Expert MySQL: Second Edition (2012)
Part III. Advanced Database Internals
Getting Started with MySQL DevelopmentPart 3 delves deeper into the MySQL system and gives you an insider’s look at what makes the system work. Chapter 11 revisits the topic of query execution in the MySQL architecture and introduces how you can conduct experiments with the source code. Chapter 12 presents the MySQL internal query representation and provides an example alternative query representation. Chapter 13 introduces the MySQL internal query optimizer; it describes an example of an alternative query optimizer that uses the internal representation implementation from the previous chapter. The chapter also shows you how to alter the MySQL source code to implement the alternative query optimizer. Chapter 14 combines the techniques from the previous chapters to implement an alternative query-processing engine.
Chapter 11. Database System Internals
This chapter presents some database-system internals concepts in preparation for studying database-system internals at a deeper level. I present more in-depth coverage of how queries are represented internally within the server and how queries are executed. I explore these topics from a more general viewpoint and then close the chapter with a discussion of how you can use the MySQL system to conduct your own experiments with the MySQL system internals. Last, I’ll introduce the database system’s internals experiment project.
Query Execution
Most database systems use either an iterative or an interpretative execution strategy. Iterative methods provide ways to produce a sequence of calls available for processing discrete operations (e.g., join, project, etc.), but are not designed to incorporate the features of the internal representation. Translation of queries into iterative methods uses techniques of functional programming and program transformation. Several algorithms generate iterative programs from relational algebra–based query specifications.
The implementation of the query-execution mechanism creates a set of defined compiled functional primitives, formed using a high-level language, that are then linked together via a call stack or procedural call sequence. When a query-execution plan is created and selected for execution, a compiler (usually the same one used to create the database system) is used to compile the procedural calls into a binary executable. Because of the high cost of the iterative method, compiled execution plans are typically stored for reuse for similar or identical queries.
Interpretative methods, on the other hand, perform query execution using existing compiled abstractions of basic operations. The query-execution plan chosen is reconstructed as a queue of method calls that are each taken off the queue and processed; the results are then placed in memory for use with the next or subsequent calls. Implementation of this strategy is often called lazy evaluation, because the available compiled methods are not optimized for best performance; rather, they are optimized for generality.
MySQL Query Execution Revisited
Query processing and execution in MySQL is interpretive. It is implemented using a threaded architecture whereby each query is given its own thread of execution. Figure 11-1 depicts a block diagram that describes the MySQL query processing methodology.
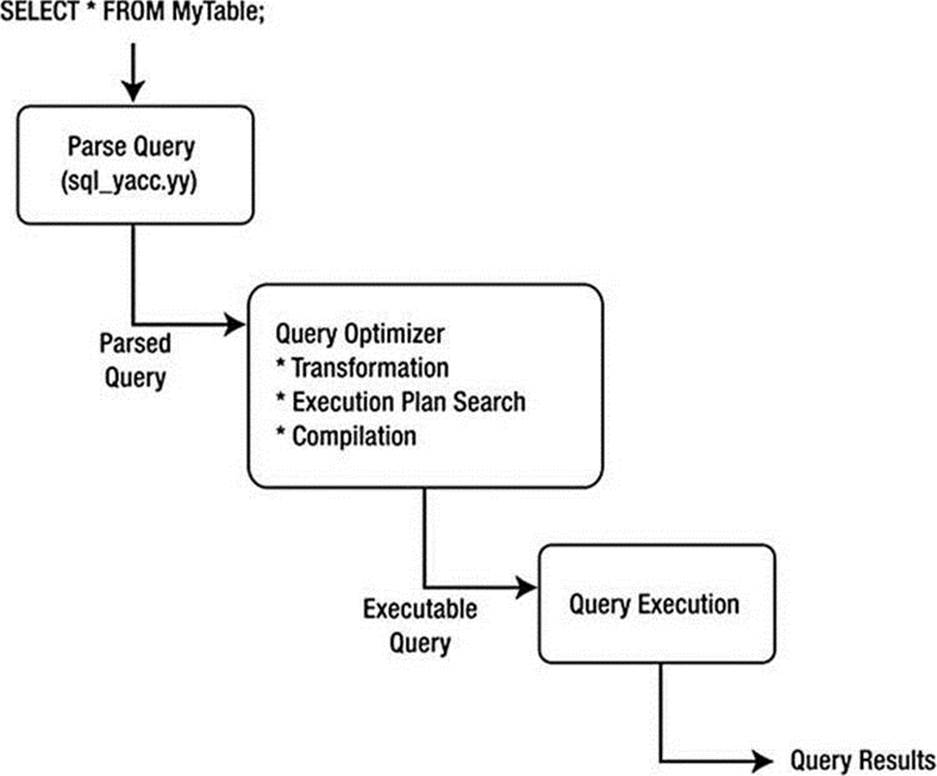
Figure 11-1. MySQL query execution
When a client issues a query, a new thread is created, and the SQL statement is forwarded to the parser for syntactic validation (or rejection due to errors). As you saw in the previous chapter, the MySQL parser is implemented using a large Lex-YACC script that is compiled with Bison. The parser constructs a data structure used to hold the query. This data structure, or query structure, can be used to execute the query. Once the query structure is created, control passes to the query processor, which performs checks such as verifying table integrity and security access. Once the required access is granted and the tables are opened (and locked if the query is an update), control is passed to individual methods that execute the basic query operations, such as select, restrict, and project. Optimization is applied to the data structure by ordering the lists of tables and operations to form a more efficient query based on common practices. This form of optimization is called a SELECT-PROJECT-JOIN query processor. The results of the query operations are returned to the client using established communication protocols and access methods.
