ZooKeeper (2013)
Part I. ZooKeeper Concepts and Basics
Chapter 2. Getting to Grips with ZooKeeper
The previous chapter discussed the requirements of distributed applications at a high level and argued that they often have common requirements for coordination. We used the master-worker example, which is representative of a broad class of practical applications, to extract a few of the commonly used primitives we described there. We are now ready to present ZooKeeper, a service that enables the implementation of such primitives for coordination.
ZooKeeper Basics
Several primitives used for coordination are commonly shared across many applications. Consequently, one way of designing a service used for coordination is to come up with a list of primitives, expose calls to create instances of each primitive, and manipulate these instances directly. For example, we could say that distributed locks constitute an important primitive and expose calls to create, acquire, and release locks.
Such a design, however, suffers from a couple of important shortcomings. First, we need to either come up with an exhaustive list of primitives used beforehand, or keep extending the API to introduce new primitives. Second, it does not give flexibility to the application using the service to implement primitives in the way that is most suitable for it.
We consequently have taken a different path with ZooKeeper. ZooKeeper does not expose primitives directly. Instead, it exposes a file system-like API comprised of a small set of calls that enables applications to implement their own primitives. We typically use recipes to denote these implementations of primitives. Recipes include ZooKeeper operations that manipulate small data nodes, called znodes, that are organized hierarchically as a tree, just like in a file system. Figure 2-1 illustrates a znode tree. The root node contains four more nodes, and three of those nodes have nodes under them. The leaf nodes are the data.
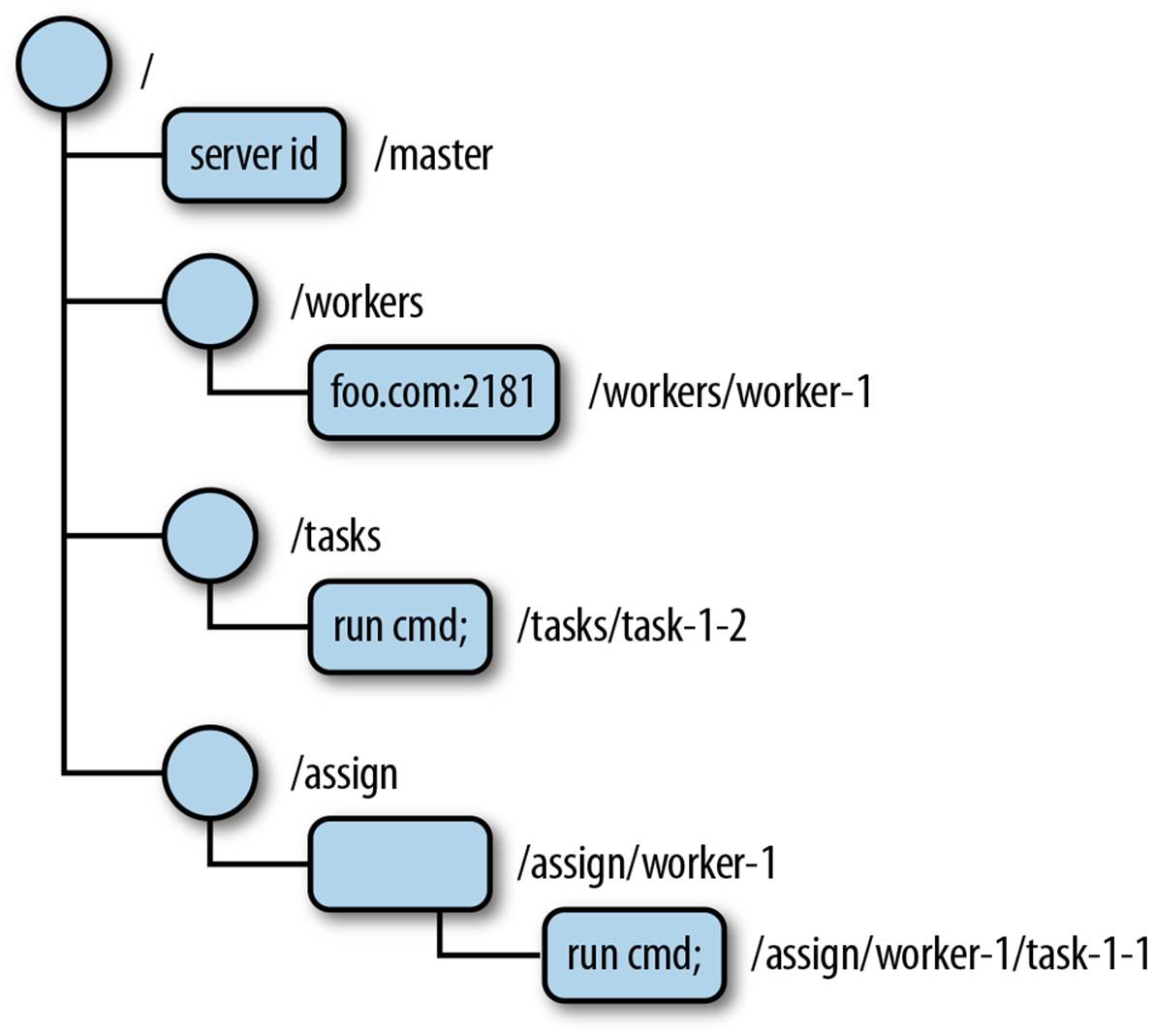
Figure 2-1. ZooKeeper data tree example
The absence of data often conveys important information about a znode. In a master-worker example, for instance, the absence of a master znode means that no master is currently elected. Figure 2-1 includes a few other znodes that could be useful in a master-worker configuration:
§ The /workers znode is the parent znode to all znodes representing a worker available in the system. Figure 2-1 shows that one worker (foo.com:2181) is available. If a worker becomes unavailable, its znode should be removed from /workers.
§ The /tasks znode is the parent of all tasks created and waiting for workers to execute them. Clients of the master-worker application add new znodes as children of /tasks to represent new tasks and wait for znodes representing the status of the task.
§ The /assign znode is the parent of all znodes representing an assignment of a task to a worker. When a master assigns a task to a worker, it adds a child znode to /assign.
API Overview
Znodes may or may not contain data. If a znode contains any data, the data is stored as a byte array. The exact format of the byte array is specific to each application, and ZooKeeper does not directly provide support to parse it. Serialization packages such as Protocol Buffers, Thrift, Avro, andMessagePack may be handy for dealing with the format of the data stored in znodes, but sometimes string encodings such as UTF-8 or ASCII suffice.
The ZooKeeper API exposes the following operations:
create /path data
Creates a znode named with /path and containing data
delete /path
Deletes the znode /path
exists /path
Checks whether /path exists
setData /path data
Sets the data of znode /path to data
getData /path
Returns the data in /path
getChildren /path
Returns the list of children under /path
One important note is that ZooKeeper does not allow partial writes or reads of the znode data. When setting the data of a znode or reading it, the content of the znode is replaced or read entirely.
ZooKeeper clients connect to a ZooKeeper service and establish a session through which they make API calls. If you are really anxious to use ZooKeeper, skip to Sessions. That section explains how to run some ZooKeeper commands from a command shell.
Different Modes for Znodes
When creating a new znode, you also need to specify a mode. The different modes determine how the znode behaves.
Persistent and ephemeral znodes
A znode can be either persistent or ephemeral. A persistent znode /path can be deleted only through a call to delete. An ephemeral znode, in contrast, is deleted if the client that created it crashes or simply closes its connection to ZooKeeper.
