NoSQL For Dummies (2015)
Part III. Bigtable Clones
Chapter 12. Bigtable Products
In This Chapter
![]() Controlling data distribution
Controlling data distribution
![]() Maximizing security
Maximizing security
![]() Increasing performance
Increasing performance
![]() Distributing data around the world
Distributing data around the world
Right now, I bet you’re feeling like a kid in a candy store, knowing that he can have only one kind of candy — but which one is the question! You’ve seen the future, and you know you want a Bigtable NoSQL database, because, as the name implies, they’re big, and they’re tabular; and whether your thing is ridiculously large datasets, government grade security, high performance with data consistency, or global distribution of your data — there’s a Bigtable out there for you!
In this chapter, I discuss each of these different use cases, to help you determine which Bigtable fits your needs.
History of Google Bigtable
Google published its Bigtable paper in 2006. This paper described for the first time a set of related technologies that Google had been using to store and manage data under its services.
Of particular interest was the design decision to avoid joins between tables, preferring instead a denormalization approach — that is, to keep copies of certain data for different uses, such as a summary record and a detail record both having “patient name” columns.
Google’s Bigtable was designed to be flexible enough to use for a variety of Google’s services. As a result, Bigtable is a general-purpose database, potentially applicable to a wide range of use cases, much like its relational database forebears.
Bigtable was built on a number of building blocks. The first was the distributed file system called GFS — Google File System. This file system is complemented by a distributed locking mechanism called Chubby, which ensures that writes and reads to a single file are atomic.
Today this design is applied in the open-source Hadoop Distributed File System (HDFS). The SSTable file format for storing data is also used. A number of today’s Bigtable clones share this capability.
A variety of architectural and mathematical techniques are applied to Bigtable, too:
· Data compression
· Sharding parts of a table (tablets) between multiple servers
· Bloom filters
Bloom filters are special “space-efficient” indexes that tell you either “this key definitely doesn’t exist” or “this key may exist” in the database. Their use reduces disk I/O operations when you’re looking up keys that may not exist.
Bigtable has inspired (sometimes along with Dynamo in the key-value world) many open source software developers to implement highly scalable wide-column stores. These column stores are highly tolerant of patchy sparse data and operate at extreme scale.
Managing Tabular Big Data
Many best practices, tricks, and tips are available for working with big data and Bigtables. I’ve highlighted just a few, but forums are full of other options, too.
 The term big data is overhyped. It refers to the management of very fast, large, variable, or complex datasets, typically involving billions of records (data) that are spread across many machines, and changing the structure of that data, in order to store it.
The term big data is overhyped. It refers to the management of very fast, large, variable, or complex datasets, typically involving billions of records (data) that are spread across many machines, and changing the structure of that data, in order to store it.
Designing a row key
HBase and Cassandra distribute data by row key. Each region server manages a different key space. This means that data distribution — and therefore, ingest and query performance — depends on the key you choose.
Consider an application that manages log files. You may be tempted to use the date and time of a message as the start of the row key. However, doing so means that the latest information will reside on the single server managing the highest row-key values.
All of your newly ingested data will hit this single server, slowing ingest performance. It’s even worse if a set of monitoring dashboards are all querying for the last five minutes worth of data, because this single server will also have the highest query load. Performance suffers — and somebody may shout at you!
Instead, make the row key something that distributes well across machines. A unique key with random values across the spectrum of possible values is a good start. Java includes a Universally Unique Identifier (UUID) class to generate such an ID. Some Bigtables have this built-in capability, too.
Instead, model your key values that are used as lookups for column names rather than row keys (you find more on this topic in the following section).
You need to be careful, though, because different key strategies create different read and write tradeoffs in terms of performance. The more random the key, the less likely adjacent rows will be stored together.
Using a very random key means you will have a faster write speed, but slower read speed — as the database scans many partitions for related data in your application. This may or may not be an issue depending on how interrelated your rows are.
 By using secondary indexes, you can alleviate this issue, because indexed fields are stored outside the storage key, which gives you the best of both worlds.
By using secondary indexes, you can alleviate this issue, because indexed fields are stored outside the storage key, which gives you the best of both worlds.
Key and value inversion
In a relational database, if you want to perform a quick lookup of table values, you add a column index. This index keeps a list of which records have which values, ordered by the value itself. This approach makes range queries (less-than and greater-than) much quicker than scanning the entire database.
