Expert MySQL: Second Edition (2012)
Part III. Advanced Database Internals
Chapter 12. Internal Query Representation
This chapter presents the first part of the advanced database technologies for the database-experiment project (DBXP). I begin by introducing the concept of the query tree structure, which is used for storing a query in memory. Next, I’ll present the query tree structure used for the project along with the first in a series of short projects for implementing the DBXP code. The chapter concludes with a set of exercises you can use to learn more about MySQL and query trees.
The Query Tree
A query tree is a tree structure that corresponds to a query, in which leaf nodes of the tree contain nodes that access a relation and internal nodes with zero, one, or more children. The internal nodes contain the relational operators. These operators include project (depicted as π), restrict (depicted as σ), and join (depicted as either θ or ![]() ).1 The edges of a tree represent data flow from bottom to top—that is, from the leaves, which correspond to reading data in the database, to the root, which is the final operator producing the query results. Figure 12-1 depicts an example of a query tree.
).1 The edges of a tree represent data flow from bottom to top—that is, from the leaves, which correspond to reading data in the database, to the root, which is the final operator producing the query results. Figure 12-1 depicts an example of a query tree.
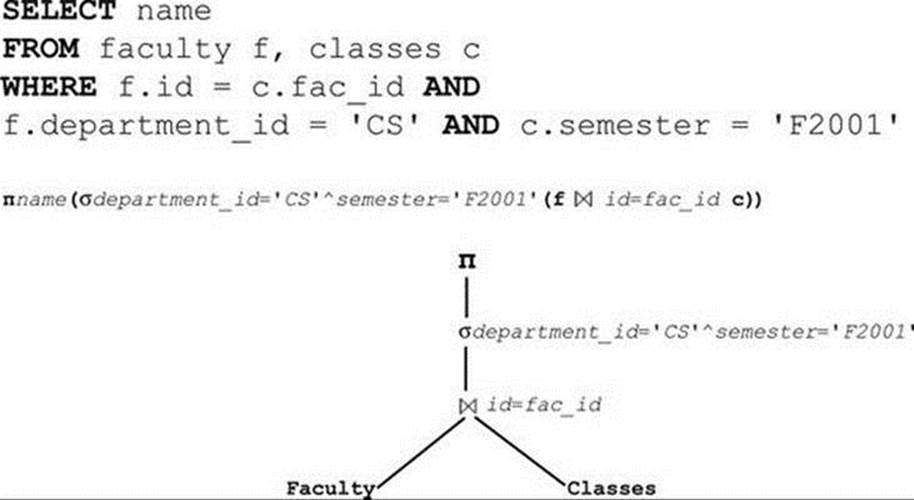
Figure 12-1. An Example Query Tree2
An evaluation of the query tree consists of evaluating an internal node operation whenever its operands are available and passing the results from evaluating the operation up the tree to the parent node. The evaluation terminates when the root node is evaluated and replaced by the tuples that form the result of the query. The following sections present a variant of the query tree structure for use in storing representations of queries in memory. The advantages of using this mechanism versus a relational calculus internal representation are shown in Table 12-1.
Table 12-1. Advantages of Using a Query Tree vs. Relational Calculus
|
Operational Requirement |
Query Tree |
Relational Calculus |
|
Can it be reduced? |
Yes. It is possible to prune the query tree prior to evaluating query plans. |
Only through application of algebraic operations. |
|
Can it support execution? |
Yes. The tree can be used to execute queries by passing dataup the tree. |
No. Requires translation to another form. |
|
Can it support relational algebra expressions? |
Yes. The tree lends itself well to relational algebra. |
No. Requires conversion. |
|
Can it be implementedin database systems? |
Yes. Tree structures are acommon data structure. |
Only through designs that model the calculus. |
|
Can it contain data? |
Yes. The tree nodes can contain data, operations, and expressions. |
No. Only the literals and variables that form the expression. |
Clearly, the query-tree internal representation is superior to the more traditional mechanism employed in modern database systems. For example, the internal representation in MySQL is that of a set of classes and structures designed to contain the query and its elements for easy (fast) traversal. It organizes data for the optimization and execution.3
There are some disadvantages to the query-tree internal representation. Most optimizers are not designed to work within a tree structure. If you wanted to use the query tree with an optimizer, the optimizer would have to be altered. Similarly, query execution will be very different from most query-processing implementations. In this case, the query execution engine will be running from the tree rather than as a separate step. These disadvantages are addressed in later chapters as I explore an alternative optimizer and execution engine.
The DBXP query tree is a tree data structure that uses a node structure that contains all of the parameters necessary to represent these operations:
· Restriction: Allows you to include results that match an expression of the attributes.
· Projection: Provides the ability to select attributes to include in the result set.
· Join: Lets you combine two or more relations to form a composite set of attributes in the result set.
· Sort (order by): Allows you to order the result set.
· Distinct: Provides the ability to reduce the result set to unique tuples.
![]() Note Distinct is an operation that is added to accomplish a relational operation that isn’t supported by most SQL implementations and is not an inherent property of relational algebra.
Note Distinct is an operation that is added to accomplish a relational operation that isn’t supported by most SQL implementations and is not an inherent property of relational algebra.
Projection, restriction, and join are the basic operations. Sort and distinct are provided as additional utility operations that assist in the formulation of a complete query tree (all possible operations are represented as nodes). Join operations can have join conditions (theta-joins) or no conditions (equi-joins). The join operation is subdivided into the operations:
· Inner: The join of two relations returning tuples where there is a match.
· Outer (left, right, full): Return all rows from at least one of the tables or views mentioned in the FROM clause, as long as those rows meet any WHERE search conditions. All rows are retrieved from the left table referenced with a left outer join, and all rows from the right table are referenced in a right outer join. All rows from both tables are returned in a full outer join. Values for attributes of nonmatching rows are returned as null values.
· Leftouter: The join of two relations returning tuples where there is a match, plus all tuples from the relation specified to the left, leaving nonmatching attributes specified from the other relation empty (null).
· Rightouter: The join of two relations returning tuples where there is a match, plus all tuples from the relation specified to the right, leaving nonmatching attributes specified from the other relation empty (null).
· Fullouter: The join of two relations returning all tuples from both relations, leaving nonmatching attributes specified from the other relation empty (null).
· Crossproduct: The join of two relations mapping each tuple from the first relation to all tuples from the other relation.
The query tree also supports some set operations. The set operations supported include:
· Intersect: The set operation where only matches from two relations with the same schema are returned.
· Union: The set operation where only the nonmatches from two relations with the same schema are returned.
What Is a Theta-Join?
You may be wondering why some joins are called equi-joins while others are called theta-joins. Equi-joins are joins in which the join condition is an equality (=). A theta-join is a join in which the join condition is an inequality (>, <, >=, <=, <>). Technically, all joins are theta-joins. Theta-joins are used less often, whereas equi-joins are common.
While the DBXP query trees provide the union and intersect operations, most database systems support unions in the form of a concatenation of result sets. Although the MySQL parser does not currently support intersect operations, however, it does support unions. Further modification of the MySQL parser is necessary to implement the intersect operation. The following sections describe the major code implementations and classes created to transform MySQL query representation to a DBXP query tree.
