Designing Evolvable Web APIs with ASP.NET (2012)
Chapter 2. Web APIs
There’s more to Web APIs than just returning a JSON payload.
In the preceding chapter, we learned about the essential aspects of the Web and HTTP, the application layer protocol that drives it. In this chapter, we’ll talk about the evolution of Web APIs, cover various Web API–related concepts, and discuss different styles and approaches for designing Web APIs.
What Is a Web API?
A Web API is a programmatic interface to a system that is accessed via standard HTTP methods and headers. A Web API can be accessed by a variety of HTTP clients, including browsers and mobile devices. Web APIs can also benefit from the web infrastructure for concerns like caching and concurrency.
What About SOAP Web Services?
SOAP services are not web-friendly. They are not easily consumable from HTTP clients, such as browsers or tools like curl. A SOAP request has to be properly encoded in a SOAP message format. The client has to have access to a Web Service Description Language (WSDL) file, which describes the actions available on the service, and also has to know how to construct the message. This means the semantics of how to interact with the system are tunneled over HTTP rather than being first class. Additionally, SOAP web services generally require all interactions to be via HTTP POST; thus, the responses are also noncachable. Finally, SOAP services do not allow one to access HTTP headers, which severely limits clients from benefitting from features of HTTP like optimistic concurrency and content negotiation.
Origins of Web APIs
In February 2000, Salesforce.com launched a new API that allowed customers to harness Salesforce capabilities directly within their applications.
Later that same year in November, eBay launched a new API that allowed developers to build ecommerce applications leveraging eBay’s infrastructure.
What differentiated these APIs from SOAP APIs (the other emerging trend)? These Web APIs were targeting third-party consumers and designed in an HTTP-friendly way. The traditional APIs of the time had been mostly designed for system integration and were SOAP-based. These APIs utilized plain old XML as the message exchange format and plain old HTTP as the protocol. This allowed them to be used from a very broad set of clients, including simple web browsers. These were the first of many such Web APIs to come.
For the next few years after Salesforce and eBay took these first steps, similar APIs started to appear on the scene. In 2002, Amazon officially introduced Amazon Web Services, followed by Flickr launching its Flickr API in 2004.
The Web API Revolution Begins
In the summer of 2005, ProgrammableWeb.com launched. Its goal was to be a one-stop shop for everything API related. It included a directory of public APIs (both SOAP and non-SOAP) containing 32 APIs, which was considerable growth from 2002. Over the next few years, however, that number would explode. APIs would run the gamut from major players such as Facebook, Twitter, Google, LinkedIn, Microsoft, and Amazon to then-small startups like YouTube and Foursquare. In November 2008, ProgrammableWeb’s directory was tracking 1,000 APIs. Four years later, at the time of this writing, that number exceeds 7,000. API growth is accelerating, as just about a year ago the number was 4,000.
In other words, it is clear that Web APIs are here to stay.
Paying Attention to the Web
The earliest Web APIs weren’t necessarily concerned with the underlying web architecture and its design constraints. This had ramifications such as the infamous Google Web Accelerator incident, which resulted in a loss of customer data and content.
In recent years, however, with an exponential rise in third-party API consumers and in devices, this has changed. Organizations are finding they can no longer afford to ignore the web architecture in their API design, because doing so has negatively impacted their ability to scale, to support a growing set of clients, and to evolve their APIs without breaking existing consumers.
The remainder of this chapter is a primer on web architecture and HTTP as they relate to building Web APIs. It will give you a foundation that will allow you to leverage the power of the Web as you begin to develop your own Web APIs using ASP.NET Web API.
Guidelines for Web APIs
This section lists some guidelines for differentiating Web APIs from other forms of APIs. In general, a key differentiator for Web APIs is that they are browser-friendly. In addition, Web APIs:
§ Can be accessed from a range of clients (including browsers at minimum).
§ Support standard HTTP methods such as those mentioned in Table 1-1. It is not required for an API to use all of the methods, but at minimum it should support GET for retrieval of resources and POST for unsafe operations.
§ Support browser-friendly formats. This means that they support formats that are easy for browsers and any other HTTP client to consume. A browser client can technically consume a SOAP message using its XML stack, but the format requires a large amount of SOAP-specific code to do it. Formats like XHTML, JSON, and Form URL encoding are very easy to consume in a browser.
§ Support browser-friendly authentication. This means that a browser client can authenticate with the server without requiring any special plugins or extensions.
Domain-Specific Media Types
In the previous chapter, we learned about the concept of media types. In addition to the general-purpose types we discussed, there are also domain-specific media types. These types carry rich application-specific semantics and are useful in particular for Web API development where there are rich system interactions rather than simple document transfer.
vCard is a domain-specific media type that provides a standard way to electronically describe contact information. It is supported in many popular address book and email applications like Microsoft Outlook, Gmail, and Apple Mail.
