Real-time Analytics with Storm and Cassandra (2015)
Chapter 10. Advance Concepts in Storm
In this chapter, we will cover the following topics:
· Building a Trident topology
· Understanding the Trident API
· Examples and illustrations
In this chapter, we will learn about transactional topologies and the Trident API. We will also explore the aspects of micro-batching and its implementation in Storm topology.
Building a Trident topology
Trident gives a batching edge to the Storm computation. It lets developers use the abstracted layer for computations over the Storm framework, giving the advantage of stateful processing with high throughput for distributed queries.
Well the architecture of Trident is the same as Storm; it's built on top of Storm to abstract a layer that adds the functionality of micro-batching and execution of SQL-like functions on top of Storm.
For the sake of analogy, one can say that Trident is a lot like Pig for batch processing in terms of concept. It has support for joins, aggregates, grouping, filters, functions, and so on.
Trident has basic batch processing features such as consistent processing and execution of process logic over the tuples exactly once.
Now to understand Trident and its working; let's look at a simple example.
The example we have picked up would achieve the following:
· Word count over the stream of sentences (a standard Storm word count kind of topology)
· A query implementation to get the sum of counts for a set of listed words
Here is the code for dissection:
FixedBatchSpout myFixedspout = new FixedBatchSpout(new Fields("sentence"), 3,
new Values("the basic storm topology do a great job"),
new Values("they get tremendous speed and guaranteed processing"),
new Values("that too in a reliable manner "),
new Values("the new trident api over storm gets user more features "),
new Values("it gets micro batching over storm "));
myFixedspout.setCycle(true);
This preceding code snippet ensures that the spout myFixedspout cycles over the set of sentences added as values. This snippet ensures that we have an endless flow of data streams into the topology and enough points to perform all micro-batching functions that we intend to.
Now we have made sure about continuous input stream let's look at the following snippet:
//creating a new trident topology
TridentTopology myTridentTopology = new TridentTopology();
//Adding a spout and configuring the fields and query
TridentState myWordCounts = topology.newStream("myFixedspout", spout)
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"))
.parallelismHint(6);
Now let's look at the code line by line to interpret how it works.
Here we start with creating a Trident topology object, which in turn gets the developer access to the Trident interfaces.
This topology, myTridentTopology, has access to a method called newStream that enables it to create a new stream to read the data from the source.
Here we use myFixedSpout from the preceding snippet that would cycle through a predefined set of sentences. In a production scenario or a real-life scenario, we will use a spout to read the streams off a queue (such as RabbitMQ, Kafka, and so on).
Now the micro-batching; who does it and how? Well the Trident framework stores the state for each source (it kind of remembers what input data it has consumed so far). This state saving is done in the Zookeeper cluster. The tagging spout in the preceding code is actually a znode, which is created in the Zookeeper cluster to save the state metadata information.
This metadata information is stored for small batches wherein the batch size is a variant based on the speed of incoming tuples; it could be few hundred to millions of tuples based on the event transactions per second (tps).
Now my spout reads and emits the stream into the field labeled as sentence. In the next line, we will split the sentence into words; that's the very same functionality that we deployed in our earlier reference to the wordCount topology.
The following is the code context capturing the working of the split functionality:
public class Split extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
collector.emit(new Values(word));
}
}
}
A very simple context splits the sentence on white space to emit each word as a tuple.
Now the topology beyond this point computes the count and stores the results in a persistent manner. The topology can be computed by using the following steps:
1. We group the stream by the word field.
2. We aggregate and persist each group using the count aggregator.
The persistent function should be written in a fashion to store the results of aggregation in a store that's actually persisting the state. The illustration in the preceding code keeps all the aggregates in memory, this snippet can be very conveniently rewritten to persist the values to IMDB in memory database systems such as memcached or Hazelcast, or stable storage such as Cassandra and so on.
Trident with Storm is so popular because it guarantees the processing of all tuples in a fail-safe manner in exactly one semantic. In situations where retry is necessary because of failures, it does that exactly once and once only, so as a developer I don't end up updating the table storage multiple times on occurrence of a failure.
