Hadoop: The Definitive Guide (2015)
Part V. Case Studies
Chapter 24. Cascading
Chris K. Wensel
Cascading is an open source Java library and API that provides an abstraction layer for MapReduce. It allows developers to build complex, mission-critical data processing applications that run on Hadoop clusters.
The Cascading project began in the summer of 2007. Its first public release, version 0.1, launched in January 2008. Version 1.0 was released in January 2009. Binaries, source code, and add-on modules can be downloaded from the project website.
Map and reduce operations offer powerful primitives. However, they tend to be at the wrong level of granularity for creating sophisticated, highly composable code that can be shared among different developers. Moreover, many developers find it difficult to “think” in terms of MapReduce when faced with real-world problems.
To address the first issue, Cascading substitutes the keys and values used in MapReduce with simple field names and a data tuple model, where a tuple is simply a list of values. For the second issue, Cascading departs from map and reduce operations directly by introducing higher-level abstractions as alternatives: Functions, Filters, Aggregators, and Buffers.
Other alternatives began to emerge at about the same time as the project’s initial public release, but Cascading was designed to complement them. Consider that most of these alternative frameworks impose pre- and post-conditions, or other expectations.
For example, in several other MapReduce tools, you must preformat, filter, or import your data into HDFS prior to running the application. That step of preparing the data must be performed outside of the programming abstraction. In contrast, Cascading provides the means to prepare and manage your data as integral parts of the programming abstraction.
This case study begins with an introduction to the main concepts of Cascading, then finishes with an overview of how ShareThis uses Cascading in its infrastructure.
See the Cascading User Guide on the project website for a more in-depth presentation of the Cascading processing model.
Fields, Tuples, and Pipes
The MapReduce model uses keys and values to link input data to the map function, the map function to the reduce function, and the reduce function to the output data.
But as we know, real-world Hadoop applications usually consist of more than one MapReduce job chained together. Consider the canonical word count example implemented in MapReduce. If you needed to sort the numeric counts in descending order, which is not an unlikely requirement, it would need to be done in a second MapReduce job.
So, in the abstract, keys and values not only bind map to reduce, but reduce to the next map, and then to the next reduce, and so on (Figure 24-1). That is, key-value pairs are sourced from input files and stream through chains of map and reduce operations, and finally rest in an output file. When you implement enough of these chained MapReduce applications, you start to see a well-defined set of key-value manipulations used over and over again to modify the key-value data stream.
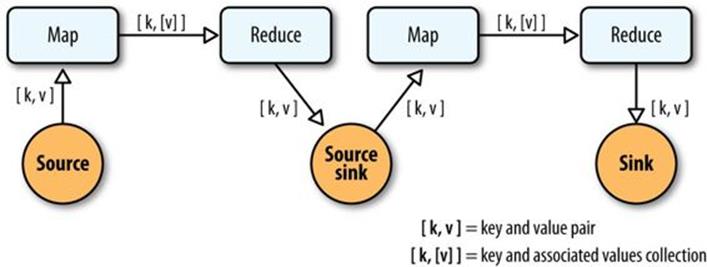
Figure 24-1. Counting and sorting in MapReduce
Cascading simplifies this by abstracting away keys and values and replacing them with tuples that have corresponding field names, similar in concept to tables and column names in a relational database. During processing, streams of these fields and tuples are then manipulated as they pass through user-defined operations linked together by pipes (Figure 24-2).
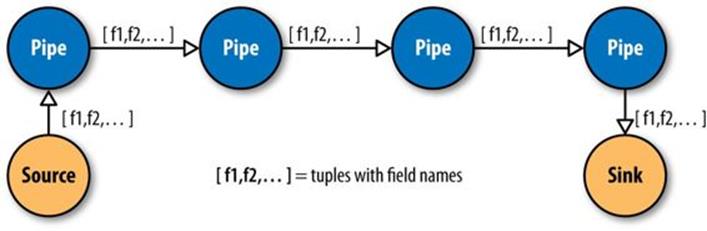
Figure 24-2. Pipes linked by fields and tuples
So, MapReduce keys and values are reduced to:
Fields
A field is a collection of either String names (such as “first_name”), numeric positions (such as 2 or –1, for the third and last positions, respectively), or a combination of both. So, fields are used to declare the names of values in a tuple and to select values by name from a tuple. The latter is like a SQL select call.
