NoSQL For Dummies (2015)
Part III. Bigtable Clones
Chapter 10. Bigtable in the Enterprise
In This Chapter
![]() Protecting your data when a server crashes
Protecting your data when a server crashes
![]() Predicting reliability of your database service’s components
Predicting reliability of your database service’s components
![]() Growing your database service as your business grows
Growing your database service as your business grows
Businesses are risk-adverse operations, and mission-critical systems rely on safeguard after safeguard, along with plan B and plan C, in case disaster strikes.
Distributed Bigtable-like databases are no exception, which requires Bigtable enthusiasts to prove that this newfangled way of managing data is reliable for high-speed and mission-critical workloads.
Thankfully, the people working on Bigtable clones are also intimately familiar with how relational database management systems (RDBMS) provide mission-critical data storage. They’ve been busily applying these lessons to Bigtables.
In this chapter, I talk about the issues that large enterprises will encounter when installing, configuring, and maintaining a mission-critical Bigtable database service.
Managing Multiple Data Centers
If all goes horribly, horribly wrong — or someone accidentally turns off all the lights in a city — you’ll need an entire backup data center, which is referred to as a disaster recovery site.
In this section, I talk about the features commonly available in Bigtable clones that help guarantee a second data center backup in case of disaster.
Active-active clustering
Perhaps your organization does “live” business in many locations in the world. If so, you need high-speed local writes to your nearest data center — so all data centers must be writable. In this scenario, all data centers are primary active data centers for their own information.
Active-active clustering writes can happen at any location. All data centers are live all the time. Data is replicated between active sites, too, in order to provide for traditional disaster recovery.
However, if the same data record is overwritten in multiple locations, you may be faced with having to choose between two options:
· Wait for the site to write this data to all data centers, slowing down your transaction times.
This option is shown in part A of Figure 10-1.
· Replicate this data asynchronously, potentially losing some of the latest data if it wasn’t replicated before an outage at one site.
· This option is shown in part B of Figure 10-1.
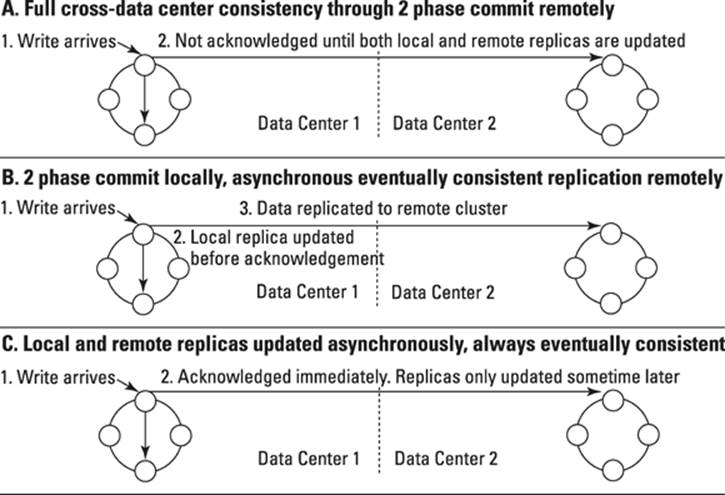
Figure 10-1: Cross-data center replication mechanisms.
 In my experience, it’s unusual to have a situation where the same record must be updated from multiple data centers. Normally, writing a new record locally and pushing that to the other sites asynchronously is sufficient. In this model, each site does accept writes, but only for a fixed number of partitions (primary keys). This still allows a global view to be generated locally, with a small chance of inconsistency only with the remote replicated data. This option is show in part C of Figure 10-1.
In my experience, it’s unusual to have a situation where the same record must be updated from multiple data centers. Normally, writing a new record locally and pushing that to the other sites asynchronously is sufficient. In this model, each site does accept writes, but only for a fixed number of partitions (primary keys). This still allows a global view to be generated locally, with a small chance of inconsistency only with the remote replicated data. This option is show in part C of Figure 10-1.
When you absolutely need fast local data center writes across the world, a globally distributed database that supports full active-active clustering is needed. Cassandra is a Bigtable database that supports global active-active clusters while preserving as much speed as possible on ingest.
Managing time
Many Bigtable databases rely on identifying the latest record by a timestamp. Of course, time is different across the world, and coming up with a reliable, globally synchronized clock is incredibly difficult. Most computer systems are accurate individually to the millisecond, with synchronization lag of a few milliseconds. For most systems this is fine, but for very large systems a more accurate time stamp mechanism is required.
