Professional Microsoft SQL Server 2014 Integration Services (Wrox Programmer to Programmer), 1st Edition (2014)
Chapter 19. Programming and Extending SSIS
WHAT’S IN THIS CHAPTER?
· Examining methods used to create custom components
· Creating custom SSIS Source adapters
· Creating custom SSIS transforms
· Creating custom SSIS Destination adapters
WROX.COM DOWNLOADS FOR THIS CHAPTER
You can find the wrox.com code downloads for this chapter at www.wrox.com/go/prossis2014 on the Download Code tab.
Once you start implementing a real-world integration solution, you may have requirements that the built-in functionality in SSIS does not meet. For instance, you may have a legacy system that has a proprietary export file format, and you need to import that data into your warehouse. You have a robust SSIS infrastructure that you have put in place that enables you to efficiently develop and manage complex ETL solutions, but how do you meld that base infrastructure with the need for customization? That’s where custom component development comes into play. Out of the box, Microsoft provides a huge list of components for you in SSIS; however, you can augment those base components with your own more specialized tasks.
The benefit here is not only to businesses but also to software vendors. You may decide to build components and sell them on the Web, or maybe start a community-driven effort on a site such as codeplex.com. Either way, the benefit you get is that your components will be built in exactly the same way that the ones that ship with SSIS are built; there is no secret sauce (besides expertise) that Microsoft adds to its components to make them behave any differently from your own. This gives you the opportunity to truly “build a better mousetrap” — if you don’t like the way that one of the built-in components behaves, you can simply build your own instead.
Building your first component may be a little challenging, but with the help of this chapter it is hoped that you will be able to overcome this. This chapter focuses on the pipeline — not because it is better than any other area of programmability within SSIS but because it will probably be the area in which you have the most benefit to gain, and it does require a slightly greater level of understanding of basic programming concepts than most SSIS developers need to create script tasks. The pipeline also gives you a glimpse of the really interesting things that Microsoft has done in SSIS. All forms of extensibility are well covered in the SQL Server documentation and samples, so don’t forget to leverage those resources as well.
THE SAMPLE COMPONENTS
Three sample components are defined in this section to demonstrate the main component types. The Transform Component is expanded in Chapter 20 to include a user interface. All code samples are available on the website for this book, which you can find atwww.wrox.com/go/prossis2014.
The pipeline, for all intents and purposes, is the way your data moves from A to B and how it is manipulated, if at all. You can find it on the Data Flow tab of your packages after you have dropped a Data Flow Task into the Control Flow. There’s no need to go into any more detail about where to find the pipeline in your package, because this has been covered elsewhere in this book.
As discussed in other chapters, Integration Services enables you to use three basic component types in the pipeline. The first component type is a Source, which retrieves data from an external location (for instance, a SQL Server query, a text file, or a Web service) and transforms the input into the internal buffer format that the pipeline expects.
The Transformation-Type Component accepts buffers of data from the pipeline on one side, does something useful with the data (for instance, sorting it, calculating totals, or multicasting the rows), and then pushes the rows downstream for the next component to consume.
The Destination-Type Component also accepts buffers of data from the pipeline on its input, but rather than write the output rows to the pipeline again, it writes them to a specific external source, such as a text file or SQL Server table.
This chapter walks you through the process of building three components — one example for each of the component types just mentioned. Note that there are further classifications of components, such as synchronous and asynchronous components, but this chapter will help you get the basics right. Following is a high-level description of what each sample component will do.
Component 1: Source Adapter
The Source adapter needs to be able to do quite a few things in order to present the data to the downstream components in the pipeline in a format that the next component understands and expects. Here is a list of what the component needs to do:
· Accept a Connection Manager. A Connection Manager is an optional component for Source adapters, since it is possible to write a Source adapter that does not require a Connection Manager. However, a Connection Manager helps to isolate the connectivity logic (such as the credentials) from the user-specific functionality (such as the query) defined in the Source adaptor. As such, a Connection Manager is highly recommended.
· Validate a Connection Manager.
· Add output columns to the component for the downstream processes.
· Connect to the Data Source.
· Get the data from the Data Source.
· Assign the correct parts of the data to the correct output columns.
· Handle any data errors.
As previously indicated, this component needs to do some work in order to present its data to the outside world. However, stick with it and you’ll see how easy this can be. Your aim in the Source adapter is to be able to take a file with a custom format, read it, and present its data to the downstream components.
The real-world sample scenario that we will cover is that there are many systems that export data in a proprietary format, which is hard to then import into another system. Assume that the legacy system exports customer data in the following format:
<START>
Name:
Age:
Married:
Salary:
<END>
As you can see, this is a nonstandard format that none of the out-of-the-box Source adapters could deal with adequately. Of course, you could use a Script Component to read and parse the file using VB or C#, but then you would need to duplicate the code in every package that needed to read this type of file. Writing a custom Source Component means that you can reuse the component in many different packages, which saves you time and simplifies maintenance compared to the scripting route.
Component 2: Transform
A transform component enables you to take data from a source, manipulate it, and then present the newly arranged data to the downstream components. This component performs the following tasks:
· Creates input columns to accept the data from upstream
· Validates the data to ensure that it conforms to the component’s expectations
· Checks the column properties because this transform will be changing them in place
· Handles the case of somebody trying to change the metadata of the transform by adding or removing inputs and/or outputs
In the scenario we will use for this component, we want to create a simple data obfuscation device that will take data from the source and reverse the contents. The catch, though, is that the column properties must be set correctly, and you can perform this operation only on certain data types.
Component 3: Destination Adapter
The Destination adapter will take the data received from the upstream component and write it to the destination. This component needs to do the following:
· Create an input that accepts the data
· Validate that the data is correct
· Accept a Connection Manager
· Validate the Connection Manager (did you get the right type of Connection Manager?)
· Connect to the Data Source
· Write data from the Data Source
For this component, we will use the opposite scenario to the one used earlier in the chapter for the Source adapter. Instead of retrieving data from source to be used in the SSIS package, in this case, we will imagine that the pipeline retrieved data from some standard source (such as SQL Server) but we now want to write the data out to a custom flat file format, perhaps as the input file for a legacy system.
The Destination adapter will basically be a reverse of the Source adapter. When it receives the input rows, it needs to create a new file with a data layout resembling that of the source file.
The components you’ll build are actually quite simple, but the point is not complexity but how you use the methods in Microsoft’s SSIS object model. You can use the methods presented for tackling these tasks as the basis for more complex operations.
THE PIPELINE COMPONENT METHODS
Components are normally described as having two distinct phases: design time and runtime. The design-time phase refers to the methods and interfaces that are called when the component is being used in a development environment — in other words, the code that is being run when the component is dragged onto the SSIS design surface, and when it is being configured. The runtime functionality refers to the calls and interfaces that are used when the component is actually being executed — in other words, when the package is being run.
When you implement a component, you inherit from the base class, Microsoft.SqlServer.Dts.Pipeline.PipelineComponent, and provide your own functionality by overriding the base methods, some of which are primarily design time, others runtime. If you are using native code to write SSIS components, then the divide between the runtime and the design time is clearer because the functionality is implemented on different interfaces. Commentary on the methods has been divided into these two sections, but there are some exceptions, notably the connection-related methods; a section on connection time–related methods is included later in this chapter.
NOTE In programming terms, a class can inherit functionality from another class, termed the base class. If the base class provides a method, and the inheriting class needs to change the functionality within this method, it can override the method. In effect, you replace the base method with your own. From within the overriding method, you can still access the base method, and call it explicitly if required, but any consumer of the new class will see only the overriding method.
Design-Time Functionality
The following methods are explicitly implemented for design time, overriding the PipelineComponent methods, although they will usually be called from within your overriding method. Not all of the methods are listed, because for some there is little more to say, and others have been grouped together according to their area of function. Refer to the SQL Server documentation for a complete list.
Some methods are described as verification methods, and these are a particularly interesting group. They provide minor functions, such as adding a column or setting a property value, and you might quite rightly assume that there is little point in ever overriding them, because there isn’t much value to add to the base implementation. These verification methods have code added to verify that the operation about to take place within the base class is allowed. The following sections expand on the types of checks you can do; if you want to build a robust component, these are well worth looking into.
Another very good reason to implement these methods as described is to reduce code. These methods will be used by both a custom user interface (UI) and the built-in component editor, or Advanced Editor. If you raise an error saying that a change is not allowed, then both user interfaces can capture this and provide feedback to the user. Although a custom UI would be expected to prevent blatantly inappropriate actions, the Advanced Editor is designed to offer all functionality, so you are protecting the integrity of your component regardless of the method used.
ProvideComponentProperties
This method is provided so you can set up your component. It is called when a component is first added to the Data Flow, and it initializes the component. It does not perform any column-level activity, because this is left to ReinitializeMetadata; when this method is invoked, there are generally no inputs or outputs to be manipulated anyway. Following are the sorts of procedures you may want to set in here:
· Remove existing settings, such as inputs and outputs. This allows the component to be rebuilt and can be useful when things go wrong.
· Add inputs and outputs, ready for column work later in the component’s lifetime. You may also define custom properties on them and specify related properties, such as linking them together for synchronous behavior.
· Define the connection requirements. By adding an item to the RuntimeConnectionCollection, you have a placeholder prepared for the Connection Manager at runtime, and inform the designer of this requirement.
· The component may have custom properties that are configurable by a user in addition to those you get free from Microsoft. These will hold settings other than the column-related one that affect the overall operation or behavior of the component.
Validate
Validate is called numerous times during the lifetime of the component, both at design time and at runtime, but the most interesting work is usually the result of a design-time call. As the name suggests, it validates that the content of the component is correct and will enable you to at least run the package. If the validation encounters a problem, then the return code used is important to determine any further actions, such as calling ReinitializeMetaData. The base class version of Validate performs its own checks in the component, and you will need to extend it further in order to cover your specific needs. Validate should not be used to change the component at all; it should only report the problems it finds.
ReinitializeMetaData
The ReinitializeMetaData method is where all the building work for your component is done. You add new columns, remove invalid columns, and generally build up the columns. It is called when the Validate method returns VS_NEEDSNEWMETADATA. It is also your opportunity to do any component repairs that need to be done, particularly regarding invalid columns, as mentioned previously.
MapInputColumn and MapOutputColumn
These methods are used to create a relationship between an input/output column and an external metadata column. An external metadata column is an offline representation of an output or input column and can be used by downstream components to create an input. For instance, you may connect your Source Component to a database table to retrieve the list of columns. However, once you disconnect from the database and edit the package in an offline manner, it may be useful for the source to “remember” the external database columns.
This functionality enables you to validate and maintain columns even when the Data Source is not available. It is not required, but it makes the user experience better. If the component declares that it will be using External Metadata (IDTSComponentMetaData100.ValidateExternalMetadata), then the user in the advanced UI will see upstream columns on the left and the external columns on the right; if you are validating your component against an output, you will see the checked list box of columns.
Input and Output Verification Methods
There are several methods you can use to deal with inputs and outputs. The three functions you may need to perform are adding, deleting, and setting a custom property. The method names clearly indicate their function:
· InsertInput
· DeleteInput
· SetInputProperty
· InsertOutput
· DeleteOutput
· SetOutputProperty
For most components, the inputs and outputs will have been configured during ProvideComponentProperties, so unless you expect a user to add additional inputs and outputs and fully support this, you should override these methods and fire an error to prevent this. Similarly, unless you support additions, you would also want to deny deletions by overriding the corresponding methods. Properties can be checked for validity during the Set methods as well.
Set Column Data Types
Two methods are used to set column data types: one for output columns and the other for external metadata columns. There is no input column equivalent, because the data types of input columns are determined by the upstream component.
· SetOutputColumnDataTypeProperties
· SetExternalMetadataColumnDataTypeProperties
These are verification methods that can be used to validate or prevent changes to a column. For example, in a Source Component, you would normally define the columns and their data types within ReinitializeMetaData. You could then overrideSetOutputColumnDataTypeProperties, and by comparing the method’s supplied data types to the existing column, you could prevent data type changes but allow length changes.
There is quite a complex relationship between all the parameters for these methods; please refer to SQL Server documentation for reference when using this method yourself.
PerformUpgrade
This method enables you to update an existing version of the component with a new version in a transparent manner on the destination machine.
RegisterEvents
This method enables you to register custom events in a Pipeline Component. You can therefore have an event fire on something happening at runtime in the package. This is then eligible to be logged in the package log.
RegisterLogEntries
This method decides which of the new custom events are going to be registered and selectable in the package log.
SetComponentProperty
In the ProvideComponentProperties method, you tell the component about any custom properties that you would like to expose to the users of the component and perhaps allow them to set. Using the SetComponentProperty verification method, you can check what the user has entered for which custom property on the component and ensure that the values are valid.
Setting Column Properties
There are three column property methods, each of which enables you to set a property for the relevant column type:
· SetInputColumnProperty
· SetOutputColumnProperty
· SetExternalMetadataColumnProperty
These are all verification methods and should be used accordingly. For example, if you set a column property during ReinitializeMetaData and want to prevent users from interfering with this, you could examine the property name (or index) and throw an exception if it is a restricted property, in effect making it read-only.
Similarly, if several properties are used in conjunction with each other at runtime to provide direction on the operation to be performed, you could enumerate all column properties to ensure that those related properties exist and have suitable values. You could assign a default value if a value is not present or raise an exception depending on the exact situation.
For an external metadata column, which will be mapped to an input or output column, any property set directly on this external metadata column can be cascaded down onto the corresponding input or output column through this overridden function.
SetUsageType
This method deals with the columns on inputs into the component. In a nutshell, you use it to select a column and to tell the component how you will treat each column. What you see coming into this method is the virtual input. This means that it is a representation of what is available for selection to be used by your component. These are the three possible usage types for a column:
· DTSUsageType.UT_IGNORED: The column will not be used by the component. You are removing this InputColumn from the InputColumnCollection. This differs from the other two usage types, which add a reference to the InputColumn to the InputColumnCollection if it does not exist already or you may be changing its Read/Write property.
· DTSUsageType.UT_READONLY: The column is read-only. The column is selected, and data can be read and used within the component but cannot be modified.
· DTSUsageType.UT_READWRITE: The column is selected, and you can read and write or change the data within your component.
