Expert MySQL: Second Edition (2012)
Part II. Extending MySQL
Chapter 10. Building Your Own Storage Engine
The MySQL pluggable architecture that enables the use of multiple storage engines is one of the most important features of the MySQL system. Many database professionals have refined advanced skills for tuning the logical structure of relational database systems to meet the needs of the data and their applications. With MySQL, database professionals can also tune the physical layer of their database systems by choosing the storage method that best optimizes the access methods for the database. That is a huge advantage over relational database systems that use only a single storage mechanism.1
This chapter guides you through the process of creating your own storage engine. I begin by explaining the details of building a storage engine plugin in some detail and then walk you through a tutorial for building a sample storage engine. If you’ve been itching to get your hands on the MySQL source code and make it do something really cool, now is the time to roll up your sleeves and refill that beverage. If you’re a little wary of making these kinds of modifications, read through the chapter and follow the examples until you are comfortable with the process.
MySQL Storage Engine Overview
A storage-engine plugin is a software layer in the architecture of the MySQL server. It is responsible for abstracting the physical data layer from the logical layers of the server, and it provides the low-level input/output (I/O) operations for the server. When a system is developed in a layered architecture, it provides a mechanism for streamlining and standardizing the interfaces between the layers. This quality measures the success of a layered architecture. A powerful feature of layered architectures is the ability to modify one layer and, provided the interfaces do not change, not alter the adjacent layers.
Oracle has reworked the architecture of MySQL (starting in version 5.0) to incorporate this layered-architecture approach. The plugin architecture was added in version 5.1, and pluggable storage engines are the most visible form of that endeavor. The storage-engine plugin empowers systems integrators and developers to use MySQL in environments in which the data requires special processing to read and write. Furthermore, the plugin architecture allows you to create your own storage engine.
One reason for doing this rather than convert the data to a format that can be ingested by MySQL is the cost of doing that conversion. For example, suppose you have a legacy application that your organization has been using for a long time. The data that the application has used are valuable to your organization and cannot be duplicated. Furthermore, you may need to use the old application. Rather than converting the data to a new format, you can create a storage engine that can read and write the data in the old format. Other examples include cases in which the data and their access methods are such that you require special data handling to ensure the most efficient means of reading and writing the data.
Furthermore, and perhaps most important, the storage-engine plugin can connect data that are not normally connected to database systems. That is, you can create storage engines to read streaming data (e.g., RSS) or other nontraditional, non-disk-stored data. Whatever your needs, MySQL can meet them by allowing you to create your own storage engines that will enable you to create an efficient, specialized relational-database system for your environment.
You can use the MySQL server as your relational-database-processing engine and wire it directly to your legacy data by providing a special storage engine that plugs directly into the server. This may not sound like an easy thing to do, but it really is.
The most important architectural element is the use of an array of single objects to access the storage engines (one object per storage engine). The control of these single objects is in the form of a complex structure called a handlerton (as in singleton—see the sidebar on singletons). A special class called a handler is a base class that uses the handlerton to complete the interface and provide the basic connectivity to enable a storage engine. I demonstrate this in Figure 10-1 later in this chapter.
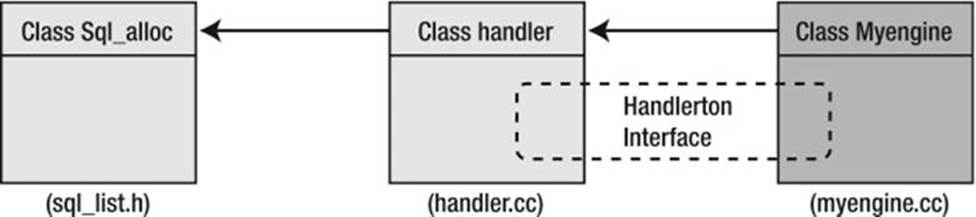
Figure 10-1. Pluggable storage-engine-class derivation
All storage engines are derived from the base-handler class, which acts as a police officer, marshaling the common access methods and function calls to the storage engine and from the storage engine to the server. In other words, the handler and handlerton structure act as an intermediary (or black box) between the storage engine and the server. As long as your storage engine conforms to the handler interface and the pluggable architecture, you can plug it into the server. All of the connection, authentication, parsing, and optimization is still performed by the server in the usual way. The different storage engines merely pass the data to and from the server in a common format, translating them to and from the specialized storage medium.
Oracle has documented the process of creating a new storage engine fairly well. As of this writing, Chapter 14 of the MySQL reference manual contains a complete explanation of the storage engine and all functions supported and required by the handler interface. I recommend reading the MySQL reference manual after you have read this chapter and worked through building the example storage engine. The MySQL reference manual in this case is best used as just that—a reference.
WHAT IS A SINGLETON?
In some situations in object-oriented programming, you may need to limit object creation so that only one object instantiation is made for a given class. One reason for this may be that the class protects a shared set of operations or data. For example, if you had a manager class designed to be a gatekeeper for access to a specific resource or data, you might be tempted to create a static or global reference to this object and therefore permit only one instance in the entire application. The use of global instances and constant structures or access functions flies in the face of the object-oriented mantra, however. Instead of doing that, you can create a specialized form of the object that restricts creation to only one instance so that it can be shared by all areas (objects) in the application. These special, one-time-creation objects are called singletons. (For more information on singletons, see http://www.codeproject.com/Articles/1921/Singleton-Pattern-its-implementation-with-C). There are a variety of ways to create singletons:
· Static variables
· Heap-registration
· Runtime type information (RTTI)
· Self-registering
· Smart singletons (like smart pointers)
Now that you know what a singleton is, you’re probably thinking that you’ve been creating these your entire career but didn’t know it!
Storage Engine Development Process
One process for developing a new storage engine can be described as a series of stages. After all, a storage engine does not merely consist of a few lines of code; therefore, the most natural way to develop something of this size and complexity is through an iterative process, in which a small part of the system is developed and tested prior to moving on to another, more complicated portion. In the tutorial that follows, I start with the most basic functions and gradually add functionality until a fully functional storage engine emerges.
The first few stages create and add the basic data read and write mechanisms. Later stages add indexing and transaction support. Depending on what features you want to add to your own storage engine, you may not need to complete all the stages. A functional storage engine should support, at a minimum, the functions defined in the first four stages.2 The stages are:
1. Stubbing the engine—The first step in the process is creating the basic storage engine that can be plugged into the server. The basic source-code files are created, the storage engine is established as a derivative of the handler-base class, and the storage engine itself is plugged into the server source code.
2. Working with tables—A storage engine would not be very interesting if it didn’t have a means of creating, opening, closing, and deleting files. This stage is the one in which you set up the basic file-handling routines and establish that the engine is working with the files correctly.
3. Reading and writing data—To complete the most basic of storage engines, you must implement the read and write methods to read and write data from and to the storage medium.3 This stage is the one in which you add those methods to read data in the storage-medium format and translate them to the MySQL internal-data format. Likewise, you write out the data from the MySQL internal-data format to the storage medium.
4. Updating and deleting data—To make the storage engine something that can be used in applications, you must also implement those methods that allow for altering data in the storage engine. This stage is the one in which the resolution of updates and deletion of data is implemented.
5. Indexing the data—A fully functional storage engine should also include the ability to permit fast random reads and range queries. This stage is the one in which you implement the secondmost complex operation of file access methods—indexing. I have provided an index class that should make this step easier for you to explore on your own.
6. Adding transaction support—The last stage of the process involves adding transaction support to the storage engine. At this stage, the storage engine becomes a truly relational-database storage mechanism suitable for use in transactional environments. This is the most complex operation of file-access methods.
Throughout this process, you should test and debug at every stage. In the sections that follow, I show you examples of debugging a storage engine and writing tests to test the various stages. All normal debugging and trace mechanisms can be used in the storage engine. You can also use the interactive debuggers and get in to see the code in action!
Source Files Needed
The source files you will be working with are typically created as a single code (or class) file and a header file. These files are named ha_<engine name>.cc and ha_<engine name>.h, respectively.4 The storage-engine source code is located in the storage directory off the main source-code tree. Inside that folder are the source code files for the various storage engines. Aside from those two files, that’s all you need to get started!
Unexpected Help
The MySQL reference manual mentions several source-code files that can be helpful in learning about storage engines. Indeed, much of what I’m including here has come from studying those resources. Oracle provides an example storage engine (called example) that provides a great starting point for creating a storage engine at stage 1. In fact, I use it to get you started in the tutorial.
The archive engine is an example of a Stage 3 engine that provides good examples of reading and writing data. If you want to see more examples of how to do the file reading, writing, and updating, the CSV engine is a good place to look. The CSV engine is an example of a Stage 4 engine (CSV can read and write data as well as update and delete data). The CSV engine differs from the naming convention, because it was one of the first to be implemented. The source files are named ha_tina.cc and ha_tina.h. Finally, to see examples of Stage 5 and 6 storage engines, examine the MyISAM and InnoDB storage engines.
Before moving on to creating your own storage engine, take time to examine these storage engines in particular. because embedded in the source code are some golden nuggets of advice and instruction on how storage engines should work. Sometimes the best way to learn and extend or emulate a system is by examining its inner workings.
The Handlerton
As I mentioned earlier, the standard interface for all storage engines is the handlerton structure. It is implemented in the handler.cc and handler.h files in the sql directory, and it uses many other structures to provide organization of all of the elements needed to support the plug-in interface and the abstracted interface.
You might be wondering how concurrency is ensured in such a mechanism. The answer is—another structure! Each storage engine is responsible for creating a shared structure that is referenced from each instance of the handler among all the threads. Naturally, this means that some code must be protected. The good news is that not only are there mutual exclusion (mutex) protection methods available, but the handlerton source code has been designed to minimize the need for these protections.
The handlerton structure is a large structure with many data items and methods. Data items are represented as their normal data types defined in the structure, but methods are implemented using function pointers. The use of function pointers is one of those brilliantly constructed mechanisms that advanced developers use to permit runtime polymorphism. It is possible to use function pointers to redirect execution to a different (but equivalent interface) function. This is one of the techniques that make the handlerton so successful.
Listing 10-1 is an abbreviated listing of the handlerton structure definition, and Table 10-1 includes a description of the more important elements.
Listing 10-1. The MySQL Handlerton Structure
struct handlerton
{
SHOW_COMP_OPTION state;
enum legacy_db_type db_type;
uint slot;
uint savepoint_offset;
int (*close_connection)(handlerton *hton, THD *thd);
int (*savepoint_set)(handlerton *hton, THD *thd, void *sv);
int (*savepoint_rollback)(handlerton *hton, THD *thd, void *sv);
int (*savepoint_release)(handlerton *hton, THD *thd, void *sv);
int (*commit)(handlerton *hton, THD *thd, bool all);
int (*rollback)(handlerton *hton, THD *thd, bool all);
int (*prepare)(handlerton *hton, THD *thd, bool all);
int (*recover)(handlerton *hton, XID *xid_list, uint len);
int (*commit_by_xid)(handlerton *hton, XID *xid);
int (*rollback_by_xid)(handlerton *hton, XID *xid);
void *(*create_cursor_read_view)(handlerton *hton, THD *thd);
void (*set_cursor_read_view)(handlerton *hton, THD *thd, void *read_view);
void (*close_cursor_read_view)(handlerton *hton, THD *thd, void *read_view);
handler *(*create)(handlerton *hton, TABLE_SHARE *table, MEM_ROOT *mem_root);
void (*drop_database)(handlerton *hton, char* path);
int (*panic)(handlerton *hton, enum ha_panic_function flag);
int (*start_consistent_snapshot)(handlerton *hton, THD *thd);
bool (*flush_logs)(handlerton *hton);
bool (*show_status)(handlerton *hton, THD *thd, stat_print_fn *print, enum ha_stat_type stat);
uint (*partition_flags)();
uint (*alter_table_flags)(uint flags);
int (*alter_tablespace)(handlerton *hton, THD *thd, st_alter_tablespace *ts_info);
int (*fill_is_table)(handlerton *hton, THD *thd, TABLE_LIST *tables,
class Item *cond,
enum enum_schema_tables);
uint32 flags; /* global handler flags */
int (*binlog_func)(handlerton *hton, THD *thd, enum_binlog_func fn, void *arg);
void (*binlog_log_query)(handlerton *hton, THD *thd,
enum_binlog_command binlog_command,
const char *query, uint query_length,
const char *db, const char *table_name);
int (*release_temporary_latches)(handlerton *hton, THD *thd);
enum log_status (*get_log_status)(handlerton *hton, char *log);
enum handler_create_iterator_result
(*create_iterator)(handlerton *hton, enum handler_iterator_type type,
struct handler_iterator *fill_this_in);
int (*discover)(handlerton *hton, THD* thd, const char *db,
const char *name,
uchar **frmblob,
size_t *frmlen);
int (*find_files)(handlerton *hton, THD *thd,
const char *db,
const char *path,
const char *wild, bool dir, List<LEX_STRING> *files);
int (*table_exists_in_engine)(handlerton *hton, THD* thd, const char *db,
const char *name);
int (*make_pushed_join)(handlerton *hton, THD* thd,
const AQP::Join_plan* plan);
const char* (*system_database)();
bool (*is_supported_system_table)(const char *db,
const char *table_name,
bool is_sql_layer_system_table);
uint32 license; /* Flag for Engine License */
void *data; /* Location for engines to keep personal structures */
};
Table 10-1. The Handlerton-structure Definition
|
Element |
Description |
|
SHOW_COMP_OPTION state |
Determines whether the storage engine is available. |
|
const char *comment |
A comment that describes the storage engine and also returned by the SHOW command. |
|
enum legacy_db_type db_type |
An enumerated value saved in the .frm file that indicates which storage engine created the file. This value is used to determine the handler class associated with the table. |
|
uint slot |
The position in the array of handlers that refers to this handlerton. |
|
uint savepoint_offset |
The size of memory needed to create savepoints for the storage engine. |
|
int (*close_connection)(. . .) |
The method used to close the connection. |
|
int (*savepoint_set)(. . .) |
The method that sets the savepoint to the savepoint offset specified in the savepoint_offset element. |
|
int (*savepoint_rollback)(. . .) |
The method to roll back (undo) a savepoint. |
|
int(*savepoint_release)(. . .) |
The method to release (ignore) a savepoint. |
|
int(*commit)(. . .) |
The commit method that commits pending transactions. |
|
int(*rollback)(. . .) |
The rollback method that rolls back pending transactions. |
|
int(*prepare)(. . .) |
The prepare method for preparing a transaction for commit. |
|
int(*recover)(. . .) |
The method to return a list of transactions being prepared. |
|
int(*commit_by_xid)(. . .) |
The method that commits a transaction by transaction ID. |
|
int(*rollback_by_xid)(. . .) |
The method that rolls back a transaction by transaction ID. |
|
void *(*create_cursor_read_view)() |
The method used to create a cursor. |
|
void (*set_cursor_read_view)(void *) |
The method used to switch to a specific cursor view. |
|
void (*close_cursor_read_view)(void *) |
The method used to close a specific cursor view. |
|
handler *(*create)(TABLE_SHARE *table) |
The method used to create the handler instance of this storage engine. |
|
int (*panic)(enum ha_panic_function flag) |
The method that is called during server shutdown and crashes. |
|
int (*start_consistent_snapshot)(…) |
The method called to begin a consistent read (concurrency). |
|
bool (*flush_logs)() |
The method used to flush logs to disk. |
|
bool (*show_status)(. . .) |
The method that returns status information for the storage engine. |
|
uint (*partition_flags)() |
The method used to return the flag used for partitioning. |
|
uint (*alter_table_flags)(. . .) |
The method used to return flag set for the ALTER TABLE command. |
|
int (*alter_tablespace)(. . .) |
The method used to return flag set for the ALTER TABLESPACE command. |
|
int (*fill_is_table)(. . .) |
The method used by the server mechanisms to fill INFORMATION_SCHEMA views (tables). |
|
uint32 flags |
Flags that indicate what features the handler supports. |
|
int (*binlog_func)(. . .) |
The method to call back to the binary-log function. |
|
void (*binlog_log_query)(. . .) |
The method used to query the binary log. |
|
int (*release_temporary_latches)(. . .) |
InnoDB specific use (see the documentation for the InnoDB engine). |
![]() Note I have omitted the comments from the code to save space. I have also skipped the less-important items of the structure for brevity. Please see the handler.h file for additional information about the handlerton structure.
Note I have omitted the comments from the code to save space. I have also skipped the less-important items of the structure for brevity. Please see the handler.h file for additional information about the handlerton structure.
The Handler Class
The other part of the equation for understanding the storage-engine plugin interface is the handler class. The handler class is derived from Sql_alloc, which means that all of the memory-allocation routines are provided through inheritance. The handler class is designed to be the implementation of the storage handler. It provides a consistent set of methods for interfacing with the server via the handlerton structure. The handlerton and handler instances work as a unit to achieve the abstraction layer for the storage-engine architecture. Figure 10-1 depicts these classes and how they are derived to form a new storage engine. The drawing shows the handlerton structure as an interface between the handler and the new storage engine.
A complete detailed investigation of the handler class is beyond the scope of this book. Instead, I demonstrate the most important and most frequently used methods of the handler class implementing the stages of the sample storage engine. I explain each of the methods implemented and called in a more narrative format later in this chapter.
As a means of introduction to the handler class, I’ve provided an excerpt of the handler class definition in Listing 10-2. Take a few moments now to skim through the class. Notice the many methods available for a wide variety of tasks, such as creating, deleting, altering tables, and methods to manipulate fields and indexes. There are even methods for crash protection, recovery, and backup.
Although the handler class is quite impressive and covers every possible situation for a storage engine, most storage engines do not use the complete list of methods. If you want to implement a storage engine with some of the advanced features provided, spend some time exploring the excellent coverage of the handler class in the MySQL reference manual. Once you become accustomed to creating storage engines, you can use the reference manual to take your storage engine to the next level of sophistication.
Listing 10-2. The Handler-class Definition
class handler :public Sql_alloc
{
...
const handlerton *ht; /* storage engine of this handler */
uchar *ref; /* Pointer to current row */
uchar *dupp_ref; /* Pointer to dupp row */
...
handler(const handlerton *ht_arg, TABLE_SHARE *share_arg)
:table_share(share_arg), ht(ht_arg),
ref(0), data_file_length(0), max_data_file_length(0), index_file_length(0),
delete_length(0), auto_increment_value(0),
records(0), deleted(0), mean_rec_length(0),
create_time(0), check_time(0), update_time(0),
key_used_on_scan(MAX_KEY), active_index(MAX_KEY),
ref_length(sizeof(my_off_t)), block_size(0),
ft_handler(0), inited(NONE), implicit_emptied(0),
pushed_cond(NULL)
{}
...
int ha_index_init(uint idx, bool sorted)
...
int ha_index_end()
...
int ha_rnd_init(bool scan)
...
int ha_rnd_end()
...
int ha_reset()
...
