Windows Internals, Sixth Edition, Part 2 (2012)
Chapter 12. File Systems
In this chapter, we present an overview of the file system formats supported by Windows. We then describe the types of file system drivers and their basic operation, including how they interact with other system components, such as the memory manager and the cache manager. Following that is a description of how to use Process Monitor from Windows Sysinternals (at http://www.microsoft.com/technet/sysinternals) to troubleshoot a wide variety of file system access problems.
In the balance of the chapter, we first describe the Common Log File System (CLFS), a transactional logging virtual file system implemented on the native Windows file system format, NTFS. Then we focus on the on-disk layout of NTFS and its advanced features, such as compression, recoverability, quotas, symbolic links, transactions (which use the services provided by CLFS), and encryption.
To fully understand this chapter, you should be familiar with the terminology introduced in Chapter 9, including the terms volume and partition. You’ll also need to be acquainted with these additional terms:
§ Sectors are hardware-addressable blocks on a storage medium. Hard disks usually define a 512-byte sector size, but they are moving to 4,096-byte sectors. (See Chapter 9.) Thus, if the sector size is 512 bytes and the operating system wants to modify the 632nd byte on a disk, it must write a 512-byte block of data to the second sector on the disk.
§ File system formats define the way that file data is stored on storage media, and they affect a file system’s features. For example, a format that doesn’t allow user permissions to be associated with files and directories can’t support security. A file system format can also impose limits on the sizes of files and storage devices that the file system supports. Finally, some file system formats efficiently implement support for either large or small files or for large or small disks. NTFS and exFAT are examples of file system formats that offer a different set of features and usage scenarios.
§ Clusters are the addressable blocks that many file system formats use. Cluster size is always a multiple of the sector size, as shown in Figure 12-1. File system formats use clusters to manage disk space more efficiently; a cluster size that is larger than the sector size divides a disk into more manageable blocks. The potential trade-off of a larger cluster size is wasted disk space, or internal fragmentation, that results when file sizes aren’t exact multiples of the cluster size.
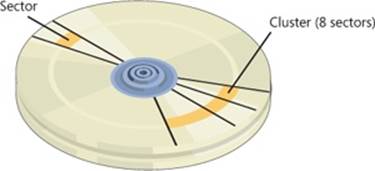
Figure 12-1. Sectors and a cluster on a disk
§ Metadata is data stored on a volume in support of file system format management. It isn’t typically made accessible to applications. Metadata includes the data that defines the placement of files and directories on a volume, for example.
Windows File System Formats
Windows includes support for the following file system formats:
§ CDFS
§ UDF
§ FAT12, FAT16, and FAT32
§ exFAT
§ NTFS
Each of these formats is best suited for certain environments, as you’ll see in the following sections.
CDFS
CDFS (%SystemRoot%\System32\Drivers\Cdfs.sys), or CD-ROM file system, is a read-only file system driver that supports a superset of the ISO-9660 format as well as a superset of the Joliet disk format. While the ISO-9660 format is relatively simple and has limitations such as ASCII uppercase names with a maximum length of 32 characters, Joliet is more flexible and supports Unicode names of arbitrary length. If structures for both formats are present on a disk (to offer maximum compatibility), CDFS uses the Joliet format. CDFS has a couple of restrictions:
§ A maximum file size of 4 GB
§ A maximum of 65,535 directories
CDFS is considered a legacy format because the industry has adopted the Universal Disk Format (UDF) as the standard for optical media.
UDF
The Windows UDF file system implementation is OSTA (Optical Storage Technology Association) UDF-compliant. (UDF is a subset of the ISO-13346 format with extensions for formats such as CD-R and DVD-R/RW.) OSTA defined UDF in 1995 as a format to replace the ISO-9660 format for magneto-optical storage media, mainly DVD-ROM. UDF is included in the DVD specification and is more flexible than CDFS. The UDF file system format has the following traits:
§ Directory and file names can be 254 ASCII or 127 Unicode characters long.
§ Files can be sparse. (Sparse files are defined later in this chapter.)
§ File sizes are specified with 64 bits.
§ Support for access control lists (ACLs).
§ Support for alternate data streams.
The UDF driver supports UDF versions up to 2.60. The UDF format was designed with rewritable media in mind. The Windows UDF driver (%SystemRoot%\System32\Drivers\Udfs.sys) provides read-write support for Blu-ray, DVD-RAM, CD-R/RW, and DVD+-R/RW drives when using UDF 2.50 and read-only support when using UDF 2.60. However, Windows does not implement support for certain UDF features such as named streams and access control lists.
FAT12, FAT16, and FAT32
Windows supports the FAT file system primarily for compatibility with other operating systems in multiboot systems, and as a format for flash drives or memory cards. The Windows FAT file system driver is implemented in %SystemRoot%\System32\Drivers\Fastfat.sys.
The name of each FAT format includes a number that indicates the number of bits that the particular format uses to identify clusters on a disk. FAT12’s 12-bit cluster identifier limits a partition to storing a maximum of 212 (4,096) clusters. Windows permits cluster sizes from 512 bytes to 8 KB, which limits a FAT12 volume size to 32 MB.
NOTE
All FAT file system types reserve the first two clusters and the last 16 clusters of a volume, so the number of usable clusters for a FAT12 volume, for instance, is slightly less than 4,096.
FAT16, with a 16-bit cluster identifier, can address 216 (65,536) clusters. On Windows, FAT16 cluster sizes range from 512 bytes (the sector size) to 64 KB (on disks with a 512-byte sector size), which limits FAT16 volume sizes to 4 GB. Disks with a sector size of 4,096 bytes allow for clusters of 256 KB. The cluster size Windows uses depends on the size of a volume. The various sizes are listed in Table 12-1. If you format a volume that is less than 16 MB as FAT by using the format command or the Disk Management snap-in, Windows uses the FAT12 format instead of FAT16.
Table 12-1. Default FAT16 Cluster Sizes in Windows
|
Volume Size |
Default Cluster Size |
|
<8 MB |
Not supported |
|
8 MB–32 MB |
512 bytes |
|
32 MB–64 MB |
1 KB |
|
64 MB–128 MB |
2 KB |
|
128 MB–256 MB |
4 KB |
|
256 MB–512 MB |
8 KB |
|
512 MB–1,024 MB |
16 KB |
|
1 GB–2 GB |
32 KB |
|
2 GB–4 GB |
64 KB |
|
>16 GB |
Not supported |
A FAT volume is divided into several regions, which are shown in Figure 12-2. The file allocation table, which gives the FAT file system format its name, has one entry for each cluster on a volume. Because the file allocation table is critical to the successful interpretation of a volume’s contents, the FAT format maintains two copies of the table so that if a file system driver or consistency-checking program (such as Chkdsk) can’t access one (because of a bad disk sector, for example), it can read from the other.

Figure 12-2. FAT format organization
Entries in the file allocation table define file-allocation chains (shown in Figure 12-3) for files and directories, where the links in the chain are indexes to the next cluster of a file’s data. A file’s directory entry stores the starting cluster of the file. The last entry of the file’s allocation chain is the reserved value of 0xFFFF for FAT16 and 0xFFF for FAT12. The FAT entries for unused clusters have a value of 0. You can see in Figure 12-3 that FILE1 is assigned clusters 2, 3, and 4; FILE2 is fragmented and uses clusters 5, 6, and 8; and FILE3 uses only cluster 7. Reading a file from a FAT volume can involve reading large portions of a file allocation table to traverse the file’s allocation chains.
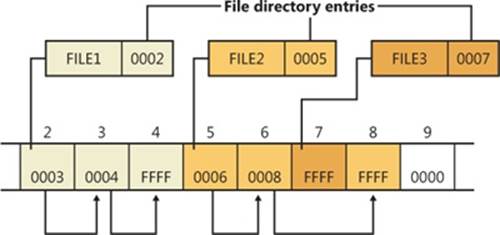
Figure 12-3. Sample FAT file-allocation chains
The root directory of FAT12 and FAT16 volumes is preassigned enough space at the start of a volume to store 256 directory entries, which places an upper limit on the number of files and directories that can be stored in the root directory. (There’s no preassigned space or size limit on FAT32 root directories.) A FAT directory entry is 32 bytes and stores a file’s name, size, starting cluster, and time stamp (last-accessed, created, and so on) information. If a file has a name that is Unicode or that doesn’t follow the MS-DOS 8.3 naming convention, additional directory entries are allocated to store the long file name. The supplementary entries precede the file’s main entry. Figure 12-4 shows a sample directory entry for a file named “The quick brown fox.” The system has created a THEQUI~1.FOX 8.3 representation of the name (that is, you don’t see a “.” in the directory entry because it is assumed to come after the eighth character) and used two more directory entries to store the Unicode long file name. Each row in the figure is made up of 16 bytes.
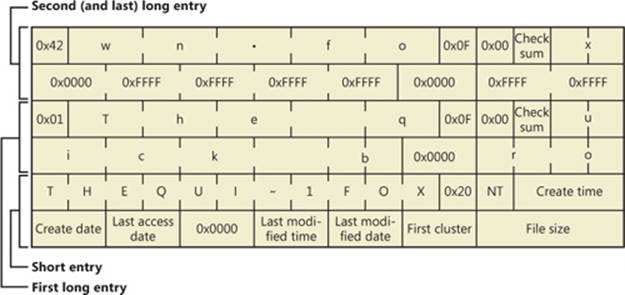
Figure 12-4. FAT directory entry
FAT32 uses 32-bit cluster identifiers but reserves the high 4 bits, so in effect it has 28-bit cluster identifiers. Because FAT32 cluster sizes can be as large as 64 KB, FAT32 has a theoretical ability to address 16-terabyte (TB) volumes. Although Windows works with existing FAT32 volumes of larger sizes (created in other operating systems), it limits new FAT32 volumes to a maximum of 32 GB. FAT32’s higher potential cluster numbers let it manage disks more efficiently than FAT16; it can handle up to 128-GB volumes with 512-byte clusters. Table 12-2shows default cluster sizes for FAT32 volumes.
Table 12-2. Default Cluster Sizes for FAT32 Volumes
|
Partition Size |
Default Cluster Size |
|
<32 MB |
Not supported |
|
32 MB–64 MB |
512 bytes |
|
64 MB–128 MB |
1 KB |
|
128 MB–256 MB |
2 KB |
|
256 MB–8 GB |
4 KB |
|
8 GB–16 GB |
8 KB |
|
16 GB–32 GB |
16 KB |
|
>32 GB |
Not supported |
Besides the higher limit on cluster numbers, other advantages FAT32 has over FAT12 and FAT16 include the fact that the FAT32 root directory isn’t stored at a predefined location on the volume, the root directory doesn’t have an upper limit on its size, and FAT32 stores a second copy of the boot sector for reliability. A limitation FAT32 shares with FAT16 is that the maximum file size is 4 GB because directories store file sizes as 32-bit values.
exFAT
Designed by Microsoft, the Extended File Allocation Table file system (exFAT, also called FAT64) is an improvement over the traditional FAT file systems and is specifically designed for flash drives. The main goal of exFAT is to provide some of the advanced functionality offered by NTFS, but without the metadata structure overhead and metadata logging that create write patterns not suited for many flash media devices. (See the description of flash media in Chapter 9). Table 12-3 lists the default cluster sizes for exFAT.
As the FAT64 name implies, the file size limit is increased to 264, allowing files up to 16 exabytes. This change is also matched by an increase in the maximum cluster size, which is currently implemented as 32 MB but can be as large as 2255 sectors. exFAT also adds a bitmap that tracks free clusters, which improves the performance of allocation and deletion operations. Finally, exFAT allows more than 1,000 files in a single directory. These characteristics result in increased scalability and support for large disk sizes.
Table 12-3. Default Cluster Sizes for exFAT Volumes
|
Volume Size |
Default Cluster Size |
|
<7 MB |
Not supported |
|
7 MB–256 MB |
4 KB |
|
256 MB–32 GB |
32 KB |
|
32 GB–256 TB |
128 KB |
|
>256 TB |
Not supported |
Additionally, exFAT implements certain features previously available only in NTFS, such as support for access control lists (ACLs) and transactions (called Transaction-Safe FAT, or TFAT). While the Windows Embedded CE implementation of exFAT includes these features, the version of exFAT in Windows does not.
NOTE
ReadyBoost (described in Chapter 10) can work with exFAT-formatted flash drives to support cache files much larger than 4 GB.
NTFS
As noted at the beginning of the chapter, the NTFS file system is the native file system format of Windows. NTFS uses 64-bit cluster numbers. This capacity gives NTFS the ability to address volumes of up to 16 exaclusters; however, Windows limits the size of an NTFS volume to that addressable with 32-bit clusters, which is slightly less than 256 TB (using 64-KB clusters). Table 12-4 shows the default cluster sizes for NTFS volumes. (You can override the default when you format an NTFS volume.) NTFS also supports 232–1 files per volume. The NTFS format allows for files that are 16 exabytes in size, but the implementation limits the maximum file size to 16 TB.
Table 12-4. Default Cluster Sizes for NTFS Volumes
|
Volume Size |
Default Cluster Size |
|
<7 MB |
Not supported |
|
7 MB–16 TB |
4 KB |
|
16 TB–32 TB |
8 KB |
|
32 TB–64 TB |
16 KB |
|
64 TB–128 TB |
32 KB |
|
128 TB–256 TB |
64 KB |
NTFS includes a number of advanced features, such as file and directory security, alternate data streams, disk quotas, sparse files, file compression, symbolic (soft) and hard links, support for transactional semantics, junction points, and encryption. One of its most significant features is recoverability. If a system is halted unexpectedly, the metadata of a FAT volume can be left in an inconsistent state, leading to the corruption of large amounts of file and directory data. NTFS logs changes to metadata in a transactional manner so that file system structures can be repaired to a consistent state with no loss of file or directory structure information. (File data can be lost unless the user is using TxF, which is covered later in this chapter.) Additionally, the NTFS driver in Windows also implements self-healing, a mechanism through which it makes most minor repairs to corruption of file system on-disk structures while Windows is running and without requiring a reboot.
We’ll describe NTFS data structures and advanced features in detail later in this chapter.
File System Driver Architecture
File system drivers (FSDs) manage file system formats. Although FSDs run in kernel mode, they differ in a number of ways from standard kernel-mode drivers. Perhaps most significant, they must register as an FSD with the I/O manager and they interact more extensively with thememory manager. For enhanced performance, file system drivers also usually rely on the services of the cache manager. Thus, they use a superset of the exported Ntoskrnl.exe functions that standard drivers use. Just as for standard kernel-mode drivers, you must have the Windows Driver Kit (WDK) to build file system drivers. (See Chapter 1, “Concepts and Tools,” in Part 1 and http://www.microsoft.com/whdc/devtools/wdk for more information on the WDK.)
Windows has two different types of file system drivers:
§ Local FSDs manage volumes directly connected to the computer.
§ Network FSDs allow users to access data volumes connected to remote computers.
Local FSDs
Local FSDs include Ntfs.sys, Fastfat.sys, Exfat.sys, Udfs.sys, Cdfs.sys, and the RAW FSD (integrated in Ntoskrnl.exe). Figure 12-5 shows a simplified view of how local FSDs interact with the I/O manager and storage device drivers. As we described in the section Volume Mountingin Chapter 9, a local FSD is responsible for registering with the I/O manager. Once the FSD is registered, the I/O manager can call on it to perform volume recognition when applications or the system initially access the volumes. Volume recognition involves an examination of a volume’s boot sector and often, as a consistency check, the file system metadata. If none of the registered file systems recognizes the volume, the system assigns the RAW file system driver to the volume and then displays a dialog box to the user asking if the volume should be formatted. If the user chooses not to format the volume, the RAW file system driver provides access to the volume, but only at the sector level—in other words, the user can only read or write complete sectors.
The goal of file system recognition is to allow the system to have an additional option for a valid but unrecognized file system other than RAW. To achieve this, the system defines a fixed data structure type (FILE_SYSTEM_RECOGNITION_STRUCTURE) that is written to the first sector on the volume. This data structure, if present, would then be recognized by the operating system, which would then notify the user that the volume contains a valid but unrecognized file system. The system will still load the RAW file system on the volume, but it will not prompt the user to format the volume. A user application or kernel-mode driver might ask for a copy of the FILE_SYSTEM_RECOGNITION_STRUCTURE by using the new file system I/O control code FSCTL_QUERY_FILE_SYSTEM_RECOGNITION.
The first sector of every Windows-supported file system format is reserved as the volume’s boot sector. A boot sector contains enough information so that a local FSD can both identify the volume on which the sector resides as containing a format that the FSD manages and locate any other metadata necessary to identify where metadata is stored on the volume.
When a local FSD recognizes a volume, it creates a device object that represents the mounted file system format. The I/O manager makes a connection through the volume parameter block (VPB) between the volume’s device object (which is created by a storage device driver) and the device object that the FSD created. The VPB’s connection results in the I/O manager redirecting I/O requests targeted at the volume device object to the FSD device object. (See Chapter 9 for more information on VPBs.)
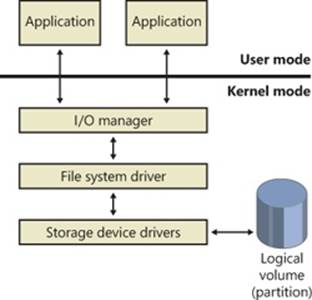
Figure 12-5. Local FSD
To improve performance, local FSDs usually use the cache manager to cache file system data, including metadata. (For more information, see Chapter 11.) FSDs also integrate with the memory manager so that mapped files are implemented correctly. For example, FSDs must query the memory manager whenever an application attempts to truncate a file in order to verify that no processes have mapped the part of the file beyond the truncation point. (See Chapter 10 for more information on the memory manager.) Windows doesn’t permit file data that is mapped by an application to be deleted either through truncation or file deletion.
Local FSDs also support file system dismount operations, which permit the system to disconnect the FSD from the volume object. A dismount occurs whenever an application requires raw access to the on-disk contents of a volume or the media associated with a volume is changed. The first time an application accesses the media after a dismount, the I/O manager reinitiates a volume mount operation for the media.
Remote FSDs
Each remote FSD consists of two components: a client and a server. A client-side remote FSD allows applications to access remote files and directories. The client FSD component accepts I/O requests from applications and translates them into network file system protocol commands (such as SMB) that the FSD sends across the network to a server-side component, which is a remote FSD. A server-side FSD listens for commands coming from a network connection and fulfills them by issuing I/O requests to the local FSD that manages the volume on which the file or directory that the command is intended for resides.
Windows includes a client-side remote FSD named LANMan Redirector (usually referred to as just the redirector) and a server-side remote FSD named LANMan Server (%SystemRoot%\System32\Drivers\Srv2.sys). Figure 12-6 shows the relationship between a client accessing files remotely from a server through the redirector and server FSDs. See Chapter 7, “Networking,” in Part 1 for more information on the redirectors and RDBSS.
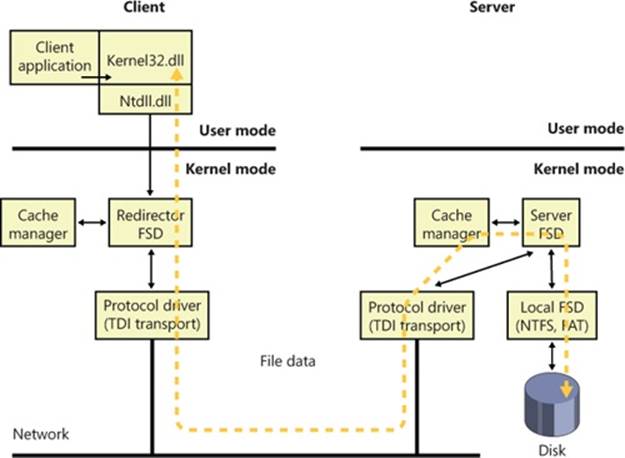
Figure 12-6. Common Internet File System file sharing
Windows relies on the Common Internet File System (CIFS) protocol to format messages exchanged between the redirector and the server.l CIFS is a version of Microsoft’s Server Message Block (SMB) protocol. (For more information on SMB, go to http://msdn.microsoft.com/en-us/library/windows/desktop/aa365233(v=vs.85).aspx.)
Like local FSDs, client-side remote FSDs usually use cache manager services to locally cache file data belonging to remote files and directories, and in such cases both must implement a distributed locking mechanism on the client as well as the server. SMB client-side remote FSDs implement a distributed cache coherency protocol, called oplock (opportunistic locking), so that the data an application sees when it accesses a remote file is the same as the data applications running on other computers that are accessing the same file see. Third-party file systems may choose to use the oplock protocol, or they may implement their own protocol. Although server-side remote FSDs participate in maintaining cache coherency across their clients, they don’t cache data from the local FSDs because local FSDs cache their own data.
Locking
It is fundamental that whenever a resource can be shared between multiple, simultaneous accessors, a serialization mechanism must be provided to arbitrate writes to that resource to ensure that only one accessor is writing to the resource at any given time. Without this mechanism, the resource may be corrupted. The locking mechanisms used by all file servers implementing the SMB protocol are the oplock and the lease. Which mechanism is used depends on the capabilities of both the server and the client, with the lease being the preferred mechanism.
Oplocks The oplock functionality is implemented in the file system run-time library (FsRtlXxx functions) and may be used by any file system driver. The client of a remote file server uses an oplock to dynamically determine which client-side caching strategy to use to minimize network traffic. An oplock is requested on a file residing on a share, by the file system driver or redirector, on behalf of an application when it attempts to open a file. The granting of an oplock allows the client to cache the file rather than send every read or write to the file server across the network. For example, a client could open a file for exclusive access, allowing the client to cache all reads and writes to the file, and then copy the updates to the file server when the file is closed. In contrast, if the server does not grant an oplock to a client, all reads and writes must be sent to the server.
Once an oplock has been granted, a client may then start caching the file, with the type of oplock determining what type of caching is allowed. An oplock is not necessarily held until a client is finished with the file, and it may be broken at any time if the server receives an operation that is incompatible with the existing granted locks. This implies that the client must be able to quickly react to the break of the oplock and change its caching strategy dynamically.
Prior to SMB 2.1, there were four types of oplocks:
§ Level 1, exclusive access This lock allows a client to open a file for exclusive access. The client may perform read-ahead buffering and read or write caching.
§ Level 2, shared access This lock allows multiple, simultaneous readers of a file and no writers. The client may perform read-ahead buffering and read caching of file data and attributes. A write to the file will cause the holders of the lock to be notified that the lock has been broken.
§ Batch, exclusive access This lock takes its name from the locking used when processing batch (.bat) files, which are opened and closed to process each line within the file. The client may keep a file open on the server, even though the application has (perhaps temporarily) closed the file. This lock supports read, write, and handle caching.
§ Filter, exclusive access This lock provides applications and file system filters with a mechanism to give up the lock when other clients try to access the same file, but unlike a Level 2 lock, the file cannot be opened for delete access, and the other client will not receive a sharing violation. This lock supports read and write caching.
In the simplest terms, if multiple client systems are all caching the same file shared by a server, then as long as every application accessing the file (from any client or the server) tries only to read the file, those reads can be satisfied from each system’s local cache. This drastically reduces the network traffic because the contents of the file are not sent to each system from the server. Locking information must still be exchanged between the client systems and the server, but this requires very low network bandwidth. However, if even one of the clients opens the file for read and write access (or exclusive write), then none of the clients can use their local caches and all I/O to the file must go immediately to the server, even if the file is never written. (Lock modes are based upon how the file is opened, not individual I/O requests.)
An example, shown in Figure 12-7, will help illustrate oplock operation. The server automatically grants a Level 1 oplock to the first client to open a server file for access. The redirector on the client caches the file data for both reads and writes in the file cache of the client machine. If a second client opens the file, it too requests a Level 1 oplock. However, because there are now two clients accessing the same file, the server must take steps to present a consistent view of the file’s data to both clients. If the first client has written to the file, as is the case inFigure 12-7, the server revokes its oplock and grants neither client an oplock. When the first client’s oplock is revoked, or broken, the client flushes any data it has cached for the file back to the server.
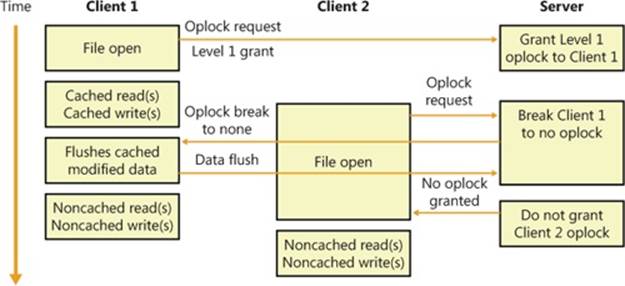
Figure 12-7. Oplock example
If the first client hadn’t written to the file, the first client’s oplock would have been broken to a Level 2 oplock, which is the same type of oplock the server would grant to the second client. Now both clients can cache reads, but if either writes to the file, the server revokes theiroplocks so that noncached operation commences. Once oplocks are broken, they aren’t granted again for the same open instance of a file. However, if a client closes a file and then reopens it, the server reassesses what level of oplock to grant the client based on which other clients have the file open and whether or not at least one of them has written to the file.
EXPERIMENT: VIEWING THE LIST OF REGISTERED FILE SYSTEMS
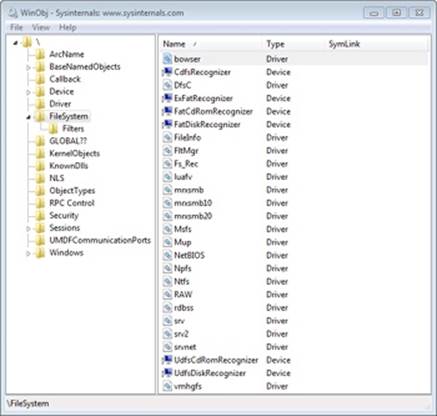
When the I/O manager loads a device driver into memory, it typically names the driver object it creates to represent the driver so that it’s placed in the \Driver object manager directory. The driver objects for any driver the I/O manager loads that have a Type attribute value of SERVICE_FILE_SYSTEM_DRIVER (2) are placed in the \FileSystem directory by the I/O manager. Thus, using a tool such as WinObj (from Sysinternals), you can see the file systems that have registered on a system, as shown in the following screen shot. (Note that some file system drivers also place device objects in the \FileSystem directory.)
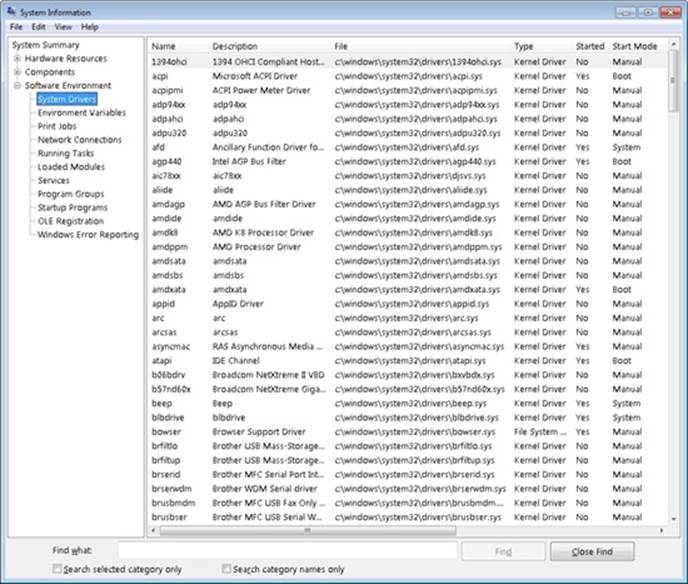
Another way to see registered file systems is to run the System Information viewer. Run Msinfo32 from the Start menu’s Run dialog box and select System Drivers under Software Environment. Sort the list of drivers by clicking the Type column, and drivers with a Type attribute of SERVICE_FILE_SYSTEM_DRIVER group together.
Note that just because a driver registers as a file system driver type doesn’t mean that it is a local or remote FSD. For example, Npfs (Named Pipe File System) is a network API driver that supports named pipes but implements a private namespace, and therefore is in some ways like a file system driver. See Chapter 7 in Part 1 for an experiment that reveals the Npfs namespace.
Leases Prior to SMB 2.1, the SMB protocol assumed an error-free network connection between the client and the server and did not tolerate network disconnections caused by transient network failures, server reboot, or cluster failovers. When a network disconnect event was received by the client, it orphaned all handles opened to the affected server(s), and all subsequent I/O operations on the orphaned handles were failed. Similarly, the server would release all opened handles and resources associated with the disconnected user session. This behavior resulted in applications losing state and in unnecessary network traffic.
