ZooKeeper (2013)
Part II. Programming with ZooKeeper
Chapter 4. Dealing with State Change
It is not uncommon to have application processes that need to learn about changes to the state of a ZooKeeper ensemble. For instance, in our example in Chapter 1, backup masters need to know that the primary master has crashed, and workers need to know when new tasks have been assigned to them. ZooKeeper clients could, of course, poll the ZooKeeper ensemble periodically to determine whether changes have occurred. Polling, however, is not efficient, especially when the expected changes are somewhat rare.
For example, let’s consider backup masters; they need to know when the primary has crashed so that they can fail over. To reduce the time it takes to recover from the primary crash, we need to poll frequently—say, every 50 ms—just for an example of aggressive polling. In this case, each backup master generates 20 requests/second. If there are multiple backup masters, we multiply this frequency by the number of backups to obtain the total request traffic generated just to poll ZooKeeper for the status of the primary master. Even if such an amount of traffic is easy for a system like ZooKeeper to deal with, primary master crashes should be rare, so most of this traffic is unnecessary. Suppose we therefore reduce the amount of polling traffic to ZooKeeper by increasing the period between requests for the status of the primary, say to 1 second. The problem with increasing this period is that it increases the time it takes to recover from a primary crash.
We can avoid this tuning and polling traffic altogether by having ZooKeeper notify interested clients of concrete events. The primary mechanism ZooKeeper provides to deal with changes is watches. With watches, a client registers its request to receive a one-time notification of a change to a given znode. For example, we can have the primary master create an ephemeral znode representing the master lock, and the backup masters register a watch for the existence of the master lock. In the case that the primary crashes, the master lock is automatically deleted and the backup masters are notified. Once the backup masters receive their notifications, they can start a new master election by trying to create a new ephemeral znode to represent the master lock, as we showed in Getting Mastership.
Watches and notifications form a general mechanism that enables clients to observe changes by other clients without having to continually poll ZooKeeper. We have illustrated with the master example, but the general mechanism is applicable to a wide variety of situations.
One-Time Triggers
Before getting deeper into watches, let’s establish some terminology. We talk about an event to denote the execution of an update to a given znode. A watch is a one-time trigger associated with a znode and a type of event (e.g., data is set in the znode, or the znode is deleted). When the watch is triggered by an event, it generates a notification. A notification is a message to the application client that registered the watch to inform this client of the event.
When an application process registers a watch to receive a notification, the watch is triggered at most once and upon the first event that matches the condition of the watch. For example, say that the client needs to know when a given znode /z is deleted (e.g., a backup master). The client executes an exists operation on /z with the watch flag set and waits for the notification. The notification comes in the form of a callback to the application client.
Each watch is associated with the session in which the client sets it. If the session expires, pending watches are removed. Watches do, however, persist across connections to different servers. Say that a ZooKeeper client disconnects from a ZooKeeper server and connects to a different server in the ensemble. The client will send a list of outstanding watches. When reregistering the watch, the server will check to see if the watched znode has changed since the watch was registered. If the znode has changed, a watch event will be sent to the client; otherwise, the watch will be reregistered at the new server.
Wait, Can I Miss Events with One-Time Triggers?
The short answer is yes: an application can miss events between receiving a notification and registering for another watch. However, this issue deserves more discussion. Missing events is typically not a problem because any changes that have occurred during the period between receiving a notification and registering a new watch can be captured by reading the state of ZooKeeper directly.
Say that a worker receives a notification indicating that a new task has been assigned to it. To receive the new task, the worker reads the list of tasks. If several more tasks have been assigned to the worker after it received the notification, reading the list of tasks via a getChildren call returns all tasks. The getChildren call also sets a new watch, guaranteeing that the worker will not miss tasks.
Actually, having one notification amortized across multiple events is a positive aspect. It makes the notification mechanism much more lightweight than sending a notification for every event for applications that have a high rate of updates. To give a trivial example, if every notification captures two events on average, we are generating only 0.5 notifications per event instead of 1 notification per event.
Getting More Concrete: How to Set Watches
All read operations in the ZooKeeper API—getData, getChildren, and exists—have the option to set a watch on the znode they read. To use the watch mechanism, we need to implement the Watcher interface, which consists of implementing a process method:
public void process(WatchedEvent event);
The WatchedEvent data structure contains the following:
§ The state of the ZooKeeper session (KeeperState): Disconnected, SyncConnected, AuthFailed, ConnectedReadOnly, SaslAuthenticated, or Expired
§ The event type (EventType): NodeCreated, NodeDeleted, NodeDataChanged, NodeChildrenChanged, or None
§ A znode path in the case that the watched event is not None
The first three events refer to a single znode, whereas the fourth event concerns the children of the znode on which it is issued. We use None when the watched event is for a change of the state of the ZooKeeper session.
There are two types of watches: data watches and child watches. Creating, deleting, or setting the data of a znode successfully triggers a data watch. Both exists and getData set data watches. Only getChildren sets child watches, which are triggered when a child znode is either created or deleted. For each event type, we have the following calls for setting a watch:
NodeCreated
A watch is set with a call to exists.
NodeDeleted
A watch is set with a call to either exists or getData.
NodeDataChanged
A watch is set with either exists or getData.
NodeChildrenChanged
A watch is set with getChildren.
When creating a ZooKeeper object (see Chapter 3), we need to pass a default Watcher object. The ZooKeeper client uses this watcher to notify the application of changes to the ZooKeeper state, in case the state of the session changes. For event notifications related to ZooKeeper znodes, you can either use the default watcher or implement a different one. For example, the getData call has two different ways of setting a watch:
public byte[] getData(final String path, Watcher watcher, Stat stat);
public byte[] getData(String path, boolean watch, Stat stat);
Both signatures pass the znode as the first argument. The first signature passes a new Watcher object (which we must have created). The second signature tells the client to use the default watcher, and only requires true as the second parameter of the call.
The stat input parameter is an instance of the Stat structure that ZooKeeper uses to return information about the znode designated by path. The Stat structure contains information about the znode, such as the timestamp of the last change (zxid) that changed this znode and the number of children in the znode.