Query Transformation
The MySQL parser must be modified to identify and parse the SQL commands. We need, however, a way to tell the parser that we want to use the DBXP implementation and not the existing query engine. To make the changes easy, I simply added a keyword (e.g., DBXP) to the SQL commands that redirects the parsing to code that converts the MySQL internal representation into the DBXP internal representation. Although this process adds some execution time and requires a small amount of extra computational work, the implementation simplifies the modifications to the parser and provides a common mechanism to compare the DBXP data structure to that of the MySQL data structure. I refer to SQL commands with the DBXP keyword as simply DBXP SQL commands.
The process of transformation4 begins in the MySQL parser, which identifies commands as being DBXP commands. The system then directs control to a class named sql_dbxp_parse.cc that manages the transformation of the parsed query from the MySQL form to the DBXP internal representation (query tree). This is accomplished by a method named buid_query_tree. This method is called only for SELECT and EXPLAIN SELECT statements.
DBXP Query Tree
The heart of the DBXP query optimizer is the DBXP internal representation data structure. It is used to represent the query once the SQL command has been parsed and transformed.
This structure is implemented as a tree structure (hence the name query tree) in which each node has zero, one, or two children. Nodes with zero children are the leaves of the tree, those with one child represent internal nodes that perform unary operations on data, and those with two children are either join or set operations. The actual node structure from the source code is shown in Listing 12-1.
Listing 12-1. DBXP Query Tree Node
/*
STRUCTURE query_node
DESCRIPTION
This this structure contains all of the data for a query node:
NodeId -- the internal id number for a node
ParentNodeId -- the internal id for the parent node (used for insert)
SubQuery -- is this the start of a subquery?
Child -- is this a Left or Right child of the parent?
NodeType -- synonymous with operation type
JoinType -- if a join, this is the join operation
join_con_type -- if this is a join, this is the "on" condition
Expressions -- the expressions from the "where" clause for this node
Join Expressions -- the join expressions from the "join" clause(s)
Relations[] -- the relations for this operation (at most 4)
PreemptPipeline -- does the pipeline need to be halted for a sort?
Fields -- the attributes for the result set of this operation
Left -- a pointer to the left child node
Right -- a pointer to the right child node
*/
struct query_node
{
query_node();
∼query_node();
int nodeid;
int parent_nodeid;
bool sub_query;
bool child;
query_node_type node_type;
type_join join_type;
join_con_type join_cond;
Item *where_expr;
Item *join_expr;
TABLE_LIST *relations[4];
bool preempt_pipeline;
List<Item> *fields;
query_node *left;
query_node *right;
};
Some of these variables are used to manage node organization and form the tree itself. Two of the most interesting are nodeid and parent_nodeid. These are used to establish parentage of the nodes in the tree. This is necessary, because nodes can be moved up and down the tree as part of the optimization process. The use of a parent_nodeid variable avoids the need to maintain reverse pointers in the tree.5
The sub_query variable is used to indicate the starting node for a subquery. Thus, the data structure can support nested queries (subqueries) without additional modification of the structure. The only caveat is that the algorithms for optimization are designed to use the subquery indicator as a stop condition for tree traversal. That is, when a subquery node is detected, optimization considers the subquery a separate entity. Once detected, the query optimization routines are rerun using the subquery node as the start of the next optimization. Thus, any number of subqueries can be supported and represented as subtrees in the tree structure. This is an important feature of the query tree that overcomes the limitation found in many internal representations.
The where_expr variable is a pointer to the MySQL Item tree that manages a typical general expression tree. We will change this later to a special class that encapsulates expressions. See Chapter 13 for more details.
The relations array is used to contain pointers to relation classes that represent the abstraction of the internal record structures found in the MySQL storage engines. The relation class provides an access layer to the data stored on disk via the storage engine handler class. The array size is currently set at 4. The first two positions (0 and 1) correspond to the left and right child, respectively. The next two positions (2 and 3) represent temporary relations, such as reordering (sorting) and the application of indexes.
![]() Note The relations array size is set at 4, which means you can process queries with up to four tables. If you need to process queries with more than four tables, you will need to change the transformation code shown later in this chapter to accept more than four tables.
Note The relations array size is set at 4, which means you can process queries with up to four tables. If you need to process queries with more than four tables, you will need to change the transformation code shown later in this chapter to accept more than four tables.
The fields attribute is a pointer to the MySQL Item class that contains the list of fields for a table. It is useful in projection operations and maintaining attributes necessary for operations on relations (e.g., the propagation of attributes that satisfy expressions but that are not part of the result set).
The last variable of interest is the preempt_pipeline variable, which is used by the DBXP Execute class to implement a loop in the processing of the data from child nodes. Loops are necessary anytime an operation requires iteration through the entire set of data (rows). For example, a join that joins two relations on a common attribute in the absence of indexes that permit ordering may require iteration through one or both child nodes in order to achieve the correct mapping (join) operation.
This class is also responsible for query optimization (described in Chapter 13). Since the query tree provides all of the operations for manipulating the tree and since query optimization is also a set of tree operations, optimization was accomplished using methods placed in a class that wraps the query tree structure (called the query tree class).
The optimizer methods implement a heuristic algorithm (described in Chapter 13 and in more detail in Chapter 14). Execution of these methods results in the reorganization of the tree into a more optimal tree and the separation of some nodes into two or more others that can also be relocated to form a more optimal tree. An optimal tree permits a more efficient execution of the query.
Cost optimization is also supported in this class using an algorithm that walks the tree, applying available indexes to the access methods for each leaf node (nodes that access the relation stores directly).
This structure can support a wide variety of operations, including restrict, project, join, set, and ordering (sorting). The query node structure is designed to represent each of these operations as a single node and can store all pertinent and required information to execute the operation in place. Furthermore, the EXPLAIN command was implemented as a postorder traversal of the tree, printing out the contents of each node starting at the leaves (see the show_plan method later in this chapter). The MySQL equivalent of this operation requires much more computational time and is implemented with a complex set of methods.
Thus, the query tree is an internal representation that can represent any query and provide a mechanism to optimize the query by manipulating the tree. Indeed, the tree structure itself simplifies optimization and enables the implementation of a heuristic optimizer by providing a means to associate query operations as nodes in a tree. This query tree therefore is a viable mechanism for use in any relational database system and can be generalized for use in a production system.
Implementing DBXP Query Trees in MySQL
This section presents the addition of the DBXP query tree structure to the MySQL source code. This first step in creating a relational database research tool is designed to show you how the query tree works and how to transform the MySQL query structure into a base query tree (not optimized). Later chapters will describe the optimizer and execution engine.
Rather than attempting to reuse the existing SELECT command, we will create new entries in the parser to implement a special version of the SELECT command with the string DBXP_SELECT. This will permit the modifications to be isolated and not confused with existing SELECTsubcomponents in the parser. The following sections show you how to add the query tree and add stubs for executing DBXP_SELECT and EXPLAIN DBXP_SELECT commands.
![]() Note The source code examples available on the Apress website for this and the following chapters contains a difference file you can use to apply to the MySQL source tree. Depending on the version of server you are using, provided it is based on version 5.6, the patch operation should apply with minimal modification. The use of difference files keeps the example code smaller and permits you to see the changes in context.
