Agile Data Science (2014)
Part I. Setup
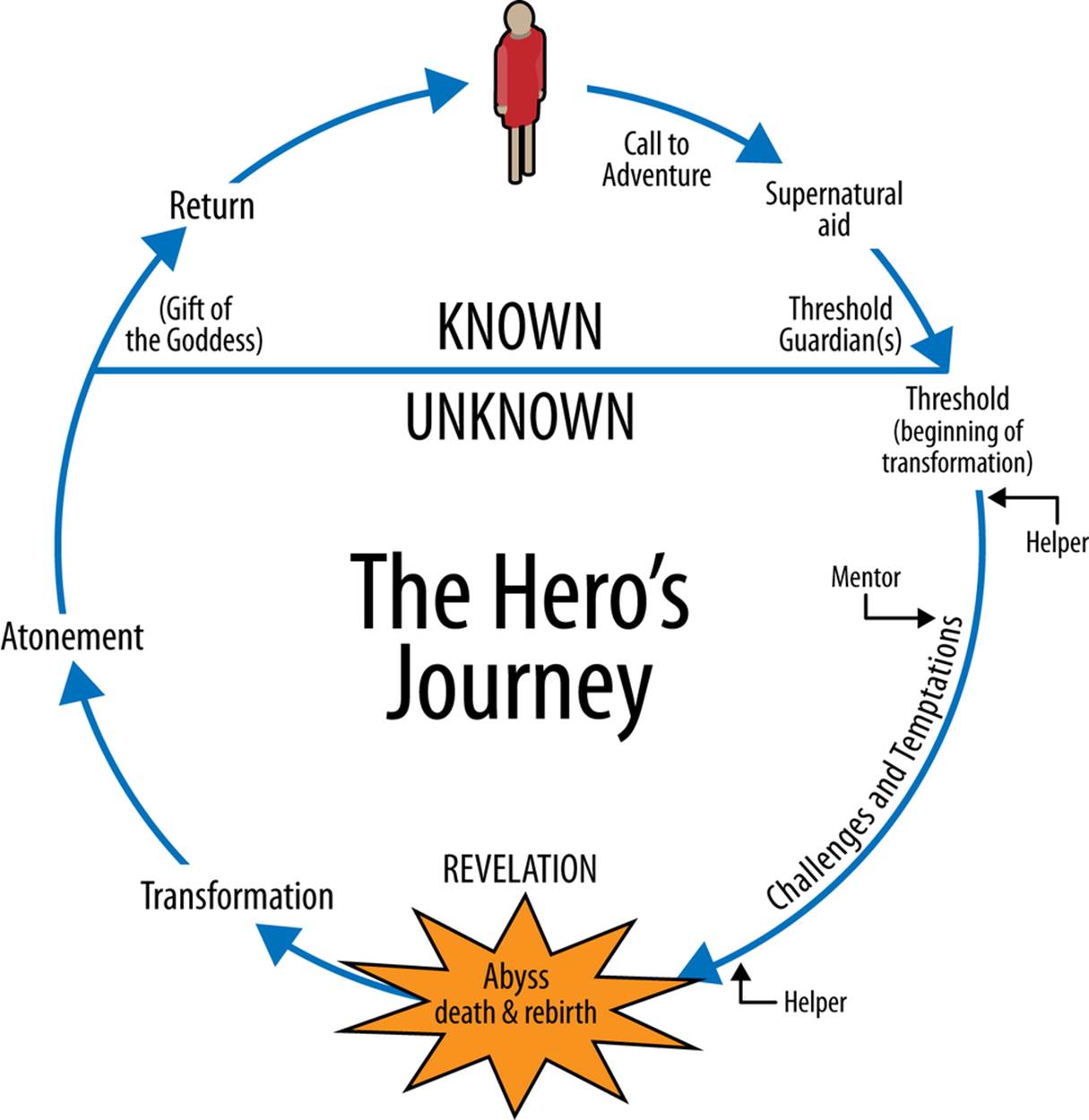
Figure 1. The Hero’s Journey, from Wikipedia
Chapter 1. Theory
We are uncovering better ways of developing software by doing it and helping others do it. Through this work we have come to value:
|
Individuals and interactions over processes and tools |
|
Working software over comprehensive documentation |
|
Customer collaboration over contract negotiation |
|
Responding to change over following a plan |
That is, while there is value in the items on the right, we value the items on the left more.