Trident works on micro-batching by creating very small batches on incoming streams, as shown in the following figure:
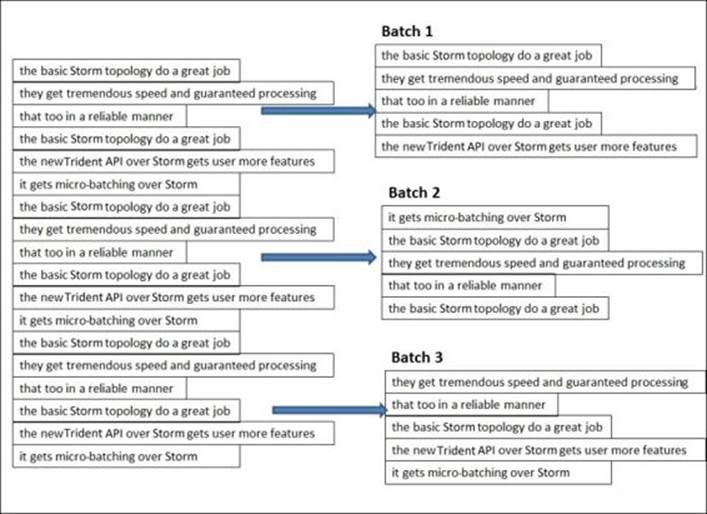
In the preceding figure, we have given a clear demonstration for micro-batching, how small batches are created over the streaming data by the Trident framework in Storm. Please remember, the preceding figure is just an illustration of micro-batching; the actual number of tuples in a batch is dependent on the tps of the incoming data on the source and is decided by the framework.
Now having achieved the micro-batching part of the problem, let's move on to the next part of the problem that is executing distributed queries on these micro batches. Trident Storm guarantees these queries to be low latency and lightning fast. In processing and semantics, these queries are very much like Remote Procedure Call (RPC), but the distinction of Storm is that it gets you a high degree of parallelism, thus making them high performance and lightning fast in their execution.
Let's have a look at integration of such DRPC-based queries with our Trident components.
The following is a code snippet for DRPC followed by an explanation:
myTridentTopology.newDRPCStream("words")
.each(new Fields("args"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.stateQuery(wordCounts, new Fields("word"), new MapGet(), new Fields("count"))
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));
In the preceding code snippet, we created a DRPC stream using myTridentTopology and over and above it, we have a function named word.
Each of the DRPC query requests are treated as its own mini batch processing job, the two arguments that do this mini job is a single tuple representing the request. For instance, in our case, the argument is a list of words separated using a space.
Here are the steps that are being executed in the previous code snippet:
· We split the argument stream into its constituent words; for example, my argument, storm trident topology, is split into individual words such as storm, trident, and topology
· Then the incoming stream is grouped by word
· Next, the state-query-operator is used to query the Trident-state-object that was generated by the first part of the topology:
o State query takes in the word counts computed by an earlier section of the topology.
o It then executes the function as specified as part of the DRPC request to query the data.
o In this case, my topology is executing the MapGet function on the query to get the count of each word; the DRPC stream, in our case, is grouped in exactly the same manner as the TridentState in the preceding section of the topology. This arrangement guarantees that all my word count queries for each word are directed to the same Trident state partition of the TridentState object that would manage the updates for the word.
· FilterNull ensures that the words that don't have a count are filtered out
· The sum aggregator then sums all the counts to get the results, which are automatically returned back to the awaiting client
Having understood the execution as per the developer-written code, let's take a look at what's boilerplate to Trident and what happens automatically behind the scenes when this framework executes.
· We have two operations in our Trident word count topology that read from or write to state—persistentAggregate and stateQuery. Trident employs the capability to batch these operations automatically to that state. So for instance, the current processing requires 10 reads and writes to the database; Trident would automatically batch them together as one read and one write. This gets you performance and ease of computation where the optimization is handled by the framework.