Note The source code examples available on the Apress website for this and the following chapters contains a difference file you can use to apply to the MySQL source tree. Depending on the version of server you are using, provided it is based on version 5.6, the patch operation should apply with minimal modification. The use of difference files keeps the example code smaller and permits you to see the changes in context.
Files Added and Changed
While following the examples in this chapter, you will create several files and modify some of the MySQL source-code files. Table 12-2 lists the files that will be added and changed.
Table 12-2. Summary of Files Added and Changed
|
File |
Description |
|
mysqld.cc |
Added the DBXP version number label to the MySQL version number |
|
lex.h |
Added DBXP tokens to the lexical hash |
|
query_tree.h |
DBXP query-tree header file (new file) |
|
query_tree.cc |
DBXP query-tree class file (new file) |
|
sql_cmd.h |
Add the DBXP_SELECT to the enum_sql_command list |
|
sql_yacc.yy |
Added SQL command parsing to the parser |
|
sql_parse.cc |
Added the code to handle the new commands to the “big switch” |
Creating the Tests
The following section explains the process of stubbing the DBXP_SELECT command, the query tree class, and the EXPLAIN DBXP_SELECT and DBXP_SELECT commands. The goal is to permit the user to enter any valid SELECT command, process the query, and return the results.
![]() Note Since the DBXP engine is an experimental engine, it is limited to queries that represent the basic operations for retrieving data. Keeping the length of these chapters to a manageable size and complexity requires that the DBXP engine not process queries with aggregates—those containing a HAVING, GROUP BY, or ORDER BY clause. (There is nothing prohibiting this, so you are free to implement these operations yourself.)
Note Since the DBXP engine is an experimental engine, it is limited to queries that represent the basic operations for retrieving data. Keeping the length of these chapters to a manageable size and complexity requires that the DBXP engine not process queries with aggregates—those containing a HAVING, GROUP BY, or ORDER BY clause. (There is nothing prohibiting this, so you are free to implement these operations yourself.)
The following sections detail the steps necessary to create these three aspects of the DBXP code. Rather than create three small tests, I’ll create a single test file and use that to test the functions. For those operations that are not implemented, you can either comment out the query statements by adding a pound sign (#) at the beginning of the command or run the test as shown and ignore the inevitable errors for commands not yet implemented (thereby keeping true to the test first development mantra). Listing 12-2 shows the Ch12.test file.
Listing 12-2. Chapter Tests (Ch12.test)
#
# Sample test to test the DBXP_SELECT and EXPLAIN DBXP_SELECT commands
#
# Test 1: Test stubbed DBXP_SELECT command.
DBXP_SELECT * FROM no_such_table;
# Test 2: Test stubbed Query Tree implementation.
DBXP_SELECT * FROM customer;
# Test 3: Test stubbed EXPLAIN DBXP_SELECT command.
EXPLAIN DBXP_SELECT * FROM customer;
Of course, you can use this test as a guide and add your own commands to explore the new code. Refer to Chapter 4 for more details on how to create and run this test using the MySQL Test Suite.
Stubbing the DBXP_SELECT Command
In this section, you’ll learn how to add a custom SELECT command to the MySQL parser. You’ll see how the parser can be modified to accommodate a new command that mimics the traditional SELECT command in MySQL.
Identifying the Modifications
You should first identify a MySQL server that has the DBXP technologies by adding a label to the MySQL version number to ensure that you can always tell that you’re connected to the modified server.
![]() Tip You can use the command SELECT VERSION() at any time to retrieve the version of the server. If you are using the MySQL command-line client, you can change the command prompt to indicate that the server you are connected to is the server with the DBXP code.
Tip You can use the command SELECT VERSION() at any time to retrieve the version of the server. If you are using the MySQL command-line client, you can change the command prompt to indicate that the server you are connected to is the server with the DBXP code.
To append the version label, open the mysqld.cc file and locate the set_server_version method. Add a statement to append a label onto the MySQL version number string. In this case, we will use “-DBXP 2.0” to represent the printing of this book. Listing 12-3 shows the modified set_server_version method.
Listing 12-3. Changes to the mysqld.cc File
static void set_server_version(void)
{
char *end= strxmov(server_version, MYSQL_SERVER_VERSION,
MYSQL_SERVER_SUFFIX_STR, NullS);
#ifdef EMBEDDED_LIBRARY
end= strmov(end, "-embedded");
#endif
#ifndef DBUG_OFF
if (!strstr(MYSQL_SERVER_SUFFIX_STR, "-debug"))
end= strmov(end, "-debug");
#endif
if (opt_log || opt_slow_log || opt_bin_log)
strmov(end, "-log"); // This may slow down system
/* BEGIN DBXP MODIFICATION */
/* Reason for Modification: */
/* This section adds the DBXP version number to the MySQL version number. */
strmov(end, "-DBXP 2.0");
/* END DBXP MODIFICATION */
}
Modifying the Lexical Structures
Now, let’s add the tokens you’ll need to identify the DBXP_SELECT command. Open the lex.h file and add the code shown in bold in Listing 12-4 to the symbols array in context.
Listing 12-4. Changes to the lex.h File
static SYMBOL symbols[] = {
...
{ "DAY_MINUTE", SYM(DAY_MINUTE_SYM)},
{ "DAY_SECOND", SYM(DAY_SECOND_SYM)},
/* BEGIN DBXP MODIFICATION */
/* Reason for MODIFICATION */
/* This section identifies the symbols and values for the DBXP token */
{ "DBXP_SELECT", SYM(DBXP_SELECT_SYM)},
/* END DBXP MODIFICATION */
{ "DEALLOCATE", SYM(DEALLOCATE_SYM)},
{ "DEC", SYM(DECIMAL_SYM)},
. . .
Add the Command Enumeration
This section explains how to add the new DBXP_SELECT command enumeration. The modifications begin with adding a new case statement to the parser command switch in the sql_parse.cc file. The switch uses enumerated values for the cases.
To add a new case, you must add a new enumerated value. These values are identified in the parser code and stored in the lex->sql_command member variable. To add a new enumerated value to the lexical parser, open the sql_cmd.h file and add the code shown in Listing 12-5 to the enum_sql_command enumeration.
Listing 12-5. Adding the DBXP_SELECT Command Enumeration
enum enum_sql_command {
...
/* BEGIN DBXP MODIFICATION */
/* Reason for Modification: */
/* This section captures the enumerations for the DBXP command tokens */
SQLCOM_DBXP_SELECT,
SQLCOM_DBXP_EXPLAIN_SELECT,
/* END DBXP MODIFICATION */
...
Adding the DBXP_SELECT Command to the MySQL Parser
Once the new enumerated value for the case statement is added, you must also add code to the parser code (sql_yacc.yy) to identify the new DBXP_SELECT statement. This is done in several parts. You’ll add a new token to the parser requiring updates to three places.
The new token, once activated, will permit the parser to distinguish a normal MySQL SELECT statement from one that you want to process with the DBXP code. We program the parser so that, when the token is present, it indicates the parser should set the sql_command variable to theSQLCOM_DBXP_SELECT value instead of the normal MySQL select enumerated value (SQLCOM_SELECT). This technique allows you to issue the same basic SELECT statement to both the normal MySQL code and the DBXP code. For example, the following SELECT statements both accomplish the same task; they just will be optimized differently. The first one will be directed to the SQLCOM_SELECT case statement, whereas the second will be directed to the SQLCOM_DBXP_SELECT case statement.
