Hacking Ubuntu (2007)
Part III: Improving Performance
Chapter List
Chapter 7: Tuning Processes
Chapter 8: Multitasking Applications
Chapter 9: Getting Graphical with Video Bling
Chapter 7: Tuning Processes
The default Ubuntu Dapper Drake installation includes some basic processes that check devices, tune the operating system, and perform housekeeping. Some of these processes are always running, while others start up periodically. Occasionally you might see your hard drive start up or grind away for a few minutes-what's going on? On mission critical servers, serious gaming boxes, and other real-time systems, unexpected processes can cause huge problems; administrators should know exactly what is running and when. The last thing a time-sensitive application needs is for a resource-intensive maintenance system to start at an unexpected time and cause the system to slow down.
In order to fine-tune your system, you will need to know what is currently running, which resources are available, and when processes start up. From there, you can tweak configurations: disable undesirable processes, enable necessary housekeeping, and adjust your kernel to better handle your needs.
Learning the Lingo
Everything that runs on the system is a process. Processes are programs that perform tasks. The tasks may range from system maintenance to configuring plug-and-play devices and anything else the user needs. System processes manage keep the operating system running, whereas user processes handle user needs.
Many processes provide services for other processes. For example, a web server is a service for handling HTTP network requests. The web server may use one or more processes to perform its task. Some services are critical to the system's operation. For example, if the system must support graphics but the X-Windows service is unavailable, then a critical service is missing.
Although most system processes are services, most user processes are applications. Applications consist of one or more processes for supporting user needs. For example, the Firefox web browser is an application that helps the user browse the web. In general, services start and end based on system needs, while applications start and end based on user needs.
None of these definitions-programs, processes, applications, and services- are very distinct. For example, the Gnome desktop consists of programs and processes that provide services to other programs and supports user needs. GDE can be called a set of programs, processes, applications, or services without any conflict.
Time to Change
Different versions of Ubuntu (and Linux) use different startup scripts and run different support processes. Knowing how one version of Linux works does not mean that you know how all versions work. For example, one of my computers has a clock that loses a few minutes after every reboot. (It's an old computer.) When I installed Ubuntu Dapper Drake (6.06), I noticed that the time was correct after a reboot. I started to look around to find out how it did that and which timeserver it was using. The first thing I noticed was that there was no script in /etc/init.d/ for setting the time. Eventually I tracked down the network startup scripts and found that the ntpdate script was moved from /etc/init.d/ (in previous Ubuntu releases) to /etc/network/if-up.d/. This script allowed me to find the network time protocol (NTP) configuration file (/etc/default/ntpdate).
A similar problem came up when I started running Ubuntu Hoary Hedgehog (5.04). Periodically the hard drives would grind when I was not doing anything. At other times it happened when I was running processes that were impacted by disk I/O- when the drives began to grind, the critical process would detect a processing problem. I quickly narrowed the disk grinding to updatedb-a caching program that works with slocate for quickly finding files. What I could not find was how this program was being started. Eventually I discovered that updatedb was started by anacron, an automated scheduler.
While it is important to know what is running, it is even more important to know how to track down running processes and tune them to your needs.
When I talk about processes, I refer to anything that generates a running process identifier (see the next section for Viewing Running Processes). Programs are the executable files on the system that generate one or more processes. Users directly use applications, while the operating system uses services.
Viewing Running Processes
The only things that consume systems resources are running processes. If your computer seems to be running slower than normal, then it is probably due to some process that is either misbehaving or consuming more resources than you have available.
There are a couple of easy ways to find out what is running. From the command line, you can use ps and top to show applications, dependencies, and resources. For example, ps -ef shows every (-e) running process in a full (-f) detailed list (see Listing 7-1). The columns show the user who runs the process (UID), the process ID (PID), the parent process ID (PPID) who spawned this process, as well as when the process was started, how long it has been running, and of course, the process itself.
Listing 7-1: Sample Listing of Running Processes from ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Sep28 ? 00:00:01 init [2]
root 2 1 0 Sep28 ? 00:00:00 [migration/0]
root 3 1 0 Sep28 ? 00:00:00 [ksoftirqd/0]
root 4 1 0 Sep28 ? 00:00:00 [watchdog/0]
root 2406 1 0 Sep28 ? 00:00:00 [kjournald]
root 2652 1 0 Sep28 ? 00:00:00 /sbin/udevd --daemon
root 3532 1 0 Sep28 ? 00:00:00 [shpchpd_event]
root 4219 1 0 Sep28 ? 00:00:00 [kjournald]
daemon 4370 1 0 Sep28 ? 00:00:00 /sbin/portmap
root 4686 1 0 Sep28 ? 00:00:00 /usr/sbin/acpid -c /etc/acpi/eve
nts -s /var/run/acpid.socket
root 4857 1 0 Sep28 ? 00:00:00 /bin/dd bs 1 if /proc/kmsg of /v
ar/run/klogd/kmsg
klog 4859 1 0 Sep28 ? 00:00:00 /sbin/klogd -P /var/run/klogd/km
sg
root 5174 1 0 Sep28 ? 00:00:00 /usr/sbin/gdm
hplip 5213 1 0 Sep28 ? 00:00:00 /usr/sbin/hpiod
hplip 5217 1 0 Sep28 ? 00:00:00 python /usr/sbin/hpssd
nobody 5303 1 0 Sep28 ? 00:00:00 /usr/sbin/danted -D
nobody 5304 5303 0 Sep28 ? 00:00:00 /usr/sbin/danted -D
nobody 5306 5303 0 Sep28 ? 00:00:00 /usr/sbin/danted -D
nobody 5308 5303 0 Sep28 ? 00:00:00 /usr/sbin/danted -D
All in the Family
There are two main branches of Unix: BSD and System V. BSD is the older branch, and provides a standard that is used by operating systems such as FreeBSD, OpenBSD, SunOS, and Mac OS X. The BSD standard defines process management, device driver naming conventions, and system directory layouts. The younger branch, System V (pronounced "System Five"), includes operating systems like HP- UX, AIX, Solaris, and IRIX. System V follows the POSIX standards and differs slightly from the BSD family. For example, BSD places all device drivers in /dev-this directory may contain hundreds of devices. POSIX defines subdirectories in /dev, so all disks will be in /dev/disk (or /dev/dsk, /dev/rdsk, and so on) and all network drivers are in /dev/net. This makes /dev a cleaner directory.
These differences also show up in the ps command. Typing ps -ef on System V generates similar output to ps -aux on BSD.
