Microsoft .NET Architecting Applications for the Enterprise, Second Edition (2014)
Part III: Supporting architectures
Chapter 9. Implementing Domain Model
Talk is cheap. Show me the code.
—Linus Torvalds
The quote at the beginning of the chapter, the essence of which we can summarize as “show me the code” (or SMTC for short), is the final sentence in a short answer that Torvalds gave on a Linux mailing list years ago. The original is here: https://lkml.org/lkml/2000/8/25/132. Since then, SMTC has been used often to break up potentially endless discussions that are headed toward analysis/paralysis.
While theory is invaluable, theory without practice is of very little use.
We debated at length about what would have been the best scenario to focus on to show the importance of modeling the business domain within a layered architecture. In the end, we went for an online store, disregarding many other scenarios we had the chance to work on in the past. In particular, Dino has interesting domain-driven design (DDD) experiences in the context of management systems, booking reservations, and sports-scoring scenarios, whereas Andrea has been active in banking, enterprise resource planning (ERP), human resources (HR), and publishing.
In the end, we decided that an online store was something that was easy to grasp for everybody, easy to modularize for us, and easy to build an effective learning path on. So in this and the following chapters, we’ll build the “I-Buy-Stuff” project and produce three different prototypes based on different supporting architectures: a domain model, Command/Query Responsibility Segregation (CQRS), and then event-sourcing.
And now, without further ado, let us just show the code.
The online store sample project
In this chapter, we’ll use a domain model as the supporting architecture. Figure 9-1 presents the home page of the sample application that comes with this chapter.
FIGURE 9-1 The home page of the I-Buy-Stuff sample application.
Selected use-cases
The customer called us to help with the development of an online store. They wanted to build a list of registered online customers and give each the opportunity to buy goods, review existing orders, receive the site’s newsletter, and join a customer-loyalty program to get discounts.
For simplicity, but without significant loss of generality, we built the application around the use-cases listed in Table 9-1.
 Important
Important
The sample application we present is simple enough to require a single bounded context. The online store scenario, however, might be sufficiently complex to require for the sake of the application the use of several bounded contexts. As an example, think of the Amazon system—given its size and complexity, there’s no way it can be a single bounded context. The number of bounded contexts depends on the complexity of the scenario and, subsequently, the number of use-cases, expected performance, and other functional and nonfunctional requirements. We’ll return to this point later in the chapter after we’re done introducing the sample project.

TABLE 9-1. List of supported use-cases
At first, it might not seem like anything fancy. It looks like just the kind of thing many developers do every day, have been doing for many days, or will likely be doing at some point in the future. The sample application also seems really close to many sample demos you have seen around ASP.NET and Windows Presentation Foundation (WPF) over the years. In particular, we remember the IBuySpy sample portal application built for ASP.NET back in the early days of the Microsoft .NET Framework.
The challenge is showing that there’s a lot to do in terms of understanding and rendering the business domain even in a common scenario that has always been handled successfully in .NET with database-centric approaches.
Selected approach
An old but still effective trick to quickly forming an idea about a book, or even a candidate while conducting a job interview, is checking what either might have to say on a topic you know very well.
An online store is something that everybody understands, and nearly every developer might have a clear idea of how to attack it. In this chapter, we’ll build it using a Domain Model approach as outlined in the previous chapter. We’ll figure out an object model that faithfully represents the business domain and assign each entity a behavior and separate domain logic from domain services.
After an analysis of requirements and defining the ubiquitous language, you should have a clear idea of which entities you are going to have. Built as a separate class library project, the domain model contains the following entities: Admin, Customer, Order, OrderItem, Product,Subscriber, and FidelityCard. Table 9-2 summarizes the expected content and behavior for each relevant entity we identified in the domain.
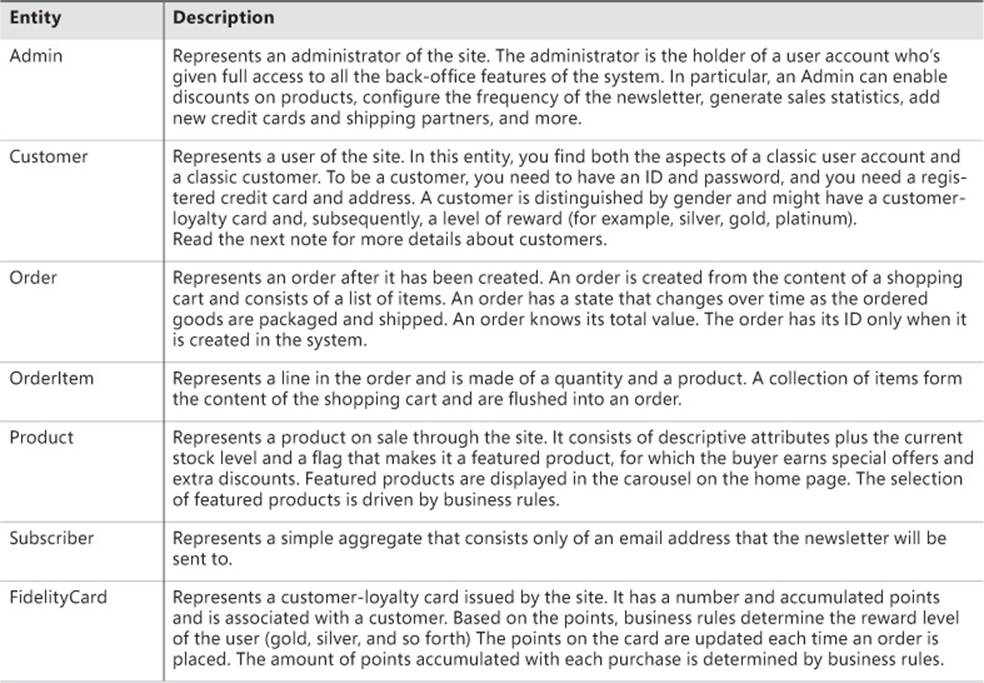
TABLE 9-2. Relevant entities in the I-Buy-Stuff business domain
 Note
Note
In our example, any customer of the store is a registered customer with a record in the system. In a more realistic scenario, a domain expert will tell you to consider a “customer” to be only a user who actually bought an item from the site at least once. Typically, users are allowed to fill the shopping cart even anonymously, but they are required to register—and become customers—when they check out and pay.
Structure of the I-Buy-Stuff project
In past chapters, we focused on the layered architecture and its role in DDD. Now it’s time to see it in action. And it starts from the structure of the solution you build in Microsoft Visual Studio 2013. Figure 9-2 provides two views of the Solution Explorer.
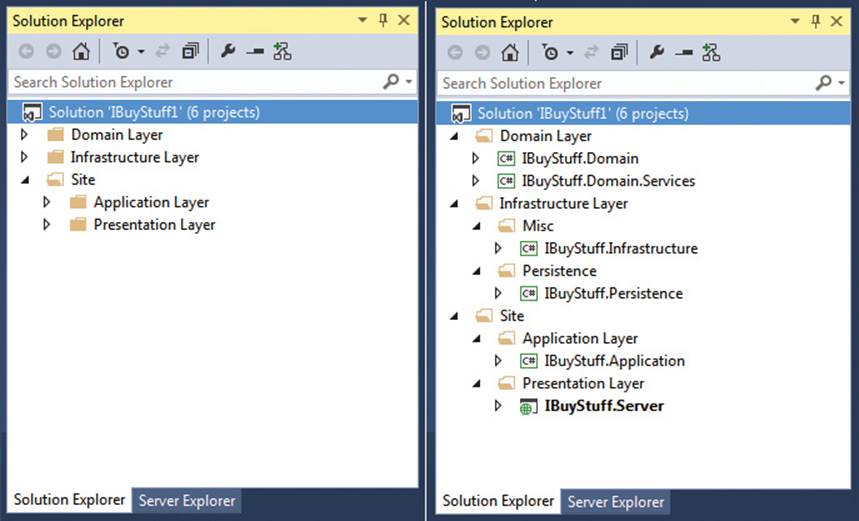
FIGURE 9-2 The I-Buy-Stuff project in the Solution Explorer of Visual Studio 2013.
The first view displays only solutions folders.
As you can see, there’s a domain layer, infrastructure layer, and site. The I-Buy-Stuff application, in fact, is an ASP.NET MVC website project under the folder Site.
From the view shown on the left in Figure 9-2, you also can perceive the neat (logical) separation between the back end and front end. The presentation and application layers are part of the front end of the system; the domain and infrastructure layers are part of the back end. The back end is used by as many front ends as you happen to have within the same bounded context, whether the front end is simply yet another user interface (web, WPF, mobile web) or just a separate application with its own use-cases (for example, a mobile app or a WPF client).
The view shown on the right in Figure 9-2 displays the actual projects being created. With the exception of IBuyStuff.Server, which is an ASP.NET MVC 5 project, all other projects are plain .NET class libraries.
