ZooKeeper (2013)
Part II. Programming with ZooKeeper
This part of the book can be read by programmers to develop skills and the right approaches to using ZooKeeper for coordination in their distributed programs. ZooKeeper comes with API bindings for Java and C. Both bindings have the same basic structures and signatures. Because the Java binding is the most popular and easiest to use, we will be using this binding in our examples. Chapter 7 introduces the C binding. The source code for the master-worker example is available in a GitHub repository.
Chapter 3. Getting Started with the ZooKeeper API
In the previous chapter we used zkCli to introduce the basic ZooKeeper operations. In this chapter we are going to see how we actually use the API in applications. Here we give an introduction of how to program with the ZooKeeper API, showing how to create a session and implement a watcher. We also start coding our master-worker example.
Setting the ZooKeeper CLASSPATH
We need to set up the appropriate classpath to run and compile ZooKeeper Java code. ZooKeeper uses a number of third-party libraries in addition to the ZooKeeper JAR file. To make typing a little easier and to make the text a little more readable we will use an environment variableCLASSPATH with all the required libraries. The script zkEnv.sh in the bin directory of the ZooKeeper distribution sets this environment variable for us. We need to source it using the following:
ZOOBINDIR="<path_to_distro>/bin"
. "$ZOOBINDIR"/zkEnv.sh
(On Windows, use the call command instead of the period and the zkEnv.cmd script.)
Once we run this script, the CLASSPATH variable will be set correctly. We will use it to compile and run our Java programs.
Creating a ZooKeeper Session
The ZooKeeper API is built around a ZooKeeper handle that is passed to every API call. This handle represents a session with ZooKeeper. As shown in Figure 3-1, a session that is established with one ZooKeeper server will migrate to another ZooKeeper server if its connection is broken. As long as the session is alive, the handle will remain valid, and the ZooKeeper client library will continually try to keep an active connection to a ZooKeeper server to keep the session alive. If the handle is closed, the ZooKeeper client library will tell the ZooKeeper servers to kill the session. If ZooKeeper decides that a client has died, it will invalidate the session. If a client later tries to reconnect to a ZooKeeper server using the handle that corresponds to the invalidated session, the ZooKeeper server informs the client library that the session is no longer valid and the handle returns errors for all operations.
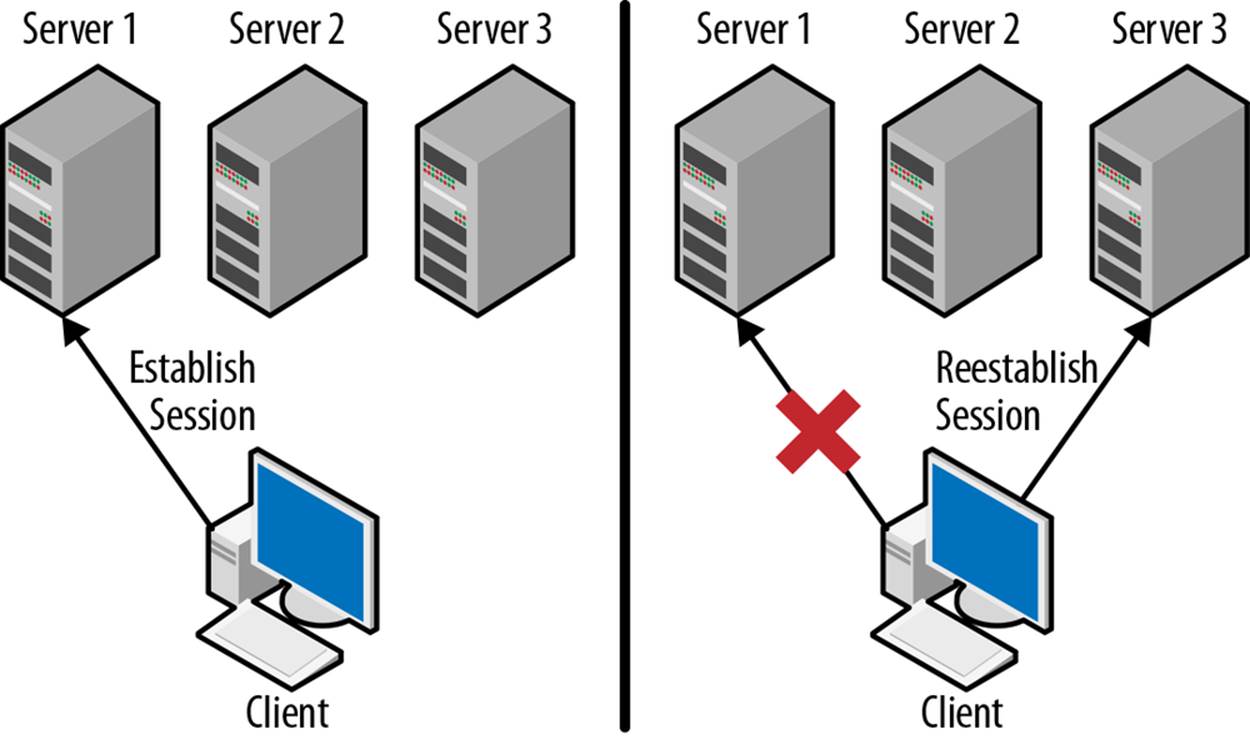
Figure 3-1. Session migration between two servers
The constructor that creates a ZooKeeper handle usually looks like:
ZooKeeper(
String connectString,
int sessionTimeout,
Watcher watcher)
where:
connectString
Contains the hostnames and ports of the ZooKeeper servers. We listed those servers when we used zkCli to connect to the ZooKeeper service.