Tuples
A tuple is simply an array of java.lang.Comparable objects. A tuple is very much like a database row or record.
And the map and reduce operations are abstracted behind one or more pipe instances (Figure 24-3):
Each
The Each pipe processes a single input tuple at a time. It may apply either a Function or a Filter operation (described shortly) to the input tuple.
GroupBy
The GroupBy pipe groups tuples on grouping fields. It behaves just like the SQL GROUP BY statement. It can also merge multiple input tuple streams into a single stream if they all share the same field names.
CoGroup
The CoGroup pipe joins multiple tuple streams together by common field names, and it also groups the tuples by the common grouping fields. All standard join types (inner, outer, etc.) and custom joins can be used across two or more tuple streams.
Every
The Every pipe processes a single grouping of tuples at a time, where the group was grouped by a GroupBy or CoGroup pipe. The Every pipe may apply either an Aggregator or a Buffer operation to the grouping.
SubAssembly
The SubAssembly pipe allows for nesting of assemblies inside a single pipe, which can, in turn, be nested in more complex assemblies.
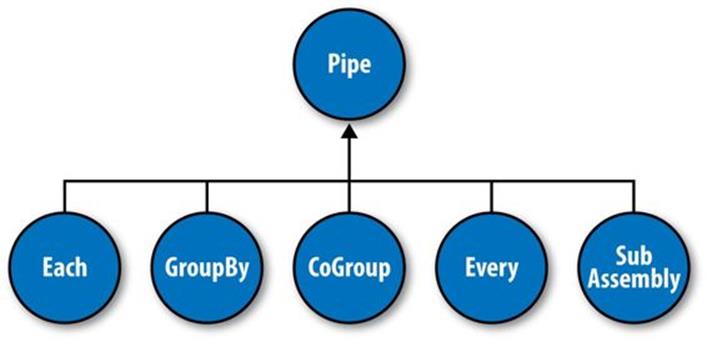
Figure 24-3. Pipe types
All these pipes are chained together by the developer into “pipe assemblies,” in which each assembly can have many input tuple streams (sources) and many output tuple streams (sinks). See Figure 24-4.
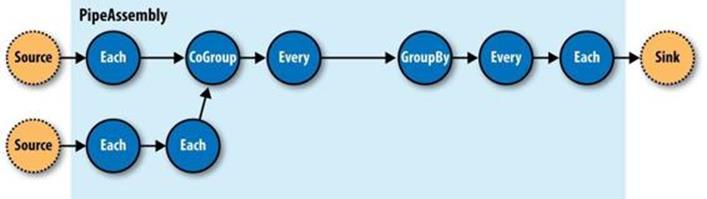
Figure 24-4. A simple PipeAssembly
On the surface, this might seem more complex than the traditional MapReduce model. And admittedly, there are more concepts here than map, reduce, key, and value. But in practice, there are many more concepts that must all work in tandem to provide different behaviors.
For example, a developer who wanted to provide a “secondary sorting” of reducer values would need to implement a map, a reduce, a “composite” key (two keys nested in a parent key), a value, a partitioner, an “output value grouping” comparator, and an “output key” comparator, all of which would be coupled to one another in varying ways, and very likely would not be reusable in subsequent applications.
In Cascading, this would be one line of code: new GroupBy(<previous>, <grouping fields>, <secondary sorting fields>), where <previous> is the pipe that came before.
Operations
As mentioned earlier, Cascading departs from MapReduce by introducing alternative operations that are applied either to individual tuples or groups of tuples (Figure 24-5):
Function
A Function operates on individual input tuples and may return zero or more output tuples for every one input. Functions are applied by the Each pipe.
Filter
A Filter is a special kind of function that returns a Boolean value indicating whether the current input tuple should be removed from the tuple stream. A Function could serve this purpose, but the Filter is optimized for this case, and many filters can be grouped by “logical” filters such as AND, OR, XOR, and NOT, rapidly creating more complex filtering operations.
Aggregator
An Aggregator performs some operation against a group of tuples, where the grouped tuples are by a common set of field values (for example, all tuples having the same “last-name” value). Common Aggregator implementations would be Sum, Count, Average, Max, and Min.
