Designing Evolvable Web APIs with ASP.NET (2012)
Chapter 1. The Internet, the World Wide Web, and HTTP
To harness the Web, you need to understand its foundations and design.
We start our journey toward Web APIs at the beginning. In the late 1960s the Advanced Research Projects Agency Network (ARPANET), a series of network-based systems connected by the TCP/IP protocol, was created by the Defense Advanced Research Projects Agenecy (DARPA). Initially, it was designed for universities and research laboratories in the US to share data. (see Figure 1-1).
ARPANET continued to evolve and ultimately led in 1982 to the creation of a global set of interconnected networks known as the Internet. The Internet was built on top of the Internet protocol suite (also known as TCP/IP), which is a collection of communication protocols. Whereas ARPANET was a fairly closed system, the Internet was designed to be a globally open system connecting private and public agencies, organizations, individuals, and insitutions.
In 1989, Tim Berners-Lee, a scientist at CERN, invented the World Wide Web, a new system for accessing linked documents via the Internet with a web browser. Navigating the documents of the Web (which were predominantly written in HTML) required a special application protocol, the Hypertext Transfer Protocol (HTTP). This protocol is at the center of what drives websites and Web APIs.
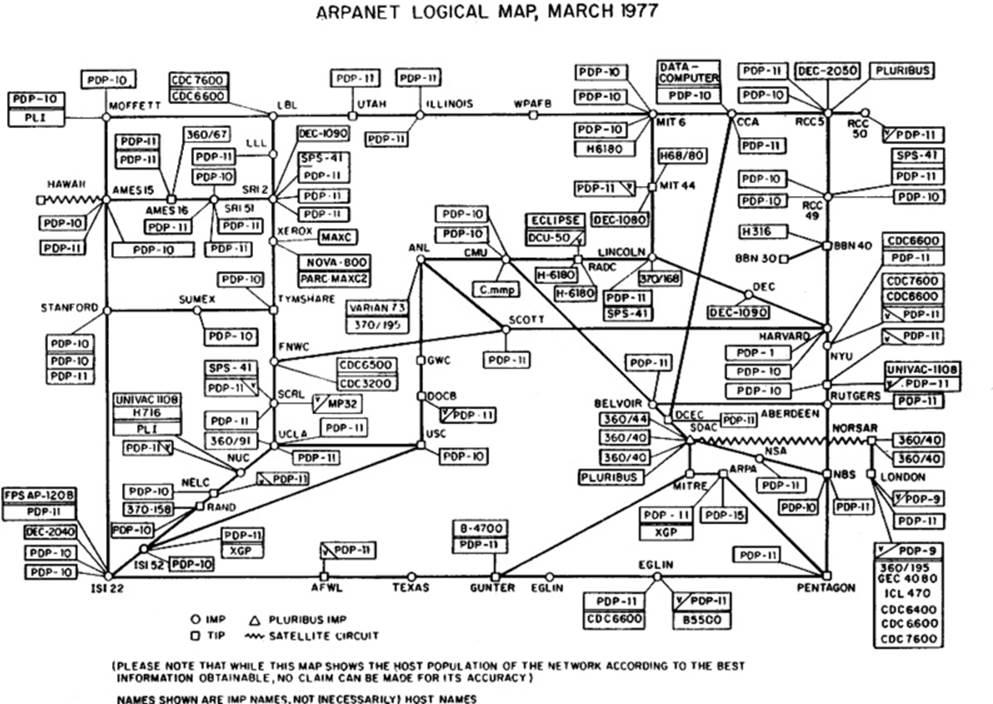
Figure 1-1. ARPANET (image from Wikimedia Commons)
In this chapter we’ll dive into the fundamentals of the web architecture and explore HTTP. This will form a foundation that will assist us as we move forward into actually designing Web APIs.
Web Architecture
The Web is built around three core concepts: resources, URIs, and representations, as shown in Figure 1-2.
A resource has a URI that identifies it and that HTTP clients will use to find it. A representation is data that is returned from that resource. Also related and significant is the media type, which defines the format of that data.
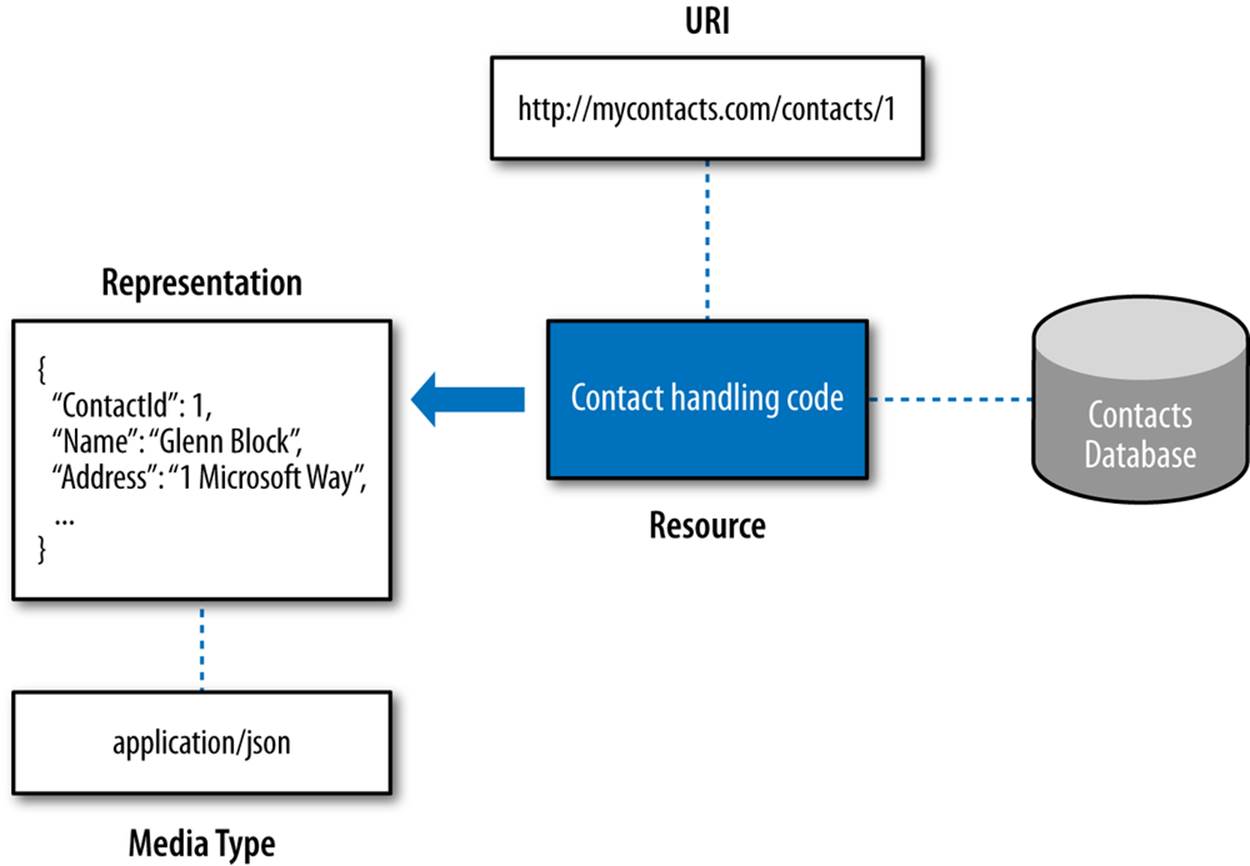
Figure 1-2. Web core concepts
Resource
A resource is anything that has a URI. The resource itself is a conceptual mapping to one or more entities. In the early years of the Web it was very common for this entity to be a file such as a document or web page. However, a resource is not limited to being file oriented. A resource can be a service that interfaces with anything such as a catalog, a device (e.g., a printer), a wireless garage door opener, or an internal system like a CRM or a procurement system. A resource can also be a streaming medium such as a video or an audio stream.
