Foundations of Coding: Compression, Encryption, Error Correction (2015)
Chapter 1. Foundations of Coding
1.2 Stream Ciphers and Probabilities
As mentioned in Section 1.1.3, the probability of transmission error in many communication channels is high. To build an efficient code in such a situation, one can consider the message to be transmitted as a bit stream, that is, a potentially infinite sequence of bits sent continuously and serially (one at a time). Each character is then transformed bit by bit for the communication over the channel. Such an approach has various advantages:
· the transformation method can change for each symbol;
· there is no error propagation on the channel; and
· it can be implemented on embedded equipment with limited memory as only a few symbols are processed at a time.
This technique is notably used in cryptography in the so-called stream cipher. Under some conditions (Section 1.2.1), such systems can produce unconditionally secure messages: for such messages, the knowledge of the ciphertext does not give any information on the plaintext. This property is also called perfect secrecy. Thus, the only possible attack on a perfect encryption scheme given a ciphertext is the exhaustive research of the secret key (such a strategy is also called brute force attack). We also use the stream cipher model to build error detection and correction principles (see convolutional codes in Chapter 4). The one-time-pad (OTP) encryption scheme is an example of a cryptographic stream cipher whose unconditional security can be proved, using probability and information theory.
Some notions of probabilities are necessary for this section and also for the rest of the book. They are introduced in Section 1.2.2.
1.2.1 The Vernam Cipher and the One-Time-Pad Cryptosystem
In 1917, during the first World War, the American company AT&T asked the scientist Gilbert Vernam to invent a cipher method the Germans would not be able to break. He came with the idea to combine the characters typed on a teleprinter with the one of a previously prepared key kept on a paper tape. In the 1920s, American secret service captain Joseph Mauborgne suggested that the key should be generated randomly and used only once. The combination of both ideas led to the OTP encryption scheme, which is up to now the only cipher to be mathematically proved as unconditionally secure.
The Vernam cipher derived from the method introduced by Gilbert Vernam. It belongs to the class of secret key cryptographic system, which means that the secret lies in one parameter of the encryption and decryption functions, which is only known by the sender and the recipient. It is also the case of Caesar's code mentioned in Section 1.1.4, in which the secret parameter is the size of the shift of the letters (or the numbers).
Mathematically speaking, the Vernam encryption scheme is as follows: for any plaintext message M and any secret key K of the same size, the ciphertext C is given by
![]()
where ![]() (also denoted by xor) is the bitwise logical “ exclusive or” operation. Actually, it consists in an addition modulo 2 ofeach bit. This usage of the “ exclusive or” was patented by Vernam in 1919. Decryption is performed using the same scheme due to the following property:
(also denoted by xor) is the bitwise logical “ exclusive or” operation. Actually, it consists in an addition modulo 2 ofeach bit. This usage of the “ exclusive or” was patented by Vernam in 1919. Decryption is performed using the same scheme due to the following property:
![]()
If K is truly random, used only once and of the same size as M i.e., ![]() ), then a third party does not obtain any information on the plaintext by intercepting the associated ciphertext (except the size of M). Vernam cipher used with those three assumptions is referred to as a OTP scheme. It is again unconditionally secure, as proved by Claude Shannon (Section 1.2.5).
), then a third party does not obtain any information on the plaintext by intercepting the associated ciphertext (except the size of M). Vernam cipher used with those three assumptions is referred to as a OTP scheme. It is again unconditionally secure, as proved by Claude Shannon (Section 1.2.5).
Exercise 1.5
Why is it necessary to throw the key away after using it, that is, why do we have to change the key for each new message?
Solution on page 282.
Exercise 1.6
Build a protocol, based on the One-time-pad system, allowing a user to connect to a secured server on Internet from any computer. The password has to be encrypted to be safely transmitted through Internet and to avoid being captured by the machine of the user.
Solution on page 282.