...
virtual int exec_bulk_update(uint *dup_key_found)
...
virtual void end_bulk_update() { return; }
...
virtual int end_bulk_delete()
...
virtual int index_read(uchar * buf, const uchar * key,
uint key_len, enum ha_rkey_function find_flag)
...
virtual int index_read_idx(uchar * buf, uint index, const uchar * key,
uint key_len, enum ha_rkey_function find_flag);
virtual int index_next(uchar * buf)
{ return HA_ERR_WRONG_COMMAND; }
virtual int index_prev(uchar * buf)
{ return HA_ERR_WRONG_COMMAND; }
virtual int index_first(uchar * buf)
{ return HA_ERR_WRONG_COMMAND; }
virtual int index_last(uchar * buf)
{ return HA_ERR_WRONG_COMMAND; }
virtual int index_next_same(uchar *buf, const uchar *key, uint keylen);
virtual int index_read_last(uchar * buf, const uchar * key, uint key_len)
...
virtual int read_range_first(const key_range *start_key,
const key_range *end_key,
bool eq_range, bool sorted);
virtual int read_range_next();
int compare_key(key_range *range);
virtual int ft_init() { return HA_ERR_WRONG_COMMAND; }
void ft_end() { ft_handler=NULL; }
virtual FT_INFO *ft_init_ext(uint flags, uint inx,String *key)
{ return NULL; }
virtual int ft_read(uchar *buf) { return HA_ERR_WRONG_COMMAND; }
virtual int rnd_next(uchar *buf)=0;
virtual int rnd_pos(uchar * buf, uchar *pos)=0;
virtual int read_first_row(uchar *buf, uint primary_key);
...
virtual int restart_rnd_next(uchar *buf, uchar *pos)
{ return HA_ERR_WRONG_COMMAND; }
virtual int rnd_same(uchar *buf, uint inx)
{ return HA_ERR_WRONG_COMMAND; }
virtual ha_rows records_in_range(uint inx, key_range *min_key,
key_range *max_key);
{ return (ha_rows) 10; }
virtual void position(const uchar *record)=0;
virtual void info(uint)=0; // see my_base.h for full description
virtual void get_dynamic_partition_info(PARTITION_INFO *stat_info,
uint part_id);
virtual int extra(enum ha_extra_function operation)
{ return 0; }
virtual int extra_opt(enum ha_extra_function operation, ulong cache_size)
{ return extra(operation); }
...
virtual int delete_all_rows()
...
virtual ulonglong get_auto_increment();
virtual void restore_auto_increment();
...
virtual int reset_auto_increment(ulonglong value)
...
virtual void update_create_info(HA_CREATE_INFO *create_info) {}
...
int ha_repair(THD* thd, HA_CHECK_OPT* check_opt);
...
virtual bool check_and_repair(THD *thd) { return TRUE; }
virtual int dump(THD* thd, int fd = −1) { return HA_ERR_WRONG_COMMAND; }
virtual int disable_indexes(uint mode) { return HA_ERR_WRONG_COMMAND; }
virtual int enable_indexes(uint mode) { return HA_ERR_WRONG_COMMAND; }
virtual int indexes_are_disabled(void) {return 0;}
virtual void start_bulk_insert(ha_rows rows) {}
virtual int end_bulk_insert() {return 0; }
virtual int discard_or_import_tablespace(my_bool discard)
...
virtual uint referenced_by_foreign_key() { return 0;}
virtual void init_table_handle_for_HANDLER()
...
virtual void free_foreign_key_create_info(char* str) {}
...
virtual const char *table_type() const =0;
virtual const char **bas_ext() const =0;
...
virtual uint max_supported_record_length() const { return HA_MAX_REC_LENGTH; }
virtual uint max_supported_keys() const { return 0; }
virtual uint max_supported_key_parts() const { return MAX_REF_PARTS; }
virtual uint max_supported_key_length() const { return MAX_KEY_LENGTH; }
virtual uint max_supported_key_part_length() const { return 255; }
virtual uint min_record_length(uint options) const { return 1; }
...
virtual bool is_crashed() const { return 0; }
...
virtual int rename_table(const char *from, const char *to);
virtual int delete_table(const char *name);
virtual void drop_table(const char *name);
virtual int create(const char *name, TABLE *form, HA_CREATE_INFO *info)=0;
...
virtual int external_lock(THD *thd __attribute__((unused)),
int lock_type __attribute__((unused)))
...
virtual int write_row(uchar *buf __attribute__((unused)))
...
virtual int update_row(const uchar *old_data __attribute__((unused)),
uchar *new_data __attribute__((unused)))
...
virtual int delete_row(const uchar *buf __attribute__((unused)))
...
};
A Brief Tour of a MySQL Storage Engine
The best way to see the handler work is to watch it in action. Therefore, let’s examine a real storage engine in use before we start building one. Follow along by compiling your server with debug if you haven’t already. Go ahead and start your server and debugger, and then attach your debugging tool to the running server, as described in Chapter 5.
I want to show you a simple storage engine in action. In this case, I use the archive storage engine. With the debugger open and the server running, open the ha_archive.cc file and place a breakpoint on the first executable line for the methods:
int ha_archive::create(...)
static ARCHIVE_SHARE *ha_archive::get_share(...)
int ha_archive::write_row(...)int ha_tina::rnd_next(...)
int ha_archive::rnd_next(...)
Once the breakpoints are set, launch the command-line MySQL client, change to the test database, and issue this command:
CREATE TABLE testarc (a int, b varchar(20), c int) ENGINE=ARCHIVE;
You should immediately see the debugger halt in the create() method. This method is where the base-data table is created. Indeed, it is one of the first things to execute. The my_create() method is called to create the file. Notice that the code is looking for a field with theAUTO_INCREMENT_FLAG set (at the top of the method); if the field is found, the code sets an error and exits. This is because the archive storage engine doesn’t support auto-increment fields. You can also see that the method is creating a meta file and checking to see that the compression routines are working properly.
Step through the code and watch the iterator. You can continue the execution at any time or, if you’re really curious, continue to step through the return to the calling function.
Now, let’s see what happens when we insert data. Go back to your MySQL client and enter this command:
INSERT INTO testarc VALUES (10, "test", -1);
This time, the code halts in the get_share() method. This method is responsible for creating the shared structure (which is stored as the .frm file) for all instances of the archive handler. As you step through this method, you can see where the code is setting the global variables and other initialization-type tasks. Go ahead and let the debugger continue execution.
The next place the code halts is in the write_row() method. This method is where the data that are passed through the buf parameter are written to disk. The record buffer (uchar *buf) is the mechanism that MySQL uses to pass rows through the system. It is a binary buffer containing the data for the row and other metadata. It is what the MySQL documentation refers to as the “internal format.” As you step through this code, you will see the engine set some statistics, do some more error checking, and eventually write the data using the methodreal_write_row() at the end of the method. Go ahead and step through that method as well.
In the real_write_row() method, you can see another field iterator. This iterator is iterating through the binary large objects (BLOB) fields and writing those to disk using the compression method. If you need to support BLOB fields, this is an excellent example of how to do so—just substitute your low-level IO call for the compression method. Go ahead and let the code continue; then return to your MySQL client and enter the command:
SELECT * FROM testarc;
The next place the code halts is in the rnd_next() method. This is where the handler reads the data file and returns the data in the record buffer (uchar *buf). Notice again that the code sets some statistics, does error checking, and then reads the data using the get_row() method. Step through this code a bit and then let it continue.
What a surprise! The code halts again at the rnd_next() method. This is because the rnd_next() method is one of a series of calls for a table scan. The method is responsible not only for reading the data but also for detecting the end of the file. Thus, in the example you’re working through, there should be two calls to the method. The first retrieves the first row of data and the second detects the end of the file (you inserted only one row). The following lists the typical sequence of calls for a table scan using the example you’ve been working through:
ha_spartan::info
ha_spartan::rnd_init
ha_spartan::extra
ha_spartan::rnd_next
ha_spartan::rnd_next
ha_spartan::extra
+−−----+−−----+−−----+
| a | b | c |
+−−----+−−----+−−----+
| 10 | test | -1 |
+−−----+−−----+−−----+
1 row in set (26.25 sec)
![]() Note The time returned from the query is actual elapsed time as recorded by the server and not execution time. Thus, the time spent in debugging counts.
Note The time returned from the query is actual elapsed time as recorded by the server and not execution time. Thus, the time spent in debugging counts.
Take some time and place breakpoints on other methods that may interest you. You can also spend some time reading the comments in this storage engine ,as they provide excellent clues to how some of the handler methods are used.
The Spartan Storage Engine
I chose for the tutorial on storage engines the concept of a basic storage engine that has all the features that a normal storage engine would have. This includes reading and writing data with index support. That is to say, it is a Stage 5 engine. I call this sample storage engine the Spartan storage engine, because in many ways it implements only the basic necessities for a viable database-storage mechanism.
I guide you through the process of building the Spartan storage using the example (ha_example) MySQL storage engine. I refer you to the other storage engines for additional information as I progress through the tutorial. While you may find areas that you think could be improved upon (and indeed there are several), refrain from making any enhancements to the Spartan engine until you have it successfully implemented to the Stage 5 level.
Let’s begin by examining the supporting class files for the Spartan storage engine.
Low-Level I/O Classes
A storage engine is designed to read and write data using a specialized mechanism that provides some unique benefits to the user. This means that the storage engines, by nature, are not going to support the same features.
Most storage engines either use C functions defined in other source files or C++ classes defined in class header and source files. For the Spartan engine, I elected to use the latter method. I created a data-file class as well as an index-file class. Holding true to the intent of this chapter and the Spartan-engine project, neither of the classes is optimized for performance. Rather, they provide a means to create a working storage engine and demonstrate most of the things you will need to do to create your own storage engine.
This section describes each of the classes in a general overview. You can follow along with the code and see how the classes work. Although the low-level classes are just the basics and could probably use a bit of fine-tuning, I think you’ll find these classes beneficial to use, and perhaps you’ll even base your own storage engine I/O on them.
The Spartan_data Class
The primary low-level I/O class for the Spartan storage engine is the Spartan_data class. This class is responsible for encapsulating the data for the Spartan storage engine. Listing 10-3 includes the complete header file for the class. As you can see from the header, the methods for this class are simplistic. I implement just the basic open, close, read, and write operations.
Listing 10-3. Spartan_data Class Header
/*
Spartan_data.h
This header defines a simple data file class for writing and reading raw
data to and from disk. The data written is in uchar format so it can be
anything you want it to be. The write_row and read_row accept the
length of the data item to be written/read.
*/
#include "my_global.h"
#include "my_sys.h"
class Spartan_data
{
public:
Spartan_data(void);
∼Spartan_data(void);
int create_table(char *path);
int open_table(char *path);
long long write_row(uchar *buf, int length);
long long update_row(uchar *old_rec, uchar *new_rec,
int length, long long position);
int read_row(uchar *buf, int length, long long position);
int delete_row(uchar *old_rec, int length, long long position);
int close_table();
long long cur_position();
int records();
int del_records();
int trunc_table();
int row_size(int length);
private:
File data_file;
int header_size;
int record_header_size;
bool crashed;
int number_records;
int number_del_records;
int read_header();
int write_header();
};
Listing 10-4 includes the complete source code for the Spartan-storage-engine data class. Notice that in the code I have included the appropriate DBUG calls to ensure my source code can write to the trace file should I wish to debug the system using the --with-debug switch. Notice also that the read and write methods used are the my_xxx platform-safe utility methods provided by Oracle.
Listing 10-4. Spartan_data Class Source Code
/*
Spartan_data.cc
This class implements a simple data file reader/writer. It
is designed to allow the caller to specify the size of the
data to read or write. This allows for variable length records
and the inclusion of extra fields (like blobs). The data are
stored in an uncompressed, unoptimized fashion.
*/
#include "spartan_data.h"
#include <my_dir.h>
#include <string.h>
Spartan_data::Spartan_data(void)
{
data_file = −1;
number_records = −1;
number_del_records = −1;
header_size = sizeof(bool) + sizeof(int) + sizeof(int);
record_header_size = sizeof(uchar) + sizeof(int);
}
Spartan_data::∼Spartan_data(void)
{
}
/* create the data file */
int Spartan_data::create_table(char *path)
{
DBUG_ENTER("SpartanIndex::create_table");
open_table(path);
number_records = 0;
number_del_records = 0;
crashed = false;
write_header();
DBUG_RETURN(0);
}
/* open table at location "path" = path + filename */
int Spartan_data::open_table(char *path)
{
DBUG_ENTER("Spartan_data::open_table");
/*
Open the file with read/write mode,
create the file if not found,
treat file as binary, and use default flags.
*/
data_file = my_open(path, O_RDWR | O_CREAT | O_BINARY | O_SHARE, MYF(0));
if(data_file == −1)
DBUG_RETURN(errno);
read_header();
DBUG_RETURN(0);
}
/* write a row of length uchars to file and return position */
long long Spartan_data::write_row(uchar *buf, int length)
{
long long pos;
int i;
int len;
uchar deleted = 0;
DBUG_ENTER("Spartan_data::write_row");
/*
Write the deleted status uchar and the length of the record.
Note: my_write() returns the uchars written or −1 on error
*/
pos = my_seek(data_file, 0L, MY_SEEK_END, MYF(0));
/*
Note: my_malloc takes a size of memory to be allocated,
MySQL flags (set to zero fill and with extra error checking).
Returns number of uchars allocated -- <= 0 indicates an error.
*/
i = my_write(data_file, &deleted, sizeof(uchar), MYF(0));
memcpy(&len, &length, sizeof(int));
i = my_write(data_file, (uchar *)&len, sizeof(int), MYF(0));
/*
Write the row data to the file. Return new file pointer or
return −1 if error from my_write().
*/
i = my_write(data_file, buf, length, MYF(0));
if (i == −1)
pos = i;
else
number_records++;
DBUG_RETURN(pos);
}
/* update a record in place */
long long Spartan_data::update_row(uchar *old_rec, uchar *new_rec,
int length, long long position)
{
long long pos;
long long cur_pos;
uchar *cmp_rec;
int len;
uchar deleted = 0;
int i = −1;
DBUG_ENTER("Spartan_data::update_row");
if (position == 0)
position = header_size; //move past header
pos = position;
/*
If position unknown, scan for the record by reading a row
at a time until found.
*/
if (position == −1) //don't know where it is...scan for it
{
cmp_rec = (uchar *)my_malloc(length, MYF(MY_ZEROFILL | MY_WME));
pos = 0;
/*
Note: my_seek() returns pos if no errors or −1 if error.
*/
cur_pos = my_seek(data_file, header_size, MY_SEEK_SET, MYF(0));
/*
Note: read_row() returns current file pointer if no error or
-1 if error.
*/
while ((cur_pos != −1) && (pos != −1))
{
pos = read_row(cmp_rec, length, cur_pos);
if (memcmp(old_rec, cmp_rec, length) == 0)
{
pos = cur_pos; //found it!
cur_pos = −1; //stop loop gracefully
}
else if (pos != −1) //move ahead to next rec
cur_pos = cur_pos + length + record_header_size;
}
my_free(cmp_rec);
}
/*
If position found or provided, write the row.
*/
if (pos != −1)
{
/*
Write the deleted uchar, the length of the row, and the data
at the current file pointer.
Note: my_write() returns the uchars written or −1 on error
*/
my_seek(data_file, pos, MY_SEEK_SET, MYF(0));
i = my_write(data_file, &deleted, sizeof(uchar), MYF(0));
memcpy(&len, &length, sizeof(int));
i = my_write(data_file, (uchar *)&len, sizeof(int), MYF(0));
pos = i;
i = my_write(data_file, new_rec, length, MYF(0));
}
DBUG_RETURN(pos);
}
/* delete a record in place */
int Spartan_data::delete_row(uchar *old_rec, int length,
long long position)
{
int i = −1;
long long pos;
long long cur_pos;
uchar *cmp_rec;
uchar deleted = 1;
DBUG_ENTER("Spartan_data::delete_row");
if (position == 0)
position = header_size; //move past header
pos = position;
/*
If position unknown, scan for the record by reading a row
at a time until found.
*/
if (position == −1) //don't know where it is...scan for it
{
cmp_rec = (uchar *)my_malloc(length, MYF(MY_ZEROFILL | MY_WME));
pos = 0;
/*
Note: my_seek() returns pos if no errors or −1 if error.
*/
cur_pos = my_seek(data_file, header_size, MY_SEEK_SET, MYF(0));
/*
Note: read_row() returns current file pointer if no error or
-1 if error.
*/
while ((cur_pos != −1) && (pos != −1))
{
pos = read_row(cmp_rec, length, cur_pos);
if (memcmp(old_rec, cmp_rec, length) == 0)
{
number_records--;
number_del_records++;
pos = cur_pos;
cur_pos = −1;
}
else if (pos != −1) //move ahead to next rec
cur_pos = cur_pos + length + record_header_size;
}
my_free(cmp_rec);
}
/*
If position found or provided, write the row.
*/
if (pos != −1) //mark as deleted
{
/*
Write the deleted uchar set to 1 which marks row as deleted
at the current file pointer.
Note: my_write() returns the uchars written or −1 on error
*/
pos = my_seek(data_file, pos, MY_SEEK_SET, MYF(0));
i = my_write(data_file, &deleted, sizeof(uchar), MYF(0));
i = (i > 1) ? 0 : i;
}
DBUG_RETURN(i);
}
/* read a row of length uchars from file at position */
int Spartan_data::read_row(uchar *buf, int length, long long position)
{
int i;
int rec_len;
long long pos;
uchar deleted = 2;
DBUG_ENTER("Spartan_data::read_row");
if (position <= 0)
position = header_size; //move past header
pos = my_seek(data_file, position, MY_SEEK_SET, MYF(0));
/*
If my_seek found the position, read the deleted uchar.
Note: my_read() returns uchars read or −1 on error
*/
if (pos != −1L)
{
i = my_read(data_file, &deleted, sizeof(uchar), MYF(0));
/*
If not deleted (deleted == 0), read the record length then
read the row.