In Figure 2-1, you can see the same contact represented as a vCard.
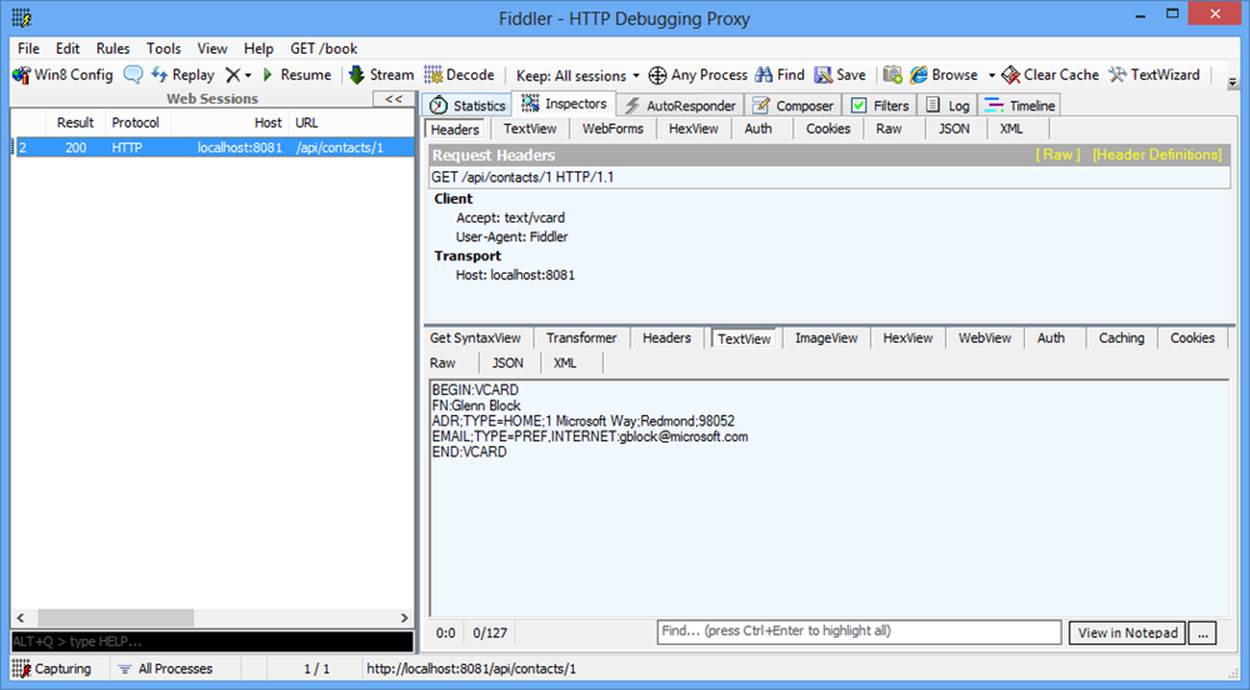
Figure 2-1. Contact vCard representation
When an email application sees a vCard it knows right away that this is contact information and how to process it. If the same application were to get raw JSON, it has no way of knowing what it received until it parses the JSON. This is because the JSON media type does not define a standard way to say “I am a contact.” The format would have to be communicated out-of-band through documentation. Assuming that information was communicated, it would be application specific and not likely supported by other email applications. In the case of the vCard, however, it is a standard that is supported by many applications across different operating systems and form factors.
We can mint new media types as applications evolve and new needs emerge by following the IANA registration process. This provides a distinct advantage because we can introduce new types and clients to consume them without affecting existing clients. As we saw in the previous chapter, clients express their media type preferences through content negotiation.
Media Type Profiles
It makes a lot of sense for media types that are used by many different clients and servers to be registered with IANA, but what if a media type is not ubiquitous and specific to an application? Should it be registered with IANA? Some say yes, but others are exploring lighter-weight mechanisms, in particular for Web APIs. Media type profiles allow servers to leverage existing media types (like XML, JSON, etc.) and provide additional information that has the application-specific semantics.
The profile link relation allows servers to return a profile link in an HTTP response. A link is an element that contains a minimum of two pieces of information: a rel (or relation) that describes the link, and a URI. In the case of a profile, the rel will be profile. It is not necessary for the URI to actually be dereferencable (meaning you can access the resource), though in many cases it will point to a document.
The challenge with using profiles today is that many media types do not currently support a way to express links, so clients would not be expected to recognize the profile even if it were in the content. For example, JSON is a very popular format used by Web APIs, but it does not support links.
Fortunately, there is a preestablished link header that can be used in any HTTP response to pass a profile.
