Effective MySQL: Backup and Recovery (2012)
Chapter 2. Understanding Backup Options
MySQL supports various different options for the backup of your database data. Each of these options has its relative strengths and weaknesses that need to be considered to determine what is most applicable for your production environment. The choice of operating system, hardware, and software configuration can affect the availability of options. There are also open source and commercial considerations for your choice of product.
In this chapter we will discuss:
• Different backup strategy needs and approaches
• Various popular MySQL backup options
• Hardware considerations
![]()
Terminology
Chapter 1 introduced a number of important terms that are essential to fully understand the principles for backup and recovery with MySQL.
|
Term |
Description |
|
static backup |
This is a backup of data at a given point in time. Generally a MySQL backup would be performed daily, for example 2:00 A.M. |
|
consistent backup |
This is a backup of data where all information pertaining to the backup is consistent. For example, a filesystem backup on a running production system would produce an inconsistent backup when copying files sequentially. This could lead to a mismatch of information between individual files. |
|
static recovery |
A recovery process involves two important initial steps; the first is the static recovery and the second is the verification of a valid static backup. |
|
point in time recovery (PITR) |
Following a successful static recovery, it is generally necessary to perform a PITR recovery of current transactions. These are all the data operations that have occurred since the static backup, i.e., since 2:00 A.M. |
|
maintenance window |
A backup is generally performed when the system is under less utilization, or in pre-determined times known as a maintenance window. This is when administration tasks including backups, software upgrades, and other maintenance can be performed with limited or restricted application access. |
![]()
Choosing a Backup Strategy
Several factors affect the choice of the type of backup you should implement for your MySQL environment. This chapter covers the bases of what backup strategies exist and what limitations you need to consider for each strategy. For a clear description of the following backup options, these are demonstrated for a single server environment. This highlights the relative strengths and weaknesses for evaluation. The design of your MySQL topology can also affect an appropriate backup and recovery strategy. The use of MySQL replication in the context of backup and recovery can be a great benefit to overcoming some of the limitations listed in this chapter. In Chapter 4 we will discuss the considerations for combining replication with the various strategies.
Before choosing a backup approach, various MySQL architecture and schema design decisions may have an impact.
Database Availability
If access to your database is not required for a period of time—for example, you are not running a 24/7 operation—there may be a common time when your database may not be required to be available. This is called a maintenance window, and it provides an opportunity for backup strategies that may not be possible if such a window is not available.
Storage Engines
As highlighted in Chapter 1, the choice of storage engine for your underlying tables can have an effect on your strategy, particularly in relation to locking and data availability with the primary included storage engines and additional storage engines supported via a plugin architecture. The InnoDB, MyISAM, ARCHIVE, MERGE, MEMORY, and BLACKHOLE engines included with the official MySQL binaries have different locking requirements and needs for consistency, which also drive different backup strategies.
In the following section we will be discussing InnoDB specific options that provide the best approach for a true hot backup.
Locking Strategies
For any backup strategy that operates with a running MySQL instance there is an important consideration of an applicable locking strategy to ensure a consistent backup. An applicable locking strategy is necessary because MySQL supports different concurrency and DML locking approaches. In MySQL not all engines support multi-versioning concurrency control (MVCC). MySQL provides two SQL commands that directly control table level locking. These are the LOCK TABLES and FLUSH TABLES commands. Many backup options detailed in this chapter handle applicable locking. This information is provided to define what options are used and available for custom management.
LOCK TABLES
The LOCK TABLES command can provide a READ or WRITE lock for one or more specified tables. The LOCAL option enables concurrent inserts to continue when applicable for MyISAM tables only. Concurrent inserts for a MyISAM table are possible when there are no holes (from deletes) in the table, or when the concurrent_insert configuration variable is set appropriately.
This command is used when the --lock-tables option is enabled with mysqldump. See the later section on SQL dump for a detailed explanation of when this option is auto-enabled.
The UNLOCK TABLES command is used to release all current locks for a session. In addition to the UNLOCK TABLES command, a session termination, a START TRANSACTION, or a LOCK TABLES on the same table name also produce an implied UNLOCK TABLES.
CAUTION Any backup that takes longer to execute then wait_timeout or interactive_timeout can result in the session being closed. This will cause an implied UNLOCK TABLES.
For more information see http://dev.mysql.com/doc/refman/5.5/en/lock-tables.html.
FLUSH TABLES
The FLUSH TABLES command, when used with the optional keywords WITH READ LOCK, will enable a consistent view of data when the command completes successfully. This occurs by taking a globally held read lock, then closing all currently open tables. This can take time to complete as this requires all running SQL statements to complete. This is not the same type of lock as a LOCK TABLES command on a list of all tables. This lock is released by issuing an UNLOCK TABLES command, or any operation that implicitly runs an UNLOCK TABLES command. This last point is very important as shown in the following example.
In session 1:

In session 2:

The command in session 2 does not complete as expected. We can confirm this by looking at the current threads in the processlist before the timeout occurs.
In session 1:
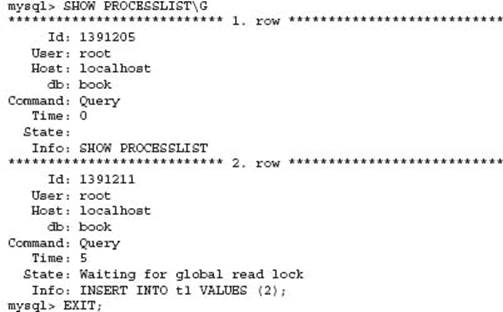
As soon as session 1 is closed, an implied UNLOCK TABLES is performed. This releases the global read lock, and the pending statement in session 2 completes immediately if the SQL statement has not timed out as per this example.
CAUTION A common flaw with backup strategies that use FLUSH TABLES WITH READ LOCK is the need to use two independent threads for the executing backup process. Running a FLUSH TABLES WITH READ LOCK command, then exiting from the current connection will automatically perform an UNLOCK TABLES. After the successful return of FLUSH TABLES WITH READ LOCK, any backup option must occur in a different concurrent thread. Only when the applicable backup option is complete should an UNLOCK TABLES be executed.
