Effective awk Programming (2015)
Part I. The awk Language
Chapter 8. Arrays in awk
An array is a table of values called elements. The elements of an array are distinguished by their indices. Indices may be either numbers or strings.
This chapter describes how arrays work in awk, how to use array elements, how to scan through every element in an array, and how to remove array elements. It also describes how awk simulates multidimensional arrays, as well as some of the less obvious points about array usage. The chapter moves on to discuss gawk’s facility for sorting arrays, and ends with a brief description of gawk’s ability to support true arrays of arrays.
The Basics of Arrays
This section presents the basics: working with elements in arrays one at a time, and traversing all of the elements in an array.
Introduction to Arrays
Doing linear scans over an associative array is like trying to club someone to death with a loaded Uzi.
—Larry Wall
The awk language provides one-dimensional arrays for storing groups of related strings or numbers. Every awk array must have a name. Array names have the same syntax as variable names; any valid variable name would also be a valid array name. But one name cannot be used in both ways (as an array and as a variable) in the same awk program.
Arrays in awk superficially resemble arrays in other programming languages, but there are fundamental differences. In awk, it isn’t necessary to specify the size of an array before starting to use it. Additionally, any number or string, not just consecutive integers, may be used as an array index.
In most other languages, arrays must be declared before use, including a specification of how many elements or components they contain. In such languages, the declaration causes a contiguous block of memory to be allocated for that many elements. Usually, an index in the array must be a positive integer. For example, the index zero specifies the first element in the array, which is actually stored at the beginning of the block of memory. Index one specifies the second element, which is stored in memory right after the first element, and so on. It is impossible to add more elements to the array, because it has room only for as many elements as given in the declaration. (Some languages allow arbitrary starting and ending indices—e.g., ‘15 .. 27’—but the size of the array is still fixed when the array is declared.)
A contiguous array of four elements might look like Figure 8-1, conceptually, if the element values are eight, "foo", "", and 30.
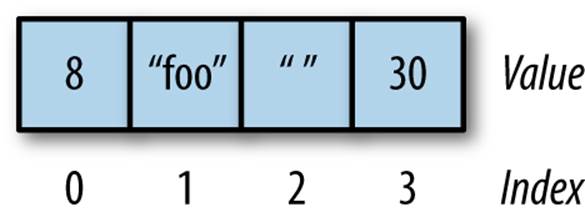
Figure 8-1. A contiguous array
Only the values are stored; the indices are implicit from the order of the values. Here, eight is the value at index zero, because eight appears in the position with zero elements before it.
Arrays in awk are different—they are associative. This means that each array is a collection of pairs—an index and its corresponding array element value:
|
Index |
Value |
|
3 |
30 |
|
1 |
"foo" |
|
0 |
8 |
|
2 |
"" |
The pairs are shown in jumbled order because their order is irrelevant.[38]
One advantage of associative arrays is that new pairs can be added at any time. For example, suppose a tenth element is added to the array whose value is "number ten". The result is:
|
Index |
Value |
|
10 |
"number ten" |
|
3 |
30 |
|
1 |
"foo" |
|
0 |
8 |
|
2 |
"" |
Now the array is sparse, which just means some indices are missing. It has elements 0–3 and 10, but doesn’t have elements 4, 5, 6, 7, 8, or 9.
Another consequence of associative arrays is that the indices don’t have to be positive integers. Any number, or even a string, can be an index. For example, the following is an array that translates words from English to French:
|
Index |
Value |
|
"dog" |
"chien" |
|
"cat" |
"chat" |
|
"one" |
"un" |
|
1 |
"un" |
Here we decided to translate the number one in both spelled-out and numeric form—thus illustrating that a single array can have both numbers and strings as indices. (In fact, array subscripts are always strings. There are some subtleties to how numbers work when used as array subscripts; this is discussed in more detail in Using Numbers to Subscript Arrays.) Here, the number 1 isn’t double-quoted, because awk automatically converts it to a string.