Persistent znodes are useful when the znode stores some data on behalf of an application and this data needs to be preserved even after its creator is no longer part of the system. For example, in the master-worker example, we need to maintain the assignment of tasks to workers even when the master that performed the assignment crashes.
Ephemeral znodes convey information about some aspect of the application that must exist only while the session of its creator is valid. For example, the master znode in our master-worker example is ephemeral. Its presence implies that there is a master and the master is up and running. If the master znode remains while the master is gone, then the system won’t be able to detect the master crash. This would prevent the system from making progress, so the znode must go with the master. We also use ephemeral znodes for workers. If a worker becomes unavailable, its session expires and its znode in /workers disappears automatically.
An ephemeral znode can be deleted in two situations:
1. When the session of the client creator ends, either by expiration or because it explicitly closed.
2. When a client, not necessarily the creator, deletes it.
Because ephemeral znodes are deleted when their creator’s session expires, we currently do not allow ephemerals to have children. There have been discussions in the community about allowing children for ephemeral znodes by making them also ephemeral. This feature might be available in future releases, but it isn’t available currently.
Sequential znodes
A znode can also be set to be sequential. A sequential znode is assigned a unique, monotonically increasing integer. This sequence number is appended to the path used to create the znode. For example, if a client creates a sequential znode with the path /tasks/task-, ZooKeeper assigns a sequence number, say 1, and appends it to the path. The path of the znode becomes /tasks/task-1. Sequential znodes provide an easy way to create znodes with unique names. They also provide a way to easily see the creation order of znodes.
To summarize, there are four options for the mode of a znode: persistent, ephemeral, persistent_sequential, and ephemeral_sequential.
Watches and Notifications
Because ZooKeeper is typically accessed as a remote service, accessing a znode every time a client needs to know its content would be very expensive: it would induce higher latency and more operations to a ZooKeeper installation. Consider the example in Figure 2-2. The second call togetChildren /tasks returns the same value, an empty set, and consequently is unnecessary.
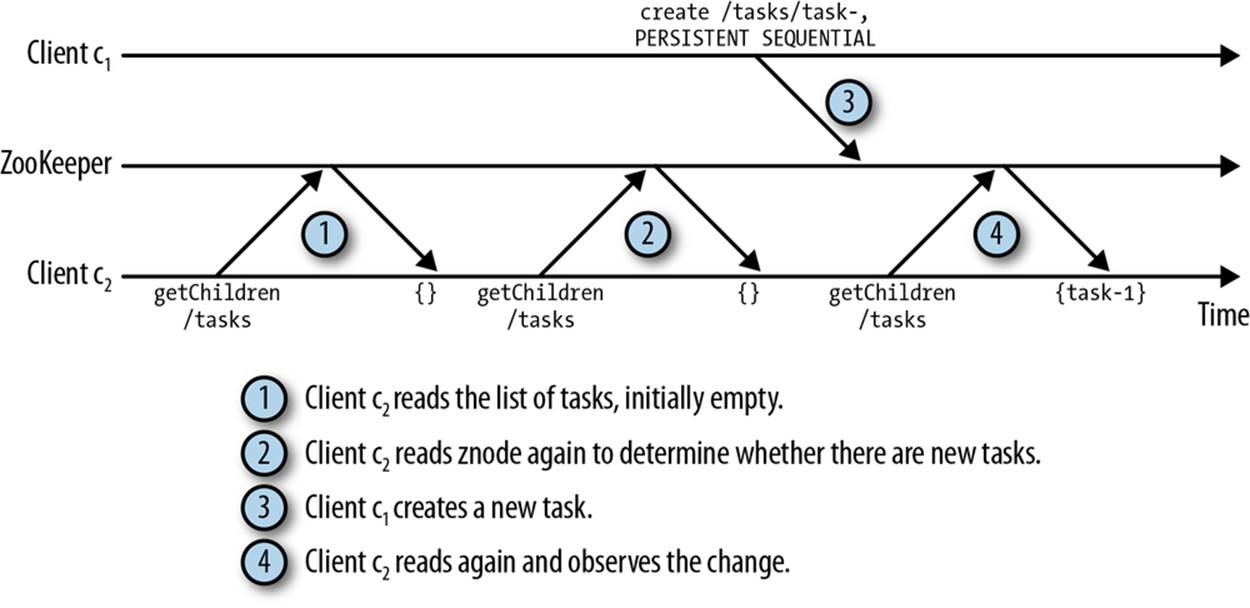
Figure 2-2. Multiple reads to the same znode
This is a common problem with polling. To replace the client polling, we have opted for a mechanism based on notifications: clients register with ZooKeeper to receive notifications of changes to znodes. Registering to receive a notification for a given znode consists of setting a watch. A watch is a one-shot operation, which means that it triggers one notification. To receive multiple notifications over time, the client must set a new watch upon receiving each notification. In the situation illustrated in Figure 2-3, the client reads new values from ZooKeeper only when it receives a notification indicating that the value of /tasks has changed.
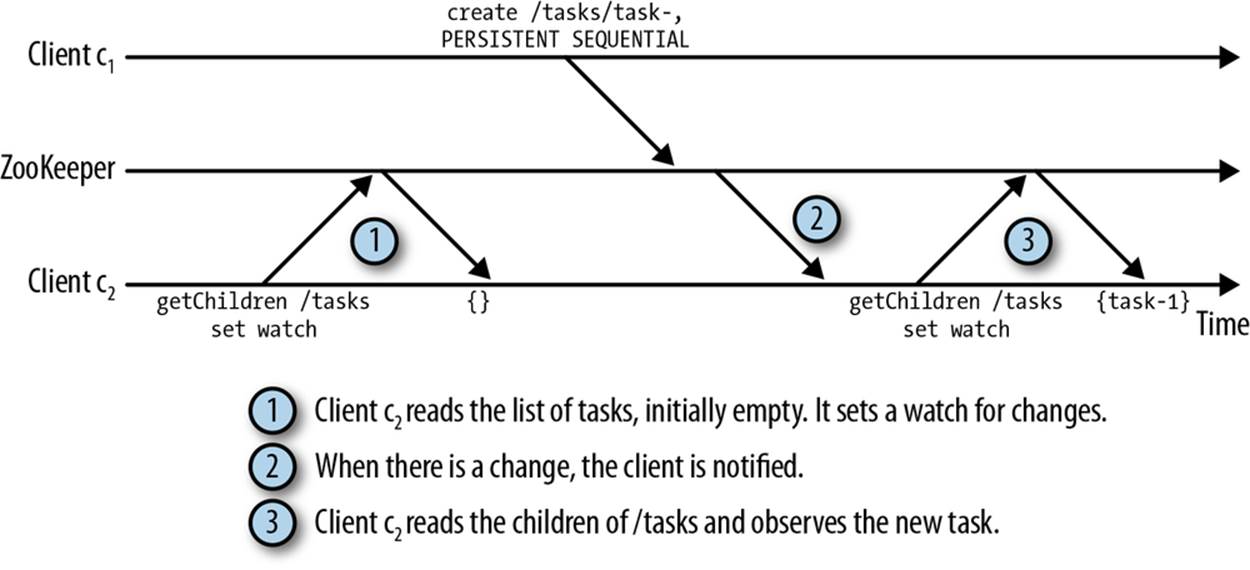
Figure 2-3. Using notifications to be informed of changes to a znode
When using notifications, there are a few things to be aware of. Because notifications are one-shot operations, it is possible that new changes will occur to a znode between a client receiving a notification for the znode and setting a new watch (but don’t worry, you won’t miss changes to the state). Let’s look at a quick example to see how it works. Suppose the following events happen in this order:
1. Client c1 sets a watch for changes to the data of /tasks.
2. Client c2 comes and adds a task to /tasks.
3. Client c1 receives the notification.
4. Client c1 sets a new watch, but before it does it, a third client, c3, comes and adds a new task to /tasks.
Client c1 eventually has this new watch set, but no notification is triggered by the change made by c3. To observe this change, c1 has to actually read the state of /tasks, which it does when setting the watch because we set watches with operations that read the state of ZooKeeper. Consequently, c1 does not miss any changes.