Important
Figure 9-2 presents distinct projects and folders for the web front end and application layer. From a conceptual standpoint, all is good and even extremely clear. However, separating such logical layers in distinct projects might create some wrinkles in the everyday management of the solution. For example, imagine you want to add a new Razor view to the project. The CSHTML file goes in the web project, whereas the view model class belongs to the Application project. The same thing happens when you add a new controller—the controller class goes to the web project, whereas the application service class goes to the Application project. This makes scaffolding a bit more complicated than it should be. In the end, although separation of concerns (SoC) is the timeless foundation of software, the way in which it happens can be adjusted to serve pragmatic purposes. We often have the entire content of the Application project you see in the example under an Application folder within the web project. And we do the same if the project is a Microsoft Windows or Windows Phone application.
Selected technologies
The projects use a bunch of .NET technologies that, for the most part, are incorporated through NuGet packages. As mentioned, the front end is an ASP.NET MVC 5 application that uses ASP.NET Identity as the framework for user authentication. Twitter Bootstrap is used for the user interface. For mobile views, we use Ratchet2 for the user interface and WURFL to perform device detection and ASP.NET display modes to do view routing.
Important
The I-Buy-Stuff application is a sort of universal web app—one codebase supporting multiple device-specific views. This is not the same as using cascading style sheets (CSS) media queries to adapt one single piece of content to multiple devices. It’s just about serving different web content generated from a single codebase. The site is still responsive but much more intelligent. We’ll return to this point in the final chapter of the book, which talks about infrastructure.
The back end of I-Buy-Stuff is based on Entity Framework Code First for persistence. The sample code you get uses a local instance of Microsoft SQL Server to create tables in the App_Data folder of the website. Finally, all dependency injection needs within the solution are managed via Microsoft Patterns and Practices Unity.
Note
We used to write our own controller factories in ASP.NET MVC to plug into Unity or other Inversion of Control (IoC) containers. Today, as far as Unity is concerned, we plug it in via the Unity.Mvc NuGet package.
Bounded contexts for an online store
The I-Buy-Stuff online store is deliberately simple and small, and the business cases it faces don’t require more than just a bounded context. For providing you with an extensive understanding of DDD, it is probably not an ideal example. On the other hand, we thought that a much more sophisticated example would have been too overwhelming.
However, we want to take some time to discuss the online store scenario in a bit more depth because it is likely to appear in a real-word context.
Decomposing the business domain in contexts
In a reasonably simple scenario, you can have three distinct bounded contexts:
![]() MembershipBC
MembershipBC
![]() OrderingBC
OrderingBC
![]() CatalogBC
CatalogBC
MembershipBC will take care of authentication and user account management. OrderingBC cares about the shopping cart and processes the order. Finally, CatalogBC is related to back-office operations, such as updating product descriptions, adding or removing products, updating stock levels, updating prices, and so forth. Figure 9-3 provides a sample context map.
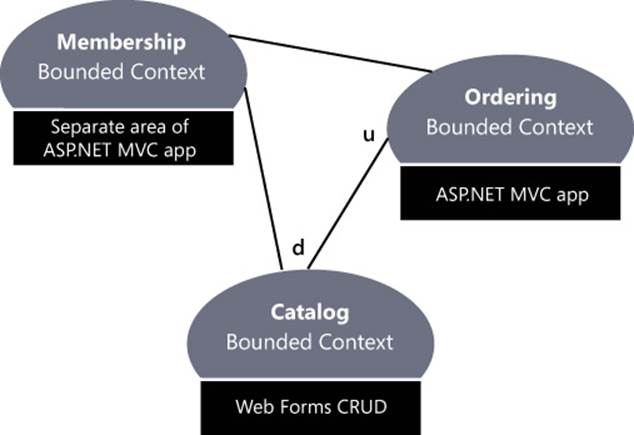
FIGURE 9-3 A sample context map for an online store system that is a bit more complete than the I-Buy-Stuff project presented in this chapter.
OrderingBC can be an ASP.NET MVC application, much like the sample I-Buy-Stuff. The membership part taken out of the main application can physically remain in the same application but configured as a distinct area. (ASP.NET MVC areas are a concept similar to a bounded context, but they are specific to ASP.NET MVC. For more information, check out Dino’s book Programming ASP.NET MVC (Microsoft Press, 2013). Finally, CatalogBC can be a plain CRUD front end on top of the database. CatalogBC is not necessarily related to DDD. It depends on the domain model being used, and it saves data to the database used to persist the domain model.
Making the contexts communicate
How can the OrderingBC bounded context be informed that a product in the catalog has been modified, added, or removed?
If OrderingBC just reads from the database every time it needs to—a quite unlikely scenario—then synchronization is automatic when CatalogBC writes to the database. Otherwise, CatalogBC can use a remote procedure call (RPC) approach and invokes an endpoint on OrderingBC, which invalidates or refreshes the cache of products. The endpoint can, in turn, simply raise a domain event.
In a larger and more sophisticated system, you can even have a service bus system connecting the various pieces of the architecture.
Adding even more bounded contexts
If the complexity of the store grows, you can consider adding bounded contexts. Here are a few examples of contexts you can add:
![]() ShippingBC This context relates to the domain model to handle any complex logistics. In our I-Buy-Stuff example, this is seen as an external service. We won’t get into the details of the interaction, but it could likely require an anticorruption layer to ensure that OrderingBC receives data always in the same way.
ShippingBC This context relates to the domain model to handle any complex logistics. In our I-Buy-Stuff example, this is seen as an external service. We won’t get into the details of the interaction, but it could likely require an anticorruption layer to ensure that OrderingBC receives data always in the same way.
![]() PricingBC This context becomes necessary when pricing is a complex subsystem based on user/product association, personal discounts, fidelity programs, reward points, and so forth.
PricingBC This context becomes necessary when pricing is a complex subsystem based on user/product association, personal discounts, fidelity programs, reward points, and so forth.
![]() PurchaseBC This context relates to the domain model required to manage a purchase system that interfaces multiple payment gateways and possibly supports other forms of payment, such as wire transfer and cash-on-delivery. In our I-Buy-Stuff example, this is seen as an external service. The sample code assumes a single payment mode and gateway, and it provides a mock for the payment in the form of an ASP.NET Web Forms page.
PurchaseBC This context relates to the domain model required to manage a purchase system that interfaces multiple payment gateways and possibly supports other forms of payment, such as wire transfer and cash-on-delivery. In our I-Buy-Stuff example, this is seen as an external service. The sample code assumes a single payment mode and gateway, and it provides a mock for the payment in the form of an ASP.NET Web Forms page.
In summary, for relatively simple systems you have a few options:
![]() Using one large bounded context
Using one large bounded context
![]() Splitting the domain into several small bounded contexts, with duplicated data, and possibly communicating through a publish/subscribe messaging system
Splitting the domain into several small bounded contexts, with duplicated data, and possibly communicating through a publish/subscribe messaging system
![]() Isolating some of the larger bounded contexts you identify and exposing them via web services
Isolating some of the larger bounded contexts you identify and exposing them via web services
There’s no general rule to determine which option is preferable. It all depends on the context and your skills and experience. And, to a good extent, it also depends on the vision and understanding of the domain you have gained. In some cases, for example, it might be savvy to recognize that querying needs might be very different from writing needs. Subsequently, it can be preferable sometimes to just design separate bounded contexts for queries. This is the essence of CQRS, which we’ll discuss in the next chapter.
Context map of the I-Buy-Stuff application
Figure 9-4 shows the context map we’re going to have for I-Buy-Stuff.
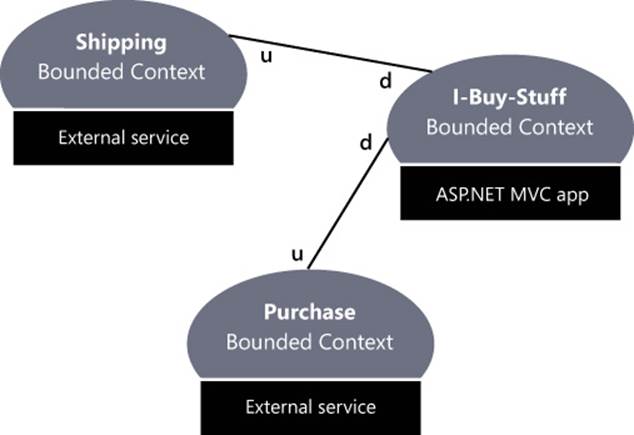
FIGURE 9-4 The context map for I-Buy-Stuff.
As you can see in the figure, the I-Buy-Stuff context is an ASP.NET MVC application and will be implemented using the Domain Model architecture. It turns out to be quite a large bounded context because it incorporates membership, ordering logic, and even an extremely simple segment of the purchase context—basically, just the gold status awards for customers.
The largest share of business logic belongs to the I-Buy-Stuff site. Shipping and Purchase bounded contexts are implemented (mocked up actually) as external services. Both external services end up being upstream to the main site. At least in the demo, for the sake of simplicity, we don’t use an anticorruption layer. Had we used that, the implementation probably would have consisted of an extra class receiving the raw information from the external service and massaging data to a known and fixed format.
The noble art of pragmatic domain modeling
The fundamental issue we see in modern software is that too often developers focus on code rather than models. This approach is not wrong per se, but it makes it so hard to manage complexity when you face it.
