IPv6 Address Planning (2015)
Part I
Chapter 1. Where We’ve Been, Where We’re Going
Introduction
I see it, but I don’t believe it.
— Georg Cantor
The standard LAN interface assignment in IPv6 is a /64. Or, to be more explicit, a subnet with 64 bits set aside for network identification and 64 bits reserved for host addresses. (If this is unfamiliar to you, don’t fret. We’ll review the basic rules of IPv6 addressing in the second chapter.) As it happens, 64 bits of host addressing makes for a pretty large decimal value:
![]() 18,446,744,073,709,551,616
18,446,744,073,709,551,616
It’s cumbersome to represent such large values, so let’s use scientific notation instead (and round the value down, too):
![]()
That’s a pretty big number (around 18 quintillion) and in IPv6, if we’re following the rules, we stick it on a single LAN interface. Here’s what that might look like in common router configuration syntax (Cisco IOS, in this case):
!
interface FastEthernet0/0
ipv6 address 2001:db8:a:1::1/64
Now if someone were to ask you to configure the same interface for IPv4, what is the first question you’d ask? Most likely some variation of the following:
“How many hosts are on the LAN segment I’m configuring the interface for?”
The reason we ask this question is that we don’t want to use more IPv4 addresses than we need to. In most situations, the answer would help determine the size of the IPv4 subnet we would configure for the interface. Variable Length Subnet Masking (VLSM) in IPv4 provides the ability to tailor the subnet size accordingly.
This practice was adopted in the early days of the Internet to conserve public (or routable) IPv4 space. But chances are the LAN we’re configuring is using private address space[1] and Network Address Translation (NAT). And while that doesn’t give us anywhere close to the number of addresses we have at our disposal in IPv6, we still have three respectably large blocks from which to allocate interface assignments:
§ 10.0.0.0/8
§ 172.16.0.0/12
§ 192.168.0.0/16
Since we can’t have overlapping IP space in the same site (at least not without VRFs or some beastly NAT configurations), we’d need to carve up one or more of those private IPv4 blocks further to provide subnets for all the interfaces in our network and, more specifically, host addresses.
But in IPv6, the question of “How many hosts are on the network segment I’m configuring the interface for?”, which is so commonplace in IPv4 address planning, has no relevance.
To see why, let’s assume x is equal to the answer. Then we’ll define n as the ratio of the addresses used to the total available addresses:
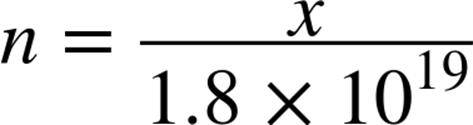
Now we can quantify how much of the available IPv6 address space we’ll consume. But the value for x can’t ever be larger than the maximum number of hosts we can have on an interface. What is that maximum?
Recall that a router or switch has to keep track of the mappings between layer 2 and layer 3 addresses. This is done through Address Resolution Protocol (ARP) in IPv4 and Neighbor Discovery (ND) in IPv6.[2] Keeping track of these mappings requires router memory and processor cycles, which are necessarily limited. Thus, the maximum of x is typically in the range of a few thousand.
This upper limit of x ensures that n will only ever be microscopically small. For example, let’s assume a router or switch could support a whopping 10,000 hosts on a single LAN segment:
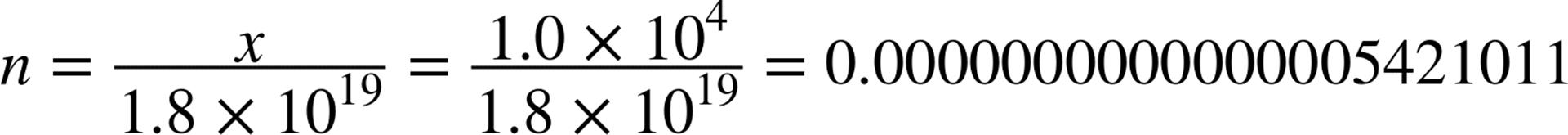
So unlike IPv4, it doesn’t matter whether we have 2, 200, or 2,000,000 hosts on a single LAN segment. How could it when the total number of addresses available in the subnet of a standard interface assignment is more than 4.3 billion IPv4 Internets?
In other words, the concepts of scarcity, waste, and conservation as we understand them in relation to IPv4 host addressing have no equivalent in IPv6.
TIP
In IPv6 addressing, the primary concern isn’t how many hosts are in a subnet, but rather how many subnets are needed to build a logical and scalable address plan (and more efficiently operate our network).
IPv4 only ever offered a theoretical maximum of around 4.3 billion host addresses.[3] By comparison, IPv6 provides 3.4x1038 (or 340 trillion trillion trillion). Because the scale of numerical values we’re used to dealing with is relatively small, the second number is so large its significance can be elusive. As a result, those working with IPv6 have developed many comparisons over the years to help illustrate its difference in size from IPv4.
All the Stars in the Universe…
Astronomers estimate that there are around 400 billion stars in the Milky Way. Galaxies, of course, come in different sizes, and ours is perhaps on the smallish side (given that their are elliptical galaxies with an estimated 100 trillion stars). But let’s assume for the sake of discussion that 400 billion stars per galaxy is a good average. With 170 trillion galaxies estimated in the known universe, that results in a total of 6.8x1025 stars.