Buffer
A Buffer is similar to an Aggregator, except it is optimized to act as a “sliding window” across all the tuples in a unique grouping. This is useful when the developer needs to efficiently insert missing values in an ordered set of tuples (such as a missing date or duration) or create a running average. Usually Aggregator is the operation of choice when working with groups of tuples, since many Aggregators can be chained together very efficiently, but sometimes a Buffer is the best tool for the job.
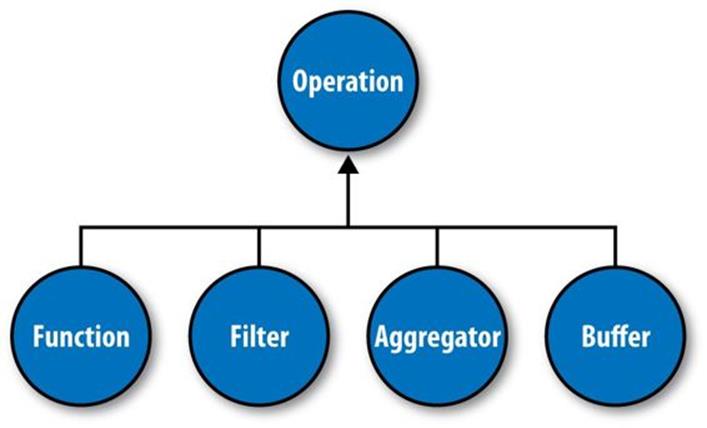
Figure 24-5. Operation types
Operations are bound to pipes when the pipe assembly is created (Figure 24-6).
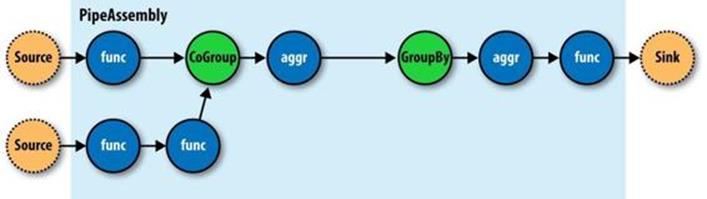
Figure 24-6. An assembly of operations
The Each and Every pipes provide a simple mechanism for selecting some or all values out of an input tuple before the values are passed to its child operation. And there is a simple mechanism for merging the operation results with the original input tuple to create the output tuple. Without going into great detail, this allows for each operation to care only about argument tuple values and fields, not the whole set of fields in the current input tuple. Subsequently, operations can be reusable across applications in the same way that Java methods can be reusable.
For example, in Java, a method declared as concatenate(String first, String second) is more abstract than concatenate(Person person). In the second case, the concatenate() function must “know” about the Person object; in the first case, it is agnostic to where the data came from. Cascading operations exhibit this same quality.
Taps, Schemes, and Flows
In many of the previous diagrams, there are references to “sources” and “sinks.” In Cascading, all data is read from or written to Tap instances, but is converted to and from tuple instances via Scheme objects:
Tap
A Tap is responsible for the “how” and “where” parts of accessing data. For example, is the data on HDFS or the local filesystem? In Amazon S3 or over HTTP?
Scheme
A Scheme is responsible for reading raw data and converting it to a tuple and/or writing a tuple out into raw data, where this “raw” data can be lines of text, Hadoop binary sequence files, or some proprietary format.
Note that Taps are not part of a pipe assembly, and so they are not a type of Pipe. But they are connected with pipe assemblies when they are made cluster executable. When a pipe assembly is connected with the necessary number of source and sink Tap instances, we get a Flow. TheTaps either emit or capture the field names the pipe assembly expects. That is, if a Tap emits a tuple with the field name “line” (by reading data from a file on HDFS), the head of the pipe assembly must be expecting a “line” value as well. Otherwise, the process that connects the pipe assembly with the Taps will immediately fail with an error.
So pipe assemblies are really data process definitions, and are not “executable” on their own. They must be connected to source and sink Tap instances before they can run on a cluster. This separation between Taps and pipe assemblies is part of what makes Cascading so powerful.
If you think of a pipe assembly like a Java class, then a Flow is like a Java object instance (Figure 24-7). That is, the same pipe assembly can be “instantiated” many times into new Flows, in the same application, without fear of any interference between them. This allows pipe assemblies to be created and shared like standard Java libraries.