One important guarantee of notifications is that they are delivered to a client before any other change is made to the same znode. If a client sets a watch to a znode and there are two consecutive updates to the znode, the client receives the notification after the first update and before it has a chance to observe the second update by, say, reading the znode data. The key property we satisfy is the one that notifications preserve the order of updates the client observes. Although changes to the state of ZooKeeper may end up propagating more slowly to any given client, we guarantee that clients observe changes to the ZooKeeper state according to a global order.
ZooKeeper produces different types of notifications, depending on how the watch corresponding to the notification was set. A client can set a watch for changes to the data of a znode, changes to the children of a znode, or a znode being created or deleted. To set a watch, we can use any of the calls in the API that read the state of ZooKeeper. These API calls give the option of passing a Watcher object or using the default watcher. In our discussion of the master-worker example later in this chapter (Implementation of a Master-Worker Example) and in Chapter 4, we will cover how to use this mechanism in more detail.
WHO MANAGES MY CACHE?
Instead of having the client manage its own cache of ZooKeeper values, we could have had ZooKeeper manage such a cache on behalf of the application. However, this would have made the design of ZooKeeper more complex. In fact, if ZooKeeper had to manage cache invalidations, it could cause ZooKeeper operations to stall while waiting for a client to acknowledge a cache invalidation request, because write operations would need a confirmation that all cached values had been invalidated.
Versions
Each znode has a version number associated with it that is incremented every time its data changes. A couple of operations in the API can be executed conditionally: setData and delete. Both calls take a version as an input parameter, and the operation succeeds only if the version passed by the client matches the current version on the server. The use of versions is important when multiple ZooKeeper clients might be trying to perform operations over the same znode. For example, suppose that a client c1 writes a znode /config containing some configuration. If another clientc2 concurrently updates the znode, the version c1 has is stale and the setData of c1 must not succeed. Using versions avoids such situations. In this case, the version that c1 uses when writing back doesn’t match and the operation fails. This situation is illustrated in Figure 2-4.
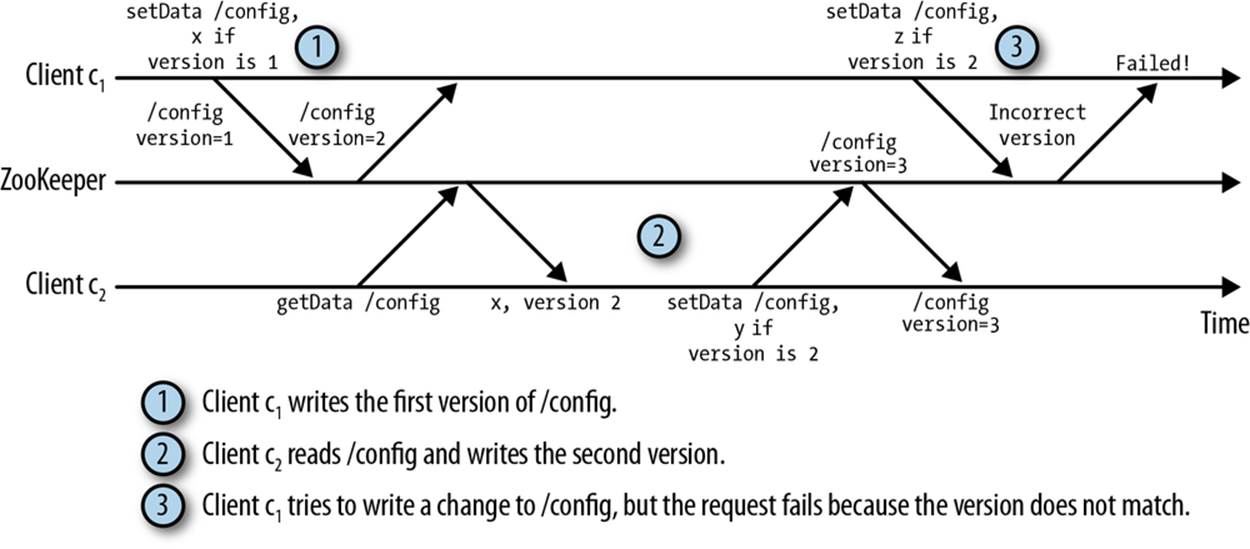
Figure 2-4. Using versions to prevent inconsistencies due to concurrent updates
ZooKeeper Architecture
Now that we have discussed at a high level the operations that ZooKeeper exposes to applications, we need to understand more of how the service actually works. Applications make calls to ZooKeeper through a client library. The client library is responsible for the interaction with ZooKeeper servers.
Figure 2-5 shows the relationship between clients and servers. Each client imports the client library, and then can communicate with any ZooKeeper node.
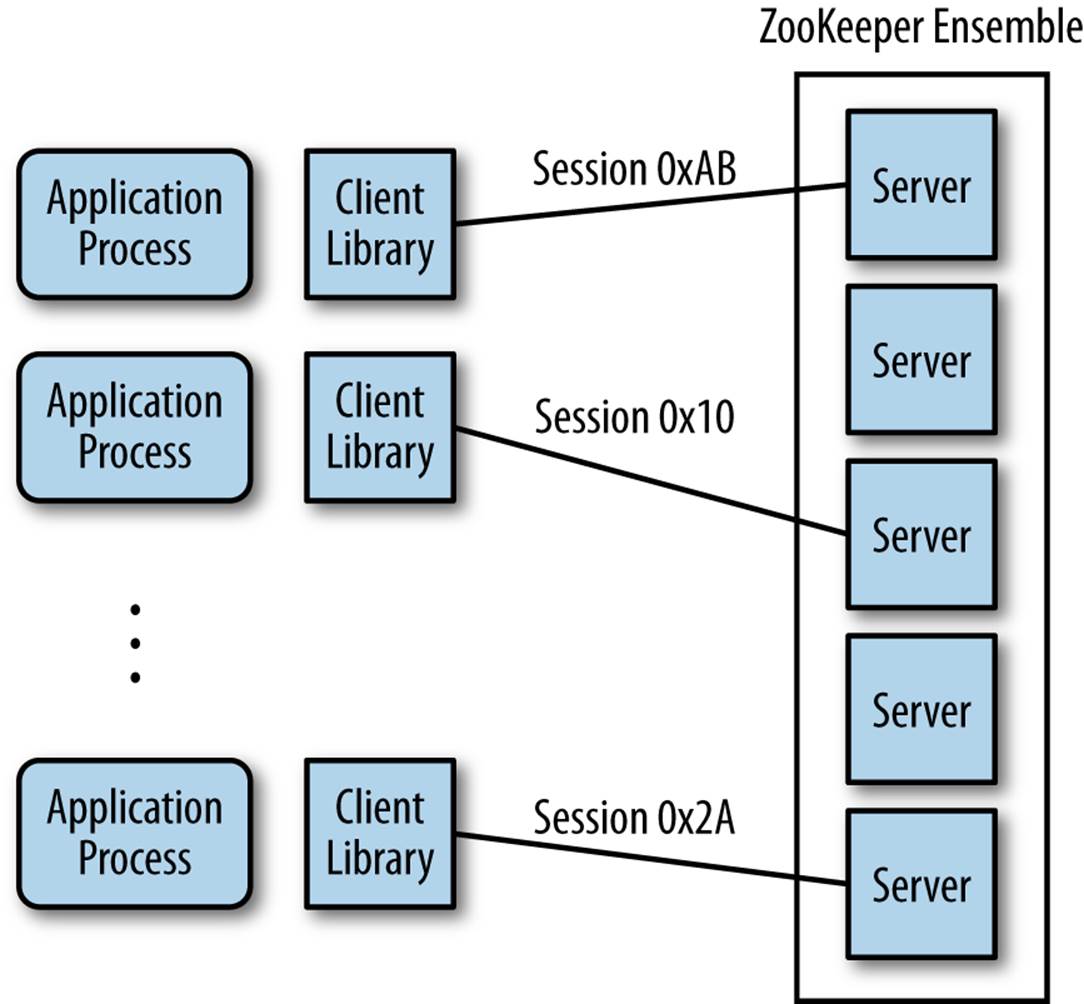
Figure 2-5. ZooKeeper architecture overview
ZooKeeper servers run in two modes: standalone and quorum. Standalone mode is pretty much what the term says: there is a single server, and ZooKeeper state is not replicated. In quorum mode, a group of ZooKeeper servers, which we call a ZooKeeper ensemble, replicates the state, and together they serve client requests. From this point on, we use the term “ZooKeeper ensemble” to denote an installation of servers. This installation could contain a single server and operate in standalone mode or contain a group of servers and operate in quorum mode.
