Agile Data Science (2014)
Part II. Climbing the Pyramid
Chapter 9. Driving Actions
In this chapter, our fifth and final agile sprint, we will translate predictions into action by diving further into what makes an email likely or not to elicit a response and turning this into an interactive feature (Figure 9-1). We’ll learn to suggest changes to email authors that will make their emails better.
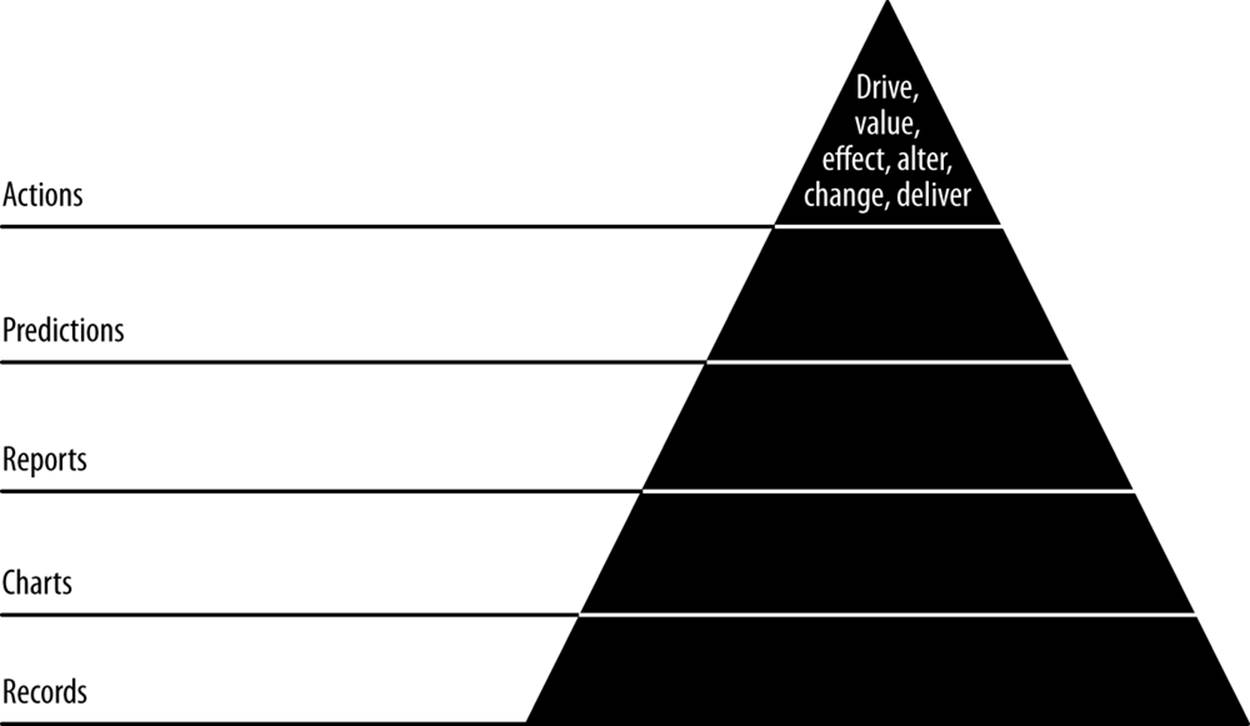
Figure 9-1. Level 5: enabling action
Up to now we’ve created charts associated with entities we’ve extracted from our emails, built entity pages that link together to form reports for interactive exploration of our data, and calculated probabilities that help us reason about the future to tell whether we can likely expect a response to an email.
This poses an opportunity to dig further. We’ve found a lever with which we can drive actions: predicting whether an email will receive a response. If we can increase the odds of a response, we’ve enabled a valuable action.
With driving actions—the improvement of emails—we have arrived at the final stage of the data-value pyramid: enabling new actions.
git clone https://github.com/rjurney/Agile_Data_Code.git
Properties of Successful Emails
We’ve already seen that the time of day has a large effect on email: people send more emails at certain times of day, and we might infer that they also reply more to emails at that time. Email is, after all, a stack, and the most recent emails are those at the top of the stack most likely to grab our attention.
We’ll use our intuition to come up with some more factors that might affect reply rates. In this chapter, we’ll go from a single conditional probability implying a prediction to multiple probabilities combined to make a real prediction about user behavior. We’ll plug this prediction into an API callable in real time, using what we’ve learned about the past to predict the future in the present.