Most Bigtables — with the exception of Hypertable — don’t have such value indexes. Instead, all indexes are performed on keys — be they row keys or column keys (column names). This means you must get used to modeling your data differently. You may also have to create your own index tables for fast lookups. Consider the traditional relational database schema shown in Figure 12-1.

Figure 12-1: Relational employee department table schema.
In this schema, adding an index in the department column allows you to perform quick lookups. On Bigtable clones, this generally isn’t possible. Some Bigtable clones provide secondary indexing that don’t speed up queries, instead they just mark columns as being queriable. Apache Cassandra has these sorts of indexes. Other Bigtables, like Hypertable, have true secondary indexes which speed up queries, like their RDBMS relations.
Instead, you need an employee department index table, where you store the department values as row keys and the employee numbers using one of two methods:
· Column names with blank values: This is where you use the column name as a “flag” on the record.
· Column families, with summary details in name and id: Allows a summary to be shown with no further lookups. Figure 12-2 shows an example of denormalization.
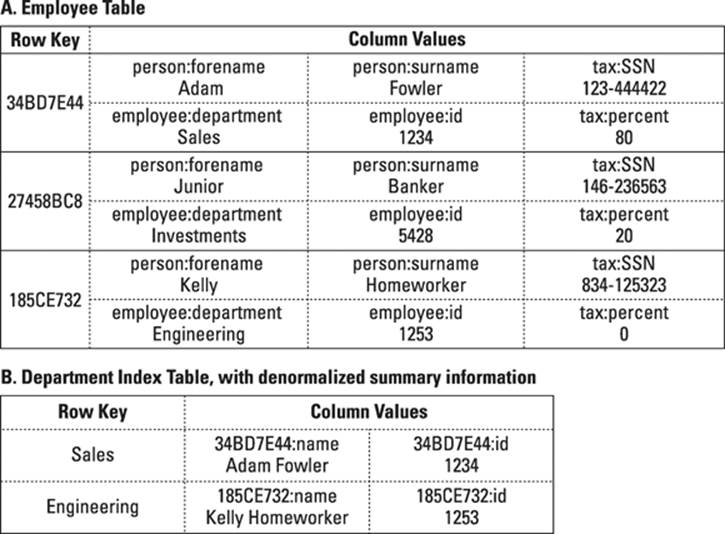
Figure 12-2: Bigtable employee department and employee implementation.
This works because the keys are automatically indexed, and all data under a row key for a particular column family are kept local to each other, making lookups fast.
As an additional benefit, if an employee is in multiple departments, then this model still works. The same cannot be said of the default relational model in Figure 12-1.
Denormalization with Bigtables
A basic key-value inversion example leaves you with two tables in a database that don’t support joins. So you have to execute two database requests to fetch all employee information for those employees in departments.
If you often perform lookups in this manner, you may want to consider another approach. For example, you always show a summary of the employees when looking up via department. In this scenario, copy some summary data from the employee details table into the employee department table. This is called denormalization and is shown in section B of Figure 12-2.
Some Bigtable clones, such as Cassandra, provide automatic column name ordering. In Figure 12-2, I use the employee’s full name in a column name, which means that I don’t have to sort the resulting data. (I kept the row key in case there are multiple John Smiths in the company!) In the application, I split the column name by semicolon when showing the name in the user interface.
In my application, I can now provide very fast lookups of employees by department and show a list of employees with summary information without significant processing or application side sorting. The only cost is a slight increase on storing this information in two ways in the same record (an example of trading disk space for higher speed read operations).
Scanning large key sets — Bloom filters
Bigtable clones, like their key-value store brethren, store data by managing a set of keys. These keys are usually hashed to balance data across a cluster.
When querying for a list of records where the key is of a particular value, you have to pass the query off to all nodes. If each node manages millions of records, then so can take some time.
This is where Bloom filters come in. You can add a Bloom filter onto column names in all Bigtable products. Rather than exhaustively scanning the whole database to answer the question “which rows have keys equaling this name,” a Bloom filter tells you “this row may be in the results” or “this row definitely isn’t in the results.” This minimizes the key space that needs to be thoroughly searched, reducing disc I/O operations and query time.