In SMB 2.1, the concept of a lease is introduced as a new type of client caching mechanism, similar to an oplock. The purpose of a lease and an oplock is the same, but a lease provides greater flexibility and much better performance.
§ Read (R), shared access Allows multiple simultaneous readers of a file, and no writers. This lease allows the client to perform read-ahead buffering and read caching.
§ Read-Handle (RH), shared access This is similar to the Level 2 oplock, with the added benefit of allowing the client to keep a file open on the server even though the accessor on the client has closed the file. (The cache manager will lazily flush the unwritten data and purge the unmodified cache pages based on memory availability.) This is superior to a Level 2 oplock because the lease does not need to be broken between opens and closes of the file handle. (In this respect, it provides semantics similar to the Batch oplock.) This type of lease is especially useful for files that are repeatedly opened and closed because the cache is not invalidated when the file is closed and refilled when the file is opened again, providing a big improvement in performance for complex I/O intensive applications.
§ Read-Write (RW), exclusive access This lease allows a client to open a file for exclusive access. This lock allows the client to perform read-ahead buffering and read or write caching.
§ Read-Write-Handle (RWH), exclusive access This lock allows a client to open a file for exclusive access. This lease supports read, write, and handle caching (similar to the Read-Handle lease).
Another advantage that a lease has over an oplock is that a file may be cached, even when there are multiple handles opened to the file on the client. (This is a common behavior in many applications.) This is implemented through the use of a lease key (implemented using a GUID), which is created by the client and associated with the File Control Block (FCB) for the cached file, allowing all handles to the same file to share the same lease state, which provides caching by file rather than caching by handle. Prior to the introduction of the lease, the oplock was broken whenever a new handle was opened to the file, even from the same client. Figure 12-8 shows the oplock behavior, and Figure 12-9 shows the new lease behavior.
Prior to SMB 2.1, oplocks could only be granted or broken, but leases can also be converted. For example, a Read lease may be converted to a Read-Write lease, which greatly reduces network traffic because the cache for a particular file does not need to be invalidated and refilled, as would be the case with an oplock break (of the Level 2 oplock), followed by the request and grant of a Level 1 oplock.
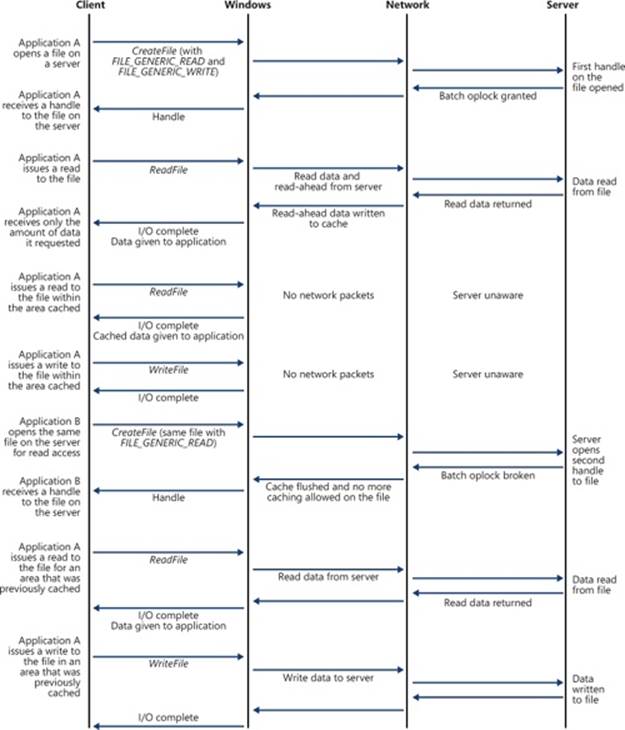
Figure 12-8. Oplock with multiple handles from the same client
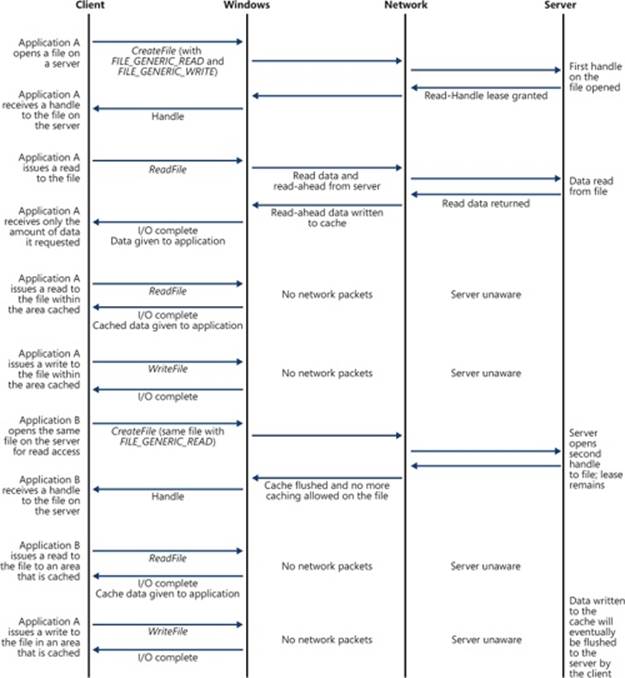
Figure 12-9. Lease with multiple handles from the same client
File System Operation
Applications and the system access files in two ways: directly, via file I/O functions (such as ReadFile and WriteFile), and indirectly, by reading or writing a portion of their address space that represents a mapped file section. (See Chapter 10 for more information on mapped files.)Figure 12-10 is a simplified diagram that shows the components involved in these file system operations and the ways in which they interact. As you can see, an FSD can be invoked through several paths:
§ From a user or system thread performing explicit file I/O
§ From the memory manager’s modified and mapped page writers
§ Indirectly from the cache manager’s lazy writer
§ Indirectly from the cache manager’s read-ahead thread
§ From the memory manager’s page fault handler
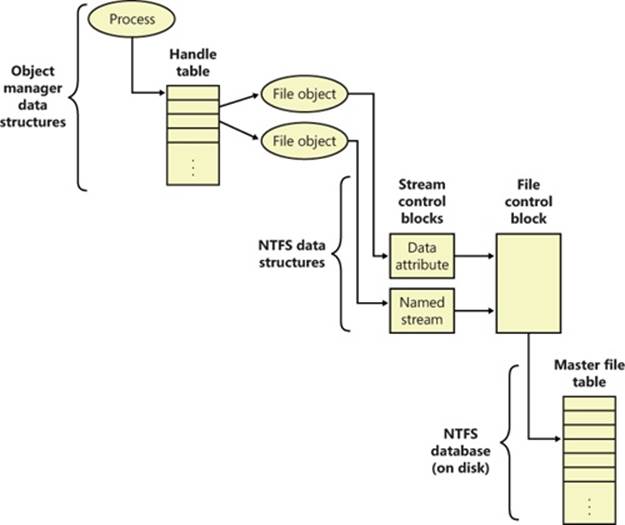
Figure 12-10. Components involved in file system I/O
The following sections describe the circumstances surrounding each of these scenarios and the steps FSDs typically take in response to each one. You’ll see how much FSDs rely on the memory manager and the cache manager.
Explicit File I/O
The most obvious way an application accesses files is by calling Windows I/O functions such as CreateFile, ReadFile, and WriteFile. An application opens a file with CreateFile and then reads, writes, or deletes the file by passing the handle returned from CreateFile to other Windows functions. The CreateFile function, which is implemented in the Kernel32.dll Windows client-side DLL, invokes the native function NtCreateFile, forming a complete root-relative path name for the path that the application passed to it (processing “.” and “..” symbols in the path name) and prefixing the path with “\??” (for example, \??\C:\Daryl\Todo.txt).
The NtCreateFile system service uses ObOpenObjectByName to open the file, which parses the name starting with the object manager root directory and the first component of the path name (“??”). Chapter 3, “System Mechanisms,” in Part 1 includes a thorough description of object manager name resolution and its use of process device maps, but we’ll review the steps it follows here with a focus on volume drive letter lookup.
The first step the object manager takes is to translate \?? to the process’s per-session namespace directory that the DosDevicesDirectory field of the device map structure in the process object references (which was propagated from the first process in the logon session by using the logon session references field in the logon session’s token). Only volume names for network shares and drive letters mapped by the Subst.exe utility are typically stored in the per-session directory, so on those systems when a name (C: in this example) is not present in the per-session directory, the object manager restarts its search in the directory referenced by the GlobalDosDevicesDirectory field of the device map associated with the per-session directory. The GlobalDosDevicesDirectory always points at the \Global?? directory, which is where Windows stores volume drive letters for local volumes. (See the section “Session Namespace” in Chapter 3 in Part 1 for more information.)
The symbolic link for a volume drive letter points to a volume device object under \Device, so when the object manager encounters the volume object, the object manager hands the rest of the path name to the parse function that the I/O manager has registered for device objects,IopParseDevice. (In volumes on dynamic disks, a symbolic link points to an intermediary symbolic link, which points to a volume device object.) Figure 12-11 shows how volume objects are accessed through the object manager namespace. The figure shows how the \GLOBAL??\C: symbolic link points to the \Device\HarddiskVolume1 volume device object.
After locking the caller’s security context and obtaining security information from the caller’s token, IopParseDevice creates an I/O request packet (IRP) of type IRP_MJ_CREATE, creates a file object that stores the name of the file being opened, follows the VPB of the volume device object to find the volume’s mounted file system device object, and uses IoCallDriver to pass the IRP to the file system driver that owns the file system device object.
When an FSD receives an IRP_MJ_CREATE IRP, it looks up the specified file, performs security validation, and if the file exists and the user has permission to access the file in the way requested, returns a success status code. The object manager creates a handle for the file object in the process’s handle table, and the handle propagates back through the calling chain, finally reaching the application as a return parameter from CreateFile. If the file system fails the create operation, the I/O manager deletes the file object it created for the file.
We’ve skipped over the details of how the FSD locates the file being opened on the volume, but a ReadFile function call operation shares many of the FSD’s interactions with the cache manager and storage driver. Both ReadFile and CreateFile are system calls that map to I/O manager functions, but the NtReadFile system service doesn’t need to perform a name lookup—it calls on the object manager to translate the handle passed from ReadFile into a file object pointer. If the handle indicates that the caller obtained permission to read the file when the file was opened, NtReadFile proceeds to create an IRP of type IRP_MJ_READ and sends it to the FSD for the volume on which the file resides. NtReadFile obtains the FSD’s device object, which is stored in the file object, and calls IoCallDriver, and the I/O manager locates the FSD from the device object and gives the IRP to the FSD.
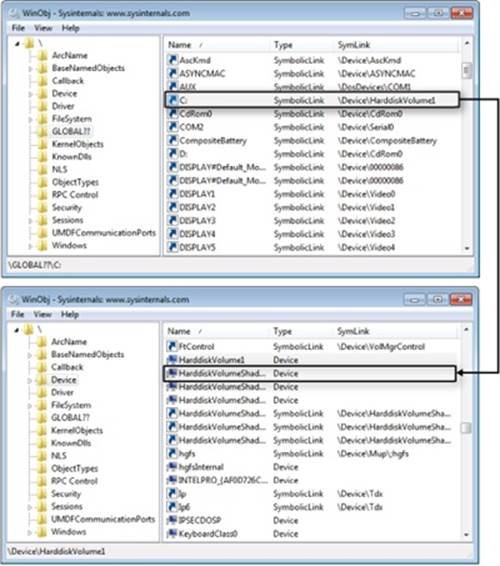
Figure 12-11. Drive-letter name resolution
If the file being read can be cached (that is, the FILE_FLAG_NO_BUFFERING flag wasn’t passed to CreateFile when the file was opened), the FSD checks to see whether caching has already been initiated for the file object. The PrivateCacheMap field in a file object points to a private cache map data structure (which we described in Chapter 11) if caching is initiated for a file object. If the FSD hasn’t initialized caching for the file object (which it does the first time a file object is read from or written to), the PrivateCacheMap field will be null. The FSD calls the cache manager’s CcInitializeCacheMap function to initialize caching, which involves the cache manager creating a private cache map and, if another file object referring to the same file hasn’t initiated caching, a shared cache map and a section object.
After it has verified that caching is enabled for the file, the FSD copies the requested file data from the cache manager’s virtual memory to the buffer that the thread passed to the ReadFile function. The file system performs the copy within a try/except block so that it catches any faults that are the result of an invalid application buffer. The function the file system uses to perform the copy is the cache manager’s CcCopyRead function. CcCopyRead takes as parameters a file object, file offset, and length.
When the cache manager executes CcCopyRead, it retrieves a pointer to a shared cache map, which is stored in the file object. Recall from Chapter 11 that a shared cache map stores pointers to virtual address control blocks (VACBs), with one VACB entry for each 256-KB block of the file. If the VACB pointer for a portion of a file being read is null, CcCopyRead allocates a VACB, reserving a 256-KB view in the cache manager’s virtual address space, and maps (using MmMapViewInSystemCache) the specified portion of the file into the view. ThenCcCopyRead simply copies the file data from the mapped view to the buffer it was passed (the buffer originally passed to ReadFile). If the file data isn’t in physical memory, the copy operation generates page faults, which are serviced by MmAccessFault.
When a page fault occurs, MmAccessFault examines the virtual address that caused the fault and locates the virtual address descriptor (VAD) in the VAD tree of the process that caused the fault. (See Chapter 10 for more information on VAD trees.) In this scenario, the VAD describes the cache manager’s mapped view of the file being read, so MmAccessFault calls MiDispatchFault to handle a page fault on a valid virtual memory address. MiDispatchFault locates the control area (which the VAD points to) and through the control area finds a file object representing the open file. (If the file has been opened more than once, there might be a list of file objects linked through pointers in their private cache maps.)
With the file object in hand, MiDispatchFault calls the I/O manager function IoPageRead to build an IRP (of type IRP_MJ_READ) and sends the IRP to the FSD that owns the device object the file object points to. Thus, the file system is reentered to read the data that it requested viaCcCopyRead, but this time the IRP is marked as noncached and paging I/O. These flags signal the FSD that it should retrieve file data directly from disk, and it does so by determining which clusters on disk contain the requested data (the exact mechanism is file-system dependent) and sending IRPs to the volume manager that owns the volume device object on which the file resides. The volume parameter block (VPB) field in the FSD’s device object points to the volume device object.
The memory manager waits for the FSD to complete the IRP read and then returns control to the cache manager, which continues the copy operation that was interrupted by a page fault. When CcCopyRead completes, the FSD returns control to the thread that called NtReadFile, having copied the requested file data—with the aid of the cache manager and the memory manager—to the thread’s buffer.
The path for WriteFile is similar except that the NtWriteFile system service generates an IRP of type IRP_MJ_WRITE and the FSD calls CcCopyWrite instead of CcCopyRead. CcCopyWrite, like CcCopyRead, ensures that the portions of the file being written are mapped into the cache and then copies to the cache the buffer passed to WriteFile.
If a file’s data is already cached (in the system’s working set), there are several variants on the scenario we’ve just described. If a file’s data is already stored in the cache, CcCopyRead doesn’t incur page faults. Also, under certain conditions, NtReadFile and NtWriteFile call an FSD’sfast I/O entry point instead of immediately building and sending an IRP to the FSD. Some of these conditions follow: the portion of the file being read must reside in the first 4 GB of the file, the file can have no locks, and the portion of the file being read or written must fall within the file’s currently allocated size.
The fast I/O read and write entry points for most FSDs call the cache manager’s CcFastCopyRead and CcFastCopyWrite functions. These variants on the standard copy routines ensure that the file’s data is mapped in the file system cache before performing a copy operation. If this condition isn’t met, CcFastCopyRead and CcFastCopyWrite indicate that fast I/O isn’t possible. When fast I/O isn’t possible, NtReadFile and NtWriteFile fall back on creating an IRP. (See the section Fast I/O in Chapter 11 for a more complete description of fast I/O.)
Memory Manager’s Modified and Mapped Page Writer
The memory manager’s modified and mapped page writer threads wake up periodically (and when available memory runs low) to flush modified pages to their backing store on disk. The threads call IoAsynchronousPageWrite to create IRPs of type IRP_MJ_WRITE and write pages to either a paging file or a file that was modified after being mapped. Like the IRPs that MiDispatchFault creates, these IRPs are flagged as noncached and paging I/O. Thus, an FSD bypasses the file system cache and issues IRPs directly to a storage driver to write the memory to disk.
Cache Manager’s Lazy Writer
The cache manager’s lazy writer thread also plays a role in writing modified pages because it periodically flushes views of file sections mapped in the cache that it knows are dirty. The flush operation, which the cache manager performs by calling MmFlushSection, triggers the memory manager to write any modified pages in the portion of the section being flushed to disk. Like the modified and mapped page writers, MmFlushSection uses IoSynchronousPageWrite to send the data to the FSD.
Cache Manager’s Read-Ahead Thread
A cache utilizes two artifacts of how programs reference code and data: temporal locality and spatial locality. The underlying concept behind temporal locality is that if a memory location is referenced, it is likely to be referenced again soon. The idea behind spatial locality is that if a memory location is referenced, other nearby locations are also likely to be referenced soon. Thus a cache typically is very good at speeding up access to memory locations that have been accessed in the near past, but it is terrible at speeding up access to areas of memory that have not yet been accessed (it has zero lookahead capability). In an attempt to populate the cache with data that will likely be used soon, the cache manager implements two mechanisms: a read-ahead thread, and Superfetch.
The cache manager includes a thread that is responsible for attempting to read data from files before an application, a driver, or a system thread explicitly requests it. The read-ahead thread uses the history of read operations that were performed on a file, which are stored in a file object’s private cache map, to determine how much data to read. When the thread performs a read-ahead, it simply maps the portion of the file it wants to read into the cache (allocating VACBs as necessary) and touches the mapped data. The page faults caused by the memory accesses invoke the page fault handler, which reads the pages into the system’s working set.
A limitation of the read-ahead thread is that it works only on open files. Superfetch was added to Windows to proactively add files to the cache before they are even opened. Specifically, the memory manager sends page-usage information to the Superfetch service (%SystemRoot%\System32\Sysmain.dll), and a file system minifilter provides file name resolution data. The Superfetch service attempts to find file-usage patterns—for example, payroll is run every Friday at 12:00, or Outlook is run every morning at 8:00. When these patterns are derived, the information is stored in a database and timers are requested. Just prior to the time the file would most likely be used, a timer fires and wakes up the Superfetch service, which then tells the memory manager to read the file into low-priority memory (using low-priority disk I/O). If the file is then opened, the data is already in memory and there is no need to wait for the data to be read from disk. If the file is not opened, the low-priority memory will be reclaimed by the system.
Memory Manager’s Page Fault Handler
We described how the page fault handler is used in the context of explicit file I/O and cache manager read-ahead, but it is also invoked whenever any application accesses virtual memory that is a view of a mapped file and encounters pages that represent portions of a file that are not yet in memory. The memory manager’s MmAccessFault handler follows the same steps it does when the cache manager generates a page fault from CcCopyRead or CcCopyWrite, sending IRPs via IoPageRead to the file system on which the file is stored.
File System Filter Drivers
A filter driver that layers over a file system driver is called a file system filter driver. (See Chapter 8, for more information on filter drivers.) The ability to see all file system requests and optionally modify or complete them enables a range of applications, including remote file replication services, file encryption, efficient backup, and licensing. Every commercial on-access virus scanner includes a file system filter driver that intercepts IRPs that deliver IRP_MJ_CREATE commands that issue whenever an application opens a file. Before propagating the IRP to the file system driver to which the command is directed, the virus scanner examines the file being opened to ensure that it’s clean of a virus. If the file is clean, the virus scanner passes the IRP on, but if the file is infected the virus scanner communicates with its associated Windows service process to quarantine or clean the file. If the file can’t be cleaned, the driver fails the IRP (typically with an access-denied error) so that the virus cannot become active.
Process Monitor
Process Monitor (Procmon), a system activity monitoring utility from Sysinternals that has been used throughout this book, is an example of a passive filter driver, which is one that does not modify the flow of IRPs between applications and file system drivers. Windows includes the file system Filter Manager (%SystemRoot%\System32\Drivers\Fltmgr.sys) as part of a port/miniport model for file system filter drivers. The file system Filter Manager greatly simplifies the development of filter drivers by interfacing a filter miniport driver to the Windows I/O system and providing services for querying file names, attaching to volumes, and interacting with other filters. Process Monitor’s file system monitoring is implemented as a minifilter driver.
Process Monitor works by extracting a file system filter device driver from its executable image (stored as a resource inside Procmon.exe) the first time you run it after a boot, installing the driver in memory, and then deleting the driver image from disk. Through the Process Monitor GUI, you can direct the driver to monitor file system activity on local volumes that have assigned drive letters, network shares, named pipes, and mail slots. When the driver receives a command to start monitoring a volume, it registers filtering callbacks with the Filter Manager, which is attached to the device object that represents a mounted file system on the volume. After an attach operation, the I/O manager redirects an IRP targeted at the underlying device object to the driver owning the attached device, in this case the Filter Manager, which sends the event to registered minifilter drivers, in this case Process Monitor.
When the Process Monitor driver intercepts an IRP, it records information about the IRP’s command, including target file name and other parameters specific to the command (such as read and write lengths and offsets) to a nonpaged kernel buffer. Every 500 milliseconds, the Process Monitor GUI program sends an IRP to Process Monitor’s interface device object, which requests a copy of the buffer containing the latest activity, and then displays the activity in its output window. Process Monitor’s use is described further in the next section, Troubleshooting File System Problems.
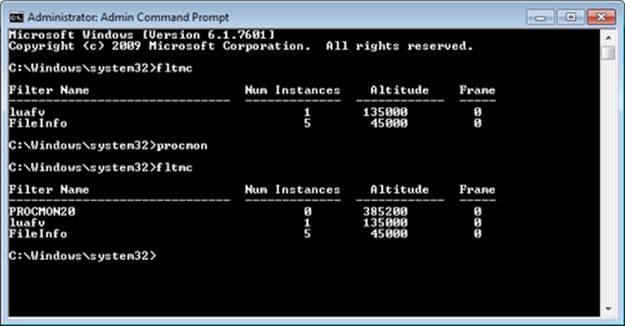
EXPERIMENT: VIEWING PROCESS MONITOR’S FILTER DRIVER
To see which file system filter drivers are loaded, start an Administrative command prompt, and run the Filter Manager control program (%SystemRoot%\System32\Fltmc.exe). Start Process Monitor (ProcMon.exe) and run Fltmc again. You’ll see that the Process Monitor’s filter driver (PROCMON20) is loaded and has a nonzero value in the Instances column. Now, exit Process Monitor and run Fltmc again. This time, you’ll see that the Process Monitor’s filter driver is still loaded, but now its instance count is zero.
Troubleshooting File System Problems
Chapter 4, “Management Mechanisms,” in Part 1 describes the way that the system and applications store data in the registry. Registry-related problems such as misconfigured security and missing registry values and keys are the source of many system and application failures. The system and applications also use files to store data, and they access executable and DLL image files. Misconfigured NTFS security and missing files or directories are therefore also a common source of system and application failures because the system and applications often make assumptions about what they should be able to access and then misbehave in unexpected ways when the assumptions are violated.
Process Monitor shows all file activity as it occurs, which makes it an ideal tool for troubleshooting file system–related system and application failures. To run Process Monitor the first time on a system, an account must have the Load Driver and Debug privileges. After loading, the driver remains resident, so subsequent executions require only the Debug privilege.
Process Monitor Basic vs. Advanced Modes
When you run Process Monitor, it starts in basic mode, which shows the file system activity most often useful for troubleshooting. When in basic mode, Process Monitor omits certain file system operations from being displayed, including:
§ I/O to NTFS metadata files
§ I/O to the paging file
§ I/O generated by the System process
§ I/O generated by the Process Monitor process
While in basic mode, Process Monitor also reports file I/O operations with friendly names rather than with the IRP types used to represent them. For example, both IRP_MJ_WRITE and FASTIO_WRITE operations display as WriteFile, and IRP_MJ_CREATE operations show as Open if they represent an open operation and as Create for the creation of new files.
EXPERIMENT: VIEWING FILE SYSTEM ACTIVITY ON AN IDLE SYSTEM
Windows file system drivers implement support for file change notification, which enables applications to request notifications of file system changes without polling for them. The Windows functions for doing so include ReadDirectoryChangesW and the FindFirstChangeNotification, FindNextChangeNotification pair. When you run Process Monitor on a system that’s idle, you should therefore not see the repeated accesses to files or directories because that activity unnecessarily negatively affects a system’s overall performance.
Run Process Monitor, and after several seconds examine the output log to see whether you can spot polling behavior. Right-click on an output line associated with polling, click Properties on the context menu, and then click the Process tab in the Properties dialog box to view details of the process performing the activity.
Process Monitor Troubleshooting Techniques
The two basic Process Monitor troubleshooting techniques for file system problems are identical to those for registry-related problems: look in a Process Monitor trace at the last thing an application did before it failed, or compare a Process Monitor trace of a failing application with a trace from a working system. See the section Process Monitor Troubleshooting Techniques in Chapter 4 in Part 1 for more information on these techniques.
Entries in a Process Monitor trace that have values of NAME NOT FOUND, NO SUCH FILE, PATH NOT FOUND, SHARING VIOLATION, and ACCESS DENIED in the Result column are ones that you should investigate. The first three are reported when an application or the system attempts to open a nonexistent file or directory. In many cases, these errors do not indicate a serious problem. When you execute a program from the Start menu’s Run dialog box without specifying its full path, for instance, Windows Explorer will search the directories listed in the system PATH environment variable for the image file until it locates the file or has searched all the listed directories. Each attempt to find the image in a directory that does not contain it results in a Process Monitor output line similar to this:
25314 7:44:27.4180943 PM Explorer.EXE 1640 CreateFile
C:\Program Files\Microsoft Windows Performance Toolkit\test.exe NAME NOT FOUND
Desired Access: Read Attributes, Disposition: Open, Options: Open Reparse Point,
Attributes: n/a, ShareMode: Read, Write, Delete, AllocationSize: n/a
Access-denied errors are a common source of file system–related application failures, and they occur when an application does not have permission to open the file or directory for the access types it desires. Some applications do not check error codes or perform error recovery, and they fail by crashing or terminating; others often display misleading error messages that mask the root cause of the error.
Buffer-overflow exploits are a serious security concern, but a code result of BUFFER OVERFLOW is simply a file system driver’s way to indicate to an application that the buffer it specified to store requested result data was too small to hold the data. Application developers use this behavior to determine how large a buffer should be because the file system driver also returns the size of the buffer required to store the data. Operations with a buffer overflow result are usually followed by the same operation with a successful result.
Process Monitor has been used extensively within Microsoft and other organizations to solve difficult or nearly impossible-to-diagnose problems.
Common Log File System
Transactional semantics for a database or a journaled file system often require keeping track of changes made to the data and metadata contained in the files or entries. Typically, these changes are stored in data structures called log records through an operation called logging. These log records can then be used to undo (roll back), redo, or validate the changes at a later time, even across system reboots.
Windows provides this kind of logging service through the Common Log File System (CLFS) to support the transactional features built into Windows, including transactional NTFS (TxF) and transactional registry (TxR), and to enable third-party developers to take advantage of similar technology. CLFS provides user-mode and kernel-mode APIs for creating, reading, and writing CLFS log files. The APIs are flexible and extensible, which allows the implementation details and structure of the log records stored in a log file to be defined by a caller. CLFS can be used by a variety of applications, such as databases; for store and forward message queues and replication agents; and for operations such as event logging, compliance logging, or even maintaining undo/redo history in an editor. The CLFS APIs provide a consistent view of a log and allow the sharing of a log between user-mode and kernel-mode components.
Although CLFS calls itself a file system, it actually provides a virtual abstraction layer on top of NTFS by using streams and containers, described later. What CLFS exposes as a single virtual log file could actually be a single physical log file, a single log file divided into multiple physical files, or even different log files each divided into multiple physical files. Later, we’ll describe how NTFS interacts with CLFS to provide transactional support.
Marshalling
Marshalling
Internally, CLFS encapsulates the functionality of the Algorithm for Recovery and Isolation Exploiting Semantics (ARIES), which allows it to provide reliable recovery and replication of operations by using an industry-approved standard. However, CLFS is not limited to supportingARIES; it is well suited to a variety of logging scenarios. You can find the full ARIES specification at www.sai.msu.su/~megera/postgres/gist/papers/concurrency/p94-mohan.pdf.