IS A RESOURCE BOUND TO AN ENTITY OR A DATABASE?
A common misnomer today with Web APIs is that each resource must map to an entity or business object backed by a database. Often, this will come up in a design conversation where someone might say, “We can’t have that resource because it will require us to create a table in the database and we have no real need for a table.” The previous definition described a mapping to one or more entities; this is an entity in the general sense of the word (i.e., it could be anything), not a business object. An application may be designed such that the resources exposed always map to business entities or tables, and in such a system the previous statement would be true. However, that is a constraint imposed by an application or framework, not the Web.
When you are building Web APIs, there are many cases where the entity/resource constraint is problematic. For example, an order processing resource actually orchestrates different systems to process an order. In this case, the resource implementation invokes various parts of the system that may themselves store state in a database. It may even store some of its own state, or not. The point is there is not a direct database correspondence for that resource. Also, there is no requirement that the orchestrated components use a database either (though in this case they do).
Keep this distinction in mind as you go forward in your Web API design. It will help you to really harness the power of the Web within you systems.
URI
As was mentioned earlier, each resource is addressable through a unique URI. You can think of a URI as a primary key for a resource. Examples of URIs are http://fabrikam.com/orders/100, http://ftp.fabrikam.com, mailto:John.Doe@example.com, telnet://192.168.1.100, and urn:isbn:978-1-449-33771-1. A URI can correspond only to a single resource, though multiple URIs can point to the same resource. Each URI is of the form scheme:hierarchical part[?query][#fragment] with the query string and fragment being optional. The hierachical part further consists of an optional authority and hierachical path.
URIs are divided into two categories, URLs and URNs. A URL (Universal Resource Locator) is an identifier that also refers to the means of accessing the resource, while a URN (Universal Resource Name) is simply a unique identifier for a resource. Each of the preceding example URIs is also a URL except the last one, which is a URN for this book. It contains no information on how to access the resource but does identify it. In practice, however, the majority of URIs you will likely see will be URLs, and for this reason the two are often used synonymously.
QUERY STRING OR NOT?
One common area of debate is whether or not you should use query strings at all. The reasoning for this has to do with caches. Some caches will automatically ignore any URI that has a query string in it. This can have a significant impact on scale, as it means all requests are directed to the origin server. Thus, some folks prefer not to use query strings and to put the information into the URI path. Google recommends[http://bit.ly/optimize-cache] not using query strings for static resources that are cachable for the same reason.
Cool URIs
A cool URI is a URI that is simple, easy to remember (like http://www.example.com/people/alice), and doesn’t change. The reason for the URI not to change is so it does not break existing systems that have linked to the URI. So, if your resources are designed with the idea that clients maintain bookmarks to them, you should consider using a cool URI. Cool URIs work really well in particular for web pages to which other sites commonly link, or that users often store in their browser favorites. It is not required that URIs be cool. As you’ll see throughout the book, there are benefits to designing APIs without exposing many cool URIs.
Representation
A representation is a snapshot of a resource’s state at a point in time. Whenever an HTTP client requests a resource, it is the representation that is returned, not the resource itself. From one request to the next, the resource state can change dramatically, thus the representation that is returned can be very different. For example, imagine an API for developer articles that exposes the top article via the URI http://devarticles.com/articles/top. Instead of returning a link to the content, the API returns a redirect to the actual article. Over time, as the top article changes, the representation (via the redirect) changes accordingly. The resource, however, is not the article in this case; it’s the logic running on the server that retrieves the top article from the database and returns the redirect. It is important to note that each resource can have one or more representations, as you’ll learn about in Content Negotiation.
Media Type
Each representation has a specific format known as a media type. A media type is a format for passing information across the Internet between clients and servers. It is indicated with a two-part identifier like text/html. Media types serve different purposes. Some are extremely general purpose, like application/json (which is a collection of values or key values) or text/html (which is primarily for documents rendered in a browser). Other media types have more constrained semantics like application/atom+xml and application/collection+json, which are designed specifically for managing feeds and lists. Then there is image/png, which is for PNG images. Media types can also be highly domain specific, like text/vcard, which is used for electronically sharing business card and contact information. For a list of some common media types you may encounter, see Appendix A.
The media type itself actually comprises two parts. The first part (before the slash) is the top-level media type. It describes general type information and common handling rules. Common top-level types are application, image, text, video, and multipart. The second part is thesubtype, which describes a very specific data format. For example, in image/png and image/gif, the top-level type tells a client this is an image, while the subtypes png and gif specify what type of image it is and how it should be handled. It is also common for the subtype to have different variants that share common semantics but are different formats. As an example, HAL (Hypertext Application Language) has JSON (application/hal+json) and XML (application/hal+xml) variants. hal+json means it’s HAL using a JSON wire format, while hal+xmlmeans the XML wire format.
