F# Deep Dives (2015)
Part 4. F# in the larger context
Chapter 12. Software quality
Phil Trelford
Software quality means different things to different groups of people. In this chapter, I’ll look at software quality through the perspective of my personal experience—which includes creating video games, writing a line of business applications, and, most recently, developing financial systems.
In video games and front office trading systems, performance is often the key quality issue. Arcade games typically run at 60 frames per second so they feel responsive to the player. Trading screens must also respond to user input in milliseconds, particularly during periods of high market activity, so users can take positions and (often more important) exit those positions if the market turns against them. As discussed in chapter 1, F# is compiled and efficient. We’ll look at techniques for monitoring performance to make sure your F# code satisfies the performance requirements of your project.
For many line of business (LOB) applications, performance is less of an issue, and the focus is on building out functionality. Getting precise requirements isn’t always easy to achieve, because often customers don’t know at the start exactly what they want. To rapidly respond to changing business requirements, code should be either extensible or modular so that parts can be replaced in isolation. In video games, the game logic is often written in a scripting language like Lua, for rapid prototyping and easy change. In F#, you can achieve similar flexibility using domain-specific languages (DSLs) like the one discussed in chapter 3. Together with the interactive style of development, these are two important reasons F# has a faster time-to-market cycle.
F# for testing
I think F# has one of the best testing stories of any language. It uses all the testing frameworks of .NET and adds its own powerful set. The F# community takes software quality seriously, which can be seen in a plethora of libraries from FsUnit for fluent assertions to FsCheck for fuzz testing.
Add to this a wealth of language-feature enablers that make testing easier. For example, the backtick notation lets you use whitespace in function names and write
``1 + 1 should equal 2``
rather than writing OnePlus1ShouldEqual2.
In my experience, testing is a great and risk-free way to introduce F# into the workflow of your company. Tests written in F# are easier to write and end up being more readable. By using F# for testing and exploration, you can also learn to write idiomatic F# code without rewriting your main system from scratch, which is never a good idea.
In this chapter, we’ll explore all the features that make F# a great language for testing, and we’ll look at many of the .NET and F# tools for testing, giving you a comprehensive reference in one place. You’ll learn about the following:
· Software quality being more than just unit tests —We’ll look at the F# development cycle, which often starts with exploratory programming, relies heavily on static types, and adds unit testing as a later step.
· Unit testing —We’ll discuss simple unit testing, as well as fluent DSLs (to make F# tests more readable) and parameterized unit tests.
· Advanced testing techniques —We’ll cover tools for fuzz testing that let you search for defects using random input generation and test doubles (that is, different ways to decouple the tests from concrete implementations).
· Automated acceptance testing —We’ll look beyond developer-generated tests and explore user stories to see how behavior-driven development (BDD) encourages developers to work with users to capture requirements.
Throughout the chapter, you’ll see plenty of F# examples using libraries, including NUnit, xUnit, FsUnit, Unquote, FsCheck, Moq, Foq, and TickSpec. If some of these names are new to you, don’t worry. That’s why you’re reading this chapter! Similar levels of automation are possible in languages other than F#, but it has been my experience that a high-level language like F# makes writing tests simpler and faster to achieve. Before diving into the code, let’s focus on the bigger picture, because software quality isn’t just about code.
What software quality really means
As mentioned in the introduction, software quality means different things to different groups:
· Developers talk about readability and maintainability of the code.
· Testers often look at acceptance tests and defect counts.
· Users think of polished visuals, responsiveness, workflow, and functionality.
This chapter looks at software quality based on practical experience from all three perspectives. As developers, we’ll look at interactive development style and unit tests. As testers, we’ll explore tools for black-box testing based on functional properties. Finally, as users, we’ll look at acceptance testing and ways of capturing the workflow and functionality.
Software quality covers both functional requirements like business rules and nonfunctional requirements like responsiveness that can require significantly different approaches. This means you must first understand the requirements before choosing and using any testing tools. Otherwise, you may be wasting your time testing a property that doesn’t matter for the problem at hand.
Understanding requirements
In the context of software systems, functional requirements capture “what the system should do,” and nonfunctional requirements capture “how the system should do it.” In other words, functional requirements capture the functionality, and nonfunctional requirements capture all the other important technical aspects such as scalability, performance, and fault tolerance, and also cost and time-to-market.
Nonfunctional requirements
From my experience in the development of video games and trading systems, performance is the most striking example of a nonfunctional requirement. Such properties need to be tracked continuously during the entire development cycle. If you “finish” writing a game but end up with code that doesn’t perform well enough, revisiting the entire codebase will be extremely difficult.
For example, trading backends must respond to high volumes of requests from thousands of clients with low latency. To ensure that a system achieves the required high performance, you can use two techniques. The first is to add key performance indicators (KPIs) at the start of the project so that you can keep track of performance throughout development. The other technique is to use exploratory testing and analyze performance as you’re writing the code. We’ll look at this in the context of F# Interactive (FSI) later in this chapter.
Note
In the 1980s and 90s, video games used the border area of the CRT screen to visually indicate how much of a frame flyback was being used by the game loop. Nowadays frameworks like Silverlight, Windows Presentation Foundation (WPF), and XNA show numerical statistics like frame rate overlaid over the application.
For a trading system, KPIs can be exposed via system performance counters or even a web-based console. I’ve found that for high-performance systems, a rapid prototyping approach based on exploratory testing works well so that you can quickly discount implementations that don’t fit the performance and focus on finding the right algorithms. F# provides a read-evaluate-print-loop (REPL) with high-precision timing via the #time directive, which makes exploratory testing particularly easy.
Functional requirements
For many LOB applications, performance is less of an issue, and the focus is on building out functionality. Getting precise functional requirements isn’t always easy to achieve, because often customers don’t know at the start exactly what they want. As software developers, you and I might complain about this, but that’s not going to make the problem go away. You need to understand that this is the case and find good ways to understand your users.
I’ve found that a collaborative approach works well, in which developers talk directly with users about requirements. Often those requirements are captured as user stories with acceptance tests. Stories and acceptance tests can be made less ambiguous by specifying functionality by example, with expected inputs and outputs.
Note
F# has access to a wide range of mature libraries for F# and the .NET Framework that aid the automation of acceptance tests. In some of them, including SpecFlow and TickSpec, scenarios are specified as plain text, making them more readable. In others, such as NaturalSpec, the scenarios are written as code, which makes them easier to run and test.
Not only are functional requirements difficult to identify initially, but they also frequently change during the development of software systems.