sessionTimeout
The time in milliseconds that ZooKeeper waits without hearing from the client before declaring the session dead. For now we will just use a value of 15000, for 15 seconds. This means that if ZooKeeper cannot communicate with a client for more than 15 seconds, ZooKeeper will terminate the client’s session. Note that this timeout is rather high, but it is useful for the experiments we will be doing later. ZooKeeper sessions typically have a timeout of 5–10 seconds.
watcher
An object we need to create that will receive session events. Because Watcher is an interface, we will need to implement a class and then instantiate it to pass an instance to the ZooKeeper constructor. Clients use the Watcher interface to monitor the health of the session with ZooKeeper. Events will be generated when a connection is established or lost to a ZooKeeper server. They can also be used to monitor changes to ZooKeeper data. Finally, if a session with ZooKeeper expires, an event is delivered through the Watcher interface to notify the client application.
Implementing a Watcher
To receive notifications from ZooKeeper, we need to implement watchers. Let’s look a bit more closely at the Watcher interface. It has the following declaration:
public interface Watcher {
void process(WatchedEvent event);
}
Not much of an interface, right? We’ll be using it heavily, but for now we will simply print the event. So, let’s start our example implementation of the Master:
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.Watcher;
public class Master implements Watcher {
ZooKeeper zk;
String hostPort;
Master(String hostPort) {
this.hostPort = hostPort; ![]()
}
void startZK() {
zk = new ZooKeeper(hostPort, 15000, this); ![]()
}
public void process(WatchedEvent e) {
System.out.println(e); ![]()
}
public static void main(String args[])
throws Exception {
Master m = new Master(args[0]);
m.startZK();
// wait for a bit
Thread.sleep(60000); ![]()
}
}
![]()
In the constructor, we do not actually instantiate a ZooKeeper object. Instead, we just save the hostPort for later. Java best practices dictate that other methods of an object should not be called until the object’s constructor has finished. Because this object implements Watcherand because once we instantiate a ZooKeeper object its Watcher callback may be invoked, we must construct the ZooKeeper object after the Master constructor has returned.
![]()
Construct the ZooKeeper object using the Master object as the Watcher callback.
![]()
This simple example does not have complex event handling. Instead, we will simply print out the event that we receive.
![]()
Once we have connected to ZooKeeper, there will be a background thread that will maintain the ZooKeeper session. This thread is a daemon thread, which means that the program may exit even if the thread is still active. Here we sleep for a bit so that we can see some events come in before the program exits.
We can compile this simple example using the following:
$ javac -cp $CLASSPATH Master.java
Once we have compiled Master.java, we run it and see the following:
$ java -cp $CLASSPATH Master 127.0.0.1:2181
... - INFO [...] - Client environment:zookeeper.version=3.4.5-1392090, ... ![]()
...
... - INFO [...] - Initiating client connection,
connectString=127.0.0.1:2181 ... ![]()
... - INFO [...] - Opening socket connection to server
localhost/127.0.0.1:2181. ...
... - INFO [...] - Socket connection established to localhost/127.0.0.1:2181,
initiating session
... - INFO [...] - Session establishment complete on server
localhost/127.0.0.1:2181, ... ![]()
WatchedEvent state:SyncConnected type:None path:null ![]()
The ZooKeeper client API produces various log messages to help the user understand what is happening. The logging is rather verbose and can be disabled using configuration files, but these messages are invaluable during development and even more invaluable if something unexpected happens after deployment.
![]()
The first few log messages describe the ZooKeeper client implementation and environment.
![]()
These log messages will be generated whenever a client initiates a connection to a ZooKeeper server. This may be the initial connection or subsequent reconnections.
![]()
This message shows information about the connection after it has been established. It shows the host and port that the client connected to and the actual session timeout that was negotiated. If the requested session timeout is too short to be detected by the server or too long, the server will adjust the session timeout.
![]()
This final line did not come from the ZooKeeper library; it is the WatchEvent object that we print in our implementation of Watcher.process(WatchedEvent e).
This example run assumes that all the needed libraries are in the lib subdirectory. It also assumes that the configuration of log4j.conf is in the conf subdirectory. You can find these two directories in the ZooKeeper distribution that you are using. If you see the following:
log4j:WARN No appenders could be found for logger
(org.apache.zookeeper.ZooKeeper).
log4j:WARN Please initialize the log4j system properly.
it means that you have not put the log4j.conf file in the classpath.