Bloom filters use up memory storage space, but they are tunable. You can tune the chance that a row matches. An incorrect match is called a false-positive match. Changing the match weight from 0.01 to 0.1 could save you half the RAM in the filter — so doing so is worth considering. In HBase, this setting is io.hfile.bloom.error.rate, which defaults to 0.1. You can also tune Cassandra by using the bloom_filter_fp_chance parameter to the decimal value desired.
Distributing data with HDFS
So you have a fantastic HBase installation that’s distributing data evenly across the whole cluster. Good work!
Now, turn your attention to data durability. What happens if a disk fails? How do you continually manage replicas? How do you perform fast appends to internal table structures?
This is where HDFS comes in. HDFS (the Hadoop Distributed File System) is based on the original Google File System. HDFS is great for ingesting very large files and spreading data across a cluster of servers.
Also, by default, HDFS maintains three copies of your data, providing redundancy across machines, and even racks of machines, in a data center.
What HDFS doesn’t do is maintain indexes or pointers to data stored within those very large files. HDFS also doesn’t allow alteration of specific parts of files stored on it. To provide indexing and support updates of data, you will need a NoSQL database running on top of HDFS. Figure 12-3 shows how an HBase cluster stores information on multiple Hadoop HDFS partitions spread across a Hadoop cluster.
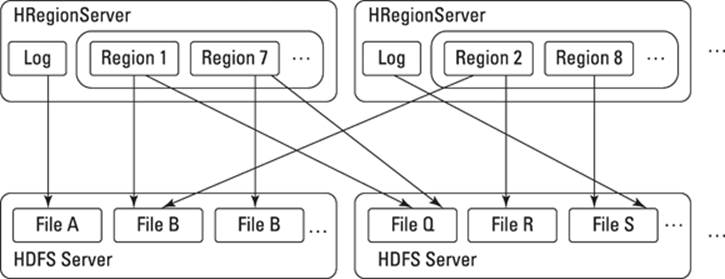
Figure 12-3: How HBase and HDFS work together to manage data.
Rather than store many small table files, HBase stores fewer, very large files one per row. New data is appended to these files. Changes are also appended, so you don’t have to modify earlier parts of an existing table file. This process fits well with the HDFS storage mechanism.
HBase provides HDFS with a way to index and find appropriate small records within very large datasets. Hadoop provides HBase with a tried and true, highly parallel, distributed file system in HDFS, as well as batch processing through MapReduce.
Batch processing Bigtable data
There are two types of database queries:
· The result needs to be known as soon as possible.
These are data analysis use cases like users searching or listing records in a database.
· The result will take time to calculate.
These are long-running aggregations or analysis and reporting jobs.
These longer running jobs typically don’t involve a user sitting in front of a screen waiting for an answer.
Answer sets may need to be processed, too, in order to generate a result, and this process requires a different way of scheduling and managing jobs. Thankfully, Hadoop MapReduce provides this functionality.
A simple Map/Reduce job typically consists of two operations:
1. The map task scans through a dataset and collates matching data in a required format.
2. The reduce task takes this data and produces an answer for the query. A reduce task’s output can also form the input of a map task, allowing for chained analysis.
An example of a simple MapReduce job is analyzing citizen detail records in a HBase database, producing the average height of citizens, grouped by age.
In this example, the map function returns a set of records with height and age information. The reduce function tallies these by age and calculates a mean average using the sum and count.
You can run more complex MapReduce jobs to feed a result from one operation as an input to another. In this way, sophisticated chains of analysis can be built.
HBase provides special table-oriented map and reduce operations. Guess what they’re called? TableMapper and TableReducer, of course! The TableMapper provides a row object, making it easy to operate on tabular data in MapReduce.
The downside to MapReduce for simple operations such as count, sum, and average is that a lot of data is shunted around to the querying MapReduce Java code. Ideally, you want these results to be calculated right next to the data, in the HBase runtime itself.
Coprocessors
HBase 0.92 introduced a coprocessors feature, which will allow HBase to eventually include built-in features like complex filtering and access control.
For now, though, you can implement pre-calculation routines with coprocessors. Rather than execute aggregate operations at query time, coprocessors provide observer instances that execute when data is read or saved. This effectively allows pre-calculation of results prior to querying. Think of them as akin to a relational database’s triggers. A variety of observation points are provided, including
· preGet, postGet: Called before and after a Get request.
· preExists, postExists: Called before and after an existence check via a Get request.
· prePut, postPut: Called before and after saving client data.
