T-SQL Querying (2015)
Chapter 10. In-Memory OLTP
Microsoft SQL Server 2014 introduces the In-Memory OLTP feature. In-Memory OLTP can produce great increases in performance, but you need to understand that the increases are not primarily because the data is resident in memory. Rather, the increases come from leveraging the fact that the data is in memory and using different data structures and methods that make database operations much more efficient. This chapter will help you to understand these different structures and methods and how to use them to unlock the performance potential of In-Memory OLTP. I’ll give a brief overview to help you understand the context, and then discuss the ways in which memory-optimized tables need to be handled differently when writing queries and designing systems.
In this chapter, I’ll base my examples primarily on the AdventureWorks sample database, as extended to include memory-optimized tables. This database can be downloaded from https://msftdbprodsamples.codeplex.com/releases/view/114491 and used on any server running a compatible version of SQL Server (SQL Server 2014 or newer Enterprise, Developer, or Eval edition).
In-Memory OLTP overview
The In-Memory OLTP system started out as a blue-sky project, where the SQL Server development team was challenged to wipe the slate clean and imagine what a database engine would look like if it were designed from scratch given today’s business and hardware landscape. This blue-sky project became the development project that was code-named Hekaton. The team made several observations about the environment in modern computing:
![]() Commodity systems now support enough memory to keep an interesting data set in memory at all times. Previously, a database management system could pull only a small subset of data into memory at one time. This data would be manipulated and then evicted from memory to make room for other data. With commodity systems that can now hold hundreds of GB of main memory, we now can hold an interesting data set in memory at all times, without the need to evict data as before.
Commodity systems now support enough memory to keep an interesting data set in memory at all times. Previously, a database management system could pull only a small subset of data into memory at one time. This data would be manipulated and then evicted from memory to make room for other data. With commodity systems that can now hold hundreds of GB of main memory, we now can hold an interesting data set in memory at all times, without the need to evict data as before.
![]() Processor clock speed is no longer increasing. Although overall chip complexity continues to increase following Moore’s Law, the clock speed has plateaued at around 3 GHz and hasn’t moved from there in many years.
Processor clock speed is no longer increasing. Although overall chip complexity continues to increase following Moore’s Law, the clock speed has plateaued at around 3 GHz and hasn’t moved from there in many years.
![]() On the other hand, the number of cores per socket is increasing. The additional complexity and power of modern CPU chips is being delivered in the form of more and more cores (both physical and virtual) per socket.
On the other hand, the number of cores per socket is increasing. The additional complexity and power of modern CPU chips is being delivered in the form of more and more cores (both physical and virtual) per socket.
The implication of the latter two observations is that each execution stream will not move faster than it did years ago, but you have many more potential parallel execution streams to work with.
The In-Memory OLTP feature of SQL Server is a different implementation than traditional SQL Server. On one hand, it is a fully integrated part of the SQL engine; on the other hand, it is an entirely new execution engine. So what is In-Memory OLTP, and what makes it different from the rest of the SQL Server engine?
Data is always in memory
In the In-Memory OLTP environment, data is always in memory. There is no concept of paging subsets of the data in and out of memory. When a table is designated as memory optimized, its rows are never paged out. Although this is a significant change in behavior, it is only the start. After all, if you have sufficient memory on a traditional database server, you have no reason to evict pages from memory. You can, however, leverage this information to do things more wisely.
Because you know you’ll never need to page data in and out of memory, you can eliminate a number of structures and features of the engine. Pages, for example, are structures whose purpose is to facilitate moving subsets of data in and out of memory. Because this system never does that, you can eliminate pages entirely. As shown in Figure 10-1, the in-memory data structure for a row in a memory-optimized table is simply the data storage for the columns themselves in native format, as well as a couple of timestamps for visibility and isolation purposes (which I’ll get into more in the “Isolation” section) and an array of pointers used for index chains.
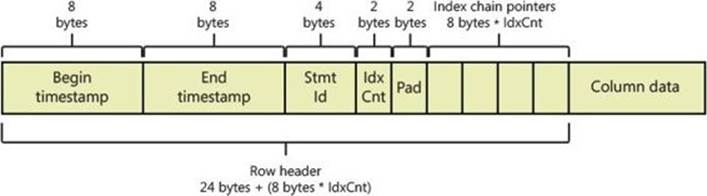
FIGURE 10-1 Memory-optimized table row format.
The begin and end timestamps are important for maintaining transaction isolation and consistency. The begin timestamp marks the time when the row version was created. Any transaction that started before this timestamp will not see this row version. The end timestamp marks the time when this row version was logically deleted. Transactions starting before this time but after the begin timestamp time will continue to see the row version so that a consistent view is provided. Transactions starting after the end timestamp time will not see this row version.
You can also dispense with the considerable infrastructure used to track which pages are in memory, which pages are in the buffer pool, where in the buffer pool a given page might be, whether the in-memory copy of the page has been modified (making it “dirty” and requiring that it eventually be flushed back out to disk), and so on. All that management just doesn’t happen, which is a significant savings in processing effort and time.
It also means that a transaction against a memory-optimized table will never have to wait and go back on the scheduler queue because it’s waiting for an IO to bring a needed page into memory.
Native compilation
This is another new innovation of In-Memory OLTP in SQL Server. In recognition of the stalled processor speed and the need to always get as much work out of every CPU cycle as possible, the In-Memory OLTP system also gives you the option to natively compile stored procedures that access only memory-optimized tables. Okay, so what does that mean?
First, the prerequisite: this capability will work only if you are creating a stored procedure and that stored procedure does not access any traditional row-based or column-based tables. The only tables that can be accessed in one of these procedures are memory-optimized tables. Also, note that the native compilation environment has a somewhat restricted T-SQL surface area, so at least for the first release, you might be required to do some workarounds if you encounter missing surface area. Some workarounds are trivial and don’t really cost anything performance-wise. Others can be prohibitive, either in terms of implementation complexity or performance impact.
Now the payback: if you create a natively compiled stored procedure, the T-SQL source is run through the standard SQL Query Optimizer and then translated into C code, which is capable of accessing the memory structures containing the rows directly. This C code is then compiled and built into a dynamic-link library (DLL), which is loaded into the SQL process dynamically, in the same way that the fundamental data-access routines are built and loaded when you first create a table.
The result of all this is that when you execute a natively compiled stored procedure, instead of looking up the T-SQL source and executing it as a series of interpreted SQL operations with many context switches along the way, a natively compiled procedure is simply a function call in the engine context. There’s not even a context switch. As discussed earlier, there’s never a stall for IO either. When we get into the locking section, you’ll discover there isn’t any reason to stall while waiting on locks or latches. In short, when a natively compiled procedure starts executing, there isn’t any reason for it to stop and wait for anything. Once it starts, it will generally run to completion without ever being stalled. This makes for an extremely efficient execution engine.
Lock and latch-free architecture
Another key facet of this architecture is that it is designed to be completely lock and latch free. Remember I discussed earlier that modern processors are delivering more and more cores per socket and that to exploit that processing power you need to enable an increasing number of parallel execution threads.
Latches are used to protect physical structures such as pages. As I mentioned, you don’t use any pages for memory-optimized data, so you have no need for page latches. In addition to this, all row and index structures are engineered to be lock free, using an optimistic concurrency model.
Most database systems, including SQL Server, are designed with a pessimistic concurrency model. Fundamentally, this means the system assumes that if two threads try to access the same data structure, a conflict might occur that causes problems. To avoid that, systems designed with pessimistic concurrency use locks. The first thread to attempt access will be granted a lock on the structure, and others that have conflicting requests will block and wait until the first thread is finished. This model does a good job at guaranteeing consistency, but it has the unfortunate effect of leading to a lot of threads waiting for locks to be released. The SQL Server development team also discovered while profiling the SQL engine that a surprising number of CPU cycles were spent just acquiring and releasing locks and latches, even when there was never a conflict or wait.
Optimistic concurrency, on the other hand, assumes that in most cases there will not be a conflict that causes inconsistency, and thus you can get by without stalling threads. Concurrency is guaranteed by checking for actual write-write conflicts and, if a conflict is found, failing the second thread that attempts to modify the same data. I’ll get into this in more detail in the “Commit validation errors” section.
The result of this is that you never have threads stalled waiting for locks or latches to be released. So, if the application is designed appropriately, you can have many execution threads running in parallel, making use of all cores in your system.
SQL Server integration
Perhaps the most unique feature of SQL Server In-Memory OLTP, compared to other in-memory offerings, is that it is fully integrated with the core database engine. You can decide on a table-by-table basis which tables should be memory optimized, which should stay in traditional row stores, and which should be in column stores. In this way, you have full control to put each piece of data in the most appropriate storage format, based on its usage and performance requirements.
So you will likely have a database that contains memory optimized, traditional tables and clustered column-store tables. You’ll need to consider some implications of crossing those boundaries, and we’ll get into those issues. On the positive side, you have the same tools to aid you in your tuning efforts.
Not only can databases have a mix of storage types, traditional row stores, memory optimized tables, and column stores, but tables containing such mixes behave like any other SQL table. The same syntax applies, the same connection methods are used, and the same management tools and utilities are used. Backup just works. AlwaysOn clusters and Availability Groups just work. As one of our early adopters said, “If you know SQL, you know Hekaton.” This existing knowledge is a significant advantage compared to moving to a different platform, because you don’t need to learn a completely new system for managing your data.
Creating memory-optimized tables
To create memory-optimized tables within a database, the database must first contain a special-purpose Memory Optimized Data filegroup. This filegroup will contain the data persisted for in-memory tables. The syntax is similar to FILESTREAM filegroups, with the exception of theCONTAINS MEMORY_OPTIMIZED_DATA option. The code to add a memory optimized data filegroup to the AdventureWorks database is shown in Listing 10-1.