This is another of the verification methods, and you should use it to ensure that the columns selected are valid. For example, the Reverse String sample shown later in the chapter can operate only on string columns, so you must check that the data type of the input column is DT_STR for string or DT_WSTR for Unicode strings. Similarly, the component performs an in-place change, so the usage type must be read/write. Setting it to read-only would cause problems during execution when you try to write the changed data back to the pipeline buffer. The Data Flow makes important decisions on column handling based on the read/write flag, and if the component writes to a read-only column, it will likely corrupt the data and the user will get incorrect results. Therefore, you should validate the columns as they are selected to ensure that they meet the design requirements for your component.
On Path Attachment
There are three closely related path attachment methods, called when the named events occur, and the first two in particular can be used to improve the user experience:
· OnInputPathAttached
· OnOutputPathAttached
· OnInputPathDetached
These methods handle situations in which, for instance, the inputs or outputs are all identical and interchangeable. Using the multicast as an example, you attach to the dangling output and another dangling output is automatically created. You detach, and the extra output is deleted.
Runtime
Runtime, also known as execution time, is when you actually work with the data, through the pipeline buffer, with columns and rows of data. The following methods are used for preparing the component, doing the job it was designed for, and then cleaning up afterward.
PrepareForExecute
This method, which is similar to the PreExecute method described next, can be used for setting up anything in the component that you will need at runtime. The difference between them is that you do not have access to the Buffer Manager, so you cannot get your hands on the columns in either the output or the input at this stage. Otherwise, the distinction between the two is very fine, so usually you will end up using PreExecute exclusively, because you will need access to the Buffer Manager anyway.
PreExecute
PreExecute is called once and once only each time the component is run, and Microsoft recommends that you do as much preparation as possible for the execution of your component in this method. In this case, you’ll use it to enumerate the columns, reading off values and properties, calling methods to get more information, and generally preparing by gathering all the information you require in advance. For instance, you may want to save references to common properties, column indexes, and state information to a variable so that you access it efficiently once you start pumping rows through the component.
This is the earliest point in the component that you will access the component’s Buffer Manager, so you have the live context of columns, as opposed to the design-time representation. As mentioned, you do the column preparation for your component in this method, because it is called only once per component execution, unlike some of the other runtime methods, which are called multiple times.
The live and design-time representations of the columns may not match. An example of this is that typically data in the buffer is not in the same order as it is in the design time. This means that just because Column1 has an index of 0 in the design time, the buffer may not have the same index for Column1. To solve this mismatch there is a function named FindColumnByLineageID that will be used to locate the columns in the buffer. An example of FindColumnByLineageID can be found later in the chapter in the “Building the Source Component” section in the ParseTheFileAndAddToBuffer function.
PrimeOutput and ProcessInput
These two methods are covered together because they are so closely linked. Essentially, these two methods reflect how the data flows through components. Sometimes you use only one of them, and sometimes you use both. There are some rules you can follow.
In a Source adapter, the ProcessInput method is never called, and all of the work is done through PrimeOutput. In a Destination adapter, the reverse is true; the PrimeOutput method is never called, and the whole of the work is done through the ProcessInput method.
Things are not quite that simple with a transformation. There are two types of transformations, and the type of transformation you are writing will dictate which method, or indeed methods, your component should call. For a discussion on synchronous versus asynchronous transformations, see Chapter 4.
· Synchronous: PrimeOutput is not called; therefore, all the work is done in the ProcessInput method. The buffer LineageIDs remain the same. For a detailed explanation of buffers and LineageIDs, please refer to Chapter 16.
· Asynchronous: Both methods are called here. The key difference between a synchronous component and an asynchronous component is that the latter does not reuse the input buffer. The PrimeOutput method hands the ProcessInput method a buffer to fill with its data.
PostExecute
You can use this method to clean up anything that you started in PreExecute. However, this is not its only function. After reading the description of the Cleanup method, covered next, you may wonder what the difference is between them. The answer is, for this release, nothing. It might be easiest to think of PostExecute as the counterpart to PreExecute.
Cleanup
As the method name suggests, this is called as the very last thing your component will do, and it is your chance to clean up whatever resources may be left. However, it is rarely used. Like PreExecute and PostExecute, you can consider Cleanup to be the opposite ofPrepareForExecute.
DescribeRedirectedErrorCode
If you are using an error output and directing rows there in case of errors, then you should expose this method to provide more information about the error. When you direct a row to the error output, you specify an error code. This method will be called by the pipeline engine, passing in that error code, and it is expected to return a full error description string for the code specified. These two values are then included in the columns of the error output.
Connection Time
The following two methods are called several times throughout the life cycle of a component, both at design time and at runtime, and are used to manage connections within the component.
AcquireConnections
This method is called both at design time and when the component executes. There is no explicit result, but the connection is normally validated and then cached in a member variable within the component for later use. At this stage, a connection should be open and ready to use.
There is a single parameter used by the AcquireConnections, which is named transaction. The transaction parameter is set to the transaction that the connection being retrieved in AcquireConnections is participating in. The transaction parameter is set to null unless a transaction has been started by the SSIS execution engine. An example of where the transaction object would not be null would be to set the SSIS package setting of TransactionOption to Required.
ReleaseConnections
If you have any open connections, as set in the AcquireConnections method, then this is where they should be closed and released. If the connection was cached in a member variable, use that reference to issue any appropriate Close or Dispose methods. For some connections, such as a File Connection Manager, this may not be relevant because only a file path string was returned, but if you took this a stage further and opened a text stream or similar on the file, it should now be closed.
Here is a list of common Connection Managers and the values that are returned.
|
CONNECTION MANAGER TYPE |
CONNECTION MANAGER NAME |
TYPE OF RETURN VALUE |
ADDITIONAL INFO |
|
ADO.NET |
ADO.NET Connection Manager |
System.Data |
ADO.NET |
|
FILE |
File Connection Manager |
System.String |
Path to the file |
|
FLATFILE |
Flat File Connection Manager |
System.String |
Path to the file |
|
SMTP |
SMTP Connection Manager |
System.String |
For example: SmtpServer=<server name>; |
|
WMI |
WMI Connection Manager |
System.Management |
WMI |
BUILDING THE COMPONENTS
Now you can move on to actually building the components. These components are simple and demonstrate the most commonly used methods when building your own components. They also help give you an idea of the composition of a component, the order in which things happen, and which method does what. While they will not implement all the available methods, these components have been built and can be extended, so why not download them and give them a go? If you happen to break them, simply revert back to a previous good copy. No programmer gets things right the first time, so breaking the component is part of the experience. (At least, that’s what programmers tell themselves at 2:00 a.m. when they are still trying to figure out why the thing isn’t doing what they wanted.)
The component classes are covered in the next sections. You will then be shown how to ensure that your component appears in the correct folder, what to put in the AssemblyInfo file, how it is registered in the global assembly cache (GAC), and how to sign the assembly. This is common to all three components, so it is covered as one topic.
Preparation
In this section of the chapter, you’ll go through the steps that are common to all the Pipeline Components. These are the basic sets of tasks you need to do before you fly into coding.
Start by opening Visual Studio 2013, and create a new project, a Class Library project, as shown in Figure 19-1.
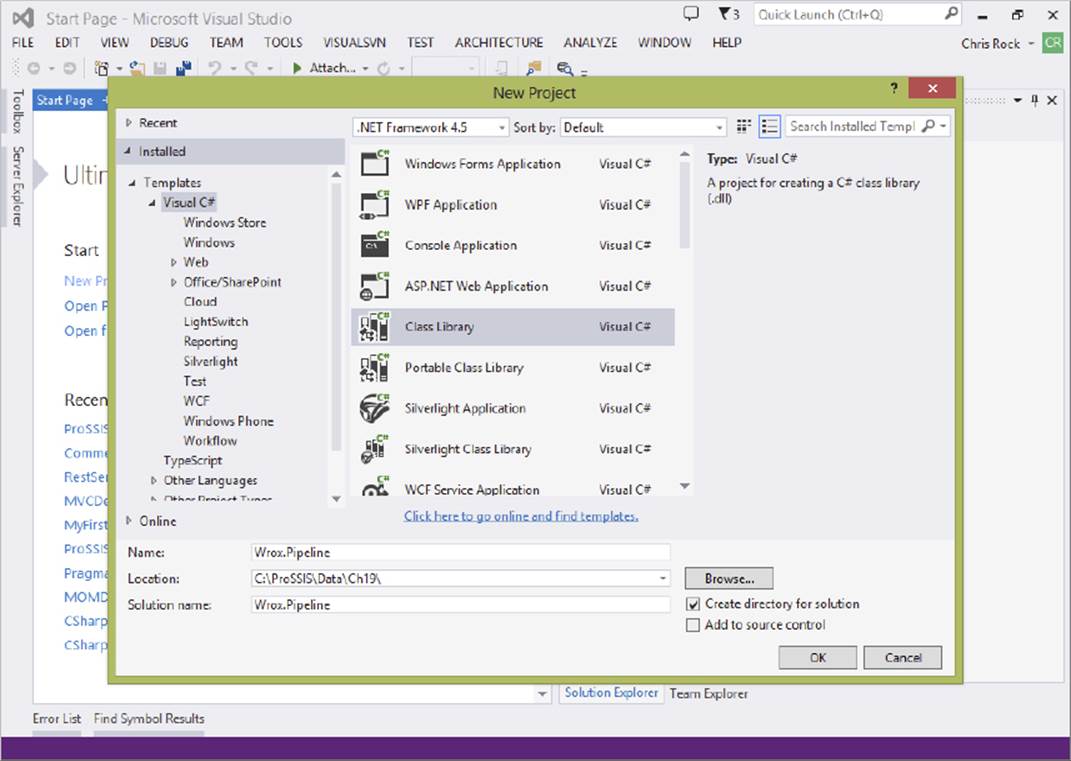
FIGURE 19-1
Now select the Add Reference option from the Project menu, and select the following assemblies, which are shown in Figure 19-2:
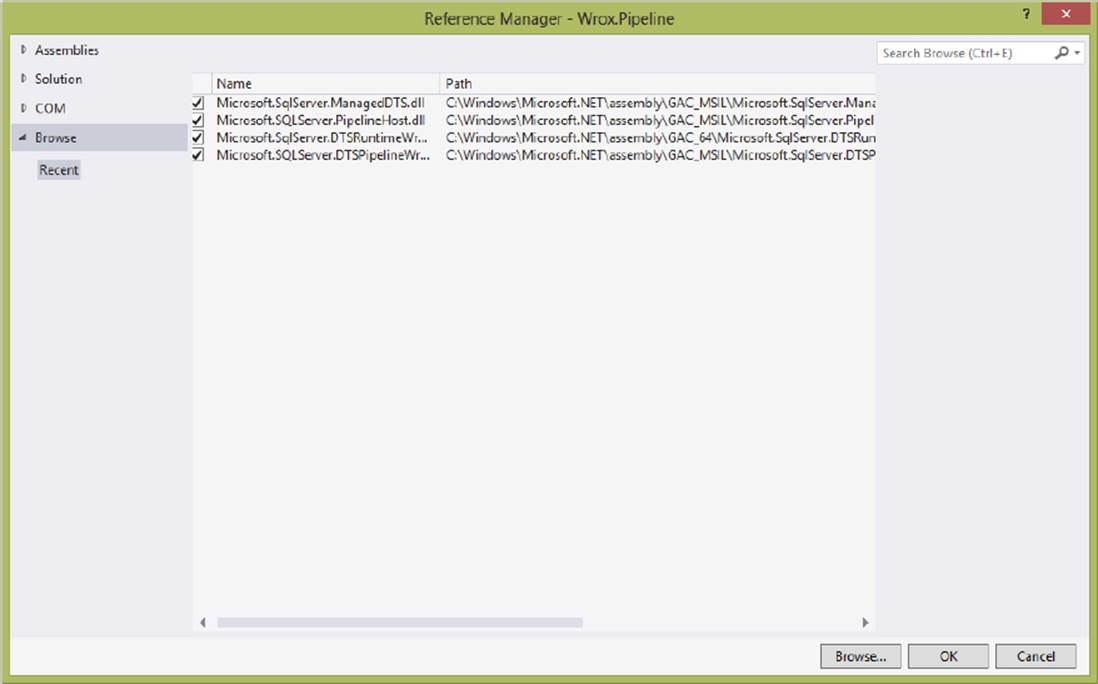
FIGURE 19-2
· Microsoft.SqlServer.DTSPipelineWrap
· Microsoft.SqlServer.DTSRuntimeWrap
· Microsoft.SqlServer.ManagedDTS
· Microsoft.SqlServer.PipelineHost
In a standard installation of SQL Server 2014 Integration Services, these reference files should be available in the directory C:\Program Files\Microsoft SQL Server\120\SDK\Assemblies\; 64-bit machines need to look in the x86 program files directory C:\Program Files (x86)\Program Files\Microsoft SQL Server\120\SDK\Assemblies.
Once you have those set up, you can start to add the Using directives. These directives tell the compiler which libraries you are going to use. Here are the directives you will need to add to the top of the class in the code editor:
#region Using directives
using System;
using System.Collections.Generic;
using System.Text;
using System.Globalization;
using System.Runtime.InteropServices;
using Microsoft.SqlServer.Dts.Pipeline;
using Microsoft.SqlServer.Dts.Pipeline.Wrapper;
using Microsoft.SqlServer.Dts.Runtime.Wrapper;
using Microsoft.SqlServer.Dts.Runtime;
#endregion
The first stage in building a component is to inherit from the PipelineComponent base class and decorate the class with DtsPipelineComponent. From this point on, you are officially working on a Pipeline Component.
namespace Wrox.Pipeline
{ [DtsPipelineComponent(
DisplayName = "Wrox Reverse String",
ComponentType = ComponentType.Transform,
IconResource = "Wrox.Pipeline.ReverseString.ico")]
public class ReverseString : PipelineComponent
{
...
The DtsPipelineComponent attribute supplies design-time information about your component, and the first key property here is ComponentType. The three options — Source, Destination, or Transformation — reflect the three tabs within the SSIS Designer Toolbox. This option determines which tab, or grouping of components, your component belongs to. The DisplayName is the text that will appear in the Toolbox, and it’s the default name of the component when it’s added to the designer screen. The IconResource is the reference to the icon in your project that will be shown to the user both in the Toolbox and when the component is dropped onto the Package Designer. This part of the code will be revisited later in the chapter when the attribute for the User Interface, which you’ll be building later, is added.