Using the earlier contact example, we can return this header to tell the client this is not just any old JSON, it’s JSON for working with example.com’s contact management system. If the client opens their browser to the URI of the link, they can get a document that describes the payload. This document can be in any format, such as the emerging Application-Level Profile Semantics (ALPS) data format, which is designed specifically for this purpose.:
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
Link: <http://example.com/contactmanagement/profile>; rel="profile"
Date: Fri, 21 Dec 2012 06:47:25 GMT
Content-Length: 183
{
"contactId":1,
"name":"Glenn Block",
"address":"1 Microsoft Way",
"city":"Redmond","State":"WA",
"zip":"98052",
"email":"gblock@microsoft.com",
"twitter":"gblock",
"self":"/contacts/1"
}
Multiple Representations
A single resource can have multiple representations, each with a different media type. To illustrate, let’s look at two different representations of the same contact resource. The first, in Figure 2-2, is a JSON representation and contains information about the contact. The second, Figure 2-3, is the avatar for the contact. Both are valid representations of state, but they have different uses.
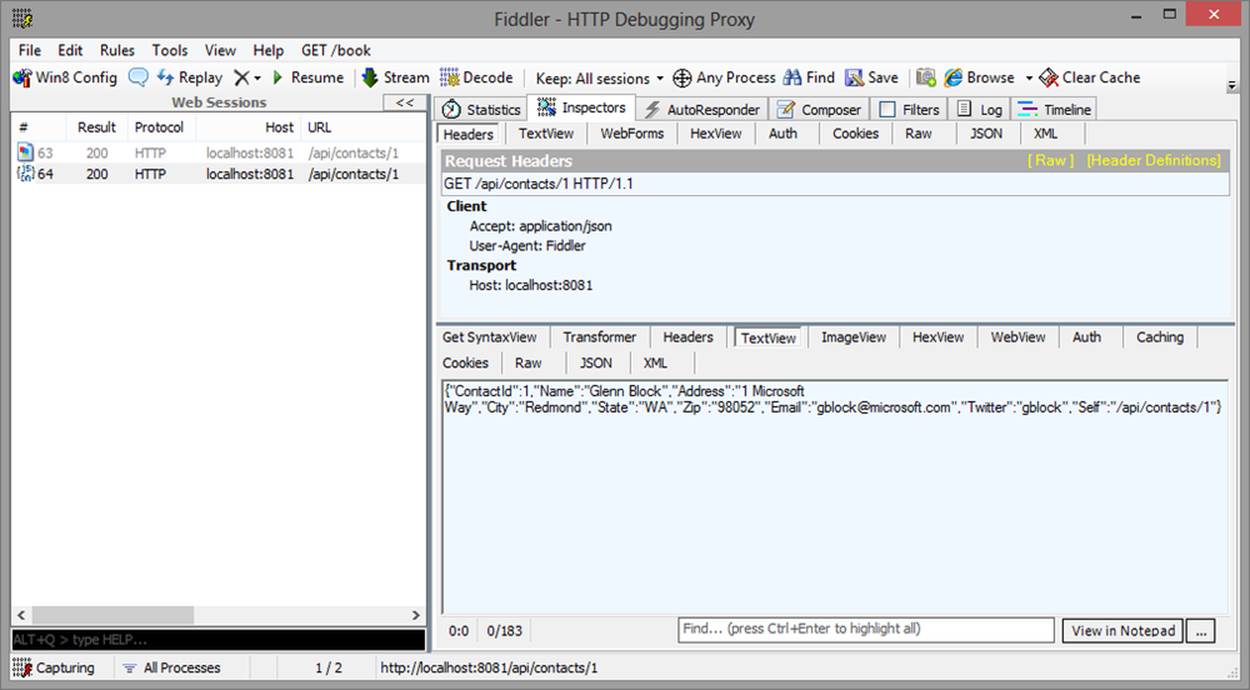
Figure 2-2. Contact JSON representation
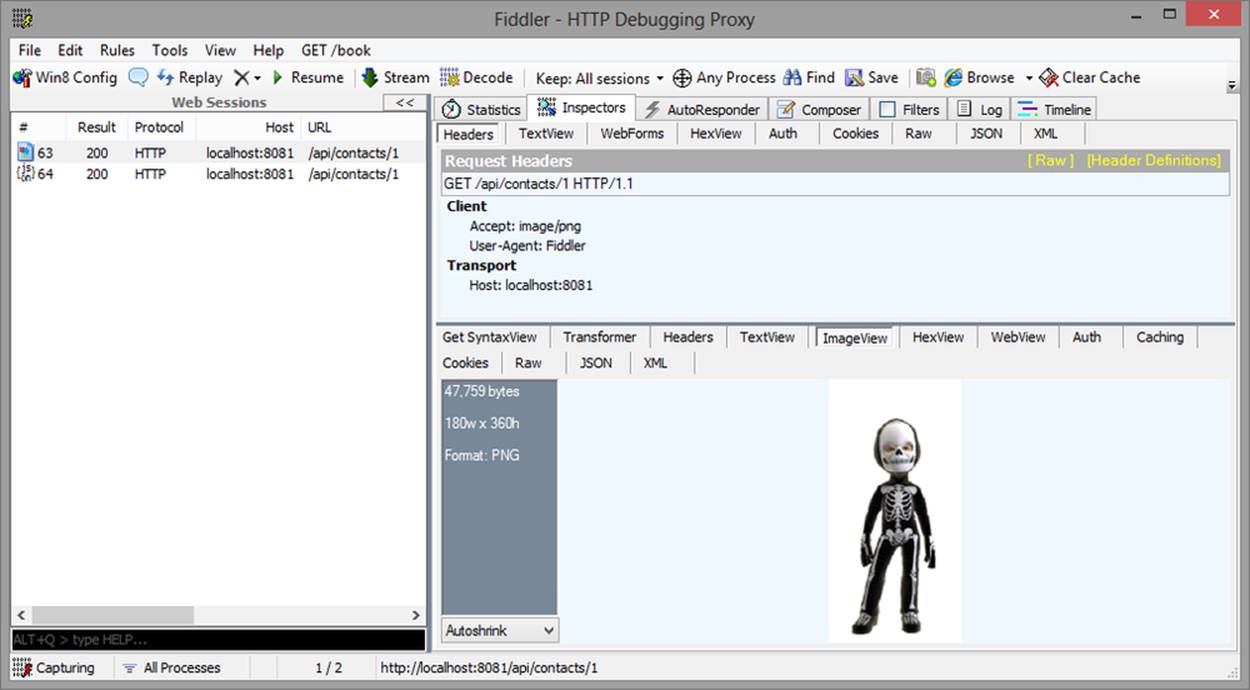
Figure 2-3. Contact PNG representation
The JSON representation will be parsed and data (such as the contact name, email address, etc.) will be extracted from the JSON and displayed to the user. The PNG representation, however, will just display as is; because it is an image, it could also easily be passed as the URL for an HTML<img> tag or consumed directly by an image viewer.
As the previous example shows, the advantage of supporting multiple representations is to allow many different clients with different capabilities to interact with your API.
API Styles
There are many different architectural styles for building Web APIs. By style we mean an approach for implementing an API over HTTP. A style is a set of common characteristics and constraints that permeate the design. Each style has trade-offs and benefits associated with it. The important thing to recognize is that the style is an application of HTTP; it is not HTTP.
For example, Gothic is a style applied to architecture. You can look at various buildings and determine which are Gothic because they possess certain qualities, such as ogival arches, ribbed vaults, and flying buttresses. In the same way, API styles share a set of qualities that manifest in different APIs. Today we see a number of styles, but they land in a spectrum with RPC on one side and REST on the other.