LISTING 10-1 Creating a memory optimized data filegroup and container
ALTER DATABASE AdventureWorks2014
ADD FILEGROUP AdventureWorks2014_mod CONTAINS MEMORY_OPTIMIZED_DATA;
GO
ALTER DATABASE CURRENT ADD FILE
(NAME='AdventureWorks2014_mod',
FILENAME='Q:\MOD_DATA\AdventureWorks2014_mod')
TO FILEGROUP AdventureWorks2014_mod;
Note that you can add more than one container (using the ADD FILE syntax, just as you would for a FILESTREAM container). All data in memory-optimized tables must be read into memory before the database can be recovered and brought online, so you need to consider the speed with which that data can be read from storage. Having multiple containers will speed up database startup by enabling the engine to process all containers in parallel. To further optimize the startup, you should spread the IO load of the checkpoint files over multiple storage devices.
After you create the memory optimized data filegroup, you can proceed to create a memory-optimized data table. You’ll see that the syntax for doing so (shown in Listing 10-2) is not significantly different from creating any other table, with the exception of some specific keywords.
LISTING 10-2 Creating a memory-optimized table
USE AdventureWorks2014;
GO
CREATE TABLE Sales.ShoppingCartItem_inmem
(
ShoppingCartItemID int IDENTITY(1,1) NOT NULL,
ShoppingCartID nvarchar(50) NOT NULL,
Quantity int NOT NULL CONSTRAINT IMDF_ShoppingCartItem_Quantity DEFAULT ((1)),
ProductID int NOT NULL,
DateCreated datetime2(7) NOT NULL
CONSTRAINT IMDF_ShoppingCartItem_DateCreated DEFAULT (sysdatetime()),
ModifiedDate datetime2(7) NOT NULL
CONSTRAINT IMDF_ShoppingCartItem_ModifiedDate DEFAULT (sysdatetime()),
CONSTRAINT IMPK_ShoppingCartItem_ShoppingCartItemID PRIMARY KEY NONCLUSTERED
HASH (ShoppingCartItemID) WITH ( BUCKET_COUNT = 1048576),
INDEX IX_CartDate NONCLUSTERED (DateCreated ASC),
INDEX IX_ProductID NONCLUSTERED HASH (ProductID) WITH ( BUCKET_COUNT = 1048576)
) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_ONLY );
GO
-- Insert the data from the original Sales.ShoppingCartItem table
-- to the new memory-optimized table
SET IDENTITY_INSERT Sales.ShoppingCartItem_inmem ON;
INSERT INTO Sales.ShoppingCartItem_inmem
(ShoppingCartItemID, ShoppingCartID, Quantity, ProductID, DateCreated, ModifiedDate)
SELECT ShoppingCartItemID, ShoppingCartID, Quantity, ProductID, DateCreated,
ModifiedDate
FROM Sales.ShoppingCartItem;
SET IDENTITY_INSERT Sales.ShoppingCartItem_inmem OFF;
Much of this is familiar syntax. There are just a few things that are done differently:
![]() Constraints and indexes are always specified as part of the CREATE TABLE statement. This is because In-Memory OLTP in SQL Server 2014 does not permit tables to be altered after creation. So constraints or indexes cannot be added after the table creation.
Constraints and indexes are always specified as part of the CREATE TABLE statement. This is because In-Memory OLTP in SQL Server 2014 does not permit tables to be altered after creation. So constraints or indexes cannot be added after the table creation.
![]() The last line contains two new options: MEMORY_OPTIMIZED and DURABILITY.
The last line contains two new options: MEMORY_OPTIMIZED and DURABILITY.
![]() MEMORY_OPTIMIZED = ON specifies that this is a memory-optimized table. Specifying OFF would result in a traditional table.
MEMORY_OPTIMIZED = ON specifies that this is a memory-optimized table. Specifying OFF would result in a traditional table.
![]() DURABILITY has two options: SCHEMA_AND_DATA and SCHEMA_ONLY. The SCHEMA_ONLY option is a special-purpose table where only the schema is persisted across restarts, and no data is persisted. DURABILITY = SCHEMA_AND_DATA specifies normal, full-durability semantics apply to this table. SCHEMA_ONLY durability is appropriate for data that needs to be accessed using transactional semantics but that does not have long-term value. Examples include data at the midpoint of an Extract, Transform, and Load (ETL) stream, where the source is still available, or various caches such as the ASP.NET Session State Cache.
DURABILITY has two options: SCHEMA_AND_DATA and SCHEMA_ONLY. The SCHEMA_ONLY option is a special-purpose table where only the schema is persisted across restarts, and no data is persisted. DURABILITY = SCHEMA_AND_DATA specifies normal, full-durability semantics apply to this table. SCHEMA_ONLY durability is appropriate for data that needs to be accessed using transactional semantics but that does not have long-term value. Examples include data at the midpoint of an Extract, Transform, and Load (ETL) stream, where the source is still available, or various caches such as the ASP.NET Session State Cache.
Creating indexes in memory-optimized tables
Indexes in memory-optimized tables in some ways are the same as any other indexes you’ve used for years. In other ways, however, they behave differently from the indexes you’re familiar with. It helps to remember that these indexes are not disk-based structures—they are memory structures. Rather than using references to pages that contain data, these indexes are made up of pointers to data structures just like the structures in a program that might be querying the database.
Clustered vs. nonclustered indexes
Traditional tables use indexes that might be either clustered or nonclustered. Clustered indexes contain the primary copy of the data for the table. Nonclustered indexes contain a subset of the columns in the table that are used as the keys for that index, as well as containing optional additional columns that are copied into the nonclustered index structures to avoid the overhead of looking up the page in the clustered index.
In memory-optimized tables, there really is no concept of clustered versus nonclustered indexes because all indexes are simply pointers to the row structure in memory. Because all columns in the row are not stored in the index structure itself, all indexes on memory-optimized tables are considered to be nonclustered. Of course, the row structure has all the columns, so you can think of every index in a memory-optimized table as being a covering index (an index that has direct access to all columns needed for a query, whether included in the index key or not). This is because it will have access to the full row without any additional lookups.
Within the nonclustered indexes used on memory-optimized tables, there are two distinct types of indexes: B-tree based indexes, which use the syntax NONCLUSTERED, and hash indexes.
Nonclustered indexes
The primary index type for use in memory-optimized tables is nonclustered. These indexes are sometimes referred to as range indexes because, unlike hash indexes, they can be used to efficiently retrieve ranges of rows using inequality predicates rather than the exact key lookups that hash indexes are designed for. Of course, like the traditional B-trees we’re more familiar with, nonclustered indexes can be used for exact key lookups, but they will not be as fast or efficient as hash indexes for that usage.
The syntax for creating a nonclustered index is simply this:
INDEX IX_CartDate NONCLUSTERED (DateCreated ASC)
You can find the context for this fragment near the end of the table definition shown earlier in Listing 10-2.
Note that all indexes in memory-optimized tables are created as part of the table, not added separately.
Nonclustered index structure
Nonclustered indexes on memory-optimized tables are different from traditional B-tree indexes in that their BW-Tree structure gives them the properties of being lock and latch free, and having variable sized pages that are always tightly packed, with no empty space.
Traditional B-tree indexes are subject to significant locking not only when an individual entry is being inserted, but also when the index needs to be rearranged. Entire ranges of the tree are commonly locked when pages need to be split or merged. BW-Tree indexes are capable of inserting pages without ever locking the structure, because they create new pages and simply switch the pointer to the page using the page-mapping table. Swapping the content of pages out also frees you from the need to create large empty pages with room for future insertions. Instead, you just create a new version of the page with the additional entry and replace the previous version of the page.
These characteristics gave rise to the name BW-Tree. As the team that invented the structure was looking for a name, they discussed the attributes: lock-free, latch-free, flash-friendly, and so on. Someone noted that it sounded like a list of current industry buzzwords that this design embodied. From this the BW-Tree (buzzword tree) was named.
The page-mapping table is the key to enabling these indexes to function without the need for locks or latches. The table provides a layer of indirection between the logical page ID within the index and the physical location of the page. Unlike traditional index pages, where the identity of the page and its physical location are bound in a one-to-one relationship, the page-mapping table gives you the ability to effectively replace the contents of an index page by swapping the physical pointer to a new copy of the index page without disrupting any of the pages that refer to it. This is diagrammed in Figure 10-2.
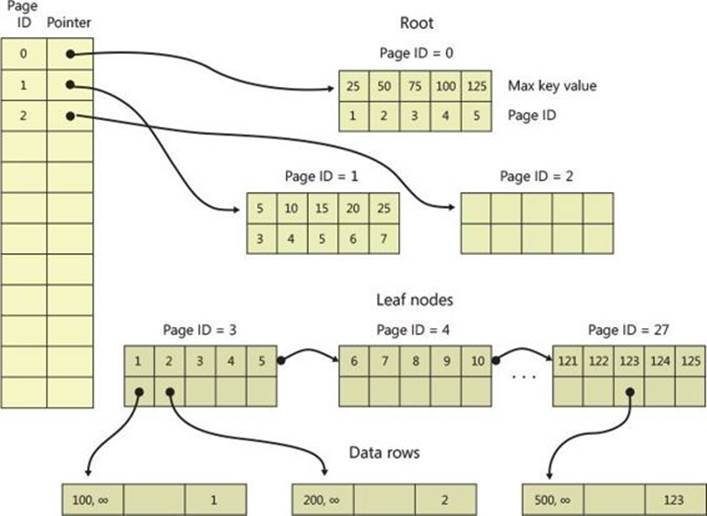
FIGURE 10-2 Nonclustered indexes.
