Foundations of Coding: Compression, Encryption, Error Correction (2015)
Chapter 2. Information Theory and Compression
2.3 Heuristics of Entropy Reduction
In practice, the Huffman algorithm (or its variants) is used coupled with other encoding processes. These processes are not always optimal in theory, but they make some reasonable assumptions on the form of the target files (i.e., the source model) in order to reduce the entropy or allow the elimination of some information one considers to be inconsequential for the use of the data.
Here, we give three examples of entropy reduction. The principle is to turn a message into another one, using some reversible transformation, so that the new message will have a lower entropy and thus will be more efficiently compressible. Therefore, the whole technique is about using a preliminary code in charge of reducing the entropy before applying the compression.
2.3.1 Run-Length Encoding(RLE)
Although statistical encoding makes good use of the most frequent characters, it does not take their position in the message into account. If the same character often appears several times in a row, it might be useful to simply encode the number of times it appears. For instance, in order to transmit a fax page, statistical encoding will encode a 0 with a short codeword, but each 0 will be written, and this will makethis code less efficient than the fax code presented in Chapter 1, especially for pages containing large white areas.
Run-length encoding (RLE) is an extension of the fax code. It reads each character one by one but, when at least three identical characters are met successively, it will rather print some special repetition code followed by the recurrent character and the number of repetitions. For example, using @ as the repetition character, the string “aabbbcddddd@ee” is encoded with “@a2@b3c@d5@@1@e2” (a little trick is necessary to make the code instantaneous if the special character is met).
Exercise 2.10
1. What would be the RLE code of the following image?
2. Is there a benefit compared to the fax code?
3. What would be the encoding on 5-bit blocks with 16 gray-levels? And the benefit of such a code? Are we able to compress more than this with this system?
4. Same question with 255 gray-levels (with at most 16 consecutive identical pixels).
5. Same questions when scanning the image in columns?
Solution on page 298.
In order to avoid problems related to the special repetition character—which is necessarily encoded as a repetition of length 1—modems use a variant of RLE called MNP5. If the same character is consecutively encountered three times, or more, the idea is to display the three characters followed by some counter indicating the number of additional occurrences of this character. One mustobviously specify a fixed number of bits allocated for this counter. If the counter reaches its maximum, the sequel is encoded with several blocks composed of the same three characters followed by a counter. For instance, the string “aabbbcddddd” is encoded as “aabbb0cddd2.” In this case, if a string on n bytes contains m repetitions of average length L, the benefit of compression is ![]() if the counter is encoded on 1 byte. Therefore, this kind of encoding scheme is very useful, for example, in black and white images where pixels having the same color are often side by side. A statistical compression can obviously be performed later on the result of an RLE scheme.
if the counter is encoded on 1 byte. Therefore, this kind of encoding scheme is very useful, for example, in black and white images where pixels having the same color are often side by side. A statistical compression can obviously be performed later on the result of an RLE scheme.
2.3.1.1 The Fax Code (end)
Let us go back to the fax code—the one we used at the beginning of our presentation of the foundations of coding (Chapter 1)—and let us complete it and give its whole compression principle.
Let us recall that the scanned information is a set of black and white pixels on which one performs an RLE on lines of 1728 characters. Black and white pixels are alternated; thus the message one wishes to encode is a sequence of numbers between 1 and 1728. These numbers will be encoded with their translations in bits, according to the following principle. Suppose that we have a uniquely decodable code that contains the encoded value of all numbers between 0 and 63, as well as the encoded value of several numbers greater than 63, in such a way that for any number greater than n, there exists some large number m in the table, such that ![]() . Therefore, n repetitions are represented with two successive codes: m repetitions and then
. Therefore, n repetitions are represented with two successive codes: m repetitions and then ![]() repetitions.
repetitions.
Figure 2.4 presents some extracts of tables showing the numbers encoding white pixels. Numbers between 0 and 63 are called terminating white codes and numbers greater than 64 are called make up white codes.