Not every operating system is strictly in the BSD or System V camp. Linux, for example, supports both BSD and POSIX. Under Linux, hard drives are usually listed in /dev/ (for example, /dev/hda and /dev/hdb) and in /dev/disk/. There are a few places where the standards conflict (for example, what goes in specific directories); in these cases, the Linux selection seems almost arbitrary. For example, the /sbin directory under BSD contains system binaries. Under POSIX, they contain statically linked executables. Under Linux, they contain both.
The Linux ps command actually supports two different output formats: BSD and POSIX. Options that begin with a dash (for example, -e, -f, or combined as -ef) follow the POSIX standard. Without the dash (for example, ps aux) ps acts like BSD.
The top command shows all running processes and can order them by memory or CPU resource usage. Unlike ps, which provides a single snapshot of the currently running applications, top refreshes every few seconds to show you what is actively running. Processes that are spawned but not active will appear further down the top listing. You can interact with top in order to change the refresh rate (type s and then enter the refresh rate in seconds) or ordering (use < and > to select the order-by column). You can also press h to see a full list of the supported commands.
The graphical System Monitor (System ![]() Administration
Administration ![]() System Monitor) also enables you to see the list of running processes (see Figure 7-1).
System Monitor) also enables you to see the list of running processes (see Figure 7-1).
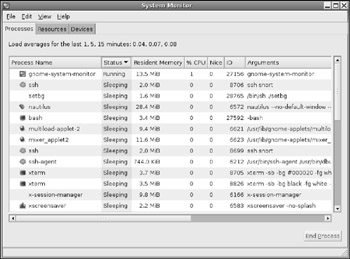
Figure 7-1: The System Monitor showing processes
Killing Processes
Under Linux, there are a maximum of 65,536 different PIDs-you cannot have more than 65,536 processes running at once. Under Ubuntu, the default maximum is 32,768 PIDs. (See "Tuning Kernel Parameters" later in this chapter; this parameter's name is kernel.pid_max.) Any new process is assigned the next available PID. As a result, it is possible to have a new process start with a lower PID than some older process. You can use the PID to kill processes using the kill command. For example to kill PID 123 use kill 123. The kill command can also be used to suspend processes (kill -STOP 123) and continue paused processes (kill -CONT 123). However, some processes do not die immediately.
|
Note |
Technically, PIDs are handles to processes and not actual processes. A multi-threaded process may have one handle for all threads, or one handle per thread. It all depends on how the process creates the threads. |
Every process is assigned a dynamic PID, but there are two exceptions: kernel and init. The kernel uses PID 0 and is not listed by ps, top, or the System Monitor. You cannot kill the kernel (with the killcommand). The init process (briefly discussed in Chapter 1) is the master parent process. Every process needs a running parent (PPID) to receive return codes and status from children. If a process' parent dies, then init becomes the parent.
|
Warning |
While you can kill init (sudo kill -9 1), you don't want to do this! Killing init will eventually crash the system since init is used to clean up dead processes. |
Killing a process kills it once; the kill signal does nothing to prevent the process from being started up again. In addition, there are some processes that cannot be killed.
§ Zombies-When a process dies, it returns an error code to its parent (PPID). A dead PID whose return code has not yet been received by its parent becomes a zombie. Zombies take up no CPU, but do take up a PID. For programmers, calling the wait() function retrieves return codes and kills zombies. In contrast, sending a kill signal to a zombie does nothing since the process is already dead.
§ I/O Bound-A process that is blocked on a kernel driver call may not process the kill signal until the kernel call returns. This is usually seen with network file system calls (NFS) when the network is down or on disk I/O when the drive is bad. For example, if you are using an NFS mounted directory and run ls, the command may hang if the network mount is bad. Sending a kill signal to the lsprocess will not immediately kill it. I've also experienced these hangs when using dd to copy a disk that was in the middle of a head-crash.
§ Interception-Some kill signals can be intercepted by applications. For example, programs can intercept the default signal (kill, kill -15, or kill -TERM). This is usually done so the program can clean up before exiting. Unfortunately, some programs don't die immediately. Other kill signals, such as kill -KILL or kill -9, cannot be intercepted.
|
Tip |
If you really want to kill a process, first use kill PID (e.g., kill 1234). This sends a TERM signal and allows well-behaved processes to clean up resources. If that does not get the result you want, try kill -1 PID. This sends a hang-up signal, telling the process that the terminal died. This signal is usually only intercepted by well-behaved processes; other processes just die. If that does not kill it, then using kill -9 PID. This is a true kill signal and cannot be intercepted by the process. (Kill -9 always reminds me of Yosemite Sam shouting, "When I say whoa, I mean WHOA!") |
Signals: Night of the Living Dead
Each signal is associated with a long name, short name, and number. The most common signals are:
§ SIGHUP, HUP, 1-This is a hang-up signal that is sent to processes when the terminal dies.
§ SIGINT, INT, 2-This is an interrupt signal. It is sent when the user presses Ctrl+C.
§ SIGKILL, KILL, 9-The true kill signal. This cannot be intercepted and causes immediate death.
§ SIGTERM, TERM, 15-This is a request to terminate signal and is the default signal sent by the kill command. Unlike KILL, TERM can be intercepted by the application.
§ SIGSTOP, STOP, 19-This signal stops the process but does not terminate it. This is sent when you press Ctrl+Z to halt the current process.
§ SIGCONT, CONT, 18-This resumes a process that is suspended by SIGSTOP. For a paused process at the command line (Ctrl+Z), typing fg will continue the process in the foreground and bgwill continue the process in the background.
§ SIGCHLD, CHLD, 17-Programmers who write spawning applications use this signal. CHLD is sent to the parent whenever any child dies.
The full list of signals is in the man page for signal (man 7 signal). Any of these representations can be used by the kill command. Typing kill -9 1234 is the same as kill -KILL 1234 and kill -SIGKILL 1234.
Signals are flags; they are not queued up. If you send a dozen TERM signals to a process before the process can handle them, then the process will only receive one TERM signal. Similarly, if a program spawns six children and all die at once, then the parent may only receive one CHLD signal. If the parent fails to check for other dead children, then the remaining children could become zombies.
Killing All Processes
Every developer I know has, at one time or another, created a spawning nightmare. Sometimes killing a process only makes another process spawn. Since spawning happens faster than a user can run psand kill, you won't be able to kill all of the processes. Fortunately, there are a couple of options.
§ Kill by name-If all the processes have the same name, you can kill them all at once using killall. For example, if my process is called mustdie, then I can use killall -9 mustdie to end all running instances of it.