An out-of-sync clock means that one site thinks it has the latest version of a record, whereas in fact another site somewhere in the world wrote an update just after the local write. Only a very few applications, though, are affected by this time difference to the extent that data becomes inconsistent. Most records are updated by the same application, process, or local team of people that wrote it in the first place. Where this isn’t the case (like in global financial services where trades can be processed anywhere), synchronization is an issue.
Google recently came up with a mechanism for a reliable global timestamp called the Google TrueTime API, and it’s at the heart of the Spanner NewSQL relational database, which stores its data in the Bigtable NoSQL columnar database.
This API depicts the concept of uncertainty in terms of current time. It uses a time interval that’s guaranteed to include the time at which an operation happened. This approach better clarifies when an operation definitely or may have happened. The time synchronization uses atomic clocks or GPS signals.
Many Bigtable databases, except Google Bigtable itself, support the concept of a record timestamp. These time stamps don’t rise quite to the level of science that Google’s TrueTime API does, but they provide a close approximation that may suffice in your particular use case. Notably, Accumulo has its own distributed time API within a cluster.
Reliability
Reliability refers to a service that’s available and can respond to your requests. It means you’re able to access the service and your data, no matter what’s going on internally in a cluster.
Conversely, if you can’t communicate with the server in the cluster and can’t access the data in the server, your database needs to handle the lack of communication.
The database also needs to handle failures. What happens if the disk drive dies? How about a single server’s motherboard? How about the network switch covering a quarter of your database cluster? These are the kinds of things that keep database administrators up at night (and employed, come to think of it).
In this section, I discuss how Bigtable databases provide features that alleviate database cluster reliability issues.
Being Google
In Google’s Bigtable paper, which I introduced in Chapter 1, its authors discuss their observations on running a large distributed database. Bigtable powers Google Analytics, Google Earth, Google Finance, Orkut, and Personalized Search. These are large systems, and Googles’ observations regarding such systems are interesting. In particular, they spotted various causes for system problems, as shown here:
· Memory corruption: Where a system’s memory state becomes invalid
· Network corruption: Where data is modified while in transit
· Large clock skew: Where servers disagree on the “current” time
· Hung machines: Where some machines don’t respond while others do
· Extended and asymmetric network partitions: Where long network lags occur, and also “split brains,” which is where a cluster of nodes is divided into two (or more) clusters unevenly, each receiving requests as if the whole cluster was still operational and communicative
· Bugs in other systems Google used: For example, dependent services like the distributed Chubby file-lock mechanism
· Overflow of GFS quotas: Effectively running out of disk space
· Planned and unplanned hardware maintenance: Where workloads in the cluster are affected
These problems affect a wide variety of distributed databases, and when assessing a particular database for its reliability in enterprise applications, you need to find out how they handle the preceding situations.
With this information, you can identify higher-risk areas of your system, including whether a single point of failure (SPoF) needs to be addressed. SPoFs are the main cause of catastrophic service unavailability, so I spend a lot of time throughout this book identifying them. I recommend you address each one I talk about for a live production service.
Ensuring availability
A table in a Bigtable database is not a physical object. Instead, data is held within tablets. These tablets are all tagged as being associated with a table name. Tablets are distributed across many servers.
If a server managing a tablet fails, then this needs to be managed. Typically, in Bigtable clones, another tablet server is elected to take over as the primary master for the tablets on the failed server. These tablets are shared between the remaining servers to prevent a single server from becoming overloaded.
How these secondary servers are selected and how long it takes them to take over operations on those tablets are important issues because they can affect data and service availability, as shown here:
· Some Bigtable clones have a master process that monitors tablet servers and then reallocates their tablets if the tablets fail or become unresponsive. These masters are also responsible for database changes like adding or removing tables, so these masters also respond to limited client requests.
· On some databases (for example, Hypertable), these master processes aren’t highly available, which means that, if the master also dies, you might have a problem. Usually, you can start another master within seconds, but it’s important to understand this needs to be done to guarantee availability.
· Other Bigtable clones (HBase, Accumulo) will have standby master processes running, with failover happening immediately and without the client knowing. Accumulo even goes so far as to have a feature — called FATE, amusingly enough — that guarantees and replays any database structure altering requests if the master fails during a modification. This prevents schema corruption of the database.
· Other databases (Cassandra) use a chatter protocol between all members of the cluster, avoiding a master process altogether. This gives Cassandra the minimum number of components, and allows every server in the cluster to look the same, all of which makes administration and setup easier, while helping guarantee availability, too.
Scalability
Anyone can create a database that looks fast on a single machine while loading and querying a handful of records. However, scaling to petabytes requires a lot of work. In this section, therefore, I highlight features that can help you scale read and write workloads.