ZooKeeper Quorums
In quorum mode, ZooKeeper replicates its data tree across all servers in the ensemble. But if a client had to wait for every server to store its data before continuing, the delays might be unacceptable. In public administration, a quorum is the minimum number of legislators required to be present for a vote. In ZooKeeper, it is the minimum number of servers that have to be running and available in order for ZooKeeper to work. This number is also the minimum number of servers that have to store a client’s data before telling the client it is safely stored. For instance, we might have five ZooKeeper servers in total, but a quorum of three. So long as any three servers have stored the data, the client can continue, and the other two servers will eventually catch up and store the data.
It is important to choose an adequate size for the quorum. Quorums must guarantee that, regardless of delays and crashes in the system, any update request the service positively acknowledges will persist until another request supersedes it.
To understand what this means, let’s look at an example that shows how things can go wrong if the quorum is too small. Say we have five servers and a quorum can be any set of two servers. Now say that servers s1 and s2 acknowledge that they have replicated a request to create a znode /z. The service returns to the client saying that the znode has been created. Now suppose servers s1 and s2 are partitioned away from the other servers and from clients for an arbitrarily long time, before they have a chance to replicate the new znode to the other servers. The service in this state is able to make progress because there are three servers available and it really needs only two according to our assumptions, but these three servers have never seen the new znode /z. Consequently, the request to create /z is not durable.
This is an example of the split-brain scenario mentioned in Chapter 1. To avoid this problem, in this example the size of the quorum must be at least three, which is a majority out of the five servers in the ensemble. To make progress, the ensemble needs at least three servers available. To confirm that a request to update the state has completed successfully, this ensemble also requires that at least three servers acknowledge that they have replicated it. Consequently, if the ensemble is able to make progress, then for every update that has completed successfully, we have at least one server available that contains a copy of that update (that is, the possible quorums intersect in at least one node).
Using such a majority scheme, we are able to tolerate the crash of f servers, where f is less than half of the servers in the ensemble. For example, if we have five servers, we can tolerate up to f = 2 crashes. The number of servers in the ensemble is not mandatorily odd, but an even number actually makes the system more fragile. Say that we use four servers for an ensemble. A majority of servers is comprised of three servers. However, this system will only tolerate a single crash, because a double crash makes the system lose majority. Consequently, with four servers, we can only tolerate a single crash, but quorums now are larger, which implies that we need more acknowledgments for each request. The bottom line is that we should always shoot for an odd number of servers.
We allow quorum sets other than majority quorums, but that is a discussion for a more advanced chapter. We discuss it in Chapter 10.
Sessions
Before executing any request against a ZooKeeper ensemble, a client must establish a session with the service. The concept of sessions is very important and quite critical for the operation of ZooKeeper. All operations a client submits to ZooKeeper are associated to a session. When a session ends for any reason, the ephemeral nodes created during that session disappear.
When a client creates a ZooKeeper handle using a specific language binding, it establishes a session with the service. The client initially connects to any server in the ensemble, and only to a single server. It uses a TCP connection to communicate with the server, but the session may be moved to a different server if the client has not heard from its current server for some time. Moving a session to a different server is handled transparently by the ZooKeeper client library.
Sessions offer order guarantees, which means that requests in a session are executed in FIFO (first in, first out) order. Typically, a client has only a single session open, so its requests are all executed in FIFO order. If a client has multiple concurrent sessions, FIFO ordering is not necessarily preserved across the sessions. Consecutive sessions of the same client, even if they don’t overlap in time, also do not necessarily preserve FIFO order. Here is how it can happen in this case:
§ Client establishes a session and makes two consecutive asynchronous calls to create /tasks and /workers.
§ First session expires.
§ Client establishes another session and makes an asynchronous call to create /assign.
In this sequence of calls, it is possible that only /tasks and /assign have been created, which preserves FIFO ordering for the first session but violates it across sessions.
Getting Started with ZooKeeper
To get started, you need to download the ZooKeeper distribution. ZooKeeper is an Apache project hosted at http://zookeeper.apache.org. If you follow the download links, you should end up downloading a compressed TAR file named something like zookeeper-3.4.5.tar.gz. On Linux, Mac OS X, or any other UNIX-like system you can use the following command to extract the distribution:
# tar -xvzf zookeeper-3.4.5.tar.gz
If you are using Windows, you will need to use a decompression tool such as WinZip to extract the distribution.
You will also need to have Java installed. Java 6 is required to run ZooKeeper.
In the distribution directory you will find a bin directory that contains the scripts needed to start ZooKeeper. The scripts that end in .sh are designed to run on UNIX platforms (Linux, Mac OS X, etc.), and the scripts that end in .cmd are for Windows. The conf directory holds configuration files. The lib directory contains Java JAR files, which are third-party files needed to run ZooKeeper. Later we will need to refer to the directory in which you extracted the ZooKeeper distribution. We will refer to this directory as {PATH_TO_ZK}.
First ZooKeeper Session
Let’s set up ZooKeeper locally in standalone mode and create a session. To do this, we use the zkServer and zkCli tools that come with the ZooKeeper distribution under bin/. Experienced administrators typically use them for debugging and administration, but it turns out that they are great for getting beginners familiar with ZooKeeper as well.
Assuming you have downloaded and unpackaged a ZooKeeper distribution, go to a shell, change directory (cd) to the project’s root, and rename the sample configuration file:
# mv conf/zoo_sample.cfg conf/zoo.cfg
Although optional, it might be a good idea to move the data directory out of /tmp to avoid having ZooKeeper filling up your root partition. You can change its location in the zoo.cfg file:
dataDir=/users/me/zookeeper
To finally start a server, execute the following:
# bin/zkServer.sh start
JMX enabled by default
Using config: ../conf/zoo.cfg
Starting zookeeper ... STARTED
#
This server command makes the ZooKeeper server run in the background. To have it running in the foreground in order to see the output of the server, you can run the following:
# bin/zkServer.sh start-foreground
This option gives you much more verbose output and allows you to see what’s going on with the server.