—The Agile Manifesto
Agile Big Data
Agile Big Data is a development methodology that copes with the unpredictable realities of creating analytics applications from data at scale. It is a guide for operating the Hadoop data refinery to harness the power of big data.
Warehouse-scale computing has given us enormous storage and compute resources to solve new kinds of problems involving storing and processing unprecedented amounts of data. There is great interest in bringing new tools to bear on formerly intractable problems, to derive entirely new products from raw data, to refine raw data into profitable insight, and to productize and productionize insight in new kinds of analytics applications. These tools are processor cores and disk spindles, paired with visualization, statistics, and machine learning. This is data science.
At the same time, during the last 20 years, the World Wide Web has emerged as the dominant medium for information exchange. During this time, software engineering has been transformed by the “agile” revolution in how applications are conceived, built, and maintained. These new processes bring in more projects and products on time and under budget, and enable small teams or single actors to develop entire applications spanning broad domains. This is agile software development.
But there’s a problem. Working with real data in the wild, doing data science, and performing serious research takes time—longer than an agile cycle (on the order of months). It takes more time than is available in many organizations for a project sprint, meaning today’s applied researcher is more than pressed for time. Data science is stuck on the old-school software schedule known as the waterfall method.
Our problem and our opportunity come at the intersection of these two trends: how can we incorporate data science, which is applied research and requires exhaustive effort on an unpredictable timeline, into the agile application? How can analytics applications do better than the waterfall method that we’ve long left behind? How can we craft applications for unknown, evolving data models?
This book attempts to synthesize two fields, agile development and big data science, to meld research and engineering into a productive relationship. To achieve this, it presents a lightweight toolset that can cope with the uncertain, shifting sea of raw data. The book goes on to show you how to iteratively build value using this stack, to get back to agility and mine data to turn it to dollars.
Agile Big Data aims to put you back in the driver’s seat, ensuring that your applied research produces useful products that meet the needs of real users.
Big Words Defined
Scalability, NoSQL, cloud computing, big data—these are all controversial terms. Here, they are defined as they pertain to Agile Big Data:
Scalability
This is the simplicity with which you can grow or shrink some operation in response to demand. In Agile Big Data, it means software tools and techniques that grow sublinearly in terms of cost and complexity as load and complexity in an application grow linearly. We use the same tools for data, large and small, and we embrace a methodology that lets us build once, rather than re-engineer continuously.
NoSQL
Short for “Not only SQL,” this means escaping the bounds imposed by storing structured data in monolithic relational databases. It means going beyond tools that were optimized for Online Transaction Processing (OLTP) and extended to Online Analytic Processing (OLAP) to use a broader set of tools that are better suited to viewing data in terms of analytic structures and algorithms. It means escaping the bounds of a single machine with expensive storage and starting out with concurrent systems that will grow linearly as users and load increase. It means not hitting a wall as soon as our database gets bogged down, and then struggling to tune, shard, and mitigate problems continuously.
The NoSQL tools we’ll be using are Hadoop, a highly parallel batch-processing system, and MongoDB, a distributed document store.
Cloud computing
Computing on the cloud means employing infrastructure as a service from providers like Amazon Web Services to compose applications at the level of data center as computer. As application developers, we use cloud computing to avoid getting bogged down in the details of infrastructure while building applications that scale.
Big data
There is a market around the belief that enormous value will be extracted from the ever-increasing pile of transaction logs being aggregated by the mission-critical systems of today and tomorrow; that’s Big Data. Big Data systems use local storage, commodity server hardware, and free and open source software to cheaply process data at a scale where it becomes feasible to work with atomic records that are voluminously logged and processed.
NOTE
Eric Tschetter, cofounder and lead architect at Metamarkets, says this about NoSQL in practice:
“I define NoSQL as the movement towards use-case specialized storage and query layer combinations. The RDBMS is a highly generic weapon that can be utilized to solve any data storage and query need up to a certain amount of load. I see NoSQL as a move toward other types of storage architectures that are optimized for a specific use-case and can offer benefits in areas like operational complexity by making assumptions about said use cases.”
