The Book of F#: Breaking Free with Managed Functional Programming (2014)
Chapter 10. Show Me the Data
Virtually every application written today requires robust mechanisms to both access and manipulate data. While the full gamut of data access technologies across the .NET Framework is available to you in F#, this chapter focuses on two specific areas: query expressions and type providers.
Query Expressions
When LINQ was added to .NET, it revolutionized the way we access data by providing a unified syntax for querying data from disparate data sources. Upon LINQ’s introduction, C# and Visual Basic were extended to include the query syntax, a SQL-like syntax with context-sensitive keywords that were really syntactic sugar over several language features, such as extension methods and lambda expressions. In this regard, F# was a little late to the party because, prior to F# 3.0, the only way to use LINQ in F# was to directly call the LINQ extension methods.
Despite their foundations in functional programming, using the LINQ methods directly has a highly object-oriented feel due to their fluent interface; sequences are passed to methods that return new sequences and the methods are typically chained with dot notation. Consider the following query, which uses the LINQ extension methods directly against an F# list to filter out odd numbers, and then sorts the results in descending order (remember to open the System.Linq namespace):
[ 1..100 ]
.Where(fun n -> n % 2 = 0)
.OrderByDescending(fun n -> n)
As you can see, chaining the method calls in this manner is much more object-oriented than functional. Query expressions, introduced with F# 3.0, changed that by providing a convenient SQL-like syntax that resembles the query syntax from C# and Visual Basic. They really are LINQ for F#.
Query expressions take the form of query { ... }. Inside the braces we identify a series of operations we want to apply to a sequence, thereby forming a query. For instance, we could rewrite the previous query as a query expression like this (explicitly opening System.Linq isn’t required for query expressions):
query { for n in [ 1..100 ] do
where (n % 2 = 0)
sortByDescending n }
Now, filtering and sorting the list looks and feels more functional. Instead of chaining method calls directly, we’re expressing the query in a more idiomatic manner that uses expression composition and function calls. Because query expressions are a wrapper around the LINQ technologies, you can use them with any sequence.
Given this simple example, one could argue that the Seq and List module functions could be used to similar effect, and in many cases, that’s true. For instance, we could easily replace the where operator with a call to Seq.filter. Likewise, we can often sort using Seq.sortBy instead of the sortBy operator. What’s not immediately apparent is that by being built upon LINQ, query expressions can offer additional optimizations, such as generating a WHERE clause in a SQL query to prevent retrieving a large data set from a database.
In the interest of simplicity, unless otherwise noted, each query expression example in this chapter will use the types and collections defined in the following QuerySource module.
module QuerySource =
open System
type film = { id : int; name : string; releaseYear : int; gross : Nullable<float> }
override x.ToString() = sprintf "%s (%i)" x.name x.releaseYear
type actor = { id : int; firstName : string; lastName : string }
override x.ToString() = sprintf "%s, %s" x.lastName x.firstName
type filmActor = { filmId : int; actorId : int }
let films =
[ { id = 1; name = "The Terminator"; releaseYear = 1984; gross = Nullable 38400000.0 }
{ id = 2; name = "Predator"; releaseYear = 1987; gross = Nullable 59735548.0 }
{ id = 3; name = "Commando"; releaseYear = 1985; gross = Nullable<float>() }
{ id = 4; name = "The Running Man"; releaseYear = 1987; gross = Nullable 38122105.0 }
{ id = 5; name = "Conan the Destroyer"; releaseYear = 1984; gross = Nullable<float>() } ]
let actors =
[ { id = 1; firstName = "Arnold"; lastName = "Schwarzenegger" }
{ id = 2; firstName = "Linda"; lastName = "Hamilton" }
{ id = 3; firstName = "Carl"; lastName = "Weathers" }
{ id = 4; firstName = "Jesse"; lastName = "Ventura" }
{ id = 5; firstName = "Vernon"; lastName = "Wells" } ]
let filmActors =
[ { filmId = 1; actorId = 1 }
{ filmId = 1; actorId = 2 }
{ filmId = 2; actorId = 1 }
{ filmId = 2; actorId = 3 }
{ filmId = 2; actorId = 4 }
{ filmId = 3; actorId = 1 }
{ filmId = 3; actorId = 5 }
{ filmId = 4; actorId = 1 }
{ filmId = 4; actorId = 4 }
(* Intentionally omitted actor for filmId = 5 *) ]
There’s nothing particularly interesting about the QuerySource module, but the types and collections defined here sufficiently represent a basic data model we can query in a variety of ways. The film and actor types also include overrides of ToString to simplify the query output.
Basic Querying
In their most basic form, query expressions consist of an enumerable for loop and a projection. The enumerable for loop defines a name for items in a source sequence. The projection identifies the data that will be returned by the query.
One of the most common projection operators is select, which equates to LINQ’s Select method and defines the structure of each item in the resulting sequence (much like Seq.map). At their most basic, select operations simply project each data item directly, like this:
query { for f in QuerySource.films do select f }
which results in:
val it : seq<QuerySource.film> =
seq
[{id = 1;
name = "The Terminator";
releaseYear = 1984;
gross = 38400000.0;};
-- snip -- ]
select operations aren’t limited to projecting only the source data item; they can also transform the source sequence to project more complex types like tuples, records, or classes. For instance, to project a tuple containing the film’s name and its release year, you could write:
query { for f in QuerySource.films do
select (f.name, f.releaseYear) }
which gives:
val it : seq<string * int> =
seq
[("The Terminator", 1984); ("Predator", 1987); ("Commando", 1985);
("The Running Man", 1987); ...]
In these simple examples, we’ve explicitly included a select operation to transform the source sequence. As query complexity grows, projecting the raw, nontransformed data items is often implied, so the select operation can often be safely omitted. In the interest of space, I’ll generally project results with ToString, but I encourage you to experiment with different projections to familiarize yourself with the query behavior.
Filtering Data
Queries often involve specifying some criteria to filter out unwanted data. There are two primary approaches to filtering with query expressions: predicate-based filters and distinct item filters.
