The Clean Architecture in PHP (2015)
THE CLEAN ARCHITECTURE
We’ve explored some messy architecture and some all around bad code. We’ve also explored some great design patterns and development principles that can lead to good, quality code.
Now we’re going to take a look at some good architectural decisions that utilize these design patterns and principles to write good, clean, solid code.
This architecture is called the Clean Architecture.
MVC, and its Limitations
When building an application, there are often several different things going on. There’s the HTML, CSS and JavaScript that presents your application to the user. There’s usually an underlying data source, whether it’s a database, an API, or flat files. Then there’s the processing code that goes in between. The code that tries to figure out what the user requested, how to act upon their request, and what data to display to them next. Finally, there’s also the business rules of the application. The rules that dictate what the application does, how things relate to one another, and what the confines of those relationships are.
When one first starts out attempting to better their code (or maybe they’re lucky enough to learn of it straight on), they quickly come across the MVC architecture. The Model-View-Controller architecture dictates a strong separation of concerns by separating the database logic, control/processing logic, and the view/UI logic. The MVC architecture does have some faults, which we’ll discuss in the next chapter, but it does provide a pretty good framework for cleanly separating code.
For those who think they already know about the MVC architecture and don’t need a refresher, feel free to skip this chapter and head on to the next.
MVC in a Diagram
Let’s have a look at a pretty picture of MVC. It commonly looks like this:
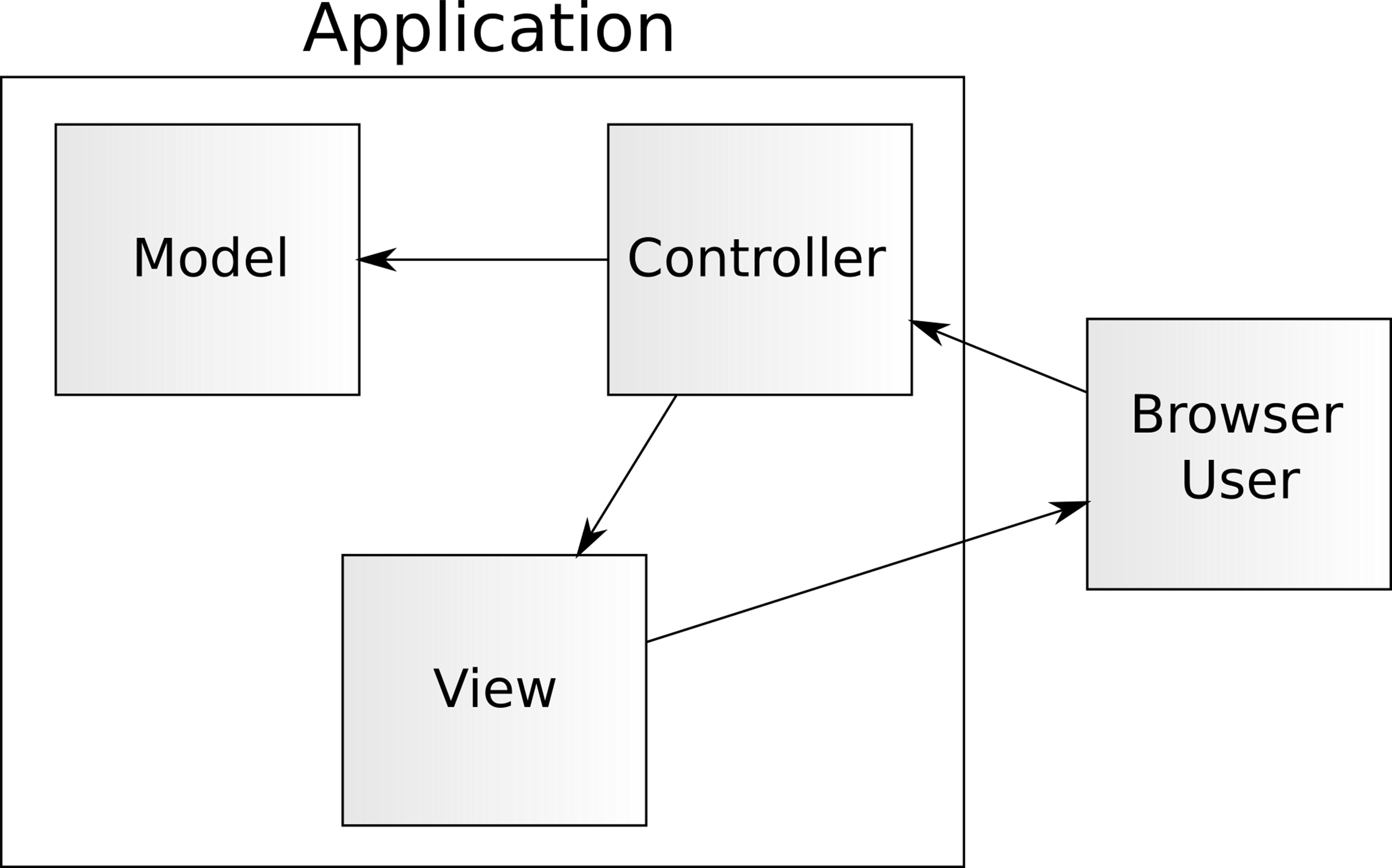
Briefly, the controller is the section of the codebase that analyzes a request and determines what to do. The user kicks off a controller by hitting a specific URL in their web browser, which then routes to the specific controller designed to handle that request (we’ll talk about routing in a bit).
The controller then manipulates some models, which are representations of data. For instance, if we hit a controller that is meant to save a new user, the controller would populate a User model with the data supplied in the post, and then persist it to the database.
Finally, the controller returns a view to the user, which is the PHP, HTML, CSS, JavaScript, and images that represent the request. In our example, after creating the new user, we might redirect off to a View User action which would display our new user’s information and give us further actions to take upon that user.
The MVC Components
The best way to discuss the MVC architecture is to discuss each component individually. We’ll start with Model and View, because, hey, that’s how the acronym goes, and we’ll end with the Controller, which is quite fitting as it ties the whole thing together, as you’ll see.
The Model
The Model in MVC is the portion of your application that represents your data. A specific model is a class that represents data. Consider this User class:
class User extends AbstractModel {
public $id;
public $alias;
public $fullName;
public $email;
}
This is a model representing a user in our system. Usually the model layer has some means for creating and hydrating these model records, as well as persisting them to the actual data storage. We’ll talk about this in more detail in Database Independence.
As a developer, we can manipulate this model like any PHP class:
$user = new User();
$user->alias = 'billybob';
$user->fullName = 'William Bob';
$user->email = 'william.bob@bobcorp.com';
Compare this to traditional use of PDO or the straight mysql_* or mysqli_* methods: here, we’re using fully backed objects that represent our data, rather than querying for it and dealing with arrays of data. We actually have representational data using this method.
The View
The View in MVC is simply what is presented to the user. In the PHP world, it is mostly composed of the HTML, CSS, and JavaScript that drive the UI. The view is also responsible for the user interaction with the application, through the use of links, buttons, JavaScript, etc. These actions may be handled entirely in the view layer, or they may make additional requests to the web server to load other data and views.
