ZooKeeper (2013)
Part III. Administering ZooKeeper
This part of the book gives you the information you need to administer ZooKeeper. The internals provide the background that lets you make critical choices such as how many ZooKeeper servers to run and how to tune their communications.
Chapter 9. ZooKeeper Internals
This chapter is a bit special compared to the others. It is not going to explicitly explain anything related to how to build applications with ZooKeeper. Instead, it explains how ZooKeeper works internally, by describing its protocols at a high level and the mechanisms it uses to tolerate faults while providing high performance. This content is important because it gives some deeper insight into why things work the way they work with ZooKeeper. This insight is important if you’re planning on running ZooKeeper. It consequently serves as background for the next chapter.
As we saw in earlier chapters, ZooKeeper runs on an ensemble of servers while clients connect to these servers to execute operations. But what exactly are these servers doing with the operations the clients send? We hinted in Chapter 2 that we elect a distinguished server that we call theleader. The remaining servers, who follow the leader, are called followers. The leader is the central point for handling all requests that change the ZooKeeper system. It acts as a sequencer and establishes the order of updates to the ZooKeeper state. Followers receive and vote on the updates proposed by the leader to guarantee that updates to the state survive crashes.
The leader and the followers constitute the core entities guaranteeing the order of state updates despite crashes. There is a third kind of server, however, called an observer. Observers do not participate in the decision process of what requests get applied; they only learn what has been decided upon. Observers are there for scalability reasons.
In this chapter, we present the protocols we use to implement the ZooKeeper ensemble and the internals of servers and clients. We start with a discussion of some common concepts that we use throughout the remainder of the chapter regarding client requests and transactions.
CODE REFERENCES
Because this is a chapter about the internals, we figured that it might be interesting to provide references to the code, so that you can match the descriptions in this chapter to the source code. Pointers to classes and methods are provided where suitable.
Requests, Transactions, and Identifiers
ZooKeeper servers process read requests (exists, getData, and getChildren) locally. When a server receives, say, a getData request from a client, it reads its state and returns it to the client. Because it serves requests locally, ZooKeeper is pretty fast at serving read-dominated workloads. We can add more servers to the ZooKeeper ensemble to serve more read requests, increasing overall throughput capacity.
Client requests that change the state of ZooKeeper (create, delete, and setData) are forwarded to the leader. The leader executes the request, producing a state update that we call a transaction. Whereas the request expresses the operation the way the client originates it, the transaction comprises the steps taken to modify the ZooKeeper state to reflect the execution of the request. Perhaps an intuitive way to explain this is to propose a simple, non-ZooKeeper operation. Say that the operation is inc(i), which increments the value of the variable i. One possible request is consequently inc(i). Say that the value of i is 10 and after incrementing it becomes 11. Using the concepts of request and transaction, the request is inc(i) and the transaction is i, 11 (variable i takes value 11).
Let’s now look at a ZooKeeper example. Say that a client submits a setData request on a given znode /z. setData should change the data of the znode and bump up the version number. So, a transaction for this request contains two important fields: the new data of the znode and the new version number of the znode. When applying the transaction, a server simply replaces the data of /z with the data in the transaction and the version number with the value in the transaction, rather than bumping it up.
A transaction is treated as a unit, in the sense that all changes it contains must be applied atomically. In the setData example, changing the data without an accompanying change to the version accordingly leads to trouble. Consequently, when a ZooKeeper ensemble applies transactions, it makes sure that all changes are applied atomically and there is no interference from other transactions. There is no rollback mechanism like with traditional relational databases. Instead, ZooKeeper makes sure that the steps of transactions do not interfere with each other. For a long time, the design used a single thread in each server to apply transactions. Having a single thread guarantees that the transactions are applied sequentially without interference. Recently, ZooKeeper has added support for multiple threads to speed up the process of applying transactions.
A transaction is also idempotent. That is, we can apply the same transaction twice and we will get the same result. We can even apply multiple transactions multiple times and get the same result, as long as we apply them in the same order every time. We take advantage of this idempotent property during recovery.
When the leader generates a new transaction, it assigns to the transaction an identifier that we call a ZooKeeper transaction ID (zxid). Zxids identify transactions so that they are applied to the state of servers in the order established by the leader. Servers also exchange zxids when electing a new leader, so they can determine which nonfaulty server has received more transactions and can synchronize their states.
A zxid is a long (64-bit) integer split into two parts: the epoch and the counter. Each part has 32 bits. The use of epochs and counters will become clear when we discuss Zab, the protocol we use to broadcast state updates to servers.
Leader Elections
The leader is a server that has been chosen by an ensemble of servers and that continues to have support from that ensemble. The purpose of the leader is to order client requests that change the ZooKeeper state: create, setData, and delete. The leader transforms each request into a transaction, as explained in the previous section, and proposes to the followers that the ensemble accepts and applies them in the order issued by the leader.
To exercise leadership, a server must have support from a quorum of servers. As we discussed in Chapter 2, quorums must intersect to avoid the problem that we call split brain: two subsets of servers making progress independently. This situation leads to inconsistent system state, and clients end up getting different results depending on which server they happen to contact. We gave a concrete example of this situation in ZooKeeper Quorums.
The groups that elect and support a leader must intersect on at least one server process. We use the term quorum to denote such subsets of processes. Quorums pairwise intersect.
PROGRESS
Because a quorum of servers is necessary for progress, ZooKeeper cannot make progress in the case that enough servers have permanently failed that no quorum can be formed. It is OK if servers are brought down and eventually boot up again, but for progress to be made, a quorum must eventually boot up. We relax this constraint when we discuss the possibility of reconfiguring ensembles in the next chapter. Reconfiguration can change quorums over time.
Each server starts in the LOOKING state, where it must either elect a new leader or find the existing one. If a leader already exists, other servers inform the new one which server is the leader. At this point, the new server connects to the leader and makes sure that its own state is consistent with the state of the leader.
If an ensemble of servers, however, are all in the LOOKING state, they must communicate to elect a leader. They exchange messages to converge on a common choice for the leader. The server that wins this election enters the LEADING state, while the other servers in the ensemble enter theFOLLOWING state.
The leader election messages are called leader election notifications, or simply notifications. The protocol is extremely simple. When a server enters the LOOKING state, it sends a batch of notification messages, one to each of the other servers in the ensemble. The message contains its currentvote, which consists of the server’s identifier (sid) and the zxid (zxid) of the most recent transaction it executed. Thus, (1,5) is a vote sent by the server with a sid of 1 and a most recent zxid of 5. (For the purposes of leader election, a zxid is a single number, but in some other protocols it is represented as an epoch and a counter.)
Upon receiving a vote, a server changes its vote according to the following rules:
1. Let voteId and voteZxid be the identifier and the zxid in the current vote of the receiver, whereas myZxid and mySid are the values of the receiver itself.