· preDelete, postDelete: Called before and after a client deletes values.
Once these aggregates are calculated, HBase needs a way to allow clients to request their values. Custom endpoints can be created to provide this data. Endpoints can communicate with any Observer instance, which allows endpoints to access pre-calculated aggregates.
Endpoints can be thought of as the equivalent of stored procedures from the relational database world. They are similar to client-side code that actually runs on the server and can be called by a range of clients.
Endpoints and Observers can perform any operation within HBase, so be sure you know what your code is doing before you deploy it! Coprocessors should provide a way to extend the inner workings of HBase in the future.
Assessing HBase
HBase is the original and best-known Bigtable clone in the NoSQL space today, and it’s tightly linked to Hadoop, which makes it an obvious NoSQL database candidate for any organization with a large Hadoop deployment.
However, if you’re thinking about using HBase, you need to consider several points. For example, HBase is written in Java, so it isn’t as fast as a database implemented in C++.
Moreover, HBase isn’t transactionally consistent, so it may not be suitable for some mission-critical workloads as a primary master store of data. Also, the fact that HBase requires HDFS storage is a barrier for organizations that don’t use Hadoop, so HBase adds more complexity to an application architecture, and requires extra knowledge to deploy it.
Not all of the issues from the relational database world have been solved in Bigtables. In a Bigtable, your data is still in a table structure, requiring at least some up-front schema design for fast operation, and it takes time to design this schema and get it right; making data fit in to a table storage model also forces you to write “plumbing” code to convert data when reading and writing to the database.
For example, HBase must be taken completely offline in order to create a new column family or new tables. This is a major barrier to ongoing agile development.
No dedicated commercial entity backs HBase. Cloudera is the only commercial company you could say offers extensive HBase support, but it’s currently selling support for three NoSQL databases on top of its Hadoop distribution. The three are Accumulo, MongoDB, and HBase. On its website, Cloudera is positioning HBase as an entry-level database for Hadoop.
Be sure that HBase has all the features you need and that you can find the right level of support and development expertise for your rollout. You’ll likely want more of this support in-house with HBase, and be sure to confirm your designs up front during rounds of proof of concept testing.
Securing Your Data
Once the excitement of getting data in and out of a system has passed — and it passes rapidly — you want to turn your attention to protecting your data.
One of the ways to protect it is to secure access to it based on specific user roles or privileges — for data such as medical records, employee addresses, and billing details.
Some industry standards require that you protect records. Credit card handling, for example, requires that after the entire card number is entered, only the last four digits are shown on screens that follow (the full card number is hidden in the application).
Cell-level security
Traditional approaches to security require that an application’s code handles security, including authenticating users, discovering their roles, and ensuring that they access only the records they’re supposed to. This has been the case with relational database management systems for years. The same is true for many Bigtable clones, too.
Where this model breaks down is in the accreditation of the database itself, with the likes of the DoD and regulators, and in the lack of a built-in permissions model.
Accreditation and certification for public groups such as defense and sensitive government agencies provide assurance to both the organizations and to the public that best practice with regards writing secure code has been followed. If security is implemented at the application level, then the application and database are accredited together as a single system. This may not be a problem for some, but if you're trying to justify the creation of a new application built on a secure database, having an accredited database is useful for providing information security assurances to the business.
Building a security model into your own code is not an easy task. You first have to build a set of security plug-ins that allow you to authenticate users and look up their roles in one or more existing corporate systems. Then you need a way to assign privileges for particular records to users. None of this is easy to build, maintain, or protect against intrusion.
Take the following summary care record example with individual user access in which I assume data is secured at the record level. This is an anti-pattern — a pattern you should not apply on a real system. It is an anti-pattern because it is incomplete, as I will discuss next when we build a complete security model for health data.
Patient: Name: Leo Fowler, Address: 12 Swansea, DoB: 06/March/2014
Permissions: Dr Dye: read+write
A summary care record is the minimum personal healthcare information required to provide emergency room care to a patient. In the UK National Health Service (NHS) this summary care record is accessible through a combination of surname, birth date, and first line of an address. It can be accessed by any emergency medical worker.
Role based access control
There are clear benefits to using a system that comes with built-in authentication, authorization, and support for role based access control (RBAC). RBAC allows privileges to be assigned not to users, but to roles, for actions on a particular record.