The value of IGNORECASE has no effect upon array subscripting. The identical string value used to store an array element must be used to retrieve it. When awk creates an array (e.g., with the split() built-in function), that array’s indices are consecutive integers starting at one. (See String-Manipulation Functions.)
awk’s arrays are efficient—the time to access an element is independent of the number of elements in the array.
Referring to an Array Element
The principal way to use an array is to refer to one of its elements. An array reference is an expression as follows:
array[index-expression]
Here, array is the name of an array. The expression index-expression is the index of the desired element of the array.
The value of the array reference is the current value of that array element. For example, foo[4.3] is an expression referencing the element of array foo at index ‘4.3’.
A reference to an array element that has no recorded value yields a value of "", the null string. This includes elements that have not been assigned any value as well as elements that have been deleted (see The delete Statement).
NOTE
A reference to an element that does not exist automatically creates that array element, with the null string as its value. (In some cases, this is unfortunate, because it might waste memory inside awk.)
Novice awk programmers often make the mistake of checking if an element exists by checking if the value is empty:
# Check if "foo" exists in a: Incorrect!
if (a["foo"] != "") …
This is incorrect for two reasons. First, it creates a["foo"] if it didn’t exist before! Second, it is valid (if a bit unusual) to set an array element equal to the empty string.
To determine whether an element exists in an array at a certain index, use the following expression:
indx in array
This expression tests whether the particular index indx exists, without the side effect of creating that element if it is not present. The expression has the value one (true) if array[indx] exists and zero (false) if it does not exist. (We use indx here, because ‘index’ is the name of a built-in function.) For example, this statement tests whether the array frequencies contains the index ‘2’:
if (2 in frequencies)
print "Subscript 2 is present."
Note that this is not a test of whether the array frequencies contains an element whose value is two. There is no way to do that except to scan all the elements. Also, this does not create frequencies[2], while the following (incorrect) alternative does:
if (frequencies[2] != "")
print "Subscript 2 is present."
Assigning Array Elements
Array elements can be assigned values just like awk variables:
array[index-expression] = value
array is the name of an array. The expression index-expression is the index of the element of the array that is assigned a value. The expression value is the value to assign to that element of the array.
Basic Array Example
The following program takes a list of lines, each beginning with a line number, and prints them out in order of line number. The line numbers are not in order when they are first read—instead, they are scrambled. This program sorts the lines by making an array using the line numbers as subscripts. The program then prints out the lines in sorted order of their numbers. It is a very simple program and gets confused upon encountering repeated numbers, gaps, or lines that don’t begin with a number:
{
if ($1 > max)
max = $1
arr[$1] = $0
}
END {
for (x = 1; x <= max; x++)
print arr[x]
}
The first rule keeps track of the largest line number seen so far; it also stores each line into the array arr, at an index that is the line’s number. The second rule runs after all the input has been read, to print out all the lines. When this program is run with the following input:
5 I am the Five man
2 Who are you? The new number two!
4 . . . And four on the floor
1 Who is number one?
3 I three you.
Its output is:
1 Who is number one?
2 Who are you? The new number two!
3 I three you.
4 . . . And four on the floor
5 I am the Five man
If a line number is repeated, the last line with a given number overrides the others. Gaps in the line numbers can be handled with an easy improvement to the program’s END rule, as follows:
END {
for (x = 1; x <= max; x++)
if (x in arr)
print arr[x]
}
Scanning All Elements of an Array
In programs that use arrays, it is often necessary to use a loop that executes once for each element of an array. In other languages, where arrays are contiguous and indices are limited to positive integers, this is easy: all the valid indices can be found by counting from the lowest index up to the highest. This technique won’t do the job in awk, because any number or string can be an array index. So awk has a special kind of for statement for scanning an array:
for (var in array)
body
This loop executes body once for each index in array that the program has previously used, with the variable var set to that index.