Obviously, it remains to formalize the notion of random number generation, give the means to perform such generation and finally, in order to prove that the system is secure, make precise what “obtaining some information” on the plaintext means. For this, the fundamental principles of information theory – which are also the basis of message compression – are now introduced.
1.2.2 Some Probability
In a cryptographic system, if one uses a key generated randomly, any discrepancy with “ true” randomness represents an angle of attack for the cryptanalysts. Randomness is also important in compression methods as any visible order, any redundancy, or organization in the message can be used not only by code breakers but also by code inventors who will see a means of expressing the message in a more dense form. But what do we call discrepancy with true randomness, and more simply what do we call randomness ? For instance, if the numbers “1 2 3 4 5 6” are drawn at lotto, one will doubt that they were really randomly generated, although stricto sensu, this combination has exactly the same probability of appearing as any other. We do not go deeply into the philosophy of randomness, but this section provides mathematical material to address randomness and its effects and to create something close to randomness.
1.2.2.1 Events and Probability Measure
An event is a possible result of a random experiment. For example, if one throws a six face die, getting the number 6 is an event. The set operators (![]() ) are used for relations between events (they stand for or, and, and except). We denote by
) are used for relations between events (they stand for or, and, and except). We denote by ![]() the set of all possible events for a given experiment. A probability measure P is a map of
the set of all possible events for a given experiment. A probability measure P is a map of ![]() onto
onto ![]() satisfying:
satisfying:
1. ![]() and
and ![]() ;
;
2. For all ![]() mutually exclusive events (
mutually exclusive events (![]() ),
), ![]() .
.
If the set of events is a discrete set or a finite set, we talk about discrete probability. For example, if the random experiment is the throw of a fair six face die, the set of events is ![]() and the probability of occurrence of each one is
and the probability of occurrence of each one is ![]() .
.
The probability function is called the probability distribution or the law of probability. A distribution is said to be uniform if all events have the same probability of occurrence.
Gibbs' lemma is a result on discrete distributions that will be useful several times in this book.
Lemma 1 (Gibbs' Lemma)
Let ![]() be two discrete probability laws with
be two discrete probability laws with ![]() and
and ![]() for all i. Then
for all i. Then
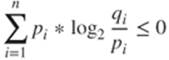
with equality if and only if ![]() for all i.
for all i.
Proof
As ![]() and
and ![]() , it is sufficient to prove the statement using the neperian logarithm. Indeed,
, it is sufficient to prove the statement using the neperian logarithm. Indeed, ![]() with equality if and only if
with equality if and only if ![]() . Hence
. Hence 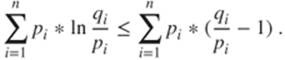
Having ![]() , we can deduce that
, we can deduce that ![]() . As a result,
. As a result, ![]() The equality holds if
The equality holds if ![]() for all i so that the approximation
for all i so that the approximation ![]() is exact.
is exact.
1.2.2.2 Conditional Probabilities and Bayes' Formula
Two events are said to be independent if ![]() .
.
The conditional probability of an event A with respect to an event B is the probability of appearance of A, knowing that B has already appeared. This probability is denoted by ![]() and defined by
and defined by
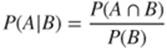
By recurrence, it is easy to show that for a set of events ![]() ,
,
![]()
Bayes' formula enables us to compute – for a set of events ![]() – the probabilities
– the probabilities ![]() as functions of the probabilities
as functions of the probabilities ![]() .
.
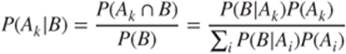
Exercise 1.7
One proposes the following secret code, which encodes two characters a and b with three different keys ![]() , and
, and ![]() : if
: if ![]() is used, then
is used, then ![]() and
and ![]() ; if
; if ![]() is used, then
is used, then ![]() and
and ![]() . Otherwise,
. Otherwise, ![]() and
and ![]() .
.
Moreover, some a priori knowledge concerning the message M and the key K is assumed: ![]() , and
, and ![]() .
.
