Scenario-Focused Engineering (2014)
Part III: The day after
CHAPTER 11 The way you work
CHAPTER 12 Lessons learned
Chapter 11. The way you work

The last couple of chapters (and a few of the appendixes) focus on what we call “the day after.” We’ve noticed a consistent pattern in teaching the Scenario-Focused Engineering workshop. Teams spend a day in our workshop, learn some techniques and approaches, and leave inspired to try some of these ideas in their own projects. But the next morning, team members wake up, get to work, and find that they aren’t quite sure what to do next. They find themselves in the same old office, with the same computer, same tools, same performance-review goals, same specs, and the same project schedule.
All of a sudden, the task of using some of the techniques and principles they just learned seems daunting. After all, the context and boundaries we set up in class do not currently exist on their team. These team members are now back in the real world, facing real problems, with real constraints and an established team culture and set of practices.
Now, the day after the workshop, they realize that the team doesn’t really have a unified notion of who the customer is, other than “someone with a computer.” They sit down to write a scenario and realize, “Hey, we don’t have real customer data to tell us which situations are most important to optimize for. Should we go get some? How? When? How much time can we take to do this?” Or, if data is available and a few team members write up a killer scenario, take a couple of hours to brainstorm, and discover a few inspiring ideas, they then realize, “We don’t have time to prototype and test, the schedule says we have to start writing code today. What do we do?”
The trouble is that the ideas in this book are pretty straightforward, and reading about them or trying them out in a controlled classroom environment can be deceivingly easy. However, in real life, putting the Fast Feedback Cycle into practice is surprisingly difficult. Many teams’ existing systems, tools, processes, and culture are optimized for the old approach to building software, in a more or less linear and hierarchical manner, and long-established habits are tough to break. For these same reasons, Agile and Lean practices can also be difficult to establish on a team, as we’ll explore in this chapter.
Adopting the Fast Feedback Cycle requires teams to change their behavior. The ideas are straightforward, and the resources and techniques exist if you know where to look for them, but until a team’s attitudes and beliefs change, it’s tough to make much progress. Motivating a group of people to collectively change their approach and start using these new methods is a classic problem of change management. As we’ve observed teams adopting new customer-focused practices, we’ve developed a deep appreciation for the extreme difficulty of changing behaviors, processes, culture, and beliefs across large groups of people.
![]() Tip
Tip
The science of change management provides models and guidelines for how best to effect change in groups of people. We discuss these in more detail in Chapter 12, “Lessons learned,” and provide a reading list of our favorite change-management texts in Appendix C.
In a way, this entire book is about changing the way you work. In previous chapters we’ve talked about how to make some of these shifts when they are relevant to a particular stage or set of activities. The focus of this chapter is on how these changes affect the meta-level systems that govern the overall management of a software project. We have seen teams make substantial overhauls of fundamental team processes and tools, such as work-item tracking, project reviews, performance-review systems, and rethinking the structure and milestones of the team’s project schedule. Teams that bake an iterative rhythm and customer focus into their process and tooling are much more successful sustaining the shift over the long term.
That said, no single tooling or project-management system works for every team. Different teams are just, well, different. A family-owned small business is very different from a multithousand-person software company. Teams building online services with rapid release cycles are very different from teams shipping a device with hard manufacturing constraints and longer lead times. Maintaining and improving a successful legacy product is very different from starting a version 1 project. One approach to tooling and project management can’t possibly serve all those needs. However, we have noticed some issues that come up in most team situations and can share a few patterns about how teams have successfully addressed them.
In this chapter we summarize these patterns as a set of nine shifts in how to manage your software project. We think these are the most important steps for enabling the Fast Feedback Cycle to fully take root in your team. Some of them require you to make a distinct change: stop doing the old thing, and start doing a new thing instead. Some of them are more subtle—keep doing what you are already doing, but consider a few more inputs or optimize for a slightly different factor. Different teams may find that some of these shifts are more important for their situation than others, or that they have already addressed some through previous investments in Lean or Agile approaches. You don’t have to make all of these shifts, or implement them all at the same time, to get good value, but they do build on one another. Keep in mind that most of our experience is with teams that range in size from 100 to as many as 3,000 people. These shifts may surface differently on smaller teams, although we suspect there will be plenty of similarities.
Shift from doing many things to focusing on a few
One of the first places that teams get stuck adopting new practices is simply finding the time to do it. Many teams, especially those working in the world of online services, are running so fast that the thought of stopping to consider who their target customer is, or doing customer testing before writing code, or even doing customer testing on their live service before shipping broadly may seem patently impossible given their fast-paced schedule and the competitive pressure they feel. Furthermore, many, many teams are so busy that stopping to learn a new set of techniques or to take on the overhead of learning a new rhythm of working can be difficult, if not impossible, to justify.
If you’ve read this book to this point, you recognize this as a penny-wise, pound-foolish attitude. Do not underestimate the cost of discovering after months of work that you’ve spent all your precious development time writing code for something that nobody wants, isn’t solving a real customer problem, or no one is willing to pay for. These are truly painful, expensive (and avoidable!) wastes of time that you should be guarding against. Plus, the extreme hurry is often unjustified. Remember the stories in Chapter 6, “Framing the problem,” about the roots and pace of innovation? We described how some of the most influential innovations of the past decade took time—usually years—to evolve from an idea to a successful implementation and were not even necessarily first to market in their categories.
What is the root cause of being too busy? Is it a scheduling problem? Yes, partly, and we’ll cover that in the next section. And certainly, a natural amount of firefighting takes place for any services business, dealing with live site issues and providing responsive customer service. But a far bigger problem is allowing a team to take on too much work in the first place, so that no matter how creatively you arrange the schedule, there just isn’t enough time to get everything done—never mind achieving high quality from the customer’s point of view or accomplishing this without burning out your team.
Of course, this isn’t obvious at the start of a project. Whether a team follows an Agile, a waterfall, or some hybrid approach to project management, teams tend to be very optimistic at the beginning. They have a lot of great ideas and an infinite amount of passion, and all the customer promises the team envisions just seem to fit. As a former colleague, Howie Dickerman, once quipped, “All plans are perfect at the start.” But any seasoned engineer knows that there will always be unforeseen problems, and the actual effort for even a modest task will take much longer than you expect. A project’s true time and effort won’t become clear until you’re deep enough into the project to be very committed, both emotionally and physically. New code becomes increasingly difficult to back out, so you are effectively trapped by all the great ideas you aspired to build but that you now find you don’t have time to finish.
All this brings us to the first shift in how to manage your project differently. You simply need to make more time and space by choosing to do less overall and put fewer things on the schedule. This allows the team to concentrate more on each area of focus and to produce a high-quality result that optimizes technical quality, customer experience, as well as business results. Choose fewer scenarios to deliver, choose fewer target customers to focus on, choose to actively work on just a few big ideas at a time. Don’t spread the team’s attention across many different, unrelated investment areas. Having a narrower focus will naturally create more buffer time to account for iteration, learning, dealing with unforeseen issues, and responding to customer feedback in a meaningful way. Focusing a team on fewer things is the single biggest lever that leaders have for improving the quality of the resulting product. When it comes to delighting customers, less really is more.
It can be scary to commit to only a few investments, but remember that the Fast Feedback Cycle will give you early and constant feedback about whether you’ve made the right choice or whether it’s time to change course. Getting a few things done with high quality is more important than getting a whole lot of things done with marginal quality.
The key behavior to introduce here is for all team leaders to commit to agreeing on a small set of focus areas and to not allow a project’s scope to creep and become larger as it progresses by adding “just one more thing.” This requires a sharp knife when you prioritize and that you stay committed to that focus. It helps to think more of sequencing than of prioritizing. What you are deciding are which areas you will focus on for now; there will be time for others later.
One way to force yourself to do less is by shortening your release cycle. A fast cycle makes it easier to say that it’s okay to do less. Plan a three-month release cycle instead of a one-year cycle, or for a one-month release instead of three months. To help control scope, focus on one change or one new area in each release cycle. Combine the shorter cycle and the “do less” mantra to catalyze the shift to happen.
SFE in action: Getting an A versus pass/fail
Joe Belfiore, Corporate Vice President, Microsoft PC, Phone, Tablet
In my job running the PC, Phone, Tablet team at Microsoft, I’ve offered a refrain that people have heard so many times in meetings or reviews that they often recite it for me in anticipation: “Is that list prioritized?”
In my view, the most critical piece of thinking you can do for yourself or your team is to become clear on priorities, and I insist that the “prioritized list” is the way to do it. At the end of the day, your focus and effort are allocated linearly, and that’s the best way to ensure that you’re spending energy where it matters most.
When we built Windows Phone 8, we had a ton of great features planned—an Action Center, new shape writing in our Word Flow keyboard, massive improvements for developers, better Live Tile flexibility, and Cortana, our new personal digital assistant. At a critical point halfway through the product cycle, we decided to help the team by clearly and loudly picking where we wanted to place our bet, and the way we communicated that decision was with a prioritized list of “where we want to get an A.” At the top of the list was Cortana, and the message was to work on this with top priority, aiming to get an A. After that item, everything else was listed in priority order, with the message that we could view the rest of the items as needing pass/fail grades instead.
The result: people did what was necessary to get a “pass” in the features that were important but weren’t our core story—and they were excited to spend all their extra effort and hours on Cortana, which really paid off in having Cortana turn out great and land well for Windows Phone 8.1. Understanding which investments needed to be good enough to pass and those for which we really needed to get an A turned out to be a great way to communicate priorities and align the focus of the entire team.
Shift from milestones to sprints
A project’s schedule can exert a powerful force on a team, setting expectations for team members for what they should be doing, how long it should take, and when they should move on to the next thing. If you want a team to start doing something new, one of the best ways you can make that happen is to build that new behavior into the team’s schedule. You are seeking to change the culture and practices of the team so that they become more iterative, and one of the best ways to do this is to enforce a baseline level of iteration in the schedule itself.
If you haven’t noticed already, most of the development world has been moving (or has already moved) toward using some flavor of Agile methodology. The reason, we believe, is quite powerful and is one of the cornerstones of this book. To be responsive to customers and solve complex needs well, you need to iterate continually, and the Agile community has done a terrific job of creating a platform and mechanisms for development teams to manage and schedule an iterative process. Typically, the basic unit of schedule in an Agile system is a sprint. A sprint, having a length of one to four weeks, is the right scale for completing an entire iteration of the Fast Feedback Cycle. The key value of a sprint is to finish it by getting customer feedback on something you’ve built so that the feedback can inform the next sprint. We recommend using Agile sprints as the underlying mechanism for managing your iterations.
You want to instill in a team the habit of thinking of its work in the context of an iteration, and that an iteration represents a full turn of the Fast Feedback Cycle. This means that even at the start of a project, the team should aim to produce something at the end of its first iteration with the expectation of getting a very quick round of customer feedback.
From a scheduling perspective, you should think of a single iteration as an atomic unit that is absolutely indivisible. Do not try to schedule dedicated time for each individual stage within the Fast Feedback Cycle, and do not try to align the entire organization to do the same activity at the same time. In a healthy iterative cadence, the stages in the Fast Feedback Cycle should happen naturally in the context of each time-boxed sprint.
But more profoundly, teams need the latitude to adjust the percentage of time within each sprint that they spend on each stage of the Fast Feedback Cycle. This depends on where they are in the project and what the most recent customer feedback says (for example, do they need to focus this iteration mostly on rewriting their scenario or on exploring lots of solutions to address the feedback they heard). And from a management perspective, you often do more harm than good if you try to get a status update from a team in the middle of an iteration. The best time to ask about status is after the team has received customer feedback and you can have a conversation that’s grounded in data about how the last iteration went and then discuss options for what directions the team might try next.
There are some nonobvious implications to the idea of handling iterations as an atomic unit. Don’t put milestones on your schedule that are linked to different phases of development. For example, don’t have any milestones called “coding start” or “design” or “feedback” or “stabilization.” Don’t encourage teams to think about the time they spend in design versus coding work. Instead, expect that at the end of their first iteration, teams should start testing concepts with customers in whatever form is most convenient, and that teams will continue iterating as quickly as they can to zoom in on the right thing, starting to code only when they have confidence about the direction. Some teams may start writing code on their very first iteration, whereas others may be able to make solid progress for several iterations without writing code. When you start writing code is highly variable across teams and depends on what scenario a team is working on and what kind of feedback it’s getting.
Here are a few ways that we’ve seen teams build iteration into their schedules:
![]() Use Agile sprints as the baseline rhythm of the schedule. Teams are expected to complete an iteration of the Fast Feedback Cycle within a single sprint and should plan to get customer feedback at the close of each sprint.
Use Agile sprints as the baseline rhythm of the schedule. Teams are expected to complete an iteration of the Fast Feedback Cycle within a single sprint and should plan to get customer feedback at the close of each sprint.
![]() Schedule customer touch points in advance at a regular interval, such as every week or every other week, and encourage teams to use those opportunities to show their latest work to customers for feedback. The regular opportunity for customer feedback forces a certain rhythm to emerge—a team will manage its time so that it has something to show to the customer for the next time. After a team receives customer feedback, that naturally kicks off the next iteration, in which the team will address whatever it learned from that round of feedback. Customer touch points create the drumbeat of iterations.