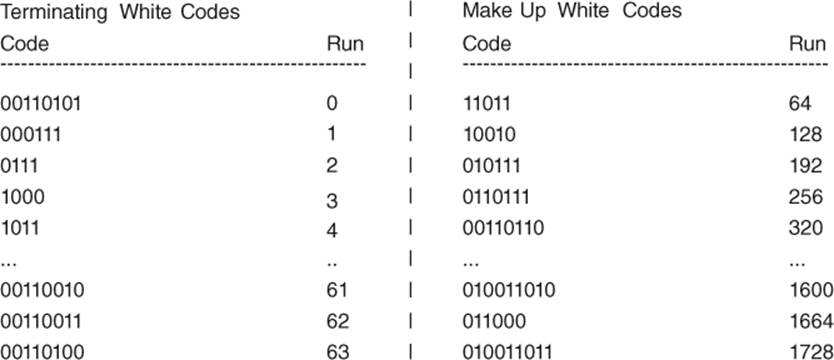
Figure 2.4 Fax code
The same tables exist for black pixels, with different encoded values, the whole composing a code uniquely decodable.
2.3.2 Move-to-Front
Another precomputation is possible if one turns an ASCII character into its value between 0 and 255 while modifying the order of the table on-the-fly. For instance, as soon as a character appears in the source, it is first encoded with its value, then it is moved to the front of the list: from now on, it will be encoded with 0, all other characters being shifted by one unit. This “ move-to-front” enables one to have more codes close to 0 than codes close to 255. Hence, entropy is modified.
For example, the string “aaaaffff” can be conceptualized as a source of entropy 1, if the table is (a,b,c,d,e,f). It is then encoded with “00005555.” The entropy of the code (considered as a source) is 1. It is also the entropy of the source. However, the code of a move-to-front will be “00005000” of entropy ![]() . The code in itself is then compressible; this is what we call entropy reduction. Under these conditions, one is able to encode the result message—and thus the initial message—a lot more efficiently.
. The code in itself is then compressible; this is what we call entropy reduction. Under these conditions, one is able to encode the result message—and thus the initial message—a lot more efficiently.
A variant of this method could be for one to move the character to the front in the list by a fixed number of characters, instead of pushing it in the first position. Hence, the most frequent characters will be located around the head of the list. This idea prefigures adaptive codes and dictionary-based codes that are presented in the next sections.
Exercise 2.11 Let A be an alphabet composed by the eight following symbols: A = (“a”, “b”, “c”, “d”, “m”, “n”, “o”, “p”).
1. One associates a number between 0 and 7 to each symbol, according to its position in the alphabet. What are the numbers representing “abcddcbamnopponm” and “abcdmnopabcdmnop”?
2. Encode the two previous strings using the “ move-to-front” technique. What do you notice?
3. How many bits are necessary in order to encode the two first numbers using the Huffman algorithm for example?
4. How many bits are necessary to encode the two numbers obtained after “ move-to-front”? Compare the entropies.
5. What does the Huffman algorithm extended to two characters give for the last number? Then what is the size of the frequency table?
6. What are the characteristics of an algorithm performing “ move-to-front” followed by some statistical code?
7. “ Move-ahead-k” is a variant of “ move-to-front” in which the character is pushed forward by only k positions instead of being pushed to the front of the stack. Encode the two previous strings with ![]() , then with
, then with ![]() and compare the entropies.
and compare the entropies.
Solution on page 299.
