Expert Oracle Database Architecture, Third Edition (2014)
Chapter 11. Indexes
Indexing is a crucial aspect of your application design and development. Too many indexes and the performance of modifications (inserts, updates, merges, and deletes) will suffer. Too few indexes and the performance of DML (including select, inserts, updates, and deletes) will suffer. Finding the right mix is critical to your application’s performance.
Frequently, I find that indexes are an afterthought in application development. I believe that this is the wrong approach. If you understand how the data will be used from the very beginning of the process, you should be able to come up with the representative set of indexes you will use in your application. Too often the approach seems to be to throw the application out there and then see where indexes are needed. This implies that you have not taken the time to understand how the data will be used and how many rows you will ultimately require. You’ll be adding indexes to this system forever as the volume of data grows over time (i.e., you’ll perform reactive tuning). You’ll have indexes that are redundant and never used; this wastes not only space but also computing resources. A few hours at the start spent properly considering when and how to index your data will save you many hours of tuning further down the road (note that I said doing so will, not might, save you many hours).
The basic aim of this chapter is to give an overview of the indexes available for use in Oracle and discuss when and where you might use them. This chapter differs from others in this book in terms of its style and format. Indexing is a huge topic—you could write an entire book on the subject—in part because indexing bridges the developer and DBA roles. The developer must be aware of indexes, how indexes apply to their applications, when to use indexes (and when not to use them), and so on. The DBA is concerned with the growth of an index, the use of storage within an index, other physical properties, and the overall performance of the database. We will be tackling indexes mainly from the standpoint of their practical use in applications. The first half of this chapter conveys the basic knowledge I believe you need to make intelligent choices about when to index and what type of index to use. The second half of the chapter answers some of the most frequently asked questions about indexes.
The various examples in this chapter require different feature releases of Oracle. When a specific example requires features found in Oracle Enterprise or Personal Edition but not Standard Edition, I’ll specify that.
An Overview of Oracle Indexes
Oracle provides many different types of indexes for us to use. Briefly, they are as follows:
· B*Tree indexes: These are what I refer to as conventional indexes. They are, by far, the most common indexes in use in Oracle and most other databases. Similar in construct to a binary tree, B*Tree indexes provide fast access, by key, to an individual row or range of rows, normally requiring few reads to find the correct row. It is important to note, however, that the “B” in “B*Tree” does not stand for binary but rather for balanced. A B*Tree index is not a binary tree at all, as we’ll see when we look at how one is physically stored on disk. The B*Tree index has several subtypes:
· Index organized tables: These are tables stored in a B*Tree structure. Whereas rows of data in a heap table are stored in an unorganized fashion (data goes wherever there is available space), data in an IOT is stored and sorted by primary key. IOTs behave just like “regular” tables as far as your application is concerned; you use SQL to access them as normal. IOTs are especially useful for information retrieval, spatial, and OLAP applications. We discussed IOTs in some detail in Chapter 10.
· B*Tree cluster indexes: These are a slight variation of conventional B*Tree indexes. They are used to index the cluster keys (see the section “Index Clustered Tables” in Chapter 10) and will not be discussed again in this chapter. Rather than having a key that points to a row, as for a conventional B*Tree, a B*Tree cluster has a cluster key that points to the block that contains the rows related to that cluster key.
· Descending indexes: Descending indexes allow for data to be sorted from big-to-small (descending) instead of small-to-big (ascending) in the index structure. We’ll take a look at why that might be important and how they work.
· Reverse key indexes: These are B*Tree indexes whereby the bytes in the key are reversed. Reverse key indexes can be used to obtain a more even distribution of index entries throughout an index that is populated with increasing values. For example, if I am using a sequence to generate a primary key, the sequence will generate values like 987500, 987501, 987502, and so on. These sequence values are monotonic, so if I were using a conventional B*Tree index, they would all tend to go the same right-hand-side block, thus increasing contention for that block. With a reverse key index, Oracle will logically index 205789, 105789, 005789, and so on instead. Oracle will reverse the bytes of the data to be stored before placing them in the index, so values that would have been next to each other in the index before the byte reversal will instead be far apart. This reversing of the bytes spreads out the inserts into the index over many blocks.
· Bitmap indexes: Normally in a B*Tree, there is a one-to-one relationship between an index entry and a row: an index entry points to a row. With bitmap indexes, a single index entry uses a bitmap to point to many rows simultaneously. They are appropriate for highly repetitive data (data with few distinct values relative to the total number of rows in the table) that is mostly read-only. Consider a column that takes on three possible values—Y, N, and NULL—in a table of 1 million rows. This might be a good candidate for a bitmap index, if, for example, you need to frequently count how many rows have a value of Y. That is not to say that a bitmap index on a column with 1,000 distinct values in that same table would not be valid—it certainly can be. Bitmap indexes should never be considered in an OLTP database for concurrency-related issues (which we’ll discuss in due course). Note that bitmap indexes require the Enterprise or Personal Edition of Oracle.
· Bitmap join indexes: These provide a means of denormalizing data in an index structure, instead of in a table. For example, consider the simple EMP and DEPT tables. Someone might ask the question, “How many people work in departments located in the city of Boston?” EMP has a foreign key to DEPT, and in order to count the employees in departments with a LOC value of Boston, we would normally have to join the tables to get the LOC column joined to the EMP records to answer this question. Using a bitmap join index, we can instead index the LOC column against the EMP table. The same caveat in regard to OLTP systems applies to a bitmap join index as a regular bitmap index.
· Function-based indexes: These are B*Tree or bitmap indexes that store the computed result of a function on a row’s column(s), not the column data itself. You can consider them an index on a virtual (or derived) column—in other words, a column that is not physically stored in the table. These may be used to speed up queries of the form SELECT * FROM T WHERE FUNCTION(DATABASE_COLUMN) = SOME_VALUE, since the value FUNCTION(DATABASE_COLUMN) has already been computed and stored in the index.
· Application domain indexes: These are indexes you build and store yourself, either in Oracle or perhaps even outside of Oracle. You tell the optimizer how selective your index is and how costly it is to execute, and the optimizer will decide whether or not to use your index based on that information. The Oracle text index is an example of an application domain index; it is built using the same tools you may use to build your own index. It should be noted that the index created here need not use a traditional index structure. The Oracle text index, for example, uses a set of tables to implement its concept of an index.
As you can see, there are many index types to choose from. In the following sections, I’ll present some technical details on how each one works and when it should be used. I would like to stress again that we will not cover certain DBA-related topics. For example, we will not discuss the mechanics of an online rebuild; rather, we will concentrate on practical application-related details.
B*Tree Indexes
B*Tree—or what I call conventional—indexes are the most commonly used type of indexing structure in the database. They are similar in implementation to a binary search tree. Their goal is to minimize the amount of time Oracle spends searching for data. Loosely speaking, if you have an index on a number column, then the structure might conceptually look like Figure 11-1.
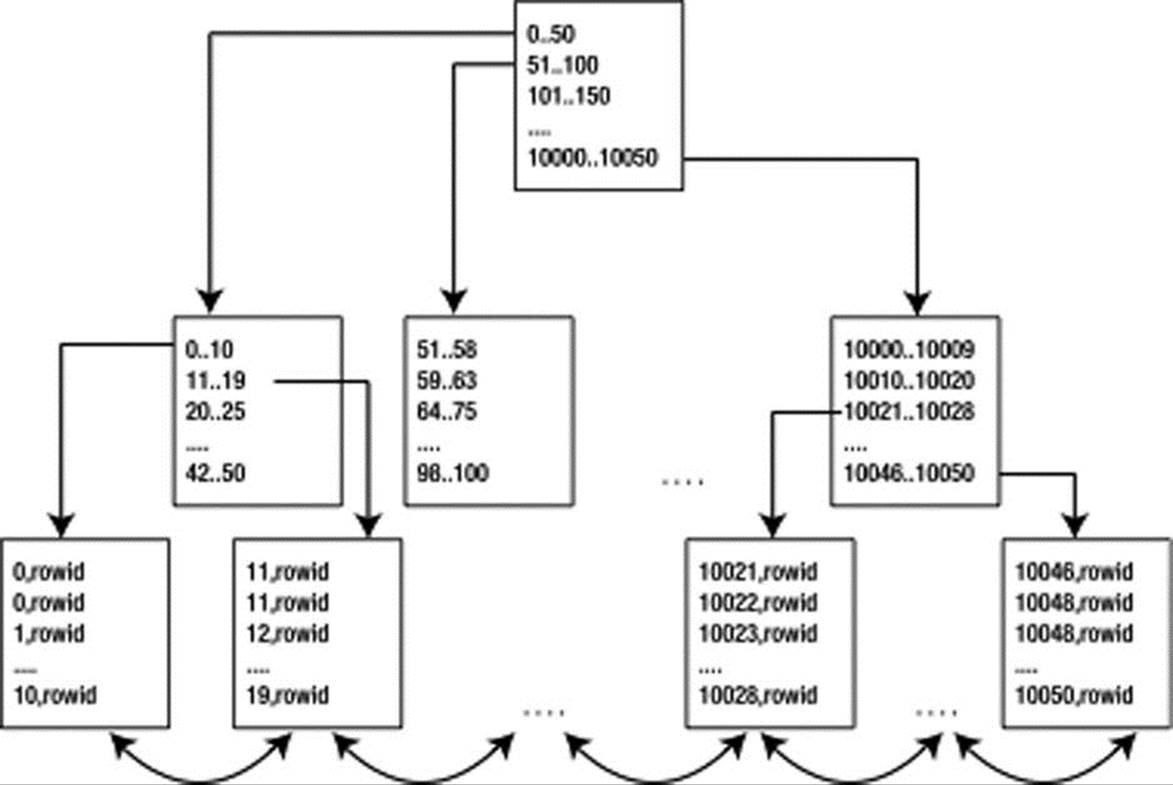
Figure 11-1. Typical B*Tree index layout
![]() Note There are block-level optimizations and compression of data that take place that make the real block structure look different from Figure 11-1. Also, the index depicted in Figure 11-1 is a nonunique index (meaning it allows duplicate key values). For example, if you wanted to find the value of 11, there are two different index entries with the value of 11.
Note There are block-level optimizations and compression of data that take place that make the real block structure look different from Figure 11-1. Also, the index depicted in Figure 11-1 is a nonunique index (meaning it allows duplicate key values). For example, if you wanted to find the value of 11, there are two different index entries with the value of 11.
The lowest level blocks in the tree, called leaf nodes or leaf blocks, contain every indexed key and a rowid that points to the row it is indexing. The interior blocks, above the leaf nodes, are known as branch blocks. They are used to navigate through the structure. For example, if we wanted to find the value 42 in the index, we would start at the top of the tree and go to the left. We would inspect that block and discover we needed to go to the block in the range “42..50”. This block would be the leaf block and point us to the rows that contained the number 42.
It is interesting to note that the leaf nodes of the index are actually a doubly linked list. Once we find out where to start in the leaf nodes (i.e., once we have found that first value), doing an ordered scan of values (also known as an index range scan) is very easy. We don’t have to navigate the structure anymore; we just go forward or backward through the leaf nodes as needed. That makes satisfying a predicate, such as the following, pretty simple:
where x between 20 and 30
Oracle finds the first index leaf block that contains the lowest key value that is 20 or greater, and then it just walks horizontally through the linked list of leaf nodes until it finally hits a value that is greater than 30.
There really is no such thing as a nonunique entry in a B*Tree index. In a nonunique index, Oracle simply stores the rowid by appending it to the key as an extra column with a length byte to make the key unique. For example, an index such as CREATE INDEX I ON T(X,Y) is conceptually CREATE UNIQUE INDEX I ON T(X,Y,ROWID). In a unique index, as defined by you, Oracle does not add the rowid to the index key. In a nonunique index, you will find that the data is sorted first by index key values (in the order of the index key) and then by rowidascending. In a unique index, the data is sorted only by the index key values.
One of the properties of a B*Tree is that all leaf blocks should be at the same level in the tree. This level is also known as the height of the index, meaning that any traversal from the root block of the index to a leaf block will visit the same number of blocks. That is, to get to the leaf block to retrieve the first row for a query of the form "SELECT INDEXED_COL FROM T WHERE INDEXED_COL = :X" will take the same number of I/Os regardless of the value of :X that is used. In other words, the index is height balanced. Most B*Tree indexes will have a height of 2 or 3, even for millions of records. This means that it will take, in general, two or three I/Os to find your key in the index—which is not too bad.
![]() Note Oracle uses two terms with slightly different meanings when referring to the number of blocks involved in traversing from an index root block to a leaf block. The first is HEIGHT, which is the number of blocks required to go from the root block to the leaf block. The HEIGHT value can be found from the INDEX_STATS view after the index has been analyzed using the ANALYZE INDEX <name> VALIDATE STRUCTURE command. The other is BLEVEL, which is the number of branch levels and differs from HEIGHT by one (it does not count the leaf blocks). The value of BLEVEL is found in the normal dictionary tables such as USER_INDEXES after statistics have been gathered.
Note Oracle uses two terms with slightly different meanings when referring to the number of blocks involved in traversing from an index root block to a leaf block. The first is HEIGHT, which is the number of blocks required to go from the root block to the leaf block. The HEIGHT value can be found from the INDEX_STATS view after the index has been analyzed using the ANALYZE INDEX <name> VALIDATE STRUCTURE command. The other is BLEVEL, which is the number of branch levels and differs from HEIGHT by one (it does not count the leaf blocks). The value of BLEVEL is found in the normal dictionary tables such as USER_INDEXES after statistics have been gathered.
For example, say we have a 10,000,000-row table (see the “Setting Up Your Environment” section at the beginning of this book for details on creating BIG_TABLE) with a primary key index on a number column:
EODA@ORA12CR1> select index_name, blevel, num_rows
2 from user_indexes
3 where table_name = 'BIG_TABLE';
INDEX_NAME BLEVEL NUM_ROWS
-------------------- ---------- ---------
BIG_TABLE_PK 2 9848991
The BLEVEL is 2, meaning the HEIGHT is 3, and it will take two I/Os to find a leaf (resulting in a third I/O). So we would expect three I/Os to retrieve any given key value from this index:
EODA@ORA12CR1> set autotrace on
EODA@ORA12CR1> select id from big_table where id = 42;
Execution Plan
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time|
---------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 6 | 2 (0)| 00:00:01|
|* 1 | INDEX UNIQUE SCAN | BIG_TABLE_PK | 1 | 6 | 2 (0)| 00:00:01|
---------------------------------------------------------------------------------
Statistics
-----------------------------------------------------------
... 3 consistent gets
1 rows processed
EODA@ORA12CR1> select id from big_table where id = 12345;
Statistics
-----------------------------------------------------------
... 3 consistent gets
... 1 rows processed
EODA@ORA12CR1> select id from big_table where id = 1234567;
Statistics
-----------------------------------------------------------
... 3 consistent gets
... 1 rows processed
The B*Tree is an excellent general-purpose indexing mechanism that works well for large and small tables, and experiences little, if any, degradation in retrieval performance as the size of the underlying table grows.
Index Key Compression
One of the interesting things you can do with a B*Tree index is compress it. This is not compression in the same manner that ZIP files are compressed; rather, this is compression that removes redundancies from concatenated (multicolumn) indexes.
We covered compressed key indexes in some detail in the section “Index Organized Tables” in Chapter 10, and we will take a brief look at them again here. The basic concept behind a compressed key index is that every entry is broken into two pieces: a prefix and suffix component. The prefix is built on the leading columns of the concatenated index and will have many repeating values. The suffix is built on the trailing columns in the index key and is the unique component of the index entry within the prefix.
By way of example, we’ll create a table and a concatenated index and measure its space without compression using ANALYZE INDEX.
![]() Note There is a common misperception that ANALYZE should not be used as a command in Oracle—that the DBMS_STATS package supersedes it. This is not true. What is true is that ANALYZE should not be used to gather statistics, but the other capabilities of ANALYZE still apply. TheANALYZE command should be used to perform operations such as validating the structure of an index (as we will later) or listing chained rows in a table. DBMS_STATS should be used exclusively to gather statistics on objects.
Note There is a common misperception that ANALYZE should not be used as a command in Oracle—that the DBMS_STATS package supersedes it. This is not true. What is true is that ANALYZE should not be used to gather statistics, but the other capabilities of ANALYZE still apply. TheANALYZE command should be used to perform operations such as validating the structure of an index (as we will later) or listing chained rows in a table. DBMS_STATS should be used exclusively to gather statistics on objects.
We’ll then re-create the index with index key compression, compressing a different number of key entries, and see the difference. Let’s start with this table and index:
EODA@ORA12CR1> create table t
2 as
3 select * from all_objects
4 where rownum <= 50000;
Table created.
EODA@ORA12CR1> create index t_idx on
2 t(owner,object_type,object_name);
Index created.
EODA@ORA12CR1> analyze index t_idx validate structure;
Index analyzed.
We then create an IDX_STATS table in which to save INDEX_STATS information, and we label the rows in the table as “noncompressed”:
EODA@ORA12CR1> create table idx_stats
2 as
3 select 'noncompressed' what, a.*
4 from index_stats a;
Table created.
Now, we could realize that the OWNER component is repeated many times, meaning that a single index block in this index will have dozens of entries, as shown in Figure 11-2.
Figure 11-2. Index block with OWNER column repeated
We could factor the repeated OWNER column out of this, resulting in a block that looks more like Figure 11-3.
Figure 11-3. Index block with OWNER column factored out
In Figure 11-3, the owner name appears once on the leaf block—not once per repeated entry. We run the following script, passing in the number 1, to re-create the scenario whereby the index is using compression on just the leading column:
drop index t_idx;
create index t_idx on
t(owner,object_type,object_name)
compress &1;
analyze index t_idx validate structure;
insert into idx_stats
select 'compress &1', a.*
from index_stats a;
For comparison reasons, we run this script not only with one column, but also two and three compressed columns, to see what happens. At the end, we query IDX_STATS and should observe this:
EODA@ORA12CR1> select what, height, lf_blks, br_blks,
2 btree_space, opt_cmpr_count, opt_cmpr_pctsave
3 from idx_stats
4 /
WHAT HEIGHT LF_BLKS BR_BLKS BTREE_SPACE OPT_CMPR_COUNT OPT_CMPR_PCTSAVE
------------- ---------- ---------- ---------- ----------- -------------- ----------------
noncompressed 2 227 1 1823120 2 28
compress 1 2 206 1 1654380 2 21
compress 2 2 162 1 1302732 2 0
compress 3 2 268 1 2149884 2 39
We see that the COMPRESS 1 index is about 90 percent the size of the noncompressed index (comparing BTREE_SPACE). The number of leaf blocks has decreased measurably. Further, when we use COMPRESS 2, the savings are even more impressive. The resulting index is about 71 percent the size of the original. In fact, using the column OPT_CMPR_PCTSAVE, which stands for optimum compression percent saved or the expected savings from compression, we could have guessed the size of the COMPRESS 2 index:
EODA@ORA12CR1> select 1823120*(1-0.28) from dual;
1823120*(1-0.28)
----------------
1312646.4
![]() Note The ANALYZE command against the noncompressed index populated the OPT_CMPR_PCTSAVE/OPT_CMPR_COUNT columns and estimated a 28 percent savings with COMPRESS 2, and we achieved just about exactly that.
Note The ANALYZE command against the noncompressed index populated the OPT_CMPR_PCTSAVE/OPT_CMPR_COUNT columns and estimated a 28 percent savings with COMPRESS 2, and we achieved just about exactly that.