The primary job of any high-performance transactional log is to allow log clients to accurately repeat history. CLFS does this by marshalling client log records into memory buffers, forcing them to stable storage (a disk volume), and reading records back on request. After a record makes it to stable storage and the storage media is intact, CLFS is able to read the record across system failures.
Both user-mode and kernel-mode clients marshal data buffers into log records that are part of a marshalling area maintained in the client’s address space. When creating a marshalling area, a client must specify the number and size of the log I/O buffers it wants to maintain in its marshaling area. The marshalling runtime implements policy on allocating log I/O buffers, appending them to the log internal queue and flushing them to disk. Clients can override the default marshalling code policy by forcing queue appends and flushes to disk via API calls.
One of the design goals of the CLFS marshalling runtime is to minimize kernel transitions, which it achieves, among other things, through log-space reservation, a requirement for supporting scenarios such as transaction rollbacks. Every time the log marshalling area talks to the CLFS driver (which implies a kernel transition for user-mode clients), the marshalling area tries to negotiate a desired amount of reserved space, usually larger than what is currently required. This means that if the client requires more space in the future, the marshalling area can immediately satisfy the new request without issuing a new kernel transition. Note, however, that if the amount of the reservation cannot be satisfied, the marshalling area will try to get just enough of the reservation to satisfy the user’s request (without extra reserved space), which could potentially lead to additional kernel transitions.
Log Types
CLFS supports two types of logs: dedicated logs and multiplexed logs (also called common logs). A dedicated log has a single stream of log records that is used by all the log’s clients. A multiplexed log has several streams: each stream has its own clients and its own memory buffers for marshalling log records, but the records from all those buffers are multiplexed into a single queue and written to a single log on stable storage. Multiplexing allows the I/O operations of several streams to be consolidated. When a log is created or opened, CLFS determines whether the log is dedicated or multiplexed depending on whether a dedicated log path or a multiplexed log path is specified.
If the request is for a client on a dedicated log (called a physical client), CLFS locates the physical file control block (FCB) object for the file proper and handles the request.
If the request is for a client on a multiplexed log (called a virtual client), CLFS locates the corresponding virtual FCB and context control block (CCB) objects to translate the request into an operation on the physical FCB object. CLFS then handles the operation on the CLFS physical FCB object as just described.
In either case, if the request is a cached read, CLFS uses the cache manager’s services for accessing cached data. (For more information on the cache manager, see Chapter 11.) Just as it does for requests from other file system drivers, the cache manager maps a view of the file and references the view, which might cause the memory manager to issue noncached reads to CLFS against the physical log. For flushes and noncached reads, CLFS finds the target container object through the log metadata and issues IRPs to NTFS directly. Figure 12-12 shows the possible CLFS paths for a request coming from user mode or kernel mode.
Because each stream of a multiplexed log provides its clients with the illusion that their stream is the entire log, CLFS must include metadata in the physical log that identifies which client each data block belongs to. This data is called the owner page and is always exactly one page (4 KB) in size. Each 512 KB of client data results in an owner page to describe it. Since dedicated logs require no tracking of client and data mapping, they don’t include owner pages. Figure 12-13 shows two clients writing log records to a multiplexed log and how the writes are kept together in a unified flush queue that can then be uniformly flushed to physical storage through a single I/O operation.
The flush queue will be emptied in the following conditions:
§ The amount of data in the flush queue exceeds a certain threshold. (The default is 40,000 bytes.)
§ The CLFS flush API is called.
§ A restart area is being written, and the log needs to be flushed beyond the restart area. (For more information on the restart area, see the section Log File Service later in this chapter.)
When flushing, CLFS scans the flush queue and determines how many entries need to be flushed. It then issues IRPs to NTFS for the corresponding log files of each of the entries and waits for all the IRPs to complete. If some IRPs fail, CLFS may re-issue IRPs (failures such as low memory condition, lack of quota, and so on are subject to retry) to redo the work and wait again.
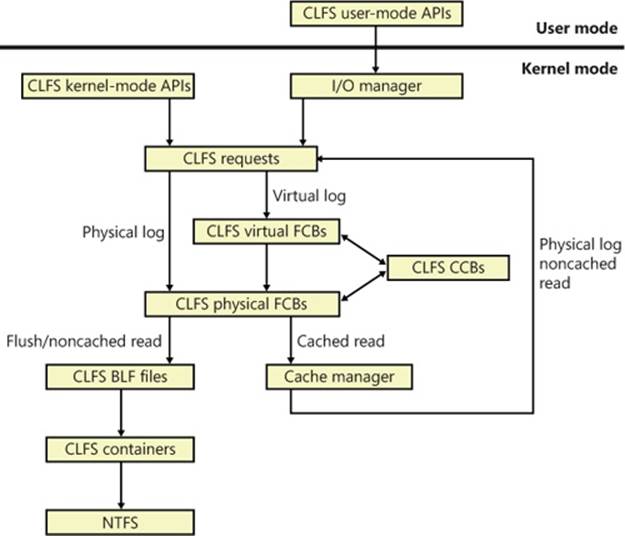
Figure 12-12. CLFS request paths
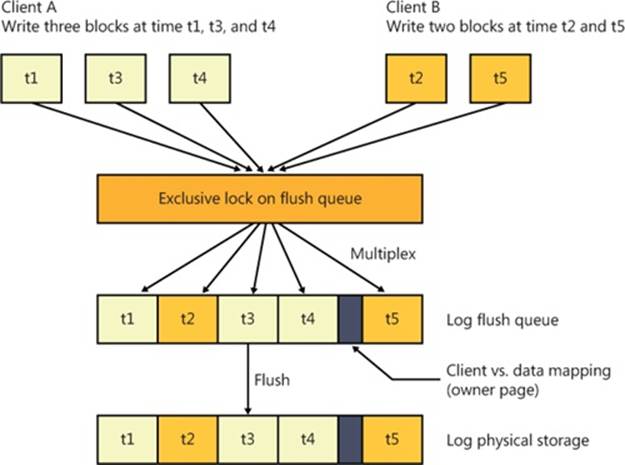
Figure 12-13. CLFS multiplexing
Log Layout
A log file is made up of a base log file (BLF) that contains metadata and up to 1,023 containers that hold the actual data. The base log file is initially 64 KB in size and grows as needed. The log metadata stores information about the log, including the beginning of the log, the container size, the container path, the location from which restart operations should be performed, the log state, the log name, and the log clients. For consistency in case a system failure occurs during a log update, the base log file stores two copies of the log metadata, and when it makes updates it overwrites the older copy. The BLF stores a value, the dump count, that indicates which copy is newer.
A container is the unit of allocation for an active physical log stream. All the containers in a log have the same size, which is a multiple of 512 KB with a 4-GB maximum size. A CLFS client grows or shrinks a log stream by adding or deleting containers from the log file. CLFS implements containers as contiguous files on the volume on which the BLF resides. Figure 12-14 shows the relationship between a base log file and the associated log data stored in containers.
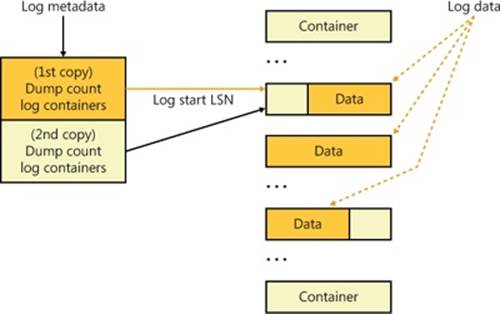
Figure 12-14. CLFS base log file and containers
Internally, the CLFS driver places the containers in a container queue to give clients a logical view of a single contiguous physical log stream; in doing so, the CLFS driver maps the physical container identifier to a logical container identifier. Containers are recycled when the tail of the active log migrates beyond the last sector of the container. Recycling a container involves moving it from the tail to the head of the container queue and appropriately updating its logical container identifier.
Log Sequence Numbers
When a client writes a record to a stream, CLFS returns a log sequence number (LSN) that identifies the log record for future reference. The LSNs assigned to the records that are written to a particular stream form an increasing sequence. That is, the LSN assigned to a record that is written to a stream is always greater than the LSN assigned to the previous record written to that same stream. Two critical LSNs that the base log file keeps track of are the log start LSN and the restart LSN, which, as described earlier, are stored in the BLF metadata.
An LSN is 64 bits wide and consists of three parts, as shown in Figure 12-15:
§ A 32-bit container index that identifies the log container where the log record resides
§ A 23-bit block offset that identifies an offset within a container
§ A 9-bit record offset that identifies a record within a block

Figure 12-15. CLFS LSN structure
Log Blocks
Because it is possible that a write to a log might fail, which is called a torn write, CLFS uses log blocks to track whether log records are fully committed to storage. CLFS stores log records within log blocks, which correspond to 512-byte sectors, and reads and writes data to a log using log blocks. Each log block includes a 2-byte sector signature at the end of each sector in the block that stores a sequence number and flags, as well as a copy of the most recently committed signatures in a signature array at the end of the block, as shown in Figure 12-16. Only if all the sector signatures in a log block are valid and match the signatures in the array, does CLFS consider the block valid. If a log block is partially written and a system failure occurs, for example, the signatures won’t match, and CLFS considers the log block invalid.
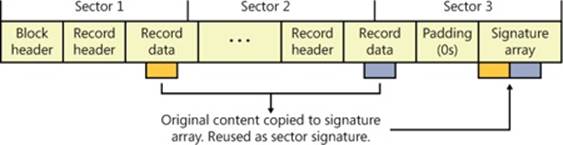
Figure 12-16. CLFS log blocks
Owner Pages
As mentioned previously, each 512-KB block of data in a multiplexed log (called a region) is correlated with its virtual log through an owner page. Each region consists of 4-KB pages, and each page contains one or more sectors, which contain log blocks. The owner page is the last page of a region, as shown in Figure 12-17. Because the owner page is itself a log block, CLFS can detect torn writes on the owner page, just as for a log record, by using the log block signature array.
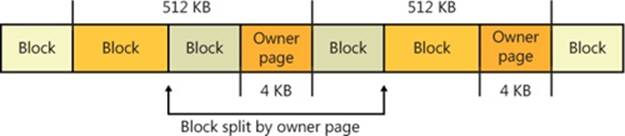
Figure 12-17. CLFS regions and owner pages
An owner page contains two kinds of information:
§ For each sector in the region, the virtual log to which the sector belongs as well as the sector’s serial number (starting from 0). There can be at most 1,024 sectors in a region.
§ For each virtual log, the minimum and maximum virtual log LSN for the region. These values give the range of valid virtual LSNs for the region.
CLFS can tell by looking at the owner page of a virtual log LSN whether the record specified by the LSN resides in the current region or not. If the record does not reside in the current region, CLFS can decide whether it should search the previous region or the next region by comparing the virtual log LSN with the virtual log LSN range for the region.
When CLFS inserts log blocks into a multiplexed log’s physical FCB flush queue, if it finds that the current log block will overlap the owner page of the current region, it splits the current log block and inserts an owner page log block after the first half of the split log block (as shown in Figure 12-17). In other words, the owner page is written to disk only after the region that it describes becomes full. When a client reopens a multiplexed log file, CLFS scans the regions and rebuilds an in-memory owner page describing the latest region for which it hasn’t written an owner page log block.
Note that when reopening the log file, CLFS doesn’t know exactly where the log end LSN is, so it must find the LSN to avoid losing data or using corrupted data. For a dedicated log, CLFS reads the log blocks sequentially until an invalid log block is found and then sets the end of the log there. For a multiplexed log, CLFS reads the last owner page (the base log file saves a copy of the last flushed owner page’s LSN when the log metadata is last flushed) and verifies it is indeed valid. CLFS then reads the next region’s owner page repeatedly until an invalid owner page is found. After that, CLFS scans backward to find the first region with only valid log data blocks. CLFS then assumes the end of the log must fall within the next region. It will scan log block by log block until an invalid log block is found and then set the end of the log there.
Translating Virtual LSNs to Physical LSNs
CLFS relies on physical LSNs to identify log blocks within a physical log. However, CLFS combines several virtual logs in a physical log for multiplexed logs and uses virtual LSNs to locate log blocks in a virtual log. Therefore, for a virtual log client, a log block can be addressed both by a physical LSN and by a virtual LSN.
To translate a virtual log LSN to a physical log LSN, CLFS follows these steps:
1. Reads the owner page for the region indicated by the virtual log LSN.
2. Checks the owner page’s virtual LSN region to see whether the virtual LSN is actually in the region or not. Most of the time the log block will be in the region.
3. If the virtual LSN is in the region, CLFS refers to the sector to client mapping in the owner page to find the physical LSN’s block offset. Given a client’s virtual LSN and its size, CLFS can calculate the virtual LSN of the next log block. Applying this rule, CLFS can deterministically calculate the physical LSN of every virtual log block in the region, as shown in Figure 12-18.
4. If the virtual LSN is not in the region, CLFS searches either the previous region or the next region depending on whether the virtual LSN is smaller or larger than the current region’s virtual LSN range.
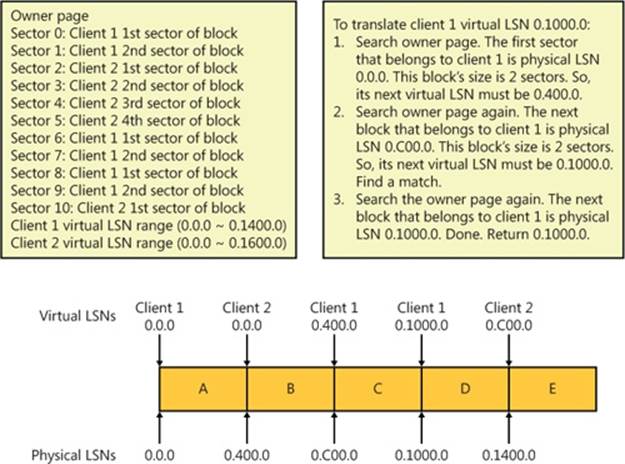
Figure 12-18. CLFS virtual to physical LSN translation
Management Policies
Each CLFS log can be defined by a set of management policies that are configurable by the client. Table 12-5 lists these policies and their usage.
Table 12-5. CLFS Management Policies
|
Policy Name |
Description |
|
ClfsMgmtPolicyMaximumSize |
Specifies the maximum size of a log. |
|
ClfsMgmtPolicyMinimumSize |
Specifies the minimum size of a log. |
|
ClfsMgmtPolicyNewContainerSize |
Specifies the size of new containers that are created. |
|
ClfsMgmtPolicyGrowthRate |
Specifies how many new containers will be added to the log each time the log grows. Can be specified as either a relative percentage or an absolute number. |
|
ClfsMgmtPolicyLogTail |
Specifies how much free space will be requested when a client is notified to move its log tail. Can be specified as either a minimum percentage of free space or a minimum number of containers. |
|
ClfsMgmtPolicyAutoShrink |
Specifies when the log will shrink based on the percentage of the log that is free. |
|
ClfsMgmtPolicyAutoGrow |
Specifies whether the log should grow when fewer than two containers are free. |
|
ClfsMgmtPolicyNewContainerPrefix |
Specifies a prefix for the file name of each container, as well as the full path to the directory where the containers are located. |
NTFS Design Goals and Features
In the following section, we’ll look at the requirements that drove the design of NTFS. Then, in the subsequent section, we’ll examine the advanced features of NTFS.
High-End File System Requirements
From the start, NTFS was designed to include features required of an enterprise-class file system. To minimize data loss in the face of an unexpected system outage or crash, a file system must ensure that the integrity of its metadata is guaranteed at all times; and to protect sensitive data from unauthorized access, a file system must have an integrated security model. Finally, a file system must allow for software-based data redundancy as a low-cost alternative to hardware-redundant solutions for protecting user data. In this section, you’ll find out how NTFS implements each of these capabilities.
Recoverability
To address the requirement for reliable data storage and data access, NTFS provides file system recovery based on the concept of an atomic transaction. Atomic transactions are a technique for handling modifications to a database so that system failures don’t affect the correctness or integrity of the database. The basic tenet of atomic transactions is that some database operations, called transactions, are all-or-nothing propositions. (A transaction is defined as an I/O operation that alters file system data or changes the volume’s directory structure.) The separate disk updates that make up the transaction must be executed atomically—that is, once the transaction begins to execute, all its disk updates must be completed. If a system failure interrupts the transaction, the part that has been completed must be undone, or rolled back. The rollback operation returns the database to a previously known and consistent state, as if the transaction had never occurred.
NTFS uses atomic transactions to implement its file system recovery feature. If a program initiates an I/O operation that alters the structure of an NTFS volume—that is, changes the directory structure, extends a file, allocates space for a new file, and so on—NTFS treats that operation as an atomic transaction. It guarantees that the transaction is either completed or, if the system fails while executing the transaction, rolled back. The details of how NTFS does this are explained in the section NTFS Recovery Support later in the chapter. In addition, NTFS uses redundant storage for vital file system information so that if a sector on the disk goes bad, NTFS can still access the volume’s critical file system data.
Security
Security in NTFS is derived directly from the Windows object model. Files and directories are protected from being accessed by unauthorized users. (For more information on Windows security, see Chapter 6, “Security,” in Part 1.) An open file is implemented as a file object with a security descriptor stored on disk in the hidden $Secure metafile, in a stream named $SDS (Security Descriptor Stream). Before a process can open a handle to any object, including a file object, the Windows security system verifies that the process has appropriate authorization to do so. The security descriptor, combined with the requirement that a user log on to the system and provide an identifying password, ensures that no process can access a file unless it is given specific permission to do so by a system administrator or by the file’s owner. (For more information about security descriptors, see the section “Security Descriptors and Access Control” in Chapter 6 in Part 1, and for more details about file objects, see the section Opening Devices in Chapter 8.)
Data Redundancy and Fault Tolerance
In addition to recoverability of file system data, some customers require that their own data not be endangered by a power outage or catastrophic disk failure. The NTFS recovery capabilities do ensure that the file system on a volume remains accessible, but they make no guarantees for complete recovery of user files. Protection for applications that can’t risk losing file data is provided through data redundancy.
Data redundancy for user files is implemented via the Windows layered driver model (explained in Chapter 8), which provides fault-tolerant disk support. NTFS communicates with a volume manager, which in turn communicates with a disk driver to write data to a disk. A volume manager can mirror, or duplicate, data from one disk onto another disk so that a redundant copy can always be retrieved. This support is commonly called RAID level 1. Volume managers also allow data to be written in stripes across three or more disks, using the equivalent of one disk to maintain parity information. If the data on one disk is lost or becomes inaccessible, the driver can reconstruct the disk’s contents by means of exclusive-OR operations. This support is called RAID level 5. (See Chapter 9 for more information on striped volumes, mirrored volumes, and RAID-5 volumes.)
Advanced Features of NTFS
In addition to NTFS being recoverable, secure, reliable, and efficient for mission-critical systems, it includes the following advanced features that allow it to support a broad range of applications. Some of these features are exposed as APIs for applications to leverage, and others are internal features:
§ Multiple data streams
§ Unicode-based names
§ General indexing facility
§ Dynamic bad-cluster remapping
§ Hard links
§ Symbolic (soft) links and junctions
§ Compression and sparse files
§ Change logging
§ Per-user volume quotas
§ Link tracking
§ Encryption
§ POSIX support
§ Defragmentation
§ Read-only support and dynamic partitioning
The following sections provide an overview of these features.
Multiple Data Streams
In NTFS, each unit of information associated with a file—including its name, its owner, its time stamps, its contents, and so on—is implemented as a file attribute (NTFS object attribute). Each attribute consists of a single stream—that is, a simple sequence of bytes. This generic implementation makes it easy to add more attributes (and therefore more streams) to a file. Because a file’s data is “just another attribute” of the file and because new attributes can be added, NTFS files (and file directories) can contain multiple data streams.
An NTFS file has one default data stream, which has no name. An application can create additional, named data streams and access them by referring to their names. To avoid altering the Windows I/O APIs, which take a string as a file name argument, the name of the data stream is specified by appending a colon (:) to the file name. Because the colon is a reserved character, it can serve as a separator between the file name and the data stream name, as illustrated in this example:
myfile.dat:stream2
Each stream has a separate allocation size (which defines how much disk space has been reserved for it), actual size (which is how many bytes the caller has used), and valid data length (which is how much of the stream has been initialized). In addition, each stream is given a separate file lock that is used to lock byte ranges and to allow concurrent access.
One component in Windows that uses multiple data streams is the Attachment Execution Service, which is invoked whenever the standard Windows API for saving Internet-based attachments is used by applications such as Internet Explorer or Outlook. Depending on which zone the file was downloaded from (such as the My Computer zone, the Intranet zone, or the Untrusted zone), Windows Explorer might warn the user that the file came from a possibly untrusted location or even completely block access to the file. For example, Figure 12-19 shows the dialog box that’s displayed when executing Process Explorer after it was downloaded from the Sysinternals site.
NOTE
If you clear the check box for Always Ask Before Opening This File, the zone identifier data stream will be removed from the file.
Figure 12-19. Security warning for files downloaded from the Internet
Other applications can use the multiple data stream feature as well. A backup utility, for example, might use an extra data stream to store backup-specific time stamps on files. Or an archival utility might implement hierarchical storage in which files that are older than a certain date or that haven’t been accessed for a specified period of time are moved to offline storage. The utility could copy the file to offline storage, set the file’s default data stream to 0, and add a data stream that specifies where the file is stored.
EXPERIMENT: LOOKING AT STREAMS
Most Windows applications aren’t designed to work with alternate named streams, but both the echo and more commands are. Thus, a simple way to view streams in action is to create a named stream using echo and then display it using more. The following command sequence creates a file named test with a stream named stream:
C:\>echo hello > test:stream
C:\>more < test:stream
hello
C:\>
If you perform a directory listing, Test’s file size doesn’t reflect the data stored in the alternate stream because NTFS returns the size of only the unnamed data stream for file query operations, including directory listings.
C:\>dir test
Volume in drive C is WINDOWS
Volume Serial Number is 3991-3040
Directory of C:\
08/01/00 02:37p 0 test
1 File(s) 0 bytes
112,558,080 bytes free
You can determine what files and directories on your system have alternate data streams with the Streams utility from Sysinternals (see the following output) or by using the /r switch in the dir command.
C:\>streams test
Streams v1.56 - Enumerate alternate NTFS data streams
Copyright (C) 1999-2007 Mark Russinovich
Sysinternals - www.sysinternals.com
C:\test:
:stream:$DATA 8
Unicode-Based Names
Like Windows as a whole, NTFS supports 16-bit Unicode 1.0/UTF-16 characters to store names of files, directories, and volumes. (The current version of the Unicode standard, version 6.1, from February 2012, supports up to 4 bytes per character and is not supported in kernel mode.) Unicode allows each character in each of the world’s major languages to be uniquely represented, which aids in moving data easily from one country to another. Unicode is an improvement over the traditional representation of international characters—using a double-byte coding scheme that stores some characters in 8 bits and others in 16 bits, a technique that requires loading various code pages to establish the available characters. Because Unicode has a unique representation for each character, it doesn’t depend on which code page is loaded. Each directory and file name in a path can be as many as 255 characters long and can contain Unicode characters, embedded spaces, and multiple periods.
General Indexing Facility
The NTFS architecture is structured to allow indexing of any file attribute on a disk volume using a B-tree structure. (Creating indexes on arbitrary attributes is not exported to users.) This structure enables the file system to efficiently locate files that match certain criteria—for example, all the files in a particular directory. In contrast, the FAT file system indexes file names but doesn’t sort them, making lookups in large directories slow.
Several NTFS features take advantage of general indexing, including consolidated security descriptors, in which the security descriptors of a volume’s files and directories are stored in a single internal stream, have duplicates removed, and are indexed using an internal security identifier that NTFS defines. The use of indexing by these features is described in the section NTFS On-Disk Structure later in this chapter.
Dynamic Bad-Cluster Remapping
Ordinarily, if a program tries to read data from a bad disk sector, the read operation fails and the data in the allocated cluster becomes inaccessible. If the disk is formatted as a fault-tolerant NTFS volume, however, the Windows volume manager dynamically retrieves a good copy of the data that was stored on the bad sector and then sends NTFS a warning that the sector is bad. NTFS will then allocate a new cluster, replacing the cluster in which the bad sector resides, and copies the data to the new cluster. It adds the bad cluster to the list of bad clusters on that volume (stored in the hidden metadata file $BadClus) and no longer uses it. This data recovery and dynamic bad-cluster remapping is an especially useful feature for file servers and fault-tolerant systems or for any application that can’t afford to lose data. If the volume manager isn’t loaded when a sector goes bad (such as early in the boot sequence), NTFS still replaces the cluster and doesn’t reuse it, but it can’t recover the data that was on the bad sector.
Hard Links
A hard link allows multiple paths to refer to the same file. (Hard links are not supported on directories.) If you create a hard link named C:\Documents\Spec.doc that refers to the existing file C:\Users\Administrator\Documents\Spec.doc, the two paths link to the same on-disk file, and you can make changes to the file using either path. Processes can create hard links with the Windows CreateHardLink function or the ln POSIX function.
NTFS implements hard links by keeping a reference count on the actual data, where each time a hard link is created for the file, an additional file name reference is made to the data. This means that if you have multiple hard links for a file, you can delete the original file name that referenced the data (C:\Users\Administrator\Documents\Spec.doc in our example), and the other hard links (C:\Documents\Spec.doc) will remain and point to the data. However, because hard links are on-disk local references to data (represented by a file record number), they can exist only within the same volume and can’t span volumes or computers.
EXPERIMENT: CREATING A HARD LINK
There are two ways you can create a hard link: the fsutil hardlink create command or the mklink utility with the /H option. In this experiment we’ll use mklink because we’ll use this utility later to create a symbolic link as well. First, create a file called test.txt and add some text to it, as shown here.
C:\>echo hello > test.txt
Now create a hard link called hard.txt as shown here:
C:\>mklink hard.txt test.txt /H
Hardlink created for hard.txt <<===>> test.txt
If you list the directory’s contents, you’ll notice that the two files will be identical in every way, with the same creation date, permissions, and file size; only the file names differ.
C:\>dir *.txt
Volume in drive C is OS
Volume Serial Number is 38D4-EA71
Directory of C:\
05/12/2012 11:55 PM 8 hard.txt
05/12/2012 11:55 PM 8 test.txt
2 File(s) 16 bytes
0 Dir(s) 10,646,011,904 bytes free
Symbolic (Soft) Links and Junctions
In addition to hard links, NTFS supports another type of file-name aliasing called symbolic links or soft links. Unlike hard links, symbolic links are strings that are interpreted dynamically and can be relative or absolute paths that refer to locations on any storage device, including ones on a different local volume or even a share on a different system. This means that symbolic links don’t actually increase the reference count of the original file, so deleting the original file will result in the loss of the data, and a symbolic link that points to a nonexisting file will be left behind. Finally, unlike hard links, symbolic links can point to directories, not just files, which gives them an added advantage.
For example, if the path C:\Drivers is a directory symbolic link that redirects to %SystemRoot%\System32\Drivers, an application reading C:\Drivers\Ntfs.sys actually reads %SystemRoot%\System\Drivers\Ntfs.sys. Directory symbolic links are a useful way to lift directories that are deep in a directory tree to a more convenient depth without disturbing the original tree’s structure or contents. The example just cited lifts the Drivers directory to the volume’s root directory, reducing the directory depth of Ntfs.sys from three levels to one when Ntfs.sys is accessed through the directory symbolic link. File symbolic links work much the same way—you can think of them as shortcuts, except they are actually implemented on the file system instead of being .lnk files managed by Windows Explorer. Just like hard links, symbolic links can be created with the mklink utility (without the /H option) or through the CreateSymbolicLink API.
Because certain legacy applications might not behave securely in the presence of symbolic links, especially across different machines, the creation of symbolic links requires the SeCreateSymbolicLink privilege, which is typically granted only to administrators. The file system also has a behavior option called SymLinkEvaluation that can be configured with the following command:
fsutil behavior set SymLinkEvaluation
By default, the Windows default symbolic link evaluation policy allows only local-to-local and local-to-remote symbolic links but not the opposite, as shown here:
C:\>fsutil behavior query SymLinkEvaluation
Local to local symbolic links are enabled
Local to remote symbolic links are enabled.
Remote to local symbolic links are disabled.
Remote to Remote symbolic links are disabled.