NOTE The risk of using a FLUSH TABLES WITH READ LOCK command for a highly concurrent system is this may take some time (i.e., seconds to minutes) to complete. This is due to any other long running statements executing. It is important that this command is monitored and terminated if necessary. While this statement is popular with snapshot options, this risk must be carefully considered for the true impact for an online application.
For more information see http://dev.mysql.com/doc/refman/5.5/en/flush.html.
A recent article on the popular MySQL Performance Blog provided a detailed description of how the combination of FLUSH TABLES WITH READ LOCK, MySQL 5.5, and InnoDB can produce an unexpected wait in order to complete locking all tables. The combination of versions, storage engines, and SQL commands can vary the expected outcome. As always, testing is a sound business practice. For more information see http://www.mysqlperformanceblog.com/2012/03/23/how-flush-tables-with-read-lock-works-with-innodb-tables/.
MySQL Topology
The decision of a backup strategy for a single server installation can be very different then for a MySQL topology that includes MySQL replication. While it may not be possible to stop or limit access to a primary MySQL instance, this approach may be possible with a MySQL replicated slave.
A full copy of your MySQL instance using MySQL replication is actually the easiest backup strategy to implement. This approach, when correctly configured, can also serve as a primary recovery option with minimal impact on production operation. Chapter 4 discusses the impacts of using MySQL replication with your backup and recovery strategy.
![]()
Static Backup Options
MySQL provides no single backup option. The following are the various popular and most common approaches to performing a static backup of a MySQL instance. This is a necessary prerequisite for a database recovery that includes a static recovery and then a possible point in time recovery (if configured).
The following options are possible for a backup of a given MySQL instance:
• Filesystem cold backup
• SQL dump
• Table extract
• Filesystem warm snapshot
• InnoDB hot backup
Filesystem Backup
When you stop the MySQL instance with a clean and proper shutdown, it is possible to perform a filesystem backup. This is a physical copy of files on the filesystem. To ensure you successfully back up all important MySQL data, the following MySQL configuration variables define various file locations that should be carefully reviewed and when applicable included in the list of files to back up. These variable values should be obtained while the server is running. Not all variables may be defined in the my.cnf file. MySQL will use pre-configured defaults for all variables not defined.
• datadir The MySQL data directory
• innodb_data_home_dir The InnoDB Data directory
• innodb_data_file_path The individual InnoDB data files, which may contain specific different directories
• log-bin The binary log directory
• log-bin-index The binary log index file
• relay-log The relay log directory
• relay-log-index The relay log index file
In addition, it is critical you also back up the MySQL configuration file as these settings are particularly necessary to successfully run MySQL. In particular the innodb_data_file_path and innodb_log_file_size include underlying file sizes that when not configured in identical size will result in your MySQL instance failing to start. Refer to Chapter 6 for more information regarding MySQL configuration variables.
Restricting application SQL access to the MySQL server to perform a file copy of a running MySQL instance is highly recommended. A file copy is a sequential process, and there is no guarantee all files will be consistent for the full copy. This is especially applicable when using InnoDB, as additional background threads operate to flush and persist underlying data from the InnoDB Buffer pool even after all MySQL access is restricted.
Disadvantages
There are several key disadvantages to this approach.
• The MySQL instance is not available during the backup.
• The recovery process requires a similarly configured system with the same operating system and directory structures.
• The MySQL instance memory buffers will be re-initialized when MySQL is restarted. This can take some time for the system to provide optimal performance for running SQL statements.
Advantages
• Simple process.
• This enables a backup to be performed with any filesystem backup tool.
SQL Dump
MySQL provides a SQL based backup option with the included client command mysqldump. This command was first introduced in Chapter 1. Using mysqldump is a practical way that requires no additional software; however, this solution is not without a number of limitations. A common use of mysqldump would be:
![]()
This command creates a backup that includes all tables, views, and stored routines for all database schemas and the master binary log position.
The one additional option that is most commonly used is --single-transaction; however, this is only applicable for an InnoDB only environment, or transactional storage engine that supports MVCC.
A number of the options shown are described in further detail.
--opt
This option is enabled by default and is equivalent to --add-drop-table, --add-locks, --create-options, --quick, --extended-insert, --lock-tables, --set-charset, and --disable-keys.
--lock-tables
This option is actually implied by the --opt option, which is enabled by default. The underlying implementation of the LOCK TABLES command uses the syntax:

The mysqldump with --lock-tables only locks the tables of one schema at one time—not all tables for all schemas. If application logic writes to two different schemas and you use a storage engine that does not support transactions, it is possible to have inconsistent data during a backup.
--lock-all-tables
This option will perform a FLUSH TABLES WITH READ LOCK command in order to produce a consistent view of data in all schemas.
--routines
Using mysqldump to back up all databases does not back up all of your schema meta-information. MySQL routines are not included by default. This can be a significant shortcoming if your recovery process does not fully test the validity of your backup. If your database includes stored procedures or functions the --routines option is necessary.
--master-data
This option is essential for any point in time recovery, which is the general requirement for all disaster recovery situations. When enabled, the output will produce a SQL command like:
![]()
You can also specify --master-data=2, which will embed this SQL statement as a comment only so this is not physically executed during the restoration of data with the mysqldump output. The importance of this option and the prerequisite configuration is discussed in the following section on point in time requirements.
--all-databases
As the name implies, all database schemas are referenced for the mysqldump command. You can also specify individual database schemas and tables on the command line. To specify specific databases use the --database option; for specific tables use --tables, and to define schemas with an exclusion list of tables use --ignore-table.
--complete-insert
The --complete-insert option provides a practical syntax for a higher level of compatibility as shown:

This is important if you separate your schema and data using mysqldump to trap errors when loading data.
By default MySQL will combine a number of rows for individual INSERT statements. This is due to the --extended-insert option that is enabled by default. If you want to generate a backup with individual INSERT statements use the --skip-extended-insert option. This will affect the recovery time of your backup.
--skip-quote-names
By default MySQL will automatically add a back tick (`) around every object name. This is used to support using reserved words and spaces in object names, two practices that are strongly not recommended. mysqldump does not quote only those objects that need this syntax, but all objects including table names, column names, index names, etc.
This is a cumbersome syntax that can be removed with --skip-quote-names, and providing you avoid the two conditions mentioned the backup file will be correctly restored.
