Microsoft .NET Architecting Applications for the Enterprise, Second Edition (2014)
Part I: Foundation
Chapter 4. Writing software of quality
As a system evolves, its complexity increases unless work is done to maintain or reduce.
—Prof. Manny Lehman
Nobody likes debt but, as harsh as it might sound, some level of debt in life is unavoidable. Technical debt in software is no exception. Abstractly speaking, technical debt is sort of a mortgage taken out on your code. You take out a mortgage every time you do quick-and-dirty things in your code. Like mortgages in life, technical debt might allow you to achieve an immediate result (for example, meeting a deadline), but that comes at the cost of interest that needs to be paid back (for example, higher costs of further maintenance and refactoring).
In Chapter 2, “Designing for success,” we identified the most common causes of technical debt. It’s a long list and includes looming deadlines, too early deadlines, and limited understanding of requirements. Sometimes it also includes limited skills, lack of collaboration, and inefficient scheduling of tasks. In addition, lack of awareness of any of these points delays taking proper action on your code and conducting fix-up procedures, thus letting technical debt grow bigger.
Back in the 1970s, Professor Manny Lehman formulated a few laws to explain the life cycle of software programs. At the foundation of Lehman’s theory, there’s the observation that any software system in development deteriorates over time as its complexity grows. Forty years later, plenty of software architects and developers have found out on their own that software deterioration is really a concrete force and must be addressed with concrete actions to survive software projects.
Lehman’s laws and concepts, like the Big Ball of Mud and Technical Debt, all refer to the same mechanics that can lead software projects down the slippery slope of failure. Lehman formulated his laws a long time ago and mostly from a mathematical perspective. Big Ball of Mud andTechnical Debt emerged more as real bites of life in the trenches.
In the end, we came to realize that all software needs to be maintained all the time it is used. Subsequently, a good piece of software is software that lends itself to being refactored effectively. Finally, the effectiveness of refactoring depends on three elements—testability, extensibility and readability—and a good number of relevant tests to catch any possible form of regression.
The art of writing testable code
For years, .NET developers relied only on debugging tools in Microsoft Visual Studio to ensure the quality of their code. The undeniable effectiveness of these tools made it worthwhile to combine two logically distinct actions: manual testing of code, and working around bugs to first reproduce and then fix them.
For years, this approach worked quite nicely.
In the past decade, however, a big change occurred under our .NET eyes: development teams became a lot more attentive to automated testing. Somehow developers figured out that automated tests were a better way to find out quickly and reliably what could be wrong and, more importantly, whether certain features were still working after some changes were made. Debuggers are still functional and in use, but mostly they’re used to proceed step by step in specific sections of code to investigate what’s wrong.
Automated testing adds a brand new dimension to software development.
Overall, we think it was just a natural change driven by a human instinct to adapt. The recognized necessity of testing software in an automated way—we could call it the necessity of applying the RAD paradigm to tests—raised another key point: writing software that is easy to test.
This is where testability fits in.
What is testability, anyway?
In the context of software architecture, a broadly accepted definition for testability describes it as the ease of performing tests on code. And testing code is just the process of checking software to ensure that it behaves as expected, contains no errors, and satisfies requirements. A popular slogan to address the importance of testing software comes from Bruce Eckel and reads like this:
If it ain’t tested, it’s broken.
On the surface, that statement is a bit provocative, but it beautifully serves the purpose of calling people’s attention to the ability to determine explicitly, automatically, and repeatedly whether or not some code works as expected.
All in all, we believe there’s no difference between testable code that works and untestable code that works. We used similar phrasing in Chapter 2 while referring to poorly written code. Well, believe it or not, there’s a strict relationship between well-written code and testable code: they’re nearly the same thing. A fundamental quality of good code, in fact, is that is must be testable. And the attribute of testability is good to have regardless of whether you actually write tests or not.
At the end of the day, testable code is loosely coupled code that uses SOLID principles (Single responsibility, Open/close, Liskov’s principles, Interface segregation, and Dependency inversion) extensively and avoids the common pitfalls of object-orientation, as discussed in Chapter 3, “Principles of software design.” In particular, the Dependency Inversion principle in one of its two flavors—Dependency Injection and Service Locator—is the trademark of testable code.
Principles of testability
Testing software is conceptually simple: just force the program to work on correct, incorrect, missing, or incomplete data, and verify whether the results are in line with any set expectations. How would you force the program to work on your input data? How would you measure the correctness of the results? And in cases of failure, how would you track the specific module that failed?
These questions are the foundation of a paradigm known as Design for Testability (DfT). Any software built in full respect of DfT principles is inherently testable and, as a pleasant side effect, it is also easy to read, understand, and subsequently maintain. DfT was developed as a general concept a few decades ago in a field that was not software. In fact, the goal of DfT was to improve the process of building low-level circuits within boards and chips. DfT defines three attributes that any unit of software must have to be easily testable:
![]() Control The attribute of control refers to the degree to which it is possible for testers to apply fixed input data to the software under test. Any piece of software should be written in a way that makes it clear what parameters are required and what return values are generated. In addition, any piece of software should abstract its dependencies—both parameters and low-level modules—and provide a way for external callers to inject them at will.
Control The attribute of control refers to the degree to which it is possible for testers to apply fixed input data to the software under test. Any piece of software should be written in a way that makes it clear what parameters are required and what return values are generated. In addition, any piece of software should abstract its dependencies—both parameters and low-level modules—and provide a way for external callers to inject them at will.
![]() Visibility The attribute of visibility is defined as the ability to observe the current state of the software under test and any output it can produce. Visibility is all about this aspect—postconditions to be verified past the execution of a method.
Visibility The attribute of visibility is defined as the ability to observe the current state of the software under test and any output it can produce. Visibility is all about this aspect—postconditions to be verified past the execution of a method.
![]() Simplicity Simple and extremely cohesive components are preferable for testing because the less you have to test, the more reliably and quickly you can do that.
Simplicity Simple and extremely cohesive components are preferable for testing because the less you have to test, the more reliably and quickly you can do that.
In general, simplicity is always a positive attribute for any system and in every context. Testing is clearly no exception.
Why is testability desirable?
As we see things, testability is much more important than the actual step of testing. Testability is an attribute of software that represents a (great) statement about its quality. Testing is a process aimed at verifying whether the code meets expectations.
Applying testability (for example, making your code easily testable) is like learning to fish; writing a unit test is like being given a fish to eat. Being given a fish resolves a problem; learning to fish is a different thing because it adds new skills, makes you stronger, and provides a way to resolve the same problem whenever it occurs.
When DfT is successfully applied, your code is generally of good quality, lends itself well to maintenance and refactoring, and can be more easily understood by any developers who happen to encounter it. In such conditions, writing unit tests is highly effective and easier overall.
The ROI of testability
The return-on-investment (ROI) of testability is all in the improved quality of the code you get. Writing classes with the goal of making them testable leads you to favor simplicity and proceed one small step a time. You can quickly catch when a given class is becoming bloated, spot where you need to inject dependencies, and identify which are the actual dependencies you need to take into account.
You can certainly produce testable code without actually writing all that many tests for each class and component. But writing tests and classes together helps you to comprehend the ROI.