Better Predictions with Naive Bayes
We can do better than employ single conditional probabilities to predict the future. We can combine more than one kind of evidence to get better accuracy in our prediction. For instance, we have computed the probability that a given email address will reply, but doesn’t the content of the message also matter? We’d like to think so. We can reason about our problem domain to think this through.
How might we figure out whether a user replies to emails at the top of the stack? Well, let’s look at the signals we’ve already prepared: Who emails whom and how often? What about email topics? We could determine similarity between emails and then, more important, who replies about what?
P(Reply | From & To)
In the previous chapter, we calculated P(reply | from & to), or “the probability of reply, given from and to email addresses,” and we displayed it in our application as a simple prediction. We’ll continue to use this meaningful data in our real-time prediction making, combining it with another factor to achieve a more accurate prediction.
To calculate P(reply | from & to), check out ch09/pig/p_reply_given_from_to.pig and run cd pig; pig -l /tmp -x local -v -w p_reply_given_from_to.pig.
Its contents will look familiar from the previous chapter.
P(Reply | Token)
Email bodies are rich in signal. Having extracted topics, what if we use the same kind of processing and associate the tokens with messages and replies to determine the probability of a reply for each token? Then, in combination, if we combine the reply probability of all tokens, we’ll have a good idea of a message’s chance of getting a reply in terms of its content.
Check out ch09/pig/p_reply_given_topics.pig. We load emails as usual, then trim them to message_id/body as an optimization. We don’t need the extra fields.
emails = load '/me/Data/test_mbox' using AvroStorage();
id_body = foreach emails generate message_id, body;
Next, we get counts for each token’s appearance in each document:
/* Tokenize text, count of each token per document */
token_records = foreach id_body generate message_id, FLATTEN(TokenizeText(body))
as token;
doc_word_totals = foreach (group token_records by (message_id, token)) generate
FLATTEN(group) as (message_id, token),
COUNT_STAR(token_records) as doc_total;
Then we calculate document size to normalize these token counts:
/* Calculate the document size */
pre_term_counts = foreach (group doc_word_totals by message_id) generate
group AS message_id,
FLATTEN(doc_word_totals.(token, doc_total)) as (token, doc_total),
SUM(doc_word_totals.doc_total) as doc_size;
Next, we divide token counts by document size to normalize them.
/* Calculate the Term Frequency */
term_freqs = foreach pre_term_counts generate
message_id as message_id,
token as token,
((double)doc_total / (double)doc_size) AS term_freq;
Finally, calculate the number of times a token has been sent, or used, overall in all emails in our corpus (inbox):
/* By Term - Calculate the SENT COUNT */
total_term_freqs = foreach (group term_freqs by token) generate
(chararray)group as token,
SUM(term_freqs.term_freq) as total_freq_sent;
Having calculated the frequencies for each token across our entire corpus, we now need to calculate the number of replies to these same emails. To do that, we trim emails down to message_id and in_reply_to as an optimization, and then join the replies by in_reply_to with the sent emails by message_id.
replies = foreach emails generate message_id, in_reply_to;
with_replies = join term_freqs by message_id LEFT OUTER, replies by in_reply_to;
Having joined our replies with a LEFT OUTER, we have a relation that contains emails that were replied to, and those that weren’t. Now we need to split the data off into parallel computations for two paths: the chance of reply, and the chance of not replying.
/* Split, because we're going to calculate P(reply|token) and P(no reply|token) */
split with_replies into has_reply if (in_reply_to is not null), no_reply if
(in_reply_to is null);
Now for each split, we calculate the probability of a reply/not reply occurring, starting with the sum of uses per token:
total_replies = foreach (group with_replies by term_freqs::token) generate
(chararray)group as token,
SUM(with_replies.term_freqs::term_freq) as total_freq_replied;
Finally, we join our overall sent-token counts and the associated reply counts to get our answer, the probability of reply for each token.