THE ORIGIN OF MEDIA TYPES
The earliest roots of media types are with ARPANET. Initially, ARPANET was a network of machines that communicated via simple text messages. As the system grew, the need for richer communication arose. Thus, a standard format was codified for those messages to allow them to contain metadata that related to processing. Over time and with the rise of email, this standard evolved into MIME (the Multipurpose Internet Mail Extensions). One of the goals of MIME was to support nontextual payloads, thus the media type was born as a means to describe the body of a MIME entity. As the Internet flourished, it became necessary to pass similar rich bodies of information across the Web without being tied to email. Thus, media types started being used to also describe the body of HTTP requests and responses, which is how they became relevant for Web APIs.
Media type registration
Media types are conventionally registered in a central registry managed by IANA, the Internet Assigned Numbers Authority. The registry itself contains a list of media types and links to their associated specifications. The registry is categorized by top-level media types with each top-level section containing a list of specific media types.
Application developers who want to design clients or servers that understand standard media types refer to the registry for the specifications. For example, if you want to build a client that understands image/png, you can navigate to the “image” section of the IANA media types pages and find “png” to get the image/png spec, as shown in Figure 1-3.
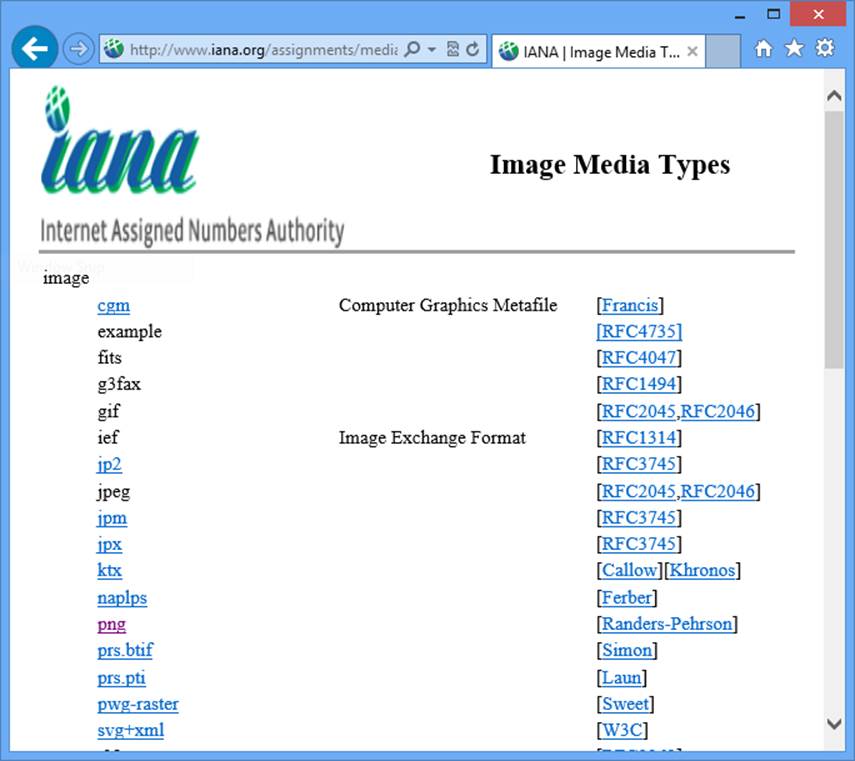
Figure 1-3. IANA registry for image
Why do we need all these different media types? The reason is because each type has either specific benefits or clients to which it is tailored. HTML is great for laying out documents such as a web page, but not necessarily the best for transferring data. JSON is great for transferring data, but it is a horribly inefficient medium for representing images. PNG is a great image format, but not ideal for scalable vector graphics; for that, we have SVG. ATOM, HAL, and Collection+JSON express richer application semantics than raw XML or JSON, but they are more constrained.
Up until this point, you’ve seen the key components of the web architecture. In the next section we will dive into HTTP—the glue that brings everything together.
HTTP
Now that we have covered the high-level web architecture, our next stop is HTTP. As HTTP is very comprehensive, we will not attempt to cover everything. Rather, we will focus on the major concepts—in particular, those that relate to building Web APIs. If you are new to HTTP, it should give you a good lay of the land. If you are not, you might pick up some things you didn’t know, but it’s also OK to skip it.
HTTP is the application-level protocol for information systems that powers the Web. HTTP was originally authored by three computer scientists: Tim Berners-Lee, Roy Fielding, and Henrik Frystyk Nielsen. It defines a uniform interface for clients and servers to transfer information across a network in a manner that is agnostic to implementation details. HTTP is designed for dynamically changing systems that can tolerate some degree of latency and some degree of staleness. This design allows intermediaries like proxy servers to intercede in communication, providing various benefits like caching, compression, and routing. These qualities of HTTP make it ideal for the World Wide Web, as it is a massive and dynamically changing and evolving network topology with inherent latency. It has also stood the test of time, powering the World Wide Web since its introduction in 1996.
Moving Beyond HTTP 1.1
HTTP is not standing still: it is actively evolving both in how we understand it and how we use it. There have been many misconceptions around the HTTP spec RFC 2616 due to ambiguities, or in some cases due to things deemed incorrect. The IETF (Internet Engineering Task Force) formed a working body known as httpbis that has created a set of drafts whose sole purpose is to clarify these misconceptions by completely replacing RFC 2616. Additionally, the group has been charged with creating the HTTP 2.0 spec. HTTP 2.0 also does not affect any of the public HTTP surface area; rather, it is a set of optimizations to the underlying transport, including adoption of the new SPDY protocol. Because httpbis exists as a replacement for the HTTP spec and provides an evolved understanding of HTTP, we’ll use that as the basis for the remainder of this section.
HTTP Message Exchange
HTTP-based systems exchange messages in a stateless manner using a request/response pattern. We’ll give you a simplified overview of the exchange. First, an HTTP client generates an HTTP request, as shown in Figure 1-4.
