Real-time Analytics with Storm and Cassandra (2015)
Chapter 7. Cassandra Partitioning, High Availability, and Consistency
In this chapter, you will understand the internals of Cassandra to learn how data partitioning is implemented and you'll learn about the hashing technique employed on Cassandra's keyset distribution. We will also get an insight into replication and how it works, and the feature of hinted handoff. We will cover the following topics:
· Data partitioning and consistent hashing; we'll look at practical examples
· Replication, consistency, and high availability
Consistent hashing
Before you understand its implication and application in Cassandra, let's understand consistent hashing as a concept.
Consistent hashing works on the concept in its name—that is hashing and as we know, for a said hashing algorithm, the same key will always return the same hash code—thus, making the approach pretty deterministic by nature and implementation. When we use this approach for sharding or dividing the keys across the nodes in the cluster, consistent hashing is the technique that determines which node is stored in which node in the cluster.
Have a look at the following diagram to understand the concept of consistent hashing; imagine that the ring depicted in the following diagram represents the Cassandra ring and the nodes are marked here in letters along with the numerals that actually mark the objects (inverted triangles) to be mapped to the ring.
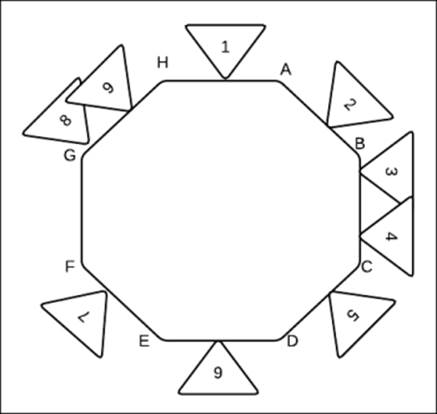
Consistent hashing for the Cassandra cluster
To compute the ownership of the object to the node it belongs to, all that's required is traversal in clockwise to encounter the next node. The node that follows the data item, which is an inverted triangle, is the node that owns the object, for example:
· 1 belongs to node A
· 2 belongs to node B
· 3 belongs to node C
· 4 belongs to node C
· 5 belongs to node D
· 6 belongs to node E
· 7 belongs to node F
· 8 belongs to node H
· 9 belongs to node H
So as you see, this uses simple hashing to compute the ownership of the key in a ring, based on owned token range.
Let's look at a practical example of consistent hashing; to explain this let's take a sample column family where the partition key value is the name.
Let's say the following is the column value data:
|
Name |
Gender |
|
Jammy |
M |
|
Carry |
F |
|
Jesse |
M |
|
Sammy |
F |
Here is what the hash-mapping would look like:
|
Partition key |
Hash value |
|
Jim |
2245462676723220000.00 |
|
Carol |
7723358927203680000.00 |
|
Johnny |
6723372854036780000.00 |
|
Suzy |
1168604627387940000.00 |
Let's say I have four nodes with the following range; here is how the data would be distributed:
|
Node |
Start range |
End range |
Partition key |
Hash value |
|
A |
9223372036854770000.00 |
4611686018427380000.00 |
Jammy |
6723372854036780000.00 |
|
B |
4611686018427380000.00 |
1.00 |
Jesse |
2245462676723220000.00 |
|
C |
0.00 |
4611686018427380000.00 |
suzy |
1168604627387940000.00 |
|
D |
4611686018427380000.00 |
9223372036854770000.00 |
Carry |
7723358927203680000.00 |
Now that you understand the concept of consistent hashing, let's look at the scenarios where the one or more node goes down and comes back up.
One or more node goes down
We are currently looking at a very common scenario where we envision that one node goes down; for instance, here we have captured two of them going down: B and E. What will happen now? Well nothing much, we'd follow the same pattern as before, which moves clockwise to find the next live node and allocate the values to that node.
So in our case, the allocations would change to the following:
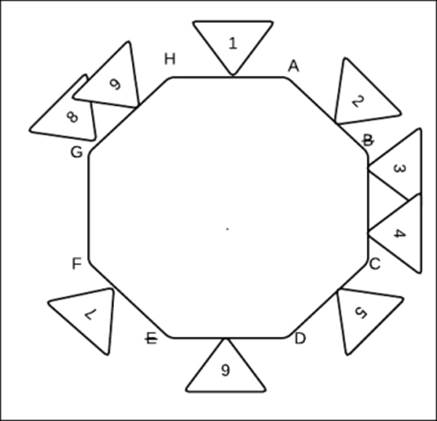
The allocation in the preceding figure is as follows:
· 1 belongs to A
· 2, 3, and 4 belong to C
· 5 belongs to D
· 6, and 7 belong to F
· 8, and 9 belong to H
One or more node comes back up
Now let's assume a scenario where node 2 comes back up; well, what happens then is again the same as on prior explanation, and the ownership is reestablished as follows:
· 1 belongs to A
· 2 belongs to B
· 3, and 4 belong to C
· 5 belongs to D
· 6, and 7 belong to F
· 8, and 9 belong to H
So, we have demonstrated that this techniques works for all situations and that's why it is used.