Yet that’s still 5 trillion times fewer than the number of available IPv6 addresses! It’s essentially impossible to visualize a quantity that large, and rational people have difficulty believing what they can’t see.
Cognitive dissonance is a term from psychology that means, roughly, the emotionally unpleasant impact of holding in one’s mind two or more ideas that are entirely inconsistent with each other. For rational people (like some network architects!), it’s generally an unpleasant state to be in. To eliminate or lessen cognitive dissonance, we will usually favor one idea over the other, sometimes quite unconsciously. Often, the favored idea is the one we’re the most familiar with. Here are the two contradictory ideas relevant to our discussion:
§ Idea 1: We must conserve IP addresses.
§ Idea 2: We have a virtually limitless supply of IP addresses.
§ Result: Contradiction and cognitive dissonance, favoring the first, (and in this case) more familiar idea.
IPV4 THINKING
Idea 1 is the essence of IPv4 Thinking, a disability affecting network architects new to IPv6 and something that we’ll often observe, and illustrate the potential impact of, as we make our way through the book.
We’ll encounter a couple more of these comparisons as we proceed. I think they’re fun — they can tickle the imagination a bit. But perhaps more importantly, they help chip away at our ingrained prejudice favoring Idea 1.
From my own experience, the sooner we shed this obsolete idea, the sooner we’ll make the best use of the new principles guiding our IPv6 address planning efforts.
Figure 1-1 offers a comparison of scale based on values for powers of 2 (binary) and 10 (decimal).
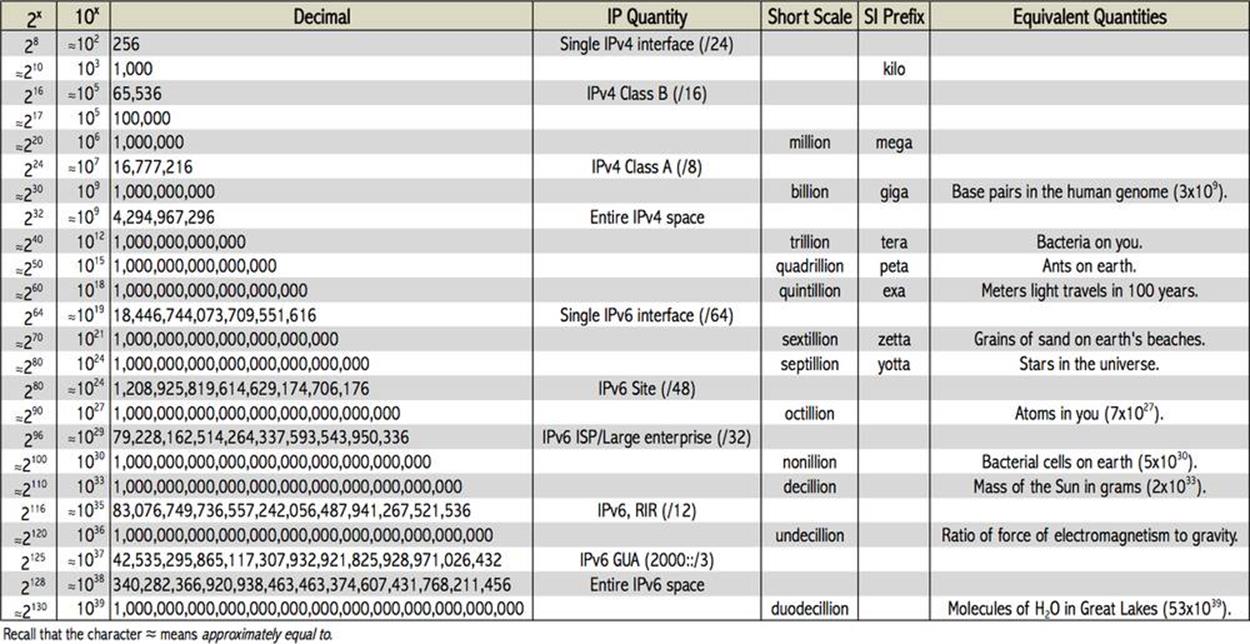
Figure 1-1. Powers of 2 comparison
4,294,967,296 VERSUS 50,000,000,000
Let’s look at a basic comparison between two rather large numbers.
Which is larger: 4,294,967,296 or 50,000,000,000?
If we re-express these values in scientific notation (rounding the first one up a bit), it’s easier to more quickly determine which is larger:
![]()
![]()
You’re probably suspecting that I didn’t just happen to pick on two random numbers to remind you that scientific notation is useful in comparing larger integers. You may have recognized the first number as the decimal expansion of 232, or the total number of addresses defined in IPv4.
But what about the second number?
That tidy 50 billion is the number of Internet-connected devices by the year 2020 as predicted by Cisco.[4] Since 50,000,000,000 is greater than 4,294,967,296 by more than an entire order of magnitude, the IPv4-only Internet would appear to have a bit of an address supply problem.
Of course, this isn’t exactly news. As we’ll read, early Internet engineers started musing about this supply problem at least as early as 1988. Even as the IPv4 Internet was taking off in the early 1990s, the Internet engineering community was already busy developing IPv4’s eventual replacement. This would eventually lead to the development of IPv6, a new network address with 96 more bits than IPv4, or 2128 theoretical addresses.