Changing requirements
Hardly anyone would argue that software requirements don’t change. Moreover, this isn’t something you should fight against. Instead, you need to write software in a way that makes it easy to adapt to changing requirements.
As mentioned earlier, video game developers often use a scripting language to write the game logic. This approach enables rapid prototyping and easy change—often without even needing to recompile the game.
Business systems can opt to take a similar approach to areas where changes are anticipated by allowing modules to be plugged into the system at runtime, or by creating abstractions that allow changes to be added, albeit at compile time. In functional-first programming languages like F#, this flexibility can be achieved using internal and external DSLs.
DSLs bring a number of benefits. Internal DSLs consist of types and functions that map closely to the business domain, and logic can be changed quickly as requirements change. External DSLs can be used to specify behavior or to configure the system. You can achieve properties similar to scripting in video games—you can change the configuration or behavior without recompiling (or even restarting) the application.
If restricted languages aren’t enough for your use case, it’s worth pointing out that F# code can also talk to scripting languages like Lua.NET, IronPython, and IronRuby. Thanks to the F# Compiler Services project (http://fsharp.github.io/FSharp.Compiler.Service), it’s also easy to embed FSI itself as a scripting language in your application.
Domain-specific languages
DSLs are languages that make it easy to solve one specific problem. They can be either external (with their own syntax and format) or internal (embedded as libraries in a host language). In chapter 3, we looked at Markdown, which is an external DSL for writing documents.
Philip Wadler has described functional programming languages as domain-specific languages for creating other domain specific languages.[1] As a functional-first language, F# makes light work of creating internal DSLs and external DSLs. The latter is demonstrated in chapter 3. Speaking of the latter, almost any well-designed F# library will seem like a DSL to some extent. You’ll see this when looking at F# testing libraries like FsUnit.
1 Philip Wadler, “A Practical Theory of Language-Integrated Query,” Functional Programming eXchange 2014, March 14, 2014, http://mng.bz/tN1e (video).
Avoiding defects early with types
It’s a common belief that the earlier a defect is found, the cheaper it is to fix, with defects discovered in production being the most expensive. A combination of compile-time type checking and automated testing can help catch defects earlier during development.
F#’s strong type system can help eliminate a number of common defects found in languages like C#, Java, and JavaScript, including the prevalent null reference exception (NRE). The introduction of null is considered a billion-dollar mistake by its inventor, Tony Hoare;[2] and to quote Don Syme, “Friends don’t let friends use null.”[3]
2 Tony Hoare, “Null References: The Billion-Dollar Mistake,” QCon London, August 25, 2009, http://mng.bz/l2MC (video).
3 Don Syme, “Keynote: F# in the Open Source World,” Progressive F# Tutorials NYC 2013, September 18, 2013, http://mng.bz/8rcO (video).
One way to find out if you have a problem with NREs is to search your bug database. For me, NREs are the most common defect I find in C# code. When programming in F#, the types that are declared in F# can’t be assigned null as a value. This doesn’t prevent NREs completely, because you can still get a null value when calling .NET or C#, but it significantly reduces the number of NRE-related issues in your code. In F#, you have to be more explicit when dealing with missing values:
|
let person = tryFindPersonByID(42) match person with | Some p -> p.Name | None -> "(unknown)" |
var person = TryFindPersonByID(42) if (person != null) then return person.Name; else return "(unknown)"; |
The two examples look similar, and they both return the name of the person only if the person has been found. But in F#, the function returns option<Person>, indicating that the value might be missing. In C#, this is indicated by returning a null value. The problem is that in C#, you could easily forget the null check and access person.Name right after you get the object. This would, of course, cause an NRE. The F# pattern matching is much safer. It even warns you if you’ve missed a case as you’re writing the code.
Not your grandfather’s static type system
The F# type system is in many ways stronger than that of C#. For numerical code, there is built-in support for units of measure, and conversion operations between types must be explicit. Other benefits of F# for mathematics were illustrated in chapter 4: F# can be read like mathematical notation, which means details aren’t lost in translation and Mathematica and MATLAB users can work in a familiar environment.
In F#, even string formatting is type checked. For example:
printf "Hello: %s" 42
This call gives a type mismatch error, because the format specifier %s indicates that the argument should be of the type string, but we’re calling it with a number instead!
Despite being more explicit, the F# type system is less verbose than the system used, for example, in C#. This is thanks to type inference, which can figure out most of the types automatically so you need to write types only when you want to be explicit.
The typical programming style in F# has other aspects that help prevent defects. By default, F# functions are typically independent and pure (free from side effects), and data structures are immutable (write-once, read many) and employ structural equality (compare by value), which makes them easier to test and less error-prone. In summary, strong typing can help avoid many defects. For other defect types, there’s automated testing.
Holistic approach to testing
I like to encourage a holistic view of testing that focuses on the qualities that are important to specific areas of your application. This means starting by understanding both functional and nonfunctional requirements and then focusing on the aspects that matter:
· Correctness is the key nonfunctional requirement when you’re implementing, for example, financial calculations where an error has potential dramatic consequences.
· Performance and scalability might be more important factors for action games and server-side services.
· Maintainability is often the key when developing LOB applications where requirements frequently change.
F# has all the tools you need to cover all of these aspects. Fuzz testing (using FsCheck or Pex) can be used to generate test inputs to explore the boundaries of an API and ensure correctness even in unexpected corner cases.
F# also works with all the major .NET unit-testing frameworks like NUnit, xUnit, and MSTest, as well as mocking libraries like Moq, Rhino Mocks, and FakeItEasy. It also adds its own libraries like Unquote, FsUnit, NaturalSpec, and TickSpec, which we’ll explore later in this chapter. Which of the tools you’ll need to use depends on your requirements and focus—whether you’re testing implementation or business scenarios. Table 1 gives a brief overview of the testing techniques.
Table 1. Relative alignment (business and implementation) of various testing approaches
|
Technique |
Business aligned |
Implementation aligned |
F# tools |
|
Exploratory testing |
No |
Yes |
Using F# Interactive is the first part of the testing story in F#. |
|
Unit testing |
No |
Yes |
NUnit, xUnit, FsUnit, and Unquote. |
|
Fuzz testing |
No |
Yes |
FsCheck, which lets you test your algorithms on sample inputs. |
|
Performance monitoring |
Yes |
Yes |
Using the #time directive in F# Interactive REPL. |
|
Specification by example |
Yes |
No |
BDD, which lets you capture user stories as specifications. |
|
User interface tests |
Yes |
No |
Canopy (http://lefthandedgoat.github.io/canopy), a library for writing user interface tests for the web. |
From exploratory to unit testing
When writing code, most F# programmers start by writing their code in F# script files and running it interactively in FSI to test it on sample inputs. In the interactive mode, you can also easily check nonfunctional requirements like performance. Once the initial prototype works (on sample inputs) and is efficient enough, you can turn it into a compiled library and add systematic unit testing. In this section, we’ll explore this approach using a simple function for calculating Scrabble scores as an example.