One important observation about watches is that currently it is not possible to remove them once set. The only two ways to remove a watch are to have it triggered or for its session to be closed or expired. This behavior is likely to change in future versions, however, because the community has been working on it for version 3.5.0.
A BIT OF OVERLOADING
We use the same watch mechanism for notifying the application of events related to the state of a ZooKeeper session and events related to znode changes. Although session state changes and znode state changes constitute independent sets of events, we rely upon the same mechanism to deliver such events for simplicity.
A Common Pattern
Before we get into some snippets for the master-worker example, let’s take a quick look at a pretty common code pattern used in ZooKeeper applications:
1. Make an asynchronous call.
2. Implement a callback object and pass it to the asynchronous call.
3. If the operation requires setting a watch, then implement a Watcher object and pass it on to the asynchronous call.
A code sample for this pattern using an asynchronous exists call looks like this:
zk.exists("/myZnode", ![]()
myWatcher,
existsCallback,
null);
Watcher myWatcher = new Watcher() { ![]()
public void process(WatchedEvent e) {
// Process the watch event
}
}
StatCallback existsCallback = new StatCallback() { ![]()
public void processResult(int rc, String path, Object ctx, Stat stat) {
// Process the result of the exists call
}
};
![]()
ZooKeeper exists call. Note that the call is asynchronous.
![]()
Watcher implementation.
![]()
exists callback.
As we will see next, we’ll make extensive use of this skeleton.
The Master-Worker Example
Let’s now look at how we deal with changes of state in the master-worker example. Here is a list of tasks that require a component to wait for changes:
§ Mastership changes
§ Master waits for changes to the list of workers
§ Master waits for new tasks to assign
§ Worker waits for new task assignments
§ Client waits for task execution result
We next show some code snippets to illustrate how to code these tasks with ZooKeeper. We provide the complete example code as part of the additional material to this book.
Mastership Changes
Recall from Getting Mastership that an application client elects itself master by creating the /master znode (we call this “running for master”). If the znode already exists, the application client determines that it is not the primary master and returns. That implementation, however, does not tolerate a crash of the primary master. If the primary master crashes, the backup masters won’t know about it. Consequently, we need to set a watch on /master so that ZooKeeper notifies the client when /master is deleted (either explicitly or because the session of the primary master has expired).
To set the watch, we create a new watcher named masterExistsWatcher and pass it to exists. Upon a notification of /master being deleted, the process call defined in masterExistsWatcher calls runForMaster:
StringCallback masterCreateCallback = new StringCallback() {
public void processResult(int rc, String path, Object ctx, String name) {
switch (Code.get(rc)) {
case CONNECTIONLOSS:
checkMaster(); ![]()
break;
case OK:
state = MasterStates.ELECTED;
takeLeadership(); ![]()
break;
case NODEEXISTS:
state = MasterStates.NOTELECTED;
masterExists(); ![]()
break;
default:
state = MasterStates.NOTELECTED;
LOG.error("Something went wrong when running for master.", ![]()
KeeperException.create(Code.get(rc), path));
}
}
};
void masterExists() {
zk.exists("/master",
masterExistsWatcher, ![]()
masterExistsCallback,
null);
}
Watcher masterExistsWatcher = new Watcher() {
public void process(WatchedEvent e) {
if(e.getType() == EventType.NodeDeleted) {
assert "/master".equals( e.getPath() );
runForMaster(); ![]()
}
}
};
![]()
In the case of a connection loss event, the client checks if the /master znode is there because it doesn’t know if it has been able to create it or not.
![]()
If OK, then it simply takes leadership.
![]()
If someone else has already created the znode, then the client needs to watch it.
![]()
If anything unexpected happens, then it logs the error and doesn’t do anything else.
![]()
This exists call is to set a watch on the /master znode.
![]()
If the /master znode is deleted, then it runs for master again.
Following the asynchronous style we used in Getting Mastership Asynchronously, we also create a callback method for the exists call that takes care of a few cases. First, it tries the exists operation again in the case of a connection loss event because it needs to set a watch on /master. Second, it is possible for the /master znode to be deleted between the execution of the create callback and the execution of the exists operation. Consequently, we need to check whether stat is null whenever the response from exists is positive (return code is OK). stat is null when the node does not exist. Third, if the return is not OK or CONNECTIONLOSS, then we check for the /master znode by getting its data. Say that the client session expires. In this case, the callback to get the data of /master logs an error message and exits. Our exists callback looks like this:
StatCallback masterExistsCallback = new StatCallback() {
public void processResult(int rc, String path, Object ctx, Stat stat) {
switch (Code.get(rc)) {
case CONNECTIONLOSS:
masterExists(); ![]()
break;
case OK:
if(stat == null) {
state = MasterStates.RUNNING;
runForMaster(); ![]()
}
break;
default:
checkMaster(); ![]()
break;
}
}
};
![]()
In the case of a connection loss, just try again.
![]()
If it returns OK, run for master only in the case that the znode is gone.
![]()
If something unexpected happens, check if /master is there by getting its data.
The result of the exists operation over /master might be that the znode has been deleted. In this case, the client needs to run for /master again because it is not guaranteed that the watch was set before the znode was deleted. If the new attempt to become primary fails, then the client knows that some other client succeeded and it tries to watch /master again. In the case the notification for /master indicates that it has been created instead of deleted, the client does not run for /master. At the same time, the corresponding exists operation (the one that has set the watch) must have returned that /master doesn’t exist, which triggers the procedure to run for /master from the exists callback.
Note that this pattern of running for master and executing exists to set a watch on /master continues for as long as the client runs and does not become a primary master. If it becomes the primary master and eventually crashes, the client can restart and reexecute this code.