The Richardson Maturity Model
The Richardson Maturity Model (RMM) by Leonard Richardson introduces a framework for classifying APIs into different levels based on how well they take advantage of web technologies.
Level 0, RPC oriented
A single URI and one HTTP method.
Level 1, Resource oriented
Many URIs, one HTTP method.
Level 2, HTTP verbs
Many URIs, each supporting multiple HTTP methods.
Level 3, Hypermedia
Resources describe their own capabilities and interactions.
The model was designed to classify the existing APIs of the time. It became wildly popular and is used by many folks in the API community for classifying their APIs today.
It was not without issue, though. The model was not created to establish a rating scale to evaluate how RESTful an API is. Unfortunately, many took it for just that and began to use it as a stick to beat others for not being RESTful enough. This appears to be one of the reasons why Leonard Richardson himself has stopped promoting it.
Throughout this chapter, you’ll dive more deeply into the different levels of RMM and see real-world examples. We’ll use the levels to discuss the benefits and trade-offs associated with how you design your API.
RPC (RMM Level 0)
At Level 0, an API uses an RPC (remote procedure call) style. It basically treats HTTP as a transport protocol for invoking functions running on a remote server. In an RPC API, the API tunnels its own semantics into the payload, with different message types generally corresponding to different methods on the remote object and using a single HTTP method, POST. The SOAP Services, XML-RPC, and POX (plain old XML) APIs are examples of Level 0.
Consider the example of an order processsing system using POX. The system exposes a single-order processing service at the URL /orderService. Each client POSTs different types of messages to that service in order to interact with it.
To create an order, a client sends the following:
POST /orderService HTTP 1.1
Content-Type: application/xml
Content-Length: xx
<createOrderRequest orderNumber = "1000">
</createOrderRequest>
The server then responds, telling the client the order has been created:
HTTP/1.1 200 OK
Content-Type: application/xml
Content-Length: xx
<createOrderResponse>
Order created
</createOrderResponse>
Notice the status is in the body itself, not via the status code. This is because HTTP is being used as a transport for a method invocation where all the data is sent in the payload.
