Scaling PHP Applications (2014)
Worker Server: Asynchronous Resque Workers
The overall goal of every website is to render the site as quickly as possible for the end-user. It’s been proven time and time again, that faster website equals happier users, more revenue, and more pageviews. The fact is- speed is an important factor and having a faster application will factor into your bottom line.
Amazon has talked about how a 100ms speed difference improved their revenue by 1%. No big deal right? In 2011, Amazon had $50 billion in revenue, so speeding up their site by 100ms improved their bottom line by $50 million.
That’s great. And so far, we’ve talked about strategies to improve speed through optimization- increasing database performance, caching slow queries, and moving to more scalable pieces of software. But what about when there’s a fixed cost, a piece of code that no matter how much you optimize, will always take seconds to run? Maybe a computational or database heavy query that’s as optimized as it’s going to get. Or a 3rd party API call to Twitter or Facebook. How can this type of workload scale without causing slow pages?
The answer is to do the work in the background, of course! When I say “in the background”, I mean in a separate process, outside of the web request. The work gets deferred for later so that the web request can render the page for the user as quickly as possible.
Why use Queues?
There’re a bunch of subpar ways to push work into the background. I know what you might be thinking- why would I want to run an entirely separate piece of software to manage my queue when I could just use this find MySQL database server that I have? Create a new table, store the jobs in it, delete them when done?
No! No! Wrong! Don’t do it!
Repeat after me. The database is not a queue. The database is not a queue. Why? Learn from my mistakes, because I started out using MySQL as a queue and it was terrible.
Pretend we created a MySQL table called jobs to handle our queuing system. If we were inserting jobs to post Facebook statuses in the background for our users, it might look like this:
|
id |
user_id |
text |
job_state |
|
1 |
1 |
Post this FB Status in the Background |
finished |
|
2 |
8 |
Some status here! |
running |
|
3 |
3 |
Scaling PHP Book is Awesome! |
running |
|
2 |
8 |
Steve needs better examples! |
pending |
In our web request, when we wanted to post a new Facebook status using the Facebook API, we’d INSERT a new row into the jobs table with the text for the status, user_id of the user, and mark the job_state as pending. So far so good.
Next, we’d have a worker process. It’d be a cronjob, running in the background. It’d search for pending jobs in MySQL to run so it could post the statuses to Facebook. We can imagine it’d look something like this:
1 <?php
2
3 $m = new mysqli("localhost", "user", "pw");
4
5 // Loop until we're out of jobs to run
6 while(1) {
7
8 // Find a job with the state set as pending
9 $job = $m->query("SELECT * FROM jobs WHERE job_state='pending' LIMIT 1");
10
11 // Quit the loop if we didn't find a job
12 if ($job->num_rows != 1) break;
13
14 // Update the job state to running so that no one else can nab it
15 $m->query("UPDATE jobs SET job_state='running' WHERE id = {$job['id']}");
16
17 // Post the status to Facebook
18 post_to_facebook($job['user_id'], $job['text']);
19
20 // Mark the job as finished.
21 $m->query("UPDATE jobs SET job_state='finished' WHERE id = {$job['id']}");
22
23 }
So far so good, right!? Wrong. This solution is broken because it can’t scale past more than worker. Why? We have a major race condition between finding the job and changing the status from pending to running. When a worker runs the query SELECT * FROM jobs WHERE job_state='pending' LIMIT 1, it’s possible that another worker can also get the same job in the milliseconds before the following UPDATE query changes job_state to running. With this race condition and more than concurrent worker, Facebooks statuses would get double posted! Catastrophe.
You can solve the race condition by using Locks, but it’s messy, slow, and just isn’t a very good solution. Use the right tool for the right job.
Getting started with Resque and php-resque
Resque is a queueing library open-sourced by GitHub that uses Redis Lists are primitives to create a reliable, fast, and persistent queueing system. Originally written in Ruby, Resque has been ported to PHP and is hands down the best way to do queueing in PHP.