2. If (voteZxid > myZxid) or (voteZxid = myZxid and voteId > mySid), keep the current vote.
3. Otherwise, change my vote by assigning myZxid to voteZxid and mySid to voteZxid.
In short, the server that is most up to date wins, because it has the most recent zxid. We’ll see later that this simplifies the process of restarting a quorum when a leader dies. If multiple servers have the most recent zxid, the one with the highest sid wins.
Once a server receives the same vote from a quorum of servers, the server declares the leader elected. If the elected leader is the server itself, it starts executing the leader role. Otherwise, it becomes a follower and tries to connect to the elected leader. Note that it is not guaranteed that the follower will be able to connect to the elected leader. The elected leader might have crashed, for example. Once it connects, the follower and the leader sync their state, and only after syncing can the follower start processing new requests.
LOOKING FOR A LEADER
The Java class in ZooKeeper that implements an election is QuorumPeer. Its run method implements the main loop of the server. When in the LOOKING state, it executes lookForLeader to elect a leader. This method basically executes the protocol we have just discussed. Before returning, the method sets the state of the server to either LEADING or FOLLOWING. OBSERVING is also an option that will be discussed later. If the server is leading, it creates a new Leader and runs it. If it is following, it creates a new Follower and runs it.
Let’s go over an example of an execution of this protocol. Figure 9-1 shows three servers, each starting with a different initial vote corresponding to the server identifier and the last zxid of the server. Each server receives the votes of the other two, and after the first round, servers s2 and s3change their votes to (1,6). Servers s2 and s3 send a new batch of notifications after changing their votes, and after receiving these new notifications, each server has notifications from a quorum with the same vote. They consequently elect server s1 to be the leader.
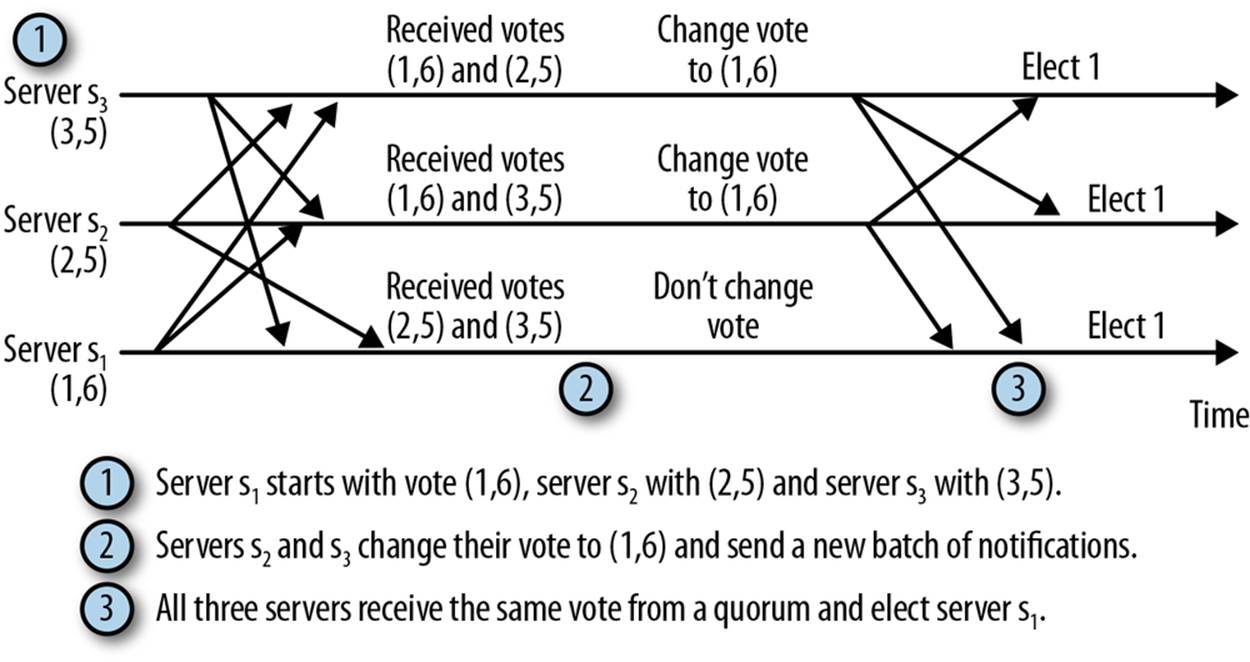
Figure 9-1. Example of a leader election execution
Not all executions are as well behaved as the one in Figure 9-1. In Figure 9-2, we show an example in which s2 makes an early decision and elects a different leader from servers s1 and s3. This happens because the network happens to introduce a long delay in delivering the message from s1to s2 that shows that s1 has the higher zxid. In the meantime, s2 elects s3. In consequence, s1 and s3 will form a quorum, leaving out s2.
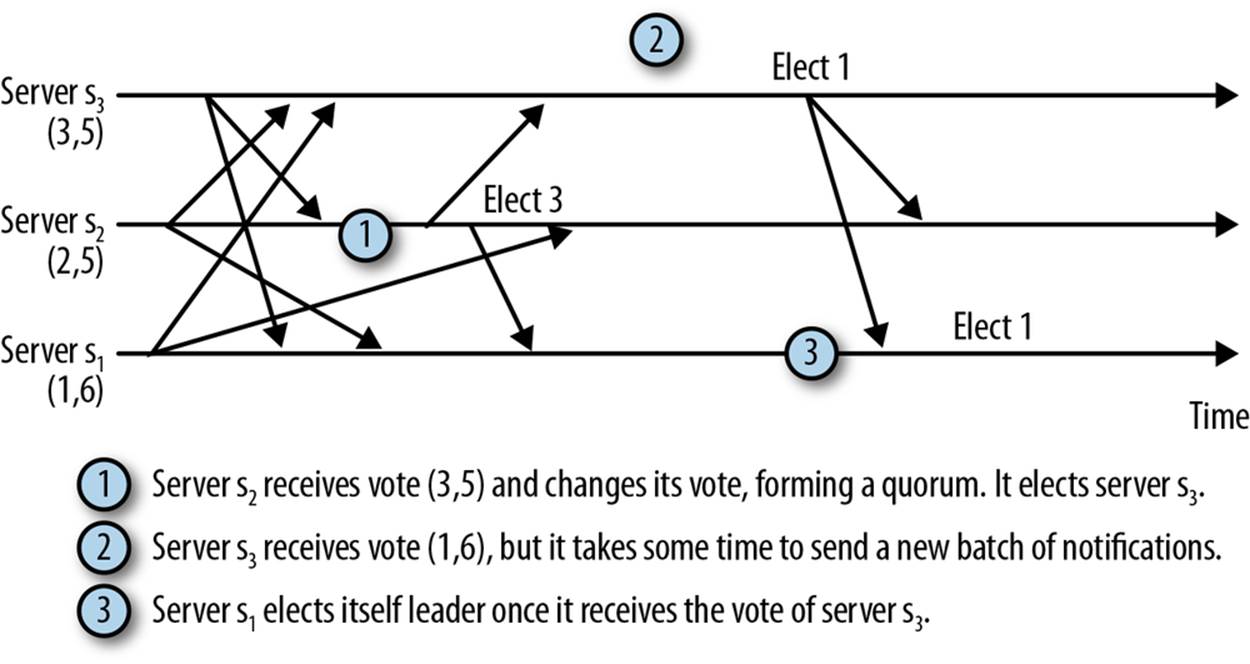
Figure 9-2. Interleaving of messages causes a server to elect a different leader
Having s2 elect a different leader does not cause the service to behave incorrectly, because s3 will not respond to s2 as leader. Eventually s2 will time out trying to get a response from its elected leader, s3, and try again. Trying again, however, means that during this time s2 will not be available to process client requests, which is undesirable.