· Trident aggregators are other highly efficient and optimized components of the framework. They don't work by the rule to transfer all the tuples to one machine and then aggregate, instead they optimize the computation by executing partial aggregations wherever possible and then transfer the results over the network, thus saving on network latency. The approach employed here is similar to combiners of the MapReduce world.
Understanding the Trident API
Trident API supports five broad categories of operations:
· Operations for manipulations of partitioning local data without network transfer
· Operations related to the repartitioning of the stream (involves the transfer of stream data over the network)
· Data aggregation over the stream (this operation do the network transfer as a part of operation)
· Grouping over a field in the stream
· Merge and join
Local partition manipulation operation
As the name suggests, these operations are locally operative over the batch on each node and no network traffic is involved for it. The following functions fall under this category.
Functions
· This operation takes single input value and emits zero or more tuples as the output
· The output of these function operations is appended to the end of the original tuple and emitted to the stream
· In cases where the function is such that no output tuple is emitted, the framework filters the input tuple too, while in other cases the input tuple is duplicated for each of the output tuples
Let's illustrate how this works with an example:
public class MyLocalFunction extends BaseFunction {
public void execute(TridentTuple myTuple, TridentCollector myCollector) {
for(int i=0; i < myTuple.getInteger(0); i++) {
myCollector.emit(new Values(i));
}
}
}
Now the next assumption, the input stream in the variable called myTridentStream has the following fields ["a", "b", "c" ] and the tuples on the stream are depicted as follows:
[10, 2, 30]
[40, 1, 60]
[30, 0, 80]
Now, let's execute the sample function created in the preceding code, as shown in the following code snippet:
mystream.each(new Fields("b"), new MyLocalFunction(), new Fields("d")))
The output expected here is as per the function it should return ["a", "b", "c", "d"], so for the preceding tuples in the stream I would get the following output:
//for input tuple [10, 2, 30] loop in the function executes twice //value of b=2
[10, 2, 30, 0]
[10, 2, 30, 1]
//for input tuple [4, 1, 6] loop in the function executes once value //of b =1
[4, 1, 6, 0]
//for input tuple [3, 0, 8]
//no output because the value of field b is zero and the for loop //would exit in first iteration itself value of b=0
Filters
Filters are no misnomers; their execution is exactly the same as their name suggests: they help us decide whether or not we have to keep a tuple or not—they do exactly what filters do, that is, remove what is not required as per a given criteria.
Let's have a look at the following snippet to see a working illustration of filter functions:
public class MyLocalFilterFunction extends BaseFunction {
public boolean isKeep(TridentTuple tuple) {
return tuple.getInteger(0) == 1 && tuple.getInteger(1) == 2;
}
}
Let's look at the sample tuples on the input stream with the fields as [ "a" , "b" , "c"]:
[1,2,3]
[2,1,1]
[2,3,4]
We execute or call the function as follows:
mystream.each(new Fields("b", "a"), new MyLocalFilterFunction())
The output would be as follows:
//for tuple 1 [1,2,3]
// no output because valueof("field b") ==1 && valueof("field a") ==2 //is not satisfied
//for tuple 1 [2,1,1]
// no output because valueof("field b") ==1 && valueof("field a") ==2 [2,1,1]
//for tuple 1 [2,3,4]
// no output because valueof("field b") ==1 && valueof("field a") ==2 //is not satisfied
partitionAggregate
The partitionAggregate function on each of the partitions over a set of tuples clubbed together as a batch. There is a behavioral difference between this function; compared to local functions that we have executed so far, this one emits a single output tuple for the stream on input tuples.
The following are other functions that can be used for various aggregates that can be executed over this framework.