We are now ready to start a client. In a different shell under the project root, run the following:
# bin/zkCli.sh
.
.
.
<some omitted output>
.
.
.
2012-12-06 12:07:23,545 [myid:] - INFO [main:ZooKeeper@438] - ![]()
Initiating client connection, connectString=localhost:2181
sessionTimeout=30000 watcher=org.apache.zookeeper.
ZooKeeperMain$MyWatcher@2c641e9a
Welcome to ZooKeeper!
2012-12-06 12:07:23,702 [myid:] - INFO [main-SendThread ![]()
(localhost:2181):ClientCnxn$SendThread@966] - Opening
socket connection to server localhost/127.0.0.1:2181.
Will not attempt to authenticate using SASL (Unable to
locate a login configuration)
JLine support is enabled
2012-12-06 12:07:23,717 [myid:] - INFO [main-SendThread ![]()
(localhost:2181):ClientCnxn$SendThread@849] - Socket
connection established to localhost/127.0.0.1:2181, initiating
session [zk: localhost:2181(CONNECTING) 0]
2012-12-06 12:07:23,987 [myid:] - INFO [main-SendThread ![]()
(localhost:2181):ClientCnxn$SendThread@1207] - Session
establishment complete on server localhost/127.0.0.1:2181,
sessionid = 0x13b6fe376cd0000, negotiated timeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null ![]()
![]()
The client starts the procedure to establish a session.
![]()
The client tries to connect to localhost/127.0.0.1:2181.
![]()
The client’s connection is successful and the server proceeds to initiate a new session.
![]()
The session initialization completes successfully.
![]()
The server sends the client a SyncConnected event.
Let’s have a look at the output. There are a number of lines just telling us how the various environment variables have been set and what JARs the client is using. We’ll ignore them for the purposes of this example and focus on the session establishment, but take your time to analyze the full output on your screen.
Toward the end of the output, we see log messages referring to session establishment. The first one says “Initiating client connection.” The message pretty much says what is happening, but an additional important detail is that it is trying to connect to one of the servers in thelocalhost/127.0.0.1:2181 connect string sent by the client. In this case, the string contains only localhost, so this is the one the connection will go for. Next we see a message about SASL, which we will ignore, followed by a confirmation that the client successfully established a TCP connection with the local ZooKeeper server. The last message of the log confirms the session establishment and gives us its ID: 0x13b6fe376cd0000. Finally, the client library notifies the application with a SyncConnected event. Applications are supposed to implement Watcherobjects that process such events. We will talk more about events in the next section.
Just to get a bit more familiar with ZooKeeper, let’s list the znodes under the root and create a znode. Let’s first confirm that the tree is empty at this point, aside from the /zookeeper znode that marks the metadata tree that the ZooKeeper service maintains:
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
What happened here? We have executed ls / and we see that there is only /zookeeper there. Now we create a znode called /workers and make sure that it is there as follows:
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 1] create /workers ""
Created /workers
[zk: localhost:2181(CONNECTED) 2] ls /
[workers, zookeeper]
[zk: localhost:2181(CONNECTED) 3]
ZNODE DATA
When we create the /workers znode, we specify an empty string ("") to say that there is no data we want to store in the znode at this point. That parameter in this interface, however, allows us to store arbitrary strings in the ZooKeeper znodes. For example, we could have replaced "" with "workers".
To wrap up this exercise, we delete the znode and exit:
[zk: localhost:2181(CONNECTED) 3] delete /workers
[zk: localhost:2181(CONNECTED) 4] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 5] quit
Quitting...
2012-12-06 12:28:18,200 [myid:] - INFO [main-EventThread:ClientCnxn$
EventThread@509] - EventThread shut down
2012-12-06 12:28:18,200 [myid:] - INFO [main:ZooKeeper@684] - Session:
0x13b6fe376cd0000 closed
Observe that the znode /workers has been deleted and the session has now been closed. To clean up, let’s also stop the ZooKeeper server:
# bin/zkServer.sh stop
JMX enabled by default
Using config: ../conf/zoo.cfg
Stopping zookeeper ... STOPPED
#
States and the Lifetime of a Session
The lifetime of a session corresponds to the period between its creation and its end, whether it is closed gracefully or expires because of a timeout. To talk about what happens in a session, we need to consider the possible states that a session can be in and the possible events that can change its state.
The main possible states of a session are mostly self-explanatory: CONNECTING, CONNECTED, CLOSED, and NOT_CONNECTED. The state transitions depend on various events that happen between the client and the service (Figure 2-6).
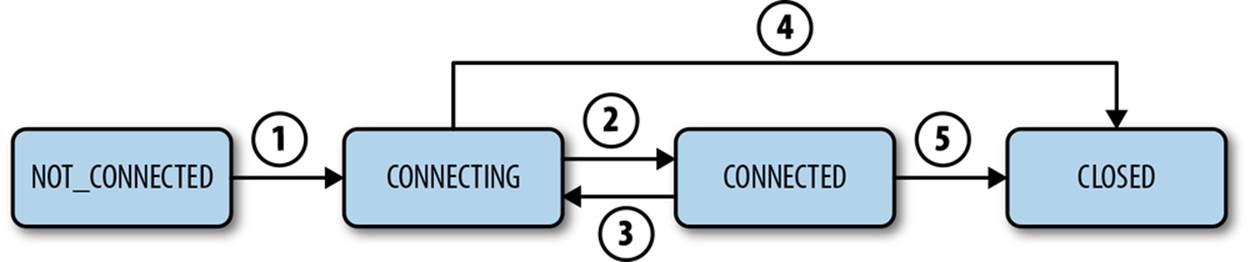
Figure 2-6. Session states and transitions
A session starts at the NOT_CONNECTED state and transitions to CONNECTING (arrow 1 in Figure 2-6) with the initialization of the ZooKeeper client. Normally, the connection to a ZooKeeper server succeeds and the session transitions to CONNECTED (arrow 2). When the client loses its connection to the ZooKeeper server or doesn’t hear from the server, it transitions back to CONNECTING (arrow 3) and tries to find another ZooKeeper server. If it is able to find another server or to reconnect to the original server, it transitions back to CONNECTED once the server confirms that the session is still valid. Otherwise, it declares the session expired and transitions to CLOSED (arrow 4). The application can also explicitly close the session (arrows 4 and 5).
WAITING ON CONNECTING DURING NETWORK PARTITIONS
If a client disconnects from a server due to a timeout, the client remains in the CONNECTING state. If the disconnection happens because the client has been partitioned away from the ZooKeeper ensemble, it will remain in this state until either it closes the session explicitly, or the partition heals and the client hears from a ZooKeeper server that the session has expired. We have this behavior because the ZooKeeper ensemble is the one responsible for declaring a session expired, not the client. Until the client hears that a ZooKeeper session has expired, the client cannot declare the session expired. The client may choose to close the session, however.
One important parameter you should set when creating a session is the session timeout, which is the amount of time the ZooKeeper service allows a session before declaring it expired. If the service does not see messages associated to a given session during time t, it declares the session expired. On the client side, if it has heard nothing from the server at 1/3 of t, it sends a heartbeat message to the server. At 2/3 of t, the ZooKeeper client starts looking for a different server, and it has another 1/3 of t to find one.
WHICH SERVER DOES IT TRY TO CONNECT TO?
In quorum mode a client has multiple choices of servers to connect to, whereas in standalone mode it must try to reconnect to the single server available. In quorum mode, the application is supposed to pass a list of servers the client can connect to and choose from.
