Introducing Microsoft SQL Server 2014: Technical Overview, 1st Edition (2014)
PART I. Database administration
CHAPTER 2. In-Memory OLTP investments
In the previous two releases of SQL Server, Microsoft built into the product a number of in-memory capabilities to increase speed and throughput and to accelerate analytics. The first of these capabilities was an in-memory analytics add-in for Excel, also known as PowerPivot, in SQL Server 2008 R2. SQL Server 2012 included in-memory Analysis Services and in-memory columnstore. SQL Server 2014 comes with a new capability, known as In-Memory OLTP, designed to accelerate OLTP workloads. This feature, along with the other in-memory capabilities, provides organizations with a holistic approach to drive real-time business with real-time insights. This chapter focuses on the new capabilities associated with In-Memory OLTP.
In-Memory OLTP overview
Microsoft first announced work on the In-Memory OLTP feature during the 2012 PASS Summit in Seattle. For the worldwide database community, which has most likely known of this feature by its project name, Hekaton, the wait has now come to an end. Microsoft SQL Server 2014 includes this impressive new database engine feature that allows organizations to achieve significant performance gains for OLTP workloads while also reducing processing times. In many cases, when In-Memory OLTP is combined with new lock-free and latch-free algorithms that are optimized for accessing memory-resident data enhancements and natively compiled stored procedures, performance improved by up to 30 times.
To give database administrators the opportunity to appreciate this new feature, this chapter not only teaches and enlightens its readers, it also aims to dispel some flawed beliefs about In-Memory OLTP. This chapter addresses a series of questions, including the following:
![]() What are In-Memory OLTP and memory-optimized tables?
What are In-Memory OLTP and memory-optimized tables?
![]() How does In-Memory OLTP work?
How does In-Memory OLTP work?
![]() Are there real-world cases that demonstrate In-Memory OLTP performance gains?
Are there real-world cases that demonstrate In-Memory OLTP performance gains?
![]() Can existing database applications be migrated to In-Memory OLTP?
Can existing database applications be migrated to In-Memory OLTP?
Let’s look under the hood to see how organizations can benefit from In-Memory OLTP.
The proliferation of data being captured across devices, applications, and services today has led organizations to work continuously on ways to lower the latency of applications while aiming to achieve maximum throughput of performance-critical data at a lower cost. Consider a financial organization that offers credit-card services to its customers. This organization must ensure that it can validate, authorize, and complete millions of transactions per second, or face the fact that it will lose financial opportunities for both itself and the vendors who use its service. Online gaming is another industry that requires maximum throughput, needing to service millions of customers who want to gamble online. Gone are the days when people made static bets on the outcome of a game. Today, people place bets in real time based on events transpiring in real time. Take, for example, a football game for which your bet depends on whether you believe the kicker will kick the winning field goal in the Super Bowl. In situations like this, the database platform must be well equipped to process millions of transactions concurrently at low latency, or the online gaming organization faces the possibility that it could experience financial ruin.
The SQL Server product group recognized that customer requirements were quickly changing in the data world and that the group needed to provide new capabilities to decrease processing times and deliver higher throughput at lower latency. Fortunately, the world was also experiencing a steady trend in the hardware industry that allowed the product group to generate these new capabilities. First, the product group realized that the cost of memory had vastly decreased over the past 20 to 25 years, while the size of memory continued to increase. Moreover, the cost of memory had reached a price point and a capacity point at which it was now viable to have large amounts of data in memory. This trend is illustrated in Figure 2-1.
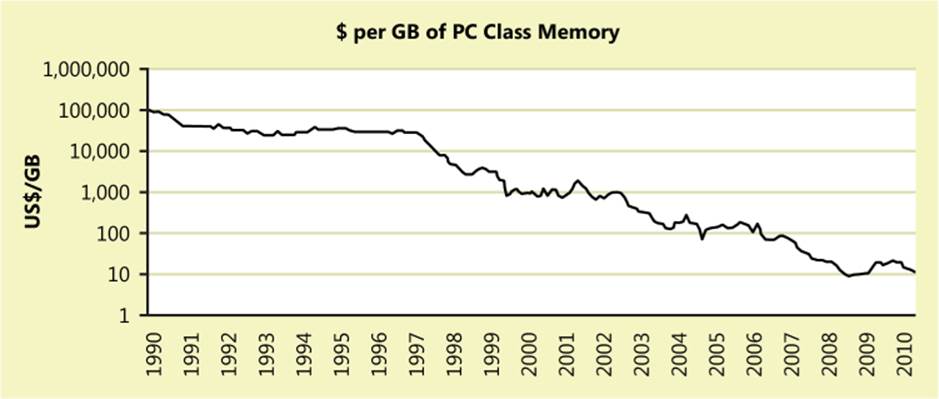
FIGURE 2-1 The price of RAM has drastically decreased over the past 20 years.
Second, the group recognized both that CPU clock rates had plateaued and that CPU clock rates were not getting any faster even after the number of cores on a processor had drastically increased, as shown in Figure 2-2. Armed with knowledge from these trends, the SQL Server team reevaluated the way SQL Server processes data from disk and designed the new In-Memory OLTP engine, which can take full advantage of the larger memory sizes that are available and use processors with more cores to significantly improve performance of OLTP applications.