Note
Scrabble is a board game in which players score points for placing words on a board. Each letter has a score, and placing letters on certain parts of the board multiplies either the letter or word score.
For now, we’ll look at calculating the score of letters and words, but we’ll get back to multipliers later in the chapter. You can see the initial prototype in the following listing.
Listing 1. Calculating the word score in Scrabble

The code is simple, but it’s interesting enough to demonstrate a number of testing techniques. The letterPoints function ![]() uses an elegant pattern-matching approach to return the value of a single letter, and wordPoints
uses an elegant pattern-matching approach to return the value of a single letter, and wordPoints ![]() iterates over all letters in a word using Seq.sumBy and sums the letter values.
iterates over all letters in a word using Seq.sumBy and sums the letter values.
To get started, you don’t need to create a project. All you need to do is create an F# script file (say, Scrabble.fsx) and copy the code into the file. Now you can check what your code does using FSI.
Exploratory testing
Exploratory testing will be familiar to users of most programming languages outside of the C family (C/C++, C#, Java, and so on) that provide a REPL—languages like Clojure, Erlang, LISP, OCaml, Ruby, and Python, to name a few. With a REPL, you can get quick feedback by setting up values and applying functions in the REPL environment. You’re also free to quickly try out a number of different implementation options before settling on one.
Note
F# is a cross-platform language, and a number of editors provide support for running F# scripts. These include Xamarin Studio and Visual Studio, but also Emacs. In other words, you can run the same script unchanged on Windows, Mac, Linux, and OpenBSD.
In Visual Studio and Xamarin Studio, you can execute lines of code by highlighting them and sending them to the FSI window (right-click or press the keyboard shortcut Alt-Enter). F# script files (*.fsx) can be edited and run either in your IDE or at the command prompt with fsi.exe.
Checking functional requirements
Once you select and evaluate the two functions from listing 1, they’ll be available in FSI and you can check how they work. The following interaction shows an example. You can either type the code directly into FSI or write it in the main source code editor and send the commands to FSI using Alt-Enter:
> wordPoints "QUARTZ";;
val it : int = 24
> wordPoints "Hello";;
System.InvalidOperationException: Letter e
at FSI_0002.letterPoints(Char _arg1) in C:\Scrabble\Script.fsx:line 12
at FSI_0036.wordPoints(String word) in C:\Scrabble\Script.fsx:line 15
at <StartupCode$FSI_0041>.$FSI_0041.main@()
The first command works as expected, but as you can see in the second case, the wordPoints function currently fails when called with a word that contains lowercase letters. This might or might not be the correct behavior, but thanks to exploratory testing, you can discover it early and modify the function to behave as expected.
Exercise 1
Let’s say that your explorative testing has revealed an issue in your original implementation, and you want to make the wordPoints function work with lowercase as well as uppercase letters. Modify the function implementation, and check that it returns 8 when called with “Hello” as an argument.
Exercise 2
In some languages, a pair of characters is used to represent a single letter. This oddity is called digraphs. For example, in Czech the characters CH represent a single letter.[4] Although C and H are distinct, standalone letters, when C is followed by H, the pair represents a single letter. So, for example CECH (guild) should be counted as [C][E][CH].
4 See “Czech,” Wikipedia, http://en.wikipedia.org/wiki/Ch_(digraph)#Czech.
As an exercise, extend the wordPoints function so that it can handle digraphs. Assuming that the value of C is 2, E is 1, H is 2, and CH is 5, the value of the word CECH should be 8 (instead of 7).
Checking nonfunctional requirements
As discussed earlier, exploratory testing can be also used to check nonfunctional requirements like performance. In FSI, the #time directive turns timing of expressions on or off. You can use it to check the performance of your function:
> #time;;
--> Timing now on
> let s = System.String(Array.create 10000000 'Z');;
Real: 00:00:00.039, CPU: 00:00:00.046, GC gen0: 0, gen1: 0, gen2: 0
val s : System.String = "ZZZZZZZZZZZ"+[9999989 chars]
> wordPoints s;;
Real: 00:00:00.097, CPU: 00:00:00.093, GC gen0: 0, gen1: 0, gen2: 0
val it : int = 100000000
In the Scrabble application, calculating the score of a word consisting of 1 million letters in less than 100 milliseconds is certainly fast enough. But if performance was your key concern, you could easily try changing the functions to run faster. For example, you could replace the Seq.sumByfunction with a mutable variable and iteration:
> let wordPointsMutable (word:string) =
let mutable sum = 0
for i = 0 to word.Length - 1 do
sum <- sum + letterPoints(word.[i])
sum;;
(...)
> wordPointsMutable s;;
Real: 00:00:00.032, CPU: 00:00:00.031, GC gen0: 0, gen1: 0, gen2: 0
val it : int = 100000000
This version of the function is longer and harder to write, but it’s about three times faster. Which of the functions should you use? This is why understanding nonfunctional requirements is important. For most applications, simplicity and readability are preferred, so the original implementation is better. But if performance is your key concern, you can choose based on a simple explorative test. Now, let’s look at the next step of the testing process: unit testing.
Unit testing
Unit testing is likely the most common testing approach, whether the tests are written before or after the system under test (SUT). Test-driven development or test-first development is prevalent in dynamic languages and some parts of the Java and .NET communities.
Within typed functional programming communities like F#, Scala, and Haskell, type-driven development or functional-first programming is common, where the types of data and functions are defined first. The defined types often underpin the domain model of the system under development (in a way similar to how tests underpin the behavior in dynamic languages). Adding tests is often the next step, and you can also often turn code snippets written during exploratory testing into automated unit tests. In both test-driven and type-driven development, some amount of upfront design is wise.
Continuous integration
For large LOB and enterprise applications, it’s useful to automate the execution of a suite of unit tests triggered on submission of changes to the source control system or to run the tests overnight. This approach can help uncover regressions made by changes as they happen. Running of tests is usually done on a dedicated machine.