Replication in Cassandra and strategies
Replicating means to create a copy. This copy makes the data redundant and thus available even when one node fails or goes down. In Cassandra, you have the option to specify the replication factor as part of the creation of the keyspace or to later modify it. Attributes that need to be specified in this context are as follows:
· Replication factor: This is a numeric value specifying the number of replicas
· Strategy: This could be simple strategy or topology strategy; this decides the placement of replicas across the cluster
Internally, Cassandra uses the row key to store replicas or copies of data across various nodes on the cluster. A replication factor of n means there are n copies of data stored on n different nodes. There are certain rules of thumb with replication, and they are as follows:
· A replication factor should never be more than the number of nodes in a cluster, or you will run into exceptions due to not enough replicas and Cassandra will start rejecting the writes and reads, though replication factor would continue uninterrupted
· A replication factor should not be so small that data is lost forever if one odd node goes down
Snitch is used to determine the physical location of nodes, attributes such as closeness to each other, and so on, which are of value when a vast amount of data is to be replicated and moved to and fro. In all such situations, network latency plays a very important part. The two strategies currently supported by Cassandra are as follows:
· Simple: This is the default strategy provided by Cassandra for all keyspaces. It employs around a single data center. It's pretty straightforward and simple in its operation; as the name suggests, the partitioner checks the key-value against the node range to determine the placement of the first replica. Thereon, the subsequent replicas are placed on the next nodes in a clockwise order. So if data item "A" has a replication of "3", and the partitioner decides the first node based on the key and ownership, on this node the subsequent replicas are created in a clockwise order.
· Network: This is the topology that is used when we have the Cassandra cluster distributed across data centers. Here, we can plan our replica placement and define how many replicas we want to place in each data center. This approach makes the data geo-redundant and thus more fail-safe in cases where the entire data center crashes. The following are two things you should consider when making a choice on replica placement across data centers:
o Each data center should be self-sufficient to satisfy the requests
o Failover or crash situations
If we have 2 replicas of datum in a data center, then we have four copies of data and each data center has a tolerance for one node failure for the consistency ONE. If we get into the node of 3 replicas of datum in a data center, then we have six copies of data and each data center has a tolerance for multiple node failures for the consistency of ONE. This strategy also permits asymmetrical replication.
Cassandra consistency
As we said in an earlier chapter, Cassandra eventually becomes consistent and follows the AP principal of the CAP theorem. Consistency refers to how up to date the information across all data replicas in a Cassandra cluster is. Cassandra does eventually guarantee consistency. Now let's have a closer look; well, let's say I have five node Cassandra clusters and a replication factor of 3. This means if I have a data item1, it would be replicated to three nodes, let's say node1, node2, and node3; let's assume the key of this datum is key1. Now if the value of this key is to be rewritten and the write operation is performed on node1, then Cassandra internally replicates the values to other replicas, which are node2 and node3. But this update happens in the background and is not immediate; this is the mechanism of eventual consistency.
Cassandra provides the concept of offering the (read and write) client applications the decision of what consistency level they want to use to read and write to the data store.
Write consistency
Let's inspect the write operation a little closely in Cassandra. Well, when a write operation is done in Cassandra, the client can specify the consistency at which the operation should be performed.
This means that if the replication factor is x and a write operation is performed with a consistency of y (where y is less than x), then Cassandra will wait for successful write to complete on y nodes before returning a successful acknowledgement to the client, marking the operation as complete. For the remaining x-y replicas, the data is propagated and replicated internally by the Cassandra processes.