sent_totals_reply_totals = JOIN total_term_freqs by token, total_replies by token;
token_reply_rates = foreach sent_totals_reply_totals
generate total_term_freqs::token as token, (double)total_freq_replied /
(double)total_freq_sent as reply_rate;
store token_reply_rates into '/tmp/reply_rates.txt';
Now, to publish our result, check out ch09/pig/publish_topics.pig. It is simple enough:
/* MongoDB libraries and configuration */
REGISTER /me/Software/mongo-hadoop/mongo-2.10.1.jar
REGISTER /me/Software/mongo-hadoop/core/target/
mongo-hadoop-core-1.1.0-SNAPSHOT.jar
REGISTER /me/Software/mongo-hadoop/pig/target/
mongo-hadoop-pig-1.1.0-SNAPSHOT.jar
DEFINE MongoStorage com.mongodb.hadoop.pig.MongoStorage();
token_reply_rates = LOAD '/tmp/reply_rates.txt' AS
(token:chararray, reply_rate:double);
store token_reply_rates into 'mongodb://localhost/agile_data.token_reply_rates'
using MongoStorage();
token_no_reply_rates = LOAD '/tmp/no_reply_rates.txt' AS
(token:chararray, reply_rate:double);
store token_no_reply_rates into 'mongodb://localhost/
agile_data.token_no_reply_rates' using MongoStorage();
p_token = LOAD '/tmp/p_token.txt' AS (token:chararray, prob:double);
store p_token into 'mongodb://localhost/agile_data.p_token' using MongoStorage();
Check our topics in MongoDB. Check out https://github.com/rjurney/Agile_Data_Code/blob/master/ch09/mongo.js. From Mongo, run:
db.token_reply_rates.ensureIndex({token: 1})
db.token_reply_rates.findOne({token:'public'})
{
"_id" : ObjectId("511700c330048b60597e7c04"),
"token" : "public",
"reply_rate" : 0.6969366812896153
}
db.token_no_reply_rates.findOne({'token': 'public'})
{
"_id" : ObjectId("518444d83004f7fadcb48b51"),
"token" : "public",
"reply_rate" : 0.4978798266965859
}
Our next step is to use these probabilities to go real-time with a prediction!
Making Predictions in Real Time
We analyze the past to understand trends that inform us about the future. We employ that data in real time to make predictions. In this section, we’ll use both data sources we’ve predicted in combination to make predictions in real time, in response to HTTP requests.
Check out ch09/classify.py. This is a simple web application that takes three arguments: from email address, to email address, and the message body, and returns whether the email will receive a reply or not.
We begin importing Flask and pymongo as usual, but we’ll also be using NLTK (the Python Natural Language Toolkit). NLTK sets the standard in open source, natural language processing. There is an excellent book on NLTK, available here: http://nltk.org/book/. We’ll be using the NLTKutility word_tokenize.
import pymongo
from flask import Flask, request
from nltk.tokenize import word_tokenize
Next, we set up MongoDB to call on our probability tables for from/to and tokens:
conn = pymongo.Connection() # defaults to localhost
db = conn.agile_data
from_to_reply_ratios = db['from_to_reply_ratios']
from_to_no_reply_ratios = db['from_to_no_reply_ratios']
p_sent_from_to = db['p_sent_from_to']
token_reply_rates = db['token_reply_rates']
token_no_reply_rates = db['token_no_reply_rates']
p_token = db['p_token']
Our controller starts simply, at the URL /will_reply. We get the arguments to the URL, from, to, and body:
app = Flask(__name__)
# Controller: Fetch an email and display it
@app.route("/will_reply")
def will_reply():
# Get the message_id, from, first to, and message body
message_id = request.args.get('mesage_id')
from = request.args.get('from')
to = request.args.get('to')
body = request.args.get('message_body')
Next we process the tokens in the message body for both cases, reply and no-reply:
# For each token in the body, if there's a match in MongoDB,
# append it and average all of them at the end
reply_probs = []
reply_rate = 1
no_reply_probs = []
no_reply_rate = 1
if(body):
for token in word_tokenize(body):
prior = p_token.find_one({'token': token}) # db.p_token.ensureIndex
({'token': 1})
reply_search = token_reply_rates.find_one({'token': token}) #
db.token_reply_rates.ensureIndex({'token': 1})
no_reply_search = token_no_reply_rates.find_one({'token': token}) #
db.token_no_reply_rates.ensureIndex({'token': 1})
if reply_search:
word_prob = reply_search['reply_rate'] * prior['prob']
print("Token: " + token + " Reply Prob: " + str(word_prob))
reply_probs.append(word_prob)
if no_reply_search:
word_prob = no_reply_search['reply_rate'] * prior['prob']
print("Token: " + token + " No Reply Prob: " + str(word_prob))
no_reply_probs.append(word_prob)
reply_ary = float(len(reply_probs))
reply_rate = sum(reply_probs) / (len(reply_probs) if len(reply_probs)
> 0 else 1)
no_reply_ary = float(len(no_reply_probs))
no_reply_rate = sum(no_reply_probs) / (len(no_reply_probs) if
len(no_reply_probs) > 0 else 1)
Look what’s happening: we tokenize the body into a list of words using NLTK, and then look up the reply probability of each word in MongoDB. We append these reply probabilities to a list, and then take the average of the list.
