Microsoft Azure Machine Learning
Chapter 8. Clustering
Birds of a feather flock together—clustering is all about this. It's an unsupervised learning where the class or label is not known. So, you get a dataset and then with the algorithm, you divide and group the instances into different clusters with an objective of keeping all the similar ones together.
Clustering has many different application areas, such as customer segmentation, social network analysis, computational biology, and many more.
In this chapter, you will start with understanding the K-means clustering algorithm and then, you will learn how to build a model using this in ML Studio.
Understanding the K-means clustering algorithm
The K-means clustering algorithm is the most popular clustering algorithm. It is simple and powerful. As the name suggests, the algorithm creates K clusters out of the dataset where K is a number you decide. For simplicity, let's consider a dataset with two features and let's plot them on a two dimensional space as one feature on x axis and the other on y axis. Again, note that as clustering is an unsupervised learning problem, no label, class, or dependent variable is required.
With the K-means algorithm, K centroids are determined for K clusters. All the points in a cluster are closest to its centroid than to any other centroids.
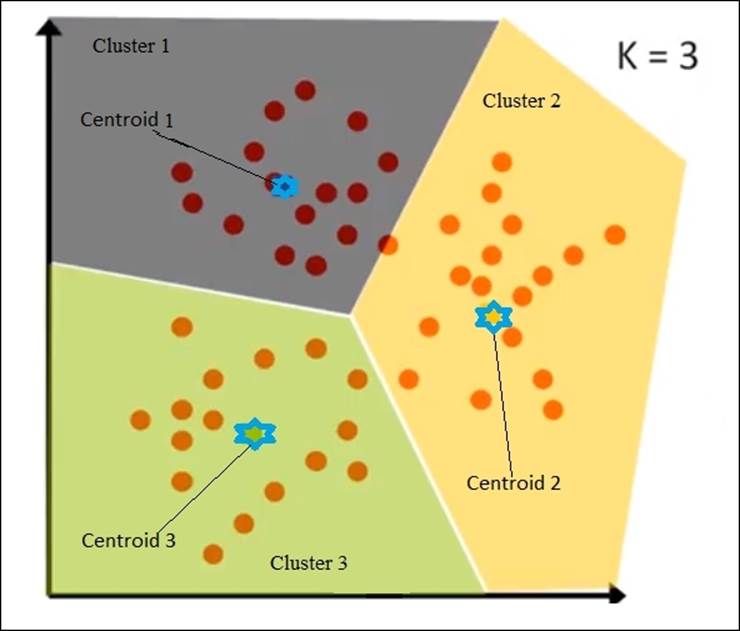
Consider K =3, where there are 3 clusters and hence 3 centroids, as you can find in the following figure. So by intuition, take any point and calculate its distance from the three centroids. The point will belong to the cluster whose centroid is the nearest.
For a point, let d1 be the distance from Centroid 1, d2 be the distance from Centroid 2, and d3 be the distance from Centroid 3.
If d2 < d1 and d2 < d3, then the point closest to centroid 2 belongs to the cluster 2. Let's take a look at the following diagram:
Creating a K-means clustering model using ML Studio
Now, it's time for you to build a clustering model by yourself. ML Studio comes with two modules specific for K-means clustering.
The URL http://www.biz.uiowa.edu/faculty/jledolter/DataMining/protein.csv contains a dataset in CSV format.