Now type the following in the code window:
public override
After you press the space bar after the word "override,” you’ll see a list of all the methods on the base class. You are now free to type away to your heart’s content and develop the component.
We cover development of the components a little later in the chapter, but for now we focus on how you deploy it into the SSIS environment once it is ready. In addition to being built, the component also needs a few other things to happen to it. If you are a seasoned developer, then this section will be old hat to you, but for anyone else, it’s important to understand what needs to happen for the components to work:
· Provide a strong name key for signing the assembly.
· Set the build output location to the PipelineComponents folder.
· Use a post-build event to install the assembly into the GAC.
· Set assembly-level attributes in the AssemblyInfo.cs file.
SSIS needs the GAC because components can be executed from within the SQL Server Data Tools, SQL Server Agent, or DTExec, all which reside in different directories. Strong names are a consequence of this requirement. The PipelineComponents folder allows the designer to discover the component and put it in the Toolbox. Additional assembly-level metadata from your component is a consequence of the fact that the strong name, including version, is persisted in the package, which causes all your packages to break if you rebuild the component unless you stop incrementing the AssemblyVersion attribute of the component.
To sign the project, right-click your C# project and choose Properties from the context menu. You are not going to look at all the tabs on the left side of the screen, only those that are relevant to what you are doing here. Figure 19-3 shows the Application tab.
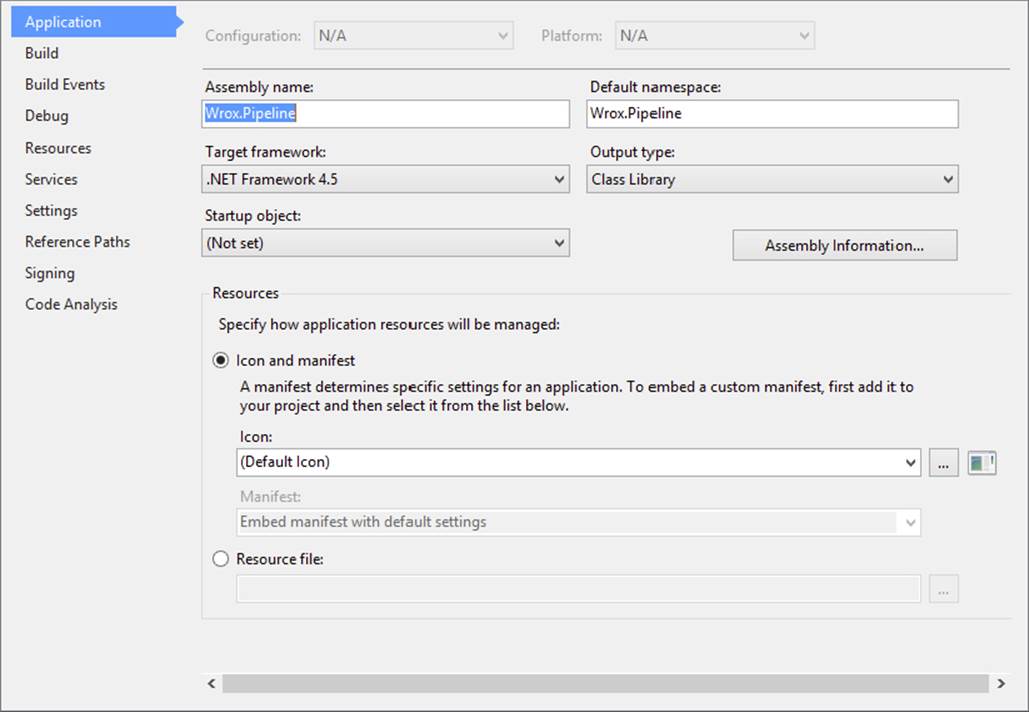
FIGURE 19-3
In this tab, the only thing you really need to do is change the assembly name to be the same as your default namespace.
In order for the SSIS designer to use a component, it must be placed in a defined folder. On a 32-bit (x86) PC, this folder is usually located here:
C:\Program Files\Microsoft SQL Server\120\DTS\PipelineComponents
If you have a 64-bit (x64) environment, then you should explicitly choose the 64-bit location:
C:\Program Files (x86)\Microsoft SQL Server\120\DTS\PipelineComponents
For your new component to work correctly, it must be placed in the global assembly cache. To copy the assemblies into the program files directory and install them with the GAC, you’re going to use a post-build event on the project. Copying the files into the preceding directories and installing them into the GAC are both required steps. You can do this manually, but it makes for faster development if you do it as part of the build process.
Click the Build Events tab. Then, in the Post-build Command Line dialog, enter the commands that will automatically do these tasks. You can also click on the “Edit Post Build . . .” button, which allows for better readability on the longer command lines. Following is an example post-build event command (see also Figure 19-4). Be sure to include the double quotes in the path statements. If this exact command doesn’t work in your development environment, then do a search for gacutil.exe on your hard drive and use its path in the manner shown here.
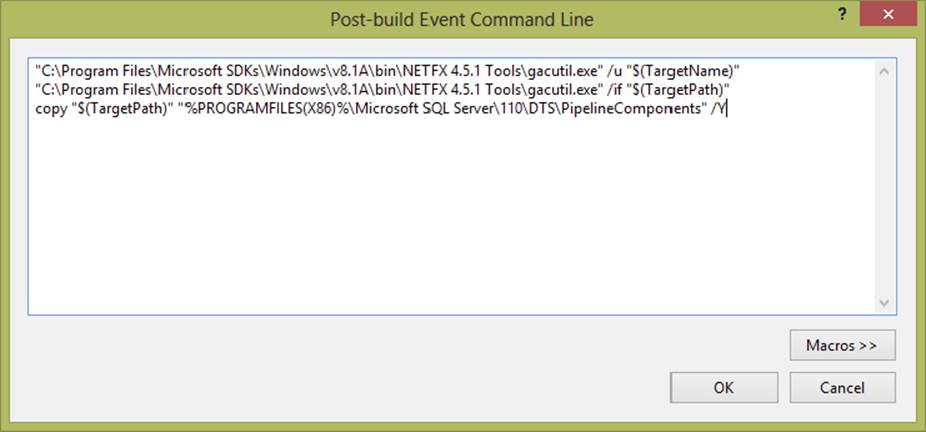
FIGURE 19-4
"C:\Program Files (x86)\Microsoft SDKs\Windows\v8.1A\Bin\NETFX 4.5.1 Tools\gacutil.exe"
/u "$(TargetName)"
"C:\Program Files (x86)\Microsoft SDKs\Windows\v8.1A\Bin\NETFX 4.5.1 Tools\gacutil.exe"
/if "$(TargetPath)"
NOTE Note that the path shown earlier is for Windows 8/2012 machines. The path on older OSs may be slightly different.
The SSIS components referenced in this project are built with .NET 4.5. This means you need to verify that you’re using the gacutil.exe file for .NET 4.5 as well. Otherwise, the gacutil steps of the post-build event will fail.
When you compile the code, Visual Studio will expand the macros shown in the preceding snippet into real paths — for instance, the first command shown will expand into the following statement, and Visual Studio will then execute it. Because you have declared the statement in the post-build event, after compiling the code the statement will run automatically and place the new library (.dll) into the GAC.
"C:\Program Files\Microsoft SDKs\Windows\v8.1A\Bin\NETFX 4.5.1 Tools\gacutil.exe"
/if "C:\SSIS\ProSSIS2014\Wrox.Pipeline\bin\debug\Wrox.Pipeline.dll"
The assembly is to be installed in the GAC, so you also need to sign it using a strong name key, which can be specified and created from the Signing page, shown in Figure 19-5.
FIGURE 19-5
NOTE Keep in mind that on some operating systems, such as Windows 7 or 8, you will be required to run the Wrox.Pipeline project in Visual Studio 2013 under the administrator account. That’s because the gacutil utility requires administrator privileges to copy files to the GAC. To run Visual Studio as the administrator, right-click the Visual Studio icon to bring up the context menu and select “Run as administrator.”
That’s all you need to do as far as the project’s properties are concerned, so now you can move on to handling the AssemblyInfo file. While most assembly attributes can be set through the Assembly Information dialog, available from the Application tab of Project Properties (refer to Figure 19-3), you require some additional settings. Shown next is the AssemblyInfo.cs file for the example project, which can be found under the Properties folder within the Solution Explorer of Visual Studio:
#region Using directives
using System;
using System.Security.Permissions;
using System.Reflection;
using System.Runtime.CompilerServices;
using System.Runtime.InteropServices;
#endregion
[assembly: AssemblyTitle("Wrox.Pipeline")]
[assembly: AssemblyDescription("A reverse string pipeline component from Wrox ")]
[assembly: AssemblyConfiguration("")]
[assembly: AssemblyProduct("Wrox.Pipeline")]
[assembly: AssemblyTrademark("")]
[assembly: AssemblyCulture("")]
[assembly: AssemblyVersion("1.0.0.0")]
[assembly: AssemblyFileVersion("1.0.0.0")]
[assembly: CLSCompliant(true)]
[assembly: PermissionSet(SecurityAction.RequestMinimum)]
[assembly: ComVisible(false)]
The first section of attributes represents general information such as company name. The AssemblyCulture attribute should be left blank unless you are experienced with working with localized assemblies and understand the implications of any change.
The AssemblyVersion attribute is worth noting; because the version is fixed, it does not use the asterisk token to generate an automatically incrementing build number. The assembly version forms part of the fully qualified assembly name, which is how a package references a component under the covers. Therefore, if you changed the version for every build, you would have to rebuild your packages for every new version of the component. In order to differentiate between versions, you should use AssemblyFileVersion, which you need to manually update.
The other attribute worth noting is CLSCompliant. Best practice dictates that the .NET classes and assemblies conform to the Command Language Specification (CLS), and compliance should be marked at the assembly level. Individual items of noncompliant code can then be decorated with the CLSCompliant attribute, marked as false. The completed samples all include this, and you can also refer to SQL Server documentation for guidance, as well as follow the simple compiler warnings that are raised when this condition is not met.
The following example shows how to deal with a noncompliant method in your component:
[CLSCompliant(false)]
public override DTSValidationStatus Validate()
{
...
Building the Source Component
As mentioned earlier, the Source adapter needs to be able to retrieve information from a file and present the data to the downstream component. The file is not your standard-looking file, and while the format is strange, it’s consistent. When you design the Destination adapter, you will write the contents of an upstream component to a file in a very similar format. After you have read this chapter, you may want to take the Source adapter and alter it slightly so that it can read a file produced by the sample Destination adapter.
If you’re following along with the book and are writing the code manually, right click on the Wrox.Pipeline project in Visual Studio and click “Add ⇒ New Item”. Select the “Class” template in the “Add New Item” dialog and create a new file named SimpleFileProcessorSource.cs.
The first method to look at is ProvideComponentProperties. This is called almost as soon as you drop the component onto the designer. Here is the method in full (SimpleFileProcessorSource.cs) before you look at its parts:
public override void ProvideComponentProperties()
{
ComponentMetaData.RuntimeConnectionCollection.RemoveAll();
RemoveAllInputsOutputsAndCustomProperties();
ComponentMetaData.Name = "Wrox Simple File Processor Source Adapter";
ComponentMetaData.Description = "Our first Source Adapter";
IDTSRuntimeConnection100 rtc =
ComponentMetaData.RuntimeConnectionCollection.New();
rtc.Name = "File To Read";
rtc.Description = "This is the file from which we want to read";
IDTSOutput100 output = ComponentMetaData.OutputCollection.New();
output.Name = "Component Output";
output.Description = "This is what downstream Components will see";
output.ExternalMetadataColumnCollection.IsUsed = true;
}
Now you can break down some of this code. The first thing the preceding code does is remove any runtime connections in the component, which you’ll be adding back soon:
ComponentMetaData.RuntimeConnectionCollection.RemoveAll();
RemoveAllInputsOutputsAndCustomProperties();
You can also remove inputs, outputs, and custom properties. Basically your component is now a clean slate. This is not strictly required for this example; however, it’s advantageous to follow this convention because it prevents any unexpected situations that may arise in more complicated components.
The following three lines of code simply help to identify your component when you look in the property pages after adding it to the designer:
ComponentMetaData.Name = "Wrox Simple File Processor";
ComponentMetaData.Description = "Our first Source Adapter";
ComponentMetaData.ContactInfo = "www.wrox.com";
The only property here that may not be obvious is ContactInfo, which simply identifies to the user the developer of the component. If a component throws a fatal error during loading or saving — for example, areas not influenced by the user-controlled settings — then the designer will show the contact information for support purposes.
Next, your component needs a runtime connection from which you can read and get the data:
IDTSRuntimeConnection100 rtc =
ComponentMetaData.RuntimeConnectionCollection.New();
rtc.Name = "File To Read";
rtc.Description = "This is the file from which we want to read";
You removed any existing connections earlier in the method, so here is where you add it back. Simply give it a name and a description.
Downstream components will see the data by having it presented to them from an output in this component. In other words, the output is the vehicle that the component uses to present data from the input file to the next component downstream. Here you add a new output to the output collection and give it a name and a description:
IDTSOutput100 output = ComponentMetaData.OutputCollection.New();
output.Name = "Component Output";
output.Description = "This is what downstream Components will see";
The final part of this component is to use ExternalMetadataColumns, which enables you to view the structure of the Data Source with no connection:
output.ExternalMetadataColumnCollection.IsUsed = true;
Here, you tell the output you created earlier that it will use ExternalMetaData columns.
The next method to look at is AcquireConnections. In this method, you want to ensure that you have a runtime connection available and that it is the correct type. You then want to retrieve the filename from the file itself. Here is the method in full (SimpleFileProcessorSource.cs):
public override void AcquireConnections(object transaction)
{
if (ComponentMetaData.RuntimeConnectionCollection["File To
Read"].ConnectionManager != null)
{ ConnectionManager cm =
Microsoft.SqlServer.Dts.Runtime.DtsConvert.GetWrapper(
ComponentMetaData.RuntimeConnectionCollection["File To Read"].
ConnectionManager);
if (cm.CreationName != "FILE")
{
throw new Exception("The Connection Manager is not a FILE Connection Manager");
}
else
{
_fil = (Microsoft.SqlServer.Dts.Runtime.DTSFileConnectionUsageType)
cm.Properties["FileUsageType"].GetValue(cm);
if (_fil != DTSFileConnectionUsageType.FileExists)
{
throw new Exception("The type of FILE connection manager must be an
Existing File");
}
else
{
_filename = ComponentMetaData.RuntimeConnectionCollection["File To
Read"].ConnectionManager.AcquireConnection(transaction).