SELECT * FROM customer;
DBXP_SELECT * FROM customer;
The code to add the new token is shown in Listing 12-6. Locate the list of tokens in the sql_yacc.yy file and add the code. (The list is in roughly alphabetical order).
Listing 12-6. Adding the Command Symbol to the Parser
%token DAY_SECOND_SYM
%token DAY_SYM /* SQL-2003-R */
/* BEGIN DBXP MODIFICATION */
/* Reason for Modification: */
/* This section defines the tokens for the DBXP commands */
%token DBXP_SELECT_SYM
/* END DBXP MODIFICATION */
%token DEALLOCATE_SYM /* SQL-2003-R */
%token DECIMAL_NUM
We also need to add the new command to the type <NONE> definition. Listing 12-7 shows this modification.
Listing 12-7. Adding the Command Syntax Operations to the Parser
%type <NONE>
/* BEGIN DBXP MODIFICATION */
/* Reason for Modification: */
/* Add the dbxp_select statement to the NONE type definition. */
query verb_clause create change select dbxp_select do drop insert replace insert2
/* END DBXP MODIFICATION */
The last area for adding the token is to add the following code to the statement section. Listing 12-8 shows the modification in context.
Listing 12-8. Adding the Command to the SELECT: section
statement:
...
| select
/* BEGIN DBXP MODIFICATION */
/* Reason for Modification: */
/* Add the dbxp_select statement to the list of statements(commands). */
| dbxp_select
/* END DBXP MODIFICATION */
| set
...
We can now add the statements to enable parsing of the DBXP_SELECT command. Listing 12-9 shows the parser code needed to identify the DBXP_SELECT command and to process the normal parts of the select command. Notice that the parser identifies the select and DBXP symbols and then provides for other parsing of the select options, fields list, and FROM clause. Immediately after that line is the code that sets the sql_command. Notice that the code also places a vertical bar (|) before the original select-command parser code. This is the “or” operator that the parser syntax uses to process variations of a command. To add this change to the parser, open the sql_yacc.yy file and locate the select: label, then add the code, as shown in Listing 12-9.
Listing 12-9. Adding the Command Syntax Operations to the Parser
/* BEGIN DBXP MODIFICATION */
/* Reason for Modification: */
/* This section captures (parses) the SELECT DBXP statement */
dbxp_select:
DBXP_SELECT_SYM DBXP_select_options DBXP_select_item_list
DBXP_select_from
{
LEX *lex= Lex;
lex->sql_command = SQLCOM_DBXP_SELECT;
}
;
/* END DBXP MODIFICATION */
select:
select_init
{
LEX *lex= Lex;
lex->sql_command= SQLCOM_SELECT;
}
;
Notice also that the code references several other labels. Listing 12-10 contains the code for these operations. The first is the DBXP_select_options, which identifies the valid options for the SELECT command. While this is very similar to the MySQL select options, it provides for only two options: DISTINCT and COUNT(*). The next operation is the DBXP_select_from code that identifies the tables in the FROM clause. It also calls the DBXP_where_clause operation to identify the WHERE clause. The next operation is the DBXP_select_item_list, which resembles the MySQL code. Last, the DBXP_where_clause operation identifies the parameters in the WHERE clause. Take some time to go through this code and follow the operations to their associated labels to see what each does. To add this code to the parser, locate theselect_from: label and add the code above it. Although it doesn’t matter where you place the code, this location seems more logical, because it is in the same area with the MySQL select operations. Listing 12-10 shows the complete source code for the DBXP_SELECT parser code.
Listing 12-10. Additional Operations for the DBXP_SELECT Command
/* BEGIN DBXP MODIFICATION */
/* Reason for Modification: */
/* This section captures (parses) the sub parts of the SELECT DBXP statement */
DBXP_select_options:
/* empty */
| DISTINCT
{
Select->options|= SELECT_DISTINCT;
}
;
DBXP_select_from:
FROM join_table_list DBXP_where_clause {};
DBXP_select_item_list:
/* empty */
| DBXP_select_item_list ',' select_item
| select_item
| '*'
{
THD *thd= YYTHD;
Item *item= new (thd->mem_root)
Item_field(&thd->lex->current_select->context,
NULL, NULL, "*");
if (item == NULL)
MYSQL_YYABORT;
if (add_item_to_list(thd, item))
MYSQL_YYABORT;
(thd->lex->current_select->with_wild)++;
};
DBXP_where_clause:
/* empty */ { Select->where= 0; }
| WHERE expr
{
SELECT_LEX *select= Select;
select->where= $2;
if ($2)
$2->top_level_item();
}
;
/* END DBXP MODIFICATION */
...
![]() Note A savvy yacc developer may spot some places in this code that can be reduced or reused from the rules for the original SELECT statement. I leave this as an exercise for those interested in optimizing this code.
Note A savvy yacc developer may spot some places in this code that can be reduced or reused from the rules for the original SELECT statement. I leave this as an exercise for those interested in optimizing this code.
Now that you’ve made the changes to the lexical parser, you have to generate the equivalent C source code. Fortunately, the normal cmake/make steps will take care of this. Simply execute these commands from the root of the source tree.
cmake .
make
If you want to check your code without waiting for the make file to process all of the source files, you can use Bison to generate these files. Open a command window and navigate to the /sql directory off the root of your source code tree. Run the command:
bison -y -d sql_yacc.yy
This generates two new files: y.tab.c and y.tab.h. These files replace the sql_yacc.cc and sql_yacc.h files, respectively. Before you copy them, make a backup of the original files. After you’ve done so, copy y.tab.c to sql_yacc.cc and y.taqb.h to sql_yacc.h.
WHAT ARE LEX AND YACC AND WHO’S BISON?
Lex stands for “lexical analyzer generator” and is used as a parser to identify tokens and literals, as well as the syntax of a language. YACC stands for “yet another compiler compiler” and is used to identify and act on the semantic definitions of the language. The use of these tools together with Bison (a YACC-compatible parser generator that generates C source code from the Lex/YACC code) provides a rich mechanism for creating subsystems that can parse and process language commands. Indeed, that is exactly how MySQL uses these technologies.
If you compile the server now, you can issue DBXP_SELECT commands, but nothing will happen. That’s because you need to add the case statement to the parser switch in sql_parse.cc. Since we do not yet have a complete DBXP engine, let’s make the exercise a bit more interesting by stubbing out the case statement. Listing 12-11 shows a complete set of scaffold code you can use to implement the DBXP_SELECT command. In this code, I use the MySQL utility classes to establish a record set. The first portion of the code sets up the field list for the fictional table. Following that are lines of code to write data values to the network stream and, finally, to send an end-of-file marker to the client. Writing data to the output stream requires calls to protocol->prepare_for_resend(), storing the data to be sent using protocol->store(), and then writing the buffer to the stream with protocol->write().