--single-transaction
When using a storage engine that supports MVCC it is possible to get a consistent view of data using the --single-transaction option. This works, for example, with the InnoDB storage engine. It does not work with the My-ISAM storage engine. This option does have an overhead, as this is one long running transaction.
--hex-blob
When your database contains binary data, the --hex-blob option will provide maximum compatibility especially when using your backup for restoration on different MySQL systems.
MySQL Replication Specific Options
Chapter 4 will discuss a number of important mysqldump options to consider when working with a MySQL slave including --master-data, --apply-slave-statements, and --dump-slave.
Additional Options
The following syntax provides a full list of possible options with mysqldump:
![]()
Benefits
As mentioned in Chapter 1, one of the benefits of mysqldump is the ASCII nature of the data. You can look at the backup file with a text editor and you can use simple tools to manipulate the data—for example, to perform a global string substitution to change the storage engine. mysqldump can also support the extraction of individual schemas and tables, providing a level of flexibility not possible with other options discussed in this chapter. While mysqldump may not be the tool of choice for your full backup and recovery strategy, understanding this command for partial data situations is important.
This command uses the MySQL client/server protocol so the mysqldump command does not have to be performed on the same host. This can help reduce the I/O writing requirement and disk capacity necessary; however, this can increase the time the command executes and network utilization. When used on a Linux or Unix operating system additional piping and redirection can enable additional features including encryption and compression.
One advantage of the SQL backup is that it enables a cross operating system compatible solution. A backup using mysqldump on Linux can be restored on a Windows platform. In addition, mysqldump also provides a --compatible option to support SQL statements that can be used with previous MySQL versions.
Because mysqldump output is an ASCII representation of data, it is possible that the size of the backup is larger than the database. For example, a 4 byte integer can be 10 characters long in ASCII.
Recovery Considerations
A backup process is only as good as a successful recovery. A mysqldump file is only a static backup. Regardless of your backup approach, this is one common component required for a true recovery solution that is to support a point in time recovery. This important recovery step has two additional requirements when producing a SQL dump. The first requirement is the master binary logs, which are enabled with --log-bin. The second is the binary log position at the time of the backup; this is obtained by the --master-data options. Chapter 6 discusses these options in detail.
Recommended Practices for Database Objects
It is recommended that you separate your table objects and table data. This has multiple benefits including ease of comparison for schema objects, ability to re-create your schema only—for example, with a test environment—and provides an easier way to split your data file for possible parallel loading. Regardless of your ultimate backup process, I would always recommend you run the following two commands to back up your schema definition and objects:

A simple approach to schema comparison is to perform a difference between files that are created with each backup. This approach is only approximate, as the order of objects is not guaranteed, and the syntax may and does change between MySQL versions. You can use this technique, however, as a quick check and confirmation of no schema changes, which is an important verification and audit.
TIP A mysqldump of database objects can provide an easy means of confirming that no objects have changed between scheduled backups. This can provide a level of auditability for system architecture.
Using Compression
Using mysqldump you can leverage the operating system to support compression. The simplest approach is to pipe the output directly into a suitable compression algorithm. For example:
![]()
While this will ensure a much smaller backup file, compression adds time to the backup process, which could affect other considerations including locking and recovery time. See Chapter 8 for a more detailed discussion on using compression to optimize the backup process.
Leveraging Network Devices
You can also use mysqldump across the network, either with a pull or push process, for example, to pull the data from the database server to another server.

The -C option enables compression in the communication when supported between the mysqldump client command and the database server. This does not compress the result, only the communication.
The push of mysqldump output can be performed several ways including with the nc (netcat) command. For example:
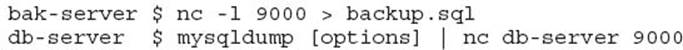
Chapter 8 provides more information regarding different options and considerations for streaming a backup.
Disadvantages
mysqldump is ideal for smaller databases. Depending on your hardware, including available RAM and hard drive speed, an appropriate database size is between 5GB and 20GB. While it is possible to use mysqldump to back up a 200GB database, this single thread approach takes time to execute. It is also impractical to restore in a timely manner due to the single threaded nature of the restoration of a mysqldump output. Ideally, leveraging techniques of separating static and online data into multiple files can provide an immediate parallelism. The mydumper utility aims to improve these features by offering parallelism capabilities. This open source utility is discussed in Chapter 8.
Table Extract
An additional form of ASCII backup is to produce a per table data file, also called a data snapshot. This option is not practical for a full system backup; however, it is ideal for time series, write once, and archival data, especially if the data has been manually partitioned. Using a hybrid approach for a backup strategy can reduce both the time and size required for your backup. This method, when used with static data, i.e., eliminating a consistency problem, and combined with mysqldump of other data, can provide a much smaller backup both in execution time and filesize. This can also translate to reduced recovery times. Generally this approach is not practical as a complete solution because it is difficult to reconcile with point in time recovery.
You can use the mysqldump command with the --tab option or SELECT INTO OUTFILE SQL syntax to achieve a per table data file. By default, these commands produce a tab separated column format, with a newline terminator for rows. If you wanted to produce a comma separated variable (CSV) dump of data, you could use the following syntax:
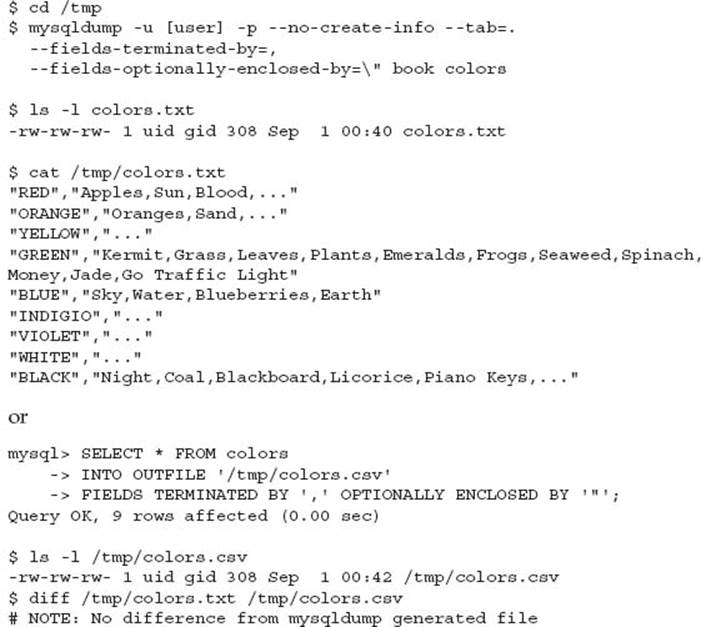
One advantage of the mysqldump command is a greater flexibility of the underlying file permissions necessary to write the output file. Using the SELECT INTO OUTFILE syntax requires the mysqld process owner (generally mysql) to have appropriate write permissions where the outfile is defined. This also produces an additional problem when compressing or moving the file, as a normal operating system user generally cannot perform this on the file created by the mysql user.