Agile Big Data Teams
Products are built by teams of people, and agile methods focus on people over process, so Agile Big Data starts with a team.
Data science is a broad discipline, spanning analysis, design, development, business, and research. The roles of Agile Big Data team members, defined in a spectrum from customer to operations, look something like Figure 1-1:

Figure 1-1. The roles in an Agile Big Data team
These roles can be defined as:
§ Customers use your product, click your buttons and links, or ignore you completely. Your job is to create value for them repeatedly. Their interest determines the success of your product.
§ Business development signs early customers, either firsthand or through the creation of landing pages and promotion. Delivers traction from product in market.
§ Marketers talk to customers to determine which markets to pursue. They determine the starting perspective from which an Agile Big Data product begins.
§ Product managers take in the perspectives of each role, synthesizing them to build consensus about the vision and direction of the product.
§ Userexperience designers are responsible for fitting the design around the data to match the perspective of the customer. This role is critical, as the output of statistical models can be difficult to interpret by “normal” users who have no concept of the semantics of the model’s output (i.e., how can something be 75% true?).
§ Interaction designers design interactions around data models so users find their value.
§ Web developers create the web applications that deliver data to a web browser.
§ Engineers build the systems that deliver data to applications.
§ Data scientists explore and transform data in novel ways to create and publish new features and combine data from diverse sources to create new value. Data scientists make visualizations with researchers, engineers, web developers, and designers to expose raw, intermediate, and refined data early and often.
§ Applied researchers solve the heavy problems that data scientists uncover and that stand in the way of delivering value. These problems take intense focus and time and require novel methods from statistics and machine learning.
§ Platform engineers solve problems in the distributed infrastructure that enable Agile Big Data at scale to proceed without undue pain. Platform engineers handle work tickets for immediate blocking bugs and implement long-term plans and projects to maintain and improve usability for researchers, data scientists, and engineers.
§ Operations/DevOps professionals ensure smooth setup and operation of production data infrastructure. They automate deployment and take pages when things go wrong.
Recognizing the Opportunity and Problem
The broad skillset needed to build data products presents both an opportunity and a problem. If these skills can be brought to bear by experts in each role working as a team on a rich dataset, problems can be decomposed into parts and directly attacked. Data science is then an efficient assembly line, as illustrated in Figure 1-2.