Using roles is easier to manage than individual user access — for example, if someone moves from one department to another. All you do is update a single user-role list in your corporate security system rather than all permissions attached to a single user. Your RBAC-based database then automatically reflects the new roles when the user next accesses it. Listing 12-1 shows a summary care record with Roles attached.
Listing 12-1: Summary Care Record (SCR) Information and RBAC Read/Write Privileges
Patient: Name: Leo Fowler, Address: 12 Swansea, DoB: 06/March/2014
Permissions: Doctor: read+write, Nurse: read
External Directory System
Role Nurse: Nurse Ratchett
Role Doctor: Dr Dye, Dr A Trainee
This shows that a user with at least one of the doctor or nurse roles can read the summary care record. This is OR Boolean logic between roles, and it’s the default RBAC mechanism used by most security systems.
The problem with such an approach is that any doctor can see the information. The roles are too wide. You can further refine them to make them more specific. As you see in Listing 12-2, now only the general practice surgery doctors can see the information.
Listing 12-2: SCR with RBAC Privileges for Two ER Doctors
Patient: Name: Leo Fowler, Address: 12 Swansea, DoB: 06/March/2014
Permissions: BrimingtonSurgeryDoctor: read+write
External Directory System
Role BrimingtonSurgeryDoctor: Dr Dye, Dr A Trainee
Now you have the opposite problem — being too specific. Now only local doctors have access. You want ER doctors to have access, too. You need a way to define exactly who has access to the record.
Compartment security
Ideally, you want to use Boolean logic as shown in Listing 12-3.
Listing 12-3: Doctor AND EmergencyRoom: read
Patient: Name: Leo Fowler, Address: 12 Swansea, DoB: 06/March/2014
Permissions: EmergencyRoom AND Doctor: read
BrimingtonSurgery AND Doctor: read+write
External Directory System
Role EmergencyRoom: Dr Kerse, Dr Shelby, Dr Death
Role Doctor: Dr Dye, Dr A Trainee, Dr Kerse, Dr Shelby, Dr Death
Role BrimingtonSurgery: Dr Dye, Dr A Trainee
This use of AND logic on roles is typically managed through named compartments. In Listing 12-3, you have a job role compartment and a department compartment.
Forcing all role assignments to use AND logic is very restrictive, so systems instead use this logic: If any assigned roles are within a compartment, then ensure that the user has ALL compartment roles; otherwise, ensure that the user has ANY of the non-compartmentalized assigned roles.
Table 12-1 shows the roles needed in this scenario when using compartment security. Here Jane the Junior Doctor who works in the Children’s Ward is trying to access (read) documents.
Table 12-1 Roles Required When Using Compartment Security
|
Record |
General Roles |
Department Compartment |
Job Role Compartment |
Result |
|
HR Policy |
Employee |
- |
- |
Read allowed |
|
Charlie Child’s Ward Notes |
Employee |
- |
Doctor |
Read allowed |
|
Children’s Ward Procedures |
Employee |
Children’s Ward |
- |
Read allowed |
|
John Doe’s SCR |
Employee |
Emergency Room |
Doctor |
Read denied |
This role assignment works well. When any role assignment includes one with a compartment, roles are required — restricting who can read the records. Where multiple compartments are mentioned, AND logic is forced — the user must have both roles to access the summary care record.
Cell-level security in Accumulo
There may be situations where you don’t have a summary record — just the main patient record. In this situation, you want to provide a summary care record filter. This filter prevents certain fields — rather than entire records — from being viewed by an unauthorized user.
Accumulo includes an extra field as part of its key. Along with the row key, column family, and column name, Accumulo includes a visibility key. This is a Boolean expression that you can use to limit visibility to certain roles defined within the system.
 This invisible key is for read security only. It’s possible, unless security settings are configured properly, for a user who cannot see a particular value to overwrite it. Thus the lack of visibility doesn’t prevent a user overwriting a value. To ensure this doesn’t happen, be sure to correctly define table visibility settings as well as cell value visibility.
This invisible key is for read security only. It’s possible, unless security settings are configured properly, for a user who cannot see a particular value to overwrite it. Thus the lack of visibility doesn’t prevent a user overwriting a value. To ensure this doesn’t happen, be sure to correctly define table visibility settings as well as cell value visibility.
Assessing Accumulo
Accumulo was originally created by the U.S. National Security Agency, so the security system is pretty flexible. Of course, you need to manage that flexibility to ensure there aren’t any gaping holes.