What Is a Compiled Query?
One often confusing area understanding what “compiled” means. A compiled query is an actual compilation of an iterative query-execution plan, but some researchers (such as C. J. Date) consider a compiled query one that has been optimized and stored for future execution. As a result, you must take care when considering using a compiled query. In this work, the use of the word compiled is avoided, because the query optimizer and execution engine do not store the query execution plan for later reuse, nor does the query execution require any compilation or assembly to work.
![]() Note The concept of a stored procedure is a saved plan—it is compiled, or optimized, for execution at a later date and can be run many times on data that meet its input parameters.
Note The concept of a stored procedure is a saved plan—it is compiled, or optimized, for execution at a later date and can be run many times on data that meet its input parameters.
Exploring MySQL Internals
How can you teach someone how an optimizer works without allowing him to get his hands dirty with a project? Furthermore, how can you be expected to know the internals of a database system without actually seeing them? I answer these questions in this section by discussing how MySQL can be used as an experimental test bed for professionals and academics alike.
Getting Started Using MySQL for Experiments
There are several ways to use MySQL to conduct experiments. For example, you could study the internal components using an interactive debugger, or you could use the MySQL system as a host for your own implementation of internal-database technologies. Another useful way to look at how the server behaves internally would be to turn on tracing and read the traces generated by using a server compiled with debug turned on. See Chapter 5 for more details on debug tracing.
If you are going to conduct experiments, use a dedicated server for the experiments. This is important if you plan to use MySQL to develop your own extensions. You don’t want to risk contamination of your development server by the experiments.
Experimenting with the MySQL Source Code
The most invasive method of experimenting with MySQL is through modifications to the source code. This involves observing the system as it runs and then designing experiments to change portions by replacing an algorithm or section of code with another, and then observing the changes in behavior. Although this approach will enable you to investigate the internal workings of MySQL, making changes to the source code in this manner may result in the server becoming too unstable for use—especially if you push the envelope of the algorithms and data structures or ,worse, violate memory references. There is no better way to learn the source code than to observe it in action, however. Tests conducted in this manner can then be used to gather data for other forms of experimentation.
Using MySQL As a Host for Experimental Technologies
A less-invasive method of conducting experiments with MySQL is by using MySQL as a host for your own experimental code. This allows you to focus on the optimizer and the execution engine without worrying about the other parts of the system. There are a great many parts to a database system. To name only a few, there are subcomponents in MySQL for network communication, data input, and access control, and even utilities for using and managing files and memory. Rather than create your own subcomponents, you can use MySQL’s resources in your own code.
I’ve implemented the experiment project described in this book using this method. I’ll show you how to connect to the MySQL parser and use the MySQL parser to read, test, and accept valid commands and redirect the code to the experimental project optimizer and execution routines.