There are a number of packages for .NET that automate application builds and running of tests, including JetBrains’ TeamCity, CruiseControl.NET, and Microsoft’s Team Foundation Server. These continuous integration servers typically expect unit tests to be specified using a common .NET unit-testing library like NUnit, xUnit, MbUnit, or MsTest; these libraries all take a similar reflection-based approach to discovering unit tests in assemblies. To install the F# runtime on a build machine without Visual Studio, download the F# tools here: http://go.microsoft.com/fwlink/?LinkId=261286.
Many F# open source projects hosted on GitHub use FAKE build scripts and the Travis continuous integration (CI) server to run tests. When you use Travis, GitHub automatically displays the build results in pull requests, and managing the open source project becomes even easier. For examples of how to set up Travis CI and FAKE build scripts, see some of the projects at https://github.com/fsharp.
In this chapter, we’ll mostly run the tests in an IDE. Both Visual Studio and Xamarin Studio support running unit tests directly. You may also consider third-party runners such as TestDriven.NET and NCrunch. F# works seamlessly with all the major unit-testing frameworks, test runners, and CI suites.
Testing Scrabble with NUnit
This chapter mainly uses NUnit, but we’ll briefly look at other testing frameworks too. NUnit is one of the first and most popular open source unit-testing frameworks for .NET. It was originally ported from JUnit, but it has evolved quite a bit on the .NET platform and has become one of the standard tools.
Setting up
To get started, you’ll need to move the Scrabble code you’ve written so far from a script file into a library project. Here, you’ll create a project containing a single F# file with a module Scrabble that contains the two functions you wrote earlier: letterPoints and wordPoints.
Typically you’ll also create an F# library project to host your tests. Sometimes it’s more convenient to create tests in the same project first and then migrate them to a separate test project afterward. NUnit (as well as other libraries) can be easily installed from inside Visual Studio using NuGet by right-clicking the project and selecting Manage NuGet Packages. On other platforms, you can download the package and install it by adding a reference to the nunit.framework.dll assembly.
Once you have a library, you can write tests. You already wrote two simple tests during the exploratory testing phase (calling the wordPoints function with “QUARTZ” and “Hello” as sample inputs), so let’s start by turning them into unit tests.
In NUnit, unit tests are defined as methods of classes or functions in modules annotated with a Test attribute. Defining classes and methods, as shown in the next listing, will be familiar to Java and C# developers.
Listing 2. Unit tests for Scrabble, using classes and members

Note that F# members names specified with backticks ![]() can contain whitespace. Using backticks can improve the readability of your tests and lets you focus on specifying what the test does. The names also appear nicely in test runners, so they’re much easier to understand.
can contain whitespace. Using backticks can improve the readability of your tests and lets you focus on specifying what the test does. The names also appear nicely in test runners, so they’re much easier to understand.
In listing 2, the test is written as an instance method ![]() in a class marked with the TestFixture attribute. In F#, you can omit some of the ceremony. You can specify tests as functions in a module:
in a class marked with the TestFixture attribute. In F#, you can omit some of the ceremony. You can specify tests as functions in a module:
module Scrabble.Tests
open NUnit.Framework
open Scrabble
let [<Test>] ``Value of QUARTZ is 24`` () =
Assert.AreEqual(24, wordPoints "QUARTZ")
For most F# projects, this is the preferred way of writing unit tests, and you’ll use this style in the rest of the chapter. Functions in a module are compiled as a type with static methods, so this approach works only with testing frameworks that support static methods. One of the first to support this was xUnit.
xUnit
xUnit was written by the original author of NUnit as a successor. Just like with NUnit, you can install xUnit with NuGet. Again, tests can be written as both classes and modules:
open Xunit
let [<Fact>] ``Value of QUARTZ is 24`` () =
Assert.AreEqual(24, wordPoints "QUARTZ")
For simple tests, the main difference from NUnit is that functions are annotated with the Fact attribute.
In this section, we use only simple test assertions that test whether the actual value equals the expected value. The next section looks at other ways of writing assertions.
Writing fluent tests with FsUnit
When writing assertions and tests, you can use the functionality provided by NUnit and xUnit out of the box. If you want to get more readable tests or better error messages, two interesting F# projects are available that make testing more pleasant: FsUnit and Unquote.
Let’s look at FsUnit first. It provides fluent assertions with functions and is built on top of existing unit-testing frameworks, including NUnit and xUnit. The following example uses NUnit, so you’ll need to add a reference to the FsUnit library for NUnit (FsUnit.NUnit.dll):
open FsUnit
let [<Test>] ``Value of QUARTZ is 24 (using FsUnit)`` () =
wordPoints "QUARTZ" |> should equal 24
let [<Test>] ``Calculating value of "Hello" should throw`` () =
TestDelegate(fun () -> wordPoints "Hello" |> ignore)
|> should throw typeof<System.InvalidOperationException>
You can continue using functions in a module and using readable names of tests, thanks to the backtick notation. The new thing is the body of the functions. Rather than using the Assert module, you’re writing the assertions using a DSL provided by FsUnit.
The key construct is the should assertion. It takes a predicate (such as equal or throw) followed by a parameter (the expected value or exception). The last argument (which you specify using the pipeline operator, |>) is the value or a function to be checked.
Writing assertions using Unquote
Unquote approaches the problem of writing assertions differently. Rather than writing assertions using a method call or using an F# DSL, you can write them as ordinary F# code, wrapped as an F# quotation (as usual, you can install Unquote using NuGet):
open Swensen.Unquote
let [<Test>] ``Value of QUARTZ is 24 (using Unquote)`` () =
test <@ wordPoints "QUARTZ" = 24 @>
The API of Unquote is simple—all you need is the test function. When using Unquote, you write assertions as quoted expressions specified between the <@ and @> symbols. This means the library is called with a quotation (or an expression tree) representing the F# predicate that should evaluate to true.
This has an interesting consequence: Unquote can provide detailed information about test failures. The reported messages are given as step-by-step F# expression evaluations. For example,
test <@ 2 + 2 = 5 @>
gives the following message:
Test failed:
2 + 2 = 5
4 = 5
false
This approach is particularly useful when you’re testing code that performs numerical computations, because the error log gives you a detailed report showing which part of the computation doesn’t behave as expected.
Unit-testing tips
Here are some hints that are important when you’re writing tests. These are useful in F# as well as other languages:
· Test behavior, not methods —Each unit test should exercise a particular behavior. It’s not unusual to generate multiple tests for a specific method.
· Negate tests —To check that the test is valid, negate the value and rerun the test. If it still fails, your test probably won’t catch regressions.
· Refactor —If you find that your tests use a common setup, consider creating a setup function or parameterizing your tests.