Listing 12-11. Modifications to the Parser Command Switch
/* BEGIN DBXP MODIFICATION */
/* Reason for Modification: */
/* This section adds the code to call the new DBXP_SELECT command. */
case SQLCOM_DBXP_SELECT:
{
List<Item> field_list;
/* The protocol class is used to write data to the client. */
Protocol *protocol= thd->protocol;
/* Build the field list and send the fields to the client */
field_list.push_back(new Item_int("Id",(longlong) 1,21));
field_list.push_back(new Item_empty_string("LastName",40));
field_list.push_back(new Item_empty_string("FirstName",20));
field_list.push_back(new Item_empty_string("Gender",2));
if (protocol->send_ result_set_metadata (&field_list,
Protocol::SEND_NUM_ROWS | Protocol::SEND_EOF))
DBUG_RETURN(TRUE);
protocol->prepare_for_resend();
/* Write some sample data to the buffer and send it with write() */
protocol->store((longlong)3);
protocol->store("Flintstone", system_charset_info);
protocol->store("Fred", system_charset_info);
protocol->store("M", system_charset_info);
if (protocol->write())
DBUG_RETURN(TRUE);
protocol->prepare_for_resend();
protocol->store((longlong)5);
protocol->store("Rubble", system_charset_info);
protocol->store("Barnie", system_charset_info);
protocol->store("M", system_charset_info);
if (protocol->write())
DBUG_RETURN(TRUE);
protocol->prepare_for_resend();
protocol->store((longlong)7);
protocol->store("Flintstone", system_charset_info);
protocol->store("Wilma", system_charset_info);
protocol->store("F", system_charset_info);
if (protocol->write())
DBUG_RETURN(TRUE);
/*
send_eof() tells the communication mechanism that we're finished
sending data (end of file).
*/
my_eof(thd);
break;
}
/* END DBXP MODIFICATION */
case SQLCOM_PREPARE:
...
This stub code returns a simulated record set to the client whenever a DBXP_SELECT command is detected. Go ahead and enter this code, and then compile and run the test.
Testing the DBXP_SELECT Command
The test we want to run is issuing a DBXP_SELECT command and verifying that the statement is parsed and processed by the new stubbed case statement. You can run the test you created earlier or simply enter a SQL statement such as the following (make sure you type the DBXP part) in a MySQL command-line client:
DBXP_SELECT * from no_such_table;
It doesn’t matter what you type after the DBXP as long as it is a valid SQL SELECT statement. Listing 12-12 shows an example of the output you should expect.
Listing 12-12. Results of Stub Test
mysql> DBXP_SELECT * from no_such_table;
+----+------------+-----------+--------+
| Id | LastName | FirstName | Gender |
+----+------------+-----------+--------+
| 3 | Flintstone | Fred | M |
| 5 | Rubble | Barnie | M |
| 7 | Flintstone | Wilma | F |
+----+------------+-----------+--------+
3 rows in set (0.23 sec)
mysql>
Adding the Query Tree Class
Now that you have a stubbed DBXP_SELECT command, you can begin to implement the DBXP-specific code to execute a SELECTcommand. In this section, I’ll show you how to add the basic query-tree class and transform the MySQL internal structure to the query tree. I don’t go all the way into the bowels of the query-tree code until the next chapter.
Adding the Query Tree Header File
Adding the query-tree class requires creating the query-tree header file and referencing it in the MySQL code. The query-tree header file is shown in Listing 12-13. Notice that I named the class Query_tree. This follows the MySQL coding guidelines by naming classes with an initial capital. Take a moment to scan through the header code. You will see there isn’t a lot of code there—just the basics of the query-tree node structure and the enumerations. Notice there are enumerations for node type, join condition type, join, and aggregate types. These enumerations permit the query-tree nodes to take on unique roles in the execution of the query. I explain more about how these are used in the next chapter.
You can create the file any way you choose (or download it). Name it query_tree.h and place it in the /sql directory of your MySQL source tree. Don’t worry about how to add it to the project; I show you how to do that in a later section.
Listing 12-13. The Query Tree Header File
/*
query_tree.h
DESCRIPTION
This file contains the Query_tree class declaration. It is responsible for containing the
internal representation of the query to be executed. It provides methods for
optimizing and forming and inspecting the query tree. This class is the very
heart of the DBXP query capability! It also provides the ability to store
a binary "compiled" form of the query.
NOTES
The data structure is a binary tree that can have 0, 1, or 2 children. Only
Join operations can have 2 children. All other operations have 0 or 1
children. Each node in the tree is an operation and the links to children
are the pipeline.
SEE ALSO
query_tree.cc
*/
#include "sql_priv.h"
#include "sql_class.h"
#include "table.h"
#include "records.h"
class Query_tree
{
public:
enum query_node_type //this enumeration lists the available
{ //query node (operations)
qntUndefined = 0,
qntRestrict = 1,
qntProject = 2,
qntJoin = 3,
qntSort = 4,
qntDistinct = 5
};
enum join_con_type //this enumeration lists the available
{ //join operations supported
jcUN = 0,
jcNA = 1,
jcON = 2,
jcUS = 3
};
enum type_join //this enumeration lists the available
{ //join types supported.
jnUNKNOWN = 0, //undefined
jnINNER = 1,
jnLEFTOUTER = 2,
jnRIGHTOUTER = 3,
jnFULLOUTER = 4,
jnCROSSPRODUCT = 5,
jnUNION = 6,
jnINTERSECT = 7
};
enum AggregateType //used to add aggregate functions
{
atNONE = 0,
atCOUNT = 1
};
/*
STRUCTURE query_node
DESCRIPTION
This this structure contains all of the data for a query node:
NodeId -- the internal id number for a node
ParentNodeId -- the internal id for the parent node (used for insert)
SubQuery -- is this the start of a subquery?
Child -- is this a Left or Right child of the parent?
NodeType -- synonymous with operation type
JoinType -- if a join, this is the join operation
join_con_type -- if this is a join, this is the "on" condition
Expressions -- the expressions from the "where" clause for this node
Join Expressions -- the join expressions from the "join" clause(s)
Relations[] -- the relations for this operation (at most 2)
PreemptPipeline -- does the pipeline need to be halted for a sort?
Fields -- the attributes for the result set of this operation
Left -- a pointer to the left child node
Right -- a pointer to the right child node
*/
struct query_node
{
query_node();
∼query_node();
int nodeid;
int parent_nodeid;
bool sub_query;
bool child;
query_node_type node_type;
type_join join_type;
join_con_type join_cond;
Item *where_expr;
Item *join_expr;
TABLE_LIST *relations[4];
bool preempt_pipeline;
List<Item> *fields;
query_node *left;
query_node *right;
};
query_node *root; //The ROOT node of the tree
∼Query_tree(void);
void ShowPlan(query_node *QN, bool PrintOnRight);
};
With the query-tree header file, you also need the query-tree source file. The source file must provide the code for the constructor and destructor methods of the query-tree class. Listing 12-14 shows the completed constructor and destructor methods. Create the query_tree.cc file and enter this code (or download it). Place this file in the /sql directory of your MySQL source tree. I show you how to add it to the project in a later section.
Listing 12-14. The Query Tree Class
/*
query_tree.cc
DESCRIPTION
This file contains the Query_tree class. It is responsible for containing the
internal representation of the query to be executed. It provides methods for
optimizing and forming and inspecting the query tree. This class is the very
heart of the DBXP query capability! It also provides the ability to store
a binary "compiled" form of the query.