Best of all? Since Resque is just a library, we don’t have to deal with another software service to setup. It just piggybacks off of our Redis installation, with no other software to install! Woohoo.
Of course, there’s a beautiful Resque UI that gives you really nice interface into your system so you can see what’s going on, monitor failure, and retry failed jobs. I recommend using the UI, but it’s not a requirement.
Installing Resque and php-resque
If you don’t want the Web UI, there is nothing to install. All you need to do is hook the php-resque library up to your code. It’s on GitHub, so you can pull it into your application anyway that you’d like, but I highly recommend that you use Composer.
Add php-resque to your composer.json file
1 {
2 "require": {
3 "chrisboulton/php-resque": ">=1.2"
4 }
5 }
And install the package
1 > php composer.phar install
Optionally, you can install the PECL proctitle extension, which will give you more informative output when you check your Resque process status from the command line.
Process 9597 is processing the twitter_replies queue
1 > pecl install -f proctitle
2 > vi /etc/php5/conf.d/proctitle.ini
3 extension=proctitle.so
If you want the option Web UI, you need to install the Resque RubyGem.
1 > apt-get install rubygems
2 > gem install resque
Setting up the Workers
With the setup so far, you can queue up background jobs but you don’t have anyway to run them. Later in the chapter, we’ll talk about the specifics of creating a new job, but we still need a process that runs in the background to handle running the jobs as they come in. Long term, I recommend using god or monit to handle monitoring the background jobs, but we can start the process manually from the command line. (In fact, the php-resque project includes a base monit configuration to get you started).
1 > VERBOSE QUEUE=* COUNT=2 APP_INCLUDE="../index.php" php resque.php
Run this way, this command would run a maximum of 2 workers, check all queues, and include your applications init/autoloader from ../index.php. The different values are discussed below.
COUNT
The COUNT value is used to set the maximum number of worker’s that will be run concurrently. Depending on the nature of your jobs (are they CPU bound? I/O bound?) you should set this atleast as high as the number of CPU cores on your machine. If your work is database or I/O bound, you can usually set it much higher. ##### QUEUES With the QUEUES variable, we can set the queues that we want this process to work on. Why would we do that? It gives you more control over the queues, allowing you dedicate more resources to certain queues and set priorities. Each queue is checked in alphabetical order, so a queue whose name begins with a will be checked before a queue that begins with z. By manually specifying the queue names, you can have specific queues checked first. If you set the value to *, it will process all of the queues.
Example value:
QUEUES=high,medium,low,post:facebook
APP_INCLUDE
Lastly, (and most importantly), you need to tell php-resque how it can autoload your code. Out of the box, it has no idea where to find your code that needs to be run, so you need to point it to a file that does your autoloading and initialization. With most frameworks, this can be yourindex.php file.
Resque Web-UI
Resque comes with a lightweight Web-UI that runs using a tiny Sinatra server. You can start it up by just running resque-web and it’ll start running in the background on port 5678. resque-web expects Redis to be running on localhost, port 6379, if you need to point it to a different Redis server, you can pass it in using a CLI argument like so: resque-web -r 192.150.0.10:6379.