§ Kill all user processes-There is a special kill command that will end all processes that you have permission to kill: kill -9 -1. As a user, this kills all of your processes, including your graphical display and terminals. But it will definitely kill any spawning loops you may have running.
|
Note |
Technically, the process ID -1 is a special case for the kill command. This means kill everything except the kill command (don't kill yourself) and init (don't kill the default parent). |
|
Warning |
Never use kill -9 -1 as root! This will kill every process-including shells and necessary system applications. This will crash your system before you can take you finger off the Enter key. If you need to kill all processes as root, use the power button or use the reboot or shutdown commands-don't use kill -9 -1. |
§ Stop processes-Infinite spawning loops usually happen because one process detects the death of another process. Instead of killing the processes, use the stop signal: kill -STOP PID or killall -STOP Name. This will prevent further spawning and enable you to kill all the sleeping processes without them re-spawning.
Identifying Resources
Your system has a lot of different resources that can be used by processes. These resources include CPU processing time, disk space, disk I/O, RAM, graphic memory, and network traffic. Fortunately, there are ways to measure each of these resources.
What's Up, /proc?
Linux provides a virtual file system that is mounted in the /proc directory. This directory lists system resources and running processes. For example:
$ ls -F /proc
1/ 3910/ 4133/ 4351/ bus/ iomem partitions
1642/ 3930/ 4135/ 4352/ cmdline ioports pmu/
1645/ 3945/ 4137/ 4363/ cpuinfo irq/ scsi/
1650/ 3951/ 4167/ 4364/ crypto kallsyms self@
1736/ 3993/ 4220/ 4382/ devices kcore slabinfo
1946/ 4/ 4224/ 5/ device-tree/ key-users stat
2/ 4009/ 4237/ 54/ diskstats kmsg swaps
20/ 4027/ 4250/ 55/ dma loadavg sys/
3/ 4057/ 4270/ 56/ driver/ locks sysrq-trigger
3310/ 4072/ 4286/ 57/ execdomains mdstat sysvipc/
3333/ 4073/ 4299/ 6/ fb meminfo tty/
3335/ 4081/ 4347/ 651/ filesystems misc uptime
3356/ 4091/ 4348/ apm fs/ modules version
3402/ 4092/ 4349/ asound/ ide/ mounts@ vmstat
3904/ 4127/ 4350/ buddyinfo interrupts net/ zoneinfo
The numbered directories match every running process. In each directory, you will find the actual running command-line and running environment. Device drivers and the kernel use non-numeric directories. These show system resources. For example, /proc/iomem shows the hardware I/O map and /proc/cpuinfo provides information about the system CPUs.
Although /proc is useful for debugging, applications should be careful when depending on it. In particular, everything is dynamic: process directories may appear and vanish quickly and some resources constantly change.
Measuring CPU
The CPU load can be measured in a couple of ways. The uptime command provides a simple summary. It lists three values: load averages for 1 minute, 5 minutes, and 15 minutes. The load is a measurement of queue time. If you have one CPU and the load is less than 1.0, then you are not consuming all of the CPU resources. A load of 2.0 means all resources are being consumed and you need twice as many CPUs to reduce any wait-time. If you have two CPUs, then a load of 1.0 indicates that both processors are operating at maximum capacity. Although a load of 1.0 won't seem sluggish, a load of 5.0 can be noticeably detectable because commands may need to wait a few seconds few moments before being processed.
While uptime provides a basic metric, top gives finer details. While running top, you can press 1 to see the load per CPU at the top of the screen and you can see which processes are consuming the most CPU resources. The command ps aux also shows CPU resources per process.
Measuring Disk Space
The commands df and du are used to identify disk space. The disk-free command (df, also sometimes called disk-full or disk-file system) lists every mounted partition and the amount of disk usage. The default output shows the information in blocks. You can also see the output in a human-readable form (-h) and see the sizes in kilobytes or megabytes: df -h. The df command also allows you to specify a file or directory name. In this case, it will show the disk usage for the partition containing the file (or directory). For example to see how much space if in the current directory, use:
$ df . # default output
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hda1 154585604 72737288 73995748 50% /
$ df -h . # human readable form
Filesystem Size Used Avail Use% Mounted on
/dev/hda1 148G 70G 71G 50% /
You can also use the System Monitor (System ![]() Administration
Administration ![]() System Monitor) to graphically show the df results (see Figure 7-2).
System Monitor) to graphically show the df results (see Figure 7-2).
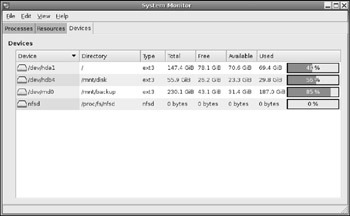
Figure 7-2: System Monitor showing available disk space
The disk-usage (du) command shows disk usage by directory. When used by itself, it will display the disk space in your current directory and every subdirectory. If you specify a directory, then it starts there instead. To see the biggest directories, you can use a command like du | sort -rn | head. This will sort all directories by size and display the top 10 biggest directories. Finally, you can use the -sparameter to stop du from listing the sizes from every subdirectory. When I am looking for disk hogs in my directory, I usually use du -s * | sort -rn | head. This lists the directories in size order. I can then enter the biggest directory and repeat the command until I find the largest files.
|
Tip |
The du command looks at every file in every subdirectory. If you have thousands of files, then this could take a while. When looking for large directories, consider the ones that take the longest to process. If every directory takes a second to display and one directory takes a minute, then you can press Ctrl+C because you probably found the biggest directory. |
Measuring Disk I/O
All processes that access a disk do so over the same I/O channel. If the channel becomes clogged with traffic, then the entire system may slow down. It is very easy for a low-CPU application to consume most of the disk I/O. While the system load will remain low, the computer will appear sluggish.
If the system seems to be running slowly, you can use iostat (sudo apt-get install sysstat) to check the performance (see Listing 7-2). Besides showing the system load, the I/O metrics from each device are displayed. I usually use iostat with the watch command in order to identify devices that seem overly active.
watch --interval 0.5 iostat
Listing 7-2: Installing and Using iostat
$ sudo apt-get install sysstat # install iostat
$ iostat
Linux 2.6.15-26-686 (chutney) 09/30/2006
avg-cpu: %user %nice %system %iowait %steal %idle
0.22 0.00 0.13 0.10 0.00 99.55
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
hda 1.98 19.46 23.12 2805161 3332264
hdb 0.18 1.39 0.46 200903 66000
sda 0.01 0.06 0.01 8612 1536
sdb 0.01 0.07 0.01 9518 1536
md0 0.01 0.11 0.01 15450 1392
After finding which device is active, you can identify where the device is mounted using the mount command:
$ mount
/dev/hda1 on / type ext3 (rw,errors=remount-ro)
proc on /proc type proc (rw)
/sys on /sys type sysfs (rw)
varrun on /var/run type tmpfs (rw)
varlock on /var/lock type tmpfs (rw)
udev on /dev type tmpfs (rw)
devpts on /dev/pts type devpts (rw,gid=5,mode=620)
devshm on /dev/shm type tmpfs (rw)
Now that you know which device is active and where it is used, you can use lsof to identify which processes are using the device. For example, if device hda is the most active and it is mounted on /, then you can use lsof / to list every process accessing the directory. If a raw device is being used, then you can specify all devices with lsof /dev or a single device (for example, hda) using lsof /dev/hda.