*/
if (deleted == 0) /* 0 = not deleted, 1 = deleted */
{
i = my_read(data_file, (uchar *)&rec_len, sizeof(int), MYF(0));
i = my_read(data_file, buf,
(length < rec_len) ? length : rec_len, MYF(0));
}
else if (i == 0)
DBUG_RETURN(−1);
else
DBUG_RETURN(read_row(buf, length, cur_position() +
length + (record_header_size - sizeof(uchar))));
}
else
DBUG_RETURN(−1);
DBUG_RETURN(0);
}
/* close file */
int Spartan_data::close_table()
{
DBUG_ENTER("Spartan_data::close_table");
if (data_file != −1)
{
my_close(data_file, MYF(0));
data_file = −1;
}
DBUG_RETURN(0);
}
/* return number of records */
int Spartan_data::records()
{
DBUG_ENTER("Spartan_data::num_records");
DBUG_RETURN(number_records);
}
/* return number of deleted records */
int Spartan_data::del_records()
{
DBUG_ENTER("Spartan_data::num_records");
DBUG_RETURN(number_del_records);
}
/* read header from file */
int Spartan_data::read_header()
{
int i;
int len;
DBUG_ENTER("Spartan_data::read_header");
if (number_records == −1)
{
my_seek(data_file, 0l, MY_SEEK_SET, MYF(0));
i = my_read(data_file, (uchar *)&crashed, sizeof(bool), MYF(0));
i = my_read(data_file, (uchar *)&len, sizeof(int), MYF(0));
memcpy(&number_records, &len, sizeof(int));
i = my_read(data_file, (uchar *)&len, sizeof(int), MYF(0));
memcpy(&number_del_records, &len, sizeof(int));
}
else
my_seek(data_file, header_size, MY_SEEK_SET, MYF(0));
DBUG_RETURN(0);
}
/* write header to file */
int Spartan_data::write_header()
{
DBUG_ENTER("Spartan_data::write_header");
if (number_records != −1)
{
my_seek(data_file, 0l, MY_SEEK_SET, MYF(0));
i = my_write(data_file, (uchar *)&crashed, sizeof(bool), MYF(0));
i = my_write(data_file, (uchar *)&number_records, sizeof(int), MYF(0));
i = my_write(data_file, (uchar *)&number_del_records, sizeof(int), MYF(0));
}
DBUG_RETURN(0);
}
/* get position of the data file */
long long Spartan_data::cur_position()
{
long long pos;
DBUG_ENTER("Spartan_data::cur_position");
pos = my_seek(data_file, 0L, MY_SEEK_CUR, MYF(0));
if (pos == 0)
DBUG_RETURN(header_size);
DBUG_RETURN(pos);
}
/* truncate the data file */
int Spartan_data::trunc_table()
{
DBUG_ENTER("Spartan_data::trunc_table");
if (data_file != −1 )
{
my_chsize(data_file, 0, 0, MYF(MY_WME));
write_header();
}
DBUG_RETURN(0);
}
/* determine the row size of the data file */
int Spartan_data::row_size(int length)
{
DBUG_ENTER("Spartan_data::row_size");
DBUG_RETURN(length + record_header_size);
}
Note the format that use to store the data. The class is designed to support reading data from disk and writing the data in memory to disk. I use a uchar pointer to allocate a block of memory for storing the rows. This really useful, because it provides the ability to write the rows in the table to disk using the internal MySQL row format. Likewise, I can read the data from disk, write them to a memory buffer, and simply point the handler class to the block of memory to be returned to the optimizer.
I may not be able to predict the exact amount of memory needed to store a row, however. Some uses of the storage engine may have tables that have variable fields or even binary large objects (BLOBs). To overcome this problem, I chose to store a single integer length field at the start of each row. This allows me to scan a file and read variable-length rows by first reading the length field and then reading the number of uchars specified into the memory buffer.
![]() Tip Whenever coding an extension for the MySQL server, always use the my_xxx utility methods. The my_xxx utility methods are encapsulations of many of the base-operating-systems functions and provide a better level of cross-platform support.
Tip Whenever coding an extension for the MySQL server, always use the my_xxx utility methods. The my_xxx utility methods are encapsulations of many of the base-operating-systems functions and provide a better level of cross-platform support.
The data class is rather straightforward and can be used to implement the basic read and write operations needed for a storage engine. I want to make the storage engine more efficient, however. To achieve good performance from my data file, I need to add an index mechanism. This is where things get a lot more complicated.
![]() Note While we won’t use the index class in the first four stages, it is good to understand this code in advance.
Note While we won’t use the index class in the first four stages, it is good to understand this code in advance.
The Spartan_index Class
To solve the problem of indexing the data file, I implement a separate index class called Spartan_index. The index class is responsible for permitting the execution of point queries (query by index for a specific record) and range queries (a series of keys either ascending or descending), as well as the ability to cache the index for fast searching. Listing 10-5 includes the complete header file for the Spartan_index class.
Listing 10-5. Spartan_index Class Header
/*
Spartan_index.h
This header file defines a simple index class that can
be used to store file pointer indexes (long long). The
class keeps the entire index in memory for fast access.
The internal-memory structure is a linked list. While
not as efficient as a btree, it should be usable for
most testing environments. The constructor accepts the
max key length. This is used for all nodes in the index.
File Layout:
SOF max_key_len (int)
SOF + sizeof(int) crashed (bool)
SOF + sizeof(int) + sizeof(bool) DATA BEGINS HERE
*/
#include "my_global.h"
#include "my_sys.h"
const long METADATA_SIZE = sizeof(int) + sizeof(bool);
/*
This is the node that stores the key and the file
position for the data row.
*/
struct SDE_INDEX
{
uchar key[128];
long long pos;
int length;
};
/* defines (doubly) linked list for internal list */
struct SDE_NDX_NODE
{
SDE_INDEX key_ndx;
SDE_NDX_NODE *next;
SDE_NDX_NODE *prev;
};
class Spartan_index
{
public:
Spartan_index(int keylen);
Spartan_index();
∼Spartan_index(void);
int open_index(char *path);
int create_index(char *path, int keylen);
int insert_key(SDE_INDEX *ndx, bool allow_dupes);
int delete_key(uchar *buf, long long pos, int key_len);
int update_key(uchar *buf, long long pos, int key_len);
long long get_index_pos(uchar *buf, int key_len);
long long get_first_pos();
uchar *get_first_key();
uchar *get_last_key();
uchar *get_next_key();
uchar *get_prev_key();
int close_index();
int load_index();
int destroy_index();
SDE_INDEX *seek_index(uchar *key, int key_len);
SDE_NDX_NODE *seek_index_pos(uchar *key, int key_len);
int save_index();
int trunc_index();
private:
File index_file;
int max_key_len;
SDE_NDX_NODE *root;
SDE_NDX_NODE *range_ptr;
int block_size;
bool crashed;
int read_header();
int write_header();
long long write_row(SDE_INDEX *ndx);
SDE_INDEX *read_row(long long Position);
long long curfpos();
};
Notice that the class implements the expected form of create, open, close, read, and write methods. The load_index() method reads an entire index file into memory, storing the index as a doubly linked list. All the index scanning and reference methods access the linked list in memory rather than accessing the disk. This saves a great deal of time and provides a way to keep the entire index in memory for fast insertion and deletion. A corresponding method, save_index(), permits you to write the index from memory back to disk. The way these methods should be used is to call load_index() when the table is opened and then save_index() when the table is closed.
You may be wondering if there could be size limitations with this approach. Depending on the size of the index, how many indexes are created, and how many entries there are, this implementation could have some limitations. For the purposes of this tutorial and for the foreseeable use of the Spartan storage engine, however, this isn’t a problem.
Another area you may be concerned about is the use of the doubly linked list. This implementation isn’t likely to be your first choice for high-speed index storage. You are more likely to use a B-tree or some variant of one to create an efficient index-access method. The linked list is easy to use, however, and it makes the implementation of a rather large set of source code a bit easier to manage. The example demonstrates how to incorporate an index class into your engine—not how to code a B-tree structure. This keeps the code simpler, because the linked list is easier to code. For the purposes of this tutorial, the linked-list structure will perform very well. In fact, you may even want to use it to form your own storage engine until you get the rest of the storage engine working, and then turn your attention to a better index class.
Listing 10-6 shows the complete source code for the Spartan_index class implementation. The code is rather lengthy, so either take some time and examine the methods or save the code reading for later and skip ahead to the description of how to start building the Spartan storage engine.
Listing 10-6. Spartan_index Class Source Code
/*
Spartan_index.cc
This class reads and writes an index file for use with the Spartan data
class. The file format is a simple binary storage of the
Spartan_index::SDE_INDEX structure. The size of the key can be set via
the constructor.
*/
#include "spartan_index.h"
#include <my_dir.h>
#include <string.h>
/* constuctor takes the maximum key length for the keys */
Spartan_index::Spartan_index(int keylen)
{
root = NULL;
crashed = false;
max_key_len = keylen;
index_file = −1;
block_size = max_key_len + sizeof(long long) + sizeof(int);
}
/* constuctor (overloaded) assumes existing file */
Spartan_index::Spartan_index()
{
root = NULL;
crashed = false;
max_key_len = −1;
index_file = −1;
block_size = −1;
}
/* destructor */
Spartan_index::∼Spartan_index(void)
{
}
/* create the index file */
int Spartan_index::create_index(char *path, int keylen)
{
DBUG_ENTER("Spartan_index::create_index");
DBUG_PRINT("info", ("path: %s", path));
open_index(path);
max_key_len = keylen;
/*
Block size is the key length plus the size of the index
length variable.
*/
block_size = max_key_len + sizeof(long long);
write_header();
DBUG_RETURN(0);
}
/* open index specified as path (pat+filename) */
int Spartan_index::open_index(char *path)
{
DBUG_ENTER("Spartan_index::open_index");
/*
Open the file with read/write mode,
create the file if not found,
treat file as binary, and use default flags.
*/
index_file = my_open(path, O_RDWR | O_CREAT | O_BINARY | O_SHARE, MYF(0));
if(index_file == −1)
DBUG_RETURN(errno);
read_header();
DBUG_RETURN(0);
}
/* read header from file */
int Spartan_index::read_header()
{
DBUG_ENTER("Spartan_index::read_header");
if (block_size == −1)
{
/*
Seek the start of the file.
Read the maximum key length value.
*/
my_seek(index_file, 0l, MY_SEEK_SET, MYF(0));
i = my_read(index_file, (uchar *)&max_key_len, sizeof(int), MYF(0));
/*
Calculate block size as maximum key length plus
the size of the key plus the crashed status byte.
*/
block_size = max_key_len + sizeof(long long) + sizeof(int);
i = my_read(index_file, (uchar *)&crashed, sizeof(bool), MYF(0));
}
else
{
i = (int)my_seek(index_file, sizeof(int) + sizeof(bool), MY_SEEK_SET, MYF(0));
}
DBUG_RETURN(0);
}
/* write header to file */
int Spartan_index::write_header()
{
int i;
DBUG_ENTER("Spartan_index::write_header");
if (block_size != −1)
{
/*
Seek the start of the file and write the maximum key length
then write the crashed status byte.
*/
my_seek(index_file, 0l, MY_SEEK_SET, MYF(0));
i = my_write(index_file, (uchar *)&max_key_len, sizeof(int), MYF(0));
i = my_write(index_file, (uchar *)&crashed, sizeof(bool), MYF(0));
}
DBUG_RETURN(0);
}
/* write a row (SDE_INDEX struct) to the index file */
long long Spartan_index::write_row(SDE_INDEX *ndx)
{
long long pos;
int i;
int len;
DBUG_ENTER("Spartan_index::write_row");
/*
Seek the end of the file (always append)
*/
pos = my_seek(index_file, 0l, MY_SEEK_END, MYF(0));
/*
Write the key value.
*/
i = my_write(index_file, ndx->key, max_key_len, MYF(0));
memcpy(&pos, &ndx->pos, sizeof(long long));
/*
Write the file position for the key value.
*/
i = i + my_write(index_file, (uchar *)&pos, sizeof(long long), MYF(0));
memcpy(&len, &ndx->length, sizeof(int));
/*
Write the length of the key.
*/
i = i + my_write(index_file, (uchar *)&len, sizeof(int), MYF(0));
if (i == −1)
pos = i;
DBUG_RETURN(pos);
}
/* read a row (SDE_INDEX struct) from the index file */
SDE_INDEX *Spartan_index::read_row(long long Position)
{
int i;
long long pos;
SDE_INDEX *ndx = NULL;
DBUG_ENTER("Spartan_index::read_row");
/*
Seek the position in the file (Position).
*/
pos = my_seek(index_file,(ulong) Position, MY_SEEK_SET, MYF(0));
if (pos != −1L)
{
ndx = new SDE_INDEX();
/*
Read the key value.
*/
i = my_read(index_file, ndx->key, max_key_len, MYF(0));
/*
Read the key value. If error, return NULL.
*/
i = my_read(index_file, (uchar *)&ndx->pos, sizeof(long long), MYF(0));
if (i == −1)
{
delete ndx;
ndx = NULL;
}
}
DBUG_RETURN(ndx);
}
/* insert a key into the index in memory */
int Spartan_index::insert_key(SDE_INDEX *ndx, bool allow_dupes)
{
SDE_NDX_NODE *p = NULL;
SDE_NDX_NODE *n = NULL;
SDE_NDX_NODE *o = NULL;
int i = −1;
int icmp;
bool dupe = false;
bool done = false;
DBUG_ENTER("Spartan_index::insert_key");
/*
If this is a new index, insert first key as the root node.
*/
if (root == NULL)
{
root = new SDE_NDX_NODE();
root->next = NULL;
root->prev = NULL;
memcpy(root->key_ndx.key, ndx->key, max_key_len);
root->key_ndx.pos = ndx->pos;
root->key_ndx.length = ndx->length;
}
else //set pointer to root
p = root;
/*
Loop through the linked list until a value greater than the
key to be inserted, then insert new key before that one.
*/
while ((p != NULL) && !done)
{
icmp = memcmp(ndx->key, p->key_ndx.key,
(ndx->length > p->key_ndx.length) ?
ndx->length : p->key_ndx.length);
if (icmp > 0) // key is greater than current key in list
{
n = p;
p = p->next;
}
/*
If dupes not allowed, stop and return NULL
*/
else if (!allow_dupes && (icmp == 0))
{
p = NULL;
dupe = true;
}
else
{
n = p->prev; //stop, insert at n->prev
done = true;
}
}
/*
If position found (n != NULL) and dupes permitted,
insert key. If p is NULL insert at end else insert in middle
of list.
*/
if ((n != NULL) && !dupe)
{
if (p == NULL) //insert at end
{
p = new SDE_NDX_NODE();
n->next = p;
p->prev = n;
memcpy(p->key_ndx.key, ndx->key, max_key_len);
p->key_ndx.pos = ndx->pos;
p->key_ndx.length = ndx->length;
}
else
{
o = new SDE_NDX_NODE();
memcpy(o->key_ndx.key, ndx->key, max_key_len);
o->key_ndx.pos = ndx->pos;
o->key_ndx.length = ndx->length;
o->next = p;
o->prev = n;
n->next = o;
p->prev = o;
}
i = 1;
}
DBUG_RETURN(i);
}
/* delete a key from the index in memory. Note:
position is included for indexes that allow dupes */
int Spartan_index::delete_key(uchar *buf, long long pos, int key_len)
{
SDE_NDX_NODE *p;
int icmp;
int buf_len;
bool done = false;
DBUG_ENTER("Spartan_index::delete_key");
p = root;
/*
Search for the key in the list. If found, delete it!
*/
while ((p != NULL) && !done)
{
buf_len = p->key_ndx.length;
icmp = memcmp(buf, p->key_ndx.key,
(buf_len > key_len) ? buf_len : key_len);
if (icmp == 0)
{
if (pos != −1)
{
if (pos == p->key_ndx.pos)
done = true;
}
else
done = true;
}
else
p = p->next;
}
if (p != NULL)
{
/*
Reset pointers for deleted node in list.
*/
if (p->next != NULL)
p->next->prev = p->prev;
if (p->prev != NULL)
p->prev->next = p->next;
else
root = p->next;
delete p;
}
DBUG_RETURN(0);
}
/* update key in place (so if key changes!) */
int Spartan_index::update_key(uchar *buf, long long pos, int key_len)
{
SDE_NDX_NODE *p;
bool done = false;
DBUG_ENTER("Spartan_index::update_key");
p = root;
/*
Search for the key.
*/
while ((p != NULL) && !done)
{
if (p->key_ndx.pos == pos)
done = true;
else
p = p->next;
}
/*
If key found, overwrite key value in node.
*/
if (p != NULL)
{
memcpy(p->key_ndx.key, buf, key_len);
}
DBUG_RETURN(0);
}
/* get the current position of the key in the index file */
long long Spartan_index::get_index_pos(uchar *buf, int key_len)
{
long long pos = −1;
DBUG_ENTER("Spartan_index::get_index_pos");
SDE_INDEX *ndx;
ndx = seek_index(buf, key_len);
if (ndx != NULL)
pos = ndx->pos;
DBUG_RETURN(pos);
}
/* get next key in list */
uchar *Spartan_index::get_next_key()
{
uchar *key = 0;
DBUG_ENTER("Spartan_index::get_next_key");
if (range_ptr != NULL)
{
key = (uchar *)my_malloc(max_key_len, MYF(MY_ZEROFILL | MY_WME));
memcpy(key, range_ptr->key_ndx.key, range_ptr->key_ndx.length);
range_ptr = range_ptr->next;
}
DBUG_RETURN(key);
}
/* get prev key in list */
uchar *Spartan_index::get_prev_key()
{
uchar *key = 0;
DBUG_ENTER("Spartan_index::get_prev_key");
if (range_ptr != NULL)
{
key = (uchar *)my_malloc(max_key_len, MYF(MY_ZEROFILL | MY_WME));
memcpy(key, range_ptr->key_ndx.key, range_ptr->key_ndx.length);
range_ptr = range_ptr->prev;
}
DBUG_RETURN(key);
}
/* get first key in list */
uchar *Spartan_index::get_first_key()
{
SDE_NDX_NODE *n = root;
uchar *key = 0;
DBUG_ENTER("Spartan_index::get_first_key");
if (root != NULL)
{
key = (uchar *)my_malloc(max_key_len, MYF(MY_ZEROFILL | MY_WME));
memcpy(key, n->key_ndx.key, n->key_ndx.length);
}
DBUG_RETURN(key);
}
/* get last key in list */
uchar *Spartan_index::get_last_key()
{
SDE_NDX_NODE *n = root;
uchar *key = 0;
DBUG_ENTER("Spartan_index::get_last_key");
while (n->next != NULL)
n = n->next;
if (n != NULL)
{
key = (uchar *)my_malloc(max_key_len, MYF(MY_ZEROFILL | MY_WME));
memcpy(key, n->key_ndx.key, n->key_ndx.length);
}
DBUG_RETURN(key);
}
/* just close the index */
int Spartan_index::close_index()
{
SDE_NDX_NODE *p;
DBUG_ENTER("Spartan_index::close_index");
if (index_file != −1)
{
my_close(index_file, MYF(0));
index_file = −1;
}
while (root != NULL)
{
p = root;
root = root->next;
delete p;
}
DBUG_RETURN(0);
}
/* find a key in the index */
SDE_INDEX *Spartan_index::seek_index(uchar *key, int key_len)
{
SDE_INDEX *ndx = NULL;
SDE_NDX_NODE *n = root;
int buf_len;
bool done = false;
DBUG_ENTER("Spartan_index::seek_index");
if (n != NULL)
{
while((n != NULL) && !done)
{
buf_len = n->key_ndx.length;
if (memcmp(n->key_ndx.key, key,
(buf_len > key_len) ? buf_len : key_len) == 0)
done = true;
else
n = n->next;
}
}
if (n != NULL)
{
ndx = &n->key_ndx;
range_ptr = n;
}
DBUG_RETURN(ndx);
}
/* find a key in the index and return position too */
SDE_NDX_NODE *Spartan_index::seek_index_pos(uchar *key, int key_len)
{
SDE_NDX_NODE *n = root;
int buf_len;
bool done = false;
DBUG_ENTER("Spartan_index::seek_index_pos");
if (n != NULL)
{
while((n->next != NULL) && !done)
{
buf_len = n->key_ndx.length;
if (memcmp(n->key_ndx.key, key,
(buf_len > key_len) ? buf_len : key_len) == 0)
done = true;
else if (n->next != NULL)
n = n->next;
}
}
DBUG_RETURN(n);
}
/* read the index file from disk and store in memory */
int Spartan_index::load_index()
{
SDE_INDEX *ndx;
int i = 1;
DBUG_ENTER("Spartan_index::load_index");
if (root != NULL)
destroy_index();
/*
First, read the metadata at the front of the index.