In particular, you can use a variety of plug-ins to link Accumulo to existing or custom authentication and authorization technologies. Having these plugins built into the database layer simplifies a system’s design and makes the overall architecture easier to accredit from a security standpoint.
Unless it has a good reason not to, the U.S. Department of Defense is mandated to use Accumulo for Bigtable workloads — not for all NoSQL use cases (such as document, triple store, or key-value), contrary to popular belief — although the NSA has been required to contribute its security and other enhancements to other open-source projects, including HBase and Cassandra.
Accumulo can also use HDFS storage, like HBase can, which fits the bill when HBase-like functionality is needed in a more security-conscious setting.
Like HBase, though, there are no larger companies providing dedicated support. Cloudera again provides support for Accumulo as a higher-end alternative to HBase.
Cloudera provides HBase, Accumulo, and MongoDB for its Hadoop offerings. Be sure that your local Cloudera team understands and has implemented Accumulo in similar organizations in the past, and where it should be used, rather than MongoDB and HBase. There are advantages and disadvantages to each database.
High-Performing Bigtables
In many situations that require high performance, moving to a Bigtable solution provides the desired result. There are always extremes, though. Sometimes you need to squeeze every last ounce of performance out of a potential implementation.
Perhaps this is to reduce the hardware required, perhaps you’re cataloging the stars in the universe, or perhaps you simply want to get the most for your money. Whatever the reason, there are options to assess.
Using a native Bigtable
Java is a great language, but it’s simply not as fast as C++. HBase, Accumulo, and Cassandra are all built as Java applications. Java is the defacto language for enterprise systems, so its status isn’t surprising.
Using C++ and operating system-provided APIs directly allows you to access lower-level, higher-performing services than the Java tier. Hypertable is a Bigtable database written in C++ from the ground up, and it provides a high performance Bigtable implementation.
Indexing data
You’ve already seen that Bigtable clones index keys like key-value stores and treat values as binary data. In some situations, though, you do in fact have to index the values themselves. Or perhaps you’re just too familiar with relational databases and want your typed columns back!
Having a database that provides strong typing on column values gives you the ability to index values and to perform other typed operations, such as sums and averages.
Hypertable provides secondary indexing for values and the column name qualifiers. These indexes allow exact match or “starts with” matches. The indexes are implemented internally by Hypertable automatically creating a table with the same name, but preceded by a caret ^ symbol.
This approach is more convenient than updating index values yourself, and ensures that index updates are transactionally consistent with the data these indexes link to, but this approach does have limitations. You’re limited to Just three operations:
· Checking a column exists
· Checking exact value matches
· Checking prefix (starts with) matches
You can’t do data-specific range queries like finding all orders with an item with a quantity greater than five. This limitation is potentially a big one if you need to perform substantial analytics over the data. Still, some indexing is always better than no indexing!
Ensuring data consistency
For mission-critical applications, it’s vital to ensure that, once written, data remains durable. If you’re using a Bigtable as the primary store of mission-critical and high-value business information, then you need an ACID compliant database.
Ensuring that data is durable, that writes are applied in the correct order, and that information is replicated in the same order that it was updated in the source database cluster are just a few of the desirable features in such a system. Also, such systems need to ensure that your database supports strong consistency or is ACID-compliant. So, be sure to ask your vendor how its database ensures the safety of your data. Specifically, ask if it’s fully ACID-compliant.
Some vendors use the term “strong consistency” because their products aren’t capable of providing ACID compliance. However, there’s a big difference between the two.
Hypertable is an ACID-compliant database for atomic operations. The only thing it lacks is the ability to group multiple atomic operations in a single transaction. In this case, if you need to modify several rows, perhaps one in a data table and another in an index table, then your update will not be ACID-compliant — each update occurs in its own window.
Assessing Hypertable
Right out of the box, Hypertable provides richer value indexing than other Bigtable clones do. Hypertable also supports HDFS as well as other file systems, including locally attached storage. Local disk storage is attractive when you want a Bigtable NoSQL database but don’t want to manage a large Hadoop cluster.
In my experience, many NoSQL implementations actually consist of three to five servers. In such an environment, a large HDFS array is overkill. Not everyone uses NoSQL to manage gazillions of bytes of information. Often, they want the schema flexibility, speed of deployment, and cost savings associated with using commodity hardware rather than traditional relational database management systems like Oracle and Microsoft SQL Server.