Predicate-Based Filters
Predicate-based filters allow you to filter data by specifying the criteria that each item in the source sequence must satisfy in order to be included in the projected sequence. To create a predicate-based filter, simply include F#’s equivalent of LINQ’s Where method, the where operator, followed by a Boolean expression (often called a predicate) in your query. (Note that parentheses are typically required around the expression.) For example, to select only the films released in 1984, you could write this:
query { for f in QuerySource.films do
where (f.releaseYear = 1984)
select (f.ToString()) }
to get:
val it : seq<string> =
seq ["The Terminator (1984)"; "Conan the Destroyer (1984)"]
When composing predicate-based filters, you must be aware of the source sequence’s underlying type. For the simple examples you’ve seen so far it hasn’t been an issue, but in many cases, particularly when you are working with IQueryable<'T> instances, you might have to deal with null values.
Null values can pose a problem in query expressions because the standard comparison operators don’t handle them. For example, if you were to query for all films that grossed no more than $40 million using the standard equality operator like this:
query { for f in QuerySource.films do
where (f.gross <= 40000000.0)
select (f.ToString()) }
you’d receive the following error because gross is defined as Nullable<float>:
QueryExpressions.fsx(53,16): error FS0001: The type 'System.Nullable<float>'
does not support the 'comparison' constraint. For example, it does not support
the 'System.IComparable' interface
To work around this limitation, you need to use the nullable operators defined in the Microsoft.FSharp.Linq.NullableOperators module. These operators look like the standard operators except that they begin with a question mark (?) when the left operand is Nullable<_>, end with a question mark when the right operand is Nullable<_>, or are surrounded by question marks when both operands are Nullable<_>. Table 10-1 lists each of the nullable operators.
Table 10-1. Nullable Operators
|
Operator |
Left Side Nullable |
Right Side Nullable |
Both Sides Nullable |
|
Equality |
?= |
=? |
?=? |
|
Inequality |
?<> |
<>? |
?<>? |
|
Greater than |
?> |
>? |
?>? |
|
Greater than or equal |
?>= |
>=? |
?>=? |
|
Less than |
?< |
<? |
?<? |
|
Less than or equal |
?<= |
<=? |
?<=? |
|
Addition |
?+ |
+? |
?+? |
|
Subtraction |
?- |
-? |
?-? |
|
Multiplication |
?* |
*? |
?*? |
|
Division |
?/ |
/? |
?/? |
|
Modulus |
?% |
%? |
?%? |
Now we can rewrite the previous query using the appropriate nullable operator like this:
open Microsoft.FSharp.Linq.NullableOperators
query { for f in QuerySource.films do
where (f.gross ?<= 40000000.0)
select (f.ToString()) }
to get:
val it : seq<string> = seq ["The Terminator (1984)"; "The Running Man (1987)"]
As you can see, the query resulted in two matches despite the underlying sequence containing some null values.
It’s possible to chain multiple predicates together with Boolean operators. For instance, to get only the films released in 1987 that grossed no more than $40 million, you could write:
query { for f in QuerySource.films do
where (f.releaseYear = 1987 && f.gross ?<= 40000000.0)
select (f.ToString()) }
which gives:
val it : seq<string> = seq ["The Running Man (1987)"]
Distinct-Item Filters
Query expressions can produce a sequence containing only the distinct values from the underlying sequence by filtering out duplicates. To achieve this, you need only include the distinct operator in your query.
The distinct operator corresponds to LINQ’s Distinct method, but unlike in C# or VB, query expressions allow you to include it directly within the query rather than as a separate method call. For example, to query for distinct release years, you could write this:
query { for f in QuerySource.films do
select f.releaseYear
distinct }
Here, we’ve projected the distinct release years to a new sequence:
val it : seq<int> = seq [1984; 1987; 1985]
Accessing Individual Items
It’s quite common for a sequence to contain multiple items when you really care about only one in particular. Query expressions include several operators for accessing the first item, the last item, or arbitrary items from a sequence.
Getting the First or Last Item
To get the first item from a sequence, you can use the head or headOrDefault operators. These operators respectively correspond to the parameterless overloads of the First and FirstOrDefault LINQ methods but use the more functional nomenclature of “head” to identify the first item (just like with F# lists). The difference between head and headOrDefault is that head raises an exception when the source sequence is empty, whereas headOrDefault returns Unchecked.defaultof<_>.
To get the first item from a sequence, simply project a sequence to one of the head operators like this:
query { for f in QuerySource.films do headOrDefault }
In this case, the result is:
val it : QuerySource.film = {id = 1;
name = "The Terminator";
releaseYear = 1984;
gross = 38400000.0;}
Similarly, you can get the last item in a sequence using either the last or lastOrDefault operators. These operators behave the same way as their head counterparts in that last raises an exception when the sequence is empty, whereas lastOrDefault does not. Depending on the underlying sequence type, getting the last item may require enumerating the entire sequence, so exercise some care because the operation could be expensive or time consuming.
Getting an Arbitrary Item
When you want to get a specific item by its index you can use the nth operator, which is equivalent to LINQ’s ElementAt method. For instance, to get the third element from the films sequence, you could structure a query like this:
query { for f in QuerySource.films do nth 2 }
Here, the result is:
val it : QuerySource.film = {id = 3;
name = "Commando";
releaseYear = 1985;
gross = null;}
Although the nth operator is useful when you already know the index, it’s more common to want the first item that matches some criteria. In those cases, you’ll want to use the find operator instead.
The find operator is equivalent to calling LINQ’s First method with a predicate. It is also similar to the where operator except that it returns only a single item instead of a new sequence. For example, to get the first film listed for 1987, you could write:
query { for f in QuerySource.films do find (f.releaseYear = 1987) }
Executing this query will give you:
val it : QuerySource.film = {id = 2;
name = "Predator";
releaseYear = 1987;
gross = 59735548.0;}
The find operator is useful for locating the first item that matches some criteria, but it doesn’t guarantee that the first match is the only match. When you want to return a single value but also need to be certain that a query result contains one and only one item (such as when you are finding an item by a key value), you can use the exactlyOne operator, which corresponds to the parameterless overload of LINQ’s Single method. For example, to get a film by its id while enforcing uniqueness, you could write:
query { for f in QuerySource.films do
where (f.id = 4)
exactlyOne }
In this case, the query yields:
val it : QuerySource.film = {id = 4;
name = "The Running Man";
releaseYear = 1987;
gross = 38122105.0;}
When the source sequence doesn’t contain exactly one item, the exactlyOne operator raises an exception. Should you want a default value when the source sequence is empty, you can use the exactlyOneOrDefault operator instead. Be warned, though, that if the source sequence includes more than one item, exactlyOneOrDefault will still raise an exception.