|
Note |
Unfortunately, there is no top-like command for disk I/O. You can narrow down the list of suspected applications using lsof, but you cannot identify which application is consuming most of the disk resources. |
Measuring Memory Usage
RAM is a limited resource on the system. If your applications allocate all available RAM, then the kernel will begin swapping memory to disk. Although swap space can allow you to run massively large applications, swap is also very slow compared to just using RAM. There are a couple of ways to view swap usage. The command swapon -s will list the available swap space and show the usage. There is usually a little swap space used, but if it is very full then you either need to allocate more swap space, install more RAM, or find out what is consuming the available RAM. The System Monitor (System ![]() Administration
Administration ![]() System Monitor) enables you to graphically view the available memory usage and swap space and identify if it is actively being used (see Figure 7-3).
System Monitor) enables you to graphically view the available memory usage and swap space and identify if it is actively being used (see Figure 7-3).
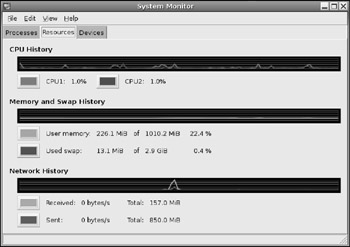
Figure 7-3: The System Monitor displaying CPU, memory, swap, and network usage
To identify which applications are consuming memory, use the top or ps aux commands. Both of these commands show memory allocation per process. In addition, the pmap command can show you memory allocations for specific process IDs.
Measuring Video Memory
The amount of memory on your video card will directly impact your display. If you have an old video card with 256 KB of RAM, then the best you can hope for is 800x600 with 16 colors. Most high-end video cards today have upwards of 128 MB of RAM, allowing monster resolutions like 1280x1024 with 32 million colors. More memory also eases animation for games and desktops. While one set of video memory holds the main picture, other memory sections can act as layers for animated elements.
There is no simple way to determine video memory. If you have a PCI memory card, then the command lspci -v will show you all PCI cards (including your video card) and all memory associated with the card. For example:
$ lspci -v | more
0000:01:00.0 VGA compatible controller: nVidia Corporation NV18 [GeForce4 MX 400
0 AGP 8x] (rev c1) (prog-if 00 [VGA])
Subsystem: Jaton Corp: Unknown device 0000
Flags: bus master, 66MHz, medium devsel, latency 248, IRQ 177
Memory at fa000000 (32-bit, non-prefetchable) [size=16M]
Memory at f0000000 (32-bit, prefetchable) [size=128M]
Expansion ROM at fbee0000 [disabled] [size=128K]
Capabilities: <available only to root>
This listing shows an NVIDIA NV18 video card with 128 MB of video RAM.
|
Tip |
On large supercomputers, lspci not only shows what is attached but also where. For example, if you have eight network cards then it can identify which slot each card is in. This is extremely useful for diagnostics in a mission-critical environment with fail-over hardware support. One example is to use (lspci -t ; lspci -v) | less to show the bus tree and each item's details. |
Measuring Network Throughput
Just as disk I/O can create a performance bottleneck, so can network I/O. While some applications poll the network for data and increase CPU load when the network is slow, most applications just wait until the network is available and do not impact the CPU's load.
If the computer seems sluggish when accessing the network, then you can check the network performance using netstat -i inet:
$ netstat -i inet
Kernel Interface table
Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 1500 0 338386 0 0 0 737350 0 0 0 BMRU
lo 16436 0 786 0 0 0 786 0 0 0 LRU
vmnet 1500 0 0 0 0 0 465 0 0 0 BMRU
vmnet 1500 0 0 0 0 0 465 0 0 0 BMRU
This shows the amount of traffic on each network interface as well as any network errors, dropped packets, and overruns. This also shows the name of the network interface (for example, eth0). When checking network usage, I usually use netstat with the watch command so I can see network usage over time:
watch --interval 0.5 netstat -i inet
|
Tip |
The netstat -i inet command shows the number of packets from every interface. You can also use ifconfig (for example, ifconfig eth0) to see more detail; ifconfig shows the number of packets and number of bytes from a particular network interface. |
The netstat -t and netstat -u commands allow you to see which network connections are active. The -t option shows TCP traffic, and -u shows UDP traffic. There are many other options including –protocol=ip to show all IP (IPv4) connections, and IPv6 connections are listed with –protocol=ip6.
To identify which processes are using the network, you can use lsof. The -i4 parameter shows which processes have IPv4 connections, -i6 displays IPv6, -i tcp lists TCP, and -i udp displays applications with open UDP sockets:
$ lsof -i4 -n # show network processes and give IP addresses as numbers
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
ssh 8699 mark 3u IPv4 120398 TCP 10.3.1.5:41525->10.3.1.3:ssh
(ESTABLISHED)
ssh 8706 mark 3u IPv4 120576 TCP 10.3.1.5:41526->10.3.7.245:ssh
(ESTABLISHED)
Finding Process Startups
While the ps command can list what is running now, and other tools show what resources are being used, there is no good tool for telling how something started in the first place. Although ps can identify the PPID, in many cases the PPID is 1-indicating init owns it. Instead, there are plenty of places where a process can be started, including boot scripts, device configuration scripts, network changes, logins, application initialization scripts, and scheduled tasks.
Inspecting Boot Scripts
The directory /etc/init.d/ contains scripts for starting and stopping system services (these are detailed in Chapter 3). These scripts are activated by links in the different rc directories (/etc/rc0.d, /etc/rc1.d, and so on). As init enters each run level, the appropriate S links are executed. For example, at run level 1, all S links in /etc/rc1.d/ are started. This includes S20single for single-user mode configuration. When the system changes levels, all K (for kill) scripts are executed before changing run levels. To find the current run level, you can either use who -r or the runlevel command.
|
Note |
The runlevel command displays the previous and current run levels. Usually the previous one is not defined (since you probably booted into the current level) and is displayed as an N (for not defined). |
$ who -r
run-level 2 2006-09-28 20:32 last=S
$ runlevel
N 2
During boot, all output from the init scripts is sent to /var/log/messages. You can use this log file to identify which processes were executed.
|
Note |
Under Dapper Drake and earlier Ubuntu versions, init is the top-most process and is critical for managing running processes. New to Edgy Eft, the System V init is being replaced with Upstart-an event driven process manager. |
Inspecting Device Startups
Dynamic device configuration is managed by udev (see Chapter 3). The udev process watches and manages plug-and-play devices. Based on the configuration in /etc/udev/rules.d/, different applications may be launched.