Figure 4-1 makes the possible interleavings of operations more explicit. If the create operation executed when running for primary master succeeds (a), the application client doesn’t have to do anything else. If the create operation fails, meaning that the node already exists, the client executes an exists operation to set a watch on the /master znode (b). Between running for master and executing the exists operation, it is possible that the /master znode gets deleted. In this case, the exists call indicates that the znode still exists, and the client simply waits for a notification. Otherwise, it tries to run for master again, trying to create the /master znode. If creating the /master znode succeeds, the watch is triggered, indicating that there has been a change to the znode (c). This notification, however, is meaningless, because the client itself made the change. If the create fails again, we restart the process by executing exists and setting a watch on /master (d).
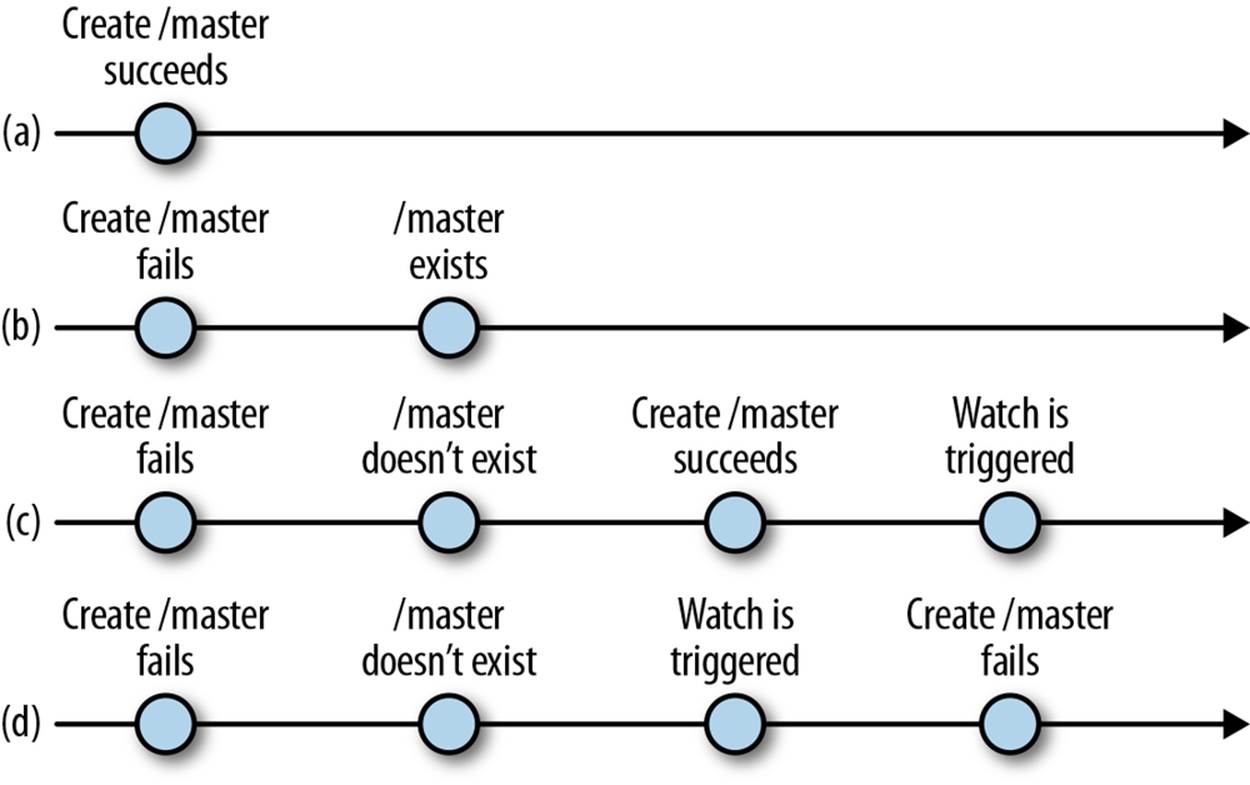
Figure 4-1. Running for master, possible interleavings
Master Waits for Changes to the List of Workers
New workers may be added to the system and old workers may be decommissioned at any time. Workers might also crash before executing their assignments. To determine the workers that are available at any one time, we register new workers with ZooKeeper by adding a znode as a child of/workers. When a worker crashes or is simply removed from the system, its session expires, automatically causing its znode to be removed. Polite workers may also explicitly close their sessions without making ZooKeeper wait for a session expiration.
The primary master uses getChildren to obtain the list of available workers and to watch for changes to the list. Sample code to obtain the list and watch for changes is as follows:
Watcher workersChangeWatcher = new Watcher() { ![]()
public void process(WatchedEvent e) {
if(e.getType() == EventType.NodeChildrenChanged) {
assert "/workers".equals( e.getPath() );
getWorkers();
}
}
};
void getWorkers() {
zk.getChildren("/workers",
workersChangeWatcher,
workersGetChildrenCallback,
null);
}
ChildrenCallback workersGetChildrenCallback = new ChildrenCallback() {
public void processResult(int rc, String path, Object ctx,
List<String> children) {
switch (Code.get(rc)) {
case CONNECTIONLOSS:
getWorkerList(); ![]()
break;
case OK:
LOG.info("Succesfully got a list of workers: "
+ children.size()
+ " workers");
reassignAndSet(children); ![]()
break;
default:
LOG.error("getChildren failed",
KeeperException.create(Code.get(rc), path));
}
}
};
![]()
workersChangeWatcher is the watcher for the list of workers.
![]()
In the case of a CONNECTIONLOSS event, we need to reexecute the operation to obtain the children and set the watch.
![]()
This call reassigns tasks of dead workers and sets the new list of workers.
We start by calling getWorkerList. This call executes getChildren asynchronously, passing workersGetChildrenCallback to process the result of the operation. If the client disconnects from a server (CONNECTIONLOSS event), the watch is not set and we don’t have a list of workers; we execute getWorkerList again to set the watch and obtain the list of workers. Upon a successful execution of getChildren, we call reassignAndSet, as in the following code:
ChildrenCache workersCache; ![]()
void reassignAndSet(List<String> children) {
List<String> toProcess;
if(workersCache == null) {
workersCache = new ChildrenCache(children); ![]()
toProcess = null; ![]()
} else {
LOG.info( "Removing and setting" );
toProcess = workersCache.removedAndSet( children ); ![]()
}
if(toProcess != null) {
for(String worker : toProcess) {
getAbsentWorkerTasks(worker); ![]()
}
}
}
![]()
Here’s the cache that holds the last set of workers we have seen.
