IPv6 Address Planning (2015)
Part III. Maintenance
Chapter 9. Managing Growth and Change
Introduction
In the last chapter, we looked at some of the tools that DDI in general and IPAM in particular provide for the provisioning and management of address and name resources.
In this chapter, we’ll explore some of the principles and best practices for managing the address plan through network and organizational growth and change.
We’ll also review how best to manage network renumbering in IPv6 (something made easier by the protocol’s improvements on handling multiple addresses).
Finally, we’ll consider some of the address planning considerations for both next-generation networks and those transition technologies besides dual-stack that remain relevant, as well as how to deal with unplanned growth.
Renumerology: IP Renumbering Made Easy…(or Somewhat Less Painful)
No matter how thorough our address planning or how diligent our address management, we’ll eventually be confronted with the requirement to renumber some or all of our network. Networks grow — and shrink — along with the businesses and organizations they support. Where growth occurs, it can be the result of corporate mergers or acquisitions, the planned deployment of new services or technologies, or just good old-fashioned network bloat as infrastucture is grafted on to work around problems as they arise. Or sometimes we have to change providers, number into a new assignment from our new provider, and out of the old one to return it.[116]
A renumbering project could theoretically apply to any sized network. But fortunately, renumbering is more often required for a subset of the overall addressable infrastructure within an organization. Readdressing an entire medium-sized or large network is a daunting task and one that can realistically only be accomplished in several phases; that is, if we’re trying to keep the network in production as we do it.[117]
For our discussion, we’ll keep our renumbering scenario limited in scope.
Renumbering in IPv4 was (and is) the inevitable consequence of the interaction of two characteristics of IPv4 subnets.
Sparse allocation can be difficult or impossible with IPv4 subnets due to the lack of bits available for the network portion of the address. Because of characteristic two, we often lack an unused contiguous subnet to increase the size of the right-sized subnet we used in characteristic one; i.e., whatever subnet was contiguous at the time the interface was originally configured has already been assigned somewhere else.
As a result, if we want to add more hosts to a segment, we’re stuck renumbering into a different subnet with sufficient addresses (or using a secondary subnet, which adds to both operational complexity and to the size of the routing table).
IPv6 was designed in part to reduce the necessity and frequency of network renumbering. For one thing, with 1.8x10^19 addresses per /64 it should never be necessary to renumber because of insufficient host addresses! But IPv6 was also designed to make renumbering as painless as possible. Recall that an IPv6 node can have as many IPv6 addresses configured from as many prefixes as may be needed or practicable.
To best understand how, we’ll review the general method for IPv6 renumbering along with a closer look at the mechanisms built into the protocol to help facilitate it. But first, let’s examine some renumbering preparations we can make.
CAUTION
Remember that a PI allocation from a RIR is portable — i.e., announceable to any regional ISP — allowing the organization that receives and numbers into it to use it indefinitely (provided they continue to meet the RIR’s policies). PA space by comparison is assigned by the ISP and must be numbered out of by the organization if they switch providers.
While it would certainly seem to make sense to an end-user organization to simply ask for PI space and reduce the possibility of having to renumber, given a change of providers, we still need to consider the effect on the global routing table that such PI allocations have. After all, every PI allocation in use is another entry in the global routing table.
For some smaller organizations and associated networks, renumbering may be eminently more manageable, reducing the need for a PI allocation and helping slow the growth rate of the global routing table.
The Lifetime and State of an Autoconfigured Address
We learned in Chapter 2 that IPv6 relies on Neighbor Discovery (ND) to allow nodes on a local segment to learn about and keep track of each other; e.g., “to discover each other’s presence, to determine each other’s link-layer addresses, to find routers, and to maintain reachability information about the paths to active neighbors.” [118]
ND also facilitates address autoconfiguration. A critical message option of this process is the Prefix Information option. This 32-byte option is included in Router Advertisements and includes a number of fields, such as type and length, as well as one for Mobile IPv6 and two reserved for future use. But the remaining fields are most relevant to the operation of address autoconfiguration. These include:
§ Prefix
§ Prefix length
§ On-Link flag
§ Autonomous flag
§ Valid Lifetime
§ Preferred Lifetime
The Prefix field contains the IPv6 network being advertised by the router. When combined with the prefix length field, it defines the prefix that will be combined with the node interface ID to autoconfigure an IPv6 address on that node.
The On-Link flag notifies a node whether a given prefix in the option is available on the local link or only available through the advertising router.
The Autonomous flag indicates to the node whether or not the included prefix is to be used for stateless address autoconfiguration. When set to 0, it informs the node to use the stateful method (i.e., DHCPv6).
The Valid and Preferred Lifetime fields enable a key enhancement of IPv6 protocol functionality over IPv4: the addition of the address lifetime concept and mechanism (and a set of address statuses associated with it).
The Valid Lifetime field is 32 bits and defines how long an address configured using the included prefix and any subsequent SLAAC address will remain valid.[119]
Similarly, the Preferred Lifetime field defines in seconds how long a prefix and SLAAC address will remain preferred. Once the Preferred Lifetime value exceeds the Valid Lifetime value, the address becomes invalid and may not be used to send or receive any packets. Thus, all valid addresses are also either preferred or deprecated. Preferred addresses can be used for any communication, while deprecated ones are not to be used for new communication (though existing communication can continue until completed). The expiration of a Valid Lifetime invalidates the address for any communication.
Either field has an infinite lifetime if set to all ones. e.g., 0xFFFFFFFF. If the Valid Lifetime is set to infinity and never expires while the Preferred Lifetime is allowed to lapse, the resulting address is permanently deprecated. Once existing sessions finish, no new sessions may be initiated from that address. (The address, however, may remain configured on the interface.)