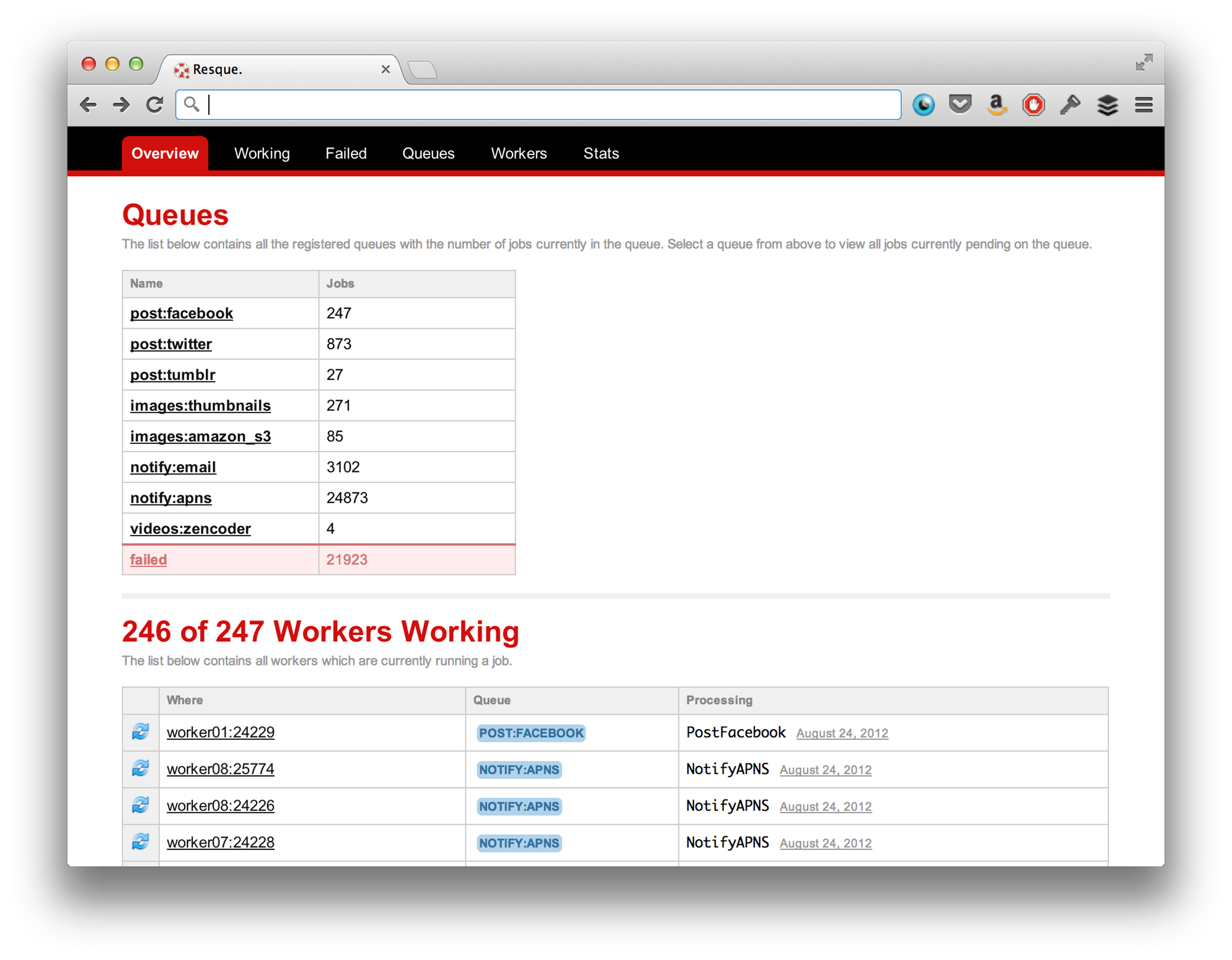
An example of the Resque UI
One area where Resque really shines is the way that it handles failure. Namely, it was built with failure on mind- Jobs will fail, and it’s important to have a complete visibility into the system. One way that it gives you this visibility is by tracking failed jobs and giving you the relevant information- what the job was, why it failed, and the ability to retry the job manually.

An example failed Resque Job
The Resque Process Model
Resque has an interesting process model behind it that it uses to handle memory leaks and failure, so it can run reliably for long-periods of time. When you start Resque, a parent (or master) process is created. The parent process polls Redis for new jobs that have been added to the queue from the client. When a new job is found, the parent process forks a new child process and the child process runs your code to handle the job. After the job finishes, the child process exits.