One simple observation from this example is that if s2 had waited a bit longer to elect a leader, it would have made the right choice. We show this situation in Figure 9-3. It is hard to know how much time a server should wait, though. The current implementation of FastLeaderElection, the default leader election implementation, uses a fixed value of 200 ms (see the constant finalizeWait). This value is longer than the expected message delay in modern data centers (less than a millisecond to a few milliseconds), but not long enough to make a substantial difference to recovery time. In case this delay (or any other chosen delay) is not sufficiently long, one or more servers will end up falsely electing a leader that does not have enough followers, so the servers will have to go back to leader election. Falsely electing a leader might make the overall recovery time longer because servers will connect and sync unnecessarily, and still need to send more messages to elect another leader.
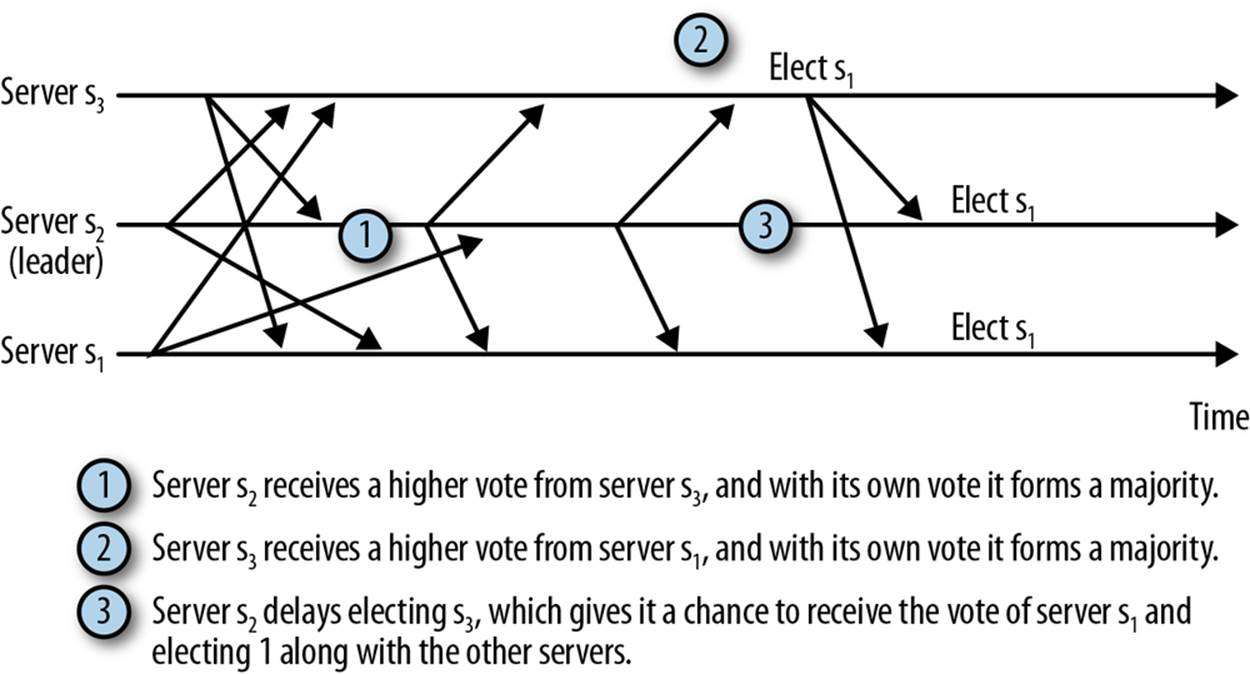
Figure 9-3. Longer delay in electing a leader
WHAT’S FAST ABOUT FAST LEADER ELECTION?
If you are wondering about it, we call the current default leader election algorithm fast for historical reasons. The initial leader election algorithm implemented a pull-based model, and the interval for a server to pull votes was about 1 second. This approach added some delay to recovery. With the current implementation, we are able to elect a leader faster.
To implement a new leader election algorithm, we need to implement the Election interface in the quorum package. To enable users to choose among the leader election implementations available, the code uses simple integer identifiers (seeQuorumPeer.createElectionAlgorithm()). The other two implementations available currently are LeaderElection and AuthFastLeaderElection, but they have been deprecated as of release 3.4.0, so in some future releases you may not even find them.
Zab: Broadcasting State Updates
Upon receiving a write request, a follower forwards it to the leader. The leader executes the request speculatively and broadcasts the result of the execution as a state update, in the form of a transaction. A transaction comprises the exact set of changes that a server must apply to the data tree when the transaction is committed. The data tree is the data structure holding the ZooKeeper state (see DataTree).
The next question to answer is how a server determines that a transaction has been committed. This follows a protocol called Zab: the ZooKeeper Atomic Broadcast protocol. Assuming that there is an active leader and it has a quorum of followers supporting its leadership, the protocol to commit a transaction is very simple, resembling a two-phase commit:
1. The leader sends a PROPOSAL message, p, to all followers.
2. Upon receiving p, a follower responds to the leader with an ACK, informing the leader that it has accepted the proposal.
3. Upon receiving acknowledgments from a quorum (the quorum includes the leader itself), the leader sends a message informing the followers to COMMIT it.
Figure 9-4 illustrates this sequence of steps. In the figure, we assume that the leader implicitly sends messages to itself.