The View is also responsible for taking models and representing them to the user of the application. For instance, for our User model, we may have a page that iterates through a collection of users and displays them in a grid:
<table>
<thead>
<tr>
<th>ID</th>
<th>Full Name</th>
<th>Email</th>
<th> </th>
</tr>
</thead>
<tbody>
<?php foreach ($this->users as $user): ?>
<tr>
<td><?= $user->id ?></td>
<td><?= $user->fullName ?></td>
<td><?= $user->email ?></td>
<td>
<a href="/users/edit/<?= $user->id ?>">
edit</a>
</td>
</tr>
<?php endforeach; ?>
</tbody>
</table>
Our view layer is very purposeful: it is meant to display data to the user. It does no processing outside of simple loops and conditionals. It doesn’t query anything directly, just manipulates the data that is given to it.
But just how does the view get its data?
The Controller
The controller is responsible for interpreting the user request and responding to it. It can load specific models relevant to the request and pass it off to a view for representation, or it can accept data from a view (via something like an HTTP POST request) and translate it to a model and persist it to the data storage.
Controllers come in many forms, but one of the most common form is an action controller. These controllers are classes that contain one or more methods, each method representing a specific request.
If we continue our user example, we might have a UsersController that is responsible for dealing with requests relevant to users:
class UserController extends AbstractController {
public function indexAction() {}
public function viewAction() {}
public function updateAction() {}
}
This example controller has three actions:
· indexAction is responsible for listing all Users
· viewAction is responsible for viewing a User
· updateAction is responsible for updating a User
On a specific request, let’s say the view customer request, the corresponding action will be called, which would process the request and prepare the required view. This might look something like:
public function viewAction() {
$id = $this->params('id');
$user = $this->repository->getByid($id);
$view = new View();
$view->setFile('users/view.phtml');
$view->setData(['customer' => $user]);
return $view;
}
This pseudo-controller action in this sample code retrieves the passed ID from some mechanism, then uses the stored UserRepository to retrieve that user. Finally, it instantiates a new view, sets the view file to render, and passes the data off using setData().
Here, we can see that the controller only cares about responding to requests. It uses the model layer to retrieve data, and then passes it off to the view layer for processing and display.
Routing
This all starts to make much more sense when you consider how routing works in web-based MVC applications. We tend to lean towards using clean URLs these days, where our URI looks like this:
/users/view/1
Or, if you’re defining RESTful URIs:
/users/1
This is a URI that would route to the UserController’s viewAction in our examples above. Traditionally when routing clean URLs to controllers, the first part of the URI, /users maps to the controller, UsersController in our example, while the part, /view, maps to the action, which, of course, is the viewAction.
This isn’t always the case, however. Must frameworks allow routing to be whatever you make it, such that any URI can map to any controller or action.
Some frameworks make this explicit and do not require any additional setup. They simply map the URI to a corresponding controller and action. Most modern frameworks require you to setup some sort of routing table that tell it which URIs map to which portions of code.
In Zend Framework 2, that looks something like this:
return [
'router' => [
'routes' => [
'user' => [
'type' => 'Literal',
'options' => [
'route' => '/users',
'defaults' => [
'controller' => 'App\Controller\Users',
'action' => 'index'
]
],
'may_terminate' => true,
'child_routes' => [
'view' => [
'type' => 'Segment',
'options' => [
'route' => '/view/[:id]',
'defaults' => [
'action' => 'view'
],
'constraints' => [
'id' => '[0-9]+',
]
]
]
]
]
]
]
];
This long-winded block of code defines two routes, /users, which routes to UsersController::indexAction(), and /users/view/[:id], which routes to UsersController:viewAction(). Both are GET requests.
You can see how flexible this can be in defining routes as they don’t have to match the controller structure whatsoever. But it is pretty verbose.
Laravel, on the other hand, takes a much simpler approach to routing:
Route::get('user/view/{id}', function($id) {
return 'Viewing User #' . $id;
});
This routing is much simpler and expressive. Any time a URI matching /users/view/{id} is hit, the anonymous function runs and returns Viewing User #{id}.
MVC Isn’t Good Enough
The MVC architecture is a great start to building robust and adaptable software, but it isn’t always enough. With only three layers in which to organize all code, the developer usually ends up with too many details in one of the layers. It’s fairly presumptuous to think that everything should be able to fit into three buckets. Either it’s a model, or a view, or a controller. The view is usually saved from being slaughtered as its role is pretty well defined, so either the controllers become overwhelmed with business logic, or the model absorbs it all. The community has for quite some time adopted the mantra of “fat model, skinny controller.”
Obese Models
This “fat model, skinny controller” mantra is all well and good, until the model layer also becomes the database abstraction and persistence layer, and now the core business logic is tightly coupled to a data source. It ultimately becomes the obese model approach. This is bad news, as it makes it difficult for us to swap out that data layer, either the actual database itself or the library that powers the abstraction of it.
As it doesn’t make any sense to put database configuration and interaction in the view layer, and it becomes messy and not reusable to place it within controllers, everything related to the database, querying, and the representation of the database, the model or entity, gets shoved into the model. However, this tightly coupling of the representative data model to the actual data source is problematic.
Let’s say, for example, through the first iteration of our application, that we store and retrieve all of our data from a relational database system. Later down the road, however, our needs and number of applications might grow, and we might decide to build a web service API to manage the interaction of data with all the applications. Since we tightly coupled our business logic and data access together in the form of a model, it becomes difficult to switch over to our API without having to touch a lot of code. Hopefully we wrote a big test suite to help us.
Maybe instead of switching primary data sources, you simply find a much better database abstraction library that you want to use. Perhaps it is a well written library that better optimizes queries, saves resources, executes faster, and is easier to write. These are some great reasons to switch. However, if you initially went down a path of merging your database implementation details with your data representation, you might end up having to rewrite the whole entire model layer just to switch to a better library.
This becomes a clear issue of violating the Single Responsibility Principle.
A nice, clean model might look like this:
class User {
public $id;
public $alias;
public $fullName;
public $email;
}
How exactly does data get into these variables from the database, and how do we save changes we make back to that database? If we add in methods and mechanisms to this User class to persist our data to the database for us, we’re then making it very hard to test and switch data sources or database abstract layers later. We’ll cover various approaches and solutions to this problem in Database Independence.
Model Layer vs Model Class vs Entities
The solution to this problem is to realize there’s a difference between the Model Layer of MVC, and the Model Class. What we have in our example above is a Model class. It’s a representation of the data. The code responsible for actually persisting that data to the database storage is part of our model layer, but should not be part of our model class. We’re mixing concerns there. One concern is a representative model of the data, and the other is the persistence of that data.
From now on, we’re going to refer to the actual model class, like the one above, as an entity. Entities are simply representational states of things that have identities and attributes unique to that identity. For instance, an Order, User, Customer, Product, Employee, Process, Quotes, etc., can all be entities.
We’re also going to stop referring to the model layer as the persistence layer. The persistence layer is simply the layer of code that is responsible for persisting data, entities, back to the data store, as well as retrieving entities from the data store based on their identity.
From here-forth, you can pretend like the word model doesn’t exist, and with that, we can drop all baggage of the obese model.
More Layers for All of the Things!
Of course our solution here is to really add another layer to the MVC paradigm. We now have EPVC, which might stand for Entity-Persistence-View-Controller if that were a thing. This doesn’t mean that every problem can be solved simply by throwing another layer at the problem. But it does make sense to split up our representation of the data with the persistence of the data as they really are two different things.