The parser and lexical analyzer identify strings of alphanumeric characters (also known as tokens) that have been defined in the parser or lexical hash. The parser tags all of the tokens with location information (the order of appearance in the stream), and identifies literals and numbers using logic that recognizes specific patterns of the nontoken strings. Once the parser is done, control returns to the lexical analyzer. The lexical analyzer in MySQL is designed to recognize specific patterns of the tokens and nontokens. Once valid commands are identified, control is then passed to the execution code for each command. The MySQL parser and lexical analyzer can be modified to include the new tokens, or keywords, for the experiment. See Chapter 7 for more details on how to modify the parser and lexical analyzer. The commands can be designed to mimic those of SQL, representing the typical data-manipulation commands, such as select, update, insert, and delete, as well as the typical data-definition commands, such as create and drop.
Once control is passed to the experimental optimization/execution engine, the experiments can be run using the MySQL internal-query-representation structures or converted to another structure. From there, experimental implementation for query optimization and execution can be run, and the results returned to the client by using the MySQL system. This allows you to use the network communication and parsing subcomponents while implementing your own internal database components.
Running Multiple Instances of MySQL
One lesser-known fact about the MySQL server is that it is possible to run multiple instances of the server on a single machine. This allows you to run your modified MySQL system on the same machine as your development installation. You may want to do this if your resources are limited or if you want to run your modified server on the same machine as another installation for comparison purposes. Running multiple instances of MySQL requires specifying certain parameters on the command line or in the configuration file.
VIRTUAL MACHINES TO THE RESCUE
You can also leverage a virtual machine to further isolate your experiments. To make the most of this option, you can configure a virtual machine with a basic MySQL server installation and then clone the machine. This permits you to run an instance of MySQL as if it were on a separate machine. Some virtual-machine environments also allow you to take snapshots of the machine while it is running, which permits you to restart the session at the moment of the snapshot. This can save you a lot of time in setting up your test environment. I often choose this method when faced with a complicated or lengthy test-environment setup.
There are many virtual environments from which to choose. The open-source Oracle VirtualBox is a great choice for academics and those looking to save money. VirtualBox runs on most platforms and offers all the features you need to set up a host of virtual MySQL servers. VMWare’s software is expensive, but it offers more features. If you run Mac OS X, VMWare’s Fusion and Parallel Desktop are both excellent low-cost alternatives.
At a minimum, you need to specify either a different TCP port or socket for the server to communicate on and specify different directories for the database files. An example of starting a second instance of MySQL on Windows is:
mysqld-debug.exe --port=3307 --datadir="c:/mysql/test_data" --console
In this example, I’m telling the server to use TCP port 3307 (the default is 3306) and to use a different data directory and run as a console application. To connect to the second instance of the server, I must tell the client to use the same port as the server. For example, to connect to my second instance, I’d launch the MySQL client utility with:
mysql.exe -uroot --port=3307
The --port parameter can also be used with the mysqladmin utility. For example, to shut down the second instance running on port 3307, issue the command:
mysqladmin.exe -uroot --port=3307 shutdown
There is a potential for problems with this technique. It is easy to forget which server you’re connected to. One way to prevent confusion or to avoid issuing a query (such as a DELETE or DROP) to the wrong server is to change the prompt on your MySQL client utilities to indicate the server to which you are connected.
For example, issue the command prompt DBXP-> to set your prompt for the MySQL client connected to the experimental server and prompt Development-> for the MySQL client connected to the development server. This technique allows you to see at a glance to which server you are about to issue a command. Examples of using the prompt command in the MySQL client are shown in Listing 11-1.
Listing 11-1. Example of Changing the MySQL Client Prompt for the Experimental Server
mysql> prompt DBXP->
PROMPT set to 'DBXP->'
DBXP->show databases;
+−−------------------+
| Database |
+−−------------------+
| information_schema |
| mysql |
| test |
+−−------------------+
3 rows in set (0.01 sec)
DBXP->
![]() Tip You can also set the current database in the prompt by using the \d option. For example, to set the prompt in the client connected to the experimental server, issue the command prompt DBXP:\d->. This sets the prompt to indicate that you are connected to the experimental server and the current database (specified by the last use command) separated by a colon (e.g., DBXP:TEST->).
Tip You can also set the current database in the prompt by using the \d option. For example, to set the prompt in the client connected to the experimental server, issue the command prompt DBXP:\d->. This sets the prompt to indicate that you are connected to the experimental server and the current database (specified by the last use command) separated by a colon (e.g., DBXP:TEST->).