What are the probabilities of having the ciphertexts 1, 2, and 3? What are the conditional probabilities that the message is a or b knowing the ciphertext? Intuitively, can we say that this code has a “ perfect secrecy”?
Solution on page 282.
Having revised the basic theory of random events, now let us present what randomness means for computers.
1.2.3 Entropy
1.2.3.1 Source of Information
Let S be the alphabet of the source message. Thus, a message is an element of ![]() . For each message, we can compute the frequencies of appearance of each element of the alphabet and build a probability distribution over S.
. For each message, we can compute the frequencies of appearance of each element of the alphabet and build a probability distribution over S.
A source of information is constituted by a couple ![]() where
where ![]() is the source alphabet and
is the source alphabet and ![]() is a probability distribution over S, namely
is a probability distribution over S, namely ![]() is the probability of occurrence of
is the probability of occurrence of ![]() in an emission. We can create a source of information with any message by building the probability distribution from the frequencies of the characters in the message.
in an emission. We can create a source of information with any message by building the probability distribution from the frequencies of the characters in the message.
The source of information ![]() is said without memory when the events (occurrences of a symbol in an emission) are independent and when their probabilities remain stable during the emission (the source is stable).
is said without memory when the events (occurrences of a symbol in an emission) are independent and when their probabilities remain stable during the emission (the source is stable).
The source is said to follow a Markov model if the probabilities of the occurrence of the characters depend on the one issued previously. In the case of dependence on one predecessor, we have the probability set ![]() , where
, where ![]() is the probability of appearance of
is the probability of appearance of![]() knowing that
knowing that ![]() has just been issued. Hence, we have
has just been issued. Hence, we have ![]() .
.
For instance, a text in English is a source whose alphabet is the set of Latin letters. The probabilities of occurrence are the frequencies of appearance of each character. As the probabilities strongly depend on the characters that have just been issued (a U is much more probable after a Q than after another U), the Markov model will be more adapted.
An image also induces a source. The characters of the alphabet are the color levels. A sound is a source whose alphabet is a set of frequencies and intensities.
A source ![]() is without redundancy if its probability distribution is uniform. This is obviously not the case for common messages, in which some letters and words are much more frequent than others. This will be the angle of attack of compression methods and also pirates trying to read a message without being authorized.
is without redundancy if its probability distribution is uniform. This is obviously not the case for common messages, in which some letters and words are much more frequent than others. This will be the angle of attack of compression methods and also pirates trying to read a message without being authorized.
1.2.3.2 Entropy of a Source
Entropy is a fundamental notion for the manipulation of a code. Indeed, it is a measure of both the amount of information we can allocate to a source (this will be useful for the compression of messages) and the level of order and redundancy of a message, the crucial information in cryptography.
The entropy of a source ![]() is
is
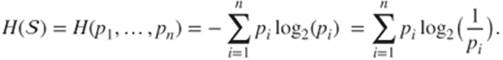
By extension, one calls entropy of a message the entropy of the source induced by this message, the probability distribution being computed from the frequencies of appearance of the characters in the message.
Property 1
Let ![]() be a source:
be a source:
![]()
Proof
We apply Gibbs' lemma to the distribution ![]() , we have
, we have ![]() for any source S. Finally, positivity is obvious noticing that the probabilities
for any source S. Finally, positivity is obvious noticing that the probabilities ![]() are less than 1.
are less than 1.
We can notice that for a uniform distribution, entropy reaches its maximum. It decreases when the distribution differs from the uniform distribution. This is why it is called a “ measure of disorder,” assuming that the greatest disorder is reached by a uniform distribution.
Exercise 1.8
What is the entropy of a source where the character 1 has probability ![]() and the character 0 has probability
and the character 0 has probability ![]() ? Why will a small entropy be good for compression?
? Why will a small entropy be good for compression?
Solution on page 282.