Since IPv6 was designed to permit the configuration of as many addresses on an interface as necessary, this mechanism helps manage the preference and selection of these addresses by the host. SLAAC has five address states that we’ll need to be aware of if we’re renumbering any network that relies on it:[120]
Tentative address
This is the state of a host address when it is first generated but not yet assigned to an interface because it is being validated as unique by the Duplicate Address Detection (DAD) that IPv6 Neighbor Discovery performs.[121]
Valid address
A live address that can be used to send and receive unicast traffic. Valid addresses can either be preferred or deprecated.
Preferred address
A valid address whose Preferred Lifetime has not been exceeded. Preferred addresses can send and receive traffic without restriction.
Deprecated address
A valid address whose Preferred Lifetime (but not Valid Lifetime) has been exceeded. Deprecated addresses should be used to send and receive traffic for existing sessions but not for new sessions.
Invalid address
An address whose Valid Lifetime has expired. It cannot be used to send or receive any traffic.
Preparing to Renumber
Most of us have experienced (i.e., been traumatized by) a major network renumbering project at least once in our careers. But for those that haven’t had the pleasure, let’s clarify what we mean when we say renumbering.
NOTE
Network renumbering is essentially a reconfiguration plan and procedure in which an existing, in-use address prefix (or set of prefixes) is replaced by a new, yet-unused address prefix (or set of prefixes).
Though the old and new prefixes are typically the same size (something which should make the renumbering plan a bit easier to put together), they don’t have to be.
An IPv6 renumbering checklist
Handling a network renumbering project is made easier — with less danger of disruption to the existing network — by using a simple checklist to remind us of all the areas of the network we’ll need to configure with new prefixes, addresses, and names.
§ Router and switch interfaces
§ Point-to-point links
§ LAN interfaces
§ Loopback and management
§ Routing protocols
§ ACLs
§ Security
§ Firewalls
§ IDS/IPS
§ Routing
§ BGP/WAN edge
§ Auto-addressing ranges
§ DHCPv6
§ SLAAC
§ Host interfaces
§ DNS entries
§ AAAA
§ PTR
§ Any applications using embedded addresses
Address abstraction
One approach for reducing the amount of overall reconfiguration necessary for any renumbering effort is to use names or variables instead of actual IPv6 addresses wherever possible. Two examples of this include:
1. The use of FQDNs instead of IP addresses (for things like VPN tunnel endpoints)
2. The use of variables and names in ACLs and flat text configuration files
This method can simplify network management in general in the long run and, if put into practice ahead of time, may reduce the amount of preparation required when network renumbering becomes necessary.
Address lifetimes and DNS TTLs
Whether end hosts on the network are relying on DHCPv6 or SLAAC, reconfiguration of addresses can be timed and tuned to reduce operational strain.
The Renumbering Method
Renumbering must usually occur in phases in order to keep the network up and running. However, depending on the operational agility and management practice of the IT organization, smaller- to medium-sized networks can possibly renumber using the flag day approach.
At the beginning of the renumbering project, the network is live using the old prefix.
The first step of renumbering (following planning, of course) is adding addresses from the new prefix to network infrastructure like routers and switches and the links that connect them. Since IPv6 has been designed to better support multiple addresses and subnets on single interfaces, this step can be accomplished without impacting production traffic using the old prefix.
The next step is to configure hosts to use addresses from the new prefix. The procedure for this will be slightly different, depending on whether you’re using DHCPv6 or SLAAC.
As we’ve discussed, most enterprise hosts will likely be using DHCPv6. At the planned time, a unicast RECONFIGURE message from the DHCPv6 server to the hosts will trigger the necessary change of addresses. Dynamic DNS will then automatically update the hosts’ AAAA and PTR records. Groups of hosts can be renumbered in stages to reduce potential operational strain and better isolate any problems that arise.
If SLAAC is in use, the procedure is a bit more involved.
First, the Valid and Preferred Lifetime settings for the existing prefix are adjusted. Neither of these timers should exceed the overall duration of the renumbering effort.
In most networks, host sessions are short-lived, so there may be little benefit in making the valid lifetime longer than the preferred lifetime for a given prefix.
However, if there are hosts on the network that maintain persistent sessions (e.g., video or real-time services), a longer valid lifetime for a prefix will provide a buffer that allows applications to continue using an address for existing sessions, even though the preferred lifetime has elapsed and the address has moved to a deprecated state.
Next, the new prefix must be added to the router or daemon configuration and advertised to the host. The updated RAs will cause the hosts to autoconfigure a new address.
At this point, host logic for address selection will determine which of the two configured addresses gets used for new sessions.[122]
Finally, once everything is stable, the old prefix and addresses can be removed from hosts, network infrastructure, and DNS.
NOTE
And speaking of DNS, I probably can’t say it any better than the IETF says it: “It is recommended that the site have an automatic and systematic procedure for updating/synchronizing its DNS records, including both forward and reverse mapping. In order to simplify the operational procedure, the network architect should combine the forward and reverse DNS updates in a single procedure. A manual on-demand updating model does not scale and increases the chance of errors.”[123]
Translation: DDI will make renumbering easier and less error-prone!
Frequent Renumbering
If your particular network design or business requirements compel you to change prefixes and/or addresses often, there are perhaps a couple of architectural and operational practices you might want to cultivate to streamline this process as much as possible.