The links between pages of the BW-Tree structure itself are all in the form of logical page IDs. These are then looked up via the page-mapping table. If you need to update a page in the index (to account for a page split or to insert a new value in the leaf nodes), you can simply build the new version of the page and change the entry in the page-mapping table to point to the new version of the page. Say you need to modify index page 101. You just create a new copy of page 101 and call it 101’, with the new contents. You change the pointer in the mapping table entry for page 101 to point to the new copy, 101’. All references to page 101 still go to page 101—you just swapped the physical page pointed to by logical page number 101 with another physical page, atomically.
Each entry in an index page has a key value (in non-leaf pages, this is the high end of the range in the page in the next level of the index) and a payload. For non-leaf pages, the payload is a page ID. For leaf pages, the payload is a pointer to the actual row or rows that match the key value.
The leaf pages are linked to each other in the order of the scan for that index. So, if the index is defined based on a key ASCENDING, each page will link to the page with the next higher grouping of key values. For DESCENDING indexes, pages will link to the leaf page with the next lower grouping of key values. You should understand that, unlike they do in normal B-tree indexes, the links do not go in both directions. This means that if an index is defined in one direction, you cannot retrieve rows in the opposite order without going through a sort step, as you’ll see a little later. Again, these links are done by page ID, not pointer, so that you can replace the contents of a page without having the change ripple through the whole structure. This linking of leaf nodes is what makes scans much more efficient—once you find the starting point of the scan, you simply follow the links between leaf pages until you reach the end point of the scan.
As with most B-tree structures, these indexes can grow and shrink as needed. This is different from the case with hash indexes where you need to pre-size the index for the expected cardinality of the table, as you will see when I discuss hash indexes later.
Nonclustered index behavior
Nonclustered indexes on memory-optimized tables behave similarly to traditional nonclustered/ B-tree indexes, with some key differences, as described in the following sections.
Indexes are latch free
Unlike traditional B-tree indexes, the index structures used for memory-optimized tables use a slightly different structure based on BW-Trees. This structure enables these indexes to operate without any locks or latches. So two threads can insert adjacent rows into an index, even causing page splits, without blocking either thread. This is done in large part by means of the page-mapping table described earlier, which facilitates replacing the contents of an index page in a single atomic operation.
Indexes are single direction
Traditional indexes can be used to produce scans in either direction; however, nonclustered indexes in memory-optimized tables can be traversed only in one direction. So if you need to retrieve data in both directions, you will need to define an index for each direction; otherwise, the scans that are not in the same direction as the index will need a sort operator to reorder the result set.
For the following examples, you use the nonclustered index on DateCreated. Note that it is specified as ASC sort order.
INDEX IX_CartDate NONCLUSTERED (DateCreated ASC)
When the following query is run against this index, you can see that the query plan is able to do a simple index seek on the nonclustered index. This is because the query and the index both use the same sort direction (ascending). (See Figure 10-3.)
SELECT DateCreated
FROM Sales.ShoppingCartItem_inmem
WHERE DateCreated BETWEEN '20131101' AND '20131201'
ORDER BY DateCreated ASC;

FIGURE 10-3 Query plan for an index seek ordered in the same direction as the index definition.
This query is the same as the preceding one, but with the opposite sort order.
SELECT DateCreated
FROM Sales.ShoppingCartItem_inmem
WHERE DateCreated BETWEEN '20131101' AND '20131201'
ORDER BY DateCreated DESC;
You can see in Figure 10-4 that because the query specified a sort order (DESC) that is not the same as the order specified for the index (ASC), the query plan needs to contain a sort operator, which adds to the cost of the query. Also, note that although both queries do the same index seek, because of the additional sort work needed, the seek now accounts for only 20 percent of the cost, meaning that the overall cost of the query has gone up five times the original cost.

FIGURE 10-4 Query plan for in index seek ordered in the opposite direction from the index definition.
Indexes are covering
As with all indexes on memory-optimized tables, the index structures contain pointers directly to the full row structure, so it is not necessary (or indeed possible) to add included columns to the index to reduce lookups. Any lookup gets you to a structure that contains all columns for the row or rows. In that sense, all indexes are “covering,” in that they directly give access to all columns in the table.
Hash indexes
Hash indexes are a new type of index for SQL Server. Hash indexes consist of a hash table, which is an array of pointers to the rows in memory. This array of pointers (buckets) is explicitly sized when the index is created.
Lookups are simply taking the key values for the set of key columns and running them through the hash function, which produces an offset in the array of pointers, which leads directly to the rows that match the hash value. The hash function is designed to spread the data as evenly and randomly across the hash buckets as possible. That means that there is explicitly no ordering within the structures of a hash index, unlike the natural ordering contained in a nonclustered index (whether on a traditional disk-based table or the style described earlier on a memory-optimized table). Of course, if there are far fewer distinct values than rows in the table, the hash function will not be able to spread the data appropriately. In the extreme case, a hash index on a TRUE | FALSE column would have only two buckets populated, regardless of how many rows were in the table. This would obviously not be a good choice. Ideally, there will be one row for each hash bucket. When multiple values hash to the same bucket, the query must follow index chain pointers to find the row needed by the query, which is not as efficient as a direct lookup of a single row.
Hash index structure
Hash indexes are structurally simple. Each hash index on a table consists of an array of hash buckets, which are memory pointers. Each bucket points to the first row that hashes to its offset in the array. For example, if you have a simple char(3) index on the Airport code, you take the key value for a row (say, SEA) and run it through the hash function. This results in an integer in the range of the number of hash buckets. If the index was created with eight buckets, every possible value hashes into a number between 0 and 7. Although it is recommended that you have at least as many buckets as you expect to have distinct key values, there is not a one-to-one mapping. There will likely be empty buckets and other buckets with more than one value in them. The overall design of hash functions is to spread the data as randomly as possible among the array of buckets provided.
As with nonclustered indexes, for each index on a table, there is a pointer in every row for index chains. When more than one row hashes to the same bucket, as in the case of duplicate values, or distinct values that hash to the same bucket, you use these pointers to chain from one row to the next, and so on, until you cover all the rows that hash to that bucket. (See Figure 10-5.)
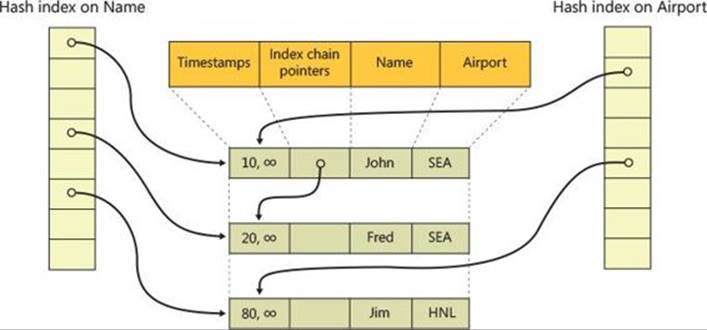
FIGURE 10-5 Hash indexes.
The syntax for creating a hash index (within the creation of the table itself) is similar to the syntax for the nonclustered index I discussed earlier and is taken from Listing 10-2:
INDEX IX_ProductID NONCLUSTERED HASH (ProductID) WITH (BUCKET_COUNT = 1048576)
Note the added HASH keyword as well as the additional clause WITH (BUCKET_COUNT = 1048576). This last clause is what sizes the array of pointers that form the root of the hash index. It is critical to note that, at least in SQL Server 2014, this array cannot be resized once the index and table are created. Unlike nonclustered indexes, hash indexes cannot dynamically resize, and once they are created, the size of the bucket array cannot be changed. This restriction can have significant performance implications, so you need to think carefully about how big the table that this index is a part of will eventually grow.
Hash index behavior
Hash indexes have a specific purpose, which is to optimize exact key lookups. As you can see, they are extremely efficient at doing this. Because all the data structures involved in the hash index are in memory, the entire lookup process translates into directly following memory pointers.
If, however, you are doing a full table scan, the system must visit every hash bucket, whether it is empty or not, and then for each populated bucket, it will follow the index chain pointers of rows that hash to the same bucket.
Unlike B-trees, there is no inherent ordering of the data within hash indexes. That has a couple of practical implications. The first is that there is no way to leverage the index structures to efficiently find a range of values. If the query predicate does not give an exact value, the resulting query will perform a full table scan, filtering for rows between the given values.
It also means you can’t leverage an index’s structure to return an ordered set. Consider the following query:
SELECT ProductID, Name FROM Production.Product ORDER BY ProductID;
When run against the traditional AdventureWorks Production.Product table, this code results in the execution plan seen in Figure 10-6:

FIGURE 10-6 Query plan for a traditional index.
Even though you specified that the results should be ordered by ProductID, there is no sort phase because the B-tree index is inherently ordered. In contrast, as seen in Figure 10-7, when the same query is run against the in-memory version of this same table, which has a hash index on ProductID, you see the following execution plan:
SELECT ProductID, Name FROM Production.Product_inmem ORDER BY ProductID;
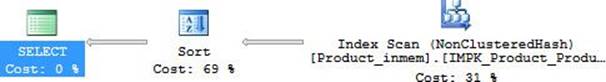
FIGURE 10-7 Query plan for the hash index.
Note that after the index scan, you still need to do a sort, because the scan of a hash index does not produce ordered results automatically.
Where hash indexes work well
Hash indexes excel at single-point lookups, where you have an exact key for the lookup. In this case, the lookup is as simple as running the keys through the hash function and then following the pointer to the data. If more than one row hashes to the same bucket, the initial pointer takes you to the first row, and then you follow the continuation pointers in each row to the next in the chain of records that all hash to that bucket.