ToString();
if (_filename == null || _filename.Length == 0)
{
throw new Exception("Nothing returned when grabbing the filename");
}
}
}
}
}
This method covers a lot of ground and is really quite interesting. The first thing you want to do is find out if you can get a Connection Manager from the runtime connection collection of the component. The runtime connection was defined duringProvideComponentProperties earlier. If it is null, then the user has not provided a runtime connection:
if (ComponentMetaData.RuntimeConnectionCollection["File To
Read"].ConnectionManager
!= null)
The next line of code is quite cool. It converts the native ConnectionManager object to a managed Connection Manager. You need the managed Connection Manager to determine what type it is and the properties:
ConnectionManager cm =
Microsoft.SqlServer.Dts.Runtime.DtsConvert.ToConnectionManager(
ComponentMetaData.RuntimeConnectionCollection["File To Read"].ConnectionManager);
Once you have the managed Connection Manager, you can start to look at some of its properties to ensure that it is what you want. All Connection Managers have a CreationName property. For this component, you want to ensure that the CreationName property is FILE, as highlighted here:
if (cm.CreationName != "FILE")
If the CreationName is not FILE, then you send an exception back to the component:
throw new Exception("The type of FILE connection manager must be an Existing
File");
You’ve established that a connection has been specified and that it is the right type. However, the FILE Connection Manager can still have the wrong usage mode specified. To determine whether it has the right mode, you have to look at another of its properties, theFileUsageType property. This can return one of four values, defined by the DTSFileConnectionUsageType enumeration:
· DTSFileConnectionUsageType.CreateFile: The file does not yet exist and will be created by the component. If the file does exist, then you can raise an error, although you may also accept this and overwrite the file. Use this type for components that create new files. This mode is more useful for Destination Components, not sources.
· DTSFileConnectionUsageType.FileExists: The file exists, and you are expected to raise an error if this is not the case.
· DTSFileConnectionUsageType.CreateFolder: The folder does not yet exist and will be created by the component. If the folder does exist, then you can decide how to handle this situation, as with CreateFile earlier. This is also more useful for destinations.
· DTSFileConnectionUsageType.FolderExists: The folder exists, and you are expected to raise an error if this is not the case.
The type you want to check for in your component is DTSFileConnectionUsageType.FileExists and you do that like this, throwing an exception if the type is not what you want:
_fil = (Microsoft.SqlServer.Dts.Runtime.DTSFileConnectionUsageType)cm.Properties
["FileUsageType"].GetValue(cm);
if (_fil != Microsoft.SqlServer.Dts.Runtime.DTSFileConnectionUsageType.FileExists)
{...}
You’re nearly done checking your Connection Manager now. At this point, you need the filename so you can retrieve the file later when you need to read it for data. You do that like this:
_filename = ComponentMetaData.RuntimeConnectionCollection
["File To Read"].ConnectionManager.AcquireConnection(transaction).ToString();
That concludes the AcquireConnections method, so you can now move straight on to the Validate method (SimpleFileProcessorSource.cs):
[CLSCompliant(false)]
public override DTSValidationStatus Validate()
{
bool pbCancel = false;
IDTSOutput100 output = ComponentMetaData.OutputCollection["Component Output"];
if (ComponentMetaData.InputCollection.Count != 0)
{
ComponentMetaData.FireError(0, ComponentMetaData.Name, "Unexpected input
found. Source components do not support inputs.", "", 0, out pbCancel);
return DTSValidationStatus.VS_ISCORRUPT;
}
if (ComponentMetaData.RuntimeConnectionCollection["File To Read"].
ConnectionManager == null)
{
ComponentMetaData.FireError(0, "Validate", "No Connection Manager
Specified.", "", 0, out pbCancel);
return DTSValidationStatus.VS_ISBROKEN;
}
// Check for Output Columns, if not then force ReinitializeMetaData
if (ComponentMetaData.OutputCollection["Component
Output"].OutputColumnCollection.Count == 0)
{
ComponentMetaData.FireError(0, "Validate", "No output columns specified.
Making call to ReinitializeMetaData.", "", 0, out pbCancel);
return DTSValidationStatus.VS_NEEDSNEWMETADATA;
}
//What about if we have output columns but we have no ExternalMetaData
// columns? Maybe somebody removed them through code.
if (DoesEachOutputColumnHaveAMetaDataColumnAndDoDatatypesMatch(output.ID)
== false)
{
ComponentMetaData.FireError(0, "Validate", "Output columns and metadata
columns are out of sync. Making call to ReinitializeMetaData.", "",
0, out pbCancel);
return DTSValidationStatus.VS_NEEDSNEWMETADATA;
}
return base.Validate();
}
The first thing this method does is check for an input. If it has an input, it raises an error back to the component using the FireError method and returns DTSValidationStatus.VS_ISCORRUPT. This is a Source adapter, and there is no place for an input. Because the data rows enter the component from the file, there is no need for a buffer input that would receive data from an upstream component.
if (ComponentMetaData.InputCollection.Count != 0)
Next, you check whether the user has specified a Connection Manager for your component. If not, then you return to the user a message indicating that a Connection Manager is required. You do this through the FireError method again. If no Connection Manager is specified, then you tell the component it is broken. Remember that you must perform the validation of any Connection Manager specified in AcquireConnections().
if (ComponentMetaData.RuntimeConnectionCollection["File To
Read"].ConnectionManager == null)
{
ComponentMetaData.FireError(0, "Validate", "No Connection Manager Specified.",
"", 0, out pbCancel);
return DTSValidationStatus.VS_ISBROKEN;
}
Now you need to check whether the output has any columns. For the initial drop onto the designer, the output will have no columns. If this is the case, the Validate() method will return DTSValidationStatus.VS_NEEDSNEWMETADATA, which in turn calls ReinitializeMetaData. You will see later what happens in that method.
if (ComponentMetaData.OutputCollection["Component
Output"].OutputColumnCollection.Count == 0)
{
ComponentMetaData.FireError(0, "Validate", "No output columns specified. Making
call to ReinitializeMetaData.", "", 0, out pbCancel);
return DTSValidationStatus.VS_NEEDSNEWMETADATA;
}
If the output has output columns, then one of the things you want to check is whether the output columns have an ExternalMetaDataColumn associated with them. Recall that for ProvideComponentProperties, it was stated that you would use anExternalMetadataColumnCollection. Therefore, for each output column, you need to ensure that there is an equivalent external metadata column and that the data type properties also match:
if (DoesEachOutputColumnHaveAMetaDataColumnAndDoDatatypesMatch(output.ID) ==
false)
{
ComponentMetaData.FireError(0, "Validate", "Output columns and metadata columns
are out of sync. Making call to ReinitializeMetaData.", "",
0, out pbCancel);
return DTSValidationStatus.VS_NEEDSNEWMETADATA;
}
The next method is used to validate some properties of the component. This is not a method provided by Microsoft that you are overriding; rather, it is completely custom code used to help you do some common work, which is why such functions are sometimes called helper methods. This rather long-named helper method, DoesEachOutputColumnHaveAMetaDataColumnAndDoDatatypesMatch, accepts as a parameter the ID of an output, so you pass in the output’s ID. This method has to do two things. First, it has to confirm that each output column has an ExternalMetadataColumn associated with it; second, it has to ensure that the two columns have the same column data type properties. Here is the method in full (SimpleFileProcessorSource.cs):
private bool DoesEachOutputColumnHaveAMetaDataColumnAndDoDatatypesMatch(int
outputID)
{
IDTSOutput100 output =
ComponentMetaData.OutputCollection.GetObjectByID(outputID);
IDTSExternalMetadataColumn100 mdc;
bool rtnVal = true;
foreach (IDTSOutputColumn100 col in output.OutputColumnCollection)
{
if (col.ExternalMetadataColumnID == 0)
{
rtnVal = false;
}
else
{
mdc = output.ExternalMetadataColumnCollection.GetObjectByID
(col.ExternalMetadataColumnID);
if (mdc.DataType != col.DataType || mdc.Length != col.Length ||
mdc.Precision != col.Precision || mdc.Scale != col.Scale ||
mdc.CodePage != col.CodePage)
{
rtnVal = false;
}
}
}
return rtnVal;
}
The first thing this method does is translate the ID passed in as a parameter to the method into an output:
IDTSOutput100 output = ComponentMetaData.OutputCollection.GetObjectByID(outputID);
Once you have that, the code loops over the output columns in that output to determine whether the ExternalMetadataColumnID associated with that output column has a value of 0 (that is, there is no value). If the code finds an instance of a value, then it sets the return value from the method to be false:
foreach (IDTSOutputColumn100 col in output.OutputColumnCollection)
{
if (col.ExternalMetadataColumnID == 0)
{
rtnVal = false;
}
...
If all output columns have a nonzero ExternalMetadataColumnID, then you move on to the second test:
mdc = output.ExternalMetadataColumnCollection.GetObjectByID
(col.ExternalMetadataColumnID);
if (mdc.DataType != col.DataType || mdc.Length != col.Length || mdc.Precision !=
col.Precision || mdc.Scale != col.Scale || mdc.CodePage != col.CodePage)
{
rtnVal = false;
}
In this part of the method, you are checking whether all the attributes of the output column’s data type match those of the corresponding ExternalMetadataColumn. If they do not, then again you return false from the method, which causes the Validate() method to callReinitializeMetaData. Notice that you use the ID rather than a name, as names can be changed by the end user.
ReinitializeMetaData is where a lot of the work happens in most components. In this component, it fixes up the output columns and the ExternalMetadataColumns. Here’s the method (SimpleFileProcessorSource.cs):
public override void ReinitializeMetaData()
{
IDTSOutput100 _profoutput = ComponentMetaData.OutputCollection["Component
Output"];
if (_profoutput.ExternalMetadataColumnCollection.Count > 0)
{
_profoutput.ExternalMetadataColumnCollection.RemoveAll();
}
if (_profoutput.OutputColumnCollection.Count > 0)
{
_profoutput.OutputColumnCollection.RemoveAll();
}
CreateOutputAndMetaDataColumns(_profoutput);
}
This is a really simple way of doing things. Basically, you are removing all the ExternalMetaDataColumns and then removing the output columns. You will then add them back using the CreateOutputAndMetaDataColumns helper method.
NOTE As an exercise, you may want to see if you can determine which columns actually need fixing, instead of just dropping and recreating them all.
CreateOutputAndMetaDataColumns is a helper method that creates the output’s output columns and the ExternalMetaData columns to go with them (SimpleFileProcessorSource.cs). This implementation is very rigid, and it presumes that the file you get will be in one format only:
private void CreateOutputAndMetaDataColumns(IDTSOutput100 output)
{
IDTSOutputColumn100 outName = output.OutputColumnCollection.New();
outName.Name = "Name";
outName.Description = "The Name value retrieved from File";
outName.SetDataTypeProperties(DataType.DT_STR, 50, 0, 0, 1252);
CreateExternalMetaDataColumn(output.ExternalMetadataColumnCollection, outName);
IDTSOutputColumn100 outAge = output.OutputColumnCollection.New();
outAge.Name = "Age";
outAge.Description = "The Age value retrieved from File";
outAge.SetDataTypeProperties(DataType.DT_I4, 0, 0, 0, 0);
//Create an external metadata column to go alongside with it
CreateExternalMetaDataColumn(output.ExternalMetadataColumnCollection, outAge);
IDTSOutputColumn100 outMarried = output.OutputColumnCollection.New();
outMarried.Name = "Married";
outMarried.Description = "The Married value retrieved from File";
outMarried.SetDataTypeProperties(DataType.DT_BOOL, 0, 0, 0, 0);
//Create an external metadata column to go alongside with it
CreateExternalMetaDataColumn(output.ExternalMetadataColumnCollection, outMarried);
IDTSOutputColumn100 outSalary = output.OutputColumnCollection.New();
outSalary.Name = "Salary";
outSalary.Description = "The Salary value retrieved from File";
outSalary.SetDataTypeProperties(DataType.DT_DECIMAL, 0, 0, 10, 0);
//Create an external metadata column to go alongside with it
CreateExternalMetaDataColumn(output.ExternalMetadataColumnCollection,
outSalary);
}
This code follows the same pattern for every column you want to create, so you’ll just look at one example here because the rest are variations of the same code. In CreateOutputAndMetaDataColumns, you first need to create an output column and add it to theOutputColumnCollection of the output, which is a parameter to the method. You give the column a name, a description, and a data type, along with details about the data type:
NOTE SetDataTypeProperties takes the name, the length, the precision, the scale, and the code page of the data type. A list of what is required for these fields can be found in Books Online.
IDTSOutputColumn100 outName = output.OutputColumnCollection.New();
outName.Name = "Name";
outName.Description = "The Name value retrieved from File";
outName.SetDataTypeProperties(DataType.DT_STR, 50, 0, 0, 1252);
Note that if you decided to use Unicode data, which does not require a code page, then the same call would have looked like this:
outName.SetDataTypeProperties(DataType.DT_WSTR, 50, 0, 0, 0);
You now create an ExternalMetaDataColumn for the OutputColumn, and you do that by calling the helper method called CreateExternalMetaDataColumn. This method takes as parameters the ExternalMetaDataColumnCollection of the output and the column for which you want to create an ExternalMetaDataColumn:
CreateExternalMetaDataColumn(output.ExternalMetadataColumnCollection, outName);
The first thing you do in the method is create a new ExternalMetaDataColumn in the ExternalMetaDataColumnCollection that was passed as a parameter. You then map the properties of the output column that was passed as a parameter to the new ExternalMetaDataColumn. Finally, you create the relationship between the two by assigning the ID of the ExternalMetaDataColumn to the ExternalMetadataColumnID property of the output column:
IDTSExternalMetadataColumn100 eColumn = externalCollection.New();
eColumn.Name = column.Name;
eColumn.DataType = column.DataType;
eColumn.Precision = column.Precision;
eColumn.Length = column.Length;
eColumn.Scale = column.Scale;
eColumn.CodePage = column.CodePage;
column.ExternalMetadataColumnID = eColumn.ID;
At this point, the base class will call the MapOutputColumn method. You can choose to override this method to ensure that the external columns and the output column match and that you want to allow the mapping to occur, but in this case you should leave the base class to simply carry on.