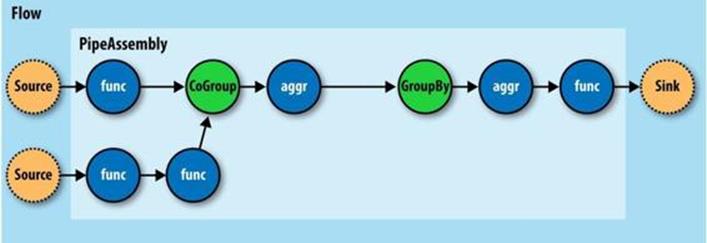
Figure 24-7. A Flow
Cascading in Practice
Now that we know what Cascading is and have a good idea of how it works, what does an application written in Cascading look like? See Example 24-1.
Example 24-1. Word count and sort
Scheme sourceScheme =
new TextLine(new Fields("line")); ![]()
Tap source =
new Hfs(sourceScheme, inputPath); ![]()
Scheme sinkScheme = new TextLine(); ![]()
Tap sink =
new Hfs(sinkScheme, outputPath, SinkMode.REPLACE); ![]()
Pipe assembly = new Pipe("wordcount"); ![]()
String regexString = "(?<!\\pL)(?=\\pL)[^ ]*(?<=\\pL)(?!\\pL)";
Function regex = new RegexGenerator(new Fields("word"), regexString);
assembly =
new Each(assembly, new Fields("line"), regex); ![]()
assembly =
new GroupBy(assembly, new Fields("word")); ![]()
Aggregator count = new Count(new Fields("count"));
assembly = new Every(assembly, count); ![]()
assembly =
new GroupBy(assembly, new Fields("count"), new Fields("word")); ![]()
FlowConnector flowConnector = new FlowConnector();
Flow flow =
flowConnector.connect("word-count", source, sink, assembly); ![]()
flow.complete();![]()
![]()
We create a new Scheme that reads simple text files and emits a new Tuple for each line in a field named “line,” as declared by the Fields instance.
![]()
We create a new Scheme that writes simple text files and expects a Tuple with any number of fields/values. If there is more than one value, they will be tab-delimited in the output file.
![]()
![]()
We create source and sink Tap instances that reference the input file and output directory, respectively. The sink Tap will overwrite any file that may already exist.
![]()
We construct the head of our pipe assembly and name it “wordcount.” This name is used to bind the source and sink Taps to the assembly. Multiple heads or tails would require unique names.
![]()
We construct an Each pipe with a function that will parse the “line” field into a new Tuple for each word encountered.
![]()
We construct a GroupBy pipe that will create a new Tuple grouping for each unique value in the field “word.”
![]()
We construct an Every pipe with an Aggregator that will count the number of Tuples in every unique word group. The result is stored in a field named “count.”
![]()
We construct a GroupBy pipe that will create a new Tuple grouping for each unique value in the field “count” and secondary sort each value in the field “word.” The result will be a list of “count” and “word” values with “count” sorted in increasing order.
![]()
![]()
We connect the pipe assembly to its sources and sinks in a Flow, and then execute the Flow on the cluster.
In the example, we count the words encountered in the input document, and we sort the counts in their natural order (ascending). If some words have the same “count” value, these words are sorted in their natural order (alphabetical).
One obvious problem with this example is that some words might have uppercase letters in some instances — for example, “the” and “The” when the word comes at the beginning of a sentence. We might consider inserting a new operation to force all the words to lowercase, but we realize that all future applications that need to parse words from documents should have the same behavior, so we’ll instead create a reusable pipe called SubAssembly, just like we would by creating a subroutine in a traditional application (see Example 24-2).
Example 24-2. Creating a SubAssembly
public class ParseWordsAssembly extends SubAssembly ![]()
{
public ParseWordsAssembly(Pipe previous)
{
String regexString = "(?<!\\pL)(?=\\pL)[^ ]*(?<=\\pL)(?!\\pL)";
Function regex = new RegexGenerator(new Fields("word"), regexString);
previous = new Each(previous, new Fields("line"), regex);
String exprString = "word.toLowerCase()";
Function expression =
new ExpressionFunction(new Fields("word"), exprString, String.class); ![]()
previous = new Each(previous, new Fields("word"), expression);
setTails(previous); ![]()
}
}
![]()
We subclass the SubAssembly class, which is itself a kind of Pipe.
