Windows Internals, Sixth Edition, Part 1 (2012)
Chapter 1. Concepts and Tools
In this chapter, we’ll introduce the key Microsoft Windows operating system concepts and terms we’ll be using throughout this book, such as the Windows API, processes, threads, virtual memory, kernel mode and user mode, objects, handles, security, and the registry. We’ll also introduce the tools that you can use to explore Windows internals, such as the kernel debugger, the Performance Monitor, and key tools from Windows Sysinternals (www.microsoft.com/technet/sysinternals). In addition, we’ll explain how you can use the Windows Driver Kit (WDK) and the Windows Software Development Kit (SDK) as resources for finding further information on Windows internals.
Be sure that you understand everything in this chapter—the remainder of the book is written assuming that you do.
Windows Operating System Versions
This book covers the most recent version of the Microsoft Windows client and server operating systems: Windows 7 (32-bit and 64-bit versions) and Windows Server 2008 R2 (64-bit version only). Unless specifically stated, the text applies to all versions. As background information,Table 1-1 lists the Windows product names, their internal version number, and their release date.
Table 1-1. Windows Operating System Releases
|
Product Name |
Internal Version Number |
Release Date |
|
Windows NT 3.1 |
3.1 |
July 1993 |
|
Windows NT 3.5 |
3.5 |
September 1994 |
|
Windows NT 3.51 |
3.51 |
May 1995 |
|
Windows NT 4.0 |
4.0 |
July 1996 |
|
Windows 2000 |
5.0 |
December 1999 |
|
Windows XP |
5.1 |
August 2001 |
|
Windows Server 2003 |
5.2 |
March 2003 |
|
Windows Vista |
6.0 (Build 6000) |
January 2007 |
|
Windows Server 2008 |
6.0 (Build 6001) |
March 2008 |
|
Windows 7 |
6.1 (Build 7600) |
October 2009 |
|
Windows Server 2008 R2 |
6.1 (Build 7600) |
October 2009 |
NOTE
The “7” in the “Windows 7” product name does not refer to the internal version number, but is rather a generational index. In fact, to minimize application compatibility issues, the version number for Windows 7 is actually 6.1, as shown in Table 1-1. This allows applications checking for the major version number to continue behaving on Windows 7 as they did on Windows Vista. In fact, Windows 7 and Server 2008 R2 have identical version/build numbers because they were built from the same Windows code base.
Foundation Concepts and Terms
In the course of this book, we’ll be referring to some structures and concepts that might be unfamiliar to some readers. In this section, we’ll define the terms we’ll be using throughout. You should become familiar with them before proceeding to subsequent chapters.
Windows API
The Windows application programming interface (API) is the user-mode system programming interface to the Windows operating system family. Prior to the introduction of 64-bit versions of Windows, the programming interface to the 32-bit versions of the Windows operating systems was called the Win32 API to distinguish it from the original 16-bit Windows API, which was the programming interface to the original 16-bit versions of Windows. In this book, the term Windows API refers to both the 32-bit and 64-bit programming interfaces to Windows.
NOTE
The Windows API is described in the Windows Software Development Kit (SDK) documentation. (See the section Windows Software Development Kit later in this chapter.) This documentation is available for free viewing online at www.msdn.microsoft.com. It is also included with all subscription levels to the Microsoft Developer Network (MSDN), Microsoft’s support program for developers. For more information, see www.msdn.microsoft.com. An excellent description of how to program the Windows base API is in the book Windows via C/C++, Fifth Edition by Jeffrey Richter and Christophe Nasarre (Microsoft Press, 2007).
The Windows API consists of thousands of callable functions, which are divided into the following major categories:
§ Base Services
§ Component Services
§ User Interface Services
§ Graphics and Multimedia Services
§ Messaging and Collaboration
§ Networking
§ Web Services
This book focuses on the internals of the key base services, such as processes and threads, memory management, I/O, and security.
WHAT ABOUT .NET?
The Microsoft .NET Framework consists of a library of classes called the Framework Class Library (FCL) and a Common Language Runtime (CLR) that provides a managed code execution environment with features such as just-in-time compilation, type verification, garbage collection, and code access security. By offering these features, the CLR provides a development environment that improves programmer productivity and reduces common programming errors. For an excellent description of the .NET Framework and its core architecture, see CLR via C#, Third Edition by Jeffrey Richter (Microsoft Press, 2010).
The CLR is implemented as a classic COM server whose code resides in a standard user-mode Windows DLL. In fact, all components of the .NET Framework are implemented as standard user-mode Windows DLLs layered over unmanaged Windows API functions. (None of the .NET Framework runs in kernel mode.) Figure 1-1 illustrates the relationship between these components:
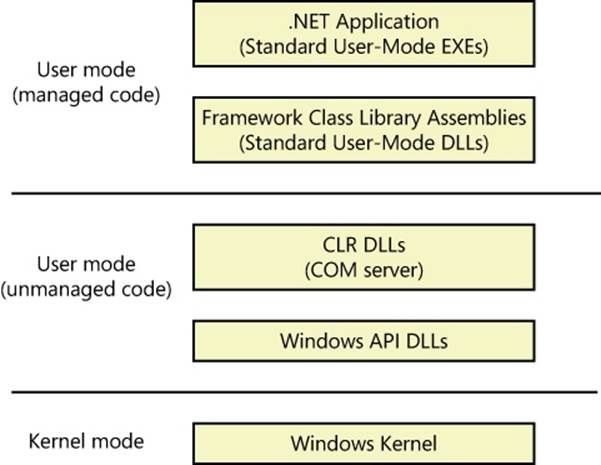
FIGURE 1-1. RELATIONSHIP BETWEEN .NET FRAMEWORK COMPONENTS
HISTORY OF THE WIN32 API
Interestingly, Win32 wasn’t slated to be the original programming interface to what was then called Windows NT. Because the Windows NT project started as a replacement for OS/2 version 2, the primary programming interface was the 32-bit OS/2 Presentation Manager API. A year into the project, however, Microsoft Windows 3.0 hit the market and took off. As a result, Microsoft changed direction and made Windows NT the future replacement for the Windows family of products as opposed to the replacement for OS/2. It was at this juncture that the need to specify the Windows API arose—before this, in Windows 3.0, the API existed only as a 16-bit interface.
Although the Windows API would introduce many new functions that hadn’t been available on Windows 3.1, Microsoft decided to make the new API compatible with the 16-bit Windows API function names, semantics, and use of data types whenever possible to ease the burden of porting existing 16-bit Windows applications to Windows NT. This explains why many function names and interfaces might seem inconsistent: –this was required to ensure that the then new Windows API was compatible with the old 16-bit Windows API.
Services, Functions, and Routines
Several terms in the Windows user and programming documentation have different meanings in different contexts. For example, the word service can refer to a callable routine in the operating system, a device driver, or a server process. The following list describes what certain terms mean in this book:
§ Windows API functions. Documented, callable subroutines in the Windows API. Examples include CreateProcess, CreateFile, and GetMessage.
§ Native system services (or system calls). The undocumented, underlying services in the operating system that are callable from user mode. For example, NtCreateUserProcess is the internal system service the Windows CreateProcess function calls to create a new process. For a definition of system calls, see the section System Service Dispatching in Chapter 3.
§ Kernel support functions (or routines). Subroutines inside the Windows operating system that can be called only from kernel mode (defined later in this chapter). For example, ExAllocatePoolWithTag is the routine that device drivers call to allocate memory from the Windows system heaps (called pools).
§ Windows services. Processes started by the Windows service control manager. For example, the Task Scheduler service runs in a user-mode process that supports the at command (which is similar to the UNIX commands at or cron). (Note: although the registry defines Windows device drivers as “services,” they are not referred to as such in this book.)
§ DLLs (dynamic-link libraries). A set of callable subroutines linked together as a binary file that can be dynamically loaded by applications that use the subroutines. Examples include Msvcrt.dll (the C run-time library) and Kernel32.dll (one of the Windows API subsystem libraries). Windows user-mode components and applications use DLLs extensively. The advantage DLLs provide over static libraries is that applications can share DLLs, and Windows ensures that there is only one in-memory copy of a DLL’s code among the applications that are referencing it. Note that nonexecutable .NET assemblies are compiled as DLLs but without any exported subroutines. Instead, the CLR parses compiled metadata to access the corresponding types and members.