Why this model?
Forking child processes to run each job makes sense from a concurrency standpoint- since PHP doesn’t have threads, it’s the best way to handle multiple jobs concurrently.
On top of that, this model also handles failure very well. Since each running job is isolated into its own process, if it crashes, throws an exception, or leaks memory, it won’t impact other jobs or the parent process. This is important, since PHP isn’t really designed for long-running processes and could very well start leaking memory. Since the child process is thrown away at the end of the job, any leaked memory can be reclaimed at the end of the job.
The downside to this model is that there is a fixed overhead for running each new job that comes in. Forking a child process is an expensive system call and puts a hard limit on the amount of new jobs/second that can be run concurrently, and can be a significant problem if you have many small, short-lived jobs. The Ruby world has overcome this with Sidekiq, a fork of Resque that uses threads for running jobs instead of the Parent/Child model. Unfortunately, PHP doesn’t support threads, but I think that we’ll eventually see a hybrid approach where child processes are used for multiple jobs and recycled after a certain amount of time- effectively giving you the best of both worlds.
My Patches
Originally, when php-resque first came out I was using my own fork of it in production. One design decision that php-resque made was bundling a Redis Library with the software. Unfortunately, the library that they bundled, Redisent did not use namespaces or take into consideration naming conventions of other Redis Libraries (namely, phpredis). Because of this, Redisent would clash with phpredis, both libraries trying to define a RedisException class, causing PHP to fail out with an error.
Originally, I changed the php-resque library to use C phpredis extension, and eventually moving over to the C extension seems to be one of the long-term goals of the project. Right now, they still bundle Redisent, but luckily have merged a patch that only defines RedisException if it doesn’t exist yet- atleast allowing the two libraries to play nice with each other.
The new code that they merged looks like this- it’s amazing how many headaches it solves.
1 <?php
2
3 if (! class_exists("Redis")) {
4 class RedisException extends Exception { }
5 }
My original patched version of php-resque is on GitHub as stevecorona/php-resque. I wouldn’t recommend using it unless you really need the performance of the C Redis Library.
Writing a Resque Job
Let’s step through the process of writing a Resque job. Pretend we have an application, it posts a status to Twitter. The naive, non-Resque version might look something like this:
1 <?php
2 class Comments_Controller extends Controller {
3 public function create() {
4 $user = $this->session->user;
5
6 $twitter = new Services_Twitter($user->username, $user->password);
7 $twitter->statuses->update($_GET['comment']);
8
9 return new View("Your comment has been posted to Twitter");
10
11 }
12 }
This code works great, but it suffers from some problems. First off, it’s slow because an API request to Twitter takes atleast 1 second. It’s also failure-prone- if Twitter is down or has momentary errors, the status won’t get posted. On top of that, it’s an easy DoS endpoint that can be used against your site. If I wanted to crash your app, I could just point my bots at this endpoint and eat up all of your PHP-FPM workers, because the API call blocks for so long. This actually happened to Twitpic, before- there’s a case study included on the topic.
Anyways, let’s refactor it into a Resque job and fix all of these issues.
Enqueing the Job
First let’s handle the frontend code, we need to refactor the code inside of the create action. Instead of posting to Twitter directly from the web request, we want to instead setup a job that can be run later.
1 <?php
2 class Comments_Controller extends Controller {
3 public function create() {
4
5 $args = array("user" => $this->session->user->id,
6 "comment" => $_GET['comment']);
7
8 Resque::enqueue("post:twitter", "PostTwitter", $args);
9 return new View("Your comment has been posted to Twitter");
10 }
11 }
That was easy. Resque::enqueue does all of the heavy lifting for us. It takes three arguments, by the way- post:twitter is the name of the queue that we want the job to go into, PostTwitter is the name of the class that we need to define with the code to run the job, and $args is an array of data that will get serialized and passed into the PostTwitter class.