It contains the protein intakes of 9 different food sources from 25 European countries. The first few instances in the dataset are listed as follows:
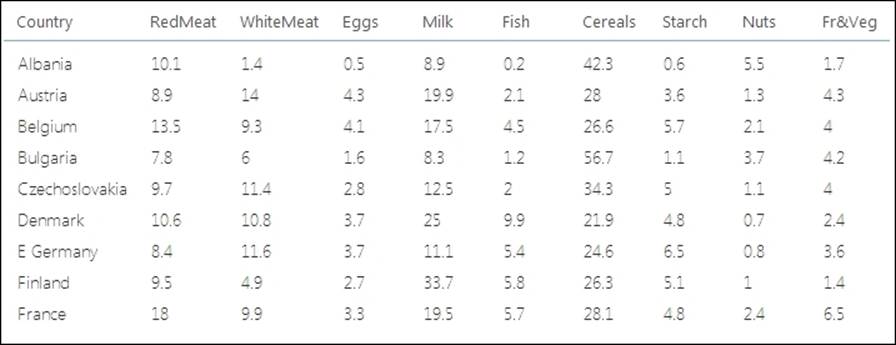
Let's build a clustering model to group the dataset into three clusters based on the protein intakes of different countries from a variety of sources.
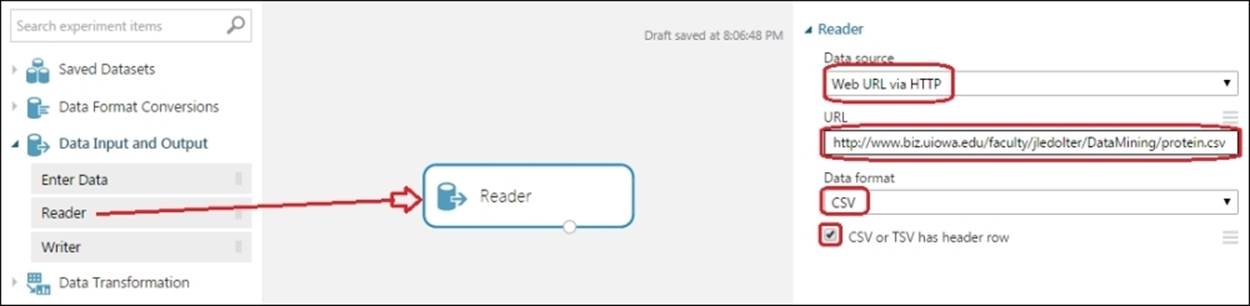
Create a new experiment and drag the Reader module under the Data Input and Output section in the modules palette to the left of the canvas. On the properties pane to the right, choose Data Source as Web URL via HTTP, Data format as CSV, and tick the checkbox for CSV or TSV has header row. Also, on the URL textbox, add the previously mentioned URL to the CSV file.
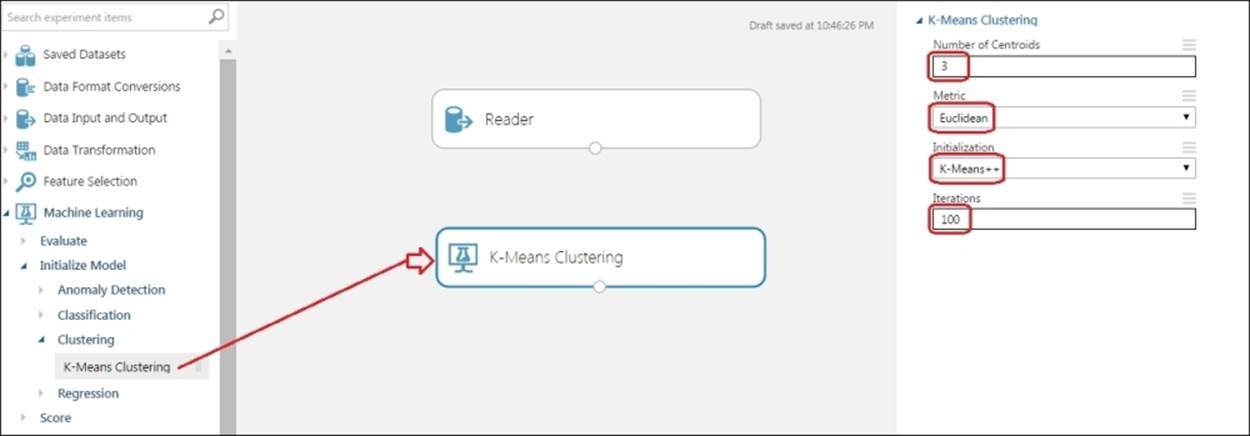
Drag the K-Means Clustering module to the canvas. This module is for the algorithm. As you need three clusters for your dataset, set the Number of Centroids option to 3 in the properties pane and leave the others with their default parameters, as shown in the following screenshot:
Drag the Train Clustering Model module to the canvas and make a connection, as shown in the following screenshot. For the Country column in the dataset, your target is to make the algorithm work based on the protein intakes. So, exclude the column and include everything else.