The decimal expansion of 2128 is 340,282,366,920,938,463,463,374,607,431,768,211,456 (or as we’ve already seen it, rounded down to one decimal place and expressed in scientific notation, 3.4x1038). This is what math geeks might call a nontrivially larger value than either 4,294,967,296 or 50,000,000,000. In fact, it’s significantly larger than 4,294,967,296 times 50,000,000,000 — around a trillion trillion times larger![5]
In the Beginning
And finally, because nobody could make up their minds and I’m sitting there in the Defense Department trying to get this program to move ahead, we haven’t built anything, I said, it’s 32 bits. That’s it. Let’s go do something. Here we are. My fault.
— Dr. Vinton G. Cerf
Back in 1977, when he chose 32 bits to use for Internet Protocol addressing, Vint Cerf might have had trouble believing that in a few decades, a global network with billions of hosts (and still using the protocol he co-invented with Bob Kahn) would have already permanently revolutionized human communication. After all, at that time, host count on the military-funded, academic research network ARPANET was just north of 100.
By January 1, 1983, host counts were still modest enough by today’s standards that the entire ARPANET could switch over from the legacy routed Network Control Protocol to TCP/IP in one day (though the transition took many years to plan). By 1990, the ARPANET had been decommissioned at the ripe old age of 20. Its host count at the time took up slightly more than half of one /19, approximately 300,000 IPv4 addresses (or about 0.007% of the overall IPv4 address space).
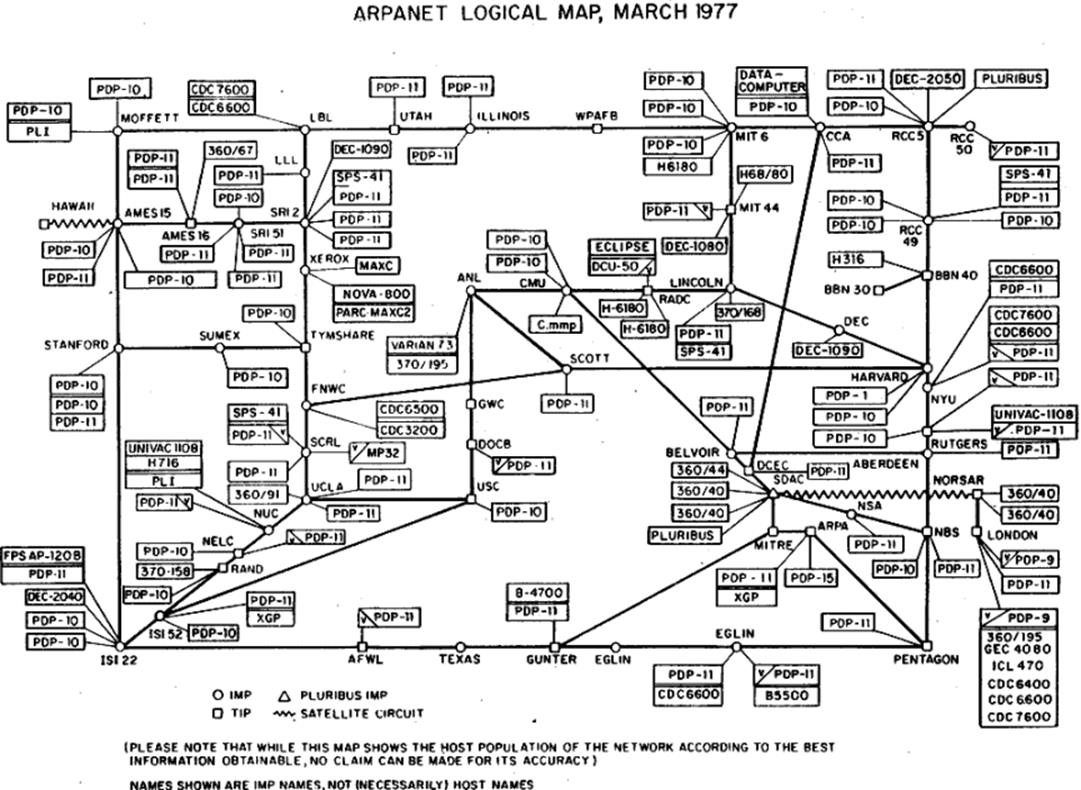
Yet, by then, the question was already at least a couple of years old: how long until 32-bit IP addresses run out?
A Dilemma of Scale
Concern about IP address exhaustion had been rising, due to the combination of the protocol’s remarkable success, along with a legacy allocation method based on classful addressing that was proving tremendously wasteful and inefficient.[6] It was not uncommon in the early days of the ARPANET for any large requesting organization to receive a Class A network,[7] or 16,777,214 addresses. With only 256 total Class A networks in the entire IP space, a smaller allocation was obviously more appropriate to avoid quickly exhausting all remaining IP address blocks. With 65,536 addresses, a Class B network[8] met the host count needs of most organizations. Each Class B also provided 256 Class C subnetworks[9] (each with 256 addresses), which could be used by the organization to establish or preserve network hierarchy. (This allowed for more efficient network management, as well as processor and router memory utilization.)