But notice what happens with COMPRESS 3. The resulting index is actually larger: 117 percent the size of the original index. This is due to the fact that each repeated prefix we remove saves the space of N copies, but adds 4 bytes of overhead on the leaf block as part of the compression scheme. By adding in the OBJECT_NAME column to the compressed key, we made that key almost unique—in this case meaning there were really no duplicate copies to factor out. Therefore, we ended up adding 4 bytes to almost every single index key entry and factoring out no repeating data. The OPT_CMPR_COUNT column in IDX_STATS is dead accurate at providing the best compression count to be used, and OPT_CMPR_PCTSAVE will tell you exactly how much savings to expect.
Now, you do not get this compression for free. The compressed index structure is now more complex than it used to be. Oracle will spend more time processing the data in this structure, both while maintaining the index during modifications and when you search the index during a query. What we are doing here is trading off increased CPU time for reduced I/O time. With compression, our block buffer cache will be able to hold more index entries than before, our cache-hit ratio might go up, and our physical I/Os should go down, but it will take a little more CPU horsepower to process the index, and it will also increase the chance of block contention. Just as in our discussion of the hash cluster, where it might take more CPU to retrieve a million random rows but half the I/O, we must be aware of the tradeoff. If you are currently CPU bound, adding compressed key indexes may slow down your processing. On the other hand, if you are I/O bound, using them may speed up things.
Reverse Key Indexes
Another feature of a B*Tree index is the ability to reverse its keys. At first you might ask yourself, “Why would I want to do that?” B*Tree indexes were designed for a specific environment and for a specific issue. They were implemented to reduce contention for index leaf blocks in “right-hand-side” indexes, such as indexes on columns populated by a sequence value or a timestamp, in an Oracle RAC environment.
![]() Note We discussed RAC in Chapter 2.
Note We discussed RAC in Chapter 2.
RAC is a configuration of Oracle in which multiple instances can mount and open the same database. If two instances need to modify the same block of data simultaneously, they will share the block by passing it back and forth over a hardware interconnect, a private network connection between the two (or more) machines. If you have a primary key index on a column populated from a sequence (a very popular implementation), everyone will be trying to modify the one block that is currently the left block on the right-hand side of the index structure as they insert new values (see Figure 11-1, which shows that higher values in the index go to the right and lower values go to the left). Modifications to indexes on columns populated by sequences are focused on a small set of leaf blocks. Reversing the keys of the index allows insertions to be distributed across all the leaf blocks in the index, though it could tend to make the index much less efficiently packed.
![]() Note You may also find reverse key indexes useful as a method to reduce contention, even in a single instance of Oracle. Again, you will mainly use them to alleviate buffer busy waits on the right-hand side of a busy index, as described in this section.
Note You may also find reverse key indexes useful as a method to reduce contention, even in a single instance of Oracle. Again, you will mainly use them to alleviate buffer busy waits on the right-hand side of a busy index, as described in this section.
Before we look at how to measure the impact of a reverse key index, let’s discuss what a reverse key index physically does. A reverse key index simply reverses the bytes of each column in an index key. If we consider the numbers 90101, 90102, and 90103, and look at their internal representation using the Oracle DUMP function, we will find they are represented as follows:
EODA@ORA12CR1> select 90101, dump(90101,16) from dual
2 union all
3 select 90102, dump(90102,16) from dual
4 union all
5 select 90103, dump(90103,16) from dual
6 /
90101 DUMP(90101,16)
---------- ---------------------
90101 Typ=2 Len=4: c3,a,2,2
90102 Typ=2 Len=4: c3,a,2,3
90103 Typ=2 Len=4: c3,a,2,4
Each one is 4 bytes in length and only the last byte is different. These numbers would end up right next to each other in an index structure. If we reverse their bytes, however, Oracle will insert the following:
90101 reversed = 2,2,a,c3
90102 reversed = 3,2,a,c3
90103 reversed = 4,2,a,c3
The numbers will end up far away from each other. This reduces the number of RAC instances going after the same block (the rightmost block) and reduces the number of block transfers between RAC instances. One of the drawbacks to a reverse key index is that you cannot use it in all cases where a regular index can be applied. For example, in answering the following predicate, a reverse key index on X would not be useful:
where x > 5
The data in the index is not sorted by X before it is stored, but rather by REVERSE(X), hence the range scan for X > 5 will not be able to use the index. On the other hand, some range scans can be done on a reverse key index. If I have a concatenated index on (X, Y), the following predicate will be able to make use of the reverse key index and will range scan it:
where x = 5
This is because the bytes for X are reversed, and then the bytes for Y are reversed. Oracle does not reverse the bytes of (X || Y), but rather stores (REVERSE(X) || REVERSE(Y)). This means all of the values for X = 5 will be stored together, so Oracle can range scan that index to find them all.
Now, assuming you have a surrogate primary key on a table populated via a sequence, and you do not need to use range scanning on this index—that is, you don’t need to query for MAX(primary_key), MIN(primary_key), WHERE primary_key < 100, and so on—then you could consider a reverse key index in high insert scenarios even in a single instance of Oracle. I set up two different tests, one in a pure PL/SQL environment and one using Pro*C to demonstrate the differences between inserting into a table with a reverse key index on the primary key and one with a conventional index. In both cases, the table used was created with the following DDL (we will avoid contention on table blocks by using ASSM so we can isolate the contention on the index blocks):
create tablespace assm
datafile size 1m autoextend on next 1m
segment space management auto;
create table t tablespace assm
as
select 0 id, owner, object_name, subobject_name,
object_id, data_object_id, object_type, created,
last_ddl_time, timestamp, status, temporary,
generated, secondary
from all_objects a
where 1=0;
alter table t add constraint t_pk primary key (id)
using index (create index t_pk on t(id)&indexType tablespace assm);
create sequence s cache 1000;
Whereby &indexType was replaced with either the keyword REVERSE, creating a reverse key index, or with nothing, thus using a “regular” index. The PL/SQL that would be run by 1, 2, 5, 10, 15, or 20 users concurrently was as follows:
create or replace procedure do_sql
as
begin
for x in ( select rownum r, OWNER, OBJECT_NAME, SUBOBJECT_NAME,
OBJECT_ID, DATA_OBJECT_ID, OBJECT_TYPE, CREATED,
LAST_DDL_TIME, TIMESTAMP, STATUS, TEMPORARY,
GENERATED, SECONDARY from all_objects )
loop
insert into t
( id, OWNER, OBJECT_NAME, SUBOBJECT_NAME,
OBJECT_ID, DATA_OBJECT_ID, OBJECT_TYPE, CREATED,
LAST_DDL_TIME, TIMESTAMP, STATUS, TEMPORARY,
GENERATED, SECONDARY )
values
( s.nextval, x.OWNER, x.OBJECT_NAME, x.SUBOBJECT_NAME,
x.OBJECT_ID, x.DATA_OBJECT_ID, x.OBJECT_TYPE, x.CREATED,
x.LAST_DDL_TIME, x.TIMESTAMP, x.STATUS, x.TEMPORARY,
x.GENERATED, x.SECONDARY );
if ( mod(x.r,100) = 0 )
then
commit;
end if;
end loop;
commit;
end;
/
Since we discussed the PL/SQL commit time optimization in Chapter 9, I now want to run a test using a different environment, so as to not be misled by this commit time optimization. I use Pro*C to emulate a data warehouse extract, transform, load (ETL) routine that processes rows in batches of 100 at a time between commits:
exec sql declare c cursor for select * from all_objects;
exec sql open c;
exec sql whenever notfound do break;
for(;;)
{
exec sql
fetch c into :owner:owner_i,
:object_name:object_name_i, :subobject_name:subobject_name_i,
:object_id:object_id_i, :data_object_id:data_object_id_i,
:object_type:object_type_i, :created:created_i,
:last_ddl_time:last_ddl_time_i, :timestamp:timestamp_i,
:status:status_i, :temporary:temporary_i,
:generated:generated_i, :secondary:secondary_i;
exec sql
insert into t
( id, OWNER, OBJECT_NAME, SUBOBJECT_NAME,
OBJECT_ID, DATA_OBJECT_ID, OBJECT_TYPE, CREATED,
LAST_DDL_TIME, TIMESTAMP, STATUS, TEMPORARY,
GENERATED, SECONDARY )
values
( s.nextval, :owner:owner_i, :object_name:object_name_i,
:subobject_name:subobject_name_i, :object_id:object_id_i,
:data_object_id:data_object_id_i, :object_type:object_type_i,
:created:created_i, :last_ddl_time:last_ddl_time_i,
:timestamp:timestamp_i, :status:status_i,
:temporary:temporary_i, :generated:generated_i,
:secondary:secondary_i );
if ( (++cnt%100) == 0 )
{
exec sql commit;
}
}
exec sql whenever notfound continue;
exec sql commit;
exec sql close c;
The Pro*C was precompiled with a PREFETCH of 100, making this C code analogous to the PL/SQL code in Oracle 10g. For example, say you have the prior Pro*C code stored in a file named t.pc, then the Pro*C compiler command looks like this:
$ proc iname=t.pc MODE=ORACLE PREFETCH=100
![]() Note In Oracle 10g Release 1 and above, a simple FOR X IN ( SELECT * FROM T ) in PL/SQL will silently array fetch 100 rows at a time, whereas in Oracle9i and before, it fetches just a single row at a time. Therefore, if you want to reproduce this example on Oracle9i and before, you will need to modify the PL/SQL code to also array fetch with the BULK COLLECT syntax.
Note In Oracle 10g Release 1 and above, a simple FOR X IN ( SELECT * FROM T ) in PL/SQL will silently array fetch 100 rows at a time, whereas in Oracle9i and before, it fetches just a single row at a time. Therefore, if you want to reproduce this example on Oracle9i and before, you will need to modify the PL/SQL code to also array fetch with the BULK COLLECT syntax.
Both would fetch 100 rows at a time and then single row insert the data into another table. The following tables summarize the differences between the various runs, starting with the single user test in Table 11-1.
Table 11-1. Performance Test for Use of Reverse Key Indexes with PL/SQL and Pro*C: Single User Case
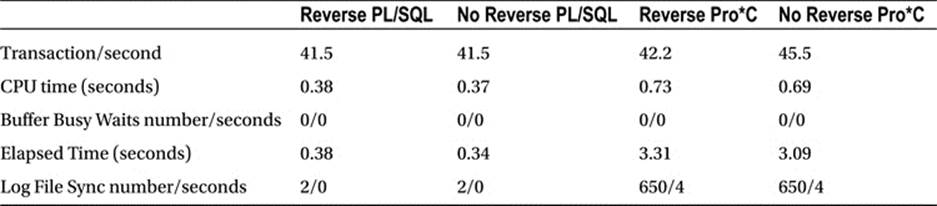
From the first single-user test, we can see that PL/SQL was measurably more efficient than Pro*C in performing this operation, a trend we’ll continue to see as we scale up the user load. Part of the reason Pro*C won’t scale as well as PL/SQL will be the log file sync waits that Pro*C must wait for, but which PL/SQL has an optimization to avoid.
It would appear from this single-user test that reverse key indexes consume slightly more CPU. This makes sense because the database must perform extra work as it carefully reverses the bytes in the key. But, we’ll see that this logic won’t hold true as we scale up the users. As we introduce contention, the overhead of the reverse key index will completely disappear. In fact, even by the time we get the two-user test, the overhead is mostly offset by the contention on the right hand side of the index, as shown in Table 11-2.
Table 11-2. Performance Test for Use of Reverse Key Indexes with PL/SQL and Pro*C: 2 Users
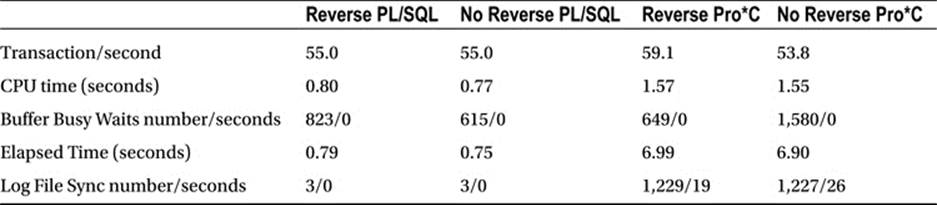
As you can see from this two-user test, PL/SQL still outperforms Pro*C, but the use of the reverse key index is showing some positive benefits on the PL/SQL side and not so much on the Pro*C side. That, too, is a trend that will continue. For the Pro*C program, the reverse key index is solving the buffer busy wait problem we have due to the contention for the rightmost block in the index structure; however, it does nothing for the log file sync waits that affect the Pro*C program. This was the main reason for performing both a PL/SQL and a Pro*C test: to see the differences between these two environments. This begs the question, why would a reverse key index apparently benefit PL/SQL but not Pro*C in this case? It comes down to the log file sync wait event. PL/SQL was able to continuously insert and rarely had to wait for the log file sync wait event upon commit, whereas Pro*C was waiting every 100 rows. Therefore, PL/SQL in this case was impacted more heavily by buffer busy waits than Pro*C was. Alleviating the buffer busy waits in the PL/SQL case allowed it to process more transactions, and so the reverse key index positively benefited PL/SQL. But in the Pro*C case, the buffer busy waits were not the issue—they were not the major performance bottleneck, so removing the waits had no impact on overall performance.
Let’s move on to the five-user test, shown in Table 11-3.
Table 11-3. Performance Test for Use of Reverse Key Indexes with PL/SQL and Pro*C: 5 Users
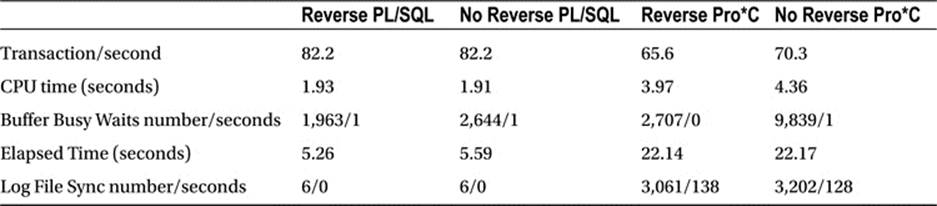
We see more of the same. PL/SQL, running full steam ahead with few log file sync waits, was very much impacted by the buffer busy waits. With a conventional index and all five users attempting to insert into the right-hand side of the index structure, PL/SQL suffered the most from the buffer busy waits and therefore benefited the most when they were reduced.
Taking a look at the ten-user test in Table 11-4, we can see the trend continues.
Table 11-4. Performance Test for Use of Reverse Key Indexes with PL/SQL and Pro*C: 10 Users
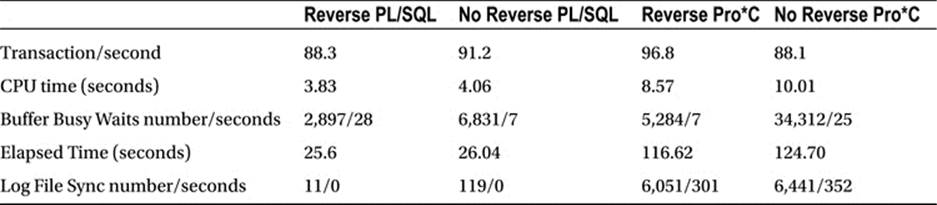
PL/SQL, in the absence of the log file sync wait, is very much helped by removing the buffer busy wait events. Pro*C is experiencing more buffer busy wait contention now but, due to the fact it is waiting on log file sync events frequently, is not benefiting. One way to improve the performance of the PL/SQL implementation with a regular index would be to introduce a small wait. That would reduce the contention on the right-hand side of the index and increase overall performance. For space reasons, I will not include the 15- and 20-user tests here, but I will confirm that the trend observed in this section continued.
![]() Tip You can download the source code for the reverse key index performance example from Apress.com. In the Chapter 11 scripts folder, there are several demo3* files (as well as the t.pc file) that automate the running of this entire test suite.
Tip You can download the source code for the reverse key index performance example from Apress.com. In the Chapter 11 scripts folder, there are several demo3* files (as well as the t.pc file) that automate the running of this entire test suite.
We can take away two things from this demonstration. A reverse key index can help alleviate a buffer busy wait situation, but depending on other factors you will get varying returns on investment. In looking at Table 11-4 for the ten-user test, the removal of buffer busy waits (the most waited for wait event in that case) affected transaction throughput marginally, but it did show increased scalability with higher concurrency levels. Doing the same thing for PL/SQL had a markedly different impact on performance: we achieved a measurable increase in throughput by removing that bottleneck.
Descending Indexes
Descending indexes were introduced in Oracle8i to extend the functionality of a B*Tree index. They allow for a column to be stored sorted in descending order (from big to small) in the index instead of ascending order (from small to big). Prior releases of Oracle (pre-Oracle8i) always supported the DESC (descending) keyword syntactically, but basically ignored it—it had no effect on how the data was stored or used in the index. In Oracle8i and above, however, the DESC keyword changes the way the index is created and used.
Oracle has had the ability to read an index backward for quite a while, so you may be wondering why this feature is relevant. For example, if we use a table T:
EODA@ORA12CR1> create table t
2 as
3 select *
4 from all_objects
5 /
Table created.
EODA@ORA12CR1> create index t_idx on t(owner,object_type,object_name);
Index created.
EODA@ORA12CR1> begin
2 dbms_stats.gather_table_stats
3 ( user, 'T', method_opt=>'for all indexed columns' );
4 end;
5 /
PL/SQL procedure successfully completed.
and query it as follows
EODA@ORA12CR1> set autotrace traceonly explain
EODA@ORA12CR1> select owner, object_type
2 from t
3 where owner between 'T' and 'Z'
4 and object_type is not null
5 order by owner DESC, object_type DESC;
Execution Plan
----------------------------------------------------------
Plan hash value: 2685572958
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5008 | 50080 | 24 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN DESCENDING | T_IDX | 5008 | 50080 | 24 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
Oracle will just read the index backward. There is no final sort step in this plan; the data is sorted. Where this descending index feature comes into play, however, is when you have a mixture of columns, and some are sorted ASC (ascending) and some DESC (descending), for example:
EODA@ORA12CR1> select owner, object_type
2 from t
3 where owner between 'T' and 'Z'
4 and object_type is not null
5 order by owner DESC, object_type ASC;
Execution Plan
----------------------------------------------------------
Plan hash value: 2813023843
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5008 | 50080 | 24 (0)| 00:00:01 |
| 1 | SORT ORDER BY | | 5008 | 50080 | 24 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | T_IDX | 5008 | 50080 | 24 (0)| 00:00:01 |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OWNER">='T' AND "OWNER"<='Z')
filter("OBJECT_TYPE" IS NOT NULL)
Oracle isn’t able to use the index we have in place on (OWNER, OBJECT_TYPE, OBJECT_NAME) anymore to sort the data. It could have read it backward to get the data sorted by OWNER DESC, but it needs to read it “forward” to get OBJECT_TYPE sorted ASC. Instead, it collected together all of the rows and then sorted. Enter the DESC index:
EODA@ORA12CR1> create index desc_t_idx on t(owner desc,object_type asc);
Index created.
EODA@ORA12CR1> select owner, object_type
2 from t
3 where owner between 'T' and 'Z'
4 and object_type is not null
5 order by owner DESC, object_type ASC;
Execution Plan
----------------------------------------------------------
Plan hash value: 2494308350
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5008 | 50080 | 2 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN | DESC_T_IDX | 5008 | 50080 | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access(SYS_OP_DESCEND("OWNER")>=HEXTORAW('A5FF') AND
SYS_OP_DESCEND("OWNER")<=HEXTORAW('ABFF'))
filter(SYS_OP_UNDESCEND(SYS_OP_DESCEND("OWNER"))>='T' AND
SYS_OP_UNDESCEND(SYS_OP_DESCEND("OWNER"))<='Z' AND "OBJECT_TYPE" IS NOT
NULL)
Once more, we are able to read the data sorted, and there is no extra sort step at the end of the plan.