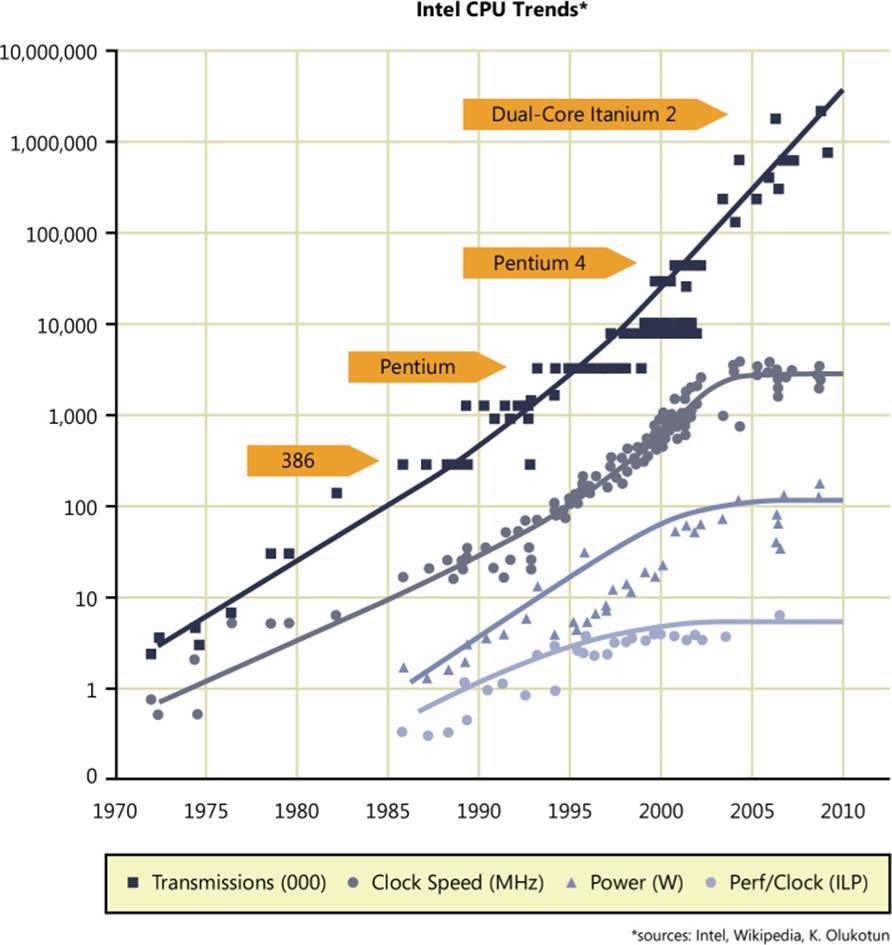
FIGURE 2-2 Stagnating growth in CPU clock speeds while the number of cores increase.
On average, most OLTP databases are 1 terabyte or less. As such, the majority of today’s production OLTP databases can reap the performance benefits of In-Memory OLTP because the whole database can fit into memory. Just imagine the possibilities should the current hardware trend continue. Perhaps in the next decade, servers will support petabytes of memory, making it possible to move the largest databases and workloads to memory. It will be interesting to see what the future holds.
In-Memory OLTP fundamentals and architecture
The next few sections discuss In-Memory OLTP fundamentals, architecture, concepts, terminology, hardware and software requirements, and some myths about how it is implemented in SQL Server 2014.
Four In-Memory OLTP architecture pillars
Before thinking about how to use In-Memory OLTP, it is important to understand the underlying architecture. In-Memory OLTP is built on four pillars. The pillars were developed in the context of industry hardware and business trends to offer customer benefits. Figure 2-3 summarizes the four pillars and associated customer benefits.
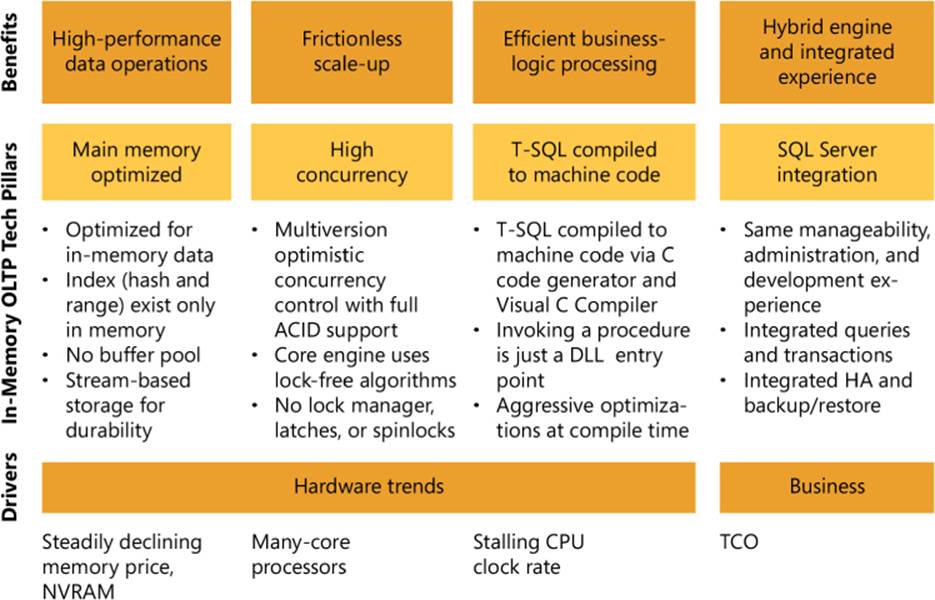
FIGURE 2-3 Pillars of In-Memory OLTP architecture.