NOTE
Query expression syntax does not include operators equivalent to the predicate-based overload of Single or SingleOrDefault.
Sorting Results
Query expressions make sorting data easy, and, in some ways, they are more flexible than the sorting functions in the various collection modules. The sorting operators allow you to sort in ascending or descending order on both nullable and non-nullable values. You can even sort by multiple values.
Sorting in Ascending Order
Sorting a sequence in ascending order requires either the sortBy or sortByNullable operators. Both of these operators are built upon LINQ’s
OrderBy method. Internally, these methods differ only by the generic constraints applied to their arguments. As their names imply, the sortBy operator is used with non-nullable values, whereas sortByNullable is used with Nullable<_> values.
With both of these operators, you need to specify the value on which to sort. For example, to sort the films by name, you could write:
query { for f in QuerySource.films do
sortBy f.name
select (f.ToString()) }
This returns the following sequence:
val it : seq<string> =
seq
["Commando (1985)"; "Conan the Destroyer (1984)"; "Predator (1987)";
"The Running Man (1987)"; ...]
Sorting in Descending Order
To sort a sequence in descending order, you use either the sortByDescending or sortByNullableDescending operators. These operators are based on LINQ’s OrderByDescending method and, like their ascending counterparts, internally differ only by the generic constraints applied to their parameters.
To sort the films sequence in descending order by name, you could write:
query { for f in QuerySource.films do
sortByDescending f.name
select (f.ToString()) }
which returns:
val it : seq<string> =
seq
["The Terminator (1984)"; "The Running Man (1987)"; "Predator (1987)";
"Conan the Destroyer (1984)"; ...]
Sorting by Multiple Values
To sort on multiple values, first sort with one of the sortBy or sortByDescending operators and then supply subsequent sort values with one of the thenBy operators. As with the primary sort operators, there are variations of thenBy that allow you to sort in ascending or descending order using both nullable and non-nullable values.
The four thenBy variations, which can appear only after one of the sortBy variations, are:
§ thenBy
§ thenByNullable
§ thenByDescending
§ thenByNullableDescending
These operators are based upon LINQ’s ThenBy and ThenByDescending methods. To see these in action, let’s sort the films sequence by releaseYear and then in descending order by gross:
query { for f in QuerySource.films do
sortBy f.releaseYear
thenByNullableDescending f.gross
select (f.releaseYear, f.name, f.gross) }
This query results in the following sorted sequence:
val it : seq<int * string * System.Nullable<float>> =
seq
[(1984, "The Terminator", 38400000.0); (1984, "Conan the Destroyer", null);
(1985, "Commando", null); (1987, "Predator", 59735548.0); ...]
You can chain additional thenBy operators to create even more complex sorting scenarios.
Grouping
Another common query operation is grouping. Query expressions provide two operators, both based on LINQ’s GroupBy method, to do just that. Both operators produce an intermediate sequence of IGrouping<_,_> instances that you refer to later in your query.
The first operator, groupBy, lets you specify the key value by which the items in the source sequence will be grouped. Each IGrouping<_,_> produced by groupBy includes the key value and a child sequence containing any items from the source sequence that matches the key. For example, to group the films by release year, you could write:
query { for f in QuerySource.films do
groupBy f.releaseYear into g
sortBy g.Key
select (g.Key, g) }
This query produces the result (formatted and abbreviated for readability):
val it : seq<int * IGrouping<int, QuerySource.film>> =
seq
[(1984, seq [{id = 1; -- snip --};
{id = 5; -- snip --}]);
(1985, seq [{id = 3; -- snip --}]);
(1987, seq [{id = 2; -- snip --};
{id = 4; -- snip --}])]
It isn’t always necessary to include the full source item in the resulting IGrouping<_,_> like the groupBy operator does. Instead, you can use the groupValBy operator to specify what to include, be it a single value from the source or some other transformation. Unlike the other operators we’ve seen so far, groupValBy takes two arguments: the value to include in the result, and the key value.
To demonstrate the groupValBy operator, let’s group the films by releaseYear again, but this time we’ll include a tuple of the film name and its gross earnings:
query { for f in QuerySource.films do
groupValBy (f.name, f.gross) f.releaseYear into g
sortBy g.Key
select (g.Key, g) }
This gives us:
val it : seq<int * IGrouping<int,(string * System.Nullable<float>)>> =
seq
[(1984,
seq [("The Terminator", 38400000.0); ("Conan the Destroyer", null)]);
(1985, seq [("Commando", null)]);
(1987, seq [("Predator", 59735548.0); ("The Running Man", 38122105.0)])]
Now, instead of the full film instance, the resulting groupings include only the data we explicitly requested.
Paginating
Query expressions allow you to easily paginate a sequence. Think about your typical search results page, where items are partitioned into some number of items (say, 10) per page. Rather than having to manage placeholders that identify which partition a user should see, you can use query expressions, which provide the skip, skipWhile, take, and takeWhile operators to help you get to the correct partition in the query itself. Each of these operators shares its name with its underlying LINQ method.
The skip and take operators both accept an integer indicating how many items to bypass or include, respectively. For example, you could compose a function to get a particular page, like this:
let getFilmPageBySize pageSize pageNumber =
query { for f in QuerySource.films do
skip (pageSize * (pageNumber - 1))
take pageSize
select (f.ToString()) }
Now, getting a particular page is only a matter of invoking the getFilmPage function. For instance, to get the first page of three items, you would write:
getFilmPageBySize 3 1
which yields:
val it : seq<string> =
seq ["The Terminator (1984)"; "Predator (1987)"; "Commando (1985)"]
Likewise, you would get the second result page as follows:
getFilmPageBySize 3 2
which gives us:
val it : seq<string> =
seq ["The Running Man (1987)"; "Conan the Destroyer (1984)"]
It’s okay to specify more items than are present in the sequence. If the end of the sequence is reached, the skip and take operators return what has been selected so far and no exceptions are thrown.