![]() Note Do not be tempted to ever leave an ORDER BY off a query. Just because your query plan includes an index does not mean the data will be returned in “some order.” The only way to retrieve data from the database in some sorted order is to include an ORDER BY on your query. There is no substitute for ORDER BY.
Note Do not be tempted to ever leave an ORDER BY off a query. Just because your query plan includes an index does not mean the data will be returned in “some order.” The only way to retrieve data from the database in some sorted order is to include an ORDER BY on your query. There is no substitute for ORDER BY.
When Should You Use a B*Tree Index?
Not being a big believer in “rules of thumb” (there are exceptions to every rule), I don’t have any rules of thumb for when to use (or not to use) a B*Tree index. To demonstrate why I don’t have any rules of thumb for this case, I’ll present two equally valid ones:
· Only use B*Tree to index columns if you are going to access a very small percentage of the rows in the table via the index.
· Use a B*Tree index if you are going to process many rows of a table and the index can be used instead of the table.
These rules seem to offer conflicting advice, but in reality, they do not—they just cover two extremely different cases. There are two ways to use an index given the preceding advice:
· As the means to access rows in a table: You will read the index to get to a row in the table. Here you want to access a very small percentage of the rows in the table.
· As the means to answer a query: The index contains enough information to answer the entire query—we will not have to go to the table at all. The index will be used as a thinner version of the table.
There are other ways as well—for example, we could be using an index to retrieve all of the rows in a table, including columns that are not in the index itself. That seemingly goes counter to both rules just presented. The case in which that would be true would be an interactive application where you are getting some of the rows and displaying them, then some more, and so on. You want to have the query optimized for initial response time, not overall throughput.
The first case (i.e., use the index if you are going to access a small percentage of the table) says if you have a table T (using the same table T from earlier) and you have a query plan that looks like this:
EODA@ORA12CR1> set autotrace traceonly explain
EODA@ORA12CR1> select owner, status
2 from t
3 where owner = USER;
Execution Plan
----------------------------------------------------------
Plan hash value: 1695850079
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| ...
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1716 | 17160 | 13 (0)| ...
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED | T | 1716 | 17160 | 13 (0)| ...
|* 2 | INDEX RANGE SCAN | DESC_T_IDX | 288 | | 2 (0)| ...
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access(SYS_OP_DESCEND("OWNER")=SYS_OP_DESCEND(USER@!))
filter(SYS_OP_UNDESCEND(SYS_OP_DESCEND("OWNER"))=USER@!)
You should be accessing a very small percentage of this table. The issue to look at here is the INDEX (RANGE SCAN) followed by the TABLE ACCESS BY INDEX ROWID. This means that Oracle will read the index and then, for the index entries, it will perform a database block read (logical or physical I/O) to get the row data. This is not the most efficient method if you are going to have to access a large percentage of the rows in T via the index (we will soon define what a large percentage might be).
In the second case (i.e., when the index can be used instead of the table), you can process 100 percent (or any percentage, in fact) of the rows via the index. You might use an index just to create a thinner version of a table. The following query demonstrates this concept:
EODA@ORA12CR1> select count(*)
2 from t
3 where owner = user;
Execution Plan
----------------------------------------------------------
Plan hash value: 293504097
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 3 | 10 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 3 | | |
|* 2 | INDEX RANGE SCAN | T_IDX | 1716 | 5148 | 10 (0)| 00:00:01 |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OWNER"=USER@!)
Here, only the index was used to answer the query—it would not matter now what percentage of rows we were accessing, as we would use the index only. We can see from the plan that the underlying table was never accessed; we simply scanned the index structure itself.
It is important to understand the difference between the two concepts. When we have to do a TABLE ACCESS BY INDEX ROWID, we must ensure we are accessing only a small percentage of the total blocks in the table, which typically equates to a small percentage of the rows, or that we need the first rows to be retrieved as fast as possible (the end user is waiting for them impatiently). If we access too high a percentage of the rows (larger than somewhere between 1 and 20 percent of the rows), then it will generally take longer to access them via a B*Tree than by just full scanning the table.
With the second type of query, where the answer is found entirely in the index, we have a different story. We read an index block and pick up many rows to process, then we go on to the next index block, and so on—we never go to the table. There is also a fast full scan we can perform on indexes to make this even faster in certain cases. A fast full scan is when the database reads the index blocks in no particular order; it just starts reading them. It is no longer using the index as an index, but even more like a table at that point. Rows do not come out ordered by index entries from a fast full scan.
In general, a B*Tree index would be placed on columns that we use frequently in the predicate of a query, and we would expect some small fraction of the data from the table to be returned or the end user demands immediate feedback. On a thin table (i.e., a table with few or small columns), this fraction may be very small. A query that uses this index should expect to retrieve 2 to 3 percent or less of the rows to be accessed in the table. On a fat table (i.e., a table with many columns or very wide columns), this fraction might go all the way up to 20 to 25 percent of the table. This advice doesn’t always seem to make sense to everyone immediately; it is not intuitive, but it is accurate. An index is stored sorted by index key. The index will be accessed in sorted order by key. The blocks that are pointed to are stored randomly in a heap. Therefore, as we read through an index to access the table, we will perform lots of scattered, random I/O. By “scattered,” I mean that the index will tell us to read block 1, block 1,000, block 205, block 321, block 1, block 1,032, block 1, and so on—it won’t ask us to read block 1, then block 2, and then block 3 in a consecutive manner. We will tend to read and reread blocks in a very haphazard fashion. This single block I/O can be very slow.
As a simplistic example of this, let’s say we are reading that thin table via an index, and we are going to read 20 percent of the rows. Assume we have 100,000 rows in the table. Twenty percent of that is 20,000 rows. If the rows are about 80 bytes apiece in size, on a database with an 8KB block size, we will find about 100 rows per block. That means the table has approximately 1,000 blocks. From here, the math is very easy. We are going to read 20,000 rows via the index; this will mean quite likely 20,000 TABLE ACCESS BY ROWID operations. We will process 20,000 table blocks to execute this query. There are only about 1,000 blocks in the entire table, however! We would end up reading and processing each block in the table on average 20 times. Even if we increased the size of the row by an order of magnitude to 800 bytes per row, and 10 rows per block, we now have 10,000 blocks in the table. Index accesses for 20,000 rows would cause us to still read each block on average two times. In this case, a full table scan will be much more efficient than using an index, as it has to touch each block only once. Any query that used this index to access the data would not be very efficient until it accesses on average less than 5 percent of the data for the 800-byte column (then we access about 5,000 blocks) and even less for the 80-byte column (about 0.5 percent or less).
Physical Organization
How the data is organized physically on disk deeply impacts these calculations, as it materially affects how expensive (or inexpensive) index access will be. Suppose you have a table where the rows have a primary key populated by a sequence. As data is added to the table, rows with sequential sequence numbers might be, in general, next to each other.
![]() Note The use of features such as ASSM or multiple FREELIST/FREELIST GROUPS will affect how the data is organized on disk. Those features tend to spread the data out, and this natural clustering by primary key may not be observed.
Note The use of features such as ASSM or multiple FREELIST/FREELIST GROUPS will affect how the data is organized on disk. Those features tend to spread the data out, and this natural clustering by primary key may not be observed.
The table is naturally clustered in order by the primary key (since the data is added in more or less that order). It will not be strictly clustered in order by the key, of course (we would have to use an IOT to achieve that); in general, rows with primary keys that are close in value will be close together in physical proximity. When you issue the query
select * from T where primary_key between :x and :y
the rows you want are typically located on the same blocks. In this case, an index range scan may be useful even if it accesses a large percentage of rows, simply because the database blocks that we need to read and reread will most likely be cached since the data is co-located. On the other hand, if the rows are not co-located, using that same index may be disastrous for performance. A small demonstration will drive this fact home. We’ll start with a table that is pretty much ordered by its primary key:
EODA@ORA12CR1> create table colocated ( x int, y varchar2(80) );
Table created.
EODA@ORA12CR1> begin
2 for i in 1 .. 100000
3 loop
4 insert into colocated(x,y)
5 values (i, rpad(dbms_random.random,75,'*') );
6 end loop;
7 end;
8 /
PL/SQL procedure successfully completed.
EODA@ORA12CR1> alter table colocated
2 add constraint colocated_pk
3 primary key(x);
Table altered.
EODA@ORA12CR1> begin
2 dbms_stats.gather_table_stats( user, 'COLOCATED');
3 end;
4 /
PL/SQL procedure successfully completed.
This table fits the description we laid out earlier with about 100 rows/block in an 8KB database. In this table, there is a very good chance that the rows with X=1, 2, 3 are on the same block. Now, we’ll take this table and purposely “disorganize” it. In the COLOCATED table, we created theY column with a leading random number, and we’ll use that fact to disorganize the data so that it will definitely not be ordered by primary key anymore:
EODA@ORA12CR1> create table disorganized
2 as
3 select x,y
4 from colocated
5 order by y;
Table created.
EODA@ORA12CR1> alter table disorganized
2 add constraint disorganized_pk
3 primary key (x);
Table altered.
EODA@ORA12CR1> begin
2 dbms_stats.gather_table_stats( user, 'DISORGANIZED');
3 end;
4 /
PL/SQL procedure successfully completed.
Arguably, these are the same tables—it is a relational database, so physical organization has no bearing on the answers returned (at least that’s what they teach in theoretical database courses). In fact, the performance characteristics of these two tables are as different as night and day, while the answers returned are identical. Given the same exact question, using the same exact query plans, and reviewing the TKPROF (SQL trace) output, we see the following:
select * from colocated where x between 20000 and 40000
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 5 0.00 0.00 0 0 0 0
Execute 5 0.00 0.00 0 0 0 0
Fetch 6675 0.06 0.21 0 14495 0 100005
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 6685 0.06 0.21 0 14495 0 100005
...
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
20001 20001 20001 TABLE ACCESS BY INDEX ROWID BATCHED COLOCATED...
20001 20001 20001 INDEX RANGE SCAN COLOCATED_PK (cr=1374 pr=0 pw=0...
********************************************************************************
select /*+ index( disorganized disorganized_pk ) */ * from disorganized
where x between 20000 and 40000
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 5 0.00 0.00 0 0 0 0
Execute 5 0.00 0.00 0 0 0 0
Fetch 6675 0.12 0.41 0 106830 0 100005
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 6685 0.12 0.41 0 106830 0 100005
...
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ------------------------------------------------------
20001 20001 20001 TABLE ACCESS BY INDEX ROWID BATCHED DISORGANIZED...
20001 20001 20001 INDEX RANGE SCAN DISORGANIZED_PK (cr=1374 pr=0 pw=0...
![]() Note I ran each query five times in order to get a good average runtime for each (hence the TKPROF output shows 100,000+ rows processed).
Note I ran each query five times in order to get a good average runtime for each (hence the TKPROF output shows 100,000+ rows processed).
I think this is pretty incredible. What a difference physical data layout can make! Table 11-5 summarizes the results.
Table 11-5. Investigating the Effect of Physical Data Layout on the Cost of Index Access
|
Table |
CPU Time |
Logical I/O |
|
Co-located |
0.21 seconds |
14,495 |
|
Disorganized |
0.41 seconds |
106,830 |
|
Co-located % |
~50% |
13% |
In my database using an 8KB block size, these tables had the following number of total blocks apiece:
EODA@ORA12CR1> select a.index_name,
2 b.num_rows,
3 b.blocks,
4 a.clustering_factor
5 from user_indexes a, user_tables b
6 where index_name in ('COLOCATED_PK', 'DISORGANIZED_PK' )
7 and a.table_name = b.table_name
8 /
INDEX_NAME NUM_ROWS BLOCKS CLUSTERING_FACTOR
-------------------- ---------- ---------- -----------------
COLOCATED_PK 100000 1252 1190
DISORGANIZED_PK 100000 1219 99929
The query against the disorganized table bears out the simple math we did earlier: we did 20,000+ logical I/Os (100,000 total blocks queried and five runs of the query). We processed each and every block 20 times! On the other hand, the physically COLOCATED data took the logical I/Os way down. Here is the perfect illustration of why rules of thumb are so hard to provide—in one case, using the index works great, and in the other it doesn’t. Consider this the next time you dump data from your production system and load it into development, as it may very well provide at least part of the answer to the question, “Why is it running differently on this machine—aren’t they identical?” They are not identical.
![]() Note Recall from Chapter 6 that increased logical I/O is the tip of the iceberg here. Each logical I/O involves one or more latches into the buffer cache. In a multiuser/CPU situation, the CPU used by the second query would have undoubtedly gone up many times faster than the first as we spin and wait for latches. The second example query not only performs more work, but also will not scale as well as the first.
Note Recall from Chapter 6 that increased logical I/O is the tip of the iceberg here. Each logical I/O involves one or more latches into the buffer cache. In a multiuser/CPU situation, the CPU used by the second query would have undoubtedly gone up many times faster than the first as we spin and wait for latches. The second example query not only performs more work, but also will not scale as well as the first.
THE EFFECT OF ARRAYSIZE ON LOGICAL I/O
It is interesting to note the effect of the ARRAYSIZE on logical I/O performed. ARRAYSIZE is the number of rows Oracle returns to a client when they ask for the next row. The client will then buffer these rows and use them before asking the database for the next set of rows. TheARRAYSIZE may have a very material effect on the logical I/O performed by a query, resulting from the fact that if you have to access the same block over and over again across calls (across fetch calls specifically, in this case) to the database, Oracle must retrieve that block again from the buffer cache. Therefore, if you ask for 100 rows from the database in a single call, Oracle might be able to fully process a database block and not need to retrieve that block again. If you ask for 15 rows at a time, Oracle might well have to get the same block over and over again to retrieve the same set of rows.
In the example earlier in this section, we were using the SQL*Plus default array fetch size of 15 rows (if you divide the total rows fetched (100005) by the number of fetch calls (6675), the result is very close to 15). If we were to compare the execution of the previous queries using 15 rows per fetch versus 100 rows per fetch, we would observe the following for the COLOCATED table:
select * from colocated a15 where x between 20000 and 40000
Rows Row Source Operation
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
20001 20001 20001 TABLE ACCESS BY INDEX ROWID BATCHED COLOCATED
(cr=2899 pr=0 pw=0 ...
20001 20001 20001 INDEX RANGE SCAN COLOCATED_PK
(cr=1374 pr=0 pw=0 ...
select * from colocated a100 where x between 20000 and 40000
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
20001 20001 20001 TABLE ACCESS BY INDEX ROWID BATCHED COLOCATED
(cr=684 pr=0 pw=0 ...
20001 20001 20001 INDEX RANGE SCAN COLOCATED_PK
(cr=245 pr=0 pw=0 ...
The first query was executed with the ARRAYSIZE of 15, and the (cr=nnnn) values in the Row Source Operation shows we performed 1,374 logical I/Os against the index and then 1,625 logical I/Os against the table (2,899–1,374; the numbers are cumulative in the Row Source Operation steps). When we increased the ARRAYSIZE to 100 from 15 (via the SET ARRAYSIZE 100 command), the amount of logical I/O against the index dropped to 245, which was the direct result of not having to reread the index leaf blocks from the buffer cache every 15 rows, but only every 100 rows. To understand this, assume that we were able to store 200 rows per leaf block. As we are scanning through the index reading 15 rows at a time, we would have to retrieve the first leaf block 14 times to get all 200 entries off it. On the other hand, when we array fetch 100 rows at a time, we need to retrieve this same leaf block only two times from the buffer cache to exhaust all of its entries.
The same thing happened in this case with the table blocks. Since the table was sorted in the same order as the index keys, we would tend to retrieve each table block less often, as we would get more of the rows from it with each fetch call.
So, if this was good for the COLOCATED table, it must have been just as good for the DISORGANIZED table, right? Not so. The results from the DISORGANIZED table would look like this:
select /*+ index( a15 disorganized_pk ) */ *
from disorganized a15 where x between 20000 and 40000
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
20001 20001 20001 TABLE ACCESS BY INDEX ROWID BATCHED DISORGANIZED
(cr=21365 pr=0 ...
20001 20001 20001 INDEX RANGE SCAN DISORGANIZED_PK
(cr=1374 pr=0...
select /*+ index( a100 disorganized_pk ) */ *
from disorganized a100 where x between 20000 and 40000
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
20001 20001 20001 TABLE ACCESS BY INDEX ROWID BATCHED DISORGANIZED
(cr=20236 pr=0 ...
20001 20001 20001 INDEX RANGE SCAN DISORGANIZED_PK
(cr=245 pr=0...
The results against the index here were identical, which makes sense, as the data stored in the index is just the same regardless of how the table is organized. The logical I/O went from 1,374 for a single execution of this query to 245, just as before. But overall the amount of logical I/O performed by this query did not differ significantly: 21,365versus 20,236. The reason? The amount of logical I/O performed against the table did not differ at all—if you subtract the logical I/O against the index from the total logical I/O performed by each query, you’ll find that both queries did 19,991 logical I/Os against the table. This is because every time we wanted N rows from the database—the odds that any two of those rows would be on the same block was very small—there was no opportunity to get multiple rows from a table block in a single call.
Every professional programming language I have seen that can interact with Oracle implements this concept of array fetching. In PL/SQL you may use BULK COLLECT or rely on the implicit array fetch of 100 that is performed for implicit cursor for loops. In Java/JDBC, there is a prefetch method on a connect or statement object. Oracle Call Interface (OCI; a C API) allows you to programmatically set the prefetch size, as does Pro*C. As you can see, this can have a material and measurable effect on the amount of logical I/O performed by your query, and it deserves your attention.
Just to wrap up this example, let’s look at what happens when we full scan the DISORGANIZED table:
select * from disorganized where x between 20000 and 30000
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 668 0.01 0.03 0 1858 0 10001
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 670 0.01 0.03 0 1858 0 10001
...
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ----------------------------------------------------
10001 10001 10001 TABLE ACCESS FULL DISORGANIZED (cr=1858 pr=0 pw=0...
Thus, in this particular case, the full scan is very appropriate due to the way the data is physically stored on disk. So why didn’t the optimizer full scan in the first place for this query? Well, it would have if left to its own design, but in the first example query against DISORGANIZED I purposely hinted the query and told the optimizer to construct a plan that used the index. In the second case, I let the optimizer pick the best overall plan.
The Clustering Factor
Next, let’s look at some of the information Oracle will use. We are specifically going to look at the CLUSTERING_FACTOR column found in the USER_INDEXES view. The Oracle Database Reference manual tells us this column has the following meaning:
Indicates the amount of order of the rows in the table based on the values of the index:
· If the value is near the number of blocks, then the table is very well ordered. In this case, the index entries in a single leaf block tend to point to rows in the same data blocks.
· If the value is near the number of rows, then the table is very randomly ordered. In this case, it is unlikely that index entries in the same leaf block point to rows in the same data blocks.