Doing this allows us to move the database away from being the core of our application to being an external resource. The entities now become the core, which leads to an entirely different way of thinking about software applications.
The Clean Architecture
So if MVC isn’t enough, if it doesn’t give us enough organization and segregation of our code base, what is the solution, and what is enough?
The Clean Architecture
The solution to this problem is what I’m going to refer to as The Clean Architecture. Not because I named it so, as near as I can tell that honor goes to “Uncle” Bob Martin who wrote in 2012 about a collection of similar architectures that all adhered to very strong forms of separation of concerns, far beyond what traditional MVC describes.
Uncle Bob describes these architectures as being:
Independent of Frameworks. The architecture does not depend on the existence of some library of feature laden software. This allows you to use such frameworks as tools, rather than having to cram your system into their limited constraints.
Testable. The business rules can be tested without the UI, Database, Web Server, or any other external element.
Independent of UI. The UI can change easily, without changing the rest of the system. A Web UI could be replaced with a console UI, for example, without changing the business rules.
Independent of Database. You can swap out Oracle or SQL Server, for Mongo, BigTable, CouchDB, or something else. Your business rules are not bound to the database.
Independent of any external agency. In fact your business rules simply don’t know anything at all about the outside world.
Framework Independence
Framework independence is huge. When a developer initially starts using frameworks for their projects, they might think that the framework is the end game for their application. They make a choice and they’re sticking with it. But that’s a terrible decision.
Framework’s live and die, and even when they don’t die, they change, leaving the project that depends on them out in the cold. Take Zend Framework, for example. The release of Zend Framework 2 was such a massive change and shift, that it was near impossible to upgrade any ZF1 application to ZF2 without a complete rewrite. Especially if you based your domain around the Zend_Model family of classes.
Not only that, but new frameworks come out all the time. The PHP framework scene is more active than it has ever been, with previous unknowns like Laravel surging in popularity, and micro-frameworks, such as Silex, starting to get due respect. The best decision yesterday is not always the best decision today.
This is why it is the utmost importance to make sure that your applications are written as framework agnostic as possible. We’ll talk about this in Framework Independence
Testable
Testability in applications of any size of are of extreme importance. Software tests are the single most important means to preventing regression errors in an application. To people who sell their software, regression bugs often mean warranty work and a loss of billable time. And for all software developers, bugs are simply a pain to deal with, often a pain to troubleshoot and fix, and, without tests, more often than not a guessing game.
When we write software, we refactor code quite often. In fact, the process of software development in general can be seen as an endless series of refactoring. As we continually write code, we’re continually evolving the application, tearing down previous implementations and replacing them with newer, better ones, or enhancing them to account for some new feature set.
Since we’re always changing what already exists, having a suite of tests that are readily available, fast to run, and comprehensive becomes very important. It can literally be the difference between quickly preventing many bugs in the first place and spending hundreds of hours trying to fix them later.
While this book doesn’t have a dedicated chapter to testing, concepts discussed throughout the book will often discuss how they help the refactoring and testing process, and why they are good practices for developing a robust and highly available test suite.
Database Independence
Database independence may not seem like an important issue when building the architecture of an application. To some developers, it matters a great deal, such as those who are developing an open source project that users may want to deploy on a variety of database systems. But if you’re developing in house software where the architecture is controlled, and often vetted and picked for very specific reasons, this doesn’t seem like a big deal.
However, just like frameworks, databases can live and die. And just like frameworks, new platforms can spring up that suddenly look like a much better solution to your problem. Take for instance the rise of NoSQL alternatives to traditional relational database management systems (RDMS) in the past decade. For some situations, a NoSQL like Mongo or Couch might be a great alternative to MySQL or PostgreSQL. But when you’ve integrated MySQL into the heart of your application, it’s a daunting task to try to rip it out and replace it with something else.
When writing a Customer Relationship Management (CRM) application, my colleagues and I went down the common path of using a relational database, PostgreSQL as our data backend. Through the course of developing the application over the next six months, we quickly realized that other applications and systems, including mobile device applications, were going to need to interface with this data.
After analyzing the situation, we decided that what we should really do is build a RESTful API and have the CRM application sit on top of it. The API would be a middle layer between the application and the database, and provide a common way of interacting with the data across all of the applications.
Since we had already developed a good chunk of the application, this could have proven challenging. However, since we had created a separate domain layer with interface contracts that our persistence layer adhered to, we were able to simply rewrite our small persistence layer to pull data from the API rather than from the database, and never had to touch any other code, like the controllers, services, etc.
We’ll discuss how we can accomplish database independence in Database Independence.
External Agency Independence
The PHP ecosystem has recently exploded with a plethora of libraries and frameworks, most of which are now, thanks to PHP-FIG and Composer, easily plopped into every project you develop. These libraries are fantastic, and speed up the development of projects for you by providing proven solutions.
But should you use them? Absolutely! You just have to be careful how you do.
Just as these wonderful libraries have sprung up, they also die off and become forgotten just as fast. What could be more frustrating than having to refactor hundreds of files because you littered usage of someone else’s library all over your code, and they decided to let it rot?
Using some tried and true design patterns, we can lessen this problem by wrapping our usage of these libraries. We’ll discuss this in intricate detail in External Agency Independence.
The Onion Architecture
One off-shoot of the Clean Architecture, and the first one I came across before I found Uncle Bob’s article, is The Onion Architecture, described by Jeffrey Palermo. While the naming of this architecture may make one think it is satire, it is, in fact, a pretty descriptive way to describe how software architecture should be built.