*/
read_header();
while(i != 0)
{
ndx = new SDE_INDEX();
i = my_read(index_file, (uchar *)&ndx->key, max_key_len, MYF(0));
i = my_read(index_file, (uchar *)&ndx->pos, sizeof(long long), MYF(0));
i = my_read(index_file, (uchar *)&ndx->length, sizeof(int), MYF(0));
if (i != 0)
insert_key(ndx, false);
}
DBUG_RETURN(0);
}
/* get current position of index file */
long long Spartan_index::curfpos()
{
long long pos = 0;
DBUG_ENTER("Spartan_index::curfpos");
pos = my_seek(index_file, 0l, MY_SEEK_CUR, MYF(0));
DBUG_RETURN(pos);
}
/* write the index back to disk */
int Spartan_index::save_index()
{
SDE_NDX_NODE *n = NULL;
int i;
DBUG_ENTER("Spartan_index::save_index");
i = my_chsize(index_file, 0L, '\n', MYF(MY_WME));
write_header();
n = root;
while (n != NULL)
{
write_row(&n->key_ndx);
n = n->next;
}
DBUG_RETURN(0);
}
int Spartan_index::destroy_index()
{
SDE_NDX_NODE *n = root;
DBUG_ENTER("Spartan_index::destroy_index");
while (root != NULL)
{
n = root;
root = n->next;
delete n;
}
root = NULL;
DBUG_RETURN(0);
}
/* Get the file position of the first key in index */
long long Spartan_index::get_first_pos()
{
long long pos = −1;
DBUG_ENTER("Spartan_index::get_first_pos");
if (root != NULL)
pos = root->key_ndx.pos;
DBUG_RETURN(pos);
}
/* truncate the index file */
int Spartan_index::trunc_index()
{
DBUG_ENTER("Spartan_data::trunc_table");
if (index_file != −1)
{
my_chsize(index_file, 0, 0, MYF(MY_WME));
write_header();
}
DBUG_RETURN(0);
}
Notice that, as with the Spartan_data class, I use the DBUG routines to set the trace elements for debugging. I also use the my_xxx platform-safe utility methods.
![]() Tip These methods can be found in the mysys directory under the root of the source tree. They are normally implemented as C functions stored in a file of the same name (e.g., the my_write.c file contains the my_write() method).
Tip These methods can be found in the mysys directory under the root of the source tree. They are normally implemented as C functions stored in a file of the same name (e.g., the my_write.c file contains the my_write() method).
The index works by storing a key using a uchar pointer to a block of memory, a position value (long long) that stores an offset location on disk used in the Spartan_data class to position the file pointer, and a length field that stores the length of the key. The length variable is used in the memory-compare method to set the comparison length. These data items are stored in a structure named SDE_INDEX. The doubly linked list node is another structure that contains an SDE_INDEX structure. The list-node structure, named SDE_NDX_NODE, also provides thenext and prev pointers for the list.
When using the index to store the location of data in the Spartan_data class file, you can call the insert_index() method, passing in the key and the offset of the data item in the file. This offset is returned on the my_write() method calls. This technique allows you to store the index pointers to data on disk and reuse that information without transforming it to position the file pointer to the correct location on disk.
The index is stored on disk in consecutive blocks of data that correspond to the size of the SDE_INDEX structure. The file has a header, which is used to store a crashed status variable and a variable that stores the maximum key length. The crashed status variable is helpful to identify the rare case in which a file has become corrupted or errors have occurred during reading or writing that compromise the integrity of the file or its metadata. Rather than use a variable-length field such as the data class, I use a fixed-length memory block to simplify the read and write methods for disk access. In this case, I made a conscious decision to sacrifice space for simplicity.
Now that you’ve had an introduction to the dirty work of building a storage engine—the low-level I/O functions—let’s see how we can build a basic storage engine. I’ll return to the Spartan_data and Spartan_index classes in later sections, discussing Stages 1 and 5, respectively.
Getting Started
The following tutorial assumes that you have your development environment configured and you have compiled the server with the debug switch turned on (see Chapter 5). I examine each stage of building the Spartan storage engine. Before you get started, you need to do one very important step: create a test file to test the storage engine so that we can drive the development toward a specific goal. Chapter 4 examined the MySQL test suite and how to create and run tests. Refer to that chapter for additional details or a refresher.
![]() Tip If you are using Windows, you may not be able to use the MySQL test suite (mysql-test-run.pl). You can use Cygwin (http://cygwin.com/) to set up a Unix-like environment and run the test suite there. If you don’t want to set up a Cygwin environment, you can still create the test file, copy and paste the statements into a MySQL client program, and run the tests that way.
Tip If you are using Windows, you may not be able to use the MySQL test suite (mysql-test-run.pl). You can use Cygwin (http://cygwin.com/) to set up a Unix-like environment and run the test suite there. If you don’t want to set up a Cygwin environment, you can still create the test file, copy and paste the statements into a MySQL client program, and run the tests that way.
The first thing you should do is create a new test to test the Spartan storage engine. Even though the engine doesn’t exist yet, in the spirit of test-driven development, you should create the test before writing the code. Let’s do that now.
The test file should begin as a simple test to create the table and retrieve rows from it. You can create a complete test file that includes all of the operations that I’ll show you, but it may be best to start out with a simple test and extend it as you progress through the stages of building the Spartan storage engine. This has the added benefit that your test will only test the current stage and not generate errors for operations not yet implemented. Listing 10-7 shows a sample basic test to test a Stage 1 Spartan storage engine.
As you go through this tutorial, you’ll be adding statements to this test, effectively building the complete test for the completed Spartan storage engine as you go.
Listing 10-7. Spartan-storage-Engine Test File(Ch10s1.test)
#
# Simple test for the Spartan storage engine
#
--disable_warnings
drop table if exists t1;
--enable_warnings
CREATE TABLE t1 (
col_a int,
col_b varchar(20),
col_c int
) ENGINE=SPARTAN;
SELECT * FROM t1;
RENAME TABLE t1 TO t2;
DROP TABLE t2;
You can create this file in the /mysql-test/t directory off the root of the source tree. When you execute it the first time, it’s OK to have errors. In fact, you should execute the test before beginning Stage 1. That way, you know the test works (it doesn’t fail). If you recall from Chapter 4, you can execute the test by using the commands from the /mysql-test directory:
%> touch r/Ch10s1.result
%> ./mysql-test-run.pl Ch10s1
%> cp r/cab.reject r/Ch10s1.result
%> ./mysql-test-run.pl Ch10s1
Did you try it? Did it produce errors? The test suite returned [failed], but if you examine the log file generated, you won’t see any errors, although you will see warnings. Why didn’t it fail? Well, it turns out that MySQL will use a default storage engine if the storage engine you specify on your create statement doesn’t exist. In this case, my MySQL server installation issued the error that the system was using the default MyISAM storage engine because the Spartan storage engine was not found. Listing 10-8 shows an example of the /mysql-test/r/Ch10s1.log file.
Listing 10-8. Example Log File from Test Run
mysql> drop table if exists t1;
mysql> CREATE TABLE t1 (
-> col_a int,
-> col_b varchar(20),
-> col_c int
-> ) ENGINE=SPARTAN;
ERROR 1286 (42000): Unknown storage engine 'SPARTAN'
mysql>
mysql> SELECT * FROM t1;
ERROR 1146 (42S02): Table 'test.t1' doesn't exist
mysql>
mysql> DROP TABLE t1;
ERROR 1051 (42S02): Unknown table 'test.t1'
Stage 1: Stubbing the Engine
The goal of this stage is to produce a stubbed storage-engine plugin. The stubbed engine will have the most basic operation of being able to choose the engine on the CREATE statement and creating the base-table meta file (.frm). I know that doesn’t sound like much, and while it doesn’t actually store anything,5 creating a stage 1 engine allows you to ensure you have all of the initial code changes necessary to register the storage engine with the server. I mentioned previously that some of these changes may not be necessary in future releases of the MySQL system. It is always a good idea to check the online reference manual for the latest changes prior to working with the MySQL source code.
Creating the Spartan Plugin Source Files
First, create a directory named spartan under the /storage directory off the main source-code tree. I use the example storage engine to get us started. The MySQL reference manual suggests using the source files for the example storage engine as your basis. The example storage engine contains all the necessary methods implemented with the correct code statements. This makes it easy to create the base source files for the Spartan storage engine.
Copy the *.cc and *.h files from the /storage/example directory to the /storage/spartan directory. You should now have two files in the spartan directory: ha_example.cc and ha_example.h. The ha_ prefix indicates that the files are derived from the handler class and represent a table handler. Rename the files ha_spartan.cc and ha_spartan.h.
![]() Note The phrase table handler has been replaced with the more recent phrase storage engine. You may encounter bits of the documentation that talk about table handlers. They are synonymous with storage engines and apply accordingly.
Note The phrase table handler has been replaced with the more recent phrase storage engine. You may encounter bits of the documentation that talk about table handlers. They are synonymous with storage engines and apply accordingly.
The next step in creating the source files is to change all occurrences of the words example and EXAMPLE to spartan and SPARTAN, respectively. You can use your favorite code editor or text processor to effect the changes. The resulting files should have all the example identifiers changed to spartan (e.g., st_example_share should become st_spartan_share). Use case sensitivity. Your storage engine won’t work if you don’t do this correctly.
Last, edit the ha_spartan.h file and add the include directive to include the spartan_data.h file as shown here:
#include "spartan_data.h"
Adding the CMakeLists.txt File
Since we are creating a new plugin and a new project, we need to create a CMakeLists.txt file so that the cmake tool can create the appropriate make file for the project. Open a new file in the /storage/spartan directory and name it CMakeLists.txt. Add to the file:
# Spartan storage engine plugin
SET(SPARTAN_PLUGIN_STATIC "spartan")
SET(SPARTAN_PLUGIN_DYNAMIC "spartan")
SET(SPARTAN_SOURCES ha_spartan.cc ha_spartan.h spartan_data.cc spartan_data.h)
MYSQL_ADD_PLUGIN(spartan ${SPARTAN_SOURCES} STORAGE_ENGINE MODULE_ONLY)
Notice that we use macros to define the sources for the plugin and use another macro to add the storage-engine-specific make file lines during the cmake operation.
Final Modifications
You need to make one other change. At the bottom of the ha_spartan.cc file, you should see a mysq_declare_plugin section. This is the code that the plugin interface uses to install the storage engine. See Chapter 9 for more details about this structure.
Feel free to modify this section to indicate that it is the Spartan storage engine. You can add your own name and comments to the code. This section isn't used yet, but when the storage-engine plugin architecture is complete, you'll need this section to enable the plug-in interface.
mysql_declare_plugin(spartan)
{
MYSQL_STORAGE_ENGINE_PLUGIN,
&spartan_storage_engine,
"Spartan",
"Chuck Bell",
"Spartan Storage Engine Plugin",
PLUGIN_LICENSE_GPL,
spartan_init_func, /* Plugin Init */
NULL, /* Plugin Deinit */
0x0100 /* 1.0 */,
func_status, /* status variables */
spartan_system_variables, /* system variables */
NULL, /* config options */
0, /* flags */
}
mysql_declare_plugin_end;
If that seemed like a lot of work for a storage-engine plugin,—it is. Fortunately, this situation will improve in future releases of the MySQL system.
Compiling the Spartan Engine
Now that all of these changes have been made, it is time to compile the server and test the new Spartan storage engine. The process is the same as with other compilations. From the root of the source tree, run the commands:
cmake .
make
Compile the server in debug mode so that you can generate trace files and use an interactive debugger to explore the source code while the server is running.
Testing Stage 1 of the Spartan Engine
Once the server is compiled, you can launch it and run it. First, install the new plugin. As we saw in Chapter 9, we can copy the compiled library (ha_spartan.so) to the plugin directory (−−plugin-dir) and execute the command:
INSTALL PLUGIN spartan SONAME 'ha_spartan.so';
Or, for Windows, this command:
INSTALL PLUGIN spartan SONAME 'ha_spartan.dll';
You may be tempted to test the server using the interactive MySQL client. That’s OK, and I did exactly that. Listing 10-9 shows the results from the MySQL client after running a number of SQL commands. In this example, I ran the SHOW STORAGE ENGINES, CREATE TABLE, SHOW CREATE TABLE, and DROP TABLE commands. The results show that these commands work and that the test should pass when I run it.
Listing 10-9. Example Manual Test of the Stage 1 Spartan Storage Engine
mysql> SHOW PLUGINS \G
*************************** 1. row ***************************
Name: binlog
Status: ACTIVE
Type: STORAGE ENGINE
Library: NULL
License: GPL
*************************** 2. row ***************************
Name: mysql_native_password
Status: ACTIVE
Type: AUTHENTICATION
Library: NULL
License: GPL
*************************** 3. row ***************************
Name: mysql_old_password
Status: ACTIVE
Type: AUTHENTICATION
Library: NULL
License: GPL
*************************** 4. row ***************************
Name: sha256_password
Status: ACTIVE
Type: AUTHENTICATION
Library: NULL
License: GPL
*************************** 5. row ***************************
Name: CSV
Status: ACTIVE
Type: STORAGE ENGINE
Library: NULL
License: GPL
*************************** 6. row ***************************
Name: MRG_MYISAM
Status: ACTIVE
Type: STORAGE ENGINE
Library: NULL
License: GPL
*************************** 7. row ***************************
Name: MEMORY
Status: ACTIVE
Type: STORAGE ENGINE
Library: NULL
License: GPL
*************************** 8. row ***************************
Name: MyISAM
Status: ACTIVE
Type: STORAGE ENGINE
Library: NULL
License: GPL
*************************** 9. row ***************************
Name: BLACKHOLE
Status: ACTIVE
Type: STORAGE ENGINE
Library: NULL
License: GPL
*************************** 10. row ***************************
Name: InnoDB
Status: ACTIVE
Type: STORAGE ENGINE
Library: NULL
License: GPL
...
*************************** 43. row ***************************
Name: partition
Status: ACTIVE
Type: STORAGE ENGINE
Library: NULL
License: GPL
43 rows in set (0.00 sec)
mysql> INSTALL PLUGIN spartan SONAME 'ha_spartan.so';
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW PLUGINS \G
*************************** 1. row ***************************
Name: binlog
Status: ACTIVE
Type: STORAGE ENGINE
Library: NULL
License: GPL
*************************** 2. row ***************************
Name: mysql_native_password
Status: ACTIVE
Type: AUTHENTICATION
Library: NULL
License: GPL
*************************** 3. row ***************************
Name: mysql_old_password
Status: ACTIVE
Type: AUTHENTICATION
Library: NULL
License: GPL
*************************** 4. row ***************************
Name: sha256_password
Status: ACTIVE
Type: AUTHENTICATION
Library: NULL
License: GPL
*************************** 5. row ***************************
Name: CSV
Status: ACTIVE
Type: STORAGE ENGINE
Library: NULL
License: GPL
*************************** 6. row ***************************
Name: MRG_MYISAM
Status: ACTIVE
Type: STORAGE ENGINE
Library: NULL
License: GPL
*************************** 7. row ***************************
Name: MEMORY
Status: ACTIVE
Type: STORAGE ENGINE
Library: NULL
License: GPL
*************************** 8. row ***************************
Name: MyISAM
Status: ACTIVE
Type: STORAGE ENGINE
Library: NULL
License: GPL
*************************** 9. row ***************************
Name: BLACKHOLE
Status: ACTIVE
Type: STORAGE ENGINE
Library: NULL
License: GPL
*************************** 10. row ***************************
Name: InnoDB
Status: ACTIVE
Type: STORAGE ENGINE
Library: NULL
License: GPL
...
*************************** 43. row ***************************
Name: partition
Status: ACTIVE
Type: STORAGE ENGINE
Library: NULL
License: GPL
*************************** 44. row ***************************
Name: Spartan
Status: ACTIVE
Type: STORAGE ENGINE
Library: ha_spartan.so
License: GPL
44 rows in set (0.00 sec)
mysql> use test;
Database changed
mysql> CREATE TABLE t1 (col_a int, col_b varchar(20), col_c int) ENGINE=SPARTAN;
Query OK, 0 rows affected (0.02 sec)
mysql> SHOW CREATE TABLE t1 \G
*************************** 1. row ***************************
Table: t1
Create Table: CREATE TABLE 't1' (
'col_a' int(11) DEFAULT NULL,
'col_b' varchar(20) DEFAULT NULL,
'col_c' int(11) DEFAULT NULL
) ENGINE=SPARTAN DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
mysql> DROP TABLE t1;
Query OK, 0 rows affected (0.00 sec)
mysql>
I know that the storage engine is working, because it is listed in the SHOW PLUGINS command and in the SHOW CREATE TABLE statement. Had the engine failed to connect, it may or may not have shown in the SHOW PLUGINS command, but the CREATE TABLE command would have specified the MyISAM storage engine instead of the Spartan storage engine.
You should also run the test you created earlier (if you’re running Linux). When you run the test this time, the test passes. That’s because the storage engine is now part of the server, and it can be recognized. Let’s put the SELECT command in and rerun the test. It should once again pass. At this point, you could add the test results to the /r directory for automated test reporting. Listing 10-10 shows the updated test.
![]() Note We will make new versions of the test for each stage, naming them Ch10sX (e.g. Ch10s1, Ch10s2, etc.).
Note We will make new versions of the test for each stage, naming them Ch10sX (e.g. Ch10s1, Ch10s2, etc.).
Listing 10-10. Updated Spartan Storage Engine Test File (Ch10s1.test)
#
# Simple test for the Spartan storage engine
#
--disable_warnings
drop table if exists t1;
--enable_warnings
CREATE TABLE t1 (
col_a int,
col_b varchar(20),
col_c int
) ENGINE=SPARTAN;
SELECT * FROM t1;
DROP TABLE t1;
That’s it for a Stage 1 engine. It is plugged in and ready for you to add the Spartan_data and spartan_index classes. In the next stage, we’ll add the ability to create, open, close, and delete files. That may not sound like much, but in the spirit of incremental development, you can add that bit and then test and debug until everything works before you move on to the more challenging operations.
Stage 2: Working with Tables
The goal of this stage is to produce a stubbed storage engine that can create, open, close, and delete data files. This stage is the one in which you set up the basic file-handling routines and establish that the engine is working with the files correctly. MySQL has provided a number of file I/O routines for you that encapsulate the lower-level functions, making them platform safe. The following is a sample of some of the functions available. See the files in the /mysys directory for more details.
