F# Deep Dives (2015)
Part 1. Introduction
Chapter 3. Parsing text-based languages
Tomas Petricek
I’ve been writing a blog for a number of years now. Since the beginning, I wanted the website to use clean and simple HTML code. Initially, I wrote articles in HTML by hand, but lately I’ve become a big fan of Markdown—a simple text-based markup language that can be used to produce clean HTML. It’s used by sites such as Stack Overflow and GitHub. But none of the existing Markdown implementations supported what I wanted: I needed an efficient parser that could be extended with custom features and that allowed me to process the document after parsing. That’s why I decided to write my own parser in F#.[1]
1 The Markdown parser I wrote is now a part of F# documentation tools available at http://tpetricek.github.io/FSharp.Formatting/.
In this chapter, I’ll describe the key elements of the project. You won’t be able to implement a parser for the entire Markdown format in just one chapter, but you’ll learn enough to be able to complete it easily. We’ll first look at the source code of a sample document and then write the document processor in five steps (see figure 1). You’ll see how to represent documents and how to parse inline text spans and blocks. Then you’ll write a translator that turns the document into HTML rendered in a web browser. Finally, we’ll look at how to process documents.
Figure 1. Steps for developing the document processor
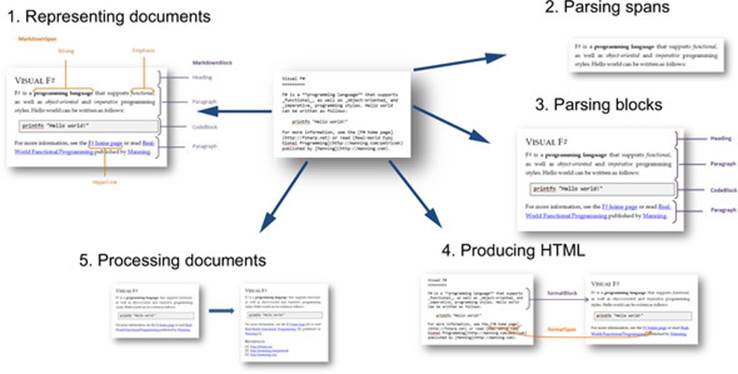
Writing a Markdown parser might sound like an ambitious goal, but you’ll see that you can implement a surprising amount of functionality in a single chapter. In terms of the business themes from chapter 1, you can quickly develop a working version (time to market), and the use of active patterns lets you tackle the complexity of parsing in an elegant and powerful way.
You might not need to implement your own text formatting engine, but you may often face similar tasks. Text processing is useful not only when working with external files (test scripts, behavior specifications, and configuration files), but also when processing user input in an application (such as commands or calculations).
Introducing the Markdown format
The Markdown format is a markup language that was designed to be as readable as possible in a plain-text form. It’s inspired by formatting marks, such as *emphasis*, that are often used in text files, emails, and README documents. It specifies the syntax precisely so it’s possible to translate Markdown documents to HTML.[2] Markdown is a popular format that has implementations in numerous languages (including a .NET implementation in C#). In this section, we’ll look at one Markdown example and explain why we need yet another implementation of a Markdown processor.
2 For more information about Markdown, see John Gruber’s Markdown page on Daring Fireball: http://daringfireball.net/projects/markdown.
Formatting text with Markdown
The formatting of Markdown documents is based on whitespace and common punctuation marks. A document consists of block elements (such as paragraphs, headings, and lists). A block element can contain emphasized text, links, and other formatting.
The following sample demonstrates some of the syntax:

This document consists of four block elements. It starts with a heading ![]() . In Markdown, headings are prefixed with a certain number of # characters at the beginning of the line; for example, ## Example is a second-level heading. An alternative style (not implemented in this chapter) is to write the text on a single line, followed by another line with a horizontal line written using = (for first-level headings) or - (for second-level headings).
. In Markdown, headings are prefixed with a certain number of # characters at the beginning of the line; for example, ## Example is a second-level heading. An alternative style (not implemented in this chapter) is to write the text on a single line, followed by another line with a horizontal line written using = (for first-level headings) or - (for second-level headings).