· Ensure speed —Tests should be fast; as a rule of thumb, they should take less than 100 ms so you can get quick feedback from your test suite.
Before looking at more advanced testing topics, the following section discusses how to combine the exploratory style of testing with the usual unit-testing style.
Combining explorative and unit testing
Exploratory testing and unit testing serve somewhat different purposes. When using exploratory testing, you can quickly call a function with different inputs created by hand to see how it works, and you can also measure nonfunctional requirements (like performance using the #timedirective). You can use unit testing to encapsulate the tests and run them automatically.
In practice, having both of the options available is extremely useful. With one handy trick, you can write code that works in either compiled mode (as a unit test) or interactive mode (by running code in FSI). The trick is to use conditional code based on whether the INTERACTIVE symbol is defined. For example, you can see the setup for unit testing the Scrabble library in the following listing.
Listing 3. Setup for testing the Scrabble library

Listing 3 starts with a preamble that can be both compiled and run in FSI. In compiled code, it just defines the name of the module containing the tests ![]() . When executed interactively, it loads the tested functionality and references all the necessary unit-testing libraries so that you can use them in FSI.
. When executed interactively, it loads the tested functionality and references all the necessary unit-testing libraries so that you can use them in FSI.
You first load the file containing the scoring functions using the #load directive ![]() . This directive loads the file and compiles it on the fly so you don’t need to recompile the library before testing it. This strategy works nicely for single files, but for larger libraries, it’s better to reference the compiled library using #r. In listing 3, you use #r to reference NUnit and FsUnit
. This directive loads the file and compiles it on the fly so you don’t need to recompile the library before testing it. This strategy works nicely for single files, but for larger libraries, it’s better to reference the compiled library using #r. In listing 3, you use #r to reference NUnit and FsUnit ![]() ; this way, they become available in FSI, and you can run the body of the test or explore how the function behaves for other inputs. To do that, select the conditional block of code, followed by the openstatements; then you can evaluate the body of the first test and modify the inputs:
; this way, they become available in FSI, and you can run the body of the test or explore how the function behaves for other inputs. To do that, select the conditional block of code, followed by the openstatements; then you can evaluate the body of the first test and modify the inputs:
> Assert.AreEqual(24, wordPoints "QUARTZ");;
val it : unit = ()
> Assert.AreEqual(25, wordPoints "QUARTZ");;
NUnit.Framework.AssertionException: Expected: 25
But was: 24
The great thing about this approach is that you get the best of both worlds. You can explore the API using FSI, but at the same time, you can run the tests as part of your build process as ordinary unit tests.
Tip
Although this chapter explains how to write F# tests for the F# library, you can use the same techniques for testing code written in C# and VB.NET. This is a risk-free way of introducing F# into the development cycle. Writing tests in F# is easy and fun, but at the same time, you’re not reimplementing your key system using a language that you’re learning.
Now that we’ve covered the basics of unit tests, let’s look at how you can easily test functions on multiple inputs using parameterized tests.
Parameterized tests
When testing functions interactively, you’ll often run the test on a number of sample inputs and check that the result is what you were expecting. You could turn this code into unit tests by writing a new test for each input, but that would make the code repetitive.
Both NUnit and xUnit provide a way to write parameterized tests, which let you test a function with a range of inputs to avoid repeating yourself. In NUnit, this is done using the Values attribute:
let [<Test>] ``Value of B,C,M,P should be 3``
([<Values('B','C','M','P')>] letter:char) =
Assert.AreEqual(3, letterPoints letter)
Here, you want to check that the value of B, C, M, and P is 3. Rather than writing four separate tests for each of the letters, you can specify the letters as parameters and capture all four cases in a single test.
The previous example is easy to write because you have a number of sample inputs, but the result is always the same. What if you wanted to check the behavior for multiple different inputs and outputs? The TestCase attribute lets you specify multiple arguments and, optionally, the expected result:
[<TestCase("HELLO",Result=8)>]
[<TestCase("QUARTZ",Result=24)>]
[<TestCase("FSHARP",Result=14)>]
let ``Sample word has the expected value`` (word:string) =
wordPoints word
In this example, you’re checking that some property holds for three explicitly specified pairs of values (in this case, input and outputs). Sometimes, you may also want to check that a property holds for all possible combinations of inputs. In NUnit, this can be done using the Combinatorialattribute:
[<Test; Combinatorial>]
let ``Word value is not zero, minus one or max value``
( [<Values(Int32.MinValue, Int32.MaxValue, 0, -1)>] value:int,
[<Values("HELLO","FSHARP","X")>] word:string) =
Assert.AreNotEqual(value, wordPoints word)
In this example, the test runner will run the test for all possible combinations of value and word, covering 12 cases in total. You’re checking that the wordPoints function doesn’t return MinValue, MaxValue, 0, or -1 for any of the sample words.
Using parameterized tests, you can cover a large number of interesting cases; and if you choose your sample inputs carefully, you can also cover the usual tricky corner cases. For some problems, it’s useful to take the next step from parameterized testing, which is to use random testing.
Writing effective unit tests
So far, we’ve looked at basic testing techniques that are similar in F# and other languages. The main difference has been that F# puts more emphasis on exploratory testing. Now, let’s look at two advanced techniques where F# gives you interesting options that you wouldn’t get otherwise. We’ll start with fuzz testing using FsCheck and then look at functional ways of writing test doubles.
Fuzz testing with FsCheck
With unit tests and parameterized tests, you test against a set of manually specified inputs. For certain functionality, such as wire protocols and collection types, unexpected defects can be caught by generating random inputs, or fuzz.
FsCheck is a random-testing library based on QuickCheck. You specify properties that functions or methods satisfy, and it tests whether the properties hold in a large number of randomly generated cases. When using FsCheck and fuzz testing in general, the key to successful testing is to find good properties that should hold (see the following sidebar).
Finding good FsCheck properties
Most tutorials introducing FsCheck, QuickCheck, and similar tools will start with a property that checks whether reversing a list twice returns the original list:
let reverseTwice (input:int list) =
List.rev (List.rev input) = input
This is a good example property, because it’s universal (it works for any list) and it tests one specific function (List.rev). But it’s a basic example, and you’d only need it when implementing your own lists. How do you write good properties?
· You can often take inspiration from mathematics. For example, some functions are associative (foo a (foo b c) = foo (foo a b) c) or commutative (foo a b = foo b a). Appending lists or strings is an example of the first case.
· When there are two ways to achieve the same thing, you can write a property that checks whether this is the case.
