Ansible for DevOps: Server and configuration management for humans (2015)
Chapter 8 - Ansible Cookbooks
Most of the book up to this point has demonstrated individual aspects of Ansible—inventory, playbooks, ad-hoc tasks, etc.—but this chapter will start to synthesize everything and show how Ansible is applied to real-world infrastructure management scenarios.
Highly-Available Infrastructure with Ansible
Real-world web applications require redundancy and horizontal scalability with multi-server infrastructure. In the following example, we’ll use Ansible to configure a complex infrastructure (illustrated below) on servers provisioned either locally via Vagrant and VirtualBox, or on a set of automatically-provisioned instances running on either DigitalOcean or Amazon Web Services:
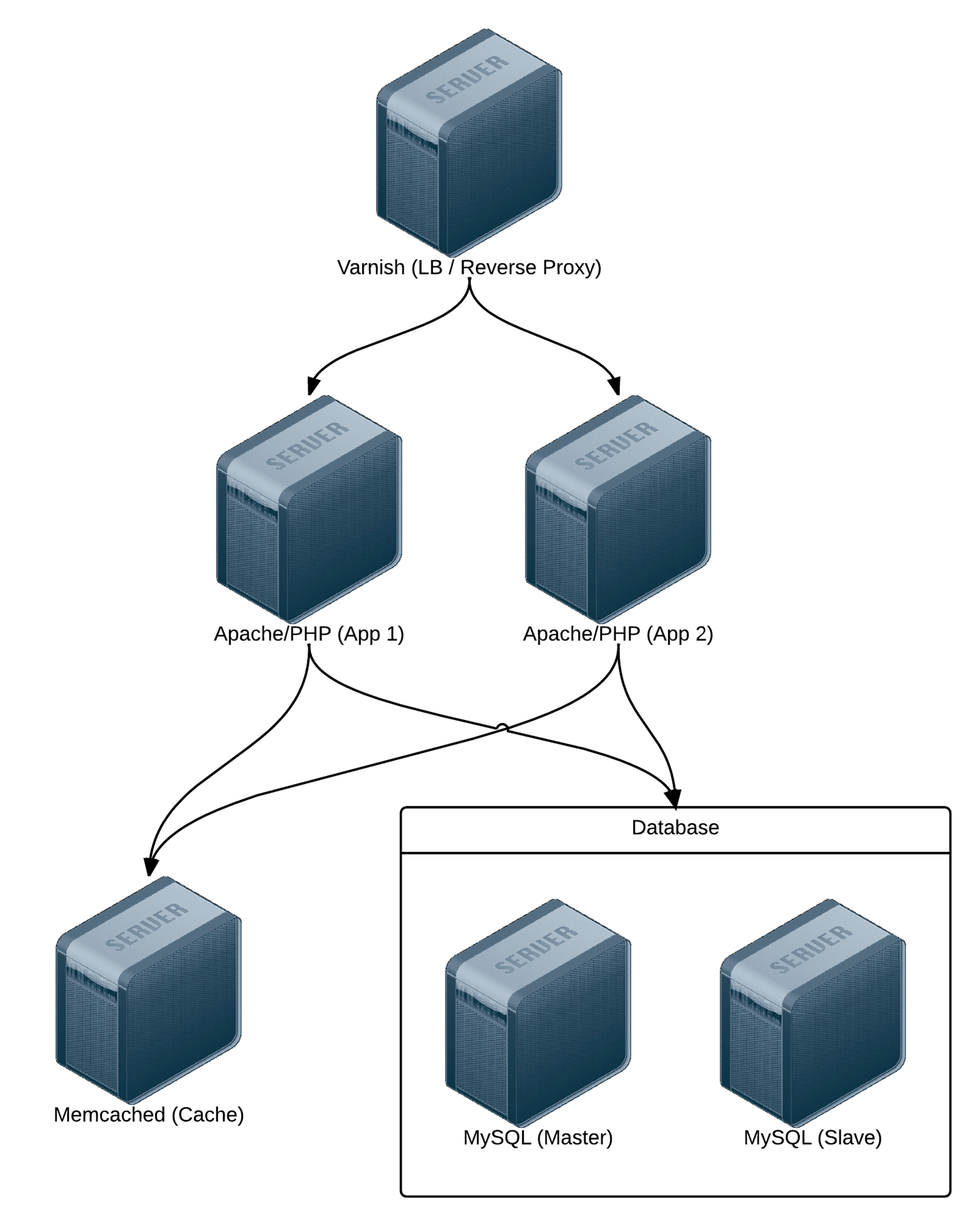
Highly-Available Infrastructure.
Varnish acts as a load balancer and reverse proxy, fronting web requests and routing them to the application servers. We could just as easily use something like Nginx or HAProxy, or even a proprietary cloud-based solution like an Amazon’s Elastic Load Balancer or Linode’s NodeBalancer, but for simplicity’s sake, and for flexibility in deployment, we’ll use Varnish.
Apache and mod_php run a PHP-based application that displays the entire stack’s current status and outputs the current server’s IP address for load balancing verification.
A Memcached server provides a caching layer that can be used to store and retrieve frequently-accessed objects in lieu of slower database storage.
Two MySQL servers, configured as a master and slave, offer redundant and performant database access; all data will be replicated from the master to the slave, and the slave can also be used as a secondary server for read-only queries to take some load off the master.
Directory Structure
In order to keep our configuration organized, we’ll use the following structure for our playbooks and configuration:
lamp-infrastructure/
inventories/
playbooks/
db/
memcached/
varnish/
www/
provisioners/
configure.yml
provision.yml
requirements.txt
Vagrantfile
Organizing things this way allows us to focus on each server configuration individually, then build playbooks for provisioning and configuring instances on different hosting providers later. This organization also keeps server playbooks completely independent, so we can modularize and reuse individual server configurations.
Individual Server Playbooks
Let’s start building our individual server playbooks (in the playbooks directory). To make our playbooks more efficient, we’ll use some contributed Ansible roles on Ansible Galaxy rather than install and configure everything step-by-step. We’re going to target CentOS 6.x servers in these playbooks, but only minimal changes would be required to use the playbooks with Ubuntu, Debian, or later versions of CentOS.
Varnish
Create a main.yml file within the the playbooks/varnish directory, with the following contents:
1 ---
2 - hosts: lamp-varnish
3 sudo: yes
4
5 vars_files:
6 - vars.yml
7
8 roles:
9 - geerlingguy.firewall
10 - geerlingguy.repo-epel
11 - geerlingguy.varnish
12
13 tasks:
14 - name: Copy Varnish default.vcl.
15 template:
16 src: "templates/default.vcl.j2"
17 dest: "/etc/varnish/default.vcl"
18 notify: restart varnish
We’re going to run this playbook on all hosts in the lamp-varnish inventory group (we’ll create this later), and we’ll run a few simple roles to configure the server:
· geerlingguy.firewall configures a simple iptables-based firewall using a couple variables defined in vars.yml.
· geerlingguy.repo-epel adds the EPEL repository (a prerequisite for varnish).
· geerlingguy.varnish installs and configures Varnish.
Finally, a task copies over a custom default.vcl that configures Varnish, telling it where to find our web servers and how to load balance requests between the servers.
Let’s create the two files referenced in the above playbook. First, vars.yml, in the same directory as main.yml:
1 ---
2 firewall_allowed_tcp_ports:
3 - "22"
4 - "80"
5
6 varnish_use_default_vcl: false
The first variable tells the geerlingguy.firewall role to open TCP ports 22 and 80 for incoming traffic. The second variable tells the geerlingguy.varnish we will supply a custom default.vcl for Varnish configuration.
Create a templates directory inside the playbooks/varnish directory, and inside, create a default.vcl.j2 file. This file will use Jinja2 syntax to build Varnish’s custom default.vcl file:
1 vcl 4.0;
2
3 import directors;
4
5 {% for host in groups['lamp-www'] %}
6 backend www{{ loop.index }} {
7 .host = "{{ host }}";
8 .port = "80";
9 }
10 {% endfor %}
11
12 sub vcl_init {
13 new vdir = directors.random();
14 {% for host in groups['lamp-www'] %}
15 vdir.add_backend(www{{ loop.index }}, 1);
16 {% endfor %}
17 }
18
19 sub vcl_recv {
20 set req.backend_hint = vdir.backend();
21
22 # For testing ONLY; makes sure load balancing is working correctly.
23 return (pass);
24 }
We won’t study Varnish’s VCL syntax in depth but we’ll run through default.vcl and highlight what is being configured:
1. (1-3) Indicate that we’re using the 4.0 version of the VCL syntax and import the directors varnish module (which is used to configure load balancing).
2. (5-10) Define each web server as a new backend; give a host and a port through which varnish can contact each host.
3. (12-17) vcl_init is called when Varnish boots and initializes any required varnish modules. In this case, we’re configuring a load balancer vdir, and adding each of the www[#] backends we defined earlier as backends to which the load balancer will distribute requests. We use a random director so we can easily demonstrate Varnish’s ability to distribute requests to both app backends, but other load balancing strategies are also available.
4. (19-24) vcl_recv is called for each request, and routes the request through Varnish. In this case, we route the request to the vdir backend defined in vcl_init, and indicate that Varnish should not cache the result.
According to #4, we’re actually bypassing Varnish’s caching layer, which is not helpful in a typical production environment. If you only need a load balancer without any reverse proxy or caching capabilities, there are better options. However, we need to verify our infrastructure is working as it should. If we used Varnish’s caching, Varnish would only ever hit one of our two web servers during normal testing.
In terms of our caching/load balancing layer, this should suffice. For a true production environment, you should remove the final return (pass) and customize default.vcl according to your application’s needs.
Apache / PHP
Create a main.yml file within the the playbooks/www directory, with the following contents:
1 ---
2 - hosts: lamp-www
3 sudo: yes
4
5 vars_files:
6 - vars.yml
7
8 roles:
9 - geerlingguy.firewall
10 - geerlingguy.repo-epel
11 - geerlingguy.apache
12 - geerlingguy.php
13 - geerlingguy.php-mysql
14 - geerlingguy.php-memcached
15
16 tasks:
17 - name: Remove the Apache test page.
18 file:
19 path: /var/www/html/index.html
20 state: absent
21 - name: Copy our fancy server-specific home page.
22 template:
23 src: templates/index.php.j2
24 dest: /var/www/html/index.php
As with Varnish’s configuration, we’ll configure a firewall and add the EPEL repository (required for PHP’s memcached integration), and we’ll also add the following roles:
· geerlingguy.apache installs and configures the latest available version of the Apache web server.
· geerlingguy.php installs and configures PHP to run through Apache.
· geerlingguy.php-mysql adds MySQL support to PHP.
· geerlingguy.php-memcached adds Memcached support to PHP.
Two final tasks remove the default index.html home page included with Apache, and replace it with our PHP app.
As in the Varnish example, create the two files referenced in the above playbook. First, vars.yml, alongside main.yml:
1 ---
2 firewall_allowed_tcp_ports:
3 - "22"
4 - "80"
Create a templates directory inside the playbooks/www directory, and inside, create an index.php.j2 file. This file will use Jinja2 syntax to build a (relatively) simple PHP script to display the health and status of all the servers in our infrastructure:
1 <?php
2 /**
3 * @file
4 * Infrastructure test page.
5 *
6 * DO NOT use this in production. It is simply a PoC.
7 */
8
9 $mysql_servers = array(
10 {% for host in groups['lamp-db'] %}
11 '{{ host }}',
12 {% endfor %}
13 );
14 $mysql_results = array();
15 foreach ($mysql_servers as $host) {
16 if ($result = mysql_test_connection($host)) {
17 $mysql_results[$host] = '<span style="color: green;">PASS</span>';
18 $mysql_results[$host] .= ' (' . $result['status'] . ')';
19 }
20 else {
21 $mysql_results[$host] = '<span style="color: red;">FAIL</span>';
22 }
23 }
24
25 // Connect to Memcached.
26 $memcached_result = '<span style="color: red;">FAIL</span>';
27 if (class_exists('Memcached')) {
28 $memcached = new Memcached;
29 $memcached->addServer('{{ groups['lamp-memcached'][0] }}', 11211);
30
31 // Test adding a value to memcached.
32 if ($memcached->add('test', 'success', 1)) {
33 $result = $memcached->get('test');
34 if ($result == 'success') {
35 $memcached_result = '<span style="color: green;">PASS</span>';
36 $memcached->delete('test');
37 }
38 }
39 }
40
41 /**
42 * Connect to a MySQL server and test the connection.
43 *
44 * @param string $host
45 * IP Address or hostname of the server.
46 *
47 * @return array
48 * Array with keys 'success' (bool) and 'status' ('slave' or 'master').
49 * Empty if connection failure.
50 */
51 function mysql_test_connection($host) {
52 $username = 'mycompany_user';
53 $password = 'secret';
54 try {
55 $db = new PDO(
56 'mysql:host=' . $host . ';dbname=mycompany_database',
57 $username,
58 $password,
59 array(PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION));
60
61 // Query to see if the server is configured as a master or slave.
62 $statement = $db->prepare("SELECT variable_value
63 FROM information_schema.global_variables
64 WHERE variable_name = 'LOG_BIN';");
65 $statement->execute();
66 $result = $statement->fetch();
67
68 return array(
69 'success' => TRUE,
70 'status' => ($result[0] == 'ON') ? 'master' : 'slave',
71 );
72 }
73 catch (PDOException $e) {
74 return array();
75 }
76 }
77 ?>
78 <!DOCTYPE html>
79 <html>
80 <head>
81 <title>Host {{ inventory_hostname }}</title>
82 <style>* { font-family: Helvetica, Arial, sans-serif }</style>
83 </head>
84 <body>
85 <h1>Host {{ inventory_hostname }}</h1>
86 <?php foreach ($mysql_results as $host => $result): ?>
87 <p>MySQL Connection (<?php print $host; ?>): <?php print $result; ?></p>
88 <?php endforeach; ?>
89 <p>Memcached Connection: <?php print $memcached_result; ?></p>
90 </body>
91 </html>
|
|
Don’t try transcribing this example manually; you can get the code from this book’s repository on GitHub. Visit the ansible-for-devops repository and download the source for index.php.j2 |

As this is the heart of the example application we’re deploying to the infrastructure, it’s necessarily a bit more complex than most examples in the book, but a quick run through follows:
· (9-23) Iterate through all the lamp-db MySQL hosts defined in the playbook inventory, and test the ability to connect to them, and whether they are configured as master or slave, using the mysql_test_connection() function defined later (40-73).