Inspecting Network Services
New network interfaces are managed by a couple of different systems. First, udev identifies the network interface (/etc/udev/rules.d/25-iftab.rules). This rule runs the interface table helper (iftab_helper) command. The helper consults the file /etc/iftab in order to identify the proper device handle. After the interface is identified, it can be brought up or down. There are four directories of scripts for managing network interfaces:
§ /etc/network/if-pre-up.d/-This contains steps that must be completed before (pre) the interface is brought up. For example, the scripts may need to load wireless drivers.
§ /etc/network/if-up.d/-These scripts are used after bringing up the configured network interface. For example, this is where the system clock is set-every time any network is brought up, the computer's clock is set.
§ /etc/network/if-down.d/-These scripts are used to remove any running configuration. For example, if you have the Postfix mail server running, then there is a script that tells Postfix to reload its configuration when an interface is taken down.
§ /etc/network/if-post-down.d/-This directory contains any cleanup stages that are needed after (post) the interface is taken down. For example, unnecessary wireless drivers can be unloaded.
|
Tip |
The /etc/network/ scripts are used when an interface is brought up and down. The /etc/init.d/networking script is used to actually bring up and down the interfaces. Interfaces are configured based on the /etc/network/interfaces file, described in Chapter 11. |
Although /etc/network/ is used only when interfaces are brought up or down, other programs like xinetd can run applications based on network connections. If you installed xinetd (sudo apt-get install xinetd), the configuration file /etc/xinetd.conf and the /etc/xinetd.d/ directory contain the list of executables that can be started by xinetd.
Inspecting Shell Startup Scripts
Each time you log in, log out, or create a new shell, configuration scripts are executed. Each of these scripts run processes. Since bash is the default shell under Ubuntu, you are likely to use the configuration scripts in Table 7-1.
|
Table 7-1: Shell Startup Scripts |
|
|
Initialization Script |
Purpose |
|
/etc/profile |
Used by every login shell, system-wide. |
|
$HOME/.bash_profile |
Used on a per-user basis. Each user can have a personalized login script. |
|
/etc/bash.bashrc |
Every interactive shell runs this system-wide configuration script. |
|
$HOME/.bashrc |
Every interactive shell runs this user-specific configuration script. |
|
/etc/bash.logout |
If you create it, this system-wide script is executed every time a user logs out. |
|
$HOME/.bash_logout |
User-specific script that is used during logout. |
All of these scripts are divided into two situations: login/logout and interactive shells. Whenever you log into your Ubuntu system, the login and interactive shell scripts are executed. When you open a terminal window, only the interactive scripts are used.
|
Tip |
The default user-specific shell scripts are stored in /etc/skel/. Use ls -la /etc/skel/ to list all of the default files. Changing these defaults will give all new user accounts the modified configuration files, but you will still need to modify existing user accounts. For system-wide changes, modify /etc/profile and /etc/bash.bashrc instead. |
Inspecting Desktop Scripts
Beyond user-level shell scripts, the graphical desktop can also run scripts. First, X-Windows runs. This starts up applications by running the script /etc/X11/xinit/xinitrc, /etc/X11/ Xsession, and /etc/X11/xinit/xserverrc. Each of these scripts set environment variables and can run applications. There are also startup scripts in /etc/X11/Xsession.d/ that are started after a user logs in, and individual users can have a $HOME/.xsession script for running applications at startup.
After X-Windows, the desktop starts. Under Ubuntu, this is Gnome. Gnome runs lots of applications that, in turn, can run many more applications. The main places to look for automatically running Gnome processes are in the /etc/X11/gdm/ directory, in the file $HOME/.gnomerc, and under System ![]() Preferences
Preferences ![]() Sessions. The /etc/X11/gdm directory contains system-wide startup scripts. The $HOME/.gnomerc script enables you to configure your own startup applications, and the graphical session configuration tool (see Figure 7-4) enables you to easily customize non-standard startups.
Sessions. The /etc/X11/gdm directory contains system-wide startup scripts. The $HOME/.gnomerc script enables you to configure your own startup applications, and the graphical session configuration tool (see Figure 7-4) enables you to easily customize non-standard startups.
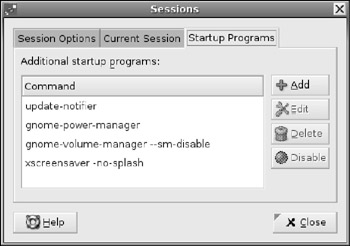
Figure 7-4: The Gnome graphical session manager showing the list of startup applications
All of these startup options can become very confusing. For example, if you want to automatically start Firefox on login, then you can add it to /etc/X11/Xsession, /etc/X11/gdm/ Xsession, /etc/X11/gdm/PostSession/Default, /etc/X11/Xsession.d/99start_ firefox, $HOME/.xsession, $HOME/.gnomerc, or use the graphical Gnome Session editor to add a startup applications. The main question to ask is, "who will want this?"
§ Everyone running X-Windows?-Use /etc/X11/Xsession or place the startup script under /etc/X11/Xsession.d/.
§ Just you running X-Windows?-Use $HOME/.xsession.
§ Everyone running Gnome?-Use /etc/X11/gdm/PostSession/Default. This will work for Gnome users, but not KDE or other desktops. KDE, XDM, and other desktops have their own configuration directories and files.
§ Just you running Gnome?-Use $HOME/.gnomerc or the graphical session editor.
|
Note |
These are not all of the possible startup hooks. There are plenty of places where code can be told to start running. If you are trying to find where an application starts, look here first or use ps and start tracking down parent processes. Most graphical processes use configuration files and any of those files could potentially run applications. |
Inspecting Gnome Applications
Just as udev watches for plug-and-play devices, so does Gnome. The Gnome desktop can identify some devices and automatically run applications. The default settings are found under System ![]() Preferences
Preferences ![]() Removable Drives and Media. The tabs show you the items you can change:
Removable Drives and Media. The tabs show you the items you can change:
§ Storage-When a CD-ROM is inserted, the default action is to either browse the disk or start the CD-ROM burner (see Figure 7-5). I usually disable the option Burn a CD or DVD when a blank disc is inserted. This does not disable your ability to right-click on an ISO image and select the burn option-it only stops the default CD-Writer application from starting. This tab also covers other types of removable media, including USB thumb drives.