Sum aggregate
Here is how the call is made to the sum aggregator function:
mystream.partitionAggregate(new Fields("b"), new Sum(), new Fields("sum"))
Let's assume the input stream has the ["a", "b"] fields, and the following are the tuples:
Partition 0:
["a", 1]
["b", 2]
Partition 1:
["a", 3]
["c", 8]
Partition 2:
["e", 1]
["d", 9]
["d", 10]
The output will be as follows:
Partition 0:
[3]
Partition 1:
[11]
Partition 2:
[20]
CombinerAggregator
The implementation of this interface provided by the Trident API returns a single tuple with a single field as an output; internally, it executes an init function on each input tuple and then after that it combines the values until only one value is left, which is returned as an output. If the combiner functions encounter a partition that doesn't have any value, "0" is emitted.
Here is the interface definition and its contracts:
public interface CombinerAggregator<T> extends Serializable {
T init(TridentTuple tuple);
T combine(T val1, T val2);
T zero();
}
The following is the implementation for the count functionality:
public class myCount implements CombinerAggregator<Long> {
public Long init(TridentTuple mytuple) {
return 1L;
}
public Long combine(Long val1, Long val2) {
return val1 + val2;
}
public Long zero() {
return 0L;
}
}
The biggest advantage these CombinerAggregators functions have over the partitionAggregate function is that it's a more efficient and optimized approach as it proceeds by performing partial aggregations before the transfer of results over the network.
ReducerAggregator
As the name suggests, this function produces an init value and then iterates over every tuple in the input stream to produce an output comprising of a single field and a single tuple.
The following is the interface contract for the ReducerAggregate interface:
public interface ReducerAggregator<T> extends Serializable {
T init();
T reduce(T curr, TridentTuple tuple);
}
Here is the implementation of this interface for count functionality:
public class myReducerCount implements ReducerAggregator<Long> {
public Long init() {
return 0L;
}
public Long reduce(Long curr, TridentTuple tuple) {
return curr + 1;
}
}
Aggregator
An Aggregator function is the most commonly used and versatile aggregator function. It has the ability to emit one or more tuples, and each can have any number of fields. They have the following interface signature:
public interface Aggregator<T> extends Operation {
T init(Object batchId, TridentCollector collector);
void aggregate(T state, TridentTuple tuple, TridentCollector collector);
void complete(T state, TridentCollector collector);
}
The execution pattern is as follows:
· The init method is a predecessor to processing of every batch. It's called before the processing of each batch. On completion, it returns an object holding the state representation of the batch, and this is passed on to the subsequent aggregate and complete methods.
· Unlike the init method, the aggregate method is called once for every tuple in the batch partition. This method can store the state, and can emit the results depending upon functionality requirements.
· The complete method is like a postprocessor; it's executed at the end, when the batch partition has been completely processed by the aggregate.
The following is the implementation of the count as an aggregator function:
public class CountAggregate extends BaseAggregator<CountState> {
static class CountState {
long count = 0;
}
public CountState init(Object batchId, TridentCollector collector) {
return new CountState();
}
public void aggregate(CountState state, TridentTuple tuple, TridentCollector collector) {
state.count+=1;
}
public void complete(CountState state, TridentCollector collector) {
collector.emit(new Values(state.count));
}
}
Numerous times we run into implementations requiring multiple aggregators to be executing simultaneously. In such cases, the concept of chaining comes in handy. Thanks to this functionality in the Trident API, we can build an execution chain of aggregators to be executed over batches of incoming stream tuples. Here is an example of these kinds of chains:
myInputstream.chainedAgg()
.partitionAggregate(new Count(), new Fields("count"))
.partitionAggregate(new Fields("b"), new Sum(), new Fields("sum"))
.chainEnd()
The execution of this chain would run the specified sum and count aggregator functions on each partition. The output would be a single tuple, with two fields holding the values of sum and count.
Operations related to stream repartitioning
As the name suggests, these stream repartitioning operations are related to the execution of functions to change the tuple partitions across the tasks. These operations involve network traffic and the results redistribute the stream, and can result in changes to an overall partitioning strategy thus impacting a number of partitions.
Here are the repartitioning functions provided by the Trident API:
· Shuffle: This executes a rebalance kind of functionality and it employs a random round robin algorithm for an even redistribution of tuples across the partitions.