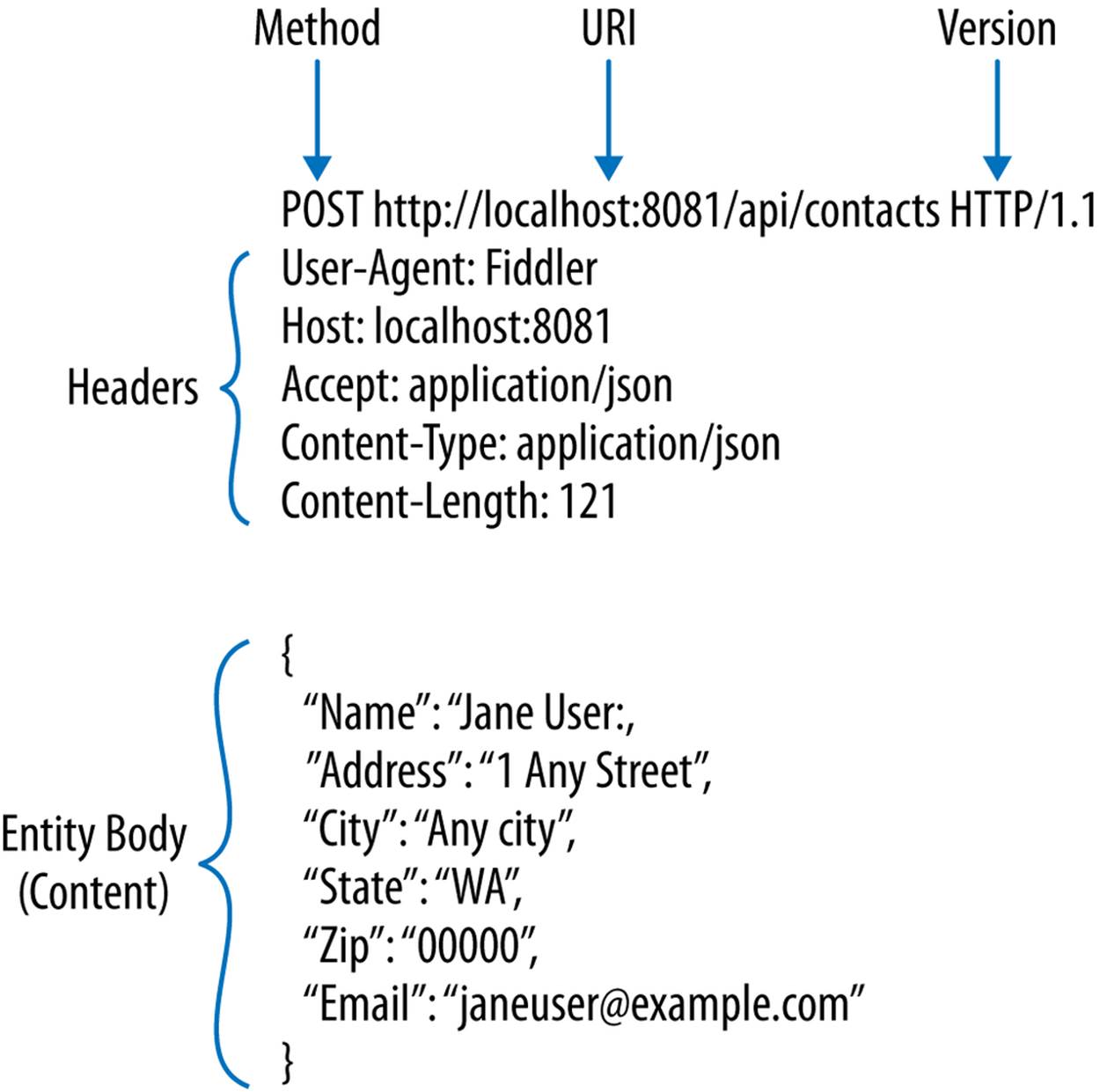
Figure 1-4. HTTP request
That request is a message that includes an HTTP version, a URI of a resource that will be accessed, request headers, an HTTP method (like GET), and an optional entity body (content). The request is then sent to an origin server where the resource presides. The server looks at the URI and HTTP method to decide if it can handle the message. If it can, it looks at the request headers that contain control information such as describing the content. The server then processes the message based on that information.
After the server has processed the message, an HTTP response, generally containing a representation of the resource (as shown in Figure 1-5), is generated.
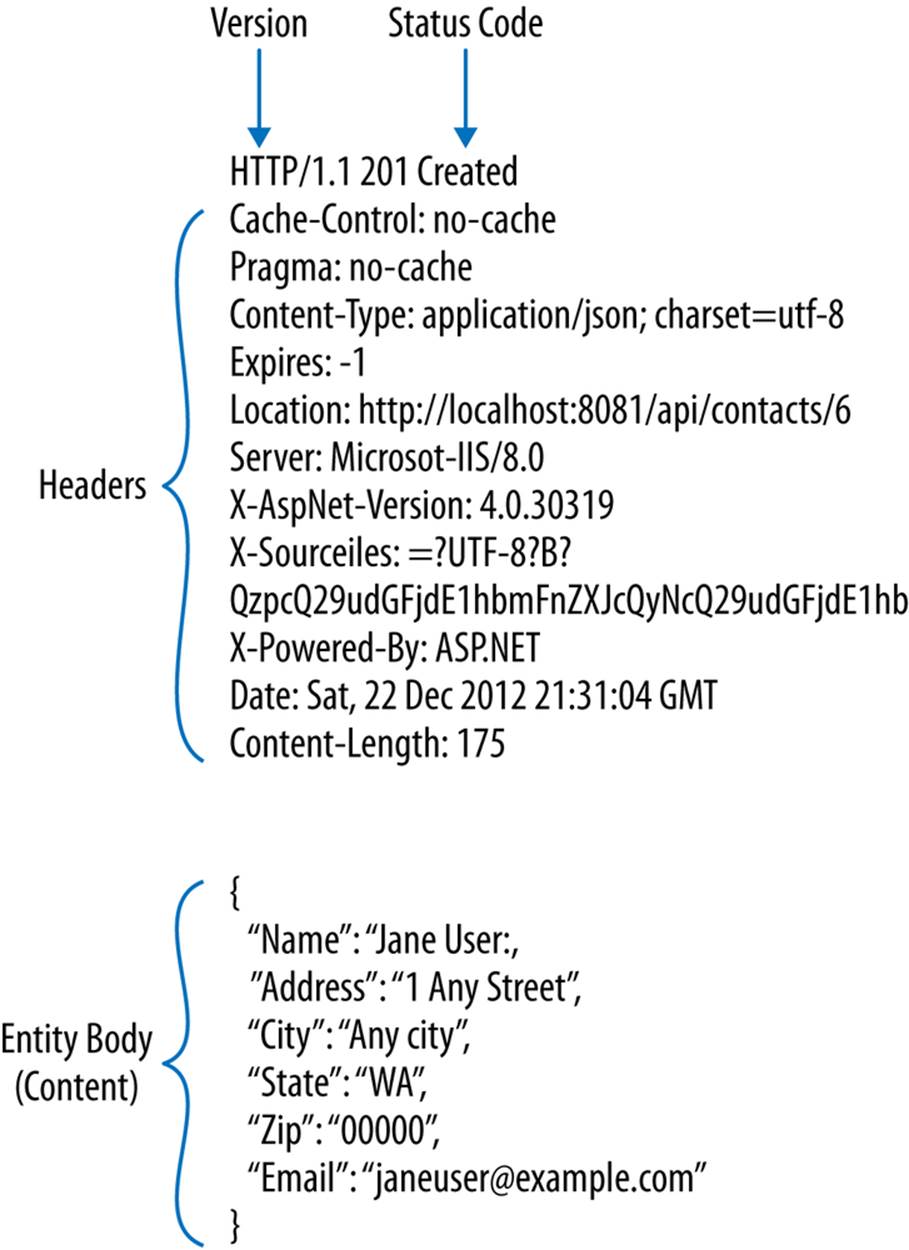
Figure 1-5. HTTP response
The response contains the HTTP version, response headers, an optional entity body (containing the representation), a status code, and a description. Similar to the server that received the message, the client will inspect the response headers using its control information to process the message and its content.
Intermediaries
Though accurate, the preceding description of HTTP message exchange leaves out an important piece: intermediaries). HTTP is a layered architecture in which each component/server has separation of concerns from others in the sytem; it is not required for an HTTP client to “see” the origin server. As the request travels along toward the origin server, it will encounter intermediaries, as shown in Figure 1-6, which are agents or components that inspect an HTTP request or response and may modify or replace it. An intermediary can immediately return a response, invoke some sort of process like logging the details, or just let it flow through. Intermediaries are beneficial in that they can improve or enhance communication. For example, a cache can reduce the response time by returning a cached result received from an origin server.