To check on the list of active orders, the client sends a getOrders request:
POST /orderService HTTP 1.1
Content-Type: application/xml
Content-Length: xx
<getOrdersRequest status="active"/>
</getOrderRequest>
The server reply contains the list of orders:
HTTP/1.1 200 OK
Content-Type: application/xml
Content-Length: xx
<getOrdersResponse>
<orders>
<order orderNumber = "1000" status="active"/>
<order orderNumber = "1200" status="active"/>
</order>
</getOrdersResponse>
To approve an order, the client sends an approval request:
POST /orderService HTTP 1.1
Content-Type: application/xml
Content-Length: xx
<approveOrderRequest orderNumber = "1000">
</approveOrderRequest>
The server responds, indicating the status of the approval:
HTTP/1.1 200 OK
Content-Type: application/xml
Content-Length: xx
<approveOrderResponse>
<error code="100">Order approval failed</error>
<reason>Missing information</reason>
</approveOrderResponse>
Similar to the status mentioned ealier, here the error code is part of the payload.
As you can see from the preceding examples, in this style the payload describes a set of operations to be performed and their results. Clients have explicit knowledge of each of the different message types associated with each “service,” which they use to interact with it.
You might be asking, why not use another method like PUT? The reason is because in this approach all requests are sent to a single endpoint (/orderService) regardless of the operation. POST is the least constrained in its definition, as it is both unsafe and nonidempotent. Each of the other methods, however, has additional constraints, making it insufficient for all operations.
One benefit of this approach is that it is very easy and simple to implement and aligns well with the existing development mental model.
Resources (RMM Level 1)
At Level 1, the API is broken out into several resources, with each resource being accessed via a single HTTP method, though the method can vary. Unlike Level 0, in this case the URI represents the operation.
Returning to the preceding order processing example, here is how the requests look for a Level 0 API. To create an order, the client sends a request to the createOrder API, passing the order in the payload:
POST /createOrder HTTP 1.1
Content-Type: application/json
Content-Length: xx
{
"orderNumber" : "1000"
}
The server then responds with an order that has an active status:
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: xx
{
"orderNumber" : "1000",
"status" : "active"
}
To retrieve the orders, the client makes a request to listOrders and specifies the filter in the query string. Notice that for retrieval the client is actually performing a GET request rather than a POST:
GET /listOrders?status=active
The server then responds with the list of orders:
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: xx
{
[
{
"orderNumber : "1000",
"status" : "active"
},
{
"orderNumber" : "1200",
"status" : "active"
}
]
}
To approve the order, the client makes a POST request to the approveOrder resource:
POST /approveOrder?orderNumber=1000
...
A common example of an API using this style is Yahoo’s Flickr API. Looking at the documentation, we see “API Methods.” Looking under galleries, we see the methods listed in Figure 2-4.
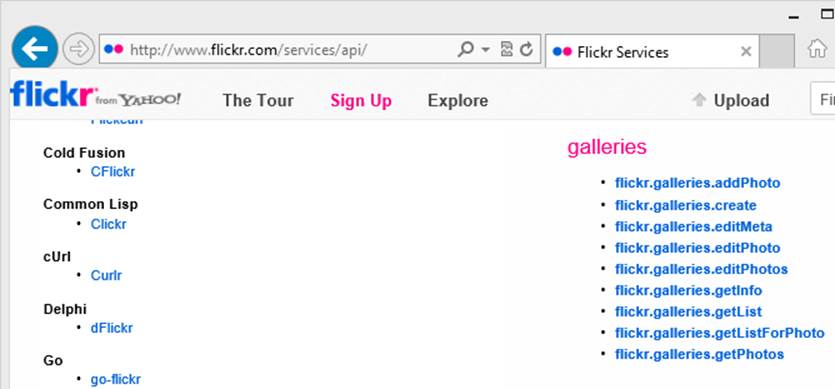
Figure 2-4. Yahoo Flickr API
There are several different URIs for working with photos. To add a photo, you’d request the addPhoto API, while to retrieve a photo you can use getPhotos. To update a photo, you can request the editPhoto or editPhoto APIs.
Notice this style is still very RPC-ish in the sense that each resource corresponds to a method on a server-side object. However, because it can use additional HTTP methods, some resources can be accessed via GET, allowing their responses to be cached as in the earlier listOrders example. This style provides additional evolvability benefits in that we can easily add new functionality to the system as resources, without having to modify existing resources, which could break current clients.
HTTP VERBS (RMM Level 2)
In the previous examples, each resource corresponded heavily to the implementation on the server, relating to one or more methods on server-side objects; thus, those examples were very functionality oriented (getOrder). A Level 2 system uses a resource-oriented approach. The API exposes one or more resources (order), which each support one or more HTTP methods. These types of APIs offer richer interactions over HTTP, supporting capabilities like caching and content negotiaion.