NOTES
The data structure is a binary tree that can have 0, 1, or 2 children. Only
Join operations can have 2 children. All other operations have 0 or 1
children. Each node in the tree is an operation and the links to children
are the pipeline.
SEE ALSO
query_tree.h
*/
#include "query_tree.h"
Query_tree::query_node::query_node()
{
where_expr = NULL;
join_expr = NULL;
child = false;
join_cond = Query_tree::jcUN;
join_type = Query_tree::jnUNKNOWN;
left = NULL;
right = NULL;
nodeid = -1;
node_type = Query_tree::qntUndefined;
sub_query = false;
parent_nodeid = -1;
}
Query_tree::query_node::∼query_node()
{
if(left)
delete left;
if(right)
delete right;
}
Query_tree::∼Query_tree(void)
{
if(root)
delete root;
}
Building the Query Tree from the MySQL Structure
What we need next is the code to perform the transformation from the MySQL internal structure to the query tree. Let’s use a helper source file rather than add the code to the sql_parse.cc file. In fact, many of the commands represented by the case statements (in the sql_parse.ccfile) are done this way. Create a new file named sql_dbxp_parse.cc. Create a new function in that file named build_query_tree as shown in Listing 12-15. The code is a basic transformation method. Take a moment to look through the code as you type it in (or download and copy and paste it into the file).
Listing 12-15. The DBXP Parser Helper File
/*
sql_dbxp_parse.cc
DESCRIPTION
This file contains methods to execute the DBXP_SELECT query statements.
SEE ALSO
query_tree.cc
*/
#include "query_tree.h"
/*
Build Query Tree
SYNOPSIS
build_query_tree()
THD *thd IN the current thread
LEX *lex IN the pointer to the current parsed structure
TABLE_LIST *tables IN the list of tables identified in the query
DESCRIPTION
This method returns a converted MySQL internal representation (IR) of a
query as a query_tree.
RETURN VALUE
Success = Query_tree * -- the root of the new query tree.
Failed = NULL
*/
Query_tree *build_query_tree(THD *thd, LEX *lex, TABLE_LIST *tables)
{
DBUG_ENTER("build_query_tree");
Query_tree *qt = new Query_tree();
Query_tree::query_node *qn = new Query_tree::query_node();
TABLE_LIST *table;
int i = 0;
int num_tables = 0;
/* Create a new restrict node. */
qn->parent_nodeid = -1;
qn->child = false;
qn->join_type = (Query_tree::type_join) 0;
qn->nodeid = 0;
qn->node_type = (Query_tree::query_node_type) 2;
qn->left = 0;
qn->right = 0;
/* Get the tables (relations) */
i = 0;
for(table = tables; table; table = table->next_local)
{
num_tables++;
qn->relations[i] = table;
i++;
}
/* Populate attributes */
qn->fields = &lex->select_lex.item_list;
/* Process joins */
if (num_tables > 0) //indicates more than 1 table processed
for(table = tables; table; table = table->next_local)
if (((Item *)table->join_cond() != 0) && (qn->join_expr == 0))
qn->join_expr = (Item *)table->join_cond();
qn->where_expr = lex->select_lex.where;
qt->root = qn;
DBUG_RETURN(qt);
}
Notice that the build_query_tree code begins with creating a new query node, identifies the tables used in the query, populates the fields list, and captures the join and where expressions. These are all basic items needed to execute the most basic of queries.
Stubbing the Query Tree Execution
Now let’s consider what it takes to create a query tree in code. Create a new function named DBXP_select_command, and copy the code from Listing 12-16. Place this function in the sql_dbxp_parse.cc file. This function will be called from the case statement in sql_parse.cc.
Listing 12-16. Handling the DBXP_SELECT Command
/*
Perform Select Command
SYNOPSIS
DBXP_select_command()
THD *thd IN the current thread
DESCRIPTION
This method executes the SELECT command using the query tree.
RETURN VALUE
Success = 0
Failed = 1
*/
int DBXP_select_command(THD *thd)
{
DBUG_ENTER("DBXP_select_command");
Query_tree *qt = build_query_tree(thd, thd->lex,
(TABLE_LIST*) thd->lex->select_lex.table_list.first);
List<Item> field_list;
Protocol *protocol= thd->protocol;
field_list.push_back(new Item_empty_string("Database Experiment Project (DBXP)",40));
if (protocol->send_result_set_metadata(&field_list,
Protocol::SEND_NUM_ROWS | Protocol::SEND_EOF))
DBUG_RETURN(TRUE);
protocol->prepare_for_resend();
protocol->store("Query tree was built.", system_charset_info);
if (protocol->write())
DBUG_RETURN(TRUE);
my_eof(thd);
DBUG_RETURN(0);
}
This code begins by calling the transformation function (build_query_tree) and then creates a stubbed result set. This time, I create a record set with only one column and one row that is used to pass a message to the client that the query tree transformation completed. Although this code isn’t very interesting, it is a placeholder for you to conduct more experiments on the query tree (see exercises at the end of the chapter). Place the sql_dbxp_parse.cc file in the /sql directory of your MySQL source tree.
Stubbing the DBXP_SELECT Command Revisited
Open the sql_parse.cc file and add a function declaration for the DBXP_select_command function, placing the declaration near the phrase mysql_execute_command. Listing 12-17 shows the complete function header for the DBXP_select_command function. Enter this code above the comment block as shown.
Listing 12-17. Modifications to the Parser Command Code
/* BEGIN DBXP MODIFICATION */
/* Reason for Modification: */
/* This section adds the code to call the new SELECT DBXP command. */
int DBXP_select_command(THD *thd);
int DBXP_explain_select_command(THD *thd);
/* END DBXP MODIFICATION */
You can now change the code in the case statement (also called the parser command switch) to call the new DBXP_select_command function. Listing 12-18 shows the complete code for calling this function. Notice that the only parameter we need to pass in is the current thread (thd). The MySQL internal query structure and all other metadata for the query are referenced via the thread pointer. As you can see, this technique cleans up the case statement quite a bit. It also helps to modularize the DBXP code to make it easier to maintain and modify for your experiments.
Listing 12-18. Modifications to the Parse Command Switch (sql_parse.cc)
/* BEGIN DBXP MODIFICATION */
/* Reason for Modification: */
/* This section adds the code to call the new DBXP_SELECT command. */
case SQLCOM_DBXP_SELECT:
{
res = DBXP_select_command(thd);
if (res)
goto error;
break;
}
/* END DBXP MODIFICATION */
case SQLCOM_PREPARE:
{
...
Before you can compile the server, you need to add the new source code files (query_tree.h, query_tree.cc, and sql_dbxp_parse.cc) to the project (make) file.
Adding the Files to the CMakeLists.txt file
Adding the project files requires modifying the CMakeLists.txt file in the /sql directory from the root of the source tree. Open the file and locate the SQL_SHARED_SOURCES_label. Add source-code files to the list of sources for compilation of the server (mysqld). Listing 12-19shows the start of the definition and the project files added.
Listing 12-19. Modifications to the CMakeLists.txt File
SET(SQL_SHARED_SOURCES
abstract_query_plan.cc
datadict.cc
...
sql_dbxp_parse.cc
query_tree.cc
...