· (25-39) Check the first defined lamp-memcached Memcached host defined in the playbook inventory, confirming the ability to connect and create, retrieve, and delete a value from the cache.
· (41-76) Define the mysql_test_connection() function which tests the the ability to connect to a MySQL server and also returns its replication status.
· (78-91) Print the results of all the MySQL and Memcached tests, along with {{ inventory_hostname }} as the page title, so we can easily see which web server is serving the viewed page.
At this point, the heart of our infrastructure—the application that will test and display the status of all our servers—is ready to go.
Memcached
Compared to the earlier playbooks, the Memcached playbook is quite simple. Create playbooks/memcached/main.yml with the following contents:
1 ---
2 - hosts: lamp-memcached
3 sudo: yes
4
5 vars_files:
6 - vars.yml
7
8 roles:
9 - geerlingguy.firewall
10 - geerlingguy.memcached
As with the other servers, we need to ensure only the required TCP ports are open using the simple geerlingguy.firewall role. Next we install Memcached using the geerlingguy.memcached role.
In our vars.yml file (again, alongside main.yml), add the following:
1 ---
2 firewall_allowed_tcp_ports:
3 - "22"
4 firewall_additional_rules:
5 - "iptables -A INPUT -p tcp --dport 11211 -s {{ groups['lamp-www'][0] }} -j AC\
6 CEPT"
7 - "iptables -A INPUT -p tcp --dport 11211 -s {{ groups['lamp-www'][1] }} -j AC\
8 CEPT"
We need port 22 open for remote access, and for Memcached, we’re adding manual iptables rules to allow access on port 11211 for the web servers only. We add one rule per lamp-www server by drilling down into each item in the the generated groups variable that Ansible uses to track all inventory groups currently available.
|
|
The principle of least privilege “requires that in a particular abstraction layer of a computing environment, every module … must be able to access only the information and resources that are necessary for its legitimate purpose” (Source: Wikipedia). Always restrict services and ports to only those servers or users that need access! |

MySQL
The MySQL configuration is more complex than the other servers because we need to configure MySQL users per-host and configure replication. Because we want to maintain an independent and flexible playbook, we also need to dynamically create some variables so MySQL will get the right server addresses in any potential environment.
Let’s first create the main playbook, playbooks/db/main.yml:
1 ---
2 - hosts: lamp-db
3 sudo: yes
4
5 vars_files:
6 - vars.yml
7
8 pre_tasks:
9 - name: Create dynamic MySQL variables.
10 set_fact:
11 mysql_users:
12 - {
13 name: mycompany_user,
14 host: "{{ groups['lamp-www'][0] }}",
15 password: secret,
16 priv: "*.*:SELECT"
17 }
18 - {
19 name: mycompany_user,
20 host: "{{ groups['lamp-www'][1] }}",
21 password: secret,
22 priv: "*.*:SELECT"
23 }
24 mysql_replication_master: "{{ groups['a4d.lamp.db.1'][0] }}"
25
26 roles:
27 - geerlingguy.firewall
28 - geerlingguy.mysql
Most of the playbook is straightforward, but in this instance, we’re using set_fact as a pre_task (to be run before the geerlingguy.firewall and geerlingguy.mysql roles) to dynamically create variables for MySQL configuration.
set_fact allows us to define variables at runtime, so we can are guaranteed to have all server IP addresses available, even if the servers were freshly provisioned at the beginning of the playbook’s run. We’ll create two variables:
· mysql_users is a list of users the geerlingguy.mysql role will create when it runs. This variable will be used on all database servers so both of the two lamp-www servers get SELECT privileges on all databases.
· mysql_replication_master is used to indicate to the geerlingguy.mysql role which database server is the master; it will perform certain steps differently depending on whether the server being configured is a master or slave, and ensure that all the slaves are configured to replicate data from the master.
We’ll need a few other normal variables to configure MySQL, so we’ll add them alongside the firewall variable in playbooks/db/vars.yml:
1 ---
2 firewall_allowed_tcp_ports:
3 - "22"
4 - "3306"
5
6 mysql_replication_user: {name: 'replication', password: 'secret'}
7 mysql_databases:
8 - { name: mycompany_database, collation: utf8_general_ci, encoding: utf8 }
We’re opening port 3306 to anyone, but according to the principle of least privilege discussed earlier, you would be justified in restricting this port to only the servers and users that need access to MySQL (similar to the memcached server configuration). In this case, the attack vector is mitigated because MySQL’s own authentication layer is used through the mysql_user variable generated in main.yml.
We are defining two MySQL variables, mysql_replication_user to be used as for master and slave replication, and mysql_databases to define a list of databases that will be created (if they don’t already exist) on the database servers.
With the configuration of the database servers complete, the server-specific playbooks are ready to go.
Main Playbook for Configuring All Servers
A simple playbook including each of the group-specific playbooks is all we need for the overall configuration to take place. Create configure.yml in the project’s root directory, with the following contents:
1 ---
2 - include: playbooks/varnish/main.yml
3 - include: playbooks/www/main.yml
4 - include: playbooks/db/main.yml
5 - include: playbooks/memcached/main.yml
At this point, if you had some already-booted servers and statically defined inventory groups like lamp-www, lamp-db, etc., you could run ansible-playbook configure.yml and you’d have a full HA infrastructure at the ready!
But we’re going to continue to make our playbooks more flexible and useful.
Getting the required roles
As mentioned in the Chapter 6, Ansible allows you to define all the required Ansible Galaxy roles for a given project in a requirements.txt file. Instead of having to remember to run ansible-galaxy install -y [role1] [role2] [role3] for each of the roles we’re using, we can create requirements.txt in the root of our project, with the following contents:
1 geerlingguy.firewall
2 geerlingguy.repo-epel
3 geerlingguy.varnish
4 geerlingguy.apache
5 geerlingguy.php
6 geerlingguy.php-mysql
7 geerlingguy.php-memcached
8 geerlingguy.mysql
9 geerlingguy.memcached
To make sure all the required dependencies are installed, run ansible-galaxy install -r requirements.txt from within the project’s root.
Vagrantfile for Local Infrastructure via VirtualBox
As with many other examples in this book, we can use Vagrant and VirtualBox to build and configure the infrastructure locally. This lets us test things as much as we want with zero cost, and usually results in faster testing cycles, since everything is orchestrated over a local private network on a (hopefully) beefy workstation.
Our basic Vagrantfile layout will be something like the following:
1. Define a base box (in this case, CentOS 6.x) and VM hardware defaults.
2. Define all the VMs to be built, with VM-specific IP addresses and hostname configurations.
3. Define the Ansible provisioner along with the last VM, so Ansible can run once at the end of Vagrant’s build cycle.
Here’s the Vagrantfile in all its glory:
1 # -*- mode: ruby -*-
2 # vi: set ft=ruby :
3
4 Vagrant.configure("2") do |config|
5 # Base VM OS configuration.
6 config.vm.box = "geerlingguy/centos6"
7 config.ssh.insert_key = false
8
9 # General VirtualBox VM configuration.
10 config.vm.provider :virtualbox do |v|
11 v.customize ["modifyvm", :id, "--memory", 512]
12 v.customize ["modifyvm", :id, "--cpus", 1]
13 v.customize ["modifyvm", :id, "--natdnshostresolver1", "on"]
14 v.customize ["modifyvm", :id, "--ioapic", "on"]
15 end
16
17 # Varnish.
18 config.vm.define "varnish" do |varnish|
19 varnish.vm.hostname = "varnish.dev"
20 varnish.vm.network :private_network, ip: "192.168.2.2"
21 end
22
23 # Apache.
24 config.vm.define "www1" do |www1|
25 www1.vm.hostname = "www1.dev"
26 www1.vm.network :private_network, ip: "192.168.2.3"
27
28 www1.vm.provision "shell",
29 inline: "sudo yum update -y"
30
31 www1.vm.provider :virtualbox do |v|
32 v.customize ["modifyvm", :id, "--memory", 256]
33 end
34 end
35
36 # Apache.
37 config.vm.define "www2" do |www2|
38 www2.vm.hostname = "www2.dev"
39 www2.vm.network :private_network, ip: "192.168.2.4"
40
41 www2.vm.provision "shell",
42 inline: "sudo yum update -y"
43
44 www2.vm.provider :virtualbox do |v|
45 v.customize ["modifyvm", :id, "--memory", 256]
46 end
47 end
48
49 # MySQL.
50 config.vm.define "db1" do |db1|
51 db1.vm.hostname = "db1.dev"
52 db1.vm.network :private_network, ip: "192.168.2.5"
53 end
54
55 # MySQL.
56 config.vm.define "db2" do |db2|
57 db2.vm.hostname = "db2.dev"
58 db2.vm.network :private_network, ip: "192.168.2.6"
59 end
60
61 # Memcached.
62 config.vm.define "memcached" do |memcached|
63 memcached.vm.hostname = "memcached.dev"
64 memcached.vm.network :private_network, ip: "192.168.2.7"
65
66 # Run Ansible provisioner once for all VMs at the end.
67 memcached.vm.provision "ansible" do |ansible|
68 ansible.playbook = "configure.yml"
69 ansible.inventory_path = "inventories/vagrant/inventory"
70 ansible.limit = "all"
71 ansible.extra_vars = {
72 ansible_ssh_user: 'vagrant',
73 ansible_ssh_private_key_file: "~/.vagrant.d/insecure_private_key"
74 }
75 end
76 end
77 end
Most of the Vagrantfile is straightforward, and similar to other examples used in this book. The last block of code, which defines the ansible provisioner configuration, contains three extra values that are important for our purposes:
1 ansible.inventory_path = "inventories/vagrant/inventory"
2 ansible.limit = "all"
3 ansible.extra_vars = {
4 ansible_ssh_user: 'vagrant',
5 ansible_ssh_private_key_file: "~/.vagrant.d/insecure_private_key"
6 }
1. ansible.inventory_path defines an inventory file to be used with the ansible.playbook. You could certainly create a dynamic inventory script for use with Vagrant, but because we know the IP addresses ahead of time, and are expecting a few specially-crafted inventory group names, it’s simpler to build the inventory file for Vagrant provisioning by hand (we’ll do this next).
2. ansible.limit is set to all so Vagrant knows it should run the Ansible playbook connected to all VMs, and not just the current VM. You could technically use ansible.limit with a provisioner configuration for each of the individual VMs, and just run the VM-specific playbook through Vagrant, but our live production infrastructure will be using one playbook to configure all the servers, so we’ll do the same locally.
3. ansible.extra_vars contains the vagrant SSH user configuration for Ansible. It’s more standard to include these settings in a static inventory file or use Vagrant’s automatically-generated inventory file, but it’s easiest to set them once for all servers here.
Before running vagrant up to see the fruits of our labor, we need to create an inventory file for Vagrant at inventories/vagrant/inventory:
1 [lamp-varnish]
2 192.168.2.2
3
4 [lamp-www]
5 192.168.2.3
6 192.168.2.4
7
8 [a4d.lamp.db.1]
9 192.168.2.5
10
11 [lamp-db]
12 192.168.2.5
13 192.168.2.6
14
15 [lamp-memcached]
16 192.168.2.7
Now cd into the project’s root directory, run vagrant up, and after ten or fifteen minutes, load http://192.168.2.2/ in your browser. Voila!

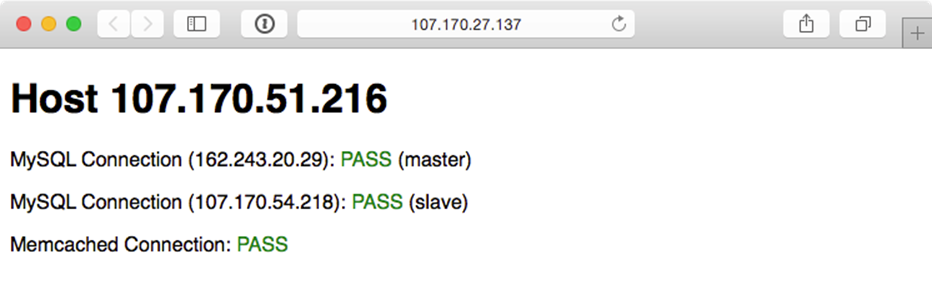
Highly Available Infrastructure - Success!
You should see something like the above screenshot; the PHP app displays the current app server’s IP address, the individual MySQL servers’ status, and the Memcached server status. Refresh the page a few times to verify Varnish is distributing requests randomly between the two app servers.
We have local infrastructure development covered, and Ansible makes it easy to use the exact same configuration to build our infrastructure in the cloud.
Provisioner Configuration: DigitalOcean
In Chapter 7, we learned provisioning and configuring DigitalOcean droplets in an Ansible playbook is fairly simple. But we need to take provisioning a step further by provisioning multiple droplets (one for each server in our infrastructure) and dynamically grouping them so we can configure them after they are booted and online.
For the sake of flexibility, let’s create a playbook for our DigitalOcean droplets in provisioners/digitalocean.yml. This will allow us to add other provisioner configurations later, alongside the digitalocean.yml playbook. As with our example in Chapter 7, we will use a local connection to provision cloud instances. Begin the playbook with:
1 ---
2 - hosts: localhost
3 connection: local
4 gather_facts: false
Next we need to define some metadata to describe each of our droplets. For simplicity’s sake, we’ll inline the droplets variable in this playbook:
6 vars:
7 droplets:
8 - { name: a4d.lamp.varnish, group: "lamp-varnish" }
9 - { name: a4d.lamp.www.1, group: "lamp-www" }
10 - { name: a4d.lamp.www.2, group: "lamp-www" }
11 - { name: a4d.lamp.db.1, group: "lamp-db" }
12 - { name: a4d.lamp.db.2, group: "lamp-db" }
13 - { name: a4d.lamp.memcached, group: "lamp-memcached" }
Each droplet is an object with two keys:
· name: The name of the Droplet for DigitalOcean’s listings and Ansible’s host inventory.