The following program uses this form of the for statement. The first rule scans the input records and notes which words appear (at least once) in the input, by storing a one into the array used with the word as the index. The second rule scans the elements of used to find all the distinct words that appear in the input. It prints each word that is more than 10 characters long and also prints the number of such words. See String-Manipulation Functions for more information on the built-in function length().
# Record a 1 for each word that is used at least once
{
for (i = 1; i <= NF; i++)
used[$i] = 1
}
# Find number of distinct words more than 10 characters long
END {
for (x in used) {
if (length(x) > 10) {
++num_long_words
print x
}
}
print num_long_words, "words longer than 10 characters"
}
See Generating Word-Usage Counts for a more detailed example of this type.
The order in which elements of the array are accessed by this statement is determined by the internal arrangement of the array elements within awk and in standard awk cannot be controlled or changed. This can lead to problems if new elements are added to array by statements in the loop body; it is not predictable whether the for loop will reach them. Similarly, changing var inside the loop may produce strange results. It is best to avoid such things.
As a point of information, gawk sets up the list of elements to be iterated over before the loop starts, and does not change it. But not all awk versions do so. Consider this program, named loopcheck.awk:
BEGIN {
a["here"] = "here"
a["is"] = "is"
a["a"] = "a"
a["loop"] = "loop"
for (i in a) {
j++
a[j] = j
print i
}
}
Here is what happens when run with gawk (and mawk):
$ gawk -f loopcheck.awk
here
loop
a
is
Contrast this to BWK awk:
$ nawk -f loopcheck.awk
loop
here
is
a
1
Using Predefined Array Scanning Orders with gawk
This subsection describes a feature that is specific to gawk.
By default, when a for loop traverses an array, the order is undefined, meaning that the awk implementation determines the order in which the array is traversed. This order is usually based on the internal implementation of arrays and will vary from one version of awk to the next.
Often, though, you may wish to do something simple, such as “traverse the array by comparing the indices in ascending order,” or “traverse the array by comparing the values in descending order.” gawk provides two mechanisms that give you this control:
§ Set PROCINFO["sorted_in"] to one of a set of predefined values. We describe this now.
§ Set PROCINFO["sorted_in"] to the name of a user-defined function to use for comparison of array elements. This advanced feature is described later in Controlling Array Traversal and Array Sorting.
The following special values for PROCINFO["sorted_in"] are available:
"@unsorted"
Array elements are processed in arbitrary order, which is the default awk behavior.
"@ind_str_asc"
Order by indices in ascending order, compared as strings; this is the most basic sort. (Internally, array indices are always strings, so with ‘a[2*5] = 1’ the index is "10" rather than numeric 10.)
"@ind_num_asc"
Order by indices in ascending order, but force them to be treated as numbers in the process. Any index with a non-numeric value will end up positioned as if it were zero.
"@val_type_asc"
Order by element values in ascending order (rather than by indices). Ordering is by the type assigned to the element (see Variable Typing and Comparison Expressions). All numeric values come before all string values, which in turn come before all subarrays. (Subarrays have not been described yet; see Arrays of Arrays.)
"@val_str_asc"
Order by element values in ascending order (rather than by indices). Scalar values are compared as strings. Subarrays, if present, come out last.
"@val_num_asc"
Order by element values in ascending order (rather than by indices). Scalar values are compared as numbers. Subarrays, if present, come out last. When numeric values are equal, the string values are used to provide an ordering: this guarantees consistent results across different versions of the C qsort() function,[39] which gawk uses internally to perform the sorting.
"@ind_str_desc"
Like "@ind_str_asc", but the string indices are ordered from high to low.
"@ind_num_desc"
Like "@ind_num_asc", but the numeric indices are ordered from high to low.
"@val_type_desc"
Like "@val_type_asc", but the element values, based on type, are ordered from high to low. Subarrays, if present, come out first.
"@val_str_desc"
Like "@val_str_asc", but the element values, treated as strings, are ordered from high to low. Subarrays, if present, come out first.