Hypertable allows access group definition. Access groups tell the database to group column families from the same rows together on the same server. Consider a summary page that needs information from two or three column families. Configuring an access group on these families allows them to be retrieved quickly from the database.
Column families in Hypertable are optional, so you can ignore family names, as you can in Cassandra. Or, when they’re required, you can use them like you can in HBase. Better still, you can mix and match approaches in the same table definition!
I really like the approach Hypertable has taken. It provides a pragmatic set of features that application programmers want in databases, without sticking to the dogma that “values are just binary objects.”
One of my favorite features is adaptive memory allocation:
· When Hypertable detects a heavy write load, more RAM is used as an in-memory region. This speeds up reads because many are written to RAM rather than to disk.
· When a significant amount of reads is detected, Hypertable automatically switches to using RAM so that more RAM is used as a read cache, which, again, minimizes disk access for reads.
Hypertable isn’t as widely used as HBase, Accumulo, or Cassandra, though. If you want the features of Hypertable, be sure you can find local expert support and developers who are experienced with Bigtable clones like Hypertable.
I have a couple of concerns about Hypertable:
· Region servers in Hypertable are highly available, with the Hypertable master reallocating regions to another server when one goes down. However, the master service isn’t highly available; it only has a standby.
This is similar to a disaster recovery approach, which means that it’s possible for a master to go down, followed promptly by a region server that isn’t replaced for a few seconds. This window of time is short, but one you need be aware of, and prior to going live with the application, you need to test failover. Data could become inaccessible if both the master and the region server are on the same rack in a data center, and the network fails on that rack.
· Hypertable is available under the more restrictive GPL version 3 license. Although an open-source license, the GPL prevents Hypertable from being embedded within a commercial product. If you want to create “black box” software that embeds Hypertable and sell it, you must obtain a commercial license from Hypertable, Inc.
The GPL is potentially restrictive. If you are a software development firm with Hypertable experts, then you may not want or need to pay for commercial support.
The GPL licensing issue is likely to affect only a few use cases, mainly OEM partners. This licensing doesn’t stop organizations from building and selling access to services that use Hypertable for storage.
Distributing Data Globally
If, like me, you have a vast collection of data spread over the world then you would appreciate features in your database to perform this data distribution for you, rather than having to code it in your application yourself. Writing this code for several database clusters creates a lot of manual work.
In my case, I use replication for my enormous collection of food recipes, but the need for replication can also happen in a variety of other situations:
· Financial transactions being done in several countries at the same time — London, New York and Singapore, for example
· International shop orders being placed in more local warehouses
· A globally distributed social network or email service with local servers, but with globally shared contacts
Substituting a key-value store
Bigtable clones can be thought of as a specific subclass of key-value stores. You can quite happily run key-value workloads on a Bigtable clone, too. If you already have a Bigtable, then you may well want to consider doing so.
If you need blazing fast writes — in the order of 100,000 writes per second or more — then a key-value store performs more quickly. In most situations, though, you probably have lighter loads, and if this is the case and you need Bigtable features only occasionally, then Cassandra may be for you. Cassandra prides itself on having features of both Bigtable and key-value stores, and takes its inspiration from both Amazon’s Dynamo and Google’s Bigtable papers. Figure 12-4 shows the differences between the two models.
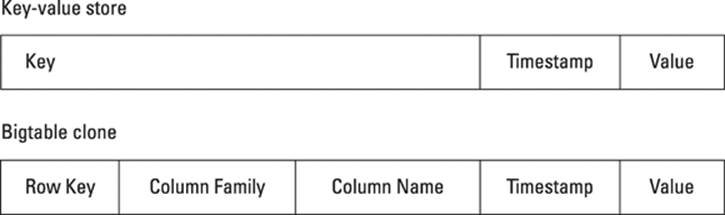
Figure 12-4: Traditional key-value store versus using a Bigtable as a key-value store.
In a key-value store, you have to design your key carefully in order to ensure evenly distributed data in a cluster and that lookups are fast. Bigtables have these key hierarchies built in with its concept of column families and column names.
Consider that you’re using a key-value store to hold data pulled from a website for later search indexing. You may want to store and retrieve data by the website domain, page URL, and the timestamp you stored it.