MULTIPROTOCOL NETWORKS
Newer network engineers and architects may find it odd that at one point most computer networks were multiprotocol at layer 3 (i.e., multiple routed protocols co-existing within a single network and on the same wire). “Ships in the night” was the phrase coined to describe such protocols sharing the same link but never interacting (at least not without some form of layer 3 translation courtesy of specialized router code or appliances).
Even if you didn’t configure and work with them directly, you probably recognize the names of these vintage routed protocols from the spines of old computer networking books at yard sales or from war stories your veteran colleagues told you down at the pub. You may have even had the unexpected challenge of troubleshooting these protocols in legacy networks where they probably ran alongside IP. AppleTalk, IPX, DLSw, DECnet, and NetBEUI are all examples of routed protocols that have been driven to virtual extinction by the ubiquity of IP. (And perhaps much like that of Homo sapiens, the enduring adaptability of IP has proven the key to its success over other contenders for evolutionary primacy.)
It is at least partly for these reasons that network admins who’ve been around a while are perhaps less perturbed by the requirement to adopt a new protocol that will run alongside IPv4. (Though I’ve encountered a few such folks, close to retirement, who’ve confided that they hope to be out the door before having to deploy IPv6. What fun they’ll be missing out on!)
But allocating Class B networks in place of Class A ones was merely slicing the same undersized pie in thinner slices. The problem of eventual IP exhaustion remained.[10] In 1992, the IETF published RFC 1338 titled “Supernetting: an Address Assignment and Aggregation Strategy.” It identified three problems:
§ Exhaustion of Class B address space
§ Growth of the routing tables beyond manageability
§ Exhaustion of all IP address space
The first problem was predicted to occur within one to three years. What was needed to slow its arrival were “right-sized” allocations that provided sufficient, but not an excessive number of, host addresses. With only 254 usable addresses, Class C networks were not large enough to provide host addresses for most organizations. By the same token, the 65,534 addresses available in a Class B were often overkill.
The second problem followed from the suggested solution for the first. If IP allocations became ever more granular to conserve remaining IP space, the routing table could grow too quickly, overwhelming hardware resources (this during a period when memory and processing power were more prohibitively expensive) and leading to global routing instability.
The subsequent recommendation and adoption of Classless Inter-Domain Routing (CIDR) helped balance these requirements. Subnetting beyond the bit boundaries of the classful networks provided right-sized allocations.[11] It also allowed for the aggregation of Class C (and other) subnets, permitting a much more controlled growth of the global routing table. The adoption of CIDR helped provide sufficient host addressing and slow the growth of the global routing table, at least in the short-term.
But the third problem would require nothing less than the development of a new protocol; ideally, one with enough addresses to eliminate the problem of exhaustion indefinitely. But that left the enormous challenge of how to transition to the new protocol from 32-bit IP. At the time, one of the protocols being considered appeared to recognize the need to keep existing production IP networks up and running with a minimum of disruption. It recommended:[12]
§ An ability to upgrade routers and hosts to the new protocol and add them to the network independently of each other
§ The persistence of existing IPv4 addressing
§ Keeping deployment costs manageable
WHAT WE MEAN BY IPV6 ADOPTION
It’s important to describe early what we mean (and don’t mean) by IPv6 adoption. For most enterprises, it will mean configuring IPv6 on at least some portion of the existing network. We’ll get into the details of how we logically carve up the network for the purposes of making IPv6 adoption easier in Chapter 5.
A second assumption is that any IPv6 configuration will occur on devices that already support IPv4 and that will continue to support IPv4 (likely for years to come). In other words, IPv4 and IPv6 will coexist in production on the same network interfaces providing transport to applications for the foreseeable future.[13] This dual-stack configuration (as contrasted with IPv4 translation to and from IPv6) is currently considered the best practice for most networks.
You’ll notice that over a long enough timeline, we are in fact migrating or transitioning to IPv6. But in the short-to-medium term, we’re just adding IPv6 to our existing IPv4 network. That’s why we prefer to say IPv6 adoption or IPv6 deployment rather than IPv6 migration or transition. It may seem like mere semantics, but it does serve a purpose: it helps dispel some of the FUD (fear, uncertainty, doubt) around IPv6 for those who are just getting started with it.
When my boss asked me to deploy IPv6, I knew he wasn’t suggesting that we turn IPv4 off after IPv6 was up and running. Rather, it was essential to keep the existing IPv4 production network live and providing the services and applications the company relied on. IPv6 was then added to the network in tightly controlled phases. For nearly all organizations, such an approach will be more manageable, less disruptive, and cheaper than a premature attempt to transition entirely to IPv6 all at once.[14]
As part of our exploration of IPv6 address planning, we’ll also learn strategies and methods for adopting IPv6 that have been reliably successful.
The one protocol meeting these requirements was known as SIPP-16 (or Simple IP Plus) and was most noteworthy for offering a 128-bit address. It was also known for being version 6 of the candidates for the next-generation Internet Protocol.[15]
IPv4 Exhaustion and NAT
While work proceeded on IPv4’s eventual replacement, other projects examined ways to slow IPv4 exhaustion.
In the early 1990s, there were various predictions for when IPv4 exhaustion would occur. The Address Lifetime Expectations (ALE)[16] working group, formed in 1993, estimated that depletion would occur sometime between 2005 and 2011. As it happened, IANA (the Internet Assigned Numbers Authority) handed out the last five routable /8s to the various RIRs (Regional Internet Registries) in February 2011.[17] In all likelihood, IPv4 exhaustion would have occurred much sooner without the adoption of NAT.