Schedule customer touch points in advance at a regular interval, such as every week or every other week, and encourage teams to use those opportunities to show their latest work to customers for feedback. The regular opportunity for customer feedback forces a certain rhythm to emerge—a team will manage its time so that it has something to show to the customer for the next time. After a team receives customer feedback, that naturally kicks off the next iteration, in which the team will address whatever it learned from that round of feedback. Customer touch points create the drumbeat of iterations.
![]() Set project reviews at regular intervals, and set the expectation that teams will present the results of an entire iteration, including customer feedback, at that review. We’ll discuss how to conduct project reviews (or, should we say, experience reviews) in more detail later in this chapter, but the important point for now is that having them on the schedule can encourage the team to develop an iterative habit. The project review acts as a forcing function to make sure that a full iteration, with the right activities, happens before the review.
Set project reviews at regular intervals, and set the expectation that teams will present the results of an entire iteration, including customer feedback, at that review. We’ll discuss how to conduct project reviews (or, should we say, experience reviews) in more detail later in this chapter, but the important point for now is that having them on the schedule can encourage the team to develop an iterative habit. The project review acts as a forcing function to make sure that a full iteration, with the right activities, happens before the review.
![]() Release code to customers more often. Iterative habits are helped by building in frequent opportunities for releasing code to users, instead of scheduling release windows only a few times per year or even monthly. Even once or twice a week might be insufficient for some services and apps for which customers expect faster turnarounds. Teams need to feel as though they can do as much iteration as needed to get to a high-quality result and not be tempted to release a solution before it’s ready just so they don’t miss a particular release window.
Release code to customers more often. Iterative habits are helped by building in frequent opportunities for releasing code to users, instead of scheduling release windows only a few times per year or even monthly. Even once or twice a week might be insufficient for some services and apps for which customers expect faster turnarounds. Teams need to feel as though they can do as much iteration as needed to get to a high-quality result and not be tempted to release a solution before it’s ready just so they don’t miss a particular release window.
If you’re not sure how long your iterations should be, a good rule of thumb is to start with two weeks. That time period is short enough that you will get customer feedback in time to avoid wasting a lot of effort on a possible dead end, but it’s long enough to give a team new to the Fast Feedback Cycle the time it needs to get through the entire cycle. It also keeps the overhead of testing with customers from becoming overwhelming as you set up a system and pipeline for regular customer feedback.
Kick-starting a significant new project deserves special attention. Especially when you are aiming to build something that’s brand-new or are making a big change to an existing product, there’s often an extra dose of ambiguity about target customers and their most important problems. In these situations, you may find it helpful to schedule your first couple of iterations to be a bit longer, which allows for more time to do in-person research to get your project rolling with solid footing in customer data. Another approach is to have a small team do some observational research ahead of time so that the broader team can begin from a good seed and can make a running start at solving those customer needs. However, remember to resist the urge to spend months preplanning. You’ll gain the biggest benefits as soon as you get through your first iteration and show your first rough prototypes to customers.
Shift from work-item lists to scenario hierarchies
One of the fundamental ways that a team manages its engineering work is with some sort of work-item tracking system. Many Agile teams use a burndown list—an ordered list of user stories that is worked on in priority order. Conventional teams are used to working with feature lists, which are usually organized under some unifying themes, priorities, or other categories. Features or other work items might be tracked during a project with tools ranging from sticky notes on the wall to a spreadsheet or a software-based work-item management system such as JIRA, Pivotal Tracker, Team Foundation Server, or many others.
While a system for tracking engineering deliverables and work items is a necessity for managing a software project that involves more than a handful of people, if your goal is to build end-to-end experiences, you actually need to be tracking more information than just the individual work items and their completion status. With the Fast Feedback Cycle, after your first few iterations (or whenever you transition to writing production code), one of the biggest challenges is to keep your focus on building complete scenarios and to be sure that the complete experiences survive intact through to shipping. The more that different teams are involved, the more important it is to track work and progress in terms of complete experiences. If a team’s primary, day-to-day view into a project shows only the atomic, technology-focused work items and not the experiences that connect them, the team will inevitably revert to its old habits and focus on building just the technology. It is very easy for a team to zoom into the task-level work and forget to keep an eye on the full end-to-end experience it’s aiming for—to stay true to the original scenarios and customer insights defined by your research.
You want everyone as they are writing code to remain mindful about which deliverables and work items need to be integrated to deliver a smooth, end-to-end experience and which situations and customers you are optimizing for. The team writing the UI code has probably been iterating with mockups all along and can see the connection points more easily. But think about the platform teams whose deliverables are a few layers away from the end-user’s experience. They also need to remember the customer experience that their work will ultimately support and should be optimized for. Also, if you find that a deliverable is at risk, you need to consider its role relative to the overall experience as you decide whether to double-down, pare back, or cut the entire scenario. If this deliverable is a crucial piece of the user experience, cutting the entire scenario is almost always better than delivering an incomplete experience. However, that is a very tough decision to make, especially if it means that you also have to cut pieces of work that are already done or are not at risk in any way. Bottom line—if you are trying to deliver end-to-end experiences, you better be tracking your work not as individual work items but within the context of those end-to-end experiences.
Story hierarchies
The first hurdle in tracking experiences is to figure out how to represent the end-to-end experiences themselves so that you can write them down and track them. How do you make experiences robust and able to be tracked and also associate them with the baseline engineering deliverables and work items? If you are using the scenario technique, or any of the other story-based framing techniques, you will craft a set of scenarios or other stories to capture the customer needs and goals you want to achieve. However, when we’ve seen teams set out to describe their customer problems and business opportunities with stories, they usually come across the same set of questions:
How many scenarios should we have? How many is too many, or too few?
How much overlap should there be between different scenarios?
What is the right level of scope for a single scenario to cover—should it cover a five-year business opportunity or describe a need that can be solved with a few well-designed features?
Remember the story about the airport, where we talked about framing—zooming in and zooming out? Should you write the scenario about the check-in process, or do you zoom out to include the customer’s entire end-to-end experience, including the early wake-up call, the traffic on the way to the airport, and the delay at the gate? Scenarios are ultimately about framing problems through storytelling, and as such they entail nearly infinite possibilities for defining the scope of the problem to focus on.
It helps a lot to think about what scope, or altitude, you are aiming for so that you can align the stories across your project at a similar elevation. Talking in a consistent way about the different levels of scope your stories cover makes it possible to track and manage the work without losing your sanity, and it helps you manage and prioritize apples with apples and oranges with oranges.
Nearly all of the teams we’ve worked with have landed on a two-level hierarchy as a way to balance large- and small-scope impact and to organize their stories into a more manageable, logical structure. This two-level story hierarchy acts as the translation layer that bridges the high-level themes—or global priorities for the project—and the specific deliverables and work items that the engineering team needs to execute.
We’ve seen a couple of teams try to make a three-level story hierarchy work, but in the end this was deemed too unwieldy and too heavy. We’ve also seen teams attempt to use a single, flat list of scenarios. However, they found it very difficult to make sense of a long, unstructured list that mixed huge scenarios (that described an extensive end-to-end situation) with unrelated, tactical scenarios of a much smaller scope. They found that some sort of organization was needed, so most of these teams added a hierarchical structure later on.
These days, most teams start with a two-level story hierarchy. In fact, we recently audited 16 of the largest Microsoft teams and found that all but two now use scenarios as standard items in their work-item hierarchies and the vast majority use a two-level hierarchy of stories of one form or another. Although different teams use different terminology, the general pattern we’ve seen is that teams build a pyramid-shaped hierarchy of stories to describe their business and customer opportunities, and use those stories to break down opportunities into actual product deliverables. The top of this framing hierarchy describes the high-level business and customer goals (themes, for example), and the bottom describes customer deliverables with enough detail that code can be written. Figure 11-1 shows an example.
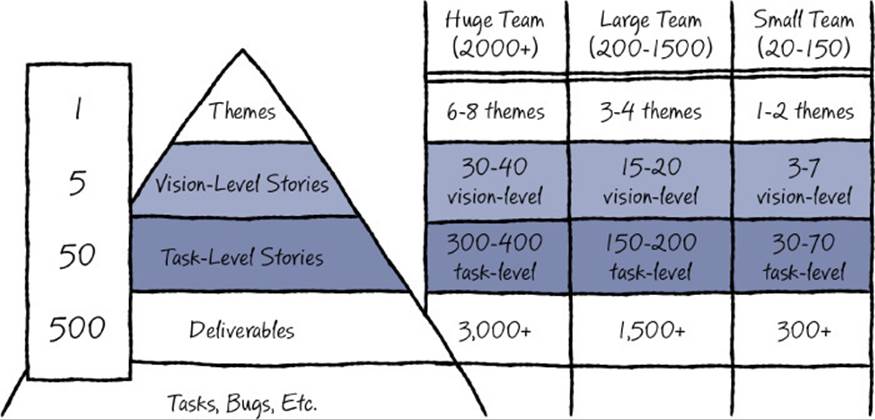
FIGURE 11-1 The breakdown of a scenario hierarchy.
We’ve observed a ratio of approximately 1:5:50:500 as the typical shape of this hierarchy. That is, 1 theme breaks down to about 5 vision-level stories, and those 5 vision-level stories break down to about 50 task-level stories, and about 500 engineering deliverables in total, and perhaps thousands of individual tasks and other work items. There is no hard and fast rule about these numbers, of course, but the general shape seems to hold. We’ve also noticed that even for the largest teams, the number of vision-level stories must be small enough that everyone on the team, especially the team’s management, can keep them at the top of their mind throughout the project’s lifetime. In light of this, there seems to be a practical cap of about 8 themes and 40 vision-level stories for even the very largest of teams (but very large teams do seem to broaden the definition of both vision-level and task-level stories to compensate for this).
![]() Mindshift
Mindshift
Too much of a good thing. The most common mistake for a team to make is to define too many vision-level scenarios. We have all experienced how difficult it is to decide not to invest in an idea that appears to be viable, even if it is clear that we have too many promising ideas to realistically pursue all of them. The reality is that the cuts will need to be made, and the sooner the better to maximize the team’s efficiency and the quality of the final solution. We have observed many teams that start out with a larger number of vision-level scenarios, but they invariably end up paring this list down to a more manageable number that aligns more closely to the ratios in the pyramid shown in Figure 11-1.
Let’s discuss each of the core layers of the scenario hierarchy in more detail.
Themes
Most teams, especially larger teams, find it useful to start a project with a small set of themes, which might also be referred to as pillars, big bets, priorities, or investment areas. A theme is typically stated as a broad goal, such as “Improve operational supportability,” “Reduce customer support calls,” or “Ship a new SDK.” Usually, these are tightly linked to strategic business goals or predetermined technology investments and serve to provide a certain amount of scoping and anchoring that helps prevent an overly broad framing at the highest level. Themes are often featured in a framing memo (see the sidebar “The framing memo” in Chapter 4, “Identifying your target customer”), along with the designations of target customers, that is issued at the very start of a project or even sometime before the bulk of the engineering team has rolled off the previous project. You can see in Figure 11-1 that the number of themes can vary quite a bit by the size of an organization. The smallest teams probably don’t need to name a theme explicitly, whereas very large teams have as many as a half-dozen themes that define a particular release horizon or a multiyear road map.
Vision-level customer stories
After themes are defined, teams write a small number of vision-level stories about their customers. Vision-level stories typically represent the broadest end-to-end scenarios that are likely to capture a cradle-to-grave customer experience and feature a significant customer insight. In practice, this layer of the pyramid is usually given a name such as Experiences, Customer Promises, User Journeys, or Meta-Scenarios. Vision-level customer stories are usually completed and delivered within a major release cycle.
Vision-level stories might use any of a number of different framing techniques. We’ve seen a few teams write full scenario narratives, user journeys, or epics at this level, and these teams benefit from using these more expansive narratives to align and clarify goals for the team. While we prefer a longer narrative at this level, some teams keep this layer of the pyramid short and sweet, with a single, inspirational one-liner that captures the core value proposition for a particular customer. This can be written as an “I can” statement or an outcome or a user story. Whether it is a short description or a full narrative, a vision-level story should be paired with a few key metrics that specify what success looks like, as well as references to the grounding research and insights about the target customer.
These bigger-scope stories are typically authored by top-level leaders in the organization, in partnership with planning, user experience, and business-strategy experts. Vision-level stories may be identified and articulated before a large new project kicks off or may be added anywhere along the way. The bulk of these stories are usually identified by small advance teams that zero in on investigating a potential area of focus for target customers and their needs.
These large-scope stories are the ones that describe the major customer problems the organization seeks to solve, and they often require that multiple engineering teams or subteams work together to deliver a complete solution. A vision-level scenario describes what kind of customer experience the final product should be able to achieve at the highest level and is closely linked with the core value proposition for the entire offering.
Vision-level scenarios are very useful for marketing teams in developing marketing plans well in advance of implementation. They are also excellent for articulating a common vision about the target customers and their needs and can be used as a North Star for getting stakeholders aligned around a common goal. Finally, as the North Star for the customer’s experience, vision-level stories should contain top-line metrics that are used in scorecards to measure how and when you have met the business and experience goals for your solution.