![]()
If this is the first time it is using the cache, then instantiate it.
![]()
The first time we get workers, there is nothing to do.
![]()
If it is not the first time, then we need to check if some worker has been removed.
![]()
If there is any worker that has been removed, then we need to reassign its tasks.
We use the cache because we need to remember what we have seen before. Say that we get the list of workers for the first time. When we get the notification that the list of workers has changed, we won’t know what exactly has changed even after reading it again unless we keep the old values. The cache class for this example simply keeps the last list the master has read and implements a couple of methods to determine what has changed.
WATCH UPON CONNECTIONLOSS
A watch for a znode is set only if the operation is successful. If the ZooKeeper operation fails to be executed because the client has disconnected, then the application needs to call it again.
Master Waits for New Tasks to Assign
Like waiting for changes to the list of workers, the primary master waits for new tasks to be added to /tasks. The master initially obtains the set of current tasks and sets a watch for changes to the set. The set is represented in ZooKeeper by the children of /tasks, and each child corresponds to a task. Once the master obtains tasks that have not been assigned, it selects a worker at random and assigns the task to the worker. We implement the assignment in assignTasks:
Watcher tasksChangeWatcher = new Watcher() { ![]()
public void process(WatchedEvent e) {
if(e.getType() == EventType.NodeChildrenChanged) {
assert "/tasks".equals( e.getPath() );
getTasks();
}
}
};
void getTasks() {
zk.getChildren("/tasks",
tasksChangeWatcher,
tasksGetChildrenCallback,
null); ![]()
}
ChildrenCallback tasksGetChildrenCallback = new ChildrenCallback() {
public void processResult(int rc,
String path,
Object ctx,
List<String> children) {
switch(Code.get(rc)) {
case CONNECTIONLOSS:
getTasks();
break;
case OK:
if(children != null) {
assignTasks(children); ![]()
}
break;
default:
LOG.error("getChildren failed.",
KeeperException.create(Code.get(rc), path));
}
}
};
![]()
Watcher implementation to handle a notification that the list of tasks has changed.
![]()
Get the list of tasks.
![]()
Assign tasks in the list.
Now we’ll implement assignTasks. It simply assigns each of the tasks in the list of children of /tasks. Before creating the assignment znode, we get the task data with getData:
void assignTasks(List<String> tasks) {
for(String task : tasks) {
getTaskData(task);
}
}
void getTaskData(String task) {
zk.getData("/tasks/" + task,
false,
taskDataCallback,
task); ![]()
}
DataCallback taskDataCallback = new DataCallback() {
public void processResult(int rc,
String path,
Object ctx,
byte[] data,
Stat stat) {
switch(Code.get(rc)) {
case CONNECTIONLOSS:
getTaskData((String) ctx);
break;
case OK:
/*
* Choose worker at random.
*/
int worker = rand.nextInt(workerList.size());
String designatedWorker = workerList.get(worker);
/*
* Assign task to randomly chosen worker.
*/
String assignmentPath = "/assign/" + designatedWorker + "/" +
(String) ctx;
createAssignment(assignmentPath, data); ![]()
break;
default:
LOG.error("Error when trying to get task data.",
KeeperException.create(Code.get(rc), path));
}
}
};
![]()
Get task data.
![]()
Select a worker randomly and assign the task to this worker.
We need to get the task data first because we delete the task znode under /tasks after assigning it. This way the master doesn’t have to remember which tasks it has assigned. Let’s look at the code for assigning a task:
void createAssignment(String path, byte[] data) {
zk.create(path,
data, Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT,
assignTaskCallback,
data); ![]()
}
StringCallback assignTaskCallback = new StringCallback() {
public void processResult(int rc, String path, Object ctx, String name) {
switch(Code.get(rc)) {
case CONNECTIONLOSS:
createAssignment(path, (byte[]) ctx);
break;
case OK:
LOG.info("Task assigned correctly: " + name);
deleteTask(name.substring( name.lastIndexOf("/") + 1 )); ![]()
break;
case NODEEXISTS:
LOG.warn("Task already assigned");
break;
default:
LOG.error("Error when trying to assign task.",
KeeperException.create(Code.get(rc), path));
}
}
};
![]()
Create an assignment. The path is of the form /assign/worker-id/task-num.
![]()
Delete the task znode under /tasks.
For new tasks, after the master selects a worker to assign the task to, it creates a znode under /assign/worker-id, where id is the identifier of the worker. Next, it deletes the znode from the list of pending tasks. The code for deleting the znode in the previous example follows the pattern of earlier code we have shown.
When the master creates an assignment znode for a worker with identifier id, ZooKeeper generates a notification for the worker, assuming that the worker has a watch registered upon its assignment znode (/assign/worker-id).
Note that the master also deletes the task znode under /tasks after assigning it successfully. This approach simplifies the role of the master when it receives new tasks to assign. If the list of tasks mixed the assigned and unassigned tasks, the master would need a way to disambiguate the tasks.
Worker Waits for New Task Assignments
One of the first steps a worker has to execute is to register itself with ZooKeeper. It does this by creating a znode under /workers, as we already discussed:
void register() {
zk.create("/workers/worker-" + serverId,
new byte[0],
Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL,
createWorkerCallback, null); ![]()
}
StringCallback createWorkerCallback = new StringCallback() {
public void processResult(int rc, String path, Object ctx, String name) {
switch (Code.get(rc)) {
case CONNECTIONLOSS:
register(); ![]()
break;
case OK:
LOG.info("Registered successfully: " + serverId);
break;
case NODEEXISTS:
LOG.warn("Already registered: " + serverId);
break;
default:
LOG.error("Something went wrong: " +
KeeperException.create(Code.get(rc), path));
}
}
};
![]()
Register the worker by creating a znode.