The skipWhile and takeWhile operators are very similar to skip and take except that instead of working against a known number of items, they skip or take items as long as a condition is met. This is useful for paging over a variable number of items according to some criteria. For example, the following function returns the films released in a given year:
let getFilmPageByYear year =
query { for f in QuerySource.films do
sortBy f.releaseYear
skipWhile (f.releaseYear < year)
takeWhile (f.releaseYear = year)
select (f.ToString()) }
Invoking this function with a year will generate a sequence containing zero or more items. For instance, invoking it with 1984 returns:
val it : seq<string> =
seq ["The Terminator (1984)"; "Conan the Destroyer (1984)"]
whereas invoking it with 1986 returns no items because the source sequence doesn’t include any films released in 1986.
If you’re wondering whether this simple example of paging by releaseYear could be simplified with a single where operator, it can. This example simply demonstrates takeWhile’s effect. where and takeWhile serve similar purposes, but distinguishing between them is important, particularly for more complex predicates. The difference between the two operators is that takeWhile stops looking as soon as it finds something that doesn’t match, but where does not.
Aggregating Data
As often as we need to present or otherwise work with tabular data, sometimes what we’re really after is an aggregated view of the data. Aggregations such as counting the number of items in a sequence, totaling some values, or finding an average are all commonly sought-after values that can be exposed through built-in query operators.
Counting the items in a sequence is easy; simply project the sequence to the count operator.
query { for f in QuerySource.films do count }
Evaluating this query tells us that five items are present in the films sequence. Be warned, though, that counting the items in a sequence can be an expensive operation; it typically requires enumerating the entire sequence, which could have a negative impact on performance. That said, theCount method on which this operator is based is smart enough to short-circuit some sequences (like arrays). If you’re counting items only to determine whether the sequence contains any data, you should instead consider using the exists operator, discussed in Detecting Items.
The remaining aggregation operators allow you to easily perform mathematical aggregations against a sequence according to a selector. The operators—minBy, maxBy, sumBy, and averageBy—allow you to calculate the minimum value, maximum value, total, or average for the values, respectively. Internally, the minBy and maxBy operators use LINQ’s Min and Max methods, respectively, but sumBy and averageBy provide their own implementations and are completely independent of LINQ.
Each of these four operators also have nullable counterparts that work against nullable values much like the sorting operators introduced in Sorting Results. To demonstrate, we’ll query the films sequence using the nullable forms.
To find the highest grossing film, we could write:
query { for f in QuerySource.films do maxByNullable f.gross }
As expected, running this query returns 59735548.0. Replacing maxByNullable with minByNullable returns 38122105.0, and sumByNullable returns 136257653.0. The averageByNullable operator doesn’t behave quite as you might expect, however.
Averaging the gross earnings using averageByNullable results in 27251530.6. What happens is that although the operator skips null values during the summation phase, it divides the sum by the count of items in the sequence regardless of how many null items were skipped. This means that the null values are effectively treated as zero, which may or may not be desirable. Later in this chapter, we’ll look at how to define a new query operator that truly ignores null values when calculating an average.
Detecting Items
Thus far, we’ve explored the many ways you can structure query expressions to transform, filter, sort, group, and aggregate sequences. Sometimes, though, you don’t really care to obtain specific items from a sequence but rather want to inspect a sequence to determine whether it contains data that matches some criterion. Instead of returning a new sequence or a specific item, the operators discussed in this section return a Boolean value indicating whether the sequence contains the desired data. Like the distinct operator, these operators are part of the query expression itself, which is another feature that distinguishes F#’s query expressions from query syntax in C# and Visual Basic.
When you want to see if a known item is contained within a sequence, you use the contains operator. Built upon LINQ’s Contains method, the contains operator accepts the item you are looking for as its argument. For instance, if we want to detect whether Kindergarten Cop is present in the films collection, we could write:
open System
open QuerySource
let kindergartenCop =
{ id = 6; name = "Kindergarten Cop"; releaseYear = 1990; gross = Nullable 91457688.0 }
query { for f in films do
contains kindergartenCop }
Invoking this query will inform you that Kindergarten Cop is not present in the collection (much to my relief). As you can see, though, the contains operator is really suitable only when you already have a reference to an item that may already be part of the collection. If you know only part of the value you’re looking for, such as the name of the film, you can revise the query to project each name and pass the name you’re looking for to contains, like this:
query { for f in QuerySource.films do
select f.name
contains "Kindergarten Cop" }
Projecting the values like this, however, isn’t particularly efficient because it involves enumerating the entire sequence prior to locating the specified item. Instead, you can turn to another operator, exists, which is based on LINQ’s Any method. The exists operator is like where except that it stops enumerating the sequence and returns true or false as soon as an item that matches its predicate is found. For example, the previous query could be expressed with exists like this:
query { for f in QuerySource.films do
exists (f.name = "Kindergarten Cop") }
Of course, the predicate supplied to exists doesn’t have to look for a specific item. We can easily determine if any films grossed at least $50 million with the following query:
open Microsoft.FSharp.Linq.NullableOperators
query { for f in QuerySource.films do
exists (f.gross ?>= 50000000.0) }
Because Predator grossed nearly $60 million, the previous query returns true. If you want to check whether every item in a sequence satisfies some condition, you can use the all operator. Based on LINQ’s All method, the all operator enumerates the sequence and returns true when each item matches the predicate. When an item that doesn’t match the predicate is encountered, enumeration stops and all returns false. For example, to see if every film grossed at least $50 million, you could construct a query like this:
query { for f in QuerySource.films do
all (f.gross ?>= 50000000.0) }
In our films collection, only one item satisfies the condition; therefore, the query returns false.
Joining Multiple Data Sources
Querying data from a single sequence is useful, but data is often spread across multiple sources. Query expressions carry forward LINQ’s join capabilities, which allow you to query data from multiple sources within a single expression. Joins in query expressions resemble enumerable forloops in that they include an iteration identifier and the source sequence but begin with the appropriate join operator and also include join criteria.
The first type of join, the inner join, uses the join operator to correlate values from one sequence with values in a second sequence. Internally, the join operator uses LINQ’s Join method to work its magic. Once the sequences are joined, values from both sequences can be referenced by subsequent operators like where or select.