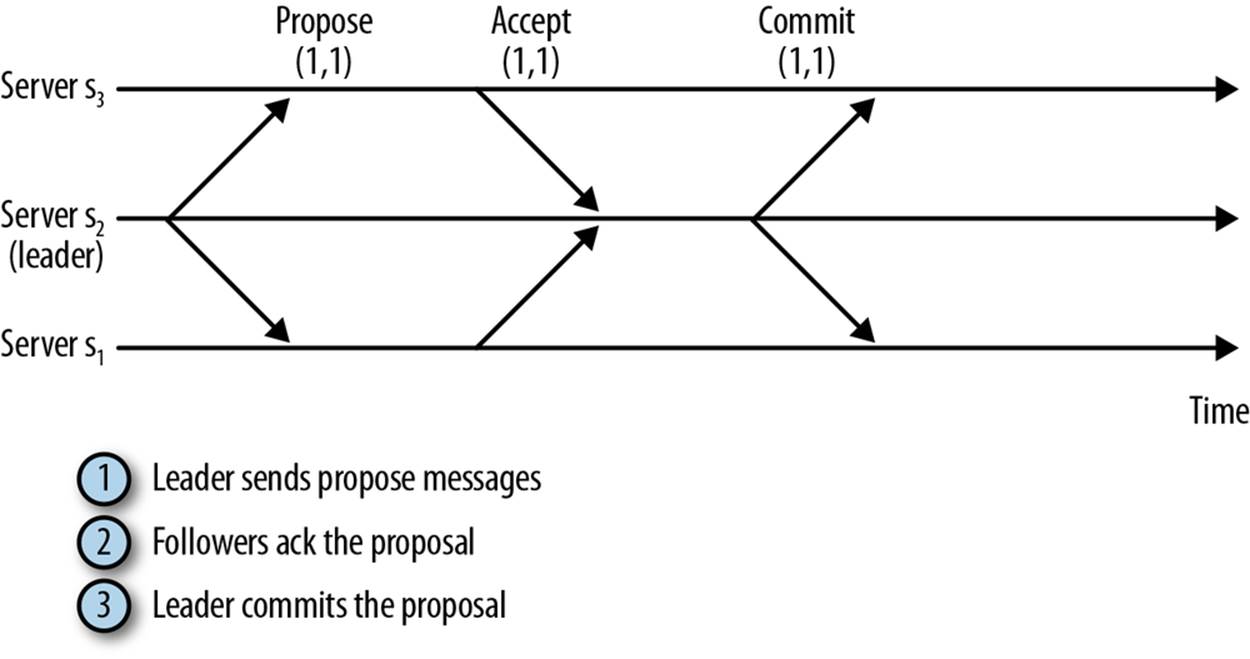
Figure 9-4. Regular message pattern to commit proposals
Before acknowledging a proposal, the follower needs to perform a couple of additional checks. The follower needs to check that the proposal is from the leader it is currently following, and that it is acknowledging proposals and committing transactions in the same order that the leader broadcasts them in.
Zab guarantees a couple of important properties:
§ If the leader broadcasts T and Tʹ in that order, each server must commit T before committing Tʹ.
§ If any server commits transactions T and Tʹ in that order, all other servers must also commit T before Tʹ.
The first property guarantees that transactions are delivered in the same order across servers, whereas the second property guarantees that servers do not skip transactions. Given that the transactions are state updates and each state update depends upon the previous state update, skipping transactions could create inconsistencies. The two-phase commit guarantees the ordering of transactions. Zab records a transaction in a quorum of servers. A quorum must acknowledge a transaction before the leader commits it, and a follower records on disk the fact that it has acknowledged the transaction.
As we’ll see in Local Storage, transactions can still end up on some servers and not on others, because servers can fail while trying to write a transaction to storage. ZooKeeper can bring all servers up to date whenever a new quorum is created and a new leader chosen.
ZooKeeper, however, does not expect to have a single active leader the whole time. Leaders may crash or become temporarily disconnected, so servers may need to move to a new leader to guarantee that the system remains available. The notion of epochs represents the changes in leadership over time. An epoch refers to the period during which a given server exercised leadership. During an epoch, a leader broadcasts proposals and identifies each one according to a counter. Remember that each zxid includes the epoch as its first element, so each zxid can easily be associated to the epoch in which the transaction was created.
The epoch number increases each time a new leader election takes place. The same server can be the leader for different epochs, but for the purposes of the protocol, a server exercising leadership in different epochs is perceived as a different leader. If a server s has been the leader of epoch 4and is currently the established leader of epoch 6, a follower following s in epoch 6 processes only the messages s sent during epoch 6. The follower may accept proposals from epoch 4 during the recovery period of epoch 6, before it starts accepting new proposals for epoch 6. Such proposals, however, are sent as part of epoch 6’s messages.
Recording accepted proposals in a quorum is critical to ensure that all servers eventually commit transactions that have been committed by one or more servers, even if the leader crashes. Detecting perfectly that leaders (or any server) have crashed is very hard, if not impossible, in many settings, so it is very possible to falsely suspect that a leader has crashed.
Most of the difficulty with implementing a broadcast protocol is related to the presence of concurrent leaders, not necessarily in a split-brain scenario. Multiple concurrent leaders could make servers commit transactions out of order or skip transactions altogether, which leaves servers with inconsistent states. Preventing the system from ever having two servers believing they are leaders concurrently is very hard. Timing issues and dropped messages might lead to such scenarios, so the broadcast protocol cannot rely on this assumption. To get around this problem, Zab guarantees that:
§ An elected leader has committed all transactions that will ever be committed from previous epochs before it starts broadcasting new transactions.
§ At no point in time will two servers have a quorum of supporters.
To implement the first requirement, a leader does not become active until it makes sure that a quorum of servers agrees on the state it should start with for the new epoch. The initial state of an epoch must encompass all transactions that have been previously committed, and possibly some other ones that had been accepted before but not committed. It is important, though, that before the leader makes any new proposals for epoch e, it commits all proposals that will ever be committed from epochs up to and including e – 1. If there is a proposal lying around from epoch eʹ < eand it is not committed by the leader of e by the time it makes the first proposal of e, the old proposal is never committed.
The second point is somewhat tricky because it doesn’t really prevent two leaders from making progress independently. Say that a leader l is leading and broadcasting transactions. At some point, a quorum of servers Q believes l is gone, and it elects a new leader, lʹ. Let’s say that T is a transaction that was being broadcast at the time Q abandoned l, and that a strict subset of Q has successfully recorded T. After lʹ is elected, enough processes not in Q also record T, forming a quorum for T. In this case, T is committed even after lʹ has been elected. But don’t worry; this is not a bug. Zab guarantees that T is part of the transactions committed by lʹ, by guaranteeing that the quorum of supporters of lʹ contain at least one follower that has acknowledged T. The key point here is that lʹ and l do not have a quorum of supporters simultaneously.
Figure 9-5 illustrates this scenario. In the figure, l is server s5, lʹ is s3, Q comprises s1 through s3, and the zxid of T is ⟨1,1⟩. After receiving the second confirmation, s5 is able to send a commit message to s4 to tell it to commit the transaction. The other servers ignore messages from s5 once they start following s3. Note that s3 acknowledged ⟨1,1⟩, so it is aware of the transaction when it establishes leadership.
We have just promised that Zab ensures the new leader lʹ does not miss ⟨1,1⟩, but how does it happen exactly? Before becoming active, the new leader lʹ must learn all proposals that servers in the old quorum have accepted previously, and it must get a promise that these servers won’t accept further proposals from previous leaders. In the example in Figure 9-5, the servers forming a quorum and supporting lʹ promise that they won’t accept any more proposals from leader l. At that point, if leader l is still able to commit any proposal, as it does with ⟨1,1⟩, the proposal must have been accepted by at least one server in the quorum that made the promise to the new leader. Recall that quorums must overlap in at least one server, so the quorum that l uses to commit and the quorum that lʹ talks to must have at least one server in common. Consequently, lʹ includes ⟨1,1⟩ in its state and propagates it to its followers.