In these APIs, it is common to have a delineation between collection resources and item resources:
§ A collection resource corresponds to the collection of child resources (e.g., http://example.com/orders). To retrieve the collection, a client issues a GET request to this resource. To add a new item to the collection a client POSTs an item to this resource.
§ An item resource corresponds to an individual child resource within a collection (e.g., http://example.com/orders/1 corresponds to order 1). To update the item resource, a client sends a PUT or PATCH request. To delete, it uses a DELETE method. It is also common to allow PUT to create the resource if it does not exist. An item resource is generally referred to as a subresource, because its URI implies a hierarchy (i.e., in /orders/1, the 1 is a child).
§ Both collection and item resources can have one or more collection and item resources as children.
Applying the order example to level style, the client now sends the following request to create an order:
POST /orders
Content-Type: application/json
Content-Length: xx
{
"orderNumber" : "1000"
}
The server than responsds with a 201 Created status code and a location header indicating the URI of the newly created resource. The response also includes an ETag header to enable caching:
HTTP/1.1 201 CREATED
Location: /orders/1000
Content-Type: application/json
Content-Length: xx
ETag: "12345"
{
"orderNumber" : "1000",
"status" : "active"
}
To list active orders, the client sends a GET request to the /active subresource under /orders:
GET /orders/active
Content-Type: application/json
Content-Length: xx
{
[
{
"orderNumber : "1000",
"status" : "active"
},
{
"orderNumber" : "1200",
"status" : "active"
}
]
}
To approve the order, the client sends a PUT request to /order/1000/approval:
PUT /orders/1000/approval
The client then responds, indicating in this case that the order approval has been rejected:
HTTP/1.1 403 Forbidden
Content-Type: application/json
Content-Length: xx
{
"error": {
"code" : "100",
"message" : "Missing information"
}
}
Looking at the preceding examples, you can see the difference in the way the client interacts with such an API. It sends requests to one or more resources using the HTTP methods to convey the intent.
A real-world example of a resource-oriented API is the GitHub API. It exposes root collection resources for each of the major areas in GitHub, including Orgs, Repositories, Pull Requests, Issues, and much more. Each collection resource has its own child item and collection resources. To interact with each resource, you use standard HTTP methods.
For example, to list repositories for the current authenticated user, we can send the following request to the repos resource:
GET http://api.github.com/users/repos/ HTTP/1.1
To create a new repository for the current authenticated user, we issue a POST to the same URI with a JSON payload specifying the repo information:
POST http://api.github.com/users/repos/ HTTP/1.1
Content-Type: application/json
Content-Length:xx
{
"name": "New-Repo",
"description": "This is a new repo",
"homepage": "https://github.com",
"private": false,
"has_issues": true,
"has_wiki": true,
"has_downloads": true
}
Crossing the Chasm Toward Resource-Centric APIs
Designing resource-oriented APIs can be challenging, as the noun-centric/non-object-oriented style is a big paradigm shift from the way developers traditionally design procedural or object-oriented APIs in 4GL programming languages. The process involves analyzing the key elements of the system that clients need to interact with and exposing those as resources.
One challenge API designers face when doing this is how to handle situations where the existing set of HTTP methods seems insufficient. For example, given an Order resource, how do you handle an approval? Should you create an Approval HTTP method? Not if you want to be a good HTTP citizen, as clients or servers would never expect to deal with an APPROVAL method. There are a couple of different ways to address this scenario.
§ Have the client do a PUT/PATCH against the resource and have Approved=True included as part of the payload. It could be either in JSON or even a form URL encoded value passed in the query string:
PATCH http://example.com/orders/1?approved=true HTTP/1.1
§ Factor out APPROVAL as a separate resource and have the client POST or PUT to it:
POST http://example.com/orders/1/approval HTTP/1.1
Hypermedia (RMM Level 3)
The last level in Richardson’s scale is hypermedia. Hypermedia are controls or affordances present in the response that clients use for interacting with related resources for transitioning the application to different states. Although RMM defines it as a strict level, that is a bit misleading. Hypermedia can be present in an API, even in an RPC-oriented one.
THE ORIGINS OF HYPERMEDIA ON THE WEB
Hypermedia and hypertext are concepts that are part of the very foundations of the Web and HTTP. In Tim Berners-Lee’s original proposal for the World Wide Web, he spoke about hypertext:
HyperText is a way to link and access information of various kinds as a web of nodes in which the user can browse at will. Potentially, HyperText provides a single user-interface to many large classes of stored information such as reports, notes, data-bases, computer documentation and on-line systems help.
He then went on to propose the creation of a new system of servers based on this concept, which has evolved to become the World Wide Web:
We propose the implementation of a simple scheme to incorporate several different servers of machine-stored information already available at CERN, including an analysis of the requirements for information access needs by experiments.