Processes, Threads, and Jobs
Although programs and processes appear similar on the surface, they are fundamentally different. A program is a static sequence of instructions, whereas a process is a container for a set of resources used when executing the instance of the program. At the highest level of abstraction, a Windows process comprises the following:
§ A private virtual address space, which is a set of virtual memory addresses that the process can use
§ An executable program, which defines initial code and data and is mapped into the process’ virtual address space
§ A list of open handles to various system resources—such as semaphores, communication ports, and files—that are accessible to all threads in the process
§ A security context called an access token that identifies the user, security groups, privileges, User Account Control (UAC) virtualization state, session, and limited user account state associated with the process
§ A unique identifier called a process ID (internally part of an identifier called a client ID)
§ At least one thread of execution (although an “empty” process is possible, it is not useful)
Each process also points to its parent or creator process. If the parent no longer exists, this information is not updated. Therefore, it is possible for a process to refer to a nonexistent parent. This is not a problem, because nothing relies on this information being kept current. In the case of ProcessExplorer, the start time of the parent process is taken into account to avoid attaching a child process based on a reused process ID. The following experiment illustrates this behavior.
EXPERIMENT: VIEWING THE PROCESS TREE
One unique attribute about a process that most tools don’t display is the parent or creator process ID. You can retrieve this value with the Performance Monitor (or programmatically) by querying the Creating Process ID. The Tlist.exe tool (in the Debugging Tools for Windows) can show the process tree by using the /t switch. Here’s an example of output from tlist /t:
C:\>tlist /t
System Process (0)
System (4)
smss.exe (224)
csrss.exe (384)
csrss.exe (444)
conhost.exe (3076) OleMainThreadWndName
winlogon.exe (496)
wininit.exe (504)
services.exe (580)
svchost.exe (696)
svchost.exe (796)
svchost.exe (912)
svchost.exe (948)
svchost.exe (988)
svchost.exe (244)
WUDFHost.exe (1008)
dwm.exe (2912) DWM Notification Window
btwdins.exe (268)
svchost.exe (1104)
svchost.exe (1192)
svchost.exe (1368)
svchost.exe (1400)
spoolsv.exe (1560)
svchost.exe (1860)
svchost.exe (1936)
svchost.exe (1124)
svchost.exe (1440)
svchost.exe (2276)
taskhost.exe (2816) Task Host Window
svchost.exe (892)
lsass.exe (588)
lsm.exe (596)
explorer.exe (2968) Program Manager
cmd.exe (1832) Administrator: C:\Windows\system32\cmd.exe - "c:\tlist.exe" /t
tlist.exe (2448)
The list indents each process to show its parent/child relationship. Processes whose parents aren’t alive are left-justified (as is Explorer.exe in the preceding example) because even if a grandparent process exists, there’s no way to find that relationship. Windows maintains only the creator process ID, not a link back to the creator of the creator, and so forth.
To demonstrate the fact that Windows doesn’t keep track of more than just the parent process ID, follow these steps:
1. Open a Command Prompt window.
2. Type title Parent (to change the window title to Parent).
3. Type start cmd (which starts a second command prompt).
4. Type title Child in the second command prompt.
5. Bring up Task Manager.
6. Type mspaint (which runs Microsoft Paint) in the second command prompt.
7. Go back to the second command prompt and type exit. (Notice that Paint remains.)
8. Switch to Task Manager.
9. Click on the Applications tab.
10. Right-click on the Parent task, and select Go To Process.
11. Right-click on this cmd.exe process, and select End Process Tree.
12. Click End Process Tree in the Task Manager confirmation message box.
The first command prompt window will disappear, but you should still see the Paint window because it was the grandchild of the command prompt process you terminated; and because the intermediate process (the parent of Paint) was terminated, there was no link between the parent and the grandchild.
A number of tools for viewing (and modifying) processes and process information are available. The following experiments illustrate the various views of process information you can obtain with some of these tools. While many of these tools are included within Windows itself and within the Debugging Tools for Windows and the Windows SDK, others are stand-alone tools from Sysinternals. Many of these tools show overlapping subsets of the core process and thread information, sometimes identified by different names.
Probably the most widely used tool to examine process activity is Task Manager. (Because there is no such thing as a “task” in the Windows kernel, the name of this tool, Task Manager, is a bit odd.) The following experiment shows the difference between what Task Manager lists as applications and processes.
EXPERIMENT: VIEWING PROCESS INFORMATION WITH TASK MANAGER
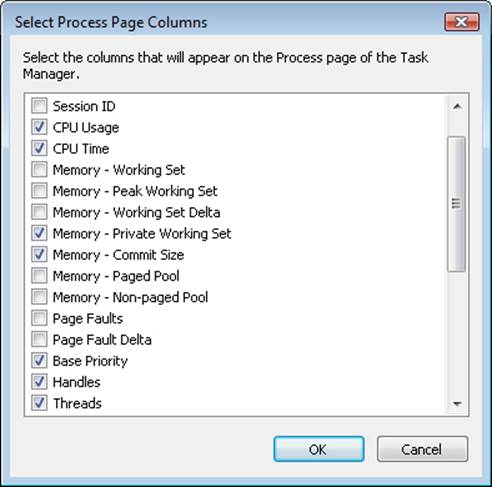
The built-in Windows Task Manager provides a quick list of the processes on the system. You can start Task Manager in one of four ways: (1) press Ctrl+Shift+Esc, (2) right-click on the taskbar and click Start Task Manager, (3) press Ctrl+Alt+Delete and click the Start Task Manager button, or (4) start the executable Taskmgr.exe. Once Task Manager has started, click on the Processes tab to see the list of processes. Notice that processes are identified by the name of the image of which they are an instance. Unlike some objects in Windows, processes can’t be given global names. To display additional details, choose Select Columns from the View menu and select additional columns to be added, as shown here:
Although the Task Manager Processes tab shows a list of processes, what the Applications tab displays isn’t as obvious. The Applications tab lists the top-level visible windows on all the desktops in the interactive window station you are connected to. (By default, there is only one interactive desktop—an application can create more by using the Windows CreateDesktop function, as is done by the Sysinternals Desktops tool.) The Status column indicates whether or not the thread that owns the window is in a window message wait state. “Running” means the thread is waiting for windowing input; “Not Responding” means the thread isn’t waiting for windowing input (for example, the thread might be running or waiting for I/O or some Windows synchronization object).
On the Applications tab, you can match a task to the process that owns the thread that owns the task window by right-clicking on the task name and choosing Go To Process as shown in the previous tlist experiment.
Process Explorer, from Sysinternals, shows more details about processes and threads than any other available tool, which is why you will see it used in a number of experiments throughout the book. The following are some of the unique things that Process Explorer shows or enables:
§ Process security token (such as lists of groups and privileges and the virtualization state)
§ Highlighting to show changes in the process and thread list
§ List of services inside service-hosting processes, including the display name and description
§ Processes that are part of a job and job details
§ Processes hosting .NET applications and .NET-specific details (such as the list of AppDomains, loaded assemblies, and CLR performance counters)
§ Start time for processes and threads
§ Complete list of memory-mapped files (not just DLLs)
§ Ability to suspend a process or a thread
§ Ability to kill an individual thread
§ Easy identification of which processes were consuming the most CPU time over a period of time (The Performance Monitor can display process CPU utilization for a given set of processes, but it won’t automatically show processes created after the performance monitoring session has started—only a manual trace in binary output format can do that.)
Process Explorer also provides easy access to information in one place, such as:
§ Process tree (with the ability to collapse parts of the tree)
§ Open handles in a process (including unnamed handles)
§ List of DLLs (and memory-mapped files) in a process
§ Thread activity within a process
§ User-mode and kernel-mode thread stacks (including the mapping of addresses to names using the Dbghelp.dll that comes with the Debugging Tools for Windows)
§ More accurate CPU percentage using the thread cycle count (an even better representation of precise CPU activity, as explained in Chapter 5)
§ Integrity level
§ Memory manager details such as peak commit charge and kernel memory paged and nonpaged pool limits (other tools show only current size)
An introductory experiment using Process Explorer follows.