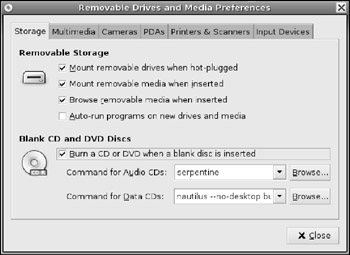
Figure 7-5: The Removable Drives and Media preferences, showing drive handlers
§ Multimedia-When you first insert an audio CD or a DVD, the default media player starts up. From the Multimedia tab (see Figure 7-6), you can change the default applications or disable the automatic startup. If you disable it, you can still run the multimedia players from the Applications ![]() Sound & Video menu.
Sound & Video menu.
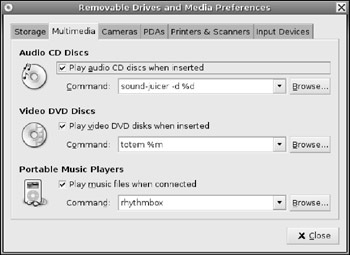
Figure 7-6: The Removable Drives and Media preferences, showing the default audio and video applications
§ Cameras-When a camera is connected, the default action is to import pictures (see Figure 7-7). On my main workstation, I usually disable this option-if I want to import pictures, then I will do it myself. This is because I usually want to download a single, specific picture, and not all of them. In contrast, my laptop is configured to automatically import pictures since I am probably traveling and want to quickly transfer pictures before taking more photos.
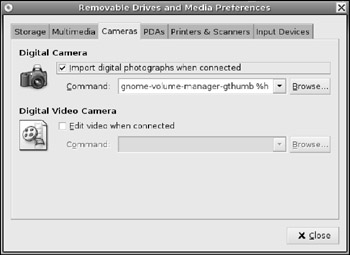
Figure 7-7: The Removable Drives and Media preferences, showing the default camera settings
§ PDAs-If you have a PDA such as a Palm or PocketPC, then you can automatically connect and synchronize with these devices.
§ Printers & Scanners-If you have a USB scanner or printer, then it may not always be connected. Normally, no programs (beyond udev) run when a printer is attached, but you could enable the default setting and add the printer to the printing system. For scanners, xsane automatically runs. You can change the default action that occurs when these devices are attached (see Figure 7-8).
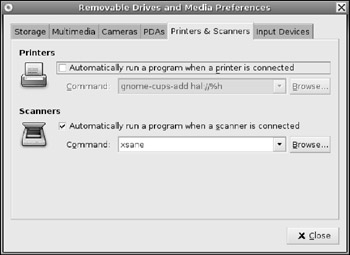
Figure 7-8: The Removable Drives and Media preferences, showing the default actions for printers and scanners
§ Input Devices-This is an interesting tab because it really does not do anything. In theory, you can connect a USB mouse, keyboard, or tablet and have an application run. In practice, the X-Windows server normally uses these devices. If they are not configured and connected before the X-server starts, then they will not be recognized as pointer devices (see Chapter 3 for configuring pointer devices). However, if you have a special application that can handle the device, then you can use these settings to run the application.
Although other spawning subsystems, such as udev and /etc/init.d/, are configurable and extendable, Gnome is fairly inflexible. You can only configure auto-run settings for items listed in this applet. If you have a new plug-and-play device that is not listed (for example, a GPS system) then you cannot make Gnome spawn an application. Instead, you will need to configure udev run the application.
|
Tip |
Configuring udev to run programs is covered in Chapter 3. See the section on Associating Applications with USB. |
Inspecting Schedulers: at, cron, and anacron
Programs that should run periodically are usually placed in a scheduler. The three common schedulers are at, cron, and anacron.
Scheduling with at
The at command specifies that an application should run at a specific time. This is used for run-once commands. For example, to start xclock in 15 minutes, you could use:
echo "DISPLAY=:0 xclock" | at now + 15 minutes
The at command takes one or more command-line statements as input. The time format can either be in an HH:MM with am or pm (for example, 3:45 pm or 3:45 PM), a date format (for example, 03/15/07), or as an offset (for example, noon + 3 hours or 8am + 6 days). Scheduled at jobs are stored in the /var/spool/cron/atjobs/ directory. You can query them using atq and remove jobs using atrm. After the process runs, any text output is e-mailed back to the user.
Scheduling with cron
While at is used for one-time applications, cron is used for repeated tasks. Each user has a crontab entry where processes can be scheduled. For example, mine has this entry:
3,18,33,48 * * * * fetchmail -U -n --invisible > /dev/null 2>&1
Each cron entry has six elements per line. The first five specify when to run, and the last element is a single command line to actually execute. The time fields are:
§ Minute-The minute to run. This can be a single value (0-59) or a comma-separated list of times (for example, 3,18 means run at 3 and 18 minutes after the hour). A star can also be used to mean every minute.
§ Hour-The hour to run. This can be a single value (0-23), a range (for example, 9-17 means hourly from 9 am to 5 pm), a comma-separated list, or a division indicating how often. For example, 9-17 means hourly from 9 am to 5 pm, but 9-17/3 means every 3 hours between 9 am and 5 pm (9 am, 12 pm, and 3 pm). A star can be used to mean every hour, and when combined with a divisor, "*/4 means every four hours.
§ Day-Day of the month to run. As with the other fields, this can be a single value (1- 31), a range, or a list and can use a divisor. A star means every day.
§ Month-Month of the year to run. This can be a single value (1-12), a range, or a list and can use a divisor. A star means every month.
§ Day of week-You can specify which weekday to run on. The days are numbers: 0-6 for Sunday through Saturday (7 can also mean Sunday). Again, this can be a value, list, or range and may include a divisor.
Usually the date specification is simple. For example, 0 12 * * 0 means to run every Sunday at noon. But it can be very complex: */3 */3 */3 */3 */3 says to run every three minutes, every third hour of every third day in every third month, but only when it corresponds with every third day of the week.
|
Tip |
Try to space cron jobs so they do not all run at once. Although I could use */15 to run fetchmail four times per hour, I use the list 3,18,33,48 instead. This prevents lots of applications from all trying to start on the hour. |
To schedule a cron task, use crontab -e. This edits your crontab file (found in /var/ spool/cron/crontabs/). You can also use crontab -l to list your crontab entries. A # at the beginning on a crontab line is a comment. I usually put the following comment at the start of my file just so I can remember what the time fields mean:
# mm ss DD MM WW command
As with at, every text output from the cronjob is e-mailed back to the user. If you don't want to receive e-mail, then add > /dev/null 2>&1 to the end of the command. This directs all output to /dev/null.