Palermo described the layers of software like the layers of the onion: moving out from the core of the onion, each layer depends on the layers deeper for integrity and purpose, but the inner layers do not depend on the outer layers. It’s best illustrated by a diagram:
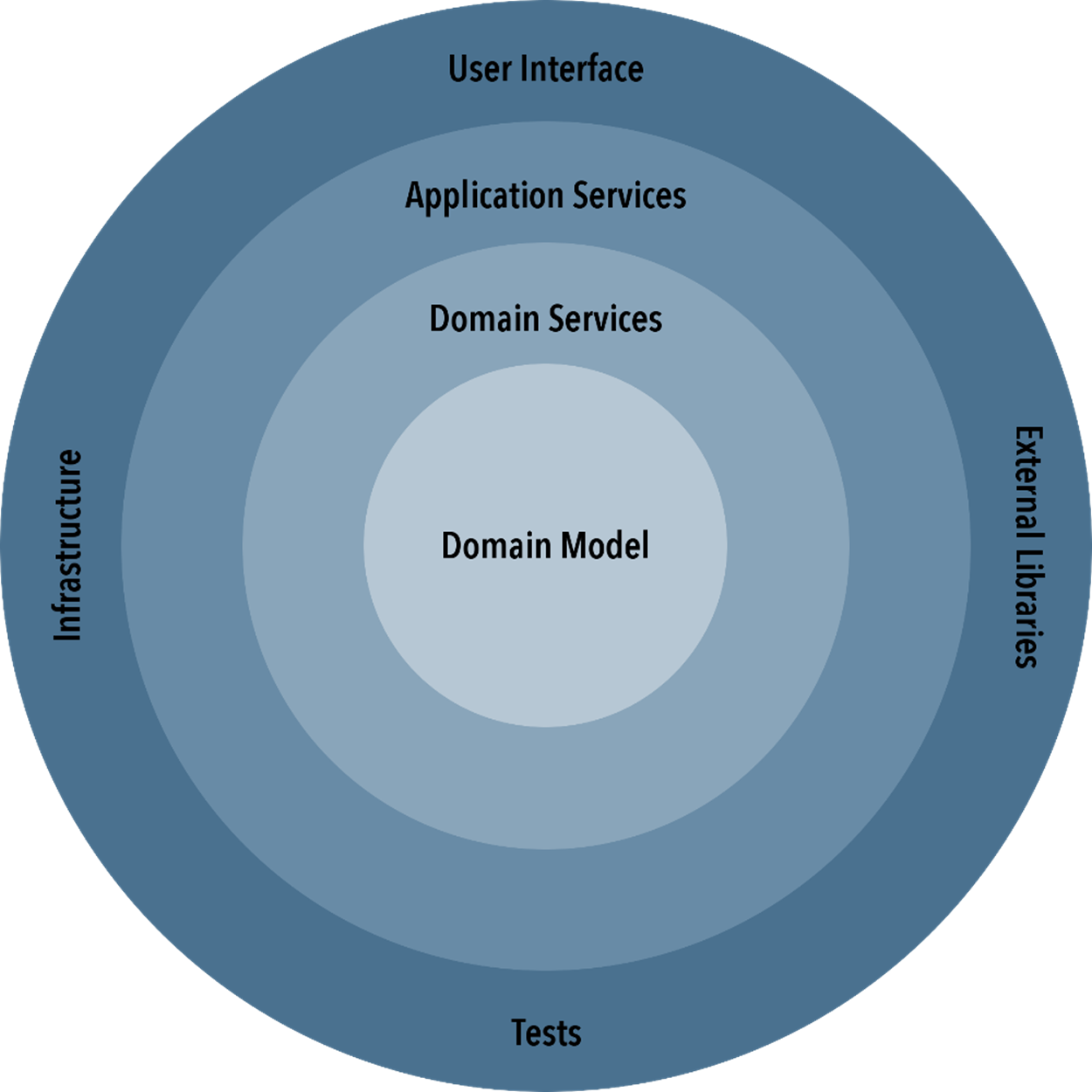
In traditional application development, the database is central to the application. It’s often designed first, and many application structure decisions are made around the database. Take it out, and the whole thing crumbles from within.
In the Onion Architecture, the domain is core to the application, and it is completely decoupled from the database. The database is no longer central, or even a required component of the application; it’s secondary. It can be swapped out at will without touching the rest of the application. It is supreme Database Independence. We’ll touch on how this works in Database Independence.
The Domain Model and Domain Services Layers
At the core of your onion is your domain model layer. This layer contains pure models or entities that are representative of the business objects in your application. They interact with one another to define relationships, and interact with nothing else. They are pure
Outside of that is your domain services layer. These are things like factories, repositories, and other services that use the core domain model
Coupled together, the domain model and domain services make up the core, most central layer of any application. They contain the business logic, and almost every other layer of the application depends on it. For instance, in a CRM application, you probably have a Customer model and various services for interacting with it that are used across many of the controllers, views, etc. of the other layers.
For all intents and purposes, the domain core is your application. Everything else is simply an extension or a client that interacts with your actual application.
The Application Services Layer
Outside of the Domain Services layer exists the Application Services. This layer is composed of application implementation. In a traditional MVC, this is your Controller layer. It is the router, which responds to an HTTP request and routes it to a specific controller and action, which may use other application services, such as authentication, data parsers or translators (maybe we’re exporting a CSV document?) and do everything necessary to bootstrap and provide the view, which is our UI.
It is important to know that nothing in our application should depend on this layer. The Application Services layer should be consider a layer that merely bootstraps our real application, which is the Domain Model and Domain Services application. Like the database, we should be able to swap this out at will with minimal effort. Maybe we started with Symfony but really want to switch to Laravel. That shouldn’t be a hard thing to do if the application is written correctly. This allows us to achieve Framework Independence, which, I’m sure you’ve guessed, we’ll talk about in more detail in Framework Independence.
The User Interface
One of the final and outermost layers of the onion is the User Interface. The UI has nothing dependent upon it, but is dependent upon every deeper layer of the onion. It requires the Application Services to give it meaning, which route through the Domain Services to get to the Domain, our meat and potatoes of our application. The view, at its core, is a representation of our domain for the user.
It sits on the outside and has nothing dependent upon it. We can refactor and hack it up at will without consequence. We could try a new templating language, or a new JavaScript framework every week, and the stability of our core application will not change.
We won’t spend any time in this book specifically talking about the User Interface, but it will be touched on in Framework Independence and during our Case Study at the end of the book.
Infrastructure
The infrastructure layer resides in an outer layer of our onion. Its responsibility is of grave importance: it provides for our domain. It defines where our data comes from and facilities the retrieving and saving of it to whatever data source it may come from, either Database, Web Services (APIs) or something else entirely. Those things sit on the outside of the application. They’re used by the Infrastructure layer, but they aren’t part of our onion. They’re simply data providers.
The Infrastructure relies on the Domain Services and Domain Model layer as they provide a contract for how the Infrastructure must work. This is done through interfaces, and we’ll cover that in the chapters on Interfaces and Dependency Injection and Database Independence.
The Infrastructure also depends upon the Application Services layer, as it is usually where the infrastructure is configured and “hooked up” to the domain. It is usually where our configuration is defined, and where our Dependency Injection Container or Service Locator is setup to provide services. We’ll see this at work in our Case Study at the end of the book.
External Libraries
External Libraries are great, and very important to our application as we discussed above. These libraries sit in a layer on the outside of our onion, and are used, much in a similar way that Infrastructure is, by the Application Services layer to provide meaning and implementation to some portion of the application. For instance, we might use a Google Maps API library to provide geocoding for addresses entered by a user.
We’ll talk about these in much detail in External Agency Independence.
Tests
Finally, our tests sit outside of the application in an outer layer of the onion. They, in various incarnations, depend on various layers of the onion in order to test them. This is not a book about testing, but just know that if your application ever relies on the existence of tests to properly function, you’ve done something horribly wrong.
Framework Independence
Frameworks like Laravel, Symfony, Zend Framework, et al provide great value to the modern day PHP developer. Frameworks tackle common problems, like authentication, database interaction, API usage, MVC, routing, etc., by providing proven solutions so that you, the developer, can get down to brass tax and start actually building the software you set out to build.
Using a framework can also go a long way to help teach and enforce good principles to inexperienced developers. You can really learn a lot by looking at and using a good PHP framework’s code base. Often, these frameworks even force you into these design patterns or principles, otherwise the framework simply won’t work.
Finally, frameworks can often speed up development time and allow the developer to ship the product faster. It makes sense: with less overhead of having to implement those common problems that frameworks handle for you, you have more time to develop your actual product. This, of course, is ignoring the ramp up period where you actually have to learn the framework, but eventually, this speed up can be realized.
The Problem with Frameworks
With all the benefits provided by these frameworks, it is often very easy to ignore the one giant negative about them. The negative that exists no matter what framework you use and no matter how good that framework is: coupling.
Having your application tightly coupled to a particular framework makes it very hard to leave that framework. You will, eventually, want to leave your beloved framework. A new framework might come out that makes development much easier and much quicker. Or a framework like Phalcon might come out that makes your code run faster. Or your framework might even disappear, either being abandoned by its developers, or reach end of life after a new version is released.