The original NAT proposal suggested that stub networks (as most corporate or enterprise networks were at the time) could share and reuse the same address range provided that these potentially duplicate host addresses were translated to unique, globally routable addresses at the organization’s edge. Initially, only one reusable, or private, Class A network was defined, but that was later expanded to the three listed at the beginning of the chapter.
The NAT proposal was attractive for many reasons. The obvious general appeal was that it would help slow the overall rate of IPv4 exhaustion. Early enterprise and corporate networks would have liked the benefit of a centralized, locally-administered solution that would be relatively easy to own and operate. From an address planning standpoint, they would also get additional architectural flexibility. Where a stub network might only qualify for a small range of routable space from an ISP, with NAT an entire /8 could be used. This would make it possible to group internal subnets according to location or function in a way that maximized operational efficiency (and as we’ll see in Chapters 4 and 5, something IPv6 universally allows for). Privately addressed networks could also maintain their addressing schemes without having to renumber if they switched providers.
But NAT also had major drawbacks, many of which persist to this day. The biggest liability was (and is) that it broke the end-to-end model of the Internet. The translation of addresses anywhere in the session path meant that hosts were no longer communicating directly. This had negative implications for both security and performance. Applications that had been written based on the assumption that hosts would communicate directly with each other could break. For instance, a NAT-enabled router would have to exchange local for global addresses in application flows that included IPv4 address literals (like FTP). Even rudimentary TCP/IP functions like packet checksums had to be manipulated (in fact, the original RFC contained sample C code to suggest how to accomplish this).[18]
Whatever NAT’s ultimate shortcomings, there’s no question that it has been enormously successful in terms of its adoption. And to be fair, it has helped extend the life of IPv4 and provide for a more manageable deployment of IPv6 following its formal arrival in 1998.
SOME FUNDAMENTAL DESIGN PRINCIPLES
Before we proceed with the specifics of IPv6 address planning, it’s probably worthwhile to articulate and examine some fundamental design principles where networks in general (and IP addressing plans in particular) are concerned. These principles are not unique to specific addressing protocols: they suggest the essence of what a network is and does. A different way of arriving at the same requirements might be to ask “What problem(s) are we trying to solve?”
It turns out that these basic requirements and first principles are really quite simple to articulate, if rather more difficult to instantiate thoroughly and maintain over time. They include:
Unique addressability
Every host or node on a network must be uniquely addressed or somehow distinguishable from other hosts.[19] IP is currently the dominant logical addressing method, while hardware addresses (typically MAC) identify individual physical interfaces. A viable network design requires a logical addressing method that will provide sufficient unique addresses (such as IPv6).
Manageability
Networks must be manageable, meaning that the methodology and tasks required to build and maintain the network must be well understood, relatively easy to replicate, and generally based on well-known protocols.
Scale
For a network to meet the needs of the business or organization, new users, applications, and services must be relatively easy to add and support. Any network design will need to plan for manageable (and cost-effective) growth.
Cost-effectiveness
As much as we might prefer otherwise, all network design must bow to economic realities. As the old engineering proverb states: “Fast, reliable, cheap: choose any two.” But more often than not, we’re obligated time and again to pick cheap first and hope for at least a modicum of fast and/or reliable. This can greatly challenge our ability to accomplish our other design principles.
Flexibility
As much as engineers might like to joke that the network would be great without all those pesky users, a network should ideally be configurable to support any existing or emerging business or organizational requirements. The difficulty in achieving such flexibility with traditional networking protocols has been one of the most persistent challenges in network engineering and has led to the development of technologies like software-defined networking (SDN).
Resilience
All networks require some measure of fault tolerance and resilience. In cases where the mission of the network is merely to enhance general business productivity, such resilience may be adequately provided by the underlying protocols and good basic network design. However, the consequence of a network outage for some organizations could be loss of revenue (or even life), and the network design must accommodate this fact.
Simplicity
Network design reflects an aesthetic that extends from the disciplines of math, science, and technology. This aesthetic often prizes the elegance of the simplest solution for any complex problem. In network design, this kind of simplicity often correlates to efficiency and the realization of our other design principles, which in turn makes any network easier to build and run.[20]
You might notice that none of these articulated first principles demand a particular set of specific protocols, whether old or new, established or emerging. The importance of this is difficult to overstate at this particular moment in the history of the Internet. The above first principles are likely to be realized through whatever combination of technologies create the path of least technological and financial resistance in turning on the next generation of Internet and network services. Hyper-scale data centers, public and private cloud services, virtualization, the Internet of Things, and emerging SDN and NFV (network function virtualization) solutions challenge traditional protocols and entrenched architectural and operational paradigms in profound ways.
IPv6 Arrives
The first formal specification for IPv6 was published late in 1998, nearly 25 years after the first network tests using IPv4.[21]
Adoption of IPv6 outside of government and academia was slow going in the early years.