Running the Watcher Example
What would have happened if we had started the master without starting the ZooKeeper service? Give it a try. Stop the service, then run Master. What do you see? The last line in the previous output, with the WatchedEvent, is not present. The ZooKeeper library isn’t able to connect to the ZooKeeper server, so it doesn’t tell us anything.
Now try starting the server, starting the Master, and then stopping the server while the Master is still running. You should see the SyncConnected event followed by the Disconnected event.
When developers see the Disconnected event, some think they need to create a new ZooKeeper handle to reconnect to the service. Do not do that! See what happens when you start the server, start the Master, and then stop and start the server while the Master is still running. You should see the SyncConnected event followed by the Disconnected event and then another SyncConnected event. The ZooKeeper client library takes care of reconnecting to the service for you. Unfortunately, network outages and server failures happen. Usually, ZooKeeper can deal with these failures.
It is important to remember that these failures also happen to ZooKeeper itself, however. A ZooKeeper server may fail or lose network connectivity, which will cause the scenario we simulated when we stopped the master. As long as the ZooKeeper service is made up of at least three servers, the failure of a single server will not cause a service outage. Instead, the client will see a Disconnected event quickly followed by a SyncConnected event.
ZOOKEEPER MANAGES CONNECTIONS
Don’t try to manage ZooKeeper client connections yourself. The ZooKeeper client library monitors the connection to the service and not only tells you about connection problems, but actively tries to reestablish communication. Often the library can quickly reestablish the session with minimal disruption to your application. Needlessly closing and starting a new session just causes more load on the system and longer availability outages.
It doesn’t look like the client is doing much besides sleeping, but as we have seen by the events coming in, there are some things happening behind the scenes. We can also see what is happening on the ZooKeeper service side. ZooKeeper has two main management interfaces: JMX and four-letter words. We discuss these interfaces in depth in Chapter 10. Right now we will use the stat and dump four-letter words to see what is happening on the server.
To use these words, we need to telnet to the client port, 2181, and type them in (pressing the Enter key after the word). For example, if we start the Master and use the stat four-letter word, we should see the following:
$ telnet 127.0.0.1 2181
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
stat
ZooKeeper version: 3.4.5-1392090, built on 09/30/2012 17:52 GMT
Clients:
/127.0.0.1:39470[1](queued=0,recved=3,sent=3)
/127.0.0.1:39471[0](queued=0,recved=1,sent=0)
Latency min/avg/max: 0/5/48
Received: 34
Sent: 33
Connections: 2
Outstanding: 0
Zxid: 0x17
Mode: standalone
Node count: 4
Connection closed by foreign host.
We see from this output that there are two clients connected to the ZooKeeper server. One is Master, and the other is the Telnet connection.
If we start the Master and use the dump four-letter word, we should see the following:
$ telnet 127.0.0.1 2181
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
dump
SessionTracker dump:
Session Sets (3):
0 expire at Wed Nov 28 20:34:00 PST 2012:
0 expire at Wed Nov 28 20:34:02 PST 2012:
1 expire at Wed Nov 28 20:34:04 PST 2012:
0x13b4a4d22070006
ephemeral nodes dump:
Sessions with Ephemerals (0):
Connection closed by foreign host.
We see from this output that there is one active session. This is the session that belongs to Master. We also see when this session is going to expire. This expiration time is based on the session timeout that we specified when we created the ZooKeeper object.
Let’s kill the Master and then repeatedly use dump to see the active sessions. You’ll notice that it takes a while for the session to go away. This is because the server will not kill the session until the session timeout has passed. Of course, the client will continually extend the expiration time as long as it keeps an active connection to a ZooKeeper server.
When the Master finishes, it would be nice if its session went away immediately. This is what the ZooKeeper.close() method does. Once close is called, the session represented by the ZooKeeper object gets destroyed.
Let’s add the close to our example program:
void stopZK() throws Exception { zk.close(); }
public static void main(String args[]) throws Exception {
Master m = new Master(args[0]);
m.startZK();
// wait for a bit
Thread.sleep(60000);
m.stopZK();
}
Now we can run Master again and use the dump four-letter word to see whether the session is still active. Because Master explicitly closed the session, ZooKeeper did not need to wait for the session to time out before shutting it down.
Getting Mastership
Now that we have a session, our Master needs to take mastership. We need to be careful, though, because there can be only one master. We also need to have multiple processes running that could become master just in case the acting master fails.
To ensure that only one master process is active at a time, we use ZooKeeper to implement the simple leader election algorithm described in The Master Role. In this algorithm, all potential masters try to create the /master znode, but only one will succeed. The process that succeeds becomes the master.
We need two things to create /master. First, we need the initial data for the znode. Usually we put some information about the process that becomes the master in this initial data. For now we will have each process pick a random server ID and use that for the initial data. We also need an access control list (ACL) for the new znode. Often ZooKeeper is used within a trusted environment, so an open ACL is used.
There is a constant, ZooDefs.Ids.OPEN_ACL_UNSAFE, that gives all permissions to everyone. (As the name indicates, this is a very unsafe ACL to use in untrusted environments.)