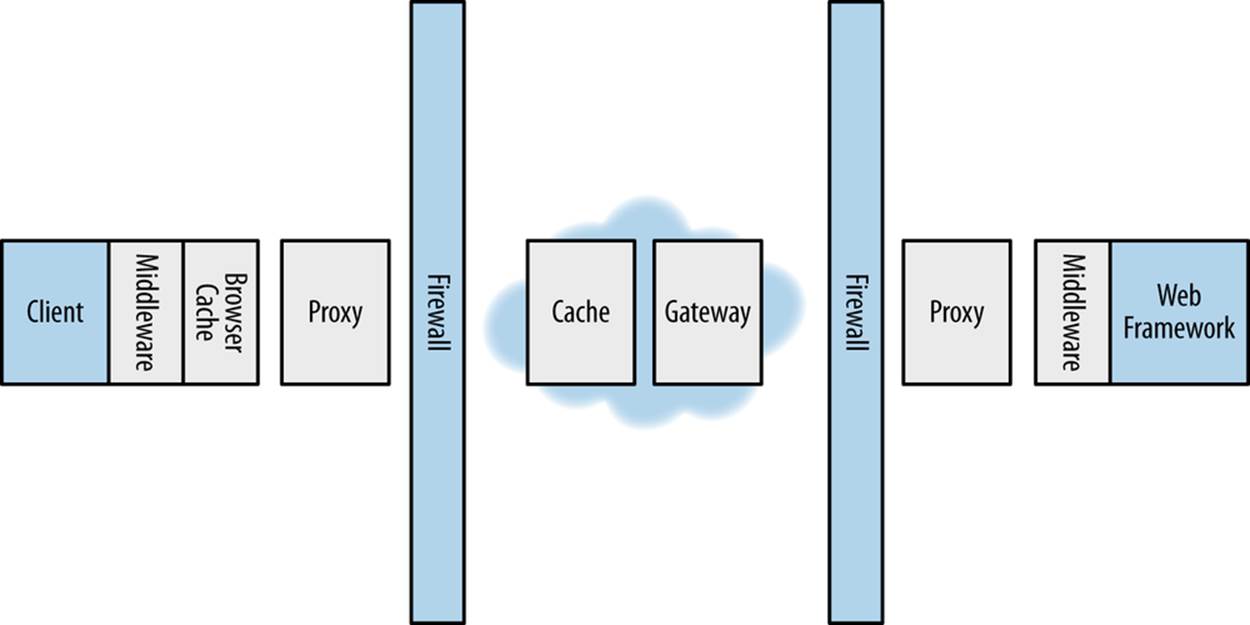
Figure 1-6. HTTP intermediaries
Notice that intermediaries can exist anywhere the request travels between the client and origin server; location does not matter. They can be running on the same machine as the client or origin server or be a dedicated public server on the Internet. They can be built in, such as the browser cache on Windows, or add-ons commonly known as middleware. ASP.NET Web API supports several pieces of middleware that can be used on the client or server, such as handlers and filters, which you will learn about in Chapters 4 and 10.
Types of Intermediaries
There are three types of intermediaries that participate in the HTTP message exchange and are visible to clients.
§ A proxy is an agent that handles making HTTP requests and receiving responses on behalf of the client. The client’s use of the proxy is deliberate, and it will be configured to use it. It is common, for example, for many organizations to have an internal proxy that users must go through in order to make requests to the Internet. A proxy that modifies requests or responses in a meaningful way is known as a transforming proxy. A proxy that does not modify messages is known as a nontransforming proxy.
§ A gateway receives inbound HTTP messages and translates them to the server’s underlying protocol, which may or may not be HTTP. The gateway also takes outbound messages and translates them to HTTP. A gateway can act on behalf of the origin server.