The final goal, however, is having good code, not good tests.
If you need to prove to yourself, or your manager, the ROI of testability, we suggest you experiment with writing classes and tests together. It turns out that the resulting tests are a regression tool and provide evidence that in all tested conditions (including common and edge cases) your code works. The tests also improve the overall design of the classes, because to write tests, you end up making the public interface of the classes easier to use.
Tests are just more code to write and maintain, and this is an extra cost.
This said, it turns out that testability is a sort of personal epiphany that each developer, and team of developers, will eventually experience—but probably not until the time is right for them.
 Note
Note
The term code smell is often used to indicate an unpleasant aspect of some code that might indicate a more serious problem. A code smell is neither a bug nor a problem per se; it still refers to code that works perfectly. However, it refers to a bad programming practice or a less-than-ideal implementation that might have a deeper impact on the rest of the code. Code smells make code weaker. Finding and removing code smells is the primary objective of refactoring. To some extent, code smells are subjective and vary by languages and paradigms.
Testing your software
Software testing happens at various levels. You have unit tests to determine whether individual components of the software meet functional requirements. You have integration tests to determine whether the software fits in the environment and infrastructure and whether two or more components work well together. Finally, you have acceptance tests to determine whether the completed system meets customer requirements.
Unit tests
Unit testing consists of writing and running a small program (referred to as a test harness) that instantiates classes and invokes all defined methods in an automatic way. The body of each method instantiates classes to test and perform some action on them and then checks the results.
In its simplest form, a test harness is a manually written program that reads test-case input values and the corresponding expected results from some external files. Then the test harness calls methods on classes to test, using input values, and compares the results with the expected values. Obviously, writing such a test harness entirely from scratch is, at a minimum, time consuming and error prone. More importantly, it is restrictive in terms of the testing capabilities you can take advantage of.
The most effective and common way to conduct unit testing is to use an automated test framework such as MSTest (the one integrated in Visual Studio), NUnit, or xUnit. Here’s a brief example of the code you need to write to test your classes with MSTest in Visual Studio:
using Microsoft.VisualStudio.TestTools.UnitTesting;
using MyMath.Model;
namespace MyMath.Model.Tests
{
[TestClass]
public class MyMathTests
{
[TestMethod]
public void TestIfFactorialIsCorrect()
{
var factorial = new Factorial();
var result = factorial.Compute(5);
Assert.AreEqual(result, 120);
}
}
}
The test harness framework processes the class shown in the preceding code, instantiates it, and runs each of the methods labeled as TestMethod. Each test method performs some work on the classes under test. In the example, the test is conducted on the class Factorial to see if the method Compute produces the expected result when it is invoked with a given argument.
Note that unit tests run repeatedly most commonly as part of the build process. A test passes if the behavior of the tested class is the one you assert. For example, the following is another legitimate test that passes if the sample BasketMatch class throws an argument exception, but it fails otherwise:
[TestMethod]
[ExpectedException(typeof(System.ArgumentException))]
public void TestIfBasketMatchThrowsIfNullIsPassed()
{
var match = new BasketMatch("12345", null, null);
return;
}
This example, however, is interesting because it leads to a subtler point. Let’s assume the code passes the test; is it guaranteed that it passed because the second or the third parameters were null? In theory, you might have a bug in the constructor that throws an argument exception if, say, the first argument is just 12345. In this case, the test passes but you missed a bug.
To be more precise, you should double the test and check independently whether the second and third parameters are null. Even better than that, you should check the parameter name of the exception being thrown. This feature is not natively supported by MSTest although some extensions exist that support this feature. One is SharpTestex, which you can see at http://sharptestex.codeplex.com. Using this syntax, you can rewrite the test as shown here:
[TestMethod]
public void TestIfBasketMatchThrowsWhenTeam1IsNull()
{
Executing.This(() => new BasketMatch("12345", null, "Visitors"))
.Should()
.Throw<ArgumentNullException>()
.And
.ValueOf
.ParamName
.Should()
.Be
.EqualTo("Team1");
}
There might be various reasons why a test doesn’t pass. In the first place, it could just be an error in the test. More likely, though, it’s an issue in the class you test. In this case, you arm yourself with the debugger, slay the bug, and fix the code. Finally, it could be a matter of dependencies.
 Important
Important
How many assertions should you have per test? Should you force yourself to have just one assertion per test in full homage to the principle of narrowly scoped tests? It’s a controversial point. Sometimes, the need for multiple assertions often hides the fact that you are testing many features within a single test. However, if you’re testing the state of an object after a given operation, you probably need to check multiple values and need multiple assertions. You can certainly find a way to express this through a bunch of tests, each with a single assertion, but it would probably be just a lot of refactoring for little gain. We don’t mind having multiple assertions per test as long as the code in the test is testing just one macro behavior.
Dealing with dependencies
When you test a method, you want to focus only on the code within that method. All that you want to know is whether that code provides the expected results in the tested scenarios. To get this, you need to get rid of all dependencies the method might have.
For example, if the method invokes another class, you assume the invoked class will always return the correct results. In this way, you eliminate at the root the risk that the method fails under test because a failure occurred down the call stack. If you test method A and it fails, the reason has to be found exclusively in the source code of method A and not in any of its dependencies.
It is highly recommended that you isolate the class being tested from its dependencies. Be aware, though, that this can happen only if the class is designed in a loosely coupled manner—for example, through dependency injection or a service locator. In an object-oriented scenario, class A depends on class B when any of the following conditions are verified:
![]() Class A derives from class B.
Class A derives from class B.
![]() Class A includes a member of class B.
Class A includes a member of class B.
![]() One of the methods of class A invokes a method of class B.
One of the methods of class A invokes a method of class B.
![]() One of the methods of class A receives or returns a parameter of class B.
One of the methods of class A receives or returns a parameter of class B.
![]() Class A depends on a class that in turn depends on class B.
Class A depends on a class that in turn depends on class B.
How can you neutralize dependencies when testing a method? You use test doubles.
Fakes and mocks
A test double is an object you use in lieu of another. A test double is an object that pretends to be the real one expected in a given scenario. A class written to consume, say, an object that implements the ILogger interface can accept a real logger object that logs to Internet Information Services (IIS) or some database table. At the same time, it also can accept an object that pretends to be a logger but just does nothing. There are two main types of test doubles: fakes and mocks.
The simplest option is to use fake objects. A fake object is a relatively simple clone of an object that offers the same interface as the original object but returns hard-coded or programmatically determined values. Here’s a sample fake object for the ILogger type:
public class FakeLogger : ILogger
{
public void Log(String message)
{
return;
}
}
As you can see, the behavior of a fake object is hard-coded; the fake object has no state and no significant behavior. From the fake object’s perspective, it makes no difference how many times you invoke a fake method and when in the flow the call occurs. Typically, you use fakes when you just want to ignore a dependency.
A more sophisticated option is using mock objects. A mock object does all that a fake does, plus something more. In a way, a mock is an object with its own personality that mimics the behavior and interface of another object.
What more does a mock provide to testers? Essentially, a mock accommodates verification of the context of the method call. With a mock, you can verify that a method call happens with the right preconditions and in the correct order with respect to other methods in the class.