Now it’s time to look at the runtime methods. PreExecute is the usual place to start for most components, but it is done slightly differently here. Normally you would enumerate the output columns and enter them into a struct, so you could easily retrieve them later. For illustration purposes, you’re not going to do that here (but you do this in the Destination adapter, so you could port what you do there into this adapter as well). The only method you are interested in with this adapter is PrimeOutput. Here is the method in full:
public override void PrimeOutput(int outputs, int[] outputIDs, PipelineBuffer[]
buffers)
{
ParseTheFileAndAddToBuffer(_filename, buffers[0]);
buffers[0].SetEndOfRowset();
}
On the face of it, this method looks really easy, but as you can see, all the work is being done by the helper method called ParseTheFileAndAddToBuffer. To that procedure you need to pass the filename you retrieved in AcquireConnections, and the buffer is buffers[0]because there is only one buffer and the collection is zero-based. You’ll look at the ParseTheFileAndAddToBuffer method in a moment, but the last thing you do in this method is call SetEndOfRowset on the buffer. This basically tells the downstream component that there are no more rows to be retrieved from the adapter.
Now consider the ParseTheFileAndAddToBuffer method in a bit more detail (SimpleFileProcessorSource.cs):
private void ParseTheFileAndAddToBuffer(string filename, PipelineBuffer buffer)
{
TextReader tr = File.OpenText(filename);
IDTSOutput100 output = ComponentMetaData.OutputCollection["Component Output"];
IDTSOutputColumnCollection100 cols = output.OutputColumnCollection;
IDTSOutputColumn100 col;
string s = tr.ReadLine();
int i = 0;
while (s != null)
{
if (s.StartsWith("<START>"))
buffer.AddRow();
if (s.StartsWith("Name:"))
{
col = cols["Name"];
i = BufferManager.FindColumnByLineageID(output.Buffer, col.LineageID);
string value = s.Substring(5);
buffer.SetString(i, value);
}
if (s.StartsWith("Age:"))
{
col = cols["Age"];
i = BufferManager.FindColumnByLineageID(output.Buffer, col.LineageID);
Int32 value;
if (s.Substring(4).Trim() == "")
value = 0;
else
value = Convert.ToInt32(s.Substring(4).Trim());
buffer.SetInt32(i, value);
}
if (s.StartsWith("Married:"))
{
col = cols["Married"];
bool value;
i = BufferManager.FindColumnByLineageID(output.Buffer, col.LineageID);
if (s.Substring(8).Trim() == "")
value = true;
else
value = s.Substring(8).Trim() != "1" ? false : true;
buffer.SetBoolean(i, value);
}
if (s.StartsWith("Salary:"))
{
col = cols["Salary"];
Decimal value;
i = BufferManager.FindColumnByLineageID(output.Buffer, col.LineageID);
if (s.Substring(7).Trim() == "")
value = 0M;
else
value = Convert.ToDecimal(s.Substring(8).Trim());
buffer.SetDecimal(i, value);
}
s = tr.ReadLine();
}
tr.Close();
}
Because this is not a lesson in C# programming, we will simply describe the points relevant to SSIS programming in this component. You start off by getting references to the output columns collection in the component:
IDTSOutput100 output = ComponentMetaData.OutputCollection["Component Output"];
IDTSOutputColumnCollection100 cols = output.OutputColumnCollection;
IDTSOutputColumn100 col;
The IDTSOutputColumn100 object will be used when you need a reference to particular columns. At this point, the columns in the file are actually in rows, so you need to pivot them into columns. First, you read a single line from the file using this code:
string s = tr.ReadLine();
For this specific source file format, you can determine that you need to add a new row to the buffer if when reading a line of text from the file it begins with the word <START>. You do that in the code shown here (remember that the variable s is assigned a line of text from the file):
if(s.StartsWith("<START>"))
buffer.AddRow();
Here, you have added a row to the buffer, but the row is empty (contains no data yet). As you read lines in the file, you test the beginning of each line. This is important because you need to know this in order to be able to grab the right column from the output columns collection and assign it the value from the text file. The first column name you test for is the "Name" column:
if (s.StartsWith("Name:"))
{
col = cols["Name"];
i = BufferManager.FindColumnByLineageID(output.Buffer, col.LineageID);
string value = s.Substring(5);
buffer.SetString(i, value);
}
The first thing you do here is check what the row begins with. In the preceding example, it is "Name:". Next, you set the IDTSColumn100 variable column to reference the Name column in the OutputColumnCollection. You need to be able to locate the column in the buffer, and to do this you need to look at the Buffer Manager. This has a method called FindColumnByLineageID that returns the integer location of the column. You need this to assign a value to the column.
To this method, you pass the output’s buffer and the column’s LineageID. Once you have that, you can use the SetString method on the buffer object to assign a value to the column by passing in the buffer column index and the value to which you want to set the column. Now you no longer have an empty row; it has one column populated with a real data value.
You pretty much do the same with all the columns for which you want to set values. The only variation is the method you call on the buffer object. The buffer object has a set<datatype> method for each of the possible data types. In this component, you need a SetInt32, a SetBoolean, and a SetDecimal method. They do not differ in structure from the SetString method at all. You can also set the value in a non-type-safe manner by using buffer[i] := value, though as a best practice this is not advised.
You can now compile the project. Assuming there are no syntax errors, the project should output the .dll in the specified folder and register it in the GAC. When SQL Server Data Tools is opened, the component should show up in the SSIS Toolbox toolbar as well.
Building the Transformation Component
In this section, you build the transformation that is going to take data from the upstream Source adapter. After reversing the strings, it will pass the data to the downstream component. In this example, the downstream component will be the Destination adapter, which you’ll write after you’re done with the transformation. The component needs a few things prepared in advance in order to execute efficiently during its lifetime (ReverseString.cs):
private ColumnInfo[] _inputColumnInfos;
const string ErrorInvalidUsageType = "Invalid UsageType for column '{0}'";
const string ErrorInvalidDataType = "Invalid DataType for column '{0}'";
CLSCompliant(false)]
public struct ColumnInfo
{
public int bufferColumnIndex;
public DTSRowDisposition columnDisposition;
public int lineageID;
}
The struct that you create here, called ColumnInfo, is something you use in various guises repeatedly in your components. It is very useful for storing details about columns that you will need later in the component. In this component, you will store theBufferColumnIndex, which indicates where the column is in the buffer, so that you can retrieve the data. You’ll store how the user wants the row to be treated in an error, and you’ll store the column’s LineageID, which helps to retrieve the column from theInputColumnCollection.
Design-Time Methods
Logically, it would make sense to code the component beginning with the design time, followed by the runtime. When your component is dropped into the SSIS Package Designer surface, it first makes a call to ProvideComponentProperties. In this component, you want to set up an input and an output, and you need to tell your component how it should handle data — as in whether it is a synchronous or an asynchronous transformation, as discussed earlier in the chapter. Just as you did with the Source adapter, we’ll look at the whole method first and then examine parts of the method in greater detail. Here is the method in full (ReverseString.cs):
public override void ProvideComponentProperties()
{
ComponentMetaData.UsesDispositions = true;
IDTSInput100 ReverseStringInput = ComponentMetaData.InputCollection.New();
ReverseStringInput.Name = "RSin";
ReverseStringInput.ErrorRowDisposition = DTSRowDisposition.RD_FailComponent;
IDTSOutput100 ReverseStringOutput = ComponentMetaData.OutputCollection.New();
ReverseStringOutput.Name = "RSout";
ReverseStringOutput.SynchronousInputID = ReverseStringInput.ID;
ReverseStringOutput.ExclusionGroup = 1;
AddErrorOutput("RSErrors", ReverseStringInput.ID,
ReverseStringOutput.ExclusionGroup);
}
Breaking it down, you first tell the component to use dispositions:
ComponentMetaData.UsesDispositions = true;
In this case, you’re telling the component that it can expect an error output. Now you move on to adding an input to the component:
// Add a new Input, and name it.
IDTSInput100 ReverseStringInput = ComponentMetaData.InputCollection.New();
ReverseStringInput.Name = "RSin";
// If an error occurs during data movement, then the component will fail.
ReverseStringInput.ErrorRowDisposition = DTSRowDisposition.RD_FailComponent;
Next, you add the output to the component:
// Add a new Output, and name it.
IDTSOutput100 ReverseStringOutput = ComponentMetaData.OutputCollection.New();
ReverseStringOutput.Name = "RSout";
// Link the Input and Output together for a synchronous behavior
ReverseStringOutput.SynchronousInputID = ReverseStringInput.ID;
This is similar to adding the input, except that you specify that this is a synchronous component by setting the SynchronousInputID on the output to the ID of the input you created earlier. If you were creating an asynchronous component, you would set theSynchronousInputID of the output to be 0, like this:
ReverseStringOutput.SynchronousInputID = 0
This tells SSIS to create a buffer for the output that is separate from the input buffer. This is not an asynchronous component, though; you will revisit some of the subtle differences later.
AddErrorOutput creates a new output on the component and tags it as being an error output by setting the IsErrorOut property to true. To the method, you pass the name of the error output you want, the input’s ID property, and the output’s ExclusionGroup. AnExclusionGroup is needed when two outputs use the same synchronous input. Setting the exclusion group enables you to direct rows to the correct output later in the component using DirectRow.
AddErrorOutput("RSErrors",
ReverseStringInput.ID,ReverseStringOutput.ExclusionGroup);
ReverseStringOutput.ExclusionGroup = 1;
That’s it for ProvideComponentProperties.
Now you’ll move on to the Validate method. As mentioned earlier, this method is called on numerous occasions, and it is your opportunity within the component to check whether what has been specified by the user is allowable by the component.
Here is your completed Validate method (ReverseString.cs):
[CLSCompliant(false)]
public override DTSValidationStatus Validate()
{
bool Cancel;
if (ComponentMetaData.AreInputColumnsValid == false)
return DTSValidationStatus.VS_NEEDSNEWMETADATA;
foreach (IDTSInputColumn100 inputColumn in
ComponentMetaData.InputCollection[0].InputColumnCollection) \
{
if (inputColumn.UsageType != DTSUsageType.UT_READWRITE)
{
ComponentMetaData.FireError(0, inputColumn.IdentificationString,
String.Format(ErrorInvalidUsageType, inputColumn.Name), "",
0, out Cancel);
return DTSValidationStatus.VS_ISBROKEN;
}
if (inputColumn.DataType != DataType.DT_STR && inputColumn.DataType !=
DataType.DT_WSTR)
{
ComponentMetaData.FireError(0, inputColumn.IdentificationString,
String.Format(ErrorInvalidDataType, inputColumn.Name), "",
0, out Cancel);
return DTSValidationStatus.VS_ISBROKEN;
}
}
return base.Validate();
}
This method will return a validation status to indicate the overall result and may cause subsequent methods to be called. Refer to the SQL Server documentation for a complete list of values (see DTSValidationStatus).
Now, to break down the Validate method. A user can easily add and remove an input from the component at any stage and later add it back. It may be the same one, but it may be a different one, presenting the component with an issue. When an input is added, the component stores the LineageIDs of the input columns. If that input is removed and another is added, those LineageIDs may have changed because something such as the query used to generate those columns may have changed. Therefore, you are presented with different columns, so you need to determine whether that has happened; if so, you need to invalidate the LineageIDs. If that’s the case, the component will call ReinitializeMetaData.
if (ComponentMetaData.AreInputColumnsValid == false)
{ return DTSValidationStatus.VS_NEEDSNEWMETADATA; }
Next, you should ensure that each of the columns in the InputColumnCollection chosen for the component has been set to READ WRITE. This is because you will be altering them in place — in other words, you will read a string from a column, reverse it, and then write it back over the old string. If they are not set to READ WRITE, you need to feed that back by returning VS_ISBROKEN. You can invoke the FireError method on the component, which results in a red cross displayed on the component, along with tooltip text indicating the exact error:
if (RSincol.UsageType != DTSUsageType.UT_READWRITE)
{
ComponentMetaData.FireError(0, inputColumn.IdentificationString,
String.Format(ErrorInvalidUsageType, inputColumn.Name), "",
0, out Cancel);
return DTSValidationStatus.VS_ISBROKEN;
}
The last thing you do in Validate is verify that the columns selected for the component have the correct data types:
if (inputColumn.DataType != DataType.DT_STR && inputColumn.DataType !=
DataType.DT_WSTR)
...
If the data type of the column is not in the list, then you again fire an error and set the return value to VS_ISBROKEN.
Now you will look at the workhorse method of so many of your components: ReinitializeMetaData. Here is the method in full (ReverseString.cs):
public override void ReinitializeMetaData()
{
if (!ComponentMetaData.AreInputColumnsValid)
{
ComponentMetaData.RemoveInvalidInputColumns();
}
base.ReinitializeMetaData();
}
Remember that if Validate returns VS_NEEDSNEWMETADATA, then the component internally automatically calls ReinitializeMetaData. The only time you do that for this component is when you have detected that the LineageIDs of the input columns are not quite as expected — that is to say, they do not exist on any upstream column and you want to remove them:
if (!ComponentMetaData.AreInputColumnsValid)
{
ComponentMetaData.RemoveInvalidInputColumns(); }
You finish by calling the base class’s ReinitializeMetaData method as well. Earlier, we referred to this method as the workhorse of your component because you can perform all kinds of triage on it to rescue the component from an aberrant user.
The SetUsageType method (ReverseString.cs) is called when the user is manipulating how the column on the input will be used by the component. In this component, this method validates the data type of the column and whether the user has set the column to be the correct usage type. The method returns an IDTSInputColumn, and this is the column being manipulated:
[CLSCompliant(false)]
public override IDTSInputColumn100 SetUsageType(int inputID, IDTSVirtualInput100
virtualInput, int lineageID, DTSUsageType usageType)
{
IDTSVirtualInputColumn100 virtualInputColumn =
virtualInput.VirtualInputColumnCollection.GetVirtualInputColumnByLineageID(
lineageID);
if (usageType == DTSUsageType.UT_READONLY)
throw new Exception(String.Format(ErrorInvalidUsageType,
virtualInputColumn.Name));
if (usageType == DTSUsageType.UT_READWRITE)
{
if (virtualInputColumn.DataType != DataType.DT_STR &&
virtualInputColumn.DataType != DataType.DT_WSTR)
{
throw new Exception(String.Format(ErrorInvalidDataType,
virtualInputColumn.Name));
}
}
return base.SetUsageType(inputID, virtualInput, lineageID, usageType);
}
The first thing the method does is get a reference to the column being changed, from the virtual input, which is the list of all upstream columns available.