If you blissfully ignore domain modeling and you still write successful code, are you doing wrong? Not at all, but you might be in trouble when the level of complexity rises. It can be on the next project or on this same project as requirements keep changing and growing.
Behavior is a game-changer
A domain model is, then, a collection of classes with properties and methods. Together they reveal the model behind the business domain. Yet for years nobody really looked into ways to dig such a model out of the darkness. In the last chapter, we outlined the pillars of a domain model and worked out the skeleton of a few classes. That was more or less the theory. When it comes to practice, there are a few aspects to consider:
![]() Understanding and implementing behavior becomes really crucial for the final success.
Understanding and implementing behavior becomes really crucial for the final success.
![]() As you need to persist the model, you should be ready to accept compromises.
As you need to persist the model, you should be ready to accept compromises.
![]() The model you work out is the API for the business domain; it must be orchestrated and connected to whatever front end you need to have in place.
The model you work out is the API for the business domain; it must be orchestrated and connected to whatever front end you need to have in place.
As hard as it might sound, we think that everyone willing to enlarge the contours of the “picture” he sees should try to use domain modeling on a domain he knows well—at least as a code kata exercise.
This is the spirit of I-Buy-Stuff.
Note
Taken from the world of karate, a code kata is an exercise that refreshes the basics of your skills. In the field of software development, it may consist of rewriting a known algorithm with a fresh mind to see if you can make improvements. For more details about the spirit of code kata, see http://codekata.com.
The typical perspective of a .NET developer
Most .NET developers have grown up following the guidelines of the Table Module pattern. The Table Module pattern essentially suggests you first create a relational data model that fits the business domain. Next, you identify primary tables in the database and build a module for each. In the end, a table module ends up being just the repository of methods that perform query and command actions against the table (say, Orders) and all of its related tables (say, OrderItems).
Methods of the table module class are directly called from the presentation layer or the application layer, if you really want to have one. Most of the time, the back-end model you get has the following aspects:
![]() Two-layer architecture, with the presentation layer calling directly into repositories or table modules.
Two-layer architecture, with the presentation layer calling directly into repositories or table modules.
![]() Table modules are plain containers of public methods with no state and expressivity limited to their names and parameter list. Extending and maintaining these classes might soon become an issue. Their structure is crystal clear in the beginning but soon becomes quite opaque.
Table modules are plain containers of public methods with no state and expressivity limited to their names and parameter list. Extending and maintaining these classes might soon become an issue. Their structure is crystal clear in the beginning but soon becomes quite opaque.
![]() Unclear definitions of models to be used in code. Should you go with DataSet objects? Should you create your own data-transfer objects? Should you leverage Entity Framework and just infer classes that reflect one-to-one the structure of the tables?
Unclear definitions of models to be used in code. Should you go with DataSet objects? Should you create your own data-transfer objects? Should you leverage Entity Framework and just infer classes that reflect one-to-one the structure of the tables?
The advent of Entity Framework first encouraged the use of designers to infer the database structure so that with a few clicks you could create an object model that mirrors the database. It was easy and effective, and it solved the last point in the preceding list.
Doc, my model is anemic
DDD pundits point out that no model needs to be anemic. As software anemia is generally measured in terms of how much behavior you have in classes, in a model just inferred from a database you have nearly no behavior. Therefore, your model is anemic.
Is software anemia a serious disease?
In humans, anemia results in weariness and is due to lack of red cells in blood. Red cells are responsible for delivering oxygen to the body tissues and bring life and energy. Similarly, in software anemia denotes a lack of energy to face change, but we wouldn’t call it a disease. An anemic model can still work effectively as long as the team is capable of managing the complexity of the domain and its evolution.
In the end, an anemic model leaves the sword of Damocles hanging over your code. According to a tale told in ancient Greece, Damocles sat on the throne with a huge sword hanging over him held only by a single hair. This is the right metaphor: all is good as long as the sword continues to hang.
The focus on behavior has two main purposes: creating objects with a public interface closer to the entities observable in the real world. This also makes it easier to perform modeling in accordance with the names and rules of the ubiquitous language.
Location of the business logic
From a more pragmatic view, focusing on behavior is essentially finding a different location for segments of the business logic. Let’s consider an Invoice class:
class Invoice
{
public string Number {get; private set;}
public DateTime Date {get; private set;}
public Customer Customer {get; private set;}
public string PayableOrder {get; private set;}
public ICollection<InvoiceLine> Lines {get; private set;}
...
}
The class doesn’t have methods. Is it wrongly written, then? Is it part of an anemic model?
An object model is not anemic if it just lacks methods on classes. An entity is anemic if there’s logic that belongs to it that is placed outside the entity class. As an example, consider the problem of calculating the estimated day of payment of an invoice. Input data consists of the date of the invoice and payment terms (immediate, 30 days, 60 days, or whatever).
If you define the method on the Invoice class, it ends up with the following signature:
DateTime EstimatedPayment()
Otherwise, if you prefer to keep all business logic in a single InvoiceModule class, it might look like this:
DateTime EstimatedPayment(Invoice invoice)
The latter receives the entity to be investigated as its sole argument. This is a possible alert that a piece of logic belongs to the entity. Where’s the “right” location for this method in a Domain Model design? A simple but effective rule to mechanize decision can be summarized as follows:
![]() If the code in the method deals only with the members of the entity, it probably belongs to the entity.
If the code in the method deals only with the members of the entity, it probably belongs to the entity.
![]() If the code needs to access other entities or value objects in the same aggregate, it probably belongs to the aggregate root.
If the code needs to access other entities or value objects in the same aggregate, it probably belongs to the aggregate root.
![]() If the code in the method needs to query or update the persistence layer or, in general, needs to acquire references outside the boundaries of the entity (or its aggregate), it’s a domain service method.
If the code in the method needs to query or update the persistence layer or, in general, needs to acquire references outside the boundaries of the entity (or its aggregate), it’s a domain service method.
If you ignore these two rules and centralize everything that in some way relates to the Invoice in a single service class that does everything—validation, data access, business logic—you’re making the entity anemic.
Entities scaffolding
A DDD entity is a plain C# class and is expected to contain both data (properties) and behavior (methods). An entity might have public properties, but it is not going to be a plain data container. Here are the hallmarks of DDD entities:
![]() A well-defined identity
A well-defined identity
![]() Behavior expressed through methods, both public and not
Behavior expressed through methods, both public and not
![]() State exposed through read-only properties
State exposed through read-only properties
![]() Very limited use of primitive types, replaced by value objects
Very limited use of primitive types, replaced by value objects
![]() A preference for factory methods over multiple constructors
A preference for factory methods over multiple constructors
Let’s find out more.
Managing the identity
The primary characteristic of an entity is the identity. The identity is any combination of data that uniquely identifies an instance of the entity class. In a way, the identity in this context is comparable to a primary key for the records of a relational table.
An identity serves the purpose of uniquely identifying the entity throughout the lifetime of the application. Developers use the identity to retrieve the reference to the entity at any time. The state of an entity might change, but the identity doesn’t. In terms of implementation, the identity is often just an integer property like an Id property. In other cases, it can be a numeric string such as a Social Security number, a VAT ID, a user name, or a combination of properties.
The identity just defines what makes two entities the same entity. An entity class, however, also needs to implement equality that uses the identity values to determine whether two entities are the same. Let’s start with an Order class like the one shown here:
public class Order
{
private readonly int _id;
public Order(int id)
{
// Validate ID here
...
_id = id;
}
public int Id
{
get {return _id;}
}
...
}
Suppose now you have two instances of the Order class that refer to the same ID:
var o1 = new Order(1);
var o2 = new Order(1);
According to the basic behavior of a .NET Framework classes, o1 and o2 are different instances. While this is correct in the general domain of the .NET Framework, it is inconsistent in the business domain you’re in. In that business domain, what matters is the ID of the order: if the ID matches, two orders are the same. This is not, however, what you get out of the box in .NET and other frameworks.
To implement a custom equality logic that uses identity values, you must override the methods Equals and GetHashCode that any .NET object exposes. Here’s an example:
public class Order
{
private readonly int _id;
...
public override bool Equals(object obj)
{
if (this == obj)
return true;
if (obj == null || GetType() != obj.GetType())
return false;
var other = (Order) obj;
// Your identity logic goes here.
// You may refactor this code to the method of an entity interface
return _id == other.Id;
}
public override int GetHashCode()
{
return Id.GetHashCode();
}
}
Important
Identity and equality are two distinct concepts, but they are related in the context of an entity. Identity is just a collection of values that make an entity unique (much like a primary key). Equality is class infrastructure that supports equality operators in the .NET Framework. Within an entity, equality is checked using identity values. As you’ll see later in the chapter, value objects do not have identity and don’t need to be retrieved later to check their state, but they still need some custom logic for equality.
Private setters
An entity has both behavior (methods) and state (properties). However, in the real world it’s likely that attributes of an entity are restricted to just a few values. A quantity of products, for example, is not exactly an integer because it is expected not to be negative. At the same time, using unsigned integers is arguable, too, because it could mean you’re allowed to place orders for over four billion items.