If you change ISPs often and are unable to secure a PI allocation for whatever reason, you might consider using ULA space along with NPTv6 (Figure 9-1).[124]
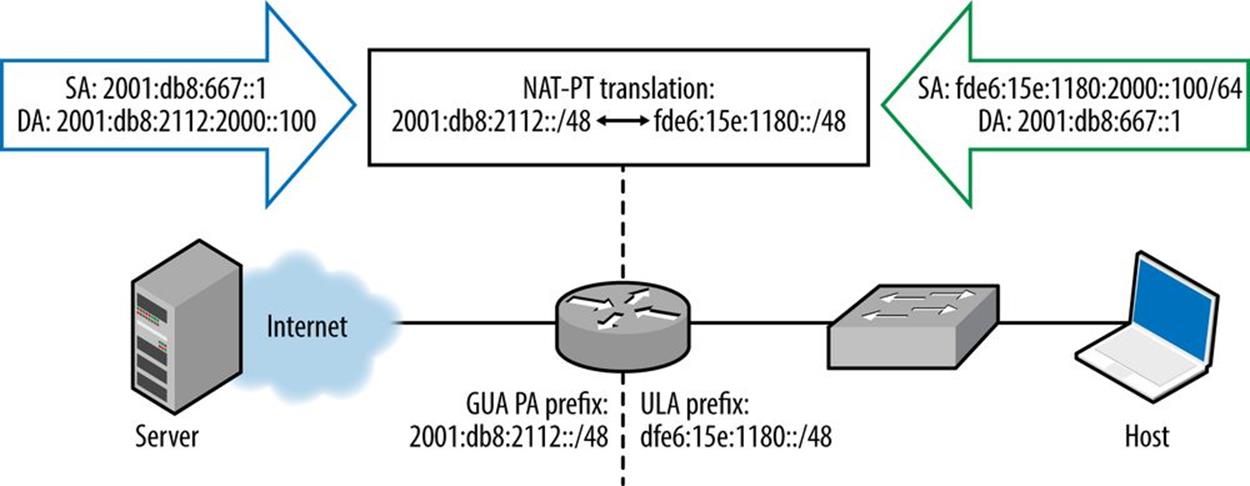
Figure 9-1. NPTv6 using ULA
In this illustration, a small enterprise is singly-homed to an ISP (and the Internet). The ISP has assigned a PA prefix to the customer, 2001:db8:2112::/48. Internally, the enterprise has deployed ULA addresses. The prefix from which these addresses are configured has been generated in the proper pseudo-random fashion to help insure that it doesn’t overlap with any other ULA assignments anywhere. That way, if this enterprise network should ever need to merge or connect to another network that is also using a ULA prefix, the probability of overlap is exceedingly unlikely. (Compare this scenario to one with an IPv4 network where the 10.0.0.0/8 network is in use.)
The host has been assigned an address from a /64 assigned from the ULA prefix, i.e., fde6:15e:1180:2000::100. The host wants to connect to a server on the IPv6 Internet offering content at the address 2001:db8:667::1. The enterprise’s edge router has been configured for NPTv6, which statelessly translates any traffic from any address in the ULA prefix fde6:15e:1180::/48 to the equivalent address using the GUA prefix 2001:db8:2112::/48 (i.e., prefix translation). The process is reversed for traffic returning to the host from the server.
In a renumbering scenario compelled by the enterprise’s switching to a new ISP (or the existing ISP needing to change the prefix assigned to the enterprise), the enterprise would have no need to renumber internally. Instead, they’d need only change the external routed GUA prefix on the edge router and within the NPTv6 configuration.
Also, in instances where small end sites within the network might frequently change addressing, it may be desirable to use DHCPv6 and prefix delegation for such sites — much as a broadband ISP might assign a prefixes to a customer’s cable modem or home router.
Unplanned Growth
IPv6 provides tremendous advantages over IPv4 in providing addressing when unexpected or unplanned growth of the network takes place. Here are general recommendations for prefix assignment size, depending on the network element being added:
§ /64s
§ New LAN segment
§ New point-to-point link
§ Any “flat” network (a single broadcast or collision domain)
§ A group of sensors
§ /48s
§ New sites
§ New data centers
§ New lab environments
§ Any location or network that requires direct reachability to the Internet
§ >/48
§ Networks of acquired or merged companies
If you’ve done your address planning correctly, you’ll have IPv6 subnets in reserve at all levels of your network hierarchy. Depending on the scope and location of the network(s) and supporting infrastructure being added, the appropriate-sized subnet can be allocated.
An Address in Cloud City
I may be just an empty flesh terminal relying on technology for all my ideas, memories, and relationships. But I am confident that all of that — everything that makes me a unique human being — is still out there somewhere, safe in a theoretical storage space owned by giant multinational corporations.
— Stephen Colbert
I would bet my signed first edition of “DNS and BIND” that had I invited you to join me in a round of technology buzzword bingo covering the last few years, your first, second, and third words would be cloud, cloud, and cloud. But setting aside whatever hype factor might accompany this set of technologies, there can be little doubt that cloud services are dramatically reshaping the way computing resources are created and consumed, especially for enterprise IT.
In spite of this ubiquity of both the technology and the term, it might still be helpful to start our discussion with a working definition of cloud. The National Institute of Standards and Technology (NIST) offers a pretty serviceable one:[125]
NOTE
“Cloud computing is a model for enabling ubiquitous, convenient, on demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction.”
It should be evident from that definition that the value proposition of cloud computing (and SDN) is founded on agility, i.e., how quickly computer, storage, and network resources can be provisioned (as well as de-provisioned) in support of IT services and applications. The on-demand aspect of these offerings allows enterprises to spend only as much as is needed on cloud services to support what they actually use (instead of the danger of either underutilizing or quickly exhausting the resources of the infrastructure they already own or must acquire).