Next, we do the same for from/to:
# Use from/to probabilities when available
ftrr = from_to_reply_ratios.find_one({'from': froms, 'to': to}) #
db.from_to_reply_ratios.ensureIndex({from: 1, to: 1})
ftnrr = from_to_no_reply_ratios.find_one({'from': froms, 'to': to}) #
db.from_to_no_reply_ratios.ensureIndex({from: 1, to: 1})
if ftrr:
p_from_to_reply = ftrr['ratio']
p_from_to_no_reply = ftnrr['ratio']
else:
p_from_to_reply = 1.0
p_from_to_no_reply = 1.0
If the from/to reply probabilities aren’t available, we use a placeholder. Finally, we evaluate the probabilities for reply and no-reply and take the larger one.
# Combine the two predictions
positive = reply_rate * p_from_to_reply
negative = no_reply_rate * p_from_to_no_reply
print "%2f vs %2f" % (positive, negative)
result = "REPLY" if positive > negative else "NO REPLY"
return render_template('partials/will_reply.html', result=result, froms=froms,
to=to, message_body=body)
Our template is simple:
<!-- Extend our site layout -->
{% extends "layout.html" %}
<!-- Include our common macro set -->
{% import "macros.jnj" as common %}
{% block content -%}
<form action="/will_reply" method="get">
<fieldset>
<label>From:</label>
<input type="text" name="from" value="{{ froms }}"></input>
<label>To:</label>
<input type="text" name="to" value="{{ to }}"></input>
<label>Body:</label>
<textarea rows="4" name="message_body" style="width: 500px">{{ message_body }}
</textarea>
</fieldset>
<button type="submit" class="btn">Submit</button>
</form>
<p>{{ result }}</p>
{% endblock -%}
And we’ll need to add a few indexes to make the queries performant:
db.p_token.ensureIndex({'token': 1})
db.token_reply_rates.ensureIndex({'token': 1})
db.token_no_reply_rates.ensureIndex({'token': 1})
db.from_to_reply_ratios.ensureIndex({from: 1, to: 1})
db.from_to_no_reply_ratios.ensureIndex({from: 1, to: 1})
Run the application with python ./index.py and then visit /will_reply and enter values that will work for your inbox (Figure 9-2).
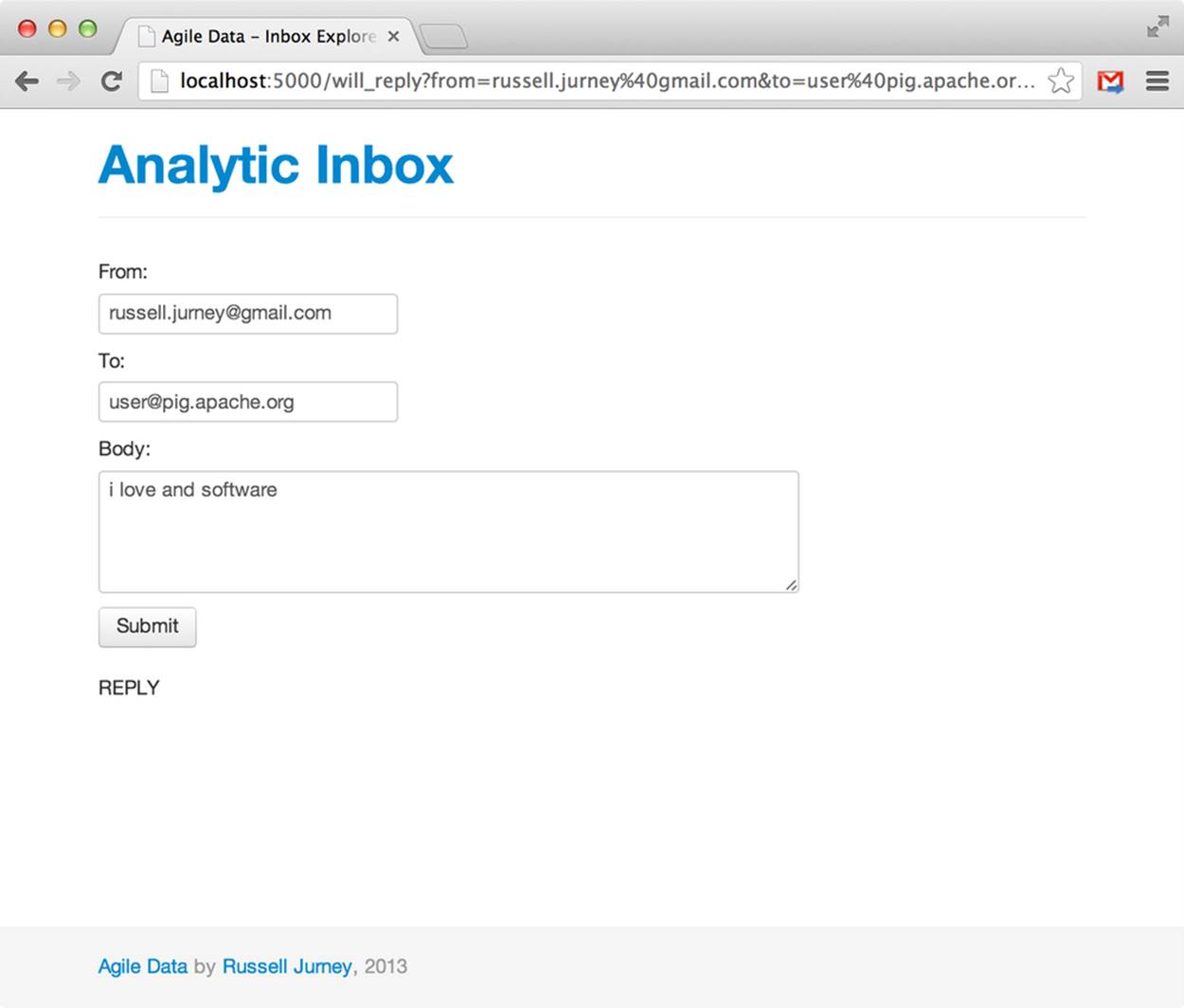
Figure 9-2. Will reply UI
Wheeeee! It’s fun to see what different content does to the chance of reply, isn’t it?
Logging Events