You can use this technique to restrict access to your modified server. If you change the port number or socket, only those who know the correct parameters can connect to the server. This will enable you to minimize the risk of exposure of the modifications to the user population. If your development environment is diverse, with a lot of experimentation and research projects that share the same resources (which is often the case in academia), you may also want to take these steps to protect your own experiments from contamination of and by other projects. This isn’t normally a problem, but it helps to take the precaution.
![]() Caution If you use binary, query, or slow-query logs, you must also specify an alternative location for the log files for each instance of the MySQL server. Failure to do so may result in corruption of your log files and/or data.
Caution If you use binary, query, or slow-query logs, you must also specify an alternative location for the log files for each instance of the MySQL server. Failure to do so may result in corruption of your log files and/or data.
Limitations and Concerns
Perhaps the most challenging aspect of using MySQL for experimentation is modifying the parser to recognize the new keyword for the SQL commands (see Chapter 7). Although not precisely a complex or new implementation language, modification of the YACC files requires careful attention to the original developers’ intent. The solution involves placing copies of the SQL syntax definitions for the new commands at the top of each of the parser-command definitions. This permits you to intercept the flow of the parser in order to redirect the query execution.
The most frequent and least trivial challenge of all is keeping up with the constant changes to the MySQL code base. Unfortunately, the frequency of upgrades is unpredictable. If you want to keep up to date with feature changes, the integration of the experimental technologies requires reinserting the modifications to the MySQL source files with each release of the source code. This is probably not a concern for anyone wanting to experiment with MySQL. If you find yourself wanting to keep up with the changes because of extensions you are writing, you should probably use a source-code-management tool or build a second server for experimentation and do your development on the original server.
![]() Tip The challenge that you are most likely to encounter is examining the MySQL code base and discovering the meaning, layout, and use of the various internal data representations. The only way to overcome this is through familiarity. I encourage you to visit and read the documentation (the online MySQL reference manual) and articles on the MySQL Web site, blogs, and message forums. They are a wealth of information. While some are difficult to absorb, the concepts presented become clearer with each reading. Resist the temptation to become frustrated with the documentation. Give it a rest, then go back later and read it again. I find nuggets of useful information every time I (re)read the technical material.
Tip The challenge that you are most likely to encounter is examining the MySQL code base and discovering the meaning, layout, and use of the various internal data representations. The only way to overcome this is through familiarity. I encourage you to visit and read the documentation (the online MySQL reference manual) and articles on the MySQL Web site, blogs, and message forums. They are a wealth of information. While some are difficult to absorb, the concepts presented become clearer with each reading. Resist the temptation to become frustrated with the documentation. Give it a rest, then go back later and read it again. I find nuggets of useful information every time I (re)read the technical material.
The Database System Internals Experiment
I built the database experiment project (DBXP) to allow you to explore the MySQL internals and to let you explore some alternative-database-system internal implementations. You can use this experiment to learn more about how database systems are constructed and how they work under the hood.
Why an Experiment?
The DBXP is an experiment rather than a solution because it is incomplete. That is, the technologies are implemented with minimal error handling, a limited feature set, and low robustness.
This doesn’t mean the DBXP technologies can’t be modified for use as replacements for the MySQL system internals; rather, the DBXP is designed for exploration rather than production.
Overview of the Experiment Project
The DBXP project is a series of classes that implement alternative algorithms and mechanisms for internal-query representation, query optimization, query execution, and file access. This not only gives you an opportunity to explore an advanced implementation of query-optimization theory, but it also enables the core of the DBXP technology to execute without modification of the MySQL internal operation. This provides the additional security that the native MySQL core executable code will not be affected by the addition of the DBXP technologies. This added benefit can help mitigate some of the risks of modifying an existing system.
Implementation of the MySQL parser (see sql_parse.cc) directs control to specific instances of the execution subprocesses by making calls to functions implemented for each SQL command. For example, the SHOW command is redirected to functions implemented in thesql_show.cc file. The MySQL parser code in sql_parse.cc needs to be modified to redirect processing to the DBXP query processor.