"@val_num_desc"
Like "@val_num_asc", but the element values, treated as numbers, are ordered from high to low. Subarrays, if present, come out first.
The array traversal order is determined before the for loop starts to run. Changing PROCINFO["sorted_in"] in the loop body does not affect the loop. For example:
$ gawk '
> BEGIN {
> a[4] = 4
> a[3] = 3
> for (i in a)
> print i, a[i]
> }'
4 4
3 3
$ gawk '
> BEGIN {
> PROCINFO["sorted_in"] = "@ind_str_asc"
> a[4] = 4
> a[3] = 3
> for (i in a)
> print i, a[i]
> }'
3 3
4 4
When sorting an array by element values, if a value happens to be a subarray then it is considered to be greater than any string or numeric value, regardless of what the subarray itself contains, and all subarrays are treated as being equal to each other. Their order relative to each other is determined by their index strings.
Here are some additional things to bear in mind about sorted array traversal:
§ The value of PROCINFO["sorted_in"] is global. That is, it affects all array traversal for loops. If you need to change it within your own code, you should see if it’s defined and save and restore the value:
§ …
§ if ("sorted_in" in PROCINFO) {
§ save_sorted = PROCINFO["sorted_in"]
§ PROCINFO["sorted_in"] = "@val_str_desc" # or whatever
§ }
§ …
§ if (save_sorted)
PROCINFO["sorted_in"] = save_sorted
§ As already mentioned, the default array traversal order is represented by "@unsorted". You can also get the default behavior by assigning the null string to PROCINFO["sorted_in"] or by just deleting the "sorted_in" element from the PROCINFO array with the delete statement. (The delete statement hasn’t been described yet; see The delete Statement.)
In addition, gawk provides built-in functions for sorting arrays; see Sorting Array Values and Indices with gawk.
Using Numbers to Subscript Arrays
An important aspect to remember about arrays is that array subscripts are always strings. When a numeric value is used as a subscript, it is converted to a string value before being used for subscripting (see Conversion of Strings and Numbers). This means that the value of the predefined variable CONVFMT can affect how your program accesses elements of an array. For example:
xyz = 12.153
data[xyz] = 1
CONVFMT = "%2.2f"
if (xyz in data)
printf "%s is in data\n", xyz
else
printf "%s is not in data\n", xyz
This prints ‘12.15 is not in data’. The first statement gives xyz a numeric value. Assigning to data[xyz] subscripts data with the string value "12.153" (using the default conversion value of CONVFMT, "%.6g"). Thus, the array element data["12.153"] is assigned the value one. The program then changes the value of CONVFMT. The test ‘(xyz in data)’ generates a new string value from xyz—this time "12.15"—because the value of CONVFMT only allows two significant digits. This test fails, because "12.15" is different from "12.153".
According to the rules for conversions (see Conversion of Strings and Numbers), integer values always convert to strings as integers, no matter what the value of CONVFMT may happen to be. So the usual case of the following works:
for (i = 1; i <= maxsub; i++)
do something with array[i]
The “integer values always convert to strings as integers” rule has an additional consequence for array indexing. Octal and hexadecimal constants (covered in Octal and hexadecimal numbers) are converted internally into numbers, and their original form is forgotten. This means, for example, that array[17], array[021], and array[0x11] all refer to the same element!
As with many things in awk, the majority of the time things work as you would expect them to. But it is useful to have a precise knowledge of the actual rules, as they can sometimes have a subtle effect on your programs.
Using Uninitialized Variables as Subscripts
Suppose it’s necessary to write a program to print the input data in reverse order. A reasonable attempt to do so (with some test data) might look like this:
$ echo 'line 1
> line 2
> line 3' | awk '{ l[lines] = $0; ++lines }
> END {
> for (i = lines - 1; i >= 0; i--)
> print l[i]
> }'
line 3
line 2
Unfortunately, the very first line of input data did not appear in the output!