Most OLTP systems use the pattern of exact key lookups of one or a few rows in their most performance-critical logic. Think of inventory updates, where you need to find a part number and change the quantity on hand, a billing system that needs to record millions of cell-phone call records per day, or an ordering system where a single order and its line items are referenced repeatedly through the business process. In all these scenarios, you can see that these processes can be greatly sped up if you have an index structure that is optimized for this pattern of access.
Things to watch out for
As fast as hash indexes are when used properly, there are cases where they can be much less efficient and cause surprising performance issues. I’ll go through a few scenarios and explain what happens to cause the problems.
Poorly configured bucket count
When a hash index is created, you are required to specify a bucket count. The bucket count should ideally be close to 1 – 2X the number of unique key values that are expected in the table. For example, if you have an index on part_no and expect 10,000 unique part numbers, you specify a BUCKET_COUNT of 10,000 – 20,000. If you use a bucket count of 100, those 10,000 part numbers get spread across only 100 buckets. So, on average, every bucket will contain 100 rows. That means, in turn, that on average a lookup, which could be a one-pointer lookup, will need to go through 50 rows before the correct row is found. If the size is further off, the performance impact is even more severe.
The other impact of undersizing hash buckets relates to performing an insert. To insert a row in a hash index where there are collisions on the hash buckets, the system has to first find the proper insertion point. If the values are all duplicates, this isn’t a big impact because you simply insert in the head of the chain. If, however, there are lots of hash collisions but NOT many duplicate values, you need to walk the chain of duplicates to find the proper place for this new value. The list is sorted by key value, so all entries for duplicate keys are grouped together within the list. New duplicates are inserted at the beginning of the group with the same key value.
Take the example of the following two tables, which is shown in Listing 10-3.
LISTING 10-3 Tables with different bucket counts
-- The first table has a bucket count of 8
CREATE TABLE dbo.tTable
(
c INT NOT NULL,
PRIMARY KEY NONCLUSTERED HASH (c) WITH ( BUCKET_COUNT = 8)
)
WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_ONLY );
-- The second table is identical except it has a bucket count of 2,000,000
CREATE TABLE dbo.tTable2
(
c int NOT NULL,
PRIMARY KEY NONCLUSTERED HASH (c) WITH ( BUCKET_COUNT = 2000000)
)
WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_ONLY );
Here you created two identical tables with a single column, which is a primary key (ensuring that there will be no duplicate values). The only difference between them is that the bucket count on the first table is 8, while the bucket count on the second is 2 million.
If you insert a modest number of rows—say, 10 or 20—you won’t see much difference in execution time. If, however, you insert 100,000 rows in each table, you do see a large difference in execution time for inserting the batch of 100,000 rows. In fact, if you plot a number of points with varying numbers of rows inserted, the elapsed time becomes exponentially larger as the row count increases. (See Table 10-1.) You use nondurable tables to eliminate log growth or other IO issues, and you use natively compiled procedures to get as efficient an execution as possible:
CREATE PROCEDURE Fill_tTable
@iterations INT
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH
(TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'us_english');
DECLARE @i INT = 0;
WHILE (@i < @iterations)
BEGIN
INSERT INTO dbo.tTable (C) VALUES (@i);
SET @i += 1;
END;
END;
GO
CREATE PROCEDURE Fill_tTable2
@iterations INT
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER AS
BEGIN ATOMIC WITH
(TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'us_english')
DECLARE @i INT = 0;
WHILE (@i < @iterations)
BEGIN
INSERT INTO dbo.tTable2 (C) VALUES (@i);
SET @i += 1;
END;
END;
GO
EXEC Fill_tTable 100000;
EXEC Fill_tTable2 100000;

TABLE 10-1 Performance comparison of the two tables with different bucket counts
Even in this trivial example, there is a significant difference in both CPU and elapsed times. In a more complex ETL load involving billions of rows, this becomes a significant performance issue.
You can determine the health of a hash index by querying the DMV sys.dm_db_xtp_hash_index_stats:
SELECT
object_name(hs.object_id) AS [object name],
hs.total_bucket_count,
hs.empty_bucket_count,
floor((cast(empty_bucket_count as float)/total_bucket_count) * 100) AS[empty_bucket_percent],
hs.avg_chain_length,
hs.max_chain_length
FROM sys.dm_db_xtp_hash_index_stats AS hs
JOIN sys.indexes AS i
ON hs.object_id=i.object_id AND hs.index_id=i.index_id;
This query produces the following results:
Object total_bucket_ empty_bucket_ empty_bucket_ avg_chain_ max_chain_
Name count count percent length length
------- ------------- ------------- ------------- ---------- -----------
tTable 8 0 0 12500 12543
tTable2 33554432 33454455 99 1 2
Here you see that for the first table, there are no empty buckets, and the average hash collision chain is 12,500. This means that by the time this table was full, insertions had to scan through over 6,000 entries on average to find the proper insertion point. For the second table, in contrast, there are nearly 2 million empty buckets, and the average chain length is 1. With this query, you look at both the empty bucket percent and the average chain length. Ideally, you’re looking for an empty bucket percent of over 30 percent and an average chain length in the single digits.
If the bucket count is oversized, the impacts are not nearly as severe, so it is always better to err on the side of oversizing. There are two impacts to oversizing:
![]() First, the hash buckets are each an 8-byte pointer, which consumes memory, so a dramatically oversized hash-bucket count will result in wasting memory. Because there is only one hash table per index, this is usually not a significant factor.
First, the hash buckets are each an 8-byte pointer, which consumes memory, so a dramatically oversized hash-bucket count will result in wasting memory. Because there is only one hash table per index, this is usually not a significant factor.
![]() The second impact comes into play when the query results in a table scan. Table scans are implemented by visiting each bucket in the index being scanned. The optimizer will choose the hash index with the lowest bucket count to scan, because that will minimize the number of buckets to be visited. If 90 percent of the buckets are empty because of an oversized hash table, the query will still need to visit every bucket, which slows down the query substantially. If you follow my recommendation that there be at least one nonclustered index on a table, this will not be a problem because the optimizer will choose the BW-Tree nonclustered index for the scan.
The second impact comes into play when the query results in a table scan. Table scans are implemented by visiting each bucket in the index being scanned. The optimizer will choose the hash index with the lowest bucket count to scan, because that will minimize the number of buckets to be visited. If 90 percent of the buckets are empty because of an oversized hash table, the query will still need to visit every bucket, which slows down the query substantially. If you follow my recommendation that there be at least one nonclustered index on a table, this will not be a problem because the optimizer will choose the BW-Tree nonclustered index for the scan.
Query predicates that don’t include all key columns
The hash function is a mathematical function, which takes all the key columns as input and produces an offset in the hash array. If the query predicate doesn’t give all the columns, the function can’t work, because it doesn’t have all the required inputs. When this happens, the hash index can’t be used. The result of this is usually a full table scan, so this error takes you from a direct pointer lookup to a full table scan, which has a disastrous effect on performance.
This situation, unfortunately, is easy to fall into because with traditional B-tree indexes, we’re used to being able to specify the leading columns of an index and get a plan that uses an index seek. When this same query is run against a hash index, the result will be a table scan if not all key columns in the hash index are provided in the query predicate. It can easily produce a situation where a direct conversion from a traditional table to a memory-optimized table can result in decreased performance, when the original queries use only leading columns. In this case, it’s better to either specify an index with fewer columns or add an additional index for the queries that cannot specify all key columns for the original index. You can see this approach in Listing 10-4, which produces the query plan shown in Figure 10-8.
LISTING 10-4 Illustration of the results of queries that specify only leading columns
CREATE TABLE dbo.IndexExample (
ID INT NOT NULL IDENTITY(1,1) PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1024),
C1 INT NOT NULL,
C2 INT NOT NULL,
C3 INT NOT NULL,
C4 INT NOT NULL,
-- Nonclustered HASH index for columns C1 & C2
INDEX IX_HashExample NONCLUSTERED HASH
(
C1, C2
)WITH ( BUCKET_COUNT = 1048576),
--Nonclustered (Bw-Tree) index for columns C3 & C4
INDEX IX_NonClusteredExample NONCLUSTERED
(
C3, C4
)
)WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA );
GO
INSERT INTO dbo.IndexExample (C1, C2, C3, C4) VALUES (1,1,1,1);
INSERT INTO dbo.IndexExample (C1, C2, C3, C4) VALUES (2,2,2,2);
--The first query uses the leading column of the hash index
SELECT C1, C2 FROM dbo.IndexExample WHERE C1 = 1;
--The second query uses the leading column of the Bw-Tree index
SELECT C1, C2 FROM dbo.IndexExample WHERE c3 = 1;

FIGURE 10-8 Plan resulting from querying the leading column of a hash index.
This is the plan you get when querying a hash index with a predicate that contains leading columns but not all the key columns from the hash index. Notice that even though there is an index on the table that includes this column, you are still doing a full table scan and then filtering rather than taking advantage of the index.
Unlike the previous example in Figure 10-8, when you query a BW-Tree index with only the leading column, and not all key columns, you can still seek using the index and avoid a full table scan. This is the behavior we’re familiar with, and it results in the plan in Figure 10-9.

FIGURE 10-9 Plan resulting from querying the leading column of a nonclustered (BW-Tree) index.
This demonstrates clearly why simply doing a straight conversion from an existing disk-based table and application to a memory-optimized table can cause surprising and negative performance results. As fast as memory-optimized tables are, they usually can’t make up for scanning millions of rows rather than doing a direct index seek. So you need to carefully consider your indexes in light of all the queries that can be done on a table.