We could also view the clustering factor as a number that represents the number of logical I/Os against the table that would be performed to read the entire table via the index. That is, the CLUSTERING_FACTOR is an indication of how ordered the table is with respect to the index itself, and when we look at these indexes we find the following:
EODA@ORA12CR1> select a.index_name,
2 b.num_rows,
3 b.blocks,
4 a.clustering_factor
5 from user_indexes a, user_tables b
6 where index_name in ('COLOCATED_PK', 'DISORGANIZED_PK' )
7 and a.table_name = b.table_name
8 /
INDEX_NAME NUM_ROWS BLOCKS CLUSTERING_FACTOR
-------------------- ---------- ---------- -----------------
COLOCATED_PK 100000 1252 1190
DISORGANIZED_PK 100000 1219 99929
![]() Note I used an ASSM managed tablespace for this section’s example, which explains why the clustering factor for the COLOCATED table is less than the number of blocks in the table. There are unformatted blocks in the upcoming COLOCATED table the HWM that do not contain data, as well as blocks used by ASSM itself to manage space, and we will not read these blocks ever in an index range scan. Chapter 10 explains HWMs and ASSM in more detail.
Note I used an ASSM managed tablespace for this section’s example, which explains why the clustering factor for the COLOCATED table is less than the number of blocks in the table. There are unformatted blocks in the upcoming COLOCATED table the HWM that do not contain data, as well as blocks used by ASSM itself to manage space, and we will not read these blocks ever in an index range scan. Chapter 10 explains HWMs and ASSM in more detail.
So the database is saying, “If we were to read every row in COLOCATED via the index COLOCATED_PK from start to finish, we would perform 1,190 I/Os. However, if we did the same to DISORGANIZED, we would perform 99,929 I/Os against the table.” The reason for the large difference is that as Oracle range scans through the index structure, if it discovers the next row in the index is on the same database block as the prior row, it does not perform another I/O to get the table block from the buffer cache. It already has a handle to one and just uses it. However, if the next row is not on the same block, then it will release that block and perform another I/O into the buffer cache to retrieve the next block to be processed. Hence the COLOCATED_PK index, as we range scan through it, will discover that the next row is almost always on the same block as the prior row. The DISORGANIZED_PK index will discover the opposite is true. In fact, we can actually see this measurement is very accurate. If we hint to the optimizer to use an index full scan to read the entire table and just count the number of non-null Y values, we can see exactly how many I/Os it will take to read the entire table via the index:
select count(Y) from
(select /*+ INDEX(COLOCATED COLOCATED_PK) */ * from colocated)
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.03 0.03 0 1399 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.03 0.03 0 1399 0 1
...
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- --------------------------------------------------
1 1 1 SORT AGGREGATE (cr=1399 pr=0 pw=0 time=34740 us)
100000 100000 100000 TABLE ACCESS BY INDEX ROWID BATCHED
COLOCATED (cr=1399 pr=0 pw=0 time=90620 us cost=1400 size=7600000...
100000 100000 100000 INDEX FULL SCAN COLOCATED_PK (cr=209 pr=0 pw=0 ...
********************************************************************************
select count(Y) from
(select /*+ INDEX(DISORGANIZED DISORGANIZED_PK) */ * from disorganized)
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.11 0.11 0 100138 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.11 0.11 0 100138 0 1
...
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ----------- ---------------------------------------------------
1 1 1 SORT AGGREGATE (cr=100138 pr=0 pw=0 time=111897 us)
100000 100000 100000 TABLE ACCESS BY INDEX ROWID BATCHED DISORGANIZED
(cr=100138 pr=0 pw=0 time=203332 us cost=100158 size=7600000 card=100000)
100000 100000 100000 INDEX FULL SCAN DISORGANIZED_PK (cr=209 pr=0 pw=0...
In both cases, the index needed to perform 209 logical I/Os (cr=209 in the Row Source Operation lines). If you subtract 209 from the total consistent reads and measure just the number of I/Os against the table, then you’ll find that they are identical to the clustering factor for each respective index. The COLOCATED_PK is a classic “the table is well ordered” example, whereas the DISORGANIZED_PK is a classic “the table is very randomly ordered” example. It is interesting to see how this affects the optimizer now. If we attempt to retrieve 25,000 rows, Oracle will now choose a full table scan for both queries (retrieving 25 percent of the rows via an index is not the optimal plan, even for the very ordered table). However, if we drop down to 10 percent (bear in mind that 10 percent is not a threshold value—it is just a number less than 25 percent that caused an index range scan to happen in this case) of the table data:
EODA@ORA12CR1> set autotrace traceonly explain
EODA@ORA12CR1> select * from colocated where x between 20000 and 30000;
Execution Plan
----------------------------------------------------------
Plan hash value: 2792740192
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost ...
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10002 | 791K| 142 ...
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| COLOCATED | 10002 | 791K| 142 ...
|* 2 | INDEX RANGE SCAN | COLOCATED_PK | 10002 | | 22 ...
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("X">=20000 AND "X"<=30000)
EODA@ORA12CR1> select * from disorganized where x between 20000 and 30000;
Execution Plan
----------------------------------------------------------
Plan hash value: 2727546897
----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10002 | 791K| 333 (1)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| DISORGANIZED | 10002 | 791K| 333 (1)| 00:00:01 |
----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("X"<=30000 AND "X">=20000)
Here we have the same table structures—the same indexes—but different clustering factors. The optimizer in this case chose an index access plan for the COLOCATED table and a full scan access plan for the DISORGANIZED table.
The key point to this discussion is that indexes are not always the appropriate access method. The optimizer may very well be correct in choosing to not use an index, as the preceding example demonstrates. Many factors influence the use of an index by the optimizer, including physical data layout. You might be tempted therefore to run out and try to rebuild all of your tables now to make all indexes have a good clustering factor, but that would be a waste of time in most cases. It will affect cases where you do index range scans of a large percentage of a table. Additionally, you must keep in mind that, in general, the table will have only one index with a good clustering factor! The rows in a table may be sorted in only one way. In the example just shown, if I had another index on the column Y it would be very poorly clustered in the COLOCATED table, but very nicely clustered in the DISORGANIZED table. If having the data physically clustered is important to you, consider the use of an IOT, a B*Tree cluster, or a hash cluster over continuous table rebuilds.
B*Trees Wrap-up
B*Tree indexes are by far the most common and well-understood indexing structures in the Oracle database. They are an excellent general-purpose indexing mechanism. They provide very scalable access times, returning data from a 1,000-row index in about the same amount of time as a 100,000-row index structure.
When to index and what columns to index are things you need to pay attention to in your design. An index does not always mean faster access; in fact, you will find that indexes will decrease performance in many cases if Oracle uses them. It is purely a function of how large of a percentage of the table you will need to access via the index and how the data happens to be laid out. If you can use the index to answer the question, accessing a large percentage of the rows makes sense, since you are avoiding the extra scattered I/O to read the table. If you use the index to access the table, you will need to ensure you are processing a small percentage of the total table.
You should consider the design and implementation of indexes during the design of your application, not as an afterthought (as I so often see). With careful planning and due consideration of how you are going to access the data, the indexes you need will be apparent in most all cases.
Bitmap Indexes
Bitmap indexes were added to Oracle in version 7.3 of the database. They are currently available with the Oracle Enterprise and Personal Editions, but not the Standard Edition. Bitmap indexes are designed for data warehousing/ad hoc query environments where the full set of queries that may be asked of the data is not totally known at system implementation time. They are specifically not designed for OLTP systems or systems where data is frequently updated by many concurrent sessions.
Bitmap indexes are structures that store pointers to many rows with a single index key entry, as compared to a B*Tree structure where there is parity between the index keys and the rows in a table. In a bitmap index, there will be a very small number of index entries, each of which points to many rows. In a conventional B*Tree, one index entry points to a single row.
Let’s say we are creating a bitmap index on the JOB column in the EMP table as follows:
EODA@ORA12CR1> create BITMAP index job_idx on emp(job);
Index created.
Oracle will store something like what is shown in Table 11-6 in the index.
Table 11-6. A Representation of How Oracle Would Store the JOB-IDX Bitmap Index
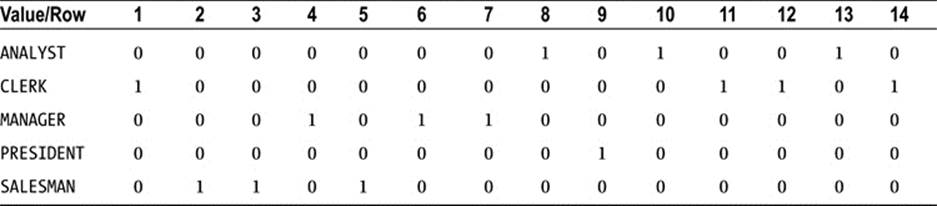
Table 11-6 shows that rows 8, 10, and 13 have the value ANALYST, whereas rows 4, 6, and 7 have the value MANAGER. It also shows us that no rows are null (bitmap indexes store null entries; the lack of a null entry in the index implies there are no null rows). If we wanted to count the rows that have the value MANAGER, the bitmap index would do this very rapidly. If we wanted to find all the rows such that the JOB was CLERK or MANAGER, we could simply combine their bitmaps from the index as, shown in Table 11-7.
Table 11-7. Representation of a Bitwise OR

Table 11-7 rapidly shows us that rows 1, 4, 6, 7, 11, 12, and 14 satisfy our criteria. The bitmap Oracle stores with each key value is set up so that each position represents a rowid in the underlying table, if we need to actually retrieve the row for further processing. Queries such as the following
select count(*) from emp where job = 'CLERK' or job = 'MANAGER';
will be answered directly from the bitmap index. A query such as this
select * from emp where job = 'CLERK' or job = 'MANAGER';
on the other hand, will need to get to the table. Here, Oracle will apply a function to turn the fact that the i’th bit is on in a bitmap, into a rowid that can be used to access the table.
When Should You Use a Bitmap Index?
Bitmap indexes are most appropriate on low distinct cardinality data (i.e., data with relatively few discrete values when compared to the cardinality of the entire set). It is not really possible to put a value on this—in other words, it is difficult to define what low distinct cardinality is truly. In a set of a couple thousand records, 2 would be low distinct cardinality, but 2 would not be low distinct cardinality in a two-row table. In a table of tens or hundreds of millions records, 100,000 could be low distinct cardinality. So, low distinct cardinality is relative to the size of the resultset. This is data where the number of distinct items in the set of rows divided by the number of rows is a small number (near zero). For example, a GENDER column might take on the values M, F, and NULL. If you have a table with 20,000 employee records in it, then you would find that 3/20000 = 0.00015. Likewise, 100,000 unique values out of 10,000,000 results in a ratio of 0.01—again, very small. These columns would be candidates for bitmap indexes. They probably would not be candidates for a having B*Tree indexes, as each of the values would tend to retrieve an extremely large percentage of the table. B*Tree indexes should be selective in general, as outlined earlier. Bitmap indexes should not be selective—on the contrary, they should be very unselective in general.
Bitmap indexes are extremely useful in environments where you have lots of ad hoc queries, especially queries that reference many columns in an ad hoc fashion or produce aggregations such as COUNT. For example, suppose you have a large table with three columns: GENDER,LOCATION, and AGE_GROUP. In this table, GENDER has a value of M or F, LOCATION can take on the values 1 through 50, and AGE_GROUP is a code representing 18 and under, 19-25, 26-30, 31-40, and 41 and over. You have to support a large number of ad hoc queries that take the following form:
select count(*)
from t
where gender = 'M'
and location in ( 1, 10, 30 )
and age_group = '41 and over';
select *
from t
where ( ( gender = 'M' and location = 20 )
or ( gender = 'F' and location = 22 ))
and age_group = '18 and under';
select count(*) from t where location in (11,20,30);
select count(*) from t where age_group = '41 and over' and gender = 'F';
You would find that a conventional B*Tree indexing scheme would fail you. If you wanted to use an index to get the answer, you would need at least three and up to six combinations of possible B*Tree indexes to access the data via the index. Since any of the three columns or any subset of the three columns may appear, you would need large concatenated B*Tree indexes on the following:
· GENDER, LOCATION, AGE_GROUP: For queries that used all three, or GENDER with LOCATION, or GENDER alone
· LOCATION, AGE_GROUP: For queries that used LOCATION and AGE_GROUP or LOCATION alone
· AGE_GROUP, GENDER: For queries that used AGE_GROUP with GENDER or AGE_GROUP alone
To reduce the amount of data being searched, other permutations might be reasonable as well in order to decrease the size of the index structure being scanned. This is ignoring the fact that a B*Tree index on such low cardinality data is not a good idea.
Here is where the bitmap index comes into play. With three small bitmap indexes, one on each of the individual columns, you will be able to satisfy all of the previous predicates efficiently. Oracle will simply use the functions AND, OR, and NOT, with the bitmaps of the three indexes together, to find the solution set for any predicate that references any set of these three columns. It will take the resulting merged bitmap, convert the 1s into rowids if necessary, and access the data (if you are just counting rows that match the criteria, Oracle will just count the 1 bits). Let’s take a look at an example. First, we’ll generate test data that matches our specified distinct cardinalities, index it, and gather statistics. We’ll make use of the DBMS_RANDOM package to generate random data fitting our distribution:
EODA@ORA12CR1> create table t
2 ( gender not null,
3 location not null,
4 age_group not null,
5 data
6 )
7 as
8 select decode( round(dbms_random.value(1,2)),
9 1, 'M',
10 2, 'F' ) gender,
11 ceil(dbms_random.value(1,50)) location,
12 decode( round(dbms_random.value(1,5)),
13 1,'18 and under',
14 2,'19-25',
15 3,'26-30',
16 4,'31-40',
17 5,'41 and over'),
18 rpad( '*', 20, '*')
19 from dual connect by level <=100000;
Table created.
EODA@ORA12CR1> create bitmap index gender_idx on t(gender);
Index created.
EODA@ORA12CR1> create bitmap index location_idx on t(location);
Index created.
EODA@ORA12CR1> create bitmap index age_group_idx on t(age_group);
Index created.
EODA@ORA12CR1> exec dbms_stats.gather_table_stats( user, 'T');
PL/SQL procedure successfully completed.
Now we’ll take a look at the plans for our various ad hoc queries from earlier:
EODA@ORA12CR1> set autotrace traceonly explain
EODA@ORA12CR1> select count(*)
2 from t
3 where gender = 'M'
4 and location in ( 1, 10, 30 )
5 and age_group = '41 and over';
Execution Plan
----------------------------------------------------------
Plan hash value: 320981916
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| ...
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 9 (0)| ...
| 1 | SORT AGGREGATE | | 1 | 13 | | ...
| 2 | BITMAP CONVERSION COUNT | | 608 | 7904 | 9 (0)| ...
| 3 | BITMAP AND | | | | | ...
| 4 | BITMAP OR | | | | | ...
|* 5 | BITMAP INDEX SINGLE VALUE| LOCATION_IDX | | | | ...
|* 6 | BITMAP INDEX SINGLE VALUE| LOCATION_IDX | | | | ...
|* 7 | BITMAP INDEX SINGLE VALUE| LOCATION_IDX | | | | ...
|* 8 | BITMAP INDEX SINGLE VALUE | AGE_GROUP_IDX | | | | ...
|* 9 | BITMAP INDEX SINGLE VALUE | GENDER_IDX | | | | ...
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("LOCATION"=1)
6 - access("LOCATION"=10)
7 - access("LOCATION"=30)
8 - access("AGE_GROUP"='41 and over')
9 - access("GENDER"='M')
This example shows the power of the bitmap indexes. Oracle is able to see the location in (1,10,30) and knows to read the index on location for these three values and logically OR together the “bits” in the bitmap. It then takes that resulting bitmap and logically ANDs that with the bitmaps for AGE_GROUP='41 AND OVER' and GENDER='M'. Then a simple count of 1s and the answer is ready.
EODA@ORA12CR1> select *
2 from t
3 where ( ( gender = 'M' and location = 20 )
4 or ( gender = 'F' and location = 22 ))
5 and age_group = '18 and under';
Execution Plan
----------------------------------------------------------
Plan hash value: 705811684
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)...
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 408 | 13872 | 68 (0)...
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| T | 408 | 13872 | 68 (0)...
| 2 | BITMAP CONVERSION TO ROWIDS | | | | ...
| 3 | BITMAP AND | | | | ...
|* 4 | BITMAP INDEX SINGLE VALUE | AGE_GROUP_IDX | | | ...
| 5 | BITMAP OR | | | | ...
| 6 | BITMAP AND | | | | ...
|* 7 | BITMAP INDEX SINGLE VALUE | LOCATION_IDX | | | ...
|* 8 | BITMAP INDEX SINGLE VALUE | GENDER_IDX | | | ...
| 9 | BITMAP AND | | | | ...
|* 10 | BITMAP INDEX SINGLE VALUE | LOCATION_IDX | | | ...
|* 11 | BITMAP INDEX SINGLE VALUE | GENDER_IDX | | | ...
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("AGE_GROUP"='18 and under')
7 - access("LOCATION"=22)
8 - access("GENDER"='F')
10 - access("LOCATION"=20)
11 - access("GENDER"='M')
This shows similar logic: the plan shows the OR’d conditions are each evaluated by AND-ing together the appropriate bitmaps and then OR-ing together those results. Throw in another AND to satisfy the AGE_GROUP='18 AND UNDER' and we have it all. Since we asked for the actual rows this time, Oracle will convert each bitmap 1 and 0 into rowids to retrieve the source data.
In a data warehouse or a large reporting system supporting many ad hoc SQL queries, this ability to use as many indexes as make sense simultaneously comes in very handy indeed. Using conventional B*Tree indexes here would not be nearly as usual or usable, and as the number of columns that are to be searched by the ad hoc queries increases, the number of combinations of B*Tree indexes you would need increases as well.
However, there are times when bitmaps are not appropriate. They work well in a read-intensive environment, but they are extremely ill suited for a write-intensive environment. The reason is that a single bitmap index key entry points to many rows. If a session modifies the indexed data, then all of the rows that index entry points to are effectively locked in most cases. Oracle cannot lock an individual bit in a bitmap index entry; it locks the entire bitmap index entry. Any other modifications that need to update that same bitmap index entry will be locked out. This will seriously inhibit concurrency, as each update will appear to lock potentially hundreds of rows preventing their bitmap columns from being concurrently updated. It will not lock every row as you might think—just many of them. Bitmaps are stored in chunks, so using the earlier EMP example we might find that the index key ANALYST appears in the index many times, each time pointing to hundreds of rows. An update to a row that modifies the JOB column will need to get exclusive access to two of these index key entries: the index key entry for the old value and the index key entry for the new value. The hundreds of rows these two entries point to will be unavailable for modification by other sessions until that UPDATE commits.
Bitmap Join Indexes
In Oracle9i an index type was added: the bitmap join index. Normally, an index is created on a single table, using only columns from that table. A bitmap join index breaks that rule and allows you to index a given table using columns from some other table. In effect, this allows you to denormalize data in an index structure instead of in the tables themselves.
Consider the simple EMP and DEPT tables. EMP has a foreign key to DEPT (the DEPTNO column). The DEPT table has the DNAME attribute (the name of the department). The end users will frequently ask questions such as “How many people work in sales?”, “Who works in sales?”, “Can you show me the top N performing people in sales?” Note that they do not ask, “How many people work in DEPTNO 30?” They don’t use those key values; rather, they use the human-readable department name. Therefore, they end up running queries such as the following:
select count(*)
from emp, dept
where emp.deptno = dept.deptno
and dept.dname = 'SALES'
/
select emp.*
from emp, dept
where emp.deptno = dept.deptno
and dept.dname = 'SALES'
/
Those queries almost necessarily have to access the DEPT table and the EMP table using conventional indexes. We might use an index on DEPT.DNAME to find the SALES row(s) and retrieve the DEPTNO value for SALES, and then use an INDEX on EMP.DEPTNO to find the matching rows; however, by using a bitmap join index we can avoid all of that. The bitmap join index allows us to index the DEPT.DNAME column, but have that index point not at the DEPT table, but at the EMP table. This is a pretty radical concept—to be able to index attributes from other tables—and it might change the way to implement your data model in a reporting system. You can, in effect, have your cake and eat it, too. You can keep your normalized data structures intact, yet get the benefits of denormalization at the same time.