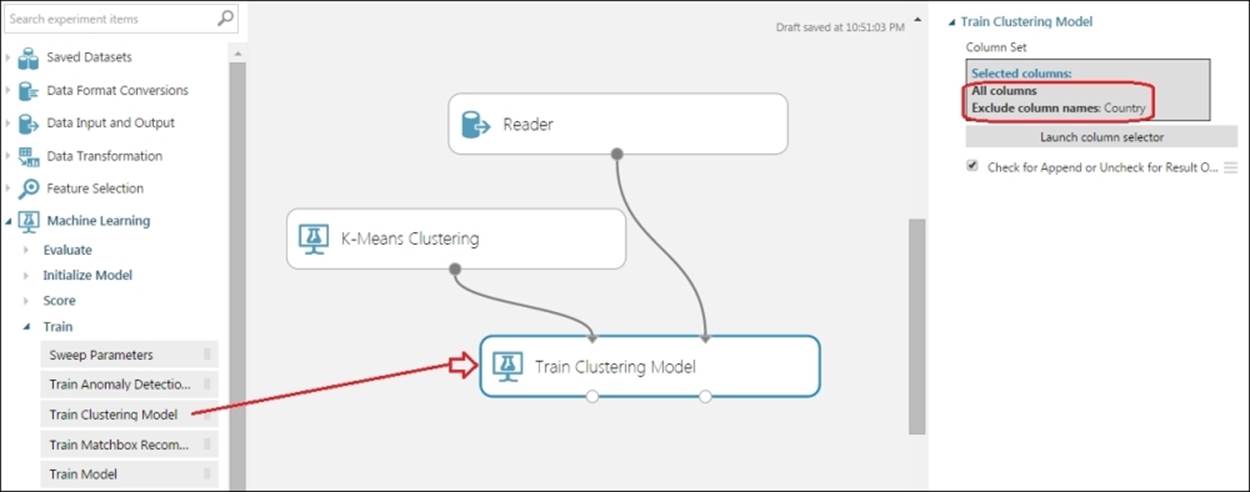
Drag the Assign to Clusters module to the canvas and make a connection, as shown in the following screenshot. Exclude the Country column and include everything else.
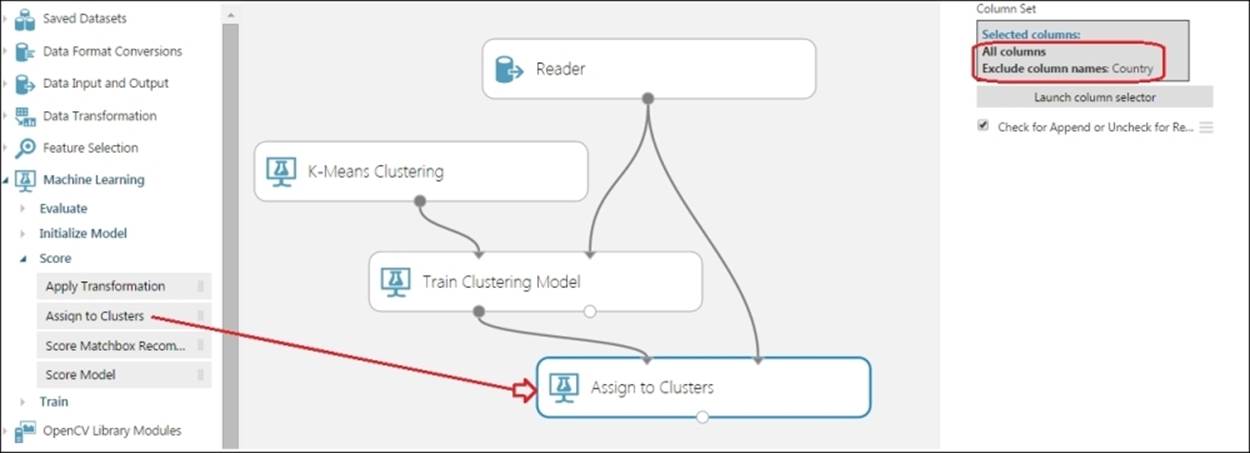
Now, drag a Project Columns module and connect the output of the Assign to Clusters module to its input. Select All columns by clicking on the Launch column selector option in the properties pane for the module, as shown in the following screenshot:
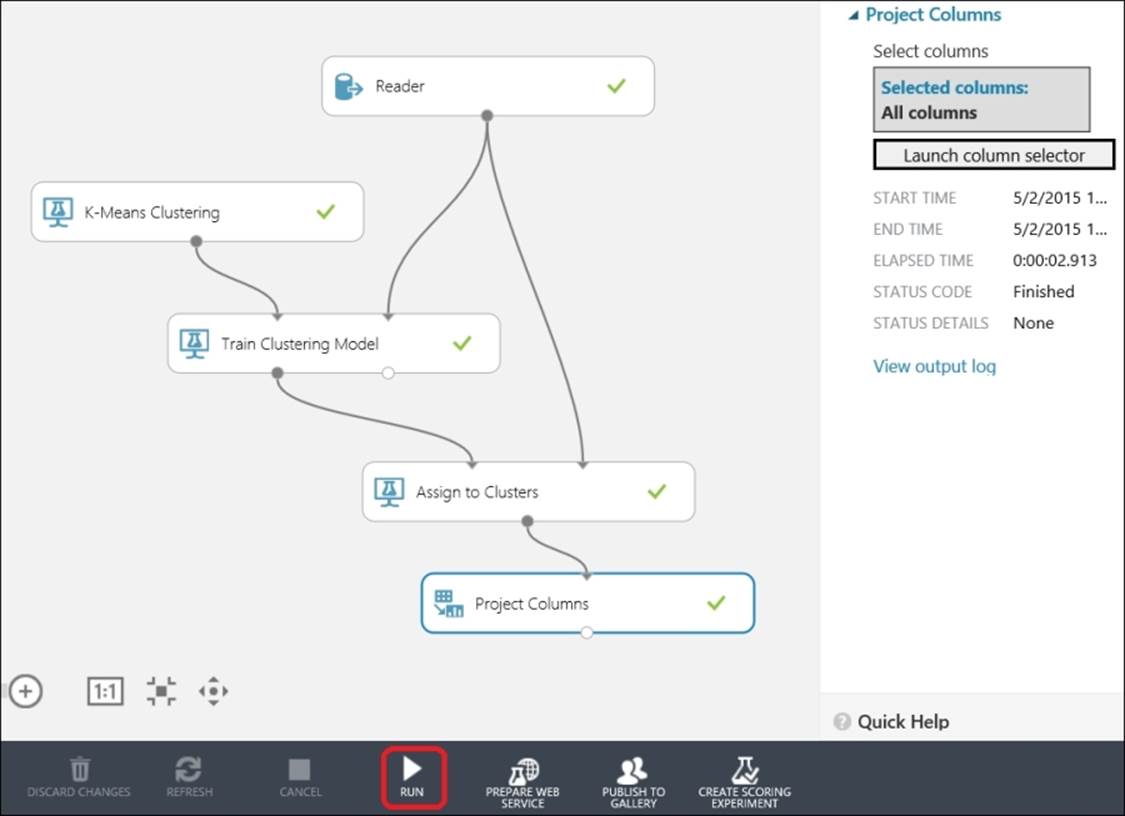
Run the experiment and right-click on the output port of the Project Columns module and visualize the output with the clusters assigned as follows:
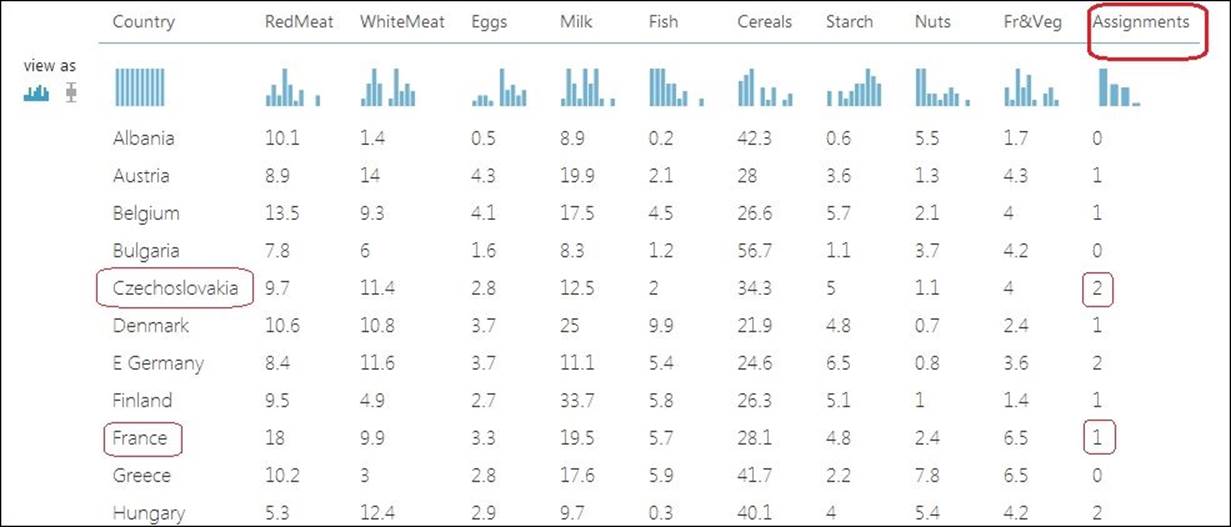
The output table has the rightmost Assignments column that contains the cluster (number) assigned to each cluster. As you can see, we've found that different countries fall into one of the three clusters based on the protein intakes, for example, Czechoslovakia belongs to cluster 2 andFrance to cluster 1.