EXPERIMENT: VIEWING PROCESS DETAILS WITH PROCESS EXPLORER
Download the latest version of Process Explorer from Sysinternals and run it. The first time you run it, you will receive a message that symbols are not currently configured. If properly configured, Process Explorer can access symbol information to display the symbolic name of the thread start function and functions on a thread’s call stack (available by double-clicking on a process and clicking on the Threads tab). This is useful for identifying what threads are doing within a process. To access symbols, you must have the Debugging Tools for Windows installed (described later in this chapter). Then click on Options, choose Configure Symbols, and fill in the path to the Dbghelp.dll in the Debugging Tools folder and a valid symbol path. For example, on a 64-bit system this configuration is correct:
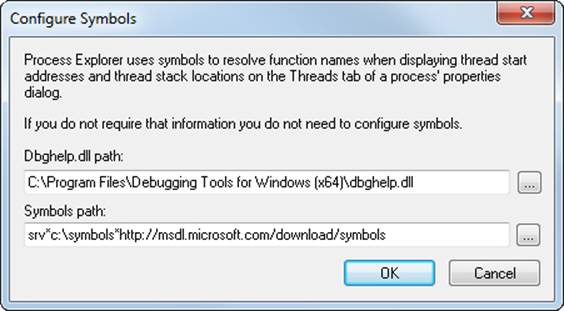
In the preceding example, the on-demand symbol server is being used to access symbols and a copy of the symbol files is being stored on the local machine in the c:\symbols folder. For more information on configuring the use of the symbol server, see http://msdn.microsoft.com/en-us/windows/hardware/gg462988.aspx.
When Process Explorer starts, it shows by default the process tree view. It has an optional lower pane that can show open handles or mapped DLLs and memory-mapped files. (These are explored in Chapter 3 in Part 1 and Chapter 10, “Memory Management” in Part 2.) It also shows tooltips for several kinds of hosting processes:
§ The services inside a service-hosting process (Svchost.exe) if you hover your mouse over the name
§ The COM object tasks inside a Taskeng.exe process (started by the Task Scheduler)
§ The target of a Rundll32.exe process (used for things such as Control Panel items)
§ The COM object being hosted inside a Dllhost.exe process
§ Internet Explorer tab processes
§ Console host processes
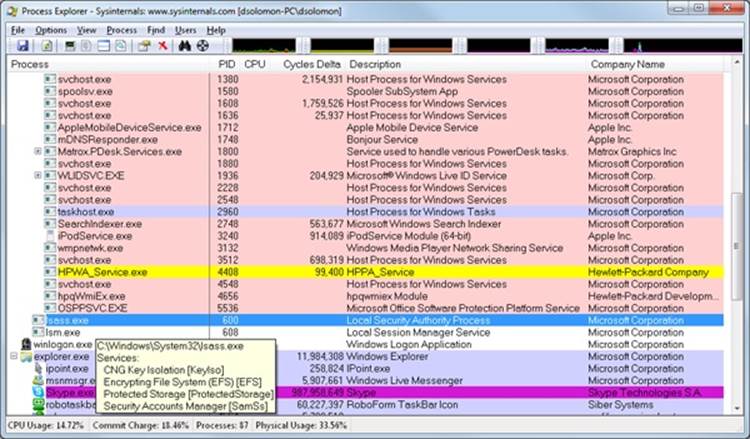
Here are a few steps to walk you through some basic capabilities of Process Explorer:
1. Notice that processes hosting services are highlighted by default in pink. Your own processes are highlighted in blue. (These colors can be configured.)
2. Hover your mouse pointer over the image name for processes, and notice the full path displayed by the tooltip. As noted earlier, certain types of processes have additional details in the tooltip.
3. Click on View, Select Columns from the Process Image tab, and add the image path.
4. Sort by clicking on the process column, and notice the tree view disappears. (You can either display tree view or sort by any of the columns shown.) Click again to sort from Z to A. Then click again, and the display returns to tree view.
5. Deselect View, Show Processes From All Users to show only your processes.
6. Go to Options, Difference Highlight Duration, and change the value to 5 seconds. Then launch a new process (anything), and notice the new process highlighted in green for 5 seconds. Exit this new process, and notice the process is highlighted in red for 5 seconds before disappearing from the display. This can be useful to see processes being created and exiting on your system.
7. Finally, double-click on a process and explore the various tabs available from the process properties display. (These will be referenced in various experiments throughout the book where the information being shown is being explained.)
A thread is the entity within a process that Windows schedules for execution. Without it, the process’ program can’t run. A thread includes the following essential components:
§ The contents of a set of CPU registers representing the state of the processor.
§ Two stacks—one for the thread to use while executing in kernel mode and one for executing in user mode.
§ A private storage area called thread-local storage (TLS) for use by subsystems, run-time libraries, and DLLs.
§ A unique identifier called a thread ID (part of an internal structure called a client ID—process IDs and thread IDs are generated out of the same namespace, so they never overlap).
§ Threads sometimes have their own security context, or token, that is often used by multithreaded server applications that impersonate the security context of the clients that they serve.
The volatile registers, stacks, and private storage area are called the thread’s context. Because this information is different for each machine architecture that Windows runs on, this structure, by necessity, is architecture-specific. The Windows GetThreadContext function provides access to this architecture-specific information (called the CONTEXT block).
NOTE
The threads of a 32-bit application running on a 64-bit version of Windows will contain both 32-bit and 64-bit contexts, which Wow64 will use to switch the application from running in 32-bit to 64-bit mode when required. These threads will have two user stacks and two CONTEXT blocks, and the usual Windows API functions will return the 64-bit context instead. TheWow64GetThreadContext function, however, will return the 32-bit context. See Chapter 3 for more information on Wow64.
FIBERS AND USER-MODE SCHEDULER THREADS
Because switching execution from one thread to another involves the kernel scheduler, it can be an expensive operation, especially if two threads are often switching between each other. Windows implements two mechanisms for reducing this cost: fibers and user-mode scheduling (UMS).
Fibers allow an application to schedule its own “threads” of execution rather than rely on the priority-based scheduling mechanism built into Windows. Fibers are often called “lightweight” threads, and in terms of scheduling, they’re invisible to the kernel because they’re implemented in user mode in Kernel32.dll. To use fibers, a call is first made to the WindowsConvertThreadToFiber function. This function converts the thread to a running fiber. Afterward, the newly converted fiber can create additional fibers with the CreateFiber function. (Each fiber can have its own set of fibers.) Unlike a thread, however, a fiber doesn’t begin execution until it’s manually selected through a call to the SwitchToFiber function. The new fiber runs until it exits or until it calls SwitchToFiber, again selecting another fiber to run. For more information, see the Windows SDK documentation on fiber functions.
UMS threads, which are available only on 64-bit versions of Windows, provide the same basic advantages as fibers, without many of the disadvantages. UMS threads have their own kernel thread state and are therefore visible to the kernel, which allows multiple UMS threads to issue blocking system calls, share and contend on resources, and have per-thread state. However, as long as two or more UMS threads only need to perform work in user mode, they can periodically switch execution contexts (by yielding from one thread to another) without involving the scheduler: the context switch is done in user mode. From the kernel’s perspective, the same kernel thread is still running and nothing has changed. When a UMS thread performs an operation that requires entering the kernel (such as a system call), it switches to its dedicated kernel-mode thread (called a directed context switch). See Chapter 5 for more information on UMS.
Although threads have their own execution context, every thread within a process shares the process’ virtual address space (in addition to the rest of the resources belonging to the process), meaning that all the threads in a process have full read-write access to the process virtual address space. Threads cannot accidentally reference the address space of another process, however, unless the other process makes available part of its private address space as a shared memory section (called a file mapping object in the Windows API) or unless one process has the right to open another process to use cross-process memory functions such as ReadProcessMemory and WriteProcessMemory.
In addition to a private address space and one or more threads, each process has a security context and a list of open handles to kernel objects such as files, shared memory sections, or one of the synchronization objects such as mutexes, events, or semaphores, as illustrated in Figure 1-2.
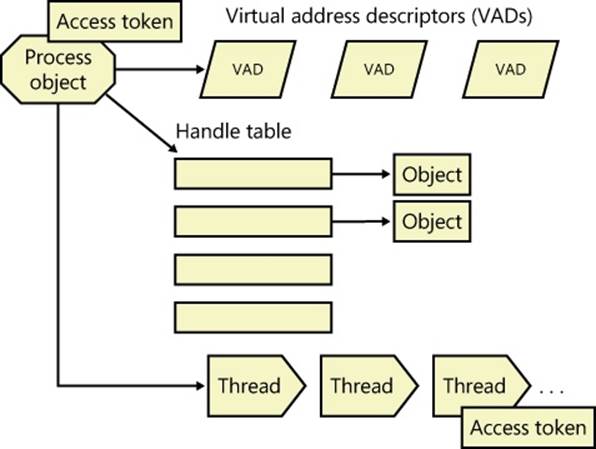
Figure 1-2. A process and its resources
Each process’ security context is stored in an object called an access token. The process access token contains the security identification and credentials for the process. By default, threads don’t have their own access token, but they can obtain one, thus allowing individual threads to impersonate the security context of another process—including processes on a remote Windows system—without affecting other threads in the process. (See Chapter 6, for more details on process and thread security.)