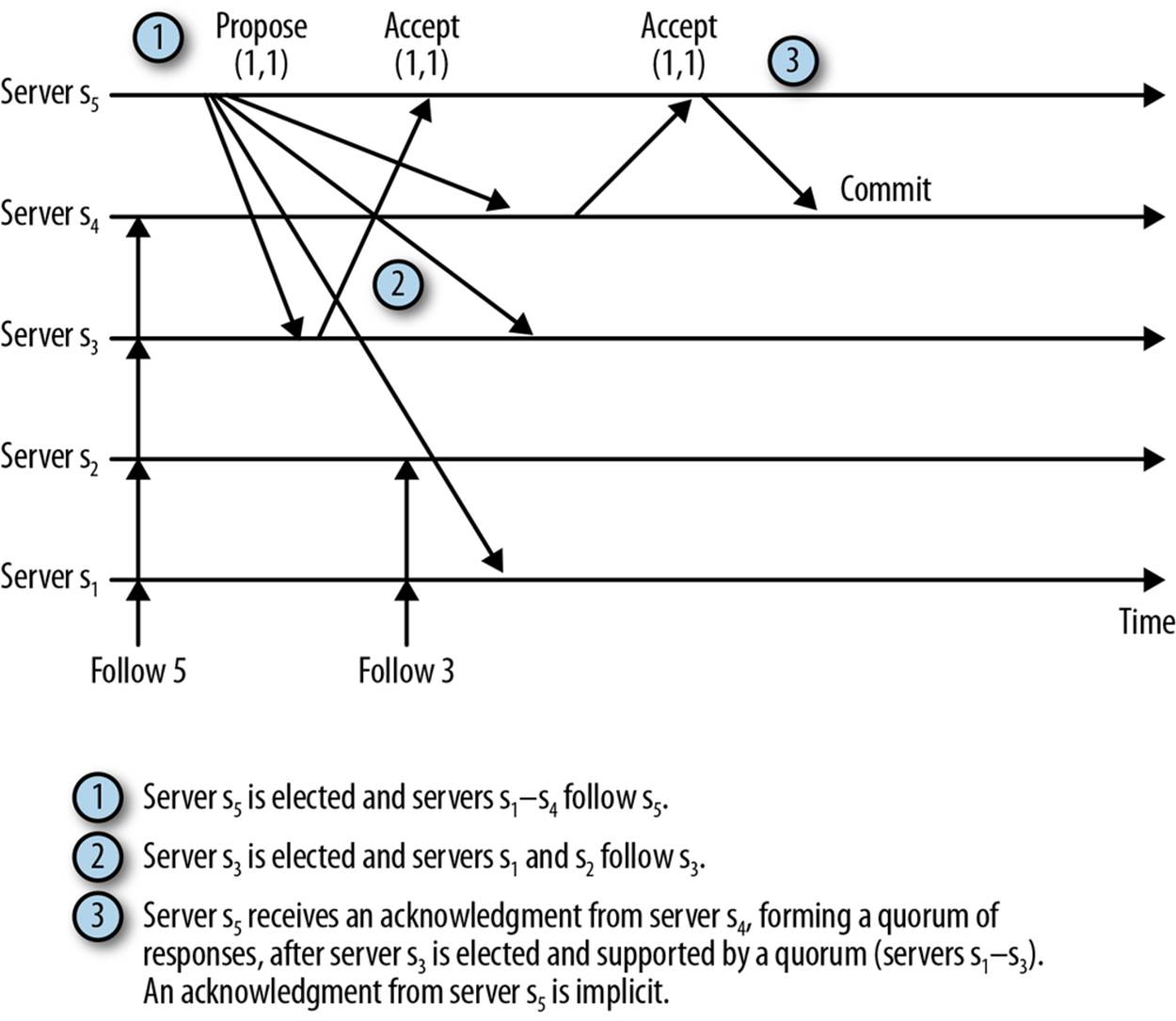
Figure 9-5. Leaders overlapping illustration
Recall that when electing a leader, servers pick the one with the highest zxid. This saves ZooKeeper from having to transfer proposals from followers to the leader; it only needs to transfer state from the leader to the followers. Say instead that we have at least one follower that has accepted a proposal that the leader hasn’t. Before syncing up with the other followers, the leader would have to receive and accept the proposal. However, if we pick the server with the highest zxid, then we can completely skip this step and jump directly into bringing the followers up to date.
When transitioning between epochs, ZooKeeper uses two different ways to update the followers in order to optimize the process. If the follower is not too far behind the leader, the leader simply sends the missing transactions. They are always the most recent transactions, because followers accept all transactions in strict order. This update is called a DIFF in the code. If the follower is lagging far behind, ZooKeeper does a full snapshot transfer, called a SNAP in the code. Doing a full snapshot transfer increases recovery time, so sending a few missing transactions is preferable, but not always possible if the follower is far behind.
The DIFF a leader sends to a follower corresponds to the proposals that the leader has in its transaction log, whereas the SNAP is the latest valid snapshot that the leader has. Later in this chapter we discuss these two types of files that we keep on disk.
DIVING INTO THE CODE
Here is a small guide to the code. Most of the Zab code is in Leader, LearnerHandler, and Follower. Instances of Leader and LearnerHandler are executed by the leader server, and Follower is executed by followers. Two important methods to look at are Leader.lead and Follower.followLeader. They are actually the methods executed when the servers transition from LOOKING to either LEADING or FOLLOWING in QuorumPeer.
For DIFF versus SNAP, follow the code in LearnerHandler.run to see how the code decides which proposals to send during a DIFF, and how snapshots are serialized and sent.
Observers
We have focused so far on leaders and followers, but there is a third kind of server that we have not discussed: observers. Observers and followers have some aspects in common. In particular, they commit proposals from the leader. Unlike followers, though, observers do not participate in the voting process we discussed earlier. They simply learn the proposals that have been committed via INFORM messages. Both followers and observers are called learners because the leader tells them about changes of state.
RATIONALE BEHIND INFORM MESSAGES
Because observers do not vote to accept a proposal, a leader does not send proposals to observers, and the commit messages that leaders send to followers do not contain the proposal itself, only its zxid. Consequently, just sending the commit message to an observer does not enable the observer to apply the proposal. That’s the reason for using INFORM messages, which are essentially commit messages containing the proposals being committed.
In short, followers get two messages whereas observers get just one. Followers get the content of the proposal in a broadcast, followed by a simple commit message that has just the zxid. In contrast, observers get a single INFORM message with the content of the committed proposal.
Servers that participate in the vote that decides which proposals are committed are called PARTICIPANT servers. A PARTICIPANT server can be either a leader or a follower. Observers, in contrast, are called OBSERVER servers.
One main reason for having observers is scalability of read requests. By adding more observers, we can serve more read traffic without sacrificing the throughput of writes. Note that the throughput of writes is driven by the quorum size. If we add more servers that can vote, we end up with larger quorums, which reduces write throughput. Adding observers, however, is not completely free of cost; each new observer induces the cost of one extra message per committed transaction. This cost is less, however, than that of adding servers to the voting process.