![]() Mindshift
Mindshift
Vision-level stories help align partners and stakeholders. Vision-level customer stories are an extremely effective tool for describing and negotiating strategic partnerships. Starting with a vision-level customer story allows different teams to find common ground more easily and avoid jumping into technical details or getting into contentious arguments about whether to use this component or that platform. These conversations are much more productive when they center on working together to meet a particular customer need that is strategically valuable for all parties. It helps to use a more complete, narrative-based approach in a vision-level story if coordinating work between multiple teams is the goal. If that vision-level story is constructed well, the customers’ motivation and personal details, their context, and the successful outcomes will all help provide a common framework in which to judge the relative merits of various technical choices. This keeps the focus on the customer’s needs instead of on the egos of the engineers or leaders involved.
Combine a vision-level scenario with quantitative data from your research, sprinkle in a few poignant, illustrative snippets from your qualitative research (direct customer quotes, a short video clip, photos, etc.) and perhaps a storyboard or sketch illustrating the customer problem, and you have a very powerful tool for aligning stakeholders.
Task-level customer stories
Each vision-level story is broken down into 5-10 smaller, task-level stories that represent the canonical customer situations the team will focus on solving. Note that task-level stories are still implementation-free; they just represent a more specific scope than a vision-level story, which is typically fairly broad. Task-level customer stories should be defined in such a way that together they cover the most important end-to-end path through the vision-level customer story—if a vision-level story is the plot line of a movie, task-level stories are the individual scenes that together make up the plot.
SFE in action: Windows Phone Cortana story hierarchy
Cortana team, Microsoft Corporation
Here is an example of a story hierarchy that shows how a theme can be broken down into several large scenarios, which can then be broken down into smaller scenarios.
Cortana is the world’s most personal personal assistant.
![]() Scenario 1 Anna can see what interests Cortana is tracking for her and can modify them to her liking.
Scenario 1 Anna can see what interests Cortana is tracking for her and can modify them to her liking.
![]() Scenario 2 Anna gets suggestions for when to leave for appointments so that she can get there on time, even when there’s traffic.
Scenario 2 Anna gets suggestions for when to leave for appointments so that she can get there on time, even when there’s traffic.
![]() Scenario 3 Anna can user her voice to set reminders so she can stay on top of her busy life.
Scenario 3 Anna can user her voice to set reminders so she can stay on top of her busy life.
• Subscenario 3a On her way to her car, Anna reads an email from Jill telling her she wants to come over and cook for Anna’s family later this week. Excited about Jill’s offer, and without looking at her phone, Anna tells her phone to remind her to speak to her husband Miles about which night would be best. Seamlessly, her phone hears what she says and adds a reminder. Anna is delighted at how quickly that was to do.
• Subscenario 3b Anna has been meaning to check in with her mom and tell her the latest stories about her young son Luca. But between her busy life and shuttling Luca around, the thought always slips her mind. Disgruntled at always forgetting, one day in the car she tells her phone to remind her to call Nana when she arrives at home. Her phone acknowledges the request and assures her it will remind her. Anna is confident that today she will not forget.
• Subscenario 3c Months after Anna has hosted a potluck, she realizes that she still has her friend Sara’s strainer and baster in her kitchen. Anna doesn’t frequently see Sara, but they are commonly in touch, so she tells her phone to remind her to make arrangements to return these items the next time she and Sara communicate. Her phone gives her a confirmation, and she’s confident that she’ll return these items promptly. She loves how her phone helps her stay on top of things.
Task-level stories typically have a size and scope such that a small, cross-discipline team of engineers can independently deliver a solution to the problems the story represents or orchestrate its delivery with a manageable set of dependencies. As their name implies, task-level stories usually correspond to a fairly discrete customer task that is described in terms of a specific customer in a specific situation with a specific outcome in mind. It is essential to pair task-level stories with a small set of specific success metrics that define what a successful customer experience would look like and that serve as criteria for declaring the story done. Teams should be able to complete the work covered by a task-level story within the next major release horizon and often much more quickly than that.
Task-level stories are where the SPICIER scenario narrative technique shines (see Chapter 6). Most teams write a SPICIER scenario at this level of the hierarchy, along with a 5-10 word title that is essential for tracking the scenario across the rest of the tools in the engineering system. Alternatively, teams can use an “I can” statement, an outcome, a user story, or another brief story format at this level in the hierarchy. Note, however, that either the vision-level stories or the task-level stories should be written as more complete narratives that capture the customer’s situation and perspective in enough detail to evoke empathy for the customer. If task-level stories are presented in a briefer format, it is essential for the vision-level stories to be more fully developed narratives so that empathy can be created and shared. We have seen the best results when both levels are written in a full narrative format.
![]() Mindshift
Mindshift
Scenario-mania: Stop the madness! You don’t have to write scenarios for every single thing your software needs to know how to do. Remember that scenarios should represent the canonical cases that you will optimize for—the lighthouse cases that show the centers of gravity of the problems you are solving and who you are focused on. As such, your scenarios will not represent every single variant, user type, or edge case that is related to that situation. If you find that you are amassing thousands of scenarios, many of which seem to be variants of one another, you’re probably overdoing it, no matter how big your team is. A portfolio of scenarios isn’t supposed to be a replacement for complete specifications. Instead, scenarios are a way to capture the most essential customer-focused situations that you will optimize around.
Deliverables, work items, and reports
As each task-level story is iterated through the Fast Feedback Cycle, that task-level story is broken down into engineering deliverables and then into work items, the actual units of engineering work that are scheduled and tracked as part of the overall effort. For a particular story, the initial set of deliverables in the first few iterations of the Fast Feedback Cycle will likely look something like “Generate at least five viable solution alternatives,” “Build wireframe prototypes,” “Generate three architecture alternatives,” or “Customer test on Friday.” In later iterations, the deliverables will include items such as “Write the code for component Y,” “Integration test pass,” and “Deploy build 735 for A/B testing.”
This part of the work-item hierarchy is typically very familiar to teams; it is generally not new. The new part is linking up work items to show which deliverables align to which stories so that progress can be tracked in the context of completing end-to-end stories, not just a pile of features.
Work-item tracking system
After you work out a story hierarchy, having the right tooling can make a huge difference, especially for larger teams of hundreds or thousands of engineers. Reflecting these new constructs and activities in the tools that a team uses on a day-to-day basis is second only to building new activities into the project schedule as a way to effectively change behaviors and build new habits. The tools should reflect the team culture that’s desired and encourage the behaviors that you want to occur. Day-to-day visibility helps remind people what they should be doing, and the tools you use reinforce behavior, both good and bad.
Ideally, you have a work-item tracking system that allows you to represent the entire scenario hierarchy, from themes down to deliverables, work items, and bugs. However, it’s equally important that this system be as automatic and easy to use as possible. If updating information is burdensome, information will be perennially out of date and therefore useless. Special effort needs to be made whenever a story is created to properly link it in the system so that subsequent deliverables and work items are filed correctly as the project progresses. As new vision-level stories and task-level stories are added, they can be prioritized alongside the current backlog of work. Also, all stories must be stack ranked, which lets the team know clearly which ones should be worked on next after a given story has met its success criteria.
![]() Tip
Tip
A few teams have had great success creating a scenario review council to provide oversight on their scenarios and help the team through the initial learning curve for these new techniques. This council is a team of champions that reviews all the scenarios to be sure they have all their components, are appropriately free of implementation details, and generally reflect SPICIER characteristics. The council also ensures that scenarios are reflected properly in the team’s tools and are linked correctly in the story hierarchy.
Reports make new behaviors visible
While a robust and easy-to-use tracking system helps everyone gain clarity on what they should be working on at any given moment, reports are what bring you the full benefits of having such a system. The right reports make a team’s current behaviors and priorities visible so that good behavior is noticed and encouraged and bad behavior and old habits don’t fly under the radar. Nothing is as motivating as a poor rating on a very visible report to kick a team into high gear.
The most useful day-to-day reports account for task-level scenarios, but reports should ideally roll up status at the level of vision-level stories as well. The tracking system should be able to show reports like these:
![]() How many deliverables (or work items) aligned to a scenario are complete vs. still in progress? This is a much more informative view than looking just at the raw completion of deliverables by functional area or team. Status is very different if you have 10 scenarios that are each only 30 percent complete versus 3 scenarios that are 90 percent complete. If your goal is to drive scenarios to completion, publishing this report weekly with the expectation that a scenario be 100 percent complete before a new scenario is pulled off the backlog would be very helpful.
How many deliverables (or work items) aligned to a scenario are complete vs. still in progress? This is a much more informative view than looking just at the raw completion of deliverables by functional area or team. Status is very different if you have 10 scenarios that are each only 30 percent complete versus 3 scenarios that are 90 percent complete. If your goal is to drive scenarios to completion, publishing this report weekly with the expectation that a scenario be 100 percent complete before a new scenario is pulled off the backlog would be very helpful.
![]() For each deliverable, which scenario (or scenarios) is it supporting? This is a particularly important view when you find that a deliverable is at risk, may need to be cut, and you need to consider which scenarios rely on it. Figure 11-2 shows a sample of these relationships.
For each deliverable, which scenario (or scenarios) is it supporting? This is a particularly important view when you find that a deliverable is at risk, may need to be cut, and you need to consider which scenarios rely on it. Figure 11-2 shows a sample of these relationships.
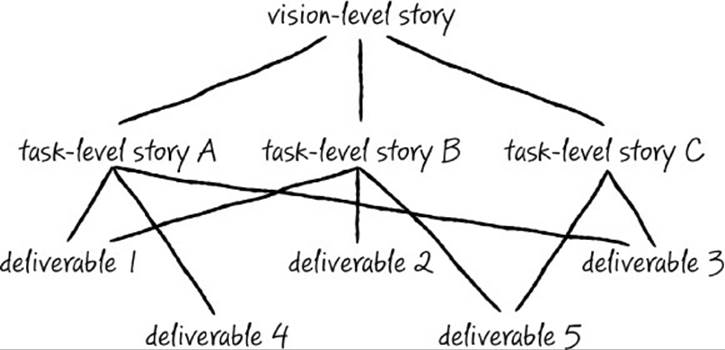
FIGURE 11-2 Deliverables often support more than one story.
![]() Tip
Tip
A single deliverable very often aligns to or supports more than one scenario. Representing this “one-to-many relationship” is a primary challenge in most work-item tracking software, which enforce strict parent-child relationships rather than multiple inheritance. In Team Foundation Server, you can use “related item” links to represent these relationships, but you still need to write custom reports to roll up this information properly. Whatever system you use must support the ability to indicate multi-inheritance—when you pull a report about completion status against one scenario, you need an accurate view of all the work that rolls up into that scenario.
![]() Which deliverables are not aligned to a scenario? You’ll always have a certain amount of baseline work that doesn’t roll up to a specific scenario (or, perhaps more accurately, is aligned to every scenario). Rather than polluting every scenario with these common work items, it’s usually better to keep them separate. However, you should look over this list regularly to be sure that one-off feature ideas and other lower-priority work isn’t hiding and being inadvertently prioritized over end-to-end experiences that have more impact.
Which deliverables are not aligned to a scenario? You’ll always have a certain amount of baseline work that doesn’t roll up to a specific scenario (or, perhaps more accurately, is aligned to every scenario). Rather than polluting every scenario with these common work items, it’s usually better to keep them separate. However, you should look over this list regularly to be sure that one-off feature ideas and other lower-priority work isn’t hiding and being inadvertently prioritized over end-to-end experiences that have more impact.
![]() Which scenario is next in line for iteration? Reflecting the product backlog in your tracking system helps focus a team on the few items it is currently working on and puts a ready supply of scenarios and ideas on deck for the team to pick up as soon as it is ready. Building this ordering into your tooling helps honor the reality that you don’t actually know how many scenarios you have time to build at any given moment, but you will work on them in priority order, one at a time, and see how far you get.
Which scenario is next in line for iteration? Reflecting the product backlog in your tracking system helps focus a team on the few items it is currently working on and puts a ready supply of scenarios and ideas on deck for the team to pick up as soon as it is ready. Building this ordering into your tooling helps honor the reality that you don’t actually know how many scenarios you have time to build at any given moment, but you will work on them in priority order, one at a time, and see how far you get.
Track all work items, not just code deliverables
It’s worth spending a moment to talk about the need to track the iteration work that happens before you write the first line of code and as you continue iterating and exploring (albeit at an increasingly finer level of granularity). You don’t want to spend several iterations of work on a scenario and have nothing to show for it in the tracking system. The team is doing vital work in that time frame, and although the work outputs or artifacts are not yet specific code deliverables, it is still important to track, publish, and communicate these work artifacts.
![]() Mindshift
Mindshift
Planning is not a phase, it is a continuous activity. Some people label these precoding activities as the “planning” phase. We’ve come to dislike the term planning because it suggests a one-time linear push to understand the customer and figure out what you are going to build. It suggests a hard line between making a plan and executing that plan, which does not jibe with an iterative approach that alters the plan as you receive feedback along the way. Every indication is that the software industry is rapidly moving to a “continuous planning” mindset, and many companies have already made that shift. We think the shift is a very good thing and encourage you to build systems and tools that expect a continuous planning approach.