However, as team size increases to satisfy the need for expertise in these diverse areas, communication overhead quickly dominates. A researcher who is eight persons away from customers is unlikely to solve relevant problems and more likely to solve arcane problems. Likewise, team meetings of a dozen individuals are unlikely to be productive. We might split this team into multiple departments and establish contracts of delivery between them, but then we lose both agility and cohesion. Waiting on the output of research, we invent specifications and soon we find ourselves back in the waterfall method.
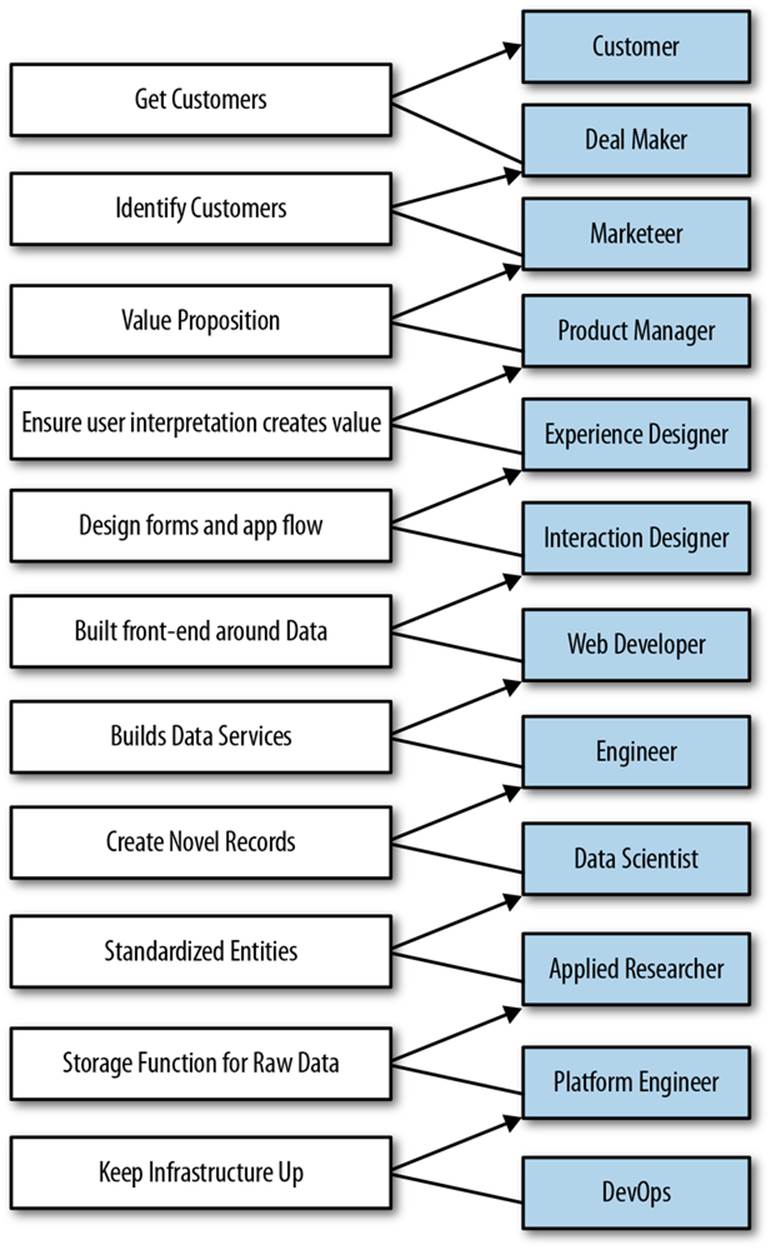
Figure 1-2. Expert contributor workflow
And yet we know that agility and a cohesive vision and consensus about a product are essential to our success in building products. The worst product problem is one team working on more than one vision. How are we to reconcile the increased span of expertise and the disjoint timelines of applied research, data science, software development, and design?
Adapting to Change
To remain agile, we must embrace and adapt to these new conditions. We must adopt changes in line with lean methodologies to stay productive.
Several changes in particular make a return to agility possible:
§ Choosing generalists over specialists
§ Preferring small teams over large teams
§ Using high-level tools and platforms: cloud computing, distributed systems, and platforms as a service (PaaS)
§ Continuous and iterative sharing of intermediate work, even when that work may be incomplete
In Agile Big Data, a small team of generalists uses scalable, high-level tools and cloud computing to iteratively refine data into increasingly higher states of value. We embrace a software stack leveraging cloud computing, distributed systems, and platforms as a service. Then we use this stack to iteratively publish the intermediate results of even our most in-depth research to snowball value from simple records to predictions and actions that create value and let us capture some of it to turn data into dollars. Let’s examine each item in detail.
Harnessing the power of generalists
In Agile Big Data we value generalists over specialists, as shown in Figure 1-3.
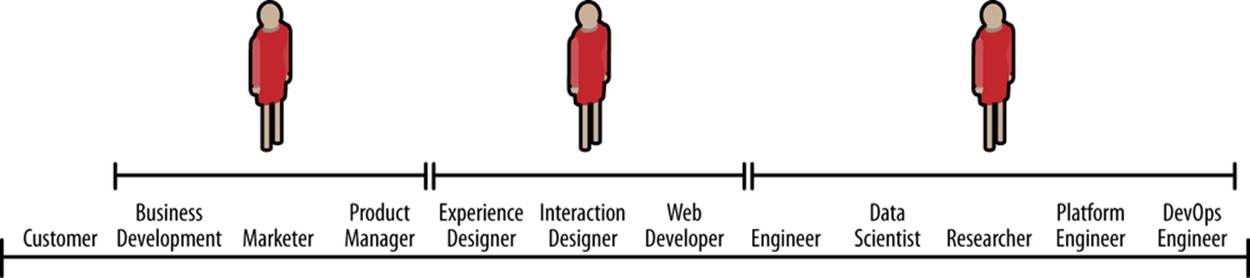
Figure 1-3. Broad roles in an Agile Big Data team
In other words, we measure the breadth of teammates’ skills as much as the depth of their knowledge and their talent in any one area. Examples of good Agile Big Data team members include:
§ Designers who deliver working CSS
§ Web developers who build entire applications and understand user interface and experience
§ Data scientists capable of both research and building web services and applications
§ Researchers who check in working source code, explain results, and share intermediate data
§ Product managers able to understand the nuances in all areas
Design in particular is a critical role on the Agile Big Data team. Design does not end with appearance or experience. Design encompasses all aspects of the product, from architecture, distribution, and user experience to work environment.