Symbolic links are implemented using an NTFS mechanism called reparse points. (Reparse points are discussed further in the section Reparse Points later in this chapter.) A reparse point is a file or directory that has a block of data called reparse data associated with it. Reparse data is user-defined data about the file or directory, such as its state or location that can be read from the reparse point by the application that created the data, a file system filter driver, or the I/O manager. When NTFS encounters a reparse point during a file or directory lookup, it returns the STATUS_REPARSE status code, which signals file system filter drivers that are attached to the volume and the I/O manager to examine the reparse data. Each reparse point type has a unique reparse tag. The reparse tag allows the component responsible for interpreting the reparse point’s reparse data to recognize the reparse point without having to check the reparse data. A reparse tag owner, either a file system filter driver or the I/O manager, can choose one of the following options when it recognizes reparse data:
§ The reparse tag owner can manipulate the path name specified in the file I/O operation that crosses the reparse point and let the I/O operation reissue with the altered path name. Junctions (described shortly) take this approach to redirect a directory lookup, for example.
§ The reparse tag owner can remove the reparse point from the file, alter the file in some way, and then reissue the file I/O operation.
There are no Windows functions for creating reparse points. Instead, processes must use the FSCTL_SET_REPARSE_POINT file system control code with the Windows DeviceIoControl function. A process can query a reparse point’s contents with the FSCTL_GET_REPARSE_POINT file system control code. The FILE_ATTRIBUTE_REPARSE_POINT flag is set in a reparse point’s file attributes, so applications can check for reparse points by using the Windows GetFileAttributes function.
Another type of reparse point that NTFS supports is the junction. Junctions are a legacy NTFS concept and work almost identically to directory symbolic links, except they can only be local to a volume. There is no advantage to using a junction instead of a directory symbolic link, except that junctions are compatible with older versions of Windows, while directory symbolic links are not.
EXPERIMENT: CREATING A SYMBOLIC LINK
This experiment shows you the main difference between a symbolic link and a hard link, even when dealing with files on the same volume. Create a symbolic link called soft.txt as shown here, pointing to the test.txt file created in the previous experiment:
C:\>mklink soft.txt test.txt
symbolic link created for soft.txt <<===>> test.txt
If you list the directory’s contents, you’ll notice that the symbolic link doesn’t have a file size and is identified by the <SYMLINK> type. Furthermore, you’ll note that the creation time is that of the symbolic link, not of the target file. The symbolic link can also have security permissions that are different from the permissions on the target file.
C:\>dir *.txt
Volume in drive C is OS
Volume Serial Number is 38D4-EA71
Directory of C:\
05/12/2012 11:55 PM 8 hard.txt
05/13/2012 12:28 AM <SYMLINK> soft.txt [test.txt]
05/12/2012 11:55 PM 8 test.txt
3 File(s) 16 bytes
0 Dir(s) 10,636,480,512 bytes free
Finally, if you delete the original test.txt file, you can verify that both the hard link and symbolic link still exist but that the symbolic link does not point to a valid file anymore, while the hard link references the file data.
Compression and Sparse Files
NTFS supports compression of file data. Because NTFS performs compression and decompression procedures transparently, applications don’t have to be modified to take advantage of this feature. Directories can also be compressed, which means that any files subsequently created in the directory are compressed.
Applications compress and decompress files by passing DeviceIoControl the FSCTL_SET_COMPRESSION file system control code. They query the compression state of a file or directory with the FSCTL_GET_COMPRESSION file system control code. A file or directory that is compressed has the FILE_ATTRIBUTE_COMPRESSED flag set in its attributes, so applications can also determine a file or directory’s compression state with GetFileAttributes.
A second type of compression is known as sparse files. If a file is marked as sparse, NTFS doesn’t allocate space on a volume for portions of the file that an application designates as empty. NTFS returns 0-filled buffers when an application reads from empty areas of a sparse file. This type of compression can be useful for client/server applications that implement circular-buffer logging, in which the server records information to a file and clients asynchronously read the information. Because the information that the server writes isn’t needed after a client has read it, there’s no need to store the information in the file. By making such a file sparse, the client can specify the portions of the file it reads as empty, freeing up space on the volume. The server can continue to append new information to the file without fear that the file will grow to consume all available space on the volume.
As with compressed files, NTFS manages sparse files transparently. Applications specify a file’s sparseness state by passing the FSCTL_SET_SPARSE file system control code to DeviceIoControl. To set a range of a file to empty, applications use the FSCTL_SET_ZERO_DATA code, and they can ask NTFS for a description of what parts of a file are sparse by using the control code FSCTL_QUERY_ALLOCATED_RANGES. One application of sparse files is the NTFS change journal, described next.
Change Logging
Many types of applications need to monitor volumes for file and directory changes. For example, an automatic backup program might perform an initial full backup and then incremental backups based on file changes. An obvious way for an application to monitor a volume for changes is for it to scan the volume, recording the state of files and directories, and on a subsequent scan detect differences. This process can adversely affect system performance, however, especially on computers with thousands or tens of thousands of files.
An alternate approach is for an application to register a directory notification by using the FindFirstChangeNotification or ReadDirectoryChangesW Windows function. As an input parameter, the application specifies the name of a directory it wants to monitor, and the function returns whenever the contents of the directory change. Although this approach is more efficient than volume scanning, it requires the application to be running at all times. Using these functions can also require an application to scan directories because FindFirstChangeNotification doesn’t indicate what changed—just that something in the directory has changed. An application can pass a buffer to ReadDirectoryChangesW that the FSD fills in with change records. If the buffer overflows, however, the application must be prepared to fall back on scanning the directory.
NTFS provides a third approach that overcomes the drawbacks of the first two: an application can configure the NTFS change journal facility by using the DeviceIoControl function’s FSCTL_CREATE_USN_JOURNAL file system control code (USN is update sequence number) to have NTFS record information about file and directory changes to an internal file called the change journal. A change journal is usually large enough to virtually guarantee that applications get a chance to process changes without missing any. Applications use the FSCTL_QUERY_USN_JOURNAL file system control code to read records from a change journal, and they can specify that the DeviceIoControl function not complete until new records are available.
Per-User Volume Quotas
Systems administrators often need to track or limit user disk space usage on shared storage volumes, so NTFS includes quota-management support. NTFS quota-management support allows for per-user specification of quota enforcement, which is useful for usage tracking and tracking when a user reaches warning and limit thresholds. NTFS can be configured to log an event indicating the occurrence to the System event log if a user surpasses his warning limit. Similarly, if a user attempts to use more volume storage then her quota limit permits, NTFS can log an event to the System event log and fail the application file I/O that would have caused the quota violation with a “disk full” error code.
NTFS tracks a user’s volume usage by relying on the fact that it tags files and directories with the security ID (SID) of the user who created them. (See Chapter 6 in Part 1 for a definition of SIDs.) The logical sizes of files and directories a user owns count against the user’s administrator-defined quota limit. Thus, a user can’t circumvent his or her quota limit by creating an empty sparse file that is larger than the quota would allow and then fill the file with nonzero data. Similarly, whereas a 50-KB file might compress to 10 KB, the full 50 KB is used for quota accounting.
By default, volumes don’t have quota tracking enabled. You need to use the Quota tab of a volume’s Properties dialog box, shown in Figure 12-20, to enable quotas, to specify default warning and limit thresholds, and to configure the NTFS behavior that occurs when a user hits the warning or limit threshold. The Quota Entries tool, which you can launch from this dialog box, enables an administrator to specify different limits and behavior for each user. Applications that want to interact with NTFS quota management use COM quota interfaces, includingIDiskQuotaControl, IDiskQuotaUser, and IDiskQuotaEvents.
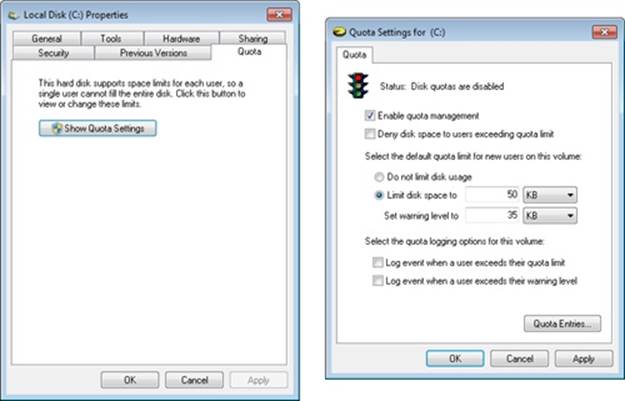
Figure 12-20. Volume Properties dialog box
Link Tracking
Shell shortcuts allow users to place files in their shell namespace (on their desktop, for example) that link to files located in the file system namespace. The Windows Start menu uses shell shortcuts extensively. Similarly, object linking and embedding (OLE) links allow documents from one application to be transparently embedded in the documents of other applications. The products of the Microsoft Office suite, including PowerPoint, Excel, and Word, use OLE linking.
Although shell and OLE links provide an easy way to connect files with one another and with the shell namespace, they can be difficult to manage if a user moves the source of a shell or OLE link (a link source is the file or directory to which a link points). NTFS in Windows includes support for a service application called distributed link-tracking, which maintains the integrity of shell and OLE links when link targets move. Using the NTFS link-tracking support, if a link target located on an NTFS volume moves to any other NTFS volume within the originating volume’s domain, the link-tracking service can transparently follow the movement and update the link to reflect the change.
NTFS link-tracking support is based on an optional file attribute known as an object ID. An application can assign an object ID to a file by using the FSCTL_CREATE_OR_GET_OBJECT_ID (which assigns an ID if one isn’t already assigned) and FSCTL_SET_OBJECT_ID file system control codes. Object IDs are queried with the FSCTL_CREATE_OR_GET_OBJECT_ID and FSCTL_GET_OBJECT_ID file system control codes. The FSCTL_DELETE_OBJECT_ID file system control code lets applications delete object IDs from files.
Encryption
Corporate users often store sensitive information on their computers. Although data stored on company servers is usually safely protected with proper network security settings and physical access control, data stored on laptops can be exposed when a laptop is lost or stolen. NTFS file permissions don’t offer protection because NTFS volumes can be fully accessed without regard to security by using NTFS file-reading software that doesn’t require Windows to be running. Furthermore, NTFS file permissions are rendered useless when an alternate Windows installation is used to access files from an administrator account. Recall from Chapter 6 in Part 1 that the administrator account has the take-ownership and backup privileges, both of which allow it to access any secured object by overriding the object’s security settings.
NTFS includes a facility called Encrypting File System (EFS), which users can use to encrypt sensitive data. The operation of EFS, as that of file compression, is completely transparent to applications, which means that file data is automatically decrypted when an application running in the account of a user authorized to view the data reads it and is automatically encrypted when an authorized application changes the data.
NOTE
NTFS doesn’t permit the encryption of files located in the system volume’s root directory or in the \Windows directory because many files in these locations are required during the boot process and EFS isn’t active during the boot process. BitLocker, described in Chapter 9, is a technology much better suited for environments in which this is a requirement because it supports full-volume encryption.
EFS relies on cryptographic services supplied by Windows in user mode, so it consists of both a kernel-mode component that tightly integrates with NTFS as well as user-mode DLLs that communicate with the Local Security Authority Subsystem (LSASS) and cryptographic DLLs.
Files that are encrypted can be accessed only by using the private key of an account’s EFS private/public key pair, and private keys are locked using an account’s password. Thus, EFS-encrypted files on lost or stolen laptops can’t be accessed using any means (other than a brute-force cryptographic attack) without the password of an account that is authorized to view the data.
Applications can use the EncryptFile and DecryptFile Windows API functions to encrypt and decrypt files, and FileEncryptionStatus to retrieve a file or directory’s EFS-related attributes, such as whether the file or directory is encrypted. A file or directory that is encrypted has theFILE_ATTRIBUTE_ENCRYPTED flag set in its attributes, so applications can also determine a file or directory’s encryption state with GetFileAttributes.
POSIX Support
As explained in Chapter 2, “System Architecture,” in Part 1, one of the mandates for Windows was to fully support the POSIX 1003.1 standard. In the file system area, the POSIX standard requires support for case-sensitive file and directory names, traversal permissions (where security for each directory of a path is used when determining whether a user has access to a file or directory), a “file-change-time” time stamp (which is different from the MS-DOS “time-last-modified” stamp), and hard links. NTFS implements each of these features.
Defragmentation
Even though NTFS makes efforts to keep files contiguous when allocating blocks to extend a file, a volume’s files can still become fragmented over time, especially if the file is extended multiple times or when there is limited free space. A file is fragmented if its data occupies discontiguous clusters. For example, Figure 12-21 shows a fragmented file consisting of five fragments. However, like most file systems (including versions of FAT on Windows), NTFS makes no special efforts to keep files contiguous (this is handled by the built-in defragmenter), other than to reserve a region of disk space known as the master file table (MFT) zone for the MFT. (NTFS lets other files allocate from the MFT zone when volume free space runs low.) Keeping an area free for the MFT can help it stay contiguous, but it, too, can become fragmented. (See the section Master File Table later in this chapter for more information on MFTs.)
Figure 12-21. Fragmented and contiguous files
To facilitate the development of third-party disk defragmentation tools, Windows includes a defragmentation API that such tools can use to move file data so that files occupy contiguous clusters. The API consists of file system controls that let applications obtain a map of a volume’sfree and in-use clusters (FSCTL_GET_VOLUME_BITMAP), obtain a map of a file’s cluster usage (FSCTL_GET_RETRIEVAL_POINTERS), and move a file (FSCTL_MOVE_FILE).
Windows includes a built-in defragmentation tool that is accessible by using the Disk Defragmenter utility (%SystemRoot%\System32\Dfrgui.exe), shown in Figure 12-22, as well as a command-line interface, %SystemRoot%\System32\Defrag.exe, that you can run interactively or schedule but that does not produce detailed reports or offer control—such as excluding files or directories—over the defragmentation process.
Figure 12-22. Disk Defragmenter
The only limitation imposed by the defragmentation implementation in NTFS is that paging files and NTFS log files cannot be defragmented.
Dynamic Partitioning
The NTFS driver allows users to dynamically resize any partition, including the system partition, either shrinking or expanding it (if enough space is available). Expanding a partition is easy if enough space exists on the disk and is performed through the FSCTL_EXPAND_VOLUME file system control code. Shrinking a partition is a more complicated process, because it requires moving any file system data that is currently in the area to be thrown away to the region that will still remain after the shrinking process (a mechanism similar to defragmentation).Shrinking is implemented by two components: the shrinking engine and the file system driver.
The shrinking engine is implemented in user mode. It communicates with NTFS to determine the maximum number of reclaimable bytes—that is, how much data can be moved from the region that will be resized into the region that will remain. The shrinking engine uses the standard defragmentation mechanism shown earlier, which doesn’t support relocating page file fragments that are in use or any other files that have been marked as unmovable with the FSCTL_MARK_HANDLE file system control code (like the hibernation file). The master file table backup ($MftMirr), the NTFS metadata transaction log ($LogFile), and the volume label file ($Volume) cannot be moved, which limits the minimum size of the shrunk volume and causes wasted space.
The file system driver shrinking code is responsible for ensuring that the volume remains in a consistent state throughout the shrinking process. To do so, it exposes an interface that uses three requests that describe the current operation, which are sent through the FSCTL_SHRINK_VOLUME control code:
§ The ShrinkPrepare request, which must be issued before any other operation. This request takes the desired size of the new volume in sectors and is used so that the file system can block further allocations outside the new volume boundary. The ShrinkPrepare request doesn’t verify whether the volume can actually be shrunk by the specified amount, but it does ensure that the amount is numerically valid and that there aren’t any other shrinking operations ongoing. Note that after a prepare operation, the file handle to the volume becomes associated with the shrink request. If the file handle is closed, the operation is assumed to be aborted.
§ The ShrinkCommit request, which the shrinking engine issues after a ShrinkPrepare request. In this state, the file system attempts the removal of the requested number of clusters in the most recent prepare request. (If multiple prepare requests have been sent with different sizes, the last one is the determining one.) The ShrinkCommit request assumes that the shrinking engine has completed and will fail if any allocated blocks remain in the area to be shrunk.
§ The ShrinkAbort request, which can be issued by the shrinking engine or caused by events such as the closure of the file handle to the volume. This request undoes the ShrinkCommit operation by returning the partition to its original size and allows new allocations outside the shrunk region to occur again. However, defragmentation changes made by the shrinking engine remain.
If a system is rebooted during a shrinking operation, NTFS restores the file system to a consistent state via its metadata recovery mechanism, explained later in the chapter. Because the actual shrink operation isn’t executed until all other operations have been completed, the volume retains its original size and only defragmentation operations that had already been flushed out to disk persist.
Finally, shrinking a volume has several effects on the volume shadow copy mechanism (for more information on VSS, see Chapter 9). Recall that the copy-on-write mechanism allows VSS to simply retain parts of the file that were actually modified while still linking to the original file data. For deleted files, this file data will not be associated with visible files but appear as free space instead—free space that will likely be located in the area that is about to be shrunk. The shrinking engine therefore communicates with VSS to engage it in the shrinking process. In summary, the VSS mechanism’s job is to copy deleted file data into its differencing area and to increase the differencing area as required to accommodate additional data. This detail is important because it poses another constraint on the size to which even volumes with ample free space can shrink.
NTFS File System Driver
As described in Chapter 8, in the framework of the Windows I/O system, NTFS and other file systems are loadable device drivers that run in kernel mode. They are invoked indirectly by applications that use Windows or other I/O APIs (such as POSIX). As Figure 12-23 shows, the Windows environment subsystems call Windows system services, which in turn locate the appropriate loaded drivers and call them. (For a description of system service dispatching, see the section “System Service Dispatching” in Chapter 3 in Part 1.)
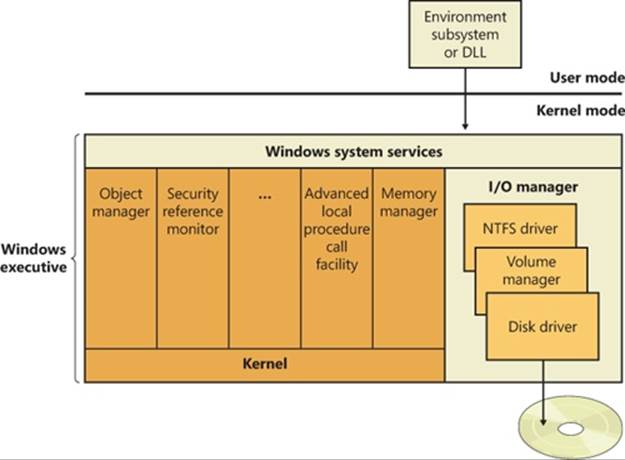
Figure 12-23. Components of the Windows I/O system
The layered drivers pass I/O requests to one another by calling the Windows executive’s I/O manager. Relying on the I/O manager as an intermediary allows each driver to maintain independence so that it can be loaded or unloaded without affecting other drivers. In addition, theNTFS driver interacts with the three other Windows executive components, shown in the left side of Figure 12-24, that are closely related to file systems.
The log file service (LFS) is the part of NTFS that provides services for maintaining a log of disk writes. The log file that LFS writes is used to recover an NTFS-formatted volume in the case of a system failure. (See the section Log File Service later in the chapter.)
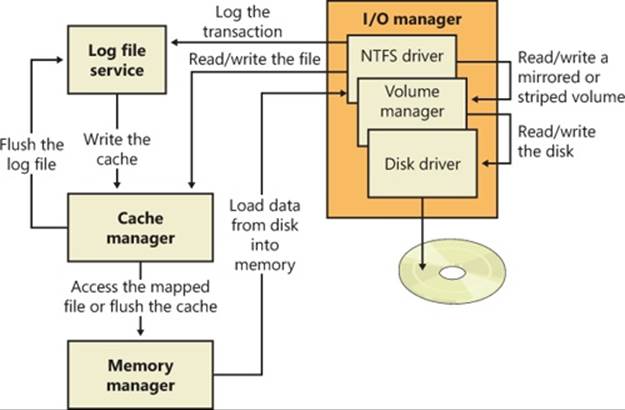
Figure 12-24. NTFS and related components
The cache manager is the component of the Windows executive that provides systemwide caching services for NTFS and other file system drivers, including network file system drivers (servers and redirectors). All file systems implemented for Windows access cached files by mapping them into system address space and then accessing the virtual memory. The cache manager provides a specialized file system interface to the Windows memory manager for this purpose. When a program tries to access a part of a file that isn’t loaded into the cache (a cache miss), the memory manager calls NTFS to access the disk driver and obtain the file contents from disk. The cache manager optimizes disk I/O by using its lazy writer threads to call the memory manager to flush cache contents to disk as a background activity (asynchronous disk writing). (For a complete description of the cache manager, see Chapter 11.)
NTFS participates in the Windows object model by implementing files as objects. This implementation allows files to be shared and protected by the object manager, the component of Windows that manages all executive-level objects. (The object manager is described in the section “Object Manager” in Chapter 3 in Part 1.)
An application creates and accesses files just as it does other Windows objects: by means of object handles. By the time an I/O request reaches NTFS, the Windows object manager and security system have already verified that the calling process has the authority to access the file object in the way it is attempting to. The security system has compared the caller’s access token to the entries in the access control list for the file object. (See Chapter 6 in Part 1 for more information about access control lists.) The I/O manager has also transformed the file handle into a pointer to a file object. NTFS uses the information in the file object to access the file on disk.
Figure 12-25 shows the data structures that link a file handle to the file system’s on-disk structure.
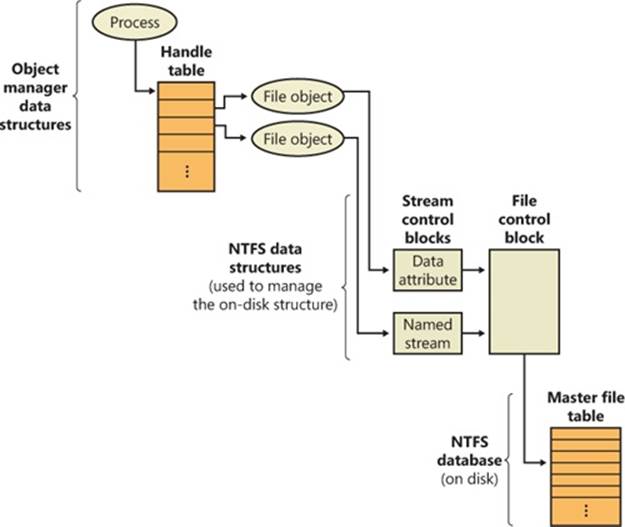
Figure 12-25. NTFS data structures
NTFS follows several pointers to get from the file object to the location of the file on disk. As Figure 12-25 shows, a file object, which represents a single call to the open-file system service, points to a stream control block (SCB) for the file attribute that the caller is trying to read or write. In Figure 12-25, a process has opened both the unnamed data attribute and a named stream (alternate data attribute) for the file. The SCBs represent individual file attributes and contain information about how to find specific attributes within a file. All the SCBs for a file point to a common data structure called a file control block (FCB). The FCB contains a pointer (actually, an index into the MFT, as explained in the section File Record Numbers later in this chapter) to the file’s record in the disk-based master file table (MFT), which is described in detail in the following section.
NTFS On-Disk Structure
This section describes the on-disk structure of an NTFS volume, including how disk space is divided and organized into clusters, how files are organized into directories, how the actual file data and attribute information is stored on disk, and finally, how NTFS data compression works.
Volumes
The structure of NTFS begins with a volume. A volume corresponds to a logical partition on a disk, and it is created when you format a disk or part of a disk for NTFS. You can also create a RAID volume that spans multiple disks by using the Windows Disk Management MMC snap-in or the diskpart (%SystemRoot%\System32\Diskpart.exe) command available from the Windows command prompt.
A disk can have one volume or several. NTFS handles each volume independently of the others. Three sample disk configurations for a 150-GB hard disk are illustrated in Figure 12-26.
Figure 12-26. Sample disk configurations
A volume consists of a series of files plus any additional unallocated space remaining on the disk partition. In the FAT file system, a volume also contains areas specially formatted for use by the file system. An NTFS volume, however, stores all file system data, such as bitmaps and directories, and even the system bootstrap, as ordinary files.
NOTE
The on-disk format of NTFS volumes on Windows 7 and Windows Server 2008 R2 is version 3.1, the same as it has been since Windows XP and Windows Server 2003. The version number of a volume is stored in its $Volume metadata file.
Clusters
The cluster size on an NTFS volume, or the cluster factor, is established when a user formats the volume with either the format command or the Disk Management MMC snap-in. The default cluster factor varies with the size of the volume, but it is an integral number of physical sectors, always a power of 2 (1 sector, 2 sectors, 4 sectors, 8 sectors, and so on). The cluster factor is expressed as the number of bytes in the cluster, such as 512 bytes, 1 KB, 2 KB, and so on.
Internally, NTFS refers only to clusters. (However, NTFS forms low-level volume I/O operations such that clusters are sector-aligned and have a length that is a multiple of the sector size.) NTFS uses the cluster as its unit of allocation to maintain its independence from physical sector sizes. This independence allows NTFS to efficiently support very large disks by using a larger cluster factor or to support newer disks that have a sector size other than 512 bytes. (See Chapter 9 for more information on disks with sectors larger than 512 bytes.) On a larger volume, use of a larger cluster factor can reduce fragmentation and speed allocation, at the cost of wasted disk space. (If the cluster size is 4,096, and a file is only 1,024 bytes, then 3,072 bytes are wasted. See Chapter 9 for more information on default cluster sizes.) Both the format command available from the command prompt and the Format menu option under the All Tasks option on the Action menu in the Disk Management MMC snap-in choose a default cluster factor based on the volume size, but you can override this size.
NTFS refers to physical locations on a disk by means of logical cluster numbers (LCNs). LCNs are simply the numbering of all clusters from the beginning of the volume to the end. To convert an LCN to a physical disk address, NTFS multiplies the LCN by the cluster factor to get the physical byte offset on the volume, as the disk driver interface requires. NTFS refers to the data within a file by means of virtual cluster numbers (VCNs). VCNs number the clusters belonging to a particular file from 0 through m. VCNs aren’t necessarily physically contiguous, however; they can be mapped to any number of LCNs on the volume.
Master File Table
In NTFS, all data stored on a volume is contained in files, including the data structures used to locate and retrieve files, the bootstrap data, and the bitmap that records the allocation state of the entire volume (the NTFS metadata). Storing everything in files allows the file system to easily locate and maintain the data, and each separate file can be protected by a security descriptor. In addition, if a particular part of the disk goes bad, NTFS can relocate the metadata files to prevent the disk from becoming inaccessible.
The MFT is the heart of the NTFS volume structure. The MFT is implemented as an array of file records. The size of each file record is fixed at 1 KB, regardless of cluster size. (The structure of a file record is described in the File Records section later in this chapter.) Logically, the MFT contains one record for each file on the volume, including a record for the MFT itself. In addition to the MFT, each NTFS volume includes a set of metadata files containing the information that is used to implement the file system structure. Each of these NTFS metadata files has a name that begins with a dollar sign ($), and is hidden. For example, the file name of the MFT is $MFT. The rest of the files on an NTFS volume are normal user files and directories, as shown in Figure 12-27.
Usually, each MFT record corresponds to a different file. If a file has a large number of attributes or becomes highly fragmented, however, more than one record might be needed for a single file. In such cases, the first MFT record, which stores the locations of the others, is called thebase file record.
Figure 12-27. File records for NTFS metadata files in the MFT
When it first accesses a volume, NTFS must mount it—that is, read metadata from the disk and construct internal data structures so that it can process application file system accesses. To mount the volume, NTFS looks in the volume boot record (VBR) (located at LCN 0), which contains a data structure call the boot parameter block (BPB), to find the physical disk address of the MFT. The MFT’s own file record is the first entry in the table; the second file record points to a file located in the middle of the disk called the MFT mirror (file name $MFTMirr) that contains a copy of the first four rows of the MFT. This partial copy of the MFT is used to locate metadata files if part of the MFT file can’t be read for some reason.
Once NTFS finds the file record for the MFT, it obtains the VCN-to-LCN mapping information in the file record’s data attribute and stores it into memory. Each run (runs are explained later in this chapter in the section Resident and Nonresident Attributes) has a VCN-to-LCN mapping and a run length because that’s all the information necessary to locate the LCN for any VCN. This mapping information tells NTFS where the runs containing the MFT are located on the disk. NTFS then processes the MFT records for several more metadata files and opens the files. Next, NTFS performs its file system recovery operation (described in the section Recovery later in this chapter), and finally, it opens its remaining metadata files. The volume is now ready for user access.