New design patterns
So now, you understand that a hash index is much more efficient in cases where the query predicate includes all the index’s key columns. You also understand that getting sorted output from a hash index will require extra steps to explicitly sort the output, and you know that if there are queries with predicates that do not include all the key columns of a hash index, this will result in very poor performance by causing a full table scan. So what do you do when you have a table that is queried in a performance-critical area of the application, using a predicate with three columns that results in a single-row lookup, and another frequent query that needs sorted output based on the first two columns?
If the performance of the BW-Tree index for exact-key lookups is acceptable, this is the simplest answer. Even though the hash index would be faster for those exact-key lookups, overall using a single BW-Tree index might be faster.
Another option if the exact-key lookup speed is critical is to define two indexes with the same key columns, one hash and one BW-Tree. The optimizer can then determine which index would most efficiently satisfy the query. Queries that require sorted output (in the same direction as the index), or that provide only leading columns, would be satisfied using the BW-Tree index.
If the exact-key queries dominate and sorted output is rarely required, it might be advantageous to define a single hash index with fewer key columns, to match the minimum number of columns provided in common query predicates. That way, you can use the hash to get the subset of rows that match those columns and then filter that set on the rest of the predicate.
In Listing 10-5, the optimizer chooses between two indexes based on the query predicates, even though the indexes have identical sets of key columns.
LISTING 10-5 Example of the optimizer choosing between indexes based on query attributes
CREATE TABLE dbo.tTable3
(
C1 int NOT NULL,
C2 int NOT NULL,
C3 int NOT NULL,
C4 int NOT NULL,
PRIMARY KEY NONCLUSTERED HASH (C4)
WITH ( BUCKET_COUNT = 2097152),
INDEX HASH_IDX NONCLUSTERED HASH (C1, C2, C3)
WITH ( BUCKET_COUNT = 2097152),
INDEX NC_IDX NONCLUSTERED (C1, C2, C3)
) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA );
GO
INSERT INTO dbo.tTable3 VALUES(1,1,1,1),(1,1,1,2),(1,1,1,3);
GO
-- Exact key lookup, will be satisfied by the hash index
SELECT C1, C2, C3, C4 FROM dbo.tTable3 WHERE C1 = 1 AND C2=1 AND C3=1;
-- Query with a range predicate will be satisfied by the BW-Tree index
SELECT C1, C2, C3, C4 FROM dbo.tTable3 WHERE C1 = 1 AND C2=1 AND C3 BETWEEN 0 AND 2;
-- Query on leading columns, will be satisfied by the BW-Tree index.
SELECT C1, C2, C3, C4 FROM dbo.tTable3 WHERE C1 = 1 AND C2=1;
Figure 10-10 illustrates the query plan for the first query, showing that when the predicate supplied all key columns and there was no ORDER BY clause, the optimizer chose the HASH_IDX index.

FIGURE 10-10 Plan for a query with exact matches on all key columns.
The next plan, which you can see in Figure 10-11, shows that when the same predicate is supplied but the third element is expressed as a range (BETWEEN), the optimizer will choose the BW-Tree index.

FIGURE 10-11 Plan for a query with a range predicate.
The final query, shown in Figure 10-12, will also generate a plan that uses a nonclustered index to find all the rows that satisfy a predicate that contains only some leading key columns.
FIGURE 10-12 Plan for a query with some leading key columns.
Execution environments
All transactions involving memory-optimized tables execute, at least in part, in a different environment than classic SQL transactions. As I’ve discussed, the In-Memory OLTP system is a distinct “engine within an engine.” The In-Memory OLTP engine has some unique properties and semantics:
![]() Memory-optimized tables are always in memory, which means that transactions won’t stall for IO, optimizer costing is somewhat different so that it accounts for all-memory access, and of course you need to have enough memory to hold all your memory-optimized data.
Memory-optimized tables are always in memory, which means that transactions won’t stall for IO, optimizer costing is somewhat different so that it accounts for all-memory access, and of course you need to have enough memory to hold all your memory-optimized data.
![]() Transactions on memory-optimized tables are all done using isolation semantics, which are entirely lock free. This is usually advantageous; however, there are some scenarios you’ll need to be aware of.
Transactions on memory-optimized tables are all done using isolation semantics, which are entirely lock free. This is usually advantageous; however, there are some scenarios you’ll need to be aware of.
Depending on how the query is executed, there are two different environments that can be used. The simpler of the two is known as query interop. This is where the query processing proceeds using the same layers of SQL Server as traditional queries, using the standard query engine. However, instead of using the layer that retrieves data from the buffer pool (or disk, if the page is not currently in buffer pool), these queries access the data directly in the In-Memory OLTP environment.
The second execution environment is via natively compiled procedures. This environment has the highest level of performance gains and execution efficiency; however, it does come with a greater number of restrictions, both in terms of T-SQL surface area, as well as transactional semantics.
Query interop
The query interop execution environment is used for ad hoc SQL queries as well as traditional stored procedures and other T-SQL modules. You can reference memory-optimized tables also from other modules like triggers, user-defined functions (UDFs), and so on. It really is nothing more than writing a T-SQL query against one or more memory-optimized tables. In this environment, you have the least amount of work to do to adapt to the In-Memory OLTP environment, because you do not need to port stored procedures to the more restrictive natively compiled surface area. This does not mean there is no work at all to do, but it means the work involved to port will be significantly smaller and simpler.
So, what are the considerations when using query interop?
Isolation
In-Memory OLTP currently offers a restricted set of isolation levels. Snapshot is the default isolation level, and Repeatable Read and Serializable isolation levels are supported. Read Uncommitted, Read Committed, and Read Committed Snapshot isolation levels are not supported with memory-optimized tables. Because the isolation level is set at a minimum at the transaction level, any transaction that involves a memory-optimized table cannot use any of the unsupported isolation levels. The entire transaction must run in the Snapshot, Repeatable Read, or Serializable isolation level.
In traditional SQL Server transactions, the default, and most common, isolation level is Read Committed. The Read Committed isolation level specifies that a transaction will see only data that has been committed, not any data that might be later rolled back. If such a transaction encounters a row that has been modified but not yet committed, the transaction will block until the update is resolved one way or the other. This is not possible in the lock-free environment of In-Memory OLTP.
Deadlocks and blocking
The following examples demonstrate the differences between traditional and in-memory environments.
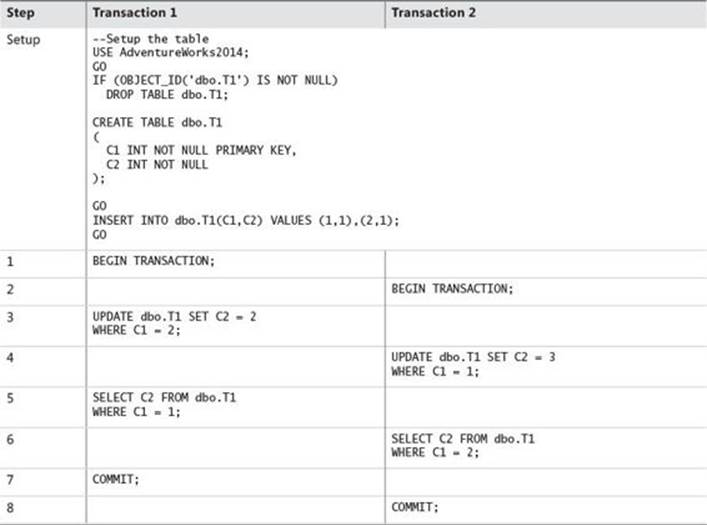
TABLE 10-2 Example of a deadlock with traditional tables
In this example, you have a simple table and two transactions accessing it:
![]() In steps 1 and 2, Transactions 1 and 2 each begin.
In steps 1 and 2, Transactions 1 and 2 each begin.
![]() In step 3, Transaction 1 updates the row where C1 = 2, acquiring an exclusive (X) lock on that row.
In step 3, Transaction 1 updates the row where C1 = 2, acquiring an exclusive (X) lock on that row.
![]() In step 4, Transaction 2 updates the row where C1 = 1, acquiring an X lock on that row.
In step 4, Transaction 2 updates the row where C1 = 1, acquiring an X lock on that row.
![]() In step 5, Transaction 1 selects from the row where C1 = 1 and blocks behind Transaction 2’s X lock.
In step 5, Transaction 1 selects from the row where C1 = 1 and blocks behind Transaction 2’s X lock.
![]() In step 6, Transaction 2 selects from the row where C1 = 2 and blocks behind Transaction 1’s X lock.
In step 6, Transaction 2 selects from the row where C1 = 2 and blocks behind Transaction 1’s X lock.
This forms a classic deadlock, and one of the transactions will be chosen as the victim and aborted.
In contrast, Table 10-3 shows what happens when the sequence is run against a memory-optimized table.
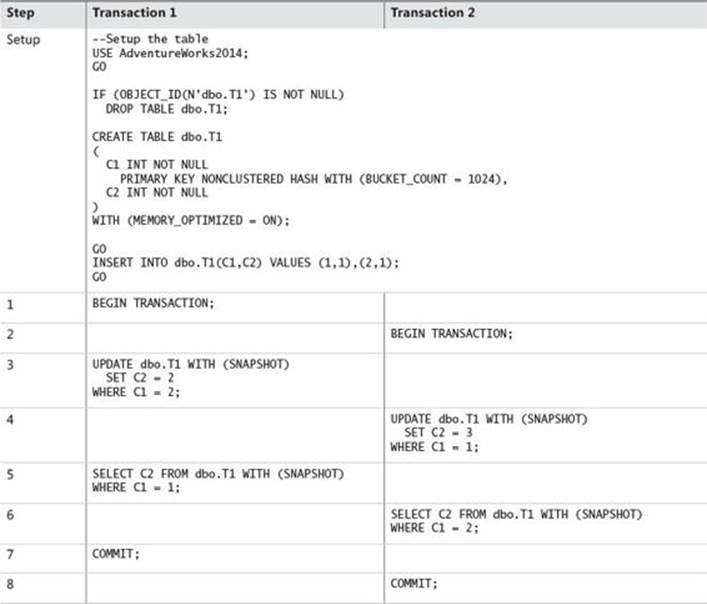
TABLE 10-3 Example of a deadlock with memory-optimized tables
![]() In steps 1 and 2, Transactions 1 and 2 each begin.
