perform searches. Then it’s just a matter of creating another searchable repository using the Spring Data customization you should be very familiar with by now.
Configuring Hibernate Search
Configuring Hibernate Search is simple. You just need to add the following two properties (in bold) to the EntityManagerFactory you configure in the RootContextConfiguration class.
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactoryBean()
{
Map<String, Object> properties = new Hashtable<>();
properties.put("javax.persistence.schema-generation.database.action",
"none");
properties.put("hibernate.search.default.directory_provider",
"filesystem");
properties.put("hibernate.search.default.indexBase", "../searchIndexes");
HibernateJpaVendorAdapter adapter = new HibernateJpaVendorAdapter();
adapter.setDatabasePlatform("org.hibernate.dialect.MySQL5InnoDBDialect");
LocalContainerEntityManagerFactoryBean factory =
new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(adapter);
factory.setDataSource(this.searchEngineDataSource());
factory.setPackagesToScan("com.wrox.site.entities");
factory.setSharedCacheMode(SharedCacheMode.ENABLE_SELECTIVE);
factory.setValidationMode(ValidationMode.NONE);
factory.setJpaPropertyMap(properties);
return factory;
}
Adding these two properties did several things.
· It enabled Hibernate ORM’s use of Hibernate Search.
· It specified that the full-text indexing should use Lucene standalone (no Solr) and save indexes to the local filesystem.
· It specified ../searchIndexes (relative to the current directory) as the location for saving the full-text indexes.
Of course, this isn’t safe if you use a cluster of Tomcats or access these indexes from more than one JVM at a time. You can also use these and similar properties with different values to configure Hibernate Search to use a Solr server, thus making this safe for a clustered environment. For the purposes of testing locally, this configuration is sufficient.
Creating a Lucene Searchable Repository
Creating a Lucene search-enabled repository is certainly different but not really more difficult than the native full-text repository you created in the previous section. As is typical, you start off with some basic interfaces like SearchableRepository andForumPostRepository.
public interface SearchableRepository<T>
{
Page<SearchResult<T>> search(String query, Pageable pageable);
}
public interface ForumPostRepository extends JpaRepository<ForumPost, Long>,
SearchableRepository<ForumPost>
{
}
As usual, the hard work happens in ForumPostRepositoryImpl, as shown in Listing 23-2. One of the key things that makes this different is the use of the org.hibernate.search.jpa.FullTextEntityManager, the pivotal interface in the Hibernate Search JPA integration. It extends EntityManager to add full-text capabilities to it. Unlike the EntityManager that Spring Framework injects, which is really a thread-bound, transaction-linked EntityManager proxy that delegates to a new EntityManager for each new transaction, theFullTextEntityManager is the real thing. This means that you have to create a new instance each time the search method is called (which is really all that is happening behind the scenes when you use Spring’s injected EntityManager proxy). Furthermore, Hibernate Search can create a FullTextEntityManager only if it has access to the actual Hibernate ORM EntityManager implementation (as opposed to a wrapper or the proxy).
LISTING 23-2: ForumPostRepositoryImpl.java
public class ForumPostRepositoryImpl implements SearchableRepository<ForumPost>
{
@PersistenceContext EntityManager entityManager;
EntityManagerProxy entityManagerProxy;
@Override
public Page<SearchResult<ForumPost>> search(String query,
Pageable pageable)
{
FullTextEntityManager manager = this.getFullTextEntityManager();
QueryBuilder builder = manager.getSearchFactory().buildQueryBuilder()
.forEntity(ForumPost.class).get();
Query lucene = builder.keyword()
.onFields("title", "body", "keywords", "user.username")
.matching(query)
.createQuery();
FullTextQuery q = manager.createFullTextQuery(lucene, ForumPost.class);
q.setProjection(FullTextQuery.THIS, FullTextQuery.SCORE);
long total = q.getResultSize();
q.setFirstResult(pageable.getOffset())
.setMaxResults(pageable.getPageSize());
@SuppressWarnings("unchecked") List<Object[]> results = q.getResultList();
List<SearchResult<ForumPost>> list = new ArrayList<>();
results.forEach(o -> list.add(
new SearchResult<>((ForumPost)o[0], (Float)o[1])
));
return new PageImpl<>(list, pageable, total);
}
private FullTextEntityManager getFullTextEntityManager()
{
return Search.getFullTextEntityManager(
this.entityManagerProxy.getTargetEntityManager()
);
}
@PostConstruct
public void initialize()
{
if(!(this.entityManager instanceof EntityManagerProxy))
throw new FatalBeanException("Entity manager " + this.entityManager +
" was not a proxy");
this.entityManagerProxy = (EntityManagerProxy)this.entityManager;
}
}
NOTE If you were using the Hibernate API directly (and not JPA), you would use the org.hibernate.search.FullTextSession interface, which adds full-text features to org.hibernate.Session, instead of FullTextEntityManager.