· group: The Ansible inventory group for the droplet.
Next we need to add a task to create the droplets, using the droplets list as a guide, and as part of the same task, register each droplet’s information in a separate dictionary, created_droplets:
15 tasks:
16 - name: Provision DigitalOcean droplets.
17 digital_ocean:
18 state: "{{ item.state | default('present') }}"
19 command: droplet
20 name: "{{ item.name }}"
21 private_networking: yes
22 size_id: "{{ item.size | default(66) }}" # 512mb
23 image_id: "{{ item.image | default(6372108) }}" # CentOS 6 x64.
24 region_id: "{{ item.region | default(4) }}" # NYC2
25 ssh_key_ids: "{{ item.ssh_key | default('138954') }}" # geerlingguy
26 unique_name: yes
27 register: created_droplets
28 with_items: droplets
Many of the options (e.g. size_id) are defined as {{ item.property | default('default_value') }}, which allows us to use optional variables per droplet. For any of the defined droplets, we could add size_id: 72 (or whatever valid value you’d like), and it would override the default value set in the task.
|
|
You could specify an SSH public key per droplet, or (as in this instance) use the same key for all hosts by providing a default. In this case, I added an SSH key to my DigitalOcean account, then used the DigitalOcean API to retrieve the key’s numeric ID (as described in the previous chapter). It’s best to use key-based authentication and add at least one SSH key to your DigitalOcean account so Ansible can connect using keys instead of insecure passwords, especially since these instances will be created with only a root account. |
We loop through all the defined droplets using with_items: droplets, and after each droplet is created add the droplet’s metadata (name, IP address, etc.) to the created_droplets variable. Next, we’ll loop through that variable to build our inventory on-the-fly so our configuration applies to the correct servers:
30 - name: Add DigitalOcean hosts to their respective inventory groups.
31 add_host:
32 name: "{{ item.1.droplet.ip_address }}"
33 groups: "do,{{ droplets[item.0].group }},{{ item.1.droplet.name }}"
34 # You can dynamically add inventory variables per-host.
35 ansible_ssh_user: root
36 mysql_replication_role: >
37 "{{ 'master' if (item.1.droplet.name == 'a4d.lamp.db.1')
38 else 'slave' }}"
39 mysql_server_id: "{{ item.0 }}"
40 when: item.1.droplet is defined
41 with_indexed_items: created_droplets.results
You’ll notice a few interesting things happening in this task:
· This is the first time we’ve used with_indexed_items. The reason for using this less-common loop feature is to add a sequential and unique mysql_server_id. Though only the MySQL servers need a server ID set, it’s simplest to dynamically create the variable for every server, so it’s available when needed. with_indexed_items sets item.0 to the key of the item, and item.1 to the value of the item.
· with_indexed_items also helps us reliably set each droplet’s group. Because the v1 DigitalOcean API doesn’t support features like tags for Droplets, we need to set up the groups on our own. Using the droplets variable we manually created earlier allows us to set the proper group for a particular droplet.
· Finally we add inventory variables per-host in add_host by adding the variable name as a key, and the variable value as the key’s value. Simple, but powerful!
|
|
There are a few different ways you can approach dynamic provisioning and inventory management for your infrastructure, and, especially if you are only targeting one cloud hosting provider, there are ways to avoid using more exotic features of Ansible (e.g. with_indexed_items) and complex if/else conditions. This example is slightly more complex due to the fact that the playbook is being created to be interchangeable with other similar provisioning playbooks. |
The final step in our provisioning is to make sure all the droplets are booted and can be reached via SSH, so at the end of the digitalocean.yml playbook, add another play to be run on hosts in the do group we just defined:
43 - hosts: do
44 remote_user: root
45 gather_facts: no
46
47 tasks:
48 - name: Wait for port 22 to become available.
49 local_action: "wait_for port=22 host={{ inventory_hostname }}"
Once we know port 22 is reachable, we know the droplet is up and ready for configuration.
We’re almost ready to provision and configure our entire infrastructure on DigitalOcean, but we need to create one last playbook to tie everything together. Create provision.yml in the project root with the following contents:
1 ---
2 - include: provisioners/digitalocean.yml
3 - include: configure.yml
That’s it! Now, assuming you set the environment variables DO_CLIENT_ID and DO_API_KEY, you can run $ ansible-playbook provision.yml to provision and configure the infrastructure on DigitalOcean.
The entire process should take about 15 minutes, and once it’s complete, you should see something like:
PLAY RECAP *****************************************************************
107.170.27.137 : ok=19 changed=13 unreachable=0 failed=0
107.170.3.23 : ok=13 changed=8 unreachable=0 failed=0
107.170.51.216 : ok=40 changed=18 unreachable=0 failed=0
107.170.54.218 : ok=27 changed=16 unreachable=0 failed=0
162.243.20.29 : ok=24 changed=15 unreachable=0 failed=0
192.241.181.197 : ok=40 changed=18 unreachable=0 failed=0
localhost : ok=2 changed=1 unreachable=0 failed=0
Visit the IP address of the varnish server and you should be greeted with a status page similar to the one generated by the Vagrant-based infrastructure:
Highly Available Infrastructure on DigitalOcean.
Because everything in this playbook is idempotent, running $ ansible-playbook provision.yml again should report no changes, and helps you verify that everything is running correctly.
Ansible will also rebuild and reconfigure any droplets that may be missing from your infrastructure. If you’re daring, and want to test this feature, just log into your DigitalOcean account, delete one of the droplets just created by this playbook (maybe one of the two app servers), then run the playbook again.
Now that we’ve tested our infrastructure on DigitalOcean, we can destroy the droplets just as easily (change the state parameter in provisioners/digitalocean.yml to default to 'absent' and run $ ansible-playbook provision.ymlagain).
Next up, we’ll build the infrastructure a third time—on Amazon’s infrastructure.
Provisioner Configuration: Amazon Web Services (EC2)
For Amazon Web Services, provisioning works slightly different. Amazon has a broader ecosystem of services surrounding EC2 instances, and for our particular example, we will need to configure security groups prior to provisioning instances.
To begin, create aws.yml inside the provisioners directory and begin the playbook the same ways as with DigitalOcean:
1 ---
2 - hosts: localhost
3 connection: local
4 gather_facts: false
EC2 instances use security groups as an AWS-level firewall (which operates outside the individual instance’s OS). We will need to define a list of security_groups alongside our EC2 instances. First, the instances:
6 vars:
7 instances:
8 - {
9 name: a4d.lamp.varnish,
10 group: "lamp-varnish",
11 security_group: ["default", "a4d_lamp_http"]
12 }
13 - {
14 name: a4d.lamp.www.1,
15 group: "lamp-www",
16 security_group: ["default", "a4d_lamp_http"]
17 }
18 - {
19 name: a4d.lamp.www.2,
20 group: "lamp-www",
21 security_group: ["default", "a4d_lamp_http"]
22 }
23 - {
24 name: a4d.lamp.db.1,
25 group: "lamp-db",
26 security_group: ["default", "a4d_lamp_db"]
27 }
28 - {
29 name: a4d.lamp.db.2,
30 group: "lamp-db",
31 security_group: ["default", "a4d_lamp_db"]
32 }
33 - {
34 name: a4d.lamp.memcached,
35 group: "lamp-memcached",
36 security_group: ["default", "a4d_lamp_memcached"]
37 }
Inside the instances variable, each instance is an object with three keys:
· name: The name of the instance, which we’ll use to tag the instance and ensure only one instance is created per name.
· group: The Ansible inventory group in which the instance should belong.
· security_group: A list of security groups into which the instance will be placed. The default security group comes is added to your AWS account upon creation, and has one rule to allow outgoing traffic on any port to any IP address.
|
|
If you use AWS exclusively, it would be best to autoscaling groups and change the design of this infrastructure a bit. For this example, we just need to ensure that the six instances we explicitly define are created, so we’re using particular names and an exact_count to enforce the 1:1 relationship. |

With our instances defined, we’ll next define a security_groups variable containing all the required security group configuration for each server:
39 security_groups:
40 - name: a4d_lamp_http
41 rules:
42 - { proto: tcp, from_port: 80, to_port: 80, cidr_ip: 0.0.0.0/0 }
43 - { proto: tcp, from_port: 22, to_port: 22, cidr_ip: 0.0.0.0/0 }
44 rules_egress: []
45 - name: a4d_lamp_db
46 rules:
47 - { proto: tcp, from_port: 3306, to_port: 3306, cidr_ip: 0.0.0.0/0 }
48 - { proto: tcp, from_port: 22, to_port: 22, cidr_ip: 0.0.0.0/0 }
49 rules_egress: []
50 - name: a4d_lamp_memcached
51 rules:
52 - { proto: tcp, from_port: 11211, to_port: 11211, cidr_ip: 0.0.0.0/0 }
53 - { proto: tcp, from_port: 22, to_port: 22, cidr_ip: 0.0.0.0/0 }
54 rules_egress: []
Each security group has a name (which was used to identify the security group in the instances list), rules (a list of firewall rules like protocol, ports, and IP ranges to limit incoming traffic), and rules_egress (a list of firewall rules to limit outgoing traffic).
We need three security groups: a4d_lamp_http to open port 80, a4d_lamp_db to open port 3306, and a4d_lamp_memcached to open port 11211.
Now that we have all the data we need to set up security groups and instances, the first task needs to to create or verify the existence of the security groups:
56 tasks:
57 - name: Configure EC2 Security Groups.
58 ec2_group:
59 name: "{{ item.name }}"
60 description: Example EC2 security group for A4D.
61 region: "{{ item.region | default('us-west-2') }}" # Oregon
62 state: present
63 rules: "{{ item.rules }}"
64 rules_egress: "{{ item.rules_egress }}"
65 with_items: security_groups
The ec2_group requires a name, region, and rules for each security group. Security groups will be created if they don’t exist, modified to match the supplied values if they do exist, or verified if they exist and match the given values.
With the security groups configured, we can provision the defined EC2 instances by looping through instances with the ec2 module:
67 - name: Provision EC2 instances.
68 ec2:
69 key_name: "{{ item.ssh_key | default('jeff_mba_home') }}"
70 instance_tags:
71 inventory_group: "{{ item.group | default('') }}"
72 inventory_host: "{{ item.name | default('') }}"
73 group: "{{ item.security_group | default('') }}"
74 instance_type: "{{ item.type | default('t2.micro')}}" # Free Tier
75 image: "{{ item.image | default('ami-11125e21') }}" # RHEL6 x64 hvm
76 region: "{{ item.region | default('us-west-2') }}" # Oregon
77 wait: yes
78 wait_timeout: 500
79 exact_count: 1
80 count_tag:
81 inventory_group: "{{ item.group | default('') }}"
82 inventory_host: "{{ item.name | default('') }}"
83 register: created_instances
84 with_items: instances
This example is slightly more complex than the DigitalOcean example, and a few parts warrant a deeper look:
· EC2 allows SSH keys to be defined by name—in my case, I have a key jeff_mba_home in my AWS account. You should set the key_name default to a key that you have in your account.
· Instance tags are tags that AWS will attach to your instance, for categorization purposes. By giving a list of keys and values, I can then use that list later in the count_tag parameter.
· t2.micro was used as the default instance type, since it falls within EC2’s free tier usage. If you just set up an account and keep all AWS resource usage within free tier limits, you won’t be billed anything.
· exact_count and count_tag work together to ensure AWS provisions only one of each of the instances we defined. The count_tag tells the ec2 module to match the given group + host and then exact_count tells the module to only provision 1 instance. If you wanted to remove all your instances, you could set exact_count to 0 and run the playbook again.
Each provisioned instance will have its metadata added to the registered created_instances variable, which we’ll use to build Ansible inventory groups for the server configuration playbooks.
86 - name: Add EC2 instances to their respective inventory groups.
87 add_host:
88 name: "{{ item.1.tagged_instances.0.public_ip }}"
89 groups: "aws,{{ item.1.item.group }},{{ item.1.item.name }}"
90 # You can dynamically add inventory variables per-host.
91 ansible_ssh_user: ec2-user
92 mysql_replication_role: >
93 {{ 'master' if (item.1.item.name == 'a4d.lamp.db.1')
94 else 'slave' }}
95 mysql_server_id: "{{ item.0 }}"
96 when: item.1.instances is defined
97 with_indexed_items: created_instances.results
This add_host example is slightly simpler than the one for DigitalOcean, because AWS attaches metadata to EC2 instances which we can re-use when building groups or hostnames (e.g. item.1.item.group). We don’t have to use list indexes to fetch group names from the original instances variable.
We still use with_indexed_items so we can use the index to generate a unique ID per server for use in building the MySQL master-slave replication.
The final step in provisioning the EC2 instances is to ensure we can connect to them before continuing, and to set selinux into permissive mode so the configuration we supply will work correctly.
86 # Run some general configuration on all AWS hosts.
87 - hosts: aws
88 gather_facts: false
89
90 tasks:
91 - name: Wait for port 22 to become available.
92 local_action: "wait_for port=22 host={{ inventory_hostname }}"
93
94 - name: Set selinux into 'permissive' mode.
95 selinux: policy=targeted state=permissive
96 sudo: yes
Since we defined ansible_ssh_user as ec2-user in the dynamically-generated inventory above, we need to ensure the selinux task runs with sudo explicitly.
Now, modify the provision.yml file in the root of the project folder, and change the provisioners include to look like the following:
1 ---
2 - include: provisioners/aws.yml
3 - include: configure.yml
Assuming the environment variables AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY are set in your current terminal session, you can run $ ansible-playbook provision.yml to provision and configure the infrastructure on AWS.