Writing a fake manually is not usually a big issue—for the most part; all the logic you need is simple and doesn’t need to change frequently. When you use fakes, you’re mostly interested in the state that a fake object might represent; you are not interested in interacting with it. Conversely, use a mock when you need to interact with dependent objects during tests. For example, you might want to know whether the mock has been invoked, and you might decide within the test what the mock object must return for a given method.
Writing mocks manually is certainly a possibility, but it is rarely an option you want to seriously consider. For the level of flexibility you expect from a mock, you need an ad hoc mocking framework. Table 4-1 lists a few popular mocking frameworks.
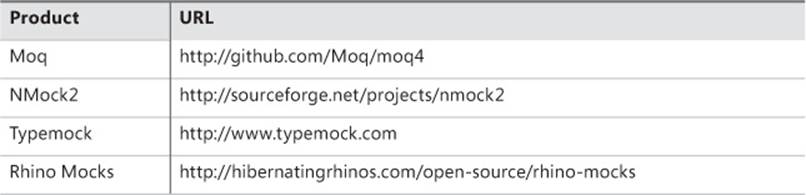
TABLE 4-1. Some popular mocking frameworks
Note that no mocking framework is currently incorporated in Visual Studio, but you can find most of them easily available via NuGet packages. Here’s a quick example of how to use a mocking framework such as Moq:
[TestMethod]
public void TestIfMethodWorks()
{
// Arrange
var logger = new Mock<ILogger>();
logger.Setup(l => l.Log(It.IsAny<String>()))
var match = new Match(“12345”, “Home”, “Visitors”, logger);
// Act
...
// Assert
...
}
The class under test—the Match class—has a dependency on an object that implements the ILogger interface:
public interface ILogger
{
void Log(String msg);
}
The mock repository supplies a dynamically created object that mocks up the interface for what the test is going to use. The mock object implements the method Log in such a way that it does nothing for whatever string argument it receives. You are not really testing the logger here; you are focusing on the Match class and providing a quick and functional mock for the logger component that the controller uses internally.
There’s no need for you to create an entire fake class; you just specify the code you need a given method to run when invoked. That’s the power of mocks (and mocking frameworks in particular) when compared to fakes.
 Note
Note
Arrange-Act-Assert (AAA) is a common pattern for structuring unit tests. First, you arrange all necessary preconditions and set up input data. Next, you act on the method you intend to test and capture some results. Finally, you assert that the expected results have been obtained.
Integration tests
Unit tests are written by developers for themselves. They exist as a regression tool and to make the team confident about the outgoing quality of the software. Unit tests basically answer questions like “Are we doing well?” or “Are we on the right track?” or “Does it break other components?” The scope of unit tests covers a single functional unit of the system. The unit is likely a class, but not all classes reach the logical level of being considered a functional unit of the system.
Integration tests are the next level of testing—that’s when you take multiple functional units and see if they can work well together. Integration tests, then, involve different parts of the system and test them in a scenario that’s really close to reality. The goal of integration tests is to get feedback about the performance and reliability of individual components. Often, integration tests cross layers and tiers of the whole system and involve databases and services.
In unit tests, you test just one unit at a time, but how many components should you test together in an integration test? Integration tests take a much longer time than unit tests to be set up and run. And this set-up time is the same every time you run them. For example, imagine a scenario where you need a component to operate on a database. Every time you run the test you must ensure the database is in a coherent state that you must restore (or check at the very minimum) before you can run the test again.
To save time in integration tests, sometimes you take the shortcut of the Big Bang pattern.
In this scenario, all or most of the components are connected and tested, all at once. You configure the system in a user-like environment and push a typical workload on it to see how it goes. In this way, you certainly save a lot of time, but if something goes wrong you might be left clueless when investigating the issue. In fact, integration tests can reveal whether parts of the system work well together, but they can hardly tell you why they are not working—and sometimes, if many parts are involved, tests also fail to tell you which specific module actually failed.
As obvious as it might sound, planning integration tests is not easy.
First, you can’t start until all involved modules are released, and modules won’t be released until they are considered finished and working by respective owners. Typically, with integration testing, you risk starting quite late, at a time in which managers are under pressure and wish to rush, maybe just hoping that it will be OK. A better strategy (if you’re allowed to follow it) is doing bottom-up integration testing, which basically consists of integrating low-level modules first and as early as possible. Each module might be just a little more than an empty box at this time, but with the help of some preliminary implementation of classes, you can see the big picture quite soon. Issues can be reported early, and fixing them can prevent other similar issues from appearing later.
![]() Tip
Tip
Preliminary implementation here also means having classes with the right interface but no logic just returning canned data. It is interesting to notice how this is in line with one of the key Test-Driven Development (TDD) prescriptions: start developing your classes, writing enough code to pass the (unit) test first. If you do so, you also position yourself well for integration tests. We’ll return to TDD in just a moment.
Note
One of the sore points of the healthcare.gov problematic startup was the lack of sufficient integration tests, which are highly critical in such as large, variegated, and distributed system. You just witnessed in the Big Bang approach to integration testing one of the most likely causes of the initial troubles. You can read an interesting and short analysis of the healthcare.gov story here: http://bit.ly/1bWPgZS.
Acceptance tests
Acceptance tests are the contracted tests you run to determine whether the fully deployed system meets your requirements. This is the only sure fact we know about acceptance tests. Who writes and runs the tests varies; therefore, the formulation of such tests also varies.
It’s a common thought—mostly absorbed from Extreme Programming—that stakeholders and QA people write acceptance tests together, starting from user stories and picking the relevant scenarios to test. Each user story can have one acceptance test or multiple tests, as appropriate. Stakeholders take care of the positive side; QA takes care of edge cases. Finally, developers review tests to ensure that actual actions make sense within the deployed system.
An acceptance test is a black-box test. All that matters is the actual result you get; no knowledge of the internals is assumed. Acceptance tests should also work as regression tests prior to candidate releases and to detect breaking changes when a newer version is released. Sounds simple? Well, it’s probably because there are a few points we left unaddressed.
In particular, how do you write acceptance tests?
In its simplest form, an acceptance test is a set of step-by-step instructions to be repeated against the fully configured system to observe outputs. To run acceptance tests often, you should find a way to automate them. This means that acceptance tests should be coded as programs whenever possible. But if you expect stakeholders to write acceptance tests, which language should they use? How do you ensure that acceptance tests are in sync with all details of implementation? Should acceptance tests exist before or after the whole system is built? All these questions have no definitive answer, and most teams just follow the recommendation of Extreme Programming and define the implementation details on a per-instance basis.
An Agile methodology, Behavior-Driven Design (BDD) was proposed by Dan North a few years ago with the declared goal of tidying up the chaos surrounding all aspects of project development, including automated acceptance tests.
Behavior-Driven Design
BDD aims to define cyclic interactions between any involved stakeholders leading to the delivery of the final product. One of the pillars of BDD is the production of well-defined outputs from each interaction. To enforce that guideline, BDD suggests you work around a number of statements that use a relatively high-level language at first. These statements are then further specified by developers up to the point they become actual code and form a concrete implementation of the system.