Here, you've found the clusters for the same training data. However, after training, you can find the clusters for new datasets as well.
Do it yourself
There is a sample dataset under the Saved Datasets option in ML Studio called Iris Two Class Data. Use this to build a K-Means Clustering model with K (Number of Centroids) = 2.
This is not a test, but did you notice that all the instances of one class fall in the same cluster? Don't be confused between the cluster number as 0 and 1 because it is just a number and it won't harm even if you read the cluster 0 as 1 and 1 as 0.
Clustering versus classification
It might be confusing for beginners to distinguish between a clustering problem and a classification problem. Classification is fundamentally different from clustering. Classification is a supervised learning problem where your class or target variable is known to train a dataset. The algorithm is trained to look at the examples (features and class or target variables) and then you score and test it with a test dataset.
Clustering, being an unsupervised learning, it works on a dataset with no label or class variable. Also, you don't perform scoring and testing with a test dataset. So, you just apply your algorithm to your data and group them into a different cluster, say 1, 2 and 3, which were not known before.
So, to put it simply, if you have a dataset and a class/label or target variable as categorical variable and you have to predict the target variable for a new dataset based on the given dataset, it's a classification problem. If you are just given a dataset with no label or target variable and you just have to group them into n clusters, then it's a clustering case.
Summary
After a quick overview of the unsupervised learning, you proceeded to understand clustering and the K-means clustering algorithm. Then, you built a clustering model using ML Studio and learned about three modules for K-means clustering.
In the next chapter, you will explore the Recommender System and learn to build a simple model for the same.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.