Scheduling with anacron
While cron runs tasks repeatedly, it makes no distinction as to the system state. The anacron service is similar to cron, but allows tasks to be run based on a relative period rather than an absolute date. For example, the default anacron installation runs updatedb (to update online man-page indexes) daily, starting at five minutes after the computer first boots up.
The configuration schedule for anacron is found in the /etc/anacrontab file. The default scripts are in /etc/cron.d/, /etc/cron.daily/, /etc/cron.weekly/, and /etc/cron.monthly/.
If you run a mission-critical system, or a computer with limited resources, then you should seriously consider looking at these configuration settings and tuning them to your needs. For example, if it is a deployed server, then you probably do not need updatedb running daily. In fact, you could disable anacron completely and move any required functionality into root's crontab (sudo crontab -e). This way, tasks such as log file rotation will happen on a predictable schedule.
Tuning Kernel Parameters
Many of the tunable performance items can be configured directly by the kernel. The command sysctl is used to view current kernel settings and adjust them. For example, to display all available parameters (in a sorted list), use:
sudo sysctl -a | sort | more
|
Note |
There are a few tunable parameters that can only be accessed by root. Without sudo, you can still view most of the kernel parameters. |
Each of the kernel parameters are in a field = value format. For example, the parameter kernel.threads-max = 16379 sets the maximum number of concurrent processes to 16,379. This is smaller than the maximum number of unique PIDs (65,536). Lowering the number of PIDs can improve performance on systems with slow CPUs or little RAM since it reduces the number of simultaneous tasks. On high-performance computers with dual processors, this value can be large. As an example, my 350 MHz iMac is set to 2,048, my dual-processor 200 MHz PC is set to 1024, and my 2.8 GHz dual processor PC is set to 16,379.
|
Tip |
The kernel configures the default number of threads based on the available resources. Installing the same Ubuntu version on different hardware may set a different value. If you need an identical system (for testing, critical deployment, or sensitive compatibility), be sure to explicitly set this value. |
There are two ways to adjust the kernel parameters. First, you can do it on the command line. For example, sudo sysctl -w kernel.threads-max=16000. This change takes effect immediately but is not permanent; if you reboot, this change will be lost. The other way to make a kernel change is to add the parameter to the /etc/sysctl.conf file. Adding the line kernel.threads-max=16000 will make the change take effect on the next reboot. Usually when tuning, you first use sysctl -w. If you like the change, then you can add it to /etc/sysctl.conf. Using sysctl -w first allows you to test modifications. In the event that everything breaks, you can always reboot to recover before committing the changes to /etc/sysctl.conf.
Computing Swap
The biggest improvement you can make to any computer runnning Ubuntu is to add RAM. In general, the speed impact from adding RAM is bigger than the impact from a faster processor. For example, increasing the RAM from 128 MB to 256 MB can turn the installation from a day job to an hour. Increasing to 1 GB of RAM shrinks the installation to minutes.
There is an old rule-of-thumb about the amount of swap space. The conventional wisdom says that you should have twice as much swap as RAM. A computer with 256 MB of RAM should start with 512 MB of swap. Although this is a good idea for memory limited systems, it isn't practical for high-end home user systems. If you have 1 GB of RAM, then you probably will never need swap space-and you are very unlikely to need 2 GB of swap unless you are planning on doing video editing or audio composition.
There is a limit to the amount of usable RAM. A 32-bit PC architecture like the Intel Pentium i686 family can only access 4 GB of RAM. This is a hardware limitation. Assuming you can insert 16 GB of RAM into the computer, only the first 4 GB will be addressable. The second limitation comes from the Linux 2.6 kernel used by Ubuntu's Dapper Drake (as well as other Linux variants). The kernel can only access 1 GB of RAM. Any remaining RAM is unused. For this reason, it is currently not worth investing in more than 1 GB of RAM. Also, since the total virtual memory (RAM + swap) is limited to 4 GB, you should not need to allocate more than 3 GB of swap on a 1 GB RAM system.
|
Note |
If you compile the kernel from scratch, there is a HIGHMEM flag that can be set to access up to 4 GB of RAM on a 32-bit architecture. Unfortunately, there is a reported performance hit since most hardware drivers cannot access the high memory. If you set this flag, then do not bother with any swap space-the total amount of memory (RAM + swap) cannot be larger than 4 GB. |
Modifying Shared Memory
Some sections of virtual memory can be earmarked for use by multiple applications. Shared memory allows different programs to communicate quickly and share large volumes of information. Applications such as X-Windows, the Gnome Desktop, Nautilus, X-session manager, Gnome Panel, Trashcan applet, and Firefox all use shared memory. If programs cannot allocate or access the shared memory that they need, then programs will fail to start.
The inter-process communication status command, ipcs, displays the current shared memory allocations as well as the PIDs that created and last accessed the memory (see Listing 7-3).
|
Tip |
There are many other flags for ipcs. For example, ipcs -m -t shows the last time the shared memory was accessed, and ipcs -m -c shows access permissions. In addition, ipcs can show semaphore and message queue allocations. |
Listing 7-3: Viewing Shared Memory Allocation
$ ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00000000 327680 nealk 600 393216 2 dest
0x00000000 360449 nealk 600 393216 2 dest
0x00000000 196610 nealk 600 393216 2 dest
0x00000000 229379 nealk 600 393216 2 dest
0x00000000 262148 nealk 600 393216 2 dest
$ ipcs -m -p
------ Shared Memory Creator/Last-op --------
shmid owner cpid lpid
327680 nealk 7267 7307
360449 nealk 7267 3930
196610 nealk 7182 7288
229379 nealk 7265 3930
262148 nealk 7284 3930
393221 nealk 7314 3930
425990 nealk 7280 3930
458759 nealk 7332 3930
$ ps -ef | grep -e 3930 -e 7280 # what processes are PID 3930 and 7280?
root 3930 3910 0 09:24 tty7 00:00:02 /usr/bin/X :0 -br -
audit 0 -auth /var/lib/gdm/:0.Xauth -nolisten tcp vt7
nealk 7280 1 0 15:22 ? 00:00:01 update-notifier
Programs can allocate shared memory in two different ways: temporary and permanent. A temporary allocation means the memory remains shared until all applications release the memory handle. When no applications remain attached (the ipcs nattch field), the memory is freed. In contrast, permanent allocations can remain even when no programs are currently using it. This allows programs to save state in a shared communication buffer.
Sometimes shared memory becomes abandoned. To forcefully free abandoned memory, use ipcrm. You will need to specify the shared memory ID found from using ipcs (the shmid column).