My coworkers and I once had a large application written using Zend Framework 1 that was very successful. When ZF1 reached end of life, and Zend Framework 2 was released, we were very excited to begin investigating upgrading. That excitement faded very quickly when we realized that ZF2 was such a backwards compatibility break that we were going to need to rewrite our application from scratch.
That’s costly.
Frameworks can be a blessing, and frameworks can be a curse if not used properly. If we had paid attention to writing our application better, in a way that did not rely so heavily and fully upon our framework, our transition to Zend Framework 2 would have been much quicker, cheaper, and a lot less stressful.
Framework Independence
The phrase “framework independence” can be quite jarring at first to the framework developer. We’re not talking about the type of independence sought by early colonists in North America. Instead, we’re talking about the ability to switch at will, easily, between one framework or another, or to using no framework at all. In a software application, the ability to leave a framework with minimal effort is a very powerful position to be in.
When writing medium to large applications, it’s important to know that the pieces of the application that are implemented using your framework aren’t your application, or at least they shouldn’t be. Any collection of controllers, forms, helpers, database abstraction, etc., is not your business application. They exist simply as a means to hydrate and display data to your users.
The domain model and domain services layers are your application. This collection of services, repositories, factories and entities are your application. The rest, the stuff the framework provides, is just a gateway or GUI sitting on top of your real application.
If your project is an inventory management system, the code that represents the inventory, the locations, and the means by which they relate to one another, is your application. This code should continue to function correctly if you were to remove the framework.
In order to gain such independence from a framework, there are several things we must remember when developing our applications and using these frameworks.
Abstract the Usage of the Framework
It is very important, as much as possible, to abstract the usage of the framework itself. Every line of code you write that directly uses a component of any framework is code you will have to rewrite if you ever try to switch frameworks.
We use several tactics to abstract the usage of a framework:
· Use Interfaces Liberally We previously discussed how we can use interfaces to define base functionality we require, type-hint to those interfaces, and then pass in concrete implementations of those interfaces using dependency injection (or some other method of inversion of control).
· Use the Adapter Pattern We also discussed the usage of the Adapter design pattern to wrap the functionality of one class and make it conform to the specification of another, such as an interface.
· Follow the principles of clean code and SOLID Writing clean code, and following the principles of SOLID, allow us to have nicely organized and grouped code, and when implemented correctly, code that doesn’t depend strongly on the framework to function.
Combining these first two tactics allows us to create a set of interfaces that define the functionality we need to use, and write classes that implement these interfaces, and simply wrap framework classes and map to their functionality to meet those interface requirements.
Additionally, making sure that our code is single-purposed, clean and short, and independent of other parts, will allow us to easily refactor away the framework usage later.
Let’s see how this works in different parts of a framework we might use.
Routes and Controllers
Many of us rely heavily on a framework’s router and controller mechanisms, as the vast majority of PHP frameworks are MVC-oriented.
How do you go about abstracting the usage of routes and controllers so that you don’t tightly couple yourself to them? This is the hardest part of an application to implement in the Clean Architecture. Routes and controllers are the entry point of your application. It is the basis by which all other work in the application is triggered.
It is pretty hard to decouple yourself completely from the framework, unless you actually stop using it. Just think about it: your first step after defining some route is to define some controller logic. This usually involves extending from some base or abstract controller:
class CustomersController extends BaseController { }
How do we decouple this from the framework? We’re immediately extending from the framework, meaning that every piece of code we write in this class from here on out is going to be coupled to our controller. It is not just the extension of BaseController, either; it is all the other mechanisms that this class provides us that our code begins to rely on.
Using Adapters to Wrap Your Controller
One approach you can take is to write controllers completely removed from your application. These essentially become very similar to services:
namespace MyApp\Controller;
class Customers {
public function index() {
return [
'users' => $this->customerRepository->getAll()
];
}
}
With an adapter that looks something like:
class CustomersController extends AbstractActionController {
protected $controller;
public function __construct(Customers $controller) {
$this->controller = $controller;
}
public function indexAction() {
return $this->controller->index();
}
}
This seems entirely like overkill. All we’re doing is simply wrapping one class in another just to call a method and pass it through. It’s a bunch of busy work just to claim we’re highly decoupled?
If you’re using a lighter framework, like Silex, this might be a little easier as controllers are a developer concept, not a framework concept proper. Those controllers only become as coupled as you make them.
Keep Your Controllers Small
Our best bet when dealing with controllers is to make sure we actually minimize the controller code. We want to follow very closely the Single Responsibility Principle we discussed previously. Each controller, and each action in the controller, should have as little code in it as possible.
Controllers should be thought of as response factories. They are responsible for building a response based on the input (the HTTP request). All logic should be passed off to either Domain Services or Application Services for processing, and the data returned from them loaded into a response and returned.
Ruby on Rails was big on the mantra of “fat model, skinny controller,” and that is at least partially sound. Having a skinny controller is very important. Having a fat model? Well, that depends on what “fat” and “model” mean to you. We’ll discuss this in depth in Database Independence. Having a skinny controller means that a controller doesn’t really do much. Let’s take this controller action, for example:
class CustomersController extends AbstractActionController {
public function indexAction() {
return [
'users' => $this->customerRepository->getAll()
];
}
}
This is a simple GET request to an index action (maybe /customers) that simply lists all customers. The controller uses the dependency injected CustomerRepository (not shown) and its getAll() method to retrieve all the customers.
Obviously we’re going to have more complex actions than indexAction(), but the point is that we want to pass all of the logic and processing to our Domain Services layer, and keep the controllers as small, tight, and single purposed as possible.
Views
Your view layer should be primarily composed of HTML, JavaScript and CSS. There should be no business logic contained within the views; only display logic. These views should be mostly transferable when switching frameworks. The only questionable part is the means by which data is presented to the view from the controller, which will probably vary by framework.
The big thing to watch out for is view services, view helpers, and/or view plugins, which many frameworks provide. These components help generate common or recurring HTML, such as links or pagination, or even forms (which we’ll talk about next). The method by which these exist will likely vary wildly by framework, and could cause quite a headache if they were very heavily relied on.
If you’re writing your own helpers, which many frameworks allow you to do, make sure that you’re writing the bulk of the code without relying on the framework, so that you can easily move this helper to a new framework. If possible, also consider writing interfaces and/or an adapter that turns your helper into something the framework expects.
Do as much as you can to make leaving the framework easy.
Another option would be to forgo your framework’s built-in view layer and use a third party library, such as Plates. This will allow you to keep your view layer intact when switching frameworks.
Forms
In my experience, forms have been one of the hardest things to deal with in projects. Doing forms cleanly and independent from the framework is near impossible. Again, we can write a bunch of adapters to abstract the usage of the framework, but that will almost certainly negate the time savings given by the framework.
The biggest rule is to make sure that no business logic whatsoever exists within the form code. Remember: business logic belongs in the Domain layer. Aside from validation rules and filtering, no logic should be contained within the forms.
Outside of that: just use them. If the bulk of your work when switching frameworks is porting the forms, you’re in pretty good shape.
Another solution to try would be to use some third party form library, so that you’re not coupled to your framework’s form classes. Something such as Aura.Input from the Aura components would suffice, and allow you to keep that code when switching frameworks. Some form libraries are light enough that you might even be able to write an adapter around them, but only do so if you’ll be able to accomplish that quickly.