The entire process should take about 15 minutes, and once it’s complete, you should see something like:
PLAY RECAP *****************************************************************
54.148.100.44 : ok=24 changed=16 unreachable=0 failed=0
54.148.120.23 : ok=40 changed=19 unreachable=0 failed=0
54.148.41.134 : ok=40 changed=19 unreachable=0 failed=0
54.148.56.137 : ok=13 changed=9 unreachable=0 failed=0
54.69.160.32 : ok=27 changed=17 unreachable=0 failed=0
54.69.86.187 : ok=19 changed=14 unreachable=0 failed=0
localhost : ok=3 changed=1 unreachable=0 failed=0
Visit the IP address of the varnish server (the first server configured) and you should be greeted with a status page similar to the one generated by the Vagrant and DigitalOcean-based infrastructure:
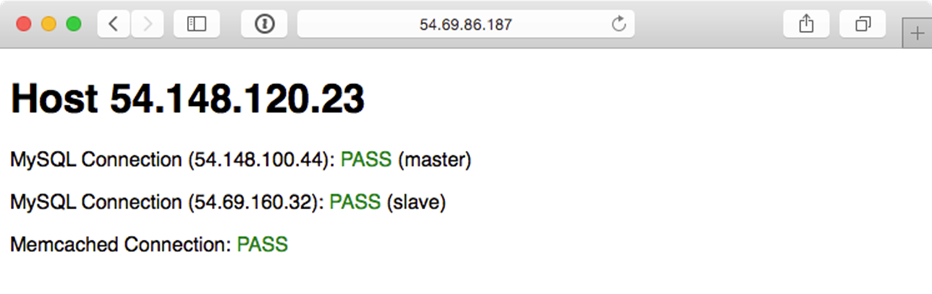
Highly Available Infrastructure on AWS EC2.
As with the earlier examples, running ansible-playbook provision.yml again should produce no changes, because everything in this playbook is idempotent. And if one of your instances were terminated, running the playbook again would recreate and reconfigure the instance in a few minutes.
To terminate all the provisioned instances, you can change the exact_count in the ec2 task to 0, and run $ ansible-playbook provision.yml again.
Summary
In the above example, an entire highly-available PHP application infrastructure was defined in a series of short Ansible playbooks, and then provisioning configuration was created to build the infrastructure on either local VMs, DigitalOcean droplets, or AWS EC2 instances.
Once you start working on building infrastructure this way—abstracting individual servers, then abstracting cloud provisioning—you’ll start to see some of Ansible’s true power in being more than just a configuration management tool. Imagine being able to create your own multi-datacenter, multi-provider infrastructure with Ansible and some basic configuration.
While Amazon, DigitalOcean, Rackspace and other hosting providers have their own tooling and unique infrastructure merits, the agility and flexibility afforded by building infrastructure in a provider-agnostic fashion lets you treat hosting providers as commodities, and gives you freedom to build more reliable, performant, and simple application infrastructure.
Even if you plan on running everything within one hosting provider’s network (or in a private cloud, or even on a few bare metal servers), Ansible provides deep stack-specific integration so you can do whatever you need to do and manage the provider’s services within your playbooks.
|
|
You can find the entire contents of this example in the Ansible for DevOps GitHub repository, in the lamp-infrastructure directory. |
ELK Logging with Ansible
Though application, database, and backup servers may be some of the most mission-critical components of a well-rounded infrastructure, one area that is equally important is a decent logging system.
In the old days, when one or two servers could handle an entire website or application, you could work with built-in logfiles and rsyslog to troubleshoot an issue or check trends in performance, errors, or overall traffic. With a typical modern infrastructure—like the example above, with six separate servers—it pays dividends to find a better solution for application, server, and firewall/authentication logging. Plain text files, logrotate, and grep don’t cut it anymore.
Among various modern logging and reporting toolsets, the ‘ELK’ stack (Elasticsearch, Logstash, and Kibana) has come to the fore as one of the best-performing and easiest-to-configure open source centralized logging solutions.
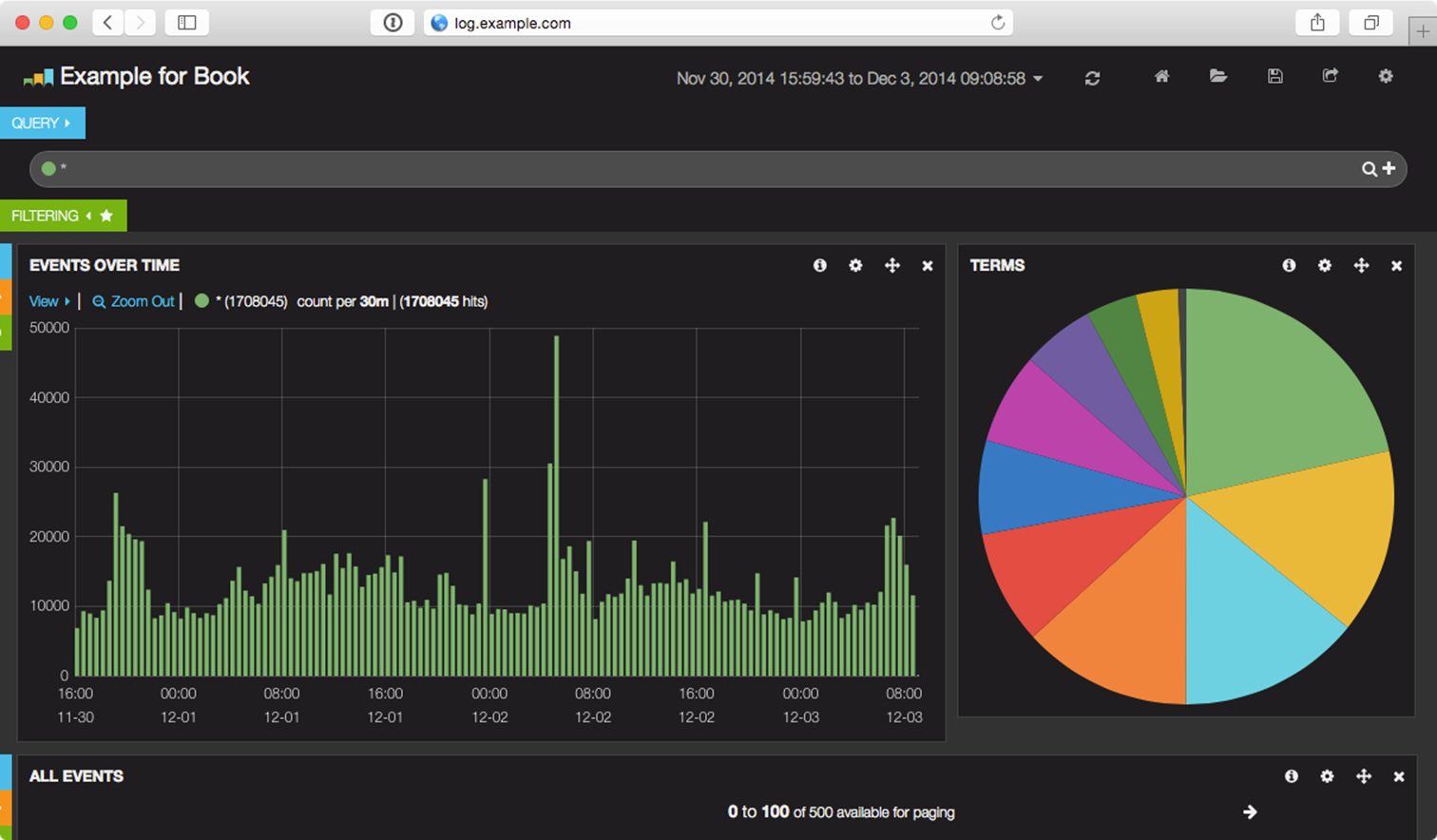
An example Kibana logging dashboard.
In our example, we’ll configure a single ELK server to handle aggregation, searching, and graphical display of logged data from a variety of other servers, and give some common configuration examples to send common system logs, webserver logs, etc.
ELK Playbook
Just like our previous example, we’re going to let a few roles from Ansible Galaxy do the heavy lifting of actually installing and configuring Elasticsearch, Logstash, and Kibana. If you’re interested in reading through the roles that do this work, feel free to peruse them after you’ve downloaded them.
In this example, rather than walking through each role and variable in detail, I’m going to highlight the important parts, but then jump immediately into how you can use this base server to aggregate logs, then how to point your other servers’ log files to it using Logstash Forwarder.
Here’s our main playbook, saved as provisioning/elk/playbook.yml:
1 - hosts: logs
2 gather_facts: yes
3
4 vars_files:
5 - vars/main.yml
6
7 pre_tasks:
8 - name: Update apt cache if needed.
9 apt: update_cache=yes cache_valid_time=86400
10
11 roles:
12 - geerlingguy.java
13 - geerlingguy.nginx
14 - geerlingguy.elasticsearch
15 - geerlingguy.elasticsearch-curator
16 - geerlingguy.kibana
17 - geerlingguy.logstash
18 - geerlingguy.logstash-forwarder
This assumes you have a logs group in your inventory with at least one server listed. The playbook includes a vars file located in provisioning/elk/vars/main.yml, so create that file, and then put the following inside:
1 ---
2 java_packages:
3 - openjdk-7-jdk
4
5 nginx_user: www-data
6 nginx_worker_connections: 1024
7 nginx_remove_default_vhost: true
8
9 kibana_server_name: logs
10 kibana_username: kibana
11 kibana_password: password
12
13 logstash_monitor_local_syslog: false
14 logstash_forwarder_files:
15 - paths:
16 - /var/log/auth.log
17 fields:
18 type: syslog
You’ll want to use a different password besides ‘password’ for kibana_password. Other options are straightforward, with the exception of the two logstash_* variables.
The first variable tells the geerlingguy.logstash role to ignore the local syslog file (in this case, we’re only interested in logging authorization attempts through the local auth.log).
The second variable gives the geerlingguy.logstash-forwarder role a list of files to monitor, along with metadata to tell logstash what kind of file is being monitored. In this case, we are only worried about the auth.log file, and we know it’s a syslog-style file. (Logstash needs to know what kind of file you’re monitoring so it can parse the logged messages correctly).
If you want to get this ELK server up and running quickly, you can create a local VM using Vagrant like you have in most other examples in the book. Create a Vagrantfile in the same directory as the provisioning folder, with the following contents:
1 # -*- mode: ruby -*-
2 # vi: set ft=ruby :
3
4 VAGRANTFILE_API_VERSION = "2"
5
6 Vagrant.configure(VAGRANTFILE_API_VERSION) do |config|
7 config.vm.box = "geerlingguy/ubuntu1204"
8
9 config.vm.provider :virtualbox do |v|
10 v.customize ["modifyvm", :id, "--natdnshostresolver1", "on"]
11 v.customize ["modifyvm", :id, "--memory", 1024]
12 v.customize ["modifyvm", :id, "--cpus", 2]
13 v.customize ["modifyvm", :id, "--ioapic", "on"]
14 end
15
16 # ELK server.
17 config.vm.define "logs" do |logs|
18 logs.vm.hostname = "logs"
19 logs.vm.network :private_network, ip: "192.168.9.90"
20
21 logs.vm.provision :ansible do |ansible|
22 ansible.playbook = "provisioning/elk/playbook.yml"
23 ansible.inventory_path = "provisioning/elk/inventory"
24 ansible.sudo = true
25 end
26 end
27
28 end
This Vagrant configuration expects an inventory file at provisioning/elk/inventory, so quickly create one with the following contents:
1 logs ansible_ssh_host=192.168.9.90 ansible_ssh_port=22
Now, run vagrant up. The build should take about five minutes, and upon completion, if you add a line like logs 192.168.9.90 to your /etc/hosts file, you can visit http://logs/ in your browser and see Kibana’s default homepage:
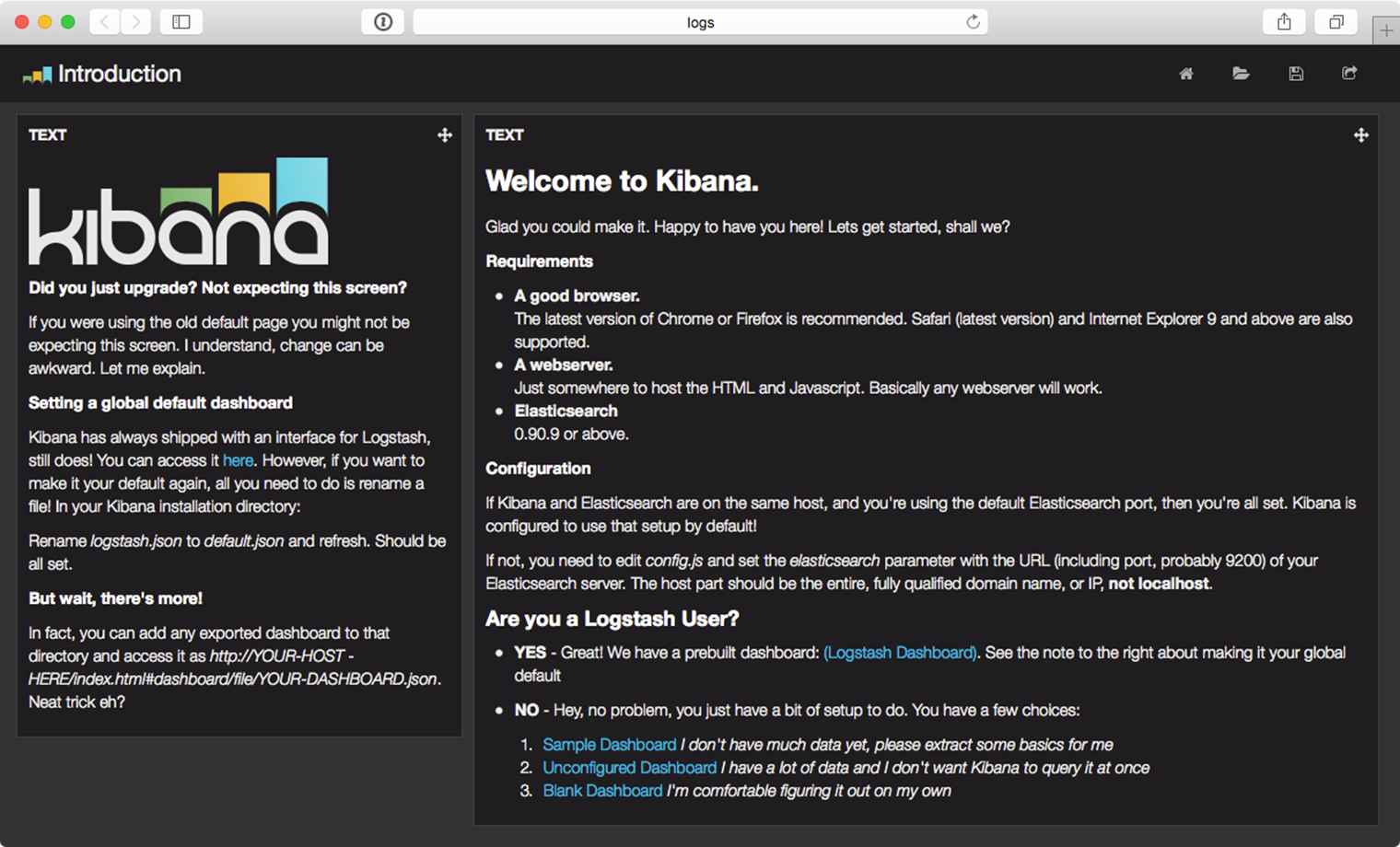
Kibana’s default homepage.