But such agility must be engineered into the cloud provider’s underlying architecture, infrastructure, and operations. The necessity of pooling compute and storage resources to support the economical and rapid scaling of services to a given client means that many such clients must share access to these resources in a cloud provider’s data center. Keeping these customers logically separate for routing, security, and SLA enforcement purposes requires unique addresses (as well as the ability to rapidly provision and deprovision them).
Meanwhile, these cloud solution providers face the same challenges confronting traditional service providers: how to use the relatively limited space available in IPv4 to scale their offerings. Since little if any public IPv4 space is left, cloud providers would need to rely on private IPv4 addressing (and possibly NAT).
Service categories have arisen as products from this concept include:
§ Software as a Service (SaaS)
§ Platform as a Service (PaaS)
§ Infrastructure as a Service (IaaS)
These services are generally public (or external to the organization) cloud offerings. Private (or internal) clouds are “homegrown,” internal to the organization (though IT can offer the same categories of service to different business units or divisions within the organization). Some organizations have adopted a hybrid cloud approach, seeking benefit from the use of some combination of both private and public clouds.
We should probably also talk about what problem cloud computing was developed to solve: namely, controlling IT costs — especially capital expenditures (CAPEX) on infrastructure while simultaneously expanding the quality and quantity of technology resources available to the organization.
Traditional corporate networks connect to external public cloud offerings via the Internet. Of course, in the age of teleworkers, remote offices, and mobile device productivity, connections to public cloud services are not limited to originating from corporate LANs. This is an argument for ensuring that CSPs offer their services over IPv6. As we’ve discussed, the broadband and mobile networks these itinerant workers rely on themselves increasingly rely on IPv6 addressing to cost-effectively solve their challenges of scale in an operationally efficient way.
The interface between the public network (or VPN) acts as a frontend to all customer traffic. Frontends often groom the arriving traffic in some way: by load-balancing it, or translating it in some way so that application or database servers on the backend with particular presentation requirements can focus on doing what they’re supposed to be doing and not have to worry about modifying arriving session traffic.
In this fashion, the frontend can be used to service requests arriving over IPv6 without regard for whether the backend network and servers comprising the cloud service are IPv6 or IPv4.
But as we’ve discussed, the elastic provisioning requirements of cloud services suggest that IPv6 adoption promises operational efficiencies and cost savings over time.
As a result, IPv6 and cloud are becoming inextricably linked. IPv6 has attributes that better enable the rapid provisioning models cloud computing requires to deliver on its promise of economical business agility. These include:
Sufficient addressing
This enables cloud providers to rapidly provision and deprovision any number of virtual servers.
Enhanced auto-addressing
The provisioning of virtual servers is better facilitated by multiple auto-addressing mechanisms, including SLAAC, as well as stateful and stateless DHCPv6.
Improved management of Layer 2 to Layer 3 mapping
ARP in IPv4 is replaced by ND in IPv6. ND’s use of multicast, as compared with broadcast in IPv4, is much more efficient and preserves LAN resources.
The abundant addressing of IPv6 provides hierarchical consistency and unlimited scale. IPAM practice can be improved to enable automation and more agile service provisioning and operations.
ADOPTING IPV6 AND CLOUD
A fairly compelling argument can be made for an organization tackling IPv6 adoption at the same time that they take steps to adopt cloud technology. Cloud and IPv6 intiatives are contemporaenous for many organizations and as a result certain synergies can be realized by combining the two.
For instance, when shopping for cloud services, a bit of additional due diligence is in order. We should determine, of course, whether the proposed CSP supports IPv6 at all. If they don’t today, when will they? And what is their take on how IPv6 fits into their overall strategy? But assuming they do support IPv6 connections from customers, does their backend support IPv6 and if not, why? Obviously, there are many other criteria for deciding on a given CSP, but perhaps we can agree that it’s better to understand up front how they perceive any necessity (or lack of it) in supporting IPv6 both externally and internally.
The Internet of Things
Remember the statistic from Chapter 1? 50 billion devices connected to the Internet by 2020.[126]
And thank goodness for IPv6, or there’d be no hope of manageably getting these devices online.
But before we explore a specific instance of what address planning for these devices might look like, let’s step back to look at the bigger picture.
Figure 9-2 illustrates the progression of Internet-connected device types in the past and up to the 50 billion mark while Figure 9-3 shows the number of Internet-connected devices per person over time.