NOTE
For the sake of clarity, the text and diagrams in this chapter depict a run as including a VCN, an LCN, and a run length. NTFS actually compresses this information on disk into an LCN/next-VCN pair. Given a starting VCN, NTFS can determine the length of a run by subtracting the starting VCN from the next VCN.
As the system runs, NTFS writes to another important metadata file, the log file (file name $LogFile). NTFS uses the log file to record all operations that affect the NTFS volume structure, including file creation or any commands, such as copy, that alter the directory structure. The log file is used to recover an NTFS volume after a system failure and is also described in the Recovery section.
Another entry in the MFT is reserved for the root directory (also known as “\”; for example, C:\). Its file record contains an index of the files and directories stored in the root of the NTFS directory structure. When NTFS is first asked to open a file, it begins its search for the file in the root directory’s file record. After opening a file, NTFS stores the file’s MFT record number so that it can directly access the file’s MFT record when it reads and writes the file later.
NTFS records the allocation state of the volume in the bitmap file (file name $BitMap). The data attribute for the bitmap file contains a bitmap, each of whose bits represents a cluster on the volume, identifying whether the cluster is free or has been allocated to a file.
The security file (file name $Secure) stores the volume-wide security descriptor database. NTFS files and directories have individually settable security descriptors, but to conserve space, NTFS stores the settings in a common file, which allows files and directories that have the same security settings to reference the same security descriptor. In most environments, entire directory trees have the same security settings, so this optimization provides a significant saving of disk space.
Another system file, the boot file (file name $Boot), stores the Windows bootstrap code if the volume is a system volume. On non-system volumes, there is code that displays an error message on the screen if an attempt is made to boot from that volume. For the system to boot, the bootstrap code must be located at a specific disk address so that the BIOS can find it. During formatting, the format command defines this area as a file by creating a file record for it. All files are in the MFT, and all clusters are either free or allocated to a file—there are no hidden files or clusters in NTFS, although some files (metadata) are not visible to users. The boot file as well as NTFS metadata files can be individually protected by means of the security descriptors that are applied to all Windows objects. Using this “everything on the disk is a file” model also means that the bootstrap can be modified by normal file I/O, although the boot file is protected from editing.
NTFS also maintains a bad-cluster file (file name $BadClus) for recording any bad spots on the disk volume and a file known as the volume file (file name $Volume), which contains the volume name, the version of NTFS for which the volume is formatted, and a number of flag bits that indicate the state and health of the volume, such as a bit that indicates that the volume is corrupt and must be repaired by the Chkdsk utility. (The Chkdsk utility is covered in more detail later in the chapter.) The uppercase file (file name $UpCase) includes a translation table between lowercase and uppercase characters. NTFS maintains a file containing an attribute definition table (file name $AttrDef) that defines the attribute types supported on the volume and indicates whether they can be indexed, recovered during a system recovery operation, and so on.
NTFS stores several metadata files in the extensions (directory name $Extend) metadata directory, including the object identifier file (file name $ObjId), the quota file (file name $Quota), the change journal file (file name $UsnJrnl), the reparse point file (file name $Reparse), and thedefault resource manager directory (directory name $RmMetadata). These files store information related to extended features of NTFS. The object identifier file stores file object IDs, the quota file stores quota limit and behavior information on volumes that have quotas enabled, the change journal file records file and directory changes, and the reparse point file stores information about which files and directories on the volume include reparse point data.
The default resource manager directory contains directories related to transactional NTFS (TxF) support, including the transaction log directory (directory name $TxfLog), the transaction isolation directory (directory name $Txf), and the transaction repair directory (file name $Repair). The transaction log directory contains the TxF base log file (file name $TxfLog.blf) and any number of log container files, depending on the size of the transaction log, but it always contains at least two: one for the Kernel Transaction Manager (KTM) log stream (file name $TxfLogContainer00000000000000000001), and one for the TxF log stream (file name $TxfLogContainer00000000000000000002). The transaction log directory also contains the TxF old page stream (file name $Tops), which we’ll describe later.
EXPERIMENT: VIEWING NTFS INFORMATION
You can use the built-in Fsutil.exe command-line program to view information about an NTFS volume, including the placement and size of the MFT and MFT zone:
C:\>fsutil fsinfo ntfsinfo c:
NTFS Volume Serial Number : 0x9a38d50e38d4ea71
Version : 3.1
Number Sectors : 0x0000000015c82ff0
Total Clusters : 0x0000000002b905fe
Free Clusters : 0x000000000013c332
Total Reserved : 0x0000000000000780
Bytes Per Sector : 512
Bytes Per Cluster : 4096
Bytes Per FileRecord Segment : 1024
Clusters Per FileRecord Segment : 0
Mft Valid Data Length : 0x0000000023db0000
Mft Start Lcn : 0x00000000000c0000
Mft2 Start Lcn : 0x00000000016082ff
Mft Zone Start : 0x0000000002751f60
Mft Zone End : 0x000000000275cd60
RM Identifier: CF7234E7-39E3-11DC-BDCE-00188BDD5F49
File Record Numbers
A file on an NTFS volume is identified by a 64-bit value called a file record number, which consists of a file number and a sequence number. The file number corresponds to the position of the file’s file record in the MFT minus 1 (or to the position of the base file record minus 1 if the file has more than one file record). The sequence number, which is incremented each time an MFT file record position is reused, enables NTFS to perform internal consistency checks. A file record number is illustrated in Figure 12-28.
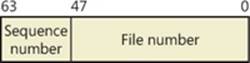
Figure 12-28. File record number
File Records
Instead of viewing a file as just a repository for textual or binary data, NTFS stores files as a collection of attribute/value pairs, one of which is the data it contains (called the unnamed data attribute). Other attributes that comprise a file include the file name, time stamp information, and possibly additional named data attributes. Figure 12-29 illustrates an MFT record for a small file.
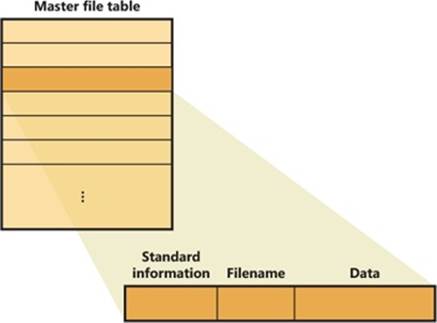
Figure 12-29. MFT record for a small file
Each file attribute is stored as a separate stream of bytes within a file. Strictly speaking, NTFS doesn’t read and write files—it reads and writes attribute streams. NTFS supplies these attribute operations: create, delete, read (byte range), and write (byte range). The read and write services normally operate on the file’s unnamed data attribute. However, a caller can specify a different data attribute by using the named data stream syntax.
Table 12-6 lists the attributes for files on an NTFS volume. (Not all attributes are present for every file.)
Table 12-6. Attributes for NTFS Files
|
Attribute |
Attribute Type Name |
Resident? |
Description |
|
Volume information |
$VOLUME_INFORMATION, $VOLUME_NAME |
Always, Always |
These attributes are present only in the $Volume metadata file. They store volume version and label information. |
|
Standard information |
$STANDARD_INFORMATION |
Always |
File attributes such as read-only, archive, and so on; time stamps, including when the file was created or last modified. |
|
Filename |
$FILE_NAME |
Maybe |
The file’s name in Unicode 1.0 characters. A file can have multiple filename attributes, as it does when a hard link to a file exists or when a file with a long name has an automatically generated “short name” for access by MS-DOS and 16-bit Windows applications. |
|
Security descriptor |
$SECURITY_DESCRIPTOR |
Maybe |
This attribute is present for backward compatibility with previous versions of NTFS and is rarely used in the current version of NTFS (3.1). NTFS stores almost all security descriptors in the $Secure metadata file, sharing descriptors among files and directories that have the same settings. Previous versions of NTFS stored private security descriptor information with each file and directory. Some files still include a $SECURITY_DESCRIPTOR attribute, such as $Boot. |
|
Data |
$DATA |
The contents of the file. In NTFS, a file has one default unnamed data attribute and can have additional named data attributes—that is, a file can have multiple data streams. A directory has no default data attribute but can have optional named data attributes. |
|
|
Index root, index allocation, and index bitmap |
$INDEX_ROOT, $INDEX_ALLOCATION, $BITMAP |
Always, Never, Maybe |
Three attributes used to implement B-tree data structures used by directories, security, quota, and other metadata files. |
|
Attribute list |
$ATTRIBUTE_LIST |
Maybe |
A list of the attributes that make up the file and the file record number of the MFT entry where each attribute is located. This attribute is present when a file requires more than one MFT file record. |
|
Object ID |
$OBJECT_ID |
Always |
A 16-byte identifier (GUID) for a file or directory. The link-tracking service assigns object IDs to shell shortcut and OLE link source files. NTFS provides APIs so that files and directories can be opened with their object ID rather than their file name. |
|
Reparse information |
$REPARSE_POINT |
Maybe |
This attribute stores a file’s reparse point data. NTFS junctions and mount points include this attribute. |
|
Extended attributes |
$EA, $EA_INFORMATION |
Maybe, Always |
Extended attributes are name/value pairs and aren’t normally used but are provided for backward compatibility with OS/2 applications. |
|
Logged utility stream |
$LOGGED_UTILITY_STREAM |
Maybe |
EFS stores data in this attribute ($EFS) that’s used to manage a file’s encryption, such as the encrypted version of the key needed to decrypt the file and a list of users who are authorized to access the file. When a file or directory becomes part of a transaction, TxF also stores transaction data in the $TXF_DATA attribute, such as the file’s unique transaction ID. |
Table 12-6 shows attribute names; however, attributes actually correspond to numeric type codes, which NTFS uses to order the attributes within a file record. The file attributes in an MFT record are ordered by these type codes (numerically in ascending order), with some attribute types appearing more than once—if a file has multiple data attributes, for example, or multiple file names. All possible attribute types (and their names) are listed in the $AttrDef metadata file.
Each attribute in a file record is identified with its attribute type code and has a value and an optional name. An attribute’s value is the byte stream composing the attribute. For example, the value of the $FILE_NAME attribute is the file’s name; the value of the $DATA attribute is whatever bytes the user stored in the file.
Most attributes never have names, although the index-related attributes and the $DATA attribute often do. Names distinguish between multiple attributes of the same type that a file can include. For example, a file that has a named data stream has two $DATA attributes: an unnamed $DATA attribute storing the default unnamed data stream and a named $DATA attribute having the name of the alternate stream and storing the named stream’s data.
File Names
Both NTFS and FAT allow each file name in a path to be as many as 255 characters long. File names can contain Unicode characters as well as multiple periods and embedded spaces. However, the FAT file system supplied with MS-DOS is limited to 8 (non-Unicode) characters for its file names, followed by a period and a 3-character extension. Figure 12-30 provides a visual representation of the different file namespaces Windows supports and shows how they intersect.
The POSIX subsystem requires the biggest namespace of all the application execution environments that Windows supports, and therefore the NTFS namespace is equivalent to the POSIX namespace. The POSIX subsystem can create names that aren’t visible to Windows and MS-DOS applications, including names with trailing periods and trailing spaces. Ordinarily, creating a file using the large POSIX namespace isn’t a problem because you would do that only if you intended the POSIX subsystem or POSIX client systems to use that file.
Figure 12-30. Windows file namespaces
The relationship between 32-bit Windows (Windows) applications and MS-DOS and 16-bit Windows applications is a much closer one, however. The Windows area in Figure 12-30 represents file names that the Windows subsystem can create on an NTFS volume but that MS-DOS and 16-bit Windows applications can’t see. This group includes file names longer than the 8.3 format of MS-DOS names, those containing Unicode (international) characters, those with multiple period characters or a beginning period, and those with embedded spaces. When a file is created with such a name, NTFS automatically generates an alternate, MS-DOS-style file name for the file. Windows displays these short names when you use the /x option with the dir command.
The MS-DOS file names are fully functional aliases for the NTFS files and are stored in the same directory as the long file names. The MFT record for a file with an autogenerated MS-DOS file name is shown in Figure 12-31.
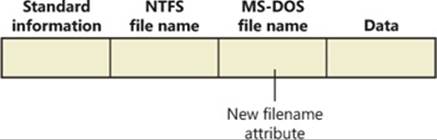
Figure 12-31. MFT file record with an MS-DOS filename attribute
The NTFS name and the generated MS-DOS name are stored in the same file record and therefore refer to the same file. The MS-DOS name can be used to open, read from, write to, or copy the file. If a user renames the file using either the long file name or the short file name, the new name replaces both the existing names. If the new name isn’t a valid MS-DOS name, NTFS generates another MS-DOS name for the file (note that NTFS only generates MS-DOS-style file names for the first file name).
NOTE
Hard links are implemented in a similar way. When a hard link to a file is created, NTFS adds another file name attribute to the file’s MFT file record. The two situations differ in one regard, however. When a user deletes a file that has multiple names (hard links), the file record and the file remain in place. The file and its record are deleted only when the last file name (hard link) is deleted. If a file has both an NTFS name and an autogenerated MS-DOS name, however, a user can delete the file using either name.
Here’s the algorithm NTFS uses (the algorithm is actually implemented in the kernel function RtlGenerate8dot3Name and is also used by other drivers, such as CDFS, FAT, and third-party file systems) to generate an MS-DOS name from a long file name:
1. Remove from the long name any characters that are illegal in MS-DOS names, including spaces and Unicode characters. Remove preceding and trailing periods. Remove all other embedded periods, except the last one.
2. Truncate the string before the period (if present) to six characters (it may already be six or fewer because this algorithm is applied when any character that is illegal in MS-DOS is present in the name); if it is two or fewer characters, generate and concatenate a four-character hex checksum string. Append the string ~n (where n is a number, starting with 1, that is used to distinguish different files that truncate to the same name). Truncate the string after the period (if present) to three characters.
3. Put the result in uppercase letters. MS-DOS is case-insensitive, and this step guarantees that NTFS won’t generate a new name that differs from the old only in case.
4. If the generated name duplicates an existing name in the directory, increment the ~n string. If n is greater than 4, and a checksum was not concatenated already, truncate the string before the period to two characters and generate and concatenate a four-character hex checksum string.
Table 12-7 shows the long Windows file names from Figure 12-30 and their NTFS-generated MS-DOS versions. The current algorithm and the examples in Figure 12-30 should give you an idea of what NTFS-generated MS-DOS-style file names look like.
NOTE
Although not generally recommended because it can cause incompatibilities with applications that rely on them, you can disable short name generation by setting HKLM\SYSTEM\CurrentControlSet\Control\FileSystem\NtfsDisable8dot3NameCreation in the registry to a DWORD value of 1 and restarting the machine.
TUNNELING
NTFS uses the concept of tunneling to allow compatibility with older programs that depend on the file system to cache certain file metadata for a period of time even after the file is gone, such as when it has been deleted or renamed. With tunneling, any new file created with the same name as the original file, and within a certain period of time, will keep some of the same metadata. The idea is to replicate behavior expected by MS-DOS programs when using the safe save programming method, in which modified data is copied to a temporary file, the original file is deleted, and then the temporary file is renamed to the original name. The expected behavior in this case is that the renamed temporary file should appear to be the same as the original file, otherwise the creation time would continuously update itself with each modification (which is how the modified time is used).
NTFS uses tunneling so that when a file name is removed from a directory, its long name and short name, as well as its creation time, are saved into a cache. When a new file is added to a directory, the cache is searched to see whether there is any tunneled data to restore. Because these operations apply to directories, each directory instance has its own cache, which is deleted if the directory is removed. NTFS will use tunneling for the following series of operations if the names used result in the deletion and re-creation of the same file name:
§ Delete + Create
§ Delete + Rename
§ Rename + Create
§ Rename + Rename
By default, NTFS keeps the tunneling cache for 15 seconds, although you can modify this timeout by creating a new value called MaximumTunnelEntryAgeInSeconds in the HKLM\SYSTEM\CurrentControlSet\Control\FileSystem registry key. Tunneling can also be completely disabled by creating a new value called MaximumTunnelEntries and setting it to 0; however, this will cause older applications to break if they rely on the compatibility behavior.
You can see tunneling in action with the following simple experiment in the command prompt:
1. Create a file called file1.
2. Wait for more than 15 seconds (the default tunnel cache timeout).
3. Create a file called file2.
4. Perform a dir /TC. Note the creation times.
5. Rename file1 to file.
6. Rename file2 to file1.
7. Perform a dir /TC. Note that the creation times are identical.
Table 12-7. NTFS-Generated File Names
|
Windows Long Name |
NTFS-Generated Short Name |
|
LongFileName |
LONGFI~1 |
|
UnicodeName.ΦDΠΛ |
UNICOD~1 |
|
File.Name.With.Dots |
FILENA~1.DOT |
|
File.Name2.With.Dots |
FILENA~2.DOT |
|
File.Name3.With.Dots |
FILENA~3.DOT |
|
File.Name4.With.Dots |
FILENA~4.DOT |
|
File.Name5.With.Dots |
FIF596~1.DOT |
|
Name With Embedded Spaces |
NAMEWI~1 |
|
.BeginningDot |
BEGINN~1 |
|
25¢.two characters |
255440~1.TWO |
|
© |
6E2D~1 |
Resident and Nonresident Attributes
If a file is small, all its attributes and their values (its data, for example) fit within the file record that describes the file. When the value of an attribute is stored in the MFT (either in the file’s main file record or an extension record located elsewhere within the MFT), the attribute is called a resident attribute. (In Figure 12-31, for example, all attributes are resident.) Several attributes are defined as always being resident so that NTFS can locate nonresident attributes. The standard information and index root attributes are always resident, for example.
Each attribute begins with a standard header containing information about the attribute, information that NTFS uses to manage the attributes in a generic way. The header, which is always resident, records whether the attribute’s value is resident or nonresident. For resident attributes, the header also contains the offset from the header to the attribute’s value and the length of the attribute’s value, as Figure 12-32 illustrates for the filename attribute.
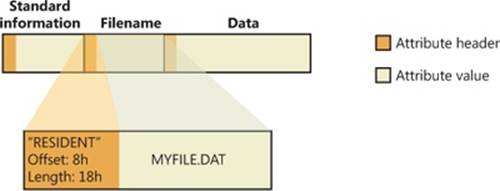
Figure 12-32. Resident attribute header and value
When an attribute’s value is stored directly in the MFT, the time it takes NTFS to access the value is greatly reduced. Instead of looking up a file in a table and then reading a succession of allocation units to find the file’s data (as the FAT file system does, for example), NTFS accesses the disk once and retrieves the data immediately.
The attributes for a small directory, as well as for a small file, can be resident in the MFT, as Figure 12-33 shows. For a small directory, the index root attribute contains an index (organized as a B-tree) of file record numbers for the files (and the subdirectories) within the directory.
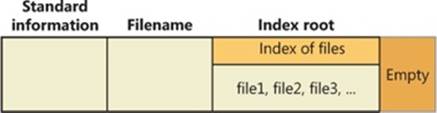
Figure 12-33. MFT file record for a small directory
Of course, many files and directories can’t be squeezed into a 1-KB, fixed-size MFT record. If a particular attribute’s value, such as a file’s data attribute, is too large to be contained in an MFT file record, NTFS allocates clusters for the attribute’s value outside the MFT. A contiguous group of clusters is called a run (or an extent). If the attribute’s value later grows (if a user appends data to the file, for example), NTFS allocates another run for the additional data. Attributes whose values are stored in runs (rather than within the MFT) are called nonresident attributes. The file system decides whether a particular attribute is resident or nonresident; the location of the data is transparent to the process accessing it.
When an attribute is nonresident, as the data attribute for a large file will certainly be, its header contains the information NTFS needs to locate the attribute’s value on the disk. Figure 12-34 shows a nonresident data attribute stored in two runs.
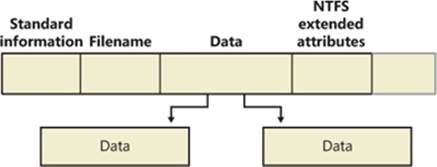
Figure 12-34. MFT file record for a large file with two data runs
Among the standard attributes, only those that can grow can be nonresident. For files, the attributes that can grow are the data and the attribute list (not shown in Figure 12-34). The standard information and filename attributes are always resident.
A large directory can also have nonresident attributes (or parts of attributes), as Figure 12-35 shows. In this example, the MFT file record doesn’t have enough room to store the B-tree that contains the index of files that are within this large directory. A part of the index is stored in theindex root attribute, and the rest of the index is stored in nonresident runs called index allocations. The index root, index allocation, and bitmap attributes are shown here in a simplified form. They are described in more detail in the next section. The standard information and filename attributes are always resident. The header and at least part of the value of the index root attribute are also resident for directories.
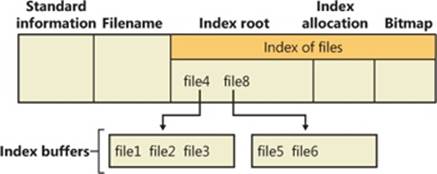
Figure 12-35. MFT file record for a large directory with a nonresident file name index
When an attribute’s value can’t fit in an MFT file record and separate allocations are needed, NTFS keeps track of the runs by means of VCN-to-LCN mapping pairs. LCNs represent the sequence of clusters on an entire volume from 0 through n. VCNs number the clusters belonging to a particular file from 0 through m. For example, the clusters in the runs of a nonresident data attribute are numbered as shown in Figure 12-36.
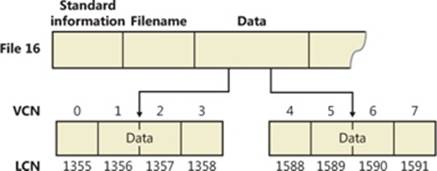
Figure 12-36. VCNs for a nonresident data attribute
If this file had more than two runs, the numbering of the third run would start with VCN 8. As Figure 12-37 shows, the data attribute header contains VCN-to-LCN mappings for the two runs here, which allows NTFS to easily find the allocations on the disk.
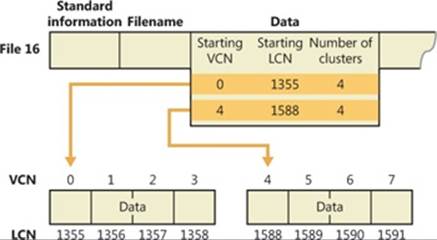
Figure 12-37. VCN-to-LCN mappings for a nonresident data attribute
Although Figure 12-36 shows just data runs, other attributes can be stored in runs if there isn’t enough room in the MFT file record to contain them. And if a particular file has too many attributes to fit in the MFT record, a second MFT record is used to contain the additional attributes (or attribute headers for nonresident attributes). In this case, an attribute called the attribute list is added. The attribute list attribute contains the name and type code of each of the file’s attributes and the file number of the MFT record where the attribute is located. The attribute list attribute is provided for those cases where all of a file’s attributes will not fit within the file’s file record or when a file grows so large or so fragmented that a single MFT record can’t contain the multitude of VCN-to-LCN mappings needed to find all its runs. Files with more than 200 runs typically require an attribute list. In summary, attribute headers are always contained within file records in the MFT, but an attribute’s value may be located outside the MFT in one or more extents.
Data Compression and Sparse Files
NTFS supports compression on a per-file, per-directory, or per-volume basis using a variant of the LZ77 algorithm, known as LZNT1. (NTFS compression is performed only on user data, not file system metadata.) You can tell whether a volume is compressed by using the WindowsGetVolumeInformation function. To retrieve the actual compressed size of a file, use the Windows GetCompressedFileSize function. Finally, to examine or change the compression setting for a file or directory, use the Windows DeviceIoControl function. (See the FSCTL_GET_COMPRESSION and FSCTL_SET_COMPRESSION file system control codes.) Keep in mind that although setting a file’s compression state compresses (or decompresses) the file right away, setting a directory’s or volume’s compression state doesn’t cause any immediate compression or decompression. Instead, setting a directory’s or volume’s compression state sets a default compression state that will be given to all newly created files and subdirectories within that directory or volume (although, if you were to set directory compression using the directory’s property page within Explorer, the contents of the entire directory tree will be compressed immediately).
The following section introduces NTFS compression by examining the simple case of compressing sparse data. The subsequent sections extend the discussion to the compression of ordinary files and sparse files.
Compressing Sparse Data
Sparse data is often large but contains only a small amount of nonzero data relative to its size. A sparse matrix is one example of sparse data. As described earlier, NTFS uses VCNs, from 0 through m, to enumerate the clusters of a file. Each VCN maps to a corresponding LCN, which identifies the disk location of the cluster. Figure 12-38 illustrates the runs (disk allocations) of a normal, noncompressed file, including its VCNs and the LCNs they map to.

Figure 12-38. Runs of a noncompressed file
This file is stored in three runs, each of which is 4 clusters long, for a total of 12 clusters. Figure 12-39 shows the MFT record for this file. As described earlier, to save space the MFT record’s data attribute, which contains VCN-to-LCN mappings, records only one mapping for each run, rather than one for each cluster. Notice, however, that each VCN from 0 through 11 has a corresponding LCN associated with it. The first entry starts at VCN 0 and covers 4 clusters, the second entry starts at VCN 4 and covers 4 clusters, and so on. This entry format is typical for a noncompressed file.
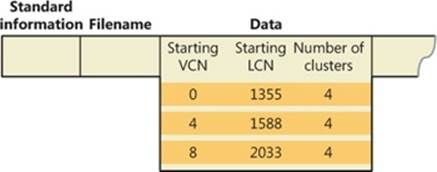
Figure 12-39. MFT record for a noncompressed file
When a user selects a file on an NTFS volume for compression, one NTFS compression technique is to remove long strings of zeros from the file. If the file’s data is sparse, it typically shrinks to occupy a fraction of the disk space it would otherwise require. On subsequent writes to the file, NTFS allocates space only for runs that contain nonzero data.
Figure 12-40 depicts the runs of a compressed file containing sparse data. Notice that certain ranges of the file’s VCNs (16–31 and 64–127) have no disk allocations.

Figure 12-40. Runs of a compressed file containing sparse data
The MFT record for this compressed file omits blocks of VCNs that contain zeros and therefore have no physical storage allocated to them. The first data entry in Figure 12-41, for example, starts at VCN 0 and covers 16 clusters. The second entry jumps to VCN 32 and covers 16 clusters.
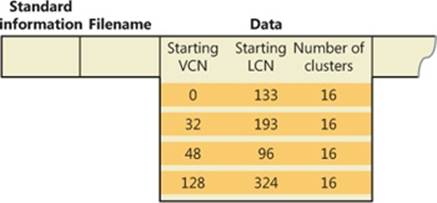
Figure 12-41. MFT record for a compressed file containing sparse data
When a program reads data from a compressed file, NTFS checks the MFT record to determine whether a VCN-to-LCN mapping covers the location being read. If the program is reading from an unallocated “hole” in the file, it means that the data in that part of the file consists of zeros, so NTFS returns zeros without further accessing the disk. If a program writes nonzero data to a “hole,” NTFS quietly allocates disk space and then writes the data. This technique is very efficient for sparse file data that contains a lot of zero data.
Compressing Nonsparse Data
The preceding example of compressing a sparse file is somewhat contrived. It describes “compression” for a case in which whole sections of a file were filled with zeros but the remaining data in the file wasn’t affected by the compression. The data in most files isn’t sparse, but it can still be compressed by the application of a compression algorithm.
In NTFS, users can specify compression for individual files or for all the files in a directory. (New files created in a directory marked for compression are automatically compressed—existing files must be compressed individually when programmatically enabling compression with FSCTL_SET_COMPRESSION.) When it compresses a file, NTFS divides the file’s unprocessed data into compression units 16 clusters long (equal to 8 KB for a 512-byte cluster, for example). Certain sequences of data in a file might not compress much, if at all; so for each compression unit in the file, NTFS determines whether compressing the unit will save at least 1 cluster of storage. If compressing the unit won’t free up at least 1 cluster, NTFS allocates a 16-cluster run and writes the data in that unit to disk without compressing it. If the data in a 16-cluster unit will compress to 15 or fewer clusters, NTFS allocates only the number of clusters needed to contain the compressed data and then writes it to disk. Figure 12-42 illustrates the compression of a file with four runs. The unshaded areas in this figure represent the actual storage locations that the file occupies after compression. The first, second, and fourth runs were compressed; the third run wasn’t. Even with one noncompressed run, compressing this file saved 26 clusters of disk space, or 41 percent.