More often than not, you will be more concerned with allocating more shared memory rather than freeing abandoned segments. For example, databases and high-performance web servers work better when there is more shared memory available. The sysctl command shows the current shared memory allocations:
$ sysctl kernel | grep shm
kernel.shmmni = 4096
kernel.shmall = 2097152
kernel.shmmax = 33554432
In this example, there is a total of 33,554,432 bytes (32 MB) of shared memory available. A single application can allocate up to 2 MB (2,097,152 bytes), and the minimal allocation unit is 4096 bytes. These sizes are plenty for most day-to-day usage, but if you plan to run a database such as Oracle, MySQL, or PostgreSQL, then you will almost certainly need to increase these values.
Changing Per User Settings
Beyond the kernel settings are parameters for configuring users. The ulimit command is built into the bash shell and provides limits for specific application. Running ulimit -a shows the current settings:
$ ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
max nice (-e) 20
file size (blocks, -f) unlimited
pending signals (-i) unlimited
max locked memory (kbytes, -l) unlimited
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) unlimited
max rt priority (-r) unlimited
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) unlimited
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
These setting show, for example, that a single user-shell can have a maximum of 1,024 open files and core dumps are disabled (size 0). Developers will probably want to enable core dumps, with ulimit -c 100 (for 100 blocks). If you want to increase the number of open files to 2,048, use ulimit -n 2048.
The user cannot change some limits. For example, if you want to increase the number of open files to 2,048 then you would use ulimit -n 2048, except only root can increase this value. In contrast, the user can always lower the value.
|
Note |
Some values have an upper limit defined by the kernel. For example, although root can increase the number of open file handles, this cannot be increased beyond the value set by the kernel parameter fs.file-max (sysctl fs.file-max). |
On a multi-user system, the administrator may want to limit the number of processes any single user can have running. This can be done by adding a ulimit statement to the /etc/ bash.bashrc script:
# Only change the maximum number of processes for users, not root.
if [ `/usr/bin/id -u` -ne 0 ] ; then
ulimit -u 2048 2>/dev/null # ignore errors if user set it lower
else
ulimit -u unlimited # root can run anything
fi
Speeding Up Boot Time
The default init scripts found in /etc/init.d/ and the /etc/rc*.d/ directories are good for most systems, but they may not be needed on your specific system. If you do not need a service then you can disable it. This can reduce the boot time for your system. In some cases, it can also speed up the overall running speed by freeing resources. Use sysv-rc-conf (sudo apt-get install sysv-rc-conf) to change the enable/disable settings. Some of the services to consider disabling include:
§ anacron-As mentioned earlier, this subsystem periodically runs processes. You may want to disable it and move any critical services to cron.
§ atd and cron-By default, there are not at or cron jobs scheduled. If you do not need these services, then they can be disabled. Personally, I would always leave them enabled since they take relatively few resources.
§ apmd-This service handles power management and is intended for older systems that do not support the ACPI interface. It only monitors the battery. If you have a newer laptop (or are not using a laptop), then you probably do not need this service enabled.
§ acpid-The acpid service monitors battery levels and special laptop buttons such as screen brightness, volume control, and wireless on/off. Although intended for laptops, it can also support some desktop computers that use special keys on the keyboard (for example, a www button to start the browser). If you are not using a laptop and do not have special buttons on your keyboard, then you probably do not need this service.
§ bluez-utiles-This provides support for BlueTooth devices. If you don't have any, then this can be disabled.
§ dns-clean, ppp, and pppd-dns-These services are used for dynamic, dial-up connections. If you do not use dialup, then these can be disabled.
§ hdparm-This system is used to tune disk drive performance. It is not essential and, unless configured, does not do anything. The configuration file is /etc/hdparm.conf and it is not enabled by default.
§ hplip-This provides Linux support for the HP Linux Image and Printing system. If you do not need it, then it can be disabled. Without this, you can still print using the lpr and CUPS systems.
§ mdadm, mdadm-raid, and lvm-These provide file system support for RAID (mdadm and mdadm-raid) and Logical Volume groups (lvm). If you do not use either, then these can be disabled.
§ nfs-common, nfs-kernel-server, and portmap-These are used by NFS-they are only present if you installed NFS support. If you do not need NFS all the time, then you can disable these and only start the services when you need them:
§ sudo /etc/init.d/portmap start
§ sudo /etc/init.d/nfs-common start
§ sudo /etc/init.d/nfs-kernel-server start
§ pcmcia and pcmciautils-These provide support for PCMCIA devices on laptops. If you do not have any PCMCIA slots on your computer, then you do not need these services.
§ powernowd and powernowd.early-These services are used to control variable-speed CPUs. Newer computers and laptops should have these enabled, but older systems (for example, my dual-processor 200 MHz PC) do not need it.
§ readahead and readahead-desktop-These services are used to preload libraries so some applications will initially start faster. In a tradeoff for speed, these services slow down the initial boot time of the system and consume virtual memory with preloaded libraries. If you have limited RAM, then you should consider disabling these services.
§ rsync-This is a replacement for the remote copy (rcp) command. Few people need this-it is used to synchronize files between computers.
§ vbesave-This services monitors the Video BIOS real-time configuration. This is an ACPI function and is usually used on laptops when switching between the laptop display and an external display. If your computer does not support APCI or does not switch between displays, then you do not need this service.
|
Tip |
There is a System |
The sysv-rc-conf command shows most of the system services. However, it does not show all of them. If the service's name ends with .sh, contains .dpkg-, or is named rc or rcS, then it is treated as a non-modifiable system service. To change these services, you will need to manually modify the /etc/init.d/ and /etc/rc*.d/ directory contents.
Leave It On!
Although there are many services that you probably do not need, there are a few that are essential. You should not turn off these essential services unless you really know what you are doing:
§ dbus-Provides messaging services.
§ gdm-This is the Gnome Desktop. Only disable this if you do not want a graphical desktop.
§ klogd-This is the kernel log daemon. Removing it disables system logging.
§ makedev and udev-These create all device nodes.
§ module-init-tools-Loads kernel modules specified in /etc/modules.
§ networking and loopback-These start and stop the network. Disabling removes the network configuration at boot.
§ procps.sh-Any kernel tuning parameters added to /etc/sysctl.conf are processed by this service.
§ urandom-This seeds the real random number generator that is used by most cryptographic system. You should leave it enabled.
As a rule of thumb, if you do not know what it is, then leave it on. Also, if the service only runs in single-user mode (rcS) that it is usually smart to not change it. Single user mode is where you should go when everything fails in order to repair the system.
Summary
Ubuntu is designed for the average computer user. As a result, there are some running processes that may not be needed and some resources that are not used optimally. Using a variety of commands, you can see what is running, what resources are available, and what resources are being used. The system can be tuned by adjusting kernel parameters, shell parameters, and settings for specific applications.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.