Another reason for observers is to have a deployment that spans multiple data centers. Scattering participants across data centers might slow down the system significantly because of the latency of links connecting data centers. With observers, update requests can be executed with high throughput and low latency in a single data center, while propagating to other data centers so that clients in other locations can consume them. Note that the use of observers does not eliminate network messages across data centers, because observers have to both forward update requests to the leader and process INFORM messages. It instead enables the messages necessary to commit updates to be exchanged in a single data center when all participants are set to run in the same data center.
The Skeleton of a Server
Leaders, followers, and observers are all ultimately servers. The main abstraction we use in the implementation of a server is the request processor. A request processor is an abstraction of the various stages in a processing pipeline, and each server implements a sequence of such request processors. We can think of each processor as an element adding to the processing of a request. After being processed by all processors in the pipeline of a server, a given request can be declared to have been fully processed.
REQUEST PROCESSORS
ZooKeeper code has an interface called RequestProcessor. The main method of the interface is processRequest, which takes a Request parameter. In a pipeline of request processors, the processing of requests for consecutive processors is usually decoupled using queues. When a processor has a request for the next processor, it queues the request, where it can wait until the next processor is ready to consume it.
Standalone Servers
The simplest pipeline in ZooKeeper is for the standalone server (class ZooKeeperServer, no replication). Figure 9-6 shows the pipeline for this type of server. It has three request processors: PrepRequestProcessor, SyncRequestProcessor, and FinalRequestProcessor.

Figure 9-6. Pipeline of a standalone server
PrepRequestProcessor accepts a client request and executes it, generating a transaction as a result. Recall that the transaction is the result of executing an operation that is to be applied directly to the ZooKeeper data tree. The transaction data is added to the Request object in the form of a header and a transaction record. Also, note that only operations that change the state of ZooKeeper induce a transaction; read operations do not result in a transaction. The attributes referring to a transaction in a Request object are null for read requests.
The next request processor is SyncRequestProcessor. SyncRequestProcessor is responsible for persisting transactions to disk. It essentially appends transactions in order to a transaction log and generates snapshots frequently. We discuss disk state in more detail in the next section of this chapter.
The next and final processor is FinalRequestProcessor. It applies changes to the ZooKeeper data tree when the Request object contains a transaction. Otherwise, this processor reads the data tree and returns to the client.
Leader Servers
When we switch to quorum mode, the server pipelines change a bit. Let’s start with the leader pipeline (class LeaderZooKeeperServer), illustrated in Figure 9-7.
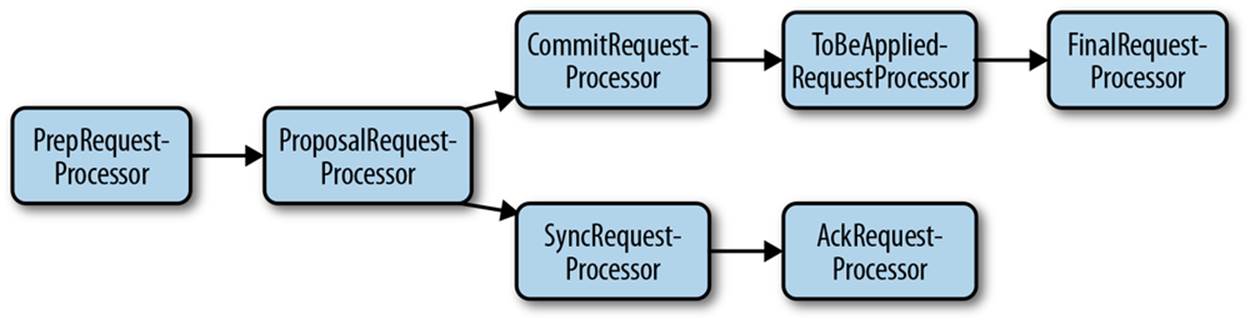
Figure 9-7. Pipeline of a leader server
The first processor is still PrepRequestProcessor, but the following processor now becomes ProposalRequestProcessor. It prepares proposals and sends them to the followers. ProposalRequestProcessor forwards all requests to CommitRequestProcessor, and additionally forwards the write requests to SyncRequestProcessor. SyncRequestProcessor works the same as it does for the standalone server, and persists transactions to disk. It ends by triggering AckRequestProcessor, a simple request processor that generates an acknowledgment back to itself. As we mentioned earlier, the leader expects acknowledgments from every server in the quorum, including itself. AckRequestProcessor takes care of this.
The other processor following ProposalRequestProcessor is CommitRequestProcessor. CommitRequestProcessor commits proposals that have received enough acknowledgments. The acknowledgments are actually processed in the Leader class (the Leader.processAck()method), which adds committed requests to a queue in CommitRequestProcessor. The request processor thread processes this queue.
The next and final processor is FinalRequestProcessor, which is the same as the one used for the standalone server. FinalRequestProcessor applies update requests and executes read requests. Before FinalRequestProcessor, there stands a simple request processor that removes elements of a list of proposals to be applied. This request processor is called ToBeAppliedRequestProcessor. The list of to-be-applied requests contains requests that have been acknowledged by a quorum and are waiting to be applied. The leader uses this list to synchronize with followers and adds to this list when processing acknowledgments. ToBeAppliedRequestProcessor removes elements from this list after processing the request with FinalRequestProcessor.
Note that only update requests get into the to-be-applied list that ToBeAppliedRequestProcessor removes items from. ToBeAppliedRequestProcessor does not do any extra processing for read requests other than processing them with FinalRequestProcessor.
Follower and Observer Servers
Let’s talk now about followers (class FollowerRequestProcessor). Figure 9-8 shows the request processors a follower uses. Note that there isn’t a single sequence of processors and that inputs come in different forms: client requests, proposals, and commits. We use arrows to specify the different paths a follower takes.
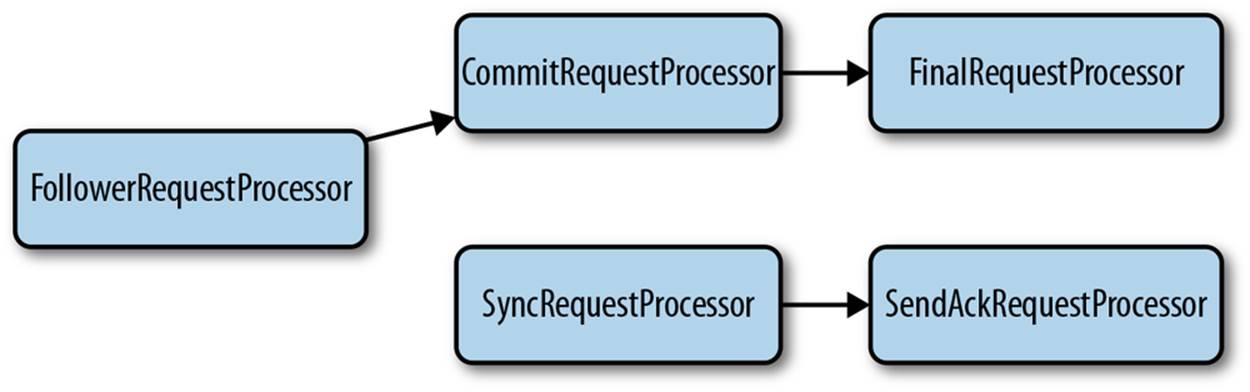
Figure 9-8. Pipeline of a follower server
We start with FollowerRequestProcessor, which receives and processes client requests. FollowerRequestProcessor forwards requests to CommitRequestProcessor, additionally forwarding write requests to the leader. CommitRequestProcessor forwards read requests directly to FinalRequestProcessor, whereas for write requests, CommitRequestProcessor must wait for a commit before forwarding to FinalRequestProcessor.