The virtual address descriptors (VADs) are data structures that the memory manager uses to keep track of the virtual addresses the process is using. These data structures are described in more depth in Chapter 10 in Part 2.
Windows provides an extension to the process model called a job. A job object’s main function is to allow groups of processes to be managed and manipulated as a unit. A job object allows control of certain attributes and provides limits for the process or processes associated with the job. It also records basic accounting information for all processes associated with the job and for all processes that were associated with the job but have since terminated. In some ways, the job object compensates for the lack of a structured process tree in Windows—yet in many ways it is more powerful than a UNIX-style process tree.
You’ll find out much more about the internal structure of jobs, processes, and threads; the mechanics of process and thread creation; and the thread-scheduling algorithms in Chapter 5.
Virtual Memory
Windows implements a virtual memory system based on a flat (linear) address space that provides each process with the illusion of having its own large, private address space. Virtual memory provides a logical view of memory that might not correspond to its physical layout. At run time, the memory manager, with assistance from hardware, translates, or maps, the virtual addresses into physical addresses, where the data is actually stored. By controlling the protection and mapping, the operating system can ensure that individual processes don’t bump into one another or overwrite operating system data. Figure 1-3 illustrates three virtually contiguous pages mapped to three discontiguous pages in physical memory.
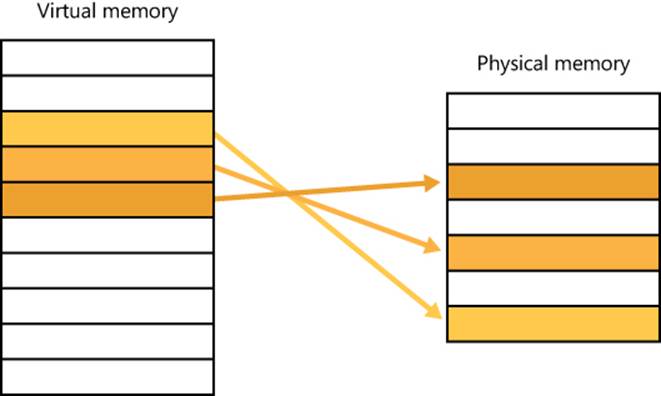
Figure 1-3. Mapping virtual memory to physical memory
Because most systems have much less physical memory than the total virtual memory in use by the running processes, the memory manager transfers, or pages, some of the memory contents to disk. Paging data to disk frees physical memory so that it can be used for other processes or for the operating system itself. When a thread accesses a virtual address that has been paged to disk, the virtual memory manager loads the information back into memory from disk. Applications don’t have to be altered in any way to take advantage of paging because hardware support enables the memory manager to page without the knowledge or assistance of processes or threads.
The size of the virtual address space varies for each hardware platform. On 32-bit x86 systems, the total virtual address space has a theoretical maximum of 4 GB. By default, Windows allocates half this address space (the lower half of the 4-GB virtual address space, from 0x00000000 through 0x7FFFFFFF) to processes for their unique private storage and uses the other half (the upper half, addresses 0x80000000 through 0xFFFFFFFF) for its own protected operating system memory utilization. The mappings of the lower half change to reflect the virtual address space of the currently executing process, but the mappings of the upper half always consist of the operating system’s virtual memory. Windows supports boot-time options (the increaseuserva qualifier in the Boot Configuration Database, described in Chapter 13, “Startup and Shutdown,” in Part 2) that give processes running specially marked programs (the large address space aware flag must be set in the header of the executable image) the ability to use up to 3 GB of private address space (leaving 1 GB for the operating system). This option allows applications such as database servers to keep larger portions of a database in the process address space, thus reducing the need to map subset views of the database. Figure 1-4 shows the two typical virtual address space layouts supported by 32-bit Windows. (Theincreaseuserva option allows anywhere from 2 to 3 GB to be used by marked applications.)
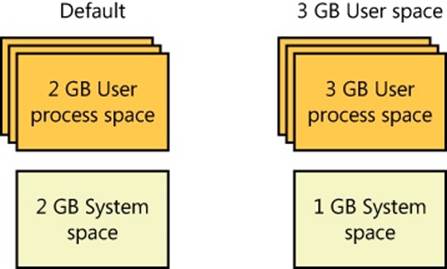
Figure 1-4. Typical address space layouts for 32-bit Windows
Although 3 GB is better than 2 GB, it’s still not enough virtual address space to map very large (multigigabyte) databases. To address this need on 32-bit systems, Windows provides a mechanism called Address Windowing Extension (AWE), which allows a 32-bit application to allocate up to 64 GB of physical memory and then map views, or windows, into its 2-GB virtual address space. Although using AWE puts the burden of managing mappings of virtual to physical memory on the programmer, it does address the need of being able to directly access more physical memory than can be mapped at any one time in a 32-bit process address space.
64-bit Windows provides a much larger address space for processes: 7152 GB on IA-64 systems and 8192 GB on x64 systems. Figure 1-5 shows a simplified view of the 64-bit system address space layouts. (For a detailed description, see Chapter 10 in Part 2.) Note that these sizes do not represent the architectural limits for these platforms. Sixty-four bits of address space is over 17 billion GB, but current 64-bit hardware limits this to smaller values. And Windows implementation limits in the current versions of 64-bit Windows further reduce this to 8192 GB (8 TB).
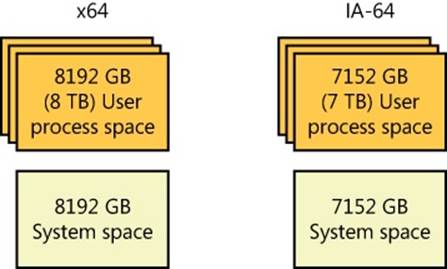
Figure 1-5. Address space layouts for 64-bit Windows
Details of the implementation of the memory manager, including how address translation works and how Windows manages physical memory, are described in Chapter 10 in Part 2.
Kernel Mode vs. User Mode
To protect user applications from accessing and/or modifying critical operating system data, Windows uses two processor access modes (even if the processor on which Windows is running supports more than two): user mode and kernel mode. User application code runs in user mode, whereas operating system code (such as system services and device drivers) runs in kernel mode. Kernel mode refers to a mode of execution in a processor that grants access to all system memory and all CPU instructions. By providing the operating system software with a higher privilege level than the application software has, the processor provides a necessary foundation for operating system designers to ensure that a misbehaving application can’t disrupt the stability of the system as a whole.
NOTE
The architectures of the x86 and x64 processors define four privilege levels (or rings) to protect system code and data from being overwritten either inadvertently or maliciously by code of lesser privilege. Windows uses privilege level 0 (or ring 0) for kernel mode and privilege level 3 (or ring 3) for user mode. The reason Windows uses only two levels is that some hardware architectures that were supported in the past (such as Compaq Alpha and Silicon Graphics MIPS) implemented only two privilege levels.
Although each Windows process has its own private memory space, the kernel-mode operating system and device driver code share a single virtual address space. Each page in virtual memory is tagged to indicate what access mode the processor must be in to read and/or write the page. Pages in system space can be accessed only from kernel mode, whereas all pages in the user address space are accessible from user mode. Read-only pages (such as those that contain static data) are not writable from any mode. Additionally, on processors that support no-execute memory protection, Windows marks pages containing data as nonexecutable, thus preventing inadvertent or malicious code execution in data areas.
32-bit Windows doesn’t provide any protection to private read/write system memory being used by components running in kernel mode. In other words, once in kernel mode, operating system and device driver code has complete access to system space memory and can bypass Windows security to access objects. Because the bulk of the Windows operating system code runs in kernel mode, it is vital that components that run in kernel mode be carefully designed and tested to ensure that they don’t violate system security or cause system instability.