When designing entities, you should only provide properties that really express the state of the entity and use setter methods only for properties that can change. Also, don’t let setters be open to just any value that fits the declared type of the property. Open setters can have nasty side effects, such as leaving entities in a temporarily invalid state.
In general, it’s good practice to mark setters as private and expose public methods to let other developers change the state of the entity. When you do so, though, pay attention to the naming convention you use and ensure it matches the ubiquitous language.
Factories and constructors
Constructors are the usual way to create instances of classes and might or might not take parameters. In a domain model, you should avoid classes with parameterless constructors. In addition, each constructor should be able to return an instance whose state is consistent with the business domain. The following code is probably inconsistent:
var request = new OrderRequest();
The newly created order request lacks any reference to a date and a customer. The date could be set by default in the body of the constructor, but not the customer ID. The following is only a tiny bit better:
var request = new OrderRequest(1234);
There are two problems here. First, when looking at the code, one can hardly guess what’s going on. An instance of OrderRequest is being created, but why and using which data? What’s 1234? This leads to the second problem: you are violating the ubiquitous language of the bounded context. The language probably says something like this: a customer can issue an order request and is allowed to specify a purchase ID. If that’s the case, here’s a better way to get a new OrderRequest instance:
var request = OrderRequest.CreateForCustomer(1234);
Constructors are unnamed methods, and using them might also raise a readability issue. But that would be the least of your worries. By using public constructors, you distract yourself and developers after you from the real reason why that instance of OrderRequest is necessary.
Constructors are unavoidable in object-oriented programming languages; just make them private and expose public static factory methods:
private OrderRequest() { ... }
public OrderRequest CreateForCustomer (int customerId)
{
var request = new OrderRequest();
...
return request;
}
A more advanced scenario is when you just arrange a separate factory service for some entities and manage things like object pooling inside.
Note
In the next chapter, you’ll see that constructors are often marked as protected instead of private. The use of protected constructors has to do with persistence and O/RM tools. When an O/RM materializes an entity instance and fills it with database content, it actually returns an instance of a dynamically created class that inherits from the entity class (for example, a proxy). This allows O/RM tools to invoke the protected default constructor; a private default constructor—as well as a sealed entity class—would make persistence through O/RM tools quite problematic.
Value objects scaffolding
Like an entity, a value object is a class that aggregates data. Behavior is not relevant in value objects; value objects might still have methods, but those are essentially helper methods. Unlike entities, though, value objects don’t need identity because they have no variable state and are fully identified by their data.
Data structure
Most of the time, a value object is a plain data container that exposes data through public getters and receives values only through the constructor. Here’s an example:
public class Address
{
public Address(string street, string number, string city, string zip)
{
Street = street;
Number = number;
City = city;
Zip = zip;
}
public string Street { get; private set; }
public string Number { get; private set; }
public string City { get; private set; }
public string Zip { get; private set; }
// Equality members
...
}
Methods can be defined, but they must be pure methods that do not alter the state. For example, you can have the following value object to represent the score of a basketball match:
public class Score
{
public Score(int team1, int team2)
{
Team1 = team1;
Team2 = team2;
}
public int Team1 { get; private set; }
public int Team2 { get; private set; }
public bool IsLeading(int index)
{
if (index != 1 && index != 2)
throw new ArgumentException(“index”);
if (index == 1 && team1 > team2) return true;
if (index == 2 && team2 > team1) return true;
return false;
}
}
The IsLeading method doesn’t alter the state of the object, but its presence will definitely make the content of the value object handier to use.
Equality
Using the .NET Framework jargon, we could say that a value object is an immutable type. An immutable is any type that doesn’t have state and requires new instances every time new values are required. As mentioned earlier in the chapter, the String type is the canonical example of an immutable type in the .NET Framework.
You need to override both the Equals and GetHashCode methods to ensure that within the model objects made of the same data are treated as equal objects. Here’s how to check whether two Address instance are the same:
public class Address
{
...
public override bool Equals(object obj)
{
if (this == obj)
return true;
if (obj == null || GetType() != obj.GetType())
return false;
var other = (Address) obj;
return string.Equals(Street, other.Street) &&
string.Equals(Number, other.Number) &&
string.Equals(City, other.City) &&
string.Equals(Zip, other.Zip);
}
public override int GetHashCode()
{
const int hashIndex = 307;
var result = (Street != null ? Street.GetHashCode() : 0);
result = (result * hashIndex) ^ (Number != null ? Number.GetHashCode() : 0);
result = (result * hashIndex) ^ (City != null ? City.GetHashCode() : 0);
result = (result * hashIndex) ^ (Zip != null ? Zip.GetHashCode() : 0);
return result;
}
}
Custom equality logic is de facto a mandatory feature in both entities and value objects.
Hash codes and equality in the .NET Framework
The .NET Framework guidelines strongly recommend that whenever you override Equals you also override GetHashCode. But why is that so?
The Equals method is always used when equality is checked explicitly, such as when your code calls Equals directly or uses the == operator. GetHashCode is not involved in the equality assessment process. Subsequently, its implementation doesn’t affect the equality evaluation. Yet, you get a compiler warning if you override Equals but not GetHashCode.
GetHashCode comes into play only if your objects are going to be stored within hash tables or used as dictionary keys. In this case, the .NET Framework uses the value returned by GetHashCode to find the corresponding entry in the hash table or dictionary. Two object instances that are the same object according to Equals but return different values according to GetHashCode will never be considered equal. As a result, different values will be picked from the hash table or dictionary.
When your objects appear as public objects in a class library, you simply have no guarantee that they will never be used within hash tables or as dictionary keys. For this reason, it is strongly recommended that you override both methods to ensure that two objects that are equal according to Equals also return the same GetHashCode value. The returned value doesn’t matter as long as it’s the same. In light of this, why not simply make GetHashCode return a constant value in all cases?
When GetHashCode returns the same value for two objects, you get a collision and Equals is called to ensure the objects are the same. A performance goal, of course, is to minimize the number of collisions by giving each object with a unique combination of values a different hash code.
Finally, note that the hash code should never change during the lifetime of an object. For this to happen, only immutable properties should be used to calculate the code. This rule fits perfectly with the guidelines for entities and value objects.
Operators overloading
Overriding Equals doesn’t let you automatically use the == and != equality operators on overridden objects. In the .NET Framework guidelines, Microsoft discourages you from overloading operators when mutable properties are used to check equality. This is not the case for entities and value objects. So operator overloading is absolutely safe. Here’s an example:
public static bool operator ==(Customer c1, Customer c2)
{
// Both null or same instance
if (ReferenceEquals(c1, c2))
return true;
// Return false if one is null, but not both
if (((object)c1 == null) || ((object)c2 == null))
return false;
return c1.Equals(c2);
}
public static bool operator !=(Customer c1, Customer c2)
{
return !(c1 == c2);
}
We discussed entities and value objects, explored their differences, and now understand equality nuances. But at the very end of the day, when are you going to use value objects in a domain model?
Expressivity
As we see it, the key benefit that value objects bring to the table is expressivity. There are two aspects of expressivity: replacing primitive types and replacing data clumps.
Primitive types are sometimes too basic for being used extensively in a model that claims to represent a piece of real-world business. Primitive types are what we actually use when we persist entities; however, at the higher abstraction level of the domain model, primitive types are often elements of vagueness. What does an integer denote? Is it a quantity, a temperature, an amount of money, a measurement? Is it an element of a range?
In the real world, you have quantity, temperature, amount—not plain integers.
While you can still use integers and be happy, using primitive types forces you to validate values any place in the model where an integer is used to mean a quantity, a measurement, an element of a range, and so forth. Not only will your validation code possibly be cumbersome to write, but it is also likely to be duplicated because it applies to the setter rather than to the type itself. Here’s how you can more effectively model an amount of money:
public sealed class Money
{
public Money(Currency currency, decimal amount)
{
Currency = currency;
Value = amount;
}
public Currency Currency { get; private set; }
public decimal Value { get; private set; }
// Add operator overloads
...
}
Currency in this example is another value object built around a symbol and a name.
In general, by using value objects, you simplify code and also produce a model closer to the ubiquitous language. In the refactoring jargon, data clumps are a well-known code smell. A data clump is when a group of data items are often used together but as independent items. Ultimately, a data clump is just an aggregation of primitive values that could easily be turned into a new object.
A good example is currency and amount in the Money value object. In the ubiquitous language, you likely have money, not currency and amount; you have addresses, not individual items like street, city, and Zip code. This is where value objects fit in.
Identifying aggregates
Let’s focus now on the entities listed in Table 9-2 and used in the sample application. The I-Buy-Stuff application is meant to be a simple online store, and this is reflected by the limited number of entities and their limited relationships. (See Figure 9-5.) In a site where we just consider a few use-cases like searching and placing an order, Customer, Order, and Product are aggregates and Customer and Product are single-entity aggregates. The same can be said for FidelityCard.

FIGURE 9-5 Aggregates of the sample domain model.