 The features covered in this chapter are specific to Bigtable clones mentioned in this book. Many other strategies are possible to achieve scalability, including:
The features covered in this chapter are specific to Bigtable clones mentioned in this book. Many other strategies are possible to achieve scalability, including:
· Use distributed file storage. Shares load across physical disks/servers, which can be done in one of the following ways:
· A local RAID (Redundant Array of Inexpensive Disk) array
· A shared storage system such as HDFS (Hadoop File System)
· Go native. Using a compiled programming language next to an operating system like C++ is always faster than a bytecode or interpreted language like Java.
Most Bigtable clones are implemented on top of Java, with Hypertable being the notable C++ exception.
· Utilize fast networks. Use at least 10-Gbps switches for high-speed operations, especially if you’re using shared network storage.
· Set up separate networks. Sometimes it’s useful to keep client-to-database network loads separate from database-to-storage or database intra-node chatter. On larger clusters, intra-node chatter can also start flooding a data network if the network is shared. On very large clusters, it’s best to have a secondary net for intra-server communication to avoid this problem.
· Write to memory with journaling. Some databases can receive writes in memory, which is very fast, while also writing a small record of the changes, called a Journal, to disk to ensure that the data is durable if the server fails. This Journal is smaller, and thus faster to save, than applying the change itself to all the database structures on disk.
Ingesting data in parallel
When writing large amounts of data to a database, spread the load. There’s no point having a 2-petabyte database spread across 100 servers if 99 percent of the new data is landing on only one of those servers, and doing so can easily lead to poor performance when data is being ingested.
Bigtable databases solve this problem by spreading data based on its row key (sometimes called a partition key). Adjacent row key values are kept near each other in the same tablets.
To ensure that new data is spread across servers, choose a row key that guarantees new records aren’t located on the same tablet on a single server, but instead are stored on many tablets spread across all servers.
· Accumulo allows you to plug in your own balancer implementations, which enables you to specify that rows can be kept together or spread across a cluster, depending on your needs.
· Accumulo and HBase also support locality groups, which keep particular columns for the same row together. This is particularly useful for guaranteeing fast read speeds. Hypertable supports locality groups, too, with a feature called access groups.
In-memory caching
A database system can experience extreme input and output load, as described here:
· In many systems, the same data is often requested. Consider a news site that shows the latest news stories across a range of segments. In this case, it’s important to keep the latest stories cached, rather than go back to disk to access them each time they’re requested.
· When high-speed writes are needed, the most efficient way to handle them is to write all the data to an in-memory database file, and just write the journal (a short description of the changes) to disk, which increases throughput while maintaining durability in the event of a system failure.
It's best to have a system that can cope with managing both high-speed writes and read caching natively and automatically. Hypertable is one such database that proactively caches data, watching how the system is used and changing memory priorities automatically.
Indexing
Like key-value stores, Bigtable clones are very good at keeping track of a large number of keys across many, if not hundreds, of database servers. Client drivers for these databases cache these key range assignments in order to minimize the lag between finding where the key is stored and requesting its value from the tablet server.
Rather than store one value, a Bigtable stores multiple values, each in a column, with columns grouped into column families. This arrangement makes Bigtable clones more like a traditional database, where the database manages stored fields.
However, Bigtables, like key-value stores, don’t generally look at or use the data type of their values. No Bigtable database in this book supports — out of the box — data types for values, though Cassandra allows secondary indexes for values. However, these secondary indexes simply allow the column value to be used for comparison in a “where” clause; they don’t speed up query times like a traditional index does.
You can apply the same workaround to indexing used in key-value stores to Bigtables. Figure 10-2 shows single and compound indexes.
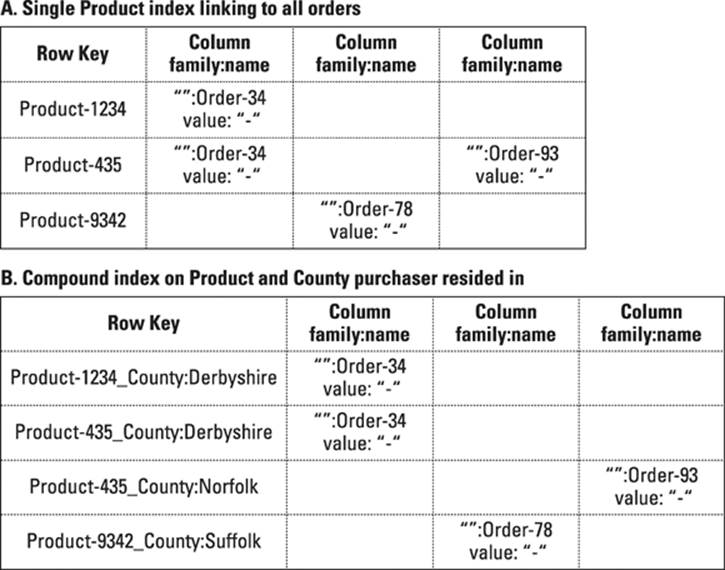
Figure 10-2: Secondary index tables in a Bigtable database.