This lack of protection also emphasizes the need to take care when loading a third-party device driver, because once in kernel mode the software has complete access to all operating system data. This weakness was one of the reasons behind the driver-signing mechanism introduced in Windows, which warns (and, if configured as such, blocks) the user if an attempt is made to add an unsigned Plug and Play driver. (See Chapter 8, “I/O System,” in Part 2 for more information on driver signing.) Also, a mechanism called Driver Verifier helps device driver writers to find bugs (such as buffer overruns or memory leaks) that can cause security or reliability issues. Driver Verifier is explained in Chapter 10 in Part 2.
On 64-bit versions of Windows, the Kernel Mode Code Signing (KMCS) policy dictates that any 64-bit device drivers (not just Plug and Play) must be signed with a cryptographic key assigned by one of the major code certification authorities. The user cannot explicitly force the installation of an unsigned driver, even as an administrator, but, as a one-time exception, this restriction can be disabled manually at boot time by pressing F8 and choosing the advanced boot option Disable Driver Signature Enforcement. This causes a watermark on the desktop wallpaper and certain digital rights management (DRM) features to be disabled.
As you’ll see in Chapter 2, user applications switch from user mode to kernel mode when they make a system service call. For example, a Windows ReadFile function eventually needs to call the internal Windows routine that actually handles reading data from a file. That routine, because it accesses internal system data structures, must run in kernel mode. The transition from user mode to kernel mode is accomplished by the use of a special processor instruction that causes the processor to switch to kernel mode and enter the system service dispatching code in the kernel which calls the appropriate internal function in Ntoskrnl.exe or Win32k.sys. Before returning control to the user thread, the processor mode is switched back to user mode. In this way, the operating system protects itself and its data from perusal and modification by user processes.
NOTE
A transition from user mode to kernel mode (and back) does not affect thread scheduling per se—a mode transition is not a context switch. Further details on system service dispatching are included in Chapter 3.
Thus, it’s normal for a user thread to spend part of its time executing in user mode and part in kernel mode. In fact, because the bulk of the graphics and windowing system also runs in kernel mode, graphics-intensive applications spend more of their time in kernel mode than in user mode. An easy way to test this is to run a graphics-intensive application such as Microsoft Paint or Microsoft Chess Titans and watch the time split between user mode and kernel mode using one of the performance counters listed in Table 1-2. More advanced applications can use newer technologies such as Direct2D and compositing, which perform bulk computations in user mode and send only the raw surface data to the kernel, reducing the time spent transitioning between user and kernel modes.
Table 1-2. Mode-Related Performance Counters
|
Object: Counter |
Function |
|
Processor: % Privileged Time |
Percentage of time that an individual CPU (or all CPUs) has run in kernel mode during a specified interval |
|
Processor: % User Time |
Percentage of time that an individual CPU (or all CPUs) has run in user mode during a specified interval |
|
Process: % Privileged Time |
Percentage of time that the threads in a process have run in kernel mode during a specified interval |
|
Process: % User Time |
Percentage of time that the threads in a process have run in user mode during a specified interval |
|
Thread: % Privileged Time |
Percentage of time that a thread has run in kernel mode during a specified interval |
|
Thread: % User Time |
Percentage of time that a thread has run in user mode during a specified interval |
EXPERIMENT: KERNEL MODE VS. USER MODE
You can use the Performance Monitor to see how much time your system spends executing in kernel mode vs. in user mode. Follow these steps:
1. Run the Performance Monitor by opening the Start menu and selecting All Programs /Administrative Tools/Performance Monitor. Select the Performance Monitor node under Performance/Monitoring Tools on the left-side tree.
2. Click the Add button (+) on the toolbar.
3. Expand the Processor counter section, click the % Privileged Time counter and, while holding down the Ctrl key, click the % User Time counter.
4. Click Add, and then click OK.
5. Open a command prompt, and do a directory scan of your C drive over the network by typing dir \\%computername%\c$ /s.
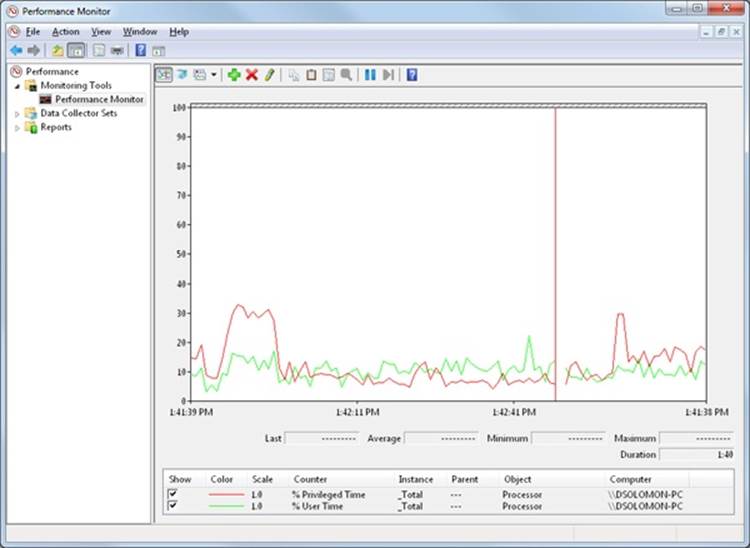
6. When you’re finished, just close the tool.
You can also quickly see this by using Task Manager. Just click the Performance tab, and then select Show Kernel Times from the View menu. The CPU usage bar will show total CPU usage in green and kernel-mode time in red.
To see how the Performance Monitor itself uses kernel time and user time, run it again, but add the individual Process counters % User Time and % Privileged Time for every process in the system:
1. If it’s not already running, run the Performance Monitor again. (If it is already running, start with a blank display by right-clicking in the graph area and selecting Remove All Counters.)
2. Click the Add button (+) on the toolbar.
3. In the available counters area, expand the Process section.
4. Select the % Privileged Time and % User Time counters.
5. Select a few processes in the Instance box (such as mmc, csrss, and Idle).
6. Click Add, and then click OK.
7. Move the mouse rapidly back and forth.
8. Press Ctrl+H to turn on highlighting mode. This highlights the currently selected counter in black.
9. Scroll through the counters at the bottom of the display to identify the processes whose threads were running when you moved the mouse, and note whether they were running in user mode or kernel mode.
You should see the Performance Monitor process (by looking in the Instance column for the mmc process) kernel-mode and user-mode time go up when you move the mouse because it is executing application code in user mode and calling Windows functions that run in kernel mode. You’ll also notice kernel-mode thread activity in a process named csrss when you move the mouse. This activity occurs because the Windows subsystem’s kernel-mode raw input thread, which handles keyboard and mouse input, is attached to this process. (See Chapter 2 for more information about system threads.) Finally, the process named Idle that you see spending nearly 100 percent of its time in kernel mode isn’t really a process—it’s a fake process used to account for idle CPU cycles. As you can observe from the mode in which the threads in the Idle process run, when Windows has nothing to do, it does it in kernel mode.
Terminal Services and Multiple Sessions
Terminal Services refers to the support in Windows for multiple interactive user sessions on a single system. With Windows Terminal Services, a remote user can establish a session on another machine, log in, and run applications on the server. The server transmits the graphical user interface to the client (as well as other configurable resources such as audio and clipboard), and the client transmits the user’s input back to the server. (Similar to the X Window System, Windows permits running individual applications on a server system with the display remoted to the client instead of remoting the entire desktop.)
The first session is considered the services session, or session zero, and contains system service hosting processes (explained in further detail in Chapter 4). The first login session at the physical console of the machine is session one, and additional sessions can be created through the use of the remote desktop connection program (Mstsc.exe) or through the use of fast user switching (described later).
Windows client editions permits a single remote user to connect to the machine, but if someone is logged in at the console, the workstation is locked (that is, someone can be using the system either locally or remotely, but not at the same time). Windows editions that include Windows Media Center allow one interactive session and up to four Windows Media Center Extender sessions.
Windows server systems support two simultaneous remote connections (to facilitate remote management—for example, use of management tools that require being logged in to the machine being managed) and more than two remote sessions if it’s appropriately licensed and configured as a terminal server.
All Windows client editions support multiple sessions created locally through a feature called fast user switching that can be used one at a time. When a user chooses to disconnect her session instead of log off (for example, by clicking Start and choosing Switch User from the Shutdown submenu or by holding down the Windows key and pressing L and then clicking the Switch User button), the current session (that is, the processes running in that session and all the sessionwide data structures that describe the session) remains active in the system and the system returns to the main logon screen. If a new user logs in, a new session is created.