In the United States, the federal government has used mandates (with moderate success) to drive IPv6 adoption among government agencies. A 2005 mandate included requirements that all IT gear should support IPv6 to the “maximum extent practicable” and that agency backbones must be using IPv6 by 2008.[22] These requirements almost certainly helped accelerate the maturation of IPv6 features and support across many vendors’ network infrastructure products. IPv6 feature parity[23] with IPv4 was also greatly enhanced by the work of the IETF during this period: nearly 200 IPv6 RFCs were published (as well as hundreds of IETF drafts).
IPv6 adoption among enterprise networks was negligible during this same time period. With so few hosts on the Internet IPv6-enabled, it made little sense to make one’s website and online resources available over it. Meanwhile, IPv4 private addressing in combination with NAT at the edge of the IT network reduced or eliminated any need to deploy IPv6 internally.
Why Not a “Flag Day” for IPv6?
Why not just set a day and switch all hosts and networks over from IPv4 to IPv6? After all, it worked for the transition from NCP to IP back in 1982. It should be obvious that even by 1998, the Internet had grown to such an extent that a “flag day” was no longer technically feasible. Even in relatively closed environments, flag days are difficult to pull off successfully — see Figure 1-2 for proof.
Much of the discussion around IPv6 adoption in this period focused on the possible appearance of a “killer app,” one that would take advantage of some technical aspect of IPv6 not available in IPv4.[24] Such an application would incentivize broad IPv6 adoption and create an incontrovertible business case for those parties waiting on the sidelines. But without widespread deployment of IPv6, there was little hope that such an application would emerge. Thus, a classic Catch-22 situation.[25]

Figure 1-2. Stockholm, Sweden in 1967 on the day they switched from left-side to right-side driving.
To try to interrupt this vicious cycle, the Internet Society in 2008 began an effort to encourage large content providers to make their popular websites available over IPv6. This effort culminated in a plan for a June 8, 2011 “World IPv6 Day” during which Google, Yahoo, Facebook, and any others that wished to participate would make their primary domains (e.g., www.google.com) and related content available over IPv6 for 24 hours. This would give the Internet a day to kick the tires of IPv6 and take it out for a test drive, and in the process, gain operational wisdom from a day-long surge of IPv6 traffic.
The event was successful enough to double IPv6 traffic on the Internet (from 0.75% to 1.5%!) and inspired the World IPv6 Launch event the following year, which encouraged anyone with publicly available content to make it available over IPv6 permanently.
More recently, large broadband subscriber and mobile companies like Comcast and Verizon are reporting that a third to more than half of their traffic now runs over IPv6, and global IPv6 penetration as measured by Google has jumped from 2% to 4% in the last nine months (Figure 1-3).[26]
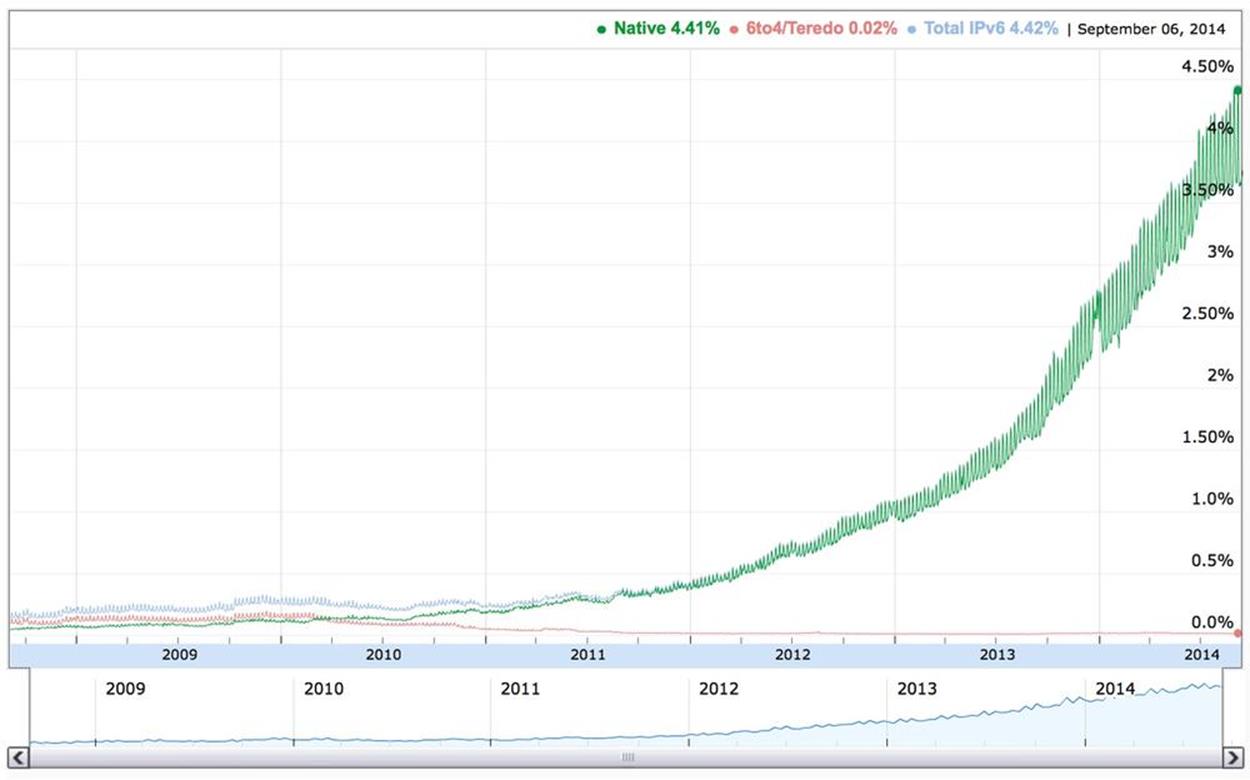
Figure 1-3. Percentage of IPv6 traffic accessing Google services
Conclusion
As mentioned previously, IANA had already allocated the last of the routable IPv4 address blocks in 2011. By April of that year, APNIC, the Asian-Pacific RIR (not to be confused with the Union-Pacific RR), had exhausted its supply of IPv4 (technically defined as running down to their last /8 of IPv4 addresses). And in September of 2012, RIPE, in Europe, had reached the same status. ARIN announced that it was entering the IPv4 exhaustion phase in April 2014, and Latin America’s LACNIC followed in June, just two months later (Figure 1-4). Africa is good for now with AFRINIC having enough IPv4 to ostensibly last through 2019.)