![]()
Try again. Note that registering again is not a problem. If the znode has already been created, we get a NODEEXISTS event back.
Adding this znode signals to the master that this worker is active and ready to process tasks. Note that we don’t use here the idle/busy status introduced in Chapter 3 to simplify the example.
We similarly create a znode /assign/worker-id so that the master can assign tasks to this worker. If we create /workers/worker-id before /assign/worker-id, we could fall into the situation in which the master tries to assign the task but cannot because the assigned parent’s znode has not been created yet. To avoid this situation, we need to create /assign/worker-id first. Moreover, the worker needs to set a watch on /assign/worker-id to receive a notification when a new task is assigned.
Once the worker has the list of tasks assigned to it, it fetches the tasks from /assign/worker-id and executes them. The worker takes each task in its list and verifies whether it has already queued the task for execution. It keeps a list of ongoing tasks for this purpose. Note that we loop through the assigned tasks of a worker in a separate thread to release the callback thread. Otherwise, we would be blocking other incoming callbacks. In our example, we use a Java ThreadPoolExecutor to allocate a thread to loop through the tasks:
Watcher newTaskWatcher = new Watcher() {
public void process(WatchedEvent e) {
if(e.getType() == EventType.NodeChildrenChanged) {
assert new String("/assign/worker-"+ serverId).equals( e.getPath() );
getTasks(); ![]()
}
}
};
void getTasks() {
zk.getChildren("/assign/worker-" + serverId,
newTaskWatcher,
tasksGetChildrenCallback,
null);
}
ChildrenCallback tasksGetChildrenCallback = new ChildrenCallback() {
public void processResult(int rc,
String path,
Object ctx,
List<String> children) {
switch(Code.get(rc)) {
case CONNECTIONLOSS:
getTasks();
break;
case OK:
if(children != null) {
executor.execute(new Runnable() { ![]()
List<String> children;
DataCallback cb;
public Runnable init (List<String> children,
DataCallback cb) {
this.children = children;
this.cb = cb;
return this;
}
public void run() {
LOG.info("Looping into tasks");
synchronized(onGoingTasks) {
for(String task : children) { ![]()
if(!onGoingTasks.contains( task )) {
LOG.trace("New task: {}", task);
zk.getData("/assign/worker-" +
serverId + "/" + task,
false,
cb,
task); ![]()
onGoingTasks.add( task ); ![]()
}
}
}
}
}
.init(children, taskDataCallback));
}
break;
default:
System.out.println("getChildren failed: " +
KeeperException.create(Code.get(rc), path));
}
}
};
![]()
Upon receiving a notification that the children have changed, get the list of children.
![]()
Execute in a separate thread.
![]()
Loop through the list of children.
![]()
Get task data to execute it.
![]()
Add task to the list of tasks being executed to avoid executing it multiple times.
SESSION EVENTS AND WATCHERS
When we disconnect from a server (for example, when the server crashes), no watches are delivered until the connection is reestablished. For this reason, session events like CONNECTIONLOSS are sent to all outstanding watch handlers. In general, applications use session events to go into a safe mode: the ZooKeeper client does not receive events while disconnected, so it should act conservatively in this state. In the case of our toy master-worker application, all actions except submitting a task are reactive, so if a master or a worker is disconnected, it simply does not trigger any action. Also, the master-worker client is not able to submit new tasks and it does not receive status notifications while disconnected.
Client Waits for Task Execution Result
Suppose an application client has submitted a task. Now it needs to know when it has been executed and its status. Recall that once a worker executes a task, it creates a znode under /status. Let’s first check the code to submit a task for execution:
void submitTask(String task, TaskObject taskCtx) {
taskCtx.setTask(task);
zk.create("/tasks/task-",
task.getBytes(),
Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT_SEQUENTIAL,
createTaskCallback,
taskCtx); ![]()
}
StringCallback createTaskCallback = new StringCallback() {
public void processResult(int rc, String path, Object ctx, String name) {
switch (Code.get(rc)) {
case CONNECTIONLOSS:
submitTask(((TaskObject) ctx).getTask(),
(TaskObject) ctx); ![]()
break;
case OK:
LOG.info("My created task name: " + name);
((TaskObject) ctx).setTaskName(name);
watchStatus("/status/" + name.replace("/tasks/", ""),
ctx); ![]()
break;
default:
LOG.error("Something went wrong" +
KeeperException.create(Code.get(rc), path));
}
}
};
![]()
Unlike previous calls to ZooKeeper, we are passing a context object, which is an instance of a Task class in our implementation.
![]()
Resubmit the task upon a connection loss. Note that resubmitting may create a duplicate of the task.
![]()
Set a watch on the status znode for this task.
HAS MY SEQUENTIAL ZNODE BEEN CREATED?
Dealing with a CONNECTIONLOSS event when trying to create a sequential znode is somewhat tricky. Because ZooKeeper assigns the sequence number, it is not possible for the disconnected client to determine whether the znode has been created when there might be concurrent requests to create sequential znodes from other clients. (Note that all the create requests we are talking about in this note refer to the children of the same znode.)
To overcome this limitation, we have to give some hint about the originator of the znode, like adding the server ID as part of the task name. Using this approach, it is possible to determine whether the task has been created by listing all task znodes.
Here we check if the status node already exists (maybe the task has been processed fast) and set a watch. We provide a watcher implementation to react to the notification of the znode creation and a callback implementation for the exists call:
ConcurrentHashMap<String, Object> ctxMap =
new ConcurrentHashMap<String, Object>();
void watchStatus(String path, Object ctx) {
ctxMap.put(path, ctx);
zk.exists(path,
statusWatcher,
existsCallback,
ctx); ![]()
}
Watcher statusWatcher = new Watcher() {
public void process(WatchedEvent e) {
if(e.getType() == EventType.NodeCreated) {
assert e.getPath().contains("/status/task-");
zk.getData(e.getPath(),
false,
getDataCallback,
ctxMap.get(e.getPath()));
}
}
};
StatCallback existsCallback = new StatCallback() {
public void processResult(int rc, String path, Object ctx, Stat stat) {
switch (Code.get(rc)) {
case CONNECTIONLOSS:
watchStatus(path, ctx);
break;
case OK:
if(stat != null) {
zk.getData(path, false, getDataCallback, null); ![]()
}
break;
case NONODE:
break; ![]()
default:
LOG.error("Something went wrong when " +
"checking if the status node exists: " +
KeeperException.create(Code.get(rc), path));
break;
}
}
};
![]()
The client propagates the context object here so that it can modify the task object (TaskObject) accordingly when it receives a notification for the status znode.