The immediate benefit to switching to this code is that it will run fast. The time it takes to enqueue the data in Redis/Resque is orders of magnitude less than the amount of time it takes to make an API call.
|
|
A note about $args Keep in mind that anything inside of $args will be serialized inside of Redis when you create the job. It’s much better to pass in simple values here instead of full-blown objects. Notice how we pass in $this->session->user->id instead of the entire user object. Using the id, we can rebuild the user object from the database inside of PostTwitter. |

Running the Job
Now that we have the queuing portion of our code refactored, we need to write a new class called PostTwitter that php-resque will instantiate when our job is processed. php-resque expects job classes to implement the perform() method, which is where we put the posting to Twitter code.
Note: The $args array passed in from the frontend will be available in the PostTwitter class as $this->args.
1 <?php
2 class PostTwitter {
3 public function perform() {
4
5 $user = User::find($this->args['user']);
6 $comment = $this->args['comment'];
7
8 $twitter = new Services_Twitter($user->username, $user->password);
9 $twitter->statuses->update($comment);
10
11 }
12 }
13 }
Let’s talk about the advantages for a second.
1. The application will always offer constant, fast performance because it’s never waiting on a third-party service.
2. The easy DoS endpoint is gone
3. If Twitter doesn’t respond or times out, the Services_Twitter will throw a Services_Twitter_Exception, causing the job to fail gracefully (which can later be retried).
Handling Failure
Appropriately handling failure in Resque is important. If an uncaught exception is thrown from your job, php-resque will assume that the job has failed and remove it from the queue. As we saw above, the nice thing is that the failed jobs are shown in the Resque Web UI with plenty of information to help you diagnose the failure and retry the job. This is very helpful when you have jobs that fail rarely and only in the case of a bug or edge-case.
However, sometimes we have jobs that predictably fail and should be retried automatically. For example, in the case of the PostTwitter class, if Twitter times out or happens to be momentarily unreachable, we don’t want to fail the job immediately. We can accomplish automatic retries by adding a little bit more code.
1 <?php
2 class PostTwitter {
3
4 const MAX_ATTEMPTS = 5;
5
6 public function setUp() {
7 Resque_Event::listen("onFailure", function($ex, $job) {
8
9 // Check to see if we have an attempts variable in
10 // the $args array. Attempts is used to track the
11 // amount of times we tried (and failed) at this job.
12 if (! isset($job->payload['args']['attempts'])) {
13 $job->payload['args']['attempts'] = 0;
14 }
15
16 // Increase the number of attempts
17 $job->payload['args']['attempts']++;
18
19 // If we haven't hit MAX_ATTEMPTS yet, recreate the job to be
20 // run again by another worker.
21 if (self::MAX_ATTEMPTS >= $job->payload['args']['attempts']) {
22 $job->recreate();
23 }
24
25 });
26 }
27
28
29 public function perform() {
30
31 $user = User::find($this->args['user']);
32 $comment = $this->args['comment'];
33
34 $twitter = new Services_Twitter($user->username, $user->password);
35 $twitter->statuses->update($comment);
36
37 }
38 }
39 }
You can see above that we didn’t modify our perform method at all. Instead, we added a setUp method, which gets called during the job creation process, and used the Resque_Event callback system to add in a hook that only gets run after a job fails. So, when our Twitter Library throws aServices_Twitter_Exception, the job will fail and call the anonymous function that we added to onFailure. Our onFailure callback checks for the existence of an attempts variable and recreates the job as long as it hasn’t hit MAX_ATTEMPTS. The reason we limit then number of attempts is to prevent runaway jobs and limit the amount of failure that can happen.
In practice, using a setup like this gives a good balance between manually handling job failure and dealing with it automatically. Some errors can simply be fixed by trying the job again, especially if they are dependent on an external API.