ZooKeeper provides per-znode ACLs with a pluggable authentication method, so if we need to we can restrict who can do what to which znode, but for this simple example, let’s stick with OPEN_ACL_UNSAFE. Of course, we want the /master znode to go away if the acting master dies. As we saw in Persistent and ephemeral znodes, ZooKeeper has ephemeral znodes for this purpose. We’ll define an EPHEMERAL znode that will automatically be deleted by ZooKeeper when the session that created it closes or is made invalid.
So, we will add the following lines to our code:
String serverId = Integer.toHexString(random.nextInt());
void runForMaster() {
zk.create("/master", ![]()
serverId.getBytes(), ![]()
OPEN_ACL_UNSAFE, ![]()
CreateMode.EPHEMERAL); ![]()
}
![]()
The znode we are trying to create is /master. If a znode already exists with that name, the create will fail. We are going to store the unique ID that corresponds to this server as the data of the /master znode.
![]()
Only byte arrays may be stored as data, so we convert the int to a byte array.
![]()
As we mentioned, we are using an open ACL.
![]()
And we are creating an EPHEMERAL node.
However, we aren’t done yet. create throws two exceptions: KeeperException and InterruptedException. We need to make sure we handle these exceptions, specifically the ConnectionLossException (which is a subclass of KeeperException) andInterruptedException. For the rest of the exceptions we can abort the operation and move on, but in the case of these two exceptions, the create might have actually succeeded, so if we are the master we need to handle them.
The ConnectionLossException occurs when a client becomes disconnected from a ZooKeeper server. This is usually due to a network error, such as a network partition, or the failure of a ZooKeeper server. When this exception occurs, it is unknown to the client whether the request was lost before the ZooKeeper servers processed it, or if they processed it but the client did not receive the response. As we described earlier, the ZooKeeper client library will reestablish the connection for future requests, but the process must figure out whether a pending request has been processed or whether it should reissue the request.
The InterruptedException is caused by a client thread calling Thread.interrupt. This is often part of application shutdown, but it may also be used in other application-dependent ways. This exception literally interrupts the local client request processing in the process and leaves the request in an unknown state.
Because both exceptions cause a break in the normal request processing, the developer cannot assume anything about the state of the request in process. When handling these exceptions, the developer must figure out the state of the system before proceeding. In case there was a leader election, we want to make sure that we haven’t been made the master without knowing it. If the create actually succeeded, no one else will be able to become master until the acting master dies, and if the acting master doesn’t know it has mastership, no process will be acting as the master.
When handling the ConnectionLossException, we must find out which process, if any, has created the /master znode, and start acting as the leader if that process is ours. We do this by using the getData method:
byte[] getData(
String path,
bool watch,
Stat stat)
where:
path
Like with most of the other ZooKeeper methods, the first parameter is the path of the znode from which we will be getting the data.
watch
Indicates whether we want to hear about future changes to the data returned. If set to true, we will get events on the Watcher object we set when we created the ZooKeeper handle. There is another version of this method that takes a Watcher object that will receive an event if changes happen. We will see how to watch for changes in future chapters, but for now we will set this parameter to false because we just want to know what the current data is.
stat
The last parameter is a Stat structure that the getData method can fill in with metadata about the znode.
Return value
If this method returns successfully (doesn’t throw an exception), the byte array will contain the data of the znode.
So, let’s change that code segment to the following, introducing some exception handling into our runForMaster method:
String serverId = Integer.toString(Random.nextLong());
boolean isLeader = false;
// returns true if there is a master
boolean checkMaster() {
while (true) {
try {
Stat stat = new Stat();
byte data[] = zk.getData("/master", false, stat); ![]()
isLeader = new String(data).equals(serverId)); ![]()
return true;
} catch (NoNodeException e) {
// no master, so try create again
return false;
} catch (ConnectionLossException e) {
}
}
}
void runForMaster() throws InterruptedException { ![]()
while (true) {
try { ![]()
zk.create("/master", serverId.getBytes(),
OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL); ![]()
isLeader = true;
break;
} catch (NodeExistsException e) {
isLeader = false;
break;
} catch (ConnectionLossException e) { ![]()
}
if (checkMaster()) break; ![]()
}
}
![]()
We surround the zk.create with a try block so that we can handle the ConnectionLossException.
![]()
This is the create request that will establish the process as the master if it succeeds.
![]()
Although the body of the catch block for the ConnectionLossException is empty because we do not break, this catch will cause the process to continue to the next line.
![]()
Check for an active master and retry if there is still no elected master.
![]()
Check for an active master by trying to get the data for the /master znode.
![]()
This line of the example shows why we need the data used in creating the /master znode: if /master exists, we use the data contained in /master to determine who the leader is. If the process received a ConnectionLossException, the current process may actually be the master; it is possible that its create request actually was processed, but the response was lost.
![]()
We let the InterruptedException bubble up the call stack by letting it simply pass through to the caller.