When the leader receives a new write request, directly or through a learner, it generates a proposal and forwards it to followers. Upon receiving a proposal, a follower sends it to SyncRequestProcessor. SyncRequestProcessor processes the request, logging it to disk, and forwards it toSendAckRequestProcessor. SendAckRequestProcessor acknowledges the proposal to the leader. After the leader receives enough acknowledgments to commit a proposal, the leader sends commit messages to the followers (and sends INFORM messages to the observers). Upon receiving a commit message, a follower processes it with CommitRequestProcessor.
To guarantee that the order of execution is preserved, CommitRequestProcessor stalls the processing of pending requests once it encounters a write request. This means any read requests that were received after a write request will be blocked until the write request passes theCommitRequestProcessor. By waiting, it guarantees that requests are executed in the received order.
The request pipeline for observers (class ObserverZooKeeperServer) is very similar to the one for followers. But because observers do not need to acknowledge proposals, it is not necessary to send acknowledgment messages back to the leader or persist transactions to disk. Discussions are under way for making observers persist transactions to disk to speed up recovery for the observers, though. Consequently, future releases of ZooKeeper might have this feature.
Local Storage
We have already mentioned transaction logs and snapshots, and that SyncRequestProcessor is the processor that writes them when processing write proposals. We’ll focus a bit more on them in this section.
Logs and Disk Use
Recall that servers use the transaction log to persist transactions. Before accepting a proposal, a server (follower or leader) persists the transaction in the proposal to the transaction log, a file on the local disk of the server to which transactions are appended in order. Every now and then, the server rolls over the log by closing the current file and creating a new one.
Because writing to the transaction log is in the critical path of write requests, ZooKeeper needs to be efficient about it. Appending to the file can be done efficiently on hard drives, but there are a couple of other tricks ZooKeeper uses to make it fast: group commits and padding. Group commits consist of appending multiple transactions in a single write to the disk. This allows many transactions to be persisted at the cost of a single disk seek.
There is one important caveat about persisting transactions to disk. Modern operating systems typically cache dirty pages and write them asynchronously to disk media. However, we need to make sure that transactions have been persisted before we move on. We consequently need to flushtransactions onto disk media. Flushing here simply means that we tell the operating system to write dirty pages to disk and return when the operation completes. Because we persist transactions in SyncRequestProcessor, this processor is the one responsible for flushing. When it is time to flush a transaction to disk in SyncRequestProcessor, we in fact do it for all queued transactions to implement the group commit optimization. If there is one single transaction queued, the processor stills execute the flush. The processor does not wait for more queued transactions, which could increase the execution latency. For a code reference, check SyncRequestProcessor.run().
DISK WRITE CACHE
A server acknowledges a proposal only after forcing a write of the transaction to the transaction log. More precisely, the server calls the commit method of ZKDatabase, which ultimately calls FileChannel.force. This way, the server guarantees that the transaction has been persisted to disk before acknowledging it. There is a caveat to this observation, though. Modern disks have a write cache that stores data to be written to disk. If the write cache is enabled, a call to force does not guarantee that, upon return, the data is on media. Instead, it could be sitting in the write cache. To guarantee that written data is on media upon returning from a call to FileChannel.force(), the disk write cache must be disabled. Operating systems have different ways of disabling it.
Padding consists of preallocating disk blocks to a file. This is done so that updates to the file system metadata for block allocation do not significantly affect sequential writes to the file. If transactions are being appended to the log at a high speed, and if blocks were not preallocated to the file, the file system would need to allocate a new block whenever it reached the end of the one it was writing to. This would induce at least two extra disk seeks: one to update the metadata and another back to the file.
To avoid interference with other writes to the system, we strongly recommend that you write the transaction log to an independent device. A second device can be used for the operating system files and the snapshots.
Snapshots
Snapshots are copies of the ZooKeeper data tree. Each server frequently takes a snapshot of the data tree by serializing the whole data tree and writing it to a file. The servers do not need to coordinate to take snapshots, nor do they have to stop processing requests. Because servers keep executing requests while taking a snapshot, the data tree changes as the snapshot is taken. We call such snapshots fuzzy, because they do not necessarily reflect the exact state of the data tree at any particular point in time.
Let’s walk through an example to illustrate this. Say that a data tree has only two znodes: /z and /z'. Initially, the data of both /z and /z' is the integer 1. Now consider the following sequence of steps:
1. Start a snapshot.
2. Serialize and write /z = 1 to the snapshot.
3. Set the data of /z to 2 (transaction T).
4. Set the data of /z' to 2 (transaction Tʹ).
5. Serialize and write /z' = 2 to the snapshot.
This snapshot contains /z = 1 and /z' = 2. However, there has never been a point in time in which the values of both znodes were like that. This is not a problem, though, because the server replays transactions. It tags each snapshot with the last transaction that has been committed when the snapshot starts—call it TS. If the server eventually loads the snapshot, it replays all transactions in the transaction log that come after TS. In this case, they are T and Tʹ. After replaying T and Tʹ on top of the snapshot, the server obtains /z = 2 and /z' = 2, which is a valid state.
An important follow-up question to ask is whether there is any problem with applying Tʹ again because it had already been applied by the time the snapshot was taken. As we noted earlier, transactions are idempotent, so as long as we apply the same transactions in the same order, we will get the same result even if some of them have already been applied to the snapshot.
To understand this process, assume that applying a transaction consists of reexecuting the corresponding operation. In the case just described, the operation sets the data of the znode to a specific value, and the value is not dependent on anything else. Say that we are setting the data of /z'unconditionally (the version number is -1 in the setData request). Reapplying the operation succeeds, but we end up with the wrong version number because we increment it twice. This can cause problems in the following way. Suppose that these three operations are submitted and executed successfully:
setData /z', 2, -1
setData /z', 3, 2
setData /a, 0, -1
The first setData operation is the same one we described earlier, but we’ve added two more setData operations to show that we can end up in a situation in which the second operation is not executed during a replay because of an incorrect version number. By assumption, all three requests were executed correctly when they were submitted. Suppose that a server loads the latest snapshot, which already contains the first setData. The server still replays the first setData operation because the snapshot is tagged with an earlier zxid. Because it reexecutes the first setData, the version does not match the one the second setData operation expects, so this operation does not go through. The third setData executes regularly because it is also unconditional.