Framework Services
Most frameworks provide helpful services to make writing day to day code much easier. These can include services that run HTTP requests or even do full API calls, components that implement an OAuth2 client to log in to those APIs, services that generate PDFs or barcodes, send emails, retrieve emails, etc. While these services provide a quick and fast way to get the job done by preventing you, the developer, from writing extraneous code, they are also a great place to run into coupling problems.
How do you run into coupling problems with these components? Simply by using them.
Consider Laravel’s Mail facade:
Mail::send('emails.hello', $data, function($message) {
$message->to('you@yoursite.com', 'You')->subject('Hello, You!');
});
Laravel makes it extremely simply to send emails, but the minute we drop this in a controller or service, we’re tightly coupling ourselves to Laravel. Remember, our goal with controllers and services are to have them as small, lightweight, and uncoupled as possible so that we can mitigate the work needed to migrate that code over to another controller system, should we ever switch framework or underlying controller/routing mechanism.
How do we solve this? Using the previously discussed adapter design pattern, the correct way to handle these services are to define an interface outlining the functionality that we need, and writing an adapter that wraps the framework code to implement that interface. Finally, the adapter should be injected into whatever client object needs it.
interface MailerInterface {
public function send($template, array $data, callable $callback);
}
Our adapter would then implement this interface:
class LaravelMailerAdapter implements MailerInterface {
protected $mailer;
public function __construct(Mailer $mailer) {
$this->mailer = $mailer;
}
public function send($template, array $data, callable $callback) {
$this->mailer->send($template, $data, $callback);
}
}
The adapter should then be injected into our controller and used, instead of directly using the Mail facade:
class MailController extends BaseController {
protected $mailer;
public function __construct(MailerInterface $mailer) {
$this->mailer = $mailer;
}
public function sendMail() {
$this->mailer->send('emails.hello', $data, function($message) {
$message->to('you@yoursite.com', 'You')->subject('Hello, You!');
});
}
}
To make this work, we’ll register our interface with Laravel’s IoC container so that when the controller is instantiated, it’ll get a proper instance of MailerInterface:
App::bind('MailerInterface', function($app) {
return new LaravelMailerAdapter($foo['mailer']);
});
Now the controller gets a concrete instance of LaravelMailerAdapter, which conforms to the controller’s dependency requirement of MailerInterface. If we ever decide to switch mailing mechanisms, we simply write a new adapter and change the binding of MailerInterface, and all our client code that previously got injected with LaravelMailerAdapter now gets whatever this new implementation is.
The popular Symfony YAML component is another great example of where a quick and easy adapter and interface allow you to be completely decoupled from the concrete implementation that Symfony provides.
The component is extremely simple to use:
$data = Symfony\Component\Yaml\Yaml::parse($file);
That’s all it takes to turn a YAML file into a PHP array. But when using this in our code, we’ll first want to create an interface to define this functionality that we need:
interface YamlParserInterface {
public function parse($fileName);
}
We then implement this interface with an adapter:
class SymfonyYamlAdapter implements YamlParserInterface {
public function parse($fileName) {
return Yaml::parse($file);
}
}
Then we simply utilize dependency injection to provide an instance of SymfonyYamlAdapter into any code that needs it:
class YamlImporter {
protected $parser;
public function __constructor(YamlParserInterface $parser) {
$this->parser = $parser;
}
public function parseUserFile($fileName) {
$users = $this->parser->parse($fileName);
foreach ($users['user'] as $user) {
// ...
}
}
}
Now we’re harnessing the power of Symfony’s YAML parser, without coupling with it. The point of doing this, again, is so that if we ever need to switch to a different YAML parsing solution in the future – for whatever reason – we can do so without changing any of our client code. We would simply write another adapter, and dependency inject that adapter in SymfonyYamlAdapter’s place.
Database Facilities
Most PHP frameworks come bundled with some sort of Database Abstract Library (DBAL), and sometimes a Query Builder library that makes it easier to build SQL queries, or maybe an Object Relational Mapping (ORM) library, either conforming to the Active Record or Data Mapper patterns. Taking advantage of these libraries can lead to easy, and rapid development of database-powered applications.
As always, though, we want to watch out for coupling too tightly to these database layers.
This is such an important topic, that the entire next chapter, Database Independence is devoted to it.
This is a Lot of Work
Are there any instances in which it’s okay to simply couple yourself to the framework? Of course. The principles outlined above only apply, in varying degrees, to the size and complexity of your application. If your application is so small in scope and function that it wouldn’t take you very long at all to entirely can it and rewrite it in a new framework, then by all means, go ahead and coupled to the framework.
It does take a lot of extra work to write code this way, so it is up to you to do a cost analysis for the project. If it is a small registration application that simply collects attendee information and saves it to the database, it’s going to be quicker to just completely rewrite it later, rather than go through all of these steps.
When the application is large in scope, like a Customer Relationship Management (CRM) system or an Enterprise Resource Planning (ERP) system, it probably makes a lot of sense to think about the future of the code right away. It probably makes a lot of sense to write the code in a way that it survives the chosen framework.
Database Independence
Often times when developing an application that uses a database for storage, the database easily becomes the center and focal point of the application. At first, this makes sense: we’re building an application on top of the database. Its sole purpose is to display and manipulate that data stored in the database. Why wouldn’t it be central to the application?
An application where the database becomes the central focal point suffers from a few problems:
1. The code is often littered with database interaction code, often times raw SQL or at least direct references and instantiation of classes that query the database. If the database, or database abstraction code, is literally all over the code base, it becomes nearly impossible to refactor that code without a time consuming effort.
2. Testing this code without using the database because very hard, if not impossible. Testing using databases is painful: you have to setup a known state for each and every test case as the code is modifying the contents of the database with each test. This can become slow to run, and test suites, to be successful and helpful, need to be fast.
So if the database shouldn’t be central to the application, what should take it’s place at the core?
Domain Models
If you paid attention to our previous discussion about the Clean Architecture, you should already know: the Domain Model is the core of our application, and central to everything else around it. Everything builds from it. So what is it exactly?
The domain model layer is a collection of classes, each representing a data object relevant to the system. These classes, called Models or Entities, are simple, plain old PHP objects.
By definition, the domain model layer, being the core of the application, cannot be dependent upon any other layer or code base (except the underlying language, such as PHP). This layer is wholly independent of anything. This makes it completely uncoupled, transferable, and quite easily testable.
A Sample Domain Model
A sample domain model for a customer might look something like this:
class Customer {
protected $id;
protected $name;
protected $creditLimit;
protected $status;
public function getId() {
return $this->id;
}
public function setId($id) {
$this->id = $id;
return $this;
}
public function getName() {
return $this->name;
}
public function setName($name) {
$this->name = $name;
return $this;
}
// ...
}
This Domain Model is a pure PHP object. It has no dependencies nor coupling, other than to PHP itself. We can use this unhindered in any of our code bases, easily transfer it to other code bases, extend it with other libraries, and very easily test it.
We’ve achieved some great things following this Domain Model implementation, but it’s only going to get us so far. Right now, we just have a simple PHP object with some getters and setters. We can’t do much with that. We’re going to have to expand on it, otherwise it’s going to be terribly painful to use.
Domain Services
Domain Services, being the next layer in the onion of our architecture, is meant to expand on this and provide meaning and value to the Domain Model. Following the rule of our architecture, layers can only have dependency upon layers deeper in the onion than it is. This is why our Domain Model layer could have no dependencies, and why our Domain Services layer can only depend upon, or couple to, the Domain Model layer.