BDD statements are centered on three points: preconditions, action, and output. You can create these statements manually using any text editor and use them as the basis of acceptance tests. Better yet, you can do your BDD work within a tool integrated with your IDE so that you start with BDD statements and end up with code and all tests—unit and integration—you might need along the way.
A typical BDD statement looks like this:
Scenario: User is tracking the score of a water polo match
Given The user on page /match
And The match is fully configured
And The match is started
When The user clicks on Goal button on the left
Then The system updates the match scoring one goal for Home
A BDD framework can transform such a simple statement into runnable code and tests. In Visual Studio 2013 (and earlier versions), you can use SpecFlow, which is available as an extension from the Visual Studio Gallery Extension. Visual Studio also comes with a few NuGet packages you can use to configure a test project to be BDD aware. For more information, check out http://www.specflow.org.
When you’re done with all Given/When/Then statements, all you do is run unit tests from the same context menu shown in Figure 4-1. Figure 4-2 shows a possible result.
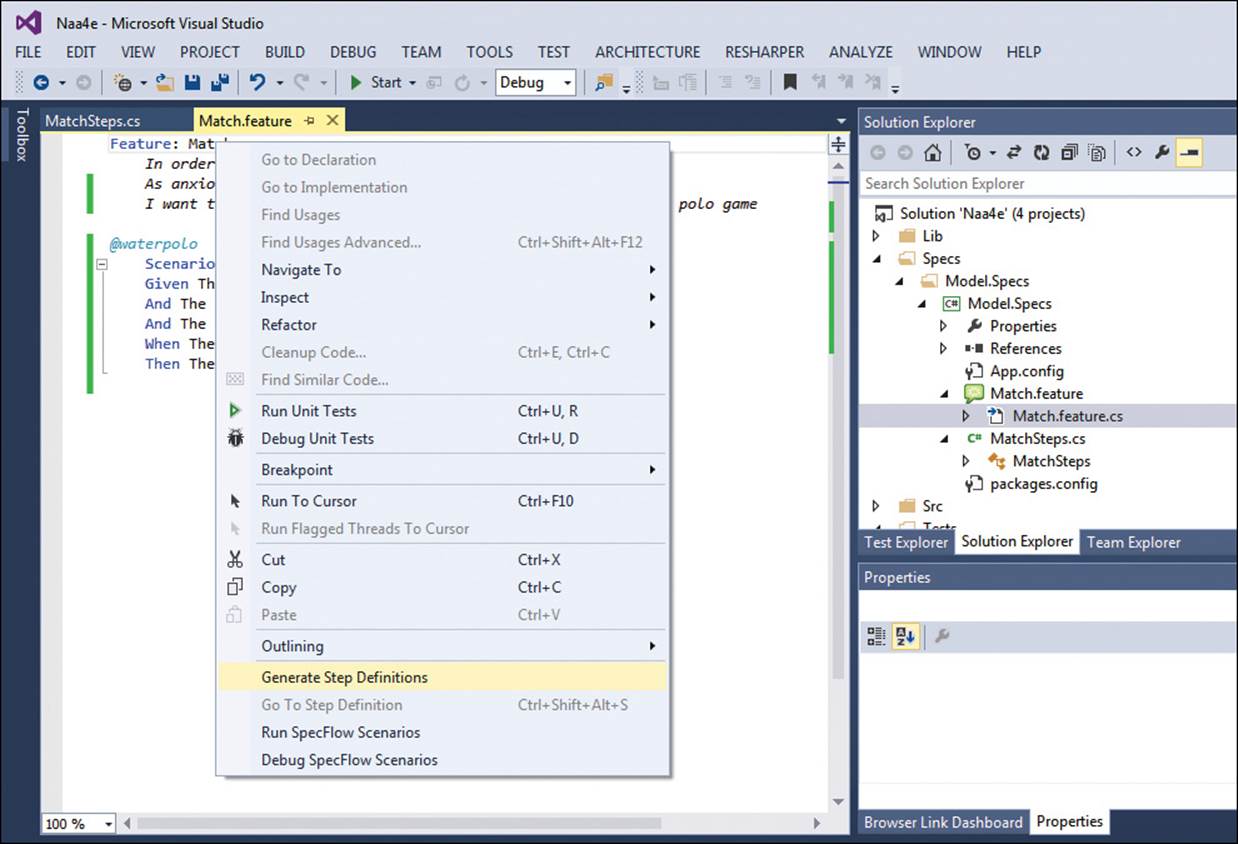
FIGURE 4-1 The SpecFlow extension in action within Visual Studio 2013.
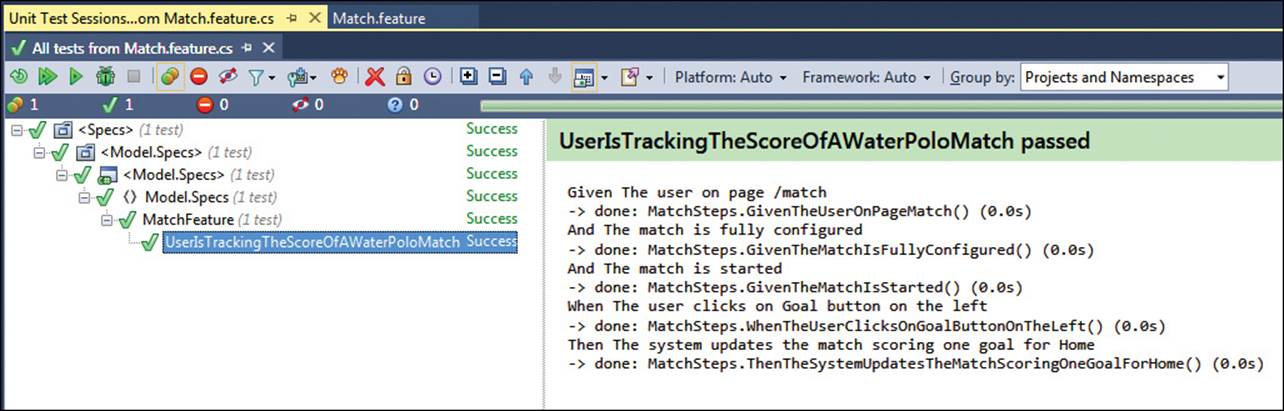
FIGURE 4-2 The results of running unit tests from SpecFlow tests.
Common practices of software testing
While everybody agrees on the importance of having tests in software projects, there are still a number of highly debatable points regarding testing that everybody resolves in their own way. These open points revolve around the role of the test, the time at which you write them, the quantity and location of tests, and more.
Let’s briefly address some of them in the hope of clarifying things a bit. Our purpose here is to aggregate different positions, add our own annotations and comments, and generate an honest summary of facts and perspectives.
In other words, we’re not doctors, so we won’t write prescriptions!
Test-Driven Development
Test-Driven Development (TDD) is a process that leads developers to write their code starting from tests. For each class or method, a TDD developer starts with an initially failing test that represents the expected behavior. Then, iteratively, the developer adds code to the method or class to make the test pass and refactors the code to improve it, whatever that means. This refactoring includes adding more functionality, improving the design, improving readability, injecting dependencies, complying with guidelines of some sort, and so forth.