Filesystem Snapshot
A more practical solution for a larger MySQL instance is to perform a filesystem snapshot. This is not actually a MySQL specific strategy, but rather a disk based operating system command using Logical Volume Manager (LVM) for direct attached drives, or applicable snapshot technology for Storage Area Network (SAN) or Network Attached Storage (NAS) providers. This may also be a feature of certain file systems, e.g., the Btrfs file system on Linux and ZFS on Solaris.
Your disk must be correctly configured with LVM prior to using any of these commands. The EffectiveMySQL website provides a detailed article on installing and configuring LVM at http://effectiveMySQL.com/article/configuring-a-new-hard-drive-for-lvm/ and on installing MySQL to utilize this LVM volume at http://effectiveMySQL.com/article/using-mysql-with-lvm.
Assuming you have a MySQL instance running on an LVM volume you can use the following command to take a filesystem snapshot:
![]()
This command uses the logical volume group (dev/db/p0) and a very small undo size for this example (-L1G). These would be modified accordingly for your environment. Calculating the necessary undo size can be difficult. If the space is not large enough, the snapshot command will report an appropriate error.
NOTE A snapshot volume does not need to be the same size as the underlying volume that contains your MySQL data. A snapshot only has to be large enough to store all data that is going to change over the time the snapshot exists.
CAUTION Always ensure you have sufficient diskspace to perform a snapshot. The pvdisplay and lvdisplay commands show total available space and the percentage of space allocated to snapshots.
CAUTION Having an active LVM snapshot comes with a performance penalty for all disk activity. While ideal for recovery purposes to have the current snapshot online, for general database performance it is best to discard the snapshot as soon as it is no longer in use. Having multiple snapshots will further degrade I/O performance.
The verification process of taking a filesystem snapshot would include:


LVM snapshots operate under the filesystem; they are thus application and filesystem agnostic. Whatever application uses these files—in this case, MySQL—needs to ensure that the files on disk are in a consistent state when the snapshot is taken. This backup approach works; however, it creates an inconsistent snapshot of MySQL. Depending on the storage engines used, the recovery process may perform an automatic recovery for this inconsistent view, or it may produce errors, for example, with MyISAM tables, which can increase the total system recovery time. Historically, automatic recovery time with InnoDB could also take a long time. This has been greatly improved with newer versions of MySQL 5.1 and 5.5.
The correct approach when using a filesystem snapshot is to place the MySQL instance into a consistent state before any command. This is achieved with the FLUSH TABLES WITH READ LOCK command. As described in the earlier section on locking, this command, when used incorrectly, does not ensure a consistent view.
The recommended steps for using a filesystem snapshot are:
• Generate a consistent MySQL view with FLUSH TABLES WITH READ LOCK. It can be difficult to predict how long this will take.
• Obtain the MySQL binary log position with SHOW MASTER STATUS and/or SHOW SLAVE STATUS.
• Run the snapshot command in a different thread. It is important you do not exit from the MySQL session for the previous commands.
• Optionally run a FLUSH BINARY LOGS.
• Release locks with UNLOCK TABLES.
• Verify the filesystem snapshot.
• Make an appropriate copy of the snapshot backup on a different server or site.
• Discard the snapshot (for optimal I/O performance).
NOTE The most common backup needed for a disaster recovery is the most recent backup. The underlying LVM logical volume for the filesystem snapshot is actually an I/O performance overhead to maintain. The backup of the snapshot and movement to an external system is a common approach. The restoration of these compressed backup files from an external system can be the most significant time component of the recovery strategy. Chapters 3 and 5 discuss these impacts in more detail.
For more information about the theory of LVM see http://en.wikipedia.org/wiki/Logical_Volume_Manager_(Linux).
Using mylvmbackup
The mylvmbackup utility now maintained by longtime MySQL community advocate Lenz Grimmer is a convenience script that wraps all of this work into a single command. You can find this utility at http://www.lenzg.net/mylvmbackup/. For example, the use of mylvmbackup when correctly installed and configured is:
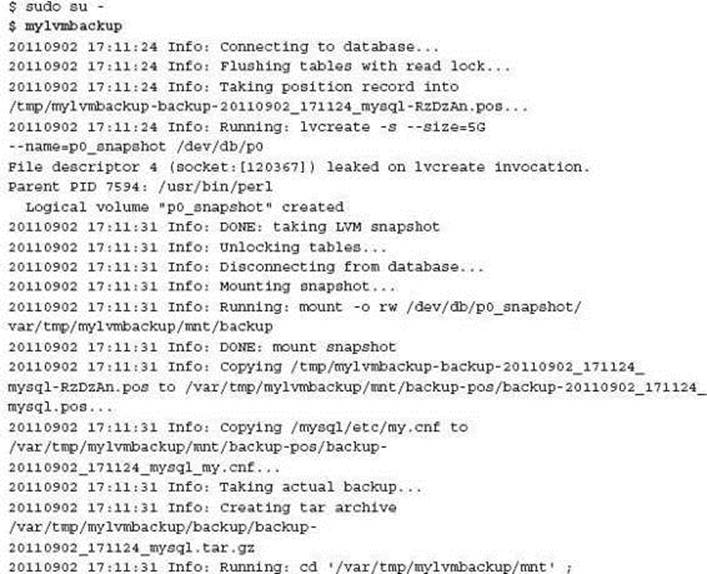
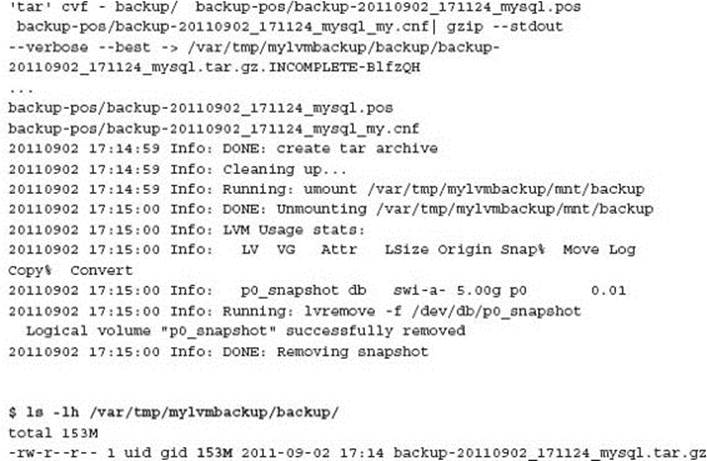
This command supports many additional features including backing up to a remote server using rsync. The Effective MySQL article at http://effective-MySQL.com/article/creating-mysql-backups-using-lvm/ provides additional information on how to correctly install and configuremylvmbackup and also lists several valuable external references.