· my_create(...): Create files
· my_open(...): Open files
· my_read(...): Read data from files
· my_write(...): Write data to files
· my_delete(...): Delete file
· fn_format(...): Create a platform-safe path statement
In this stage, I show you how to incorporate the Spartan_data class for the low-level I/O. I walk you through each change and include the completed method source code for each change.
Updating the Spartan Source Files
First, either download the compressed source files from the Apress Web site’s catalog page for this book, and copy them into your /storage/spartan directory. Or use the spartan_data.cc and spartan_data.h files that you created earlier.
Since I’m using Spartan_data class to handle the low-level I/O, I need to create an object pointer to hold an instance of that class. I need to place it somewhere where it can be shared so that there won’t be two or more instances of the class trying to read the same file. While that may be OK, it is more complicated and would require a bit more work. Instead, I place an object reference in the Spartan handler’s shared structure.
![]() Tip After you make each change, compile the spartan project to make sure there are no errors. Correct any errors before proceeding to the next change.
Tip After you make each change, compile the spartan project to make sure there are no errors. Correct any errors before proceeding to the next change.
Updating the Header File
Open the ha_spartan.h file and add the object reference to the st_spartan_share structure. Listing 10-11 shows the completed code change (comments omitted for brevity). Once you have this change made, recompile the spartan source files to make sure there aren’t any errors.
Listing 10-11. Changes to Share Structure in ha_spartan.h
/*
Spartan Storage Engine Plugin
*/
#include "my_global.h" /* ulonglong */
#include "thr_lock.h" /* THR_LOCK, THR_LOCK_DATA */
#include "handler.h" /* handler */
#include "spartan_data.h"
class Spartan_share : public Handler_share {
public:
mysql_mutex_t mutex;
THR_LOCK lock;
Spartan_data *data_class;
Spartan_share();
∼Spartan_share()
{
thr_lock_delete(&lock);
mysql_mutex_destroy(&mutex);
if (data_class != NULL)
delete data_class;
data_class = NULL;
}
};
...
Updating the Class File
The next series of modifications are done in the ha_spartan.cc file. Open that file and locate the constructor for the new Spartan_share class. Since there is an object reference now in the share structure, we need to instantiate it when the share is created. Add the instantiation of the Spartan_data class to the method. Name the object reference data_class. Listing 10-12 shows an excerpt of the method with changes.
![]() Tip If you are using Windows, and IntelliSense in Visual Studio does not recognize the new Spartan_data class, you need to repair the .ncb file. Exit Visual Studio, delete the .ncb file from the source root, and then rebuild mysqld. This may take a while, but when it is done, IntelliSense will work again.
Tip If you are using Windows, and IntelliSense in Visual Studio does not recognize the new Spartan_data class, you need to repair the .ncb file. Exit Visual Studio, delete the .ncb file from the source root, and then rebuild mysqld. This may take a while, but when it is done, IntelliSense will work again.
Listing 10-12. Changes to the Spartan_data class constructor in ha_spartan.cc
Spartan_share::Spartan_share()
{
thr_lock_init(&lock);
mysql_mutex_init(ex_key_mutex_Spartan_share_mutex,
&mutex, MY_MUTEX_INIT_FAST);
data_class = new Spartan_data();
}
Naturally, you also need to destroy the object reference when the share structure is destroyed. Locate the destructor method and add the code to destroy the data-class object reference. Listing 10-13 shows an excerpt of the method with the changes.
Listing 10-13. Changes to the Spartan_data destructor in ha_spartan.h
class Spartan_share : public Handler_share {
public:
mysql_mutex_t mutex;
THR_LOCK lock;
Spartan_data *data_class;
Spartan_share();
∼Spartan_share()
{
thr_lock_delete(&lock);
mysql_mutex_destroy(&mutex);
if (data_class != NULL)
delete data_class;
data_class = NULL;
}
};
The handler instance of the Spartan storage engine also must provide the file extensions for the data files. Since there is both a data and an index file, you need to create two file extensions. Define the file extensions and add them to the ha_spartan_exts array. Use .sde for the data file and .sdi for the index file. MySQL uses these extensions for deleting files and other maintenance operations. Locate the ha_spartan_exts array, add the #defines above it, and add those definitions to the array. Listing 10-14 shows the changes to the array structure.
Listing 10-14. Changes to the ha_spartan_exts Array in ha_spartan.cc
#define SDE_EXT ".sde"
#define SDI_EXT ".sdi"
static const char *ha_spartan_exts[] = {
SDE_EXT,
SDI_EXT,
NullS
};
The first operation you need to add is the create file operation. This will create the empty file to contain the data for the table. Locate the create() method and add the code to get a copy of the share structure, then call the data class create_table() method and close the table.Listing 10-15 shows the updated create method. I show you how to add the index class in a later stage.
Listing 10-15. Changes to the create() Method in ha_spartan.cc
int ha_spartan::create(const char *name, TABLE *table_arg,
HA_CREATE_INFO *create_info)
{
DBUG_ENTER("ha_spartan::create");
char name_buff[FN_REFLEN];
if (!(share = get_share()))
DBUG_RETURN(1);
/*
Call the data class create table method.
Note: the fn_format() method correctly creates a file name from the
name passed into the method.
*/
if (share->data_class->create_table(fn_format(name_buff, name, "", SDE_EXT,
MY_REPLACE_EXT|MY_UNPACK_FILENAME)))
DBUG_RETURN(−1);
share->data_class->close_table();
DBUG_RETURN(0);
}
The next operation you need to add is the open-file operation. This will open the file that contains the data for the table. Locate the open() method and add the code to get a copy of the share structure and open the table. Listing 10-16 shows the updated open method.
Listing 10-16. Changes to the open() Method in ha_spartan.cc
int ha_spartan::open(const char *name, int mode, uint test_if_locked)
{
DBUG_ENTER("ha_spartan::open");
char name_buff[FN_REFLEN];
if (!(share = get_share()))
DBUG_RETURN(1);
/*
Call the data class open table method.
Note: the fn_format() method correctly creates a file name from the
name passed into the method.
*/
share->data_class->open_table(fn_format(name_buff, name, "", SDE_EXT,
MY_REPLACE_EXT|MY_UNPACK_FILENAME));
thr_lock_data_init(&share->lock,&lock,NULL);
DBUG_RETURN(0);
}
The next operation you need to add is the delete-file operation. This will delete the files that contain the data for the table. Locate the delete_table() method and add the code to close the table and call the my_delete() function to delete the table. Listing 10-17 shows the updated delete method. I’ll show you how to add the index class in a later stage.
Listing 10-17. Changes to the delete_table() Method in ha_spartan.cc
int ha_spartan::delete_table(const char *name)
{
DBUG_ENTER("ha_spartan::delete_table");
char name_buff[FN_REFLEN];
/*
Call the mysql delete file method.
Note: the fn_format() method correctly creates a file name from the
name passed into the method.
*/
my_delete(fn_format(name_buff, name, "", SDE_EXT,
MY_REPLACE_EXT|MY_UNPACK_FILENAME), MYF(0));
DBUG_RETURN(0);
}
There is one last operation that many developers forget to include. The RENAME TABLE command allows users to rename tables. Your storage handler must also be able to copy the file to a new name and then delete the old one. While the MySQL server handles the rename of the .frmfile, you need to perform the copy for the data file. Locate the rename_table() method and add the code to call the my_copy() function to copy the data file for the table. Listing 10-18 shows the updated rename-table method. Later, I show you how to add the index class .
Listing 10-18. Changes to the rename_table() Method in ha_spartan.cc
int ha_spartan::rename_table(const char * from, const char * to)
{
DBUG_ENTER("ha_spartan::rename_table ");
char data_from[FN_REFLEN];
char data_to[FN_REFLEN];
my_copy(fn_format(data_from, from, "", SDE_EXT,
MY_REPLACE_EXT|MY_UNPACK_FILENAME),
fn_format(data_to, to, "", SDE_EXT,
MY_REPLACE_EXT|MY_UNPACK_FILENAME), MYF(0));
/*
Delete the file using MySQL's delete file method.
*/
my_delete(data_from, MYF(0));
DBUG_RETURN(0);
}
OK, you now have a completed Stage 2 storage engine. All that is left to do is to compile the server and run the tests.
![]() Note Be sure to copy the updated ha_spartan.so (or ha_spartan.dll) to your plugin directory. If you forget this step, you may spend a lot of time trying to discover why your Stage 2 engine isn’t working properly.
Note Be sure to copy the updated ha_spartan.so (or ha_spartan.dll) to your plugin directory. If you forget this step, you may spend a lot of time trying to discover why your Stage 2 engine isn’t working properly.
Testing Stage 2 of the Spartan Engine
When you run the test again, you should see all of the statements complete successfully. There are, however, two things the test doesn’t verify for you. First, you need to make sure the .sde file was created and deleted. Second, you need to make sure the rename command works.
Testing the commands for creating and dropping the table is easy. Launch your server and then a MySQL client. Issue the CREATE statement from the test, and then use your file browser to navigate to the /data/test folder. There you should see two files: t1.frm and t1.sde. Return to your MySQL client and issue the DROP statement. Then return to the /data/test folder and verify that the files are indeed deleted.
Testing the command that renames the table is also easy. Repeat the CREATE statement test and then issue the command:
RENAME TABLE t1 TO t2;
Once you run the RENAME command, you should be able to issue a SELECT statement and even a DROP statement that operate on the renamed table. This should produce an output like:
mysql> RENAME TABLE t1 to t2;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM t2;
Empty set (0.00 sec)
mysql> DROP TABLE t2;
Query OK, 0 rows affected (0.00 sec)
Use your file browser to navigate to the /data/test folder. There you should see two files: t2.frm and t2.sde. Return to your MySQL client and issue the DROP statement. Then return to the /data/test folder and verify that the files are indeed deleted.
Now that you have verified that the RENAME statement works, add that to the test file and rerun the test. The test should complete without errors. Listing 10-19 shows the updated Ch10s2.test file.
Listing 10-19. Updated Spartan Storage Engine Test File (Ch10s2.test)
#
# Simple test for the Spartan storage engine
#
--disable_warnings
drop table if exists t1;
--enable_warnings
CREATE TABLE t1 (
col_a int,
col_b varchar(20),
col_c int
) ENGINE=SPARTAN;
SELECT * FROM t1;
RENAME TABLE t1 TO t2;
DROP TABLE t2;
Well, that’s it for a Stage 2 engine. It is plugged in and creates, deletes, and renames files. In the next stage, we’ll add the ability to read and write data.
Stage 3: Reading and Writing Data
The goal of this stage is to produce a working storage engine that can read and write data. In this stage, I show you how to incorporate the Spartan_data class for reading and writing data. I walk you through each change and include the completed method source code for each change.
Updating the Spartan Source Files
Making a Stage 3 engine requires updates to the basic reading process (described earlier).To implement the read operation, you’ll be making changes to the rnd_init(), rnd_next(), position(), and rnd_pos() methods in the ha_spartan.cc file. The position() andrnd_pos() methods are used during large sorting operations and use an internal buffer to store the rows. The write operation requires changes to only the write_row() method.
Updating the Header File
The position methods require that you store a pointer—either a record offset position or a key value to be used in the sorting operations. Oracle provides a nifty way of doing this, as you’ll see in the position methods in a moment. Open the ha_spartan.h file and add thecurrent_position variable to the ha_spartan class. Listing 10-20 shows an excerpt with the changes.
Listing 10-20. Changes to the ha_spartan Class in ha_spartan.h
class ha_spartan: public handler
{
THR_LOCK_DATA lock; /* MySQL lock */
Spartan_share *share; ///< Shared lock info
Spartan_share *get_share(); ///< Get the share
off_t current_position; /* Current position in the file during a file scan */
public:
ha_spartan(handlerton *hton, TABLE_SHARE *table_ar);
∼ha_spartan()
{
}
...
Updating the Source File
Return to the ha_spartan.cc file, as that is where the rest of the changes need to be made. The first method you need to change is rnd_init(). Here is where you need to set the initial conditions for a table scan. In this case, you set the current position to 0 (start of file) and the number of records to 0, and specify the length of the item you want to use for the sorting methods. Use a long long, since that is the data type for the current position in the file. Listing 10-21 shows the updated method with the changes.
Listing 10-21. Changes to the rnd_init() Method in ha_spartan.cc
int ha_spartan::rnd_init(bool scan)
{
DBUG_ENTER("ha_spartan::rnd_init");
current_position = 0;
stats.records = 0;
ref_length = sizeof(long long);
DBUG_RETURN(0);
}
![]() Caution This is the point at which we start adding functionality beyond that of the example engine. Be sure to correctly specify your return codes. The example engine tells the optimizer that a function is not supported by issuing the return statementDBUG_RETURN(HA_ERR_WRONG_COMMAND);. Be sure to change these to something other than the wrong command return code (e.g., 0).
Caution This is the point at which we start adding functionality beyond that of the example engine. Be sure to correctly specify your return codes. The example engine tells the optimizer that a function is not supported by issuing the return statementDBUG_RETURN(HA_ERR_WRONG_COMMAND);. Be sure to change these to something other than the wrong command return code (e.g., 0).
The next method you need to change is rnd_next(), which is responsible for getting the next record from the file and detecting the end of the file. In this method, you can call the data class read_row() method, passing in the record buffer, the length of the buffer, and the current position in the file. Notice the return for the end of the file and the setting of more statistics. The method also records the current position so that the next call to the method will advance the file to the next record. Listing 10-22 shows the updated method with the changes.
Listing 10-22. Changes to the rnd_next() Method in ha_spartan.cc
int ha_spartan::rnd_next(uchar *buf)
{
int rc;
DBUG_ENTER("ha_spartan::rnd_next");
MYSQL_READ_ROW_START(table_share->db.str, table_share->table_name.str,
TRUE);
/*
Read the row from the data file.
*/
rc = share->data_class->read_row(buf, table->s->rec_buff_length,
current_position);
if (rc != −1)
current_position = (off_t)share->data_class->cur_position();
else
DBUG_RETURN(HA_ERR_END_OF_FILE);
stats.records++;
MYSQL_READ_ROW_DONE(rc);
DBUG_RETURN(rc);
}
The Spartan_data class is nice, because it stores the records in the same format as the MySQL internal buffer. In fact, it just writes a few uchars of a header for each record, storing a deleted flag and the record length (for use in scanning and repairing). If you were working on a storage engine that stored the data in a different format, you would need to perform the translation at this point. A sample of how that translation could be accomplished is found in the ha_tina.cc file. The process looks something like:
for (Field **field=table->field ; *field ; field++)
{
/* copy field data to your own storage type */
my_value = (*field)->val_str();
my_store_field(my_value);
}
In this example, you are iterating through the field array, writing out the data in your own format. Look for the ha_tina::find_current_row() method for an example.
The next method you need to change is position(), which records the current position of the file in the MySQL pointer-storage mechanism. It is called after each call to rnd_next(). The methods for storing and retrieving these pointers are my_store_ptr() andmy_get_ptr(). The store-pointer method takes a reference variable (the place you want to store something), the length of what you want to store, and the thing you want to store as parameters. The get-pointer method takes a reference variable and the length of what you are retrieving, and it returns the item stored. These methods are used in the case of an order by rows where the data will need to be sorted. Take a look at the changes for the position() method shown in Listing 10-23 to see how you can call the store-pointer method.
Listing 10-23. Changes to the position() Method in ha_spartan.cc
void ha_spartan::position(const uchar *record)
{
DBUG_ENTER("ha_spartan::position");
my_store_ptr(ref, ref_length, current_position);
DBUG_VOID_RETURN;
}
The next method you need to change is rnd_pos(), which is where you’ll retrieve the current position stored and then read in the row from that position. Notice that in this method we also increment the read statistic ha_read_rnd_next_count. This provides the optimizer information about how many rows there are in the table, and it can be helpful in optimizing later queries. Listing 10-24 shows the updated method with the changes.
Listing 10-24. Changes to the rnd_pos() Method in ha_spartan.cc
int ha_spartan::rnd_pos(uchar *buf, uchar *pos)
{
int rc;
DBUG_ENTER("ha_spartan::rnd_pos");
MYSQL_READ_ROW_START(table_share->db.str, table_share->table_name.str,
TRUE);
ha_statistic_increment(&SSV::ha_read_rnd_next_count);
current_position = (off_t)my_get_ptr(pos,ref_length);
rc = share->data_class->read_row(buf, current_position, -1);
MYSQL_READ_ROW_DONE(rc);
DBUG_RETURN(rc);
}
The next method you need to change is info(), which returns information to the optimizer to help choose an optimal execution path. This is an interesting method to implement, and when you read the comments in the source code, it’ll seem humorous. What you need to do in this method is to return the number of records. Oracle states that you should always return a value of 2 or more. This disengages portions of the optimizer that are wasteful for a record set of one row. Listing 10-25 shows the updated info() method.
Listing 10-25. Changes to the info() Method in ha_spartan.cc
int ha_spartan::info(uint flag)
{
DBUG_ENTER("ha_spartan::info");
/* This is a lie, but you don't want the optimizer to see zero or 1 */
if (stats.records < 2)
stats.records= 2;
DBUG_RETURN(0);
}
The last method you need to change is write_row(); you’ll be writing the data to the data file using the Spartan_data class again. Like the read, the Spartan_data class needs only to write the record buffer to disk preceded by a delete status flag and the record length. Listing 10-26 shows the updated method with the changes.
Listing 10-26. Changes to the write_row() Method in ha_spartan.cc
int ha_spartan::write_row(uchar *buf)
{
DBUG_ENTER("ha_spartan::write_row");
long long pos;
SDE_INDEX ndx;
ha_statistic_increment(&SSV::ha_write_count);
/*
Begin critical section by locking the spartan mutex variable.
*/
mysql_mutex_lock(&share->mutex);
pos = share->data_class->write_row(buf, table->s->rec_buff_length);
/*
End section by unlocking the spartan mutex variable.
*/
mysql_mutex_unlock(&share->mutex);
DBUG_RETURN(0);
}
Notice that once again I have placed a mutex (for example, critical section) around the write so that no two threads can write at the same time. Now is a good time to compile the server and debug any errors. When that is done, you’ll have a completed a Stage 3 storage engine. All that is left to do is to compile the server and run the tests.
Testing Stage 3 of the Spartan Engine
When you run the test again, you should see all of the statements complete successfully. If you are wondering why I always begin with running the test from the last increment, it’s because you want to make sure that none of the new code broke anything that the old code was doing. In this case, you can see that you can still create, rename, and delete tables. Now, let’s move on to testing the read and write operations.