In our example, we simply pass the InterruptedException to the caller and thus let it bubble up. Unfortunately, in Java there aren’t clear guidelines for how to deal with thread interruption, or even what it means. Sometimes the interruptions are used to signal threads that things are being shut down and they need to clean up. In other cases, an interruption is used to get control of a thread, but execution of the application continues.
Our handling of InterruptedException depends on our context. If the InterruptedException will bubble up and eventually close our zk handle, we can let it go up the stack and everything will get cleaned up when the handle is closed. If the zk handle is not closed, we need to figure out if we are the master before rethrowing the exception or asynchronously continuing the operation. This latter case is particularly tricky and requires careful design to handle properly.
Our main method for the Master now becomes:
public static void main(String args[]) throws Exception {
Master m = new Master(args[0]);
m.startZK();
m.runForMaster(); ![]()
if (isLeader) {
System.out.println("I'm the leader"); ![]()
// wait for a bit
Thread.sleep(60000);
} else {
System.out.println("Someone else is the leader");
}
m.stopZK();
}
![]()
Our call to runForMaster, a method we implemented earlier, will return either when the current process has become the master or when another process is the master.
![]()
Once we develop the application logic for the master, we will start executing that logic here, but for now we content ourselves with announcing victory and then waiting 60 seconds before exiting main.
Because we aren’t handling the InterruptedException directly, we will simply exit the program (and therefore close our ZooKeeper handle) if it happens. Of course, the master doesn’t do much before shutting down. In the next chapter, the master will actually start managing the tasks that get queued to the system, but for now let’s start filling in the other components.
Getting Mastership Asynchronously
In ZooKeeper, all synchronous calls have corresponding asynchronous calls. This allows us to issue many calls at a time from a single thread and may also simplify our implementation. Let’s revisit the mastership example, this time using asynchronous calls.
Here is the asynchronous version of create:
void create(String path,
byte[] data,
List<ACL> acl,
CreateMode createMode,
AsyncCallback.StringCallback cb, ![]()
Object ctx) ![]()
This version of create looks exactly like the synchronous version except for two additional parameters:
![]()
An object containing the function that serves as the callback
![]()
A user-specified context (an object that will be passed through to the callback when it is invoked)
This call will return immediately, usually before the create request has been sent to the server. The callback object often takes data, which we can pass through the context argument. When the result of the create request is received from the server, the context argument will be given to the application through the callback object.
Notice that this create doesn’t throw any exceptions, which can simplify things for us. Because the call is not waiting for the create to complete before returning, we don’t have to worry about the InterruptedException; because any request errors are encoded in the first parameter in the callback, we don’t have to worry about KeeperException.
The callback object implements StringCallback with one method:
void processResult(int rc, String path, Object ctx, String name)
The asynchronous method simply queues the request to the ZooKeeper server. Transmission happens on another thread. When responses are received, they are processed on a dedicated callback thread. To preserve order, there is a single callback thread and responses are processed in the order they are received.
The parameters of processResult have the following meanings:
rc
Returns the result of the call, which will be OK or a code corresponding to a KeeperException
path
The path that we passed to the create
ctx
Whatever context we passed to the create
name
The name of the znode that was created
For now, path and name will be equal if we succeed, but if CreateMode.SEQUENTIAL is used, this will not be true.
CALLBACK PROCESSING
Because a single thread processes all callbacks, if a callback blocks, it blocks all callbacks that follow it. This means that generally you should not do intensive operations or blocking operations in a callback. There may be times when it’s legitimate to use the synchronous API in a callback, but it should generally be avoided so that subsequent callbacks can be processed quickly.
So, let’s start writing our master functionality. Here, we create a masterCreateCallback object that will receive the results of the create call:
static boolean isLeader;
static StringCallback masterCreateCallback = new StringCallback() {
void processResult(int rc, String path, Object ctx, String name) {
switch(Code.get(rc)) { ![]()
case CONNECTIONLOSS: ![]()
checkMaster();
return;
case OK: ![]()
isLeader = true;
break;
default: ![]()
isLeader = false;
}
System.out.println("I'm " + (isLeader ? "" : "not ") +
"the leader");
}
};
void runForMaster() {
zk.create("/master", serverId.getBytes(), OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL, masterCreateCallback, null); ![]()
}
![]()
We get the result of the create call in rc and convert it to a Code enum to switch on. rc corresponds to a KeeperException if rc is not zero.
![]()
If the create fails due to a connection loss, we will get the CONNECTIONLOSS result code rather than the ConnectionLossException. When we get a connection loss, we need to check on the state of the system and figure out what we need to do to recover. We do this in thecheckMaster method, which we will implement next.
![]()
Woohoo! We are the leader. For now we will just set isLeader to true.
![]()
If any other problem happened, we did not become the leader.
![]()
We kick things off in runForMaster when we pass the masterCreateCallback object to the create method. We pass null as the context object because there isn’t any information that we need to pass from runForMaster to themasterCreateCallback.processResult method.