TIP A snapshot is a great way to perform software updates. There is no need to back up and remove the snapshot for this operation. If the update fails you can roll back to the snapshot just taken.
Designing Appropriate LVM Volumes
There are several considerations for optimizing the use of LVM and MySQL. Ensure you have a dedicated logical volume for your MySQL instance. This should include the data and InnoDB transactional logs. This is critical for a successful recovery. A snapshot is an atomic operation for all files at the same time per logical volume. Having data and InnoDB transaction logs on separate volumes would not ensure a consistent snapshot, as this would be performed separately per volume. While the MySQL binary logs are good to keep with your MySQL backup, for a highly loaded system, it may be beneficial to separate this from your MySQL data volume. MySQL log files, or other monitoring or instrumentation, can also cause overhead; the goal should be to minimize your disk footprint to ensure the most optimal recovery time.
Limiting other operations that affect your data during the execution of a filesystem snapshot can also improve the performance. For example, disabling or limiting batch processes and reporting can reduce additional system load.
Other Considerations
Using filesystem snapshots can be a disk I/O intensive operation. If your system is already heavily loaded, the addition of an active snapshot is an overhead that could add up to 20 percent extra load. In addition, the compressing and/or copying of the snapshot, while necessary for a backup strategy, may add more stress to the system.
The ZFS filesystem, available with Solaris, FreeBSD, and other free Solaris derivative operating systems, provides a native snapshot command that works very efficiently with the designed copy-on-write principle. The Btrfs filesystem for Linux is another snapshot efficient option. Other filesystem types such as xfs can provide different performance benefits for disk I/O and management with snapshots.
InnoDB Hot Backup
For an InnoDB only MySQL instance there are two products that can perform a hot non-blocking backup. These are MySQL Enterprise Backup (MEB), formally known as InnoDB Hot Backup, and XtraBackup.
The process of performing a hot backup is different from both the mysqldump and filesystem snapshot approaches, as it integrates with features and functionality within InnoDB to produce a solution that provides a consistent version of data in a non-locking manner. These tools duplicate some of the features of the InnoDB storage engine by keeping a copy of all InnoDB transactional log engines (aka redo logs) and performing a copy of data consistent with InnoDB data page management. Both products will also perform a warm backup of a MySQL installation that has a mixture of InnoDB and other storage engines.
NOTE In addition to supporting an InnoDB only application, these hot backup options do support MyISAM backups for the mysql meta-schema and any other tables; however, this requires table locking.
MySQL Enterprise Backup (MEB)
MEB is available as part of MySQL Enterprise Edition, a commercial offering that is provided by Oracle when purchasing a MySQL subscription. MEB provides a hot backup solution for a MySQL environment.
Downloading the Software You can download MySQL Enterprise Backup for evaluation from the Oracle Software Delivery website at https://edelivery.oracle.com/. You must first sign up for free, accept the licensing agreement, and download the appropriate version via a web browser. Currently MySQL Enterprise Backup is available in the following distribution packages:
• RHEL/OL 4 32bit/64bit
• RHEL/OL 5 32bit/64bit
• RHEL/OL 6 32bit/64bit
• SuSE 10 32bit/64bit
• SuSE 11 32bit/64bit
• Generic Linux 32bit/64bit
• Windows 32bit/64bit
• Solaris 10 32bit/64bit
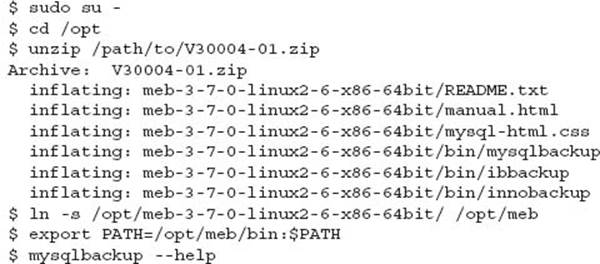
The following steps install a downloaded version of the generic Linux 64bit software:
Running a Full Backup
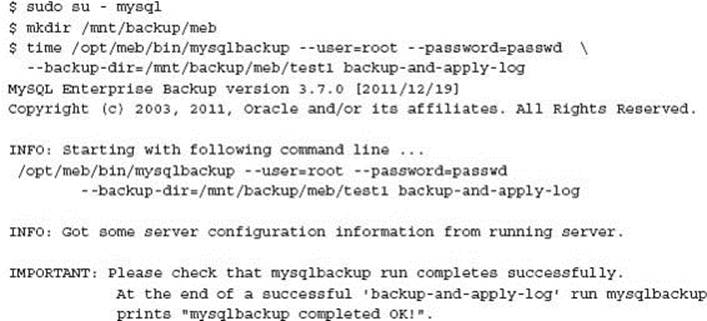


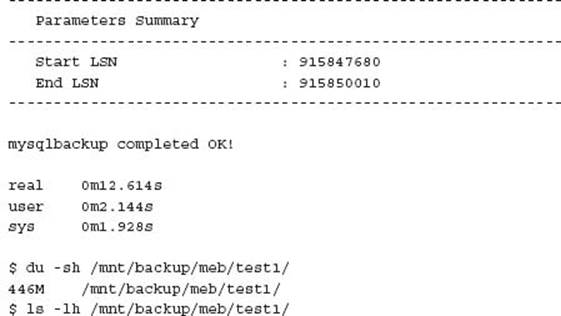

NOTE The --with-timestamp option will create an appropriate date/time sub-directory for each backup using MySQL Enterprise Backup.