Testin these functions is easy. Launch your server and then a MySQL client. If you have deleted the test table, re-create it and then issue the command:
INSERT INTO t1 VALUES(1, "first test", 24);
INSERT INTO t1 VALUES(4, "second test", 43);
INSERT INTO t1 VALUES(3, "third test", -2);
After each statement, you should see the successful insertion of the records. If you encounter errors (which you shouldn’t), launch your debugger, set breakpoints in all of the read and write methods in the ha_spartan.cc file, and then debug the problem. You should not look any further than the ha_spartan.cc file, because that is the only file that could contain the source of the error.6
Now you can issue a SELECT statement and see what the server sends back to you. Enter the command:
SELECT * FROM t1;
You should see all three rows returned. Listing 10-27 shows the results of running the query.
Listing 10-27. Results of Running INSERT/SELECT Statements
mysql> INSERT INTO t1 VALUES(1, "first test", 24);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO t1 VALUES(4, "second test", 43);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO t1 VALUES(3, "third test", -2);
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM t1;
+−−-----+−−-----------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−-----------+−−-----+
| 1 | first test | 24 |
| 4 | second test | 43 |
| 3 | third test | -2 |
+−−-----+−−-----------+−−-----+
3 rows in set (0.00 sec)
mysql>
Now that you have verified that the read and writes work, add tests for those operations to the test file and rerun the test. The test should complete without errors. Listing 10-28 shows the updated Ch10s3.test file.
Listing 10-28. Updated Spartan-storage-engine Test File (Ch10s3.test)
#
# Simple test for the Spartan storage engine
#
--disable_warnings
drop table if exists t1;
--enable_warnings
CREATE TABLE t1 (
col_a int,
col_b varchar(20),
col_c int
) ENGINE=SPARTAN;
SELECT * FROM t1;
INSERT INTO t1 VALUES(1, ìfirst testî, 24);
INSERT INTO t1 VALUES(4, ìsecond testî, 43);
INSERT INTO t1 VALUES(3, ìthird testî, -2);
SELECT * FROM t1;
RENAME TABLE t1 TO t2;
SELECT * FROM t2;
DROP TABLE t2;
That’s it for a Stage 3 engine. It is now a basic read/write storage engine that does all of the basic necessities for reading and writing data. In the next stage, we add the ability to update and delete data.
Stage 4: Updating and Deleting Data
The goal of this stage is to produce a working storage engine that can update and delete data. In this stage, I show you how to incorporate the Spartan_data class for updating and deleting data. I walk you through each change and include the completed-method source code for each change.
The Spartan_data class performs updating in place. That is, the old data are overwritten with the new data. Deletion is performed by marking the data as deleted and skipping the deleted records on reads. The read_row() method in the Spartan_data class skips the deleted rows. This may seem as if it will waste a lot of space, and that could be true if the storage engine were used in a situation in which there are lots of deletes and inserts. To mitigate that possibility, you can always dump and then drop the table, and reload the data from the dump. This will remove the empty records. Depending on how you plan to build your own storage engine, this may be something you need to reconsider.
Updating the Spartan Source Files
This stage requires you to update the update_row(), delete_row(), and delete_all_rows() methods. The delete_all_rows() method is a time-saving method used to empty a table all at once rather than a row at a time. The optimizer may call this method for truncation operations and when it detects a mass-delete query.
Updating the Header File
There are no changes necessary to the ha_spartan.h file for a Stage 4 storage engine.
Updating the Source File
Open the ha_spartan.cc file and locate the update_row() method. This method has the old record and the new record buffers passed as parameters. This is great, because we don’t have indexes and must do a table scan to locate the record! Fortunately, the Spartan_data class has the update_row() method that will do that work for you. Listing 10-29 shows the updated method with the changes.
Listing 10-29. Changes to the update_row() Method in ha_spartan.cc
/* update a record in place */
long long Spartan_data::update_row(uchar *old_rec, uchar *new_rec,
int length, long long position)
{
DBUG_ENTER("ha_spartan::update_row");
/*
Begin critical section by locking the spartan mutex variable.
*/
mysql_mutex_lock(&share->mutex);
share->data_class->update_row((uchar *)old_data, new_data,
table->s->rec_buff_length, current_position -
share->data_class->row_size(table->s->rec_buff_length));
/*
End section by unlocking the spartan mutex variable.
*/
mysql_mutex_unlock(&share->mutex);
DBUG_RETURN(0);
}
The delete_row() method is similar to the update method. In this case, we call the delete_row() method in the Spartan_data class, passing in the buffer for the row to delete, the length of the record buffer, and -1 for the current position to force the table scan. Once again, the data-class method does all the heavy lifting for you. Listing 10-30 shows the updated method with the changes.
Listing 10-30. Changes to the delete_row() Method in ha_spartan.cc
int ha_spartan::update_row(const uchar *old_data, uchar *new_data)
{
DBUG_ENTER("ha_spartan::update_row");
/*
Begin critical section by locking the spartan mutex variable.
*/
mysql_mutex_lock(&share->mutex);
share->data_class->update_row((uchar *)old_data, new_data,
table->s->rec_buff_length, current_position -
share->data_class->row_size(table->s->rec_buff_length));
/*
End section by unlocking the spartan mutex variable.
*/
mysql_mutex_unlock(&share->mutex);
DBUG_RETURN(0);
}
The last method you need to update is delete_all_rows(). This deletes all data in the table. The easiest way to do that is to delete the data file and re-create it. The Spartan_data class does this a little differently. The trunc_table() method resets the file pointer to the start of the file and truncates the file using the my_chsize() method. Listing 10-31 shows the updated method with the changes.
Listing 10-31. Changes to the delete_all_rows() Method in ha_spartan.cc
int ha_spartan::delete_all_rows()
{
DBUG_ENTER("ha_spartan::delete_all_rows");
/*
Begin critical section by locking the spartan mutex variable.
*/
mysql_mutex_lock(&share->mutex);
share->data_class->trunc_table();
/*
End section by unlocking the spartan mutex variable.
*/
mysql_mutex_unlock(&share->mutex);
DBUG_RETURN(0);
}
Now compile the server and debug any errors. When that is done, you’ll have a completed Stage 4 engine. All that is left to do is to compile the server and run the tests.
Testing Stage 4 of the Spartan Engine
First, verify that everything is working in the Stage 3 engine, and then move on to testing the update and delete operations. When you run the test again, you should see all of the statements complete successfully.
The update and delete tests require you to have a table created and to have data in it. You can always add data using the normal INSERT statements as before. Feel free to add your own data and fill up the table with a few more rows.
When you have some data in the table, select one of the records and issue an update command for it using something like:
UPDATE t1 SET col_b = "Updated!" WHERE col_a = 1;
When you run that command followed by a SELECT * command, you should see the row updated. You can then delete a row by issuing a delete command such as:
DELETE FROM t1 WHERE col_a = 3;
When you run that command followed by a SELECT * command, you should see that the row has been deleted. An example of what this sequence of commands would produce is:.
mysql> DELETE FROM t1 WHERE col_a = 3;
Query OK, 1 row affected (0.01 sec)
mysql> SELECT * FROM t1;
+−−-----+−−-----------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−-----------+−−-----+
| 4 | second test | 43 |
| 4 | tenth test | 11 |
| 5 | Updated! | 100 |
+−−-----+−−-----------+−−-----+
3 rows in set (0.00 sec)
mysql>
Have we missed something? Savvy software developers may notice that this test isn’t comprehensive and does not cover all possibilities that the Spartan_data class has to consider. For example, deleting a row in the middle of the data isn’t the same as deleting one at the beginning or at the end of the file. Updating the data is the same.
That’s OK, because you can add that functionality to the test file. You can add more INSERT statements to add some more data, and then update the first and last rows and one in the middle. You can do the same for the delete operation. Listing 10-32 shows the updated Ch10s4.testfile.
Listing 10-32. Updated Spartan-storage-engine Test File (Ch10s4.test)
#
# Simple test for the Spartan storage engine
#
--disable_warnings
drop table if exists t1;
--enable_warnings
CREATE TABLE t1 (
col_a int,
col_b varchar(20),
col_c int
) ENGINE=SPARTAN;
SELECT * FROM t1;
INSERT INTO t1 VALUES(1, ìfirst testî, 24);
INSERT INTO t1 VALUES(4, ìsecond testî, 43);
INSERT INTO t1 VALUES(3, ìfourth testî, -2);
INSERT INTO t1 VALUES(4, ìtenth testî, 11);
INSERT INTO t1 VALUES(1, ìseventh testî, 20);
INSERT INTO t1 VALUES(5, ìthird testî, 100);
SELECT * FROM t1;
UPDATE t1 SET col_b = ìUpdated!î WHERE col_a = 1;
SELECT * from t1;
UPDATE t1 SET col_b = ìUpdated!î WHERE col_a = 3;
SELECT * from t1;
UPDATE t1 SET col_b = ìUpdated!î WHERE col_a = 5;
SELECT * from t1;
DELETE FROM t1 WHERE col_a = 1;
SELECT * FROM t1;
DELETE FROM t1 WHERE col_a = 3;
SELECT * FROM t1;
DELETE FROM t1 WHERE col_a = 5;
SELECT * FROM t1;
RENAME TABLE t1 TO t2;
SELECT * FROM t2;
DROP TABLE t2;
Notice that I’ve added some rows that have duplicate values. You should expect the server to update and delete all matches for rows with duplicates. Run that test and see what it does. Listing 10-33 shows an example of the expected results for this test. When you run the test under the test suite, it should complete without errors.
Listing 10-33. Sample Results of Stage 4 Test
mysql> INSTALL PLUGIN spartan SONAME 'ha_spartan.so';
Query OK, 0 rows affected (0.01 sec)
mysql> use test;
Database changed
mysql>
mysql> CREATE TABLE t1 (
-> col_a int,
-> col_b varchar(20),
-> col_c int
-> ) ENGINE=SPARTAN;
Query OK, 0 rows affected (0.01 sec)
mysql>
mysql> SELECT * FROM t1;
Empty set (0.00 sec)
mysql> INSERT INTO t1 VALUES(1, "first test", 24);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO t1 VALUES(4, "second test", 43);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO t1 VALUES(3, "fourth test", -2);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO t1 VALUES(4, "tenth test", 11);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO t1 VALUES(1, "seventh test", 20);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO t1 VALUES(5, "third test", 100);
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM t1;
+−−-----+−−------------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−------------+−−-----+
| 1 | first test | 24 |
| 4 | second test | 43 |
| 3 | fourth test | -2 |
| 4 | tenth test | 11 |
| 1 | seventh test | 20 |
| 5 | third test | 100 |
+−−-----+−−------------+−−-----+
6 rows in set (0.00 sec)
mysql> UPDATE t1 SET col_b = "Updated!" WHERE col_a = 1;
Query OK, 2 rows affected (0.00 sec)
Rows matched: 2 Changed: 2 Warnings: 0
mysql> SELECT * from t1;
+−−-----+−−-----------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−-----------+−−-----+
| 1 | Updated! | 24 |
| 4 | second test | 43 |
| 3 | fourth test | -2 |
| 4 | tenth test | 11 |
| 1 | Updated! | 20 |
| 5 | third test | 100 |
+−−-----+−−-----------+−−-----+
6 rows in set (0.00 sec)
mysql> UPDATE t1 SET col_b = "Updated!" WHERE col_a = 3;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SELECT * from t1;
+−−-----+−−-----------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−-----------+−−-----+
| 1 | Updated! | 24 |
| 4 | second test | 43 |
| 3 | Updated! | -2 |
| 4 | tenth test | 11 |
| 1 | Updated! | 20 |
| 5 | third test | 100 |
+−−-----+−−-----------+−−-----+
6 rows in set (0.01 sec)
mysql> UPDATE t1 SET col_b = "Updated!" WHERE col_a = 5;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SELECT * from t1;
+−−-----+−−-----------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−-----------+−−-----+
| 1 | Updated! | 24 |
| 4 | second test | 43 |
| 3 | Updated! | -2 |
| 4 | tenth test | 11 |
| 1 | Updated! | 20 |
| 5 | Updated! | 100 |
+−−-----+−−-----------+−−-----+
6 rows in set (0.00 sec)
mysql> DELETE FROM t1 WHERE col_a = 1;
Query OK, 2 rows affected (0.00 sec)
mysql> SELECT * FROM t1;
+−−-----+−−-----------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−-----------+−−-----+
| 4 | second test | 43 |
| 3 | Updated! | -2 |
| 4 | tenth test | 11 |
| 5 | Updated! | 100 |
+−−-----+−−-----------+−−-----+
4 rows in set (0.00 sec)
mysql> DELETE FROM t1 WHERE col_a = 3;
Query OK, 1 row affected (0.01 sec)
mysql> SELECT * FROM t1;
+−−-----+−−-----------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−-----------+−−-----+
| 4 | second test | 43 |
| 4 | tenth test | 11 |
| 5 | Updated! | 100 |
+−−-----+−−-----------+−−-----+
3 rows in set (0.00 sec)
mysql> DELETE FROM t1 WHERE col_a = 5;
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM t1;
+−−-----+−−-----------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−-----------+−−-----+
| 4 | second test | 43 |
| 4 | tenth test | 11 |
+−−-----+−−-----------+−−-----+
2 rows in set (0.00 sec)
mysql> RENAME TABLE t1 TO t2;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM t2;
+−−-----+−−-----------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−-----------+−−-----+
| 4 | second test | 43 |
| 4 | tenth test | 11 |
+−−-----+−−-----------+−−-----+
2 rows in set (0.00 sec)
mysql> DROP TABLE t2;
Query OK, 0 rows affected (0.00 sec)
mysql>
That’s it for a Stage 4 engine. It is now a basic read/write/update/delete storage engine. In the next stage, we’ll add the index class to make queries more efficient.
Stage 5: Indexing the Data
The goal of this stage is to produce a working storage engine that includes support for a single index (with a little work, you can make it have multiple indexes). In this stage, I show you how to incorporate the Spartan_index class for indexing the data. Many changes need to be made. I recommend reading through this section before beginning to follow along with the changes.
Begin by adding the Spartan_index class files to the CMakeLists.txt file as shown below.
# Spartan storage engine plugin
SET(SPARTAN_PLUGIN_STATIC "spartan")
SET(SPARTAN_PLUGIN_DYNAMIC "spartan")
SET(SPARTAN_SOURCES
ha_spartan.cc ha_spartan.h
spartan_data.cc spartan_data.h
spartan_index.cc spartan_index.h
)
MYSQL_ADD_PLUGIN(spartan ${SPARTAN_SOURCES} STORAGE_ENGINE MODULE_ONLY)
TARGET_LINK_LIBRARIES(spartan mysys)
The Spartan_index class works by saving the record pointer to the corresponding row in the Spartan_data class. When the server searches for a record by the primary key, it can use the Spartan_index class to find the record pointer, and then access the record directly by issuing a direct read call via the Spartan_data class. This makes the process of reading a random record much faster than performing a table scan.
The source code in this section is designed to work for the most basic of indexing operations. Depending on how complex your queries become, these changes should suffice for most situations. I walk you through each change and include the completed method source code for each change.
Updating the Spartan Source Files
The Spartan_index class simply saves the current position of the file along with the key. The methods in ha_spartan.cc you’ll need to update include index_read(), index_read_idx(), index_next(), index_prev(), index_first(), and index_last(). These methods read values from the index and iterate through the index, as well as go to the front and back (start, end) of the index. Fortunately, the Spartan_index class provides all of these operations.
Updating the Header File
To use the index class, first add a reference to the spartan_index.h file in the ha_spartan.h header file. Listing 10-34 shows the completed code change (I’ve omitted comments for brevity). Once you have this change made, recompile the spartan source files to make sure there aren’t any errors.
Listing 10-34. Changes to Spartan_share class in ha_spartan.h
#include "my_global.h" /* ulonglong */
#include "thr_lock.h" /* THR_LOCK, THR_LOCK_DATA */
#include "handler.h" /* handler */
#include "spartan_data.h"
#include "spartan_index.h"
class Spartan_share : public Handler_share {
public:
mysql_mutex_t mutex;
THR_LOCK lock;
Spartan_data *data_class;
Spartan_index *index_class;
Spartan_share();
∼Spartan_share()
{
thr_lock_delete(&lock);
mysql_mutex_destroy(&mutex);
if (data_class != NULL)
delete data_class;
data_class = NULL;
if (index_class != NULL)
delete index_class;
index_class = NULL;
}
};
...
Open the ha_spartan.h file and add the #include directive to include the spartan_index.h header file as shown above.
Once that is complete, open the ha_spartan.cc file and add the index-class initialization to the constructor.. Listing 10-35 shows the completed code change. Once you have this change made, recompile the spartan source files to make sure there aren’t any errors.
Listing 10-35. Changes to Spartan_data constructor in ha_spartan.cc
Spartan_share::Spartan_share()
{
thr_lock_init(&lock);
mysql_mutex_init(ex_key_mutex_Spartan_share_mutex,
&mutex, MY_MUTEX_INIT_FAST);
data_class = new Spartan_data();
index_class = new Spartan_index();
}
You need to make a few other changes while you have the header file open. You have to add flags to tell the optimizer what index operations are supported. You also have to set the boundaries for the index parameters: the maximum number of keys supported, the maximum length of the keys, and the maximum key parts. For this stage, set the parameters as shown in Listing 10-36. I’ve included the entire set of changes you need to make to the file. Notice the table_flags() method. This is where you tell the optimizer what limitations the storage engine has. I have set the engine to disallow BLOBs and not permit auto-increment fields. A complete list of these flags can be found in handler.h.
Listing 10-36. Changes to the ha_spartan Class Definition in ha_spartan.h
/*
The name of the index type that will be used for display
don't implement this method unless you really have indexes
*/
const char *index_type(uint inx) { return "Spartan_index"; }
/*
The file extensions.
*/
const char **bas_ext() const;
/*
This is a list of flags that says what the storage engine
implements. The current table flags are documented in
handler.h
*/
ulonglong table_flags() const
{
return (HA_NO_BLOBS | HA_NO_AUTO_INCREMENT | HA_BINLOG_STMT_CAPABLE);
}
/*
This is a bitmap of flags that says how the storage engine
implements indexes. The current index flags are documented in
handler.h. If you do not implement indexes, just return zero
here.
part is the key part to check. First key part is 0
If all_parts it's set, MySQL want to know the flags for the combined
index up to and including 'part'.
*/
ulong index_flags(uint inx, uint part, bool all_parts) const
{
return (HA_READ_NEXT | HA_READ_PREV | HA_READ_RANGE |
HA_READ_ORDER | HA_KEYREAD_ONLY);
}
/*
unireg.cc will call the following to make sure that the storage engine can
handle the data it is about to send.
Return *real* limits of your storage engine here. MySQL will do
min(your_limits, MySQL_limits) automatically
There is no need to implement ..._key_... methods if you don't suport
indexes.
*/
uint max_supported_keys() const { return 1; }
uint max_supported_key_parts() const { return 1; }
uint max_supported_key_length() const { return 128; }
If you were to execute the SHOW INDEXES FROM command on a table created with the Spartan engine, you would see the results of the above code changes, as shown in Listing 10-37. Notice the index type reported in the output.