Let’s find out more about the aggregates. From the behavior perspective, though, given the order-focused use-cases we’re considering, the most interesting aggregate is Order. However, some interesting considerations apply to Customer too.
The Customer aggregate
The customer is characterized by some personal data such as name, address, user name, and payment details. We’re clearly assuming that our online store has just one type of customer and doesn’t distinguish, for example, between corporate customers and private customers. A corporate customer, for example, might have multiple users shopping under the same customer account. Take a look at Figure 9-6.
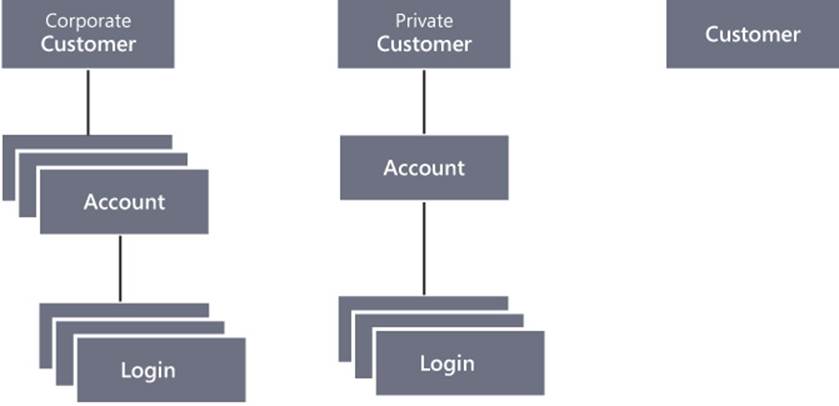
FIGURE 9-6 Three possible ways of organizing the abstract Customer aggregate in an online store application.
The first diagram represents a corporate customer that, under a single financial account, can have multiple users (for example, some of the employees) with different shipping addresses and who log into the system using various credentials. The central graph represents a private customer with a single user account. Finally, the third graph represents the implementation we use in this chapter, where the customer entity represents a single user account and credentials are stored within the Customer entity itself.
Note
As we said earlier in the note around Table 9-2, for most domain experts of online stores, users and customers will be distinct concepts and entities. This doesn’t affect the generality of our example, but it’s important to keep in mind to realize the subtlety and depth of domain-driven design.
Another aspect to consider is the login into the system. Should you consider using distinct entities to hold credentials and the rest of the data and behavior? That’s probably what you will want to do most of the time. There are two further considerations to point you in this direction:
![]() Each customer or account can have multiple ways to log in, including credentials stored in the local system and multiple social logins.
Each customer or account can have multiple ways to log in, including credentials stored in the local system and multiple social logins.
![]() If you use ASP.NET Identity to implement authentication, then, at the current stage of technology you are forced to make user classes implement a fixed external interface (the IUser interface). This would reduce the POCO (plain-old C# object) status of the domain.
If you use ASP.NET Identity to implement authentication, then, at the current stage of technology you are forced to make user classes implement a fixed external interface (the IUser interface). This would reduce the POCO (plain-old C# object) status of the domain.
In the sample application, the customer coincides with the user who logs in. The Customer class has the following structure:
public class Customer : IAggregateRoot
{
public static Customer CreateNew(Gender gender, string id,
string firstname, string lastname, string email)
{
var customer = new Customer {
CustomerId = id,
Address = Address.Create(),
Payment = NullCreditCard.Instance,
Email = email,
FirstName = firstname,
LastName = lastname,
Gender = gender
};
return customer;
}
public string CustomerId { get; private set; }
public string PasswordHash { get; private set; }
public string FirstName { get; private set; }
public string LastName { get; private set; }
public string Email { get; private set; }
public Gender Gender { get; private set; }
public string Avatar { get; private set; }
public Address Address { get; private set; }
public CreditCard Payment { get; private set; }
public ICollection<Order> Orders { get; private set; }
// More methods here such as SetDefaultPaymentMode.
// A customer may have a default payment mode (e.g., credit card), but
// different orders can be paid in different ways.
...
}
When the customer is created, the Name property indicates the login name whereas FirstName and LastName identify the full display name. Credit card and address information can be added through ad hoc methods. The customer is created through the canonical Register page of most websites, and credentials are stored in the local database. If the user logs in via Facebook or Twitter, a new customer instance is also created if it doesn’t exist.
Note
You can see that with this extremely simple approach the same individual ends up with two distinct customer records if she logs in via Twitter and Facebook. That makes it necessary to improve the code to support multiple logins for each customer. Ideally, you might want to maintain a table of accounts and establish a one-to-many relationship with customers.
The concrete implementation you find in the sample code uses ASP.NET Identity facilities to do logins and logouts. However, it bypasses ASP.NET Identity entirely when it comes to adding, retrieving, and validating users. The reason is to avoid making the domain model explicitly dependent on the ASP.NET Identity framework. Figure 9-7 outlines a possible adjustment to the model to keep login outside the domain model and link multiple user names to the same customer instance.
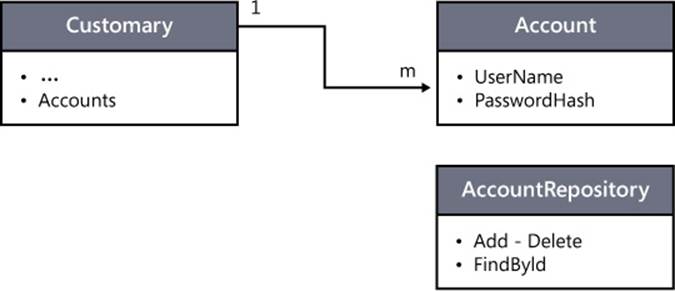
FIGURE 9-7 Keeping the login infrastructure outside the domain model.
The Account entity is a new aggregate. Its repository exposes methods for basic CRUD operations and can retrieve a matching customer when given a user ID. The user ID is what comes out of the ASP.NET Identity login process.
Note
Using the schema shown in Figure 9-7, where Account is part of the domain, makes the whole model more flexible and easier to adapt to real scenarios. It doesn’t solve, however, the issue of mixing the domain model with a dependency on the ASP.NET Identity IUser interface. If you want to leverage the built-in facilities of ASP.NET Identity as far as management of the accounts is concerned, you should keep authentication concerns out of the domain model. If you see Account as part of one of the entities, we recommend that you use the account repository to do CRUD instead of the canonical user store object of ASP.NET Identity.
The Product aggregate
One of the responsibilities of an entity is carrying data and data stems from the expected behavior of the entity. The Product entity must tell the world about its description and pricing. In addition, for the purposes of use-cases, it must possible to know whether the product is currently “featured” on the site and what the current stock level is. The following description is mostly fine:
public class Product : IAggregateRoot
{
public int Id {get; private set;}
public string Description {get; private set;}
public Money UnitPrice {get; private set;}
public int StockLevel {get; private set;}
public bool Featured {get; private set;}
// Methods
public void SetAsFeatured() { ... }
...
// Identity management as for Customer
...
}
Let’s consider the StockLevel property. At first, the integer used to define the stock level can be changed into an unsigned integer because negative values are not expected to be valid values for what the property represents. Even better, an ad hoc value object can be created to represent a quantity as a natural number.
As you can see, though, the StockLevel, like all properties in the code snippet, has a private setter. This means that the property is read-only and, subsequently, reading it as an integer is fine. Who’s going to set the StockLevel property? There are two possible scenarios:
![]() The object is materialized only from the persistence layer.
The object is materialized only from the persistence layer.
![]() The object has a factory method if it’s allowed to be instantiated from client code.
The object has a factory method if it’s allowed to be instantiated from client code.
Actually, the second option is not credible businesswise, though a factory method might be helpful to have for implementation purposes.
The StockLevel property indicates in this simple model the number of items of a given product we have in store. This number is decreased as orders are placed and increased when the store manager refills the stock by placing orders to vendors. Subsequently, a method is necessary to programmatically modify the stock level of a product. The store manager is part of the back office, which is a different bounded context.
The Order aggregate
In I-Buy-Stuff, an order is created when processing the content of a shopping cart, which is represented by an ShoppingCart class. The skeleton of the class is shown here:
public class Order : IAggregateRoot
{
public int OrderId { get; private set; }
public Customer Buyer { get; private set; }
public OrderState State { get; private set; }
public DateTime Date { get; private set; }
public Money Total { get; private set; }
public ICollection<OrderItem> Items { get; private set; }
...
}
The class needs to have a public factory method because at some point business logic needs to create an order while processing a request. When creating an order, you specify the ID and reference the customer. The date is set automatically, so it is the state of the order.