This example showed the backup-and-apply-log option. It is also possible to create a backup with two separate commands by running MEB with backup and then apply-log.
For more information see the MySQL documentation at http://dev.mysql.com/doc/mysql-enterprise-backup/3.7/en/mysqlbackup.backup.html.
Chapter 8 discusses additional options for MySQL Enterprise Backup including compression, incremental, and remote backups.
Security To improve access permissions for a privileged user performing a backup with MEB, the following privileges are required:

For more information refer to the MEB manual at http://dev.mysql.com/doc/mysql-enterprise-backup/3.7/en/mysqlbackup.privileges.html.
Monitoring In addition to text output of the mysqlbackup command, information is recorded in the mysql schema. For example:
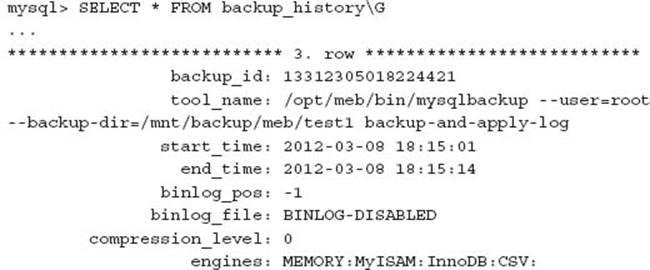


This can be disabled with the --no-history-logging option.
More Information For more information on the features of MySQL Enterprise Backup visit http://www.mysql.com/products/enterprise/backup.html.
XtraBackup
XtraBackup is an open source offering by Percona that can perform an InnoDB hot backup. This tool also has additional features for the support of the XtraDB storage engine, an open source variant of InnoDB.
Downloading the Software XtraBackup is available in three different versions. This is because XtraBackup actually includes an embedded version of the MySQL server and MySQL client libraries. You can download the software from http://www.percona.com/downloads/XtraBackup/.
For example, when using the Ubuntu 64bit MySQL 5.5 version of XtraBackup, the following commands download and install the software. Refer to the previously mentioned link to obtain the most current version of XtraBackup for your applicable operating system. At the publication of this book the current version is 2.0.0.

CAUTION XtraBackup may require the installation of the library package for Asynchronous I/O (libaio1 on Ubuntu, libaio on RHEL). This is also required for MySQL versions 5.5 or greater.
NOTE In the prior version of XtraBackup, the package name was xtrabackup. It is now percona-xtrabackup.
--backup The XtraBackup backup process is a two stage operation. The first operation with the --backup option performs the physical backup. The second operation with the --prepare option performs an internal crash recovery of the copied tablespace files and accumulated transactional logs to produce a consistent backup that can then be restored in a timely manner.
Using the directory structure of the MySQL installation that was referenced in the LVM section the following syntax will perform a backup. The --datadir parameter should be adjusted accordingly for your MySQL instance.
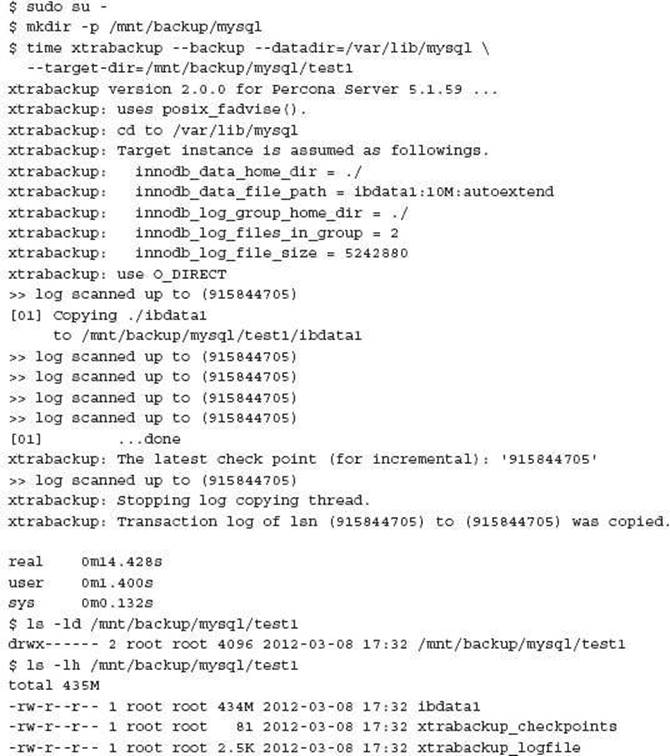
--prepare The prepare step of XtraBackup launches the embedded version of InnoDB, performs a crash recovery of the data and accumulated transaction logs, and produces a clean and consistent version that is ready for any recovery requirements.
This step can occur on any server that has the backup files and the same version of XtraBackup installed. This does not need to occur on the machine the backup was taken.
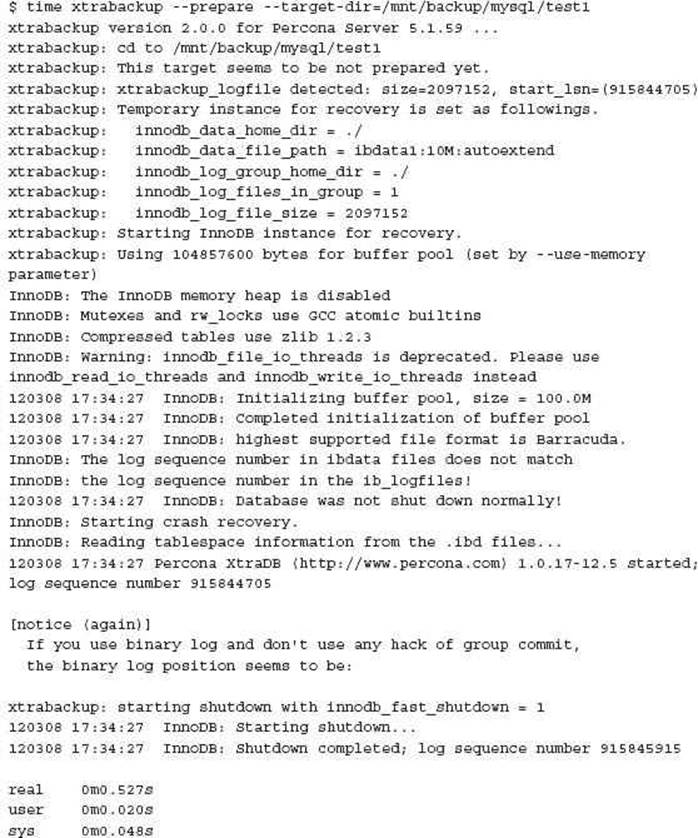
For saving additional time in the recovery process, you can run the --prepare option a second time to prepare clean InnoDB transaction logs. This is not a required step.