In steps 1 and 2, Transactions 1 and 2 each begin.
![]() In step 2, Transaction 1 updates the row where C1 = 2, creating a new version of that row.
In step 2, Transaction 1 updates the row where C1 = 2, creating a new version of that row.
![]() In step 3, Transaction 2 updates the row where C1 = 1, creating a new version of that row.
In step 3, Transaction 2 updates the row where C1 = 1, creating a new version of that row.
![]() In step 4, Transaction 1 selects from the row where C1 = 1 and sees the original version of that row (because Transaction 2 has not yet committed).
In step 4, Transaction 1 selects from the row where C1 = 1 and sees the original version of that row (because Transaction 2 has not yet committed).
![]() In step 5, Transaction 2 selects from the row where C1 = 2 and sees the original version of that row (because Transaction 1 has not yet committed).
In step 5, Transaction 2 selects from the row where C1 = 2 and sees the original version of that row (because Transaction 1 has not yet committed).
Commit validation errors
When two transactions against a memory-optimized table have a write-write conflict, both transactions cannot be allowed to succeed. Instead, if a second transaction attempts to modify a row before the first transaction modifying the same row has committed, the second transaction updating the row will fail. This is very different behavior than the case of traditional tables, where one transaction will just block until the first update is complete.
Consider Table 10-4, where you create a memory-optimized table and then have two transactions attempting to modify the same row.
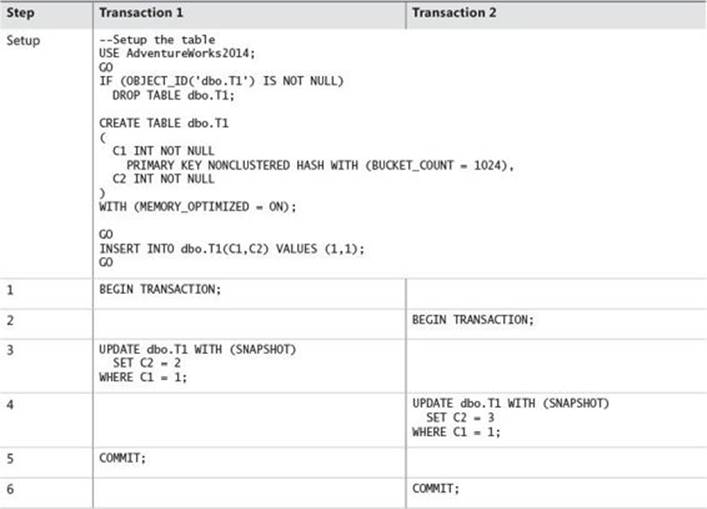
TABLE 10-4 Example of blocking versus commit error in a memory-optimized table
![]() In steps 1 and 2, Transaction 1 and Transaction 2 issue BEGIN TRANSACTION statements starting the context.
In steps 1 and 2, Transaction 1 and Transaction 2 issue BEGIN TRANSACTION statements starting the context.
![]() In step 3, Transaction 1 then updates a row in the database. This creates a new row version with a timestamp that is more recent than the start of either transaction.
In step 3, Transaction 1 then updates a row in the database. This creates a new row version with a timestamp that is more recent than the start of either transaction.
![]() In step 4, Transaction 2 attempts to modify the same row. It detects that the row has been modified and that it is not yet committed. In this instance, the transaction cannot proceed, and Transaction 2 fails with the following error:
In step 4, Transaction 2 attempts to modify the same row. It detects that the row has been modified and that it is not yet committed. In this instance, the transaction cannot proceed, and Transaction 2 fails with the following error:
Msg 41302, Level 16, State 110, Line 8
The current transaction attempted to update a record that has been updated since this
transaction started. The transaction was aborted.
Msg 3998, Level 16, State 1, Line 8
Uncommittable transaction is detected at the end of the batch. The transaction is rolled
back.
The statement has been terminated.
Table 10-5 presents an example of the differences between the blocking behavior of traditional tables and the commit error that results for in-memory tables.
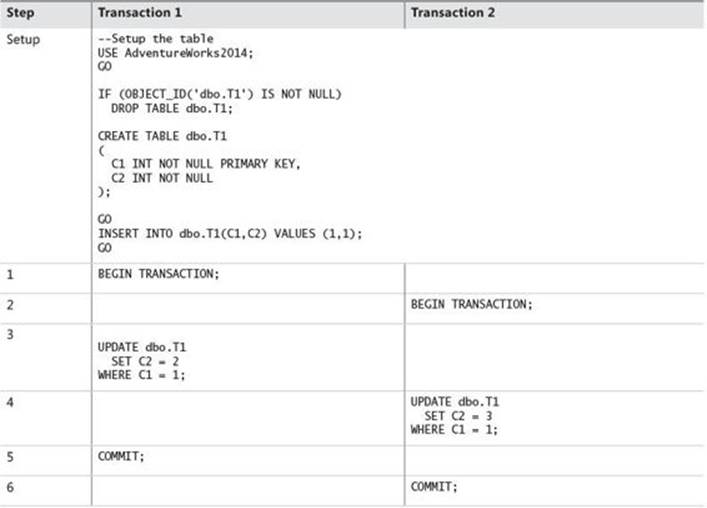
TABLE 10-5 Example of blocking versus commit error in a traditional table
By contrast, if the same series of updates had been attempted against a non-memory-optimized table, the following happens:
![]() In steps 1 and 2, Transaction 1 and Transaction 2 issue BEGIN TRANSACTION statements starting the context.
In steps 1 and 2, Transaction 1 and Transaction 2 issue BEGIN TRANSACTION statements starting the context.
![]() In step 3, Transaction 1 then updates a row in the database. It acquires an exclusive lock on the row.
In step 3, Transaction 1 then updates a row in the database. It acquires an exclusive lock on the row.
![]() In step 4, Transaction 2 attempts to modify the same row, but it is blocked by Transaction 1’s exclusive lock. It will stall and wait until Transaction 1 completes.
In step 4, Transaction 2 attempts to modify the same row, but it is blocked by Transaction 1’s exclusive lock. It will stall and wait until Transaction 1 completes.
![]() In step 5, Transaction 1 completes by committing. This releases the lock on the row, and Transaction 2 proceeds with its update.
In step 5, Transaction 1 completes by committing. This releases the lock on the row, and Transaction 2 proceeds with its update.
![]() In step 6, Transaction 2 completes by committing.
In step 6, Transaction 2 completes by committing.
Note that in the case of the memory-optimized table, because Transaction 2’s update would not complete, the value of C2 would be 2, as updated by Transaction 1. In the case of a traditional table, Transaction 2 would eventually succeed, so the final value of C2 would be 3.
To deal with these commit validation errors, transactions should be written with the same sort of logic that would be applied to deadlock retries, as shown in Listing 10-6.
LISTING 10-6 Retry logic for validation failures
-- number of retries – tune based on the workload
DECLARE @retry INT = 10;
WHILE (@retry > 0)
BEGIN
BEGIN TRY
-- exec usp_my_native_proc @param1, @param2, ...
-- or
-- BEGIN TRANSACTION
-- ...
-- COMMIT TRANSACTION
SET @retry = 0;
END TRY
BEGIN CATCH
SET @retry -= 1;
IF (@retry > 0 AND error_number() in (41302, 41305, 41325, 41301, 1205))
BEGIN
-- These errors cannot be recovered and continued from. The transaction must
-- be rolled back and completely retried.
-- The native proc will simply rollback when an error is thrown, so skip the
-- rollback in that case.
IF XACT_STATE() = -1
ROLLBACK TRANSACTION;
-- use a delay if there is a high rate of write conflicts (41302)
-- length of delay should depend on the typical duration of conflicting
-- transactions
-- WAITFOR DELAY '00:00:00.001';
END
ELSE
BEGIN
-- insert custom error handling for other error conditions here
-- throw if this is not a qualifying error condition
THROW;
END;
END CATCH;
END;
Cross-database queries
With SQL Server 2014, you cannot execute a query that accesses a memory-optimized table and any table on another database, whether the database is in the same instance or in another instance. You can, however, use memory-optimized table variables in cross-database transactions.
Parallelism
Transactions that access memory-optimized tables in any way will not use parallel plans. This is a limitation of SQL Server 2014 that will likely be removed in a future release. These transactions will effectively have a Degree of Parallelism (MAXDOP) of 1. This can have severe implications for the performance of the queries, which in some cases can overwhelm the performance advantages of the memory-optimized tables. For example, if you are joining a memory-optimized table with a table based on a Clustered Column Store index, you would expect that these two technologies, which are each extremely fast in their own realms, would work very well together. Unfortunately, the column store performance design is based on high degrees of parallelism. Column stores are able to use all cores of the system in parallel to perform scans of huge data sets in a very short time. When a memory-optimized table is introduced to that query, the overall parallelism of the query is dropped to 1, and the performance of column store indexes is severely affected.