![]()
The status znode is already there, so the client needs to get it.
![]()
If the status znode is not there yet, which should typically be the case, the client does nothing.
An Alternative Way: Multiop
Multiop was not in the original design of ZooKeeper, but was added in version 3.4.0. Multiop enables the execution of multiple ZooKeeper operations in a block atomically. The execution is atomic in the sense that either all operations in a multiop block succeed or all fail. For example, we can delete a parent znode and its child in a multiop block. The only possible outcomes are that either both operations succeed or both fail. It is not possible for the parent to be deleted while leaving one of its children around, or vice versa.
To use the multiop feature:
1. Create an Op object to represent each ZooKeeper operation you intend to execute through a multiop call. ZooKeeper provides an Op implementation for each of the operations that change state: create, delete, and setData.
2. Within the Op object, call a static method provided by Op for that operation.
3. Add this Op object to an Iterable Java object, such as a list.
4. Call multi on the list.
The following example illustrates this process:
Op deleteZnode(String z) { ![]()
return Op.delete(z, -1); ![]()
}
...
List<OpResult> results = zk.multi(Arrays.asList(deleteZnode("/a/b"),
deleteZnode("/a")); ![]()
![]()
Create an Op object for the delete call.
![]()
Return the object by calling the appropriate Op method.
![]()
Execute both delete calls as a unit by using the multi call and passing them as a list of Op instances.
The call to multi returns a list of OpResult objects, each one specialized to the corresponding operation. For example, for the delete operation we have a DeleteResult class, which extends OpResult. The methods and data exposed by each result object depend on the operation type.DeleteResult offers only equals and hashCode methods, whereas CreateResult exposes the path of the operation and a Stat object. In the presence of errors, ZooKeeper returns an instance of ErrorResult containing an error code.
The multi call also has an asynchronous version. Here are the signatures of the synchronous and asynchronous methods:
public List<OpResult> multi(Iterable<Op> ops) throws InterruptedException,
KeeperException;
public void multi(Iterable<Op> ops, MultiCallback cb, Object ctx);
Transaction is a wrapper for multi with a simpler interface. We can create an instance of Transaction, add operations, and commit the transaction. The previous example rewritten using Transaction looks like this:
Transaction t = new Transaction();
t.delete("/a/b", -1);
t.delete("/a", -1);
List<OpResult> results = t.commit();
The commit call also has an asynchronous version that takes as input a MultiCallback object and a context object:
public void commit(MultiCallback cb, Object ctx);
multiop can simplify our master-worker implementation in at least one place. When assigning a task, the master in previous examples has created the corresponding assignment znode and then deleted the task znode under /tasks. If the master crashes before deleting the znode under/tasks, we are left with a task in /tasks that has already been assigned. Using multiop, we can create the znode representing the assignment of the task under /assign and delete the znode representing the task under /tasks atomically. Using this approach, we guarantee that no task znode under /tasks has been already assigned. If a backup takes over the role of master, it is not necessary to disambiguate the tasks in /tasks: they are all unassigned.
Another feature that multiop offers is the possibility of checking the version of a znode to enable operations over multiple znodes that read the state of ZooKeeper and write back some data—possibly a modification of what has been read. The version of the znode that is checked does not change, so this call enables a multiop that checks the version of a znode that is not modified. This feature is useful when the changes to one or more znodes are conditional upon the version of another znode. Say that in our master-worker example, the master needs to have the clients adding new tasks under a path that the master specifies. For example, the master could ask clients to create new tasks as children of /tasks-mid, where mid is the master identifier. The master stores this path as the data of the /master-path znode. A client that needs to add a new task first reads/master-path and picks its current version with Stat. Next, the client creates a new task znode under /tasks-mid as part of the a multiop call, and it also checks that the version of /master-path matches the one it has read.
The signature of check is similar to that of setData, but it doesn’t include data:
public static Op check(String path, int version);
If the version of the znode in the given path does not match, the multi call fails. To illustrate, this is roughly how the code would look if we were to implement the example we have just discussed:
byte[] masterData = zk.getData("/master-path", false, stat); ![]()
String parent = new String(masterData); ![]()
...
zk.multi(Arrays.asList(Op.check("/master-path", stat.getVersion()),
Op.create(, modify(z1Data),-1), ![]()
![]()
Get the data of /master.
![]()
Extract the path from the /master znode.
![]()
multi call with two operations.
Note that if we store the path along with the master ID in /master, this scheme does not work. The /master znode is created every time by a new master, which makes its version consistently 1.
Watches as a Replacement for Explicit Cache Management
It is undesirable from the application’s perspective to have clients accessing ZooKeeper every time they need to get the data for a given znode, the list of children of a znode, or anything else related to the ZooKeeper state. Instead, it is much more efficient to have clients cache values locally and use them at will. Once such values change, of course, you want ZooKeeper to notify the clients so they can update the caches. These notifications are the same ones that we have been talking about to this point, and as before, application clients register to receive such notifications through watches. In short, these watches enable clients to cache a local version of a value (such as the data of a znode or its list of children) and to receive notifications when that value changes.
An alternative to the approach that the ZooKeeper designers have adopted would be to cache transparently on behalf of the client all ZooKeeper state it accesses and to invalidate the values transparently when there are updates to cached data. Implementing such a cache coherence scheme could be costly, however, because clients might not need to cache all ZooKeeper state they access, and servers would need to invalidate cached state nonetheless. To implement invalidation, servers would have to either keep track of the cache content for each client or broadcast invalidation requests. Both options are expensive for a large number of clients and undesirable from our perspective.