Main memory optimized
As a result of the steady decline in the price of memory and the rapid rate at which the size of memory was growing, putting tables in main memory became feasible, thereby replacing the need to place and access tables on disk. With this change came a significant reduction in the time required to gain access to tables, because pages were no longer required to be read into cache from disk. New functionality, such as hash indexes and nonclustered range indexes, can exploit data that is in physical memory rather than on disk, which allows for faster access and higher performance in data operations.
T-SQL compiled to machine code
The SQL Server product group recognized that if it could reduce the number of instructions needed to execute the same logic, it could do the same work and also decrease processing time. The product group implemented this idea by transforming SQL stored procedures to a C program and then compiling the program into a DLL by using the Visual C compiler. The resulting machine code replaced stored procedures and the usual interpretation of logic through query execution. This made it possible to run a stored procedure by using fewer instructions, leading to more efficient business-logic processing that was significantly faster. With the optimization in processing time, internal testing at the lower level of the storage engine verified that machine code could reduce the instruction count by 30 to 50 times, which resulted in a proportional increase in throughput and in lower latency.
High concurrency
SQL Server has scaled extremely well because of the performance and scalability improvements made over the past releases. Unfortunately, certain application patterns—for example, a last page insert in the clustering key order or concurrent updates of hot pages—still suffered latch contention and did not scale as well as a result. The additional improvements implemented through In-Memory OLTP in SQL Server 2014 allow for higher concurrency. First, the product group did away with page structures for accessing memory-optimized tables. This means that no paging or latching occurs to create bottlenecks. Second, the core engine uses lock-free algorithm structures that are based on multiversion optimistic concurrency control with full ACID (atomic, consistent, isolated, and durable) support. These improvements remove common scalability bottlenecks and provide high concurrency and frictionless scale-up opportunities to increase overall performance when memory–optimized tables are used.
SQL Server integration
The SQL Server product group decided that In-Memory OLTP should be easy to consume and that performance-critical tables should take advantage of this feature. What evolved from this idea is an In-Memory OLTP engine that is fully integrated into the SQL Server Database Engine and managed with a familiar set of tools. People who are familiar with SQL Server can quickly make use of the benefits of In-Memory OLTP because the management, administration, and development experiences are the same. Moreover, In-Memory OLTP works seamlessly with other features, such as AlwaysOn Availability Groups, AlwaysOn Failover Cluster Instances, replication, backups, and restores.
In-Memory OLTP concepts and terminology
The following section reviews In-Memory OLTP concepts and terminology:
![]() Disk-based tables This is the traditional way SQL Server has stored data since the product’s inception. Data in a table is stored in 8-KB pages and read and written to disk. Each table also had its own data and index pages.
Disk-based tables This is the traditional way SQL Server has stored data since the product’s inception. Data in a table is stored in 8-KB pages and read and written to disk. Each table also had its own data and index pages.
![]() Memory-optimized tables Memory–optimized tables are the alternative to traditional disk-based tables and follow the new structures associated with In-Memory OLTP. The primary store for memory-optimized tables is main memory, but a second copy in a different format is maintained on disk for durability purposes.
Memory-optimized tables Memory–optimized tables are the alternative to traditional disk-based tables and follow the new structures associated with In-Memory OLTP. The primary store for memory-optimized tables is main memory, but a second copy in a different format is maintained on disk for durability purposes.
![]() Native compilation To achieve faster data access and efficient query execution, SQL Server natively compiles stored procedures that access memory-optimized tables into native DLLs. When stored procedures are natively compiled, the need for additional compilation and interpretation is reduced. Also, compilation provides additional performance enhancements, as compared with using memory-optimized tables alone.
Native compilation To achieve faster data access and efficient query execution, SQL Server natively compiles stored procedures that access memory-optimized tables into native DLLs. When stored procedures are natively compiled, the need for additional compilation and interpretation is reduced. Also, compilation provides additional performance enhancements, as compared with using memory-optimized tables alone.
![]() Interop In this process, interpreted Transact-SQL batches and stored procedures are used instead of a natively compiled stored procedure when accessing data in a memory-optimized table. Interop is used to simplify application migration.
Interop In this process, interpreted Transact-SQL batches and stored procedures are used instead of a natively compiled stored procedure when accessing data in a memory-optimized table. Interop is used to simplify application migration.
![]() Cross-container transactions This is a hybrid approach in which transactions use both memory-optimized tables and disk-based tables.
Cross-container transactions This is a hybrid approach in which transactions use both memory-optimized tables and disk-based tables.