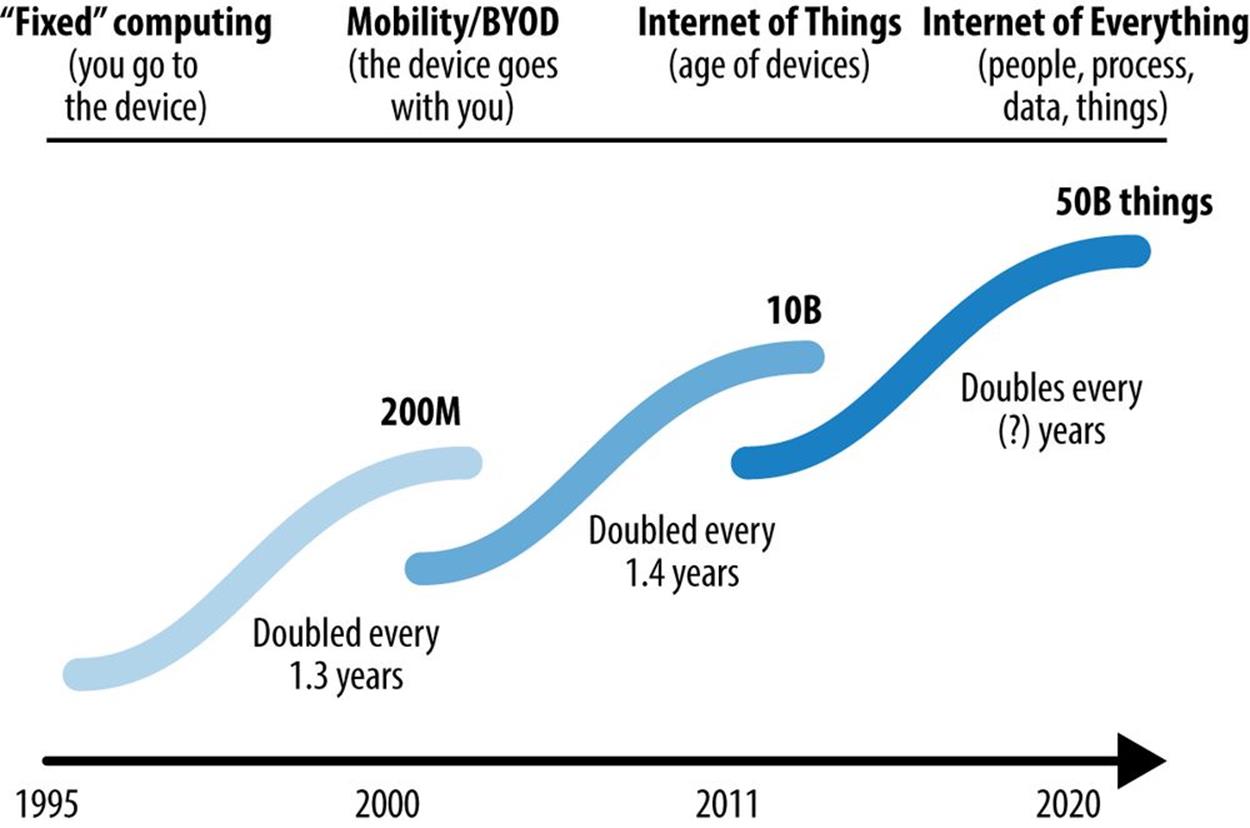
Figure 9-2. Internet-connected devices over time
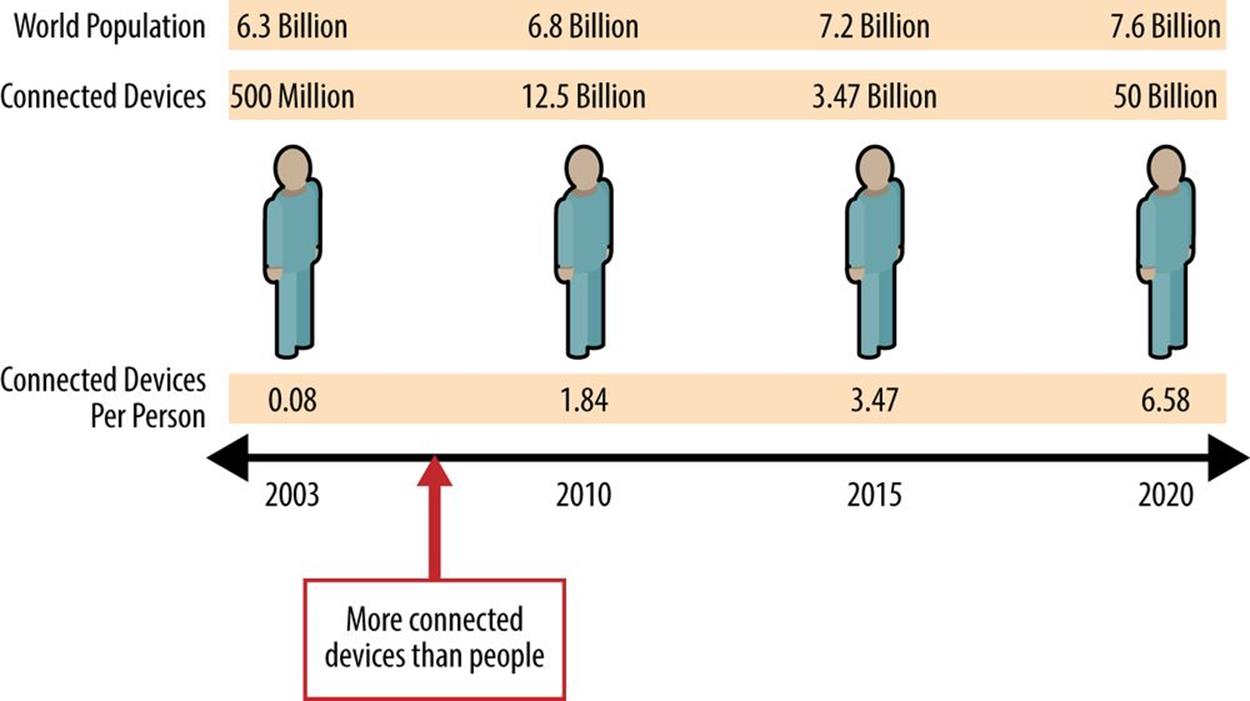
Figure 9-3. Internet-connected devices per person
Beyond the devices we’re already acutely aware of (tablets, smartphones, laptops, routers, switches, etc.), what makes up the things in the Internet of Things?
§ Utility distribution (Electric/H2O/Gas)
§ Home meters
§ Smart grid
§ Smart home (lighting/HVAC)
§ Home appliances
§ Sensors
§ Automotive
§ Industrial
§ Agricultural
§ Infrastructure
§ Medical devices
§ Wearables
§ Biochipped animals
At some point in the future, existing and new devices will comprise an Internet of Everything (IoE), potentially allowing data collected from every device to be leveraged to help solve economic, environmental, and social problems. Figure 9-4 and Figure 9-5 illustrate the relationships between the things in IoT and the data, people, and processes that will drive the IoE.