The shown indexing method is limited, though, because you need to know in advance what combinations of fields are required in order to build an index table for each combination of query terms. The indexes are also consistent only if the Bigtable database supports transactions, or real time updates of the indexes during a write operation.
If the database doesn’t support automatic index table updates within a transaction boundary, then for a split second, the database will hold data but have no index for it. Databases with transactions can update both the data table and index table(s) in a single atomic transaction, ensuring consistency in your database indexes. This is especially critical if the server you’re writing to dies after writing the value, but before writing the index — the row value may never be searchable! In this case, you must check for data inconsistencies manually on server failover.
Hypertable is a notable exception because it does provide limited key qualifier indexes (used to check whether a column exists for a given row) and value indexes (used for equals, starts with, and regular expression matches). These indexes do not support ranged less-than or greater-than queries, though.
Other general-purpose indexing schemes are available for use with Bigtable clones. One such project is Culvert (https://github.com/booz-allen-hamilton/culvert). This project aimed to produce a general-purpose secondary indexing approach for multiple Bigtable implementations over HDFS. HBase and Accumulo are supported.
This project has been dormant since January 2012, but the code still works. In the future it may no longer work with the latest databases, requiring organizations to build their own version. This means knowing about Culvert’s approach could help you design your own indexing strategy.
Commercial support vendors, such as Sqrrl Enterprise for Accumulo, provide their own proprietary secondary indexing implementations. If you need this type of indexing, do consider those products. Similarly, the Solr search engine has also been used on top of Bigtable clones.
 Using an additional search engine tier takes up much more storage (field values are stored twice) and may not be transactionally consistent if it’s updated outside of a database transaction. Cassandra, which ensures consistent Solr index updates, is the notable exception in the DataStax Enterprise version.
Using an additional search engine tier takes up much more storage (field values are stored twice) and may not be transactionally consistent if it’s updated outside of a database transaction. Cassandra, which ensures consistent Solr index updates, is the notable exception in the DataStax Enterprise version.
Solr is a useful option for full-text indexing of JSON documents stored as values in Bigtables. But if you’re storing documents, it’s better to consider a document store.
Aggregating data
In transactional database systems, individual rows are created and updated, whereas in analytical systems, they’re queried in batches and have calculations applied over them.
If you need to provide high-speed analytics for large amounts of data, then you need a different approach. Ideally, you want the ability to run aggregation calculations close to the data itself, rather than send tons of information over the network to the client application to process.
All Bigtable clones in this book support HDFS for storage and Hadoop Map/Reduce for batch processing. Accumulo is prominent because it includes a native extension mechanism that, in practice, may prove more efficient for batch processing than Hadoop Map/Reduce.
Accumulo iterators are plug-in Java extensions that you can write yourself and use to implement a variety of low-level query functionality. You can use them to:
· Shard data across tablet servers.
· Sort data (for storing the most recent data first).
· Filter data (used for attribute-based access control).
· Aggregate data (sum, mean average, and so on).
HBase coprocessors introduced recently in HBase 0.92 also allow similar functionality as Accumulo offers. They also will eventually allow HBase to have similar security (visibility iterator) functionality as Accumulo.
Configuring dynamic clusters
After you parallelize your data as much as possible, you may discover that you need to add more servers to your cluster in order to handle the load. This requires rebalancing the data across a cluster in order to even out the query and ingest loads. This rebalancing is particularly important when you need to increase the size of your cluster to take on larger application loads.
You can support cluster elasticity in Bigtable clones by adding more servers and then instructing the master, or entire cluster for master-less Bigtable clones like Cassandra, to redistribute the tablets across all instances. This operation is similar to server failover in most Bigtable implementations.
The control of the HDFS area is moved to a new server, which then may have to replay the journal (often called the write ahead log — WAL) if the changes haven’t been flushed to HDFS. On some databases, like HBase, this process can take ten minutes to finish.
Once you’ve scaled out, you may decide you want to scale back, especially if during peak periods of data ingestion, you added more servers only to receive more parallel information. This is common for systems where information is submitted by a particular well known deadline, like for government tax-return deadlines. Again, this requires redistribution of the tablets, reversing the preceding scale out process.
Configuring and starting this process is in many cases a manual exercise. You can’t join a Bigtable to a cluster and have that cluster magically reassign tablets without issuing a command to the cluster. Some commercial enterprise versions, such as DataStax Enterprise, do automate this process.