Upon first glance, we would think that this program should have worked. The variable lines is uninitialized, and uninitialized variables have the numeric value zero. So, awk should have printed the value of l[0].
The issue here is that subscripts for awk arrays are always strings. Uninitialized variables, when used as strings, have the value "", not zero. Thus, ‘line 1’ ends up stored in l[""]. The following version of the program works correctly:
{ l[lines++] = $0 }
END {
for (i = lines - 1; i >= 0; i--)
print l[i]
}
Here, the ‘++’ forces lines to be numeric, thus making the “old value” numeric zero. This is then converted to "0" as the array subscript.
Even though it is somewhat unusual, the null string ("") is a valid array subscript. (d.c.) gawk warns about the use of the null string as a subscript if --lint is provided on the command line (see Command-Line Options).
The delete Statement
To remove an individual element of an array, use the delete statement:
delete array[index-expression]
Once an array element has been deleted, any value the element once had is no longer available. It is as if the element had never been referred to or been given a value. The following is an example of deleting elements in an array:
for (i in frequencies)
delete frequencies[i]
This example removes all the elements from the array frequencies. Once an element is deleted, a subsequent for statement to scan the array does not report that element and using the in operator to check for the presence of that element returns zero (i.e., false):
delete foo[4]
if (4 in foo)
print "This will never be printed"
It is important to note that deleting an element is not the same as assigning it a null value (the empty string, ""). For example:
foo[4] = ""
if (4 in foo)
print "This is printed, even though foo[4] is empty"
It is not an error to delete an element that does not exist. However, if --lint is provided on the command line (see Command-Line Options), gawk issues a warning message when an element that is not in the array is deleted.
All the elements of an array may be deleted with a single statement by leaving off the subscript in the delete statement, as follows:
delete array
Using this version of the delete statement is about three times more efficient than the equivalent loop that deletes each element one at a time.
This form of the delete statement is also supported by BWK awk and mawk, as well as by a number of other implementations.
NOTE
For many years, using delete without a subscript was a common extension. In September 2012, it was accepted for inclusion into the POSIX standard. See the Austin Group website.
The following statement provides a portable but nonobvious way to clear out an array:[40]
split("", array)
The split() function (see String-Manipulation Functions) clears out the target array first. This call asks it to split apart the null string. Because there is no data to split out, the function simply clears the array and then returns.
CAUTION
Deleting all the elements from an array does not change its type; you cannot clear an array and then use the array’s name as a scalar (i.e., a regular variable). For example, the following does not work:
a[1] = 3
delete a
a = 3
Multidimensional Arrays
A multidimensional array is an array in which an element is identified by a sequence of indices instead of a single index. For example, a two-dimensional array requires two indices. The usual way (in many languages, including awk) to refer to an element of a two-dimensional array namedgrid is with grid[x,y].
Multidimensional arrays are supported in awk through concatenation of indices into one string. awk converts the indices into strings (see Conversion of Strings and Numbers) and concatenates them together, with a separator between them. This creates a single string that describes the values of the separate indices. The combined string is used as a single index into an ordinary, one-dimensional array. The separator used is the value of the built-in variable SUBSEP.
For example, suppose we evaluate the expression ‘foo[5,12] = "value"’ when the value of SUBSEP is "@". The numbers 5 and 12 are converted to strings and concatenated with an ‘@’ between them, yielding "5@12"; thus, the array element foo["5@12"] is set to "value".
Once the element’s value is stored, awk has no record of whether it was stored with a single index or a sequence of indices. The two expressions ‘foo[5,12]’ and ‘foo[5 SUBSEP 12]’ are always equivalent.
The default value of SUBSEP is the string "\034", which contains a nonprinting character that is unlikely to appear in an awk program or in most input data. The usefulness of choosing an unlikely character comes from the fact that index values that contain a string matching SUBSEP can lead to combined strings that are ambiguous. Suppose that SUBSEP is "@"; then ‘foo["a@b", "c"]’ and ‘foo["a", "b@c"]’ are indistinguishable because both are actually stored as ‘foo["a@b@c"]’.