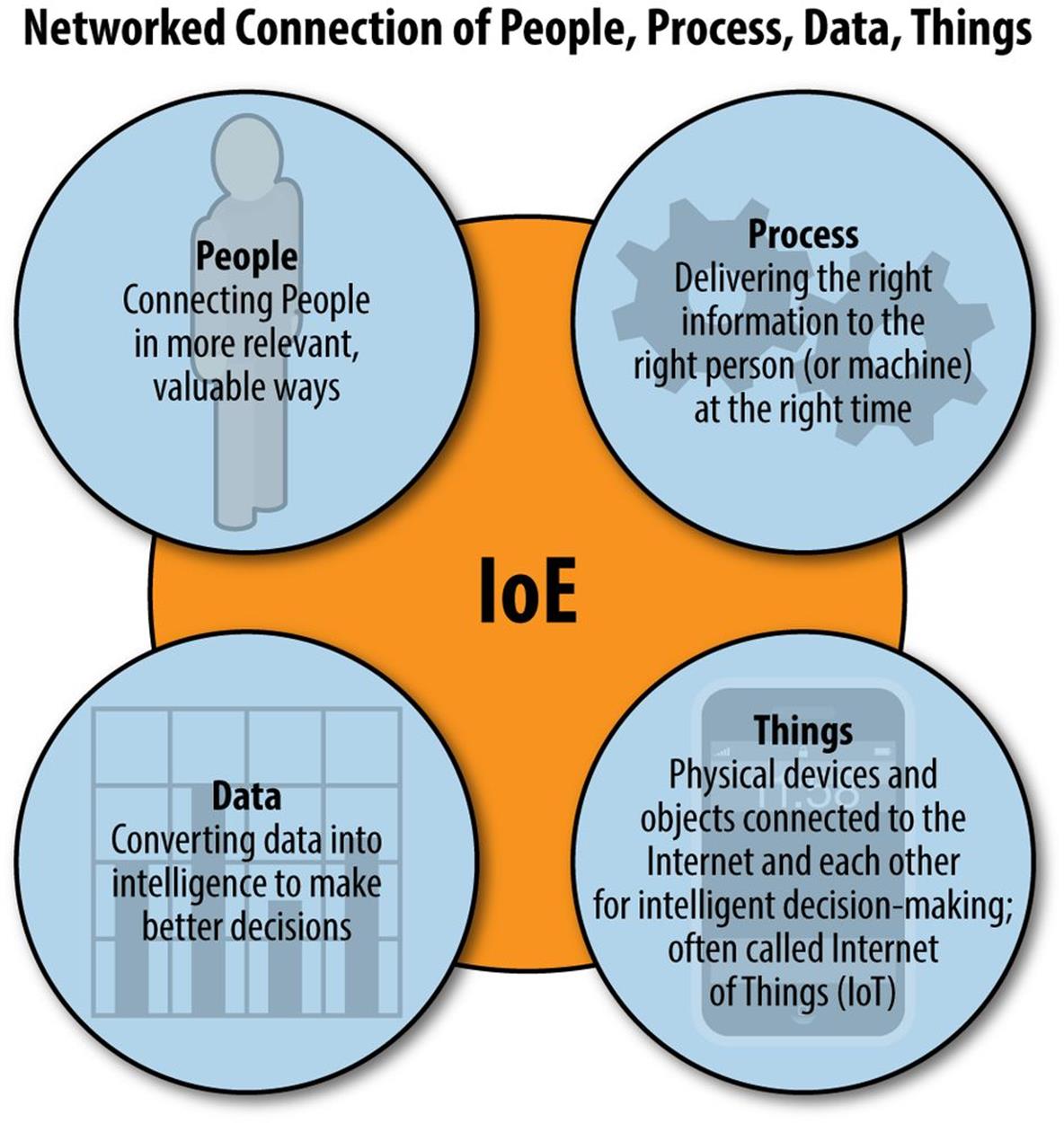
Figure 9-4. Internet of Everything
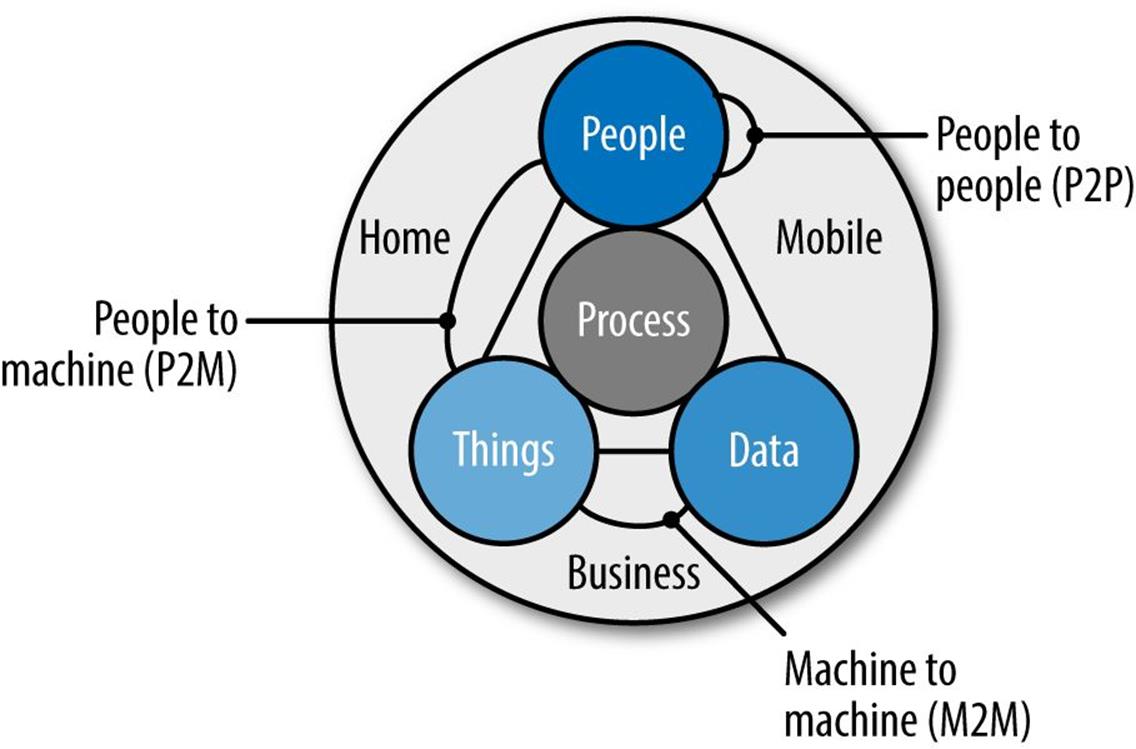
Figure 9-5. Internet of Everything
Why IPv6 for the Internet of Things? We’ve already mentioned the obvious reason: sufficient unique addresses for tens of billions of devices. But there are other reasons why IPv6 is critical to the success of the IoT. These reasons have to do with the unusual characteristics of many IoT devices themselves.