Here’s the index we would create for this example:
EODA@ORA12CR1> create bitmap index emp_bm_idx
2 on emp( d.dname )
3 from emp e, dept d
4 where e.deptno = d.deptno
5 /
Index created.
Note how the beginning of the CREATE INDEX looks “normal” and creates the index INDEX_NAME on the table. But from there on, it deviates from “normal.” We see a reference to a column in the DEPT table: D.DNAME. We see a FROM clause, making this CREATE INDEX statement resemble a query. We have a join condition between multiple tables. This CREATE INDEX statement indexes the DEPT.DNAME column, but in the context of the EMP table. If we ask those questions mentioned earlier, we would find the database never accesses the DEPT at all, and it need not do so because the DNAME column now exists in the index pointing to rows in the EMP table. For purposes of illustration, we will make the EMP and DEPT tables appear large (to avoid having the CBO think they are small and full scanning them instead of using indexes):
EODA@ORA12CR1> begin
2 dbms_stats.set_table_stats( user, 'EMP',
3 numrows => 1000000, numblks => 300000 );
4 dbms_stats.set_table_stats( user, 'DEPT',
5 numrows => 100000, numblks => 30000 );
6 dbms_stats.delete_index_stats( user, 'EMP_BM_IDX' );
7 end;
8 /
PL/SQL procedure successfully completed.
![]() Note You might be wondering why I invoked DELETE_INDEX_STATS above, it is because in Oracle 10g and above, a CREATE INDEX automatically does a COMPUTE STATISTICS as it creates the index. Therefore, in this case, Oracle was “tricked—it thinks it sees a table with 1,000,000 rows and a teeny tiny index on it (the table really only has 14 rows after all). The index statistics were accurate, the table statistics were “fake.” I needed to “fake” the index statistics as well—or I could have loaded the table up with 1,000,000 records before indexing it.
Note You might be wondering why I invoked DELETE_INDEX_STATS above, it is because in Oracle 10g and above, a CREATE INDEX automatically does a COMPUTE STATISTICS as it creates the index. Therefore, in this case, Oracle was “tricked—it thinks it sees a table with 1,000,000 rows and a teeny tiny index on it (the table really only has 14 rows after all). The index statistics were accurate, the table statistics were “fake.” I needed to “fake” the index statistics as well—or I could have loaded the table up with 1,000,000 records before indexing it.
And then we’ll perform our queries:
EODA@ORA12CR1> set autotrace traceonly explain
EODA@ORA12CR1> select count(*)
2 from emp, dept
3 where emp.deptno = dept.deptno
4 and dept.dname = 'SALES'
5 /
Execution Plan
----------------------------------------------------------
Plan hash value: 2538954156
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 3 | 7 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 3 | | |
| 2 | BITMAP CONVERSION COUNT | | 250K| 732K| 7 (0)| 00:00:01 |
|* 3 | BITMAP INDEX SINGLE VALUE| EMP_BM_IDX | | | | |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("EMP"."SYS_NC00009$"='SALES')
As you can see, to answer this particular question, we did not have to actually access either the EMP or DEPT table—the entire answer came from the index itself. All the information needed to answer the question was available in the index structure.
Further, we were able to skip accessing the DEPT table and, using the index on EMP that incorporated the data we needed from DEPT, gain direct access to the required rows:
EODA@ORA12CR1> select emp.*
2 from emp, dept
3 where emp.deptno = dept.deptno
4 and dept.dname = 'SALES'
5 /
Execution Plan
----------------------------------------------------------
Plan hash value: 4261295901
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)...
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10000 | 849K | 6139 (1)...
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 10000 | 849K | 6139 (1)...
| 2 | BITMAP CONVERSION TO ROWIDS | | | | ...
|* 3 | BITMAP INDEX SINGLE VALUE | EMP_BM_IDX | | | ...
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("EMP"."SYS_NC00009$"='SALES')
Bitmap join indexes do have a prerequisite. The join condition must join to a primary or unique key in the other table. In the preceding example, DEPT.DEPTNO is the primary key of the DEPT table, and the primary key must be in place, otherwise an error will occur:
EODA@ORA12CR1> create bitmap index emp_bm_idx
2 on emp( d.dname )
3 from emp e, dept d
4 where e.deptno = d.deptno
5 /
from emp e, dept d
*
ERROR at line 3:
ORA-25954: missing primary key or unique constraint on dimension
Bitmap Indexes Wrap-up
When in doubt, try it out (in your non-OLTP system, of course). It is trivial to add a bitmap index to a table (or a bunch of them) and see what it does for you. Also, you can usually create bitmap indexes much faster than B*Tree indexes. Experimentation is the best way to see if they are suited for your environment. I am frequently asked, “What defines low cardinality?” There is no cut-and-dried answer for this. Sometimes it is 3 values out of 100,000. Sometimes it is 10,000 values out of 1,000,000. Low cardinality doesn’t imply single-digit counts of distinct values. Experimentation is the way to discover if a bitmap is a good idea for your application. In general, if you have a large, mostly read-only environment with lots of ad hoc queries, a set of bitmap indexes may be exactly what you need.
Function-Based Indexes
Function-based indexes were added to Oracle 8.1.5. They are now a feature of Standard Edition, whereas in releases prior to Oracle9i Release 2 they were a feature of Enterprise Edition.
Function-based indexes give us the ability to index computed columns and use these indexes in a query. In a nutshell, this capability allows you to have case-insensitive searches or sorts, search on complex equations, and extend the SQL language efficiently by implementing your own functions and operators and then searching on them.
There are many reasons why you would want to use a function-based index, with the following chief among them:
· They are easy to implement and provide immediate value.
· They can be used to speed up existing applications without changing any of their logic or queries.
The following subsections provide relevant cases of implementing function-based indexes.
A Simple Function-Based Index Example
Consider the following example. We want to perform a case-insensitive search on the ENAME column of the EMP table. Prior to function-based indexes, we would have approached this in a very different manner. We would have added an extra column to the EMP table called UPPER_ENAME, for example. This column would have been maintained by a database trigger on INSERT and UPDATE; that trigger would simply have set NEW.UPPER_NAME := UPPER(:NEW.ENAME). This extra column would have been indexed. Now with function-based indexes, we remove the need for the extra column.
We begin by creating a copy of the demo EMP table in the SCOTT schema and adding some data to it:
EODA@ORA12CR1> create table emp
2 as
3 select *
4 from scott.emp
5 where 1=0;
Table created.
EODA@ORA12CR1> insert into emp
2 (empno,ename,job,mgr,hiredate,sal,comm,deptno)
3 select rownum empno,
4 initcap(substr(object_name,1,10)) ename,
5 substr(object_type,1,9) JOB,
6 rownum MGR,
7 created hiredate,
8 rownum SAL,
9 rownum COMM,
10 (mod(rownum,4)+1)*10 DEPTNO
11 from all_objects
12 where rownum < 10000;
9999 rows created.
Next, we will create an index on the UPPER value of the ENAME column, effectively creating a case-insensitive index:
EODA@ORA12CR1> create index emp_upper_idx on emp(upper(ename));
Index created.
Finally, we’ll analyze the table since, as noted previously, we need to make use of the CBO to use function-based indexes. As of Oracle 10g, this step is technically unnecessary, as the CBO is used by default and dynamic sampling would gather the needed information, but gathering statistics is a more correct approach.
EODA@ORA12CR1> begin
2 dbms_stats.gather_table_stats
3 (user,'EMP',cascade=>true);
4 end;
5 /
PL/SQL procedure successfully completed.
We now have an index on the UPPER value of a column. Any application that already issues case-insensitive queries like the following will make use of this index, gaining the performance boost an index can deliver:
EODA@ORA12CR1> set autotrace traceonly explain
EODA@ORA12CR1> select *
2 from emp
3 where upper(ename) = 'KING';
Execution Plan
----------------------------------------------------------
Plan hash value: 3831183638
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)...
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 110 | 2 (0)...
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 2 | 110 | 2 (0)...
|* 2 | INDEX RANGE SCAN | EMP_UPPER_IDX | 2 | | 1 (0)...
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access(UPPER("ENAME")='KING')
Before this feature was available, every row in the EMP table would have been scanned, uppercased, and compared. In contrast, with the index on UPPER(ENAME), the query takes the constant KING to the index, range scans a little data, and accesses the table by rowid to get the data. This is very fast.
This performance boost is most visible when indexing user-written functions on columns. Oracle 7.1 added the ability to use user-written functions in SQL, so we could do something like this:
SQL> select my_function(ename)
2 from emp
3 where some_other_function(empno) > 10
4 /
This was great because we could now effectively extend the SQL language to include application-specific functions. Unfortunately, however, the performance of the preceding query was a bit disappointing at times. Say the EMP table had 1,000 rows in it. The functionSOME_OTHER_FUNCTION would be executed 1,000 times during the query, once per row. In addition, assuming the function took one-hundredth of a second to execute, this relatively simple query now takes at least ten seconds.
Let’s look at a real example, where we’ll implement a modified SOUNDEX routine in PL/SQL. Additionally, we’ll use a package global variable as a counter in our procedure, which will allow us to execute queries that make use of the MY_SOUNDEX function and see exactly how many times it was called:
EODA@ORA12CR1> create or replace package stats
2 as
3 cnt number default 0;
4 end;
5 /
Package created.
EODA@ORA12CR1> create or replace
2 function my_soundex( p_string in varchar2 ) return varchar2
3 deterministic
4 as
5 l_return_string varchar2(6) default substr( p_string, 1, 1 );
6 l_char varchar2(1);
7 l_last_digit number default 0;
8
9 type vcArray is table of varchar2(10) index by binary_integer;
10 l_code_table vcArray;
11
12 begin
13 stats.cnt := stats.cnt+1;
14
15 l_code_table(1) := 'BPFV';
16 l_code_table(2) := 'CSKGJQXZ';
17 l_code_table(3) := 'DT';
18 l_code_table(4) := 'L';
19 l_code_table(5) := 'MN';
20 l_code_table(6) := 'R';
21
22
23 for i in 1 .. length(p_string)
24 loop
25 exit when (length(l_return_string) = 6);
26 l_char := upper(substr( p_string, i, 1 ) );
27
28 for j in 1 .. l_code_table.count
29 loop
30 if (instr(l_code_table(j), l_char ) > 0 AND j <> l_last_digit)
31 then
32 l_return_string := l_return_string || to_char(j,'fm9');
33 l_last_digit := j;
34 end if;
35 end loop;
36 end loop;
37
38 return rpad( l_return_string, 6, '0' );
39 end;
40 /
Function created.
Notice in this function, we are using a keyword, DETERMINISTIC. This declares that the preceding function, when given the same inputs, will always return the exact same output. This is needed to create a function-based index on a user-written function. We must tell Oracle that the function is DETERMINISTIC and will return a consistent result given the same inputs. We are telling Oracle that this function should be trusted to return the same value, call after call, given the same inputs. If this were not the case, we would receive different answers when accessing the data via the index versus a full table scan. This deterministic setting implies, for example, that we cannot create an index on the function DBMS_RANDOM.RANDOM, the random number generator. Its results are not deterministic; given the same inputs, we’ll get random output. The built-in SQL function UPPER used in the first example, on the other hand, is deterministic, so we can create an index on the UPPER value of a column.
Now that we have the function MY_SOUNDEX, let’s see how it performs without an index. This uses the EMP table we created earlier with about 10,000 rows in it:
EODA@ORA12CR1> set autotrace on explain
EODA@ORA12CR1> variable cpu number
EODA@ORA12CR1> exec :cpu := dbms_utility.get_cpu_time
PL/SQL procedure successfully completed.
EODA@ORA12CR1> select ename, hiredate
2 from emp
3 where my_soundex(ename) = my_soundex('Kings')
4 /
ENAME HIREDATE
---------- ---------
Ku$_Chunk_ 17-DEC-13
Ku$_Chunk_ 17-DEC-13
Ku$_Chunk_ 17-DEC-13
Ku$_Chunk_ 17-DEC-13
Execution Plan
----------------------------------------------------------
Plan hash value: 3956160932
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100 | 1900 | 24 (9)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| EMP | 100 | 1900 | 24 (9)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("MY_SOUNDEX"("ENAME")="MY_SOUNDEX"('Kings'))
EODA@ORA12CR1> set autotrace off
EODA@ORA12CR1> begin
2 dbms_output.put_line
3 ( 'cpu time = ' || round((dbms_utility.get_cpu_time-:cpu)/100,2) );
4 dbms_output.put_line( 'function was called: ' || stats.cnt );
5 end;
6 /
cpu time = .2
function was called: 9916
PL/SQL procedure successfully completed.
We can see this query took two-tenths of a CPU second to execute and had to do a full scan on the table. The function MY_SOUNDEX was invoked almost 10,000 times (according to our counter). We’d like it to be called much less frequently, however.
![]() Note In older releases (pre-Oracle 10g Release 2), the function would be called many more times than observed above. In fact, it would be invoked approximately 20,000 times—twice for each row! Oracle 10g Release 2 and above use the DETERMINISTIC hint to reduce the number of times it feels inclined to invoke the function.
Note In older releases (pre-Oracle 10g Release 2), the function would be called many more times than observed above. In fact, it would be invoked approximately 20,000 times—twice for each row! Oracle 10g Release 2 and above use the DETERMINISTIC hint to reduce the number of times it feels inclined to invoke the function.
Let’s see how indexing the function can speed up things. The first thing we’ll do is create the index as follows:
EODA@ORA12CR1> create index emp_soundex_idx on
2 emp( substr(my_soundex(ename),1,6) )
3 /
Index created.
The interesting thing to note in this CREATE INDEX command is the use of the SUBSTR function. This is because we are indexing a function that returns a string. If we were indexing a function that returned a number or date, this SUBSTR would not be necessary. The reason we mustSUBSTR the user-written function that returns a string is that such functions return VARCHAR2(4000) types. That may well be too big to be indexed—index entries must fit within about three quarters the size of a block. If we tried, we would receive (in a tablespace with a 4KB block size) the following:
EODA@ORA12CR1> create index emp_soundex_idx on
2 emp( my_soundex(ename) ) tablespace ts4k;
emp( my_soundex(ename) ) tablespace ts4k
*
ERROR at line 2:
ORA-01450: maximum key length (3118) exceeded
It is not that the index actually contains any keys that large, but that it could as far as the database is concerned. But the database understands SUBSTR. It sees the inputs to SUBSTR of 1 and 6, and knows the biggest return value from this is six characters; hence, it permits the index to be created. This size issue can get you, especially with concatenated indexes. Here is an example on an 8KB block size tablespace:
EODA@ORA12CR1> create index emp_soundex_idx on
2 emp( my_soundex(ename), my_soundex(job) );
emp( my_soundex(ename), my_soundex(job) )
*
ERROR at line 2:
ORA-01450: maximum key length (6398) exceeded
The database thinks the maximum key size is 8,000 bytes and fails the CREATE statement once again. So, to index a user-written function that returns a string, we should constrain the return type in the CREATE INDEX statement. In this example, knowing that MY_SOUNDEX returns at most six characters, we are substringing the first six characters.
We are now ready to test the performance of the table with the index on it. We would like to monitor the effect of the index on INSERTs as well as the speedup for SELECTs to see the effect on each. In the unindexed test case, our queries take over one second, and if we were to runSQL_TRACE and TKPROF during the inserts, we could observe that without the index, the insert of 9,999 records took about 0.30 seconds:
insert into emp NO_INDEX
(empno,ename,job,mgr,hiredate,sal,comm,deptno)
select rownum empno,
initcap(substr(object_name,1,10)) ename,
substr(object_type,1,9) JOB,
rownum MGR,
created hiredate,
rownum SAL,
rownum COMM,
(mod(rownum,4)+1)*10 DEPTNO
from all_objects
where rownum < 10000
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.08 0.08 0 0 0 0
Execute 1 0.15 0.22 0 2745 13763 9999
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 2 0.23 0.30 0 2745 13763 9999
But with the index, it takes about 0.57 seconds:
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.07 0.07 0 0 0 0
Execute 1 0.39 0.49 131 2853 23313 9999
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 2 0.46 0.57 131 2853 23313 9999
This was the overhead introduced in the management of the new index on the MY_SOUNDEX function—both in the performance overhead of simply having an index (any type of index will affect insert performance) and the fact that this index had to call a stored procedure 9,999 times.
Now, to test the query, we’ll just rerun the query:
EODA@ORA12CR1> exec stats.cnt := 0
PL/SQL procedure successfully completed.
EODA@ORA12CR1> exec :cpu := dbms_utility.get_cpu_time
PL/SQL procedure successfully completed.
EODA@ORA12CR1> set autotrace on explain
EODA@ORA12CR1> select ename, hiredate
2 from emp
3 where substr(my_soundex(ename),1,6) = my_soundex('Kings')
4 /
ENAME HIREDATE
---------- ---------
Ku$_Chunk_ 17-DEC-13
Ku$_Chunk_ 17-DEC-13
Ku$_Chunk_ 17-DEC-13
Ku$_Chunk_ 17-DEC-13
Plan hash value: 1897478402
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost ...
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100 | 3300 | 12 ...
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 100 | 3300 | 12 ...
|* 2 | INDEX RANGE SCAN | EMP_SOUNDEX_IDX | 40 | | 1 ...
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access(SUBSTR("EODA"."MY_SOUNDEX"("ENAME"),1,6)="MY_SOUNDEX"('Kings'))
EODA@ORA12CR1> set autotrace off
EODA@ORA12CR1> begin
2 dbms_output.put_line
3 ( 'cpu time = ' || round((dbms_utility.get_cpu_time-:cpu)/100,2) );
4 dbms_output.put_line( 'function was called: ' || stats.cnt );
5 end;
6 /
cpu time = .01
function was called: 1
PL/SQL procedure successfully completed.
If we compare the two examples (unindexed versus indexed), we find that the insert into the indexed table was affected by a little more than twice the runtime. However, the select went from two-tenths of a second to effectively instantly. The important things to note here are the following:
· The insertion of 9,999 records took approximately two times longer. Indexing a user-written function will necessarily affect the performance of inserts and some updates. You should realize that any index will impact performance, of course. For example, I did a simple test without the MY_SOUNDEX function, just indexing the ENAME column itself. That caused the INSERT to take about one second to execute—the PL/SQL function is not responsible for the entire overhead. Since most applications insert and update singleton entries, and each row took less than 1/10,000 of a second to insert, you probably won’t even notice this in a typical application. Since we insert a row only once, we pay the price of executing the function on the column once, not the thousands of times we query the data.
· While the insert ran two times slower, the query ran many times faster. It evaluated the MY_SOUNDEX function a few times instead of almost 10,000 times. The difference in performance of our query here is measurable and quite large. Also, as the size of our table grows, the full scan query will take longer and longer to execute. The index-based query will always execute with nearly the same performance characteristics as the table gets larger.
· We had to use SUBSTR in our query. This is not as nice as just coding WHERE MY_SOUNDEX(ename)=MY_SOUNDEX( 'King' ), but we can easily get around that, as we will see shortly.
So, the insert was affected, but the query ran incredibly fast. The payoff for a small reduction in insert/update performance is huge. Additionally, if you never update the columns involved in the MY_SOUNDEX function call, the updates are not penalized at all (MY_SOUNDEX is invoked only if the ENAME column is modified and its value changed).