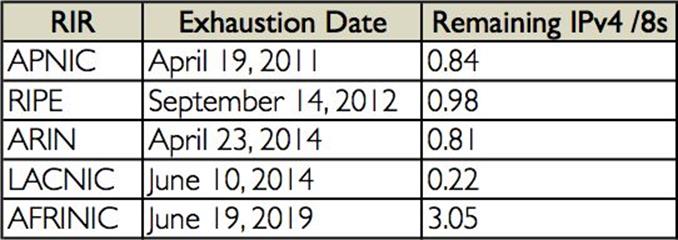
Figure 1-4. IPv4 exhaustion by region
To put it bluntly, by the time you’re reading this book, IPv4 will most likely be exhausted everywhere but in Africa. And as we’ve learned, IPv6 adoption is accelerating, by some metrics, exponentially. To stay connected to the whole Internet, you’re going to need IPv6 addresses and an address plan to guide their deployment.
THE UNEQUAL DISTRIBUTION OF IPV4
Another critical factor that is impacting the rate of IPv6 adoption is the unequal distribution of IPv4 addresses globally.
The Internet originated and saw its early growth concentrated in the US. Early allocations of IPv4 addresses, especially of the class A type, eventually led to a disproportionate global distribution of IPv4, one that favored the US (Figure 1-5).[27]
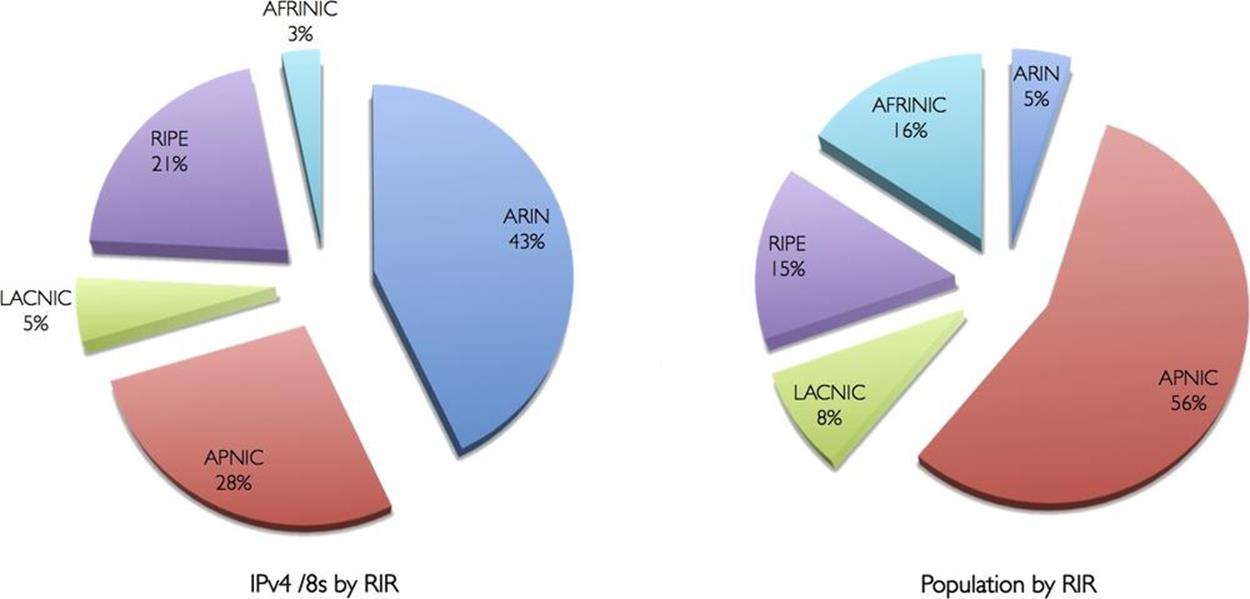
Figure 1-5. Percentage of IPv4 /8s compared to human population by RIR
Over time, as other regions began to expand their Internet penetration, this uneven distribution of addresses, combined with the explosive growth of mobile Internet, very likely led to earlier exhaustion of IPv4 in population-dense Asia and Europe.