To solve this problem, the initialize method first casts the EntityManager to an org.springframework.orm.jpa.EntityManagerProxy, an interface that the Spring-injected EntityManager implements. This method is called only once, but getFullTextEntityManager is called every time a FullTextEntityManager is needed, and only within a transaction. It calls getTargetEntityManager on the EntityManagerProxy to retrieve the actual Hibernate ORM EntityManager implementation. It then uses the org.hibernate.search.jpa.Search static methodgetFullTextEntityManager to get the FullTextEntityManager from the underlying EnityManager instance.
When the search method has a FullTextEntityManager, it creates an org.hibernate.search.query.dsl.QueryBuilder for the ForumPost entity. It then uses this builder to create an org.apache.lucene.search.Query for the query string supplied and the ForumPost fields you want to search. Notice the use of dot notation (the bold in Listing 23-2) to trigger searching the username field of the User entity in the user field. You can use the dot notation to nest as many levels deep as you need to into indexed embedded entities. Also note that you could use the Lucene API directly to create this query, instead of the QueryBuilder, if you wanted.
Next, the code retrieves an org.hibernate.search.jpa.FullTextQuery for the Lucene Query and the ForumPost entity. The FullTextQuery is a javax.persistence.Query capable of executing all the necessary Lucene and JPA queries. It sets the projections for the query, telling Hibernate Search to return the entity as the first element in an Object array (FullTextQuery.THIS) and the relevance score as the second element (FullTextQuery.SCORE) for each result in the result list. This is practically identical to the technique you used in the previous section to retrieve the entity and the score together.
Finally, the code gets the expected total result size, sets the pagination boundaries, gets the result list, and converts it to a Page of SearchResult<ForumPost>s. The only caveat to keep in mind is that Lucene does not participate in the JPA transaction, so it’s possible that the number of results can change between the call to getResultSize and getResultList.
Testing the Search Engine
The last step that you need to take before testing your Apache Lucene repository is to create a transactional service, controller, and user interface. The MainService and DefaultMainService are extremely simple, and really serve only as a @Transactional-marked pass-through between the controller and the repository. The MainController is equally simple. It forgoes many of the validation and checking routines that you are used to because this is just a test of Lucene’s searching capabilities. It responds to requests for the homepage with a simple form for creating new forum postings in the view /WEB-INF/jsp/view/add.jsp. The controller methods that handle searching should look very familiar to you because they are nearly identical to those in the TicketController from the Customer Support application. Finally, the /WEB-INF/jsp/view/search.jsp view handles displaying the search form, search results, and paging, also in a fashion very similar to the Customer Support application.
Now that you have reviewed the rest of this code, take the following steps to test it out:
1. Compile the application and start Tomcat from your IDE. You should see the Lucene index files directory appear in the Tomcat home directory (likely C:\Program Files\Apache Software Foundation\Tomcat 8.0 if you use Windows).
2. Go to http://localhost:8080/forums/ in your favorite browser and create several forum postings first. Alternate the usernames you supply for each posting between Nicholas, Sarah, Mike, and John. These are the users prepopulated in the database you created earlier.
3. After you create several postings with varying content, click the search link and try some different search queries. Make sure you also search for one or two usernames to find postings by those users.
SUMMARY
You covered a great deal of material in this chapter. You learned about some basic concepts of searching and indexing data, and explored how you can create extremely complex queries using the JPA criteria API. You were introduced to the concept of full-text searching, and learned how to create full-text indexes in MySQL and execute full-text searches using JPA. You also explored Apache Lucene and Hibernate Search, and created indexed entities and a repository capable of searching for those entities using a Lucene full-text index. It’s important to note that you really only scratched the surface with Apache Lucene and Hibernate Search. Many hundreds of pages could be written about their use and capabilities, and hopefully this chapter has spurred your interest to research those topics further.
The next chapter wraps up the Java Persistence API topics. You learn how to create some complex mappings and finally include those Java 8 Date and Time types in your entities using JPA converters. You also learn about those @ManyToOne and @JoinTable annotations you saw in the last section of this chapter.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.