· Broadcast: This does what the name suggests; it broadcasts and transmits each tuple to every target partition.
· partitionBy: This function works on hashing and mod on a set of specified fields so that the same fields are always moved to the same partitions. As an analogy, one can assume that the functioning of this is similar to the fields grouping that we learned about initially in Storm groupings.
· global: This is identical to the global grouping of streams in a Storm, and in this case, the same partition is chosen for all the batches.
· batchGlobal: All tuples in a batch are sent to the same partition (so they kind of stick together), but different batches can be delivered to different partitions.
Data aggregations over the streams
Storm's Trident framework provides two kinds of operations for performing aggregations:
· aggregate: We have covered this in an earlier section, and it works in isolated partitions without involving network traffic
· persistentAggregate: This performs aggregate across partitions, but the difference is that it stores the results in a source of state
Grouping over a field in a stream
Grouping operations work in analogy to group by the operations in a relational model with the only differential being that the ones in the Storm framework execute over a stream of tuples from the input source.
Let's understand this more closely with the help of the following figure:
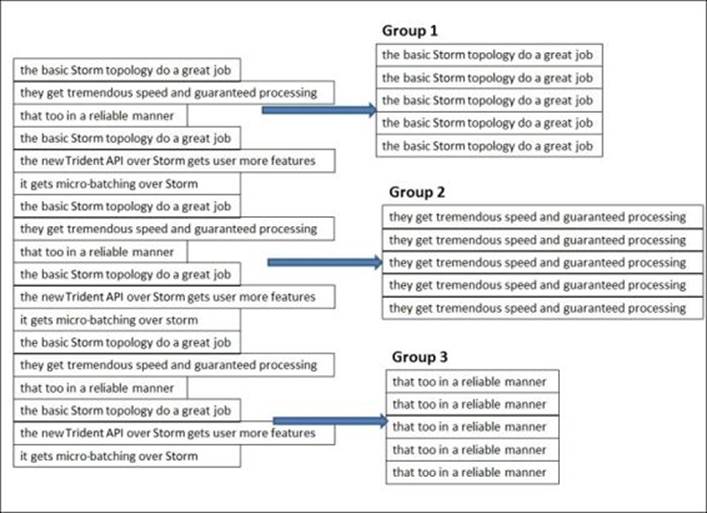
These operations in the Storm Trident run over a stream of tuples of several different partitions.
Merge and join
The merges and joins APIs provide interfaces for merging and joining various streams together. This is possible using a variety of ways provided as follows:
· Merge: As the name suggests, merge merges two or more streams together and emits the merged stream as the output field of the first stream:
· myTridentTopology.merge(stream1,stream2,stream3);
· Join: This operation works as the traditional SQL join function, but with the difference that it applies to small batches instead of entire infinite streams coming out of the spout
For example, consider a join function where Stream 1 has fields such as ["key", "val1", "val2"] and Stream 2 has ["x", "val1"], and from these functions we execute the following code:
myTridentTopology.join(stream1, new Fields("key"), stream2, new Fields("x"), new Fields("key", "a", "b", "c"));
As a result, Stream 1 and Stream 2 would be joined using key and x, wherein key would join the field for Stream 1 and x would join the field for Stream 2.
The output tuples emitted from the join would have the following:
· The list of all the join fields; in our case, it would be key from Stream 1 and x from Stream 2.
· A list of all the fields that are not join fields from all the streams involved in the join operation in the same order as they are passed to the join operation. In our case, it's a and b respectively for val1 and val2 of Stream 1, and c for val1 from Stream 2 (note that this step also removes the ambiguity of field names if any ambiguity is present within the stream, in our case val1 field was ambiguous between both the streams).
When operations like join happen on streams that are being fed in the topology from different spouts, the framework ensures that the spouts are synchronized with respect to batch emission, so that every join computation can include tuples from a batch of each spout.