Regardless of which party manages the client cache—ZooKeeper directly or the ZooKeeper application—notifying clients of updates can be performed either synchronously or asynchronously. Synchronously invalidating state across all clients holding a copy would be inefficient, because clients often proceed at different paces and consequently slow clients would force other clients to wait. Such differences become more frequent as the size of the client population increases.
The notifications approach that the designers opted for can be perceived as an asynchronous way of invalidating ZooKeeper state on the client side. ZooKeeper queues notifications to clients, and such notifications are consumed asynchronously. This invalidation scheme is also optional; it is up to the application to decide what parts of the ZooKeeper state require invalidation for any given client. These design choices are a better match for the use cases of ZooKeeper.
Ordering Guarantees
There are a few important observations to keep in mind with respect to ordering when implementing applications with ZooKeeper.
Order of Writes
ZooKeeper state is replicated across all servers forming the ensemble of an installation. The servers agree upon the order of state changes and apply them using the same order. For example, if a ZooKeeper server applies a state change that creates a znode /z followed by a state change that deletes a znode /z', all servers in the ensemble must also apply these changes, and in the same order.
Servers, however, do not necessarily apply state updates simultaneously. In fact, they rarely do. Servers most likely apply state changes at different times because they proceed at different speeds, even if the hardware they run upon is fairly homogeneous. There are a number of reasons that could cause this time lag, such as operating system scheduling and background tasks.
Applying state updates at different times is typically not a problem for applications because they still perceive the same order of updates. Applications may perceive it, however, if ZooKeeper state is communicated through hidden channels, as we discuss next.
Order of Reads
ZooKeeper clients always observe the same order of updates, even if they are connected to different servers. But it is possible for two clients to observe updates at different times. If they communicate outside ZooKeeper, the difference becomes apparent.
Let’s consider the following situation:
§ A client c1 updates the data of a znode /z and receives an acknowledgment.
§ Client c1 sends a message through a direct TCP connection to a client c2 saying that it has changed the state of /z.
§ Client c2 reads the state of /z but observes a state previous to the update of c1.
We call this a hidden channel because ZooKeeper doesn’t know about the clients’ extra communication. Now c2 has stale data. This situation is illustrated in Figure 4-2.
To avoid reading stale data, we advise that applications use ZooKeeper for all communication related to the ZooKeeper state. For example, to avoid the situation just described, c2 could set a watch on /z instead of receiving a direct message from c1. With a watch, c2 learns of the change to/z and eliminates the hidden channel problem.
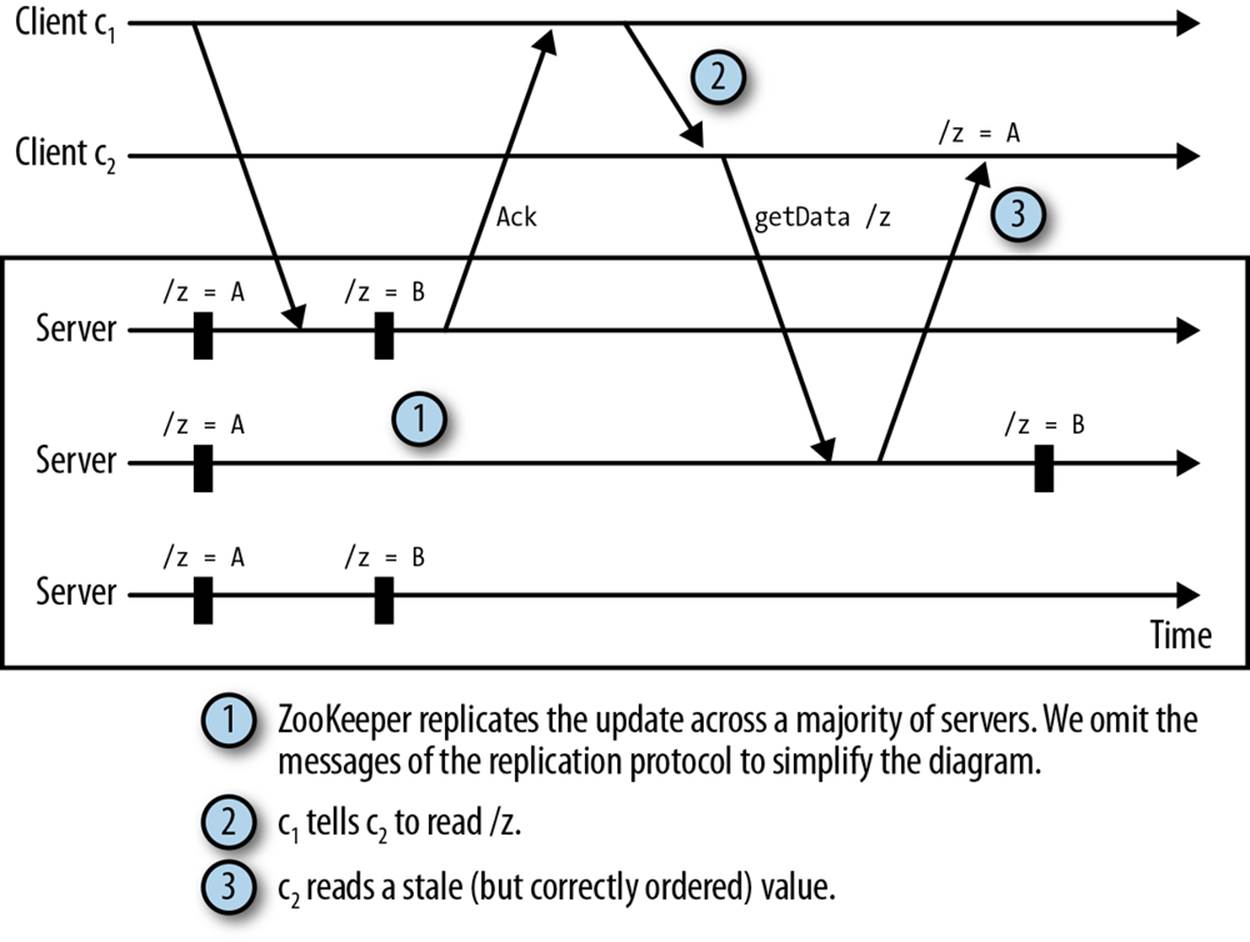
Figure 4-2. Example of the hidden channel problem
Order of Notifications
ZooKeeper orders notifications with respect to other notifications and asynchronous replies, respecting the order of updates to the system state. Say that ZooKeeper orders two state updates u and uʹ, with uʹ following u. If u and uʹ modify znodes /a and /b, respectively, and a client c has a watch set on /a, c is able to observe the update uʹ only by, say, reading /b after receiving the notification corresponding to u.