Listing 10-37. Example of SHOW INDEXES FROM output
mysql> show indexes from test.t1 \G
*************************** 1. row ***************************
Table: t1
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: col_a
Collation: A
Cardinality: NULL
Sub_part: NULL
Packed: NULL
Null:
Index_type: Spartan_index
Comment:
Index_comment:
1 row in set (0.00 sec)
One last thing needs to be added. Identifying the key in a record turns out to be easy but not very intuitive. To make things easier to work with, I’ve written two helper methods: get_key(), which finds the key field and returns its value or 0 if there are no keys, and get_key_len(), which returns the length of the key. Add their definitions to the class header file (ha_spartan.h):
uchar *get_key();
int get_key_len();
You will implement these methods in the ha_spartan.cc class file.
Updating the Class File
Now would be a good time to compile and check for errors. When you’re done, start the modifications for the index methods.
First, go back through the open, create, close, write, update, delete, and rename methods, and add the calls to the index class to maintain the index. The code to do this involves identifying the field that is the key and then saving the key and its position to the index for retrieval later.
The open method must open both the data and the index files together. The only extra step is to load the index into memory. Locate the open() method in the class file, and add the calls to the index class for opening the index and loading the index into memory. Listing 10-38 shows the method with the changes.
Listing 10-38. Changes to the open() Method in ha_spartan.cc
int ha_spartan::open(const char *name, int mode, uint test_if_locked)
{
DBUG_ENTER("ha_spartan::open");
char name_buff[FN_REFLEN];
if (!(share = get_share()))
DBUG_RETURN(1);
/*
Call the data class open table method.
Note: the fn_format() method correctly creates a file name from the
name passed into the method.
*/
share->data_class->open_table(fn_format(name_buff, name, "", SDE_EXT,
MY_REPLACE_EXT|MY_UNPACK_FILENAME));
share->index_class->open_index(fn_format(name_buff, name, "", SDI_EXT,
MY_REPLACE_EXT|MY_UNPACK_FILENAME));
share->index_class->load_index();
thr_lock_data_init(&share->lock,&lock,NULL);
DBUG_RETURN(0);
}
The create method must create both the data and the index files together. Locate the create() method in the class file, and add the calls to the index class for creating the index. Listing 10-39 shows the method with the changes.
Listing 10-39. Changes to the create() Method in ha_spartan.cc
int ha_spartan::create(const char *name, TABLE *table_arg,
HA_CREATE_INFO *create_info)
{
DBUG_ENTER("ha_spartan::create");
char name_buff[FN_REFLEN];
char name_buff2[FN_REFLEN];
if (!(share = get_share()))
DBUG_RETURN(1);
/*
Call the data class create table method.
Note: the fn_format() method correctly creates a file name from the
name passed into the method.
*/
if (share->data_class->create_table(fn_format(name_buff, name, "", SDE_EXT,
MY_REPLACE_EXT|MY_UNPACK_FILENAME)))
DBUG_RETURN(−1);
share->data_class->close_table();
if (share->index_class->create_index(fn_format(name_buff2, name, "", SDI_EXT,
MY_REPLACE_EXT|MY_UNPACK_FILENAME),
128))
{
DBUG_RETURN(−1);
}
share->index_class->close_index();
DBUG_RETURN(0);
}
The close method must close both the data and the index files together. Since the index class uses an in-memory structure to store all changes, it must be written back to disk. Locate the close() method in the class file, and add the calls to the index class for saving, destroying the in-memory structure and closing the index. Listing 10-40 shows the method with the changes.
Listing 10-40. Changes to the close() Method in ha_spartan.cc
int ha_spartan::close(void)
{
DBUG_ENTER("ha_spartan::close");
share->data_class->close_table();
share->index_class->save_index();
share->index_class->destroy_index();
share->index_class->close_index();
DBUG_RETURN(0);
}
Now let’s make the changes to the writing and reading methods. Since it is possible that no keys will be used, the method must check that there is a key to be added. To make things easier to work with, I’ve written two helper methods: get_key(), which finds the key field and returns its value or 0 if there are no keys, and get_key_len(), which returns the length of the key. Listing 10-41 shows these two helper methods. Add those methods now to the ha_spartan.cc file.
Listing 10-41. Additional Helper Methods in ha_spartan.cc
uchar *ha_spartan::get_key()
{
uchar *key = 0;
DBUG_ENTER("ha_spartan::get_key");
/*
For each field in the table, check to see if it is the key
by checking the key_start variable. (1 = is a key).
*/
for (Field **field=table->field ; *field ; field++)
{
if ((*field)->key_start.to_ulonglong() == 1)
{
/*
Copy field value to key value (save key)
*/
key = (uchar *)my_malloc((*field)->field_length,
MYF(MY_ZEROFILL | MY_WME));
memcpy(key, (*field)->ptr, (*field)->key_length());
}
}
DBUG_RETURN(key);
}
int ha_spartan::get_key_len()
{
int length = 0;
DBUG_ENTER("ha_spartan::get_key");
/*
For each field in the table, check to see if it is the key
by checking the key_start variable. (1 = is a key).
*/
for (Field **field=table->field ; *field ; field++)
{
if ((*field)->key_start.to_ulonglong() == 1)
/*
Copy field length to key length
*/
length = (*field)->key_length();
}
DBUG_RETURN(length);
}
The write method must both write the record to the data file and insert the key into the index file. Locate the write_row() method in the class file and add the calls to the index class to insert the key if one is found. Listing 10-42 shows the method with the changes.
Listing 10-42. Changes to the write_row() Method in ha_spartan.cc
int ha_spartan::write_row(uchar *buf)
{
DBUG_ENTER("ha_spartan::write_row");
long long pos;
SDE_INDEX ndx;
ha_statistic_increment(&SSV::ha_write_count);
/*
Begin critical section by locking the spartan mutex variable.
*/
mysql_mutex_lock(&share->mutex);
ndx.length = get_key_len();
memcpy(ndx.key, get_key(), get_key_len());
pos = share->data_class->write_row(buf, table->s->rec_buff_length);
ndx.pos = pos;
if ((ndx.key != 0) && (ndx.length != 0))
share->index_class->insert_key(&ndx, false);
/*
End section by unlocking the spartan mutex variable.
*/
mysql_mutex_unlock(&share->mutex);
DBUG_RETURN(0);
}
The update method is also a little different. It must change both the record in the data file and the key in the index. Since the index uses an in-memory structure, the index file must be changed, saved to disk, and reloaded.
![]() Note Savvy programmers will note something in the code for the Spartan_index that could be made to prevent the reloading step. Do you know what it is? Here’s a hint: what if the index-class update method updated the key and then repositioned it in the memory structure? I’ll leave that experiment up to you. Go into the index code and improve it.
Note Savvy programmers will note something in the code for the Spartan_index that could be made to prevent the reloading step. Do you know what it is? Here’s a hint: what if the index-class update method updated the key and then repositioned it in the memory structure? I’ll leave that experiment up to you. Go into the index code and improve it.
Locate the update_row() method in the class file and add the calls to the index class to update the key if one is found. Listing 10-43 shows the method with the changes.
Listing 10-43. Changes to the update_row() Method in ha_spartan.cc
int ha_spartan::update_row(const uchar *old_data, uchar *new_data)
{
DBUG_ENTER("ha_spartan::update_row");
/*
Begin critical section by locking the spartan mutex variable.
*/
mysql_mutex_lock(&share->mutex);
share->data_class->update_row((uchar *)old_data, new_data,
table->s->rec_buff_length, current_position -
share->data_class->row_size(table->s->rec_buff_length));
if (get_key() != 0)
{
share->index_class->update_key(get_key(), current_position -
share->data_class->row_size(table->s->rec_buff_length),
get_key_len());
share->index_class->save_index();
share->index_class->load_index();
}
/*
End section by unlocking the spartan mutex variable.
*/
mysql_mutex_unlock(&share->mutex);
DBUG_RETURN(0);
}
The delete method isn’t as complicated. In this case, the method just needs to delete the data row and remove the index from the in-memory structure, if one is found. Locate the delete_row() method in the class file and add the calls to the index class to delete the key, if one is found.Listing 10-44 shows the method with the changes.
Listing 10-44. Changes to the delete_row() Method in ha_spartan.cc
int ha_spartan::delete_row(const uchar *buf)
{
DBUG_ENTER("ha_spartan::delete_row");
long long pos;
if (current_position > 0)
pos = current_position -
share->data_class->row_size(table->s->rec_buff_length);
else
pos = 0;
/*
Begin critical section by locking the spartan mutex variable.
*/
mysql_mutex_lock(&share->mutex);
share->data_class->delete_row((uchar *)buf,
table->s->rec_buff_length, pos);
if (get_key() != 0)
share->index_class->delete_key(get_key(), pos, get_key_len());
/*
End section by unlocking the spartan mutex variable.
*/
mysql_mutex_unlock(&share->mutex);
DBUG_RETURN(0);
}
Likewise, the method for deleting all rows is very easy. In this case, we want to delete all data from the data and index file. Locate the delete_all_rows() method in the class file and add the calls to the index class to destroy the index and truncate the index file. Listing 10-45 shows the method with the changes.
Listing 10-45. Changes to the delete_all_rows() Method in ha_spartan.cc
int ha_spartan::delete_all_rows()
{
DBUG_ENTER("ha_spartan::delete_all_rows");
/*
Begin critical section by locking the spartan mutex variable.
*/
mysql_mutex_lock(&share->mutex);
share->data_class->trunc_table();
share->index_class->destroy_index();
share->index_class->trunc_index();
/*
End section by unlocking the spartan mutex variable.
*/
mysql_mutex_unlock(&share->mutex);
DBUG_RETURN(0);
}
The delete_table() method must delete both the data and index files. Locate the delete_table() method and add the code to call the my_delete() function to delete the index. Listing 10-46 shows the method with the changes.
Listing 10-46. Changes to the delete_table() Method in ha_spartan.cc
int ha_spartan::delete_table(const char *name)
{
DBUG_ENTER("ha_spartan::delete_table");
char name_buff[FN_REFLEN];
/*
Call the mysql delete file method.
Note: the fn_format() method correctly creates a file name from the
name passed into the method.
*/
my_delete(fn_format(name_buff, name, "", SDE_EXT,
MY_REPLACE_EXT|MY_UNPACK_FILENAME), MYF(0));
/*
Call the mysql delete file method.
Note: the fn_format() method correctly creates a file name from the
name passed into the method.
*/
my_delete(fn_format(name_buff, name, "", SDI_EXT,
MY_REPLACE_EXT|MY_UNPACK_FILENAME), MYF(0));
DBUG_RETURN(0);
}
The last change to the general read and write file operations is to the rename_table() method. The rename_table() method for the index follows the same pattern as the previous changes. Locate the rename_table() method in the class file and add the code to copy the index file. Listing 10-47 shows the method with the changes.
Listing 10-47. Changes to the rename_table() Method in ha_spartan.cc
int ha_spartan::rename_table(const char * from, const char * to)
{
DBUG_ENTER("ha_spartan::rename_table ");
char data_from[FN_REFLEN];
char data_to[FN_REFLEN];
char index_from[FN_REFLEN];
char index_to[FN_REFLEN];
my_copy(fn_format(data_from, from, "", SDE_EXT,
MY_REPLACE_EXT|MY_UNPACK_FILENAME),
fn_format(data_to, to, "", SDE_EXT,
MY_REPLACE_EXT|MY_UNPACK_FILENAME), MYF(0));
my_copy(fn_format(index_from, from, "", SDI_EXT,
MY_REPLACE_EXT|MY_UNPACK_FILENAME),
fn_format(index_to, to, "", SDI_EXT,
MY_REPLACE_EXT|MY_UNPACK_FILENAME), MYF(0));
/*
Delete the file using MySQL's delete file method.
*/
my_delete(data_from, MYF(0));
my_delete(index_from, MYF(0));
DBUG_RETURN(0);
}
Wow! That was a lot of changes. As you can see, supporting indexes has made the code much more complicated. I hope you now have a better appreciation for just how well the existing storage engines in MySQL are built. Now, let’s move on to making the changes to the indexing methods.
Several methods must be implemented to complete the indexing mechanism for a Stage 5 storage engine. Note as you go through these methods that some return a row from the data file based on the index passed in, whereas others return a key. The documentation isn’t clear about this, and the name of the parameter doesn’t give us much of a clue, but I show you how they are used. These methods must return either a key not found or an end-of-file return code. Take care to code these return statements correctly, or you could encounter some strange query results.
The first method is the index_read_map() method. This sets the row buffer to the row in the file that matches the key passed in. If the key passed in is null, the method should return the first key value in the file. Locate the index_read_map() method and add the code to get the file position from the index and read the corresponding row from the data file. Listing 10-48 shows the method with the changes.
Listing 10-48. Changes to the index_read_map() Method in ha_spartan.cc
int ha_spartan::index_read_map(uchar *buf, const uchar *key,
key_part_map keypart_map __attribute__((unused)),
enum ha_rkey_function find_flag
__attribute__((unused)))
{
int rc;
long long pos;
DBUG_ENTER("ha_spartan::index_read");
MYSQL_INDEX_READ_ROW_START(table_share->db.str, table_share->table_name.str);
if (key == NULL)
pos = share->index_class->get_first_pos();
else
pos = share->index_class->get_index_pos((uchar *)key, keypart_map);
if (pos == −1)
DBUG_RETURN(HA_ERR_KEY_NOT_FOUND);
current_position = pos + share->data_class->row_size(table->s->rec_buff_length);
rc = share->data_class->read_row(buf, table->s->rec_buff_length, pos);
share->index_class->get_next_key();
MYSQL_INDEX_READ_ROW_DONE(rc);
DBUG_RETURN(rc);
}
The next index method is index_next(). This method gets the next key in the index and returns the matching row from the data file. It is called during range index scans. Locate the index_next() method and add the code to get the next key from the index and read a row from the data file. Listing 10-49 shows the method with the changes.
Listing 10-49. Changes to the index_next() Method in ha_spartan.cc
int ha_spartan::index_next(uchar *buf)
{
int rc;
uchar *key = 0;
long long pos;
DBUG_ENTER("ha_spartan::index_next");
MYSQL_INDEX_READ_ROW_START(table_share->db.str, table_share->table_name.str);
key = share->index_class->get_next_key();
if (key == 0)
DBUG_RETURN(HA_ERR_END_OF_FILE);
pos = share->index_class->get_index_pos((uchar *)key, get_key_len());
share->index_class->seek_index(key, get_key_len());
share->index_class->get_next_key();
if (pos == −1)
DBUG_RETURN(HA_ERR_KEY_NOT_FOUND);
rc = share->data_class->read_row(buf, table->s->rec_buff_length, pos);
MYSQL_INDEX_READ_ROW_DONE(rc);
DBUG_RETURN(rc);
}
The next index method is also a range query. The index_prev() method gets the previous key in the index and returns the matching row from the data file. It is called during range index scans. Locate the index_prev() method and add the code to get the previous key from the index and read a row from the data file. Listing 10-50 shows the method with the changes.
Listing 10-50. Changes to the index_prev() Method in ha_spartan.cc
int ha_spartan::index_prev(uchar *buf)
{
int rc;
uchar *key = 0;
long long pos;
DBUG_ENTER("ha_spartan::index_prev");
MYSQL_INDEX_READ_ROW_START(table_share->db.str, table_share->table_name.str);
key = share->index_class->get_prev_key();
if (key == 0)
DBUG_RETURN(HA_ERR_END_OF_FILE);
pos = share->index_class->get_index_pos((uchar *)key, get_key_len());
share->index_class->seek_index(key, get_key_len());
share->index_class->get_prev_key();
if (pos == −1)
DBUG_RETURN(HA_ERR_KEY_NOT_FOUND);
rc = share->data_class->read_row(buf, table->s->rec_buff_length, pos);
MYSQL_INDEX_READ_ROW_DONE(rc);
DBUG_RETURN(rc);
}
Notice that I had to move the index pointers around a bit to get the code for the next and previous to work. Range queries generate two calls to the index class the first time it is used: the first one gets the first key (index_read), and then the second calls the next key (index_next). Subsequent index calls are made to index_next(). Therefore, I must call the Spartan_index class method get_prev_key() to reset the keys correctly. This would be another great opportunity to rework the index class to work better with range queries in MySQL.
The next index method is also a range query. The index_first() method gets the first key in the index and returns it. Locate the index_first() method, and add the code to get the first key from the index and return the key. Listing 10-51 shows the method with the changes.
Listing 10-51. Changes to the index_first() Method in ha_spartan.cc
int ha_spartan::index_first(uchar *buf)
{
int rc;
uchar *key = 0;
DBUG_ENTER("ha_spartan::index_first");
MYSQL_INDEX_READ_ROW_START(table_share->db.str, table_share->table_name.str);
key = share->index_class->get_first_key();
if (key == 0)
DBUG_RETURN(HA_ERR_END_OF_FILE);
else
rc = 0;
memcpy(buf, key, get_key_len());
MYSQL_INDEX_READ_ROW_DONE(rc);
DBUG_RETURN(rc);
}
The last index method is one of the range queries as well. The index_last() method gets the last key in the index and returns it. Locate the index_last() method and add the code to get the last key from the index and return the key. Listing 10-52 shows the method with the changes.
Listing 10-52. Changes to the index_last() Method in ha_spartan.cc
int ha_spartan::index_last(uchar *buf)
{
int rc;
uchar *key = 0;
DBUG_ENTER("ha_spartan::index_last");
MYSQL_INDEX_READ_ROW_START(table_share->db.str, table_share->table_name.str);
key = share->index_class->get_last_key();
if (key == 0)
DBUG_RETURN(HA_ERR_END_OF_FILE);
else
rc = 0;
memcpy(buf, key, get_key_len());
MYSQL_INDEX_READ_ROW_DONE(rc);
DBUG_RETURN(rc);
}
Now compile the server and debug any errors. When that is done, you will have a completed Stage 5 engine. All that is left to do is compile the server and run the tests.
If you decide to debug the Spartan-storage-engine code, you may notice during debugging that some of the index methods may not get called. That is because the index methods are used in a variety of ways in the optimizer. The order of calls depends a lot on the choices that the optimizer makes. If you are curious (like me) and want to see each method fire, you’ll need to create a much larger data set and perform more complex queries. You can also check the source code and the reference manual for more details about each of the methods supported in the handler class.
Testing Stage 5 of the Spartan Engine
When you run the test again, you should see all of the statements complete successfully. Verify that everything is working in the Stage 4 engine and then move on to testing the index operations.
The index tests will require you to have a table created and to have data in it. You can always add data using the normal INSERT statements as before. Now you need to test the index. Enter a command that has a WHERE clause on the index column (col_a), such as:
SELECT * FROM t1 WHERE col_a = 2;
When you run that command, you should see the row returned. That isn’t very interesting, is it? You’ve done all that work, and it just returns the row anyway. The best way to know that the indexes are working is to have large data tables with a diverse range of index values. That would take a while to do, and I encourage you to do so.