In the example, we assume that the order is created when the customer clicks to check out. There will likely be a domain service to orchestrate the checkout process; one of the steps is the creation of the order. The factory of the order can be marked internal and can use a nonpublic constructor:
internal static Order CreateFromShoppingCart(ShoppingCart cart)
{
var order = new Order(cart.CustomerId, cart.Customer);
return order;
}
protected Order(int orderId, Customer customer)
{
OrderId = orderId;
State = OrderState.Pending;
Total = Money.Zero;
Date = DateTime.Today;
Items = new Collection<OrderItem>();
Buyer = customer;
}
To modify the state of the order and add items, you need ad hoc methods. Here are some methods that change the state:
public void Cancel()
{
if (State != OrderState.Pending)
throw new InvalidOperationException(
“Can’t cancel an order that is not pending.”);
State = OrderState.Canceled;
}
public void MarkAsShipped()
{
if (State != OrderState.Pending)
throw new InvalidOperationException(
“Can’t mark as shipped an order that is not pending.”);
State = OrderState.Shipped;
}
As you can see, it’s not rocket science, but using these methods instead of plain setters improves the readability of the code and, more importantly, keeps it aligned to the ubiquitous language. The conventions used here to name methods, in fact, cannot be arbitrary. Terms like Archive andMarkAsShipped should be taken from the ubiquitous language and reflect the terminology used within the business.
Note
Such methods are often implemented as void methods. This makes total sense because they just represent actions. However, depending on the context it might be interesting to consider a fluent interface. You just make the method return this, and it enables chaining calls and makes the whole thing more readable. It’s a possibility to consider.
There are a few interesting things to say about the Items and Total properties. Let’s start with bringing up some issues related to having collections in an aggregate. We describe the issues and provide some suggestions. The definitive answer, though, will come in the next chapter and from the use of a different DDD supporting architecture—CQRS instead of Domain Model.
The Items property is defined as a collection. This means that any code that receives an Order instance can enumerate the content of the collection but can’t add or remove items. Unfortunately, there’s no easy way to prevent that client code from accessing and updating content within the collection. Even worse, this aspect remains unaltered even if you further restrict the collection to a basic IEnumerable<T>. The following code is always allowed and, in addition, you can always use LINQ to select a particular order within the collection:
someOrder.Items.First().Quantity++;
In our scenario, an order is read-only. It gets created out of the checkout process; it can’t be modified, but it can be viewed. So you want the Items collection to be consumed as read-only content. How can you prevent changes on the objects within the collection? Unfortunately, even the following won’t work:
public class Order
{
private Collection<OrderItem> _items = new Collection<OrderItem>();
public ICollection<OrderItem> Items
{
get { return _items.AsReadOnly(); }
}
}
The Items collection is read-only, but you can still retrieve individual elements and change them programmatically.
The definitive solution to this problem comes with the separation between queries and commands and with the provision of different models for reading and writing operations. We’ll cover this in the next two chapters.
The Total property indicates the total value of the order. How should you deal with that? The property is there to please code that consumes the content of the order. In theory, the total of an order can be calculated on demand, iterating on the order items graph with an ad hoc method:
public Money GetTotal()
{
var amount = Items.Sum(item => item.GetTotal().Value);
return new Money(Currency.Default, amount);
}
This solution, though, has a significant drawback. It forces the Order instance to have in memory the entire graph of items. There might be scenarios in which you just want to know the about the total of the order, without all the details. A method like GetTotal will force the deserialization of the entire graph and create much more traffic to and from the database.
By having a simple property on the Order, you can decide intelligently whether or not to deserialize the entire graph. The Total property can be set by the order repository when it returns an instance (which could be a simple SUM operation at the SQL level), or it can be the result of some redundancy in the relational schema of the database. Whenever the order is persisted, the current total is calculated and saved for further queries.
The FidelityCard aggregate
The FidelityCard aggregate is an extremely simple class that summarizes through the accrual of points the activity of a customer within the site.
public class FidelityCard
{
public static FidelityCard CreateNewCard(string number, Customer customer)
{
var card = new FidelityCard {Number = number, Owner = customer};
return card;
}
protected FidelityCard()
{
Number = “”;
Owner = UnknownCustomer.Instance;
Points = 0;
}
public string Number { get; private set; }
public Customer Owner { get; private set; }
public int Points { get; private set; }
public int AddPoints(int points)
{
Points += points;
return Points;
}
}
Each order a customer places increases the total points on the card, and those points are then used to determine a reward status the customer can use to get additional discounts. All the logic of discounts and levels is inspired by the business domain and can be as complex and varying as the real world requires.
The content of a FidelityCard object is used by domain services to calculate reward levels and discounts.
Special cases
In the context of a domain model, one of the most commonly used accessory design patterns is the Special Case pattern, which is defined here: http://martinfowler.com/eaaCatalog/specialCase.html. The pattern addresses a simple question: when some code needs to return, say, a Customerobject but no suitable object is found, what is the best practice? Should you return NULL? Should you return odd values? Should you make an otherwise clean API overly complex and make it distinguish whether or not a result exists? Have a look at this code. It belongs to theOrderRepository class of I-Buy-Stuff and retrieves an order by ID while restricting the search to a particular customer ID:
public Order FindByCustomerAndId(int id, string customerId)
{
using (var db = new DomainModelFacade())
{
try
{
var order = (from o in db.Orders
where o.OrderId == id &&
o.Buyer.CustomerId == customerId
select o).First();
return order;
}
catch (InvalidOperationException)
{
return new NotFoundOrder();
}
}
}
The First method throws if the order is not found. In this case, the code returns a newly created instance of the class NotFoundOrder:
public class NotFoundOrder : Order
{
public static NotFoundOrder Instance = new NotFoundOrder();
public NotFoundOrder() : base(0, UnknownCustomer.Instance)
{
}
}
NotFoundOrder is just a derived class that sets all properties to their default values. Any code that expects an Order can deal with NotFoundOrder as well; and type checking helps you figure out if something went wrong:
if(order is NotFoundOrder)
{
...
}
This is the gist of the Special Case pattern. On top of this basic implementation, you can add as many additional features as you want, including a singleton instance.
Persisting the model
A domain model exists to be persisted, and typically an O/RM will do the job. All that an O/RM does as far as persistence is concerned is map properties to columns of a database table and manage reads and writes. This is only a 10,000-foot, bird’s-eye view, though.
What an O/RM does for you
Generally speaking, an O/RM has responsibilities that can be summarized in four points:
![]() CRUD
CRUD
![]() Query engine
Query engine
![]() Transactional engine
Transactional engine
![]() Concurrency
Concurrency
The query and transactional engines refer to two specific design patterns: the Query Object pattern (which you can see at http://martinfowler.com/eaaCatalog/queryObject.html), and the Unit of Work pattern (which you can see at http://martinfowler.com/eaaCatalog/unitOfWork.html).
Today, on the .NET platform nearly all O/RMs offer an idiomatic implementation of the Query Object pattern based on the LINQ syntax. The Unit of Work is offered through the capabilities of the O/RM root object. In Entity Framework, this object is ObjectContext in its various flavors, such as DbContext.
An O/RM is an excellent productivity tool. It doesn’t really do magical things, but it saves you a lot of cumbersome and error-prone coding. All that it requires is instructions on how to map properties of objects in the domain model to columns of relational database tables.
When it comes to this, you realize that the database is really important even if you do domain-driven design and build a model that is persistence ignorant and stay as agnostic as possible with regard to databases. In a nutshell, the database and the O/RM are two constraints that typically force you to make concessions and introduce in the model features that only serve the need of persistence.
Making concessions to persistence
The most common concession that you, as a Domain Model architect, have to make to an O/RM is the availability of default constructors on all persistent classes.
protected Customer()
{
// Place here any initialization code you may need
...
}
The constructor is required for the O/RM to materialize an entity from the database. In other words, it still needs low-level tools to create an instance of that class. Factory methods are an abstraction that serves the purpose of the ubiquitous language. The constructor, on the other hand, is the only known way that compilers in C# (and other object-oriented languages) allow you to create fresh instances of a class.
Nicely enough, though, you can use O/RM tools to hide the default parameterless constructor from public view. When materializing an entity from databases, an O/RM usually returns the instance of a dynamically created class that inherits from the real entity. In this way, the dynamically generated code gains access to the protected constructor.
Beyond this point, other changes you might be forced to do to make the model persistent depend on the capabilities and quirks of the O/RM of choice. For example, up until version 5, Entity Framework was unable to deal with enum types. In version 6.1, it is still unable to handle, at least in a default way, arrays of primitive types.
Note
When it comes to arrays, database experts might tell you that arrays do not fit nicely in the world of databases and that you should ideally find a solution that doesn’t require arrays. The point is that relational databases don’t offer a way to read and write arrays directly. As a result, storing arrays requires workarounds, but it is neither impossible nor particularly hard. Yet, when you think about the model in a database-agnostic way, arrays might be excellent modeling tools for business aspects that require sequences of related data.
All this is to say that first you should strive to get an ideal domain model that matches the features of the ubiquitous language; next, you should strive to make it suitable to the O/RM of choice (notably Entity Framework) to persist it.
Note
Entity Framework is certainly not the only O/RM available for the .NET Framework. A popular competitor is NHibernate. The perception, however, is that the fierce debate about which of the two to use no longer matters. And because it is tightly integrated with Visual Studio, Entity Framework is the first option that many consider. In addition, there’s a long list of products available from vendors such as Devxpress and Telerik. It’s really mostly a matter of preference.
The Entity Framework Code-First approach
Entity Framework is the O/RM provided by Microsoft .NET. It was not even released when we wrote the first edition of this book. It can be considered the most natural choice today for any .NET project—nearly a de facto standard.