For applications that want to be aware of running in a terminal server session, there are a set of Windows APIs for programmatically detecting that as well as for controlling various aspects of Terminal Services. (See the Windows SDK and the Remote Desktop Services API for details.)
Chapter 2 describes briefly how sessions are created and has some experiments showing how to view session information with various tools, including the kernel debugger. The Object Manager section in Chapter 3 describes how the system namespace for objects is instantiated on a per-session basis and how applications that need to be aware of other instances of themselves on the same system can accomplish that. Finally, Chapter 10 in Part 2 covers how the memory manager sets up and manages sessionwide data.
Objects and Handles
In the Windows operating system, a kernel object is a single, run-time instance of a statically defined object type. An object type comprises a system-defined data type, functions that operate on instances of the data type, and a set of object attributes. If you write Windows applications, you might encounter process, thread, file, and event objects, to name just a few examples. These objects are based on lower-level objects that Windows creates and manages. In Windows, a process is an instance of the process object type, a file is an instance of the file object type, and so on.
An object attribute is a field of data in an object that partially defines the object’s state. An object of type process, for example, would have attributes that include the process ID, a base scheduling priority, and a pointer to an access token object. Object methods, the means for manipulating objects, usually read or change the object attributes. For example, the open method for a process would accept a process identifier as input and return a pointer to the object as output.
NOTE
Although there is a parameter named ObjectAttributes that a caller supplies when creating an object using the kernel object manager APIs, that parameter shouldn’t be confused with the more general meaning of the term as used in this book.
The most fundamental difference between an object and an ordinary data structure is that the internal structure of an object is opaque. You must call an object service to get data out of an object or to put data into it. You can’t directly read or change data inside an object. This difference separates the underlying implementation of the object from code that merely uses it, a technique that allows object implementations to be changed easily over time.
Objects, through the help of a kernel component called the object manager, provide a convenient means for accomplishing the following four important operating system tasks:
§ Providing human-readable names for system resources
§ Sharing resources and data among processes
§ Protecting resources from unauthorized access
§ Reference tracking, which allows the system to know when an object is no longer in use so that it can be automatically deallocated
Not all data structures in the Windows operating system are objects. Only data that needs to be shared, protected, named, or made visible to user-mode programs (via system services) is placed in objects. Structures used by only one component of the operating system to implement internal functions are not objects. Objects and handles (references to an instance of an object) are discussed in more detail in Chapter 3.
Security
Windows was designed from the start to be secure and to meet the requirements of various formal government and industry security ratings, such as the Common Criteria for Information Technology Security Evaluation (CCITSE) specification. Achieving a government-approved security rating allows an operating system to compete in that arena. Of course, many of these capabilities are advantageous features for any multiuser system.
The core security capabilities of Windows include discretionary (need-to-know) and mandatory integrity protection for all shareable system objects (such as files, directories, processes, threads, and so forth), security auditing (for accountability of subjects, or users and the actions they initiate), user authentication at logon, and the prevention of one user from accessing uninitialized resources (such as free memory or disk space) that another user has deallocated.
Windows has three forms of access control over objects. The first form—discretionary access control—is the protection mechanism that most people think of when they think of operating system security. It’s the method by which owners of objects (such as files or printers) grant or deny access to others. When users log in, they are given a set of security credentials, or a security context. When they attempt to access objects, their security context is compared to the access control list on the object they are trying to access to determine whether they have permission to perform the requested operation.
Privileged access control is necessary for those times when discretionary access control isn’t enough. It’s a method of ensuring that someone can get to protected objects if the owner isn’t available. For example, if an employee leaves a company, the administrator needs a way to gain access to files that might have been accessible only to that employee. In that case, under Windows, the administrator can take ownership of the file so that he can manage its rights as necessary.
Finally, mandatory integrity control is required when an additional level of security control is required to protect objects that are being accessed from within the same user account. It’s used both to isolate Protected Mode Internet Explorer from a user’s configuration and to protect objects created by an elevated administrator account from access by a nonelevated administrator account. (See Chapter 6 for more information on User Account Control—UAC.)
Security pervades the interface of the Windows API. The Windows subsystem implements object-based security in the same way the operating system does; the Windows subsystem protects shared Windows objects from unauthorized access by placing Windows security descriptors on them. The first time an application tries to access a shared object, the Windows subsystem verifies the application’s right to do so. If the security check succeeds, the Windows subsystem allows the application to proceed.
For a comprehensive description of Windows security, see Chapter 6.
Registry
If you’ve worked at all with Windows operating systems, you’ve probably heard about or looked at the registry. You can’t talk much about Windows internals without referring to the registry because it’s the system database that contains the information required to boot and configure the system, systemwide software settings that control the operation of Windows, the security database, and per-user configuration settings (such as which screen saver to use).
In addition, the registry is a window into in-memory volatile data, such as the current hardware state of the system (what device drivers are loaded, the resources they are using, and so on) as well as the Windows performance counters. The performance counters, which aren’t actually “in” the registry, are accessed through the registry functions. See Chapter 4 for more on how performance counter information is accessed from the registry.
Although many Windows users and administrators will never need to look directly into the registry (because you can view or change most configuration settings with standard administrative utilities), it is still a useful source of Windows internals information because it contains many settings that affect system performance and behavior. (If you decide to directly change registry settings, you must exercise extreme caution; any changes might adversely affect system performance or, worse, cause the system to fail to boot successfully.) You’ll find references to individual registry keys throughout this book as they pertain to the component being described. Most registry keys referred to in this book are under the systemwide configuration, HKEY_LOCAL_MACHINE, which we’ll abbreviate throughout as HKLM.
For further information on the registry and its internal structure, see Chapter 4.
Unicode
Windows differs from most other operating systems in that most internal text strings are stored and processed as 16-bit-wide Unicode characters. Unicode is an international character set standard that defines unique 16-bit values for most of the world’s known character sets.
Because many applications deal with 8-bit (single-byte) ANSI character strings, many Windows functions that accept string parameters have two entry points: a Unicode (wide, 16-bit) version and an ANSI (narrow, 8-bit) version. If you call the narrow version of a Windows function, there is a slight performance impact as input string parameters are converted to Unicode before being processed by the system and output parameters are converted from Unicode to ANSI before being returned to the application. Thus, if you have an older service or piece of code that you need to run on Windows but this code is written using ANSI character text strings, Windows will convert the ANSI characters into Unicode for its own use. However, Windows never converts the data inside files—it’s up to the application to decide whether to store data as Unicode or as ANSI.
Regardless of language, all versions of Windows contain the same functions. Instead of having separate language versions, Windows has a single worldwide binary so that a single installation can support multiple languages (by adding various language packs). Applications can also take advantage of Windows functions that allow single worldwide application binaries that can support multiple languages.
For more information about Unicode, see www.unicode.org as well as the programming documentation in the MSDN Library.
Digging into Windows Internals
Although much of the information in this book is based on reading the Windows source code and talking to the developers, you don’t have to take everything on faith. Many details about the internals of Windows can be exposed and demonstrated by using a variety of available tools, such as those that come with Windows and the Windows debugging tools. These tool packages are briefly described later in this section.
To encourage your exploration of Windows internals, we’ve included “Experiment” sidebars throughout the book that describe steps you can take to examine a particular aspect of Windows internal behavior. (You already saw a few of these sections earlier in this chapter.) We encourage you to try these experiments so that you can see in action many of the internals topics described in this book.
Table 1-3 shows a list of the principal tools used in this book and where they come from.
Table 1-3. Tools for Viewing Windows Internals
|
Tool |
Image Name |
Origin |
|
Startup Programs Viewer |
AUTORUNS |
Sysinternals |
|
Access Check |
ACCESSCHK |
Sysinternals |
|
Dependency Walker |
DEPENDS |
www.dependencywalker.com |
|
Global Flags |
GFLAGS |
Debugging tools |
|
Handle Viewer |
HANDLE |
Sysinternals |
|
Kernel debuggers |
WINDBG, KD |
Debugging tools, Windows SDK |
|
Object Viewer |
WINOBJ |
Sysinternals |
|
Performance Monitor |
PERFMON.MSC |
Windows built-in tool |
|
Pool Monitor |
POOLMON |
Windows Driver Kit |
|
Process Explorer |
PROCEXP |
Sysinternals |
|
Process Monitor |
PROCMON |
Sysinternals |
|
Task (Process) List |
TLIST |
Debugging tools |
|
Task Manager |
TASKMGR |
Windows built-in tool |
Performance Monitor
We’ll refer to the Performance Monitor found in the Administrative Tools folder on the Start menu (or via Control Panel) throughout this book; specifically, we’ll focus on the Performance Monitor and Resource Monitor. The Performance Monitor has three functions: system monitoring, viewing performance counter logs, and setting alerts (by using data collector sets, which also contain performance counter logs and trace and configuration data). For simplicity, when we refer to the Performance Monitor, we are referring to the System Monitor function within the tool.