Some of this work happens before you have fully formulated a specific scenario, but as soon as you have a scenario articulated, all other deliverables involved in the iteration of that scenario around the Fast Feedback Cycle should be captured in the system.
Reflecting this important work among the deliverables in your work-item tracking system is a great way to legitimize these new behaviors and unequivocally communicate to the team that they are an expected part of the engineering team’s work. It also gives managers a lot more information about the true status of a team in the early iterations of a project. These deliverables could include outputs such as customer research data, synthesized insights, defined metrics, solution ideas brainstormed, low-fidelity prototypes, customer feedback on prototypes, and so on.
Shift from ad hoc user testing to regular customer touch points
One of the biggest practical barriers to getting customer feedback is tracking down target customers you can interact with. It’s time-consuming and expensive for each team to find its own customers to talk with or to work with user researchers to set up specific ad hoc testing sessions. When you wait to schedule user testing when you need it, you end up waiting around, because recruiting a set of customers who can all participate on the dates you need them and fit your screening criteria can easily take a week or more. In a Fast Feedback Cycle, a few days can be a long time, and wasting them creates a significant inefficiency in the system.
Teams can gain faster access to customers, especially to consumers, by going where their customers are—malls, coffee shops, train stations, trailheads, and so on. But while this is worth doing occasionally, especially because it can provide opportunities for more in situ observation, it’s too expensive and time-consuming to use as the everyday approach to customer testing throughout the entire project. In addition, this approach doesn’t work at all for some demographics of customers.
A better practice is to have dedicated staff set up a constant pipeline of customers who will come into your offices, usability labs, or so on, on a regular basis. This way, target customers are always available for teams to check in with. Having this infrastructure makes it drop-dead easy for teams to test with customers regularly so that the right behaviors can occur naturally in the course of the team’s work. When you know that a customer is going to be available in just a few days, you tend to queue up more and more questions, ideas, sketches, and prototypes that you want feedback on. You keep the customer at the front of your mind, and the conversations and feedback you get during testing happen at the right time to immediately inform your thinking.
Most teams have found that the right cadence for customer testing is weekly. They specify a particular day of the week (usually Thursday or Friday) to bring in a few representative target customers. You can schedule customers at the same time of day or spread the schedule across the day. Teams typically try to bring in at least three customers per target segment (possibly more, depending on team and project size) to be sure that they can discern the patterns in the customer feedback versus the outliers.1
With this infrastructure in place, teams can count on getting feedback on a particular day. This regular, predictable opportunity really helps anchor an iterative cadence in the team. When the team knows that a customer will be there on Friday, the team naturally schedules its work to take advantage of that opportunity, and this encourages a fast iterative cycle.
Regularly scheduling customers for feedback also lets teams easily have a very quick customer touch point—often just 10 or 15 minutes is plenty to test out your latest ideas, where a full one- to two-hour dedicated user test would have been overkill. You get efficiencies by effectively sharing a pool of customers across the parts of the team that are working on different scenarios but focused on the same target customers and each needs only a portion of the customers’ time.
The expectation is that most teams will be ready for customer feedback only every two weeks (say, at the end of a two-week sprint), but on any given week there are usually plenty of interim questions and artifacts that can benefit from a customer’s view. We’ve found that putting effort into creating a steady and regular pipeline of customers is transformative in reducing barriers to team members getting customer feedback quickly and continually throughout the project.
Shift from bug counts to experience metrics
Many software teams are accustomed to gauging project status on the basis of how much code has been written and how much work remains. However, in addition to measuring project completion based on how many unresolved bugs you have or how many tasks you have completed, you need to hold yourself accountable to a much higher bar. Yes, you still want to track bugs and tasks and who is doing what, but if the ultimate goal is to deliver a product that customers really love, how will you know when you have achieved that? How do you know when you are done?
This is where the success metrics you identify in each scenario become vital. These experience metrics provide a clear goal that you need to meet and also act as the exit gate for that scenario. Simply put, if your scenario isn’t achieving its success criteria goals, you’re not done.
Altering the definition of completion to center it on the customer is a big shift for many teams that are used to thinking about “Code complete” and “ZBB” (zero bug bounce) as major milestones on the way to shipping. One of the structural pieces that needs to be in place to enable this shift is the regular customer pipeline we discussed in the previous section. Furthermore, teams need to establish the habit to check their top experience metrics regularly and to report on them during management reviews or whenever project status is communicated. At the end of this section, we discuss building scorecards, which are a great tool for tracking experience metrics and for keeping the customer at the center of the team’s work.
Three kinds of metrics
You should be tracking lots of different metrics as part of any software project, and chances are that you’re already tracking many of them. Although many teams tend to track metrics for business goals and technical completion and operational performance, many teams neglect to give the same attention to experience metrics, despite the fact that these are the lynchpin of defining and measuring overall product health.
Figure 11-3 shows a model that our colleagues Mike Tholfsen, Steve Herbst, Jeremy Jobling, and others have proposed that we find particularly helpful. This model presents a holistic view of the types of metrics that should be tracked for any software project. The model captures the fact that achieving business objectives (that is, getting people to pay money) depends on delivering experiences that customers value (that is, allowing customers to do things that are important to them in ways that are better than those offered by any available alternative). Further, delivering a good experience can only rest upon stable and performant technology.
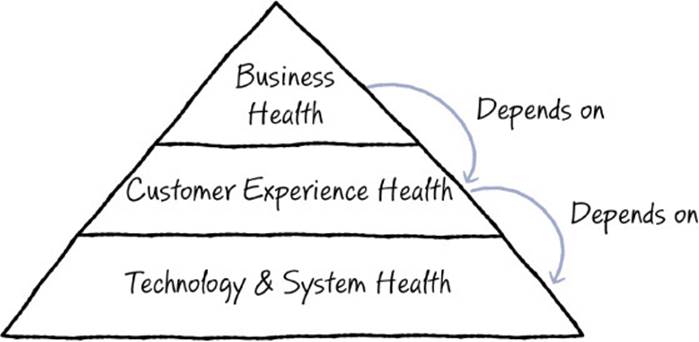
FIGURE 11-3 Business success depends on a great customer experience, which depends on solid technology and system performance. You must measure all three levels to have a complete picture of the health of your company.
As Steve Herbst asserts, “When populated with measurable, solution-free, data-supported metrics at all levels, the health pyramid provides a living ‘thesis of success’ that can be used to prioritize investments and drive overall product health.”2
Working up from the bottom, measure the foundation of a successful product—solid technology that is operating with good performance, scalability, reliability, and so on. To provide a great customer experience, those basics surely need to be in place, and most engineering teams are adept at tracking and improving these technology and system-health metrics.
However, even the most complete set of system-level metrics doesn’t tell you whether the customer experience is any good. It’s entirely possible to have a perfectly functional, performant system but still have a lousy customer experience.
The next tier in the diagram relates to metrics that focus on assessing the experience from the customer’s point of view. Are customers delighted with the product? Is it solving a real need for them? How satisfied are they with the solution you have provided?
However, knowing that you have a strong customer experience is not enough either. It’s possible to have very happy customers but a failing business. For instance, perhaps your happy customers aren’t coming back frequently enough, or aren’t paying you enough to cover your costs, or aren’t interacting with your advertisements. You need to have metrics specific to the business health as well.3
Customer-experience metrics are the ones most often forgotten. Most engineering teams are great at tracking their system metrics, and they find that business metrics are a necessity for staying in business. Customer-experience metrics can be overlooked, even though they may provide the missing link in learning why a terrific technology may not be translating into business success. If you want to build solutions that customers love to use, you need to actively track customer-experience metrics. In fact, many experts these days believe that optimizing for customer satisfaction is the single most important factor to manage. Monetization approaches can be fixed and technology can be improved, but if the customer experience isn’t great, you’ll never develop a loyal customer base, and the rest doesn’t matter.
While it’s important to track metrics at all three tiers to get a complete picture, we will focus the rest of this section on the center tier—customer-experience metrics.
Measuring customer experience
We discussed the importance of identifying the key metrics for your scenarios back in Chapter 6. As you consider what problem you are seeking to solve for customers, you identify what success for those customers would look like, along with a few metrics and specific goals that would best indicate whether the customer-experience goal has been reached. These metrics are typically easiest to manage if they are quantitative, but they can and should be a mix of both subjective (SAY data) and objective (DO data) metrics.
Here are examples of customer-experience metrics that you might find helpful to build into your scenarios and tracking system:
![]() Performance metrics that report on customer completion of a job. These can be measured during in-person testing with a stopwatch and careful note taking or online via your instrumentation or usage telemetry. You might capture performance metrics such as:
Performance metrics that report on customer completion of a job. These can be measured during in-person testing with a stopwatch and careful note taking or online via your instrumentation or usage telemetry. You might capture performance metrics such as:
How long did it take the customer to complete the task?
How many errors did the customer make?
What percentage of customers were able to complete the task without help?
![]() Perception metrics that report on a specific emotional state, positive or negative. This is most often captured by a question on a post-experience questionnaire, either online or in person. These perception questions can be used to measure a wide variety of emotions, such as satisfied, fun, magical, useful, or quick. Here are some questions that you might ask to measure perception:
Perception metrics that report on a specific emotional state, positive or negative. This is most often captured by a question on a post-experience questionnaire, either online or in person. These perception questions can be used to measure a wide variety of emotions, such as satisfied, fun, magical, useful, or quick. Here are some questions that you might ask to measure perception:
On a scale of 1 to 5, how satisfied are you with that experience?
On a scale of 1 to 5, how confident are you that your document is saved and will be available for you the next time you need it?
![]() Outcome-based metrics identify a clear outcome and the criteria that customers require to consider their experience a success. This type of measurement is usually expressed in two parts: “Was the outcome achieved?” and “Did it meet the criteria?” Most often, criteria for success are based on time (eight seconds or less) or effort (less than two clicks). Examples of outcome-based metrics are:
Outcome-based metrics identify a clear outcome and the criteria that customers require to consider their experience a success. This type of measurement is usually expressed in two parts: “Was the outcome achieved?” and “Did it meet the criteria?” Most often, criteria for success are based on time (eight seconds or less) or effort (less than two clicks). Examples of outcome-based metrics are:
I find the media I want in no more than three clicks.
My requested information is displayed in no more than five seconds.
I trust that my data is more secure than the way I used to store it.
![]() Global customer-satisfaction metrics report on overall customer satisfaction. They are typically used to track customer satisfaction with a whole product, although they can be used at a smaller scope. Net Promoter Score (NPS) tracks how likely a customer is to recommend your product to a friend. Customer Satisfaction (CSAT) and Net Satisfaction (NSAT) track customer satisfaction. Loyalty metrics ask how likely your customer is to buy from you again. Brand metrics track the customer’s awareness and attitudes toward your brand.
Global customer-satisfaction metrics report on overall customer satisfaction. They are typically used to track customer satisfaction with a whole product, although they can be used at a smaller scope. Net Promoter Score (NPS) tracks how likely a customer is to recommend your product to a friend. Customer Satisfaction (CSAT) and Net Satisfaction (NSAT) track customer satisfaction. Loyalty metrics ask how likely your customer is to buy from you again. Brand metrics track the customer’s awareness and attitudes toward your brand.
The science of summative data
When you want to know whether you have achieved your experience goals, you need to gather what is called summative data.
In contrast to formative data, which helps you figure out which problem to solve and identify the best solution, summative data tells you, with statistical confidence, whether you are meeting your success criteria and whether you are ready to ship. It’s worth knowing a few things about the science of summative data to be sure that the way you are gathering metrics is actually giving you valid results and you are paying attention to statistical significance. The biggest factor to consider when you gather summative data is whether you have a sample size big enough to provide statistically valid data.
If you want to get data from a live service and you have instrumentation in place to capture your metrics, getting summative data is pretty straightforward. All you need to do is analyze the data you’ve collected because, by definition, you are collecting data on your entire population (which better be a big enough sample size; if it isn’t, you have bigger problems to solve).
However, if you haven’t shipped yet or don’t have any working code, getting summative data is a bit more complex and nuanced. But don’t let that stop you. It is important to check your experience metrics repeatedly and to track how well you are doing against them as you iterate your solutions. Capturing experience metrics is not something you should do only in the endgame when you are ready to ship.
In the absence of live usage telemetry or A/B systems, you can capture summative data in two main ways: benchmarks and trending metrics over time.
Capturing benchmarks
A benchmark is a specific, statistically valid measurement of user behavior or attitude that you can say with confidence represents an entire customer segment. For instance, you might conduct benchmark testing on a product to find out how long customers take to complete a particular scenario, how many errors they made, or how they felt about the experience afterward. You might do benchmark testing on your competitor’s product as well and compare the results for your product against the results for theirs.
Usually, benchmarks are captured by using a formal usability test, where you measure as precisely as possible whatever key metrics you are trying to track. Exactly how a usability test is facilitated matters much more in a summative benchmark test than in a discount usability test. Variability and bias can be introduced into the data through inconsistent facilitation. In a discount usability study, if you are focused on uncovering problems and confusions, this variability and bias may not get in the way. But when you are gathering summative data, that bias and variability can dramatically alter the outcome, and that is definitely not what you want in summative data.