Let’s see how to make it so the query does not have to use the SUBSTR function call. The use of the SUBSTR call could be error-prone—our end users have to know to SUBSTR from 1 for six characters. If they use a different size, the index will not be used. Also, we want to control in the server the number of bytes to index. This will allow us to reimplement the MY_SOUNDEX function later with 7 bytes instead of 6 if we want to. We can hide the SUBSTR with a virtual column in Oracle Database 11g Release 1 and above—or a view in any release quite easily as follows:
EODA@ORA12CR1> create or replace view emp_v
2 as
3 select ename, substr(my_soundex(ename),1,6) ename_soundex, hiredate
4 from emp
5 /
View created.
EODA@ORA12CR1> exec stats.cnt := 0;
PL/SQL procedure successfully completed.
EODA@ORA12CR1> exec :cpu := dbms_utility.get_cpu_time
PL/SQL procedure successfully completed.
EODA@ORA12CR1> select ename, hiredate
2 from emp_v
3 where ename_soundex = my_soundex('Kings')
4 /
ENAME HIREDATE
---------- ---------
Ku$_Chunk_ 17-DEC-13
Ku$_Chunk_ 17-DEC-13
Ku$_Chunk_ 17-DEC-13
Ku$_Chunk_ 17-DEC-13
EODA@ORA12CR1> begin
2 dbms_output.put_line
3 ( 'cpu time = ' || round((dbms_utility.get_cpu_time-:cpu)/100,2) );
4 dbms_output.put_line( 'function was called: ' || stats.cnt );
5 end;
6 /
cpu time = .01
function was called: 1
PL/SQL procedure successfully completed.
We would see the same sort of query plan we did with the base table. All we have done here is hide the SUBSTR( F(X), 1, 6 ) function call in the view itself. The optimizer still recognizes that this virtual column is, in fact, the indexed column and so does the right thing. We see the same performance improvement and the same query plan. Using this view is as good as using the base table—better even, because it hides the complexity and allows us to change the size of the SUBSTR later.
In Oracle 11g Release 1 and above, we have another choice for implementation. Rather than using a view with a “virtual column,” we can use a real virtual column. Using the feature involves dropping our existing function-based index:
EODA@ORA12CR1> drop index emp_soundex_idx;
Index dropped.
And then adds the virtual column to the table and indexing that column:
EODA@ORA12CR1> alter table emp
2 add
3 ename_soundex as
4 (substr(my_soundex(ename),1,6))
5 /
Table altered.
EODA@ORA12CR1> create index emp_soundex_idx
2 on emp(ename_soundex);
Index created.
Now we can just query the base table—no extra view layer involved at all:
EODA@ORA12CR1> exec stats.cnt := 0;
PL/SQL procedure successfully completed.
EODA@ORA12CR1> exec :cpu := dbms_utility.get_cpu_time
PL/SQL procedure successfully completed.
EODA@ORA12CR1> select ename, hiredate
2 from emp
3 where ename_soundex = my_soundex('Kings')
4 /
ENAME HIREDATE
---------- ---------
Ku$_Chunk_ 17-DEC-13
Ku$_Chunk_ 17-DEC-13
Ku$_Chunk_ 17-DEC-13
Ku$_Chunk_ 17-DEC-13
EODA@ORA12CR1> begin
2 dbms_output.put_line
3 ( 'cpu time = ' || round((dbms_utility.get_cpu_time-:cpu)/100,2) );
4 dbms_output.put_line( 'function was called: ' || stats.cnt );
5 end;
6 /
cpu time = 0
function was called: 1
PL/SQL procedure successfully completed.
Indexing Only Some of the Rows
In addition to transparently helping out queries that use built-in functions like UPPER, LOWER, and so on, function-based indexes can be used to selectively index only some of the rows in a table. As we’ll discuss a little later, B*Tree indexes do not contain entries for entirely NULL keys. That is, if you have an index I on a table T (as follows) and you have a row where A and B are both NULL, there will be no entry in the index structure.
Create index I on t(a,b);
This comes in handy when you are indexing just some of the rows in a table.
Consider a large table with a NOT NULL column called PROCESSED_FLAG that may take one of two values, Y or N, with a default value of N. New rows are added with a value of N to signify not processed, and as they are processed, they are updated to Y to signify processed. We would like to index this column to be able to retrieve the N records rapidly, but there are millions of rows and almost all of them are going to have a value of Y. The resulting B*Tree index will be large, and the cost of maintaining it as we update from N to Y will be high. This table sounds like a candidate for a bitmap index (this is low cardinality, after all), but this is a transactional system and lots of people will be inserting records at the same time with the processed column set to N and, as we discussed earlier, bitmaps are not good for concurrent modifications. When we factor in the constant updating of N to Y in this table as well, then bitmaps would be out of the question, as this process would serialize entirely.
So, what we would really like is to index only the records of interest (the N records). We’ll see how to do this with function-based indexes, but before we do, let’s see what happens if we just use a regular B*Tree index. Using the standard BIG_TABLE script described in the setup section at the beginning of the book, we’ll update the TEMPORARY column, flipping the Ys to Ns and the Ns to Ys:
EODA@ORA12CR1> update big_table set temporary = decode(temporary,'N','Y','N');
1000000 rows updated.
And we’ll check out the ratio of Ys to Ns:
EODA@ORA12CR1> select temporary, cnt,
2 round( (ratio_to_report(cnt) over ()) * 100, 2 ) rtr
3 from (
4 select temporary, count(*) cnt
5 from big_table
6 group by temporary
7 )
8 /
T CNT RTR
- ---------- ----------
Y 998728 99.87
N 1272 .13
As we can see, of the 1,000,000 records in the table, only about one-fifth of 1 percent of the data should be indexed. If we use a conventional index on the TEMPORARY column (which is playing the role of the PROCESSED_FLAG column in this example), we would discover that the index has 1,000,000 entries, consumes almost 14MB of space, and has a height of 3:
EODA@ORA12CR1> create index processed_flag_idx
2 on big_table(temporary);
Index created.
EODA@ORA12CR1> analyze index processed_flag_idx
2 validate structure;
Index analyzed.
EODA@ORA12CR1> select name, btree_space, lf_rows, height from index_stats;
NAME BTREE_SPACE LF_ROWS HEIGHT
-------------------- ----------- ---------- ----------
PROCESSED_FLAG_IDX 14528892 1000000 3
Any retrieval via this index would incur three I/Os to get to the leaf blocks. This index is not only wide, but also tall. To get the first unprocessed record, we will have to perform at least four I/Os (three against the index and one against the table).
How can we change all of this? We need to make it so the index is much smaller and easier to maintain (with less runtime overhead during the updates). Enter the function-based index, which allows us to simply write a function that returns NULL when we don’t want to index a given row and returns a non-NULL value when we do. For example, since we are interested just in the N records, let’s index just those:
EODA@ORA12CR1> drop index processed_flag_idx;
Index dropped.
EODA@ORA12CR1> create index processed_flag_idx
2 on big_table( case temporary when 'N' then 'N' end );
Index created.
EODA@ORA12CR1> analyze index processed_flag_idx validate structure;
Index analyzed.
EODA@ORA12CR1> select name, btree_space, lf_rows, height from index_stats;
NAME BTREE_SPACE LF_ROWS HEIGHT
-------------------- ----------- ---------- ----------
PROCESSED_FLAG_IDX 32016 1272 2
That is quite a difference—the index is some 32KB, not 14MB. The height has decreased as well. If we use this index, we’ll perform one less I/O than we would using the previous taller index.
Implementing Selective Uniqueness
Another useful technique with function-based indexes is to use them to enforce certain types of complex constraints. For example, suppose you have a table with versioned information, such as a projects table. Projects have one of two statuses: either ACTIVE or INACTIVE. You need to enforce a rule such that “Active projects must have a unique name; inactive projects do not.” That is, there can only be one active “project X,” but you could have as many inactive project Xs as you like.
The first response from a developer when they hear this requirement is typically, “We’ll just run a query to see if there are any active project Xs, and if not, we’ll create ours.” If you read Chapter 7, you understand that such a simple implementation cannot work in a multiuser environment. If two people attempt to create a new active project X at the same time, they’ll both succeed. We need to serialize the creation of project X, but the only way to do that is to lock the entire projects table (not very concurrent) or use a function-based index and let the database do it for us.
Building on the fact that we can create indexes on functions, that entire null entries are not made in B*Tree indexes, and that we can create a UNIQUE index, we can easily do the following:
Create unique index active_projects_must_be_unique
On projects ( case when status = 'ACTIVE' then name end );
This will do it. When the status column is ACTIVE, the NAME column will be uniquely indexed. Any attempt to create active projects with the same name will be detected, and concurrent access to this table is not compromised at all.
Caveat Regarding ORA-01743
One quirk I have noticed with function-based indexes is that if you create one on the built-in function TO_DATE, it will not succeed in some cases:
EODA@ORA12CR1> create table t ( year varchar2(4) );
Table created.
EODA@ORA12CR1> create index t_idx on t( to_date(year,'YYYY') );
create index t_idx on t( to_date(year,'YYYY') )
*
ERROR at line 1:
ORA-01743: only pure functions can be indexed
This seems strange, since we can sometimes create a function using TO_DATE, like so:
EODA@ORA12CR1> create index t_idx on t( to_date('01'||year,'MMYYYY') );
Index created.
The error message that accompanies this isn’t too illuminating either:
EODA@ORA12CR1> !oerr ora 1743
01743, 00000, "only pure functions can be indexed"
// *Cause: The indexed function uses SYSDATE or the user environment.
// *Action: PL/SQL functions must be pure (RNDS, RNPS, WNDS, WNPS). SQL
// expressions must not use SYSDATE, USER, USERENV(), or anything
// else dependent on the session state. NLS-dependent functions
// are OK.
We are not using SYSDATE. We are not using the user environment (or are we?). No PL/SQL functions are used, and nothing about the session state is involved. The trick lies in the format we used: YYYY. That format, given the same exact inputs, will return different answers depending on what month you call it in. For example, anytime in the month of May the YYYY format will return May 1, in June it will return June 1, and so on:
EODA@ORA12CR1> select to_char( to_date('2015','YYYY'),
2 'DD-Mon-YYYY HH24:MI:SS' )
3 from dual;
TO_CHAR(TO_DATE('200
--------------------
01-May-2015 00:00:00
It turns out that TO_DATE, when used with YYYY, is not deterministic! That is why the index cannot be created: it would only work correctly in the month you created it in (or insert/updated a row in). So, it is due to the user environment, which includes the current date itself.
To use TO_DATE in a function-based index, you must use a date format that is unambiguous and deterministic—regardless of what day it is currently.
Function-Based Indexes Wrap-up
Function-based indexes are easy to use and implement, and they provide immediate value. They can be used to speed up existing applications without changing any of their logic or queries. Many orders of magnitude improvement may be observed. You can use them to precompute complex values without using a trigger. Additionally, the optimizer can estimate selectivity more accurately if the expressions are materialized in a function-based index. You can use function-based indexes to selectively index only rows of interest as demonstrated earlier with the PROCESSED_FLAGexample. You can, in effect, index a WHERE clause using that technique. Lastly, you can use function-based indexes to implement a certain kind of integrity constraint: selective uniqueness (e.g., “The fields X, Y, and Z must be unique when some condition is true”).
Function-based indexes will affect the performance of inserts and updates. Whether or not that warning is relevant to you is something you must decide. If you insert and very infrequently query the data, this might not be an appropriate feature for you. On the other hand, keep in mind that you typically insert a row once and you query it thousands of times. The performance hit on the insert (which your individual end user will probably never notice) may be offset many thousands of times by speeding up the queries. In general, the pros heavily outweigh any of the cons in this case.
Application Domain Indexes
Application domain indexes are what Oracle calls extensible indexing. They allow you to create your own index structures that work just like indexes supplied by Oracle. When someone issues a CREATE INDEX statement using your index type, Oracle will run your code to generate the index. If someone analyzes the index to compute statistics on it, Oracle will execute your code to generate statistics in whatever format you care to store them in. When Oracle parses a query and develops a query plan that may make use of your index, Oracle will ask you how costly this function is to perform as it is evaluating the different plans. In short, application domain indexes give you the ability to implement a new index type that does not exist in the database as of yet. For example, if you develop software that analyzes images stored in the database, and you produce information about the images, such as the colors found in them, you could create your own image index. As images are added to the database, your code is invoked to extract the colors from the images and store them somewhere (wherever you want to store them). At query time, when the user asks for all blue images, Oracle will ask you to provide the answer from your index when appropriate.
The best example of an application domain index is Oracle’s own text index. This index is used to provide keyword searching on large text items. You may create a simple text index like this:
EODA@ORA12CR1> create index myindex on mytable(docs)
2 indextype is ctxsys.context
3 /
Index created.
And then use the text operators the creators of that index type introduced into the SQL language.
select * from mytable where contains( docs, 'some words' ) > 0;
It will even respond to commands such as the following:
EODA@ORA12CR1> begin
2 dbms_stats.gather_index_stats( user, 'MYINDEX' );
3 end;
4 /
PL/SQL procedure successfully completed.
It will participate with the optimizer at runtime to determine the relative cost of using a text index over some other index or a full scan. The interesting thing about all of this is that you or I could have developed this index. The implementation of the text index was done without inside kernel knowledge. It was done using the dedicated, documented, and exposed API. The Oracle database kernel is not aware of how the text index is stored (the APIs store it in many physical database tables per index created). Oracle is not aware of the processing that takes place when a new row is inserted. Oracle text is really an application built on top of the database, but in a wholly integrated fashion. To you and me, it looks just like any other Oracle database kernel function, but it is not.
I personally have not found the need to go and build a new exotic type of index structure. I see this particular feature as being of use mostly to third-party solution providers that have innovative indexing techniques.
I think the most interesting thing about application domain indexes is that they allow others to supply new indexing technology I can use in my applications. Most people will never make use of this particular API to build a new index type, but most of us will use the end results. Virtually every application I work on seems to have some text associated with it, XML to be dealt with, or images to be stored and categorized. The Oracle Multimedia set of functionality, implemented using the Application Domain Indexing feature, provides these capabilities. As time passes, the set of available index types grows. We’ll take a more in-depth look at the text index in a subsequent chapter.
Invisible Indexes
In Oracle Database 11g and higher, you have the option of making an index invisible to the optimizer. The index is only invisible in the sense that the optimizer won’t use the index when creating an execution plan. You can either create an index as invisible or alter an existing index to be invisible. Here we create a table, load it with test data, generate statistics, and then create an invisible index:
EODA@ORA12CR1> create table t(x int);
Table created.
EODA@ORA12CR1> insert into t select round(dbms_random.value(1,10000)) from dual
2 connect by level <=10000;
EODA@ORA12CR1> exec dbms_stats.gather_table_stats(user,'T');
PL/SQL procedure successfully completed.
EODA@ORA12CR1> create index ti on t(x) invisible;
Index created.
Now we turn on autotrace and run a query where one would expect the optimizer to use the index when generating an execution plan:
EODA@ORA12CR1> set autotrace traceonly explain
EODA@ORA12CR1> select * from t where x=5;
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 8 | 7 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T | 2 | 8 | 7 (0)| 00:00:01 |
--------------------------------------------------------------------------
The prior output shows that the index wasn’t used by the optimizer. You can toggle an index’s visibility to the optimizer during a session by setting the OPTIMIZER_USE_INVISIBLE_INDEXES initialization parameter to TRUE (the default is FALSE). For example, for the currently connected session, the following instructs the optimizer to consider invisible indexes when generating an execution plan:
EODA@ORA12CR1> alter session set optimizer_use_invisible_indexes=true;
Rerunning the prior query shows the optimizer now takes advantage of the index:
EODA@ORA12CR1> select * from t where x=5;
-------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 8 | 1 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| TI | 2 | 8 | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------
If you want all sessions to consider using invisible indexes, then alter the OPTIMIZER_USE_INVISIBLE_INDEXES parameter via the ALTER SYSTEM statement. This makes all invisible indexes visible to the optimizer when generating execution plans.
You can make an index permanently visible to the optimizer by altering it to visible:
EODA@ORA12CR1> alter index ti visible;
Index altered.
Keep in mind that although an invisible index may be invisible to the optimizer, it can still impact performance in the following ways:
· Invisible indexes consume space and resources as the underlying table has records inserted, updated, or deleted. This could impact performance (slow down DML statements).
· Oracle can still use an invisible index to prevent certain locking situations when a B*Tree index is placed on a foreign key column.
· If you create a unique invisible index, the uniqueness of the columns will be enforced regardless of the visibility setting.
Therefore, even if you create an index as invisible, it can still influence the behavior of SQL statements. It would be erroneous to assume that an invisible index has no impact on the applications using the tables on which invisible indexes exist. Invisible indexes are only invisible in the sense that the optimizer won’t consider them for use when generating execution plans unless instructed to do so.
So what is the usefulness of invisible indexes? These indexes still have to be maintained (hence slowing performance), but cannot be used by queries that can’t see them (hence never boosting performance). One example would be if you wanted to drop an index from a production system. The idea being you could make the index invisible and see if performance suffered. In this case, before dropping the index, you’d also have to be careful that the index wasn’t placed on a foreign key column or wasn’t being used to enforce uniqueness. Another example would be where you wanted to add an index to a production system and test it to determine if performance improved. You could add the index as invisible and selectively make it visible during a session to determine its usefulness. Here again, you’d also have to be mindful that even though the index is invisible, it will consume space and require resources to maintain.
Multiple Indexes on the Same Column Combinations
Prior to Oracle Database 12c, you could not have multiple indexes defined on one table with the exact same combination of columns. For example:
EODA@ORA11GR2> create table t(x int);
Table created.
EODA@ORA11GR2> create index ti on t(x);
Index created.
EODA@ORA11GR2> create bitmap index tb on t(x) invisible;
ERROR at line 1:
ORA-01408: such column list already indexed
Starting with 12c, you can define multiple indexes on the same set of columns. However, you can only do this if the indexes are physically different; for example, when one index is created as a B*Tree index, and the second index as a bitmap index. Also, there can be only one visible index for the same combination of columns on a table. Therefore, running the prior CREATE INDEX statements works in an Oracle 12c database:
EODA@ORA12CR1> create table t(x int);
Table created.
EODA@ORA12CR1> create index ti on t(x);
Index created
EODA@ORA12CR1> create bitmap index tb on t(x) invisible;
Index created
Why would you want two indexes defined on the same set of columns? Say you had originally built a data warehouse star schema with all B*Tree indexes on the fact table foreign key columns, and later discover through testing that bitmap indexes will perform better for the types of queries applied to the star schema. Therefore, you want to convert to bitmap indexes as seamlessly as possible. So you first build the bitmap indexes as invisible. Then when you’re ready, you can drop the B*Tree indexes and then alter the bitmap indexes to be visible.
Indexing Extended Columns
With the advent of Oracle 12c, the VARCHAR2, NVARCHAR2, and RAW datatypes can now be configured to store up to 32,767 bytes of information (previously, the limit was 4,000 bytes for VARCHAR2 and NVARCHAR2, and 2000 bytes for RAW). Since Chapter 12 contains the details for enabling a database with extended datatypes, I won’t repeat that information here. The focus of this section is to explore indexing extended columns.
Let’s start by creating a table with an extended column and then try to create a regular B*Tree index on that column:
EODA@O12CE> create table t(x varchar2(32767));
Table created.
![]() Note If you attempt to create a table with a VARCHAR2 column greater than 4,000 bytes in a database that hasn’t been configured for extended datatypes, Oracle will throw an ORA-00910: specified length too long for its datatype message.