![]() Durable and nondurable tables By default, memory–optimized tables are completely durable and offer full ACID support. Note that memory-optimized tables that are not durable are still supported by SQL Server, but the contents of a table exist only in memory and are lost when the server restarts. The syntax DURABILITY=SCHEMA_ONLY is used to create nondurable tables.
Durable and nondurable tables By default, memory–optimized tables are completely durable and offer full ACID support. Note that memory-optimized tables that are not durable are still supported by SQL Server, but the contents of a table exist only in memory and are lost when the server restarts. The syntax DURABILITY=SCHEMA_ONLY is used to create nondurable tables.
Hardware and software requirements for memory-optimized tables
A unified experience for organizations has been created in every area—including but not limited to deployment and support—through the tight integration of In-Memory OLTP with SQL Server 2014. However, before you try this new capability, you should become acquainted with the requirements for using memory-optimized tables. In addition to the general hardware and software requirements for installing SQL Server 2014 (described in Chapter 1, “SQL Server 2014 editions and engine enhancements”), here are the requirements for using memory-optimized tables:
![]() Production environments require the 64-bit Enterprise edition of SQL Server 2014 with the Database Engine Services component. The Developer edition can also be used when developing and testing. The 32-bit environments are not supported.
Production environments require the 64-bit Enterprise edition of SQL Server 2014 with the Database Engine Services component. The Developer edition can also be used when developing and testing. The 32-bit environments are not supported.
![]() To store data in tables and also in indexes, SQL Server requires sufficient memory. You must configure memory to accommodate memory-optimized tables and to have indexes be fully resident in memory.
To store data in tables and also in indexes, SQL Server requires sufficient memory. You must configure memory to accommodate memory-optimized tables and to have indexes be fully resident in memory.
![]() When configuring memory for SQL Server, you should account for the size of the buffer pool needed for the disk-based tables and for other internal structures.
When configuring memory for SQL Server, you should account for the size of the buffer pool needed for the disk-based tables and for other internal structures.
![]() The processor used for the instance of SQL Server must support the cmpxchg16b instruction.
The processor used for the instance of SQL Server must support the cmpxchg16b instruction.
In-Memory OLTP use cases
Many use cases show the benefits of In-Memory OLTP. Consider these scenarios:
![]() An application that is incurring high latch contention can alleviate this contention and scale up by converting tables from disk-based tables to memory-optimized tables.
An application that is incurring high latch contention can alleviate this contention and scale up by converting tables from disk-based tables to memory-optimized tables.
![]() Natively compiled stored procedures can be used to address low-latency scenarios because In-Memory OLTP reduces the response times associated with poor performing procedures (assuming that business logic can be compiled).
Natively compiled stored procedures can be used to address low-latency scenarios because In-Memory OLTP reduces the response times associated with poor performing procedures (assuming that business logic can be compiled).
![]() Many scale-out operations that require only read access suffer from CPU performance bottlenecks. By moving the data to In-Memory OLTP, it is possible to significantly reduce CPU. With higher scalability, this allows you to take advantage of existing processing resources to achieve higher throughput.
Many scale-out operations that require only read access suffer from CPU performance bottlenecks. By moving the data to In-Memory OLTP, it is possible to significantly reduce CPU. With higher scalability, this allows you to take advantage of existing processing resources to achieve higher throughput.
![]() Think about the data-staging and load phases of a typical ETL process. At times, numerous operations need to be completed, including gathering data from an outside source and uploading it to a staging table in SQL Server, making changes to the data, and then transferring the data to a target table. For these types of operations, nondurable memory-optimized tables provide an efficient way to store staging data by completely eliminating storage cost, including transactional logging.
Think about the data-staging and load phases of a typical ETL process. At times, numerous operations need to be completed, including gathering data from an outside source and uploading it to a staging table in SQL Server, making changes to the data, and then transferring the data to a target table. For these types of operations, nondurable memory-optimized tables provide an efficient way to store staging data by completely eliminating storage cost, including transactional logging.
Myths about In-Memory OLTP
Before moving on to the next section and walking through some In-Memory OLTP examples, it’s useful to rectify some of the misconceptions surrounding In-Memory OLTP.
![]() Myth 1: SQL Server In-Memory OLTP is a recent response to competitors’ offerings Work on In-Memory OLTP commenced approximately four years ago in response to business and hardware trends occurring in the industry.
Myth 1: SQL Server In-Memory OLTP is a recent response to competitors’ offerings Work on In-Memory OLTP commenced approximately four years ago in response to business and hardware trends occurring in the industry.
![]() Myth 2: In-Memory OLTP is like DBCC PINTABLE DBCC PINTABLE was an old operation in SQL Server 7 that made it possible for the pages associated with a table to be read into the buffer pool and remain in memory instead of being removed or deleted. Although there are some similarities, In-Memory OLTP is a new design focused on optimizing in-memory data operations. There are no pages or buffer pool for memory-optimized tables.