There’s another way. You can launch the server, attach breakpoints (using your debugger) in the source code, and issue the index-based queries. That may sound like lots of work, and you may not have time to run but a few examples. That’s fine, because you can add that functionality to the test file. You can add the key column to the CREATE and add more SELECT statements with WHERE clauses to perform point and range queries. Listing 10-53 shows the updated Ch10s5.test file.
Listing 10-53. Updated Spartan Storage Engine Test File (Ch10s5.test)
#
# Simple test for the Spartan storage engine
#
--disable_warnings
drop table if exists t1;
--enable_warnings
CREATE TABLE t1 (
col_a int KEY,
col_b varchar(20),
col_c int
) ENGINE=SPARTAN;
INSERT INTO t1 VALUES (1, "first test", 24);
INSERT INTO t1 VALUES (2, "second test", 43);
INSERT INTO t1 VALUES (9, "fourth test", -2);
INSERT INTO t1 VALUES (3, 'eighth test', -22);
INSERT INTO t1 VALUES (4, "tenth test", 11);
INSERT INTO t1 VALUES (8, "seventh test", 20);
INSERT INTO t1 VALUES (5, "third test", 100);
SELECT * FROM t1;
UPDATE t1 SET col_b = "Updated!" WHERE col_a = 1;
SELECT * from t1;
UPDATE t1 SET col_b = "Updated!" WHERE col_a = 3;
SELECT * from t1;
UPDATE t1 SET col_b = "Updated!" WHERE col_a = 5;
SELECT * from t1;
DELETE FROM t1 WHERE col_a = 1;
SELECT * FROM t1;
DELETE FROM t1 WHERE col_a = 3;
SELECT * FROM t1;
DELETE FROM t1 WHERE col_a = 5;
SELECT * FROM t1;
SELECT * FROM t1 WHERE col_a = 4;
SELECT * FROM t1 WHERE col_a >= 2 AND col_a <= 5;
SELECT * FROM t1 WHERE col_a = 22;
DELETE FROM t1 WHERE col_a = 5;
SELECT * FROM t1;
SELECT * FROM t1 WHERE col_a = 5;
UPDATE t1 SET col_a = 99 WHERE col_a = 8;
SELECT * FROM t1 WHERE col_a = 8;
SELECT * FROM t1 WHERE col_a = 99;
RENAME TABLE t1 TO t2;
SELECT * FROM t2;
DROP TABLE t2;
Notice that I’ve changed some of the INSERT statements to make the index methods work. Run that test and see what it does. Listing 10-54 shows an example of the expected results for this test. When you run the test under the test suite, it should complete without errors.
Listing 10-54. Sample Results of Stage 5 Test
mysql> INSTALL PLUGIN spartan SONAME 'ha_spartan.so';
Query OK, 0 rows affected (0.01 sec)
mysql> use test;
Database changed
mysql> CREATE TABLE t1 (col_a int, col_b varchar(20), col_c int) ENGINE=SPARTAN;
Query OK, 0 rows affected (0.04 sec)
mysql> INSERT INTO t1 VALUES (1, "first test", 24);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO t1 VALUES (2, "second test", 43);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO t1 VALUES (9, "fourth test", -2);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO t1 VALUES (3, 'eighth test', -22);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO t1 VALUES (4, "tenth test", 11);
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO t1 VALUES (8, "seventh test", 20);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO t1 VALUES (5, "third test", 100);
Query OK, 1 row affected (0.01 sec)
mysql> SELECT * FROM t1;
+−−-----+−−------------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−------------+−−-----+
| 1 | first test | 24 |
| 2 | second test | 43 |
| 9 | fourth test | -2 |
| 3 | eighth test | -22 |
| 4 | tenth test | 11 |
| 8 | seventh test | 20 |
| 5 | third test | 100 |
+−−-----+−−------------+−−-----+
7 rows in set (0.00 sec)
mysql> UPDATE t1 SET col_b = "Updated!" WHERE col_a = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SELECT * from t1;
+−−-----+−−------------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−------------+−−-----+
| 1 | Updated! | 24 |
| 2 | second test | 43 |
| 9 | fourth test | -2 |
| 3 | eighth test | -22 |
| 4 | tenth test | 11 |
| 8 | seventh test | 20 |
| 5 | third test | 100 |
+−−-----+−−------------+−−-----+
7 rows in set (0.00 sec)
mysql> UPDATE t1 SET col_b = "Updated!" WHERE col_a = 3;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SELECT * from t1;
+−−-----+−−------------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−------------+−−-----+
| 1 | Updated! | 24 |
| 2 | second test | 43 |
| 9 | fourth test | -2 |
| 3 | Updated! | -22 |
| 4 | tenth test | 11 |
| 8 | seventh test | 20 |
| 5 | third test | 100 |
+−−-----+−−------------+−−-----+
7 rows in set (0.01 sec)
mysql> UPDATE t1 SET col_b = "Updated!" WHERE col_a = 5;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SELECT * from t1;
+−−-----+−−------------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−------------+−−-----+
| 1 | Updated! | 24 |
| 2 | second test | 43 |
| 9 | fourth test | -2 |
| 3 | Updated! | -22 |
| 4 | tenth test | 11 |
| 8 | seventh test | 20 |
| 5 | Updated! | 100 |
+−−-----+−−------------+−−-----+
7 rows in set (0.00 sec)
mysql> DELETE FROM t1 WHERE col_a = 1;
Query OK, 1 row affected (0.01 sec)
mysql> SELECT * FROM t1;
+−−-----+−−------------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−------------+−−-----+
| 2 | second test | 43 |
| 9 | fourth test | -2 |
| 3 | Updated! | -22 |
| 4 | tenth test | 11 |
| 8 | seventh test | 20 |
| 5 | Updated! | 100 |
+−−-----+−−------------+−−-----+
6 rows in set (0.00 sec)
mysql> DELETE FROM t1 WHERE col_a = 3;
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM t1;
+−−-----+−−------------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−------------+−−-----+
| 2 | second test | 43 |
| 9 | fourth test | -2 |
| 4 | tenth test | 11 |
| 8 | seventh test | 20 |
| 5 | Updated! | 100 |
+−−-----+−−------------+−−-----+
5 rows in set (0.01 sec)
mysql> DELETE FROM t1 WHERE col_a = 5;
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM t1;
+−−-----+−−------------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−------------+−−-----+
| 2 | second test | 43 |
| 9 | fourth test | -2 |
| 4 | tenth test | 11 |
| 8 | seventh test | 20 |
+−−-----+−−------------+−−-----+
4 rows in set (0.00 sec)
mysql> SELECT * FROM t1 WHERE col_a = 4;
+−−-----+−−----------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−----------+−−-----+
| 4 | tenth test | 11 |
+−−-----+−−----------+−−-----+
1 row in set (0.01 sec)
mysql> SELECT * FROM t1 WHERE col_a >= 2 AND col_a <= 5;
+−−-----+−−-----------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−-----------+−−-----+
| 2 | second test | 43 |
| 4 | tenth test | 11 |
+−−-----+−−-----------+−−-----+
2 rows in set (0.00 sec)
mysql> SELECT * FROM t1 WHERE col_a = 22;
Empty set (0.01 sec)
mysql> DELETE FROM t1 WHERE col_a = 5;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM t1;
+−−-----+−−------------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−------------+−−-----+
| 2 | second test | 43 |
| 9 | fourth test | -2 |
| 4 | tenth test | 11 |
| 8 | seventh test | 20 |
+−−-----+−−------------+−−-----+
4 rows in set (0.00 sec)
mysql> SELECT * FROM t1 WHERE col_a = 5;
Empty set (0.00 sec)
mysql> UPDATE t1 SET col_a = 99 WHERE col_a = 8;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SELECT * FROM t1 WHERE col_a = 8;
Empty set (0.01 sec)
mysql> SELECT * FROM t1 WHERE col_a = 99;
+−−-----+−−------------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−------------+−−-----+
| 99 | seventh test | 20 |
+−−-----+−−------------+−−-----+
1 row in set (0.00 sec)
mysql> RENAME TABLE t1 TO t2;
Query OK, 0 rows affected (0.01 sec)
mysql> SELECT * FROM t2;
+−−-----+−−------------+−−-----+
| col_a | col_b | col_c |
+−−-----+−−------------+−−-----+
| 2 | second test | 43 |
| 9 | fourth test | -2 |
| 4 | tenth test | 11 |
| 99 | seventh test | 20 |
+−−-----+−−------------+−−-----+
4 rows in set (0.01 sec)
mysql> DROP TABLE t2;
Query OK, 0 rows affected (0.00 sec)
mysql>
That’s it for a Stage 5 engine. It is now a basic read/write/update/delete storage engine with indexing, which is the stage at which most of the storage engines in MySQL are implemented. Indeed, for all but transactional environments, this should be sufficient for your storage needs. In the next stage, I discuss the much more complex topic of adding transaction support.
Stage 6: Adding Transaction Support
Currently, the only storage engine in MySQL that supports transactions is InnoDB.7 Transactions provide a mechanism that permits a set of operations to execute as a single atomic operation. For example, if a database was built for a banking institution, the macro operations of transferring money from one account to another (money removed from one account and placed in another) would preferably be executed completely without interruption. Transactions permit these operations to be encased in an atomic operation that will back out any changes should an error occur before all operations are complete, thus avoiding data being removed from one table and never making it to the next table. A sample set of operations in the form of SQL statements encased in transactional commands is shown in Listing 10-55.
Listing 10-55. Sample Transaction SQL Commands
START TRANSACTION;
UPDATE SavingsAccount SET Balance = Balance—100
WHERE AccountNum = 123;
UPDATE CheckingAccount SET Balance = Balance + 100
WHERE AccountNum = 345;
COMMIT;
In practice, most database professionals specify the MyISAM table type if they require faster access and InnoDB if they need transaction support. Fortunately, Oracle has provided the storage-engine plugin with the capability to support transactions.
The facilities for performing transactions in storage engines is supported by the start_stmt() and external_lock() methods. The start_stmt() method is called when a transaction is started. The external_lock() method is used to signal a specific lock for a table and is called when an explicit lock is issued. Your storage engine must implement the new transaction in the start_stmt() method by creating a savepoint and registering the transaction with the server using the trans_register_ha() method. This method takes as parameters the current thread, whether you want to set the transaction across all threads, and the address of your handlerton. Calling this causes the transaction to start. An example implementation of the start_stmt() method is shown in Listing 10-56.
Listing 10-56. Example start_stmt() Method Implementation
int my_handler::start_stmt(THD *thd, thr_lock_type lock_type)
{
DBUG_ENTER("my_handler::index_last");
int error= 0;
/*
Save the transaction data
*/
my_txn *txn= (my_txn *) thd->ha_data[my_handler_hton.slot];
/*
If this is a new transaction, create it and save it to the
handler's slot in the ha_data array.
*/
if (txn == NULL)
thd->ha_data[my_handler_hton.slot]= txn= new my_txn;
/*
Start the transaction and create a savepoint then register
the transaction.
*/
if (txn->stmt == NULL && !(error= txn->tx_begin()))
{
txn->stmt= txn->new_savepoint();
trans_register_ha(thd, FALSE, &my_handler_hton);
}
DBUG_RETURN(error);
}
Starting a transaction from external_lock() is a bit more complicated. MySQL calls the external_lock() method for every table in use at the start of a transaction. Thus, you have some more work to do to detect the transaction and process it accordingly. This can be seen in the check of the trx->active_trans flag. The start transaction operation is also implied when the external_lock() method is called for the first table. Listing 10-57 shows an example implementation of the external_lock() method (some sections are omitted for brevity). See theha_innodb.cc file for the complete code.
Listing 10-57. Example external_lock() Method Implementation (from InnoDB)
int ha_innobase::external_lock(THD* thd, int Lock_type)
{
row_prebuilt_t* prebuilt = (row_prebuilt_t*) innobase_prebuilt;
trx_t* trx;
DBUG_ENTER("ha_innobase::external_lock");
DBUG_PRINT("enter",("lock_type: %d", lock_type));
update_thd(thd);
trx = prebuilt->trx;
prebuilt->sql_stat_start = TRUE;
prebuilt->hint_need_to_fetch_extra_cols = 0;
prebuilt->read_just_key = 0;
prebuilt->keep_other_fields_on_keyread = FALSE;
if (lock_type == F_WRLCK) {
/* If this is a SELECT, then it is in UPDATE TABLE ...
or SELECT ... FOR UPDATE */
prebuilt->select_lock_type = LOCK_X;
prebuilt->stored_select_lock_type = LOCK_X;
}
if (lock_type != F_UNLCK)
{
/* MySQL is setting a new table lock */
trx->detailed_error[0] = '\0';
/* Set the MySQL flag to mark that there is an active
transaction */
if (trx->active_trans == 0) {
innobase_register_trx_and_stmt(thd);
trx->active_trans = 1;
} else if (trx->n_mysql_tables_in_use == 0) {
innobase_register_stmt(thd);
}
trx->n_mysql_tables_in_use++;
prebuilt->mysql_has_locked = TRUE;
...
DBUG_RETURN(0);
}
/* MySQL is releasing a table lock */
trx->n_mysql_tables_in_use--;
prebuilt->mysql_has_locked = FALSE;
/* If the MySQL lock count drops to zero we know that the current SQL
statement has ended */
if (trx->n_mysql_tables_in_use == 0) {
...
DBUG_RETURN(0);
}
Now that you’ve seen how to start transactions, let’s see how they are stopped (also known as committed or rolled back). Committing a transaction just means writing the pending changes to disk, storing the appropriate keys, and cleaning up the transaction. Oracle provides a method in the handlerton (int (*commit)(THD *thd, bool all)) that can be implemented using the function description shown here. The parameters are the current thread and whether you want the entire set of commands committed.
int (*commit)(THD *thd, bool all);
Rolling back the transaction is more complicated. In this case, you have to undo everything that was done since the last start of the transaction. Oracle supports rollback using a callback in the handlerton (int (*rollback)(THD *thd, bool all)) that can be implemented using the function description shown here. The parameters are the current thread and whether the entire transaction should be rolled back.
int (*rollback)(THD *thd, bool all);
To implement transactions, the storage engine must provide some sort of buffer mechanism to hold the unsaved changes to the database. Some storage engines use heap-like structures; others use queues and similar internal-memory structures. If you are going to implement transactions in your storage engine, you’ll need to create an internal-caching (sometimes called versioning) mechanism. When a commit is issued, the data must be taken out of the buffer and written to disk. When a rollback occurs, the operations must be canceled and their changes reversed.
Savepoints are another transaction mechanism available to you for managing data during transactions. Savepoints are areas in memory that allow you to save information. You can use them to save information during a transaction. For example, you may want to save information about an internal buffer that you implement to store the “dirty” or “uncommitted” changes. The savepoint concept was created for just such a use.
Oracle provides several savepoint operations that you can define in your handlerton. These appear in lines 13 through 15 in the handlerton structure shown in Listing 10-1. The method descriptions for the savepoint methods are:
uint savepoint_offset;
int (*savepoint_set)(THD *thd, void *sv);
int (*savepoint_rollback)(THD *thd, void *sv);
int (*savepoint_release)(THD *thd, void *sv);
The savepoint_offset value is the size of the memory area you want to save. The savepoint_set() method allows you to set a value to the parameter sv and save it as a savepoint. The savepoint_rollback() method is called when a rollback operation is triggered. In this case, the server returns the information saved in sv to the method. Similarly, savepoint_release() is called when the server responds to a release savepoint event and also returns the data via the sv that was set as a savepoint. For more information about savepoints, see the MySQL source code and online reference manual.
![]() Tip For excellent examples of how the transaction facilities work, see the ha_innodb.cc source files. You can also find information in the online reference manual.
Tip For excellent examples of how the transaction facilities work, see the ha_innodb.cc source files. You can also find information in the online reference manual.
Simply adding transaction support using the MySQL mechanisms is not the end of the story. Storage engines that use indexes8 must provide mechanisms to permit transactions. These operations must be capable of marking nodes that have been changed by operations in a transaction, saving the original values of the data that have changed until such time that the transaction is complete. At this point, all the changes are committed to the physical store (for both the index and the data). This will require making changes to the Spartan_index class.
Clearly, implementing transactions in a storage-engine plugin requires a lot of careful thought and planning. I strongly suggest that if you are going to implement transactional support in your storage engine, you study the BDB and InnoDB storage engines as well as the online reference manual. You may even want to set up your debugger and watch the transactions execute. Whichever way you go with your implementation of transactions, rest assured that if you get it working, you will have something special. There are few excellent storage engines that support transactions and none (so far) that exceed the capabilities of the native MySQL storage engines.
Summary
In this chapter, I’ve taken you on a tour of the storage-engine plugin source code and showed you how to create your own storage engine. Through the Spartan storage engine, you learned how to construct a storage engine that can read and write data and that supports concurrent access and indexing. Although I explain all of the stages of building this storage engine, I leave adding transactional support for you to experiment with.
I have also not implemented all possible functions of a storage handler. Rather, I implemented just the basics. Now that you’ve seen the basics in action and had a chance to experiment, I recommend studying the online documentation and the source code while you design your own storage engine.
If you found this chapter a challenge, it’s OK. Creating a database physical-storage mechanism is not a trivial task. I hope you come away from this chapter with a better understanding of what it takes to build a storage engine and a proper respect for those MySQL storage engines that implement indexing and transaction support. Neither of these tasks are trivial endeavors.
Finally, I have seen several areas of possible improvement for the data and index classes I have provided. While the data class seems fine for most applications, the index class could be improved. If you plan to use these classes as a jumping-off point for your own storage engine, I suggest getting your storage engine working with the classes as they are now and then going back and either updating or replacing them.
I recommend updating several areas in particular in the index class. Perhaps the most important change I recommend is changing the internal buffer to a more efficient tree structure. There are many to choose from, such as the ubiquitous B-tree or hash mechanism. I also suggest that you change the way the class handles range queries. Last, changes need to be made to handle transaction support. The class needs to support whatever buffer mechanism you use to handle commits and rollbacks.
In the next chapter, I discuss some advanced topics in database-server design and implementation. The chapter will prepare you for using the MySQL server source code as an experimental platform for studying database-system internals.
1 The use of clustered indexes and other data-file optimizations notwithstanding.
2 Some special storage engines may not need to write data at all. For example, the BLACKHOLE storage engine does not actually implement any write functions. Hey, it’s a blackhole!
3 It is more correct to refer to the data the storage engine is reading and writing as a storage medium, because there is nothing that stipulates that the data must reside on traditional data-storage mechanisms.
4 The MyISAM and InnoDB storage engines contain additional source files. These are the oldest of the storage engines, and they are the most complex.
5 The inspiration for this chapter was the lack of coverage available for those seeking to develop their own storage engines. Very few references go beyond creating a Stage 1 engine in their examples.
6 Well, maybe the low-level I/O source code. It’s always possible that I’ve missed something or that something has changed in the server since I wrote that class.
7 The cluster storage engine (NDB) also supports transactions.
8 For the record, it is possible to have a Stage 6 engine that does not support indexes. Indexes are not required for transaction processing. Uniqueness should be a concern, however, and performance will suffer.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.