This is an extreme example of the performance effects of the current limitations of parallelism in In-Memory OLTP queries, but there are many other cases where the effect might still be felt, even if it is not nearly as pronounced. Fortunately, it is simple to detect when this might be the issue in a performance problem by looking at the query plan of the disk-based query and comparing it with the plan for the memory-optimized query.
You can see from the first plan that the parallel operator is used consistently throughout the plan, while in the second plan from the memory-optimized query, the plan is entirely based on serial operators.
You can also look at or search the XML representation of the query plan for the <RelOp> tags and look for the Parallel attribute:
<RelOp AvgRowSize="121" EstimateCPU="0.27821" EstimateIO="0" EstimateRebinds="0"
EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="22475.9" LogicalOp="Inner Join"
NodeId="4" Parallel="true" PhysicalOp="Hash Match" EstimatedTotalSubtreeCost="29.8961">
In a query with memory-optimized tables, this looks like the following:
<RelOp AvgRowSize="90" EstimateCPU="2.51839" EstimateIO="0" EstimateRebinds="0"
EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="99900" LogicalOp="Inner Join"
NodeId="7" Parallel="false" PhysicalOp="Hash Match" EstimatedTotalSubtreeCost="20.3456">
To validate that this is indeed the problem, you can execute the query on the disk-based tables, where performance is as expected, with the MAXDOP query hint set to 1, and see if the results are still consistent.
Cardinality and statistics
For the query optimizer to properly determine the optimum query plan, it needs the input of the estimated cardinality of the tables involved, as well as estimates for the number of rows in each table that will satisfy the query predicates. SQL Server will automatically create and update statistics to make sure the optimizer has accurate information to work with. There are heuristics for when an update gets triggered, because there is cost involved in building the new statistics.
In-Memory OLTP has some behaviors that are not what you might be used to in classic SQL. Some of them are fundamental to the architecture, and others are the result of limitations in SQL Server 2014 and will likely change in future releases.
Statistics and natively compiled procedures
Because natively compiled procedures are optimized via the SQL Server optimizer before the code is compiled into a DLL, they do not change when the data or statistics change. Outside of the memory-optimized OLTP environment, changing statistics would trigger a recompile of queries including stored procedures, but for natively compiled procedures, this does not occur.
![]() Note
Note
When setting up a new table to be memory optimized, if possible it is best to load data into the table before creating any natively compiled stored procedures that will access it. That way, the optimizer will have more valid data to work with, and the procedure will have a more optimum plan.
If the content of a table accessed by a natively compiled procedure changes sufficiently enough that performance starts to degrade, you might need to drop and re-create the stored procedure to force it to be recompiled with the current statistics.
Updating statistics
With SQL Server 2014, when statistics on a memory-optimized table are updated, the engine does not use sampling as it would for traditional tables. Instead, it will perform a full scan of the table or tables. Although this will generally give more accurate results, it will take significantly longer, which can cause some disruptions in performance.
ATOMIC blocks
Natively compiled procedures are required to consist of exactly one atomic block. It must encapsulate all of the T-SQL logic in the procedure.
An ATOMIC block is a new concept introduced in SQL Server 2014. It represents a set of statements that are all guaranteed to succeed or fail as a unit, atomically. ATOMIC blocks interact with SQL transactions in the following ways:
![]() If there is a current SQL transaction, the ATOMIC block will create a savepoint and join in the existing transaction.
If there is a current SQL transaction, the ATOMIC block will create a savepoint and join in the existing transaction.
![]() If there is no current transaction, the ATOMIC block will create one whose scope is the block itself.
If there is no current transaction, the ATOMIC block will create one whose scope is the block itself.
![]() If there is an exception thrown by the block, the block is rolled back as a whole.
If there is an exception thrown by the block, the block is rolled back as a whole.
![]() If the block succeeds, the savepoint it created is committed, and if it created its own transaction, that transaction is committed.
If the block succeeds, the savepoint it created is committed, and if it created its own transaction, that transaction is committed.
You can think of the entire block being modeled as if it were a single statement. Thus, it is not possible to create, roll back, or commit transactions within that block. Any commits or rollbacks must be done outside of the context of an atomic block.
Natively compiled procedures
As I mentioned, natively compiled stored procedures are extremely efficient, because they are precompiled into DLLs and loaded into the engine context. Note that there is some overhead involved in transitioning between the interpreted environment you use for interop queries, or for stored procedures that do not access memory-optimized tables, and the natively compiled environment. For very small amounts of logic (single statement transactions, for example), you will likely find better performance by just performing the query directly in interop. However, the more logic you can execute within the context of a native procedure, the more benefit you will see.
To get the most out of natively compiled procedures, you should try to do as much business logic as possible within each invocation of a native procedure. One way to pass a large unit of work into a native procedure for processing entirely within the procedure is to pass in a set of rows in the form of a table-valued parameter (TVP).
TVPs
To be accessed from inside a natively compiled procedure, TVPs must be memory optimized. This presents a great advantage that goes beyond natively compiled procedures. Memory-optimized TVPs can be used by traditional T-SQL procedures in much the same way as temp tables can, and in many cases they are far more efficient because they don’t need to be instantiated in tempdb. The syntax for creating a memory-optimized table type can be seen in the AdventureWorks sample mentioned earlier, which is shown in Listing 10-7.
LISTING 10-7 Memory-optimized table type
CREATE TYPE Sales.SalesOrderDetailType_inmem AS TABLE(
OrderQty SMALLINT NOT NULL,
ProductID INT NOT NULL,
SpecialOfferID INT NOT NULL,
LocalID INT NOT NULL,
INDEX IX_ProductID NONCLUSTERED HASH
(
ProductID
) WITH ( BUCKET_COUNT = 8),
INDEX [IX_SpecialOfferID] NONCLUSTERED HASH
(
SpecialOfferID
) WITH ( BUCKET_COUNT = 8)
)
WITH ( MEMORY_OPTIMIZED = ON );
This is then used in the calling of a native procedure, as shown in Listing 10-8.
LISTING 10-8 Using a table-valued parameter with a native procedure
---------------------------------------------------------------------
-- Table Valued Parameters
---------------------------------------------------------------------
-- Delete the old objects if they exist
IF (OBJECT_ID('Sales.usp_InsertSalesOrder_inmem') IS NOT NULL)
DROP PROCEDURE Sales.usp_InsertSalesOrder_inmem;
IF (TYPE_ID('Sales.SalesOrderDetailType_inmem') IS NOT NULL)
DROP TYPE Sales.SalesOrderDetailType_inmem;
-- Memory Optimized Table Type
CREATE TYPE Sales.SalesOrderDetailType_inmem AS TABLE(
OrderQty SMALLINT NOT NULL,
ProductID INT NOT NULL,
SpecialOfferID INT NOT NULL,
LocalID INT NOT NULL,
INDEX IX_ProductID NONCLUSTERED HASH
(
ProductID
) WITH ( BUCKET_COUNT = 8),
INDEX [IX_SpecialOfferID] NONCLUSTERED HASH
(
SpecialOfferID
) WITH ( BUCKET_COUNT = 8)
)
WITH ( MEMORY_OPTIMIZED = ON );
GO
--Using a table valued parameter with a native proc
CREATE PROCEDURE Sales.usp_InsertSalesOrder_inmem
@SalesOrderID INT OUTPUT,
@DueDate DATETIME2(7) NOT NULL,
@CustomerID INT NOT NULL,
@BillToAddressID INT NOT NULL,
@ShipToAddressID INT NOT NULL,
@ShipMethodID INT NOT NULL,
@SalesOrderDetails Sales.SalesOrderDetailType_inmem READONLY,
@Status TINYINT NOT NULL = 1,
@OnlineOrderFlag BIT NOT NULL = 1,
@PurchaseOrderNumber NVARCHAR(25) = NULL,
@AccountNumber NVARCHAR(15) = NULL,
@SalesPersonID INT NOT NULL = -1,
@TerritoryID INT = NULL,
@CreditCardID INT = NULL,
@CreditCardApprovalCode VARCHAR(15) = NULL,
@CurrencyRateID INT = NULL,
@Comment NVARCHAR(128) = NULL
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH
(TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'us_english')
DECLARE @OrderDate DATETIME2 NOT NULL = sysdatetime();
DECLARE @SubTotal MONEY NOT NULL = 0;
SELECT @SubTotal = ISNULL(SUM(p.ListPrice * (1 - so.DiscountPct)),0)
FROM @SalesOrderDetails od
JOIN Sales.SpecialOffer_inmem so ON od.SpecialOfferID=so.SpecialOfferID
JOIN Production.Product_inmem p ON od.ProductID=p.ProductID;
INSERT INTO Sales.SalesOrderHeader_inmem
( DueDate,
Status,
OnlineOrderFlag,
PurchaseOrderNumber,
AccountNumber,
CustomerID,
SalesPersonID,
TerritoryID,
BillToAddressID,
ShipToAddressID,
ShipMethodID,
CreditCardID,
CreditCardApprovalCode,
CurrencyRateID,
Comment,
OrderDate,
SubTotal,
ModifiedDate)
VALUES
(
@DueDate,
@Status,
@OnlineOrderFlag,
@PurchaseOrderNumber,
@AccountNumber,
@CustomerID,
@SalesPersonID,
@TerritoryID,
@BillToAddressID,
@ShipToAddressID,
@ShipMethodID,
@CreditCardID,
@CreditCardApprovalCode,
@CurrencyRateID,
@Comment,
@OrderDate,
@SubTotal,
@OrderDate
);
SET @SalesOrderID = SCOPE_IDENTITY();
INSERT INTO Sales.SalesOrderDetail_inmem
(
SalesOrderID,
OrderQty,
ProductID,
SpecialOfferID,
UnitPrice,
UnitPriceDiscount,
ModifiedDate
)
SELECT
@SalesOrderID,
od.OrderQty,
od.ProductID,
od.SpecialOfferID,
p.ListPrice,
p.ListPrice * so.DiscountPct,
@OrderDate
FROM @SalesOrderDetails od
JOIN Sales.SpecialOffer_inmem so
ON od.SpecialOfferID=so.SpecialOfferID
JOIN Production.Product_inmem p ON od.ProductID=p.ProductID;
END;
GO
Here you see the parameter @SalesOrderDetails being passed in as the table variable type defined earlier, Sales.SalesOrderDetailType_inmem. It is then used to insert a whole block of rows into a memory-optimized table, using the INSERT INTO...SELECT FROM syntax. Without this capability, you would need to iterate through the set of rows in a wrapper procedure, calling a native procedure that inserted a single row for each individual row. That would have been far less efficient than using a TVP and accomplishing all of this logic in a single invocation.