To get valid benchmark data, you need many more customers than you need for a quick discount usability test. For example, in a discount usability test (which is perfectly appropriate for fueling rapid iteration), you might test with five customers from the same target customer segment. However, to get statistically valid benchmark data, you need to test with at least 15-25 customers from the same segment.
Doing a benchmark usability test is worth the effort (such as after a release) to get a baseline measurement that can be used to judge future releases or to compare the customer experience of your product against a competitor’s. Doing a true benchmark test to get an accurate “snapshot in time” is a case where you would be well served to engage an expert researcher to design the test, facilitate it, and analyze the numbers to produce the results.
However, throughout the bulk of the project you rarely need to have such statistically significant data. Usually it’s enough to know whether the latest iteration made the key metrics worse or better or had no effect. Specifically quantifying the change or making it statistically bulletproof is overkill if you’re just trying to see whether you’re headed in the right direction.
Trending key metrics over time
Thankfully, most engineering teams can use a much cheaper and more pragmatic way to track their summative metrics. The basic idea is to identify the most important metrics you have set out to achieve and then collect data against those metrics in the same way every time you interact with a customer. Over time, as you talk with more and more customers, you will reach a statistically significant population, and in the meantime you’ll develop a good idea (but not a guaranteed one) about which way the trendline is heading. (Because of its reliance on trending data, we like to call this the trendline approach.)
You can use different tactics for both perception and performance metrics. For perception metrics, you can develop a brief questionnaire and use that questionnaire as a follow-up to any customer touch point for a given experience. Capturing performance metrics accurately can be a bit more difficult because of the potential for variability. If your goal isn’t ultimate precision, but is more about being good enough (for example, is the editing task taking five minutes or five seconds?), you can get performance data during usability tests or other customer interactions in a couple of ways. First, you can take careful notes that answer questions about the specific experience, such as “Did they complete the task successfully, or didn’t they?” Or you can count and note specific metrics, such as the number of errors a customer hits or the number of times a customer clicks, or by literally using a stopwatch to time how long a user takes to perform a particular action. Keeping the prompts and measurement approaches as consistent as possible helps you minimize (but not eliminate) facilitation variability.
By asking the same questions and taking the same measurements over the course of multiple tests—each time bringing in a handful of people—you will accumulate the number of data points that is more statistically robust. In this way, you can get some initial data by capturing smaller sample sizes, and the more often you test with customers, the larger your sample size becomes and the more confident you can be that your results are valid. While the trendline technique doesn’t fully replace the need to gather benchmarks (when you must know a specific statistic for a particular version of your product or service), you can use this approach as a pretty good way to track your experience metrics over time and see whether you are on track to achieve your goals.
![]() Tip
Tip
Watch for regressions out of left field. One reason that you measure your metrics frequently is that it’s quite common for an experience metric to regress because of an unrelated feature or because a section of code was added (often times by a partner team) that you didn’t realize would have an impact. For example, an unrelated piece of code might introduce latency and slow down your feature’s response time; or a new feature, integrated by another team, might make your features confusing when the features run side by side; or your very simple path through a scenario might become complicated when more options are added. When an experience tests well, you are not done. You have to test the experience over time to make sure that it doesn’t regress.
By testing frequently, you get a good indication of a trendline and see whether you are heading in the right direction (are you slowly getting better or worse?). Based on that assessment, you know whether you are getting close to the original goals laid out in your framing or are a long way off. Often, the right balance between trendlines and benchmarks is to capture trendlines for all your metrics throughout the project but then, just before or just after you release your solution, switch to capturing benchmarks to get a formal set of stats that you can use to compare future versions against.
Experience scorecards
Most engineering teams are adept at tracking metrics on the progress of their project. We’ve all seen these reports and dashboards. We’ve created them and used them in decision making and in reporting status to management. All of us are familiar with tracking bug counts, bug trendlines, velocity, klocs (kilo—thousands—of lines of code), etc. And in leadership meetings, it’s also typical to view, analyze, and make decisions based on business scorecards, which show data such as revenue, usage, growth (or lack of growth), costs, market penetration, competitors, industry movement, and similar measures. These engineering and business scorecards are used by leaders to run the business and to assess progress against goals. Teams should also include a scorecard that tracks the customer experience, or how the customer views a team’s product, service, or device.
A great place to track customer metrics is on an experience scorecard. Instead of building a scorecard for each major feature area, component, or team involved, focus your scorecards on the end-to-end experiences you are building. Keeping a scorecard with customer-focused, end-to-end metrics is a key tool for keeping your focus on the big picture—for ensuring that you’re really meeting the goals you aimed at and are solving the customer problem you intended to solve.
Many teams end up combining their metrics into a single dashboard that includes not only customer-experience metrics but also relevant system, technical, and business metrics for that area. Some also include execution progress, such as how much work is left to build the code and the number of active bugs, to give a holistic view of the state and health of the project. This dashboard should include an overall experience scorecard that rolls up top-line status across all the vision-level stories for a particular release time frame, and a way to drill into status for the task-level stories. The scorecard provides a foundation for regular project or executive reviews and can serve as a constant reminder of the vision-level scenarios that all of the team’s work should be aligned to.
Scorecards might report status as specific numerical values, when those are available, or more often by using a red/yellow/green system. Usually scorecards report trendline data because full benchmarks or telemetry-based usage data (with stronger statistical significance) aren’t yet available. If this is true for your scorecard, it’s best to show trends (up, down, no change) or sparklines alongside the raw metric and summarize that as an overall status (red, yellow, green, no data).
Figures 11-4, 11-5, and 11-6 show different examples of experience scorecards.
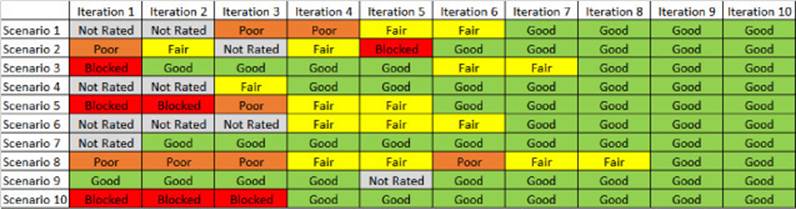
FIGURE 11-4 A scorecard of the overall experience rating over multiple iterations.
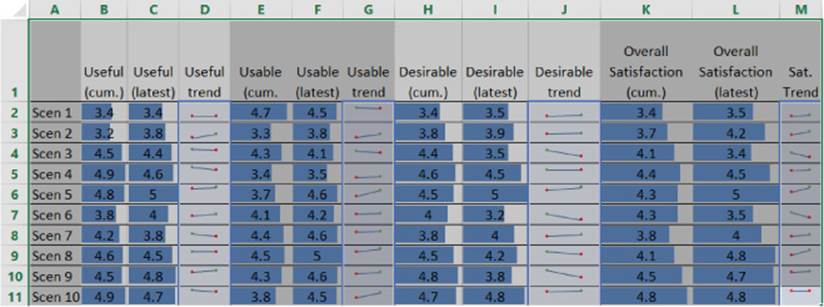
FIGURE 11-5 A scorecard of cumulative scores for useful, usable, desirable, and overall satisfaction, along with sparklines showing the direction of the trendline.
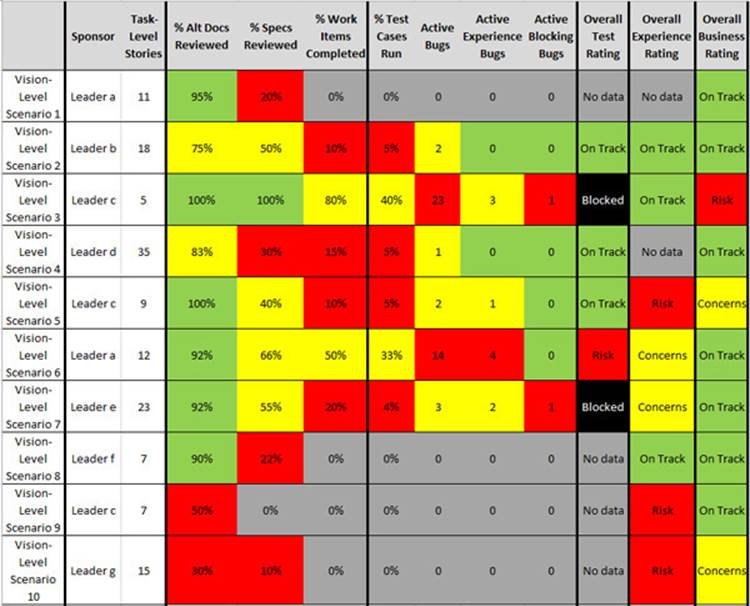
FIGURE 11-6 A scorecard showing a mix of execution metrics along with overall test, experience, and business ratings for each vision-level scenario. Note that work on the lower-priority scenarios has been deprioritized until higher-priority scenarios are more fully on track.
No matter which format you use, scorecards should be updated frequently, whenever customer feedback results in new metrics to report. Some teams invest in telemetry that feeds scorecards automatically, but be careful that the promise of future ease doesn’t cause you to wait too long to start capturing your first metrics (some teams invest so heavily in the infrastructure to do this that they don’t get around to actually capturing metrics until very late). And perhaps this should go without saying, but be sure that the metrics you are capturing come from actual target customers, not internal colleagues testing the system.
Shift from building components to building experience slices
In Chapter 8, “Building prototypes and coding,” we discussed the need to change how you sequence your coding work. Rather than build components one at a time in relative isolation, it’s better to write code in vertical slices so that you always have an end-to-end experience you can test with customers at the end of each iteration. Slicing is originally an Agile technique and was intended to help engineering teams organize development work into chunks small enough that they could be coded within a single sprint but still provide customers with something for feedback at the end of the sprint to help inform the next one.
Writing code in slices instead of as components can be a big shift for teams in how code is written, how teams of software developers work together, and how work is assigned across developers. It’s important to explicitly consider slicing in your schedule, tools, and other parts of your engineering system in order to support this approach to sequencing development work.
This section offers more guidance for how to think about coding experience slices and illustrates how a sequence of slices grows into a fully implemented end-to-end experience. As we mentioned, most projects start with a vision-level story, which is broken down into several task-level stories. For each task-level story, or scenario, you usually start with several noncode prototypes and iterate them based on customer feedback. Once you have identified a solution approach that is testing well with customers (and works for both the business plan and technical feasibility), it’s usually time to start coding in earnest.
To start coding, the first step is to take the proposed solution for the task-level story and slice it into thin, vertical paths that represent a single, streamlined way that a customer might travel through the experience you’re developing. Build the code for the most visible, most important, or riskiest slice, and then get customer feedback on it to determine whether you need to work more on that slice, thicken that slice with some additional functionality, or move on to a different slice within that story. Do this until you have implemented all the experience slices needed to complete the task-level story, and continue to iterate them using customer feedback until you create an end-to-end experience that meets your stated goals.
Let’s work through an example to illustrate the details of how a slicing approach would work and to show how you might choose which slices to add based on customer feedback. Imagine that you’re building a travel website. Here’s a task-level story written in user-story format:
AS AN infrequent traveler
I CAN book a flight and rental car that meet my budget and schedule
SO THAT I can take my family to visit Grandma for her 60th birthday bash
First, you would make a few prototypes of your travel website and iterate them with customers until you land on a rough layout for a site that allows your customers to book both flights and rental cars. Now you’re ready to start coding. However, this is a pretty big story, more than you can implement in one sprint or iteration. So you need to define the slices for this website and choose a slice to start with. The first slice of this user story might be very, very thin, maybe something as simple as giving the user a way to pick a destination city for a one-way flight. You might even limit this slice so that the user can select only a single city, say San Francisco, as a way to further simplify the problem at the start.
Figure 11-7 shows a conceptual view of this first thin slice, overlaid on your solution’s architecture. Note that it goes all the way from the top presentation layer to the bottom platform layer. However, it does not necessarily touch every component in the architecture. It also doesn’t completely build out any of the components of the architecture; rather, you are building a thin slice of an end-to-end experience that spans many of the solution’s components. For this sprint, you are concerned with building only enough of each component so that the experience slice itself can be built. To achieve this, you may end up stubbing out or faking some parts of the platform to make it buildable in one iteration.
FIGURE 11-7 An experience slice that cuts vertically through your architecture.
Congratulations, the first slice is complete, and you have a very tiny experience: the user can use your site to reserve a one-way flight to San Francisco. The next step is to show your functional slice to customers and get some feedback to inform your next sprint.
Customer feedback may tell you that you’re on the right path, so you can go ahead and add round-trip ticketing and the capability to select from many cities. In your next iteration, you “thicken up” your first slice to include this additional functionality. Next, customers inform you that the experience of selecting the flight is good enough for what they need, but what they really want to do next is rent a car once they get to their destination. In this case, you create a new slice that provides the smallest experience you need to enable the user to reserve a rental car. At first, you might not even do the integration work to connect this new slice to the existing flight reservation slice.