In a key-value store, you can design a key like this:
Key: AB28C4F2-com.wiley.www-/index.html
This uses a GUID or similar random string as the first part of the key to ensure that, during ingest, the data is distributed across a cluster. This key also uses a timestamp qualifier for the time the page was indexed.
Whereas, in a Bigtable, you could use the column family and name fields, too:
Key: AB28C4F2 Column Family: com.wiley.www Name: /index.html
This key allows you to be more flexible when querying, because you can easily pull back all web pages for a domain or a specific page in a domain, which you can do quickly because a query is based only on the exact value of a key. This approach eliminates you having to trawl all keys for lexicographic (partial string) matches.
Cassandra doesn’t support column family names. Instead, you merge the preceding column family and page name or use two columns (the domain with a blank value). Cassandra does, however, allow you to specify an index of keys across values. So, in the preceding example, you could set up an index over key, domain, and page name.
I can ensure that entire domain content lookups are quick because the first key is the partition key in Cassandra, which keeps all data together for all pages in the same domain.
Inserting data fast
Cassandra manages its own storage, rather than farm it off to HDFS, like HBase does. As a result Cassandra offers some advantages, with the first being that it can manage and throttle compactions. A compaction, also called a merge, occurs every so often as Cassandra appends data to its database files and marks data for deletion. This deleted data builds up over time, requiring compaction. The benefit is higher ingest rates. Another advantage is that Cassandra doesn’t need to go over the network to access data storage.
With Cassandra, you also have the advantage of using local SSDs, perhaps by writing the journal to an SSD and writing data to RAM and flushing it to a spinning disk later. This, too, aids the speed of ingestion.
You can also run Cassandra with both spinning disk HDDs and SSD disks for the same database. Perhaps some data is read more often and other data less often. This differently accessed data may even be columns on the same record. Storing these individual often-read columns on SSDs and the rest on a spinning disk boosts speed, without you having to replace every disk with an expensive SSD.
Replicating data globally
Cassandra is unique in allowing a cluster to be defined across geographic boundaries and providing tolerance of network partitions to ensure data is available worldwide when needed.
A Cassandra ring is a list of servers across server racks and data centers. You can configure Cassandra so that a replica is on the same rack, another on a different rack (in case that rack’s network goes down), and maybe even another two copies in other data centers.
This enables maximum replication and ensures that data can always be accessed. However, note that all these replicated copies — whether in the same data center or another one — are replicated synchronously. This means it’s possible for the replicas to disagree on the current value of a data item.
Consistency is guaranteed by configuring the client driver accessing Cassandra. By using a setting of ONE, you indicate you don’t care about consistency; you're happy with any copy.
By using a setting of LOCAL_QUARUM, you’re saying you want the value agreed on and returned by, for example, two out of three servers within just the local cluster. Specifying ALL requires that all servers in the cluster that contain a copy of that value are in agreement.
There are a variety of other settings to consider. A full list of the consistency settings their meaning can be found on the Apache Cassandra website: http://cassandra.apache.org
Assessing Cassandra
Cassandra allows partitioning and writing data when its primary master is unavailable. It’s, therefore, not an ACID-compliant database, so in some cases, the data will be inconsistent or replicas will disagree on the correct value.
You need to be aware of this issue when building an application on Cassandra. A read repair feature is available to help with this issue, but when you use it, there’s a potential ten-percent loss in performance. However, this may well be a good tradeoff for your purposes.
Global master-master replication is a great feature to have, but given that it can be used asynchronously, it doesn’t provide a true “always consistent” master-master replication that you may be familiar with in the relational database world. Ensuring that the client uses full consistency leads to slower usage times.
Cassandra also doesn’t support column families. This gives it a data model somewhere in between a key-value store and a Bigtable. This may or may not be an issue in your applications.
Cassandra’s CQL query language will be familiar to most people who are familiar with the relational database and SQL world, which helps lower barriers to entry for existing database developers.
Cassandra does manage local storage very well. SSDs are recommended for at least part of the data managed. Using local SSD storage will always provide faster storage and retrieval in comparison to delegating file system management to a separate tier like HDFS.
Also, with no single points of failure anywhere in the architecture, Cassandra is easy to install and maintain, and it’s capable of being very fast.
In Chapter 13, I discuss Apache Cassandra and the commercial company DataStax that provides support for Cassandra.