NOTE
In the documentary The Lost Interview, Steve Jobs said this about design: “Designing a product is keeping five thousand things in your brain and fitting them all together in new and different ways to get what you want. And every day you discover something new that is a new problem or a new opportunity to fit these things together a little differently. And it’s that process that is the magic.”
Leveraging agile platforms
In Agile Big Data, we use the easiest-to-use, most approachable distributed systems, along with cloud computing and platforms as a service, to minimize infrastructure costs and maximize productivity. The simplicity of our stack helps enable a return to agility. We’ll use this stack to compose scalable systems in as few steps as possible. This lets us move fast and consume all available data without running into scalability problems that cause us to discard data or remake our application in flight. That is to say, we only build it once.
Sharing intermediate results
Finally, to address the very real differences in timelines between researchers and data scientists and the rest of the team, we adopt a sort of data collage as our mechanism of mending these disjointed scales. In other words, we piece our app together from the abundance of views, visualizations, and properties that form the “menu” for our application.
Researchers and data scientists, who work on longer timelines than agile sprints typically allow, generate data daily—albeit not in a “publishable” state. In Agile Big Data, there is no unpublishable state. The rest of the team must see weekly, if not daily (or more often), updates in the state of the data. This kind of engagement with researchers is essential to unifying the team and enabling product management.
That means publishing intermediate results—incomplete data, the scraps of analysis. These “clues” keep the team united, and as these results become interactive, everyone becomes informed as to the true nature of the data, the progress of the research, and how to combine clues into features of value. Development and design must proceed from this shared reality. The audience for these continuous releases can start small and grow as they become presentable (as shown in Figure 1-4), but customers must be included quickly.
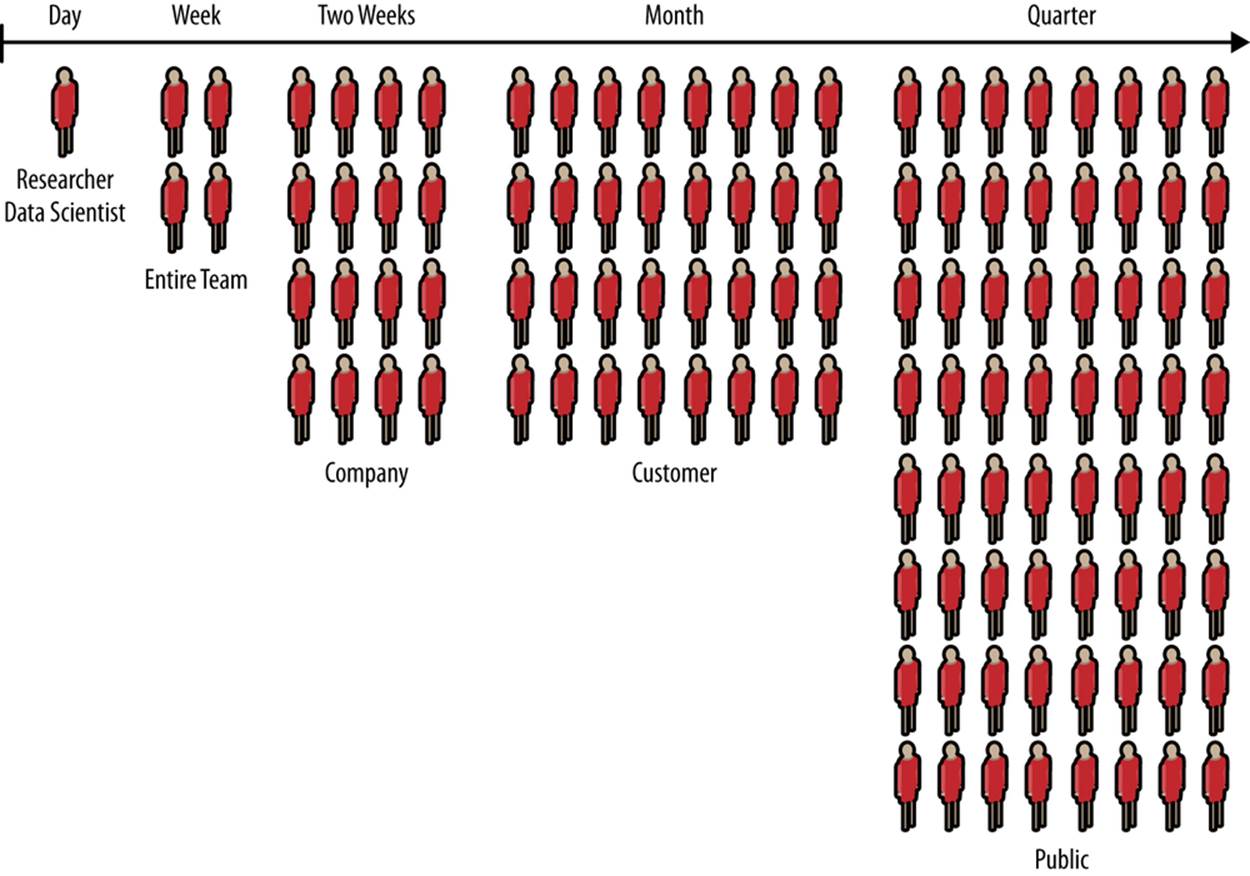
Figure 1-4. Growing audience from conception to launch
Agile Big Data Process
The Agile Big Data process embraces the iterative nature of data science and the efficiency our tools enable to build and extract increasing levels of structure and value from our data.
Given the spectrum of skills within a data product team, the possibilities are endless. With the team spanning so many disciplines, building web products is inherently collaborative. To collaborate, teams need direction: every team member passionately and stubbornly pursuing a common goal. To get that direction, you require consensus.