Now we have to implement the checkMaster method. This method looks a bit different because, unlike in the synchronous case, we string the processing logic together in the callbacks, so we do not see a sequence of events in checkMaster. Instead, we see things get kicked off with thegetData method. Subsequent processing will continue in the DataCallback when the getData operation completes:
DataCallback masterCheckCallback = new DataCallback() {
void processResult(int rc, String path, Object ctx, byte[] data,
Stat stat) {
switch(Code.get(rc)) {
case CONNECTIONLOSS:
checkMaster();
return;
case NONODE:
runForMaster();
return;
}
}
}
void checkMaster() {
zk.getData("/master", false, masterCheckCallback, null);
}
The basic logic of the synchronous and asynchronous versions is the same, but in the asynchronous version we do not have a while loop. Instead, the error handling is done with callbacks and new asynchronous operations.
At this point the synchronous version may appear simpler to implement than the asynchronous version, but as we will see in the next chapter, our applications are often driven by asynchronous change notifications, so building everything asynchronously may result in simpler code in the end. Note that asynchronous calls also do not block the application, allowing it to make progress with other things—perhaps even submitting new ZooKeeper operations.
Setting Up Metadata
We will use the asynchronous API to set up the metadata directories. Our master-worker design depends on three other directories: /tasks, /assign, and /workers. We can count on some kind of system setup to make sure everything is created before the system is started, or a master can make sure these directories are created every time it starts up. The following code segment will create these paths. There isn’t really any error handling in this example apart from handling a connection loss:
public void bootstrap() {
createParent("/workers", new byte[0]); ![]()
createParent("/assign", new byte[0]);
createParent("/tasks", new byte[0]);
createParent("/status", new byte[0]);
}
void createParent(String path, byte[] data) {
zk.create(path,
data,
Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT,
createParentCallback,
data); ![]()
}
StringCallback createParentCallback = new StringCallback() {
public void processResult(int rc, String path, Object ctx, String name) {
switch (Code.get(rc)) {
case CONNECTIONLOSS:
createParent(path, (byte[]) ctx); ![]()
break;
case OK:
LOG.info("Parent created");
break;
case NODEEXISTS:
LOG.warn("Parent already registered: " + path);
break;
default:
LOG.error("Something went wrong: ",
KeeperException.create(Code.get(rc), path));
}
}
};
![]()
We don’t have any data to put in these znodes, so we are just passing an empty byte array.
![]()
Because of that, we don’t have to worry about keeping track of the data that corresponds to each znode, but often there is data unique to a path, so we will track the data using the callback context of each create call. It may seem a bit strange that we pass data in both the second and fourth parameters of create, but the data passed in the second parameter is the data to be written to the new znode and the data passed in the fourth will be made available to the createParentCallback.
![]()
If the callback gets a CONNECTIONLOSS return code, we want to simply retry the create, which we can do by calling createPath. However, to call createPath we need the data that was used in the original create. We have that data in the ctx object that was passed to the callback because we passed the creation data as the fourth parameter of the create. Because the context object is separate from the callback object, we can use a single callback object for all of the creates.
In this example you will notice that there isn’t any difference between a file (a znode that contains data) and a directory (a znode that contains children). Every znode can have both.
Registering Workers
Now that we have a master, we need to set up the workers so that the master has someone to boss around. According to our design, each worker is going to create an ephemeral znode under /workers. We can do this quite simply with the following code. We will use the data in the znode to indicate the state of the worker:
import java.util.*;
import org.apache.zookeeper.AsyncCallback.DataCallback;
import org.apache.zookeeper.AsyncCallback.StringCallback;
import org.apache.zookeeper.AsyncCallback.VoidCallback;
import org.apache.zookeeper.*;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.AsyncCallback.ChildrenCallback;
import org.apache.zookeeper.KeeperException.Code;
import org.apache.zookeeper.data.Stat;
import org.slf4j.*;
public class Worker implements Watcher {
private static final Logger LOG = LoggerFactory.getLogger(Worker.class);
ZooKeeper zk;
String hostPort;
String serverId = Integer.toHexString(random.nextInt());
Worker(String hostPort) {
this.hostPort = hostPort;
}
void startZK() throws IOException {
zk = new ZooKeeper(hostPort, 15000, this);
}
public void process(WatchedEvent e) {
LOG.info(e.toString() + ", " + hostPort);
}
void register() {
zk.create("/workers/worker-" + serverId,
"Idle".getBytes(), ![]()
Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL, ![]()
createWorkerCallback, null);
}
StringCallback createWorkerCallback = new StringCallback() {
public void processResult(int rc, String path, Object ctx,
String name) {
switch (Code.get(rc)) {
case CONNECTIONLOSS:
register(); ![]()
break;
case OK:
LOG.info("Registered successfully: " + serverId);
break;
case NODEEXISTS:
LOG.warn("Already registered: " + serverId);
break;
default:
LOG.error("Something went wrong: "
+ KeeperException.create(Code.get(rc), path));
}
}
};
public static void main(String args[]) throws Exception {
Worker w = new Worker(args[0]);
w.startZK();
w.register();
Thread.sleep(30000);
}
}
![]()
We will be putting the status of the worker in the data of the znode that represents the worker.