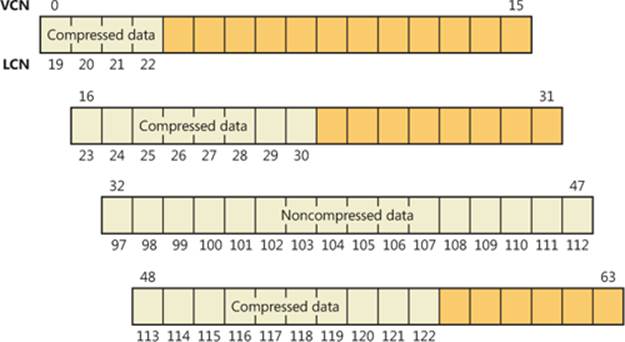
Figure 12-42. Data runs of a compressed file
NOTE
Although the diagrams in this chapter show contiguous LCNs, a compression unit need not be stored in physically contiguous clusters. Runs that occupy noncontiguous clusters produce slightly more complicated MFT records than the one shown in Figure 12-42.
When it writes data to a compressed file, NTFS ensures that each run begins on a virtual 16-cluster boundary. Thus the starting VCN of each run is a multiple of 16, and the runs are no longer than 16 clusters. NTFS reads and writes at least one compression unit at a time when it accesses compressed files. When it writes compressed data, however, NTFS tries to store compression units in physically contiguous locations so that it can read them all in a single I/O operation. The 16-cluster size of the NTFS compression unit was chosen to reduce internalfragmentation: the larger the compression unit, the less the overall disk space needed to store the data. This 16-cluster compression unit size represents a trade-off between producing smaller compressed files and slowing read operations for programs that randomly access files. The equivalent of 16 clusters must be decompressed for each cache miss. (A cache miss is more likely to occur during random file access.) Figure 12-43 shows the MFT record for the compressed file shown in Figure 12-42.
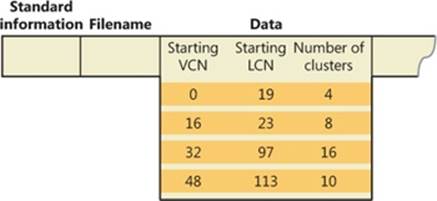
Figure 12-43. MFT record for a compressed file
One difference between this compressed file and the earlier example of a compressed file containing sparse data is that three of the compressed runs in this file are less than 16 clusters long. Reading this information from a file’s MFT file record enables NTFS to know whether data in the file is compressed. Any run shorter than 16 clusters contains compressed data that NTFS must decompress when it first reads the data into the cache. A run that is exactly 16 clusters long doesn’t contain compressed data and therefore requires no decompression.
If the data in a run has been compressed, NTFS decompresses the data into a scratch buffer and then copies it to the caller’s buffer. NTFS also loads the decompressed data into the cache, which makes subsequent reads from the same run as fast as any other cached read. NTFS writes any updates to the file to the cache, leaving the lazy writer to compress and write the modified data to disk asynchronously. This strategy ensures that writing to a compressed file produces no more significant delay than writing to a noncompressed file would.
NTFS keeps disk allocations for a compressed file contiguous whenever possible. As the LCNs indicate, the first two runs of the compressed file shown in Figure 12-42 are physically contiguous, as are the last two. When two or more runs are contiguous, NTFS performs disk read-ahead, as it does with the data in other files. Because the reading and decompression of contiguous file data take place asynchronously before the program requests the data, subsequent read operations obtain the data directly from the cache, which greatly enhances read performance.
Sparse Files
Sparse files (the NTFS file type, as opposed to files that consist of sparse data, described earlier) are essentially compressed files for which NTFS doesn’t apply compression to the file’s nonsparse data. However, NTFS manages the run data of a sparse file’s MFT record the same way it does for compressed files that consist of sparse and nonsparse data.
The Change Journal File
The change journal file, \$Extend\$UsnJrnl, is a sparse file in which NTFS stores records of changes to files and directories. Applications like the Windows File Replication Service (FRS) and the Windows Search service make use of the journal to respond to file and directory changes as they occur.
The journal stores change entries in the $J data stream and the maximum size of the journal in the $Max data stream. Entries are versioned and include the following information about a file or directory change:
§ The time of the change
§ The reason for the change (see Table 12-8)
§ The file or directory’s attributes
§ The file or directory’s name
§ The file or directory’s MFT file record number
§ The file record number of the file’s parent directory
§ The security ID
§ The update sequence number (USN) of the record
§ Additional information about the source of the change (a user, the FRS, and so on)
Table 12-8. Change Journal Change Reasons
|
Identifier |
Reason |
|
USN_REASON_DATA_OVERWRITE |
The data in the file or directory was overwritten |
|
USN_REASON_DATA_EXTEND |
Data was added to the file or directory |
|
USN_REASON_DATA_TRUNCATION |
The data in the file or directory was truncated |
|
USN_REASON_NAMED_DATA_OVERWRITE |
The data in a file’s data stream was overwritten |
|
USN_REASON_NAMED_DATA_EXTEND |
The data in a file’s data stream was extended |
|
USN_REASON_NAMED_DATA_TRUNCATION |
The data in a file’s data stream was truncated |
|
USN_REASON_FILE_CREATE |
A new file or directory was created |
|
USN_REASON_FILE_DELETE |
A file or directory was deleted |
|
USN_REASON_EA_CHANGE |
The extended attributes for a file or directory changed |
|
USN_REASON_SECURITY_CHANGE |
The security descriptor for a file or directory was changed |
|
USN_REASON_RENAME_OLD_NAME |
A file or directory was renamed; this is the old name |
|
USN_REASON_RENAME_NEW_NAME |
A file or directory was renamed; this is the new name |
|
USN_REASON_INDEXABLE_CHANGE |
The indexing state for the file or directory was changed (whether or not the Indexing service will process this file or directory) |
|
USN_REASON_BASIC_INFO_CHANGE |
The file or directory attributes and/or the time stamps were changed |
|
USN_REASON_HARD_LINK_CHANGE |
A hard link was added or removed from the file or directory |
|
USN_REASON_COMPRESSION_CHANGE |
The compression state for the file or directory was changed |
|
USN_REASON_ENCRYPTION_CHANGE |
The encryption state (EFS) was enabled or disabled for this file or directory |
|
USN_REASON_OBJECT_ID_CHANGE |
The object ID for this file or directory was changed |
|
USN_REASON_REPARSE_POINT_CHANGE |
The reparse point for a file or directory was changed, or a new reparse point (such as a symbolic link) was added or deleted from a file or directory |
|
USN_REASON_STREAM_CHANGE |
A new data stream was added to or removed from a file or renamed |
|
USN_REASON_TRANSACTED_CHANGE |
This value is added (ORed) to the change reason to indicate that the change was the result of a recent commit of a TxF transaction |
|
USN_REASON_CLOSE |
The handle to a file or directory was closed, indicating that this is the final modification made to the file in this series of operations |
EXPERIMENT: READING THE CHANGE JOURNAL
You can use the Usndump.exe command-line program from Winsider Seminars & Solutions (www.winsiderss.com/tools/usndump/usndump.htm) to dump the contents of the change journal if the current volume has one. You can also create, delete, or query journal information with the built-in Fsutil.exe utility, as shown here:
C:\>fsutil usn queryjournal c:
Usn Journal ID : 0x01c89ddaec1b9648
First Usn : 0x0000000038140000
Next Usn : 0x000000003a22fa50
Lowest Valid Usn : 0x0000000000000000
Max Usn : 0x00000fffffff0000
Maximum Size : 0x0000000002000000
Allocation Delta : 0x0000000000400000
The output indicates the maximum size of the change journal on the volume and its current state. As a simple experiment to see how NTFS records changes in the journal, create a file called Usn.txt in the current directory, rename it to UsnNew.txt, and then dump the journal with Usndump, as shown here:
C:\>echo hello > Usn.txt
C:\>ren Usn.txt UsnNew.txt
C:\>Usndump.exe
...
File Ref# : 0x4000000001be9
ParentFile Ref# : 0x300000000a962
USN : 0xfc54d8
SecurityId : 0x00000000
Reason : 0x00000100 (USN_REASON_FILE_CREATE)
Name (014) : Usn.txt
File Ref# : 0x4000000001be9
ParentFile Ref# : 0x300000000a962
USN : 0xfc5528
SecurityId : 0x00000000
Reason : 0x00000102 (USN_REASON_DATA_EXTEND USN_REASON_FILE_CREATE)
Name (014) : Usn.txt
File Ref# : 0x4000000001be9
ParentFile Ref# : 0x300000000a962
USN : 0xfc5578
SecurityId : 0x00000000
Reason : 0x80000102 (USN_REASON_DATA_EXTEND USN_REASON_FILE_CREATE)
Name (014) : Usn.txt
File Ref# : 0x4000000001be9
ParentFile Ref# : 0x300000000a962
USN : 0xfc55c8
SecurityId : 0x00000000
Reason : 0x00001000 (USN_REASON_RENAME_OLD_NAME)
Name (014) : Usn.txt
File Ref# : 0x4000000001be9
ParentFile Ref# : 0x300000000a962
USN : 0xfc5618
SecurityId : 0x00000000
Reason : 0x00002000 (USN_REASON_RENAME_NEW_NAME)
Name (020) : UsnNew.txt
File Ref# : 0x4000000001be9
ParentFile Ref# : 0x300000000a962
USN : 0xfc5668
SecurityId : 0x00000000
Reason : 0x80002000 (USN_REASON_RENAME_NEW_NAME)
Name (020) : UsnNew.txt
The entries reflect the individual modification operations involved in the operations underlying the command-line operations.
The journal is sparse so that it never overflows; when the journal’s on-disk size exceeds the maximum defined for the file, NTFS simply begins zeroing the file data that precedes the window of change information having a size equal to the maximum journal size, as shown inFigure 12-44. To prevent constant resizing when an application is continuously exceeding the journal’s size, NTFS shrinks the journal only when its size is twice an application-defined value over the maximum configured size.
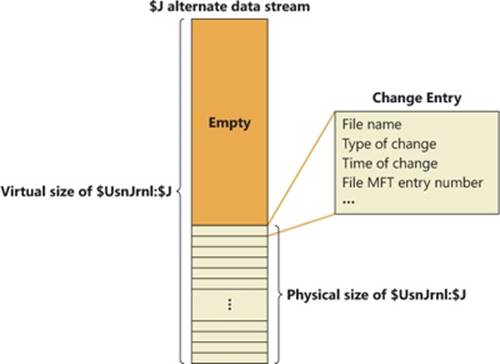
Figure 12-44. Change journal ($UsnJrnl) space allocation
Indexing
In NTFS, a file directory is simply an index of file names—that is, a collection of file names (along with their file record numbers) organized as a B-tree. To create a directory, NTFS indexes the filename attributes of the files in the directory. The MFT record for the root directory of a volume is shown in Figure 12-45.
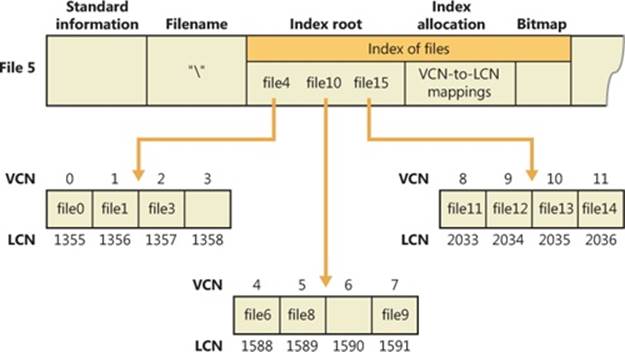
Figure 12-45. File name index for a volume’s root directory
Conceptually, an MFT entry for a directory contains in its index root attribute a sorted list of the files in the directory. For large directories, however, the file names are actually stored in 4-KB, fixed-size index buffers (which are the nonresident value of the index allocation attribute) that contain and organize the file names. Index buffers implement a B-tree data structure, which minimizes the number of disk accesses needed to find a particular file, especially for large directories. The index root attribute contains the first level of the B-tree (root subdirectories) and points to index buffers containing the next level (more subdirectories, perhaps, or files).
Figure 12-45 shows only file names in the index root attribute and the index buffers (file6, for example), but each entry in an index also contains the record number in the MFT where the file is described and time stamp and file size information for the file. NTFS duplicates the time stamps and file size information from the file’s MFT record. This technique, which is used by FAT and NTFS, requires updated information to be written in two places. Even so, it’s a significant speed optimization for directory browsing because it enables the file system to display each file’s time stamps and size without opening every file in the directory.
The index allocation attribute maps the VCNs of the index buffer runs to the LCNs that indicate where the index buffers reside on the disk, and the bitmap attribute keeps track of which VCNs in the index buffers are in use and which are free. Figure 12-45 shows one file entry per VCN (that is, per cluster), but file name entries are actually packed into each cluster. Each 4-KB index buffer will typically contain about 20 to 30 file name entries (depending on the lengths of the file names within the directory).
The B-tree data structure is a type of balanced tree that is ideal for organizing sorted data stored on a disk because it minimizes the number of disk accesses needed to find an entry. In the MFT, a directory’s index root attribute contains several file names that act as indexes into the second level of the B-tree. Each file name in the index root attribute has an optional pointer associated with it that points to an index buffer. The index buffer it points to contains file names with lexicographic values less than its own. In Figure 12-45, for example, file4 is a first-level entry in the B-tree. It points to an index buffer containing file names that are (lexicographically) less than itself—the file names file0, file1, and file3. Note that the names file1, file3, and so on that are used in this example are not literal file names but names intended to show the relative placement of files that are lexicographically ordered according to the displayed sequence.
Storing the file names in B-trees provides several benefits. Directory lookups are fast because the file names are stored in a sorted order. And when higher-level software enumerates the files in a directory, NTFS returns already-sorted names. Finally, because B-trees tend to grow wide rather than deep, NTFS’s fast lookup times don’t degrade as directories grow.
NTFS also provides general support for indexing data besides file names, and several NTFS features—including object IDs, quota tracking, and consolidated security—use indexing to manage internal data.
The B-tree indexes are a generic capability of NTFS and are used for organizing security descriptors, security IDs, object IDs, disk quota records, and reparse points. Directories are referred to as file name indexes, while other types of indexes are known as view indexes.
Object IDs
In addition to storing the object ID assigned to a file or directory in the $OBJECT_ID attribute of its MFT record, NTFS also keeps the correspondence between object IDs and their file record numbers in the $O index of the \$Extend\$ObjId metadata file. The index collates entries by object ID (which is a GUID), making it easy for NTFS to quickly locate a file based on its ID. This feature allows applications, using undocumented native API functionality, to open a file or directory using its object ID. Figure 12-46 demonstrates the correspondence of the $ObjId metadata file and $OBJECT_ID attributes in MFT records.
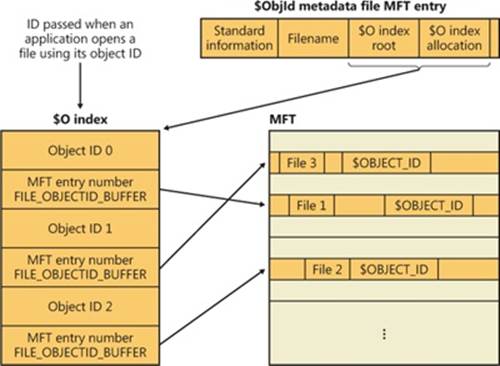
Figure 12-46. $ObjId and $OBJECT_ID relationships
Quota Tracking
NTFS stores quota information in the \$Extend\$Quota metadata file, which consists of the named index root attributes $O and $Q. Figure 12-47 shows the organization of these indexes. Just as NTFS assigns each security descriptor a unique internal security ID, NTFS assigns eachuser a unique user ID. When an administrator defines quota information for a user, NTFS allocates a user ID that corresponds to the user’s SID. In the $O index, NTFS creates an entry that maps an SID to a user ID and sorts the index by SID; in the $Q index, NTFS creates a quota control entry. A quota control entry contains the value of the user’s quota limits, as well as the amount of disk space the user consumes on the volume.
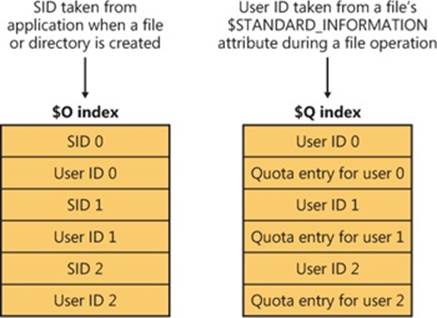
Figure 12-47. $Quota indexing
When an application creates a file or directory, NTFS obtains the application user’s SID and looks up the associated user ID in the $O index. NTFS records the user ID in the new file or directory’s $STANDARD_INFORMATION attribute, which counts all disk space allocated to the file or directory against that user’s quota. Then NTFS looks up the quota entry in the $Q index and determines whether the new allocation causes the user to exceed his or her warning or limit threshold. When a new allocation causes the user to exceed a threshold, NTFS takes appropriate steps, such as logging an event to the System event log or not letting the user create the file or directory. As a file or directory changes size, NTFS updates the quota control entry associated with the user ID stored in the $STANDARD_INFORMATION attribute. NTFS uses the NTFS generic B-tree indexing to efficiently correlate user IDs with account SIDs and, given a user ID, to efficiently look up a user’s quota control information.
Consolidated Security
NTFS has always supported security, which lets an administrator specify which users can and can’t access individual files and directories. NTFS optimizes disk utilization for security descriptors by using a central metadata file named $Secure to store only one instance of each security descriptor on a volume.
The $Secure file contains two index attributes—$SDH (Security Descriptor Hash) and $SII (Security ID Index)—and a data-stream attribute named $SDS (Security Descriptor Stream), as Figure 12-48 shows. NTFS assigns every unique security descriptor on a volume an internalNTFS security ID (not to be confused with a Windows SID, which uniquely identifies computers and user accounts) and hashes the security descriptor according to a simple hash algorithm. A hash is a potentially nonunique shorthand representation of a descriptor. Entries in the $SDH index map the security descriptor hashes to the security descriptor’s storage location within the $SDS data attribute, and the $SII index entries map NTFS security IDs to the security descriptor’s location in the $SDS data attribute.
When you apply a security descriptor to a file or directory, NTFS obtains a hash of the descriptor and looks through the $SDH index for a match. NTFS sorts the $SDH index entries according to the hash of their corresponding security descriptor and stores the entries in a B-tree. If NTFS finds a match for the descriptor in the $SDH index, NTFS locates the offset of the entry’s security descriptor from the entry’s offset value and reads the security descriptor from the $SDS attribute. If the hashes match but the security descriptors don’t, NTFS looks for another matching entry in the $SDH index. When NTFS finds a precise match, the file or directory to which you’re applying the security descriptor can reference the existing security descriptor in the $SDS attribute. NTFS makes the reference by reading the NTFS security identifier from the $SDH entry and storing it in the file or directory’s $STANDARD_INFORMATION attribute. The NTFS $STANDARD_INFORMATION attribute, which all files and directories have, stores basic information about a file, including its attributes, time stamp information, and security identifier.
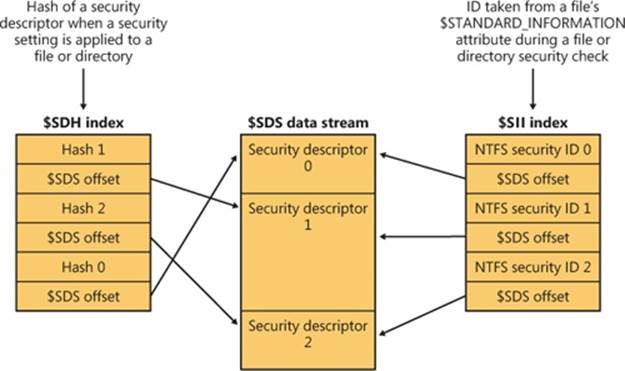
Figure 12-48. $Secure indexing
If NTFS doesn’t find in the $SDH index an entry that has a security descriptor that matches the descriptor you’re applying, the descriptor you’re applying is unique to the volume and NTFS assigns the descriptor a new internal security ID. NTFS internal security IDs are 32-bit values, whereas SIDs are typically several times larger, so representing SIDs with NTFS security IDs saves space in the $STANDARD_INFORMATION attribute. NTFS then adds the security descriptor to the end of the $SDS data attribute, and it adds to the $SDH and $SII indexes entries that reference the descriptor’s offset in the $SDS data.
When an application attempts to open a file or directory, NTFS uses the $SII index to look up the file or directory’s security descriptor. NTFS reads the file or directory’s internal security ID from the MFT entry’s $STANDARD_INFORMATION attribute. It then uses the $Secure file’s $SII index to locate the ID’s entry in the $SDS data attribute. The offset into the $SDS attribute lets NTFS read the security descriptor and complete the security check. NTFS stores the 32 most recently accessed security descriptors with their $SII index entries in a cache so that it will access the $Secure file only when the $SII isn’t cached.
NTFS doesn’t delete entries in the $Secure file, even if no file or directory on a volume references the entry. Not deleting these entries doesn’t significantly decrease disk space because most volumes, even those used for long periods, have relatively few unique security descriptors.
NTFS’s use of generic B-tree indexing lets files and directories that have the same security settings efficiently share security descriptors. The $SII index lets NTFS quickly look up a security descriptor in the $Secure file while performing security checks, and the $SDH index lets NTFS quickly determine whether a security descriptor being applied to a file or directory is already stored in the $Secure file and can be shared.
Reparse Points
As described earlier in the chapter, a reparse point is a block of up to 16 KB of application-defined reparse data and a 32-bit reparse tag that are stored in the $REPARSE_POINT attribute of a file or directory. Whenever an application creates or deletes a reparse point, NTFS updates the \$Extend\$Reparse metadata file, in which NTFS stores entries that identify the file record numbers of files and directories that contain reparse points. Storing the records in a central location enables NTFS to provide interfaces for applications to enumerate all a volume’s reparse points or just specific types of reparse points, such as mount points. (See Chapter 9 for more information on mount points.) The \$Extend\$Reparse file uses the generic B-tree indexing facility of NTFS by collating the file’s entries (in an index named $R) by reparse point tags and file record numbers.
Transaction Support
By leveraging the Kernel Transaction Manager (KTM) support in the kernel, as well as the facilities provided by the Common Log File System that were described earlier, NTFS implements a transactional model called transactional NTFS or TxF. TxF provides a set of user-mode APIs that applications can use for transacted operations on their files and directories and also a file system control (FSCTL) interface for managing its resource managers.
NOTE
Support for TxF was added to the NTFS driver without actually changing the format of the NTFS data structures, which is why the NTFS format version number, 3.1, is the same as it has been since Windows XP and Windows Server 2003. TxF achieves backward compatibility by reusing the attribute type ($LOGGED_UTILITY_STREAM) that was previously used only for EFS support instead of adding a new one.
The overall architecture for TxF, shown in Figure 12-49, uses several components:
§ Transacted APIs implemented in the Kernel32.dll library
§ A library for reading TxF logs (%SystemRoot%\System32\Txfw32.dll)
§ A COM component for TxF logging functionality (%SystemRoot\System32\Txflog.dll)
§ The transactional NTFS library inside the NTFS driver
§ The CLFS infrastructure for reading and writing log records
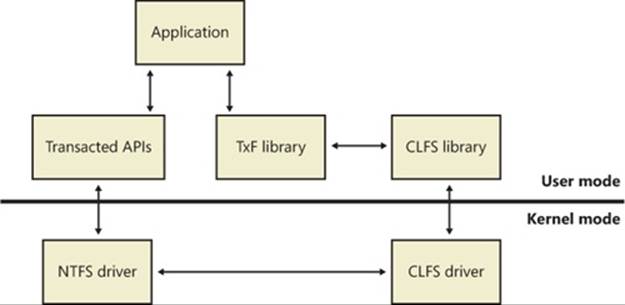
Figure 12-49. TxF architecture
Isolation
Although transactional file operations are opt-in, just like the transactional registry (TxR) operations described in Chapter 4 in Part 1, TxF has an impact on regular applications that are not transaction-aware because it ensures that the transactional operations are isolated. For example, if an antivirus program is scanning a file that’s currently being modified by another application via a transacted operation, TxF must ensure that the scanner reads the pretransaction data, while applications that access the file within the transaction work with the modified data. This model is called read-committed isolation.
Read-committed isolation involves the concept of transacted writers and transacted readers. The former always view the most up-to-date version of a file, including all changes made by the transaction that is currently associated with the file. At any given time, there can be only one transacted writer for a file, which means that its write access is exclusive. Transacted readers, on the other hand, have access only to the committed version of the file at the time they open the file. They are therefore isolated from changes made by transacted writers. This allows for readers to have a consistent view of a file, even when a transacted writer commits its changes. To see the updated data, the transacted reader must open a new handle to the modified file.
Nontransacted writers, on the other hand, are prevented from opening the file by both transacted writers and transacted readers, so they cannot make changes to the file without being part of the transaction. Nontransacted readers act similarly to transacted readers in that they see only the file contents that were last committed when the file handle was open. Unlike transacted readers, however, they do not receive read-committed isolation, and as such they always receive the updated view of the latest committed version of a transacted file without having to open a new file handle. This allows non-transaction-aware applications to behave as expected.
To summarize, TxF’s read-committed isolation model has the following characteristics:
§ Changes are isolated from transacted readers
§ Changes are rolled back (undone) if the associated transaction is rolled back, if the machine crashes, or if the volume is forcibly dismounted.
§ Changes are flushed to disk if the associated transaction is committed.
EXPERIMENT: UNDERSTANDING AND MANAGING TRANSACTIONS
In this experiment we’ll use the Transactdemo.exe tool to create a new file, add some data to it as part of a transaction, and see how nontransacted clients interact with the file while the transaction is active. First, open a Command Prompt window and run Transactdemo.exe:
C:\>Transactdemo.exe
Transaction Demo v1.0
by Mark Russinovich
Transaction created: {5CD5E900-9DA8-11DD-8379-005056C00008}
Created C:\TransactionDemo.txt.
Pass TransDemo the GUID listed above to see the transacted file.
Rollback or commit transaction? (r/c):
Transactdemo creates C:\TransactionDemo.txt within a transaction that it has not committed. Open a second Command Prompt window, and use the dir command to look for the presence of the TransactionDemo.txt file:
C:\>dir transactiondemo.txt
Volume in drive C is OS
Volume Serial Number is 0C30-686E
Directory of C:\
File Not Found
According to this second command prompt, the file doesn’t even exist. Now simulate a nontransacted writer by trying to add data to the file via the echo command:
C:\>echo Hello > TransactionDemo.txt
The function attempted to use a name that is reserved for use by another transaction.
As expected, nontransacted writers are blocked from modifying the file.
The %SystemRoot%\System32\Ktmutil.exe and %SystemRoot%\System32\Fsutil.exe built-in applications can be very useful for dealing with transactional operations on the file system. For example, you can get a list of all current transactions on the system with the following command:
C:\>ktmutil tx list
TxGuid Description
-------------------------------------- -----------------------------------------------
{5cd5e900-9da8-11dd-8379-005056c00008} Demo Transaction?
Note that the GUID matches what Transactdemo returned. With the GUID, you can now use the Fsutil command to query information about the transaction and to commit it or roll it back. For example, here’s how to list the files part of the transaction and the owner account:
C:\>fsutil transaction query all {5cd5e900-9da8-11dd-8379-005056c00008}
dwOutcome: 1
dwIsolationLevel: 0
dwIsolationFlags: 0
dwTimeout: -1
Owner: BUILTIN\Administrators
Number of Files: 1
---- \TransactionDemo.txt
Although the Transactdemo tool presents you with the option to roll back or commit the current transaction, the Fsutil utility allows commits or rollbacks to any ongoing transaction your account has access to. Go back to the command prompt where you ran Transactdemo and press C to commit the transaction, after which the file becomes a standard nontransacted file.
Transactional APIs
TxF implements transacted versions of the Windows file I/O APIs, which use the suffix Transacted:
§ Create APIs CreateDirectoryTransacted, CreateFileTransacted, CreateHardLinkTransacted, CreateSymbolicLinkTransacted
§ Find APIs FindFirstFileNameTransacted, FindFirstFileTransacted, FindFirstStreamTransacted
§ Query APIs GetCompressedFileSizeTransacted, GetFileAttributesTransacted, GetFullPathNameTransacted, GetLongPathNameTransacted
§ Delete APIs DeleteFileTransacted, RemoveDirectoryTransacted
§ Copy and Move/Rename APIs CopyFileTransacted, MoveFileTransacted
§ Set APIs SetFileAttributesTransacted
In addition, some APIs automatically participate in transacted operations when the file handle they are passed is part of a transaction, like one created by the CreateFileTransacted API. Table 12-9 lists Windows APIs that have modified behavior when dealing with a transacted file handle.