Building and maintaining consensus while collaborating is the hardest part of building software. The principal risk in software product teams is building to different blueprints. Clashing visions result in incohesive holes that sink products.
Applications are sometimes mocked before they are built: product managers conduct market research, while designers iterate mocks with feedback from prospective users. These mocks serve as a common blueprint for the team.
Real-world requirements shift as we learn from our users and conditions change, even when the data is static. So our blueprints must change with time. Agile methods were created to facilitate implementation of evolving requirements, and to replace mockups with real working systems as soon as possible.
Typical web products—those driven by forms backed by predictable, constrained transaction data in relational databases—have fundamentally different properties than products featuring mined data. In CRUD applications, data is relatively consistent. The models are predictable SQL tables or documents, and changing them is a product decision. The data’s “opinion” is irrelevant, and the product team is free to impose its will on the model to match the business logic of the application.
In interactive products driven by mined data, none of that holds. Real data is dirty. Mining always involves dirt. If the data isn’t dirty, it wouldn’t be data mining. Even carefully extracted and refined mined information can be fuzzy and unpredictable. Presenting it on the consumer Internet requires long labor and great care.
In data products, the data is ruthlessly opinionated. Whatever we wish the data to say, it is unconcerned with our own opinions. It says what it says. This means the waterfall model has no application. It also means that mocks are an insufficient blueprint to establish consensus in software teams.
Mocks of data products are a specification of the application without its essential character, the true value of the information being presented. Mocks as blueprints make assumptions about complex data models they have no reasonable basis for. When specifying lists of recommendations, mocks often mislead. When mocks specify full-blown interactions, they do more than that: they suppress reality and promote assumption. And yet we know that good design and user experience are about minimizing assumption. What are we to do?
The goal of agile product development is to identify the essential character of an application and to build that up first before adding features. This imparts agility to the project, making it more likely to satisfy its real, essential requirements as they evolve. In data products, that essential character will surprise you. If it doesn’t, you are either doing it wrong, or your data isn’t very interesting. Information has context, and when that context is interactive, insight is not predictable.