Kibana helpfully links to an example dashboard for Logstash (under the “Are you a Logstash User?” section), and if you select it, you should see a live dashboard that shows logged activity for the past day:
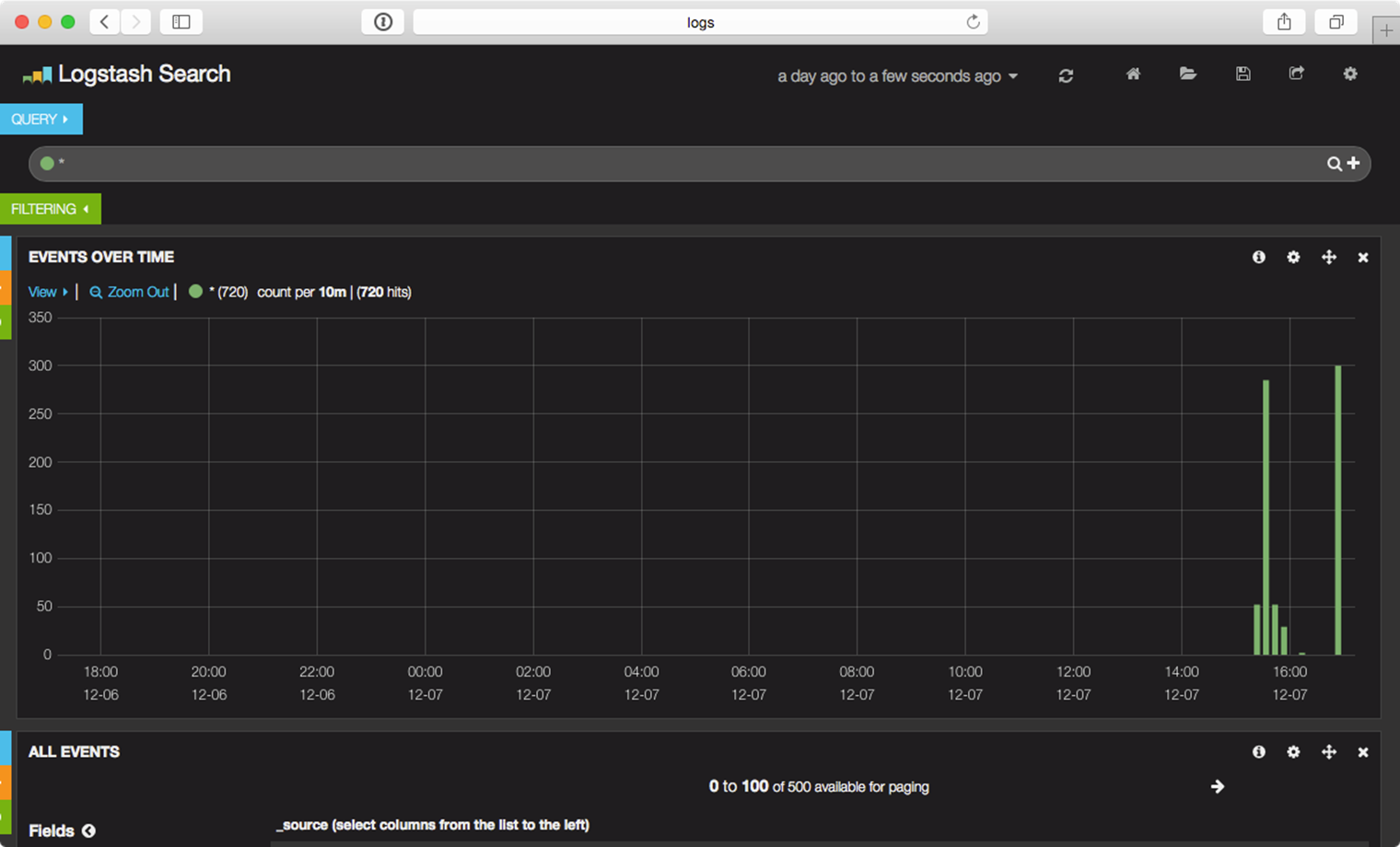
Kibana’s default Logstash dashboard.
This example won’t dive too deep into customizing Kibana’s dashboard customization, since there are many guides to using Kibana available freely, including Kibana’s official guide. For our purposes, we’ll use the default dashboard.
|
|
This example uses Kibana 3.x, but a stable release of Kibana 4.x is on the horizon (as of early 2015). Some of the screenshots may show a different interface than the latest release, but this book will likely be updated with newer screenshots and updated guides once the 4.x release comes out. |
Forwarding Logs from Other Servers
It’s great that we have the ELK stack running; Elasticsearch will store and make available log data with one search index per day, Logstash will listening for log entries, Logstash Forwarder will send entries in /var/log/auth.log to Logstash, and Kibana will organize the logged data with useful visualizations.
Configuring additional servers to direct their logs to our new Logstash server is fairly simple using Logstash Forwarder. The basic steps we’ll follow are:
1. Set up another server in the Vagrantfile.
2. Set up an Ansible playbook to install and configure Logstash Forwarder alongside the application running on the server.
3. Boot the server and watch as the logs are forwarded to the main ELK server.
Let’s begin by creating a new Nginx web server. It’s useful to monitor webserver access logs for a variety of reasons, not the least of which is to watch for traffic spikes and increases in non-200 responses for certain resources. Add the following server definition inside the Vagrantfile, just after the end of the ELK server definition:
28 # Web server.
29 config.vm.define "webs" do |webs|
30 webs.vm.hostname = "webs"
31 webs.vm.network :private_network, ip: "192.168.9.91"
32
33 webs.vm.provision :ansible do |ansible|
34 ansible.playbook = "provisioning/web/playbook.yml"
35 ansible.inventory_path = "provisioning/web/inventory"
36 ansible.sudo = true
37 end
38 end
We’ll next set up the simple playbook to install and configure both Nginx and Logstash Forwarder, at provisioning/web/playbook.yml:
1 - hosts: webs
2 gather_facts: yes
3
4 vars_files:
5 - vars/main.yml
6
7 pre_tasks:
8 - name: Update apt cache if needed.
9 apt: update_cache=yes cache_valid_time=86400
10
11 roles:
12 - geerlingguy.nginx
13 - geerlingguy.logstash-forwarder
14
15 tasks:
16 - name: Set up virtual host for testing.
17 copy:
18 src: files/example.conf
19 dest: /etc/nginx/conf.d/example.conf
20 owner: root
21 group: root
22 mode: 0644
23 notify: restart nginx
This playbook installs the geerlingguy.nginx and geerlingguy.logstash-forwarder roles, and in the tasks, there is an additional task to configure one virtualhost in a Nginx configuration directory, via the file example.conf. Create that file now (at the path provisioning/web/files/example.conf), and define one Nginx virtualhost for our testing:
1 server {
2 listen 80 default_server;
3
4 root /usr/share/nginx/www;
5 index index.html index.htm;
6
7 access_log /var/log/nginx/access.log combined;
8 error_log /var/log/nginx/error.log debug;
9 }
Since this is the only server definition, and it’s set as the default_server on port 80, all requests will be directed to it. We routed the access_log to /var/log/nginx/access.log, and told Nginx to write log entries using the combinedformat, which is what our Logstash server will expect for nginx access logs.
Next, set up the required variables to tell the nginx and logstash-forwarder roles how to configure their respective services. Inside provisioning/web/vars/main.yml:
1 ---
2 nginx_user: www-data
3 nginx_worker_connections: 1024
4 nginx_remove_default_vhost: true
5
6 logstash_forwarder_logstash_server: 192.168.9.90
7 logstash_forwarder_logstash_server_port: 5000
8
9 logstash_forwarder_files:
10 - paths:
11 - /var/log/secure
12 fields:
13 type: syslog
14 - paths:
15 - /var/log/nginx/access.log
16 fields:
17 type: nginx
The nginx variables ensure Nginx will run optimally on our Ubuntu server, and remove the default virtualhost entry. The logstash_forwarder variables tell geerlingguy.logstash-forwarder what logs to forward to our central log server:
· logstash_forwarder_logstash_server and _port: Defines the server IP or domain and port to which logs should be transported.
· logstash_forwarder_files: Defines a list of paths and fields, which identify a file or list of files to be transported to the log server, along with a type for the files. In this case, the authentication log (/var/log/secure) is a syslog-formatted log file, and /var/log/nginx/access.log is of type nginx (which will be parsed correctly on the Logstash server since it’s in the combined log format popularized by Apache).
|
|
Note that this demonstration configuration is not using a custom certificate to authenticate logging connections. You should normally configure your own secure certificate and give the logstash-forwarder role the path to the certificate using the logstash_forwarder_ssl_certificate_file variable. If you use the example provided with the project, you could expose your logging infrastructure to the outside, plus you’ll get a ***SECURITY RISK*** warning in the logs every time the Logstash role is run. |
To allow Vagrant to pass the proper connection details to Ansible, create provisioning/web/inventory with the webs host details:
1 webs ansible_ssh_host=192.168.9.91 ansible_ssh_port=22
Run vagrant up again. Vagrant should verify that the first server (logs) is running, then create and run the Ansible provisioner on the newly-defined webs Nginx server.
You can load http://192.168.9.91/ or http://webs/ in your browser, and you should see a Welcome to nginx! message on the page. You can refresh the page a few times, then switch back over to http://logs/ to view some new log entries on the ELK server:
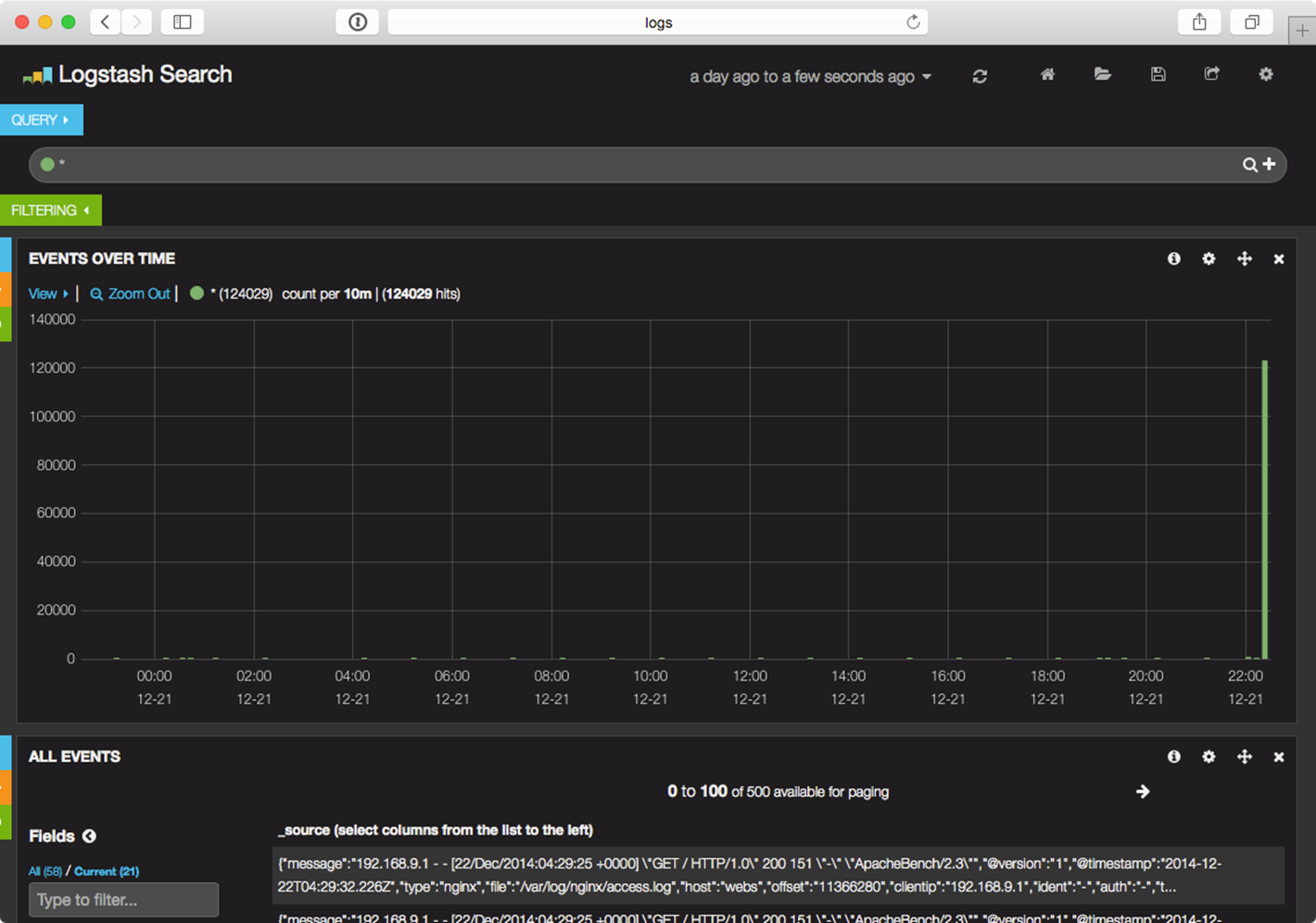
Entries populating the Logstash Search Kibana dashboard.