You continue getting feedback after every slice, looking for places where your implementation might be off the mark and identifying and prioritizing the most important pieces to tackle next, based on customer feedback as well as business and technology needs. But the key is that at the end of every iteration, whether you build a new slice or add functionality to an existing one, there is always a tangible customer experience that demonstrates the new functionality. This is good both for continuing to iterate the experience as well as for identifying technical integration issues as quickly as possible.
Putting it all together, Figure 11-8 shows how our travel website example might play out. After iterating prototypes to identify a basic design approach, the first code slice implemented the code to allow the user to pick a single, one-way destination. Based on the first round of feedback, the team decided to thicken up that slice in the second sprint by adding functionality: the user can select from multiple cities and get a round-trip ticket. At this point, the end-to-end experience of choosing the flight destination is sufficient for the target customers and the next priority is renting a car. The third sprint implements the capability to choose a rental car, based on designs that were sketched out in the earlier prototypes or possibly through a quick round of additional sketches or prototypes created at this point. The fourth sprint integrates the code for choosing flights and choosing a rental car. The final code sprint adds more functionality to the car-rental slice to provide a choice of rental agencies and to be able to reserve car seats for the kids, completing the end-to-end experience for this task-level story.
FIGURE 11-8 Progression of work artifacts from prototypes through multiple code slices, over successive iterations of the Fast Feedback Cycle.
Although this is a simplistic example, it illustrates the pattern of building up successive vertical slices to enable a full end-to-end experience that completes a task-level story. When you build code in experience slices rather than as discrete components, at each step you can get customer feedback to correct the course of your designs, capture data against your key metrics, figure out what features should be implemented next, and identify when you have gotten to a minimum viable product (MVP) that is complete enough and has high enough quality to ship to customers.
Shift from upfront specs to alternatives, prototypes, and documentation
This is a case where the shift is subtle. To be clear, we’re not arguing that you should stop writing specs. However, the timing of when specs are written, what kind of specs to write, and the nature of the information in the specs may need to change to best align with an iterative approach.
The first issue is timing. It should be obvious to you after reading this far that writing a big, long document that details how a single solution idea should work without doing any customer testing is a nonstarter. The likelihood that your first idea is wrong is high. You may even be barking up the entirely wrong tree. Writing and rewriting a long document takes a huge amount of effort, all of which might be wasted, and developers don’t like to read long documents anyway. The idea of writing a long, detailed specification and then handing it off to a development team for coding (over the course of many weeks or months) is quickly dying.
Teams have realized that pictures and prototypes are a lot easier than paragraphs to iterate. It is much more efficient to spend most of your planning effort doing some iteration with prototypes, trying different alternatives, and getting customer feedback that confirms you are on the right track. Only after you have narrowed in on a pretty stable approach is it worth trying to document those ideas in any amount of detail.
Remember that the original goal of a spec is to communicate to the team what needs to be built so that everyone is clear on the plan and can do their part. To best achieve the same goal with an iterative approach, you effectively split what used to be the full functional spec into three different forms: the alternatives doc, the prototype, and the detailed specs or documentation for individual technology components.
The alternatives (alts) doc
The first document to write is sometimes called a one-page spec or a page-one spec (even though these documents are almost always longer than one page). Recently, we’ve seen teams begin to call this a scenario spec, or an alternatives, or “alts,” doc.
An alts doc is written for each scenario during the first couple of iterations of the Fast Feedback Cycle. It’s used to kick off a new project and communicate the scenario narrative along with a few proposed solution directions. It is a very helpful document because it provides just enough information to enable prioritization of which scenarios to work on when a team is forming or adding work to a product backlog. It also captures the latest proposed solution alternatives, which helps stimulate internal feedback on feasibility and business tradeoffs. In effect, the alts doc describes the assumptions and the hypotheses that the team is about to test with the iterative process and its current best guess about which avenues to try.
One of the biggest benefits of writing an alts doc is that it formalizes and enforces the expectation that teams actually consider several different viable alternatives before they decide on a solution path. Scheduling a project review to present alts docs to leaders is a good forcing function to make sure this work is done and taken seriously. Getting in the habit of writing alts docs whenever you start work on a new scenario is a particularly good practice to instill in a team that is just making the transition to using the Fast Feedback Cycle.
An alts doc typically contains the following:
![]() Target customer Describes the specific target customer for this scenario and any relevant data on segmentation, size, unique characteristics, etc.
Target customer Describes the specific target customer for this scenario and any relevant data on segmentation, size, unique characteristics, etc.
![]() Key insights A short list of the key insights about this customer that motivated this scenario, originating from research.
Key insights A short list of the key insights about this customer that motivated this scenario, originating from research.
![]() Scenario narrative The latest draft of the scenario narrative (or whatever other framing technique you are using).
Scenario narrative The latest draft of the scenario narrative (or whatever other framing technique you are using).
![]() Success criteria The proposed success criteria and customer experience metrics that will define when a solution for this scenario is done and good enough to ship.
Success criteria The proposed success criteria and customer experience metrics that will define when a solution for this scenario is done and good enough to ship.
![]() Alternative solutions Describes three to five proposed solutions. These should be rough descriptions, not fully detailed. Using a storyboard, a few sketches, or a mockup for each proposed solution is often the best way to communicate these at this point in a project.
Alternative solutions Describes three to five proposed solutions. These should be rough descriptions, not fully detailed. Using a storyboard, a few sketches, or a mockup for each proposed solution is often the best way to communicate these at this point in a project.
![]() Customer feedback Includes top-line learnings from the first round or two of customer feedback as factors in deciding which solution path or paths to pursue.
Customer feedback Includes top-line learnings from the first round or two of customer feedback as factors in deciding which solution path or paths to pursue.
![]() Pros and cons A short list of benefits and possible problems with each solution direction, including customer experience issues, technical feasibility issues, and business issues. Writing this section encourages the team to think through these issues and invites feedback from reviewers on additional pros and cons that the team may not have noticed yet.
Pros and cons A short list of benefits and possible problems with each solution direction, including customer experience issues, technical feasibility issues, and business issues. Writing this section encourages the team to think through these issues and invites feedback from reviewers on additional pros and cons that the team may not have noticed yet.
![]() Key constraints A list of any notable constraints in available technical platforms, timing, partnerships, or other hard factors to consider.
Key constraints A list of any notable constraints in available technical platforms, timing, partnerships, or other hard factors to consider.
The prototype
The utility of the alts doc—although it’s highly valuable for kicking off a project and facilitating prioritization—is relatively short-lived. The workhorse of the iterative process really is a series of prototypes, as we have discussed at length in this book. As you iterate, the latest prototypes—whether they are simple sketches, grayscale mockups, click-through wireframes, functional code, or even production code—will typically be the best representation of the team’s current progress. This means that the prototype itself, especially as you hone in on a particular solution approach and your prototype becomes more detailed, will serve part of the role that the functional specification used to serve.
Functional specs
Some teams find that a prototype is sufficient for describing the current plan in enough detail for team members to do their work and do not need to write additional specs. However, many times, you also need to document those nitty-gritty details for all the things that are nonnegotiable—that just have to get done—and document team decisions as they are made. This is often true for larger teams, for projects with larger scope, and for teams whose work is not fully visible in a user-interface prototype.
The functional spec should use photos or screenshots of the prototype wherever possible, but it should also include text, tables, and flow charts that describe edge cases, logic paths, exceptions, boundaries, underlying algorithms, and other architectural considerations that the team needs to follow as the code is fleshed out. This document might also describe or specify aesthetic details that may not be present in the prototype and may include a “redline” drawing of the interface that details fonts, colors, and spacing with precise pixel dimensions.
In the end, this document might look a lot like a spec that earlier was written at the very beginning of a project. However, this document should be written a lot later in the process than people are used to. When it is prepared too early, the plan has too much uncertainty, and the spec quickly becomes out of date—and often never gets updated. It’s better to wait until the foundations are solid; then the document won’t be as hard to maintain and will better serve the purpose it’s intended for.
As we said, this spec is also a great place to park the list of requirements, the very specific and detailed items that have to get done but usually won’t surface in the scenarios themselves. We don’t mean to belittle these details. Often, it takes work to gather these details, and they offer a lot of value to the team. For example, your solution might need to account for a large and complicated set of relevant tax issues whose details are nonnegotiable. Discovering and documenting these details is important, but because there isn’t room for interpretation, there’s not much need for iteration or customer feedback. These details are what they are, so document them in the spec.
![]() Tip
Tip
A number of teams now use a single OneNote notebook for their specs, using separate tabs for the functional spec, test spec, international spec, and dev/architecture spec so that all the information for a particular scenario is in the same place. Some teams also create tabs for the scenario, brainstorming lists, storyboards, and prototype artifacts. OneNote handles simultaneous editing by multiple users very gracefully and avoids the source control and explicit edit-and-track-changes rigmarole in Word that sometimes discourages team members from updating the docs right away.
Shift from component reviews to experience reviews
Team leaders play a pivotal role in helping cultural and process changes take root in the team. Many teams find that holding regular project reviews is a good way for team leaders to stay in touch with the team’s progress and provide team members with ongoing coaching and feedback. Project reviews can act as another forcing function for taking on a specific new activity and reporting on it in the review, which makes reviews a powerful lever for driving behavioral change in a team. Reviews are also a time when leaders can encourage cultural change by clearly articulating their expectations, setting values and cultural norms, and holding teams accountable for new behavior they want to see.
Superformal project reviews are rarely efficient in today’s fast-paced world. Thankfully, most teams are already shifting from formalized project reviews—infrequent dog-and-pony shows that take weeks to prepare for and that carefully present the team’s work in the best possible light—to more frequent, informal conversations with leaders about status and issues. Project reviews work best when teams and leaders focus on sharing what’s really going on, both the good and the bad, and openly discuss alternatives for dealing with problems or risks, taking advantage of the expertise of different people in the room. The ideal mindset in a project review is, “We’re in this together, so let’s put our heads together.” Creating this kind of trusting, honest, open space requires leaders to act more as coaches and mentors than as judges and decision makers and to value failed experiments as learning opportunities that get a team closer to an optimal solution—not the result of poor team performance.
However, a further shift needs to happen. Instead of scheduling a project review for each product, component area, or functional team, schedule a project review for each vision-level story. Start focusing project reviews on your target customers and the end-to-end experiences that you are trying to deliver for them. These experiences typically cut across individual teams and require multiple teams to come together to fully represent the status of an end-to-end experience, a format that is much different from typical project reviews.
Yes, you need to continue to track and monitor how your project is progressing against the business and technical metrics you’ve used in the past. But it’s important also to frequently check in on customers, to track how the end-to-end solution is progressing toward delighting them, and to make sure that all the pieces are coming together to make that delight a reality. These goals are best accomplished in the context of a review that focuses on an end-to-end experience, as opposed to splitting information across multiple project reviews for each team or functional component. You want to ship complete, end-to-end experiences, not individual components and not your org chart.
Here are some practices to consider when planning experience reviews:
![]() Change the name To help send a signal to teams that this review is a different sort than perhaps happened in the past, rename it to emphasize the new scope and behaviors you want to see. Consider naming it something like “experience review” or “scenario review,” and don’t use terms such as “component review,” “team review,” or “project review.”
Change the name To help send a signal to teams that this review is a different sort than perhaps happened in the past, rename it to emphasize the new scope and behaviors you want to see. Consider naming it something like “experience review” or “scenario review,” and don’t use terms such as “component review,” “team review,” or “project review.”
![]() Focus on vision-level stories Each review should focus on a vision-level story and show how all the task-level stories align and come together into an end-to-end experience. Always start the review with a reminder of the target customer, the specific vision-level story, and the task-level stories or scenarios that align with it.
Focus on vision-level stories Each review should focus on a vision-level story and show how all the task-level stories align and come together into an end-to-end experience. Always start the review with a reminder of the target customer, the specific vision-level story, and the task-level stories or scenarios that align with it.
![]() Sponsor attends the review Each vision-level story should have a designated leadership sponsor, and it is essential for this sponsor to be at the experience review.
Sponsor attends the review Each vision-level story should have a designated leadership sponsor, and it is essential for this sponsor to be at the experience review.
![]() Cross-team attendance Leads or representatives from each team who need to contribute to a specific vision-level story should be present at the experience review. This means that many team leads likely need to attend multiple experience reviews. Keeping this overhead manageable is one reason not to be actively working on too many vision-level stories at any given time.
Cross-team attendance Leads or representatives from each team who need to contribute to a specific vision-level story should be present at the experience review. This means that many team leads likely need to attend multiple experience reviews. Keeping this overhead manageable is one reason not to be actively working on too many vision-level stories at any given time.
![]() Everyone can listen in These reviews should not be private, closed-door affairs with only the leaders of the teams involved. Rather, anyone from the teams directly affected or from other areas of the project should be allowed to listen in and perhaps even participate. You can limit the people in the room to those who are directly involved with leading the relevant teams, but set up a video stream that others can watch from their desk and also provide a way for remote attendees to contribute questions or comments. Enabling a “side channel” of text conversation that takes place in parallel with the meeting is a great practice and allows the team to freely discuss, raise questions, and make suggestions without disturbing the main meeting. Have one person in the review room listen to the side channel and pull in relevant ideas, suggestions, and questions. Or, when possible, project the ongoing side conversation into the meeting room so that it is visible to all attendees and runs alongside the main content being reviewed.