The first step in the DBXP query processor is to convert the MySQL internal-query representation to the experimental internal representation. The internal representation chosen is called a query tree, in which each node contains an atomic relational operation (select, project, join, etc.) and the links represent data flow. Figure 11-2 shows a conceptual example of a query tree. In the example, I use the notation: project/select (Π), restrict (Σ), and join (Φ). The arrows represent how data would flow from the tables up to the root. A join operation is represented as a node with two children. As data are presented from each child, the join operation is able to process that data and pass the results to the next node up in the tree (its parent). Each node can have zero, one, or two children and has exactly one parent.
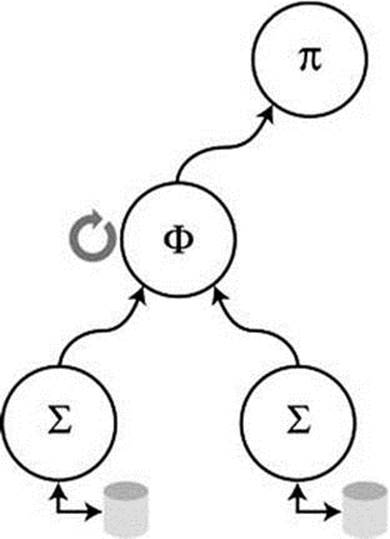
Figure 11-2. Query tree concept
The query tree was chosen because it permits the DBXP query optimizer to use tree-manipulation algorithms. That is, optimization uses the tree structure and tree-manipulation algorithms to arrange nodes in the tree in a more efficient execution order. Furthermore, execution of the optimized query is accomplished by traversing the tree to the leaf nodes, performing the operation as specified by the node, and passing information back up the links. This technique also made possible execution in a pipeline fashion, with data passed from the leaf nodes to the root node one data item at a time.
Traversing the tree down to a leaf for one data item and returning it back up the tree (a process known as pulsing) permits each node to process one data item, returning one row at a time in the result set. This pulsing, or polling, of the tree permits the execution of the pipeline. The result is a faster initial return of query results and a perceived faster transmission time of the query results to the client. Witnessing the query results returning more quickly—although not all at once—gives the user the perception of faster queries.
Using MySQL to host the DBXP implementation begins at the MySQL parser, where the DBXP code takes over the optimization and execution of the query and then returns the results to the client one row at a time using the MySQL network-communications utilities.
Components of the Experiment Project
The experiment project is designed to introduce you to alternatives to how database-systems internals could be implemented and to allow you to explore the implementations by adding your own modifications to the project. DBXP is implemented using a set of simple C++ classes that represent objects in a database system.
There are classes for tuples, relations, indexes, and the query tree. Additional classes have been added to manage multiuser access to the tables. An example high-level architecture of the DBXP is shown in Figure 11-3.
A complete list of the major classes in the project is shown in Table 11-1. The classes are stored in source files by the same name as the class (e.g., the Attribute class is defined and implemented in the files named attribute.h and attribute.cc, respectively).
Table 11-1. Database Internals Experiment Project Classes
|
Class |
Description |
|
Query_tree |
Provides internal representation of the query. Also contains thequery optimizer. |
|
Expression |
Provides an expression evaluation mechanism. |
|
Attribute |
Operations for storing and manipulating an attribute (column) for a tuple (row). |
These classes represent the basic building blocks of a database system. Chapters 12 through 14 contain a complete explanation of the query tree, heuristic optimizer, and pipeline execution algorithms. The chapters also include overviews of the utility. I’ll show you the implementation details of some parts (the most complex) of the DBXP implementation and leave the rest for you to implement as exercises.