Note If you attempt to create a table with a VARCHAR2 column greater than 4,000 bytes in a database that hasn’t been configured for extended datatypes, Oracle will throw an ORA-00910: specified length too long for its datatype message.
Next, we attempt to create an index on the extended column:
EODA@O12CE> create index ti on t(x);
create index ti on t(x)
*
ERROR at line 1:
ORA-01450: maximum key length (6398) exceeded
We’ve seen this error previously in this chapter. An error is thrown because Oracle imposes a maximum length on the index key, which is about three-fourths of the block size (the block size for the database in this example is 8K). Even though there aren’t any entries in this index yet, Oracle knows that it’s possible that index key could be larger than 6,398 bytes for a column that can contain up 32,767 bytes, and therefore won’t allow you to create an index in this scenario.
That doesn’t mean you can’t index extended columns, rather you have to use techniques that limit the length of the index key to less than 6,398 bytes. With that in mind, a few options become apparent:
· Create virtual column based on SUBSTR or STANDARD_HASH functions, and then create an index on the virtual column.
· Create a function-based index using SUBSTR or STANDARD_HASH functions.
· Create a tablespace based on a larger block size; for example, a 16K block size would allow for index keys the size of approximately 12,000 bytes. Having said that, if you need 12,000 bytes for an index key, then you’re probably doing something wrong and need to rethink what you’re doing. This method will not be explored.
Let’s start by looking at the virtual column solution.
Virtual Column Solution
The idea here is to first create a virtual column applying a SQL function on the extended column that returns a value less than 6,398 bytes. Then that virtual column can be indexed and this provides a mechanism for better performance when issuing queries against extended columns. An example will demonstrate this. First, create a table with an extended column:
EODA@O12CE> create table t(x varchar2(32767));
Table created.
Now insert some test data into the table:
EODA@O12CE> insert into t select to_char(level)|| rpad('abc',10000,'xyz')
2 from dual connect by level < 1001
3 union
4 select to_char(level)
5 from dual connect by level < 1001;
2000 rows created.
Now suppose that you know the first ten characters of the extended column are sufficiently selective enough to return small portions of the rows in the table. Therefore, you create a virtual column based on a substring of the extended column:
EODA@O12CE> alter table t add (xv as (substr(x,1,10)));
Table altered.
Now create an index on the virtual column and gather statistics:
EODA@O12CE> create index te on t(xv);
Index created.
EODA@O12CE> exec dbms_stats.gather_table_stats(user,'T');
PL/SQL procedure successfully completed.
Now when querying the virtual column, the optimizer can take advantage of the index in equality and range predicates in the WHERE clause; for example:
EODA@O12CE> set autotrace traceonly explain
EODA@O12CE> select count(*) from t where x = '800';
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5011 | 2 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5011 | | |
|* 2 | TABLE ACCESS BY INDEX ROWID BATCHED| T | 1 | 5011 | 2 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | TE | 1 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Notice that even though the index is on the virtual column, the optimizer can still use it when querying directly against the extended column X (and not the virtual column XV). The optimizer can also use this type of index in a range-type search:
EODA@O12CE> select count(*) from t where x >'800' and x<'900';
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5011 | 4 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5011 | | |
|* 2 | TABLE ACCESS BY INDEX ROWID BATCHED| T | 239 | 1169K| 4 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | TE | 241 | | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Like the SUBSTR function, you can also base a virtual column on the STANDARD_HASH function. The STANDARD_HASH function can be applied to a long character string and return a fairly unique RAW value much less than 6,398 bytes. Let’s look at a couple of examples using a virtual column based on STANDARD_HASH.
Assuming the same table and seed data as used with the prior SUBSTR examples, here we add a virtual column to the table using STANDARD_HASH, create an index, and generate statistics:
EODA@O12CE> alter table t add (xv as (standard_hash(x)));
Table altered.
EODA@O12CE> create index te on t(xv);
Index created.
EODA@O12CE> exec dbms_stats.gather_table_stats(user,'T');
PL/SQL procedure successfully completed.
The STANDARD_HASH works well when using equality predicates in the WHERE clause. For example:
EODA@O12CE> set autotrace traceonly explain
EODA@O12CE> select count(*) from t where x='300';
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5025 | 2 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5025 | | |
|* 2 | TABLE ACCESS BY INDEX ROWID BATCHED| T | 1 | 5025 | 2 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | TE | 1 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
The index on a STANDARD_HASH–based virtual column allows for efficient equality-based searches, but does not work for range-based searches, as the data is stored in an index based on the randomized hash value; for example:
EODA@O12CE> select count(*) from t where x >'800' and x<'900';
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5004 | 6 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5004 | | |
|* 2 | TABLE ACCESS FULL| T | 239 | 1167K| 6 (0)| 00:00:01 |
---------------------------------------------------------------------------
Function-Based Index Solution
The concept here is that you’re building an index and applying a function to it in a way that limits the length of the index key and also results in a usable index. Here I use the same code (as in the prior section) to create a table with an extended column and populate it with test data:
EODA@O12CE> create table t(x varchar2(32767));
Table created.
EODA@O12CE> insert into t
2 select to_char(level)|| rpad('abc',10000,'xyz')
3 from dual connect by level < 1001
4 union
5 select to_char(level)
6 from dual connect by level < 1001;
2000 rows created.
Now suppose you’re familiar with the data and know that the first ten characters of the extended columns are usually sufficient for identifying a row; therefore, you create an index on the substring of the first ten characters and generate statistics for the table:
EODA@O12CE> create index te on t(substr(x,1,10));
Index created.
EODA@O12CE> exec dbms_stats.gather_table_stats(user,'T');
PL/SQL procedure successfully completed.
The optimizer can use an index like this when there are equality and range predicates in the WHERE clause. Some examples will illustrate this:
EODA@O12CE> set autotrace traceonly explain
EODA@O12CE> select count(*) from t where x = '800';
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 16407 | 2 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 16407 | | |
|* 2 | TABLE ACCESS BY INDEX ROWID BATCHED| T | 1 | 16407 | 2 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | TE | 8 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
This example uses a range predicate:
EODA@O12CE> select count(*) from t where x>'200' and x<'400';
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5011 | 6 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5011 | | |
|* 2 | TABLE ACCESS BY INDEX ROWID BATCHED| T | 477 | 2334K| 6 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | TE | 479 | | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Assuming the same table and seed data as used with the prior SUBSTR examples, here we add a function-based index using STANDARD_HASH:
EODA@O12CE> create index te on t(standard_hash(x));
Now verify that an equality-based search uses the index:
EODA@O12CE> set autotrace traceonly explain
EODA@O12CE> select count(*) from t where x = '800';
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5004 | 4 (0)| 00:00:01|
| 1 | SORT AGGREGATE | | 1 | 5004 | | |
|* 2 | TABLE ACCESS BY INDEX ROWID BATCHED| T | 1 | 5004 | 4 (0)| 00:00:01|
|* 3 | INDEX RANGE SCAN | TE | 8 | | 1 (0)| 00:00:01|
--------------------------------------------------------------------------------------------
This allows for efficient equality-based searches, but does not work for range-based searches, as the data is stored in an index based on the randomized hash value.
Frequently Asked Questions and Myths About Indexes
As I said in the introduction to this book, I field lots of questions about Oracle. I am the Tom behind the “Ask Tom” column in Oracle Magazine and at http://asktom.oracle.com, where I answer people’s questions about the Oracle database and tools. In my experience, the topic of indexes attracts the most questions. In this section, I answer some of the most frequently asked questions. Some of the answers may seem like common sense, while other answers might surprise you. Suffice it to say, there are lots of myths and misunderstandings surrounding indexes.
Do Indexes Work on Views?
A related question is, “How can I index a view?” Well, the fact is that a view is nothing more than a stored query. Oracle will replace the text of the query that accesses the view with the view definition itself. Views are for the convenience of the end user or programmer—the optimizer works with the query against the base tables. Any and all indexes that could have been used if the query had been written against the base tables will be considered when you use the view. To index a view, you simply index the base tables.
Do Nulls and Indexes Work Together?
B*Tree indexes, except in the special case of cluster B*Tree indexes, do not store completely Null entries, but bitmap and cluster indexes do. This side effect can be a point of confusion, but it can actually be used to your advantage when you understand what not storing entirely null keys implies.
To see the effect of the fact that Null values are not stored, consider this example:
EODA@ORA12CR1> create table t ( x int, y int );
Table created.
EODA@ORA12CR1> create unique index t_idx on t(x,y);
Index created.
EODA@ORA12CR1> insert into t values ( 1, 1 );
1 row created.
EODA@ORA12CR1> insert into t values ( 1, NULL );
1 row created.
EODA@ORA12CR1> insert into t values ( NULL, 1 );
1 row created.
EODA@ORA12CR1> insert into t values ( NULL, NULL );
1 row created.
EODA@ORA12CR1> analyze index t_idx validate structure;
Index analyzed.
EODA@ORA12CR1> select name, lf_rows from index_stats;
NAME LF_ROWS
------------------------------ ----------
T_IDX 3
The table has four rows, whereas the index only has three. The first three rows, where at least one of the index key elements was not Null, are in the index. The last row with (NULL, NULL) is not in the index. One of the areas of confusion is when the index is a unique index, as just shown. Consider the effect of the following three INSERT statements:
EODA@ORA12CR1> insert into t values ( NULL, NULL );
1 row created.
EODA@ORA12CR1> insert into t values ( NULL, 1 );
insert into t values ( NULL, 1 )
*
ERROR at line 1:
ORA-00001: unique constraint (EODA.T_IDX) violated
EODA@ORA12CR1> insert into t values ( 1, NULL );
insert into t values ( 1, NULL )
*
ERROR at line 1:
ORA-00001: unique constraint (EODA.T_IDX) violated
The new (NULL, NULL) row is not considered to be the same as the old row with (NULL, NULL):
EODA@ORA12CR1> select x, y, count(*)
2 from t
3 group by x,y
4 having count(*) > 1;
X Y COUNT(*)
---------- ---------- ----------
2
This seems impossible; our unique key isn’t unique if we consider all Null entries. The fact is that, in Oracle, (NULL, NULL) is not the same as (NULL, NULL) when considering uniqueness—the SQL standard mandates this. (NULL,NULL) and (NULL,NULL) are considered the same with regard to aggregation, however. The two are unique for comparisons but are the same as far as the GROUP BY clause is concerned. That is something to consider: each unique constraint should have at least one NOT NULL column to be truly unique.
The question that comes up with regard to indexes and Null values is, “Why isn’t my query using the index?” The query in question is something like the following:
select * from T where x is null;
This query cannot use the index we just created—the row (NULL, NULL) simply is not in the index, hence the use of the index would return the wrong answer. Only if at least one of the columns is defined as NOT NULL can the query use an index. For example, the following shows Oracle will use an index for an X IS NULL predicate if there is an index with X on the leading edge and at least one other column in the index is defined as NOT NULL in the base table:
EODA@ORA12CR1> create table t ( x int, y int NOT NULL );
Table created.
EODA@ORA12CR1> create unique index t_idx on t(x,y);
Index created.
EODA@ORA12CR1> insert into t values ( 1, 1 );
1 row created.
EODA@ORA12CR1> insert into t values ( NULL, 1 );
1 row created.
EODA@ORA12CR1> begin
2 dbms_stats.gather_table_stats(user,'T');
3 end;
4 /
PL/SQL procedure successfully completed.
When we go to query that table this time, we’ll discover this:
EODA@ORA12CR1> set autotrace on
EODA@ORA12CR1> select * from t where x is null;
X Y
---------- ----------
1
Execution Plan
...
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 1 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| T_IDX | 1 | 5 | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------
Previously, I said that you can use to your advantage the fact that totally Null entries are not stored in a B*Tree index—here is how. Say you have a table with a column that takes exactly two values. The values are very skewed; say, 90 percent or more of the rows take on one value and 10 percent or less take on the other value. You can index this column efficiently to gain quick access to the minority rows. This comes in handy when you would like to use an index to get to the minority rows, but you want to full scan to get to the majority rows, and you want to conserve space. The solution is to use a Null for majority rows and whatever value you want for minority rows or, as demonstrated earlier, use a function-based index to index only the non-null return values from a function.
Now that you know how a B*Tree will treat Null values, you can use that to your advantage and take precautions with unique constraints on sets of columns that all allow Nulls (be prepared to have more than one row that is all Null as a possibility in this case).
Should Foreign Keys Be Indexed?
The question of whether or not foreign keys should be indexed comes up frequently. We touched on this subject in Chapter 6 when discussing deadlocks. There, I pointed out that unindexed foreign keys are the biggest single cause of deadlocks that I encounter, due to the fact that an update to a parent table’s primary key or the removal of a parent record will place a table lock on the child table (no modifications to the child table will be allowed until the statement completes). This locks many more rows than it should and decreases concurrency. I see it frequently when people are using a tool that generates the SQL to modify a table. The tool generates an UPDATE statement that updates every column in the table, regardless of whether or not the value was modified. This, in effect, updates the primary key (even though they never changed the value). For example, Oracle Forms will do this by default, unless you tell it to just send modified columns over to the database. In addition to the table lock issue that might hit you, an unindexed foreign key is bad in the following cases as well:
· When you have an ON DELETE CASCADE and have not indexed the child table. For example, EMP is child of DEPT. DELETE FROM DEPT WHERE DEPTNO = 10 should cascade to EMP. If DEPTNO in EMP is not indexed, you will get a full table scan of EMP. This full scan is probably undesirable, and if you delete many rows from the parent table, the child table will be scanned once for each parent row deleted.
· When you query from the parent to the child. Consider the EMP/DEPT example again. It is very common to query the EMP table in the context of a DEPTNO. If you frequently query the following to generate a report or something, you’ll find not having the index in place will slow down the queries:
select *
from dept, emp
where emp.deptno = dept.deptno
and dept.dname = :X;
This is the same argument I gave for indexing the NESTED_COLUMN_ID of a nested table in Chapter 10. The hidden NESTED_COLUMN_ID of a nested table is nothing more than a foreign key.
So, when do you not need to index a foreign key? In general, when the following conditions are met:
· You do not delete from the parent table.
· You do not update the parent table’s unique/primary key value, either purposely or by accident (via a tool).
· You do not join from the parent table to the child table, or more generally, the foreign key columns do not support an important access path to the child table and you do not use them in predicates to select data from this table (such as DEPT to EMP).
If you satisfy all three criteria, feel free to skip the index—it is not needed and will slow down DML on the child table. If you do any of the three, be aware of the consequences.
As a side note, if you believe that a child table is getting locked via an unindexed foreign key and you would like to prove it (or just prevent it in general), you can issue the following:
ALTER TABLE <child table name> DISABLE TABLE LOCK;
Now, any UPDATE or DELETE to the parent table that would cause the table lock will receive the following:
ERROR at line 1:
ORA-00069: cannot acquire lock -- table locks disabled for <child table name>
This is useful in tracking down the piece of code that is doing what you believe should not be done (no UPDATEs or DELETEs of the parent primary key), as the end users will immediately report this error back to you.
Why Isn’t My Index Getting Used?
There are many possible causes of this. In this section, we’ll take a look at some of the most common.
Case 1
We’re using a B*Tree index, and our predicate does not use the leading edge of an index. In this case, we might have a table T with an index on T(x,y). We query SELECT * FROM T WHERE Y = 5. The optimizer will tend not to use the index since our predicate did not involve the column X—it might have to inspect each and every index entry in this case (we’ll discuss an index skip scan shortly where this is not true). It will typically opt for a full table scan of T instead. That does not preclude the index from being used. If the query was SELECT X,Y FROM T WHERE Y = 5, the optimizer would notice that it did not have to go to the table to get either X or Y (they are in the index) and may very well opt for a fast full scan of the index itself, as the index is typically much smaller than the underlying table. Note also that this access path is only available with the CBO.
Another case whereby the index on T(x,y) could be used with the CBO is during an index skip scan. The skip scan works well if—and only if—the leading edge of the index (X in the previous example) has very few distinct values and the optimizer understands that. For example, consider an index on (GENDER, EMPNO) where GENDER has the values M and F, and EMPNO is unique. A query such as
select * from t where empno = 5;
might consider using that index on T to satisfy the query in a skip scan method, meaning the query will be processed conceptually like this:
select * from t where GENDER='M' and empno = 5
UNION ALL
select * from t where GENDER='F' and empno = 5;
It will skip throughout the index, pretending it is two indexes: one for Ms and one for Fs. We can see this in a query plan easily. We’ll set up a table with a bivalued column and index it:
EODA@ORA12CR1> create table t
2 as
3 select decode(mod(rownum,2), 0, 'M', 'F' ) gender, all_objects.*
4 from all_objects
5 /
Table created.
EODA@ORA12CR1> create index t_idx on t(gender,object_id);
Index created.
EODA@ORA12CR1> exec dbms_stats.gather_table_stats( user, 'T' );
PL/SQL procedure successfully completed.
Now, when we query this, we should see the following:
EODA@ORA12CR1> set autotrace traceonly explain
EODA@ORA12CR1> select * from t t1 where object_id = 42;
Execution Plan
...
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 91 | 4 (0)| 00:00:01|
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| T | 1 | 91 | 4 (0)| 00:00:01|
|* 2 | INDEX SKIP SCAN | T_IDX | 1 | | 3 (0)| 00:00:01|
--------------------------------------------------------------------------------------------
The INDEX SKIP SCAN step tells us that Oracle is going to skip throughout the index, looking for points where GENDER changes values and read down the tree from there, looking for OBJECT_ID=42 in each virtual index being considered. If we increase the number of distinct values for GENDER measurably, as follows, we’ll see that Oracle stops seeing the skip scan as being a sensible plan:
EODA@ORA12CR1> update t set gender = chr(mod(rownum,256));
17944 rows updated.
EODA@ORA12CR1> exec dbms_stats.gather_table_stats( user, 'T', cascade=>TRUE );
PL/SQL procedure successfully completed.
It would have 256 mini indexes to inspect, and it opts for a full table scan to find our row
EODA@ORA12CR1> set autotrace traceonly explain
EODA@ORA12CR1> select * from t t1 where object_id = 42;
Execution Plan
...
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 92 | 274 (1)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T | 1 | 92 | 274 (1)| 00:00:01 |
--------------------------------------------------------------------------
Case 2
We’re using a SELECT COUNT(*) FROM T query (or something similar) and we have a B*Tree index on table T. However, the optimizer is full scanning the table, rather than counting the (much smaller) index entries. In this case, the index is probably on a set of columns that can contain Nulls. Since a totally Null index entry would never be made, the count of rows in the index will not be the count of rows in the table. Here the optimizer is doing the right thing—it would get the wrong answer if it used the index to count rows.
Case 3
For an indexed column, we query using the following and find that the index on INDEXED_COLUMN is not used:
select * from t where f(indexed_column) = value
This is due to the use of the function on the column. We indexed the values of INDEXED_COLUMN, not the value of F(INDEXED_COLUMN). The ability to use the index is curtailed here. We can index the function if we choose to do it.
Case 4
We have indexed a character column. This column contains only numeric data. We query using the following syntax:
select * from t where indexed_column = 5
Note that the number 5 in the query is the constant number 5 (not a character string). The index on INDEXED_COLUMN is not used. This is because the preceding query is the same as the following:
select * from t where to_number(indexed_column) = 5
We have implicitly applied a function to the column and, as noted in case 3, this will preclude the use of the index. This is very easy to see with a small example. In this example, we’re going to use the built-in package DBMS_XPLAN. This package is available only with Oracle9i Release 2 and above (in Oracle9i Release 1, we will use AUTOTRACE instead to see the plan easily, but we will not see the predicate information—that is only available in Oracle9i Release 2 and above):
EODA@ORA12CR1> create table t ( x char(1) constraint t_pk primary key,
2 y date );
Table created.