Until now, all of the queries we’ve written have used only the films collection. Recall that when we created the QuerySource module at the beginning of the chapter, we also defined two other collections: actors and filmActors. Together, the films, actors, and filmActorscollections model a many-to-many relationship between films and actors, with filmActors serving as the junction table. We can use the join operator to bring these three collections together in a single query like this:
query { for f in QuerySource.films do
join fa in QuerySource.filmActors on (f.id = fa.filmId)
join a in QuerySource.actors on (fa.actorId = a.id)
select (f.name, f.releaseYear, a.lastName, a.firstName) }
Joining multiple sequences together merely requires us to include a join expression for each sequence and identify the relationship between them through their members and an equality operator. Invoking this query results in the following sequence (truncated per FSI):
val it : seq<string * int * string * string> =
seq
[("The Terminator", 1984, "Schwarzenegger", "Arnold");
("The Terminator", 1984, "Hamilton", "Linda");
("Predator", 1987, "Schwarzenegger", "Arnold");
("Predator", 1987, "Weathers", "Carl"); ...]
F# exposes LINQ’s GroupJoin function through the groupJoin operator. This lets you join two sequences, but instead of selecting items that satisfy the join criterion individually, you project each item that satisfies the join criterion into another sequence you can subsequently reference within your query. You can use this intermediate sequence to create a hierarchical data structure that resembles the IGrouping<_,_> instances created by the groupBy operator.
Consider the following query, which creates a hierarchy where each actor is grouped by the films in which he or she appears:
query { for f in QuerySource.films do
groupJoin fa in QuerySource.filmActors on (f.id = fa.filmId) into junction
select (f.name, query { for j in junction do
join a in QuerySource.actors on (j.actorId = a.id)
select (a.lastName, a.firstName) } ) }
Here, we use the groupJoin operator to create an intermediate sequence named junction. Inside the projected tuple, we have a nested query where we join actors to junction and project individual actor names. This results in the following sequence, which I’ve formatted for readability:
val it : seq<string * seq<string * string>> =
seq
[("The Terminator", seq [("Schwarzenegger", "Arnold");
("Hamilton", "Linda")]);
("Predator", seq [("Schwarzenegger", "Arnold");
("Weathers", "Carl");
("Ventura", "Jesse")]);
("Commando", seq [("Schwarzenegger", "Arnold");
("Wells", "Vernon")]);
("The Running Man", seq [("Schwarzenegger", "Arnold");
("Ventura", "Jesse")]);
...]
As you can see, the outer query (the films part) returns a single sequence of tuples. Nested within each item is another sequence containing the actors associated with that film. What isn’t apparent from these truncated results is that when none of the items in the joined sequence satisfies the join criterion (as is the case for Conan the Destroyer), the sequence created by the groupJoin operation is empty.
If you prefer to flatten the results of a groupJoin rather than return them as a hierarchy, you can follow the groupJoin operation with another enumerable for loop, using the junction sequence as the loop source. Here, the previous query is restructured to return each actor inline with the film:
query { for f in QuerySource.films do
groupJoin fa in QuerySource.filmActors on (f.id = fa.filmId) into junction
for j in junction do
join a in QuerySource.actors on (j.actorId = a.id)
select (f.name, f.releaseYear, a.lastName, a.firstName) }
The result of this query is the same as for an inner join, so I won’t repeat the output here. In most cases, you’d want to use the join operator to forego the overhead associated with creating the intermediate junction sequence, but there is one place where using a groupJoin like this makes sense: left outer joins.
By default, if no items satisfy the join criterion in a group join, the result is an empty sequence. However, if you use the DefaultIfEmpty method with the resulting sequence, you’ll get a new sequence containing a single item that’s the default value for the underlying type. To perform a left outer join in your query, you can use the groupJoin operator as we did in the previous query but include a call to DefaultIfEmpty in your enumerable for loop—for example, j.DefaultIfEmpty(). Alternatively, you can use the leftOuterJoin operator to achieve the same result.
Unfortunately, left outer joins are one area where the dissonance between F# and the rest of the .NET Framework can cause a lot of misery. But this is really a problem only when you’re working with the core F# types. Consider the following query:
query { for f in QuerySource.films do
leftOuterJoin fa in QuerySource.filmActors on (f.id = fa.filmId) into junction
for j in junction do
join a in QuerySource.actors on (j.actorId = a.id)
select (f.name, f.releaseYear, a.lastName, a.firstName) }
|> Seq.iter (printfn "%O")
When this query enumerates (via Seq.iter), it raises a NullReferenceException as soon as it tries to join in the actors for Conan the Barbarian. Because there are no entries for that film in the filmActors sequence, the call to DefaultIfEmpty in the left outer join causes the sole entry in junction to be null.
Wait, what? Null? Isn’t filmActor a record type? How can it possibly be null if null isn’t a valid value for record types? The answer lies in the fact that by calling into .NET Framework methods we’ve left the confines of the F# sandbox. null may not be valid for record types in F#, but the Common Language Runtime has no notion of a record type; all it knows are value and reference types and, from its perspective, a record type is just a reference type. Therefore, null is a valid value. Unfortunately, because our code is all in F# and the F# compiler enforces the value constraints around the record type, we can’t handle the null value with pattern matching or if...then expressions. We can’t even use the AllowNullLiteral attribute on the type because the compiler doesn’t allow that either.
Working around this issue is a bit of a pain. We can start by splitting the query into two parts: one that joins actors to filmActors and another that joins in films, like this:
let actorsFilmActors =
query { for a in QuerySource.actors do
join fa in QuerySource.filmActors on (a.id = fa.actorId)
select (fa.filmId, a) }
query { for f in QuerySource.films do
leftOuterJoin (id, a) in actorsFilmActors on (f.id = id) into junction
for (_, a) in junction do
select (f.name, a.lastName, a.firstName) }
This is a good start, but we’ll still get a NullReferenceException with the Tuple pattern match in the enumerable for loop for junction because F# doesn’t allow null for tuples either. There is yet another workaround we can use: an upcast to obj.
query { for f in QuerySource.films do
leftOuterJoin (id, a) in actorsFilmActors on (f.id = id) into junction
for x in junction do
select (match (x :> obj) with
| null -> (f.name, "", "")
| _ -> let _, a = x
(f.name, a.lastName, a.firstName))
}
null may not be a valid value for a tuple, but it certainly is for obj. By explicitly upcasting to obj, we can use pattern matching to detect the null value and return the appropriate tuple instead of raising the exception.