Hypermedia is derived from hypertext and expands to more than just simple documents to include content such as graphics, audio, and video. Roy Fielding used the term in Chapter 5 of his dissertation on network architecture, where he discusses Representational State Transfer (REST). He defines right off the bat that hypermedia is a key component of REST:
This chapter introduces and elaborates the Representational State Transfer (REST) architectural style for distributed hypermedia systems.
There are two primary categories of hypermedia affordances: links and forms. To see the role each plays, let’s look at HTML.
HTML has many different hypermedia affordances, including <A href>, <FORM>, and <IMG> tags. When viewing an HTML page in a browser, a user is presented with a set of different links from the server that are rendered in the browser. Those links are identified by the user via either the link description or an image. The user then clicks the links of interest. The page can also include forms. If a form is present, such as for creating an order, the user can fill out the form fields and click Submit. In either case, the user is able to navigate the system without any knowledge of the underlying URI.
In the same way, a hypermedia API can be consumed by a nonbrowser client. Similar to the HTML example, the links and forms are present but can be rendered in different formats, including XML and JSON. For more on forms, see “Hypermedia and Forms” on CodeBetter.
A link in a hypermedia API includes a minimum of two components:
§ A URI to the related resource
§ A rel that identifies the relationship between the linked resource and the current resource
The rel (and possibly other metadata) is the identifier that the user agent cares about. The rel indicates how the resource to which the link points relates to the current resource.
MEASURING HYPERMEDIA AFFORDANCES WITH H-FACTORS
Mike Amundsen has created a measurement called an H-factor designed to measure the level of hypermedia syupport within a media type. H-factors are divided into two groups with their own factors:
§ Link support
§ [LE]Embedding links
§ [LO]Outbound links
§ [LT]Templated queries
§ [LN]Nonidempotent updates
§ [LI]Idempotent updates
§ Control data support
§ [CR]Control data for read requests
§ [CU]Control data for update requests
§ [CM]Control data for interface methods
§ [CL]Control data for links
H-factors are a useful way to compare and contrast the different types of hypermedia APIs that exist.
Returning to the order example, we can now see how hypermedia will play in. In each of the aforementioned scenarios, the client has complete knowledge of the URI space. In the hypermedia case, however, the client knows only about one root URI, which it goes to in order to discover the available resources in the system. This URI acts almost like a home page—in fact, it is a home resource:
GET /home
Accept: application/json; profile="http://example.com/profile/orders"
In this case, the client sends an Accept header with an orders profile:
HTTP/1.1 200 OK
Content-Type: application/json; profile="http://example.com/profile/orders"
Content-Length: xx
{
"links" : [
{"rel":"orders", "href": "/orders"},
{"rel":"shipping", "href": "/shipping"}
{"rel":"returns", "href": "/returns"}
]
}
The home resource contains pointers to the other parts of the system—in this case, orders, shipping, and returns. To find out how to interact with the resources that the links point to, the developer building the client can reference the profile documentation at the profile URL just indicated. The document states that if a client sees a link with a rel of orders, it can POST an order to that resource to create a new one. The content type can just be JSON, as the server will try to determine the correct elements:
POST /orders
Content-Type: application/json
Content-Length: xx
{
"orderNumber" : "1000"
}
Here is the response:
HTTP/1.1 201 CREATED
Location: /orders/1000
Content-Type: application/json; profile="http://example.com/profile/orders"
Content-Length: xx
ETag: "12345"
{
"orderNumber" : "1000",
"status" : "active"
"links" : [
{"rel":"self", "href": "/orders/1000"},
{"rel":"approve", "href": "/orders/1000/approval"}
{"rel":"cancel", "href": "/orders/1000/cancellation"}
{"rel":"hold", "href": "/orders/1000/hold"}
]
}
Notice that in addition to the order details, the server has included several links that are applicable specifically for the current order:
§ "self" identifies the URL for the order itself. This is useful as a bookmark to the order resource.
§ "approve" identifies a resource for approving the order.
§ "cancel" identifies a resource for placing a cancellation.
§ "hold" identifies a resource for putting the order on hold.
Now that the client has the order, it can follow the approval link. The profile spec indicates that the client should do a PUT against the URL associated with a rel of approve in order to approve the order:
PUT /orders/1000/approval
Content-Type: application/json
The response will be identical to the Level 2 response:
HTTP/1.1 403 Forbidden
Content-Type: application/json; profile="http://example.com/profile/orders"
Content-Length: xx
{
"error": {
"code" : "100",
"message" : "Missing information"
}
}
Paypal recently introduced a new payments API that incorporates hypermedia in its responses.