Essentially, Entity Framework comes in two flavors: Database First and Code First. There’s also a third flavor, called Model First, but it’s a hybrid, middle-way approach that uses the visual diagram model and was soon superseded by Code First. The Database-First approach reads the structure of an existing database and returns a set of anemic classes you can extend with methods using the partial class mechanism. The Code-First approach consists of writing a set of classes—for example, a Domain Model, as discussed so far. Next, you add an extra layer of code (or data annotations) to map properties to tables. This mapping layer tells the O/RM about the database to create (or expect), its relationships, its constraints and tables and, more importantly, it tells the O/RM where to save or read property values.
The I-Buy-Stuff example uses the Code-First approach.
Code-First delivers a persistence layer centered on a class that inherits from DbContext. Here’s an example:
public class DomainModelFacade : DbContext
{
static DomainModelFacade()
{
Database.SetInitializer(new SampleAppInitializer());
}
public DomainModelFacade() : base(“naa4e-09”)
{
Products = base.Set<Product>();
Customers = base.Set<Customer>();
Orders = base.Set<Order>();
FidelityCards = base.Set<FidelityCard>();
}
public DbSet<Order> Orders { get; private set; }
public DbSet<Customer> Customers { get; private set; }
public DbSet<Product> Products { get; private set; }
public DbSet<FidelityCard> FidelityCards { get; private set; }
protected override void OnModelCreating(DbModelBuilder modelBuilder)
{
...
}
}
The string passed to the constructor is the name of the database or the name of an entry in the configuration file indicating where to read details about the connection string and the data provider. When you install Code First via NuGet, you get the SQL Server engine as the default data provider and the LocalDb engine for storage.
The DbSet properties abstract the tables being created, and the initializer class can be used to automate the creation, dropping, and filling of the database mostly for the purposes of an initial setup or for debugging.
Mapping properties to columns
In Code First, there are two ways to map properties to columns. You can use data annotation attributes in the source code of domain classes, or you can use the fluent Code-First API and write configuration classes bound together in the OnModelCreating overridable method.
Overall, we recommend the fluent API rather than data annotations. The reason is that data annotations are intrusive and add noise to an otherwise persistent ignorant domain model isolated from infrastructure technologies.
Here’s some code you want to have in the mapping layer:
modelBuilder.ComplexType<Money>();
modelBuilder.ComplexType<Address>();
modelBuilder.ComplexType<CreditCard>();
modelBuilder.Configurations.Add(new FidelityCardMap());
modelBuilder.Configurations.Add(new OrderMap());
modelBuilder.Configurations.Add(new CustomerMap());
modelBuilder.Configurations.Add(new OrderItemMap());
modelBuilder.Configurations.Add(new CurrencyMap());
The ComplexType method lets you tell the O/RM that the specified type is a complex type in the Entity Framework jargon, which is a concept close to what a value object is in a domain model. The remaining code in the snippet shows mapping classes each taking care of the configuration of an entity. Note, though, that in case of need you also can have a mapping class for a complex type. It all depends on the instructions you have for the O/RM. Let’s look at a couple of examples:
public class OrderMap : EntityTypeConfiguration<Order>
{
public OrderMap()
{
ToTable(“Orders”);
HasKey(t => t.OrderId);
HasRequired(o => o.Buyer);
HasMany(o => o.Items);
}
}
The method HasKey declares the primary key, whereas HasRequired sets a required foreign-key relationship to a single Customer object. Finally, HasMany defines a one-to-many relationship for OrderItem objects.
The following excerpt, on the other hand, shows how to configure columns from properties:
Property(o => o.OrderId)
.IsRequired()
.HasMaxLength(10)
.HasColumnName(“Id”);
The net effect is that the table Orders is going to have a column named Id mapped to the property OrderId. At the database level, the column doesn’t accept null values and any content longer than 10 characters. Similar methods exist to make a value auto-generated by the database:
Ignore(p => p.Name);
Finally, the Ignore method is used to tell the O/RM that the specified property shouldn’t be persisted. This is what happens, for example, when the property has a computed getter in the C# code.
Implementing the business logic
As it often happens, not all the business logic that is required—whether it is rules or tasks—fits into the classes of the domain model. At a minimum, you need to have persistence logic stored in repository classes. Most likely, you need domain services. In the I-Buy-Stuff example, there are two main tasks—finding an order and placing an order.
Note
Before we delve deeper into domain services, let’s clarify how the call moves from the web user interface down to the domain layer. As mentioned, our example is an ASP.NET MVC application. This means that any user action (for example, button clicking) ends up in an action method call on a controller class. In Chapter 6, “The presentation layer,” we introduced application services to contain any orchestration logic that gets content from the raw HTTP input and returns whatever is required for the controller to produce an HTTP response. Application services, though, don’t directly deal with objects in the HTTP context.
Finding an order
Here’s the code you find in the controller method that receives the user’s request to retrieve a given order. As you can see, the controller method yields to an application service that gets data from the HTTP request and produces a response ready to be transmitted back as HTML, JSON, or whatever else is suitable:
public ActionResult SearchResults(int id)
{
var model = _service.FindOrder(id, User.Identity.Name);
return View(model);
}
The application service method—FindOrder, in the example—calls domain services and repositories as appropriate, does any data adaptation that might be necessary to call into the domain layer, and returns a view model.
Another option for organizing this code might be splitting responsibilities between the application service and controller so that the application service just does orchestration and returns raw data that the controller then packages up in a view model.
Important
Note that the view model class is a plain container of data that might come in the form of domain entities or data-transfer objects.
Here’s the actual implementation of the application service method. Admittedly, in this particular case having an application service is probably overkill because all it does is call a repository method. However, we invite you to consider the underlying pattern first and then apply any simplification that might work. The shortest path is always preferable as long as you know what you’re doing and where you really want to go! In general, however, authorization code and even app validations might be additional code for the application services.
public SearchOrderViewModel FindOrder(int orderId, string customerId)
{
var order = _orderRepository.FindByCustomerAndId(orderId, customerId);
if (order is NullOrder)
return new SearchOrderViewModel();
return SearchOrderViewModel.CreateFromOrder(order);
}
Note
We mentioned repositories in the prior chapter, and we’re mentioning repositories extensively in this one. We provide more details about their role and implementation in Chapter 14, “The infrastructure layer.”
Placing an order
When the user clicks to start shopping on the site, the system serves up the user interface shown in Figure 9-8. The following code governs the process:
public ActionResult New()
{
var customerId = User.Identity.Name;
var shoppingCartModel = _service.CreateShoppingCartForCustomer(customerId);
shoppingCartModel.EnableEditOnShoppingCart = true;
SaveCurrentShoppingCart(shoppingCartModel);
return View(“shoppingcart”, shoppingCartModel);
}
FIGURE 9-8 The shopping cart for the current user.
The helper application service creates an empty shopping cart for the user and enables interactive UI controls to add or remove items. The shopping cart is saved in the session state for further reference. Note that the actual ShoppingCart type is defined in the domain because it carries information that makes up an order request. On the presentation layer, though, the ShoppingCart is wrapped in a view-model type enriched with the UI-related properties required to render the HTML page. This also includes the full list of products the user can choose from.
The shopping page lets the user add and remove products from the cart. Every add/remove action generates a roundtrip; the state of the shopping cart is retrieved from the session state, updated, and then saved back.
public ActionResult AddToShoppingCartCommand(int productId, int quantity=1)
{
var cartModel = RetrieveCurrentShoppingCart();
cartModel = _service.AddProductToShoppingCart(cart, productId, quantity);
SaveCurrentShoppingCart(cartModel);
return RedirectToAction(“AddTo”);
}
The application service adds an element to the shopping cart:
public ShoppingCartViewModel AddProductToShoppingCart(
ShoppingCartViewModel cart, int productId, int quantity)
{
var product = (from p in cart.Products where p.Id == productId select p).Single();
cart.OrderRequest.AddItem(quantity, product);
return cart;
}
The AddItem method on the ShoppingCart domain object contains a bit of logic to increase the quantity if the product is already in the cart:
public ShoppingCart AddItem(int quantity, Product product)
{
var existingItem = (from i in Items
where i.Product.Id == product.Id
select i).SingleOrDefault();
if (existingItem != null)
{
existingItem.Quantity++;
return this;
}
// Create new item
Items.Add(ShoppingCartItem.Create(quantity, product));
return this;
}
The checkout button leads to the page in Figure 9-9. Note that the shopping cart is now rendered in read mode and all actionable buttons are not displayed.