To test whether a particular index sequence exists in a multidimensional array, use the same operator (in) that is used for single-dimensional arrays. Write the whole sequence of indices in parentheses, separated by commas, as the left operand:
if ((subscript1, subscript2, …) in array)
…
Here is an example that treats its input as a two-dimensional array of fields; it rotates this array 90 degrees clockwise and prints the result. It assumes that all lines have the same number of elements:
{
if (max_nf < NF)
max_nf = NF
max_nr = NR
for (x = 1; x <= NF; x++)
vector[x, NR] = $x
}
END {
for (x = 1; x <= max_nf; x++) {
for (y = max_nr; y >= 1; --y)
printf("%s ", vector[x, y])
printf("\n")
}
}
When given the input:
1 2 3 4 5 6
2 3 4 5 6 1
3 4 5 6 1 2
4 5 6 1 2 3
the program produces the following output:
4 3 2 1
5 4 3 2
6 5 4 3
1 6 5 4
2 1 6 5
3 2 1 6
Scanning Multidimensional Arrays
There is no special for statement for scanning a “multidimensional” array. There cannot be one, because, in truth, awk does not have multidimensional arrays or elements—there is only a multidimensional way of accessing an array.
However, if your program has an array that is always accessed as multidimensional, you can get the effect of scanning it by combining the scanning for statement (see Scanning All Elements of an Array) with the built-in split() function (see String-Manipulation Functions). It works in the following manner:
for (combined in array) {
split(combined, separate, SUBSEP)
…
}
This sets the variable combined to each concatenated combined index in the array, and splits it into the individual indices by breaking it apart where the value of SUBSEP appears. The individual indices then become the elements of the array separate.
Thus, if a value is previously stored in array[1, "foo"], then an element with index "1\034foo" exists in array. (Recall that the default value of SUBSEP is the character with code 034.) Sooner or later, the for statement finds that index and does an iteration with the variablecombined set to "1\034foo". Then the split() function is called as follows:
split("1\034foo", separate, "\034")
The result is to set separate[1] to "1" and separate[2] to "foo". Presto! The original sequence of separate indices is recovered.
Arrays of Arrays
gawk goes beyond standard awk’s multidimensional array access and provides true arrays of arrays. Elements of a subarray are referred to by their own indices enclosed in square brackets, just like the elements of the main array. For example, the following creates a two-element subarray at index 1 of the main array a:
a[1][1] = 1
a[1][2] = 2
This simulates a true two-dimensional array. Each subarray element can contain another subarray as a value, which in turn can hold other arrays as well. In this way, you can create arrays of three or more dimensions. The indices can be any awk expressions, including scalars separated by commas (i.e., a regular awk simulated multidimensional subscript). So the following is valid in gawk:
a[1][3][1, "name"] = "barney"
Each subarray and the main array can be of different length. In fact, the elements of an array or its subarray do not all have to have the same type. This means that the main array and any of its subarrays can be nonrectangular, or jagged in structure. You can assign a scalar value to the index 4of the main array a, even though a[1] is itself an array and not a scalar:
a[4] = "An element in a jagged array"
The terms dimension, row, and column are meaningless when applied to such an array, but we will use “dimension” henceforth to imply the maximum number of indices needed to refer to an existing element. The type of any element that has already been assigned cannot be changed by assigning a value of a different type. You have to first delete the current element, which effectively makes gawk forget about the element at that index:
delete a[4]
a[4][5][6][7] = "An element in a four-dimensional array"
This removes the scalar value from index 4 and then inserts a three-level nested subarray containing a scalar. You can also delete an entire subarray or subarray of subarrays:
delete a[4][5]
a[4][5] = "An element in subarray a[4]"
But recall that you can not delete the main array a and then use it as a scalar.