Characteristics of IoT Devices
As you may have guessed, IoT devices can be quite different than the fixed and mobile devices that have made up the bulk of connected Internet nodes up till now. For instance, many, if not most, of the connected devices will share the following characteristics shown in Table 9-1:
Table 9-1. Characteristics of IoT devices
|
Characteristic |
Unit(Scale) |
|
Small packet size |
Bytes(~100) |
|
Low cost |
Cents(50) |
|
Low power |
Milliamps(~1) |
|
Limited memory and processing |
Kilobytes(~100) |
|
Low bandwidth |
Kilobytes/second(~100) |
|
Lossy wireless |
Megahertz(<1000) |
These limits to available power, bandwidth, and processing capability drive the standards and protocols required to connect such devices and lead to the need to reduce their complexity (thus reducing cost).
Part of the complexity of IoT deployments is that there are competing standards and propietary technologies attempting to make the best of the strict “scale down” engineering requirements stemming from IoT device characteristics.
For instance, several low-power wireless standards exist, as shown in Table 9-2:
Table 9-2. Low-power wireless standards
|
Name |
Standard |
|
DECT ULE |
ETSI 300-175 |
|
ZigBee |
802.15.4 |
|
Bluetooth “Smart” |
Part of Bluetooth 4.0 |
|
Z-Wave |
G.9959 |
IPv6 in particular, and IP in general is one way to help accomplish this. Engineers focused on IoT are fond of calling IP the integration protocol for the promise it holds in stitching together different lower layer protocols.
This is the focus of the IETF 6LoWPAN effort. The associated standards introduce methods to scale IPv6 down in order to work within the IoT device constraints (Table 9-3).
Table 9-3. 6LoWPAN standards
|
Standard |
Purpose |
|
RFC 6775 |
Neighbor discovery/address registration |
|
RFC 4944 |
Basic encapsulation for 802.15.4 links |
|
RFC 6282 |
Stateless header compression |
With IPv6 successfully scaled down to work in constrained device networks of various types, routing for these networks can also be standardized. This approach reduces the so-called Internet of Gateways problem where silos created by various IoT device network solutions end up using different layer 3 protocols, requiring translation and reducing scalability.
Routing standardization is provided by RPL (pronounced “ripple”), or routing protocol for low-power and lossy networks. The limited bandwidth and low rates of packet delivery in LLNs create requirements to support multiple modes of traffic flow: exclusively between endpoints (point-to-point), as well as between endpoints and a central control point (multipoint-to-point) and vice-versa (point-to-multipoint).
Figure 9-6 shows an example of an LLN topology applied in the form of a simple last-mile smart grid infrastructure with redundancy.
The LLN itself is indicated as a Neighborhood Area Network (NAN), perhaps a radio mesh of smart meters. But it could also be any collection of constrained devices requiring interconnectivity and communication to a central system.