|
|
If you refresh the page a few times, and no entries show up in the Kibana Logstash dashboard, it could be that Nginx is buffering the log entries. In this case, keep refreshing a while (so you generate a few dozen or hundred entries), and Nginx will eventually write the entries to disk (thus allowing Logstash Forwarder to convey the logs to the Logstash server). Read more about Nginx log buffering in the Nginx’s ngx_http_log_module documentation. |
A few requests being logged through logstash forwarder isn’t all that exciting. Let’s use the popular ab tool available most anywhere to put some load on the web server. On a modest MacBook Air, running the command below resulted in Nginx serving around 1,200 requests per second.
ab -n 20000 -c 50 http://webs/
During the course of the load test, I set Kibana to show only the past 5 minutes of log data, automatically refreshed every 5 seconds, and I could monitor the requests on the ELK server just a few seconds after they were served by Nginx:
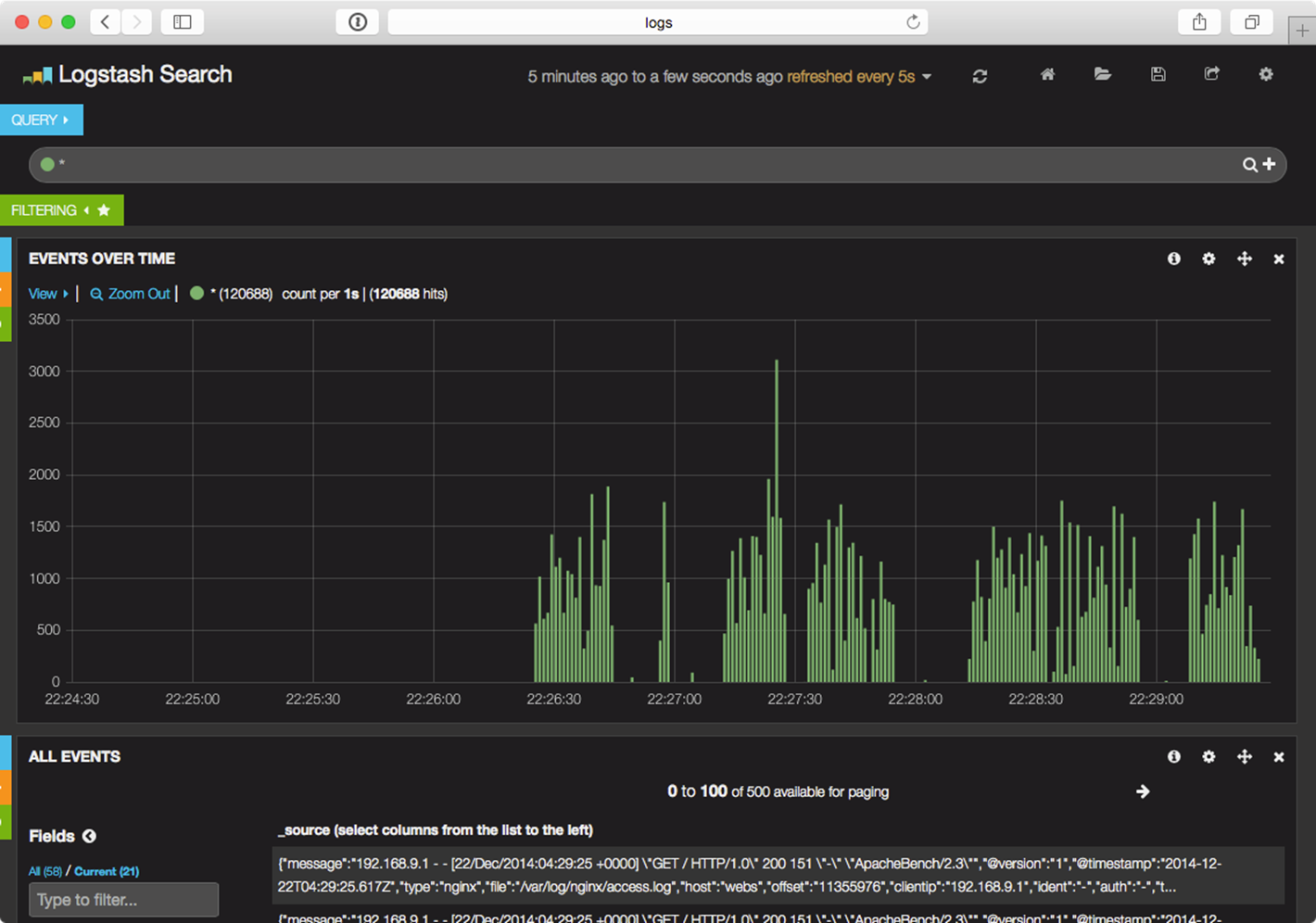
Monitoring a deluge of Nginx requests in near-realtime.
Logstash Forwarder uses a highly-efficient TCP-like protocol, Lumberjack, to transmit log entries securely between servers. With the right tuning and scaling, you can efficiently process and display thousands of requests per second across your infrastructure! For most, even the simple example demonstrated above would adequately cover an entire infrastructure’s logging and log analysis needs.
Summary
Log aggregation and analysis are two fields that see constant improvements and innovation. There are many SaaS products and proprietary solutions that can assist with logging, but few match the flexibility, security, and TCO of Elasticsearch, Logstash and Kibana.
Ansible is the simplest way to configure an ELK server and direct all your infrastructure’s pertinent log data to the server.
GlusterFS Distributed File System Configuration with Ansible
Modern infrastructure often involves some amount of horizontal scaling; instead of having one giant server, with one storage volume, one database, one application instance, etc., most apps use two, four, ten, or dozens of servers.

Monitoring a deluge of Nginx requests in near-realtime.
Many applications can be scaled horizontally with ease, but what happens when you need shared resources, like files, application code, or other transient data, to be shared on all the servers? And how do you have this data scale out with your infrastructure, in a fast but reliable way? There are many different approaches to synchronizing or distributing files across servers:
· Set up rsync either on cron or via inotify to synchronize smaller sets of files on a regular basis.
· Store everything in a code repository (e.g. Git, SVN, etc.) and deploy files to each server using Ansible.
· Have one large volume on a file server and mount it via NFS or some other file sharing protocol.
· Have one master SAN that’s mounted on each of the servers.
· Use a distributed file system, like Gluster, Lustre, Fraunhofer, or Ceph.
Some options are easier to set up than others, and all have benefits—and drawbacks. Rsync, git, or NFS offer simple initial setup, and low impact on filesystem performance (in many scenarios). But if you need more flexibility and scalability, less network overhead, and greater fault tolerance, you will have to consider something that requires more configuration (e.g. a distributed file system) and/or more hardware (e.g. a SAN).
GlusterFS is licensed under the AGPL license, has good documentation, and a fairly active support community (especially in the #gluster IRC channel). But to someone new to distributed file systems, it can be daunting to get set it up the first time.
Configuring Gluster - Basic Overview
To get Gluster working on a basic two-server setup (so you can have one folder that’s synchronized and replicated across the two servers—allowing one server to go down completely, and the other to still have access to the files), you need to do the following:
1. Install Gluster server and client on each server, and start the server daemon.
2. (On both servers) Create a ‘brick’ directory (where Gluster will store files for a given volume).
3. (On both servers) Create a directory to be used as a mount point (a directory where you’ll have Gluster mount the shared volume).
4. (On both servers) Use gluster peer probe to have Gluster connect to the other server.
5. (On one server) Use gluster volume create to create a new Gluster volume.
6. (On one server) Use gluster volume start to start the new Gluster volume.
7. (On both servers) Mount the gluster volume (adding a record to /etc/fstab to make the mount permanent).
Additionally, you need to make sure you have the following ports open on both servers (so Gluster can communicate): TCP ports 111, 24007-24011, 49152-49153, and UDP port 111. (You need to add an additional TCP port in the 49xxx range for each extra server in your Gluster cluster.)
Configuring Gluster with Ansible
The following example is adapted from the gluster.yml file I’m using for my Raspberry Pi Dramble cluster (a cluster of Raspberry Pis running a Drupal website).
First, we need to punch a hole in the firewall for all the required ports. I am using the geerlingguy.firewall role on all my servers, so in my vars files, I added:
firewall_allowed_tcp_ports:
- 22
- 80
# For Gluster.
- 111
# Port-mapper for Gluster 3.4+.
# - 2049
# Gluster Daemon.
- 24007
# 24009+ for Gluster <= 3.3; 49152+ for Gluster 3.4+ (one port per server).
- 24009
- 24010
- 24011
# Gluster inline NFS server.
- 38465
- 38466
- 38467
firewall_allowed_udp_ports:
- 111
Next, I’ll include the geerlingguy.glusterfs role in my playbook to install GlusterFS on my servers (like most of the geerlingguy.* roles, this role works with Debian, Ubuntu, RedHat, and CentOS):
roles:
- geerlingguy.firewall
- geerlingguy.glusterfs
Then, I include a separate task include file with the Gluster configuration in my main playbook:
tasks:
- include: gluster.yml
Inside that file:
1 ---
2 - name: Ensure Gluster brick and mount directories exist.
3 file:
4 path: "{{ item }}"
5 state: directory
6 owner: root
7 group: www-data
8 mode: 0775
9 with_items:
10 - "{{ gluster_brick_dir }}"
11 - "{{ gluster_mount_dir }}"
12
13 # Gluster volume configuration.
14 - name: Check if Gluster volumes already exist.
15 shell: "gluster volume info"
16 changed_when: false
17 register: gluster_volume_info
18
19 - name: Connect to Gluster peers.
20 shell: "gluster peer probe {{ item }}"
21 register: gluster_peer_probe
22 changed_when: "'already in peer list' not in gluster_peer_probe.stdout"
23 failed_when: false
24 with_items: groups.webservers
25 when: "'Volume Name: gluster' not in gluster_volume_info.stdout"
26
27 - name: Create Gluster volume.
28 shell: "gluster volume create {{ gluster_brick_name }} {{ gluster_brick_config\
29 }}"
30 register: gluster_volume_create
31 changed_when: "'successful' in gluster_volume_create.stdout"
32 when:
33 "inventory_hostname == groups.webservers[0]
34 and 'Volume Name: gluster' not in gluster_volume_info.stdout"
35
36 - name: Ensure Gluster volume is started.
37 shell: "gluster volume start {{ gluster_brick_name }}"
38 register: gluster_volume_start
39 changed_when: "'successful' in gluster_volume_start.stdout"
40 when:
41 "inventory_hostname == groups.webservers[0]
42 and 'Volume Name: gluster' not in gluster_volume_info.stdout"
43
44 # Mount configuration.
45 - name: Ensure the Gluster volume is mounted.
46 mount:
47 name: "{{ gluster_mount_dir }}"
48 src: "{{ groups.webservers[0] }}:/{{ gluster_brick_name }}"
49 fstype: glusterfs
50 opts: "defaults,_netdev"
51 state: mounted
The first task ensures the brick and mount directories exist and have the appropriate permissions for our application. Next, gluster peer probe links all the servers together. Then, on only one of the servers (in this case, the first of the webservers inventory group), the Gluster volume is created and started.
Finally, an entry is added to /etc/fstab and then the volume is mounted at gluster_mount_dir (using Ansible’s mount module, which configures /etc/fstab and mounts the volume for us).
There were a few different Jinja2 variables I used to make the Gluster configuration and volume mounting simple and flexible (a task include like this is very flexible and could be used for many different server configurations). Define these variables separately, like so:
1 gluster_mount_dir: /mnt/gluster
2 gluster_brick_dir: /srv/gluster/brick
3 gluster_brick_name: gluster
4 # Note: This is hardcoded for 2 webservers. Adjust accordingly.
5 gluster_brick_config:
6 "replica 2 transport tcp
7 {{ groups.webservers[0] }}:{{ gluster_brick_dir }}
8 {{ groups.webservers[1] }}:{{ gluster_brick_dir }}"
Most of these vars are self-explanatory, but the gluster_brick_config variable deserves a little more explanation. That variable tells Gluster to set up two replicas (one full replica on each server), using the tcp transport method, then it lists each server that will have a share of the volume, followed by the path to that share.
If you have two servers, this should work perfectly. If you have three servers, you will need to adjust the configuration to either use three replicas or use a different data partitioning scheme. If you have four or more servers, you just need an even number of replicas to allow Gluster to replicate data appropriately.
Summary
Deploying distributed file systems like Gluster can seem challenging, but Ansible simplifies the process, and more importantly, does so idempotently; each time you run the playbook again, it will ensure everything stays configured as you’ve set it.
Ansible 1.9.x’s inclusion of the gluster_volume module will make this process even simpler, since the built-in module will handle edge cases and general configuration even better than we did above.
You can view this configuration in its full context in the Raspberry Pi Dramble project on GitHub (see, specifically, the file playbooks/web/gluster.yml).
Mac Provisioning with Ansible and Homebrew
The next example will be specific to the Mac (since that’s the author’s platform of choice), but the principle behind it applies universally. How many times have you wanted to hit the ‘reset’ button on your day-to-day workstation or personal computer? How much time to you spend automating configuration and testing of applications and infrastructure at your day job, and how little do you spend automating your own local environment?
Over the past few years, as I’ve gone through four Macs (one personal, three employer-provided), I decided to start fresh on each new Mac (rather than transfer all my cruft from my old Mac to my new Mac through Apple’s Migration Assistant). I had a problem, though; I had to spend at least 4-6 hours on each Mac, downloading, installing, and configuring everything. Another problem: since I actively used at least two separate Macs, I had to manually install and configure new software on both Macs whenever I wanted to try a new tool.