The Domain Services layer can consist of several things, but is usually made up of:
· Repositories, classes that define how entities should be retrieved and persisted back to some data storage, whether it be a database, API, XML or some other data source. At the Domain Services layer, these are simply interfaces that define a contract that the actual storage mechanism must define.
· Factories, are simply classes that take care of the creation of entities. They may contain complex logic about how entities should be built in certain circumstances.
· Services, are classes that implement logic of things to do with entities. These can be services such as invoicing or cost buildup or classes that build and calculate relationships between entities.
All of these are implemented only using the Domain Model and other Domain Services classes. Again, they have no dependence or coupling to anything else.
Repositories
Repositories are responsible for defining how Domain Model entities should be retrieved from and persisted to data storage. At the Domain Services layer, these should simply be interfaces that some other layer will define. Essentially, we’re providing a contract to follow so that other layers of our application can remain uncoupled to an implementation. This allows that implementation to be easily changed, either by switching out what is used in production, or maybe just switching out what storage is used during testing.
A sample repository might look like this:
interface CustomerRepositoryInterface {
public function getAll();
public function getBy($conditions);
public function getById($id);
public function save(Customer $customer);
}
As you can see, again, we have a simple PHP interface, uncoupled from anything but the Domain Model (through the usage of Customer). This interface doesn’t do anything. It simply defines a contract to be followed by an actual implementation. We’ll talk about that implementation inDatabase Infrastructure / Persistence in a little bit.
The Domain Services layer should contain a definition of all the repositories an application will need to properly function, as well as each repository containing all the methods that the application will need to interact with the data.
Factories
Factories are responsible for creating objects. At first, that seems a little silly as creating an object is as simple as:
$customer = new Customer();
It’s not always this easy, however. Sometimes, complex logic goes into creating a customer. If you notice above when we defined the Customer class, we gave it a credit limit and status attribute. It might be that all customers get set to a certain state when they’re created such that these two attributes are always set to a predefined value. If we were to continue with simple instantiation:
$customer = new Customer();
$customer->setCreditLimit(0);
$customer->setStatus('pending');
Now let’s assume we might have several different places in the code where we create customers. We now have to repeat this code all over the place. If these default rules ever change, we then have several places we need to go change the code. If we miss some, now we have bugs in the code.
Using a factory lets us consolidate that code and make it reusable:
class CustomerFactory {
public function create() {
$customer = new Customer();
$customer->setCreditLimit(0);
$customer->setStatus('pending');
return $customer;
}
}
Now, wherever we need to create a customer, we can simply use our factory:
$customer = (new CustomerFactory())->create();
If our business logic ever changes, all we need to do is simply update the factory, and each customer creation point will follow the new rules.
The skillful developer might see an even easier solution to this problem: just throw the defaults in the class or constructor:
class Customer {
protected $id;
protected $name;
protected $creditLimit = 0;
protected $status = 'pending';
}
This is true: that does look much simpler, and it’s completely due to the simplicity of the example. However, let’s say we have an account manager that needs to be assigned to every new customer, and to pick them, we need to find the next available account manager (whatever that might mean in the context of our application):
class CustomerFactory {
protected $managerRepository;
public function __construct(AccountManagerRepositoryInterface $repo) {
$this->managerRepository = $repo;
}
public function create() {
$customer = new Customer();
$customer->setAccountManager(
$this->managerRepository->getNextAvailable()
);
}
}
As our business rules and domain logic become more complex, using these factories start to make sense. The important thing to remember is that these factories are completely decoupled from the actual data storage. Their only dependence is upon the Domain Model.
So how exactly does an instance of AccountManagerRepositoryInterface get into the CustomerFactory? And what exactly is the implementation of that interface? We’ll cover that soon in Database Infrastructure / Persistence.
Services
Services, simply put, are responsible for doing things. These are usually processes, such as invoice runs or some kind of cost build up analysis. Anything that involves business logic that is not either creational (which belongs in a factory), or retrieving or persisting data (which belongs in a repository). These services can depend on repository interfaces and factories to do their work.
Let’s look at an example service for generating invoices based off orders:
class BillingService {
protected $orderRepository;
protected $invoiceRepository;
protected $invoiceFactory;
public function __construct(
OrderRepositoryInterface $order,
InvoiceRepositoryInterface $invoice,
InvoiceFactory $factory
) {
$this->orderRepository = $order;
$this->invoiceRepository = $invoice;
$this->invoiceFactory = $factory;
}
public function generateInvoices(\DateTime $invoiceDate) {
$orders = $this->ordersRepository
->getActiveBillingOrders($invoiceDate);
foreach ($orders as $order) {
$invoice = $this->invoiceFactory->create($order);
$this->invoiceRepository->save($invoice);
}
}
}
This service is pretty simple, because it leverages the power of the OrderRepository given to it to retrieve orders, and the InvoiceFactory to generate invoice objects. It then simply persists them to the database using the InvoiceRepository. The BillingService can now be used anywhere that invoices need to be generated for whatever means of ordering the system needs implement. This is abstracted away into the service, so that the code is not repeated all over the place.
Further, this code does not depend on a specific data store whatsoever, instead, asking for an implementation of both OrderRepositoryInterface and InvoiceRepositoryInterface. If those dependencies are satisfied with concrete implementations, the Service works correctly finding orders to invoice and generating those invoices.
This code is powerful, but dead simple. It’s coupled to nothing but the rest of our Domain Model and Domain Services layer. It is 100% decoupled from any specific database implementation.
Database Infrastructure / Persistence
So far we’ve discussed taking the database from the core of the application, and replacing it with a robust Domain Model and Domain Services core that encompass the primary functionality of our application. Now the heavy parts of our application are decoupled, well-written, and quite testable. At some point, however, we have to bring the database back into the picture. A data-centric application without some sort of data storage implementation is going to be a failure, regardless of how clean and testable the code base is. So how do we get the database back in the picture?
Now that we’ve fleshed out our Domain Model and Domain Services layers, we can start to build out our Persistence layer, which is part of the infrastructure layer of our onion. The persistence layer is responsible for retrieve and persisting data to our data storage, whatever that may be. In our case, it’s probably going to be a relational database system, such as MySQL or PostgreSQL. Or maybe it might be a NoSQL variant or an API services layer that provides our data.
For instance, if we were using a relational database and using the Doctrine ORM library to provide persistence, we might implement our CustomerRepositoryInterface like so:
class CustomerRepository implements CustomerRepositoryInterface {
protected $entityManager;
protected $entityClass = 'MyVendor\Domain\Entity\Customer';
public function __construct(EntityManager $entityManager) {
$this->entityManager = $entityManager;
}
public function getAll() {
return $this->entityManager
->getRepository($this->entityClass)->getAll();
}
public function getById($id) {
return $this->entityManager->find(
$this->entityClass,
$id
);
}
}
This is a really simple implementation of a repository using Doctrine ORM. Of course, to use Doctrine, we also have various mapping files and configurations we need to setup to get things to work, but this is our basic repository. We’re also missing the definition of a couple methods above, but have simply omitted them for brevity. Were we actually trying to run this code, we’d get an error that we didn’t implement all methods of the interface.
It implements our CustomerRepositoryInterface, such that anything requesting an instance of this interface would be fully satisfied by using this concrete class.