Examples and illustrations
One of the other out-of-the-box and popular implementations of Trident is reach topology, which is a pure DRPC topology that finds the reach of a URL on demand. Let's first understand some of the jargon before we delve deeper.
Reach is basically a sum total of the count of Twitter users exposed to a URL.
Reach computation is a multistep process that can be attained by the following examples:
· Get all the users who have ever tweeted a URL
· Fetch the follower tree of each of these users
· Assemble the huge follower sets fetched previously
· Count the set
Well, looking at the skeletal algorithm entailed previously, you can make out that it is beyond the capability of a single machine and we'd need a distributed compute engine to achieve it. It's an ideal candidate of the Storm Trident framework, as you have the capability to execute highly parallel computations at each step across the cluster.
· Our Trident reach topology would be sucking data from two large data banks
· Bank A is the URL to the originator bank, wherein all the URLs would be stored along with the name of the user who had tweeted them
· Bank B is the user follower bank; this data bank will have a user to follow the mapping for all Twitter users
The topology would be defined as follows:
TridentState urlToTweeterState = topology.newStaticState(getUrlToTweetersState());
TridentState tweetersToFollowerState = topology.newStaticState(getTweeterToFollowersState());
topology.newDRPCStream("reach")
.stateQuery(urlToTweeterState, new Fields("args"), new MapGet(), new Fields("tweeters"))
.each(new Fields("tweeters"), new ExpandList(), new Fields("tweeter"))
.shuffle()
.stateQuery(tweetersToFollowerState, new Fields("tweeter"), new MapGet(), new Fields("followers"))
.parallelismHint(200)
.each(new Fields("followers"), new ExpandList(), new Fields("follower"))
.groupBy(new Fields("follower"))
.aggregate(new One(), new Fields("one"))
.parallelismHint(20)
.aggregate(new Count(), new Fields("reach"));
In the preceding topology, we perform the following steps:
1. Create a TridentState object for both data banks (URL to the originator Bank A and users to follow Bank B).
2. The newStaticState method is used for the instantiation of state objects for data banks; we have the capability to run the DRPC queries over the source states created earlier.
3. In execution, when the reach of a URL is to be computed, we perform a query using the Trident state for data bank A to fetch the list of all the users who have ever tweeted with this URL.
4. The ExpandList function creates and emits one tuple for each of the tweeters of the URL in query.
5. Next, we fetch the follower of each tweeter fetched previously. This step needs the highest degree of parallelism, thus we use shuffle grouping here for even load distribution across all instances of the bolt. In our reach topology, this is the most intense compute step.
6. Once we have the list of followers of the tweeter of the URL, we execute an operation analog to filter unique followers only.
7. We arrive at unique followers by grouping them together and then using the one aggregator. The latter simply emits 1 for each group and in the next step all these are counted together to arrive at the reach.
8. Then we count the followers (unique) thus arriving at the reach of the URL.
Quiz time
Q.1. State whether the following statements are true or false:
1. DRPC is a stateless, Storm processing mechanism.
2. If a tuple fails to execute in a Trident topology, the entire batch is replayed.
3. Trident lets the user implement windowing functions over streaming data.
4. Aggregators are more efficient then partitioned Aggregators.
Q.2. Fill in the blanks:
1. _______________ is the distributed version of RPC.
2. _______________ is the basic micro-batching framework over Storm.
3. The ___________________functions are used to remove tuples based on certain criteria or conditions from the stream batches.
Q.3. Create a Trident topology to find the tweeters who have the maximum number of tweets in the last 5 minutes.
Summary
In this chapter, we have pretty much covered everything about Storm and its advanced concepts with giving you the change to get hands-on with the Trident and DRPC topologies. You learned about Trident and its need and application, the DRPC topologies, and the various functions available in the Trident API.
In the next chapter, we will explore other technology components that go hand in hand with Storm and are necessary for building end-to-end solutions with Storm. We will touch upon areas of distributed caches and Complex Event Processing (CEP) with memcache and Esper in conjunction with Storm.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.