When trying to connect to a different server, it is important for the ZooKeeper state of this server to be at least as fresh as the last ZooKeeper state the client has observed. A client cannot connect to a server that has not seen an update that the client might have seen. ZooKeeper determines freshness by ordering updates in the service. Every change to the state of a ZooKeeper deployment is totally ordered with respect to all other executed updates. Consequently, if a client has observed an update in position i, it cannot connect to a server that has only seen iʹ < i. In the ZooKeeper implementation, the transaction identifiers that the system assigns to each update establish the order.
Figure 2-7 illustrates the use of transaction identifiers (zxids) for reconnecting. After the client disconnects from s1 because it times out, it tries s2, but s2 has lagged behind and does not reflect a change known to the client. However, s3 has seen the same changes as the client, so it is safe to connect.
ZooKeeper with Quorums
The configuration we have used so far is for a standalone server. If the server is up, the service is up, but if the server fails, the whole service comes down with it. This doesn’t quite live up to the promise of a reliable coordination service. To truly get reliability, we need to run multiple servers.
Fortunately, we can run multiple servers even if we only have a single machine. We just need to set up a more sophisticated configuration.
In order for servers to contact each other, they need some contact information. In theory servers can use multicasts to discover each other, but we want to support ZooKeeper ensembles that span multiple networks in addition to single networks that support multiple ensembles.
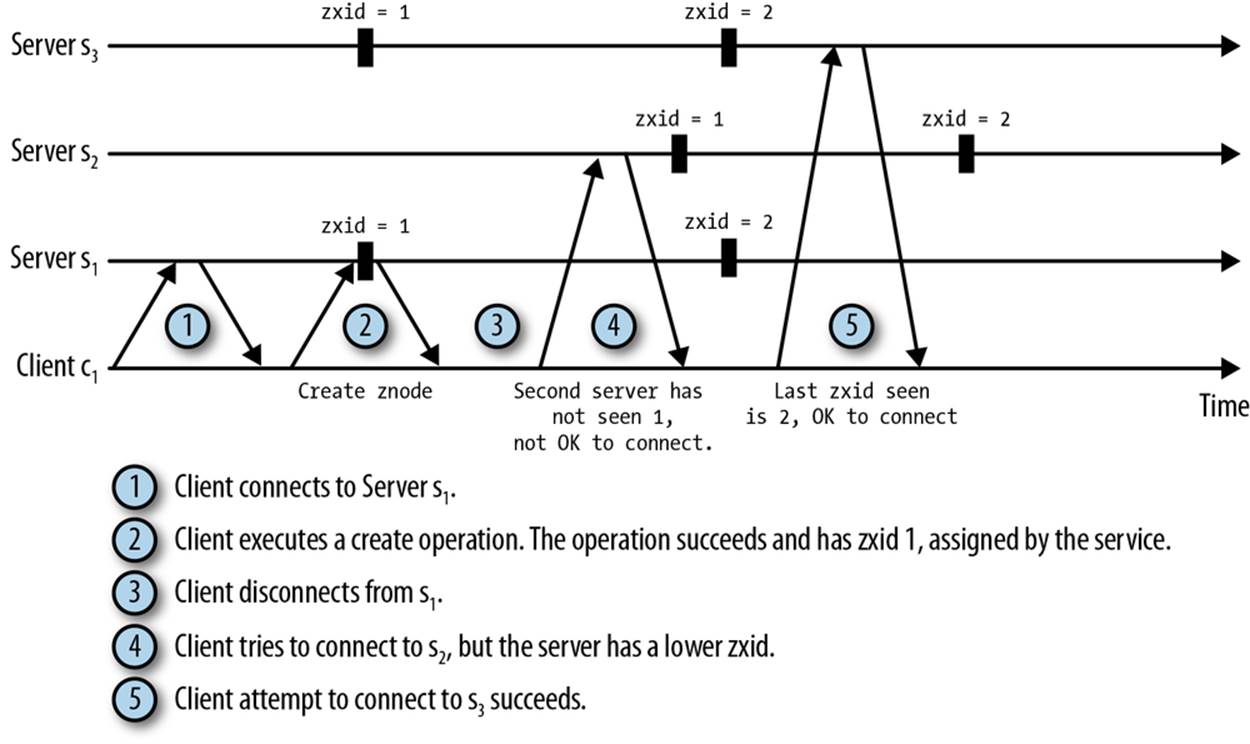
Figure 2-7. Example of client reconnecting
To accomplish this, we are going to use the following configuration file:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=./data
clientPort=2181
server.1=127.0.0.1:2222:2223
server.2=127.0.0.1:3333:3334
server.3=127.0.0.1:4444:4445
We’ll concentrate on the last three lines here, the server.n entries. The rest are general configuration parameters that will be explained in Chapter 10.
Each server.n entry specifies the address and port numbers used by ZooKeeper server n. There are three colon-separated fields for each server.n entry. The first field is the hostname or IP address of server n. The second and third fields are TCP port numbers used for quorum communication and leader election. Because we are starting up three server processes on the same machine, we need to use different port numbers for each entry. Normally, when running each server process on its own server, each server entry will use the same port numbers.
We also need to set up some data directories. We can do this from the command line with the following commands:
mkdir z1
mkdir z1/data
mkdir z2
mkdir z2/data
mkdir z3
mkdir z3/data
When we start up a server, it needs to know which server it is. A server figures out its ID by reading a file named myid in the data directory. We can create these files with the following commands:
echo 1 > z1/data/myid
echo 2 > z2/data/myid
echo 3 > z3/data/myid
When a server starts up, it finds the data directory using the dataDir parameter in the configuration file. It obtains the server ID from mydata and then uses the corresponding server.n entry to set up the ports it listens on. When we run ZooKeeper server processes on different machines, they can all use the same client ports and even use exactly the same configuration files. But for this example, running on one machine, we need to customize the client ports for each server.
So, first we create z1/z1.cfg using the configuration file we discussed at the beginning of this section. We then create configurations z2/z2.cfg and z3/z3.cfg by changing clientPort to be 2182 and 2183, respectively.
Now we can start a server. Let’s begin with z1:
$ cd z1
$ {PATH_TO_ZK}/bin/zkServer.sh start ./z1.cfg
Log entries for the server go to zookeeper.out. Because we have only started one of three ZooKeeper servers, the service will not be able to come up. In the log we should see entries of the form:
... [myid:1] - INFO [QuorumPeer[myid=1]/...:2181:QuorumPeer@670] - LOOKING
... [myid:1] - INFO [QuorumPeer[myid=1]/...:2181:FastLeaderElection@740] -
New election. My id = 1, proposed zxid=0x0
... [myid:1] - INFO [WorkerReceiver[myid=1]:FastLeaderElection@542] -
Notification: 1 ..., LOOKING (my state)
... [myid:1] - WARN [WorkerSender[myid=1]:QuorumCnxManager@368] - Cannot
open channel to 2 at election address /127.0.0.1:3334
Java.net.ConnectException: Connection refused
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.PlainSocketImpl.doConnect(PlainSocketImpl.java:351)
The server is frantically trying to connect to other servers, and failing. If we start up another server, we can form a quorum:
$ cd z2
$ {PATH_TO_ZK}/bin/zkServer.sh start ./z2.cfg
If we examine the zookeeper.out log for the second server, we see:
... [myid:2] - INFO [QuorumPeer[myid=2]/...:2182:Leader@345] - LEADING
- LEADER ELECTION TOOK - 279
... [myid:2] - INFO [QuorumPeer[myid=2]/...:2182:FileTxnSnapLog@240] -
Snapshotting: 0x0 to ./data/version-2/snapshot.0
This indicates that server 2 has been elected leader. If we now look at the log for server 1, we see:
... [myid:1] - INFO [QuorumPeer[myid=1]/...:2181:QuorumPeer@738] -
FOLLOWING
... [myid:1] - INFO [QuorumPeer[myid=1]/...:2181:ZooKeeperServer@162] -
Created server ...