The second block is a paragraph ![]() , followed by a code sample
, followed by a code sample ![]() and one more paragraph. The text in paragraphs is formatted using ** (strong) and _ (emphasis). Both asterisks and underscores can be used for strong and emphasized text—one character means emphasis, and two characters means strong text. You can also create hyperlinks, as demonstrated by the last line.
and one more paragraph. The text in paragraphs is formatted using ** (strong) and _ (emphasis). Both asterisks and underscores can be used for strong and emphasized text—one character means emphasis, and two characters means strong text. You can also create hyperlinks, as demonstrated by the last line.
From a programming language perspective, formats such as Markdown can be viewed as domain-specific languages (DSLs).
External domain-specific languages
The term domain-specific languages (DSLs) refers to programming languages that are designed to solve problems in a particular domain or field. DSLs are useful when you need to solve a large number of problems of the same class. In that case, the time spent developing the DSL will be balanced out by the time you save when using the DSL to solve particular problems.
DSLs can be categorized into two groups. Internal DSLs are embedded in another language (like F# or C#). Functions from the List module with the pipelining operator (|>) can be viewed as a DSL. They solve a specific problem—list processing—and solve it well without other dependencies.
External DSLs are languages that aren’t constructed on top of other languages. They may be used as embedded strings (for example, regular expressions or SQL) or as standalone files (including Markdown, configuration files, Makefile, or behavior specifications using languages such as Cucumber[3]). In this chapter, we’ll focus on this class of DSLs. As the examples demonstrate, the application range for external DSLs is broad.
3 For more information, see chapter 12, which discusses behavior-driven development (BDD).
Now that I’ve introduced the Markdown format and DSLs in general, let’s look at a number of benefits that you can expect from a Markdown parser written in F#.
Why another Markdown parser?
Markdown is a well-established format, and a number of existing tools convert it to HTML. Most of these are written using regular expressions, and there are implementations for almost any platform, including .NET. So why do we need yet another processor? Here are a few reasons:
· Creating a custom syntax extension for Markdown is difficult when using an implementation based on regular expressions. It’s hard to find where the syntax is being processed, and changing a regular expression can lead to various unexpected interactions.
· Most of the tools transform Markdown directly to HTML. This makes it hard to add a custom processing step, such as one that processes all code samples in the document before generating HTML.
· HTML is the only supported output. What if you wanted to turn Markdown documents into another document format, such as Word or LaTeX?
· Performing a single regular-expression replacement may be efficient, but if the processor performs a huge number of them, the code can get CPU-intensive. A custom implementation may give you better performance.
As discussed in chapter 1, languages like F# often let you implement better algorithms, because they allow you to tackle more complex problems. This is exactly what we’ll do in this chapter—we’ll implement a new parser that’s more extensible and readable. The key element of the solution is an elegant functional representation of the document structure.
Representing Markdown documents
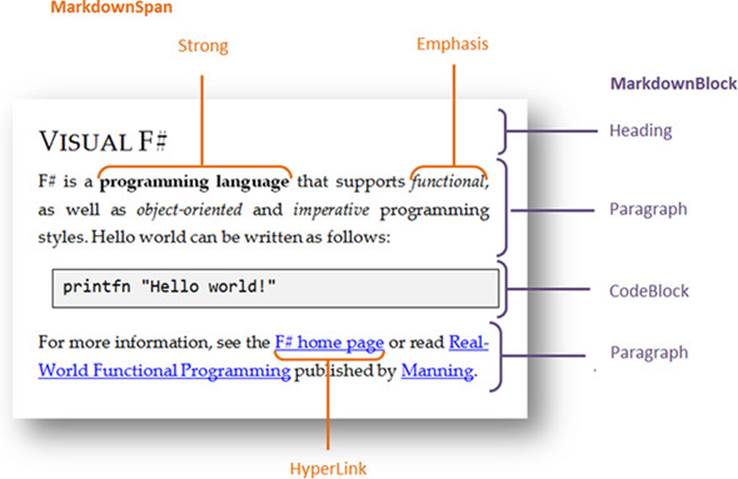
When solving problems in functional languages, the first question you often need to answer is, “What data structures do I need, to represent the data that I work with?” In the case of a Markdown processor, the data structure represents a document; and as discussed earlier, a document consists of blocks of different kinds. Some of the blocks (like a paragraph) may contain additional inline formatting and hyperlinks (see figure 2).