The following is an extract of a response for a payment issued using the new API:
"links": [
{
"href": "https://api.sandbox.paypal.com/v1/payments/sale/1KE480",
"rel": "self",
"method": "GET"
},
{
"href": "https://api.sandbox.paypal.com/v1/payments/sale/1KE480/refund",
"rel": "refund",
"method": "POST"
},
{
"href": "https://api.sandbox.paypal.com/v1/payments/payment/PAY-34629814W",
"rel": "parent_payment",
"method": "GET"
}
As you can see, it contains the self link mentioned previously, as well as links for submitting for a refund and accessing the parent payment. Notice that, in addition to the standard href and rel members, each link contains a method member that advises the client on which HTTP method it should use. In this case, the media type Paypal returns is application/json. This means the client cannot simply tell by the response headers that the payload is in fact a Paypal payload. However, the Paypal documentation explains the rel, and that it is possible to navigate the system without hardcoding against URLs.
In each of the previous examples, hypermedia provides the benefit that the client has to know only a single root URL to access the API and get the initial response. From that point on, it follows its nose by navigating to whatever URLs the server serves up. The server is free to change those URLs and offer the client specifically targeted links without affecting other clients. As with all things, there are trade-offs.
Implementing a hypermedia system is significantly more difficult, and is a mind shift. More moving parts are introduced into the system as part of the implementation. In addition, using hypermedia-based approaches for APIs is a young and evolving “science,” so you do have some of your work cut out for you. In many cases the trade-off is worth it, in particular if you are building an open system that needs to support many third-party clients.
REST
REST, or Representational State Transfer, is probably one of the most misunderstood terms in Web API development today. Most people equate REST with anything that is easy to access over HTTP and forget about its constraints completely.
The term’s roots are from Roy Fielding’s previously mentioned dissertation on network-based architecture. In it, Roy describes REST as an architectural style for distributed hypermedia systems. In other words, REST is not a technology, it is not a framework, and it is not a design pattern. It is a style. There is no “one true way” to do REST, and as a result, there are many flavors of RESTful systems. However, what is most important is that all RESTful systems manifest themselves in a set of constraints, which will be mentioned in more depth in the following section.
The other common misunderstanding is that you must build a RESTful system. This is not the case. The RESTful constraints are designed to create a system that achieves a certain set of goals—in particular, a system that can evolve over a long period of time and can tolerate many different clients and many different changes without breaking those clients.
REST Constraints
REST defines the following six constraints (including one optional) as part of the style:
Client-server
A RESTful system is designed to separate out the UI concerns from the backend. Clients are decoupled from the server, thus allowing both to evolve independently.
Stateless
For each request in a RESTful system, all of the application state is kept on the client and transferred in the request. This allows the server to receive all the information it needs to process the request without having to track each individual client. Removing statefulness from the server allows the application to easily scale.
Cache
Data within a request must be able to be identified as cachable. This allows client and server caches to act on behalf of the origin server and to return cached representations. Cachability greatly reduces latency, increases user-perceived performance, and improves overall system scale, as it decreases the load on the server.
Uniform interface
RESTful systems use a standardized interface for system interaction.
Identification of resources
This means that the point of interaction in a RESTful system is a resource. This is the same resource that we discussed earlier.
Self-descriptive messages
This means that each message contains all the information necessary for clients and servers to interact. This includes the URI, HTTP method, headers, media type, and more.
Manipulation of resources through representations
As we covered previously, a resource can have one or more representations. In a RESTful system, it is through these representations that resource state is communicated.
Hypermedia as the engine of application state
Previously we discussed hypermedia and the role it plays in driving the flow of the application. That model is a core component of a RESTful system.
Layered system
Components within a RESTful system are layered and composed with each component having a limited view of the system. This allows layers to be introduced to adapt between legacy clients and servers and enables intermediaries to provide additional services like caching, enforcing security policies, compression, and more.
Code on demand
This allows clients to dynamically download code that executes on the client in order to help it interact with the system. One very popular example of this is the way client-side JavaScript executes in the browser, as it is downloaded on demand. Being able to introduce new application code improves the the system’s capacity to evolve and be extended. Because it reduces visibility, however, this constraint is considered optional.
As you can see, building a RESTful system is not free and not necessarily easy. There have been many books written in depth on the topics just mentioned. Although making a system RESTful is not trivial, it can be worth the investment depending on the system’s needs. For this reason, this book does not focus on REST but rather focuses on evolvability and techniques to achieve that when building your Web APIs. Each of these techniques is a pathway toward a fully RESTful system but provides a benefit in its own right.
Put another way, focus on the needs of your system and not whether you can stamp it with a “REST” badge or not.
For more clarification on REST as a term, Kelly Sommers has a well-written post that covers this topic in more detail.
To learn more about building RESTful and hypermedia-based systems, check out REST in Practice (O’Reilly) and Building Hypermedia APIs with HTML5 and Node (O’Reilly).
Conclusion
In this chapter, we learned about the origin of APIs, explored the growth of APIs in the industry, and dove into APIs themselves. Now it’s time to meet ASP.NET Web API, Microsoft’s answer to building APIs. In the next chapter, you’ll learn about the framework, its design goals, and how to get started with it for API development.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.