Myth 2: In-Memory OLTP is like DBCC PINTABLE DBCC PINTABLE was an old operation in SQL Server 7 that made it possible for the pages associated with a table to be read into the buffer pool and remain in memory instead of being removed or deleted. Although there are some similarities, In-Memory OLTP is a new design focused on optimizing in-memory data operations. There are no pages or buffer pool for memory-optimized tables.
![]() Myth 3: In-memory databases are new separate products Unlike with many of its competitors, In-Memory OLTP is fully integrated into SQL Server 2014. If you know SQL Server, you know In-Memory OLTP.
Myth 3: In-memory databases are new separate products Unlike with many of its competitors, In-Memory OLTP is fully integrated into SQL Server 2014. If you know SQL Server, you know In-Memory OLTP.
![]() Myth 4: You can use In-Memory OLTP in an existing SQL Server application without any changes In reality, a few changes are required. At the very least, some changes to the schema will need to be made.
Myth 4: You can use In-Memory OLTP in an existing SQL Server application without any changes In reality, a few changes are required. At the very least, some changes to the schema will need to be made.
![]() Myth 5: Since tables are in memory, the data is not durable or highly available—I will lose it after a server crash In reality, In-Memory OLTP is fully durable and includes several highly available features, including AlwaysOn features. Data is persisted on disk and will survive a server crash.
Myth 5: Since tables are in memory, the data is not durable or highly available—I will lose it after a server crash In reality, In-Memory OLTP is fully durable and includes several highly available features, including AlwaysOn features. Data is persisted on disk and will survive a server crash.
In-Memory OLTP integration and application migration
A before-and-after illustration is the best way to compare the internal behavior of SQL Server when transactions are processed using traditional disk-based tables as opposed to memory-optimized tables. Figure 2-4 shows how a traditional transaction from a client application is processed using disk-based tables. Figure 2-6, shown later in the chapter, demonstrates the processing behavior when the same tables are migrated to memory-optimized tables and the In-Memory OLTP engine is used. Both figures also illustrate how tightly coupled In-Memory OLTP is with the Database Engine component.
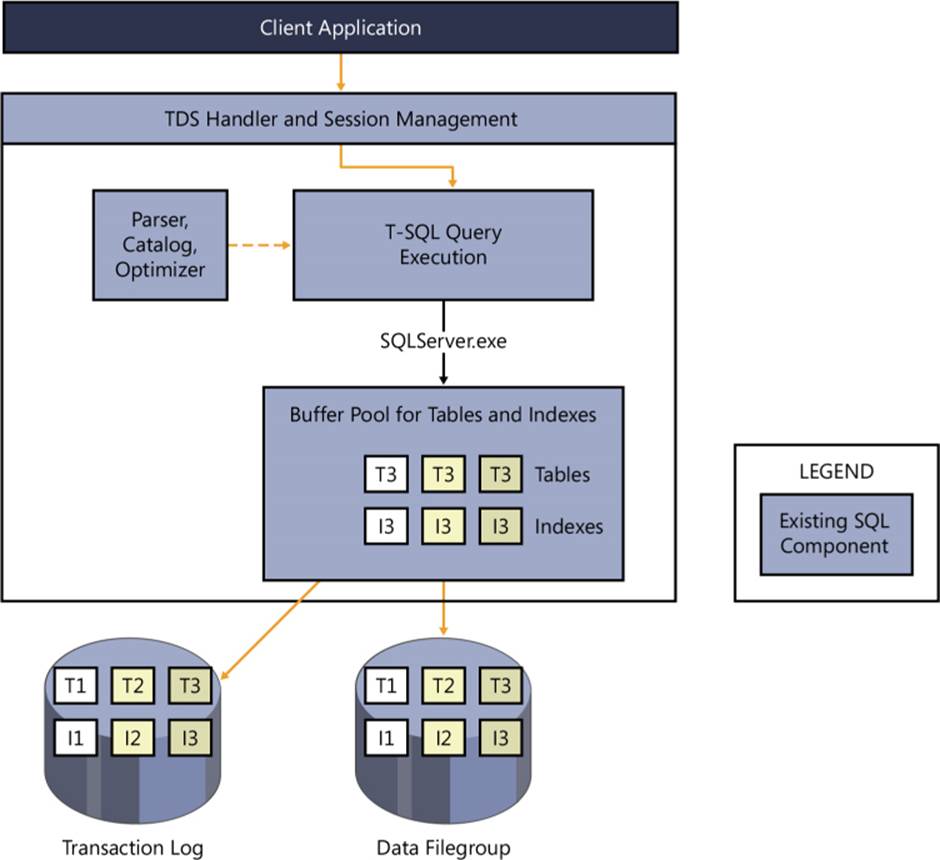
FIGURE 2-4 Client application process using disk-based table access.
In Figure 2-4, the SQL Server Database Engine communicates with the client application by using a Microsoft communication format called a Tabular Data Stream (TDS). The transaction goes through a parser and a catalog and an optimizer, and the T-SQL query is compiled for execution. During execution, the data is fetched from storage into the buffer pool for changes. At the time the transaction is committed, the log records are flushed to disk. The changes to the data and index pages are flushed to disk asynchronously.
Will In-Memory OLTP improve performance?