Extending Query Expressions
As you’ve seen in the previous sections, query expressions provide an easy and expressive way to work with data. Query expressions also offer another benefit that really sets them apart from query syntax in C# and Visual Basic: They’re fully extensible. In this section, I’ll show a few additional operators. We’ll start by plugging a hole in the built-in operators by defining operators that expose the parameterized overloads of Single and SingleOrDefault. We’ll then move on to a more complex example that allows us to calculate an average by disregarding all null values.
Example: ExactlyOneWhen
Recall from Getting an Arbitrary Item that the exactlyOne and exactlyOneOrDefault operators expose the parameterless versions of LINQ’s Single and SingleByDefault operators, but no such operators exist for the overloads that accept a predicate. We can easily define our own operators to expose these methods by leveraging the power of F# type extensions.
To create the custom operators, we need to extend the QueryBuilder class found within the Microsoft.FSharp.Linq namespace. This class defines the methods that ultimately serve as the query operators. Fundamentally, the type extension we’ll define is no different than any other type extension; we need only to include a few attributes so the compiler knows how the functions should behave within a query expression.
Here is the code listing in full:
open System
open Microsoft.FSharp.Linq
type QueryBuilder with
① [<CustomOperation("exactlyOneWhen")>]
member ② __.ExactlyOneWhen (③ source : QuerySource<'T,'Q>,
④ [<ProjectionParameter>] selector) =
System.Linq.Enumerable.Single (source.Source, Func<_,_>(selector))
[<CustomOperation("exactlyOneOrDefaultWhen")>]
member __.ExactlyOneOrDefaultWhen (source : QuerySource<'T,'Q>,
[<ProjectionParameter>] selector) =
System.Linq.Enumerable.SingleOrDefault (source.Source, Func<_,_>(selector))
This snippet defines two extension methods on the QueryBuilder class: exactlyOneWhen and exactlyOneOrDefaultWhen. Because these are so similar, we’ll just focus on the exactlyOneWhen operator. The first item of interest is the CustomOperation attribute ① applied to the method itself. This attribute indicates that the method should be available within a query expression and the operator name.
Next, the method’s this identifier is two underscore characters ② to be consistent with the other operator definitions. The source parameter at ③, annotated as QuerySource<'T, 'Q>, identifies the sequence the operator will work against.
Immediately following source is the selector parameter ④. This parameter is a function that will be applied against every item in source to determine whether it should be selected. The ProjectionParameter attribute applied to selector instructs the compiler that the function is implied to accept 'T (as inferred from source) so that you can write the selector function as if you were working directly with an instance; that is, if you’re querying the films collection and have used f as your iteration identifier, you could write f.id = 4. WithoutProjectionParameter, you’d have to use the full lambda syntax (or a formal function) instead of just the expression.
With the new operators defined, we can now write queries that use them. For instance, to use the exactlyOneWhen operator to find a film by id, you would write:
query { for f in QuerySource.films do
exactlyOneWhen (f.id = 4) }
As you can see, with these operators you no longer need to include the where operator to filter the results before checking that the sequence contains only a single item.
Example: AverageByNotNull
For a more complex example of a custom operator, let’s provide an alternative to the averageByNullable operator we used in Aggregating Data to compute the average gross earnings for our films. The calculation resulted in the average being reported as 27251530.6 because the two null values were excluded from the sum but the divisor was still five. If you wanted to truly ignore the null values and divide the total by three, the averageByNullable operator wouldn’t help you, but you could define a custom operator like this:
open System
open Microsoft.FSharp.Linq
type QueryBuilder with
-- snip --
[<CustomOperation("averageByNotNull")>]
member inline __.AverageByNotNull< 'T, 'Q, 'Value
when 'Value :> ValueType
and 'Value : struct
and 'Value : (new : unit -> 'Value)
and 'Value : (static member op_Explicit : 'Value -> float)>
(source : QuerySource<'T, 'Q>,
[<ProjectionParameter>] selector : 'T -> Nullable<'Value>) =
source.Source
|> Seq.fold
(fun (s, c) v -> let i = v |> selector
if i.HasValue then
(s + float i.Value, c + 1)
else (s, c))
(0.0, 0)
|> (function
| (_, 0) -> Nullable<float>()
| (sum, count) -> Nullable(sum / float count))
Notice that the AverageByNotNull method incorporates many of the same principles as exactlyOneWhen and exactlyOneOrDefaultWhen; that is, they each involve the CustomOperation and ProjectionParameter attributes. Where AverageByNotNull differs is that it’s defined as inline to ensure that the generic parameters can be resolved. Because they’re so similar, I’ve based the signature and generic constraints for AverageByNotNull largely upon that of the averageByNullable operator, although I’ve simplified it a bit for demonstration purposes.
Now that we’ve defined the averageByNotNull operator, we can include it in a query like this:
query { for f in QuerySource.films do
averageByNotNull f.gross }
Invoking this query returns 45419217.67, a stark contrast from 27251530.6 as returned by averageByNullable.
Type Providers
Along with query expressions, the other “killer feature” of F# 3.0 is type providers. Type providers were developed to abstract away creation of the types, properties, and methods necessary to work with external data because this process is often tedious, error prone, and difficult to maintain.
Many type providers can be likened to traditional object-relational mapping (ORM) tools like NHibernate or Entity Framework, although their scope is potentially much greater. ORM tools typically require a great deal of configuration to be used effectively. Although there are tools that simplify this process for many of the more popular ORM technologies, they still require plenty of maintenance. ORM-like type providers aim to remove this overhead by automating type generation as part of the compilation process.
The other primary use for type providers is to simplify otherwise complex interfaces. Consider how cumbersome and error-prone something like matching strings with regular expressions can be. Regular expression syntax is confusing enough on its own, but getting named captures from the match collection requires using string keys to identify the values you’re trying to access. A regular expression type provider can simplify the interface by generating types that correspond to the named captures in the regular expression.
