NoSQL For Dummies (2015)
Part II. Key-Value Stores
In this part. . .
· Segment your customers for better targeting.
· Know your customer segments better with personas.
· Find what value different customers bring to your company.
· Visit www.dummies.com/extras/nosql for great Dummies content online.
Chapter 4. Common Features of Key-Value Stores
In This Chapter
![]() Ensuring that your data is always available
Ensuring that your data is always available
![]() Deciding on how to add keys to your data
Deciding on how to add keys to your data
![]() Managing your data in a key-value store
Managing your data in a key-value store
Key-value stores are no frills stores that generally delegate all value-handling to the application code itself. Like other types of NoSQL databases, they are highly distributed across a cluster of commodity servers.
A particular benefit of key-value stores is their simplicity. Redis, for example, is only 20,000 lines of code! It can be embedded into an application easily and quickly.
Throughput is the name of the game. Many using a key-value store will sacrifice database features to gain better performance. Key-value stores lack secondary indexes, and many of them eschew synchronized updates (thus also eschewing guaranteed transactional consistency) to their data’s replicas in order to maximize throughput.
In this chapter, I cover how to configure a key-value store to ensure that no matter what happens to the database servers in your cluster, your data is always available.
Key-value stores also place some constraints on how you model your data for storage. I talk about the best strategies for this, including information on setting appropriate keys for your data records, and indexing strategies.
Managing Availability
As with other NoSQL database types, with key-value stores, you can trade some consistency for some availability. Key-value stores typically provide a wide range of consistency and durability models — that is, between availability and partition tolerance and between consistent and partition tolerance.
Some key-value stores go much further on the consistency arm, abandoning BASE for full ACID transactional consistency support. Understanding where to draw the line can help you shorten the list of potential databases to consider for your use case.
Trading consistency
Key-value stores typically trade consistency in the data (that is, the ability to always read the latest copy of a value immediately after an update) in order to improve write times.
Voldemort, Riak, and Oracle NoSQL are all eventually consistent key-value stores. They use a method called read repair. Here are the two steps involved in read repair:
1. At the time of reading a record, determine which of several available values for a key is the latest and most valid one.
2. If the most recent value can’t be decided, then the database client is presented with all value options and is left to decide for itself.
 Good examples for using eventually consistent key-value stores include sending social media posts and delivering advertisements to targeted users. If a tweet arrives late or a five-minute-old advertisement is shown, there’s no catastrophic loss of data.
Good examples for using eventually consistent key-value stores include sending social media posts and delivering advertisements to targeted users. If a tweet arrives late or a five-minute-old advertisement is shown, there’s no catastrophic loss of data.
Implementing ACID support
Aerospike and Redis are notable exceptions to eventual consistency. Both use shared-nothing clusters, which means each key has the following:
· A master node: Only the masters provide answers for a single key, which ensures that you have the latest copy.
· Multiple slave replica nodes: These contain copies of all data on a master node. Aerospike provides full ACID transactional consistency by allowing modifications to be flushed immediately to disk before the transaction is flagged as complete to the database client.
Aerospike manages to do that at very high speeds (which refutes claims that having ACID decreases write speed). Aerospike natively handles raw SSDs for data-writing by bypassing slower operating systems’ file system support.
Of course, more SSDs mean higher server costs. You may decide that using Redis (configured to flush all data to disk as it arrives) is fast enough and guarantees sufficient durability for your needs. The default setting in Redis is to flush data to disk every few seconds, leaving a small window of potential data loss if a server fails.
Here are some examples of when you may need an ACID-compliant key-value store:
· When receiving sensor data that you need for an experiment.
· In a messaging system where you must guarantee receipt.
Redis, for example, provides a Publish/Subscribe mechanism that acts as a messaging server back end. This feature combined with ACID support allows for durable messaging.
Managing Keys
Key-value stores’ fast read capabilities stem from their use of well-defined keys. These keys are typically hashed, which gives a key-value store a very predictable way of determining which partition (and thus server) data resides on. A particular server manages one or more partitions.
A good key enables you to uniquely identify the single record that answers a query without having to look at any values within that record. A bad key will require that your application code interprets your record to determine if it does, in fact, match the query.
If you don’t design your key well, you may end up with one server having a disproportionately heavier load than the others, leading to poor performance. Using the current system-time as a key, for example, pushes all new data onto the last node in the cluster, which leads to a nightmare scenario of rebalancing. (Similar to what happens to me when I eat a burger. The more I place into the same large bucket — my mouth — the slower I get!)
Partitioning
Partition design is important because some key-value stores, such as Oracle NoSQL, do not allow the number of partitions to be modified once a cluster is created. Their distribution across servers, though, can be modified. So start with a large number of partitions that you can spread out in the future.
One example of partitioning is Voldemort’s consistent hashing approach, as shown in Figure 4-1. Here you see the same partitions spread across three servers initially and then across four servers later. The number of partitions stays the same, but their allocation is different across servers. The same is true of their replicas.
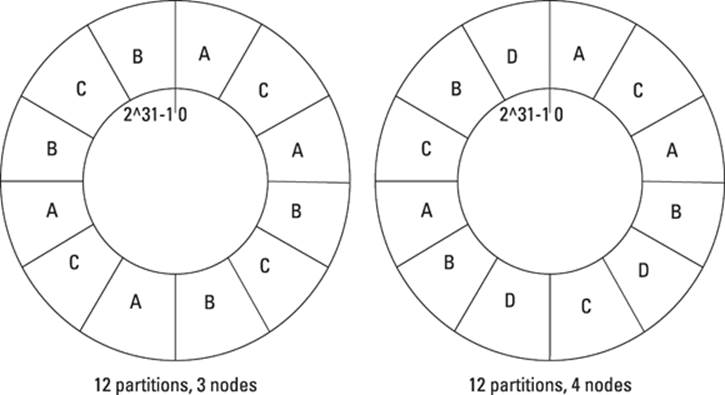
Figure 4-1: Consistent hashing partition allocation in Voldemort.