To restore order to this madness, I wrapped up all the configuration I could into a set of dotfiles and used git to synchronize the dotfiles to all my workstations.
However, even with the assistance of Homebrew, a great package manager for OS X, there was still a lot of manual labor involved in installing and configuring my favorite apps and command line tools.
Running Ansible playbooks locally
We’ve seen examples of running playbooks with connection: local earlier, when provisioning virtual machines in the cloud through our local workstation; but you can perform any Ansible task using a local connection. This is how we’ll configure our local workstation using Ansible.
I usually begin building a playbook with the basic scaffolding in place, and fill in details as I go. You can follow along by creating the playbook main.yml with:
1 ---
2 - hosts: localhost
3 user: jgeerling
4 connection: local
5
6 vars_files:
7 - vars/main.yml
8
9 roles: []
10
11 tasks: []
We’ll store any variables we need in the included vars/main.yml file. The user is set to my local user account, in this case, jgeerling, so file permissions are set for my account, and tasks are run under my own account to minimize surprises.
|
|
If certain tasks need to be run with sudo privileges, you can add sudo: yes to the task, and either run the playbook with --ask-sudo-pass (in which case, Ansible will prompt you for your sudo password before running the playbook), or run the playbook normally, and wait for Ansible to prompt you for your sudo password. |
Automating Homebrew package and app management
Since I use Homebrew (billed as “the missing package manager for OS X”) for most of my application installation and configuration, I created the role geerlingguy.homebrew, which installs homebrew, then installs all the applications and packages I configure in a few simple variables.
The next step, then, is to add the Homebrew role and configure the required variables. Inside main.yml, update the roles section:
9 roles:
10 - geerlingguy.homebrew
Then add the following into vars/main.yml:
1 ---
2 homebrew_installed_packages:
3 - ansible
4 - sqlite
5 - mysql
6 - php56
7 - python
8 - ssh-copy-id
9 - cowsay
10 - pv
11 - drush
12 - wget
13 - brew-cask
14
15 homebrew_taps:
16 - caskroom/cask
17 - homebrew/binary
18 - homebrew/dupes
19 - homebrew/php
20 - homebrew/versions
21
22 homebrew_cask_appdir: /Applications
23 homebrew_cask_apps:
24 - google-chrome
25 - firefox
26 - sequel-pro
27 - sublime-text
28 - vagrant
29 - vagrant-manager
30 - virtualbox
Homebrew has a few tricks up its sleeve, like being able to manage general packages like PHP, MySQL, Python, Pipe Viewer, etc. natively (using commands like brew install [package] and brew uninstall package), and can also install and manage general application installation for many Mac apps, like Chrome, Firefox, VLC, etc. using brew cask.
To anyone who’s set up a new Mac the old-fashioned way—download 15 .dmg files, mount them, drag the applications to the Applications folder, eject them, delete the .dmg files—Homebrew’s simplicity and speed are a godsend. This Ansible playbook has so far automated that process completely, so you don’t even need to run the Homebrew commands manually! The geerlingguy.homebrew role uses Ansible’s built-in homebrew module to manage package installation, and some custom tasks to manage cask applications.
Configuring Mac OS X through dotfiles
Just like there’s a homebrew role on Galaxy made for configuring and installing packages via Homebrew, there’s a dotfiles role you can use to download and configure your local dotfiles.
|
|
Dotfiles are named as such because they are, simply, files that begin with a . placed in your home directory. Many programs and shell environments read local configuration from dotfiles, so dotfiles are a simple, efficient, and easily-synchronized method of customizing your development environment for maximum efficiency. |

In this example, we’ll use the author’s dotfiles, but you can tell the role to use whatever set of dotfiles you want.
Add another role to the roles list:
9 roles:
10 - geerlingguy.homebrew
11 - geerlingguy.dotfiles
Then, add the following three variables to your vars/main.yml file:
2 dotfiles_repo: https://github.com/geerlingguy/dotfiles.git
3 dotfiles_repo_local_destination: ~/repositories/dotfiles
4 dotfiles_files:
5 - .bash_profile
6 - .gitignore
7 - .inputrc
8 - .osx
9 - .vimrc
The first variable gives the git repository URL for the dotfiles to be cloned. The second gives a local path for the repository to be stored, and the final variable tells the role which dotfiles it should use from the specified repository.
The dotfiles role clones the specified dotfiles repository locally, then symlinks every one of the dotfiles specified in dotfiles_files into your home folder (removing any existing dotfiles of the same name).
If you want to run the .osx dotfile, which adjusts many system and application settings, add in a new task under the tasks section in the main playbook:
1 tasks:
2 - name: Run .osx dotfiles.
3 shell: ~/.osx --no-restart
4 changed_when: false
In this case, the .osx dotfile allows a --no-restart flag to be passed to prevent the script from restarting certain apps and services including Terminal—which is good, since you’d likely be running the playbook from within Terminal.
At this point, you already have the majority of your local environment set up. Copying additional settings and tweaking things further is an exercise in adjusting your dotfiles or including another playbook that copies or links preference files into the right places.
I’m constantly tweaking my own development workstation, and for the most part, all my configuration is wrapped up in my Mac Development Ansible Playbook, available on GitHub. I’d encourage you to fork that project, as well as my dotfiles, if you’d like to get started automating the build of your own development workstation. Even if you don’t use a Mac, most of the structure is similar; just substitute a different package manager, and start automating everything!
Summary
Ansible is the best way to automate infrastructure provisioning and configuration. Ansible can also be used to configure your own worstation or workstations, saving you time and frustration in doing so yourself. Unfortunately, you can’t yet provision yourself a new top-of-the-line workstation with Ansible!
You can find the full playbook I’m currently using to configure my Macs on GitHub: Mac Development Ansible Playbook.
Docker-based Infrastructure with Ansible
Docker is a highly optimized platform for building and running containers on local machines and servers in a highly efficient manner. You can think of Docker containers as sort-of lightweight virtual machines. This book won’t go into the details of how Docker and Linux containers work, but will provide an introduction to how Ansible can integrate with Docker to build, manage, and deploy containers.
|
|
Prior to running example Docker commands or building and managing containers using Ansible, you’ll need to make sure Docker is installed on either your workstation or a VM or server where you’ll be testing everything. Please see the installation guide for Docker for help installing Docker on whatever platform you’re using. |

A brief introduction to Docker containers
Starting with an extremely simple example, let’s build a docker image from a Dockerfile. In this case, we just want to show how Dockerfiles work, and how we can use Ansible to build the image in the same way you could using the command line with docker build.
Let’s start with a really simple Dockerfile:
1 # Build an example Docker container image.
2 FROM busybox
3 MAINTAINER Jeff Geerling <geerlingguy@mac.com>
4
5 # Run a command when the container starts.
6 CMD ["/bin/true"]
This Docker container doesn’t do much, but that’s okay; we just want to build it and verify that it’s present and working—first with Docker, then with Ansible.
Save the above file as Dockerfile inside a new directory, and then on the command line, run the following command to build the container:
$ docker build -t test .
After a few seconds, the docker image should be built, and if you list all local images with docker image, you should see your new test image (along with the busybox image, which was used as a base):
$ docker images
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
test latest 50d6e6479bc7 About a minute ago 2.433 MB
busybox latest 4986bf8c1536 2 weeks ago 2.433 MB
If you want to run the container image you just created, enter the following:
$ docker run --name=test test
This creates a docker container with the name test, and starts the container. Since the only thing our container does is calls /bin/true, the container will run the command, then exit. You can see the current status of all your containers (whether or not they’re actively running) with the docker ps -a command:
$ docker ps -a
CONTAINER ID IMAGE [...] CREATED STATUS
bae0972c26d4 test:latest [...] 3 seconds ago Exited (0) 2 seconds ago
You can control the container using either the container ID (in this case, bae0972c26d4) or the name (test); start with docker start [container], stop with docker stop [container], delete/remove with docker rm [container].
If you delete the container (docker rm test) and delete the image you built (docker rmi test), you can experiment with the Dockerfile by changing it and rebuilding the image (with docker build), and running the resulting image (with docker run). As an example, if you change the command from /bin/true to /bin/false, then run build and run the container, docker ps -a will show that the container exited with the status code 1 instead of 0.
For our purposes, this is a simple enough introduction to how Docker works. To summarize:
· Dockerfiles contain the instructions Docker uses to build containers.
· docker build builds Dockerfiles and generates container images.
· docker images lists all images present on the system.
· docker run runs created images.
· docker ps -a lists all containers, both running and stopped.
When developing Dockerfiles to containerize your own applications, you will likely want to get familiar with the Docker CLI and how the process works from a manual perspective. But when building the final images and running them on your servers, Ansible can help ease the process.
Using Ansible to build and manage containers
Ansible has a built-in Docker module that integrates nicely with Docker for container management. We’re going to use it to automate the building and running of the container managed by the Dockerfile we just created.
Move the Dockerfile you had into a subdirectory, and create a new Ansible playbook (call it main.yml) in the project root directory. The directory layout should look like:
docker/
main.yml
test/
Dockerfile
Inside the new playbook, add the following:
1 ---
2 - hosts: localhost
3 connection: local
4
5 tasks:
6 - name: Build Docker image from Dockerfiles.
7 docker_image:
8 name: test
9 path: test
10 state: build
The playbook uses the docker_image module to build an image. Provide a name for the image, the path to the Dockerfile (in this case, inside the test directory), and tell Ansible via the state parameter whether the image should be present, absent, or built (via build).
|
|
Ansible’s Docker integration may require you to install an extra Docker python library on the system running the Ansible playbook. For example, on ArchLinux, if you get the error “failed to import Python module”, you will need to install the python2-docker-py package. |
|
|
The docker_image module is listed as being deprecated as of early 2015. The module’s functionality will soon be moved into the main docker module, but until that time, this playbook should work as-is. |

Run the playbook ($ ansible-playbook main.yml), and then list all the Docker images ($ docker images). If all was successful, you should see a fresh test image in the list.
Run docker ps -a again, though, and you’ll see that the new test image was never run and is absent from the output. Let’s remedy that by adding another task to our Ansible playbook:
12 - name: Run the test container.
13 docker:
14 image: test:latest
15 name: test
16 state: running
If you run the playbook again, Ansible will run the docker container. Check the list of containers with docker ps -a, and you’ll note that the test container is again present.
You can remove the container and the image via ansible by changing the state parameter to absent for both tasks.
|
|
This playbook assumes you have both Docker and Ansible installed on whatever host you’re using to test Docker containers. If this is not the case, you may need to modify the example so the Ansible playbook is targeting the correct hosts and using the right connection settings. Additionally, if the user account under which you run the playbook can’t run docker commands, you may need to use sudo with this playbook. |

|
|
The code example above can be found in the Ansible for DevOps GitHub repository. |
Building a Flask app with Ansible and Docker
Let’s build a more useful Docker-powered environment, with a container that runs our application (built with Flask, a lightweight Python web framework), and a container that runs a database (MySQL), along with a data container. We need a separate data container to persist the MySQL database, because data changed inside the MySQL container is lost every time the container stops.

Docker stack for Flask App
We’ll create a VM using Vagrant to run our Docker containers so the same Docker configuration can be tested on on any machine capable of running Ansible and Vagrant. Create a docker folder, and inside it, the following Vagrantfile:
1 # -*- mode: ruby -*-
2 # vi: set ft=ruby :
3
4 VAGRANTFILE_API_VERSION = "2"
5
6 Vagrant.configure(VAGRANTFILE_API_VERSION) do |config|
7 config.vm.box = "geerlingguy/ubuntu1404"
8 config.vm.network :private_network, ip: "192.168.33.39"
9 config.ssh.insert_key = false
10
11 config.vm.provider :virtualbox do |v|
12 v.customize ["modifyvm", :id, "--name", "docker.dev"]
13 v.customize ["modifyvm", :id, "--natdnshostresolver1", "on"]
14 v.customize ["modifyvm", :id, "--memory", 1024]
15 v.customize ["modifyvm", :id, "--cpus", 2]
16 v.customize ["modifyvm", :id, "--ioapic", "on"]
17 end
18
19 # Enable provisioning with Ansible.
20 config.vm.provision "ansible" do |ansible|
21 ansible.playbook = "provisioning/main.yml"
22 end
23
24 end
We’ll use Ubuntu 14.04 for this example, and we’ve specified an Ansible playbook (provisioning/main.yml) to set everything up. Inside provisioning/main.yml, we need to first install and configure Docker (which we’ll do using the Ansible Galaxy role angstwad.docker_ubuntu), then run some additional setup tasks, and finally build and start the required Docker containers:
1 ---
2 - hosts: all
3 sudo: yes
4
5 roles:
6 - role: angstwad.docker_ubuntu
7
8 tasks:
9 - include: setup.yml
10 - include: docker.yml
We’re using sudo for everything because Docker either requires root privileges, or requires the current user account to be in the docker group. It’s simplest for our purposes to set everything up with sudo.
Angstwad’s docker_ubuntu role requires no additional settings or configuration, so we can move on to setup.yml (in the same provisioning directory alongside main.yml):
1 ---
2 - name: Install Pip.
3 apt: name=python-pip state=installed
4 sudo: yes
5
6 - name: Install Docker Python library.
7 pip: name=docker-py state=present
8 sudo: yes
Ansible needs the docker-py library in order to control Docker via Python, so we install pip, then use it to install docker-py.
Next is the meat of the playbook, docker.yml (also in the provisioning directory). The first task is building docker images for our data, application, and database containers:
1 ---
2 - name: Build Docker images from Dockerfiles.
3 docker_image:
4 name: "{{ item.name }}"
5 tag: "{{ item.tag }}"
6 path: "/vagrant/provisioning/{{ item.directory }}"
7 state: build
8 with_items:
9 - { name: data, tag: "data", directory: data }
10 - { name: www, tag: "flask", directory: www }
11 - { name: db, tag: mysql, directory: db }
Don’t worry that we haven’t created the actual Dockerfiles required to create the Docker images yet; we’ll do that after we finish structuring everything with Ansible.