![]()
We create a Java expression function that will call toLowerCase() on the String value in the field named “word.” We must also pass in the Java type the expression expects “word” to be — in this case, String. (Janino is used under the covers.)
![]()
We tell the SubAssembly superclass where the tail ends of our pipe subassembly are.
First, we create a SubAssembly pipe to hold our “parse words” pipe assembly. Because this is a Java class, it can be reused in any other application, as long as there is an incoming field named “word” (Example 24-3). Note that there are ways to make this function even more generic, but they are covered in the Cascading User Guide.
Example 24-3. Extending word count and sort with a SubAssembly
Scheme sourceScheme = new TextLine(new Fields("line"));
Tap source = new Hfs(sourceScheme, inputPath);
Scheme sinkScheme = new TextLine(new Fields("word", "count"));
Tap sink = new Hfs(sinkScheme, outputPath, SinkMode.REPLACE);
Pipe assembly = new Pipe("wordcount");
assembly =
new ParseWordsAssembly(assembly); ![]()
assembly = new GroupBy(assembly, new Fields("word"));
Aggregator count = new Count(new Fields("count"));
assembly = new Every(assembly, count);
assembly = new GroupBy(assembly, new Fields("count"), new Fields("word"));
FlowConnector flowConnector = new FlowConnector();
Flow flow = flowConnector.connect("word-count", source, sink, assembly);
flow.complete();
![]()
We replace Each from the previous example with our ParseWordsAssembly pipe.
Finally, we just substitute in our new SubAssembly right where the previous Every and word parser function were used in the previous example. This nesting can continue as deep as necessary.
Flexibility
Let’s take a step back and see what this new model has given us — or better yet, what it has taken away.
You see, we no longer think in terms of MapReduce jobs, or Mapper and Reducer interface implementations and how to bind or link subsequent MapReduce jobs to the ones that precede them. During runtime, the Cascading “planner” figures out the optimal way to partition the pipe assembly into MapReduce jobs and manages the linkages between them (Figure 24-8).
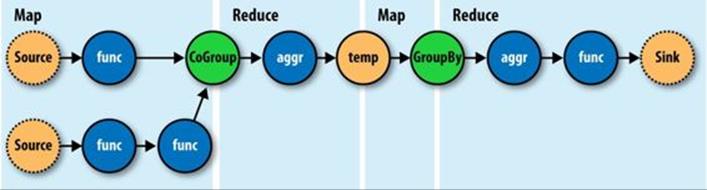
Figure 24-8. How a Flow translates to chained MapReduce jobs
Because of this, developers can build applications of arbitrary granularity. They can start with a small application that just filters a logfile, then iteratively build more features into the application as needed.
Since Cascading is an API and not a syntax like strings of SQL, it is more flexible. First off, developers can create domain-specific languages (DSLs) using their favorite languages, such as Groovy, JRuby, Jython, Scala, and others (see the project site for examples). Second, developers can extend various parts of Cascading, such as allowing custom Thrift or JSON objects to be read and written to and allowing them to be passed through the tuple stream.
Hadoop and Cascading at ShareThis
ShareThis is a sharing network that makes it simple to share any online content. With the click of a button on a web page or browser plug-in, ShareThis allows users to seamlessly access their contacts and networks from anywhere online and share the content via email, IM, Facebook, Digg, mobile SMS, and similar services, without ever leaving the current page. Publishers can deploy the ShareThis button to tap into the service’s universal sharing capabilities to drive traffic, stimulate viral activity, and track the sharing of online content. ShareThis also simplifies social media services by reducing clutter on web pages and providing instant distribution of content across social networks, affiliate groups, and communities.
As ShareThis users share pages and information through the online widgets, a continuous stream of events enter the ShareThis network. These events are first filtered and processed, and then handed to various backend systems, including AsterData, Hypertable, and Katta.
The volume of these events can be huge; too large to process with traditional systems. This data can also be very “dirty” thanks to “injection attacks” from rogue systems, browser bugs, or faulty widgets. For this reason, the developers at ShareThis chose to deploy Hadoop as the preprocessing and orchestration frontend to their backend systems. They also chose to use Amazon Web Services to host their servers on the Elastic Computing Cloud (EC2) and provide long-term storage on the Simple Storage Service (S3), with an eye toward leveraging Elastic MapReduce (EMR).