Everyone can listen in These reviews should not be private, closed-door affairs with only the leaders of the teams involved. Rather, anyone from the teams directly affected or from other areas of the project should be allowed to listen in and perhaps even participate. You can limit the people in the room to those who are directly involved with leading the relevant teams, but set up a video stream that others can watch from their desk and also provide a way for remote attendees to contribute questions or comments. Enabling a “side channel” of text conversation that takes place in parallel with the meeting is a great practice and allows the team to freely discuss, raise questions, and make suggestions without disturbing the main meeting. Have one person in the review room listen to the side channel and pull in relevant ideas, suggestions, and questions. Or, when possible, project the ongoing side conversation into the meeting room so that it is visible to all attendees and runs alongside the main content being reviewed.
![]() Only report on full iterations Experience reviews are best done at the end of an iteration, when the team has gone through each stage of the Fast Feedback Cycle and can demonstrate the experience and report on customer feedback. You can also show progress against success metrics by using the latest experience scorecard. Report on the ideas you tried, what you built to show customers, how customers responded, and how far you are from being done. This approach should create an open space to discuss possible next steps and whether you should continue in the direction you’re going or try something new. It also helps bring to the surface any issues that are blocking the team from making further progress. In contrast, holding a project review in the middle of an iteration encourages teams (and especially leaders) to speculate about how customers will react, which just isn’t productive. If you could predict what customers think, you wouldn’t need an iterative approach in the first place.
Only report on full iterations Experience reviews are best done at the end of an iteration, when the team has gone through each stage of the Fast Feedback Cycle and can demonstrate the experience and report on customer feedback. You can also show progress against success metrics by using the latest experience scorecard. Report on the ideas you tried, what you built to show customers, how customers responded, and how far you are from being done. This approach should create an open space to discuss possible next steps and whether you should continue in the direction you’re going or try something new. It also helps bring to the surface any issues that are blocking the team from making further progress. In contrast, holding a project review in the middle of an iteration encourages teams (and especially leaders) to speculate about how customers will react, which just isn’t productive. If you could predict what customers think, you wouldn’t need an iterative approach in the first place.
![]() Hold them regularly An experience review shouldn’t be a one-time event; experience reviews are most helpful if they happen on a regular basis. Many teams have found that a monthly cadence is about right, which for most teams means reporting on two two-week iterations. This pace avoids too much overhead but is frequent enough to ensure that cross-team alignment is being managed actively and that teams are not drifting away from one another.
Hold them regularly An experience review shouldn’t be a one-time event; experience reviews are most helpful if they happen on a regular basis. Many teams have found that a monthly cadence is about right, which for most teams means reporting on two two-week iterations. This pace avoids too much overhead but is frequent enough to ensure that cross-team alignment is being managed actively and that teams are not drifting away from one another.
![]() Keep the content appropriate to the maturity of the project If work on a vision-level story only just started, the first review should focus on the target customer, alignment to strategy, and how task-level stories align to the vision-level stories. Leaders should not press for details about engineering deliverables prematurely. This encourages teams to skip steps, which could result in costly mistakes. As you get further into a project, add technical and other details that are appropriate for the phase of the project. But do not focus the review on aspirational next steps. Rather, stay focused on the data you have at hand—what experiments you’ve tried, how customers responded, and what directions the team is planning to try next.
Keep the content appropriate to the maturity of the project If work on a vision-level story only just started, the first review should focus on the target customer, alignment to strategy, and how task-level stories align to the vision-level stories. Leaders should not press for details about engineering deliverables prematurely. This encourages teams to skip steps, which could result in costly mistakes. As you get further into a project, add technical and other details that are appropriate for the phase of the project. But do not focus the review on aspirational next steps. Rather, stay focused on the data you have at hand—what experiments you’ve tried, how customers responded, and what directions the team is planning to try next.
![]() Demo the customer experience As the project progresses, keep the focus of the review on what the experience looks like end to end, not on the guts and plumbing of how it is built. Keep it real and reality based—don’t focus on abstract models, but what the actual product would look like. If the experience is an API, show the object hierarchy, the methods, and their signatures. If the experience is a user interface, show the latest storyboards or mockups, even if they are very rough. And if you have working code, by all means show that. We have been surprised to see even very technical, plumbing-oriented teams find that showing storyboards in project reviews was an extremely helpful way to communicate the experience to leaders.
Demo the customer experience As the project progresses, keep the focus of the review on what the experience looks like end to end, not on the guts and plumbing of how it is built. Keep it real and reality based—don’t focus on abstract models, but what the actual product would look like. If the experience is an API, show the object hierarchy, the methods, and their signatures. If the experience is a user interface, show the latest storyboards or mockups, even if they are very rough. And if you have working code, by all means show that. We have been surprised to see even very technical, plumbing-oriented teams find that showing storyboards in project reviews was an extremely helpful way to communicate the experience to leaders.
![]() Show the alternatives Create an expectation for these reviews that teams should show not just their current “best” solution idea but also the alternatives. The reason to do this is twofold. First, it creates a forcing function to ensure that teams truly do consider alternatives and that those alternatives were meaningfully different from one another, not just variations on a theme. It’s not crazy to ask to see the worst idea a team came up with because that idea will not only be entertaining but show the breadth of ideas that were considered. Second, sometimes an audience with fresh eyes will notice a “blend” that the team hasn’t—a solution that combines ideas from multiple alternatives. Blends often show the way to powerful, innovative solutions.
Show the alternatives Create an expectation for these reviews that teams should show not just their current “best” solution idea but also the alternatives. The reason to do this is twofold. First, it creates a forcing function to ensure that teams truly do consider alternatives and that those alternatives were meaningfully different from one another, not just variations on a theme. It’s not crazy to ask to see the worst idea a team came up with because that idea will not only be entertaining but show the breadth of ideas that were considered. Second, sometimes an audience with fresh eyes will notice a “blend” that the team hasn’t—a solution that combines ideas from multiple alternatives. Blends often show the way to powerful, innovative solutions.
How leaders can help
More than any other aspect of an experience review, the behavior of leaders is what helps a team make the shift to a customer-focused, iterative approach—or not. If, during the experience reviews, leaders reiterate the importance of the new approaches—the values and culture they expect—and hold teams accountable for acting this way, the team quickly gets the message that it is safe to try this new approach and that they will be rewarded for doing so. However, if leaders are ambivalent about the new approach—or worse, unintentionally undermine it by not adapting their own behaviors, language, and expectations for the team—that is a sure way to stall real change from taking place.
The biggest change leaders need to make is to stop speaking on behalf of customers. They need to stop using their personal knowledge and experience to purport to know which ideas will work best and what customers really want. One reason this shift is so difficult is that a leader’s personal knowledge, experience, and smarts are likely what got the leader promoted to this position in the first place. Over time, these leaders have grown into the role of a HiPPO—the highest-paid person with an opinion—and the team has come to rely on their judgment for decision making. However, remember that when teams test their ideas through experimentation, teams correctly predict what will actually work for customers only a third of the time. The HiPPO is no different. (See the section “Why get feedback?,” in Chapter 9 for more information about statistics on making successful predictions.)
Having a leader internalize this reality and stop making it a personal responsibility to be the decision maker can actually be quite freeing. Leaders no longer need to feel as though they should know all the answers, and their job becomes much more about making sure that the team is asking the right questions at the right time and is doing the due diligence with customers to answer those questions with high confidence.
Here are some essential questions that leaders should ask at experience reviews (if these questions aren’t proactively addressed by the attendees):
![]() Who is the target customer? Make sure that teams are focused on the target customers laid out in the original business plans. Listen for plans that sound like they are trying to be all things for all people (too generic or not focused, like peanut butter spread across a piece of bread), and redirect teams to focus on a specific end-to-end experience for a stated target customer, even though this might mean a compromised experience for other, lower-priority customers at times. Help teams understand that this tradeoff is okay and expected, and that it will actually produce better results overall. Listen to make sure that the same target customer is addressed across the task-level stories for a vision-level story or an end-to-end experience. Also listen to be sure that the target customer the team is using aligns to one of the targets chosen and communicated to the team as central to the business strategy.
Who is the target customer? Make sure that teams are focused on the target customers laid out in the original business plans. Listen for plans that sound like they are trying to be all things for all people (too generic or not focused, like peanut butter spread across a piece of bread), and redirect teams to focus on a specific end-to-end experience for a stated target customer, even though this might mean a compromised experience for other, lower-priority customers at times. Help teams understand that this tradeoff is okay and expected, and that it will actually produce better results overall. Listen to make sure that the same target customer is addressed across the task-level stories for a vision-level story or an end-to-end experience. Also listen to be sure that the target customer the team is using aligns to one of the targets chosen and communicated to the team as central to the business strategy.
![]() Is this approach aligned with our business strategy? Be sure that teams aren’t ignoring the realities of the business. It’s easy for a team to get sucked into cool user experiences and technical details and forget monetization. Focusing on a target customer that is explicitly tied to your business strategy helps a lot, but it’s not the only business aspect to worry about. Testing the visible parts of the monetization plan with customers is an important aspect of iterating an experience to be sure that it works.
Is this approach aligned with our business strategy? Be sure that teams aren’t ignoring the realities of the business. It’s easy for a team to get sucked into cool user experiences and technical details and forget monetization. Focusing on a target customer that is explicitly tied to your business strategy helps a lot, but it’s not the only business aspect to worry about. Testing the visible parts of the monetization plan with customers is an important aspect of iterating an experience to be sure that it works.
![]() What scenario is this focused on? Listen for scenarios that are thinly disguised feature ideas. Remember that scenarios should be implementation-free descriptions of a specific real-world customer situation. If teams seem off-track, remind them of which vision-level and task-level stories they are supposed to be solving, or ask what they’ve learned that tells them that they need to adjust those stories.
What scenario is this focused on? Listen for scenarios that are thinly disguised feature ideas. Remember that scenarios should be implementation-free descriptions of a specific real-world customer situation. If teams seem off-track, remind them of which vision-level and task-level stories they are supposed to be solving, or ask what they’ve learned that tells them that they need to adjust those stories.
![]() What are your success criteria? Success criteria should be built into each vision-level and task-level story, and teams should be tracking and reporting metrics against those criteria, ideally on a scorecard. If success metrics haven’t been met, the experience isn’t done yet and needs more iteration. It’s the leader’s job to insist on meeting the quality bar.
What are your success criteria? Success criteria should be built into each vision-level and task-level story, and teams should be tracking and reporting metrics against those criteria, ideally on a scorecard. If success metrics haven’t been met, the experience isn’t done yet and needs more iteration. It’s the leader’s job to insist on meeting the quality bar.
![]() When was the last time you got customer feedback? Any team that comes to a review without recent customer feedback should be told that this isn’t acceptable. Waiting until the code is written is almost always too late to get the first feedback from customers. Coach teams to get customer feedback from real customers early, before ideas are fully developed or directions are set. Postpone the first experience review until at least one round of customer feedback has occurred. Teams should continue getting customer feedback at every iteration. Risk grows as the time period between a team’s customer touch points increases.
When was the last time you got customer feedback? Any team that comes to a review without recent customer feedback should be told that this isn’t acceptable. Waiting until the code is written is almost always too late to get the first feedback from customers. Coach teams to get customer feedback from real customers early, before ideas are fully developed or directions are set. Postpone the first experience review until at least one round of customer feedback has occurred. Teams should continue getting customer feedback at every iteration. Risk grows as the time period between a team’s customer touch points increases.
![]() What do customers think about that? Listen for teams that start sounding as though they are building a solution for the individuals on the team, not the stated target customer. Coach them to keep the focus on what customers like and dislike—the customers’ perspectives, opinions, needs, wants, dreams, and pet peeves. If the team doesn’t know this information or is making too many assumptions, these are good questions to ask at the next round of customer observation.
What do customers think about that? Listen for teams that start sounding as though they are building a solution for the individuals on the team, not the stated target customer. Coach them to keep the focus on what customers like and dislike—the customers’ perspectives, opinions, needs, wants, dreams, and pet peeves. If the team doesn’t know this information or is making too many assumptions, these are good questions to ask at the next round of customer observation.
![]() What course corrections have you made based on customer feedback? This is a good question to ask to be sure that teams are actually listening to feedback and not just cherry-picking feedback that reinforces their personal opinions. Projects always have course corrections, at least small ones, and often a couple of bigger ones. A team that tells you that all their ideas have worked 100 percent the first time is highly suspect. Similarly, late discoveries and mistakes should be the topic of a postmortem—how could you have tested with customers to have discovered this problem earlier?
What course corrections have you made based on customer feedback? This is a good question to ask to be sure that teams are actually listening to feedback and not just cherry-picking feedback that reinforces their personal opinions. Projects always have course corrections, at least small ones, and often a couple of bigger ones. A team that tells you that all their ideas have worked 100 percent the first time is highly suspect. Similarly, late discoveries and mistakes should be the topic of a postmortem—how could you have tested with customers to have discovered this problem earlier?