The following table shows the various consistency levels and their implication where we have ANY that has the benefit of the highest availability with the lowest consistency, and ALL that offers the highest consistency but the lowest availability. So, being a client, one has to review the use case before deciding upon which consistency to choose. The following is a table with a few popular options and their implications:
|
Consistency level |
Implication |
|
ANY |
The write operation is returned as successful when the datum is written onto at least one node, where the node could either be a replica node or a non-replica node |
|
ONE |
The write operation is returned as successful when the datum is written onto at least one replica node |
|
TWO |
The write operation is returned as successful when the datum is written onto at least two replica nodes |
|
QUORUM |
The write operation is returned as successful when the datum is written to the quorum of the replica node (where the quorum is n/2+1, and n is the replication factor) |
|
ALL |
The write operation is returned as successful when the datum is written onto all replica nodes |
The following figure depicting the write operation on a four-node cluster, which has a replication factor of 3 and consistency of 2:
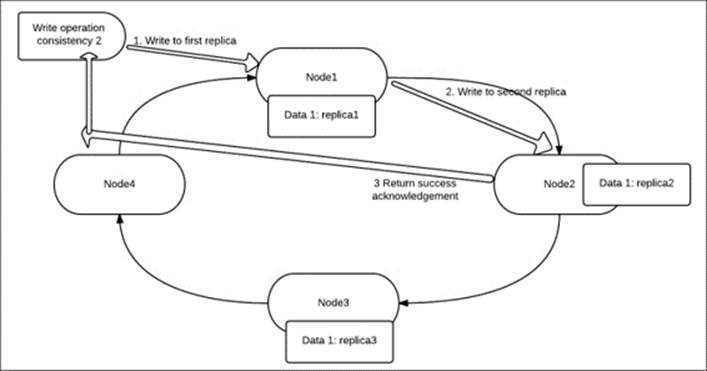
So as you see, the write operation is completed in three steps:
· A write is issued from the client
· The write is executed and completed on replica1
· The write is executed and completed on replica2
· An acknowledgement is issued to the client when a write is successfully completed
Read consistency
The read consistency is analogues to write consistency, it denotes how many replicas should respond or confirm their alignment to the data being returned to read operation before the results are returned to the client querying the Cassandra data store. This means if on an N node cluster with a replication factor of x, a read query is issued with a read consistency of y (y is less than x), then Cassandra would check the y replicas and then return the results. The results are validated on the basis that the most recent data is used to satisfy the request, and this is verified by the timestamp associated with each column.
The following Cassandra Query Language (CQL), fetch the data from the column family with quorum consistency as follows:
SELECT * FROM mytable USING CONSISTENCY QUORUM WHERE name='shilpi';
The functions of the CQL are as follows:
|
Consistency level |
Implication |
|
ONE |
A read request is serviced by the response from the closest replica |
|
TWO |
A read request is serviced by the most recent response from one of the two closest replicas |
|
THREE |
This level returns the most recent data from three of the closest replicas |
|
QUORUM |
A read request is serviced by the most recent responses from the quorum of replicas |
|
ALL |
A read request is serviced by the most recent response from all the replicas |
Consistency maintenance features
In the previous section, we discussed read and write consistency in depth, and one thing that came clear is that Cassandra doesn't provide or work towards total consistency at the time the read or write operation is performed; it executes and completes the request as per client's consistency specifications. Another feature is eventual consistency, which highlights that there is some magic behind the veil that guarantees that eventually all data will be consistent. Now this magic is performed by certain components within Cassandra, and some are mentioned as follows:
· Read repair: This service ensures that data across all the replicas is and up to date. This way, the row is consistent and has been updated with recent values across all replicas. This operation is executed by a job. Cassandra is running to execute repair read operation issued by the coordinator.
· Anti-entropy repair service: This service ensures that the data that's not read very frequently, or when a downed host joins back, is in consistent a state. This is a regular cluster maintenance operation.
· Hinted handoff: This is another unique and wonderful operation on Cassandra. When the write operation is executed, the coordinator issues a write operation to all replicas, irrespective of the consistency specified and waits for an acknowledgement. As soon as the acknowledgement count reaches the value mentioned on consistency of the operation, the thread is completed and the client is notified about its success. On the remaining replicas, the values are written using hinted handoffs. The hinted handoff approach is a savior when a few nodes are down. Let's say one of the replicas is down and a write operation is executed with a consistency of ANY; in that case, one replica takes the write operation and hints to the neighboring replicas, which are currently down. When the downed replicas are revived, then the values are written back to them by taking hints from live replicas.
Quiz time
Q.1. State whether the following statements are true or false:
1. Cassandra has a default consistency of ALL.
2. QUORUM is the consistency level that provides the highest availability.
3. Cassandra uses a snitch to identify the closeness of the nodes.
4. Cassandra reads and writes features have consistency level 1 by default.
Q.2. Fill in the blanks:
1. _______________ is used to determine the physical closeness of the nodes.
2. _______________ is the consistency that provides the highest availability and lowest availability.
3. The ___________ is the service that ensures that a node, which has been down for a while, is correctly updated with the latest changes.
Q.3. Execute the following use case to see Cassandra high availability and replications:
1. Create a four-node Cassandra cluster.
2. Create a keyspace with a replication factor of 3.
3. Add some data into a column family under this keyspace.
4. Attempt to retrieve data using read consistency with using ALL in select query.
5. Shut down the Cassandra daemon on one node and repeat step 4 from the other three live nodes.
6. Shut down the Cassandra daemon on one node and repeat step 4 from the other three live nodes using the consistency ANY.
7. Shut down two nodes and update an existing value using a write consistency of ANY.
8. Attempt a read using ANY.
9. Bring back the nodes that are down and execute read using the consistency ALL from all four nodes.
Summary
In this chapter, you have understood the concepts of replication and data partitioning in Cassandra. We also understood the replication strategy and the concept of eventual consistency. The exercise at the end of the chapter is a good hands-on exercise to help you understand the concepts covered in the chapter in a practical way.
In the next chapter, we will discuss the gossip protocols, Cassandra cluster maintenance, and management features.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.