It turns out that TDD brings a few basic facts to the table:
![]() Tests are not the primary goal of TDD. Quite the reverse: tests are focused on letting the ideal design emerge naturally out of continuous refactoring.
Tests are not the primary goal of TDD. Quite the reverse: tests are focused on letting the ideal design emerge naturally out of continuous refactoring.
![]() The ultimate goal of tests in TDD is not high code coverage but better design.
The ultimate goal of tests in TDD is not high code coverage but better design.
![]() Continuous refactoring is not optional. Refactoring is the substance of TDD much more than tests are.
Continuous refactoring is not optional. Refactoring is the substance of TDD much more than tests are.
TDD is one of those topics that divides people into two opposite and strongly opinionated (even fighting) camps. Many think that just because TDD is extensively based on tests, unit tests are the ultimate goal (and code coverage along with it). At a second glance, these people wonder where the benefits of TDD actually are, because writing silly tests for a basic method seems, well, just like a lot of overhead. Next, these people form the opinion that, well, tests can be added at a later time and only in the areas of code where you need them to be in order to catch regression. In the end, these people tend to be against TDD and sometimes say it is of little use.
As we tried to summarize in the initial bulleted points of this section, we feel that there’s a common misunderstanding regarding TDD. Tests are the means, not the end. TDD, on the other hand, is a plain software developments process that is as good as many others out there. TDD is not a referendum on unit tests. To use the words of Robert C. Martin, “The act of writing a unit test is more an act of design than of verification.” In the end, TDD is about design and just uses tests as the means to achieve good design. At the end of the process, though, you hopefully have well-designed code and, as a free premium, a bunch of tests with a high level of code coverage.
You must be well aware of the role of tests if you embrace TDD, and you must be similarly aware of the role of refactoring. You can’t claim you’re doing TDD if you stop at the code that makes any test pass. Refactoring is the tool you use to get better design.
Like any other process, in any field of the industry, TDD is not perfect. In particular, TDD involves a bit of work and continuous throwing away of tests and code. In a way, TDD never gives you the feeling that a class or a method is well done at some point, but this is the nature of iteration, after all.
Anyway, writing tests on the way to understanding code implies a change of mindset. Some companies force this change on developers.
Our opinion is that if you’re looking for a large-scale improvement in code quality and the skills of individual developers, TDD probably is—all things considered—the best option because it gives you a step-by-step procedure: write a failing test, add code, make the test pass, refactor, repeat. Because your code must pass tests, you’re led to loosen up its design, handle dependencies carefully, avoid static and global methods, keep classes lean and mean, always choose the simplest option—all things that make code better.
Can I write my tests later?
Because TDD is a plain software-development process, it’s not a mandatory choice and is not the only safe way to clean code. You can design your code effectively using other, equally valid, techniques. When you have code, though, it’s reasonable to say you need tests. If you don’t do TDD—where tests are part of the process—tests become your end at some point. And you just write them when you need them and for the areas of code where you think they are required.
You can sure write tests after you write the code.
That’s not necessarily good or bad; it’s just a different software-development process. In this case, tests are for validation and regression and represent an additional item and cost in the project workspace. As such, it is an item (and a cost) that can be cut off in the face of looming deadlines or tight budgets.
In TDD, tests are an integral part of the software-development process. If you write code first and tests later when you need them, then tests and code are separate entities.
In the end, tests serve the purpose of validating code and catching regression. And these are fundamental aspects of modern code development. An interesting reading on the test-first vs. test-after debate can be found at the following site: http://hadihariri.com/2012/10/01/tdd-your-insurance-policy.
Should I care about code coverage?
The primary purpose of unit and integration tests is to make the development team confident about the quality of the software they’re producing. Basically, unit testing informs the team whether they are doing well and are on the right track. But how reliable are the results of your tests?
In general, successful testing seems to be a good measure of quality if tests cover enough code; but no realistic correlation has ever been proven to exist between code coverage and actual software quality. And likewise, no common agreement has ever been reached on what “enough” means in numbers. Some say 80 percent of code coverage is good; some do not even bother quoting a figure. For sure, forms of full code coverage are actually impractical to achieve maybe not even possible.
Code coverage is a rather generic term that can refer to quite a few different calculation criteria, such as function, statement, decision, and path coverage. Function coverage measures whether each function in the program has been executed in some tests. Statement coverage looks more granularly at individual lines of the source code. Decision coverage measures the branches (such as an if statement) evaluated, whereas path coverage checks whether every possible route through a given part of the code has been executed.
Each criterion provides a viewpoint into the code, but what you get back are only numbers to be interpreted. So it might seem that testing all the lines of code (that is, getting a hypothetical 100 percent statement coverage) is a great thing; however, a higher value for path coverage is probably more desirable because it looks into actual code paths. Code coverage is useful because it lets you identify which code hasn’t been touched by tests. At the same time, it doesn’t tell you much about how well tests have exercised the code. Want a nice example?
Imagine a method that processes an integer.
You can have 100 percent statement coverage for it, but if you lack a test in which the method receives an out-of-range, invalid value, you might get an exception at run time in spite of all the successful tests you have run.
Code coverage and the Ariadne 5 disaster
As reported, back in 1996 the Ariadne 5 rocket self-destroyed 40 seconds after takeoff because of an overflow exception that went unhandled up through the code until it reached the self-destroy module, which told the rocket it was out of orbit and it was safer to destroy it. (The full story is here: http://www.around.com/ariane.html.)
Admittedly, we didn’t take any look at the source code of the project. However, if the reports are correct we can easily guess that the code contained a method attempting the conversion of a floating point into an unsigned integer. We also have no idea of the code coverage for the project, but we assume you don’t try to launch a $7 billion rocket without a good deal of tests.
No matter what the actual code coverage was, we’d say that a test checking a very large, out-of-range floating point value would have been easy to write and would have warned about the problem. Or such a text was written but its results were blissfully ignored.
Figure 4-3 shows the output of the code-coverage tool in Visual Studio 2013. As you can see, it’s just numbers that mean very little without interpretation and context.
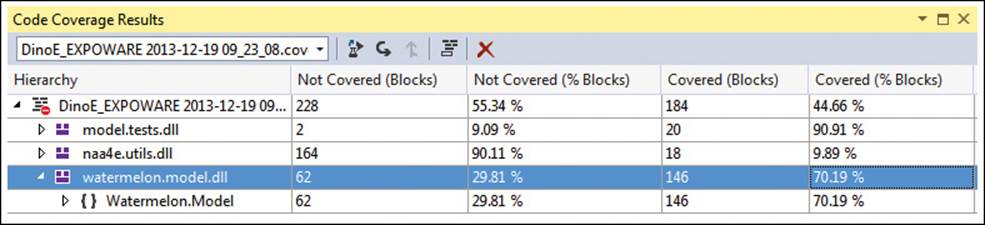
FIGURE 4-3 The Code Coverage user interface in Visual Studio 2013.
In the end, code coverage is just a number subject to specific measurement. The relevance of tests is what really matters. Blindly increasing the code coverage or, worse yet, requiring that developers reach a given threshold of coverage is no guarantee of anything. A well-tested application is an application that has high coverage of relevant scenarios.
Which part of my code should I test?