![]() Caution Be sure to use spaces when formatting the lists when modifying the cmake files.
Caution Be sure to use spaces when formatting the lists when modifying the cmake files.
Testing the Query Tree
Once the server is compiled without errors, you can test it using a SQL statement. Unlike the last test, you should enter a valid SQL command that references objects that exist. You could either run the test (see Listing 12-20) as described in an earlier section or enter the following command in the MySQL command-line client:
DBXP_SELECT * from customer;
Listing 12-20. Results of DBXP_SELECT Test
mysql> DBXP_SELECT * FROM customer;
+--------------------------------------------------+
| Database Experiment Project (DBXP) |
+--------------------------------------------------+
| Query tree was built. |
+--------------------------------------------------+
1 row in set (0.00 sec)
mysql>
You’ve stubbed out the DBXP_SELECT operation and built a query tree, but that isn’t very interesting. What if we could see what the query looks like? We’ll create a function that works like the EXPLAIN command, only instead of a list of information about the query, we’ll create a graphical representation6 of the query in tree form.
Showing Details of the Query Tree
Adding a new command requires adding a new enumeration for a new case statement in the parser switch in sql_parse.cc and adding the parser code to identify the new command. You also have to add the code to execute the new command to the sql_DBXP_parse.cc file. While creating and adding an EXPLAIN command to the parser that explains query trees sounds complicated, the EXPLAIN SELECT command is available in MySQL, so we can copy a lot of that code and reuse much of it.
Adding the EXPLAIN DBXP_SELECT Command to the MySQL Parser
To add the new enumeration to the parser, open the sql_lex.h file and add an enumeration named SQLCOM_DBXP_EXPLAIN_SELECT following the code for the SQLCOM_DBXP_SELECT enumeration. Listing 12-21 shows the completed code changes. Once the code is added, you can regenerate the lexical hash as described earlier.
Listing 12-21. Adding the EXPLAIN Enumeration
/* A Oracle compatible synonym for show */
describe:
/* BEGIN DBXP MODIFICATION */
/* Reason for Modification: */
/* This section captures (parses) the EXPLAIN (DESCRIBE) DBXP statements */
describe_command DBXP_SELECT_SYM DBXP_select_options DBXP_select_item_list
DBXP_select_from
{
LEX *lex= Lex;
lex->sql_command = SQLCOM_DBXP_EXPLAIN_SELECT;
lex->select_lex.db= 0;
lex->verbose= 0;
}
/* END DBXP MODIFICATION */
...
Notice that in this code, the parser identifies an EXPLAIN DBXP_SELECT command. In fact, it calls many of the same operations as the DBXP_SELECT parser code. The only difference is that this code sets the sql_command to the new enumeration (SQLCOM_DBXP_EXPLAIN_SELECT).
The changes to the parser switch statement in sql_parse.cc require adding the function declaration for the code in sql_DBXP_parse.cc that will execute the EXPLAIN command. Open the sql_parse.cc file and add the function declaration for the EXPLAIN function. Name the function DBXP_explain_select_command (are you starting to see a pattern?). Add this at the same location as the DBXP_select_command function declaration. Listing 12-22 shows the complete code for both DBXP commands.
Listing 12-22. Modifications to the Parser Command Code
/* BEGIN DBXP MODIFICATION */
/* Reason for Modification: */
/* This section adds the code to call the new DBXP_SELECT command. */
int DBXP_select_command(THD *thd);
int DBXP_explain_select_command(THD *thd);
/* END DBXP MODIFICATION */
You also need to add the new case statement for the DBXP explain command. The statements are similar to the case statement for the DBXP_SELECT command. Listing 12-23 shows the new case statement added.
Listing 12-23. Modifications to the Parser Switch Statement
/* BEGIN DBXP MODIFICATION */
/* Reason for Modification: */
/* This section adds the code to call the new DBXP_SELECT command. */
case SQLCOM_DBXP_SELECT:
{
res = DBXP_select_command(thd);
if (res)
goto error;
break;
}
case SQLCOM_DBXP_EXPLAIN_SELECT:
{
res = DBXP_explain_select_command(thd);
if (res)
goto error;
break;
}
/* END DBXP MODIFICATION */
Creating a show_plan Function
The EXPLAIN DBXP_SELECT command shows the query path as a tree printed out within the confines of character text. The EXPLAIN code is executed in a function named show_plan in the sql_DBXP_parse.cc file. A helper function named write_printf is used to make theshow_plan code easier to read. Listings 12-24 and 12-25 show the completed code for both of these methods.
Listing 12-24. Adding a Function to Capture the Protocol Store and Write Statements
/*
Write to vio with printf.
SYNOPSIS
write_printf()
Protocol *p IN the Protocol class
char *first IN the first string to write
char *last IN the last string to write
DESCRIPTION
This method writes to the vio routines printing the strings passed.
RETURN VALUE
Success = 0
Failed = 1
*/
int write_printf(Protocol *p, char *first, const char *last)
{
char *str = new char[1024];
DBUG_ENTER("write_printf");
strcpy(str, first);
strcat(str, last);
p->prepare_for_resend();
p->store(str, system_charset_info);
p->write();
delete str;
DBUG_RETURN(0);
}
Notice that the write_printf code calls the protocol->store and protocol->write functions to write a line of the drawing to the client. I’ll let you explore the show_plan source code shown in Listing 12-25 to see how it works. I’ll show you an example of the code executing in the next section. The code uses a postorder traversal to generate the query plan from the query tree, starting at the root. Add these methods to the sql_DBXP_parse.cc file.
Listing 12-25. The show_plan Source Code
/*
Show Query Plan
SYNOPSIS
show_plan()
Protocol *p IN the MySQL protocol class
query_node *Root IN the root node of the query tree
query_node *qn IN the starting node to be operated on.
bool print_on_right IN indicates the printing should tab to the right
of the display.
DESCRIPTION
This method prints the execute plan to the client via the protocol class
WARNING
This is a RECURSIVE method!
Uses postorder traversal to draw the quey plan
RETURN VALUE
Success = 0
Failed = 1
*/
int show_plan(Protocol *p, Query_tree::query_node *root,
Query_tree::query_node *qn, bool print_on_right)
{
DBUG_ENTER("show_plan");
/* spacer is used to fill white space in the output */
char *spacer = (char *)my_malloc(80, MYF(MY_ZEROFILL | MY_WME));
char *tblname = (char *)my_malloc(256, MYF(MY_ZEROFILL | MY_WME));
int i = 0;
if(qn != 0)
{
show_plan(p, root, qn->left, print_on_right);
show_plan(p, root, qn->right, true);
/* draw incoming arrows */
if(print_on_right)
strcpy(spacer, " | ");
else
strcpy(spacer, " ");
/* Write out the name of the database and table */
if((qn->left == NULL) && (qn->right == NULL))
{
/*
If this is a join, it has 2 children, so we need to write
the children nodes feeding the join node. Spaces are used
to place the tables side-by-side.