§ A tunnel creates a private channel between two connections without modifying any of the messages. An example of a tunnel is when two clients communicate via HTTPS through a firewall.
IS A CDN AN INTERMEDIARY?
Another common mechanism for caching on the Internet is a content delivery network (CDN), a distributed set of machines that cache and return static content. There are many popular CDN offerings, such as Akamai, that companies use to cache their content. So is a CDN an intermediary? The answer is that it depends on how the request is passing to the CDN. If the client makes a direct request to it, then it is acting as an origin server. Some CDNs, however, can also act as a gateway, where the client does not see the CDN, but it actually acts on behalf of the origin server as a cache and returns the content.
HTTP Methods
HTTP provides a standard set of methods that form the interface for a resource. Since the original HTTP spec was published, the PATCH method has also been approved. As shown earlier in Figure 1-4, the method appears as part of the request itself. Next is a description of the common methods API authors implement.
GET
Retrieves information from a resource. If the resource is returned, the server should return a status code 200 (OK).
HEAD
Identical to a GET, except it returns headers and not the body.
POST
Requests that the server accept the enclosed entity to be processed by the target resource. As part of the processing, the server may create a new resource, though it is not obliged to. If it does create a resource, it should return a 201 (Created) or 202 (Accepted) code and return a location header telling the client where it can find the new resource. If it does not create a resource, it should return a 200 (OK) or a 204 (No Content) code. In practice, POST can handle just about any kind of processing and is not constrained.
PUT
Requests that the server replace the state of the target resource at the specified URI with the enclosed entity. If a resource exists for the current representation, it should return a 200 (OK) or a 204 (No Content) code. However, if the resource does not exist, the server can create it. If it does, it should return a 201 (Created) code. The main difference between POST and PUT is that POST expects the data that is sent to be processed, while PUT expects the data to be replaced or stored.
DELETE
Requests that the server remove the entity located at the specified URI. If the resource is immediately removed, the server should return a 200 code. If it is pending, it should return a 202 (Accepted) or a 204 (No Content)..
OPTIONS
Requests that the server return information about its capabilities. Most commonly, it returns an Allow header specifying which HTTP methods are supported, though the spec leaves it completely open-ended. For example, it is entirely feasible to list which media types the server supports.OPTIONS can also return a body, supplying further information that cannot be represented in the headers.
PATCH
Requests that the server do a partial update of the entity at the specified URI. The content of the patch should have enough information that the server can use to apply the update. If the resource exists, the server can be updated and should return a 200 (OK) or a 204 (No Content)code. As with PUT, if the resource does not exist, the server can create it. If it does, it should return a code of 201 (Created). A resource that supports PATCH can advertise it in the Allow header of an OPTIONS response. The Accept-Patch header also allows the server to indicate an acceptable list of media types the client can use for sending a PATCH. The spec implies that the media type should carry the semantics to communicate to the server the partial update information. json-patch is a proposed media type in draft that provides a structure for expressing operations within a patch.
TRACE
Requests that the server return the request it received. The server will return the entire request message in the body with a content-type of message/http. This is useful for diagnostics, as clients can see which proxies the request passed through and how the request may have been modified by intermediaries.
Conditional requests
One of the additional features of HTTP is that it allows clients to make conditional requests. This type of request requires the client to send special headers that provide the server with information it needs to process the request. The headers include If-Match, If-NoneMatch, and If-ModifiedSince. Each of these headers will be described in further detail in Table B-2 in Appendix B.
§ A conditional GET is when a client sends headers that the server can use to determine if the client’s cached representation is still valid. If it is, the server returns a 304 (Not Modified) code rather than the representation. A conditional GET reduces the network traffic (as the response is much smaller), and also reduces the server workload.
§ A conditional PUT is when a client sends headers that the server can use to determine if the client’s cached representation is still valid. If it is, the server returns a 409 (Preconditions Failed). A conditional PUT is used for concurrency. It allows a client to determine at the time of doing the PUT whether another user changed the data.
Method properties
HTTP methods can have the following additional properties:
§ A safe method is a method that does not cause any side effects from the user when the request is made. This does not mean that there are no side effects at all, but it means that the user can safely make requests using the method without worrying about changing the state of the system.
§ An idempotent method is a method in which making one request to the resource has the same effect as requesting it multiple times. All safe methods are by definition idempotent; however, there are methods that are not safe and are still idempotent. As with a safe method, there is no guarantee that a request with an idempotent method won’t result in any side effects on the server, but the user does not have to be concerned.
§ A cachable method is a method that can possibly receive a cached response for a previous request from an intermediary cache.
Table 1-1 lists the HTTP methods and whether they are safe or idempotent.
Table 1-1. HTTP methods
|
Method |
Safe |
Idempotent |
Cachable |
|
GET |
Yes |
Yes |
Yes |
|
HEAD |
Yes |
Yes |
Yes |
|
POST |
No |
No |
No |
|
PUT |
No |
Yes |
No |
|
DELETE |
No |
Yes |
No |
|
OPTIONS |
Yes |
Yes |
No |
|
PATCH |
No |
Yes |
No |
|
TRACE |
Yes |
Yes |
No |
Of the methods listed, the most common set used by API builders today are GET, PUT, POST, DELETE, and HEAD. PATCH, though new, is also becoming very common.
There are several benefits to having a standard set of HTTP methods:
§ Any HTTP client can interact with an HTTP resource that is following the rules. Methods like OPTIONS provide discoverability for the client so it can learn how those interactions will take place.
§ Servers can optimize. Proxy servers and web servers can provide optimizations based on the chosen method. For example, cache proxies know that GET requests can be cached; thus, if you do a GET, the proxy may be able to return a cached representation rather than having the request travel all the way to the server.
Headers
HTTP messages contain header fields that provide information to clients and servers, which they should use to process the request. There are four types of headers: message, request, response, and representation.