In Figure 4-3, you get an average of 44 percent for the project, but coverage is fairly low in a utility library and much higher in a library that implements the model used by the application. Does that mean something?
As we see things, a utility library is a relatively static thing: either it works or it does not. If a function there is found to be buggy, it gets fixed, and that’s it. If the utility you write there—say, a function that shortens strings and adds an ellipsis at the end—is quite generic and can be called from various places, you might still want to have some tests to exercise it, especially with edge cases. But unit tests are probably more relevant and extend to common cases and edge cases in the areas where the code does its business.
You can generically call it the business layer or, more specifically and in line with the vision of this book, the domain layer. You should focus your testing efforts where critical decisions involving the logic of the application are made. Figure 4-4 shows a typical workflow following a user action. The command passes through the application layer and results in a sequence of orchestrated calls to various pieces of the back end, including external services, the domain model, domain services, and the persistence layer. When a response has been produced, it is formatted back for the user interface. The shading in Figure 4-4 indicates the priority of testing, with the darkest shading indicating the items with the highest priority for testing.
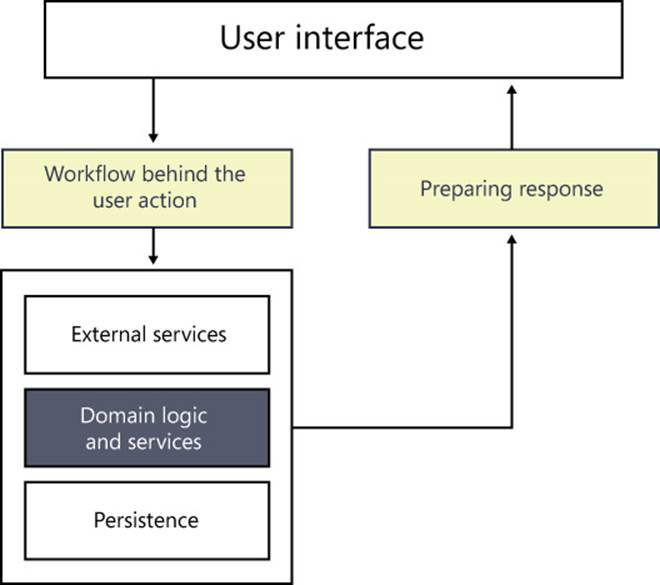
FIGURE 4-4 The darkest colors indicate the items for which testing is the highest priority.
The domain layer is the most complex part and the part most affected by requirements churn. Subsequently, it is the part where most bugs might manifest. Orchestration and adapters to and from presentation formats have the more mechanical parts of the application, and their behavior can be observed in many other ways: by code inspections, reviews, QA testing, and plain debugging.
As a more general rule, we’d say that you should prioritize tests for components consumed by a lot of other components, logical components where a deep understanding of the requirements is essential, and components owned by multiple developers. Don’t blindly sit down and write tests, and don’t force your developers into that. It’s silly to have lots of tests that have no chance to ever fail.
Note
When writing a unit test, you should know a lot of details about the internals of the unit you’re testing. Unit testing is, in fact, a form of white-box testing, as opposed to black-box testing in which the tester needs no knowledge of the internals and limits testing to entering given input values and expecting given output values.
Automating the buildup of unit tests
Suppose you’re not a TDD fanatic. At some point, you might just happen to have a C# class and no unit tests for it. Where would you start getting some? Because you wrote the code, you are the best person to determine what’s critical to test. However, it’s always too easy for humans to miss, skip, or underestimate an edge case, especially in a potentially large codebase. As a result, all tests might pass, but the code can still fail.
The Microsoft Pex add-in for Visual Studio can come to your rescue because it aims to understand the logic of your code and suggest relevant tests you need to have. Internally, Pex employs static analysis techniques to build its knowledge of the behavior of your code.
In addition, if you have parameterized tests in your test project, Pex can figure out which combination of parameters needs be passed to give you full coverage of possible scenarios. Finally, if you use .NET Code Contracts in your code, Pex will use that information to fine-tune the unit tests it suggests or generates for you.
In summary, Pex is an innovative white-box testing tool that can be used in two ways: as an aid to generate nontrivial unit tests, and as a peer reviewer who can quickly look at your code and find holes and omissions in it. You can download Pex from http://research.microsoft.com/en-us/projects/pex.
The practice of code extensibility
As mentioned by Dave Thomas and Andy Hunt, authors of the aforementioned book The Pragmatic Programmer (Addison-Wesley, 1999), all programming work is a form of maintenance. Only a few minutes after being typed for the first time, a class enters its infinite maintenance cycle. Most of the time, maintenance entails refactoring the existing codebase to patterns or just to a cleaner design. However, under the capable umbrella of the term maintenance also falls the attribute of code extensibility—namely, extending existing code with new functions that integrate well with existing functions.
We can say for code extensibility nearly the same that Donald Knuth said of optimization: when prematurely done, it can be the root of all software evil. The ego of many developers is strongly stimulated by the idea of writing code that can be extended with limited effort. This might easily lead to over-engineering. A picture is worth a thousand words here: Figure 4-5 shows what we mean. The picture was inspired by the comic strip at http://xkcd.com/974.
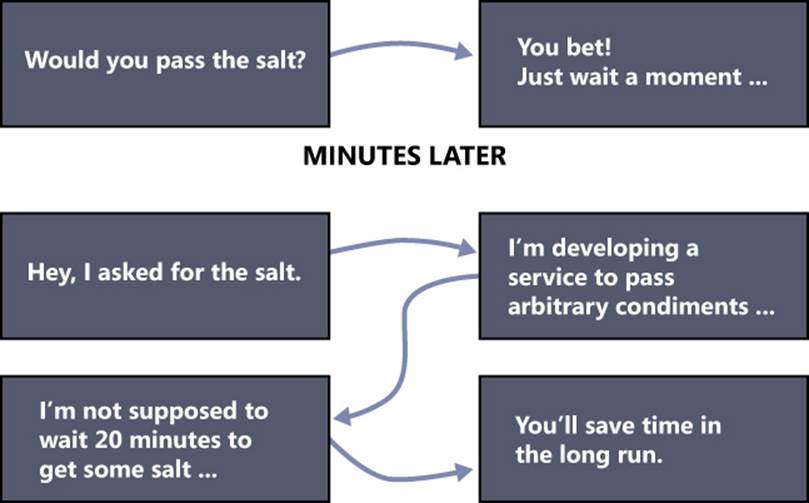
FIGURE 4-5 The general problem of over-engineering.
When the attribute of extensibility is fundamental, you might want to consider the following three aspects in your code: interface-based design, plugin architecture, and state machines.
 Important
Important
Most of the time, you need to find evidence that you need a more extensible and flexible design. The need for a more abstract and flexible design is the typical outcome of a refactoring session. A more extensible design can also surface in the early stage of sprints when you’re about to implement a new feature.
Interface-based design
Interfaces represent a contract set between two software parties. When a software component—say, a class—declares it can handle a given interface, the net effect is that it can then work with any other component, either one existing today or to be written in the future, that exposes the same interface. This concept is at the foundation of extensible code.