After loading the snapshot and replaying the log, the state of the server is incorrect because it does not include the second setData request. This execution violates durability and the property that there are no gaps in the sequence of requests executed.
Such problems with reapplying requests are taken care of by turning transactions into state deltas generated by the leader. When the leader generates a transaction for a given request, as part of generating the transaction, it includes the changes in the request to the znode or its data and specifies a fixed version number. Reapplying a transaction consequently does not induce inconsistent version numbers.
Servers and Sessions
Sessions constitute an important abstraction in ZooKeeper. Ordering guarantees, ephemeral znodes, and watches are tightly coupled to sessions. The session tracking mechanism is consequently very important to ZooKeeper.
One important task of ZooKeeper servers is to keep track of sessions. The single server tracks all sessions when running in standalone mode, whereas the leader tracks them in quorum mode. The leader server and the standalone server in fact run the same session tracker (seeSessionTracker and SessionTrackerImpl). A follower server simply forwards session information for all the clients that connect to it to the leader (see LearnerSessionTracker).
To keep a session alive, a server needs to receive heartbeats for the session. Heartbeats come in the form of new requests or explicit ping messages (see LearnerHandler.run()). In both cases, the server touches sessions by updating the session expiration time (seeSessionTrackerImpl.touchSession()). In quorum mode, a leader sends a PING message to learners and the learners send back the list of sessions that have been touched since the last PING. The leader sends a ping to learners every half a tick. A tick (described in Basic Configuration) is the minimum unit of time that ZooKeeper uses, expressed in milliseconds. So, if the tick is set to be 2 seconds, then the leader sends a ping every second.
Two important points govern session expiration. A data structure called the expiry queue (see ExpiryQueue) keeps session information for the purposes of expiration. The data structure keeps sessions in buckets, each bucket corresponding to a range of time during which the sessions are supposed to expire, and the leader expires the sessions in one bucket at a time. To determine which bucket to expire, if any, a thread checks the expiry queue to find out when the next deadline is. The thread sleeps until this deadline, and when it wakes up it polls the expiry queue for a new batch of sessions to expire. This batch can, of course, be empty.
To maintain the buckets, the leader splits time into expirationInterval units and assigns each session to the next bucket that expires after the session expiration time. The function doing the assignment essentially rounds the expiration time of a session up to the next higher interval. More concretely, the function evaluates this expression to determine which bucket a session belongs in when its session expiration time is updated:
(expirationTime / expirationInterval + 1) * expirationInterval
To provide an example, say that expirationInterval is 2 and the expirationTime for a given session occurs at time 10. We assign this session to bucket 12 (the result of (10/2 + 1) * 2). Note that expirationTime keeps increasing as we touch the session, so we move the session to buckets that expire later accordingly.
One major reason for using a scheme of buckets is to reduce the overhead of checking for session expiration. A ZooKeeper deployment might have thousands of clients and consequently thousands of sessions. Checking for session expiration in a fine-grained manner is not suitable in such situations. Related to this comment, note that if the expirationInterval is short, ZooKeeper ends up performing session expiration checks in a fine-grained manner. The expirationInterval is currently one tick, which is typically on the order of seconds.
Servers and Watches
Watches (see Watches and Notifications) are one-time triggers set by read operations, and each watch is triggered by a specific operation. To manage watches on the server side, a ZooKeeper server implements watch managers. An instance of the WatchManager class is responsible for keeping a list of current watches that are registered and for triggering them. All types of servers (standalone, leader, follower, and observer) process watches in the same way.
The DataTree class keeps a watch manager for child watches and another for data watches, the two types of watches discussed in Getting More Concrete: How to Set Watches. When processing a read operation that sets a watch, the class adds the watch to the manager’s list of watches. Similarly, when processing a transaction, the class finds out whether any watches are to be triggered for the corresponding modification. If there are watches to be triggered, the class calls the trigger method of the manager. Both adding a watch and triggering a watch start with the execution of a read request or a transaction in FinalRequestProcessor.
A watch triggered on the server side is propagated to the client. The class responsible for this is the server cnxn object (see the ServerCnxn class), which represents the connection between the client and the server and implements the Watcher interface. The Watcher.process method serializes the watch event to a format that can be used to transfer it over the wire. The ZooKeeper client receives the serialized version of the watch event, transforms it back to a watch event, and propagates it to the application.
Watches are tracked only in memory. They are never persisted to the disk. When a client disconnects from a server, all its watches are removed from memory. Because client libraries also keep track of their outstanding watches, they will reestablish any outstanding watches on the new server that they connect with.
Clients
There are two main classes in the client library: ZooKeeper and ClientCnxn. The ZooKeeper class implements most of the API, and this is the class a client application must instantiate to create a session. Upon creating a session, ZooKeeper associates a session identifier to it. The identifier is actually generated on the server side of the service (see SessionTrackerImpl).
The ClientCnx class manages the client socket connection with a server. It maintains a list of ZooKeeper servers it can connect to and transparently switches to a different server when a disconnection takes place. Upon reconnecting a session to a different server, the client also resets pending watches (see ClientCnxn.SendThread.primeConnection()). This reset is enabled by default, but can be disabled by setting disableAutoWatchReset.
Serialization
For the serialization of messages and transactions to send over the network and to store on disk, ZooKeeper uses Jute, which grew out of Hadoop. Now the two code bases have evolved separately. Check the org.apache.jute package in the ZooKeeper code base for the Jute compiler code. (For a long time the ZooKeeper developer team has been discussing options for replacing Jute, but we haven’t found a suitable replacement so far. It has served us well, though, and it hasn’t been critical to replace it.)
The main definition file for Jute is zookeeper.jute. It contains all definitions of messages and file records. Here is an example of a Jute definition we have in this file:
module org.apache.zookeeper.txn {
...
class CreateTxn {
ustring path;
buffer data;
vector<org.apache.zookeeper.data.ACL> acl;
boolean ephemeral;
int parentCVersion;
}
...
}
This example defines a module containing the definition of a create transaction. The module maps to a ZooKeeper package.
Takeaway Messages
This chapter has discussed core ZooKeeper mechanisms. Leader election is critical for availability. Without it, a ZooKeeper ensemble cannot stay up reliably. Having a leader is necessary but not sufficient. ZooKeeper also needs the Zab protocol to propagate state updates, which guarantees a consistent state despite possible crashes of the ZooKeeper servers.
We have reviewed the types of servers: standalone, leader, follower, and observer. They differ in important ways with respect to the mechanisms they implement and the protocols they execute. Their use also has implications for a given deployment. For example, adding observers enables higher read throughput without affecting write throughput. Adding observers, however, does not increase the overall availability of the system.
Internally, ZooKeeper servers implement a number of mechanisms and data structures. Here we have focused on the implementation of sessions and watchers, important concepts to understand when implementing ZooKeeper applications.
Although we have provided pointers to the code in this chapter, the goal was not to provide an exhaustive view of the source code. We strongly encourage the reader to fetch a copy of the code and go over it, using the pointers here as starting points.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.