This ordering enables applications to use watches to implement safety properties. Say that a znode /z is created or deleted to indicate that some configuration stored in ZooKeeper is invalid. Guaranteeing that clients are notified of the creation or deletion of /z before any actual change is made to the configuration is important to make sure that clients won’t read an invalid configuration.
To make it more concrete, say that we have a znode /config that is the parent of a number of other znodes containing application configuration metadata: /config/m1, /config/m2, …, /config/m_n_. For the purposes of this example, it doesn’t matter what the content of the znodes actually is. Say that a master application process needs to update these nodes by invoking setData on each znode, and it can’t have a client reading a partial update to these znodes. One solution is to have the master create a /config/invalid znode before it starts updating the configuration znodes. Other clients that need to read this state watch /config/invalid and avoid reading it if the invalid znode is present. Once the invalid znode is deleted, meaning that a new valid set of configuration znodes is available, clients can proceed to read that set.
For this particular example, we could alternatively have used multiop to execute all setData operations to the /config/m[1-n] znodes atomically instead of using a znode to mark some state as partially modified. In instances in which atomicity is the problem, we can use multiopinstead of relying upon an extra znode and notifications. The notification mechanism, however, is more general and is not constrained to atomicity.
Because ZooKeeper orders notifications according to the order of the state updates that trigger the notifications, clients can rely upon perceiving the true order of ZooKeeper state changes through their notifications.
LIVENESS VERSUS SAFETY
We have used the notifications mechanism extensively for liveness in this chapter. Liveness is about making sure that the system eventually makes progress. Notifications of new tasks and new workers are examples of events related to liveness. If a master is not notified of a new task, the task will never be executed. Not executing a submitted task constitutes absence of liveness, at least from the perspective of the client that submitted the task.
This last example of atomic updates to a set of configuration znodes is different: it is about safety, not liveness. Reading the znodes while they are being updated might lead to a client reading an inconsistent configuration. The invalid znode makes sure that clients read the state only when a valid configuration is available.
For the liveness examples we have seen, the order of delivery of notifications is not particularly important. As long as clients eventually learn of those events, they will make progress. For safety, however, receiving a notification out of order might lead to incorrect behavior.
The Herd Effect and the Scalability of Watches
One issue to be aware of is that ZooKeeper triggers all watches set for a particular znode change when the change occurs. If there are 1,000 clients that have set a watch on a given znode with a call to exists, then 1,000 notifications will be sent out when the znode is created. A change to a watched znode might consequently generate a spike of notifications. Such a spike could affect, for example, the latency of operations submitted around the time of the spike. When possible, we recommend avoiding such a use of ZooKeeper in which a large number of clients watch for a change to a given znode. It is much better to have only a few clients watching any given znode at a time, and ideally at most one.
One way around this problem that doesn’t apply in every case but might be useful in some is the following. Say that n clients are competing to acquire a lock (e.g., a master lock). To acquire the lock, a process simply tries to create the /lock znode. If the znode exists, the client watches the znode for deletion. When the znode is deleted, the client tries again to create /lock. With this strategy, all clients watching /lock receive a notification when /lock is deleted. A different approach is to have each client create a sequential znode /lock/lock-. Recall that ZooKeeper adds a sequence number to the znode, automatically making it /lock/lock-xxx, where xxx is a sequence number. We can use the sequence number to determine which client acquires the lock by granting it to the client that created the znode under /lock with the smallest sequence number. In this scheme, a client determines if it has the smallest sequence number by getting the children of /lock with getChildren. If the client doesn’t have the smallest sequence number, it watches the next znode in the sequence determined by the sequence numbers. For example, say we have three znodes: /lock/lock-001, /lock/lock-002, and /lock/lock-003. In this example:
§ The client that created /lock/lock-001 has the lock.
§ The client that created /lock/lock-002 watches /lock/lock-001.
§ The client that created /lock/lock-003 watches /lock/lock-002.
This way each node has at most one client watching it.
Another dimension to be aware of is the state generated with watches on the server side. Setting a watch creates a Watcher object on the server. According to the YourKit profiler, setting a watch adds around 250 to 300 bytes to the amount of memory consumed by the watch manager of a server. Having a very large number of watches implies that the watch manager consumes a nonnegligible amount of server memory. For example, having 1 million outstanding watches gives us a ballpark figure of 0.3 GB. Consequently, a developer must be mindful of the number of watches outstanding at any time.
Takeaway Messages
In a distributed system, there are many events that trigger actions. ZooKeeper provides efficient mechanisms for keeping track of important events that require processes in the system to react. Examples we have discussed here are related to the regular flow of applications (e.g., execution of tasks) or crash faults (e.g., master crashes).
One key ZooKeeper feature that we have used is notifications. ZooKeeper clients register watches with ZooKeeper to receive notifications upon changes to the ZooKeeper state. The order of notifications delivered is important; clients must not observe different orders for the changes to the ZooKeeper state.
One particular feature that is useful when dealing with changes is the multi call. It enables multiple operations to be executed in a block and often avoids race conditions in distributed applications when clients are reacting to events and changing the ZooKeeper state.
We expect most applications to follow the pattern we present here, although variants are of course possible and acceptable. We have focused on the asynchronous API because we encourage developers to use it. The asynchronous API enables applications to use ZooKeeper resources more efficiently and to obtain higher performance.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.