Figure 2-4 depicts a traditional scenario using disk-based tables. Although the processing times are sufficient in this example, it is not hard to conceive that further optimization of the database application’s performance will be needed one day. When that day comes, organizations can use the native tools in SQL Server to help them determine whether In-Memory OLTP is right for their environment. Specifically, organizations can use the Analysis, Migrate and Report (AMR) tool built into SQL Server Management Studio. The following steps can determine whether In-Memory OLTP is right for an organization:
1. Establish a system performance baseline.
2. Configure the Management Data Warehouse (MDW).
3. Configure data collection.
4. Run a workload.
5. Run the AMR tool.
6. Analyze results from AMR reports and migrate tables.
7. Migrate stored procedures.
8. Run workload again and collect performance metrics.
9. Compare new workload performance results to the original baseline.
10. Complete.
Ultimately, the AMR tool analyzes the workload to determine whether In-Memory OLTP will improve performance. It also helps organizations plan and execute their migration to memory-optimized tables. In addition, the report provides scan statistics, contention statistics, execution statistics, table references, and migration issues to ensure that organizations are given a wealth of information to further assist them with their analysis and eventually their migration.
Using the Memory Optimization Advisor to migrate disk-based tables
After running the AMR tool and identifying a table to port to In-Memory OLTP, you can use the Table Memory Optimization Advisor to help migrate specific disk-based tables to memory-optimized tables. Do this by right-clicking a table in Management Studio and then selecting Memory Optimization Advisor. This step invokes a wizard that begins conducting validation tests and providing migration warnings, as illustrated in Figure 2-5. The wizard also requires users to make a number of decisions about memory optimization, such as selecting which memory-optimized filegroup to use, the logical file name, and the file path. Finally, the wizard allows users to rename the original table, estimates current memory cost in megabytes, and prompts users to specify whether to use data durability for copying table data to the new memory-optimized table.
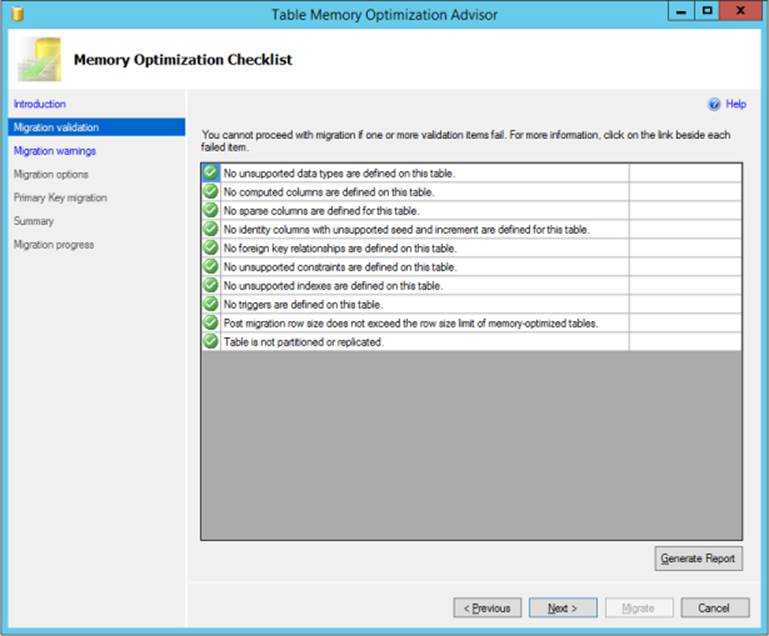
FIGURE 2-5 Using the Table Memory Optimization Advisor checklist to migrate disk-based tables.
Analyzing In-Memory OLTP behavior after memory-optimized table migration
Now it’s time to take account of Figure 2-6. Let’s assume that the AMR tool made a recommendation to migrate Tables 1 and 2 in the example depicted in Figure 2-4 to memory-optimized tables. Figure 2-6 focuses on In-Memory OLTP behavior after migration to memory-optimized tables has occurred and stored procedures have been natively compiled.
A new area of memory is added for memory-optimized tables and indexes. In addition, a full suite of new DMVs, XEvents, and instrumentation is also added, allowing the engine to keep track of memory utilization. Finally, a memory-optimized filegroup, which is based on the semantics of FILESTREAM, is also added. Access to memory-optimized tables can occur via query interop, natively compiled stored procedures, or a hybrid approach. In addition, indexes for In-Memory OLTP are not persisted. They reside only in memory and are loaded when the database is started or is brought online.
Query interop is the easiest way to migrate the application to In-Memory OLTP and access memory-optimized tables. This method does not use native compilations. It uses either ad hoc interpreted Transact-SQL or traditional stored procedures, which is the approach depicted by option 1 in Figure 2-6. As an alternative, natively compiled stored procedures are the fastest way to access data in memory-optimized tables. This approach is depicted by option 2 in Figure 2-6.