EODA@ORA12CR1> insert into t values ( '5', sysdate );
1 row created.
EODA@ORA12CR1> explain plan for select * from t where x = 5;
Explained.
EODA@ORA12CR1> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 1601196873
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 12 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T | 1 | 12 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(TO_NUMBER("X")=5)
As you can see, it full scanned the table. And even if we were to hint the following query, it uses the index, but not for a UNIQUE SCAN as we might expect—it is FULL SCANNING this index:
EODA@ORA12CR1> explain plan for select /*+ INDEX(t t_pk) */ * from t where x = 5;
Explained.
EODA@ORA12CR1> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 180604526
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 12 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| T | 1 | 12 | 3 (0)| 00:00:01 |
|* 2 | INDEX FULL SCAN | T_PK | 1 | | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TO_NUMBER("X")=5)
The reason lies in the last line of output there: filter(TO_NUMBER("X")=5). There is an implicit function being applied to the database column. The character string stored in X must be converted to a number prior to comparing to the value 5. We cannot convert 5 to a string, since our NLS settings control what 5 might look like in a string (it is not deterministic), so we convert the string into a number, and that precludes the use of the index to rapidly find this row. If we simply compare strings to strings
EODA@ORA12CR1> explain plan for select * from t where x = '5';
Explained.
EODA@ORA12CR1> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 1303508680
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 12 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 1 | 12 | 2 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | T_PK | 1 | | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("X"='5')
we get the expected INDEX UNIQUE SCAN, and we can see the function is not being applied. You should always avoid implicit conversions anyway. Always compare apples to apples and oranges to oranges. Another case where this comes up frequently is with dates. We try to query
-- find all records for today
select * from t where trunc(date_col) = trunc(sysdate);
and discover that the index on DATE_COL will not be used. We can either index the TRUNC(DATE_COL) or, perhaps more easily, query using range comparison operators. The following demonstrates the use of greater than and less than on a date. Once we realize that the condition
TRUNC(DATE_COL) = TRUNC(SYSDATE)
is the same as the condition
select *
from t
where date_col >=trunc(sysdate)
and date_col < trunc(sysdate+1)
this moves all of the functions to the right-hand side of the equation, allowing us to use the index on DATE_COL (and provides the same result as WHERE TRUNC(DATE_COL) = TRUNC(SYSDATE)).
If possible, you should always remove the functions from database columns when they are in the predicate. Not only will doing so allow for more indexes to be considered for use, but it will also reduce the amount of processing the database needs to do. In the preceding case, when we used
where date_col >=trunc(sysdate)
and date_col < trunc(sysdate+1)
the TRUNC values are computed once for the query, and then an index could be used to find just the qualifying values. When we used TRUNC(DATE_COL) = TRUNC(SYSDATE), the TRUNC(DATE_COL) had to be evaluated once per row for every row in the entire table (no indexes).
Case 5
The index, if used, would actually be slower. I see this often—people assume that, of course, an index will always make a query go faster. So, they set up a small table, analyze it, and find that the optimizer doesn’t use the index. The optimizer is doing exactly the right thing in this case. Oracle (under the CBO) will use an index only when it makes sense to do so. Consider this example:
EODA@ORA12CR1> create table t(x int);
Table created.
EODA@ORA12CR1> insert into t select rownum from dual connect by level < 1000000;
999999 rows created.
EODA@ORA12CR1> create index ti on t(x);
Index created.
EODA@ORA12CR1> exec dbms_stats.gather_table_stats(user,'T');
PL/SQL procedure successfully completed.
If we run a query that needs a relatively small percentage of the table, as follows
EODA@ORA12CR1> set autotrace on explain
EODA@ORA12CR1> select count(*) from t where x < 50;
COUNT(*)
----------
49
Execution Plan
...
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 3 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
|* 2 | INDEX RANGE SCAN| TI | 49 | 245 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
it will happily use the index; however, we’ll find that when the estimated number of rows to be retrieved via the index crosses a threshold (which varies depending on various optimizer settings, physical statistics, version, and so on), we’ll start to observe a full table scan:
EODA@ORA12CR1> select count(*) from t where x < 1000000;
COUNT(*)
----------
999999
Execution Plan
----------------------------------------------------------
...
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 620 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
|* 2 | TABLE ACCESS FULL| T | 999K | 4882K| 620 (1)| 00:00:01 |
---------------------------------------------------------------------------
This example shows the optimizer won’t always use an index and, in fact, it makes the right choice in skipping indexes. While tuning your queries, if you discover that an index isn’t used when you think it ought to be, don’t just force it to be used—test and prove first that the index is indeed faster (via elapsed and I/O counts) before overruling the CBO. Reason it out.
Case 6
There aren’t fresh statistics for tables. The tables used to be small, but now when we look at them, they have grown quite large. An index will now make sense, whereas it didn’t originally. If we generate statistics for the table, it will use the index.
Without correct statistics, the CBO cannot make the correct decisions.
Index Case Summary
In my experience, these six cases are the main reasons I find that indexes are not being used. It usually boils down to a case of “They cannot be used—using them would return incorrect results,” or “They should not be used—if they were used, performance would be terrible.”
Myth: Space Is Never Reused in an Index
This is a myth that I would like to dispel once and for all: space is reused in an index. The myth goes like this: you have a table, T, in which there is a column, X. At some point, you put the value X=5 in the table. Later you delete it. The myth is that the space used by X=5 will not be reused unless you put X=5 back into the index later. The myth states that once an index slot is used, it will be there forever and can be reused only by the same value. A corollary to this is the myth that free space is never returned to the index structure, and a block will never be reused. Again, this is simply not true.
The first part of the myth is trivial to disprove. All we need to do is to create a table like this:
EODA@ORA12CR1> create table t ( x int, constraint t_pk primary key(x) );
Table created.
EODA@ORA12CR1> insert into t values (1);
1 row created.
EODA@ORA12CR1> insert into t values (2);
1 row created.
EODA@ORA12CR1> insert into t values (9999999999);
1 row created.
EODA@ORA12CR1> analyze index t_pk validate structure;
Index analyzed.
EODA@ORA12CR1> select lf_blks, br_blks, btree_space from index_stats;
LF_BLKS BR_BLKS BTREE_SPACE
---------- ---------- -----------
1 0 7996
So, according to the myth, if I delete from T where X=2, that space will never be reused unless I reinsert the number 2. Currently, this index is using one leaf block of space. If the index key entries are never reused upon deletion, and I keep inserting and deleting and never reuse a value, this index should grow like crazy. Let’s see:
EODA@ORA12CR1> begin
2 for i in 2 .. 999999
3 loop
4 delete from t where x = i;
5 commit;
6 insert into t values (i+1);
7 commit;
8 end loop;
9 end;
10 /
PL/SQL procedure successfully completed.
EODA@ORA12CR1> analyze index t_pk validate structure;
Index analyzed.
EODA@ORA12CR1> select lf_blks, br_blks, btree_space from index_stats;
LF_BLKS BR_BLKS BTREE_SPACE
---------- ---------- -----------
1 0 7996
This shows the space in the index was reused. As with most myths, however, there is a nugget of truth in there. The truth is that the space used by that initial number 2 would remain on that index block forever. The index will not coalesce itself. This means if I load a table with values 1 to 500,000 and then delete every other row (all of the even numbers), there will be 250,000 holes in the index on that column. Only if I reinsert data that will fit onto a block where there is a hole will the space be reused. Oracle will make no attempt to shrink or compact the index. This can be done via an ALTER INDEX REBUILD or COALESCE command. On the other hand, if I load a table with values 1 to 500,000 and then delete from the table every row where the value was 250,000 or less, I would find the blocks that were cleaned out of the index were put back onto theFREELIST for the index. This space can be totally reused.
If you recall, this was the second myth: index space is never reclaimed. It states that once an index block is used, it will be stuck in that place in the index structure forever and will only be reused if you insert data that would go into that place in the index anyway. We can show that this is false as well. First, we need to build a table with about 500,000 rows in it. For that, we’ll use the big_table script found in the Setting Up Your Environment section in the front of this book. After we have that table with its corresponding primary key index, we’ll measure how many leaf blocks are in the index and how many blocks are on the FREELIST for the index. Also, with an index, a block will only be on the FREELIST if the block is entirely empty, unlike a table. So any blocks we see on the FREELIST are completely empty and available for reuse:
EODA@ORA12CR1> select count(*) from big_table;
COUNT(*)
----------
500000
![]() Note In the following PL/SQL, the index reported on must be built in an MSSM tablespace, and not ASSM. If you attempt to run this against an index in an ASSM tablespace, you’ll receive an “ORA-10618: Operation not allowed on this segment” message.
Note In the following PL/SQL, the index reported on must be built in an MSSM tablespace, and not ASSM. If you attempt to run this against an index in an ASSM tablespace, you’ll receive an “ORA-10618: Operation not allowed on this segment” message.
EODA@ORA12CR1> declare
2 l_freelist_blocks number;
3 begin
4 dbms_space.free_blocks
5 ( segment_owner => user,
6 segment_name => 'BIG_TABLE_PK',
7 segment_type => 'INDEX',
8 freelist_group_id => 0,
9 free_blks => l_freelist_blocks );
10 dbms_output.put_line( 'blocks on freelist = ' || l_freelist_blocks );
11 end;
12 /
blocks on freelist = 0
PL/SQL procedure successfully completed.
EODA@ORA12CR1> select leaf_blocks from user_indexes where index_name = 'BIG_TABLE_PK';
LEAF_BLOCKS
-----------
1043
Before we perform this mass deletion, we have no blocks on the FREELIST and there are 1,043 blocks in the leafs of the index, holding data. Now, we’ll perform the delete and measure the space utilization again:
EODA@ORA12CR1> delete from big_table where id <= 250000;
250000 rows deleted.
EODA@ORA12CR1> commit;
Commit complete.
EODA@ORA12CR1> declare
2 l_freelist_blocks number;
3 begin
4 dbms_space.free_blocks
5 ( segment_owner => user,
6 segment_name => 'BIG_TABLE_PK',
7 segment_type => 'INDEX',
8 freelist_group_id => 0,
9 free_blks => l_freelist_blocks );
10 dbms_output.put_line( 'blocks on freelist = ' || l_freelist_blocks );
11 dbms_stats.gather_index_stats
12 ( user, 'BIG_TABLE_PK' );
13 end;
14 /
blocks on freelist = 520
PL/SQL procedure successfully completed.
EODA@ORA12CR1> select leaf_blocks from user_indexes where index_name = 'BIG_TABLE_PK';
LEAF_BLOCKS
-----------
523
As we can see, over half of the index is on the FREELIST now (520 blocks) and there are only 523 leaf blocks. If we add 523 and 520, we get the original 1043. This means the blocks are totally empty and ready to be reused (blocks on the FREELIST for an index must be empty, unlike blocks on the FREELIST for a heap organized table).
This demonstration highlights two points:
· Space is reused on index blocks as soon as a row comes along that can reuse it.
· When an index block is emptied, it can be taken out of the index structure and may be reused later. This is probably the genesis of this myth in the first place: blocks are not visible as having free space on them in an index structure as they are in a table. In a table, you can see blocks on the FREELIST, even if they have data on them. In an index, you will only see completely empty blocks on the FREELIST; blocks that have at least one index entry (and remaining free space) will not be as clearly visible.
Myth: Most Discriminating Elements Should Be First
This seems like common sense. If you are going to create an index on the columns C1 and C2 in a table T with 100,000 rows, and you find C1 has 100,000 distinct values and C2 has 25,000 distinct values, you would want to create the index on T(C1,C2). This means that C1 should be first, which is the commonsense approach. The fact is, when comparing vectors of data (consider C1, C2 to be a vector), it doesn’t matter which you put first. Consider the following example. We will create a table based on ALL_OBJECTS and an index on the OWNER, OBJECT_TYPE, andOBJECT_NAME columns (least discriminating to most discriminating) and also on OBJECT_NAME, OBJECT_TYPE, and OWNER:
EODA@ORA12CR1> create table t as select * from all_objects;
Table created.
EODA@ORA12CR1> create index t_idx_1 on t(owner,object_type,object_name);
Index created.
EODA@ORA12CR1> create index t_idx_2 on t(object_name,object_type,owner);
Index created.
EODA@ORA12CR1> select count(distinct owner), count(distinct object_type),
2 count(distinct object_name ), count(*)
3 from t;
COUNT(DISTINCTOWNER) COUNT(DISTINCTOBJECT_TYPE)
COUNT(DISTINCTOBJECT_NAME) COUNT(*)
-------------------- -------------------------- -------------------------- ----------
34 36 30813 50253
Now, to show that neither is more efficient space-wise, we’ll measure their space utilization:
EODA@ORA12CR1> analyze index t_idx_1 validate structure;
Index analyzed.
EODA@ORA12CR1> select btree_space, pct_used, opt_cmpr_count, opt_cmpr_pctsave
2 from index_stats;
BTREE_SPACE PCT_USED OPT_CMPR_COUNT OPT_CMPR_PCTSAVE
----------- --------- -------------- ----------------
2526832 89 2 28
EODA@ORA12CR1> analyze index t_idx_2 validate structure;
Index analyzed.
EODA@ORA12CR1> select btree_space, pct_used, opt_cmpr_count, opt_cmpr_pctsave
2 from index_stats;
BTREE_SPACE PCT_USED OPT_CMPR_COUNT OPT_CMPR_PCTSAVE
----------- --------- -------------- ----------------
2510776 90 0 0
They use nearly the exact same amount of space—there are no major differences there. However, the first index is a lot more compressible if we use index key compression, as evidenced by the OPT_CMPR_PCTSAVE value. There is an argument for arranging the columns in the index in order from the least discriminating to the most discriminating. Now let’s see how they perform, to determine if either index is generally more efficient than the other. To test this, we’ll use a PL/SQL block with hinted queries (so as to use one index or the other):
EODA@ORA12CR1> alter session set sql_trace=true;
Session altered.
EODA@ORA12CR1> declare
2 cnt int;
3 begin
4 for x in ( select /*+FULL(t)*/ owner, object_type, object_name from t )
5 loop
6 select /*+ INDEX( t t_idx_1 ) */ count(*) into cnt
7 from t
8 where object_name = x.object_name
9 and object_type = x.object_type
10 and owner = x.owner;
11
12 select /*+ INDEX( t t_idx_2 ) */ count(*) into cnt
13 from t
14 where object_name = x.object_name
15 and object_type = x.object_type
16 and owner = x.owner;
17 end loop;
18 end;
19 /
PL/SQL procedure successfully completed.
These queries read every single row in the table by means of the index. The TKPROF report shows us the following:
SELECT /*+ INDEX( t t_idx_1 ) */ COUNT(*) FROM T
WHERE OBJECT_NAME = :B3 AND OBJECT_TYPE = :B2 AND OWNER = :B1
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 50253 0.69 0.67 0 0 0 0
Fetch 50253 0.46 0.49 0 100850 0 50253
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 100507 1.15 1.16 0 100850 0 50253
...
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
1 1 1 SORT AGGREGATE (cr=2 pr=0 pw=0 time=16 us)
1 1 1 INDEX RANGE SCAN T_IDX_1 (cr=2 pr=0 pw=0 time=12...
********************************************************************************
SELECT /*+ INDEX( t t_idx_2 ) */ COUNT(*) FROM T
WHERE OBJECT_NAME = :B3 AND OBJECT_TYPE = :B2 AND OWNER = :B1
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 50253 0.68 0.66 0 0 0 0
Fetch 50253 0.48 0.48 0 100834 0 50253
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 100507 1.16 1.15 0 100834 0 50253
...
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
1 1 1 SORT AGGREGATE (cr=2 pr=0 pw=0 time=13 us)
1 1 1 INDEX RANGE SCAN T_IDX_2 (cr=2 pr=0...
They processed the same exact number of rows and very similar numbers of blocks (minor variations coming from accidental ordering of rows in the table and consequential optimizations made by Oracle), used equivalent amounts of CPU time, and ran in about the same elapsed time (run this same test again and the CPU and ELAPSED numbers will be a little different, but on average they will be the same). There are no inherent efficiencies to be gained by placing the indexed columns in order of how discriminating they are, and as stated previously, with index key compression there is an argument for putting the least selective first. If you run the preceding example with COMPRESS 2 on the indexes, you’ll find that the first index will perform about two-thirds the I/O of the second, given the nature of the query in this case.
However, the fact is that the decision to put column C1 before C2 must be driven by how the index is used. If you have many queries like the following, it makes more sense to place the index on T(C2,C1):
select * from t where c1 = :x and c2 = :y;
select * from t where c2 = :y;
This single index could be used by either of the queries. Additionally, using index key compression (which we looked at with regard to IOTs and will examine further later), we can build a smaller index if C2 is first. This is because each value of C2 repeats itself, on average, four times in the index. If C1 and C2 are both, on average, 10 bytes in length, the index entries for this index would nominally be 2,000,000 bytes (100,000 × 20). Using index key compression on (C2, C1), we could shrink this index to 1,250,000 (100,000 × 12.5), since three out of four repetitions ofC2 could be suppressed.
In Oracle 5 (yes, version 5), there was an argument for placing the most selective columns first in an index. It had to do with the way version 5 implemented index compression (not the same as index key compression). This feature was removed in version 6 with the addition of row-level locking. Since then, it is not true that putting the most discriminating entries first in the index will make the index smaller or more efficient. It seems like it will, but it will not. With index key compression, there is a compelling argument to go the other way since it can make the index smaller. However, it should be driven by how you use the index, as previously stated.
Summary
In this chapter, we covered the different types of indexes Oracle has to offer. We started with the basic B*Tree index and looked at various subtypes of this index, such as the reverse key index (designed for Oracle RAC) and descending indexes for retrieving data sorted in a mix of descending and ascending order. We spent some time looking at when you should use an index and why an index may not be useful in various circumstances.
We then looked at bitmap indexes, an excellent method for indexing low to medium cardinality data in a data warehouse (read-intensive, non-OLTP) environment. We covered the times it would be appropriate to use a bitmapped index and why you would never consider one for use in an OLTP environment—or any environment where multiple users must concurrently update the same column.
We moved on to cover function-based indexes, which are actually special cases of B*Tree and bitmapped indexes. A function-based index allows us to create an index on a function of a column (or columns), which means that we can precompute and store the results of complex calculations and user-written functions for blazingly fast index retrieval later. We looked at some important implementation details surrounding function-based indexes, such as the necessary system- and session-level settings that must be in place for them to be used. We followed that with examples of function-based indexes usinWg both built-in Oracle functions and user-written ones. Lastly, we looked at a few caveats with regard to function-based indexes.
We then examined a very specialized index type called the application domain index. Rather than go into how to build one of those from scratch (which involves a long, complex sequence of events), we looked at an example that had already been implemented: the text index.
We then discussed a couple of 12c topics: indexing extended columns and multiple indexes on the same column combinations. With indexing extended columns this requires either using a virtual column and associated index or a function-based index. When indexing the same column combinations you must use different physical index types and only one index can be designated as visible.
We closed with some of the most frequently asked questions on indexes as well as some myths about indexes. This section covered topics ranging from the simple question “Do indexes work with views?” to the more complex and subtle myth “Space is never reused in an index.” We answered these questions and debunked the myths mostly through example, demonstrating the concepts as we went along.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.