Retry logic
We discussed earlier that there are situations where transactions will fail with validation errors, which are a new class of errors not seen outside of memory-optimized table logic and that need to be handled with retry logic similar to what might be used for deadlock retries. The two primary errors to be dealt with are write conflict errors (error 41302) and commit dependency failures (error 41301). In general, these are rare errors, but they should be handled properly to avoid unnecessary application failures. You can see an example of this retry logic in Listing 10-6.
Cross-container queries
The term cross-container queries refers to queries that access tables in the memory-optimized area as well as traditional disk-based tables. Because these two areas of the database engine use different methods to ensure consistency, some restrictions apply regarding the isolation levels that can be used.
Table 10-6 shows which isolation levels can be combined and which ones will not work successfully together.
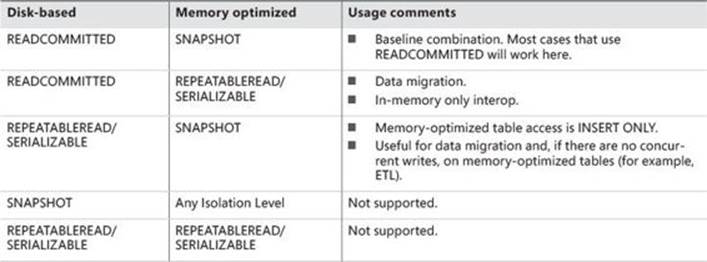
TABLE 10-6 Cross-container isolation levels
Surface-area restrictions
The implementation of In-Memory OLTP in SQL Server 2014 has a number of restrictions in surface area, both in the Data Definition Language (DDL) for defining the schema and the Data Manipulation Language (DML) for accessing the tables. Although these restrictions are expected to ease over time, for now you need to deal with them. In some cases, there are ready workarounds. In other cases, there are somewhat cumbersome workarounds, and for some situations the limitations might make a specific operation or table not suitable for migration until the limitations are removed. In this section, I’ll discuss some of the more significant limitations and strategies for dealing with them. You can find the full list of restrictions and pointers to documentation on them in Books Online at http://msdn.microsoft.com/en-us/library/dn246937(v=sql.120).aspx.
Table DDL
The following restrictions exist in SQL Server 2014 for table schema DDL:
![]() Computed columns These are not supported for memory-optimized tables. You will need to remove them from the table definition and simulate their functionality in the select statements or procedures that retrieve data from the table.
Computed columns These are not supported for memory-optimized tables. You will need to remove them from the table definition and simulate their functionality in the select statements or procedures that retrieve data from the table.
![]() Foreign-key constraints Because these are not supported, I recommend that application logic performing any update operation (insert, update, or delete) on a table with a critical relationship to another table be validated in application logic to avoid inconsistency. This validation can be done in the form of wrappers around the DML statement to validate consistency or it can be inline in the application code.
Foreign-key constraints Because these are not supported, I recommend that application logic performing any update operation (insert, update, or delete) on a table with a critical relationship to another table be validated in application logic to avoid inconsistency. This validation can be done in the form of wrappers around the DML statement to validate consistency or it can be inline in the application code.
![]() Check constraints Like foreign-key constraints, check constraints must be simulated in application code that wraps the update statement that could violate the condition.
Check constraints Like foreign-key constraints, check constraints must be simulated in application code that wraps the update statement that could violate the condition.
![]() Unique constraints These are not supported directly; however, all memory-optimized tables that have the durability of SCHEMA AND DATA must have a unique primary-key index. In many cases, this unique index will serve as a unique constraint.
Unique constraints These are not supported directly; however, all memory-optimized tables that have the durability of SCHEMA AND DATA must have a unique primary-key index. In many cases, this unique index will serve as a unique constraint.
![]() ALTER TABLE Altering tables in any way is not supported in SQL Server 2014. If you want to change the definition of a table or its indexes, you need to unload, drop, re-create, and reload the table. This includes any change or addition to the indexes on the table.
ALTER TABLE Altering tables in any way is not supported in SQL Server 2014. If you want to change the definition of a table or its indexes, you need to unload, drop, re-create, and reload the table. This includes any change or addition to the indexes on the table.
![]() Large Object (LOB) data types (for example, varchar(max), image, xml, text, and ntext) Memory-optimized tables have a maximum row size of 8,060 bytes for all columns combined. Although you can have columns such as varbinary(8000), you cannot use (max), which would exceed the 8,060-byte limit. When a larger LOB is needed, it is often faster to chunk the column up in 8,000-byte records and reassemble on retrieval than to leave the data in a traditional table. For an example of how this can be done, you can look at the implementation of the ASP.NET Session State Cache using memory-optimized tables, which has been published on CodePlex at https://msftdbprodsamples.codeplex.com/releases/view/125282.
Large Object (LOB) data types (for example, varchar(max), image, xml, text, and ntext) Memory-optimized tables have a maximum row size of 8,060 bytes for all columns combined. Although you can have columns such as varbinary(8000), you cannot use (max), which would exceed the 8,060-byte limit. When a larger LOB is needed, it is often faster to chunk the column up in 8,000-byte records and reassemble on retrieval than to leave the data in a traditional table. For an example of how this can be done, you can look at the implementation of the ASP.NET Session State Cache using memory-optimized tables, which has been published on CodePlex at https://msftdbprodsamples.codeplex.com/releases/view/125282.
![]() Clustered indexes This isn’t a restriction as much as a need to have an understanding of how indexes work for these tables. Because the indexes on memory-optimized tables are all effectively pointers to the actual data, there is no distinction between clustered and nonclustered indexes. Because the row data doesn’t physically reside in the index structure, all indexes on memory-optimized tables are NONCLUSTERED. They can be considered to be covering, because the index directly references all columns in the table.
Clustered indexes This isn’t a restriction as much as a need to have an understanding of how indexes work for these tables. Because the indexes on memory-optimized tables are all effectively pointers to the actual data, there is no distinction between clustered and nonclustered indexes. Because the row data doesn’t physically reside in the index structure, all indexes on memory-optimized tables are NONCLUSTERED. They can be considered to be covering, because the index directly references all columns in the table.
DML
The natively compiled stored procedures in SQL Server 2014 have some restrictions with regard to the surface area that is available, which might require workarounds. In some cases, these restrictions might indicate that a given stored procedure would be better left running in interop mode. There are many cases where procedures can be split into a wrapper procedure in interop and an inner procedure that is natively compiled. The outer wrapper contains constructs that are unsupported inside natively compiled procedures, and an inner procedure that is natively compiled, to perform the most perf-sensitive logic. Here are some key constructs to consider:
![]() Cursors These are not supported in natively compiled procedures. Instead, and as a general best practice, use set-based logic or a WHILE loop.
Cursors These are not supported in natively compiled procedures. Instead, and as a general best practice, use set-based logic or a WHILE loop.
![]() Subqueries Subqueries nested inside another query are not supported. Either rewrite the query or perform it in interop mode.
Subqueries Subqueries nested inside another query are not supported. Either rewrite the query or perform it in interop mode.
![]() SELECT INTO The SELECT INTO syntax is not supported; however, it can be rewritten as INSERT INTO Table SELECT.
SELECT INTO The SELECT INTO syntax is not supported; however, it can be rewritten as INSERT INTO Table SELECT.
![]() Cross-database transactions With SQL Server 2014, transactions that touch memory-optimized tables cannot access data in another database, regardless of whether they are local or remote.
Cross-database transactions With SQL Server 2014, transactions that touch memory-optimized tables cannot access data in another database, regardless of whether they are local or remote.
![]() EXECUTE, INSERT EXEC You cannot call a stored procedure from within a natively compiled procedure. In some cases, to comply with this restriction you must inline code that had been factored out.
EXECUTE, INSERT EXEC You cannot call a stored procedure from within a natively compiled procedure. In some cases, to comply with this restriction you must inline code that had been factored out.
![]() Outer Join, Union Outer joins or unions must be implemented by aggregating smaller queries, usually using a local, memory-optimized table variable.
Outer Join, Union Outer joins or unions must be implemented by aggregating smaller queries, usually using a local, memory-optimized table variable.
![]() Disjunctions (OR, IN) These are not supported in natively compiled procedures. You must create queries for each of the cases and then aggregate the results.
Disjunctions (OR, IN) These are not supported in natively compiled procedures. You must create queries for each of the cases and then aggregate the results.
Conclusion
You saw that the In-Memory OLTP system in SQL Server 2014 has the potential to speed up database operations dramatically—in some cases representing a game-changer to the business. However, this does not remove the need to understand the performance issues you’re trying to solve and to figure out what bottlenecks are causing them. By understanding the ways in which this new environment behaves differently from traditional database tables, you can realize great gains.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.