1.2.3.3 Joint Entropies, Conditional Entropies
The definition of entropy can be easily extended to several sources. Let ![]() and
and ![]() be two sources without memory, whose events are not necessarily independent. Let
be two sources without memory, whose events are not necessarily independent. Let ![]() and
and ![]() ; then
; then ![]() is the probability of joint occurrence of
is the probability of joint occurrence of ![]() and
and ![]() and
and ![]() is the probability of the conditional occurrence of
is the probability of the conditional occurrence of ![]() and
and ![]() .
.
We call joint entropy of ![]() and
and ![]() the quantity
the quantity
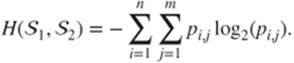
For example, if the sources ![]() and
and ![]() are independent, then
are independent, then ![]() for all
for all ![]() . In this case, we can easily show that
. In this case, we can easily show that ![]() .
.
On the contrary, if the events of ![]() and
and ![]() are not independent, we might want to know the amount of information in one source, knowing one event of the other source. Thus, we compute the conditional entropy of
are not independent, we might want to know the amount of information in one source, knowing one event of the other source. Thus, we compute the conditional entropy of ![]() relative to the value of
relative to the value of ![]() , given by
, given by
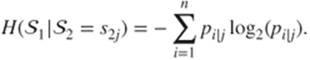
Finally, we extend this notion to a conditional entropy of ![]() knowing
knowing ![]() , which is the amount of information remaining in
, which is the amount of information remaining in ![]() if the law of
if the law of ![]() is known:
is known:
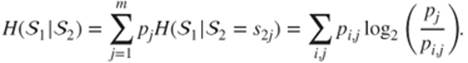
This notion is crucial in cryptography. Indeed, it is very important for all ciphertexts to have a strong entropy in order to prevent the signs of organization in a message from giving some information on the way it was encrypted. Moreover, it is also important for entropy to remain strong even if a third party manages to obtain some important information concerning the plaintext. For instance, if some mails are transmitted, then they share common patterns in Headers; yet this knowledge should typically not provide information on the secret key used to encrypt the mails.
Then, we have the simple – but important – following relations:
![]()
with equality if and only if ![]() and
and ![]() are independent; and also
are independent; and also
![]()
However, the entropy of a source without memory does not capture all the order or the disorder included in a message on its own. For example, the messages “1 2 3 4 5 6 1 2 3 4 5 6” and “3 1 4 6 4 6 2 1 3 5 2 5” have the same entropy; yet the first one is sufficiently ordered to be described by a formula, such as “1…6 1…6,” which is probably not the case for the second one. To consider this kind of organization, we make use of the extensions of asource.
1.2.3.4 Extension of a Source
Let ![]() be a Source without memory. The kth extension
be a Source without memory. The kth extension ![]() of
of ![]() is the couple
is the couple ![]() , where
, where ![]() is the set of all words of length k over S and
is the set of all words of length k over S and ![]() the probability distribution defined as follows: for a word
the probability distribution defined as follows: for a word ![]() , then
, then ![]() .
.
Example 1.1
If ![]() , then
, then ![]() and
and ![]() .
.
If ![]() is a Markov source, we define
is a Markov source, we define ![]() in the same way, and for a word
in the same way, and for a word ![]() , then
, then ![]() .
.
Property 2
Let ![]() be a source, and
be a source, and ![]() its kth extension, then
its kth extension, then
![]()
In other words this property stresses the fact that the amount of information of a source extended to k characters is exactly k times the amount of information of the original source. This seems completely natural.
However, this does not apply to the amount of information of a message (a file for instance) “ extended” to blocks of k characters. More precisely, it is possible to enumerate the occurrences of the characters in a message to compute their distribution and then the entropy of a source that would have the same probabilistic characteristics. Indeed, this is used to compress files as it will be seen in Chapter 2. Now if the message is “ extended” in the sense that groups of k characters are formed and the occurrences of each group is computed to get their distribution, then the entropy of this “ message extension” is necessarily lower than ktimes the entropy corresponding to the original message as shown in the following.