Message headers
Apply to both request and response messages and relate to the message itself rather than the entity body. They include:
§ Headers related to intermediaries, including Cache-Control, Pragma, and Via
§ Headers related to the message, including Transfer-Encoding and Trailer
§ Headers related to the request, including Connection, Upgrade, and Date
Request headers
Apply generally to the request message and not to the entity body, with the exception of the Range header. They include:
§ Headers about the request, including Host, Expect, and Range
§ Headers for authentication credentials, including User-Agent and From
§ Headers for content negotiation, including Accept, Accept-Language, and Accept-Encoding
§ Headers for conditional requests, including If-Match, If-None-Match, and If-Modified-Since
Response headers
Apply to the response message and not the entity body. They include:
§ Headers for providing information about the target resource, including Allow and Server
§ Headers providing additional control data, such as Age and Location
§ Headers related to the selected representation, including ETag, Last-Modified, and Vary
§ Headers related to authentication challenges, including Proxy-Authenticate and WWW-Authenticate
Representation headers
Apply generally to the request or response entity body (content). They include:
§ Headers about the entity body itself including Content-Type, Content-Length, Content-Location, and Content-Encoding
§ Headers related to caching of the entity body, including Expires
For a comprehensive list and description of the standard headers in the HTTP specification, see Appendix B.
The HTTP specification continues to be extended. New headers can be proposed and approved by organizations like the IETF (Internet Engineering Task Force) or the W3C (World Wide Web Consortium) as extensions of the HTTP protocol. Two such examples, which are covered in later chapters of the book, are RFC 5861, which introduces new caching headers, and the CORS specification, which introduces new headers for cross origin access.
HTTP Status Codes
HTTP responses always return status codes and a description of whether the request succeeded; it is the responsibility of an origin server to always return both pieces of information. Both inform the client whether or not the request was accepted or failed and suggest possible next actions. The description is human-readable text describing the status code. Status codes range from 4xx to 5xx. Table 1-2 indicates the different categories of status codes and the associated references in httpbis.
Table 1-2. HTTP status codes
|
Range |
Description |
Reference |
|
1xx |
The request has been received and processing is continuing. |
http://tools.ietf.org/html/draft-ietf-httpbis-p2-semantics-21#section-7.2 |
|
2xx |
The request has been accepted, received, and understood. |
http://tools.ietf.org/html/draft-ietf-httpbis-p2-semantics-21#section-7.3 |
|
3xx |
Further action is required to complete the request. |
http://tools.ietf.org/html/draft-ietf-httpbis-p2-semantics-21#section-7.4 |
|
4xx |
The request is invalid and cannot be completed. |
http://tools.ietf.org/html/draft-ietf-httpbis-p2-semantics-21#section-7.5 |
|
5xx |
The server has failed trying to complete the request. |
http://tools.ietf.org/html/draft-ietf-httpbis-p2-semantics-21#section-7.6 |
Status codes can be directly associated with other headers. In the following snippet, the server has returned a 201, indicating that a new resource was created. The Location header indicates to the client the URI of the created resources. Thus, HTTP Clients should automatically check for the Location in the case of a 201.
HTTP/1.1 201 Created
Cache-Control: no-cache
Pragma: no-cache
Content-Type: application/json; charset=utf-8
Location: http://localhost:8081/api/contacts/6
Content Negotiation
HTTP servers often have multiple ways to represent the same resources. The representations can be based on a variety of factors, including different capabilities of the client or optimizations based on the payload. For example, you saw how the Contact resource returns a vCard representation tailored to clients such as mail programs. HTTP allows the client to participate in the selection of the media type by informing the server of its preferences. This dance of selection between client and server is what is known as content negotiation, or conneg.
Caching
As we learned in Method properties, some responses are cachable—in particular, the responses for GET and HEAD requests. The main benefit of caching is to improve general performance and scale on the Internet. Caching helps clients and origin servers in the following ways:
§ Clients are helped because the number of roundtrips to the server is reduced, and because the response payload is reduced for many of those roundtrips.
§ Servers are helped because intermediaries can return cached representations, thus reducing the load on the origin server.
An HTTP cache is a storage mechanism that manages adding, retrieving, and removing responses from the origin server to the cache. Caches will try to handle only requests that use a cachable method; all other requests (with noncachable methods) will be automatically forwarded to the origin server. The cache will also forward to the origin server requests that are cacheable, but that are either not present in the cache or expired.
httpbis defines a pretty sophisticated mechanism for caching. Though there are many finer details, HTTP caching is fundamentally based on two concepts: expiration and validation.
Expiration
A response has expired or becomes stale if its age in the cache is greater than the maximum age, which is specified via a max-age CacheControl directive in the response. It will also expire if the current date on the cache server exceeds the expiration date, which is specified via the response Expires header. If the response has not expired, it is eligible for the cache to serve it; however, there are other pieces of control data (see Caching and negotiated responses) coming from the request and the cached response that may prevent it from being served.
Validation
When a response has expired, the cache must revalidate it. Validation means the cache will send a conditional GET request (see Conditional requests) to the server asking if the cached response is still valid. The conditional request will contain a cache validator—for example, an If-Modified-Since header with the Last-Modified value of the response and/or an If-None-Match header with the response’s ETag value. If the origin server determines it is still valid, it will return a body-less response with a status code of 304 Not Modified, along with an updated expiration date. If the response has changed, the origin server will return a new response, which will ultimately get served by the cache and replace the current cached representation.
SERVING STALE RESPONSES
HTTP does provide for caches to serve stale responses under certain conditions, such as if the origin server is unreachable. In these conditions, a cache may still serve stale responses as long as a Warning header is included in the response to inform the client. “HTTP Cache-Control Extensions for Stale Content,” by Mark Nottingham, proposes new Cache-Control directives (seeCache behaviors) to address these conditions.
The stale-while-revalidate directive allows a cache to serve up stale content while it is in the process of validating it in order to hide the latency of the validation. The stale-if-error directive allows the cache to serve up content whenever there is an error that could be due to the network or the origin server being unavailable. Both directives inform caches that it is OK to serve stale content if these headers are present, while the aforementioned Warning header informs clients that the content they have is actually stale.
Note that RFC 5861 is marked as informational, meaning it has not been standardized; thus, all caches may not support these additional directives.
Invalidation
Once a response has been cached, it can also be invalidated. Generally, this will happen because the cache observes a request with an unsafe method to a resource that it has previously cached. Because a request was made that modifies the state of the resource, the cache knows that its representation is invalid. Additionally, the cache should invalidate the Location and Content-Location responses for the same unsafe request if the response was not an error.