Of course, this functionality looks pretty generic and unspecific to our CustomerRepository. We could easily break this out into an abstract class so that we can prevent duplicate functionality being littered about all of our repositories:
abstract class AbstractRepository {
protected $entityManager;
protected $entityClass = '';
public function __construct(EntityManager $entityManager) {
$this->entityManager = $entityManager;
if (empty($this->entityClass)) {
throw new \RuntimeException(
'entityClass not specified for ' . __CLASS__
);
}
}
public function getAll()
{
return $this->entityManager
->getRepository($this->entityClass)->getAll();
}
public function getById($id)
{
return $this->entityManager->find(
$this->entityClass,
$id
);
}
}
Our CustomerRepository then simply becomes:
class CustomerRepository extends AbstractRepository
implements CustomerRepositoryInterface {
protected $entityClass = 'MyVendor\Domain\Entity\Customer';
}
Now we only need to add customer-specific logic to this repository, as needed.
Utilizing Persistence
The Persistence layer is meant to sit on one of the outer layers of the onion. It is not central to the application. Again, our Domain Model and Domain Services are. The Persistence layer simply provides meaning to that Domain Services layer by implementing the repository interfaces that we setup. Nothing should be dependent upon this Persistence layer. In fact, we should be able to swap out Persistence layers with other implementations, and all of the code that ends up using this layer (through using the interfaces) should be none the wiser, and continue to function properly.
We’ll experiment with this concept once we start working on our Case Study.
Using Dependency Injection to Fulfill Contracts
So we’ve defined plenty of interfaces in our Domain Services layer and implemented them with concrete classes in our Persistence layer. We’ve discussed that nothing can directly depend on this Persistence layer, so just how exactly do we use it in our application?
We previously discussed Dependency Injection as a means of preventing coupling, and that’s just what we’d use here. Any time any class needs a concrete implementation of a repository, it should declare a dependency to the interface, instead. For instance, when we discussed our Factory that needed to find the next available account manager, remember, we only asked for an interface:
class CustomerFactory {
protected $managerRepository;
public function __construct(AccountManagerRepositoryInterface $repo) {
$this->managerRepository = $repo;
}
// ...
}
The CustomerFactory is deeper in the onion than that persistence layer, so it can’t be dependent upon a concrete CustomerRepository, nor would we want it to be. Instead, it declares, via the constructor, that it needs something that implements AccountManagerRepositoryInterface. It doesn’t care what you give it, so long as the what is passed in adheres to the interface. We call this programming by contract.
So how exactly does a CustomerRepository get into the CustomerFactory? Whatever means is responsible for instantiating this Factory would take care of passing in the correct implementation:
$customerFactory = new CustomerFactory(
new CustomerRepository($entityManager)
);
How this works is largely dependent upon your framework and how it handles Dependency Injection Containers or Service Locators. We’ll discuss this more when we talk about the framework, and explore how it works in our Case Study. The important thing to note here is that our code should only be dependent upon interfaces, not concrete implementations of the Persistence layer.
Organizing the Code
We’ve discussed Entities, Services, Factories, Repository interfaces and concrete Repositories. Where do we put all this stuff?
It makes sense to logically separate the layers of your application to their own root fielders, even if the shared parent folder is the same. We have essentially talked about two layers, Domain and Persistence. So starting there might be a good idea, and then grouping each component type under those two folders:
src/
Domain/
Entity/
Factory/
Repository/
Service/
Persistence/
Repository/
Following the PSR-4 autoloading standard, we’d also have similar namespaces, for instance:
MyVendor\Project\Domain\Entity\Customer
I’ve taken this one step further in a series of applications that actually share the same Domain (and ultimately, database). Domain and Persistence have both been broken up into separate code repositories, all loaded into several parent projects using Composer. It’s the ultimate in separation of concerns: the code bases are literally separate. Granted, that doesn’t mean they’re decoupled.
How you want to organize your code is up to you. My ultimate recommendation is to keep the layers segregated out into at least their own folders.
Wrapping it Up
The purpose for taking the database away from being the center of our application is so that we are no longer dependent and coupled to that database. This gives us the freedom to swap out database flavors, or even add in a middle layer such as an API in between our application and the database, without having to rewrite our entire application. It also gives us the flexibility in switching out database libraries, say going from Doctrine to Laravel’s Eloquent ORM.
We’ll next look at applying some similar principals to the developer’s framework of choice, and explore how we can limit decoupling in Framework Independence.
External Agency Independence
With the arrival of Composer, the PHP scene suddenly exploded with a myriad of packages, libraries, components, and tools that could easily be dropped into any project, and even autoloaded magically through the Composer autoloader. It is now easier than it has ever been to load third party libraries into your source code and solve challenges easily and quickly.
A simple glance at the instructions for many of these projects on GitHub shows how painfully easy it is to get them installed and integrated. Usually, installation instructions are followed by a quick little snippet or two of example usage.
Not so fast.
Every time we pull in one of these third party libraries and use it directly within our client code, we’re tightly coupling ourselves to it.
How long is this code going to be around? Is it going to be actively maintained? What if our needs outgrow what it provides? It’s likely that at some point, we may need to abandon this library for another solution. The more tightly coupled we are to this library, the harder it’s going to be to switch to something else.
Using Interfaces, Adapters and Dependency Injection
Of course, we’ve already explored the solution to this problem when we discussed how to handle framework services. The solution was pretty simple:
1. Create an interface defining the functionality we need
2. Write an adapter that wraps the third party code, making it conform to our interface
3. Require an implementation of that interface to be injected into whatever client code needs it
Let’s look at another example of this.
The Geocoder PHP library provides a great library for geocoding services, itself with several adapters to use a variety of different services to provide the geocoding. Let’s say our app simply needs to be able to get the longitude + latitude for any given address.
We first define an interface for this need:
interface GeocoderInterface {
public function geocodeAddress($address);
}
This is fairly straight forward. We need this in a controller which interacts with some mapping:
class AddressController {
protected $geocoder;
public function __construct(
GeocoderInterface $geocoder
) {
$this->geocoder = $geocoder;
}
public function geocode() {
return $this->geocoder->geocodeAddress(
$this->params('address')
);
}
}
Now all we need to do to make this code work is provide something that implements GeocoderInterface, and inject that into the controller when it is instantiated. Our adapter provides the needed concrete implementation:
class GeocoderPhpAdapter {
protected $geocoder;
public function __construct(Geocoder $geocoder) {
$this->geocoder = $geocoder;
}
public function geocodeAddress($address) {
$results = $this->geocoder->geocode($address);
return [
'longitude' => $results['longitude'],
'latitude' => $results['latitude']
];
}
}
We’re also injecting the $geocoder into this adapter as we may want to have different configurations for different circumstances:
$geocoder = new GeocoderPhpAdapter(
new Geocoder(
new GoogleMapsProvider(new CurlHttpAdapter())
)
);
That’s a lot of dependency injection!
Benefits
We want to make sure we have flexibility and freedom in our applications. Specifically, we need the ability to switch out third party libraries, whenever necessary, for whatever reason, easily and quickly.
Not only does it safeguard us against a library going away or no longer providing what we need, but it can make testing easier through mocking, and also makes refactoring easier, as it encapsulates all functionality of the third party library into one place.
We’ll use this strategy extensively whenever we use third party libraries throughout the Case Study.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.