Property 3
Let ![]() be a message of size n,
be a message of size n, ![]() be the source whose probabilities correspond to the occurrences of the successive k-tuples of
be the source whose probabilities correspond to the occurrences of the successive k-tuples of ![]() and
and ![]() be the kth extension of the induced source
be the kth extension of the induced source ![]() . Then
. Then
![]()
Proof
We give some details for ![]() . Let
. Let ![]() be the probabilities of the induced source
be the probabilities of the induced source ![]() those of the second extension
those of the second extension ![]() and
and ![]() those of an source induced by the successive pairs of elements of M,
those of an source induced by the successive pairs of elements of M, ![]() . Gibbs lemma, page 17, applied to
. Gibbs lemma, page 17, applied to ![]() and
and ![]() shows that
shows that 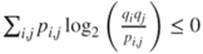 . This is also
. This is also
1.1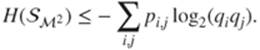
Now, denote by ![]() the number of occurrences of the i symbol in
the number of occurrences of the i symbol in ![]() . With
. With ![]() , we have
, we have ![]() . Also denote by
. Also denote by ![]() the number of occurrences of the pair
the number of occurrences of the pair ![]() in
in ![]() . Then
. Then ![]() and
and ![]() . We also have
. We also have ![]() so that
so that ![]() .
.
Therefore, the right-hand side of Inequation (1.1 ) can be rewritten as follows:
1.2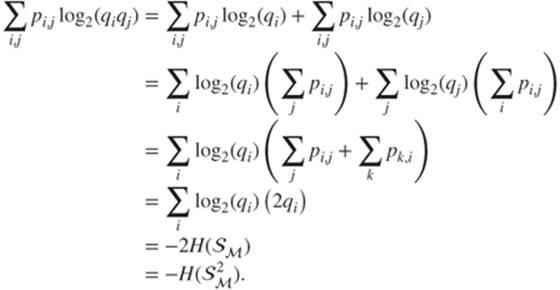
This proves that Inequation (1.1 ) is actually
![]()
This construction generalizes to any k, in the same manner, by enumeration of all the k-tuples.
The following example illustrates both situations.
Example 1.2
The messages “ 1 2 3 4 5 6 1 2 3 4 5 6” and “ 3 1 4 6 4 6 2 1 3 5 2 5” have the same entropy taking the first extension of the source: six characters of probability one ![]() each, giving an entropy of
each, giving an entropy of ![]() . With the second extension of the source
. With the second extension of the source ![]() , we obtain
, we obtain ![]() possible groups of probability
possible groups of probability ![]() each and the entropy conforms to Property 2:
each and the entropy conforms to Property 2: ![]() . However, for example, when regrouping the messages in blocks of two characters, we have
. However, for example, when regrouping the messages in blocks of two characters, we have
· (12)(34)(56)(12)(34)(56): three different couples of probability ![]() each corresponding to an entropy of
each corresponding to an entropy of ![]() .
.
· All the same, the sequence (31)(46)(46)(21)(35)(25) gives five different couples and is of entropy ![]() .
.
In both cases, the entropy obtained is definitely lower than twice the entropy of the original message. We will make this statement precise in Property 4.
Property 4
Let ![]() be a message of size n and let
be a message of size n and let ![]() be the source whose probabilities correspond to the occurrences of the successive k-tuples of
be the source whose probabilities correspond to the occurrences of the successive k-tuples of ![]() . Then
. Then
![]()
Proof
There are ![]() k-tuples in the message
k-tuples in the message ![]() . Besides, entropy is maximal for the greatest number of distinct possible k-tuples with the same number of occurrences. In this case, the corresponding source would contain at most
. Besides, entropy is maximal for the greatest number of distinct possible k-tuples with the same number of occurrences. In this case, the corresponding source would contain at most ![]() distinct characters of probability of occurrence
distinct characters of probability of occurrence ![]() . Thus, the entropy is
. Thus, the entropy is ![]() .
.