ETags
An entity-tag, or ETag, is a validator for the currently selected representation at a point in time. It is represented as a quoted opaque identifier and should not be parsed by clients. The server can return an ETag (which it also caches) in the response via the ETag header. A client can save that ETag to use as a validator for a future conditional request, passing the ETag as the value for an If-Match or If-None-Match header. Note that the client in this case may be an intermediary cache. The server matches up the ETag in the request against the existing ETag it has for the requested resource. If the resource has been modified in the time since the ETag was generated, then the resource’s ETag on the server will have changed and there will not be a match.
There are two types of ETags:
§ A strong ETag is guaranteed to change whenever the server representation changes. A strong ETag must be unique across all other representations of the same resource (e.g., 123456789).
§ A weak ETag is not guaranteed to be up to date with the resource state. It also does not have the constraints of being unique across other representations of the same resource. A weak ETag must be proceeded with W/ (e.g., W/123456789).
Strong ETags are the default and should be preferred for conditional requests.
Caching and negotiated responses
Caches support the ability to serve negotiated responses through the usage of the Vary header. The Vary header allows the origin server to specify one or more header fields that it used as part of performing content negotiation. Whenever a request comes in that matches a representation in the cache that has a Vary header, the values for those fields must match in the request in order for that representation to be eligible to be served.
The following is an example of a response using the Vary header to specify that the Accept header was used:
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
Content-Length: 183
Vary: Accept
Cache behaviors
The Cache-Control header gives instructions to caching mechanisms through which that request/response passes related to its cachability. The instructions can be provided by either the origin server as part of the response, or the client as part of the request. The header value is a list of caching directives that specifies things like whether or not the content is cachable, where it may be stored, what its expiration policy is, and when it should be revalidated or reloaded from the origin server. For example, the no-cache directive tells caches they must always revalidate the cached response before serving it.
The Pragma header can specify a no-cache value that is equivalent to the no-cache Cache-Control directive.
Following is an example of a response using the Cache-Control header. In this case, it is specifying the max age for caches as 3,600 seconds (1 hour) from the Last-Modified date. It also specifies that cache servers must revalidate with the origin server once the cached representation has expired before returning it again:
HTTP/1.1 200 OK
Cache-Control: must-revalidate, max-age=3600
Content-Type: application/json; charset=utf-8
Last-Modified: Wed, 26 Dec 2012 22:05:15 GMT
Date: Thu, 27 Dec 2012 01:05:15 GMT
Content-Length: 183
For a detailed walkthrough of caching in action, see Appendix D. For more on HTTP caching in general, see “Things Caches Do,” by Ryan Tomayko, and “How Web Caches Work,” by Mark Nottingham.
Authentication
HTTP provides an extensible framework for servers that allows them to protect their resources and allows clients to access them through authentication. Servers can protect one or more of their resources, with each resource being assigned to a logical partition known as a realm. Each realm can have its own authentication scheme, or method of authorization it supports.
Upon receiving a request for accessing a protected resource, the server will return a response with a status 401 Unauthorized or a status 403 Forbidden. The response will also contain a WWW-Authenticate header containing a challenge, indicating that the client must authenticate to access the resource. The challenge is an extensible token that describes the authentication scheme and additional authentication parameters. For example, the challenge for accessing a protected contacts resource that specifies the use of the HTTP basic authentication scheme is Basic realm="contacts".
To explore how this challenge/response mechanism works in more detail, see Appendix E.
Authentication Schemes
In the previous section we learned about the framework for authentication. RFC 2617 then defines two concrete authentication mechanisms.
Basic
In this scheme, credentials are sent as a Base64-encoded username and password separated by a colon in clear text. Basic Auth is conventionally combined with TLS (HTTPS) due to its inherent unsecure nature; thus, its advantage is that it is extremely easy to implement and access (including from browser clients), which makes it an attractive choice for many API authors.
Digest
In Digest, the user’s credentials are sent in clear text. Digest addresses this problem by using a checksum (MAC) that the client sends, which the server can use to validate the credentials. However, this scheme has several security and performance disadvantages and is not often used.
The following is an example of an HTTP Basic challenge response after an attempt to access a protected resource:
HTTP/1.1 401 Unauthorized
...
WWW-Authenticate: Basic realm="Web API Book"
...
As you can see, the server has returned a 401, including a WWW-Authenticate header indicating that the client must authenticate using HTTP Basic:
GET /resource HTTP/1.1
...
Authorization: Basic QWxpY2U6VGhlIE1hZ2ljIFdvcmRzIGFyZSBTcXVlYW1pc2ggT3NzaWZyYWdl
The client then sends back the original request, including the Authorization header, in order to access the protected resource.
Additional Authentication Schemes
There are additional authentication schemes that have appeared since RFC 2617, including vendor-specific mechanisms:
AWS Authentication
This scheme, used for authenticating to Amazon Web Services S3, involves the client concatenating several parts of the request to form a string. The user then uses his AWS shared secret access key to calculate an HMAC (hash message authentication code), which is used to sign the request.
Azure Storage
Windows Azure offers several different schemes to access Windows Azure Storage services, each of which involves using a shared key to sign the request.
Hawk
This new scheme, authored by Eran Hammer, provides a general-purpose shared key auth mechanism similar to AWS and Azure. The key is also never used directly in the requests; rather, it is used to calculate a MAC value that is included in the request. This prevents the key from being intercepted such as in a man-in-the-middle (MITM) attack.
OAuth 2.0
Using this framework allows a resource owner (the user) to delegate permission to a client to access a protected resource from a resource server on her behalf. An authentication server grants the client a limited use access token, which the client can then use to access the resource. The clear advantage here is that the user’s credentials are never directly exchanged with the client application attempting to access the resource.
You’ll learn more about HTTP authentication mechanisms and implementing them (including OAuth) in Chapters 15 and 16.
Conclusion
In this chapter we’ve taken a broad-brush approach at surveying the HTTP landscape. The concepts covered were not meant for completeness but rather to help you wade into the pool of HTTP and give you a basic foundation for your ASP.NET Web API development. You’ll notice we’ve included further references for each of the items discussed. These references will prove invaluable as you actually move forward with your Web API development, so keep them in your back pocket! On to APIs!
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.