You then perform the tests to ensure the column is suitable, before proceeding with the request through the base class. In this case, you want to ensure that the user picks only columns of type string. Note that this method looks a lot like the Validate method. The only real difference is that the Validate method, obviously, returned a different object, but it also reported errors back to the component. Validate uses the FireError method, but SetUsageType throws an exception; in SetUsageType you are checking against theVirtualInput, and in Validate() you check against the Input100. (We used to use FireError here, but the results bubbled back to the user weren’t as predictable, and we were advised that the correct behavior is to throw a new exception.) This method along with others such as InsertOutput, DeleteInput, InsertInput, OnInputAttached, and so on are important because they are the key verification methods you can use that enable you to validate in real time a change that is made to your component, and prevent it if necessary.
The InsertOutput design-time method is called when a user attempts to add an output to the component. In this component, you want to prohibit that, so if the user tries to add an output, you should throw an exception indicating that it is not allowed:
[CLSCompliant(false)]
public override IDTSOutput100 InsertOutput(DTSInsertPlacement insertPlacement, int
outputID)
{
throw new Exception("You cannot insert an output (" +
outputID.ToString() + ")");
}
You do the same when the user tries to add an input to your component in the InsertInput method:
[CLSCompliant(false)]
public override IDTSInput100 InsertInput(DTSInsertPlacement insertPlacement, int
inputID)
{
throw new Exception("You cannot insert an input (" +
inputID.ToString() + ")");
}
Notice again how in both methods you throw an exception in order to tell users that what they requested is not allowed.
If the component were asynchronous, you would need to add columns to the output yourself. You have a choice of methods in which to do this. If you want to add an output column for every input column selected, then the SetUsageType method is probably the best place to do that. This is something about which Books Online agrees. Another method for doing this might be OnInputPathAttached.
The final two methods you’ll look at for the design-time methods are the opposite of the previous two. Instead of users trying to add an output or an input to your component, they are trying to remove one of them. You do not want to allow this either, so you can use the DeleteOutput and the DeleteInput methods to tell them. Here are the methods as implemented in your component.
First the DeleteInput method (ReverseString.cs):
[CLSCompliant(false)]
public override void DeleteInput(int inputID)
{
throw new Exception("You cannot delete an input");
}
Now the DeleteOutput method:
[CLSCompliant(false)]
public override void DeleteOutput(int outputID)
{
throw new Exception("You cannot delete an output");
}
That concludes the code for the design-time part of your Transformation Component.
Runtime Methods
The first runtime method you’ll be using is the PreExecute method. As mentioned earlier, this is called once in your component’s life, and it is where you typically do most of your setup using the state-holding struct mentioned at the top of this section. It is the first opportunity you get to access the Buffer Manager, providing access to columns within the buffer, which you will need in ProcessInput as well. Keep in mind that you will not be getting a call to PrimeOutput, because this is a synchronous component, and PrimeOutput is not called in a synchronous component. Here is the PreExecute method in full (ReverseString.cs):
public override void PreExecute()
{
// Prepare array of column information. Processing requires
// lineageID so we can do this once in advance.
IDTSInput100 input = ComponentMetaData.InputCollection[0];
_inputColumnInfos = new ColumnInfo[input.InputColumnCollection.Count];
for (int x = 0; x < input.InputColumnCollection.Count; x++)
{
IDTSInputColumn100 column = input.InputColumnCollection[x];
_inputColumnInfos[x] = new ColumnInfo();
_inputColumnInfos[x].bufferColumnIndex =
BufferManager.FindColumnByLineageID(input.Buffer, column.LineageID);
_inputColumnInfos[x].columnDisposition = column.ErrorRowDisposition;
_inputColumnInfos[x].lineageID = column.LineageID;
}
}
This method first gets a reference to the input collection. The collection is zero-based, and because you have only one input, you have used the indexer and not the name, though you could have used the name as well:
IDTSInput100 input = ComponentMetaData.InputCollection[0];
At the start of this section was a list of the things your component would need later. This included a struct that you were told you would use in various guises, and it also included an array of these structs. You now need to size the array, which you do here by setting it to the count of columns in the InputColumnCollection for your component:
_inputColumnInfos = new ColumnInfo[input.InputColumnCollection.Count];
Now you loop through the columns in the InputColumnCollection. For each of the columns, you create a new instance of a column and a new instance of the struct:
IDTSInputColumn100 column = input.InputColumnCollection[x];
_inputColumnInfos[x] = new ColumnInfo();
You then read from the column the details you require and store them in the ColumnInfo object. The first thing you want to retrieve is the column’s location in the buffer. You cannot simply do this according to the order that you added them to the buffer. Though this would probably work, it is likely to catch you out at some point. You can find the column in the buffer by using a method called FindColumnByLineageID on the BufferManager object. This method takes the buffer and the LineageID of the column that you wish to find as arguments:
_inputColumnInfos[x].bufferColumnIndex =
BufferManager.FindColumnByLineageID(input.Buffer, column.LineageID);
You now need only two more details about the input column: the LineageID and the ErrorRowDisposition. Remember that ErrorRowDisposition tells the component how to treat an error:
_inputColumnInfos[x].columnDisposition = column.ErrorRowDisposition;
_inputColumnInfos[x].lineageID = column.LineageID;
When you start to build your own components, you will see how useful this method really is. You can use it to initialize any counters you may need or to open connections to Data Sources as well as anything else you think of.
The final method to look at for this component is ProcessInput. Recall that this is a synchronous transformation as dictated in ProvideComponentProperties, and this is the method in which the data is moved and manipulated. This method contains a lot of information that will help you understand the buffer and what to do with the columns in it when you receive them. It is called once for every buffer passed.
Here is the method in full (ReverseString.cs):
public override void ProcessInput(int inputID, PipelineBuffer buffer)
{
int errorOutputID = -1;
int errorOutputIndex = -1;
int GoodOutputId = -1;
IDTSInput100 inp = ComponentMetaData.InputCollection.GetObjectByID(inputID);
#region Output IDs
GetErrorOutputInfo(ref errorOutputID, ref errorOutputIndex);
// There is an error output defined
errorOutputID = ComponentMetaData.OutputCollection["RSErrors"].ID;
GoodOutputId = ComponentMetaData.OutputCollection["ReverseStringOutput"].ID;
#endregion
while (buffer.NextRow())
{
// Check if we have columns to process
if (_inputColumnInfos.Length == 0)
{
// We do not have to have columns. This is a Sync component so the
// rows will flow through regardless. Could expand Validate to check
// for columns in the InputColumnCollection
buffer.DirectRow(GoodOutputId);
}
else
{
try
{
for (int x = 0; x < _inputColumnInfos.Length; x++)
{
ColumnInfo columnInfo = _inputColumnInfos[x];
if (!buffer.IsNull(columnInfo.bufferColumnIndex))
{
// Get value as character array
char[] chars =
buffer.GetString(columnInfo.bufferColumnIndex)
.ToString().ToCharArray();
// Reverse order of characters in array
Array.Reverse(chars);
// Reassemble reversed value as string
string s = new string(chars);
// Set output value in buffer
buffer.SetString(columnInfo.bufferColumnIndex, s);
}
}
buffer.DirectRow(GoodOutputId);
}
catch(Exception ex)
{
switch (inp.ErrorRowDisposition)
{
case DTSRowDisposition.RD_RedirectRow:
buffer.DirectErrorRow(errorOutputID, 0, buffer.CurrentRow);
break;
case DTSRowDisposition.RD_FailComponent:
throw new Exception("Error processing " + ex.Message);
case DTSRowDisposition.RD_IgnoreFailure:
buffer.DirectRow(GoodOutputId);
break;
}
}
}
}
}
There is a lot going on in this method, so we’ll break it down to make it more manageable. The first thing you do is find out from the component the location of the error output:
int errorOutputID = -1;
int errorOutputIndex = -1;
int GoodOutputId = -1;
#region Output IDs
GetErrorOutputInfo(ref errorOutputID, ref errorOutputIndex);
errorOutputID = ComponentMetaData.OutputCollection["RSErrors"].ID;
GoodOutputId = ComponentMetaData.OutputCollection["ReverseStringOutput"].ID;
#endregion
The method GetErrorOutput returns the output ID and the index of the error output. Remember that you defined the error output in ProvideComponentProperties with the AddErrorOutput function.
Because you could have many inputs to a component, you want to isolate the input for this component. You can do that by finding the output that is passed into the method:
IDTSInput100 inp = ComponentMetaData.InputCollection.GetObjectByID(inputID);
You need this because you want to know what to do with the row if you encounter an issue. You provided a default value for the ErrorRowDisposition property of the input in ProvideComponentProperties, but this can be overridden in the UI.
Next, you want to check that the upstream buffer has not called SetEndOfRowset, which would mean that it has no more rows to send after the current buffer; however, the current buffer might still contain rows. You then loop through the rows in the buffer like this:
while (buffer.NextRow())
...
You then check whether the user asked for any columns to be manipulated. Because this is a synchronous component, all columns and rows are going to flow through even if you do not specify any columns for the component. Therefore, you specify that if there are no input columns selected, the row should be passed to the normal output. You do this by looking at the size of the array that holds the collection of ColumnInfo struct objects:
if (_inputColumnInfos.Length == 0)
{
buffer.DirectRow(GoodOutputId);
}
If the length of the array is not zero, then the user has asked the component to perform an operation on the column. In turn, you need to grab each of the ColumnInfo objects from the array so you can look at the data. Here you begin your loop through the columns, and for each column you create a new instance of the ColumnInfo struct:
for (int x = 0; x < _inputColumnInfos.Length; x++)
{
ColumnInfo columnInfo = _inputColumnInfos[x];
...
You now have a reference to that column and are ready to start manipulating it. You first convert the column’s data into an array of chars:
char[] chars =
buffer.GetString(columnInfo.bufferColumnIndex).ToString().ToCharArray();
The interesting part of this line is the method GetString() on the buffer object. It returns the string data of the column and accepts as an argument the index of the column in the buffer. This is really easy, because you stored that reference earlier in the PreExecutemethod.
Now that you have the char array, you can perform some operations on the data. In this case, you want to reverse the string. This code is not particular to SSIS, and it’s a trivial example of string manipulation, but you can imagine doing something more useful here such as encryption, cleaning, or formatting:
Array.Reverse(chars);
string s = new string(chars);
Now you reassign the changed data back to the column using the SetString() method on the buffer:
buffer.SetString(columnInfo.bufferColumnIndex, s);
Again, this method takes as one of the arguments the index of the column in the buffer. It also takes the string you want to assign to that column. You can see now why it was important to ensure that this column is read/write. If there was no error, you point the row to the good output buffer:
buffer.DirectRow(GoodOutputId);
If you encounter an error, you want to redirect this row to the correct output or alternately throw an error. You do that in the catch block:
catch(Exception ex)
{
switch (inp.ErrorRowDisposition)
{
case DTSRowDisposition.RD_RedirectRow:
buffer.DirectErrorRow(errorOutputID, 0, buffer.CurrentRow);
break;
case DTSRowDisposition.RD_FailComponent:
throw new Exception("Error processing " + ex.Message);
case DTSRowDisposition.RD_IgnoreFailure:
buffer.DirectRow(GoodOutputId);
break;
}
}
The code is mostly self-explanatory. If the input was configured by the user to redirect the row to the error output, then you do that. If it was told to fail the component or the user did not specify anything, then you throw an exception. Otherwise, the component is asked to just ignore the errors and allow the error row to flow down the normal output.
How would this have looked had it been an asynchronous transformation? You would get a buffer from both PrimeOutput and ProcessInput. The ProcessInput method would contain the data and structure that came into the component, and PrimeOutput would contain the structure that the component expects to pass on. The trick here is to get the data from one buffer into the other. Here is one way you can approach it.
At the class level, create a variable of type PipelineBuffer, something like this:
PipelineBuffer _pipelinebuffer;
In PrimeOutput, assign the output buffer to this buffer:
public override void PrimeOutput(int outputs, int[] outputIDs, PipelineBuffer[]
buffers)
{
_pipelinebuffer = buffers[0];
}
You now have a cached version of the buffer from PrimeOutput, and you can go straight over to ProcessInput and use it. Books Online has a great example of doing this in an asynchronous component: navigate to “asynchronous outputs.”
NOTE Don’t hesitate to look through Books Online. Microsoft has done a fantastic job of including content that offers good, solid examples. Also search for the SSIS component samples on http://msdn.microsoft.com/en-us/. Visithttp://sqlsrvintegrationsrv.codeplex.com/ for some open-source components that you can download, change, and use. The projects here are also a great learning tool because the authors are usually expert SSIS developers.
Building the Destination Adapter
The requirement for the Destination adapter is that it accepts an input from an upstream component of any description and converts it to a format similar to that seen in the Source adapter. The component will use a FILE Connection Manager, and as shown in earlier components, this involves a significant amount of validation. You also need to validate whether the component is structurally correct; if it isn’t, you need to correct things.
If you’re following along with the book and are writing the code manually, right-click on the Wrox.Pipeline project in Visual Studio and click “Add ⇒ New Item”. Select the “Class” template in the “Add New Item” dialog and create a new file named ProfSSISDestAdapter.cs.
The first thing you always need to do is declare some variables that will be used throughout the component (ProfSSISDestAdapter.cs). You also need to create the very valuable state-information struct that is going to store the details of the columns, which will be needed in PreExecute and ProcessInput:
#region Variables
private ArrayList _columnInfos = new ArrayList();
private Microsoft.SqlServer.Dts.Runtime.DTSFileConnectionUsageType _fil;
private string _filename;
FileStream _fs;
StreamWriter _sw;
#endregion
You should quickly run through the meaning of these variables and when they will be needed. The _columnInfos variable is used to store ColumnInfo objects, which describe the columns in the InputColumnCollection. The _fil variable is used to validate the type of FILEConnection Manager the user has assigned to your component. _filename stores the name of the file that is retrieved from the FILE Connection Manager. The final two variables, _fs and _sw, are used when you write to the text file in ProcessInput. Now take a look at theColumnInfo struct:
#region ColumnInfo
private struct ColumnInfo
{
public int BufferColumnIndex;
public string ColumnName;
}
#endregion
The struct is used to store the index number of the column in the buffer and the name of the column.