In this overview, we will focus on the “log processing pipeline” (Figure 24-9). This pipeline simply takes data stored in an S3 bucket, processes it (as described shortly), and stores the results back into another bucket. The Simple Queue Service (SQS) is used to coordinate the events that mark the start and completion of data processing runs. Downstream, other processes pull data to load into AsterData, pull URL lists from Hypertable to source a web crawl, or pull crawled page data to create Lucene indexes for use by Katta. Note that Hadoop is central to the ShareThis architecture. It is used to coordinate the processing and movement of data between architectural components.
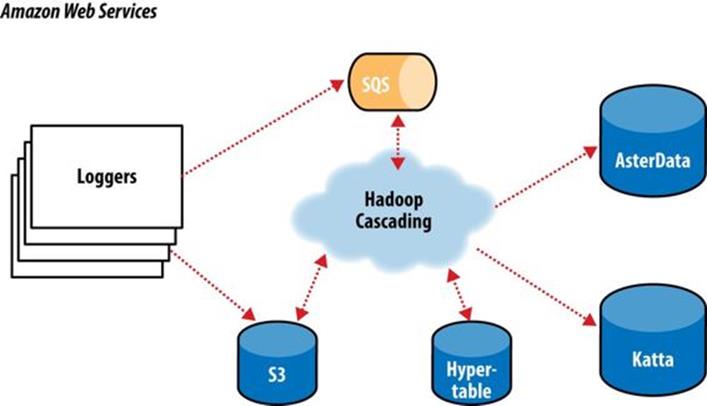
Figure 24-9. The ShareThis log processing pipeline
With Hadoop as the frontend, all the event logs can be parsed, filtered, cleaned, and organized by a set of rules before ever being loaded into the AsterData cluster or used by any other component. AsterData is a clustered data warehouse that can support large datasets and that allows for complex ad hoc queries using a standard SQL syntax. ShareThis chose to clean and prepare the incoming datasets on the Hadoop cluster and then to load that data into the AsterData cluster for ad hoc analysis and reporting. Though that process would have been possible with AsterData, it made a lot of sense to use Hadoop as the first stage in the processing pipeline to offset load on the main data warehouse.
Cascading was chosen as the primary data processing API to simplify the development process, codify how data is coordinated between architectural components, and provide the developer-facing interface to those components. This represents a departure from more “traditional” Hadoop use cases, which essentially just query stored data. Cascading and Hadoop together provide a better and simpler structure for the complete solution, end to end, and thus provide more value to the users.
For the developers, Cascading made it easy to start with a simple unit test (created by subclassing cascading.ClusterTestCase) that did simple text parsing and then to layer in more processing rules while keeping the application logically organized for maintenance. Cascading aided this organization in a couple of ways. First, standalone operations (Functions, Filters, etc.) could be written and tested independently. Second, the application was segmented into stages: one for parsing, one for rules, and a final stage for binning/collating the data, all via theSubAssembly base class described earlier.
The data coming from the ShareThis loggers looks a lot like Apache logs, with date/timestamps, share URLs, referrer URLs, and a bit of metadata. To use the data for analysis downstream, the URLs needed to be unpacked (parsing query-string data, domain names, etc.). So, a top-level SubAssembly was created to encapsulate the parsing, and child subassemblies were nested inside to handle specific fields if they were sufficiently complex to parse.
The same was done for applying rules. As every Tuple passed through the rules SubAssembly, it was marked as “bad” if any of the rules were triggered. Along with the “bad” tag, a description of why the record was bad was added to the Tuple for later review.
Finally, a splitter SubAssembly was created to do two things. First, it allowed for the tuple stream to split into two: one stream for “good” data and one for “bad” data. Second, the splitter binned the data into intervals, such as every hour. To do this, only two operations were necessary: the first to create the interval from the timestamp value already present in the stream, and the second to use the interval and good/bad metadata to create a directory path (for example, 05/good/, where “05” is 5 a.m. and “good” means the Tuple passed all the rules). This path would then be used by the Cascading TemplateTap, a special Tap that can dynamically output tuple streams to different locations based on values in the Tuple. In this case, the TemplateTap used the “path” value to create the final output path.