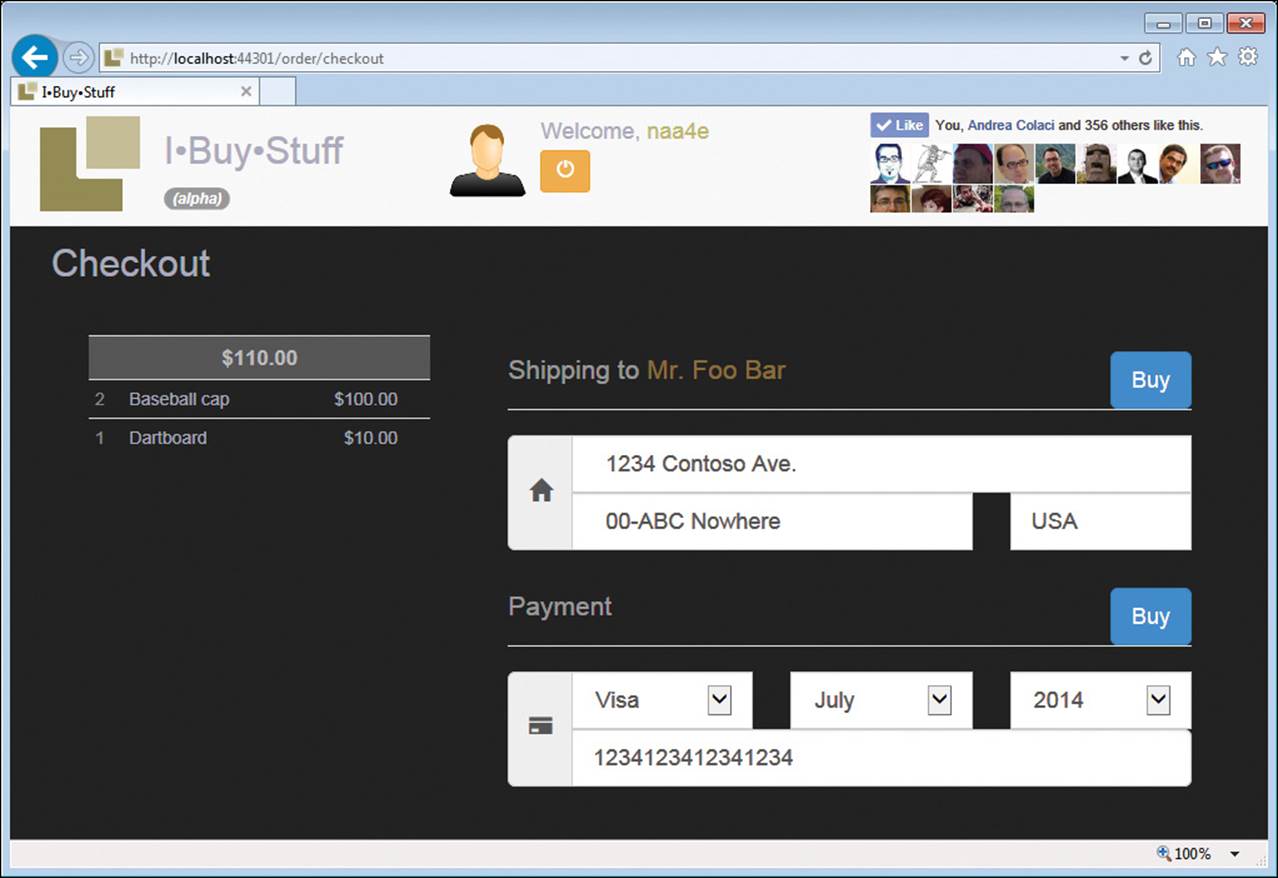
FIGURE 9-9 The checkout page of the I-Buy-Stuff site.
Note that the controller method that receives the command to add an item to the cart (or remove an item from it) in the end redirects to the AddTo action instead of just rendering the next view. This is done to avoid a repeated form submission if the user refreshes the page. In response to a refresh action (for example, when F5 is pressed), browsers just repeat the last action. Thanks to the redirect, however, the last action is a GET, not a POST.
Processing the order request
When the user finally clicks the Buy button, it’s time for the order to be processed and created. At this time, company policies and business rules must be applied. In general, processing the order is based on a workflow that is orchestrated by the application service invoked from the controller. The typical steps of the workflow are checking the availability of ordered goods, processing payment, forwarding shipping details, and storing order data in the database.
Most of these actions can be carried out in silent mode. Payment, though, might require that an external page be displayed to let the user interact with the banking back end. If payment requires its own user interface, you split the processing of the order into two phases: before and after payment. If not, you can implement the processing of the payment and synchronization with the shipping company as two parallel tasks using the .NET Framework Parallel API. Here’s how to split checkout into two steps:
public ActionResult Checkout(CheckoutInputModel checkout)
{
// Pre-payment steps
var cart = RetrieveCurrentShoppingCart();
var response = _service.ProcessOrderBeforePayment(cart, checkout);
if (!response.Denied)
return Redirect(Url.Content(“~/fake_payment.aspx?returnUrl=/order/endcheckout”));
TempData[“ibuy-stuff:denied”] = response;
return RedirectToAction(“Denied”);
}
public ActionResult EndCheckout(string transactionId)
{
// Post-payment steps
var cart = RetrieveCurrentShoppingCart();
var response = _service.ProcessOrderAfterPayment(cart, transactionId);
var action = response.Denied ? “denied” : “processed”;
return View(action, response);
}
The method ProcessOrderBeforePayment on the application service saves checkout information (shipping address and payment details) and checks the stock level of ordered products. Depending on the policies enabled, it might also need to place a refill order to bring the stock level back to a safe value. If something goes wrong (for example, some goods are not available), the response is stored in TempData to be displayed by the Denied page across a page redirect.
Note
TempData is an ASP.NET MVC facility specifically created to persist request data temporarily across a redirect. This feature exists to enable the Post-Redirect-Get pattern, which protects against the bad effects of page refreshes.
If pre-payment checks go well, the method redirects to the payment page. This is where payment occurs. When done, the page redirects back to the specified URL. In doing so, the payment page will pass the transaction ID that demonstrates payment. (This is a general description of how most payment APIs actually work.)
The post-payment phase might include booking a delivery through the shipping company back end, registering the order in the system, updating the stock level, and updating the records of the fidelity card.
Fidelity card (or customer loyalty program)
Once the order is in the system, a few additional tasks might still be required. In a way, adding an order generates an event within the domain that might require one or more handlers. This introduces the point of domain events. In general, a domain event is an event that might be raised within the context of the domain model. Domain events are simply a way for the architect to clean up the design and enable himself to handle situations in a more flexible way.
In particular, the requirements we have for I-Buy-Stuff state that whenever an order is created the system must update the stock level of the products and add points to the fidelity card of the customer.
Both operations can be coded as plain method calls executed at the end of the ProcessOrderAfterPayment method in the application service class. It’s plain and simple, and it just works.
However, the logic behind the fidelity card is subject to change as marketing campaigns are launched, ended, or modified. The aforementioned implementation might turn out to be a bit too rigid in terms of maintenance and lead to frequent updates to the binary code. A more extensible design of what might happen once the order is created might smooth the work required in the long run to keep the system aligned to the business needs.
Domain events try to address this scenario. A domain event can be implemented as a plain C# event in some aggregate class, or it can be implemented through a sort of publish/subscribe mechanism, where the information is put on a bus and registered handlers get it and process it as appropriate. More importantly, handlers can be loaded and registered using a dependency-injection interface so that adding and removing a handler is as easy and lightweight as editing the configuration file of the application.
Summary
This chapter is an attempt to give substance to concepts and ideas that too often remain confined in the space of basic tutorials or in theory. We didn’t just present a domain model where classes have behavior and factories and make limited use of primitive types. We actually presented a multilayer ASP.NET MVC application that proceeds end-to-end from presentation down to the creation of an order in a scenario that is not an unrealistic CRUD.
Along the way, we turned into practice concepts we introduced in past chapters and showed that, while database structure is not a primary concern when modeling, it still is a constraint and concessions are often necessary to make the object model persistent.
We invite you to take a thorough look at the full source code of the I-Buy-Stuff application. The text in the chapter emphasized choices around the domain model; however, the code contains a lot more details and solutions that might be interesting to look at.
Finishing with a smile
StackOverflow.com, TopEdge.com, and other websites contain an endless collection of jokes about developers. In particular, we looked for jokes about developers and light bulbs. Here’s our selection:
![]() How many developers are needed to change a light bulb? None. The light bulb works just fine in their offices.
How many developers are needed to change a light bulb? None. The light bulb works just fine in their offices.
![]() How many developers are needed to change a light bulb? None. It’s a hardware problem.
How many developers are needed to change a light bulb? None. It’s a hardware problem.
![]() How many testers are needed to change a light bulb? They can only assert the room is dark, but they can’t actually fix the problem.
How many testers are needed to change a light bulb? They can only assert the room is dark, but they can’t actually fix the problem.
![]() How many Java developers are needed to change a light bulb? Well, the question is ill-posed and shows you’re still thinking procedurally. A properly designed light bulb object would inherit a change method from a base light bulb class. Therefore, all you have to do is send a light bulb change message.
How many Java developers are needed to change a light bulb? Well, the question is ill-posed and shows you’re still thinking procedurally. A properly designed light bulb object would inherit a change method from a base light bulb class. Therefore, all you have to do is send a light bulb change message.
![]() How many Prolog developers does it take to change a light bulb? Yes.
How many Prolog developers does it take to change a light bulb? Yes.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.