Figure 2. You can see how MarkdownBlock elements and different MarkdownSpan elements are used to format the sample document. All other unmarked text is represented as Literal.
The types that model Markdown documents are shown and explained in the following listing.
Listing 1. Representation of a Markdown document

The listing defines the types as mutually recursive using the and keyword, for two reasons. First, the MakdownSpans and MarkdownSpan types are mutually recursive, and they both reference each other. Second, starting with a type that represents the entire document rather than starting from the span makes the explanation easier to follow.
Now that you have a representation of your documents, you can take the next step and start implementing the parser. We’ll start with a direct solution and improve it later on.
Parsing spans using recursive functions
Despite the rise of alternative input methods, such as pen-based input and touch, the most common way to write computer documents is still to type them on a keyboard. The purpose of a parser is to turn the stream of characters into a richer structure. In this chapter, the structure is a representation of a document, but the same problem appears elsewhere—whether you’re parsing configuration files, user-scenario specifications, or even binary files.
The first implementation of a Markdown parser that we’ll look at will use a number of mutually recursive functions that model different states of the parser and call each other when the parser transitions between states. This style of parser is called a recursive descent parser because it “descends” into new states when it reaches a symbol that begins a syntactic construct you want to parse. To keep the initial version simple, let’s focus on inline formatting (the MarkdownSpans type), demonstrated in figure 3.
Figure 3. In this and the next section, you’ll write a parser that processes inline formatting commands for strong text, emphasis, and inline code. The parser generates a sequence of MarkdownSpan elements.

For example, inline code in Markdown is written as `code`. To parse this syntax, the parser needs to switch to a parsingInlineBody state when it finds the opening backtick (`). In this state, it continues consuming characters until it finds the closing backtick, and then it returns back to the main state, waiting for other formatting markup. This functionality is implemented in the following listing.
Listing 2. Parsing the inline code span
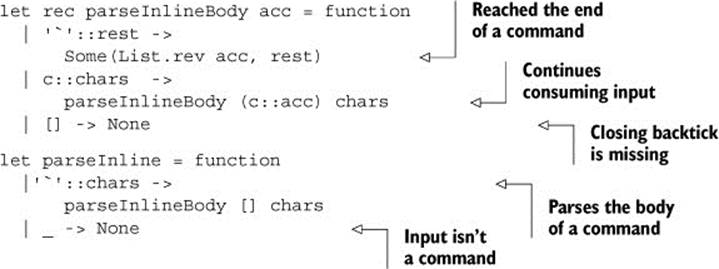
The parseInline function represents the entry point for parsing the inline code command. It employs pattern matching using function to accept List as a single input argument and tests whether it starts with a backtick. If that’s the case, it continues parsing using parseInlineBody; otherwise it returns None.
The parseInlineBody function keeps the body characters that have been consumed so far in the acc parameter. When it finds the end of the command, it returns the body (in the correct order) together with the remaining unprocessed characters. Otherwise, it continues processing the input until it reaches the end.
To test the parseInline function, you can use F# interactively and test whether it succeeds in parsing some sample input that starts with an inline code command:
![]()
Note
Italic in the code snippets is used to indicate the output from commands entered in the F# Interactive (FSI) console.
The result is an option type, because the function fails if the string doesn’t start with the inline code command. If it succeeds, it returns a tuple consisting of the body and the unconsumed input.
Parsers for inline commands such as **strong text** could be written in the same style. To complete the parsing of inline spans, you’d need to write a main parsing function that takes an input and turns it into a sequence of Literals, inline code, and other spans. The parseSpansfunction is shown in the following listing.