Table 12-9. API Behavior Changed by TxF
|
API Name |
Change |
|
CloseHandle |
Transactions will not be committed until all applications close transacted handles to the file. |
|
CreateFileMapping, MapViewOfFile |
Modifications to mapped views of a file part of a transaction will be associated with the transaction themselves. |
|
FindNextFile, ReadDirectoryChanges, GetInformationByHandle, GetFileSize |
If the file handle is part of a transaction, read-isolation rules will be applied to these operations. |
|
GetVolumeInformation |
Function will return FILE_SUPPORTS_TRANSACTIONS if the volume supports TxF. |
|
ReadFile, WriteFile |
Read and write operations to a transacted file handle will be part of the transaction. |
|
SetFileInformationByHandle |
Changes to the FileBasicInfo, FileRenameInfo, FileAllocationInfo, FileEndOfFileInfo, and FileDispositionInfo classes will be transacted if the file handle is part of a transaction. |
|
SetEndOfFile, SetFileShortName, SetFileTime |
Changes will be transacted if the file handle is part of a transaction. |
Resource Managers
Just like TxR uses a resource manager (RM) to keep track of transactional metadata and log files, TxF uses a default resource manager, one for each volume, to keep track of its transactional state. TxF, however, also supports additional resource managers called secondary resource managers. These resource managers can be defined by application writers and have their metadata located in any directory of the application’s choosing, defining their own transactional work units for undo, backup, restore, and redo operations. TxF uses the default resource manager for transacted APIs, and applications that use transactions with the Distributed Transaction Coordinator or the .NET Framework’s System.Transaction classes create and manage secondary TxF resource managers with TxF resource manager file system control commands. Applications can create and manage secondary RMs by using file system control codes defined for TxF, such as FSCTL_TXFS_CREATE_SECONDARY_RM, FSCTL_TXFS_START_RM, and FSCTL_TXFS_SHUTDOWN_RM. When a secondary RM is created, it must be made consistent by one or more FSCTL_TXFS_ROLLFORWARD_REDO calls followed by FSCTL_TXFS_ROLLFORWARD_UNDO, which redo and/or undo operations that were stored in the log but never committed (such as in the case of a machine crash). We’ll cover the recovery procedure for resource managers shortly. Both the default resource manager and secondary resource managers contain a number of metadata files and directories that describe their current state:
§ The $Txf directory, which is where files are linked when they are deleted or overwritten by transactional operations. If a file is deleted in a transaction, read-isolation rules specify that nontransacted readers should still be able to access the file before the delete operation is actually committed. This isolation is achieved by moving the transaction-deleted file into the $Txf directory. The NTFS driver will then keep track of the isolation by inserting a temporary structure in the SCB of the parent directory where the deleted file was originally located. In this way, the file will continue to show up if the parent is enumerated, and it will store the file record number, allowing the file to be opened. When the transaction is committed, NTFS deletes the temporary structure and deletes the file from the $Txf directory. On the other hand, if the transaction is rolled back, NTFS moves the file back to its original directory.
§ The $Tops, or TxF Old Page Stream (TOPS) file, which contains a default data stream and an alternate data stream called $T. The default stream for the TOPS file contains metadata about the resource manager, such as its GUID, its CLFS log policy, and the LSN at which recovery should start. The $T stream contains file data that is partially overwritten by a transactional writer (as opposed to a full overwrite, which would move the file into the $Txf directory). NTFS keeps a structure in memory that keeps track of which parts of a file are being modified under a transaction so that nontransacted readers can still access the noncommitted data by having their reads forwarded to $Tops:$T. When the transaction is committed or aborted, the pages are either moved from the $T stream into the original file or simply thrown out in the case of an abort.
§ The TxF log files, which are CLFS log files storing transaction records. For the default resource manager, these files are part of the $TxfLog directory, but secondary resource managers can store them anywhere. TxF uses a multiplexed base log file called $TxfLog.blf. The file \$Extend\$RmMetadata\$TxfLog\$TxfLog contains two streams: the KtmLog stream used for Kernel Transaction Manager metadata records, and the TxfLog stream, which contains the TxF log records. Each stream is stored in CLFS log containers that start with $TxfLogContainer and are followed by a unique, increasing ID, such as 00000000000000000001. As the TxF log grows, more container files are created.
As described earlier, the default resource manager stores its files in the \$Extend\$RmMetadata directory on each NTFS-formatted volume on the machine.
EXPERIMENT: QUERYING RESOURCE MANAGER INFORMATION
You can use the built-in %SystemRoot%\System32\Fsutil.exe command-line program to query information about the default resource manager, as well as to create, start, and stop secondary resource managers and configure their logging policies and behaviors. The following command queries information about the default resource manager, which is identified by the root directory (\):
C:\>fsutil resource info \
RM Identifier: CF7234E7-39E3-11DC-BDCE-00188BDD5F49
KTM Log Path for RM: \Device\HarddiskVolume3\$Extend\$RmMetadata\$TxfLog\
$TxfLog::KtmLog
Space used by TOPS: 79 Mb
TOPS free space: 100%
RM State: Active
Running transactions: 0
One phase commits: 0
Two phase commits: 1
System initiated rollbacks: 0
Age of oldest transaction: 00:00:00
Logging Mode: Simple
Number of containers: 2
Container size: 10 Mb
Total log capacity: 20 Mb
Total free log space: 14 Mb
Minimum containers: 2
Maximum containers: 20
Log growth increment: 2 container(s)
Auto shrink: Not enabled
RM prefers availability over consistency.
As mentioned, the fsutil resource command has many options for configuring TxF resource managers, including the ability to create a secondary resource manager in any directory of your choice. For example, you can use the fsutil resource create c:\rmtest command to create a secondary resource manager in the Rmtest directory, followed by the fsutil resource start c:\rmtestcommand to initiate it. Note the presence of the $Tops and $TxfLogContainer* files and of the TxfLog and $Txf directories in this folder.
On-Disk Implementation
As shown earlier in Table 12-6, TxF uses the $LOGGED_UTILITY_STREAM attribute type to store additional data for files and directories that are or have been part of a transaction. This attribute is called $TXF_DATA and contains important information that allows TxF to keep active offline data for a file part of a transaction. The attribute is permanently stored in the MFT; that is, even after the file is not part of a transaction anymore, the stream remains, for reasons we’ll explain shortly. The major components of the attribute are shown in Figure 12-50.

Figure 12-50. $TXF_DATA attribute
The first field shown is the file record number of the root of the resource manager responsible for the transaction associated with this file. For the default resource manager, the file record number is 5, which is the file record number for the root directory (\) in the MFT, as shown earlier in Figure 12-27. TxF needs this information when it creates an FCB for the file so that it can link it to the correct resource manager, which in turn needs to create an enlistment for the transaction when a transacted file request is received by NTFS. (For more information on enlistments and transactions, see the KTM section in Chapter 3 in Part 1.)
Another important piece of data stored in the $TXF_DATA attribute is the TxF file ID, or TxID, and this explains why $TXF_DATA attributes are never deleted. Because NTFS writes file names to its records when writing to the transaction log, it needs a way to uniquely identify files in the same directory that may have had the same name. For example, if sample.txt is deleted from a directory in a transaction and later a new file with the same name is created in the same directory (and as part of the same transaction), TxF needs a way to uniquely identify the two instances of sample.txt. This identification is provided by a 64-bit unique number, the TxID, that TxF increments when a new file (or an instance of a file) becomes part of a transaction. Because they can never be reused, TxIDs are permanent, so the $TXF_DATA attribute will never be removed from a file.
Last but not least, three CLFS LSNs are stored for each file part of a transaction. Whenever a transaction is active, such as during create, rename, or write operations, TxF writes a log record to its CLFS log. Each record is assigned an LSN, and that LSN gets written to the appropriate field in the $TXF_DATA attribute. The first LSN is used to store the log record that identifies the changes to NTFS metadata in relation to this file. For example, if the standard attributes of a file are changed as part of a transacted operation, TxF must update the relevant MFT file record, and the LSN for the log record describing the change is stored. TxF uses the second LSN when the file’s data is modified. Finally, TxF uses the third LSN when the file name index for the directory requires a change related to a transaction the file took part in, or when a directory was part of a transaction and received a TxID.
The $TXF_DATA attribute also stores internal flags that describe the state information to TxF and the index of the USN record that was applied to the file on commit. A TxF transaction can span multiple USN records that may have been partly updated by NTFS’s recovery mechanism (described shortly), so the index tells TxF how many more USN records must be applied after a recovery.
Logging Implementation
As mentioned earlier, each time a change is made to the disk because of an ongoing transaction, TxF writes a record of the change to its log. TxF uses a variety of log record types to keep track of transactional changes, but regardless of the record type, all TxF log records have a generic header that contains information identifying the type of the record, the action related to the record, the TxID that the record applies to, and the GUID of the KTM transaction that the record is associated with.
A redo record specifies how to reapply a change part of a transaction that’s already been committed to the volume if the transaction has actually never been flushed from cache to disk. An undo record, on the other hand, specifies how to reverse a change part of a transaction that hasn’t been committed at the time of a rollback. Some records are redo-only, meaning they don’t contain any equivalent undo data, while other records contain both redo and undo information.
Through the TOPS file, TxF maintains two critical pieces of data, the base LSN and the restart LSN. The base LSN determines the LSN of the first valid record in the log, while the restart LSN indicates at which LSN recovery should begin when starting the resource manager. When TxF writes a restart rec-ord, it updates these two values, indicating that changes have been made to the volume and flushed out to disk—meaning that the file system is fully consistent up to the new restart LSN.
TxF also writes compensating log records, or CLRs. These records store the actions that are being performed during transaction rollback (explained next). They’re primarily used to store the undo-next LSN, which allows the recovery process to avoid repeated undo operations by bypassing undo records that have already been processed, a situation that can happen if the system fails during the recovery phase and has already performed part of the undo pass. Finally, TxF also deals with prepare records, abort records, and commit records, which describe the state of the KTM transactions related to TxF.
Recovery Implementation
When a resource manager starts because of an FSCTL_TXFS_START_RM call (or, for the default resource manager, as soon as the volume is mounted), TxF runs the recovery process. It reads the TOPS file to determine the restart LSN, where the recovery process should start, and then reads each record forward through the log (called the redo pass). As each record is being processed, TxF opens the file referenced by the record and compares the LSN in the $TXF_DATA attribute with the LSN in the record. If the LSN stored in the attribute is greater than or equal to the LSN of the log record, the action is not applied because the on-disk copy of the file is as new or newer than that of the log record action. If the LSN is not greater than or equal to the LSN in the record, the log contains information about the file that was never written to the file itself. In this case, TxF applies whichever action was recorded in the log record and updates the LSN in the $TXF_DATA attribute with the LSN from the record.
As TxF is processing its redo pass, it builds its transaction table, which describes the operations that it has completed; if it encounters an abort or commit record along the way, TxF discards the related transactions. By the end of the redo pass, TxF parses the final transaction table and connects to the KTM to see whether the KTM recorded a commit or an abort for the transactions. (KTM stores this information in the KtmLog stream of the TxF multiplexed log, as explained earlier.)
After TxF has finished communicating with the KTM, it looks at any leftover transactions in the transaction table and begins the undo pass. In the undo pass, TxF aborts all the remaining transactions in the transaction table by traversing each transaction’s undo LSN chain and applying the undo action for each log record. At the end of the undo pass, the resource manager is consistent and initialized.
This process is very similar to the log file service’s recovery procedure, which is described later in more detail. You should refer to this description for a complete picture of the standard transactional recovery mechanisms.
NTFS Recovery Support
NTFS recovery support ensures that if a power failure or a system failure occurs, no file system operations (transactions) will be left incomplete and the structure of the disk volume will remain intact without the need to run a disk repair utility. The NTFS Chkdsk utility is used to repair catastrophic disk corruption caused by I/O errors (bad disk sectors, electrical anomalies, or disk failures, for example) or software bugs. But with the NTFS recovery capabilities in place, Chkdsk is rarely needed.
As mentioned earlier (in the section Recoverability), NTFS uses a transaction-processing scheme to implement recoverability. This strategy ensures a full disk recovery that is also extremely fast (on the order of seconds) for even the largest disks. NTFS limits its recovery procedures to file system data to ensure that at the very least the user will never lose a volume because of a corrupted file system; however, unless an application takes specific action (such as flushing cached files to disk), NTFS’s recovery support doesn’t guarantee user data to be fully updated if a crash occurs. This is the job of transactional NTFS (TxF).
The following sections detail the transaction-logging scheme NTFS uses to record modifications to file system data structures and explain how NTFS recovers a volume if the system fails.
Design
NTFS implements the design of a recoverable file system. These file systems ensure volume consistency by using logging techniques (sometimes called journaling) originally developed for transaction processing. If the operating system crashes, the recoverable file system restores consistency by executing a recovery procedure that accesses information that has been stored in a log file. Because the file system has logged its disk writes, the recovery procedure takes only seconds, regardless of the size of the volume (unlike in the FAT file system, where the repair time is related to the volume size). The recovery procedure for a recoverable file system is exact, guaranteeing that the volume will be restored to a consistent state.
A recoverable file system incurs some costs for the safety it provides. Every transaction that alters the volume structure requires that one record be written to the log file for each of the transaction’s suboperations. This logging overhead is ameliorated by the file system’s batching of log records—writing many records to the log file in a single I/O operation. In addition, the recoverable file system can employ the optimization techniques of a lazy write file system. It can even increase the length of the intervals between cache flushes because the file system metadata can be recovered if the system crashes before the cache changes have been flushed to disk. This gain over the caching performance of lazy write file systems makes up for, and often exceeds, the overhead of the recoverable file system’s logging activity.
Neither careful write nor lazy write file systems guarantee protection of user file data. If the system crashes while an application is writing a file, the file can be lost or corrupted. Worse, the crash can corrupt a lazy write file system, destroying existing files or even rendering an entire volume inaccessible.
The NTFS recoverable file system implements several strategies that improve its reliability over that of the traditional file systems. First, NTFS recoverability guarantees that the volume structure won’t be corrupted, so all files will remain accessible after a system failure. Second, although NTFS doesn’t guarantee protection of user data in the event of a system crash—some changes can be lost from the cache—applications can take advantage of the NTFS write-through and cache-flushing capabilities to ensure that file modifications are recorded on disk at appropriate intervals.
Both cache write-through—forcing write operations to be immediately recorded on disk—and cache flushing—forcing cache contents to be written to disk—are efficient operations. NTFS doesn’t have to do extra disk I/O to flush modifications to several different file system data structures because changes to the data structures are recorded—in a single write operation—in the log file; if a failure occurs and cache contents are lost, the file system modifications can be recovered from the log. Furthermore, unlike the FAT file system, NTFS guarantees that user data will be consistent and available immediately after a write-through operation or a cache flush, even if the system subsequently fails.
Metadata Logging
NTFS provides file system recoverability by using the same logging technique used by TxF, which consists of recording all operations that modify file system metadata to a log file. Unlike TxF, however, NTFS’s built-in file system recovery support doesn’t make use of CLFS but uses an internal logging implementation called the log file service (which is not a background service process as described in Chapter 4 in Part 1). Another difference is that while TxF is used only when callers opt in for transacted operations, NTFS records all metadata changes so that the file system can be made consistent in the face of a system failure.
Log File Service
The log file service (LFS) is a series of kernel-mode routines inside the NTFS driver that NTFS uses to access the log file. NTFS passes the LFS a pointer to an open file object, which specifies a log file to be accessed. The LFS either initializes a new log file or calls the Windows cache manager to access the existing log file through the cache, as shown in Figure 12-51. Note that although LFS and CLFS have similar sounding names, they are separate logging implementations used for different purposes, although their operation is similar in many ways.
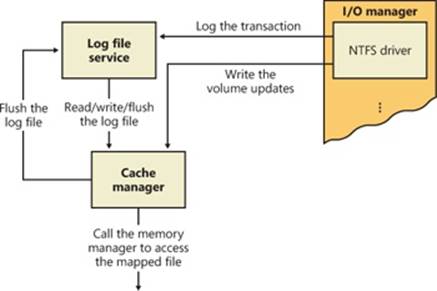
Figure 12-51. Log file service (LFS)
The LFS divides the log file into two regions: a restart area and an “infinite” logging area, as shown in Figure 12-52.
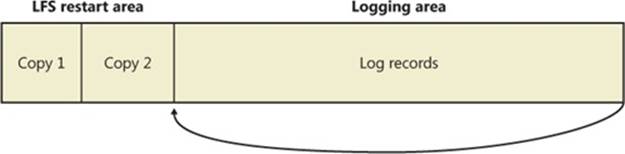
Figure 12-52. Log file regions
NTFS calls the LFS to read and write the restart area. NTFS uses the restart area to store context information such as the location in the logging area at which NTFS will begin to read during recovery after a system failure. The LFS maintains a second copy of the restart data in case the first becomes corrupted or otherwise inaccessible. The remainder of the log file is the logging area, which contains transaction records NTFS writes to recover a volume in the event of a system failure. The LFS makes the log file appear infinite by reusing it circularly (while guaranteeing that it doesn’t overwrite information it needs). Just like CLFS, the LFS uses LSNs to identify records written to the log file. As the LFS cycles through the file, it increases the values of the LSNs. NTFS uses 64 bits to represent LSNs, so the number of possible LSNs is so large as to be virtually infinite.
NTFS never reads transactions from or writes transactions to the log file directly. The LFS provides services that NTFS calls to open the log file, write log records, read log records in forward or backward order, flush log records up to a specified LSN, or set the beginning of the log file to a higher LSN. During recovery, NTFS calls the LFS to perform the same actions as described in the TxF recovery section: a redo pass for nonflushed committed changes, followed by an undo pass for noncommitted changes.
Here’s how the system guarantees that the volume can be recovered:
1. NTFS first calls the LFS to record in the (cached) log file any transactions that will modify the volume structure.
2. NTFS modifies the volume (also in the cache).
3. The cache manager prompts the LFS to flush the log file to disk. (The LFS implements the flush by calling the cache manager back, telling it which pages of memory to flush. Refer back to the calling sequence shown in Figure 12-51.)
4. After the cache manager flushes the log file to disk, it flushes the volume changes (the metadata operations themselves) to disk.
These steps ensure that if the file system modifications are ultimately unsuccessful, the corresponding transactions can be retrieved from the log file and can be either redone or undone as part of the file system recovery procedure.
File system recovery begins automatically the first time the volume is used after the system is rebooted. NTFS checks whether the transactions that were recorded in the log file before the crash were applied to the volume, and if they weren’t, it redoes them. NTFS also guarantees that transactions not completely logged before the crash are undone so that they don’t appear on the volume.
Log Record Types
The NTFS recovery mechanism uses similar log record types as the TxF recovery mechanism: update records, which correspond to the redo and undo records that TxF uses, and checkpoint records, which are similar to the restart records used by TxF. Figure 12-53 shows three update records in the log file. Each record represents one suboperation of a transaction, creating a new file. The redo entry in each update record tells NTFS how to reapply the suboperation to the volume, and the undo entry tells NTFS how to roll back (undo) the suboperation.
Figure 12-53. Update records in the log file
After logging a transaction (in this example, by calling the LFS to write the three update records to the log file), NTFS performs the suboperations on the volume itself, in the cache. When it has finished updating the cache, NTFS writes another record to the log file, recording the entire transaction as complete—a suboperation known as committing a transaction. Once a transaction is committed, NTFS guarantees that the entire transaction will appear on the volume, even if the operating system subsequently fails.
When recovering after a system failure, NTFS reads through the log file and redoes each committed transaction. Although NTFS completed the committed transactions from before the system failure, it doesn’t know whether the cache manager flushed the volume modifications to disk in time. The updates might have been lost from the cache when the system failed. Therefore, NTFS executes the committed transactions again just to be sure that the disk is up to date.
After redoing the committed transactions during a file system recovery, NTFS locates all the transactions in the log file that weren’t committed at failure and rolls back each suboperation that had been logged. In Figure 12-53, NTFS would first undo the T1 c suboperation and then follow the backward pointer to T1 b and undo that suboperation. It would continue to follow the backward pointers, undoing suboperations, until it reached the first suboperation in the transaction. By following the pointers, NTFS knows how many and which update records it must undo to roll back a transaction.
Redo and undo information can be expressed either physically or logically. As the lowest layer of software maintaining the file system structure, NTFS writes update records with physical descriptions that specify volume updates in terms of particular byte ranges on the disk that are to be changed, moved, and so on, unlike TxF, which uses logical descriptions that express updates in terms of operations such as “delete file A.dat.” NTFS writes update records (usually several) for each of the following transactions:
§ Creating a file
§ Deleting a file
§ Extending a file
§ Truncating a file
§ Setting file information
§ Renaming a file
§ Changing the security applied to a file
The redo and undo information in an update record must be carefully designed because although NTFS undoes a transaction, recovers from a system failure, or even operates normally, it might try to redo a transaction that has already been done or, conversely, to undo a transaction that never occurred or that has already been undone. Similarly, NTFS might try to redo or undo a transaction consisting of several update records, only some of which are complete on disk. The format of the update records must ensure that executing redundant redo or undo operations isidempotent, that is, has a neutral effect. For example, setting a bit that is already set has no effect, but toggling a bit that has already been toggled does. The file system must also handle intermediate volume states correctly.
In addition to update records, NTFS periodically writes a checkpoint record to the log file, as illustrated in Figure 12-54.
Figure 12-54. Checkpoint record in the log file
A checkpoint record helps NTFS determine what processing would be needed to recover a volume if a crash were to occur immediately. Using information stored in the checkpoint record, NTFS knows, for example, how far back in the log file it must go to begin its recovery. After writing a checkpoint record, NTFS stores the LSN of the record in the restart area so that it can quickly find its most recently written checkpoint record when it begins file system recovery after a crash occurs—this is similar to the restart LSN used by TxF for the same reason.
Although the LFS presents the log file to NTFS as if it were infinitely large, it isn’t. The generous size of the log file and the frequent writing of checkpoint records (an operation that usually frees up space in the log file) make the possibility of the log file filling up a remote one. Nevertheless, the LFS, just like CLFS, accounts for this possibility by tracking several operational parameters:
§ The available log space
§ The amount of space needed to write an incoming log record and to undo the write, should that be necessary
§ The amount of space needed to roll back all active (noncommitted) transactions, should that be necessary
If the log file doesn’t contain enough available space to accommodate the total of the last two items, the LFS returns a “log file full” error, and NTFS raises an exception. The NTFS exception handler rolls back the current transaction and places it in a queue to be restarted later.
To free up space in the log file, NTFS must momentarily prevent further transactions on files. To do so, NTFS blocks file creation and deletion and then requests exclusive access to all system files and shared access to all user files. Gradually, active transactions either are completed successfully or receive the “log file full” exception. NTFS rolls back and queues the transactions that receive the exception.
Once it has blocked transaction activity on files as just described, NTFS calls the cache manager to flush unwritten data to disk, including unwritten log file data. After everything is safely flushed to disk, NTFS no longer needs the data in the log file. It resets the beginning of the log file to the current position, making the log file “empty.” Then it restarts the queued transactions. Beyond the short pause in I/O processing, the “log file full” error has no effect on executing programs.
This scenario is one example of how NTFS uses the log file not only for file system recovery but also for error recovery during normal operation. You’ll find out more about error recovery in the following section.
Recovery
NTFS automatically performs a disk recovery the first time a program accesses an NTFS volume after the system has been booted. (If no recovery is needed, the process is trivial.) Recovery depends on two tables NTFS maintains in memory: a transaction table, which behaves just like the one TxF maintains, and a dirty page table, which records which pages in the cache contain modifications to the file system structure that haven’t yet been written to disk. This data must be flushed to disk during recovery.
NTFS writes a checkpoint record to the log file once every 5 seconds. Just before it does, it calls the LFS to store a current copy of the transaction table and of the dirty page table in the log file. NTFS then records in the checkpoint record the LSNs of the log records containing the copied tables. When recovery begins after a system failure, NTFS calls the LFS to locate the log records containing the most recent checkpoint record and the most recent copies of the transaction and dirty page tables. It then copies the tables to memory.
The log file usually contains more update records following the last checkpoint record. These update records represent volume modifications that occurred after the last checkpoint record was written. NTFS must update the transaction and dirty page tables to include these operations. After updating the tables, NTFS uses the tables and the contents of the log file to update the volume itself.
To perform its volume recovery, NTFS scans the log file three times, loading the file into memory during the first pass to minimize disk I/O. Each pass has a particular purpose:
1. Analysis
2. Redoing transactions
3. Undoing transactions
Analysis Pass
During the analysis pass, as shown in Figure 12-55, NTFS scans forward in the log file from the beginning of the last checkpoint operation to find update records and use them to update the transaction and dirty page tables it copied to memory. Notice in the figure that the checkpoint operation stores three records in the log file and that update records might be interspersed among these records. NTFS therefore must start its scan at the beginning of the checkpoint operation.
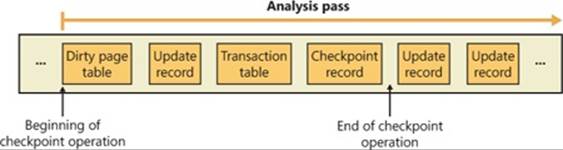
Figure 12-55. Analysis pass
Most update records that appear in the log file after the checkpoint operation begins represent a modification to either the transaction table or the dirty page table. If an update record is a “transaction committed” record, for example, the transaction the record represents must be removed from the transaction table. Similarly, if the update record is a “page update” record that modifies a file system data structure, the dirty page table must be updated to reflect that change.
Once the tables are up to date in memory, NTFS scans the tables to determine the LSN of the oldest update record that logs an operation that hasn’t been carried out on disk. The transaction table contains the LSNs of the noncommitted (incomplete) transactions, and the dirty page table contains the LSNs of records in the cache that haven’t been flushed to disk. The LSN of the oldest update record that NTFS finds in these two tables determines where the redo pass will begin. If the last checkpoint record is older, however, NTFS will start the redo pass there instead.
NOTE
In the TxF recovery model, there is no distinct analysis pass. Instead, as described in the TxF recovery section, TxF performs the equivalent work in the redo pass.
Redo Pass
During the redo pass, as shown in Figure 12-56, NTFS scans forward in the log file from the LSN of the oldest update record, which it found during the analysis pass. It looks for “page update” records, which contain volume modifications that were written before the system failure but that might not have been flushed to disk. NTFS redoes these updates in the cache.
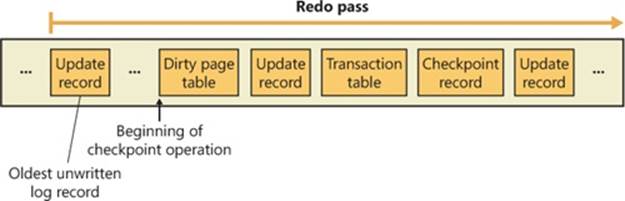
Figure 12-56. Redo pass
When NTFS reaches the end of the log file, it has updated the cache with the necessary volume modifications, and the cache manager’s lazy writer can begin writing cache contents to disk in the background.
Undo Pass
After it completes the redo pass, NTFS begins its undo pass, in which it rolls back any transactions that weren’t committed when the system failed. Figure 12-57 shows two transactions in the log file; transaction 1 was committed before the power failure, but transaction 2 wasn’t. NTFS must undo transaction 2.
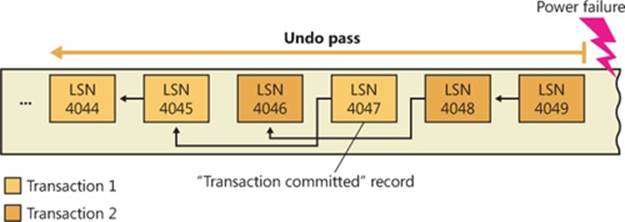
Figure 12-57. Undo pass
Suppose that transaction 2 created a file, an operation that comprises three suboperations, each with its own update record. The update records of a transaction are linked by backward pointers in the log file because they are usually not contiguous.