NOTE The xtrabackup command does not create date/time based subdirectories during the backup process.
Backing Up All MySQL Data As you can see from the XtraBackup commands, only InnoDB specific data is included. To capture all MySQL data, the innobackupex wrapper script packages all the necessary work into a single command. For example:

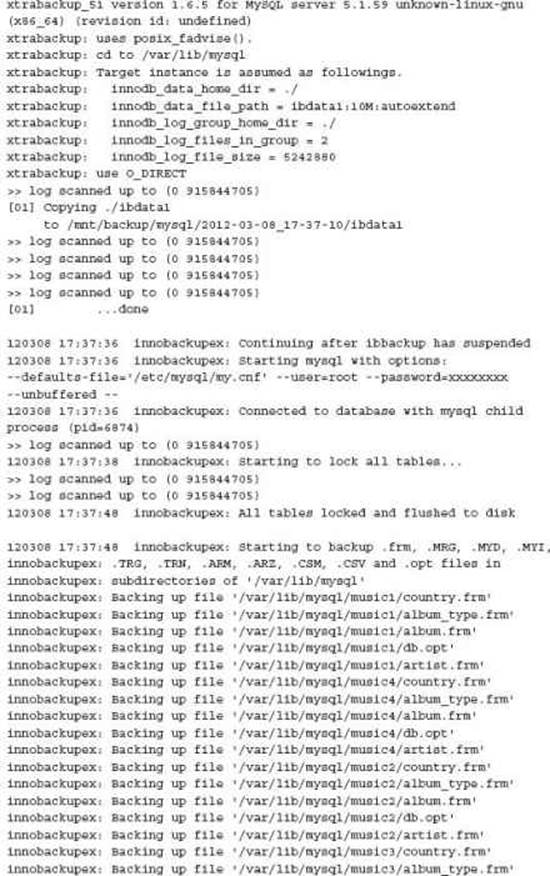
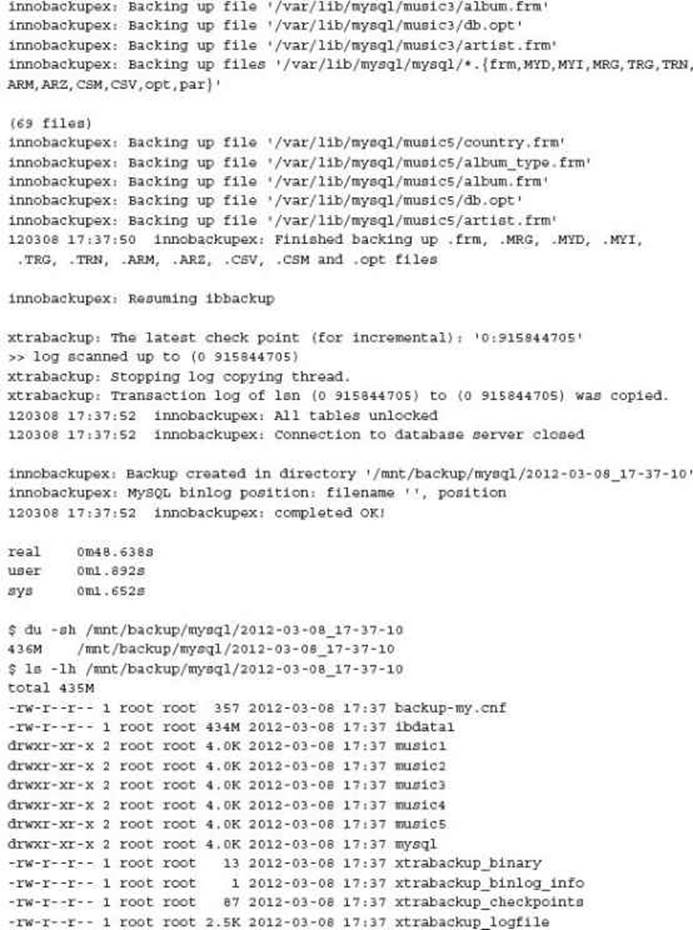
This command will automatically place the backup in a date/time defined sub-directory. This can be disabled with the --no-timestamp option.
More Information For more information on XtraBackup visit http://www.percona.com/docs/wiki/percona-xtrabackup:xtrabackup:start.
Options Not Discussed
There are several other commands and techniques that are not discussed in detail. These include:
• mysqlhotcopy is an included utility that is applicable for MyISAM tables only. This utility should not be used as this is no longer maintained.
• ibbackup is the historical name for InnoDB Hot Backup. This has been improved and is now called MySQL Enterprise Backup.
• mydumper (http://www.mydumper.org/) is a high performance tool providing many features over mysqldump including parallelism, consistency with transactional and non-transactional tables, and binary log management. Refer to Chapter 8 for more information.
• mt-parallel-dump is a deprecated Maatkit tool that attempted to perform parallel mysqldump commands. The author has recommended this product no longer be used.
• MySQL online backup that was under development in MySQL versions 5.2 and 6.0 was never incorporated into future development.
• Zmanda Recovery Manager for MySQL (http://www.zmanda.com/backup-mysql.html) provides a user interface and management tool for MySQL backups; however, it does not provide any additional functionality that is not described in this chapter.
• DRBD (Distributed Replicated Block Device) is not discussed as a possible MySQL backup option. DRBD can be used to provide a more highly available system; however, this is not specifically a backup and recovery approach.
CAUTION Be wary of GUI editors that offer a backup solution or a generic tool that fits all database solutions. A production system requires a production strength backup solution tailored to your business needs and objectives.