![]()
If the process dies we want the znode representing the worker to get cleaned up, so we use the EPHEMERAL flag. That means that we can simply look at the children of /workers to get the list of available workers.
![]()
Because this process is the only one that creates the ephemeral znode representing the process, if there is a connection loss during the creation of the znode, it can simply retry the creation.
As we have seen earlier, because we are registering an ephemeral node, if the worker dies the registered znode representing that node will go away. So this is all we need to do on the worker’s side for group membership.
We are also putting status information in the znode representing the worker. This allows us to check the status of the worker by simply querying ZooKeeper. Currently, we have only the initializing and idle statuses; however, once the worker starts actually doing things, we will want to set other status information.
Here is our implementation of setStatus. This method works a little bit differently from methods we have seen before. We want to be able to set the status asynchronously so that it doesn’t delay regular processing:
StatCallback statusUpdateCallback = new StatCallback() {
public void processResult(int rc, String path, Object ctx, Stat stat) {
switch(Code.get(rc)) {
case CONNECTIONLOSS:
updateStatus((String)ctx); ![]()
return;
}
}
};
synchronized private void updateStatus(String status) {
if (status == this.status) { ![]()
zk.setData("/workers/" + name, status.getBytes(), -1,
statusUpdateCallback, status); ![]()
}
}
public void setStatus(String status) {
this.status = status; ![]()
updateStatus(status); ![]()
}
![]()
We save our status locally in case a status update fails and we need to retry.
![]()
Rather than doing the update in setStatus, we create an updateStatus method that we can use in setStatus and in the retry logic.
![]()
There is a subtle problem with asynchronous requests that we retry on connection loss: things may get out of order. ZooKeeper is very good about maintaining order for both requests and responses, but a connection loss makes a gap in that ordering, because we are creating a new request. So, before we requeue a status update, we need to make sure that we are requeuing the current status; otherwise, we just drop it. We do this check and retry in a synchronized block.
![]()
We do an unconditional update (the third parameter; the expected version is –1, so version checking is disabled), and we pass the status we are setting as the context object.
![]()
If we get a connection loss event, we simply need to call updateStatus with the status we are updating. (We passed the status in the context parameter of setData.) The updateStatus method will do checks for race conditions, so we do not need to do those here.
To understand the problems with reissuing operations on a connection loss a bit more, consider the following scenario:
1. The worker starts working on task-1, so it sets the status to working on task-1.
2. The client library tries to issue the setData, but encounters networking problems.
3. After the client library determines that the connection has been lost with ZooKeeper and before statusUpdateCallback is called, the worker finishes task-1 and becomes idle.
4. The worker asks the client library to issue a setData with Idle as the data.
5. Then the client processes the connection lost event; if updateStatus does not check the current status, it would then issue a setData with working on task-1.
6. When the connection to ZooKeeper is reestablished, the client library faithfully issues the two setData operations in order, which means that the final state would be working on task-1.
By checking the current status before reissuing the setData in the updateStatus method, we avoid this scenario.
ORDER AND CONNECTIONLOSSEXCEPTION
ZooKeeper is very strict about maintaining order and has very strong ordering guarantees. However, care should be taken when thinking about ordering in the presence of multiple threads. One common scenario where multiple threads can cause errors involves retry logic in callbacks. When reissuing a request due to a ConnectionLossException, a new request is created and may therefore be ordered after requests issued on other threads that occurred after the original request.
Queuing Tasks
The final component of the system is the Client application that queues new tasks to be executed on a worker. We will be adding znodes under /tasks that represent commands to be carried out on the worker. We will be using sequential znodes, which gives us two benefits. First, the sequence number will indicate the order in which the tasks were queued. Second, the sequence number will create unique paths for tasks with minimal work. Our Client code looks like this:
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.Watcher;
public class Client implements Watcher {
ZooKeeper zk;
String hostPort;
Client(String hostPort) { this.hostPort = hostPort; }
void startZK() throws Exception {
zk = new ZooKeeper(hostPort, 15000, this);
}
String queueCommand(String command) throws KeeperException {
while (true) {
try {
String name = zk.create("/tasks/task-", ![]()
command.getBytes(), OPEN_ACL_UNSAFE,
CreateMode.SEQUENTIAL); ![]()
return name; ![]()
break;
} catch (NodeExistsException e) {
throw new Exception(name + " already appears to be running");
} catch (ConnectionLossException e) { ![]()
}
}
public void process(WatchedEvent e) { System.out.println(e); }
public static void main(String args[]) throws Exception {
Client c = new Client(args[0]);
c.start();
String name = c.queueCommand(args[1]);
System.out.println("Created " + name);
}
}
![]()
We are creating the znode representing a task under /tasks. The name will be prefixed with task-.
![]()
Because we are using CreateMode.SEQUENTIAL, a monotonically increasing suffix will be appended to task-. This guarantees that a unique name will be created for each new task and the task ordering will be established by ZooKeeper.
![]()
Because we can’t be sure what the sequence number will be when we call create with CreateMode.SEQUENTIAL, the create method returns the name of the new znode.