The Performance Monitor provides more information about how your system is operating than any other single utility. It includes hundreds of base and extensible counters for various objects. For each major topic described in this book, a table of the relevant Windows performance counters is included.
The Performance Monitor contains a brief description for each counter. To see the descriptions, select a counter in the Add Counters window and select the Show Description check box.
Although all the low-level system monitoring we’ll do in this book can be done with the Performance Monitor, Windows also includes a Resource Monitor utility (accessible from the start menu or from the Task Manager Performance tab) that shows four primary system resources: CPU, Disk, Network, and Memory. In their basic states, these resources are displayed with the same level of information that you would find in Task Manager. However, they also provide sections that can be expanded for more information.
When expanded, the CPU tab displays information about per-process CPU usage, just like Task Manager. However, it adds a column for average CPU usage, which can give you a better idea of which processes are most active. The CPU tab also includes a separate display of services and their associated CPU usage and average. Each service hosting process is identified by the service group it is hosting. As with Process Explorer, selecting a process (by clicking its associated check box) will display a list of named handles opened by the process, as well as a list of modules (such as DLLs) that are loaded in the process address space. The Search Handles box can also be used to search for which processes have opened a handle to a given named resource.
The Memory section displays much of the same information that one can obtain with Task Manager, but it is organized for the entire system. A physical memory bar graph displays the current organization of physical memory into either hardware reserved, in use, modified, standby, and free memory. See Chapter 10 in Part 2 for the exact meaning of these terms.
The Disk section, on the other hand, displays per-file information for I/Os in a way that makes it easy to identify the most accessed, written to, or read from files on the system. These results can be further filtered down by process.
The Networking section displays the active network connections and which processes own them, as well as how much data is going through them. This information makes it possible to see background network activity that might be hard to detect otherwise. In addition, the TCP connections that are active on the system are shown, organized by process, with data such as the remote and local port and address, and packet latency. Finally, a list of listening ports is displayed by process, allowing an administrator to see which services (or applications) are currently waiting for connections on a given port. The protocol and firewall policy for each port and process is also shown.
Note that all of the Windows performance counters are accessible programmatically. The section HKEY_PERFORMANCE_DATA in Chapter 4 has a brief description of the components involved in retrieving performance counters through the Windows API.
Kernel Debugging
Kernel debugging means examining internal kernel data structures and/or stepping through functions in the kernel. It is a useful way to investigate Windows internals because you can display internal system information not available through any other tools and get a clearer idea of code flows within the kernel.
Before describing the various ways you can debug the kernel, let’s examine a set of files that you’ll need in order to perform any type of kernel debugging.
Symbols for Kernel Debugging
Symbol files contain the names of functions and variables and the layout and format of data structures. They are generated by the linker and used by debuggers to reference and display these names during a debug session. This information is not usually stored in the binary image because it is not needed to execute the code. This means that binaries are smaller and faster. However, this means that when debugging, you must make sure that the debugger can access the symbol files that are associated with the images you are referencing during a debugging session.
To use any of the kernel debugging tools to examine internal Windows kernel data structures (such as the process list, thread blocks, loaded driver list, memory usage information, and so on), you must have the correct symbol files for at least the kernel image, Ntoskrnl.exe. (The section Architecture Overview in Chapter 2 explains more about this file.) Symbol table files must match the version of the image they were taken from. For example, if you install a Windows Service Pack or hot fix that updates the kernel, you must obtain the matching, updated symbol files.
While it is possible to download and install symbols for various versions of Windows, updated symbols for hot fixes are not always available. The easiest solution to obtain the correct version of symbols for debugging is to use the Microsoft on-demand symbol server by using a special syntax for the symbol path that you specify in the debugger. For example, the following symbol path causes the debugging tools to load required symbols from the Internet symbol server and keep a local copy in the c:\symbols folder:
srv*c:\symbols*http://msdl.microsoft.com/download/symbols
For detailed instructions on how to use the symbol server, see the debugging tools help file or the Web page http://msdn.microsoft.com/en-us/windows/hardware/gg462988.aspx.
Debugging Tools for Windows
The Debugging Tools for Windows package contains advanced debugging tools used in this book to explore Windows internals. The latest version is included as part of the Windows Software Development Kit (SDK). These tools can be used to debug user-mode processes as well as the kernel. (See the following sidebar.)
NOTE
The Debugging Tools for Windows are updated frequently and released independently of Windows operating system versions, so check often for new versions.
USER-MODE DEBUGGING
The debugging tools can also be used to attach to a user-mode process and examine and/or change process memory. There are two options when attaching to a process:
§ Invasive. Unless specified otherwise, when you attach to a running process, the DebugActiveProcess Windows function is used to establish a connection between the debugger and the debugee. This permits examining and/or changing process memory, setting breakpoints, and performing other debugging functions. Windows allows you to stop debugging without killing the target process, as long as the debugger is detached, not killed.
§ Noninvasive. With this option, the debugger simply opens the process with the OpenProcess function. It does not attach to the process as a debugger. This allows you to examine and/or change memory in the target process, but you cannot set breakpoints.
You can also open user-mode process dump files with the debugging tools. User-mode dump files are explained in Chapter 3 in the section on exception dispatching.
There are two debuggers that can be used for kernel debugging: a command-line version (Kd.exe) and a graphical user interface (GUI) version (Windbg.exe). Both provide the same set of commands, so which one you choose is a matter of personal preference. You can perform three types of kernel debugging with these tools:
§ Open a crash dump file created as a result of a Windows system crash. (See Chapter 14, “Crash Dump Analysis,” in Part 2 for more information on kernel crash dumps.)
§ Connect to a live, running system and examine the system state (or set breakpoints if you’re debugging device driver code). This operation requires two computers—a target and a host. The target is the system being debugged, and the host is the system running the debugger. The target system can be connected to the host via a null modem cable, an IEEE 1394 cable, or a USB 2.0 debugging cable. The target system must be booted in debugging mode (either by pressing F8 during the boot process and selecting Debugging Mode or by configuring the system to boot in debugging mode using Bcdedit or Msconfig.exe). You can also connect through a named pipe, which is useful when debugging through a virtual machine product such as Hyper-V, Virtual PC, or VMWare, by exposing the guest operating system’s serial port as a named pipe device.
§ Windows systems also allow you to connect to the local system and examine the system state. This is called local kernel debugging. To initiate local kernel debugging with WinDbg, open the File menu, choose Kernel Debug, click on the Local tab, and then click OK. The target system must be booted in debugging mode. An example output screen is shown in Figure 1-6. Some kernel debugger commands do not work when used in local kernel debugging mode (such as creating a memory dump with the .dump command—however, this can be done with LiveKd, described later in this section).
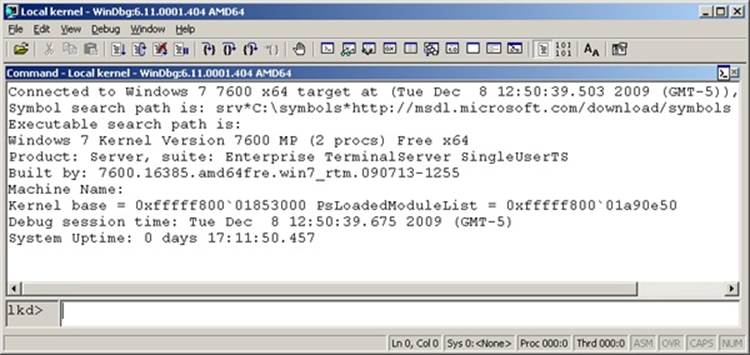
Figure 1-6. Local kernel debugging
Once connected in kernel debugging mode, you can use one of the many debugger extension commands (commands that begin with “!”) to display the contents of internal data structures such as threads, processes, I/O request packets, and memory management information. Throughout this book, the relevant kernel debugger commands and output are included as they apply to each topic being discussed. An excellent companion reference is the Debugger.chm help file, contained in the WinDbg installation folder, which documents all the kernel debugger functionality and extensions. In addition, the dt (display type) command can format over 1000 kernel structures because the kernel symbol files for Windows contain type information that the debugger can use to format structures.