2.3.3 Burrows–Wheeler Transform(BWT)
The idea behind the heuristic of Michael Burrows and David Wheeler is to sort the characters of a string to make move-to-front and RLE the most efficient possible. Obviously, the problem is that it is impossible in general to recover the initial string from its sorted version! Therefore, the trick is to sort the string and send some intermediate string—with a better entropy than the initial string—that will also enable one to recover the initial string. For example, let us consider the string “COMPRESSED.” It is a question of creating all possible shifts as presented in Figure 2.5 and then sorting the lines according to the alphabetic and lexicographic order. Therefore, the first column F of the new matrix is the sorted string of all letters in the source word. The last column is called L. Only the first and the last columns are written, because they are the only important ones for the code. In the figure and in the text, we put the indices for the characters that are repeated; these indices simplify the visual understanding of the transform. However, they are not taken into account in the decoding algorithm: indeed, the order of the characters is necessarily preserved between L and F.

Figure 2.5 BWT on COMPRESSED
Obviously, in order to compute F (the first column) and L (the last column), it is not necessary to store the whole shift matrix: a simple pointer running along the string is enough. Thus this first phase is quite obvious. Nevertheless, if only F is sent, how do we compute the reverse transform?
Here the solution is to send the string L instead of F: even if L is not sorted, it is still taken from the sorted version of an almost identical string, only shifted by one letter. Therefore, one can hope that this method preserves the properties of the sorting and that entropy will be reduced. The magic of decoding comes from the knowledge of this string, coupled with the knowledge of the primary index (the number of the line containing the first character of the initial string; in Figure 2.5, it is 4—considering numbers between 0and 8) enables one to recover the initial string. It is enough to sort L in order to recover F. Then, one computes a transform vector H containing the correspondence of the indexes between L and F, namely, the index in L of each character taken in the sorted order inF. For Figure 2.5, this gives ![]() , because C is in position 4—the primary index in L—then
, because C is in position 4—the primary index in L—then ![]() is in position 0 in L, and
is in position 0 in L, and ![]() is in position 8, and so on. Then, one must notice that putting L before F in column, in each line, two consecutive letters must necessarily be consecutive in the initial string: indeed, because of the shift, the last letter becomes the first one and the first one becomes the second one. This can also be explained by the fact that for all j,
is in position 8, and so on. Then, one must notice that putting L before F in column, in each line, two consecutive letters must necessarily be consecutive in the initial string: indeed, because of the shift, the last letter becomes the first one and the first one becomes the second one. This can also be explained by the fact that for all j, ![]() . Then, it is enough to follow this sequence of couples of letters to recover the initial string, as explained in Algorithm 2.6.
. Then, it is enough to follow this sequence of couples of letters to recover the initial string, as explained in Algorithm 2.6.
Exercise 2.12 (BWT Code Analysis)
1. The last column L of the sorted matrix of the Burrows–Wheeler Transform (BWT) contains packets of identical characters, that is why L can be efficiently compressed. However, the first column F would even be more efficiently compressible if it was totally sorted. Why does one select L rather than F as the encoded message?
2. 2. Let us consider the string S = “sssssssssh.” Compute L and its move-to-front compression.
3. Practical implementation: BWT is efficient on long strings S of length n. In practice, it is, therefore, inconceivable to store the whole ![]() permutation matrix. In fact, it is enough to order these permutations. For this, one needs to be able to compare two permutations.
permutation matrix. In fact, it is enough to order these permutations. For this, one needs to be able to compare two permutations.
a. Give an index that enables one to designate and differentiate permutations on the initial string.
b. Give an algorithm, compare_permutations, which, given as input a string S and two integers i and j, computes a Boolean function. This algorithm must decide whether the string shifted i times is before the string shifted j times, according to the order obtained by sorting all the permutations with the alphabetic order.
c. Determine the memory space required in order to compute BWT.
d. How does one compute L and the primary index from the permutation table?
Solution on page 299.
Therefore, in the output of the BWT, one obtains—in general—a string of lower entropy, well suited for a move-to-front followed by a RLE. The compression tool bzip2 detailed in Figure 2.6 uses this sequence of entropy reductions before performing the Huffman encoding. In Section 2.4.2, we see that this technique is among the most efficient ones nowadays.

Figure 2.6 bzip2
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.