Regardless of which need type providers satisfy, they all offer three primary benefits:
§ Making data-centric exploratory programming more accessible by eliminating the need to manually create mappings and type definitions
§ Eliminating the administrative burden of manually maintaining mappings or other type definitions
§ Reducing the likelihood of errors caused by undetected changes to the underlying data structure
A full discussion of type providers goes well beyond the scope of this book. Instead, this section is intended to introduce many of the type providers that are available to you either as part of the core F# distribution or through some popular third-party libraries. After you’ve seen what’s available, we’ll discuss how to initialize and use a few type providers to easily get the data you care about.
Available Type Providers
F# 3.0 includes several type providers out of the box. Table 10-2 lists the built-in providers and a brief description of each.
Table 10-2. Built-in Type Providers
|
Provider |
Description |
|
DbmlFile |
Provides the types that correspond to a SQL Server database as described in a Database Markup Language file (.dbml) |
|
EdmxFile |
Provides the types that correspond to a database as described by a LINQ-to-Entities mapping file (.edmx) |
|
ODataService |
Provides the types that correspond to those returned by an OData service |
|
SqlDataProvider |
Provides the types that correspond to a SQL Server database |
|
SqlEntityProvider |
Provides the types that correspond to a database according to a LINQ-to-Entities mapping |
|
WsdlService |
Provides the types that correspond to those returned by a WSDL-based web service |
The list of built-in type providers is pretty sparse and is focused on database or database-like sources. Even so, what’s provided covers a fairly large number of use cases. Should your data fall outside of the cases covered by the built-in types, you can define custom type providers, but doing so is outside the scope of this book.
Before you start down the path of building your own type providers, you should see if there are any third-party providers that will meet your needs. At the time of this writing, several popular libraries include a number of useful type providers, most notably: FSharpx and FSharp.Data.Table 10-3 lists several of the type providers in each library to give you an idea of what’s readily available and the diversity of uses for type providers. This list is not meant to be exhaustive; there are definitely other libraries available.
Table 10-3. Some Available Third-Party Type Providers
|
Provider |
Description |
FSharpx |
FSharp.Data |
|
AppSettingsProvider |
Provides types that correspond to the nodes in the AppSettings section of a configuration file |
|
|
|
CsvProvider |
Provides types that allow for easy parsing of comma-separated value (CSV) files |
|
|
|
ExcelProvider |
Provides the types necessary for working with an Excel workbook |
|
|
|
FileSystemProvider |
Provides the types necessary for working with the filesystem |
|
|
|
JsonProvider |
Provides types that represent a JavaScript Object Notation (JSON) document |
|
|
|
RegexProvider |
Provides types that allow for inspecting regular expression matches |
|
|
|
XamlProvider |
Provides types that allow for easy XAML parsing |
|
|
|
XmlProvider |
Provides types that represent an XML document |
|
Using Type Providers
Regardless of which type provider you need, initializing one always follows the same basic pattern:
type name = providerName<parameters>
In the preceding syntax, name is the name by which you’ll access the provider’s capabilities, providerName identifies the provider type itself, and parameters are the provider-specific arguments that control the provider’s behavior. Parameters will typically include things like a connection string or the path to the data source, but ultimately each type provider is responsible for defining the parameters it accepts.
The first time a provider is used within Visual Studio, you’ll be presented with a security dialog like the one pictured in Figure 10-1.
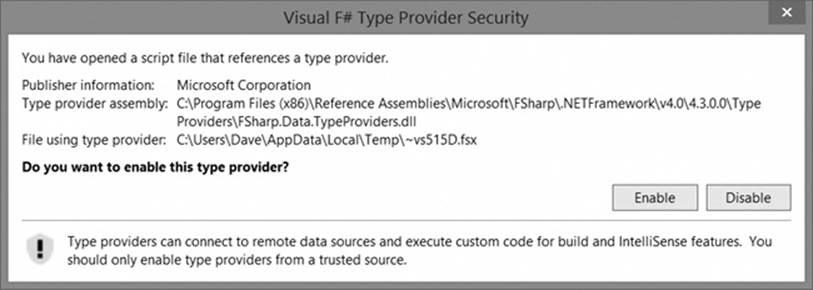
Figure 10-1. Type Provider Security dialog
As the dialog indicates, type providers can connect to remote data sources and execute custom code for build and IntelliSense features. Once you’ve enabled or disabled a type provider, you won’t be prompted again. If you want to change your selection at a later time, you can find a listing of type providers under F# Tools in the Visual Studio Options dialog.
Example: Accessing an OData Service
This first example uses the ODataService type provider to query the publicly available Northwind sample OData service from http://www.odata.org/. To start, we need to reference two assemblies:
#r "System.Data.Services.Client"
#r "FSharp.Data.TypeProviders"
The first assembly includes several Windows Communication Foundation (WCF) classes required by the ODataService provider. Though we don’t use the WCF types directly within this example, failure to add the reference will result in compilation errors. The second assembly contains the provider itself. With these assemblies referenced, we can now open the namespace that contains the ODataService provider:
open Microsoft.FSharp.Data.TypeProviders
Next, we include a type definition that references the appropriate type provider along with the address to the Northwind service:
type northwind =
ODataService<"http://services.odata.org/V3/Northwind/Northwind.svc/">
The ODataService provider takes the supplied address, appends $metadata, and then proceeds to construct and import the types described by the service. In order to do anything with the service, we need to obtain a data context via the provider type like this:
let svc = northwind.GetDataContext()
With the data context established, we now have everything we need to query the data. Here we’ll use a query expression to get some invoice information from the Northwind service.
let invoices =
query { for i in svc.Invoices do
sortByNullableDescending i.ShippedDate
select (i.OrderDate, i.CustomerName, i.ProductName)
take 5 }
There’s nothing out of the ordinary with the preceding query; it uses standard query operators to select OrderDate, CustomerName, and ProductName from the five most recently shipped invoices. What is exceptional is that with no more effort than pointing the type provider at the OData service, we have a full type hierarchy that models the types exposed by the service.
NOTE
Not all of the standard query operators are supported by every data source. For example, join is not supported by OData, so including it in a query with two OData sources will result in an error.