EXPERIMENT: DISPLAYING TYPE INFORMATION FOR KERNEL STRUCTURES
To display the list of kernel structures whose type information is included in the kernel symbols, type dt nt!_* in the kernel debugger. A sample partial output is shown here:
lkd> dt nt!_*
nt!_LIST_ENTRY
nt!_LIST_ENTRY
nt!_IMAGE_NT_HEADERS
nt!_IMAGE_FILE_HEADER
nt!_IMAGE_OPTIONAL_HEADER
nt!_IMAGE_NT_HEADERS
nt!_LARGE_INTEGER
You can also use the dt command to search for specific structures by using its wildcard lookup capability. For example, if you were looking for the structure name for an interrupt object, type dt nt!_*interrupt*:
lkd> dt nt!_*interrupt*
nt!_KINTERRUPT
nt!_KINTERRUPT_MODE
nt!_KINTERRUPT_POLARITY
nt!_UNEXPECTED_INTERRUPT
Then you can use dt to format a specific structure as shown next:
lkd> dt nt!_kinterrupt
nt!_KINTERRUPT
+0x000 Type : Int2B
+0x002 Size : Int2B
+0x008 InterruptListEntry : _LIST_ENTRY
+0x018 ServiceRoutine : Ptr64 unsigned char
+0x020 MessageServiceRoutine : Ptr64 unsigned char
+0x028 MessageIndex : Uint4B
+0x030 ServiceContext : Ptr64 Void
+0x038 SpinLock : Uint8B
+0x040 TickCount : Uint4B
+0x048 ActualLock : Ptr64 Uint8B
+0x050 DispatchAddress : Ptr64 void
+0x058 Vector : Uint4B
+0x05c Irql : UChar
+0x05d SynchronizeIrql : UChar
+0x05e FloatingSave : UChar
+0x05f Connected : UChar
+0x060 Number : Uint4B
+0x064 ShareVector : UChar
+0x065 Pad : [3] Char
+0x068 Mode : _KINTERRUPT_MODE
+0x06c Polarity : _KINTERRUPT_POLARITY
+0x070 ServiceCount : Uint4B
+0x074 DispatchCount : Uint4B
+0x078 Rsvd1 : Uint8B
+0x080 TrapFrame : Ptr64 _KTRAP_FRAME
+0x088 Reserved : Ptr64 Void
+0x090 DispatchCode : [4] Uint4B
Note that dt does not show substructures (structures within structures) by default. To recurse through substructures, use the –r switch. For example, using this switch to display the kernel interrupt object shows the format of the _LIST_ENTRY structure stored at the InterruptListEntry field:
lkd> dt nt!_kinterrupt -r
nt!_KINTERRUPT
+0x000 Type : Int2B
+0x002 Size : Int2B
+0x008 InterruptListEntry : _LIST_ENTRY
+0x000 Flink : Ptr64 _LIST_ENTRY
+0x000 Flink : Ptr64 _LIST_ENTRY
+0x008 Blink : Ptr64 _LIST_ENTRY
+0x008 Blink : Ptr64 _LIST_ENTRY
+0x000 Flink : Ptr64 _LIST_ENTRY
+0x008 Blink : Ptr64 _LIST_ENTRY
The Debugging Tools for Windows help file also explains how to set up and use the kernel debuggers. Additional details on using the kernel debuggers that are aimed primarily at device driver writers can be found in the Windows Driver Kit documentation.
LiveKd Tool
LiveKd is a free tool from Sysinternals that allows you to use the standard Microsoft kernel debuggers just described to examine the running system without booting the system in debugging mode. This approach might be useful when kernel-level troubleshooting is required on a machine that wasn’t booted in debugging mode—certain issues might be hard to reproduce reliably, so a reboot with the debug option enabled might not readily exhibit the error.
You run LiveKd just as you would WinDbg or Kd. LiveKd passes any command-line options you specify to the debugger you select. By default, LiveKd runs the command-line kernel debugger (Kd). To have it run WinDbg, specify the –w switch. To see the help files for LiveKd switches, specify the –? switch.
LiveKd presents a simulated crash dump file to the debugger, so you can perform any operations in LiveKd that are supported on a crash dump. Because LiveKd is relying on physical memory to back the simulated dump, the kernel debugger might run into situations in which data structures are in the middle of being changed by the system and are inconsistent. Each time the debugger is launched, it starts with a fresh view of the system state. If you want to refresh the snapshot, quit the debugger (with the q command), and LiveKd will ask you whether you want to start it again. If the debugger enters a loop in printing output, press Ctrl+C to interrupt the output and quit. If it hangs, press Ctrl+Break, which will terminate the debugger process. LiveKd will then ask you whether you want to run the debugger again.
Windows Software Development Kit
The Windows Software Development Kit (SDK) is available as part of the MSDN subscription program or can be downloaded for free from msdn.microsoft.com. Besides the Debugging Tools, it contains the documentation, C header files, and libraries necessary to compile and link Windows applications. (Although Microsoft Visual C++ comes with a copy of these header files, the versions contained in the Windows SDK always match the latest version of the Windows operating systems, whereas the version that comes with Visual C++ might be an older version that was current when Visual C++ was released.) From an internals perspective, items of interest in the Windows SDK include the Windows API header files (\Program Files\Microsoft SDKs\Windows\v7.0A\Include). A few of these tools are also shipped as sample source code in both the Windows SDK and the MSDN Library.
Windows Driver Kit
The Windows Driver Kit (WDK) is also available through the MSDN subscription program, and just like the Windows SDK, it is available for free download. The Windows Driver Kit documentation is included in the MSDN Library.
Although the WDK is aimed at device driver developers, it is an abundant source of Windows internals information. For example, while Chapter 8 in Part 2 describes the I/O system architecture, driver model, and basic device driver data structures, it does not describe the individual kernel support functions in detail. The WDK documentation contains a comprehensive description of all the Windows kernel support functions and mechanisms used by device drivers in both a tutorial and reference form.
Besides including the documentation, the WDK contains header files (in particular, ntddk.h, ntifs.h, and wdm.h) that define key internal data structures and constants as well as interfaces to many internal system routines. These files are useful when exploring Windows internal data structures with the kernel debugger because although the general layout and content of these structures are shown in this book, detailed field-level descriptions (such as size and data types) are not. A number of these data structures (such as object dispatcher headers, wait blocks, events, mutants, semaphores, and so on) are, however, fully described in the WDK.
So if you want to dig into the I/O system and driver model beyond what is presented in this book, read the WDK documentation (especially the Kernel-Mode Driver Architecture Design Guide and Reference manuals). You might also find useful Programming the Microsoft Windows Driver Model, Second Edition by Walter Oney (Microsoft Press, 2002) and Developing Drivers with the Windows Driver Foundation by Penny Orwick and Guy Smith (Microsoft Press, 2007).
Sysinternals Tools
Many experiments in this book use freeware tools that you can download from Sysinternals. Mark Russinovich, coauthor of this book, wrote most of these tools. The most popular tools include Process Explorer and Process Monitor. Note that many of these utilities involve the installation and execution of kernel-mode device drivers and thus require (elevated) administrator privileges, though they can run with limited functionality and output in a standard (or nonelevated) user account.
Since the Sysinternals tools are updated frequently, it is best to make sure you have the latest version. To be notified of tool updates, you can follow the Sysinternals Site Blog (which has an RSS feed).
For a description of all the tools, a description of how to use them, and case studies of problems solved, see Windows Sysinternals Administrator’s Reference (Microsoft Press, 2011) by Mark Russinovich and Aaron Margosis.
For questions and discussions on the tools, use the Sysinternals Forums.
Conclusion
In this chapter, you’ve been introduced to the key Windows technical concepts and terms that will be used throughout the book. You’ve also had a glimpse of the many useful tools available for digging into Windows internals. Now we’re ready to begin our exploration of the internal design of the system, beginning with an overall view of the system architecture and its key components.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.