· If you’re working with floating-point numbers, you can often write a property that checks whether the result is less than or greater than a certain number. This approach can help you catch errors with special values such as NaN, +Infinity, and –Infinity.
· Fuzz testing is great for testing custom data structures and collections. You can relate the state of a collection (such as length or emptiness) before and after some operation (such as adding or removing an element).
· When testing collections, you can often use oracle, another implementation of the same collection that has different nonfunctional properties (for example, it’s slower) but implements the same functionality.
Going back to the Scrabble scoring example, here are two simple properties that you can check using FsCheck.
Listing 4. Specifying Scrabble properties

The properties are functions that take some inputs and return a Boolean value. When you pass them to FsCheck, it generates random values for the inputs.
Listing 4 defines two properties. The first ![]() checks that if you generate a word consisting of any number of repetitions of the letter C, the value of the word is the value of a letter C multiplied by the number of repetitions. Note that you take the argument as uint8. This way, you guarantee that FsCheck always gives you a nonnegative, small number as an input.
checks that if you generate a word consisting of any number of repetitions of the letter C, the value of the word is the value of a letter C multiplied by the number of repetitions. Note that you take the argument as uint8. This way, you guarantee that FsCheck always gives you a nonnegative, small number as an input.
The second property ![]() takes any character as an input and checks that the value returned by letterPoints is greater than 0. Let’s see what happens when you let FsCheck test your properties, first using FSI:
takes any character as an input and checks that the value returned by letterPoints is greater than 0. Let’s see what happens when you let FsCheck test your properties, first using FSI:
> Check.Quick(repetitionsMultiply);;
Ok, passed 100 tests.
val it : unit = ()
> Check.Quick(letterPositive);;
Falsifiable, after 1 test (1 shrink) (StdGen (1752732694,295861605)):
'a'
For the first property, FsCheck generates 100 random inputs and reports that the property holds for all of them. For the second property, you get an error—in fact, it fails for the first input chosen by FsCheck, which is the lowercase letter a. This is an error in the property. When called on characters other than letters A to Z, the letterPoints function throws an exception.
To address this common problem, FsCheck provides the ==> operator. When you write cond ==> prop, the prop property is checked only when the cond condition holds. You can see this in action in the next listing, which also wraps the Check.Quick calls as NUnit tests.
Listing 5. Wrapping properties as unit tests

In both tests, you specify the property inline as a lambda function. In the first test, you check that letterPoints returns a positive number when the letter is valid. Note that the call needs to be done lazily so it’s run only when the condition is true. You can wrap it with the lazy keyword, and FsCheck evaluates it lazily. The second test is similar, but you now take both letters to be repeated and a number of repetitions.
Note
Using the ==> operator works nicely when the number of invalid inputs isn’t too high. When you need to build more specific inputs, you can also specify custom data generators that randomly generate inputs that satisfy all your requirements.
In addition to what you’ve seen so far, FsCheck is useful for fuzz testing, because it can shrink the input data to the smallest set that will make the test fail. For example, it won’t report that a property fails for a long list containing exotic numbers; instead, it tries to find a minimal list and usually finds one containing just a few simple values.
Avoiding dependencies with test doubles
Unit tests should test the system under test (SUT) in isolation. Assuming the SUT’s dependencies are parameterized, test doubles can be used instead of concrete implementations, which may be inflexible or expensive to set up and tear down, particularly systems that use a network or the filesystem, like a database. Mock objects are a concrete example of test doubles; but when testing functional code, you can work at a finer-grained level and start by providing test doubles of functions.
Method and function stubs
Let’s say you have a function that, given a raw price, calculates the price with tax:
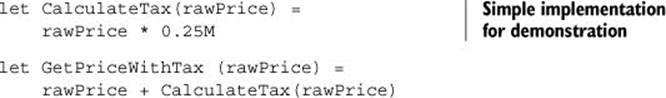
In this snippet, the CalculateTax function is simple, but in a realistic system, it may go to a service or database to compute the value. The example introduces coupling between GetPriceWithTax and a concrete implementation of CalculateTax, which makes it difficult to test the functionality of GetPriceWithTax in isolation. To make the function testable, you can pass the CalculateTax function as an argument:
let GetPriceWithTax calculateTax rawPrice =
rawPrice + calculateTax(rawPrice)
Now the function can be more easily tested. You can provide a method stub for CalculateTax, rather than using the actual, possibly hard-to-test, implementation:
let [<Test>] ``price with tax should include tax`` () =
let price, tax = 100.0M, 15.0M
let calculateTax _ = tax
Assert.AreEqual(price+tax, GetPriceWithTax calculateTax price)
The snippet implements a test double for the actual CalculateTax function, called calculateTax (with a lowercase c). The underscore character in the function declaration signifies that the argument is ignored, so the function always returns 15.0M. The test can then easily make sureGetPriceWithTax adds the original price and the calculated tax.
Method and function stubs are a simple but effective technique when you’re writing functions with a relatively small number of dependencies. But even with more dependencies, you don’t always need the full power of mocking frameworks.
Object expressions
Sometimes a function’s or method’s dependencies are defined as interfaces. For small interfaces, F# has a convenient built-in syntax called an object expression that lets you create an instance inline.
Say you want to test a function that supports depositing monies in a foreign currency. You may have an external currency service defined as an interface:
type ICurrencyService =
abstract GetConversionRate :
fromCurrency:string * toCurrency:string -> decimal
The implementation of the interface would probably be an F# object type, but when you want to write a test for a function that relies on the service, you’ll need a simple implementation. For example, a stub for the currency service that always returns 10.0M can be generated with the following object expression:
let service =
{ new ICurrencyService with
member service.GetConversionRate(_,_) = 10.0M }
Object expressions require all members to be defined, which is impractical for larger interfaces. In practice, assuming you stick to the single-responsibility principle, your interfaces should be pretty small; but not all implementers stick to this principle. In that case, F# lets you use a wide range of mocking libraries.
Mocking libraries
A plethora of .NET mocking libraries are available for generating test doubles over larger interfaces and abstract classes. Some of the more popular ones are NSubstitute, FakeItEasy, and Moq. Going through all of them could easily require a whole chapter, so we’ll look at just two. The accompanying sidebar shows a brief example of Moq, so you can see the F# syntax.