... [myid:1] - INFO [QuorumPeer[myid=1]/...:2181:Follower@63] - FOLLOWING
- LEADER ELECTION TOOK - 212
Server 1 has also become active as a follower of server 2. We now have a quorum of servers (two out of three) available.
At this point the service is available. Now we need to configure the clients to connect to the service. The connect string lists all the host:port pairs of the servers that make up the service. In this case, that string is "127.0.0.1:2181, 127.0.0.1:2182, 127.0.0.1:2183". (We’re including the third server, even though we never started it, because it can illustrate some useful properties of ZooKeeper.)
We use zkCli.sh to access the cluster using:
$ {PATH_TO_ZK}/bin/zkCli.sh -server 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
When the server connects, we should see a message of the form:
[myid:] - INFO [...] - Session establishment
complete on server localhost/127.0.0.1:2182 ...
Note the port number, 2182 in this case, in the log message. If we stop the client with Ctrl-C and restart it various times, we will see the port number change between 2181 and 2182. We may also notice a failed connection attempt to 2183 followed by a successful connection attempt to one of the other ports.
SIMPLE LOAD BALANCING
Clients connect in a random order to servers in the connect string. This allows ZooKeeper to achieve simple load balancing. However, it doesn’t allow clients to specify a preference for a server to connect to. For example, if we have an ensemble of five ZooKeeper servers with three on the West Coast and two on the East Coast, to make sure clients connect only to local servers we may want to put only the East Coast servers in the connect string of the East Coast clients, and only the West Coast servers in the connect string of the West Coast clients.
The connection attempts to show how you can achieve reliability by running multiple servers (but in a production environment, of course, you will do so on different physical hosts). For most of this book, including the next few chapters, we stick with a standalone server for development because it is much easier to start and manage and makes the examples more straightforward. One of the nice things about ZooKeeper is that, apart from the connect string, it doesn’t matter to the clients how many servers make up the ZooKeeper service.
Implementing a Primitive: Locks with ZooKeeper
One simple example of what we can do with ZooKeeper is implement critical sections through locks. There are multiple flavors of locks (e.g., read/write locks, global locks) and several ways to implement locks with ZooKeeper. Here we discuss a simple recipe just to illustrate how applications can use ZooKeeper; we do not consider other variants of locks.
Say that we have an application with n processes trying to acquire a lock. Recall that ZooKeeper does not expose primitives directly, so we need to use the ZooKeeper interface to manipulate znodes and implement the lock. To acquire a lock, each process p tries to create a znode, say /lock. If p succeeds in creating the znode, it has the lock and can proceed to execute its critical section. One potential problem is that p could crash and never release the lock. In this case, no other process will ever be able to acquire the lock again, and the system could seize up in a deadlock. To avoid such situations, we just have to make the /lock znode ephemeral when we create it.
Other processes that try to create /lock fail so long as the znode exists. So, they watch for changes to /lock and try to acquire the lock again once they detect that /lock has been deleted. Upon receiving a notification that /lock has been deleted, if a process pʹ is still interested in acquiring the lock, it repeats the steps of attempting to create /lock and, if another process has created the znode already, watching it.
Implementation of a Master-Worker Example
In this section we will implement some of the functionality of the master-worker example using the zkCli tool. This example is for didactic purposes only, and we do not recommend building systems using zkCli. The goal of using zkCli is simply to illustrate how we implement coordination recipes with ZooKeeper, putting aside much of the detail needed for a real implementation. We’ll get into implementation details in the next chapter.
The master-worker model involves three roles:
Master
The master watches for new workers and tasks, assigning tasks to available workers.
Worker
Workers register themselves with the system, to make sure that the master sees they are available to execute tasks, and then watch for new tasks.
Client
Clients create new tasks and wait for responses from the system.
Let’s now go over the different roles and the exact steps each role needs to perform.
The Master Role
Because only one process should be a master, a process must lock mastership in ZooKeeper to become the master. To do this, the process creates an ephemeral znode called /master:
[zk: localhost:2181(CONNECTED) 0] create -e /master "master1.example.com:2223" ![]()
Created /master
[zk: localhost:2181(CONNECTED) 1] ls / ![]()
[master, zookeeper]
[zk: localhost:2181(CONNECTED) 2] get /master ![]()
"master1.example.com:2223"
cZxid = 0x67
ctime = Tue Dec 11 10:06:19 CET 2012
mZxid = 0x67
mtime = Tue Dec 11 10:06:19 CET 2012
pZxid = 0x67
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x13b891d4c9e0005
dataLength = 26
numChildren = 0
[zk: localhost:2181(CONNECTED) 3]
![]()
Create a master znode to get mastership. We use the -e flag to indicate that we are creating an ephemeral znode.
![]()
List the root of the ZooKeeper tree.
![]()
Get the metadata and data of the /master znode.
What has just happened? We first created an ephemeral znode with path /master. We added the host information to the znode in case others need to contact it outside ZooKeeper. It is not strictly necessary to add the host information, but we did so just to show that we can add data if needed. To make the znode ephemeral, we added the -e flag. Remember that an ephemeral node is automatically deleted if the session in which it has been created closes or expires.
Let’s say now that we use two processes for the master role, although at any point in time there can be at most one active master. The other process is a backup master. Say that the other process, unaware that a master has been elected already, also tries to create a /master znode. Let’s see what happens:
[zk: localhost:2181(CONNECTED) 0] create -e /master "master2.example.com:2223"
Node already exists: /master
[zk: localhost:2181(CONNECTED) 1]
ZooKeeper tells us that a /master node already exists. This way, the second process knows that there is already a master. However, it is possible that the active master may crash, and the backup master may need to take over the role of active master. To detect this, we need to set a watch on the /master node as follows:
[zk: localhost:2181(CONNECTED) 0] create -e /master "master2.example.com:2223"
Node already exists: /master
[zk: localhost:2181(CONNECTED) 1] stat /master true
cZxid = 0x67
ctime = Tue Dec 11 10:06:19 CET 2012
mZxid = 0x67
mtime = Tue Dec 11 10:06:19 CET 2012
pZxid = 0x67
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x13b891d4c9e0005
dataLength = 26
numChildren = 0
[zk: localhost:2181(CONNECTED) 2]
The stat command gets the attributes of a znode and allows us to set a watch on the existence of the znode. Having the parameter true after the path sets the watch. In the case that the active primary crashes, we observe the following:
[zk: localhost:2181(CONNECTED) 0] create -e /master "master2.example.com:2223"
Node already exists: /master
[zk: localhost:2181(CONNECTED) 1] stat /master true
cZxid = 0x67
ctime = Tue Dec 11 10:06:19 CET 2012
mZxid = 0x67
mtime = Tue Dec 11 10:06:19 CET 2012
pZxid = 0x67
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x13b891d4c9e0005
dataLength = 26
numChildren = 0
[zk: localhost:2181(CONNECTED) 2]
WATCHER::
WatchedEvent state:SyncConnected type:NodeDeleted path:/master
[zk: localhost:2181(CONNECTED) 2] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 3]
Note the NodeDeleted event at the end of the output. This event indicates that the active primary has had its session closed, or it has expired. Note also that the /master znode is no longer there. The backup primary should now try to become the active primary by trying to create the/master znode again:
[zk: localhost:2181(CONNECTED) 0] create -e /master "master2.example.com:2223"
Node already exists: /master
[zk: localhost:2181(CONNECTED) 1] stat /master true
cZxid = 0x67
ctime = Tue Dec 11 10:06:19 CET 2012
mZxid = 0x67
mtime = Tue Dec 11 10:06:19 CET 2012
pZxid = 0x67
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x13b891d4c9e0005
dataLength = 26
numChildren = 0
[zk: localhost:2181(CONNECTED) 2]
WATCHER::
WatchedEvent state:SyncConnected type:NodeDeleted path:/master
[zk: localhost:2181(CONNECTED) 2] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 3] create -e /master "master2.example.com:2223"
Created /master
[zk: localhost:2181(CONNECTED) 4]
Because it succeeds in creating the /master znode, the client now becomes the active master.