Accessing data on partitions
Key-value stores are highly distributed with no single point of failure. This means there’s no need for a master coordinating node to keep track of servers within a cluster. Cluster management is done automatically by a chat protocol between nodes in the server.
You can use a trick in the client driver to squeeze maximum performance out of retrieving and storing keys and values — the client driver keeps track of which servers hold which range of keys. So the client driver always knows which server to talk to.
Most databases, NoSQL included, pass a request on to all members of a cluster. That cluster either accepts the write internally or passes it one under the hood to the correct node. This setup means an extra network trip between nodes is possible, which can add to latency.
In order to avoid discovery latency, most key-value stores’ client drivers maintain a metadata list of the current nodes in a cluster and which partition key ranges each nod manages. In this way, the client driver can contact the correct server, which makes operations faster.
If a new node is added to a cluster and the metadata is out of date, the cluster informs the client driver, which then downloads the latest cluster metadata before resending the request to the correct node. This way maximum throughput is maintained with a minimum of overhead during development. Another side benefit is that there’s no need for a load balancer to pass queries on to the next available, or least-busy, server — only one server (or read replica server) ever receives a client request, so there’s no need for load balancing.
Managing Data
Once you manage the keys appropriately, you’re ready to design how to store data and ensure that it’s safe and always accessible for the work you need to do, which I explain in this section.
Data types in key-value stores
Key-value stores typically act as “buckets” for binary data. Some databases do provide strong internal data typing and even schema support. Others simply provide convenient helper functions in their client drivers for serializing common application data structures to a key-value store. Examples include maps, lists, and sorted sets.
Oracle NoSQL can operate in two modes:
· Simple binary store
· Highly structured Avro schema support
An Avro schema is akin to a relational database schema — enforcing a very stringent set of format rules on JavaScript Object Notation (JSON) data stored within the database, as illustrated here:
{username: “afowler”, sessionid: 13452673, since: 1408318745, theme: “bluesky”}
You define an Avro schema using a JSON document. This is an example of the Avro schema for the stored data shown previously:
{“type”: “record”,“namespace”: “com.example”,“name”: “UserSession”,“fields”: [
{“name”: “username”, “type”: [“string”,”null”]},
{“name”: “sessionid”, “type”: “int”},
{“name”: “since”, “type”: “long”},
{“name”: “theme”, “type”: [“string”,”null”]}
]}
An Avro schema provides very strong typing in the database for when schema is important. In the preceding example, you see string data, a numeric session id, a date (milliseconds, since the Unix Time Epoch, as a long integer), and a personalization setting for the theme to use on the website.
Also notice that the type of username and theme has two options — string and null, which is how you instruct Oracle NoSQL that null values are allowed. I could have left theme as a string and provided an additional configuration parameter of “default”: “bluesky”.
Other NoSQL databases provide secondary indexes on any arbitrary property of a value that has JSON content. Riak, for example, provides secondary indexes based on document partitioning — basically, a known property within a JSON document is indexed with a type. This allows for range queries (less than or greater than) in addition to simple equal and not equal comparisons. Riak manages to provide range queries without a stringent schema — just simple index definition. If the data is there, it’s added to the index.
Replicating data
Storing multiple copies of the same data in other servers, or even racks of servers, helps to ensure availability of data if one server fails. Server failure happens primarily in the same cluster.
You can operate replicas two main ways:
· Master-slave: All reads and writes happen to the master. Slaves take over and receive requests only if the master fails.
Master-slave replication is typically used on ACID-compliant key-value stores. To enable maximum consistency, the primary store is written to and all replicas are updated before the transaction completes. This mechanism is called a two-phase commit and creates extra network and processing time on the replicas.
· Master-master: Reads and writes can happen on all nodes managing a key. There’s no concept of a “primary” partition owner.
Master-master replicas are typically eventually consistent, with the cluster performing an automatic operation to determine the latest value for a key and removing older, stale values.
In most key-value stores, this happens slowly — at read time. Riak is the exception here because it has an anti-entropy service checking for consistency during normal operations.
Versioning data
In order to enable automatic conflict resolution, you need a mechanism to indicate the latest version of data. Eventually consistent key-value stores achieve conflict resolution in different ways.
Riak uses a vector-clock mechanism to predict which copy is the most recent one. Other key-value stores use simple timestamps to indicate staleness. When conflicts cannot be resolved automatically, both copies of data are sent to the client. Conflicting data being sent to the client can occur in the following situation:
1. Client 1 writes to replica A ‘Adam: {likes: Cheese}’.
2. Replica A copies data to replica B.
3. Client 1 updates data on replica A to ‘Adam: {likes: Cheese, hates: sunlight}’.
At this point, replica A doesn’t have enough time to copy the latest data to replica B.
4. Client 2 updates data on replica B to ‘Adam: {likes: Dogs, hates: kangaroos}’.
At this point, replica A and replica B are in conflict and the database cluster cannot automatically resolve the differences.
An alternative mechanism is to use time stamps and trust them to indicate the latest data. In such a situation, it’s common sense for the application to check that the time stamps read the latest value before updating the value. They are checking for the check and set mechanism, which basically means ‘If the latest version is still version 2, then save my version 3’. This mechanism is sometimes referred to as read match update (RMU) or read match write (RMW). This mechanism is the default mechanism employed by Oracle NoSQL, Redis, Riak, and Voldemort.