At this point, it is time to look at the ProvideComponentProperties method, which is where you set up the component and prepare it for use by an SSIS package, as in the other two components. Here’s the method in full (ProfSSISDestAdapter.cs):
public override void ProvideComponentProperties()
{
ComponentMetaData.RuntimeConnectionCollection.RemoveAll();
RemoveAllInputsOutputsAndCustomProperties();
ComponentMetaData.Name = "Wrox SSIS Destination Adapter";
ComponentMetaData.Description = "Our first Destination Adapter";
ComponentMetaData.ContactInfo = "www.wrox.com";
IDTSRuntimeConnection100 rtc =
ComponentMetaData.RuntimeConnectionCollection.New();
rtc.Name = "File To Write";
rtc.Description = "This is the file to which we want to write";
IDTSInput100 input = ComponentMetaData.InputCollection.New();
input.Name = "Component Input";
input.Description = "This is what we see from the upstream component";
input.HasSideEffects = true;
}
The first part of the method gets rid of any runtime Connection Managers that the component may have and removes any custom properties, inputs, and outputs it may contain. This makes the component a clean slate to which you can now add back anything it may need:
ComponentMetaData.RuntimeConnectionCollection.RemoveAll();
RemoveAllInputsOutputsAndCustomProperties();
The component requires one connection, defined as follows:
IDTSRuntimeConnection100 rtc = ComponentMetaData.RuntimeConnectionCollection.New();
rtc.Name = "File To Write";
rtc.Description = "This is the file to which we want to write";
The preceding piece of code gives the user the opportunity to specify a Connection Manager for the component. This will be the file to which you write the data from upstream.
Next, you add back the input:
IDTSInput100 input = ComponentMetaData.InputCollection.New();
input.Name = "Component Input";
input.Description = "This is what we see from the upstream component";
This is what the upstream component will connect to, and through which you will receive the data from the previous component. You need to ensure that the IDTSInput100 object of the component remains in the execution plan, regardless of whether it is attached, by setting the HasSideEffects property to true. This means that at runtime, the SSIS execution engine is smart enough to “prune” from the package any components that are not actually doing any work. You need to explicitly tell SSIS that this component is doing work (external file writes) by setting this property:
input.HasSideEffects = true;
After completing the ProvideComponentProperties method, you can move on to the AcquireConnections method (ProfSSISDestAdapter.cs). This method is not really any different from the AcquireConnections method you saw in the Source adapter; the method is shown in full but without being described in detail. If you need line-by-line details about what’s happening, you can refer back to the Source adapter. This method accomplishes the following tasks:
· Checks whether the user has supplied a Connection Manager to the component.
· Checks whether the Connection Manager is a FILE Connection Manager.
· Ensures that the FILE Connection Manager has a FileUsageType property value of DTSFileConnectionUsageType.CreateFile. (This is different from the Source, which required an existing file.)
· Gets the filename from the Connection Manager.
public override void AcquireConnections(object transaction)
{
bool pbCancel = false;
if (ComponentMetaData.RuntimeConnectionCollection["File To
Write"].ConnectionManager != null)
{
ConnectionManager cm =
Microsoft.SqlServer.Dts.Runtime.DtsConvert.GetWrapper(
ComponentMetaData.RuntimeConnectionCollection["File To Write"]
.ConnectionManager);
if (cm.CreationName != "FILE")
{
ComponentMetaData.FireError(0, "Acquire Connections", "The Connection
Manager is not a FILE Connection Manager", "", 0, out pbCancel);
throw new Exception("The Connection Manager is not a FILE Connection
Manager");
}
else
{
_fil = (DTSFileConnectionUsageType)cm.Properties["FileUsageType"]
.GetValue(cm);
if (_fil != DTSFileConnectionUsageType.CreateFile)
{
ComponentMetaData.FireError(0, "Acquire Connections",
"The type of FILE connection manager must be Create File", "",
0, out pbCancel);
throw new Exception("The type of FILE connection manager must be
Create File");
}
else
{
_filename = ComponentMetaData.RuntimeConnectionCollection
["File To Read"].ConnectionManager.AcquireConnection(transaction)
.ToString();
if (_filename == null || _filename.Length == 0)
{
ComponentMetaData.FireError(0, "Acquire Connections", "Nothing
returned when grabbing the filename", "", 0, out pbCancel);
throw new Exception("Nothing returned when grabbing the filename");
}
}
}
}
}
A lot of ground is covered in the AcquireConnections method. Much of this code is covered again in the Validate method, which you will visit now. The Validate method also checks whether the input to the component is correct; if it isn’t, you try to fix what is wrong by calling ReinitializeMetaData. Here is the Validate method (ProfSSISDestAdapter.cs):
[CLSCompliant(false)]
public override DTSValidationStatus Validate()
{
bool pbCancel = false;
if (ComponentMetaData.OutputCollection.Count != 0)
{
ComponentMetaData.FireError(0, ComponentMetaData.Name,
"Unexpected Output
Found. Destination components do not support outputs.", "",
0, out pbCancel);
return DTSValidationStatus.VS_ISCORRUPT;
}
if (ComponentMetaData.RuntimeConnectionCollection["File To Write"]
.ConnectionManager == null)
{
ComponentMetaData.FireError(0, "Validate", "No Connection Manager returned",
"", 0, out pbCancel);
return DTSValidationStatus.VS_ISCORRUPT;
}
if (ComponentMetaData.AreInputColumnsValid == false)
{
ComponentMetaData.InputCollection["Component Input"]
InputColumnCollection.RemoveAll();
return DTSValidationStatus.VS_NEEDSNEWMETADATA;
}
return base.Validate();
}
The first check in the method ensures that the component has no outputs:
bool pbCancel = false;
if (ComponentMetaData.OutputCollection.Count != 0)
{
ComponentMetaData.FireError(0, ComponentMetaData.Name, "Unexpected Output found.
Destination components do not support outputs.", "", 0, out pbCancel);
return DTSValidationStatus.VS_ISCORRUPT;
}
You now want to ensure that the user specified a Connection Manager. Remember that you are only validating the fact that a Connection Manager is specified, not whether it is a valid type. The extensive checking of the Connection Manager is done inAcquireConnections().
if (ComponentMetaData.RuntimeConnectionCollection["File To
Write"].ConnectionManager == null)
{
ComponentMetaData.FireError(0, "Validate", "No Connection Manager returned", "",
0, out pbCancel);
return DTSValidationStatus.VS_ISCORRUPT;
}
The final thing you do in this method is to check whether the input columns are valid. Valid in this instance means that the columns in the input collection reference existing columns in the upstream component. If this is not the case, you call the trustyReinitializeMetaData method.
if (ComponentMetaData.AreInputColumnsValid == false)
{
ComponentMetaData.InputCollection["Component Input"]
.InputColumnCollection.RemoveAll();
return DTSValidationStatus.VS_NEEDSNEWMETADATA;
}
The return value DTSValidationStatus.VS_NEEDSNEWMETADATA means that the component will now call ReinitializeMetaData to try to sort out the problems with the component. Here is that method in full:
public override void ReinitializeMetaData()
{
IDTSInput100 _profinput = ComponentMetaData.InputCollection["Component Input"];
_profinput.InputColumnCollection.RemoveAll();
IDTSVirtualInput100 vInput = _profinput.GetVirtualInput();
foreach (IDTSVirtualInputColumn100 vCol in vInput.VirtualInputColumnCollection)
{
this.SetUsageType(_profinput.ID, vInput, vCol.LineageID,
DTSUsageType.UT_READONLY);
}
}
NOTE Notice that the columns are blown away in ReinitializeMetaData and built again from scratch. A better solution is to test what the invalid columns are and try to fix them. If you cannot fix them, you could remove them, and then the user could reselect at leisure. Books Online has an example of doing this.
The IDTSVirtualInput and IDTSVirtualInputColumnCollection in this component need a little explanation. There is a subtle difference between these two objects and their input equivalents. The “virtual” objects are what your component could have as inputs — that is to say, they are upstream inputs and columns that present themselves as available to your component. The inputs themselves are what you have chosen for your component to have as inputs from the virtual object. In the ReinitializeMetaData method, you start by removing all existing input columns:
IDTSInput100 _profinput = ComponentMetaData.InputCollection["Component Input"];
_profinput.InputColumnCollection.RemoveAll();
You then get a reference to the input’s virtual input:
IDTSVirtualInput100 vInput = _profinput.GetVirtualInput();
Now that you have the virtual input, you can add an input column to the component for every virtual input column you find:
foreach (IDTSVirtualInputColumn100 vCol in vInput.VirtualInputColumnCollection)
{
this.SetUsageType(_profinput.ID, vInput, vCol.LineageID,
DTSUsageType.UT_READONLY);
}
The SetUsageType method simply adds an input column to the input column collection of the component, or removes it depending on your UsageType value. When a user adds a connector from an upstream component that contains its output to this component and attaches it to this component’s input, the OnInputAttached method is called. This method has been overridden in the component herein:
public override void OnInputPathAttached(int inputID)
{
IDTSInput100 input = ComponentMetaData.InputCollection.GetObjectByID(inputID);
IDTSVirtualInput100 vInput = input.GetVirtualInput();
foreach (IDTSVirtualInputColumn100 vCol in vInput.VirtualInputColumnCollection)
{
this.SetUsageType(inputID, vInput, vCol.LineageID, DTSUsageType.UT_READONLY);
}
}
This method is the same as the ReinitializeMetaData method except that you don’t need to remove the input columns from the collection. This is because if the input is not mapped to the output of an upstream component, there can be no input columns.
That completes the design-time methods for your component. You can now move on to look at the runtime methods. You are going to be looking at only two methods: PreExecute and ProcessInput.
PreExecute is executed only once in this component (ProfSSISDestAdapter.cs), so you want to do as much preparation work as you can in this method. It is also the first opportunity in the component to access the Buffer Manager, which contains the columns. In this component, you use it for two things: getting the information about the component’s input columns and storing essential details about them:
public override void PreExecute()
{
IDTSInput100 input = ComponentMetaData.InputCollection["Component Input"];
foreach (IDTSInputColumn100 inCol in input.InputColumnCollection)
{
ColumnInfo ci = new ColumnInfo();
ci.BufferColumnIndex = BufferManager.FindColumnByLineageID(input.Buffer,
inCol.LineageID);
ci.ColumnName = inCol.Name;
_columnInfos.Add(ci);
}
// Open the file
_fs = new FileStream(_filename, FileMode.OpenOrCreate, FileAccess.Write);
_sw = new StreamWriter(_fs);
}
First you get a reference to the component’s input:
IDTSInput100 input = ComponentMetaData.InputCollection["Component Input"];
Then you loop through the input’s InputColumnCollection:
foreach (IDTSInputColumn100 inCol in input.InputColumnCollection)
{
For each input column you find, you need to create a new instance of the ColumnInfo struct. You then assign to the struct values you can retrieve from the input column itself and the Buffer Manager. You assign these values to the struct and finally add them to the array that is holding all the ColumnInfo objects:
ColumnInfo ci = new ColumnInfo();
ci.BufferColumnIndex = BufferManager.FindColumnByLineageID(input.Buffer,
inCol.LineageID);
ci.ColumnName = inCol.Name;
_columnInfos.Add(ci);
Doing things this way will enable you to move more quickly through the ProcessInput method. The last thing you do in the PreExecute method is get a reference to the file to which you want to write:
_fs = new FileStream(_filename, FileMode.OpenOrCreate, FileAccess.Write);
_sw = new StreamWriter(_fs);
You will use this in the next method, ProcessInput (ProfSSISDestAdapter.cs). ProcessInput is where you are going to keep reading the rows that are coming from the upstream component. While there are rows, you write those values to a file. This is a very simplistic view of what needs to be done, so you should have a look at how to make that happen.
public override void ProcessInput(int inputID, PipelineBuffer buffer)
{
while (buffer.NextRow())
{
_sw.WriteLine("<START>");
for (int i = 0; i < _columnInfos.Count; i++)
{
ColumnInfo ci = (ColumnInfo)_columnInfos[i];
if (buffer.IsNull(ci.BufferColumnIndex))
{
_sw.WriteLine(ci.ColumnName + ":");
}
else
{
_sw.WriteLine(ci.ColumnName + ":" +
buffer[ci.BufferColumnIndex].ToString());
}
}
_sw.WriteLine("<END>");
}
if (buffer.EndOfRowset) _sw.Close();
}
The first thing you do is check whether there are still rows in the buffer:
while (buffer.NextRow())
{
...
You now need to loop through the array that is holding the collection of ColumnInfo objects that were populated in the PreExecute method:
for (int i = 0; i < _columnInfos.Count; i++)
For each iteration, you create a new instance of the ColumnInfo object:
ColumnInfo ci = (ColumnInfo)_columnInfos[i];
You now need to retrieve from the buffer object the value of the column whose index you will pass in from the ColumnInfo object. If the value is not null, you write the value of the column and the column name to the text file. If the value is null, you write just the column name to the text file. Again, because you took the time to store these details in a ColumnInfo object earlier, retrieving these properties is easy.
if (buffer.IsNull(ci.BufferColumnIndex))
{
_sw.WriteLine(ci.ColumnName + ":");
}
else
{
_sw.WriteLine(ci.ColumnName + ":" + buffer[ci.BufferColumnIndex].ToString());
}
Finally, you check whether the upstream component has called SetEndOfRowset; if so, you close the file stream:
if (buffer.EndOfRowset) _sw.Close();
Having concluded your look at the Destination adapter, you are ready to learn how you get SSIS to recognize your components and what properties you need to assign to them.
USING THE COMPONENTS
In this section you install the components you have created into the SSIS design environment so you can use them to build packages. You then learn how to debug the components so you can troubleshoot any coding issues they contain.
Installing the Components
Unlike previous versions of BIDS pre SQL Server 2012, there is no Choose Items dialog for SQL Server Data Tools SSIS components. To add a component to the SSIS Toolbox:
1. Open SQL Server Data Tools and then create or open an SSIS solution.
2. Create a new Data Flow Task and then double-click it to enter the Data Flow panel. The Wrox.Pipeline components will automatically appear in the SSIS Toolbox (see Figure 19-6).
FIGURE 19-6
The components show up automatically because they are copied to the %PROGRAMFILES%\Microsoft SQL Server\120\DTS\PipelineComponents directory in your project’s post-build event.