Workers, Tasks, and Assignments
Before we discuss the steps taken by workers and clients, let’s first create three important parent znodes, /workers, /tasks, and /assign:
[zk: localhost:2181(CONNECTED) 0] create /workers ""
Created /workers
[zk: localhost:2181(CONNECTED) 1] create /tasks ""
Created /tasks
[zk: localhost:2181(CONNECTED) 2] create /assign ""
Created /assign
[zk: localhost:2181(CONNECTED) 3] ls /
[assign, tasks, workers, master, zookeeper]
[zk: localhost:2181(CONNECTED) 4]
The three new znodes are persistent znodes and contain no data. We use these znodes in this example to tell us which workers are available, tell us when there are tasks to assign, and make assignments to workers.
In a real application, these znodes need to be created either by a primary process before it starts assigning tasks or by some bootstrap procedure. Regardless of how they are created, once they exist, the master needs to watch for changes in the children of /workers and /tasks:
[zk: localhost:2181(CONNECTED) 4] ls /workers true
[]
[zk: localhost:2181(CONNECTED) 5] ls /tasks true
[]
[zk: localhost:2181(CONNECTED) 6]
Note that we have used the optional true parameter with ls, as we did before with stat on the master. The true parameter, in this case, creates a watch for changes to the set of children of the corresponding znode.
The Worker Role
The first step by a worker is to notify the master that it is available to execute tasks. It does so by creating an ephemeral znode representing it under /workers. Workers use their hostnames to identify themselves:
[zk: localhost:2181(CONNECTED) 0] create -e /workers/worker1.example.com
"worker1.example.com:2224"
Created /workers/worker1.example.com
[zk: localhost:2181(CONNECTED) 1]
Note from the output that ZooKeeper confirms that the znode has been created. Recall that the master has set a watch for changes to the children of /workers. Once the worker creates a znode under /workers, the master observes the following notification:
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/workers
Next, the worker needs to create a parent znode, /assign/worker1.example.com, to receive assignments, and watch it for new tasks by executing ls with the second parameter set to true:
[zk: localhost:2181(CONNECTED) 0] create -e /workers/worker1.example.com
"worker1.example.com:2224"
Created /workers/worker1.example.com
[zk: localhost:2181(CONNECTED) 1] create /assign/worker1.example.com ""
Created /assign/worker1.example.com
[zk: localhost:2181(CONNECTED) 2] ls /assign/worker1.example.com true
[]
[zk: localhost:2181(CONNECTED) 3]
The worker is now ready to receive assignments. We will look at assignments next, as we discuss the role of clients.
The Client Role
Clients add tasks to the system. For the purposes of this example, it doesn’t matter what the task really consists of. Here we assume that the client asks the master-worker system to run a command cmd. To add a task to the system, a client executes the following:
[zk: localhost:2181(CONNECTED) 0] create -s /tasks/task- "cmd"
Created /tasks/task-0000000000
We make the task znode sequential to create an order for the tasks added, essentially providing a queue. The client now has to wait until the task is executed. The worker that executes the task creates a status znode for the task once the task completes. The client determines that the task has been executed when it sees that a status znode for the task has been created; the client consequently must watch for the creation of the status znode:
[zk: localhost:2181(CONNECTED) 1] ls /tasks/task-0000000000 true
[]
[zk: localhost:2181(CONNECTED) 2]
The worker that executes the task creates a status znode as a child of /tasks/task-0000000000. That is the reason for watching the children of /tasks/task-0000000000 with ls.
Once the task znode is created, the master observes the following event:
[zk: localhost:2181(CONNECTED) 6]
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/tasks
The master next checks the new task, gets the list of available workers, and assigns it to worker1.example.com:
[zk: 6] ls /tasks
[task-0000000000]
[zk: 7] ls /workers
[worker1.example.com]
[zk: 8] create /assign/worker1.example.com/task-0000000000 ""
Created /assign/worker1.example.com/task-0000000000
[zk: 9]
The worker receives a notification that a new task has been assigned:
[zk: localhost:2181(CONNECTED) 3]
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged
path:/assign/worker1.example.com
The worker then checks the new task and sees that the task has been assigned to it:
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged
path:/assign/worker1.example.com
[zk: localhost:2181(CONNECTED) 3] ls /assign/worker1.example.com
[task-0000000000]
[zk: localhost:2181(CONNECTED) 4]
Once the worker finishes executing the task, it adds a status znode to /tasks:
[zk: localhost:2181(CONNECTED) 4] create /tasks/task-0000000000/status "done"
Created /tasks/task-0000000000/status
[zk: localhost:2181(CONNECTED) 5]
and the client receives a notification and checks the result:
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged
path:/tasks/task-0000000000
[zk: localhost:2181(CONNECTED) 2] get /tasks/task-0000000000
"cmd"
cZxid = 0x7c
ctime = Tue Dec 11 10:30:18 CET 2012
mZxid = 0x7c
mtime = Tue Dec 11 10:30:18 CET 2012
pZxid = 0x7e
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 5
numChildren = 1
[zk: localhost:2181(CONNECTED) 3] get /tasks/task-0000000000/status
"done"
cZxid = 0x7e
ctime = Tue Dec 11 10:42:41 CET 2012
mZxid = 0x7e
mtime = Tue Dec 11 10:42:41 CET 2012
pZxid = 0x7e
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 8
numChildren = 0
[zk: localhost:2181(CONNECTED) 4]
The client checks the content of the status znode to determine what has happened to the task. In this case, it has been successfully executed and the result is “done.” Tasks can of course be more sophisticated and even involve another distributed system. The bottom line here is that regardless of what the task actually is, the mechanism to execute it and convey the results through ZooKeeper is in essence the same.
Takeaway Messages
We have gone through a number of basic ZooKeeper concepts in this chapter. We have seen the basic functionality that ZooKeeper offers through its API and explored some important concepts about its architecture, like the use of quorums for replication. It is not important at this point to understand how the ZooKeeper replication protocol works, but it is important to understand the notion of quorums because you specify the number of servers when deploying ZooKeeper. Another important concept discussed here is sessions. Session semantics are critical for the ZooKeeper guarantees because they mostly refer to sessions.
To provide a preliminary understanding of how to work with ZooKeeper, we have used the zkCli tool to access a ZooKeeper server and execute requests against it. We have shown the main operations of the master-worker example executed with this tool. When implementing a real ZooKeeper application, you should not use this tool; it is there mostly for debugging and monitoring purposes. Instead, you’ll use one of the language bindings ZooKeeper offers. In the next chapters, we will be using Java to implement our examples.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.