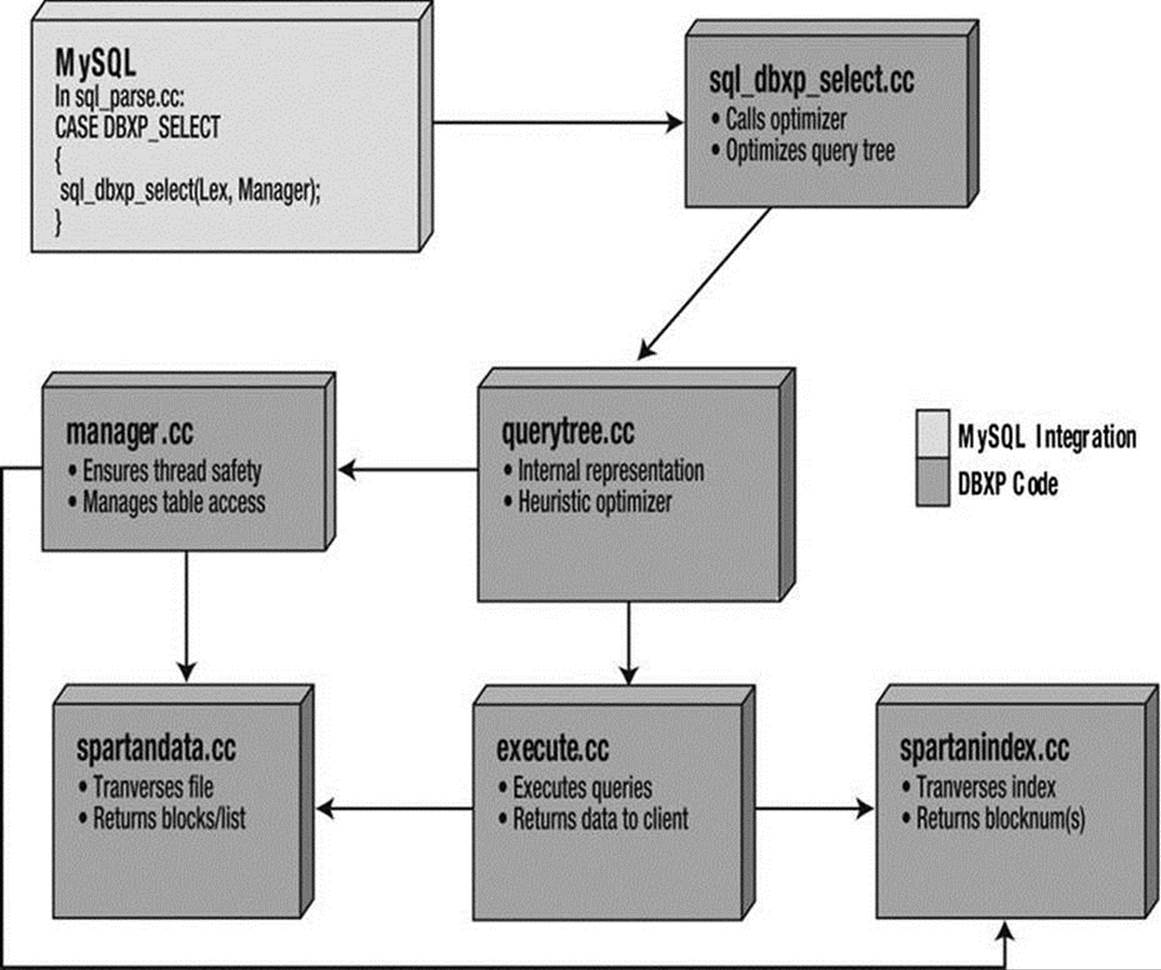
Figure 11-3. High-level diagram of the experiment project
![]() Note Suggestions on how to use the experiment project in a classroom setting are presented in the introduction section of this book.
Note Suggestions on how to use the experiment project in a classroom setting are presented in the introduction section of this book.
Conducting the Experiments
Running the experiments requires modifying the cmake files for the new project and compiling them with the MySQL server. None of the project files requires any special compilation or libraries. Details of the modifications to the MySQL configuration and cmake files are discussed in the next chapter, in which I show you how to stub out the SQL commands for the experiment.
If you haven’t tried the example programs from the previous chapters I’ve included the basic process for building and running the DBXP experiment projects below.
1. Modify the CMakeLists.txt file in the /sql folder.
2. Run ‘cmake.’ from the root of the source tree.
3. Run ‘make’ from the root of the source tree.
4. Stop your server and copy the executable to your binary directory.
5. Restart the server and connect via the MySQL client to run the DBXP SQL commands.
Summary
In this chapter, I have presented some of the more complex database-internal technologies. You learned about how queries are represented internally within the server and how they are executed. More important, you discovered how MySQL can be used to conduct your own database-internals experiments. The knowledge of these technologies should provide you with a greater understanding of why and how the MySQL system was built and how it executes.
In the next chapter, I show you more about internal-query representation through an example implementation of a query-tree structure. The next chapter begins a series of chapters designed as a baseline for you to implement your own query optimizer and execution engine. If you’ve ever wondered what it takes to build a database system, the next chapters will show you how to get started on your own query engine.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.