*/
if(qn->node_type == Query_tree::qntJoin)
{
strcpy(tblname, spacer);
strcat(tblname, qn->relations[0]->db);
strcat(tblname, ".");
strcat(tblname, qn->relations[0]->table_name);
if(strlen(tblname) < 15)
strcat(tblname, " ");
else
strcat(tblname, " ");
strcat(tblname, qn->relations[1]->db);
strcat(tblname, ".");
strcat(tblname, qn->relations[1]->table_name);
write_printf(p, tblname, "");
write_printf(p, spacer, " | |");
write_printf(p, spacer, " | ----------------------------");
write_printf(p, spacer, " | |");
write_printf(p, spacer, " V V");
}
else
strcpy(tblname, spacer);
strcat(tblname, qn->relations[0]->db);
strcat(tblname, ".");
strcat(tblname, qn->relations[0]->table_name);
write_printf(p, tblname, "");
write_printf(p, spacer, " |");
write_printf(p, spacer, " |");
write_printf(p, spacer, " |");
write_printf(p, spacer, " V");
}
}
else if((qn->left != 0) && (qn->right != 0))
{
write_printf(p, spacer, " | |");
write_printf(p, spacer, " | ----------------------------");
write_printf(p, spacer, " | |");
write_printf(p, spacer, " V V");
}
else if((qn->left != 0) && (qn->right == 0))
{
write_printf(p, spacer, " |");
write_printf(p, spacer, " |");
write_printf(p, spacer, " |");
write_printf(p, spacer, " V");
}
else if(qn->right != 0)
{
}
write_printf(p, spacer, "-------------------");
/* Write out the node type */
switch(qn->node_type)
{
case Query_tree::qntProject:
{
write_printf(p, spacer, "| PROJECT |");
write_printf(p, spacer, "-------------------");
break;
}
case Query_tree::qntRestrict:
{
write_printf(p, spacer, "| RESTRICT |");
write_printf(p, spacer, "-------------------");
break;
}
case Query_tree::qntJoin:
{
write_printf(p, spacer, "| JOIN |");
write_printf(p, spacer, "-------------------");
break;
}
case Query_tree::qntDistinct:
{
write_printf(p, spacer, "| DISTINCT |");
write_printf(p, spacer, "-------------------");
break;
}
default:
{ write_printf(p, spacer, "| UNDEF |");
write_printf(p, spacer, "-------------------");
break;
}
}
write_printf(p, spacer, "| Access Method: |");
write_printf(p, spacer, "| iterator |");
write_printf(p, spacer, "-------------------");
if(qn == root)
{
write_printf(p, spacer, " |");
write_printf(p, spacer, " |");
write_printf(p, spacer, " V");
write_printf(p, spacer, " Result Set");
}
}
my_free(spacer);
my_free(tblname);
DBUG_RETURN(0);
}
The last things you need to do are to add the code to perform the DBXP EXPLAIN command, call the show_plan() method, and return a result to the client. Listing 12-26 shows the complete code for this function. Notice that in this function, I build the query tree and then create a field list using a single-character string column named “Execution Path,” and then call show_plan to write the plan to the client.
Listing 12-26. The DBXP EXPLAIN Command Source Code
/*
Perform EXPLAIN command.
SYNOPSIS
DBXP_explain_select_command()
THD *thd IN the current thread
DESCRIPTION
This method executes the EXPLAIN SELECT command.
RETURN VALUE
Success = 0
Failed = 1
*/
int DBXP_explain_select_command(THD *thd)
{
DBUG_ENTER("DBXP_explain_select_command");
Query_tree *qt = build_query_tree(thd, thd->lex,
(TABLE_LIST*) thd->lex->select_lex.table_list.first);
List<Item> field_list;
Protocol *protocol= thd->protocol;
field_list.push_back(new Item_empty_string("Execution Path",NAME_LEN));
if (protocol->send_result_set_metadata(&field_list,
Protocol::SEND_NUM_ROWS | Protocol::SEND_EOF))
DBUG_RETURN(TRUE);
protocol->prepare_for_resend();
show_plan(protocol, qt->root, qt->root, false);
my_eof(thd);
DBUG_RETURN(0);
}
Now, let’s compile the server and give it a go with the test file.
Testing the DBXP EXPLAIN Command
As with the previous tests, you can either use the test described in an earlier section or enter a valid SQL command in the MySQL command-line client. Listing 12-27 shows an example of what the query-execution path would look like. It should be stated at this point that the query is not optimized and will appear as a single node. Once you add the optimizer (see Chapter 11), the query execution path will reflect the appropriate execution for the query statement entered.
Listing 12-27. Results of the DBXP EXPLAIN Test
mysql> EXPLAIN DBXP_SELECT * FROM customer;
+--------------------------+
| Execution Path |
+--------------------------+
| test.customer |
| | |
| | |
| | |
| V |
| ------------------- |
| | PROJECT | |
| ------------------- |
| | Access Method: | |
| | iterator | |
| ------------------- |
| | |
| | |
| V |
| Result Set |
+--------------------------+
15 rows in set (0.00 sec)
mysql>
This is much more interesting than a dull listing of facts. Adding the EXPLAIN command at this stage of the DBXP project allows you to witness and diagnose how the optimizer is forming the query tree. You’ll find this very helpful when you begin your own experiments.
If you haven’t been doing so thus far, you should run the complete test that tests all three portions of the code presented in this chapter.
Summary
I presented in this chapter some of the more complex database internal technologies. You learned how queries are represented internally within the MySQL server as they are parsed and processed via the “big switch.” More important, you discovered how MySQL can be used to conduct your own database internal experiments with the query-tree class. Knowing these technologies should provide you with a greater understanding of why and how the MySQL internal components are built.
In the next chapter, I show you more about internal-query representation through an example implementation of a query-tree optimization strategy. If you’ve ever wondered what it takes to build an optimizer for a relational database system, the next chapter will show you an example of a heuristic query optimizer using the query tree class.
EXERCISES
The following lists represent the types of activities you might want to conduct as experiments (or as a class assignment) to explore relational-database technologies.
1. The query in Figure 12-1 exposes a design flaw in one of the tables. What is it? Does the flaw violate any of the normal forms? If so, which one?
2. Explore the TABLE structure and change the DBXP_SELECT stub to return information about the table and its fields.
3. Change the EXPLAIN DBXP_SELECT command to produce an output similar to the MySQL EXPLAIN SELECT command.
4. Modify the build_query_tree function to identify and process the LIMIT clause.
5. How can the query tree query_node structure be changed to accommodate HAVING, GROUP BY, and ORDER clauses?
1 Strangely, few texts give explanations for the choice of symbol. Traditionally, θ represents a theta-join and ![]() represents a natural join, but most texts interchange these concepts, resulting in all joins represented using one or the other symbol (and sometimes both).
represents a natural join, but most texts interchange these concepts, resulting in all joins represented using one or the other symbol (and sometimes both).
2 Although similar drawings have appeared in several places in the literature, Figure 12-1 contains a subtle nuance of database theory that is often overlooked. Can you spot the often-misused trait? Hint: What is the domain of the semester attribute? Which rule has been violated by encoding data in a column?
3 Some would say it shouldn’t have to, as the MySQL internal structure is used to organize the data for the optimizer. Query trees, on the other hand, are designed to be optimized and executed in place.
4 Although many texts on the subject of query processing disagree about how each process is differentiated, they do agree that certain distinct process steps must occur.
5 A practice strongly discouraged by Knuth and other algorithm gurus.
6 As graphical as a command-line interface will allow, anyway.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.