Moq
Moq provides a fluent API for setting up the subset of members you require on an interface for a test. For example, if you want to pass in an IList<T> instance where the Count property returns 0, you can write

You pipe the result to ignore ![]() because in F#, return values must be ignored explicitly. For a friendlier experience with F#, try Moq.FSharp.Extensions, available from NuGet, which defines extension methods for this and other cases so you can write the following:
because in F#, return values must be ignored explicitly. For a friendlier experience with F#, try Moq.FSharp.Extensions, available from NuGet, which defines extension methods for this and other cases so you can write the following:
let instance = mock.SetupGet(fun x -> x.Count).Returns(0).End
Moq (as well as other .NET libraries) can be used with F#, but it doesn’t use all the features that are available in F#. An alternative is to use Foq, which is a mocking library with an API similar to Moq’s but written and focused on F#. Foq can be deployed via NuGet or as a single file, Foq.fs. It supports both F# quotations, as seen earlier with Unquote, as well as .NET LINQ expressions.
Foq lets you define instances of interfaces and abstract classes with one line per member or a set of methods in a way similar to object expressions. The following example builds a test double for the IList<char> interface.
Listing 6. Mocking the IList interface with Foq

To make it easier to specify the behavior of test double, Foq uses a combination of F# quotations with the custom operator --> to define the behavior. The With method in the example returns a quotation that represents the mapping from different properties, indexers, and methods to the expected values. Each mapping is specified using the --> operator, which symbolizes returning a value.
When creating the test double, Foq looks at the code quotation and creates an implementation of the interface according to the specification. In this example, the specification defines the behavior of the Count property ![]() , the indexer
, the indexer ![]() , and the Contains method
, and the Contains method ![]() .
.
The topics discussed so far were by no means an exhaustive coverage of the options for writing unit tests in F#, but they cover the most interesting aspects, ranging from exploratory testing to powerful fuzz-testing libraries and simplified testing of test doubles. Next, we’ll turn our attention from code-aligned testing to business-aligned techniques.
Acceptance testing
Up until now, we’ve been focusing on techniques like unit testing that ensure technical quality—that the code you’ve written behaves as you expect. From a business point of view, the solution should behave as the user expects. One good way to understand what the business expects is to specify example scenarios. A scenario indicates which outputs you get for given inputs. Such scenarios can be used as a form of documentation and acceptance criteria for a feature.
For high-value business features that are key to the operation of a solution, it’s sometimes useful to run the example scenarios against the solution, in a way similar to unit tests, while keeping the automation close to the business language. This strategy has the advantage of making it easier to change the implementation of key features, say for performance or a new platform, without having to rewrite the scenarios.
This technique has a number of monikers, including automated acceptance testing, specification by example, and behavior-driven development (BDD). In this section, we’ll focus on BDD.
Behavior-driven development
BDD is a relatively new (circa 2003) Agile software development approach that focuses on communication—encouraging collaboration between developers, quality assurance, and business participants. Through discussion with stakeholders, scenarios in which the software will be used are written to build a clear understanding of the desired behavior.
In a similar fashion, in order to arrange, act, and assert in unit testing, scenarios are specified in plain text in a structured form composed of these steps:
Given some context
When some event occurs
Then I expect some outcome
Developers and testers use these scenarios as acceptance criteria to drive development. Some of the acceptance tests may be automated and others checked through manual testing. A feature may be considered done when the tests pass for all its scenarios.
Many libraries exist to assist with automation of acceptance tests. Some automate execution of business-readable text files, whereas others attempt to stay close to the business language via an internal DSL (a language implemented in the host language).
Note
This section will focus on the automation side, but to effectively practice BDD, your focus should be primarily on the requirements side.
We’ll begin this section with a quick overview of the tools that exist outside of the F# world and then look at TickSpec, which is a BDD library that’s specifically focused on F#.
State of the art
Cucumber is probably the best known BDD framework as of 2014. It executes plain-text files written in a business-readable DSL (known as Gherkin) as automated tests. Each file describes a feature and its scenarios. During execution, steps of a scenario are matched against step definitions consisting of a regular expression and a function to execute. Cucumber is written in Ruby, and it has benefited from Ruby’s light syntax and expressiveness to minimize the ceremony while defining step definitions:
Given /a customer buys a black jumper/ do
end
A number of open source BDD frameworks are available for .NET that can parse Gherkin-based text specification files. These include NBehave (http://nbehave.org), Raconteur (http://raconteur.github.io), SpecFlow (http://specflow.org), StorEvil (https://github.com/davidmfoley/storevil), and TickSpec (http://tickspec.codeplex.com).
Typically, .NET BDD frameworks take a reflection-based approach (as per unit tests). Listing 7 shows a comparison of different ways for defining a Given step definition that should match a Gherkin line “Given a customer buys a black jumper”, written using SpecFlow, StorEvil, and TickSpec.
Listing 7. Specifying a Given step in SpecFlow, StorEvil, and TickSpec

In SpecFlow ![]() , the step definition is defined in a Given attribute, which contains the regular expression to match against the Gherkin file line. StorEvil
, the step definition is defined in a Given attribute, which contains the regular expression to match against the Gherkin file line. StorEvil ![]() supports reflection-based pattern matching representing spaces in C# method names as underscores. In F#, you can be even nicer. TickSpec
supports reflection-based pattern matching representing spaces in C# method names as underscores. In F#, you can be even nicer. TickSpec ![]() supports F# backtick method names that can contain whitespace.
supports F# backtick method names that can contain whitespace.
A reflection-based approach requires a compile-and-run cycle to test a feature. For iterative development in larger applications, the REPL-based approach may be more appropriate for faster feedback. Matters can be improved for .NET developers by running individual tests in isolation using tools like TestDriven.NET and ReSharper, but this still doesn’t mitigate the build step. For this reason, the TickSpec library also supports development in the F# REPL. Let’s take a more detailed look at TickSpec.
Specifying behavior with TickSpec
I developed the TickSpec library back in 2010 to take advantage of some of the unique features of F# for testing, like backtick methods and active patterns. The library has been used successfully in many commercial settings and has been particularly popular in the finance industry. I also used it extensively during development of the open source spreadsheet project Cellz, available on CodePlex (http://cellz.codeplex.com).
In this section, you’ll return to the Scrabble example and use TickSpec to specify the expected behavior of Scrabble scoring. You’ll start with the simple functions implemented so far and then add support for multipliers.
Specifying Scrabble scoring
You can test the earlier Scrabble implementation by specifying the scoring of a number of example words. The following scenario defines that the score for the three-letter word POW would be 8 (P = 3, O = 1, and W = 4). Written in the Gherkin syntax, the scenario looks like this:
Scenario: POW
Given an empty scrabble board
When player 1 plays "POW" at 8E
Then she scores 8
To automate the scenario via reflection using TickSpec, you’ll write an F# module with functions to match the three lines. You already have the wordPoints function, so the code that implements the steps just needs to add the value of each played word and check that the sum matches the expected score. Here’s the definition of the steps.