Although we’ve defined the invoices binding, the query execution is deferred until we actually enumerate the sequence. For simplicity, we can do so by piping the sequence to Seq.iter, which we’ll use to print each item like this:
invoices |> Seq.iter (printfn "%A")
Invoking the preceding code printed the following items when I ran it, but your results may differ if the source data changes:
(5/4/1998 12:00:00 AM, "Drachenblut Delikatessen", "Jack's New England Clam Chowder")
(4/30/1998 12:00:00 AM, "Hungry Owl All-Night Grocers", "Sasquatch Ale")
(4/30/1998 12:00:00 AM, "Hungry Owl All-Night Grocers", "Boston Crab Meat")
(4/30/1998 12:00:00 AM, "Hungry Owl All-Night Grocers", "Jack's New England Clam Chowder")
(5/4/1998 12:00:00 AM, "Tortuga Restaurante", "Chartreuse verte")
So far, the ODataService provider has been a black box; as long as you give it a valid address, it usually just works and you don’t have to think about how. This is particularly great when you’re doing exploratory coding, but it can be frustrating when the provider isn’t returning what you expect. Fortunately, there are a couple of events you can subscribe to in order to gain some insight into what the provider is doing: SendingRequest and ReadingEntity.
The SendingRequest event occurs whenever the provider creates a new HttpWebRequest, whereas ReadingEntity occurs after data has been read into an entity. For the purposes of this discussion, we’ll focus on SendingRequest because it can show exactly what is being requested and help you refine your queries.
Probably the most helpful thing to do with SendingRequest is interrogate the RequestUri property of the WebRequest object that’s associated with the SendingRequestEventArgs. RequestUri includes the full address of the OData request, so once you have it, you can paste it into a browser (or other diagnostic utility such as Fiddler) and refine it. One easy way to get the URI is to simply print it to the console like this:
svc.DataContext.SendingRequest.Add (fun args -> printfn "%O" args.Request.RequestUri)
So long as the preceding snippet is executed before the query is enumerated, the URI will be printed ahead of the results. In the case of the query described in this section, the printed URI is: http://services.odata.org/V3/ Northwind/Northwind.svc/Invoices()?$orderby=ShippedDate%20desc&$top=5&$select= OrderDate, CustomerName, ProductName.
For your convenience, the entire example from this section, including the subscription to SendingRequest, is reproduced in its entirety here:
#r "System.Data.Services.Client"
#r "FSharp.Data.TypeProviders"
open Microsoft.FSharp.Data.TypeProviders
type northwind =
ODataService<"http://services.odata.org/V3/Northwind/Northwind.svc/">
let svc = northwind.GetDataContext()
let invoices =
query { for i in svc.Invoices do
sortByNullableDescending i.ShippedDate
select (i.OrderDate, i.CustomerName, i.ProductName)
take 5 }
svc.DataContext.SendingRequest.Add (fun args -> printfn "%O" args.Request.RequestUri)
invoices |> Seq.iter (printfn "%A")
Example: Parsing a String with RegexProvider
For this example, we’ll look at how the RegexProvider from the FSharpx project can generate types that correspond to a regular expression, providing you with a remarkable degree of safety when working with matches. To use this provider, you’ll need to obtain theFSharpx.TypeProviders.Regex package from NuGet or download the source from GitHub (https://github.com/fsharp/fsharpx/).
As with the ODataProvider example, we’ll start by referencing some assemblies and opening some namespaces:
#r "System.Drawing"
#r @"..\packages\FSharpx.TypeProviders.Regex.1.8.41\lib\40\FSharpx.TypeProviders.Regex.dll"
open System
open System.Drawing
Because I created this script as part of a project that included the FSharp.TypeProviders.Regex package from NuGet, I simply referenced the package directly via a relative path; the path to the assembly may be different on your machine depending on how you obtained the assembly and its version.
With the assemblies referenced and the common namespaces opened, we can now create the type provider. Creating a RegexProvider is similar to creating the ODataService except that, instead of a URI, RegexProvider takes a regular expression pattern. For this example, we’ll create the RegexProvider with a simple pattern that matches hexadecimal RGB values. (The space before the verbatim string is significant. Without the space, the compiler would try to interpret the string as a quoted expression, which is definitely not what we want.)
type colorRegex =
FSharpx.Regex< @"^#(?<Red>[\dA-F]{2})(?<Green>[\dA-F]{2})(?<Blue>[\dA-F]{2})$">
The RegexProvider works a bit differently than the ODataService in that it’s not really intended for use as a query source. Instead, we’ll write a function that uses the type provider to convert a hexadecimal string into a standard .NET Color instance if it matches the regular expression pattern.
let convertToRgbColor color =
let inline hexToDec hex = Convert.ToInt32(hex, 16)
let m = color |> ① colorRegex().Match
if m.Success then
Some (Color.FromArgb(② m.Red.Value |> hexToDec,
③ m.Green.Value |> hexToDec,
④ m.Blue.Value |> hexToDec))
else None
In the preceding code, we push the supplied color string into the Match method of a new instance of the colorRegex①. The value returned by Match is similar to the Match object returned when we’re using regular expressions directly (through the Regex class inSystem.Text.RegularExpressions), but as you can see at ②, ③, and ④, it also includes named properties that match the named groups defined within the source regular expression! This means that you don’t have to fumble with magic strings to access the individual named captures!
To test this, we merely need to pass some strings to the convertToRgbColor function. Here we invoke the function for each string in a list:
[ ""; "#FFFFFF"; "#000000"; "#B0C4DE" ]
|> List.iter
(convertToRgbColor >>
(function
| None -> printfn "Not a color"
| Some(c) -> printfn "%O" c))
Evaluating this code should result in the following:
Not a color
Color [A=255, R=255, G=255, B=255]
Color [A=255, R=0, G=0, B=0]
Color [A=255, R=176, G=196, B=222]
As you can see, the first string didn’t match the color pattern so it was not converted, whereas the remaining three items were converted and written accordingly.
Summary
With the addition of query expressions and type providers in F# 3.0, F# took massive strides toward being an even better language for data-intensive development work.
Query expressions bring the power of LINQ to the language with an idiomatic flair. With them, you can easily compose complex queries for analyzing and presenting data from a variety of data sources. Furthermore, the extensible nature of query expressions makes them well suited for more complex needs.
Type providers further expand upon F#’s already rich data experience by abstracting away the details of creating types that map to different data sources. They greatly improve a developer’s ability to perform exploratory programming in data-centric scenarios because the developer doesn’t need to be as concerned about how to access the data. Finally, type providers can add an extra degree of safety to the code by detecting changes to the underlying data structures as part of the build process.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.