Listing 3. Parsing spans using functions

The core functionality is implemented using pattern matching. To recognize the three different cases, you need to match on both the result of parseInline and on the original input. If the text starts with an inline code span ![]() , you emit three groups of spans:
, you emit three groups of spans:
· A Literal formed by the characters immediately before the inline code span (or nothing if there were no preceding characters)
· An InlineCode span formed by the parsed body
· Other span elements obtained by a recursive call to parseSpans
If the input doesn’t start with any command ![]() , you add the current character to the list of unprocessed characters and continue processing recursively. Finally, when you reach the end of the input list
, you add the current character to the list of unprocessed characters and continue processing recursively. Finally, when you reach the end of the input list ![]() , you need to emit the last Literal consisting of unprocessed elements.
, you need to emit the last Literal consisting of unprocessed elements.
Tip
The parseSpans function is implemented as a recursive sequence expression. The cases where the function needs to process the rest of the input are implemented as a recursive call using the yield! keyword. This doesn’t cause performance issues, because the recursive call is in a tail-calllocation. Just as with standard tail-call recursion, the F# compiler optimizes tail-call recursion in sequence expressions so the current stack frame (and a corresponding IEnumerator object) will be dropped and can be garbage collected.
You started writing a parser so you could read Markdown documents stored in plain text files. The code that you started writing in this section would get you there, but it has a number of limitations. If you added functions to parse more commands (like parseInline), you’d have to call them all before you could pattern-match on the result. This would make the code inelegant (imagine match with 10 arguments!) and also inefficient (they would all be executed before you could inspect the result of the first one). One way to improve this code is to use F# active patterns.
Implementing the parser using active patterns
Parsers rely heavily on pattern matching. Listing 2 uses patterns such as '`'::rest and [] to identify the start of a command. Checking the elements of a list is a low-level technique, because it uses the representation directly and doesn’t express any higher-level intention.
Active patterns are an F# language feature that provides a higher-level abstraction for pattern matching. You can use them to specify that you want input starting with a specified list; input that’s delimited by the specified character or characters (on each side), input that’s bracketed by given opening and closing characters, or even input that starts with an inline code span. Ideally, you’d like to write something like this:
match chars with
| Delimited ['`'] (body, rest) ->
// Parsed body delimited by the backtick (e.g. `hello`)
| Delimited ['*'; '*' ] (body, rest) ->
// Parsed body delimited by double asterisk (e.g. **hello**)
In this example, Delimited is an active pattern that recognizes text wrapped between opening and closing sequence of symbols. This goes beyond the standard patterns for lists (such as x::xs for separating the head and tail). Active patterns execute user-defined code. In the case ofDelimited, it recursively traverses the list and finds the end of the delimiter. Now let’s see how you can implement such an active pattern.
Parsing spans using active patterns
You could modify the code in listing 2 to define an InlineCode active pattern and add a number of other, similar, active patterns to recognize strong or emphasized text. That would work, but it would make the code slightly repetitive.
A better technique is to use parameterized active patterns. These are active patterns that take one or more input parameters, much like functions that take input parameters. The parameters define the behavior of the pattern, so a single active pattern can recognize an entire class of cases, just as the behavior of a function depends on its parameters.
As I suggested previously, most inline Markdown commands can be handled using a single parameterized active pattern. The Delimited pattern detects a string that starts with specified characters, contains some body, and then ends with the same character sequence. To detect inline code, you can use the Delimited pattern with ['`'] as an argument.
The implementation of the Delimited pattern and a few helper functions and patterns is shown in listing 4. This code implements a new version of the parseSpans function, so if you’re typing the code, you can comment out the implementation from listing 3; but you’ll still need the rest of the code from earlier.