The developers also created a fourth SubAssembly — this one to apply Cascading Assertions during unit testing. These assertions double-checked that rules and parsing subassemblies did their job.
In the unit test in Example 24-4, we see the splitter isn’t being tested, but it is added in another integration test not shown.
Example 24-4. Unit testing a Flow
public void testLogParsing() throws IOException
{
Hfs source = new Hfs(new TextLine(new Fields("line")), sampleData);
Hfs sink =
new Hfs(new TextLine(), outputPath + "/parser", SinkMode.REPLACE);
Pipe pipe = new Pipe("parser");
// split "line" on tabs
pipe = new Each(pipe, new Fields("line"), new RegexSplitter("\t"));
pipe = new LogParser(pipe);
pipe = new LogRules(pipe);
// testing only assertions
pipe = new ParserAssertions(pipe);
Flow flow = new FlowConnector().connect(source, sink, pipe);
flow.complete(); // run the test flow
// Verify there are 98 tuples and 2 fields, and matches the regex pattern
// For TextLine schemes the tuples are { "offset", "line" }
validateLength(flow, 98, 2, Pattern.compile("^[0-9]+(\\t[^\\t]*){19}$"));
}
For integration and deployment, many of the features built into Cascading allowed for easier integration with external systems and for greater process tolerance.
In production, all the subassemblies are joined and planned into a Flow, but instead of just source and sink Taps, trap Taps were planned in (Figure 24-10). Normally, when an operation throws an exception from a remote mapper or reducer task, the Flow will fail and kill all its managed MapReduce jobs. When a Flow has traps, any exceptions are caught and the data causing the exception is saved to the Tap associated with the current trap. Then the next Tuple is processed without stopping the Flow. Sometimes you want your Flows to fail on errors, but in this case, the ShareThis developers knew they could go back and look at the “failed” data and update their unit tests while the production system kept running. Losing a few hours of processing time was worse than losing a couple of bad records.
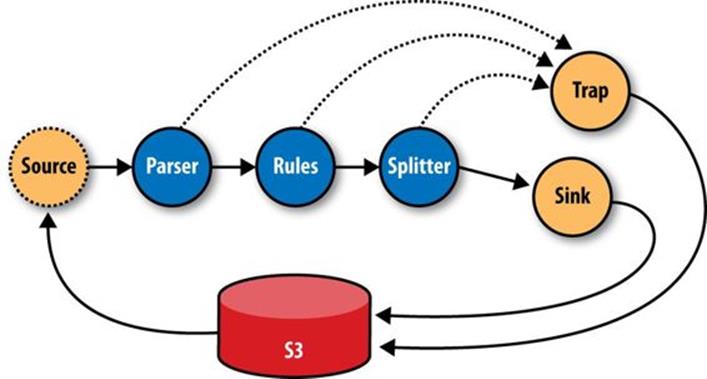
Figure 24-10. The ShareThis log processing flow
Using Cascading’s event listeners, Amazon SQS could be integrated. When a Flow finishes, a message is sent to notify other systems that there is data ready to be picked up from Amazon S3. On failure, a different message is sent, alerting other processes.
The remaining downstream processes pick up where the log processing pipeline leaves off on different independent clusters. The log processing pipeline today runs once a day; there is no need to keep a 100-node cluster sitting around for the 23 hours it has nothing to do, so it is decommissioned and recommissioned 24 hours later.
In the future, it would be trivial to increase this interval on smaller clusters to every 6 hours, or 1 hour, as the business demands. Independently, other clusters are booting and shutting down at different intervals based on the needs of the business units responsible for those components. For example, the web crawler component (using Bixo, a Cascading-based web-crawler toolkit developed by EMI and ShareThis) may run continuously on a small cluster with a companion Hypertable cluster. This on-demand model works very well with Hadoop, where each cluster can be tuned for the kind of workload it is expected to handle.
Summary
Hadoop is a very powerful platform for processing and coordinating the movement of data across various architectural components. Its only drawback is that the primary computing model is MapReduce.
Cascading aims to help developers build powerful applications quickly and simply, through a well-reasoned API, without needing to think in MapReduce and while leaving the heavy lifting of data distribution, replication, distributed process management, and liveness to Hadoop.
Read more about Cascading, join the online community, and download sample applications by visiting the project website.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.