This leads us to the problem of randomness and its generation. A sequence of numbers randomly generated should meet harsh criteria – in particular, it should have a strong entropy. The sequence “ 1 2 3 4 5 6 1 2 3 4 5 6” would not be acceptable as one can easily notice some kind of organization. The sequence “ 3 1 4 6 4 6 2 1 3 5 2 5” would be more satisfying – having a higher entropy when considering successive pairs of characters. We detail the random number generators in Section 1.3.7.
1.2.4 Steganography and Watermarking
Entropy is a powerful tool to model the information in a code. For instance, it can be used to detect steganography by a study of the quantity of information contained in a device.
Steganography is the art of covering information. The knowledge of the mere existence of some covert information could then be sufficient to discover this information.
Steganographic devices include invisible ink, microdot in images, Digital Right Management (DRM), information encoding in white spaces of a plaintext, and so on.
Nowadays, steganography is quite often combined with cryptography in order to not only conceal the existence of information but also keep its secrecy even if its existence is revealed. It is also combined with error-correcting codes. Indeed, even if the resultingstegotext is modified and some parts of the information are altered, the information remains accessible if sufficiently many bits remain unchanged by the media modification.
Digital watermarking is a variant of steganography, which is used to conceal some information into digital media such as images, audio, or video.
We distinguish two major kinds of watermarking:
· Fragile watermarking is very close to classical steganography, it is usually invisible and used to detect any modification of the stream. For instance, secure paper money often encloses fragile watermarks that disappear after photocopy.
· Robust watermarking might be visible and should at least partially resist to simple modifications of the source as lossy compression. This is what is required for instance for Digital Right Management.
It is difficult to hide a large quantity of information into a media without begin detectable. Indeed, consider a covering media M, some information X and a stegotext S where the information is embedded into the covertext. As the stegotext should not be very different from the covertext to be undetected, the quantity of information in the stegotext should be very close to that of the covertext added to that of the embedded information: ![]() . Therefore, a classical steganalysis is to compute the entropy of a suspected media and compare it to classical values of unmarked ones. If the obtained entropy is significantly higher than the average, then it can mean that some additional information if carried by this media. In other words, to remain undetected steganography must use a small quantity of information into a large media.
. Therefore, a classical steganalysis is to compute the entropy of a suspected media and compare it to classical values of unmarked ones. If the obtained entropy is significantly higher than the average, then it can mean that some additional information if carried by this media. In other words, to remain undetected steganography must use a small quantity of information into a large media.
Exercise 1.9
We have hidden a number in the spacing of this text. Can you find it?
Solution on page 283.
We will see an example of watermarking of digital images using the JPEG format in Section 2.5.3.
1.2.5 Perfect Secrecy
Using the concept of entropy, it is also now possible to make precise the concept of unconditional security (also called perfect secrecy).
An encryption scheme is said unconditionally secure or perfect if the ciphertext C does not give any information on the initial plaintext M; hence, the entropy of M knowing C is equal to the entropy of M:
![]()
In other words, unconditional security means that M and C are statistically independent.
Exercise 1.10 (Perfect Secrecy of the One-Time-Pad Encryption Scheme)
1. We consider a secret code wherein the key K is generated randomly for each message M. Prove that ![]() .
.
2. Using conditional entropies and the definition of a Vernam code, prove that in a Vernam code (![]() ), we always have
), we always have ![]() ; deduce the relations between the conditional entropies of M, C, and K.
; deduce the relations between the conditional entropies of M, C, and K.
3. Prove that the OTP system is a perfect encryption scheme.
Solution on page 283.
1.2.6 Perfect Secrecy in Practice and Kerckhoffs' Principles
Now, we have an encryption method (the one-time-pad) and the proof of its security. It is the only known method to be proved unconditionally secure. Yet in order to use this method in practice, we should be able to generate random keys of the same size of the message, which is far from being trivial. One solution is to rely on PRNG (Section 1.3.7) to create the successive bits of the key that are combined with the bit stream of the plaintext. It leads to a bitwise encryption (stream cipher) as illustrated in Figure 1.2.