If the components are not displayed in the SSIS Toolbox, ensure that you are referencing the SQL Server 2014 versions of the references, not any of the previous versions of SQL Server, and that the post-build event in your project is copying the files to the correct directory for your installation of Integration Services.
Debugging Components
Debugging components is a really great feature of SSIS. If you are a Visual Studio.NET developer, you should easily recognize the interface. If you’re not familiar with Visual Studio, this section explains what you need to know to become proficient in debugging your components.
There are two phases for debugging. The design time can be debugged only while you’re developing your package, so it makes sense that you need to use SQL Server Data Tools to do this. The second phase, which is the runtime experience, is slightly different. You can still use SQL Server Data Tools, though, and when your package runs, the component will stop at breakpoints you designate. You need to set up a few things first, though. You can also use DTExec to fire the package straight from Visual Studio. The latter method saves you the cost of invoking another instance of Visual Studio. The component you are going to debug is the Reverse String Transformation.
Design Time
This section describes the process of debugging the component at design time. Open the Visual Studio Wrox.Pipeline C# project and set a C# breakpoint at ProvideComponentProperties (SSIS also has breakpoints, which are discussed further in Chapter 18). Now create a new SSIS project in SQL Server Data Tools. In the package, add a Data Flow Task and double-click it. If your component is not in the Toolbox already, add it now.
You need to create a full pipeline in this package because you’ll be using it later when you debug the runtime. Therefore, get an OLE DB or ADO.NET Connection Manager and point it to the AdventureWorks database. Now add an OLE DB or ADO.NET Source adapter to the design surface and configure it to use the Connection Manager you just created. Point the source to one of the tables in AdventureWorks — perhaps Person.Person — and select the columns you want to use.
Before adding your new components to the designer, you need to attach to the SQL Server Data Tools instance (DevEnv.exe) from the Wrox.Pipeline project you’re working in so that it can receive the methods fired by the component. To do that, in the Visual Studio Wrox.Pipeline C# project, select Debug ⇒ Attach to Process. The Attach to Process dialog opens (see Figure 19-7), where you can choose what you want to debug, as well as which process.
FIGURE 19-7
The process you’re interested in is the package you’re currently building. This shows up in the Available Processes list as ProSSIS2014_ISProject – Microsoft Visual Studio (the name you see may differ). Just above this window is a small box containing the words “Managed (v4.0) code.” This tells the debugger what you want to debug in the component. Three options are available, which you can view by clicking the Select button to the right of the label: Managed, Native, and Script.
Highlight the process for your package and click Attach. If you look down now at the status bar in your component’s design project, you should see a variety of debug symbols being loaded. Go back to the SSIS package and drop the Reverse String Transformation onto the design surface. Because one of the first things a component does after it is dropped into a package is call ProvideComponentProperties, you should immediately see your component break into the code in its design project, as shown in Figure 19-8.
FIGURE 19-8
As you can see, the breakpoint on ProvideComponentProperties in the component’s design project has been hit. This is indicated by a yellow arrow inside the red breakpoint circle on the left. You are now free to debug the component as you would any other piece of managed code in Visual Studio.NET. If you’re familiar with debugging, a number of windows appear at this point at the bottom of the IDE, such as Locals, Autos, and Call Stack. These can help you get to the root of any debugging problems, but you don’t need to use them now.
To leave debugging mode, return to Visual Studio and select Debug ⇒ Stop Debugging.
Building the Complete Package
Because the package already has a source and Transformation Component on it, you just need to add a destination. First make sure you have both configured the Reverse String Transformation to reverse some of the columns by double-clicking it and selected the required columns in the custom UI (or the Advanced UI if you have not built the custom UI yet, which is discussed in Chapter 20).
In the SSIS Connections pane, create a new File Connection Manager, setting the Usage Type to Create File. Enter a filename in a location of your choice, and then close the Connection Manager dialog.
Drop the Destination Component you have just built onto the design surface and connect the output of the Reverse String Transformation to the input of the destination. Open the destination’s editor, and on the first tab of the Advanced Editor, set the File to Write property value to the name of the connection you just created. Flip over to the Input Columns tab in the editor, and select which columns you want to write to the output file.
Runtime Debugging
As promised, in this section you are going to look at two ways of debugging. As with design-time debugging, the first is through the SQL Server Data Tools designer. The other is by using DTExec and the package properties. Using SQL Server Data Tools is similar to the design-time method with a subtle variation.
You should now have a complete pipeline with the Reverse String Transformation in the middle. If you don’t, quickly create a pipeline like the one shown in Figure 19-9.
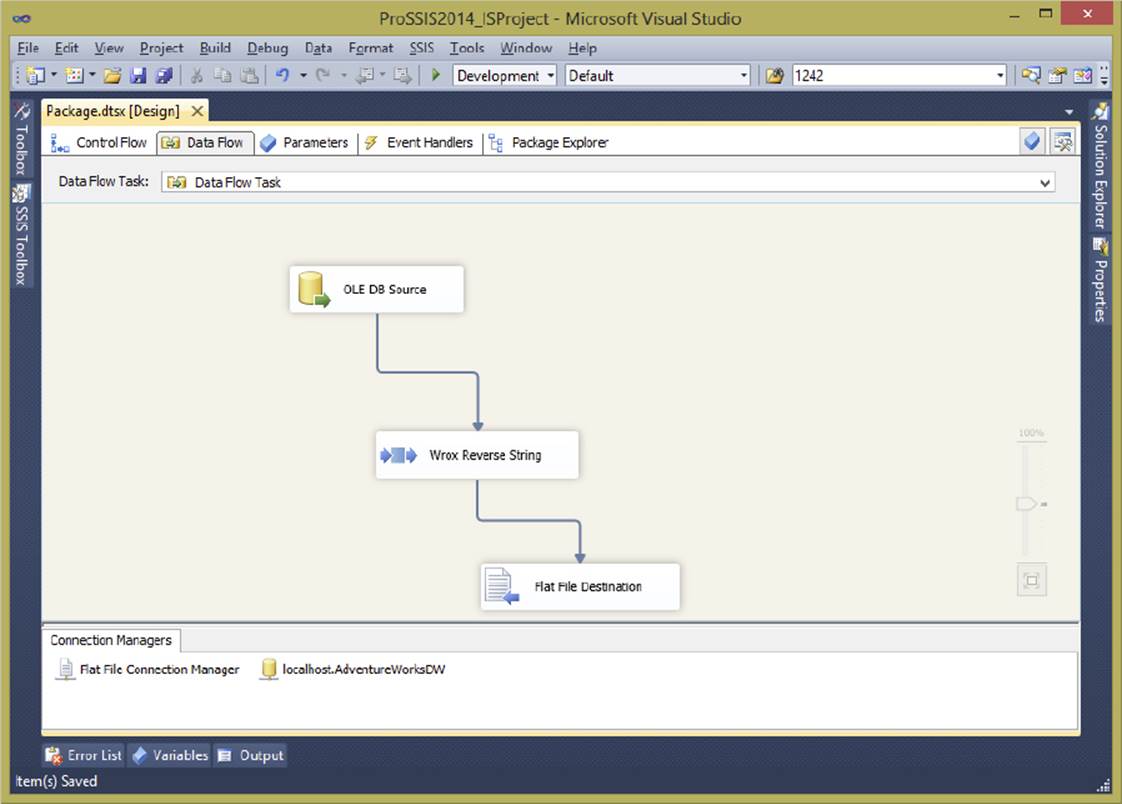
FIGURE 19-9
NOTE Instead of a real destination that writes to a file or database, it is often useful to write to a so-called trash destination. You can use a Row Count Transformation or Union All Transformation for this purpose.
You now need to add a breakpoint to the Data Flow Task that is hit when the Data Flow Task hits the OnPreExecute event. You need to do this so that you can attach your debugger to the correct process at runtime. Right-click the Data Flow Task itself and select Edit Breakpoints. The Set Breakpoints dialog will appear, as shown in Figure 19-10.
FIGURE 19-10
To execute your SSIS package, press F5 and allow the breakpoint in the Data Flow Task to be hit. When you hit the breakpoint, switch back to the component’s design process and follow the steps detailed earlier for design-time debugging in order to get to the screen where you chose what process to debug.
When you execute a package in the designer, it is not really the designer that is doing the work. It hands off the execution to a process called DtsDebugHost.exe. This is the package that you want to attach to, as shown in Figure 19-11. You will probably see two of these processes listed; the one you want has Managed listed under the Type column (don’t attach to the process showing x86 as the type).
FIGURE 19-11
Click Attach and watch the debug symbols being loaded by the project. Before returning to the SSIS package, you need to set a breakpoint on one of the runtime methods used by your component, such as PreExecute. Return to the SSIS project and press F5 again. This will release the package from its suspended state and allow the package to flow on. Now when the Reverse String Component hits its PreExecute method, you should be able to debug what it is doing. In Figure 19-12, this user put a breakpoint on a line of code that enables him or her to look at the “input” variable in the Locals window.
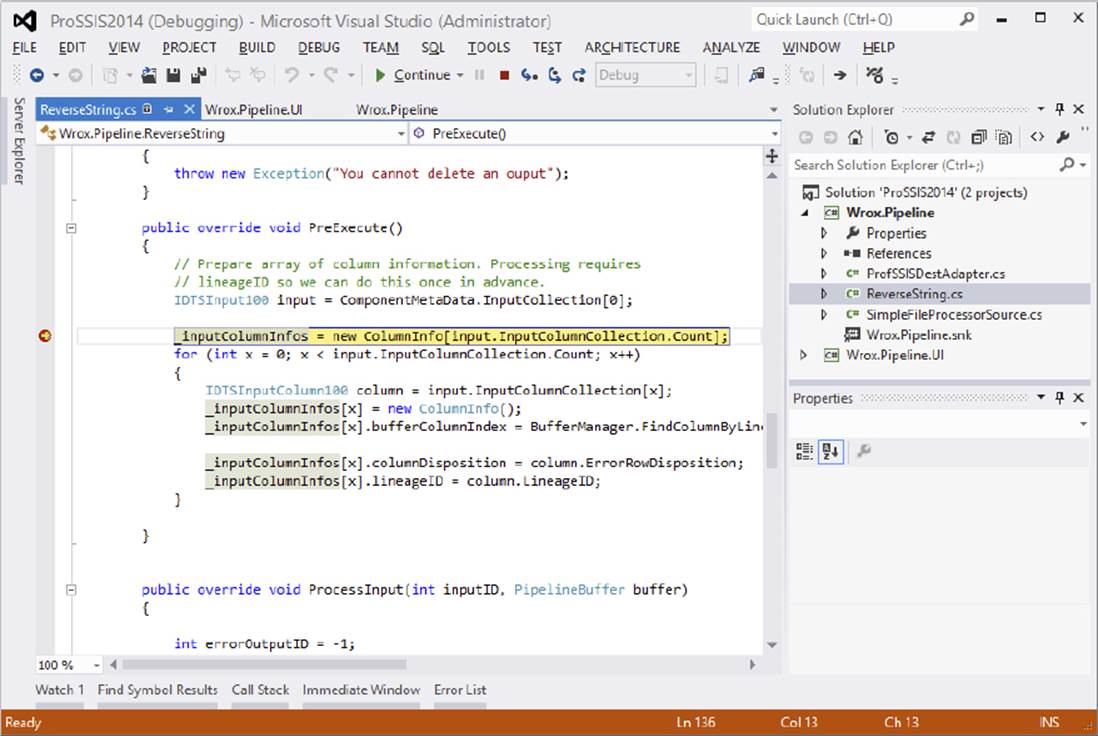
FIGURE 19-12
That concludes your look at the first method for debugging the runtime. The second method involves SQL Server Data Tools indirectly because you need to create a package like this one that you can call later. After that, you don’t need SQL Server Data Tools at all. You do, however, still need the component’s design project open. Open your Visual Studio Reverse String C# project’s properties and look at the Debug tab on the left, which should look similar to Figure 19-13.
FIGURE 19-13
As you can see, you have said that you want to start an external program to debug. That program is DTExec, which is the new and more powerful version of DTSRun. On the command line, you pass a parameter /FILE to DTExec. This tells DTExec the name and location of the package you just built. Make sure the file path to your package is valid, and ensure that you still have a C# breakpoint set on PreExecute, and press F5 in your project. A DOS window will appear where you will see some messages fly past; these are the same messages you would see in the designer. Eventually you will get to your breakpoint, and it will break in exactly the same way that it did when you were using SQL Server Data Tools. Why might you use one approach over the other? The most obvious answer is speed. It is much faster to get to where you want to debug your component using DTExec than it is doing the same in SQL Server Data Tools. The other advantage is that you don’t need two tools open at the same time. You can focus on your component’s design project and not worry about SQL Server Data Tools at all.
UPGRADING TO SQL SERVER 2014
If you already built components in SQL Server 2008 and you want to use them in SQL Server 2014, you have to update the references and recompile the components. There weren’t any significant changes to SSIS from 2012, and all components compiled to run against 2012 will automatically work in 2014.
Microsoft has retained the same interface names used in SQL Server 2008 (for example, IDTSInput100) so the upgrade process is straightforward. To upgrade, simply open your old Visual Studio 2008 project in Visual Studio 2010, 2012 or 2013. The project will upgrade automatically to the new Visual Studio format. You then need to update the references to the latest SQL Server 2014 Integration Services components referenced in the beginning of the chapter. Most of the code should be the same, as the interfaces haven’t changed that much between SQL Server 2008, 2012, and 2014 in reference to the SSIS interfaces. Everything should compile, and you should be able to run your components in the SQL Server 2014 SQL Server Data Tools environment.
SUMMARY
In this chapter, you have built Pipeline Components. Although designing your own components isn’t exactly like falling off a log, once you get a handle on what methods do what, when they are called, and what you can possibly use them for, you can certainly create new components with only a moderate amount of programming knowledge. After you learn the basic patterns, it is simple to develop your second, third, and tenth components. The components you designed here are very simple in nature, but it is hoped that this chapter provided you with the confidence to experiment with some of your own unique requirements. In Chapter 20, you learn how to create custom user interfaces for your components. While this is not a necessary step (because SSIS provides a default UI for custom components), it can make your components more user-friendly, especially if they are tricky to configure.
NOTE One area that we weren’t able to cover in this chapter is how to build a custom Connection Manager. For more help on building a Connection Manager you can visit http://msdn.microsoft.com/en-us/library/ms403359.aspx.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.