The built-in functions that take array arguments can also be used with subarrays. For example, the following code fragment uses length() (see String-Manipulation Functions) to determine the number of elements in the main array a and its subarrays:
print length(a), length(a[1]), length(a[1][3])
This results in the following output for our main array a:
2, 3, 1
The ‘subscript in array’ expression (see Referring to an Array Element) works similarly for both regular awk-style arrays and arrays of arrays. For example, the tests ‘1 in a’, ‘3 in a[1]’, and ‘(1, "name") in a[1][3]’ all evaluate to one (true) for our array a.
The ‘for (item in array)’ statement (see Scanning All Elements of an Array) can be nested to scan all the elements of an array of arrays if it is rectangular in structure. In order to print the contents (scalar values) of a two-dimensional array of arrays (i.e., in which each first-level element is itself an array, not necessarily of the same length), you could use the following code:
for (i in array)
for (j in array[i])
print array[i][j]
The isarray() function (see Getting Type Information) lets you test if an array element is itself an array:
for (i in array) {
if (isarray(array[i]) {
for (j in array[i]) {
print array[i][j]
}
}
else
print array[i]
}
If the structure of a jagged array of arrays is known in advance, you can often devise workarounds using control statements. For example, the following code prints the elements of our main array a:
for (i in a) {
for (j in a[i]) {
if (j == 3) {
for (k in a[i][j])
print a[i][j][k]
} else
print a[i][j]
}
}
See Traversing Arrays of Arrays for a user-defined function that “walks” an arbitrarily dimensioned array of arrays.
Recall that a reference to an uninitialized array element yields a value of "", the null string. This has one important implication when you intend to use a subarray as an argument to a function, as illustrated by the following example:
$ gawk 'BEGIN { split("a b c d", b[1]); print b[1][1] }'
error→ gawk: cmd. line:1: fatal: split: second argument is not an array
The way to work around this is to first force b[1] to be an array by creating an arbitrary index:
$ gawk 'BEGIN { b[1][1] = ""; split("a b c d", b[1]); print b[1][1] }'
a
Summary
§ Standard awk provides one-dimensional associative arrays (arrays indexed by string values). All arrays are associative; numeric indices are converted automatically to strings.
§ Array elements are referenced as array[indx]. Referencing an element creates it if it did not exist previously.
§ The proper way to see if an array has an element with a given index is to use the in operator: ‘indx in array’.
§ Use ‘for (indx in array) …’ to scan through all the individual elements of an array. In the body of the loop, indx takes on the value of each element’s index in turn.
§ The order in which a ‘for (indx in array)’ loop traverses an array is undefined in POSIX awk and varies among implementations. gawk lets you control the order by assigning special predefined values to PROCINFO["sorted_in"].
§ Use ‘delete array[indx]’ to delete an individual element. To delete all of the elements in an array, use ‘delete array’. This latter feature has been a common extension for many years and is now standard, but may not be supported by all commercial versions of awk.
§ Standard awk simulates multidimensional arrays by separating subscript values with commas. The values are concatenated into a single string, separated by the value of SUBSEP. The fact that such a subscript was created in this way is not retained; thus, changing SUBSEP may have unexpected consequences. You can use ‘(sub1, sub2, …) in array’ to see if such a multidimensional subscript exists in array.
§ gawk provides true arrays of arrays. You use a separate set of square brackets for each dimension in such an array: data[row][col], for example. Array elements may thus be either scalar values (number or string) or other arrays.
§ Use the isarray() built-in function to determine if an array element is itself a subarray.
[38] The ordering will vary among awk implementations, which typically use hash tables to store array elements and values.
[39] When two elements compare as equal, the C qsort() function does not guarantee that they will maintain their original relative order after sorting. Using the string value to provide a unique ordering when the numeric values are equal ensures that gawk behaves consistently across different environments.
[40] Thanks to Michael Brennan for pointing this out.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.