![]()
Point in Time Requirements
The static backup of a MySQL instance is only the first step of a strategy that will result in a successful recovery. In addition to a backup strategy that provides a backup option to a specific time when the backup was taken, it is generally necessary to perform a point in time recovery to either the most current transactions before a physical disaster, or a time before some human created situation. This is known as a point in time recovery (PITR) that is performed by applying the MySQL binary logs to a recovered snapshot.
Binary Logs
When enabled, the MySQL binary logs record all DML and DDL statements that are performed on a MySQL instance. It is possible for users with appropriate privileges to disable the binary log for individual session statements or globally. This could produce an inconsistent version of data during a recovery process or replication topology. It is important that application users are not given the SUPER permission for this reason.
The binary logs are enabled with the --log-bin option that is detailed in Chapter 6. The SHOW BINARY LOGS command provides a list of current binary logs managed by MySQL. The SHOW MASTER LOGS command produces the same output.
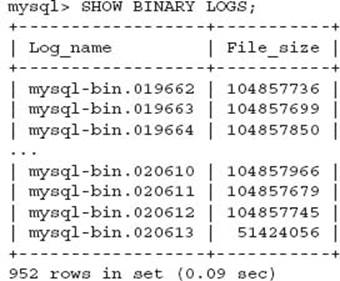
These binary log entries match the underlying files defined by the --log-bin option.
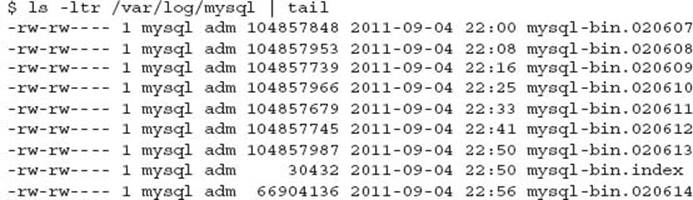
A high volume system can easily record 500MB per minute of binary logs, and this can have a large impact on available diskspace. The --expire-logs-days option removes these files automatically after the defined number of days. Alternatively, it is important that you use the PURGE BINARY LOGS command to remove these files instead of removing the files from the file system manually, as there is an internal reference between the database and the filesystem.
CAUTION A system administrator deleting MySQL binary log files via an operating system command is a potential disaster situation. The appropriate MySQL command should always be used to remove binary log files.
Binary Log Position
Depending on the chosen backup option you may also need to capture the current binary log position in order to be able to successfully perform a restoration. The SHOW MASTER STATUS provides the current position. For example:

This information can be obtained with the --master-data option when using the mysqldump command.
Binary Log Backup Options
The backup of the binary logs is just as important as a backup of your database. Several options exist including filesystem copy, replication, and other disk based technologies.
File Copy
The binary logs are sequential files that can easily be copied to an external server without any impact on ensuring consistency with the running MySQL database. It is possible to perform a remote synchronization of files—for example, with the rsync command—on a regular frequency to ensure a secondary copy of the master server binary logs.
Replication
The use of MySQL replication is an easy way to have a copy of the binary log data on a secondary system. When using MySQL replication, a copy of the binary log entries is written to the relay log on the MySQL slave. While this is a copy, there is no accurate reference between the master log file and position and the corresponding relay log file and position. The relay log is not a good way to have a copy of what is in the binary log. Relay log files have a much shorter longevity by default than the master binary logs. The use of --log-slave-updates would be a more practical choice. Chapter 4 discusses in more detail various options for understanding the binary logs in a MySQL replication topology.
DRBD
It is possible to easily create a mirrored binary log implementation using additional software including DRBD. This ensures you have a consistent copy of all binary logs on a separate server.
![]()
Hardware Considerations
Having available diskspace and network bandwidth are the most important hardware considerations for supporting MySQL backups.
The most likely recovery will be from the most current backup. If you have insufficient diskspace to store this on your primary server, the time for data transfer in a recovery situation may be the most significant portion of time.
If you have insufficient diskspace on your primary server and you store your backup compressed, the time to uncompress your backup may be the most significant component of time.
A common design decision is between using direct attached disk versus a Network Attached Storage device. The choice to use a Storage Area Network (SAN) as a backup solution is not a practical option. In fact, relying solely on SAN is a greater likelihood of a disaster. The use of snapshotting and archiving functionality in addition to SAN usage is necessary for a fully functioning DR plan.
To ensure great network connectivity, using dedicated network connections for application use and internal use ensures copying backup files during peak time does not saturate your network. Network bonding is a further simple hardware option that will reduce the impact of a physical hardware network failure.
![]()
Data Source Consistency
Producing a consistent database backup may involve ensuring the consistency of external sources. The design of a database system that stores images in the database is a common argument put forward for ensuring data consistency. This is, however, a classic example where the inclusion of large static objects in the database has a far greater overhead, both in database performance and in database backup and recovery time. The correct design of a disaster recovery (DR) strategy should ensure that images are never stored in the database, as this has a direct effect and is detrimental to an optimal solution.
There are examples for a backup strategy where consistency is not necessary for an entire MySQL instance. The inclusion of backup or copy tables in a MySQL schema is a prime candidate for defining a different schema and excluding this entire schema during a mysqldump backup.
The inclusion of large static data or archive data that is managed and updated infrequently can also be separated using an individual schema, for example, when using mysqldump. This level of separation may not be applicable for different backup options.
![]()
Backup Security
While not discussed in this book, it is an important consideration that your backup files meet applicable security requirements. To obtain important company information, does an intruder need to compromise the security of your production server, or just your backup server?
![]()
Conclusion
In this chapter we discussed the primary backup options that are possible for a given MySQL server. Knowing the relative risks of various strategies may alter your plan for how you design a complex system. The use of MySQL replication or other topology options can affect backup options. Knowing and understanding your application, your data, and your rate of data change can also introduce possible optimizations for a hybrid approach.
Producing a suitable backup strategy is only a prerequisite step to the more critical recovery process with considerations for consistency, timeliness, and gradients of data availability. While a full and successful recovery is essential, the time to perform a recovery is one important business requirement that could affect the viability of your entire business. Chapter 3 discusses important business requirements that can affect the technical decisions for choosing the backup and recovery strategy of your MySQL environment.
The SQL statements and web links listed in this chapter can be downloaded from http://effectivemysql.com/book/backup-recovery/.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.