The criticality of this approach is in the number of software components you should design with extensibility in mind. It’s highly impractical to have all classes designed to be extensible and receive interfaces for every single piece of strategy they need to deal with. Failing on this point is what leads you right to over-engineering.
The challenge—and trust us, it is really a tough challenge—is just figuring out when extracting an interface from a strategy and sharing it between multiple components is something that really gives you more value.
Plugin architecture
When the word extensibility is uttered many just think of plugins. A plugin is an external component that adds a specific feature to an existing application that was not originally part of it. For this to happen, though, the host application must be designed in such a way it detects and handles plugins.
The host application dictates the programming interface of plugins, determines unilaterally what data plugins receive once they are loaded, and specifies when they are invoked and where they must be placed to be recognized. The host application also needs to have a special layer of code that handles the loading and unloading of available plugins.
There are many ways to write a plugin-based architecture. The substance of such an architecture is well summarized by the Plugin pattern as described by Martin Fowler. (See http://martinfowler.com/eaaCatalog/plugin.html.) Your code at some point (called the extension point) uses a component to perform a given task. The task is abstracted to an interface or base class. The class uses an ad hoc layer to read from a centralized configuration the registered plugins, and it uses a factory to instantiate them. The canonical example of a plugin-based architecture is a website using an Inversion of Control (IoC) framework and having configuration centralized to a section of the web.config file.
When you have a plugin-based architecture, one problem you sometimes run into is sharing the state of the application with the plugins. The problem might not show if all plugins just work with data injected through methods at given extension points. If this plain approach doesn’t work, you should consider centralizing the data model for the system so that all plugins have equal access to the data.
State machines
State machines are a common way to break complex tasks into manageable steps that implement some narrowly defined behavior. In its simplest form, a state machine is a switch statement. In a switch statement, you can easily add an extra case with related code. It’s easy and effective.
Whenever you find an area of code that might expand to incorporate multiple tasks and cases, wrapping it in a state machine, or more generally in a sort of black box, is a good move toward extensibility.
Writing code that others can read
We’re both watching our remaining hair turn gray, whichmeans we started writing code at a time when common people looked at developers as weird human beings—half scientist and half magician. We were all pioneers some 20 years ago, and we used to make a point—often just a funny point—of hiding our code from others. Not because we didn’t want others to read our code, but just to prove we were smarter. So it was considered smarter to write code in a way that others couldn’t read and understand.
This attitude might never have changed much over time if one of the key problems software architects face when working in a team is ensuring that code is understandable and written according to common conventions.
Do you remember the International Obfuscated C Code Contest (IOCCC)? If not, we suggest you visit http://www.ioccc.org. IOCCC is an open contest that takes place every year. Participants submit some working C code that solves a problem—any problem. “What’s the deal?” you might ask. Well, the funny thing is that the winner is not selected because of an innovative algorithm, performance, compactness, or other common metrics. The only metrics that really matter is how obscure and obfuscated the C code is. You can find the source code of winning programs of past years at http://www.ioccc.org/years.html. Figure 4-6 shows the listing of one such program.
FIGURE 4-6 The source code of a program which participated to the IOCCC contest.
The code is guaranteed to work well, but it is quite hard to make sense of what it does.
Well beyond the fun of an obfuscated C contest, readability in programming is critical. If code that gets checked in is perfect and won’t be touched anymore at any time, you could accept that it is written in an obfuscated manner. In any other case, other developers (and often the same developer who originally wrote it) might find it hard to understand the code because it was not written with good practices in mind.
We said and heard this a gazillion times; we know it. Yet, readability is often neglected—maybe not always entirely neglected, but neglected just enough to result in some extra waste of time (and money) when the existing code needs to be reworked or new people need to be trained on the internals of the system being built.
Readability as a software attribute
Maintainability is known to be one of the key attributes of software, at least according to the ISO/IEC 9126 paper. For more information, refer to http://en.wikipedia.org/wiki/ISO/IEC_9126.
Maintainability, however, results from various factors, one of which is certainly readability. Code that is hard to read is also hard to understand for everybody, including the author. Our friend Kevlin Henney recently wrapped up in the 140 characters of a tweet a juicy piece of wisdom about code readability. Kevlin tweeted that a common fallacy is to assume that authors of incomprehensible code will somehow be able to express themselves lucidly and clearly in comments, as a way to dissolve any lack of clarity about the code.
We couldn’t agree more. Comments are part of the code, but it’s not comments that significantly augment the readability of a piece of code. Comments are just like icing on the cake; comments are not the cake. Furthermore, comments might not be the type of icing you like to have on the cake.
Toward a commonly accepted definition of readability
If you’re not completely convinced of the importance of having readable code, consider that any developers who put their hands on code they don’t clearly understand are capable of making the code even worse. It’s not simply a matter of aiming for the highest possible level of quality; it’s purely a matter of saving money.
Unfortunately, readability is a very subjective matter and arranging some automatic tools to check and report the readability level of the code is nearly impossible. Anyway, we would bet the house that even in the quite utopian scenario of having automatic readability-measurement tools available, most people would simply consider them highly unreliable.
We dare say that readability is an attribute of code that developers should learn right at the beginning of their careers and develop and improve over time. Like style and good design, readability should not be reserved for experts and, more importantly, not postponed to when you just have enough time for it.
As a seasoned developer today, you know very well that you are never going to have enough time for anything but just writing the code. That’s why good developers manage to write readable code “by default.”
A matter of respect
Putting any effort into keeping code readable is primarily a matter of respect for other developers on the team. As a StackOverflow user posted at some point, you should always write your code as if the person who ends up maintaining what you write is a violent psychopath who knows where you live. Less dramatically, aim to make your code editable by any developer while you’re offline and hiking in the middle of the Death Valley. In addition, you should not forget that the developer who ends up maintaining your code, one day, might just be you.
There’s a nice story we can tell regarding this point.
Some years ago, Dino was looking for content on a well-hidden area of the Microsoft .NET Framework. Google and Bing combined could return only one article from some remote online magazine. The article was not completely sufficient to clarify the obscure points Dino was facing. So, a bit frustrated, Dino started complaining about the author of the article who didn’t do that great of a job. But the author, well, it was him.
When reading other people’s code, a couple of things usually drive you crazy. One aspect that makes reading code hard is the unclear goal of data structures and algorithms used in the code. Another is that strategies developers apply in the code are sometimes not so obvious to readers and not well clarified through comments. It seems the author is trying to kid you, as if she’s participating in some obfuscated code contest. This is where good comments are required.
Readability is also about money
Imagine the following scenario. You have a large codebase written in Java and need to port it to .NET. If it sounds weird at first, consider that there are at least a couple of realistic situations in which it can really happen. One is when you try to port a native Android application to the Windows Phone platform. Another is when you are in the process of building a library for various platforms. Suppose you face some code like the following:
// Find the smallest number in a list of integers
private int mininList(params int[] numbers)
{
var min = Int32.MaxValue;
for (var i = 0; i < numbers.length; i++) {
int number = numbers[i];
if (number < min)
min = number;
}
return min;
}
And then later on, in the same file, you find something like this:
var number = mininList(x, y);
As a margin (but not marginal) note, consider that no savvy C# developer would likely write similar code. In C#, in fact, you can rely on LINQ to reduce the code to one line or two. But let’s assume that having such code is acceptable. There’s more about it that should be said.