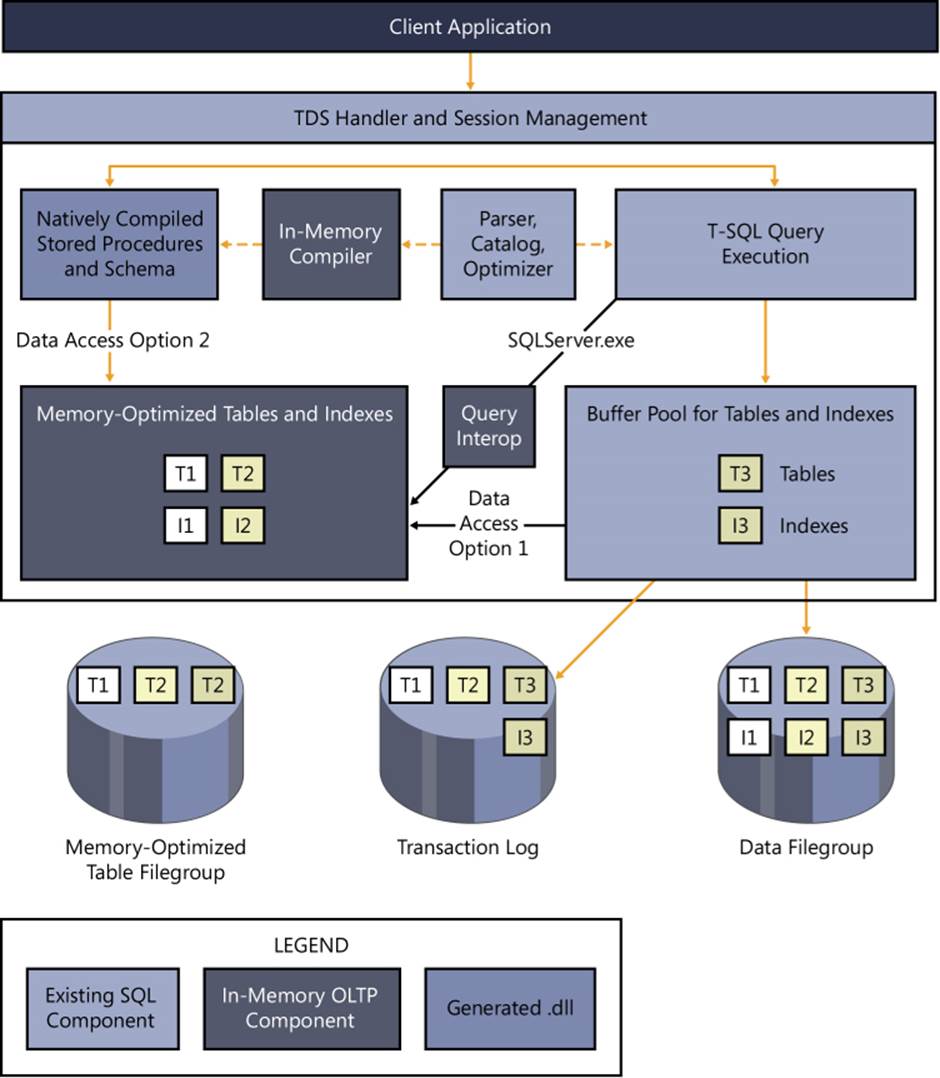
FIGURE 2-6 Client application process based on memory-optimized table access.
Using In-Memory OLTP
The following examples outline how to use In-Memory OLTP and memory-optimized tables to improve performance of OLTP applications through efficient, memory-optimized data access and native compilation of business logic.
Enabling In-Memory OLTP in a database
In-Memory OLTP must be enabled in a database before the new capabilities can be employed. Enable In-Memory OLTP by using the following Transact-SQL statements:
CREATE DATABASE [In-MemoryOLTP]
ON
PRIMARY(NAME = [In-MemoryOLTP_data],
FILENAME = 'c:\data\In-MemoryOLTP_db.mdf', size=500MB)
, FILEGROUP [In-MemoryOLTP_db] CONTAINS MEMORY_OPTIMIZED_DATA( -- In-MemoryOLTP_db is the
name of the memory-optimized filegroup
NAME = [In-MemoryOLTP_FG_Container], -- In-MemoryOLTP_FG_Container is the logical name of
a memory-optimized filegroup container
FILENAME = 'c:\data\In-MemoryOLTP_FG_Container') -- physical path to the container
LOG ON (name = [In-MemoryOLTP_log], Filename='C:\data\In-MemoryOLTP_log.ldf', size=500MB)
GO
The Transact-SQL statements create a database named In-MemoryOLTP and also add a memory-optimized filegroup container and filegroup to the database.
Create memory-optimized tables and natively compile stored procedures
With the filegroup and filegroup container added to the database, the next step is to create memory-optimized tables in the sample database and natively compile the stored procedures to reduce the instructions needed and improve performance. The following sample code executes this step and also creates memory-optimized indexes:
use [In-MemoryOLTP]
go
create table [sql]
(
c1 int not null primary key,
c2 nchar(48) not null
)
go
create table [hash]
(
c1 int not null primary key nonclustered hash with (bucket_count=1000000),
c2 nchar(48) not null
) with (memory_optimized=on, durability = schema_only)
go
create table [hash1]
(
c1 int not null primary key nonclustered hash with (bucket_count=1000000),
c2 nchar(48) not null
) with (memory_optimized=on, durability = schema_only)
go
CREATE PROCEDURE yy
@rowcount int,
@c nchar(48)
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
declare @i int = 1
while @i <= @rowcount
begin
INSERT INTO [dbo].[hash1] values (@i, @c)
set @i += 1
end
END
GO
Execute queries to demonstrate performance when using memory-optimized tables
Now that the database, memory-optimized tables, and stored procedures are created, it’s time to evaluate the performance gains by executing the following scripts and comparing the processing times of the disk-based table and interpreted Transact-SQL, the memory-optimized table with the hash index and interpreted Transact-SQL, and the memory-optimized table with the hash index and a natively compiled stored procedure.