Listing 8. Specification of Scrabble scoring

When evaluating the scenario, you need to keep some private state ![]() that represents the score calculated so far. Individual step definitions update or check the score. For example, starting with an empty board
that represents the score calculated so far. Individual step definitions update or check the score. For example, starting with an empty board ![]() resets the score to 0.
resets the score to 0.
The last two definitions use regular expressions to match variable parameters. For example, in the When statement ![]() , the sequence (\d+) signifies matching a number, in this case the player number. TickSpec automatically converts these parameters to arguments of the specified type.
, the sequence (\d+) signifies matching a number, in this case the player number. TickSpec automatically converts these parameters to arguments of the specified type.
As the Gherkin specification is executed, the state is set to the initial value and then updated by adding the score of the added word. Finally, the Then statement ![]() checks that the final result matches the expected value.
checks that the final result matches the expected value.
Specifying examples using tables
To make the specification more comprehensive, you can add scenarios that specify the value of several other words. Writing these as separate scenarios would be repetitive. Fortunately, TickSpec makes it possible to parameterize the scenario with an example table. The following listing shows a scenario that checks the Scrabble scoring for a number of two-letter words.
Listing 9. Scenario specifying scoring of two-letter words
Scenario: 2-Letter Words
Given an empty scrabble board
When player 1 plays "<word>" at 8E
Then she scores <score>
Examples:
| word | score |
| AT | 2 |
| DO | 3 |
| BE | 4 |
The scenario in listing 9 will run against the step definitions you’ve already defined, so you don’t need to write any more code for now. The runner will execute a new scenario for each row in the example table, substituting each row’s column values with the name in the scenario marked between the < and > symbols.
TickSpec also supports multiple example tables per scenario, in which case it generates a combinatorial set of values. You can also specify shared examples, which are applied to all scenarios in the feature file. Before extending the scoring example, check the accompanying sidebar, which lists a number of hints for writing good, business-relevant feature files.
What makes a good feature file?
· Write in the language of the business domain, not programming.
· Use plain English.
· Use active voice.
· Use short sentences.
· Use backgrounds for repeated setup.
· Use an example tables for repeating inputs.
· Test one thing at a time.
So far, the scenarios can only describe words being placed on the Scrabble board. The next step is to add support for specifying multipliers.
Specifying the behavior of multipliers
The Scrabble board contains a number of special positions that affect the score. You have to deal with double-letter scores (DLS) that multiply the value of a single letter, triple-word scores (TWS) that multiply the value of the entire created word by 3, and with the center star, which multiplies the word value by 2.
Let’s start by looking at the scenarios you want to implement. This example specifies three sample words with a number of additional properties on some of the letters or the entire word.
Listing 10. Specification of Scrabble scoring with multipliers

In the first scenario ![]() , the player plays the word QUANT so that the letter Q is on a position that multiplies its value by 2. The letter T is on the center star, so the value of the entire world is multiplied by 2 as well.
, the player plays the word QUANT so that the letter Q is on a position that multiplies its value by 2. The letter T is on the center star, so the value of the entire world is multiplied by 2 as well.
A neat way of modeling the properties of the scenario is to define an F# discriminated union type. One case of the union corresponds to one kind of step in the specification:
type Property =
| Word of string
| DLS of char
| TWS
| CenterStar
As you execute the scenario, you’ll collect the described properties. The score for a single scenario can now be defined as a fold over properties collected, as follows.
Listing 11. Calculating the score as a fold over properties

When using a fold to calculate the score, you need to keep two pieces of state: the total value of letters and words placed on the board and the multiplier for the word value. The multiplier needs to be kept separate so you can first sum all the letters and then, at the end, multiply the total sum by the multiplier ![]() .
.
The lambda function that updates the state uses pattern matching and implements the Scrabble logic. One notable new feature is that when players use all seven letters ![]() , they get a 50-point bonus.
, they get a 50-point bonus.
The design where you use properties to represent individual steps works nicely with the step definitions. The methods implementing individual steps add properties to a collection. As you can see in the next listing, this approach makes it easy to define the steps.
Listing 12. Step definitions for Scrabble scoring with multipliers

All the step definitions follow the same pattern. As before, they use regular expressions to specify the Gherkin language line that corresponds to the step. A new attribute, BeforeScenario, resets the board before anything else happens ![]() .
.
There are three ways to create a word: ![]() creates a standalone word;
creates a standalone word; ![]() adds a prefix to an existing string, forming a longer word; and
adds a prefix to an existing string, forming a longer word; and ![]() occurs when a word is formed because two other words are aligned. The remaining steps collect all the multipliers
occurs when a word is formed because two other words are aligned. The remaining steps collect all the multipliers ![]() and check that the score matches your expectations
and check that the score matches your expectations ![]() .
.
Using BDD in practice
Hopefully you’re now convinced that F# provides an elegant way to develop BDD step definitions. From experience, I believe this can be a good way to gain value from introducing F# to an organization.
Regardless of your language preference, given that your business specifications could outlive your current platform and programming language, I recommend choosing a framework that’s based on the well-supported Gherkin business language so you’re not locked in to a specific technology in the future. Businesses are reporting real business value from adopting BDD; in Gojko Adzic’s Specification by Example (Manning, 2011) the author examines more than 50 case studies of this style of technique.
Summary
The main theme of this chapter was taking a holistic perspective of software quality. When talking about software quality, people often focus on unit testing and neglect to consider the bigger picture, which is crucial for successful software development.
We began by looking at requirements. Understanding both functional and nonfunctional requirements is crucial for choosing the indicators that matter. For example, in my experience with gaming and trading, nonfunctional requirements such as performance play an extremely important role. These requirements can often be checked during development using the exploratory development style. Of course, unit testing is crucial for checking the correctness of an implementation, and we looked at a number of elegant ways of using F# libraries (like FsCheck) and F# features (like providing a function as a test double).
Finally, we shifted our attention and looked at behavior-driven development. BDD is gaining real traction in the development community with plenty of talks at conferences and user groups on the subject, along with blog articles and books now available.
About the author

Phil Trelford is an active member of the software development community, regularly attending and speaking at user groups and conferences, blogging, and contributing to open source projects. He is a co-organizer of the London F# User Group and a founding member of the F# Foundation. He has written a number of popular F# libraries, such as Foq and TickSpec.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.