![]()
If we lose a connection while we have a create pending, we will simply retry the create. This may create multiple znodes for the task, causing it to be created twice. For many applications this execute-at-least-once policy may work fine. Applications that require an execute-at-most-once policy must do more work: we would need to create each of our task znodes with a unique ID (the session ID, for example) encoded in the znode name. We would then retry the create only if a connection loss exception happened and there were no znodes under/tasks with the session ID in their name.
When we run the Client application and pass a command, a new znode will be created in /tasks. It is not an ephemeral znode, so even after the Client application ends, any znodes it has created will remain.
The Admin Client
Finally, we will write a simple AdminClient that will show the state of the system. One of the nice things about ZooKeeper is that you can use the zkCli utility to look at the state of the system, but usually you will want to write your own admin client to more quickly and easily administer the system. In this example, we will use getData and getChildren to get the state of our master-worker system.
These methods are simple to use. Because they don’t change the state of the system, we can simply propagate errors that we encounter without having to deal with cleanup.
This example uses the synchronous versions of the calls. The methods also have a watch parameter that we are setting to false because we really want to see the current state of the system and will not be watching for changes. We will see in the next chapter how we use this parameter to track changes in the system. For now, here’s our AdminClient code:
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.Watcher;
public class AdminClient implements Watcher {
ZooKeeper zk;
String hostPort;
AdminClient(String hostPort) { this.hostPort = hostPort; }
void start() throws Exception {
zk = new ZooKeeper(hostPort, 15000, this);
}
void listState() throws KeeperException {
try {
Stat stat = new Stat();
byte masterData[] = zk.getData("/master", false, stat); ![]()
Date startDate = new Date(stat.getCtime()); ![]()
System.out.println("Master: " + new String(masterData) +
" since " + startDate);
} catch (NoNodeException e) {
System.out.println("No Master");
}
System.out.println("Workers:");
for (String w: zk.getChildren("/workers", false)) {
byte data[] = zk.getData("/workers/" + w, false, null); ![]()
String state = new String(data);
System.out.println("\t" + w + ": " + state);
}
System.out.println("Tasks:");
for (String t: zk.getChildren("/assign", false)) {
System.out.println("\t" + t);
}
}
public void process(WatchedEvent e) { System.out.println(e); }
public static void main(String args[]) throws Exception {
AdminClient c = new AdminClient(args[0]);
c.start();
c.listState();
}
}
![]()
We put the name of the master as the data for the /master znode, so getting the data for the /master znode will give us the name of the current master. We aren’t interested in changes, which is why we pass false to the second parameter.
![]()
We can use the information in the Stat structure to know how long the current master has been master. The ctime is the number of seconds since the epoch after which the znode was created. See java.lang.System.currentTimeMillis() for details.
![]()
The ephemeral znode has two pieces of information: it indicates that the worker is running, and its data has the state of the worker.
The AdminClient is very simple: it simply runs through the data structures for our master-worker example. Try it out by starting and stopping a Master and some Workers, and running the Client a few times to queue up some tasks. The AdminClient will show the state of the system as things change.
You might be wondering if there is any advantage to using the asynchronous API in the AdminClient. ZooKeeper has a pipelined implementation designed to handle thousands of simultaneous requests. This is important because there are various sources of latency in the system, the largest of which are the disk and the network. Both of these components have queues that are used to efficiently use their bandwidth. The getData method does not do any disk access, but it must go over the network. With synchronous methods we let the pipeline drain between each request. If we are using the AdminClient in a relatively small system with tens of workers and hundreds of tasks, this might not be a big deal, but if we increase those numbers by an order of magnitude, the delay might become significant.
Consider a scenario in which the round trip time for a request is 1 ms. If the process needs to read 10,000 znodes, 10 seconds will be spent just on network delays. We can shorten that time to something much closer to 1 second using the asynchronous API.
Using the basic implementation of the Master, Worker, and Client, we have the beginnings of our master-worker system, but right now nothing is really happening. When a task gets queued, the master needs to wake up and assign the task to a worker. Workers need to find out about tasks assigned to them. Clients need to be able to know when tasks are finished. If a master fails, another master-in-waiting needs to take over. If a worker fails, its tasks need to get assigned to other workers. In upcoming chapters we will cover the concepts necessary to implement this needed functionality.
Takeaway Messages
The commands we use in zkCli correspond closely to the API we use when programming with ZooKeeper, so it can be useful to do some initial experimentation with zkCli to try out different ways to structure application data. The API is so close to the commands in zkCli that you could easily write an application that matches commands used when experimenting with zkCli. There are some caveats, though. First, when using zkCli we usually are in a stable environment where unexpected failures don’t happen. For code we are going to deploy, we have to handle error cases that complicate the code substantially. The ConnectionLossException in particular requires the developer to examine the state of the system to properly recover. (Remember, ZooKeeper helps organize distributed state and provides a framework for handling failures; it doesn’t make failures go away, unfortunately.) Second, it is worthwhile to become comfortable with the asynchronous API. It can give big performance benefits and can simplify error recovery.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.