Scheduling Jobs
In the classic Resque setup, jobs are run FIFO (first-in, first-out) order, with no specific timing. This usually works well if you want your jobs to be run immediately, but doesn’t fit all use cases if you want jobs to have a cool down period or be run around a specific time instead of immediately.
You can hack something together with cron, but instead of doing that I recommend checking out the php-resque-scheduler plugin. It gives you the ability to create jobs for future times instead of right now.
Post to Twitter in 1 hour
1 ResqueScheduler::enqueueIn(3600, 'post:twitter', 'PostTwitter', $args);
Post to Twitter at a specific time (4PM on 11/19)
1 $date = new DateTime('2012-11-09 16:00:00');
2 ResqueScheduler::enqueueIn($date, 'post:twitter', 'PostTwitter', $args);
Alternatives to Resque
There’s a never ending list of alternatives for queueing solutions. For 99.9% of cases, Resque is simply going to be the best choice.
1. It’s built on Redis, so it’s fast, reliable, and has constant performance.
2. With Redis RDB and AOF, queues are persistent to disk- you won’t lose anything in a crash.
3. The library is well-tested and heavily used, so you don’t have to worry about bugs.
4. There is a high amount of visibility into the system.
5. It’s unlikely that you’d need to scale your Redis server, but if you had to you can take advantage of the normal scaling methods- sharding and master/slave replication.
6. Overall, it’s simple. The complexity of the entire system is low.
Kestrel
Kestrel is a queuing system written by Twitter in Scala. Being in Scala, it runs on the JVM and is pretty fast. In fact, it was our first choice at Twitpic because it came out way before Resque was even around.
Pros
· Runs on the JVM, so it’s reliable and fast.
· Uses Memcached API, so you use Memcached client to interact with it
· Fan-out queues. The idea is that you insert a job into one queue and it automatically distributes it to many other queues. Great if you are putting the same job into different queues.
Cons
· Memory hog, JVM GC pauses cause inconstant response time
· Library is lower-level than Resque, have to roll-your-own functionality
· Infrequent updates by Twitter team
Gearman
Gearman is a PHP extension and daemon for queuing, and thus it has very tight PHP integration. It’s used by both Flickr and Digg.
There really aren’t any advantages to using Gearman over Resque. It uses its own proprietary server, so I ask- why add more layers to your stack when you can reuse existing pieces since you’re likely to be using Redis for caching or sessions anyways?
Beanstalkd
Beanstalkd, is another queuing server written in C. It has a handful of PHP clients. Similar to Resque but with a more complex API, including better priority control, pausing jobs, and job scheduling.
If you need these features, it’s worth checking out but there’s less documentation available than with Resque.
RabbitMQ
RabbitMQ is one of the faster (if not THE fastest) messaging queue available. It’s written in Erlang and I’ve even heard of people that are pushing streaming video through it. Crazy. It can push 100k messages per second, per CPU core.
It’s also probably the most robust messaging queue out there, too. It includes every feature under the sun. The downside is that it’s complex. Setting it up, configuring it, and integrating into your code is a big undertaking. There are books on RabbitMQ. That should tell you something.
If you need to process 100,000s of background jobs per second than use RabbitMQ. Otherwise- don’t. Most sites- even big ones like Twitter and Twitpic are able to run on Kestrel and Resque. Choose the simpler solution here.
Have a weird use case? Sure, use RabbitMQ if it seems like it fits but just expect to dump some engineering and learning time into it. Meanwhile, you can have Resque up and running in 5 minutes.
Things you should put in a queue
Here are some common things that you should put into your queue.
· Storing user uploads on S3? Do that in a queue.
· Resizing images
· ANY 3rd Party API Call- Twitter, Facebook, Tumblr. Always.
· PDF Generation
· Sending emails- SMTP servers can timeout.
· Heavy database inserts (Twitter-like social networks pre-calculate timelines. That means, if you have 500 followers, when you post a new tweet Twitter does 500 database inserts.)
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.