Like our earlier usage of docker_image, we supply a name, path, and state for each image. In this example, we’re also adding a tag, which behaves like a git tag, allowing future Docker commands to use the images we created at a specific version. We’ll be building three containers, data, www, and db, and we’re pointing docker to the path /vagrant/provisioning/[directory], where [directory] contains the Dockerfile and any other helpful files to be used to build the Docker image.
After building the images, we will need to start each of them (or at least make sure a container is present, in the case of the data container—since you can use data volumes from non-running containers). We’ll do that in three separate docker tasks:
13 # Data containers don't need to be running to be utilized.
14 - name: Run a Data container.
15 docker:
16 image: data:data
17 name: data
18 state: present
19
20 - name: Run a Flask container.
21 docker:
22 image: www:flask
23 name: www
24 state: running
25 command: python /opt/www/index.py
26 ports: "80:80"
27
28 - name: Run a MySQL container.
29 docker:
30 image: db:mysql
31 name: db
32 state: running
33 volumes_from: data
34 command: /opt/start-mysql.sh
35 ports: "3306:3306"
Each of these containers’ configuration is a little more involved than the previous. In the case of the first container, it’s just present; Ansible will ensure a data container is present.
For the Flask container, we need to make sure our app is running, and continues running, so in this case (unlike our earlier usage of /bin/true to run a container briefly and exit), we are providing an explicit command to run:
26 command: python /opt/www/index.py
Calling the script directly will launch the app in the foreground and log everything to stdout, making it easy to inspect what’s going on with docker logs [container] if needed.
Additionally, we want to map the container’s port 80 to the host’s port 80, so external users can load pages over HTTP. This is done using the ports option, passing data just as you would using Docker’s --publish syntax.
The Flask container will have a static web application running on it, and has no need for extra non-transient file storage, but the MySQL container will mount a data volume from the data container so it has a place to store data that won’t vanish when the container dies and is restarted.
Thus, for the db container, we have two special options; the volumes_from option, which mounts volumes from the specified container (in this case, the data container), and the command, which calls a shell script to start MySQL. We’ll get to why we’re running a shell script and not launching a MySQL daemon directly in a bit.
Now that we have the playbook structured to build our simple Docker-based infrastructure, we’ll build out each of the three Dockerfiles and related configuration to support the data, www, and db containers.
At this point, we should have a directory structure like:
docker/
provisioning/
data/
db/
www/
docker.yml
main.yml
setup.yml
Vagrantfile
Data storage container
For the data storage container, we don’t need much; we just need to create a directory and set it as an exposed mount point using VOLUME:
1 # Build a simple MySQL data volume Docker container.
2 FROM busybox
3 MAINTAINER Jeff Geerling <geerlingguy@mac.com>
4
5 # Create data volume for MySQL.
6 RUN mkdir /var/lib/mysql
7 VOLUME /var/lib/mysql
We create a directory (line 6) and expose the directory as a volume (line 7) which can be mounted by the host or other containers. Save the above into a new file, docker/provisioning/data/Dockerfile.
|
|
This container builds on top of the official busybox base image. Busybox is an extremely simple distribution that’s linux-like, but doesn’t contain every option or application generally found in popular distributions like Debian, Ubuntu, or RedHat. Since we only need to create and share a directory, we don’t need any additional ‘baggage’ inside the container. In the Docker world, it’s best to use the most minimal base images possible, and only install and run the bare necessities inside each container to support the container’s app. |

Flask container
Flask is a lightweight Python web framework “based on Werkzeug, Jinja 2 and good intentions”. It’s a great web framework for small, fast, and robust websites and apps, or even a simple API. For our purposes, we need to build a Flask app that connects to a MySQL database and displays the status of the connection on a simple web page (very much like our PHP example, in the earlier Highly-Available Infrastructure example).
Here’s the code for the Flask app (save it as docker/provisioning/www/index.py.j2):
1 # Infrastructure test page.
2 from flask import Flask
3 from flask import Markup
4 from flask import render_template
5 from flask.ext.sqlalchemy import SQLAlchemy
6
7 app = Flask(__name__)
8
9 # Configure MySQL connection.
10 db = SQLAlchemy()
11 db_uri = 'mysql://admin:admin@{{ host_ip_address }}/information_schema'
12 app.config['SQLALCHEMY_DATABASE_URI'] = db_uri
13 db.init_app(app)
14
15 @app.route("/")
16 def test():
17 mysql_result = False
18 try:
19 if db.session.query("1").from_statement("SELECT 1").all():
20 mysql_result = True
21 except:
22 pass
23
24 if mysql_result:
25 result = Markup('<span style="color: green;">PASS</span>')
26 else:
27 result = Markup('<span style="color: red;">FAIL</span>')
28
29 # Return the page with the result.
30 return render_template('index.html', result=result)
31
32 if __name__ == "__main__":
33 app.run(host="0.0.0.0", port=80)
This simple app defines one route (/), listens on every interface on port 80, and shows a MySQL connection status page rendered by the template index.html. There’s nothing particularly complicated in this application, but there is one Jinja2 varible ({{ host_ip_address }}) which an Ansible playbook will replace during deployment), and the app has a few dependencies (like flask-sqlalchemy) which will need to be installed via the Dockerfile.
Since we are using a Jinja2 template to render the page, let’s create that template in docker/provisioning/www/templates/index.html (Flask automatically picks up any templates inside a templates directory):
1 <!DOCTYPE html>
2 <html>
3 <head>
4 <title>Flask + MySQL Docker Example</title>
5 <style>* { font-family: Helvetica, Arial, sans-serif }</style>
6 </head>
7 <body>
8 <h1>Flask + MySQL Docker Example</h1>
9 <p>MySQL Connection: {{ result }}</p>
10 </body>
11 </html>
In this case, the .html template contains a Jinja2 variable ({{ result }}), and Flask will fill in that variable with the status of the MySQL connection.
Now that we have the app defined, we need to build the container to run the app. Here’s a Dockerfile that will install all the required dependencies, then copy a simple Ansible playbook and the app itself into place, so we can do the more complicated configuration (like copying a template with variable replacement) through Ansible:
1 # A simple Flask app container.
2 FROM ansible/ubuntu14.04-ansible
3 MAINTAINER Jeff Geerling <geerlingguy@mac.com>
4
5 # Install Flask app dependencies.
6 RUN apt-get install -y libmysqlclient-dev python-dev
7 RUN pip install flask flask-sqlalchemy mysql-python
8
9 # Install playbook and run it.
10 COPY playbook.yml /etc/ansible/playbook.yml
11 COPY index.py.j2 /etc/ansible/index.py.j2
12 COPY templates /etc/ansible/templates
13 RUN mkdir -m 755 /opt/www
14 RUN ansible-playbook /etc/ansible/playbook.yml --connection=local
15
16 EXPOSE 80
Instead of installing apt and pip packages using Ansible, we’ll install them using RUN commands in the Dockerfile. This allows those commands to be cached by Docker. Generally, more complicated package installation and configuration is easier and more maintainable inside Ansible, but in the case of simple package installation, having Docker cache the steps so future docker build commands take seconds instead of minutes is worth the verbosity of the Dockerfile.
At the end of the Dockerfile, we run a playbook (which should be located in the same directory as the Dockerfile), and expose port 80 so the app can be accessed via HTTP by the outside world. We’ll create the app deployment playbook next.
|
|
Purists might cringe at the sight of an Ansible playbook inside a Dockerfile, and for good reason! Commands like the ansible-playbook command cover up configuration that might normally be done (and cached) within Docker. Additionally, using the ansible/ubuntu14.04-ansiblebase image (which includes Ansible) requires an initial download that’s 50+ MB larger than a comparable debian or ubuntu image without Ansible. However, for brevity and ease of maintenance, we’re using Ansible to manage all the app configuration inside the container (otherwise we’d need to run a bunch of verbose and incomprehensible shell commands to replace Ansible’s template functionality). |

For the Flask app to function properly, we’ll need to get the host_ip_address, then replace the variable in the index.py.j2 template. Create the Flask deployment playbook at docker/provisioning/www/playbook.yml:
1 ---
2 - hosts: localhost
3 sudo: yes
4
5 tasks:
6 - name: Get host IP address.
7 shell: "/sbin/ip route|awk '/default/ { print $3 }'"
8 register: host_ip
9 changed_when: false
10
11 - name: Set host_ip_address variable.
12 set_fact:
13 host_ip_address: "{{ host_ip.stdout }}"
14
15 - name: Copy Flask app into place.
16 template:
17 src: /etc/ansible/index.py.j2
18 dest: /opt/www/index.py
19 mode: 0755
20
21 - name: Copy Flask templates into place.
22 copy:
23 src: /etc/ansible/templates
24 dest: /opt/www
25 mode: 0755
The shell command that registers the host_ip (which is used in the next task to generate the host_ip_address variable) is a simple way to retrieve the IP while still letting Docker do it’s own virtual network management.
The last two tasks copy the flask app and templates directory into place.
The docker/provisioning/www directory should now contain the following:
www/
templates/
index.html
Dockerfile
index.py.j2
playbook.yml
MySQL container
We’ve configured MySQL a few times throughout this book, so little time will be spent discussing how MySQL is set up. We’ll instead dive into how MySQL is configured to work inside a docker container, with a persistent data volume from the previously-configured data container.
First, we’ll create a really simple Ansible playbook to install and configure MySQL using the geerlingguy.mysql role:
1 ---
2 - hosts: localhost
3 sudo: yes
4
5 vars:
6 mysql_users:
7 - name: admin
8 host: "%"
9 password: admin
10 priv: "*.*:ALL"
11
12 roles:
13 - geerlingguy.mysql
This playbook is quite simple; it just sets up one MySQL user using the mysql_users variable, and then runs geerlingguy.mysql. Save it as docker/provisioning/db/playbook.yml.
Next, we need to account for the fact that there are two conditions under which MySQL will be started:
1. When Docker builds the container initially (using docker build through Ansible’s docker_image module).
2. When we launch the container and pass in the data volume (using docker run through Ansible’s docker module).
In the latter case, the data volume’s /var/lib/mysql directory will supplant the container’s own directory, but it will be empty! Therefore, instead of just launching the MySQL daemon as we launched the Flask app in the wwwcontainer, we need to build a small shell script to run on container start to detect if MySQL has already been setup inside /var/lib/mysql, and if not, reconfigure MySQL so the data is there.
Here’s a simple script to do just that—using the playbook we just created to do most of the heavy lifting. Save this as docker/provisioning/db/start-mysql.sh:
1 #!/bin/bash
2
3 # If connecting to a new data volume, we need to reconfigure MySQL.
4 if [[ ! -d /var/lib/mysql/mysql ]]; then
5 rm -f ~/.my.cnf
6 mysql_install_db
7 ansible-playbook /etc/ansible/playbook.yml --connection=local
8 mysqladmin shutdown
9 fi
10
11 exec /usr/bin/mysqld_safe
This bash script checks if there’s already a mysql directory inside MySQL’s default data directory, and if not (as is the case when we run the container with the data volume), it will remove any existing .my.cnf connection file, run mysql_install_db to initialize MySQL, then run the playbook, and shut down MySQL.
Once that’s all done (or if the persistent data volume has already been set up previously), MySQL is started with the mysqld_safe startup script which, according to the MySQL documentation, is “the recommended way to start a mysqld server on Unix”.
Next comes the Dockerfile, where we’ll make sure the playbook.yml playbook and start-mysql.sh script are put in the right places, and expose the MySQL port so other containers can connect to MySQL.
1 # A simple MySQL container.
2 FROM ansible/ubuntu14.04-ansible
3 MAINTAINER Jeff Geerling <geerlingguy@mac.com>
4
5 # Install required Ansible roles.
6 RUN ansible-galaxy install geerlingguy.mysql
7
8 # Copy startup script.
9 COPY start-mysql.sh /opt/start-mysql.sh
10 RUN chmod +x /opt/start-mysql.sh
11
12 # Install playbook and run it.
13 COPY playbook.yml /etc/ansible/playbook.yml
14 RUN ansible-playbook /etc/ansible/playbook.yml --connection=local
15
16 EXPOSE 3306
Just as with the Flask app container, we’re using a base image with Ubuntu 14.04 and Ansible. This time, since we’re doing a bit more configuration via the playbook, we also need to install the geerlingguy.mysql role via Ansible Galaxy.
The start-mysql.sh script needs to be in the location where we’re calling it with command: /opt/start-mysql.sh in the docker.yml file we set up much earlier, so we copy it in place, then give +x permissions so Docker can execute the file.
Finally, the Ansible playbook that configures MySQL is copied into place, then run, and port 3306 is exposed.
The docker/provisioning/db directory should now contain the following:
db/
Dockerfile
playbook.yml
start-mysql.sh
Ship it!
Now that everything’s in place, you should be able to cd into the main docker directory, and run vagrant up. After 10 minutes or so, Vagrant should show that Ansible provisioning was successful, and if you visit http://192.168.33.39/ in your browser, you should see something like the following:

Docker orchestration success!
If you see “MySQL Connection: PASS”, congratulations, everything worked! If it shows ‘FAIL’, you might need to give the MySQL a little extra time to finish it’s reconfiguration, since it has to rebuild the database on first launch. If the page doesn’t show up at all, you might want to compare your code with the Docker LAMP example on GitHub.
Summary
The entire Docker LAMP example is available on GitHub, if you want to clone it and try it locally.
The Docker examples in this book barely scratch the surface of what makes Docker a fascinating and useful application deployment tool. As of the writing of this book, Docker is still in its infancy, so there are dozens of ways to manage the building of Dockerfiles, the deployment of images, and the running and linking of containers. Ansible is a solid contender in this space, and can even be used within a Dockerfile to simplify complex container configurations.
_________________________________________
/ Any sufficiently advanced technology is \
| indistinguishable from magic. |
\ (Arthur C. Clarke) /
-----------------------------------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.