Code Review and Pair Programming
To avoid systemic errors, data scientists share their code with the rest of the team on a regular basis, so code review is important. It is easy to fix errors in parsing that hide systemic errors in algorithms. Pair programming, where pairs of data hackers go over code line by line, checking its output and explaining the semantics, can help detect these errors.
Agile Environments: Engineering Productivity
Rows of cubicles like cells of a hive. Overbooked conference rooms camped and decamped. Microsoft Outlook a modern punchcard. Monolithic insanity. A sea of cubes.
Deadlines interrupted by oscillating cacophonies of rumors shouted, spread like waves uninterrupted by naked desks. Headphone budgets. Not working, close together. Decibel induced telecommuting. The open plan.
Competing monstrosities seeking productivity but not finding it.
—Poem by author
Generalists require more uninterrupted concentration and quiet than do specialists. That is because the context of their work is broader, and therefore their immersion is deeper. Their environment must suit this need.
Invest in two to three times the space of a typical cube farm, or you are wasting your people. In this setup, some people don’t need desks, which drives costs down.
We can do better. We should do better. It costs more, but it is inexpensive.
In Agile Big Data, we recognize team members as creative workers, not office workers. We therefore structure our environment more like a studio than an office. At the same time, we recognize that employing advanced mathematics on data to build products requires quiet contemplation and intense focus. So we incorporate elements of the library as well.
Many enterprises limit their productivity enhancement of employees to the acquisition of skills. However, about 86% of productivity problems reside in the work environment of organizations. The work environment has effect on the performance of employees. The type of work environment in which employees operate determines the way in which such enterprises prosper.
—Akinyele Samuel Taiwo
It is much higher cost to employ people than it is to maintain and operate a building, hence spending money on improving the work environment is the most cost effective way of improving productivity because of small percentage increase in productivity of 0.1% to 2% can have dramatic effects on the profitability of the company.
—Derek Clements-Croome and Li Baizhan
Creative workers need three kinds of spaces to collaborate and build together. From open to closed, they are: collaboration space, personal space, and private space.
Collaboration Space
Collaboration space is where ideas are hatched. Situated along main thoroughfares and between departments, collaborative spaces are bright, open, comfortable, and inviting. They have no walls. They are flexible and reconfigurable. They are ever-changing, always being rearranged, and full of bean bags, pillows, and comfortable chairs. Collaboration space is where you feel the energy of your company: laughter, big conversations, excited voices talking over one another. Invest in and showcase these areas. Real, not plastic, plants keep sound from carrying—and they make air!
Private Space
Private space is where deadlines get met. Enclosed and soundproof, private spaces are libraries. There is no talking. Private space minimizes distractions: think dim light and white noise. There are bean bags, couches, and chairs, but ergonomics demand proper workstations too. These spaces might include separate sit/stand desks with docking stations behind (bead) curtains with 30-inch customized LCDs.
Personal Space
Personal space is where people call home. In between collaboration and private space in its degree of openness, personal space should be personalized by each individual to suit his or her needs (e.g., shared office or open desks, half or whole cube). Personal space should come with a menu and a budget. Themes and plant life should be encouraged. This is where some people will spend most of their time. On the other hand, given adequate collaborative and private space, a notebook, and a mobile device, some people don’t need personal space at all.
Above all, the goal of the agile environment is to create immersion in data through the physical environment: printouts, posters, books, whiteboard, and more, as shown in Figure 1-5.

Figure 1-5. Data immersion through collage
Realizing Ideas with Large-Format Printing
Easy access to large-format printing is a requirement for the agile environment. Visualization in material form encourages sharing, collage, expressiveness, and creativity.
The HP DesignJet 111 is a 24-inch-wide large format printer that costs less than $1,000. Continuous ink delivery systems are available for less than $100 that bring the operational cost of large-format printing—for instance, 24 × 36 inch posters—to less than one dollar per poster.
At this price point, there is no excuse not to give a data team easy access to several large-format printers for both plain-paper proofs and glossy prints. It is very easy to get people excited about data across departments when they can see concrete proof of the progress of the data science team.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.