The NTFS transaction table lists the LSN of the last-logged update record for each noncommitted transaction. In this example, the transaction table identifies LSN 4049 as the last update record logged for transaction 2. As shown from right to left in Figure 12-58, NTFS rolls back transaction 2.
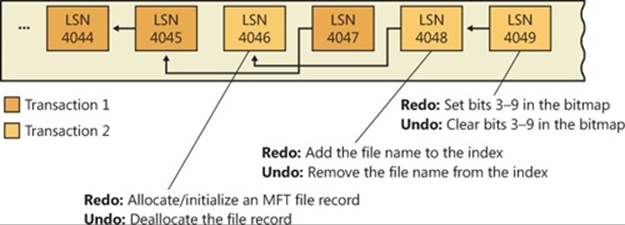
Figure 12-58. Undoing a transaction
After locating LSN 4049, NTFS finds the undo information and executes it, clearing bits 3 through 9 in its allocation bitmap. NTFS then follows the backward pointer to LSN 4048, which directs it to remove the new file name from the appropriate file name index. Finally, it follows the last backward pointer and deallocates the MFT file record reserved for the file, as the update record with LSN 4046 specifies. Transaction 2 is now rolled back. If there are other noncommitted transactions to undo, NTFS follows the same procedure to roll them back. Because undoing transactions affects the volume’s file system structure, NTFS must log the undo operations in the log file. After all, the power might fail again during the recovery, and NTFS would have to redo its undo operations!
When the undo pass of the recovery is finished, the volume has been restored to a consistent state. At this point, NTFS is prepared to flush the cache changes to disk to ensure that the volume is up to date. Before doing so, however, it executes a callback that TxF registers for notifications of LFS flushes. Because TxF and NTFS both use write-ahead logging, TxF must flush its log through CLFS before the NTFS log is flushed to ensure consistency of its own metadata. (And similarly, the TOPS file must be flushed before the CLFS-managed log files.) NTFS then writes an “empty” LFS restart area to indicate that the volume is consistent and that no recovery need be done if the system should fail again immediately. Recovery is complete.
NTFS guarantees that recovery will return the volume to some preexisting consistent state, but not necessarily to the state that existed just before the system crash. NTFS can’t make that guarantee because, for performance, it uses a “lazy commit” algorithm, which means that the log file isn’t immediately flushed to disk each time a “transaction committed” record is written. Instead, numerous “transaction committed” records are batched and written together, either when the cache manager calls the LFS to flush the log file to disk or when the LFS writes a checkpoint record (once every 5 seconds) to the log file. Another reason the recovered volume might not be completely up to date is that several parallel transactions might be active when the system crashes and some of their “transaction committed” records might make it to disk whereas others might not. The consistent volume that recovery produces includes all the volume updates whose “transaction committed” records made it to disk and none of the updates whose “transaction committed” records didn’t make it to disk.
NTFS uses the log file to recover a volume after the system fails, but it also takes advantage of an important “freebie” it gets from logging transactions. File systems necessarily contain a lot of code devoted to recovering from file system errors that occur during the course of normal file I/O. Because NTFS logs each transaction that modifies the volume structure, it can use the log file to recover when a file system error occurs and thus can greatly simplify its error handling code. The “log file full” error described earlier is one example of using the log file for errorrecovery.
Most I/O errors that a program receives aren’t file system errors and therefore can’t be resolved entirely by NTFS. When called to create a file, for example, NTFS might begin by creating a file record in the MFT and then enter the new file’s name in a directory index. When it tries to allocate space for the file in its bitmap, however, it could discover that the disk is full and the create request can’t be completed. In such a case, NTFS uses the information in the log file to undo the part of the operation it has already completed and to deallocate the data structures it reserved for the file. Then it returns a “disk full” error to the caller, which in turn must respond appropriately to the error.
NTFS Bad-Cluster Recovery
The volume manager included with Windows (VolMgr) can recover data from a bad sector on a fault-tolerant volume, but if the hard disk doesn’t perform bad-sector remapping or runs out of spare sectors, the volume manager can’t perform bad-sector replacement to replace the bad sector. (See Chapter 9 for more information on the volume manager.) When the file system reads from the sector, the volume manager instead recovers the data and returns the warning to the file system that there is only one copy of the data.
The FAT file system doesn’t respond to this volume manager warning. Moreover, neither FAT nor the volume manager keeps track of the bad sectors, so a user must run the Chkdsk or Format utility to prevent the volume manager from repeatedly recovering data for the file system. Both Chkdsk and Format are less than ideal for removing bad sectors from use. Chkdsk can take a long time to find and remove bad sectors, and Format wipes all the data off the partition it’s formatting.
In the file system equivalent of a volume manager’s bad-sector replacement, NTFS dynamically replaces the cluster containing a bad sector and keeps track of the bad cluster so that it won’t be reused. (Recall that NTFS maintains portability by addressing logical clusters rather than physical sectors.) NTFS performs these functions when the volume manager can’t perform bad-sector replacement. When a volume manager returns a bad-sector warning or when the hard disk driver returns a bad-sector error, NTFS allocates a new cluster to replace the one containing the bad sector. NTFS copies the data that the volume manager has recovered into the new cluster to reestablish data redundancy.
Figure 12-59 shows an MFT record for a user file with a bad cluster in one of its data runs as it existed before the cluster went bad. When it receives a bad-sector error, NTFS reassigns the cluster containing the sector to its bad-cluster file, $BadClus. This prevents the bad cluster from being allocated to another file. NTFS then allocates a new cluster for the file and changes the file’s VCN-to-LCN mappings to point to the new cluster. This bad-cluster remapping (introduced earlier in this chapter) is illustrated in Figure 12-59. Cluster number 1357, which contains the bad sector, must be replaced by a good cluster.
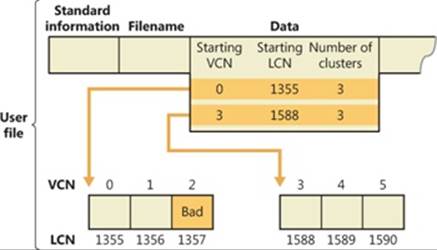
Figure 12-59. MFT record for a user file with a bad cluster
Bad-sector errors are undesirable, but when they do occur, the combination of NTFS and the volume manager provides the best possible solution. If the bad sector is on a redundant volume, the volume manager recovers the data and replaces the sector if it can. If it can’t replace the sector, it returns a warning to NTFS, and NTFS replaces the cluster containing the bad sector.
If the volume isn’t configured as a redundant volume, the data in the bad sector can’t be recovered. When the volume is formatted as a FAT volume and the volume manager can’t recover the data, reading from the bad sector yields indeterminate results. If some of the file system’s control structures reside in the bad sector, an entire file or group of files (or potentially, the whole disk) can be lost. At best, some data in the affected file (often, all the data in the file beyond the bad sector) is lost. Moreover, the FAT file system is likely to reallocate the bad sector to the same or another file on the volume, causing the problem to resurface.
Like the other file systems, NTFS can’t recover data from a bad sector without help from a volume manager. However, NTFS greatly contains the damage a bad sector can cause. If NTFS discovers the bad sector during a read operation, it remaps the cluster the sector is in, as shown in Figure 12-60. If the volume isn’t configured as a redundant volume, NTFS returns a “data read” error to the calling program. Although the data that was in that cluster is lost, the rest of the file—and the file system—remains intact; the calling program can respond appropriately to the data loss, and the bad cluster won’t be reused in future allocations. If NTFS discovers the bad cluster on a write operation rather than a read, NTFS remaps the cluster before writing and thus loses no data and generates no error.
The same recovery procedures are followed if file system data is stored in a sector that goes bad. If the bad sector is on a redundant volume, NTFS replaces the cluster dynamically, using the data recovered by the volume manager. If the volume isn’t redundant, the data can’t be recovered, so NTFS sets a bit in the $Volume metadata file that indicates corruption on the volume. The NTFS Chkdsk utility checks this bit when the system is next rebooted, and if the bit is set, Chkdsk executes, repairing the file system corruption by reconstructing the NTFS metadata.
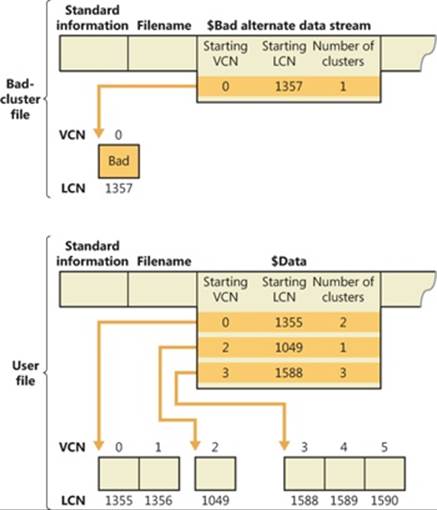
Figure 12-60. Bad-cluster remapping
In rare instances, file system corruption can occur even on a fault-tolerant disk configuration. A double error can destroy both file system data and the means to reconstruct it. If the system crashes while NTFS is writing the mirror copy of an MFT file record—of a file name index or of the log file, for example—the mirror copy of such file system data might not be fully updated. If the system were rebooted and a bad-sector error occurred on the primary disk at exactly the same location as the incomplete write on the disk mirror, NTFS would be unable to recover the correct data from the disk mirror. NTFS implements a special scheme for detecting such corruptions in file system data. If it ever finds an inconsistency, it sets the corruption bit in the volume file, which causes Chkdsk to reconstruct the NTFS metadata when the system is next rebooted. Because file system corruption is rare on a fault-tolerant disk configuration, Chkdsk is seldom needed. It is supplied as a safety precaution rather than as a first-line data recovery strategy.
The use of Chkdsk on NTFS is vastly different from its use on the FAT file system. Before writing anything to disk, FAT sets the volume’s dirty bit and then resets the bit after the modification is complete. If any I/O operation is in progress when the system crashes, the dirty bit is left set and Chkdsk runs when the system is rebooted. On NTFS, Chkdsk runs only when unexpected or unreadable file system data is found and NTFS can’t recover the data from a redundant volume or from redundant file system structures on a single volume. (The system boot sector isduplicated—in the last sector of a volume—as are the parts of the MFT [$MftMirr] required for booting the system and running the NTFS recovery procedure. This redundancy ensures that NTFS will always be able to boot and recover itself.)
Table 12-10 summarizes what happens when a sector goes bad on a disk volume formatted for one of the Windows-supported file systems according to various conditions we’ve described in this section.
Table 12-10. Summary of NTFS Data Recovery Scenarios
|
Scenario |
With a Disk That Supports Bad-Sector Remapping and Has Spare Sectors |
With a Disk That Does Not Perform Bad-Sector Remapping or Has No Spare Sectors |
|
Fault-tolerant volume[a]. |
1. Volume manager recovers the data. 2. Volume manager performs bad-sector replacement. 3. File system remains unaware of the error. |
1. Volume manager recovers the data. 2. Volume manager sends the data and a bad-sector error to the file system. 3. NTFS performs cluster remapping. |
|
Non-fault-tolerant volume |
1. Volume manager can’t recover the data. 2. Volume manager sends a bad-sector error to the file system. 3. NTFS performs cluster remapping. Data is lost.[b] |
1. Volume manager can’t recover the data. 2. Volume manager sends a bad-sector error to the file system. 3. NTFS performs cluster remapping. Data is lost. |
|
[a] A fault-tolerant volume is one of the following: a mirror set (RAID-1) or a RAID-5 set [b] In a write operation, no data is lost: NTFS remaps the cluster before the write. |
||
If the volume on which the bad sector appears is a fault-tolerant volume—a mirrored (RAID-1) or RAID-5 volume—and if the hard disk is one that supports bad-sector replacement (and that hasn’t run out of spare sectors), it doesn’t matter which file system you’re using (FAT or NTFS). The volume manager replaces the bad sector without the need for user or file system intervention.
If a bad sector is located on a hard disk that doesn’t support bad sector replacement, the file system is responsible for replacing (remapping) the bad sector or—in the case of NTFS—the cluster in which the bad sector resides. The FAT file system doesn’t provide sector or cluster remapping. The benefits of NTFS cluster remapping are that bad spots in a file can be fixed without harm to the file (or harm to the file system, as the case may be) and that the bad cluster will not be used ever again.
Self-Healing
With today’s multiterabyte storage devices, taking a volume offline for a consistency check can result in a service outage of many hours. Recognizing that many disk corruptions are localized to a single file or portion of metadata, NTFS implements a self-healing feature to repair damage while a volume remains online. When NTFS detects corruption, it prevents access to the damaged file or files and creates a system worker thread that performs Chkdsk-like corrections to the corrupted data structures, allowing access to the repaired files when it has finished. Access to other files continues normally during this operation, minimizing service disruption.
You can use the fsutil repair set command to view and set a volume’s repair options, which are summarized in Table 12-11. The Fsutil utility uses the FSCTL_SET_REPAIR file system control code to set these settings, which are saved in the VCB for the volume.
Table 12-11. NTFS Self-Healing Behaviors
|
Flag |
Behavior |
|
SET_REPAIR_ENABLED |
Enable self-healing for the volume. |
|
SET_REPAIR_WARN_ABOUT_DATA_LOSS |
If the self-healing process is unable to fully recover a file, specifies whether the user should be visually warned. |
|
SET_REPAIR_DISABLED_AND_BUGCHECK_ON_CORRUPTION |
If the NtfsBugCheckOnCorrupt NTFS registry value was set by using fsutil behavior set NtfsBugCheckOnCorrupt 1 and this flag is set, the system will crash with a STOP error 0x24, indicating file system corruption. This setting is automatically cleared during boot time to avoid repeated reboot cycles. |
In all cases, including when the visual warning is disabled (the default), NTFS will log any self-healing operation it undertook in the System event log.
Apart from periodic automatic self-healing, NTFS also supports manually initiated self-healing cycles through the FSCTL_INITIATE_REPAIR and FSCTL_WAIT_FOR_REPAIR control codes, which can be initiated with the fsutil repair initiate and fsutil repair wait commands. This allows the user to force the repair of a specific file and to wait until repair of that file is complete.
To check the status of the self-healing mechanism, the FSCTL_QUERY_REPAIR control code or the fsutil repair query command can be used, as shown here:
C:\>fsutil repair query c:
Self healing is enabled for volume c: with flags 0x1.
flags: 0x01 - enable general repair
0x08 - warn about potential data loss
0x10 - disable general repair and bugcheck once on first corruption
Encrypting File System Security
As covered in Chapter 9, BitLocker encrypts and protects volumes from offline attacks, but once a system is booted BitLocker’s job is done. The Encrypting File System (EFS) protects individual files and directories from other authenticated users on a system. When choosing how to protect your data, it is not an “either/or” choice between BitLocker and EFS; each provides protection from specific—and nonoverlapping—threats. Together BitLocker and EFS provide a “defense in depth” for the data on your system.
The paradigm used by EFS is to encrypt files and directories using symmetric encryption (a single key that is used for encrypting and decrypting the file). The symmetric encryption key is then encrypted using asymmetric encryption (one key for encryption—often referred to as the “public” key—and a different key for decryption—often referred to as the “private” key) for each user who is granted access to the file. The details and theory behind these encryption methods is beyond the scope of this book; however, a good primer is available athttp://msdn.microsoft.com/en-us/library/windows/desktop/aa380251(v=vs.85).aspx.
EFS works with the Windows Cryptography Next Generation (CNG) APIs, and thus may be configured to use any algorithm supported by (or added to) CNG. By default, EFS will use the Advanced Encryption Standard (AES) for symmetric encryption (256-bit key) and the Rivest-Shamir-Adleman (RSA) public key algorithm for asymmetric encryption (2,048-bit keys).
Users can encrypt files via Windows Explorer by opening a file’s Properties dialog box, clicking Advanced, and then selecting the Encrypt Contents To Secure Data option, as shown in Figure 12-61. (A file may be encrypted or compressed, but not both.) Users can also encrypt files via a command-line utility named Cipher (%SystemRoot%\System32\Cipher.exe) or programmatically using Windows APIs such as EncryptFile and AddUsersToEncryptedFile.
Windows automatically encrypts files that reside in directories that are designated as encrypted directories. When a file is encrypted, EFS generates a random number for the file that EFS calls the file’s File Encryption Key (FEK). EFS uses the FEK to encrypt the file’s contents using symmetric encryption. EFS then encrypts the FEK using the user’s asymmetric public key and stores the encrypted FEK in the $EFS alternate data stream for the file. The source of the public key may be administratively specified to come from an assigned X.509 certificate or a smartcard or randomly generated (which would then be added to the user’s certificate store, which can be viewed using the Certificate Manager (%SystemRoot%\System32\Certmgr.msc). After EFS completes these steps, the file is secure: other users can’t decrypt the data without the file’s decrypted FEK, and they can’t decrypt the FEK without the private key.
Figure 12-61. Encrypt files by using the Advanced Attributes dialog box
Symmetric encryption algorithms are typically very fast, which makes them suitable for encrypting large amounts of data, such as file data. However, symmetric encryption algorithms have a weakness: you can bypass their security if you obtain the key. If multiple users want to share one encrypted file protected only using symmetric encryption, each user would require access to the file’s FEK. Leaving the FEK unencrypted would obviously be a security problem, but encrypting the FEK once would require all the users to share the same FEK decryption key—another potential security problem.
Keeping the FEK secure is a difficult problem, which EFS addresses with the public key–based half of its encryption architecture. Encrypting a file’s FEK for individual users who access the file lets multiple users share an encrypted file. EFS can encrypt a file’s FEK with each user’s public key and can store each user’s encrypted FEK in the file’s $EFS data stream. Anyone can access a user’s public key, but no one can use a public key to decrypt the data that the public key encrypted. The only way users can decrypt a file is with their private key, which the operating system must access. A user’s private key decrypts the user’s encrypted copy of a file’s FEK. Public key–based algorithms are usually slow, but EFS uses these algorithms only to encrypt FEKs. Splitting key management between a publicly available key and a private key makes key management a little easier than symmetric encryption algorithms do and solves the dilemma of keeping the FEK secure.
Several components work together to make EFS work, as the diagram of EFS architecture in Figure 12-62 shows. EFS support is merged into the NTFS driver. Whenever NTFS encounters an encrypted file, NTFS executes EFS functions that it contains. The EFS functions encrypt and decrypt file data as applications access encrypted files. Although EFS stores an FEK with a file’s data, users’ public keys encrypt the FEK. To encrypt or decrypt file data, EFS must decrypt the file’s FEK with the aid of CNG key management services that reside in user mode.
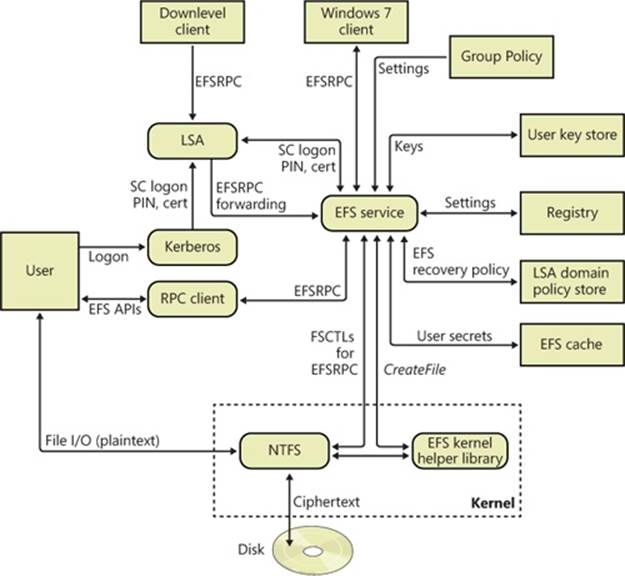
Figure 12-62. EFS architecture
The Local Security Authority Subsystem (LSASS; %SystemRoot%\System32\Lsass.exe) manages logon sessions but also hosts the EFS service. For example, when EFS needs to decrypt an FEK to decrypt file data a user wants to access, NTFS sends a request to the EFS service inside LSASS.
Encrypting a File for the First Time
The NTFS driver calls its EFS helper functions when it encounters an encrypted file. A file’s attributes record that the file is encrypted in the same way that a file records that it is compressed (discussed earlier in this chapter). NTFS has specific interfaces for converting a file from nonencrypted to encrypted form, but user-mode components primarily drive the process. As described earlier, Windows lets you encrypt a file in two ways: by using the cipher command-line utility or by checking the Encrypt Contents To Secure Data check box in the Advanced Attributes dialog box for a file in Windows Explorer. Both Windows Explorer and the cipher command rely on the EncryptFile Windows API that Advapi32.dll (Advanced Windows APIs DLL) exports.
EFS stores only one block of information in an encrypted file, and that block contains an entry for each user sharing the file. These entries are called key entries, and EFS stores them in the data decryption field (DDF) portion of the file’s EFS data. A collection of multiple key entries is called a key ring because, as mentioned earlier, EFS lets multiple users share encrypted files.
Figure 12-63 shows a file’s EFS information format and key entry format. EFS stores enough information in the first part of a key entry to precisely describe a user’s public key. This data includes the user’s security ID (SID) (note that the SID is not guaranteed to be present), the container name in which the key is stored, the cryptographic provider name, and the asymmetric key pair certificate hash. Only the asymmetric key pair certificate hash is used by the decryption process. The second part of the key entry contains an encrypted version of the FEK. EFS uses the CNG to encrypt the FEK with the selected asymmetric encryption algorithm and the user’s public key.
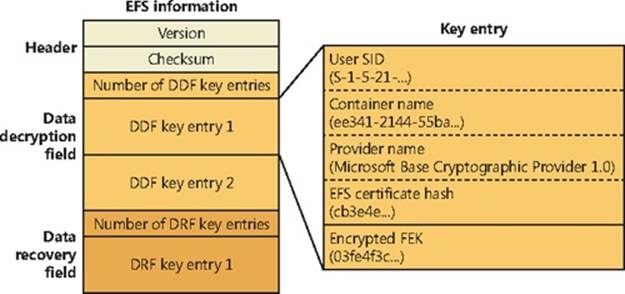
Figure 12-63. Format of EFS information and key entries
EFS stores information about recovery key entries in a file’s data recovery field (DRF). The format of DRF entries is identical to the format of DDF entries. The DRF’s purpose is to let designated accounts, or recovery agents, decrypt a user’s file when administrative authority must have access to the user’s data. For example, suppose a company employee forgot his or her logon password. An administrator can reset the user’s password, but without recovery agents, no one can recover the user’s encrypted data.
Recovery agents are defined with the Encrypted Data Recovery Agents security policy of the local computer or domain. This policy is available from the Local Security Policy MMC snap-in, as shown in Figure 12-64. When you use the Add Recovery Agent Wizard (by right-clickingEncrypting File System and then clicking Add Data Recovery Agent), you can add recovery agents and specify which private/public key pairs (designated by their certificates) the recovery agents use for EFS recovery. Lsasrv interprets the recovery policy when it initializes and when it receives notification that the recovery policy has changed. EFS creates a DRF key entry for each recovery agent by using the cryptographic provider registered for EFS recovery.
Figure 12-64. Encrypted Data Recovery Agents group policy
In the final step in creating EFS information for a file, Lsasrv calculates a checksum for the DDF and DRF by using the MD5 hash facility of Base Cryptographic Provider 1.0. Lsasrv stores the checksum’s result in the EFS information header. EFS references this checksum during decryption to ensure that the contents of a file’s EFS information haven’t become corrupted or been tampered with.
Encrypting File Data
When a user encrypts an existing file, the following process occurs:
1. The EFS service opens the file for exclusive access.
2. All data streams in the file are copied to a plaintext temporary file in the system’s temporary directory.
3. An FEK is randomly generated and used to encrypt the file by using DESX or 3DES, depending on the effective security policy.
4. A DDF is created to contain the FEK encrypted by using the user’s public key. EFS automatically obtains the user’s public key from the user’s X.509 version 3 file encryption certificate.
5. If a recovery agent has been designated through Group Policy, a DRF is created to contain the FEK encrypted by using RSA and the recovery agent’s public key.
EFS automatically obtains the recovery agent’s public key for file recovery from the recovery agent’s X.509 version 3 certificate, which is stored in the EFS recovery policy. If there are multiple recovery agents, a copy of the FEK is encrypted by using each agent’s public key, and a DRF is created to store each encrypted FEK.
NOTE
The file recovery property in the certificate is an example of an enhanced key usage (EKU) field. An EKU extension and extended property specify and limit the valid uses of a certificate. File Recovery is one of the EKU fields defined by Microsoft as part of the Microsoft public key infrastructure (PKI).
6. EFS writes the encrypted data, along with the DDF and the DRF, back to the file. Because symmetric encryption does not add additional data, file size increase is minimal after encryption. The metadata, consisting primarily of encrypted FEKs, is usually less than 1 KB. File size in bytes before and after encryption is normally reported to be the same.
7. The plaintext temporary file is deleted.
When a user saves a file to a folder that has been configured for encryption, the process is similar except that no temporary file is created.
The Decryption Process
When an application accesses an encrypted file, decryption proceeds as follows:
1. NTFS recognizes that the file is encrypted and sends a request to the EFS driver.
2. The EFS driver retrieves the DDF and passes it to the EFS service.
3. The EFS service retrieves the user’s private key from the user’s profile and uses it to decrypt the DDF and obtain the FEK.
4. The EFS service passes the FEK back to the EFS driver.
5. The EFS driver uses the FEK to decrypt sections of the file as needed for the application.
NOTE
When an application opens a file, only those sections of the file that the application is using are decrypted because EFS uses cipher block chaining. The behavior is different if the user removes the encryption attribute from the file. In this case, the entire file is decrypted and rewritten as plaintext.
6. The EFS driver returns the decrypted data to NTFS, which then sends the data to the requesting application.
Backing Up Encrypted Files
An important aspect of any file encryption facility’s design is that file data is never available in unencrypted form except to applications that access the file via the encryption facility. This restriction particularly affects backup utilities, in which archival media store files. EFS addresses this problem by providing a facility for backup utilities so that the utilities can back up and restore files in their encrypted states. Thus, backup utilities don’t have to be able to decrypt file data, nor do they need to encrypt file data in their backup procedures.
Backup utilities use the EFS API functions OpenEncryptedFileRaw, ReadEncryptedFileRaw, WriteEncryptedFileRaw, and CloseEncryptedFileRaw in Windows to access a file’s encrypted contents. After a backup utility opens a file for raw access during a backup operation, the utility calls ReadEncryptedFileRaw to obtain the file data.
EXPERIMENT: VIEWING EFS INFORMATION
EFS has a handful of other API functions that applications can use to manipulate encrypted files. For example, applications use the AddUsersToEncryptedFile API function to give additional users access to an encrypted file and RemoveUsersFromEncryptedFile to revoke users’ access to an encrypted file. Applications use the QueryUsersOnEncryptedFile function to obtain information about a file’s associated DDF and DRF key fields. QueryUsersOnEncryptedFile returns the SID, certificate hash value, and display information that each DDF and DRF key field contains. The following output is from the EFSDump utility, from Sysinternals, when an encrypted file is specified as a command-line argument:
C:\>efsdump test.txt
EFS Information Dumper v1.02
Copyright (C) 1999 Mark Russinovich
Systems Internals - http://www.sysinternals.com
test.txt:
DDF Entry:
DARYL\Mark:
CN=Mark,L=EFS,OU=EFS File Encryption Certificate
DRF Entry:
Unknown user:
EFS Data Recovery
You can see that the file test.txt has one DDF entry for user Mark and one DRF entry for the EFS Data Recovery agent, which is the only recovery agent currently registered on the system.
Copying Encrypted Files
When an encrypted file is copied, the system does not decrypt the file and re-encrypt it at its destination; it just copies the encrypted data and the EFS alternate data streams to the specified destination. However, if the destination does not support alternate data streams—if it is not an NTFS volume (such as a FAT volume) or is a network share (even if the network share is an NTFS volume)—the copy cannot proceed normally because the alternate data streams would be lost. If the copy is done with Explorer, a dialog box informs the user that the destination volume does not support encryption and asks the user whether the file should be copied to the destination unencrypted. If the user agrees, the file will be decrypted and copied to the specified destination. If the copy is done from a command prompt, the copy command will fail and return the error message “The specified file could not be encrypted”.
Conclusion
Windows supports a wide variety of file system formats accessible to both the local system and remote clients. The file system filter driver architecture provides a clean way to extend and augment file system access, and NTFS provides a reliable, secure, scalable file system format for local file system storage. In the next chapter, we’ll look at startup and shutdown in Windows.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.