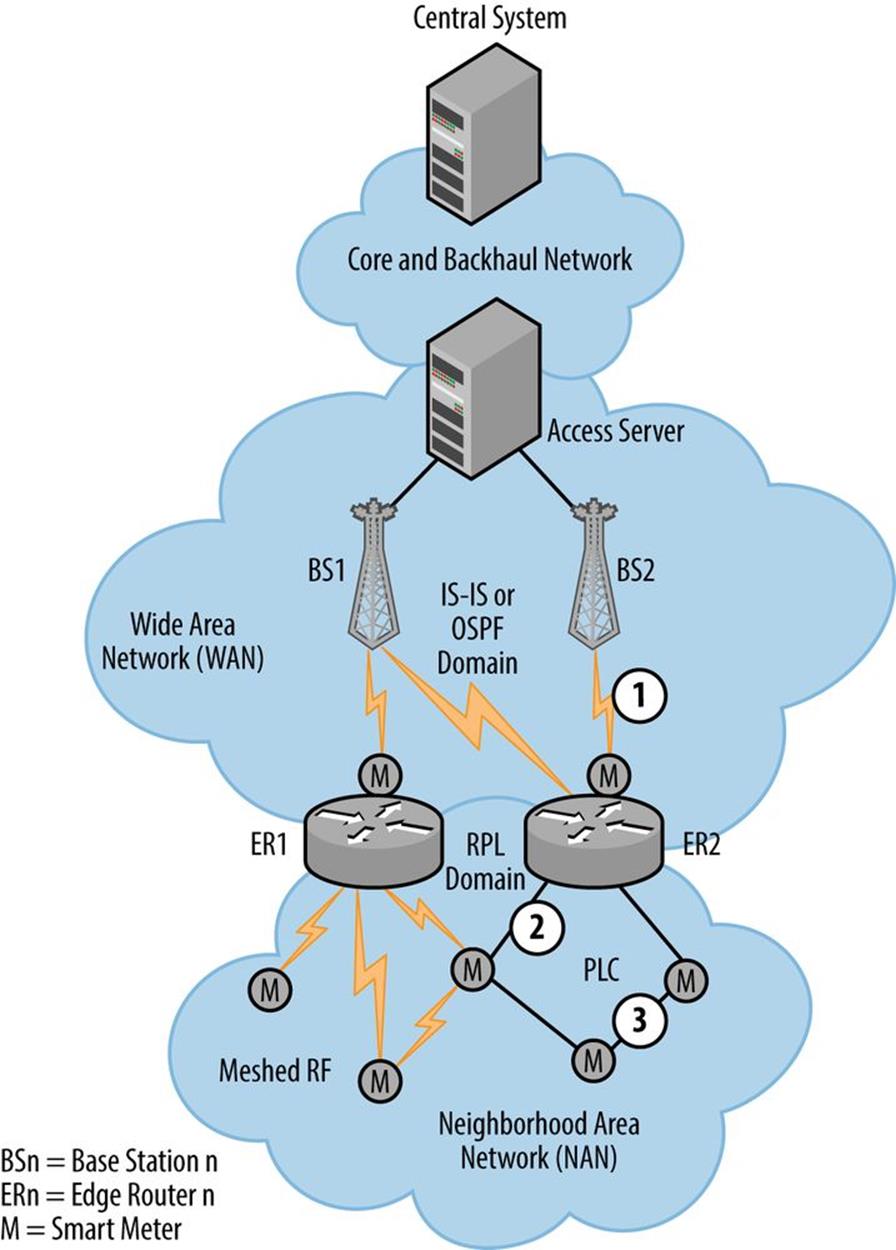
Figure 9-6. Last-mile smart grid infrastructure
IPv6 Address Planning for IoT Deployments
Though IoT networks, such as smart grids for utilities, may ultimately consist of several million devices, for ease of management and maximum scalability, subnets of no more than a few thousand nodes may be desirable. These subnets may logically terminate at edge routers, which will also likely be the interface to the WAN or LAN, the routing protocol redistribution point (if RPL is in use), and the location (or gateway to) the required auto-addressing configuration components.
It’s very likely that an organization’s device network architecture will be consistent and repeatable for discrete locations providing the same application set. Because of this, an IoT deployment often follows the same design practice that is common for ISPs and data-center deployments: a cookie-cutter architecture consisting of well-defined infrastructure modules with configurations standardized (except those configuration elements unique to that module).
Such uniform architectures lend themselves well to a similarly uniform address planning approach.
NOTE
This generalized topology imagines that most, if not all, device networks will be stub networks connected to a distribution and/or core layer to provide more operationally familiar routing (e.g., OSPF or IS-IS) with sub-second convergence times. In other words, any required communication between devices within these stub networks would necessarily be carried through the distribution or core layer. RPL provides true distance vector routing with a minimum of control traffic more suitable for an LLN. This may permit the construction of more complex topologies supporting communication between many thousands of devices.
Three Suggestions for IoT IPv6 Address Assignments
1. Assigning a default subnet size of a /64 to the device network (e.g., the NAN in the above illustration). A /64 assignment would usually preclude any prefix delegation within the constrained network. But the feasibility of successfully incorporating PD given the processing limits of IoT devices is probably low.
2. Using prefix delegation to assign a /56 or /60 to the device network gateways (e.g., in the previous illustration, PD to the border routers in the WANs directly connected to the NANs).
3. Setting aside a /48 per region, per device network application. A /48 guarantees portability on the Internet if needed but is still large enough to provide sufficient /64 subnets for the application the device network is providing across a given region.
Summary
The practice of renumbering needn’t always remain the laborious and costly process it has frequently been in the past. As we’ve learned, IPv6 provides mechanisms that make it more manageable. And in fact, the resulting evolution of renumbering practice should happen concurrently with leveraging IPv6 to provide addressing and address management for the new network environments such as cloud, IoT, and SDN — environments that will prove critical to scaling the next phase of the Internet.
[116] At least some of NAT’s traditional appeal for organizations is that it could help prevent or delay the need to renumber.
[117] In some sense, deploying dual-stack IPv6 and the eventual migration to native IPv6 is renumbering an entire network, but considering the fact that most organizations will do this over the course of years, such a project is made much more manageable as a result.
[118] RFC 4861, Neighbor Discovery for IP Version 6 (IPv6).
[119] Also, how long the included prefix will be used for determining on-link status.
[120] RFC 4862, IPv6 Stateless Address Autoconfiguration.
[121] RFC 4862.
[122] The proper address selection logic is defined in RFC 6724, Default Address Selection for Internet Protocol Version 6 (IPv6).
[123] RFC 6879, IPv6 Enterprise Network Renumbering Scenarios, Considerations, and Methods.
[124] RFC 6296, IPv6-to-IPv6 Network Prefix Translation.
[125] The NIST Definition of Cloud Computing, NIST Special Publication 800-145.
[126] 50 billion sounds like a large number (and it is), but it only equals slightly more than seven devices per person for the global population. It’s quite easy to imagine a scenario where a person is the logical endpoint of many, many more devices than seven.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.