We’ve come full circle—from collecting to analyzing events, inferring things about the future, and then serving these insights up in real time. Now our application is generating logs that are new events, and the data cycle closes:
127.0.0.1 - - [10/Feb/2013 20:50:32] "GET /favicon.ico HTTP/1.1" 404 -
{u'to': u'**@****.com.com', u'_id': ObjectId('5111f1cd30043dc319d96141'),
u'from': u'russell.jurney@gmail.com', u'ratio': 0.54}
127.0.0.1 - - [10/Feb/2013 20:50:39] "GET /will_reply/?
from=russell.jurney@gmail.com&to=**@****.com.com&body=startup HTTP/1.1" 200 -
127.0.0.1 - - [10/Feb/2013 20:50:40] "GET /favicon.ico HTTP/1.1" 404 -
{u'to': u'**@****.com.com', u'_id': ObjectId('5111f1cd30043dc319d96141'),
u'from': u'russell.jurney@gmail.com', u'ratio': 0.54}
127.0.0.1 - - [10/Feb/2013 20:50:45] "GET /will_reply/?
from=russell.jurney@gmail.com&to=**@****.com.com&body=startup HTTP/1.1" 200 -
{u'to': u'**@****.com.com', u'_id': ObjectId('5111f1cd30043dc319d96141'),
u'from': u'russell.jurney@gmail.com', u'ratio': 0.54}
127.0.0.1 - - [10/Feb/2013 20:51:04] "GET /will_reply/?
from=russell.jurney@gmail.com&to=**@****.com.com&body=i%20work%20at%20a
%20hadoop%20startup HTTP/1.1" 200 -
127.0.0.1 - - [10/Feb/2013 20:51:04] "GET /favicon.ico HTTP/1.1" 404 -
{u'to': u'**@****.com.com', u'_id': ObjectId('5111f1cd30043dc319d96141'),
u'from': u'russell.jurney@gmail.com', u'ratio': 0.54}
127.0.0.1 - - [10/Feb/2013 20:51:08] "GET /will_reply/?
from=russell.jurney@gmail.com&to=**@****.com.com&body=i%20work%20at%20a
%20hadoop%20startup HTTP/1.1" 200 -
We might log these events and include them in our analysis to further refine our application. In any case, having satisfied our mission to enable new actions, we’ve come to a close. We can now run our emails through this filter to understand how likely we are to receive a reply and change the emails accordingly.
Conclusion
In this chapter, we have created a prediction service that helps to drive an action: enabling better emails by predicting whether a response will occur. This is the highest level of the data-value pyramid, and it brings this book to a close. We’ve come full circle from creating simple document pages to making real-time predictions.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.