set statistics time off
set nocount on
-- inserts - 1 at a time
declare @starttime datetime2 = sysdatetime(),
@timems int
declare @i int = 1
declare @rowcount int = 100000
declare @c nchar(48) = N'12345678901234567890123456789012345678'
-----------------------------
--- disk-based table and interpreted Transact-SQL
-----------------------------
begin tran
while @i <= @rowcount
begin
insert into [sql] values (@i, @c)
set @i += 1
end
commit
set @timems = datediff(ms, @starttime, sysdatetime())
select 'Disk-based table and interpreted Transact-SQL: ' + cast(@timems as varchar(10)) +
' ms'
-----------------------------
--- Interop Hash
-----------------------------
set @i = 1
set @starttime = sysdatetime()
begin tran
while @i <= @rowcount
begin
insert into [hash] values (@i, @c)
set @i += 1
end
commit
set @timems = datediff(ms, @starttime, sysdatetime())
select ' memory-optimized table with hash index and interpreted Transact-SQL: ' + cast(@
timems as varchar(10)) + ' ms'
-----------------------------
--- Compiled Hash
-----------------------------
set @starttime = sysdatetime()
exec yy @rowcount, @c
set @timems = datediff(ms, @starttime, sysdatetime())
select 'memory-optimized table with hash index and native Stored Procedure:' + cast(@
timems as varchar(10)) + ' ms'
The processing times are illustrated in the results window of SQL Server Management Studio. Using commodity hardware such as eight virtual processors and 14 GB of RAM, the processing time of the disk-based table and interpreted Transact-SQL was 3,219ms. The memory-optimized table with a hash index and interpreted Transact-SQL took 1015ms, and the memory-optimized table with a hash index and natively compiled stored procedure took 94ms. This clearly demonstrates a significantly faster processing time—approximately 34 times faster.
Appendix
Memory-optimized table
CREATE TABLE
[ database_name . [ schema_name ] . | schema_name . ]
table_name
( { <column_definition>
| [ <table_constraint> ] [ ,...n ]
| [ <table_index> ] [ ,...n ]
} )
[ WITH ( <table_option> [ ,...n ] ) ]
[ ; ]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
NOT NULL
[ <column_constraint> ]
[ <column_index> ]
<data type> ::=
[ type_schema_name . ] type_name [ ( precision [ , scale ]) ]
<column_constraint> ::=
[ CONSTRAINT constraint_name ]
{ PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT
= <bucket_count>) }
< table_constraint > ::=
[ CONSTRAINT constraint_name ]
{ PRIMARY KEY NONCLUSTERED HASH (column [ ,...n ] )
WITH (BUCKET_COUNT = <bucket_count>) }
<column_index> ::=
[ INDEX index_name ]
{ HASH WITH (BUCKET_COUNT = <bucket_count>) }
<table_index> ::=
[ INDEX index_name ]
[ INDEX constraint_name ]
{ HASH (column [ ,...n ] ) WITH (BUCKET_COUNT
= <bucket_count>) }
<table_option> ::=
{
[MEMORY_OPTIMIZED = {ON | OFF}]
| [DURABILITY = {SCHEMA_ONLY | SCHEMA_AND_DATA}]
}
Natively compiled stored procedure
CREATE { PROC | PROCEDURE } [schema_name.] procedure_name
[ { @parameter data_type } [ = default ] [ OUT | OUTPUT ]
[READONLY]] ] [ ,...n ]
[ WITH <procedure_option> [ ,...n ] ]
AS
{
[ BEGIN [ATOMIC WITH ( <set_option> [ ,...n ] ) ] ]
sql_statement [;] [ ...n ]
[ END ]
}
[;]
<procedure_option> ::=
| EXECUTE AS clause
| NATIVE_COMPILATION
| SCHEMABINDING
<set_option> ::=
LANGUAGE = [ N ] 'language'
| TRANSACTION ISOLATION LEVEL = { REPEATABLE READ | SERIALIZABLE | SNAPSHOT }
[ | DATEFIRST = number
| DATEFORMAT = format ]
<sql_statement>:
-DECLARE variable
-SET -IF/WHILE -TRY/CATCH/THROW -RETURN
-SELECT [TOP <n>] <column_list>
FROM <table>
[WHERE <predicate>]
[ORDER BY <expression_list>]
INSERT <table> [(<column_list>)] VALUES (<value_list>)
INSERT <table> [(<column_list>)] SELECT …
UPDATE <table> SET <assignment_list> [WHERE <predicate>]
DELETE <table> [WHERE <predicate>]
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.