First, comes the name of the method. The convention used here is arguable: the name misses a verb and uses a mixed casing logic. Something like GetMinFromList would probably be a better name. Second, we reach the most debatable point of the private qualifier used in the declaration and the usage of the method within the class. Because it is marked private, the method is used only within the class; it’s actually invoked only once and only to return the minimum of two integers. Even without using LINQ, a call to Math.Min would have done the trick.
When you encounter similar code, you can’t avoid stopping and wondering why that code is there. It’s not so much that you want to blame the author; it’s only that you want to make sure you’re not missing any critical part of it. The code represents potentially reusable pieces of code that can be called from a variety of places in the entire codebase. So marking it as private is total nonsense. However, if the method is used only once, why mark it as public?
Developers know very well the power of the YAGNI rule—you ain’t gonna need it—and reasonably tend not to expose code that is not strictly needed. So it could be that the author of the code considered the function to be potentially reusable but not at the time it was written. That’s why that function was written to be easily turned into a reusable helper function but marked private to be visible only within the host class.
In the end, it is not unlikely that the code resulted from some well-defined strategy. However, the strategy—if any—is hard to figure out for external readers. This is exactly the type of situation where a few lines of comments would clearly explain the motivation behind the decision.
When I encountered that code, it took me some time to first look a lot more carefully at it. Then I felt the need to contact the team to make sure I was not missing hidden points. Then I changed the implementation to use a plain LINQ call. It was quite a few years ago, but I was hired to port the code to .NET. In the end, the company paid for an extra hour of my time.
If you miss adding appropriate comments, you are not being a good citizen in the city of code.
Some practical rules for improving readability
Code readability is one of those topics whose importance is widely recognized, but that it is really hard to formalize. At the same time, without some formalization, code readability is nearly an empty concept. Overall, a sort of rule of the three Cs can be defined to define readability: comments, consistency, and clarity.
Comments
Modern IDEs make it easy to define institutional comments like a descriptive line for the function, parameters, and return value. All you need to do is think of the text to add and let the IDE do the rest. You should consider these comments mandatory, at least for any public piece of code you might have, and make the effort to write significant text for them.
Banning obvious comments is another fundamental point on the way to improved readability. Obvious comments just add noise and no relevant information. By definition, a comment is any explanatory text for any decision you make in the code that is not obvious per se. A good comment can only be an insightful remark about a particular aspect of the code. Everything else is just noisy and potentially harmful.
Consistency
The second “C” on the way to readability is consistency. Every development team should have guidelines for writing code, and it’s best for such guidelines to be company-wide. The point is not about having good or not-so-good guidelines. The benefit is simply in having, and honoring, guidelines. The value of coding the same thing always in the same way is invaluable.
Suppose for a moment that you are writing a library that does string manipulation. In several places within this library, you need to check whether a string contains a given substring. How would you do that?
In the .NET Framework, as well as in the Java SDK, you have at least two ways of achieving the same thing: using the Contains or IndexOf method. The two methods, though, serve quite different purposes. The method Contains returns a Boolean value and just tells you whether or not the substring is contained in a given string. The method IndexOf, on the other hand, returns the 0-based index where the searched string is located. If there’s no contained substring, IndexOf returns -1.
From a purely functional perspective, therefore, Contains and IndexOf can be used to achieve the same goals; however, they give a different message to a code reader and often force the reader to take a second look at the code to see if there’s a special reason to use IndexOf instead ofContains to check for a substring. A single second pass of reading a line of code is not a problem, but when this happens on an entire codebase of thousands of lines of code, it does have an impact on time and subsequently on costs—the cost of not having highly readable code.
As a developer, you should aim to write clean code the first time and not hope to have enough time someday to clean it up. As a team leader, you should enforce code guidelines through check-in policies. Ideally, you should not allow check-in of any code that doesn’t pass a consistency test.
Clarity
The third “C” of code readability is clarity. Code is clear if you style it in a way to make it read well and easily. This includes grouping and nesting code appropriately. In general, IF statements add a lot of noise to the code. Sometimes conditional statements—a pillar of programming languages—can’t be avoided, but limiting the number of IF statements keeps nesting under control and makes code easier to read. Sometimes a SWITCH is clearer than many IFs. Code-assistant tools often offer to replace many consecutive IF branches with a single SWITCH. It’s just a click or two away: you really have no excuses.
Some tasks might require a few lines of code, and it might be inappropriate to perform an “Extract Method” refactoring on it. In this case, it is good to keep these lines in blocks separated with blank lines. It doesn’t change the substance of things; it just makes the code a bit easier to read.
These are just two basic examples of things you can do to make your code better from a purely aesthetic perspective. Finally, if you are looking for inspiration on how to style your source code, take a look at some open-source projects. Open-source software is written for many people to read and understand it. It might be a real source of inspiration, and you might want to extract your own guidelines from there.
Short makes it better
Have you ever wondered why newspapers and magazines print their text in columns? Well, there’s a reason for that.
The reason is that long lines make it hard for human eyes to read. When it comes to code, you should apply that same principle and limit both the horizontal length of lines and the vertical scrolling of the methods.
But what is the ideal length of a method’s body?
Absolute numbers that work for every developer and every project are nearly impossible to find. In general, we say that when you reach 30 lines, an alarm bell should ring. This length suggests it’s time you consider refactoring. More generally, a limited use of the scrollbars tends to be a good statement about the style of your code.
Summary
In our opinion, the quality of code is measured against three parameters: testability, extensibility, and readability.
Testability ensures in the first place that the code is well articulated in distinct and interoperating components that are, for the most part, loosely coupled. This statement stems from the fact that you can write tests on your code. If you can do that, your code is componentized and each component can be tested in isolation. Finding bugs, and especially fixing bugs, becomes easier. When it comes to measuring the quality of code, unit tests matter. It’s not so much because the code passes them, but because you can write them with ease.
In modern times, any code is written to be extended and improved. Maintaining code is the only known way to write code these days. This means that separation of concerns, loose coupling, and built-in mechanisms for extensibility and dependency injection are concepts every developer should master and apply. As a team leader, you should aim to improve all developers on your team on that count.
Anyone who raises the theme of code quality gets exposed to one common objection: writing clean code is hard and takes a lot of time. In other words, clean code is not a sustainable form of development for many teams. Clean code leads to losing productivity.
Productivity is more than important, but focusing on productivity alone costs too much because it can lead to low-quality code that is difficult and expensive to maintain. And, if it’s hard to maintain, where’s the benefit?
Finishing with a smile
See http://www.murphys-laws.com for an extensive listing of computer (and noncomputer) related laws and corollaries. Here are a few you might enjoy:
![]() Real programmers don’t comment their code. If it was hard to write, it should be hard to understand.
Real programmers don’t comment their code. If it was hard to write, it should be hard to understand.
![]() 90% of a programmer’s errors come from data from other programmers.
90% of a programmer’s errors come from data from other programmers.
![]() Software bugs are impossible to detect by anybody except the end user.
Software bugs are impossible to detect by anybody except the end user.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.