Figure 1.2 Bitwise encryption (Stream cipher)
However, key exchange protocols between the sender and the recipient remain problematic as the keys cannot be used twice and are generally big (as big as the message).
Exercise 1.11 (Imperfection Mesure and Unicity Distance)
We consider messages M written in English, randomly chosen keys K and ciphertexts C, produced by an imperfect code over the ![]() letters alphabet. A length l string is denoted by
letters alphabet. A length l string is denoted by ![]() and we suppose that any key is chosen uniformly from the spaceK. The unicity distance of a code is the average minimal length d (number of letters) of a ciphertext required to find the key. In other words d satisfies
and we suppose that any key is chosen uniformly from the spaceK. The unicity distance of a code is the average minimal length d (number of letters) of a ciphertext required to find the key. In other words d satisfies ![]() : if you know d letters of a ciphertext, you have, at least theoretically, enough information to recover the used key.
: if you know d letters of a ciphertext, you have, at least theoretically, enough information to recover the used key.
1. For a given symmetric cipher, knowing the key and the cleartext is equivalent to knowing the key and the ciphertext: ![]() . From this and the choice of the key, deduce a relation between
. From this and the choice of the key, deduce a relation between ![]() with the unicity distance d.
with the unicity distance d.
2. Using Table 1.1, the entropy of this book is roughly ![]() per character. What is therefore the entropy of a similar plaintext of d letters?
per character. What is therefore the entropy of a similar plaintext of d letters?
3. What is the entropy of a randomly chosen string over the alphabet with ![]() letters ? Use these entropies to bound
letters ? Use these entropies to bound ![]() for a good cipher.
for a good cipher.
4. Overall, deduce a lower bound for the unicity distance depending on the information contained in the key.
5. If the cipher consists in choosing a single permutation of the alphabet, deduce the average minimal number of letters required to decipher a message encoded with this permutation.
Solution on page 283.
In general, coding schemes are not perfect, and theoretical proofs of security are rare. Empirical principles often state the informal properties we can expect from a cryptosystem. Auguste Kerckhoffs formalized the first and most famous ones in 1883in his article “ La cryptographie militaire,” which was published in the “ Journal des Sciences Militaires.” Actually, his article contains six principles, which are now known as “ Kerckhoffs' principles.” We will summarize three of them, the most useful nowadays:
1. Security depends more on the secrecy of the key than on the secrecy of the algorithm. For a long time, the security of a cryptosystem concerned the algorithms that were used in this system. For instance, this was the case of Caesar encryption (Section 1.1) or of the ADFVGX code, used by German forces during World War I. Security is illusory because, sooner or later, details of the algorithm are going to be known and its potential weaknesses will be exploited. In addition, it is easier to change a key if it is compromised than to change the whole cryptosystem. Moreover, you can believe in the resistance of public cryptosystems as they are continuously attacked: selection is rough, therefore if a cryptosystem, whose internal mechanisms are freely available, still resists the continuous attacks performed by many cryptanalysts, then there are more chances that the system is really secure.
2. Decryption without the key must be impossible (in reasonable time);
3. Finding the key from a plaintext and its ciphertext must be impossible (in reasonable time).
Therefore, one must always assume that the attacker knows all the details of the cryptosystem. Although these principles have been known for a long time, many companies continue to ignore them (voluntarily or not). Among the most media-related recent examples, one may notice the A5/0 and A5/1 encryption algorithms that are used in Global System for Mobile Communications (GSM) and most of all Content Scrambling System (CSS) software for the protection against DVD copying. The latter algorithms were introduced in 1996 and hacked within weeks, despite the secrecy surrounding the encryption algorithm.
Following the Kerckhoffs principles, it is possible to devise codes that are not perfect but tend toward this property. In Section 1.3, we, for instance, see how to build codes which use a single (short) key and make the exchange protocol less time consuming than the OTP. The idea is to split the message into blocks such that each of them is encrypted separately.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.