![]() Tip
Tip
A great phrase for leaders to use liberally is, “We reserve the right to get smarter.” Stating this gives teams permission to pick a direction to move forward with and make progress, with the understanding that they might well change their mind or improve the plan based on customer feedback or other learnings, and that this is expected and good and supported by their leadership.
![]() What alternatives have you considered? Leaders should set a clear expectation for the minimum number of alternatives (typically three, five, or even nine) that a team should consider before making a decision. Whether deciding on a user-interface design or picking a technical architecture, better decisions result when teams do the due diligence to force themselves to generate and consider multiple credible options before narrowing in on a plan. Require that teams present these alternatives in their reviews.
What alternatives have you considered? Leaders should set a clear expectation for the minimum number of alternatives (typically three, five, or even nine) that a team should consider before making a decision. Whether deciding on a user-interface design or picking a technical architecture, better decisions result when teams do the due diligence to force themselves to generate and consider multiple credible options before narrowing in on a plan. Require that teams present these alternatives in their reviews.
![]() What data do you have to support that decision? Listen for teams that are making big decisions based on gut instincts, personal experience, or ego. Require teams to back up their decisions with data—customer data, technical data, business data—and to truly consider alternatives and not fall in love with their first good idea.
What data do you have to support that decision? Listen for teams that are making big decisions based on gut instincts, personal experience, or ego. Require teams to back up their decisions with data—customer data, technical data, business data—and to truly consider alternatives and not fall in love with their first good idea.
![]() Tip
Tip
Leaders should be cautious about asking “How exactly are we going to implement this?” too soon. Until the experience has been iterated and a viable direction is found that is good for customers, technically feasible, and sound businesswise, it’s premature to expect teams to make specific technical decisions. Let the iterative process work through the technology and architecture decisions as well as the decisions about the customer’s experience. Allow some time for the best approach to shake out. The question to ask is, “What alternatives are you considering for how we might implement this?”
Shift from individual focus to team focus
A pervasive but subtle shift that underlies everything we’ve discussed is to take a more collaborative approach to iterating ideas through the Fast Feedback Cycle. It’s a subtle shift because you still want individuals who have particular expertise to take the lead at different times. But, generally, people need to be better plugged in to the overall work of the team, participate in key decisions, and be more aware of the work of others. Here are a few structural steps you can implement to help encourage teams to collaborate more:
![]() Office space4 Creating an office layout that balances individual and group spaces can make a profound difference in how a team operates. Historically, Microsoft offices were designed as individual workspaces: each person was given a private office, complete with a door to close. Recently, buildings have been remodeled to favor open environments to promote more team collaboration. The team we work on has been part of a particularly interesting experiment over the past six years. We spent the first three years together in a team room, where we sat together, enjoyed peripheral awareness of one another’s work, participated in numerous impromptu conversations, and scheduled collaborations and meetings regularly, all in our own space. Guess what? The extroverts on the team thrived, and yes, work was done in a more collaborative manner. But more introverted team members sometimes found it difficult to be productive (or they wore headphones most of the time). Then we moved to a different building and spent two years back in a traditional layout with individual offices. It’s remarkable—with just a few walls in the way and even though our offices were adjacent to each other in the same hallway—how difficult it was to retain the collaborative approach we were used to. In the last year, we moved back to a more open layout, and it’s been like a breath of fresh air. We were reminded of how much the physical architecture can encourage particular work styles. Our team room seats six people and also has several adjoining private spaces, called “phone rooms” and “focus rooms,” that can be used for small meetings or time alone. The blend of team rooms and private spaces, and some specific, facilitated conversations about team-room norms (like taking phone calls outside and not eating smelly fish), created an environment that captures the strengths of an open plan and also fixes many of its weaknesses, especially for more introverted team members.
Office space4 Creating an office layout that balances individual and group spaces can make a profound difference in how a team operates. Historically, Microsoft offices were designed as individual workspaces: each person was given a private office, complete with a door to close. Recently, buildings have been remodeled to favor open environments to promote more team collaboration. The team we work on has been part of a particularly interesting experiment over the past six years. We spent the first three years together in a team room, where we sat together, enjoyed peripheral awareness of one another’s work, participated in numerous impromptu conversations, and scheduled collaborations and meetings regularly, all in our own space. Guess what? The extroverts on the team thrived, and yes, work was done in a more collaborative manner. But more introverted team members sometimes found it difficult to be productive (or they wore headphones most of the time). Then we moved to a different building and spent two years back in a traditional layout with individual offices. It’s remarkable—with just a few walls in the way and even though our offices were adjacent to each other in the same hallway—how difficult it was to retain the collaborative approach we were used to. In the last year, we moved back to a more open layout, and it’s been like a breath of fresh air. We were reminded of how much the physical architecture can encourage particular work styles. Our team room seats six people and also has several adjoining private spaces, called “phone rooms” and “focus rooms,” that can be used for small meetings or time alone. The blend of team rooms and private spaces, and some specific, facilitated conversations about team-room norms (like taking phone calls outside and not eating smelly fish), created an environment that captures the strengths of an open plan and also fixes many of its weaknesses, especially for more introverted team members.
![]() Broader, multidiscipline teams Most engineers are used to working on cross-discipline teams that include program, project, or product managers, as well as developers and testers. However, many of the activities that teams need to do to fulfill the promise of the Fast Feedback Cycle benefit from including experts in user research and design as well. For many projects, product planning, marketing, support, and operations are also highly useful. Resourcing multidiscipline teams that include these specialties as first-class members is essential.5
Broader, multidiscipline teams Most engineers are used to working on cross-discipline teams that include program, project, or product managers, as well as developers and testers. However, many of the activities that teams need to do to fulfill the promise of the Fast Feedback Cycle benefit from including experts in user research and design as well. For many projects, product planning, marketing, support, and operations are also highly useful. Resourcing multidiscipline teams that include these specialties as first-class members is essential.5
![]() Mindshift
Mindshift
A designer is a designer is a designer, right? No, not quite. It’s worth distinguishing between different flavors of designers because each can have quite different skill sets and backgrounds to contribute to the team. The three you’re most likely to run into are interaction designers, graphic designers, and industrial designers. Interaction designers offer the most generally useful skill set and focus on creating smooth workflows to allow people to interact with software naturally and seamlessly. Interaction designers may not be particularly talented artists—their sketches may not look any better than yours—but they are probably great at quickly generating alternatives and thinking through sequences and customer experiences. They are also great at information architecture and at understanding human perceptual and behavioral strengths and limitations. In comparison, graphic designers create beautiful aesthetics that coordinate the form and function of a solution. Industrial designers create physical products that you can touch and that tend to have extensive manufacturing constraints to manage. There are other specialty disciplines as well, for sound, animation, information architecture, and so on. It’s rare (but not impossible) for one person to have deep expertise in more than one area, so as you build your team, be thoughtful about what skill sets you really need.
![]() Pairing and swarming Introduce the idea of “pairing”—two people working together on a task who take turns driving and observing. This is similar to the idea in extreme programming (XP) of pair programming, but it can be applied not just to two developers writing code together but also to two team members sketching storyboards, working through details of a spec, drafting a PowerPoint presentation, sorting through customer feedback, or any other task. Whether you are writing code or sketching new experiences, the interplay of two brains usually makes for a better deliverable with fewer bugs. When you have a big problem to solve or lots of data to analyze, swarming may help. Swarming is where the entire team drops everything and works together to focus on solving a single, urgent problem or to make fast progress on a particular scenario. Both pairing and swarming formalize the idea of collaboration as a natural part of the team’s work and give the team a vocabulary for it.
Pairing and swarming Introduce the idea of “pairing”—two people working together on a task who take turns driving and observing. This is similar to the idea in extreme programming (XP) of pair programming, but it can be applied not just to two developers writing code together but also to two team members sketching storyboards, working through details of a spec, drafting a PowerPoint presentation, sorting through customer feedback, or any other task. Whether you are writing code or sketching new experiences, the interplay of two brains usually makes for a better deliverable with fewer bugs. When you have a big problem to solve or lots of data to analyze, swarming may help. Swarming is where the entire team drops everything and works together to focus on solving a single, urgent problem or to make fast progress on a particular scenario. Both pairing and swarming formalize the idea of collaboration as a natural part of the team’s work and give the team a vocabulary for it.
![]() Performance-review process If your performance review process emphasizes individual work and shipping code frequently no matter what (and deemphasizes teamwork and customer satisfaction), you will have a tough time getting the Fast Feedback Cycle to take root in your team. Building a performance-review system that factors in how well people collaborate as well as customer satisfaction can help align extrinsic rewards and motivations to the values you are trying to establish in your team’s culture. For instance, you might align bonuses to the customer satisfaction of the solution that the entire team delivered or to how well the team met its stated scenario metrics at release. Keep in mind that social science research is clear that extrinsic rewards are not a particularly powerful motivator on their own. However, when extrinsic rewards are in direct conflict with the culture you are trying to establish, you are definitely going to run into problems. Be sure to align the team’s performance-review process to the values and culture you intend to build, or at least make sure they are not in conflict.
Performance-review process If your performance review process emphasizes individual work and shipping code frequently no matter what (and deemphasizes teamwork and customer satisfaction), you will have a tough time getting the Fast Feedback Cycle to take root in your team. Building a performance-review system that factors in how well people collaborate as well as customer satisfaction can help align extrinsic rewards and motivations to the values you are trying to establish in your team’s culture. For instance, you might align bonuses to the customer satisfaction of the solution that the entire team delivered or to how well the team met its stated scenario metrics at release. Keep in mind that social science research is clear that extrinsic rewards are not a particularly powerful motivator on their own. However, when extrinsic rewards are in direct conflict with the culture you are trying to establish, you are definitely going to run into problems. Be sure to align the team’s performance-review process to the values and culture you intend to build, or at least make sure they are not in conflict.
![]() Public spaces Using public spaces to unify the team and encourage collaboration is a great tactic. Hanging up posters of target customers, personas, key scenarios, success criteria/metrics, or other framing info helps to informally involve everyone in a set of shared goals. The museum approach we discussed in Chapter 5 also helps bring a team together. Whether you are covering the walls with customer research or the latest solution sketches, display the recent work artifacts in a place that is visible and frequented by team members. By doing this, you let the entire team gain a rough idea of the state of progress simply by walking the halls. Even better, you can encourage feedback by keeping a pile of sticky notes and a Sharpie pen adjacent to work that’s in question and asking team members for their comments or feedback.
Public spaces Using public spaces to unify the team and encourage collaboration is a great tactic. Hanging up posters of target customers, personas, key scenarios, success criteria/metrics, or other framing info helps to informally involve everyone in a set of shared goals. The museum approach we discussed in Chapter 5 also helps bring a team together. Whether you are covering the walls with customer research or the latest solution sketches, display the recent work artifacts in a place that is visible and frequented by team members. By doing this, you let the entire team gain a rough idea of the state of progress simply by walking the halls. Even better, you can encourage feedback by keeping a pile of sticky notes and a Sharpie pen adjacent to work that’s in question and asking team members for their comments or feedback.
What doesn’t change?
Despite what can feel like massive structural changes, many aspects of an engineering team’s work don’t need to change at all. Teams still need to write great code. They need a system to track bugs, profiling tools to measure performance, deployment tools to ship code to production, a fast and reliable build system, and all of the other sundry things that are used every day in engineering projects.
In fact, we didn’t even begin to cover many, many aspects of managing an engineering team in this chapter, as well as various project management techniques. You can read piles of books on that stuff, and some of our favorites are listed at the end of the book in Appendix C. In particular, many Agile techniques—from scrum teams, daily standups, test-driven development (TDD), acceptance test-driven development (ATDD), extreme programming (XP), and more—are great techniques to include in your team’s project management and engineering system and very compatible with the ideas in this book. Similarly, we’ve mentioned Lean Startup techniques throughout this book as great tools for various stages of the Fast Feedback Cycle. These are also very complementary.
As we wrote at the end of Chapter 2, don’t forget what you already know. The focus of this chapter, and this book, is on the areas where we’ve found that teams need to amend their current systems and tools to bring more rigor into building great customer experiences. By and large, these are additions to current practices and not substitutes.
Notes
1. The description of the quick pulse study approach in Chapter 9, “Observing customers: Getting feedback,” provides more details on how you can structure a schedule to prepare for, conduct, and debrief a customer touch point on a weekly basis.
2. Steve Herbst, private communication with the authors.
3. You can find a wealth of information about good business metrics. Some helpful sources beyond the basics of revenue and profit include average revenue per user (ARPU), cost of goods sold (COGS), and customer acquisition cost. Also consider Dave McClure’s so-called pirate metrics—AARRR: acquisition, activation, retention, referral, revenue. Dave McClure, “Startup Metrics for Pirates: AARRR,” Master of 500 Hats (blog), September 6, 2007, http://500hats.typepad.com/500blogs/2007/09/startup-metrics.html.
4. Some good books are available that discuss the importance of the workplace environment and its role in the creative process. One we like comes from the Institute of Design (d.school) at Stanford University: Make Space: How to Set the Stage for Creative Collaboration, by Scott Doorley and Scott Witthoft (Wiley, 2012).
5. Interestingly, we’ve noticed a pattern in which teams tend to make a business case for and hire additional user research and design staff within a year of training with our foundational workshop.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.