A further consequence of this rapid growth and suboptimal distribution of addresses has been the proliferation of entries in the global IPv4 routing table, which has recently exceeded 512K entries. Because many older routers in the core of the Internet have memory or configuration limits on total IPv4 prefixes set at 512K, this has caused outages due to routes above and beyond the 512K limit being dropped.
We’ll discuss this issue in relation to IPv6 routing in Chapter 10.
[1] RFC 1918, Address Allocation for Private Internets.
[2] RFC 4861, Neighbor Discovery for IP version 6 (IPv6). Keep in mind that RFCs are often updated (or even obsoleted) by new ones. When referring to them, check the updated by and obsoletes cross-references at the top of the RFC to make sure you have the most up-to-date information you might need.
[3] After reserved addresses (such as experimental, multicast, etc.) are deducted, IPv4 offers closer to 3.7 billion globally unique addresses.
[4] Trends such as mobile device proliferation and the Internet of Things (or Everything) have produced wildly divergent estimates for Internet-connected devices by 2020. They range from 20 billion on the low end all the way up to 200 billion.
[5] And in case it isn’t obvious, the entire 50 billion devices would fit quite neatly into one /64 (360 million times, actually).
[6] The success of IPv4 was (and is) at least partly a function of its remarkable simplicity. The formal protocol specification contained in RFC 791 is less than 50 pages long and notorious for its modest scope: providing for addressing and fragmentation.
[7] A /8 in Classless Inter-Domain Routing (CIDR) notation.
[8] A /16 in CIDR notation.
[9] A /24 in CIDR notation.
[10] From the remaining allocatable IP space to be carved up for Class B networks, you had to subtract the Class A networks already allocated.
[11] This method of “right-sizing” subnets for host counts using CIDR would become an entrenched architectural method that, as we’ll learn, can be a serious impediment to properly designing your IPv6 addressing plan.
[12] And as you’ll discover in Chapter 3, these IPv6 adoption requirements are still very relevant.
[13] Enabling the forward march of human progress, as well as the reliable delivery of cat videos.
[14] It’s worth noting that some organizations running a dual-stack architecture today are taking steps to make their networks IPv6-only. For example, Facebook is planning on removing IPv4 completely from its internal network within the next year. Reasons for such a move may vary among organizations, but the biggest motivator for running a single stack is likely the aniticipated reductions to the complexity and cost of network operations (e.g., less time to troubleshoot network issues, perform maintenance and configuration, etc.).
[15] The also-rans were ST2 and ST2+, aka IPv5 and IPv7, which offered a 64-bit address. Other next-generation candidate replacements for IP included TUBA (or TCP/UDP Over CLNP-Addressed Networks) and CATNIP (or Common Architecture for the Internet).
[16] Based on the acronym, and their affinity for hotel bars as the best setting for getting things done at meetings, I shouldn’t need to explicitly mention that this was an IETF effort.
[17] More information on the RIRs, their function and policies, is provided in Chapter 6.
[18] RFC 1631, The IP Network Address Translator (NAT).
[19] In IPv6, we extend this requirement to the interface.
[20] As we’ll explore in Chapter 3 when we discuss what we mean by IPv6 adoption, the path to realizing this principle isn’t necessarily a direct one.
[21] RFC 2460, Internet Protocol, Version 6 (IPv6) Specification. Also, formal in this case refers to the IETF draft standard stage as described in RFC 2026, The Internet Standards Process — Revision 3. It’s perhaps important to keep in mind that earlier IPv6 RFCs (especially proposed standard RFC 1883 from December of 1995) provided specifications critical to faciliating the development of the “rough consensus and running code” (that famous founding tenet of the IETF) for IPv6.
[22] See the official Transition Planning for Internet Protocol Version 6 (IPv6) memorandum.
[23] Feature parity, as you’ve probably inferred, refers to the equivalent support and performance for a given feature in both IPv4 and IPv6. We’ll discuss this in more detail in Chapter 3.
[24] As we have come to recognize, the “killer app” turned out to be the Internet itself. Without IPv6, the Internet cannot continue to grow in the economical and manageable way required for its potential scale.
[25] “There was only one catch and that was Catch-22, which specified that a concern for one’s own safety in the face of dangers that were real and immediate was the process of a rational mind…Orr would be crazy to fly more missions and sane if he didn’t, but if he was sane he had to fly them. If he flew them he was crazy and didn’t have to; but if he didn’t want to he was sane and had to. Yossarian was moved very deeply by the absolute simplicity of this clause of Catch-22 and let out a respectful whistle. ‘That’s some catch, that Catch-22,’ he observed. ‘It’s the best there is,’ Doc Daneeka agreed.” -Joseph Heller, Catch-22.
[26] Google IPv6 Statistics. In the US, this figure is approaching 10% — or around 22.3 million users. IPv6 expert and O’Reilly author Silvia Hagen recently calculated that global user adoption of IPv6 will reach 50% by 2017.
[27] Source: Internet World Stats.
Part I. Preparation
The next three chapters seek to establish some critical context for the IPv6 address planning principles in the chapters that follow. You’re welcome to think of it as kind of a crash course in IPv6: just the right depth of the right kind of IPv6 knowledge to create a better foundation for our main topic and task at hand. If the essentials of IPv6 addressing and adoption are already old hat to you, please feel free to skip ahead to Part II to get right to the design principles and practices.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.