Listing 4. Implementing the Delimited active pattern

The two core functions in the listing implement the parsing of bracketed text—text that starts with a specified character list and ends with a (possibly different) character list. The parseBracketed function takes two parameters specifying the opening and closing sequences. It’s implemented using function, meaning it will immediately pattern-match on its third argument. When the input starts with opening, the Starts-With pattern returns the remaining input as chars. If that’s the case, the function then calls parseBracketedBody, which keeps accumulating the body (in the acc parameter) until it finds the closing character sequence ![]() or the end of the input
or the end of the input ![]() .
.
Finally, the Delimited active pattern ![]() is defined using partial function application. It calls the parseBracketed function using the same sequence of characters, as both the opening and closing sequence.
is defined using partial function application. It calls the parseBracketed function using the same sequence of characters, as both the opening and closing sequence.
This is all you need for parsing inline code and emphasized and strong text. For other spans, you’ll also need an active pattern that takes both parameters separately. Equipped with the Delimited pattern, it’s now easy to update the parseSpans function from listing 3 to elegantly parse most of the formatting. You can see the new version in the following listing.
Listing 5. Parsing Markdown spans using active patterns


This function has the same structure as the earlier version, but the pattern matching on chars is now implemented using active patterns. This means you no longer have to call individual parsing functions in advance. Instead, you just match on chars and then write a number of patterns to identify various commands.
In the pattern-matching, the syntax Delimited ['`'] invokes the active pattern with an argument that specifies the delimiter. This is followed by a (body, chars) pattern that defines two symbols to hold the delimited body and the remaining input.
When you parse the InlineCode span, you convert the parsed body to a string using the toString function. Conversely, emphasized or strong text may contain other formatting or hyperlinks. This means you call parseSpans recursively once more during the parsing to process the body of the emphasized or strong text.
This function is powerful, and this kind of abstraction is exactly what makes F# great for handling complex problems while keeping the time to market reasonable. The function handles three different formatting commands, but all of them are encoded using a single flexible active pattern.
The following F# Interactive session tests the 'margin-top:12.0pt;margin-right:0cm; margin-bottom:12.0pt;margin-left:0cm;text-align:center;line-height:normal'>
The input “important code and emphasized” should be parsed as a strong span containing a Literal “important” and inline code “code”, followed by a Literal “and” and an emphasized span containing “emphasized”. The F# Interactive output shows that the input is parsed as expected. Although you don’t do this step here, you could copy the output and turn it into an assertion in a unit test for the parse-Spans function.
To practice your F# programming skills, exercises 1 and 2 suggest two extensions of parseSpans that you can implement as the next steps. Exercise 2 requires going back to the representation of Markdown documents (listing 1) and adding a new kind of MarkdownSpan.
Exercise 1
One feature of the Markdown format that I introduced earlier is the syntax for writing inline hyperlinks. The HyperLink case was also included in the MarkdownSpan type declaration, so your task here is just to add the parsing of hyperlinks to parseSpans.
The syntax for hyperlinks is as follows:
For more information, see [F# home page](http://fsharp.net).
You can read the syntax as a link body bracketed using square brackets, [ and ], immediately followed by a URL bracketed using parentheses, ( and ).
The best way to parse the syntax is to define a Bracketed parameterized active pattern that behaves like Delimited but takes two parameters (opening and closing characters). Then you can write a nested pattern (using Bracketed twice) to match the input against [link body]rest. This gives you the link body and the rest of the input. You can then match the rest of the input against (link url)rest.
If you want to make further extensions, you can look at the Markdown syntax (http://daringfireball.net/projects/markdown/syntax) and try implementing the remaining features. Note that the syntax for images is almost the same as the syntax for hyperlinks, so they can be parsed in a uniform way if you define an active pattern for the common part. We don’t have enough space to implement all the features in this chapter, so we’ll now move on to the next part of the parser.
Exercise 2
Another useful feature of Markdown is the ability to add a hard line break (which is translated to the <br /> element in HTML). To support this feature, you first need to go back to the definition of MarkdownSpan and add a new HardLineBreak case without any properties.
A hard line break is written as two spaces followed by both the \n\r characters or by either of them. Parsing the syntax in parseSpans should be easy: you just need to match the input list against a list starting with these three or four characters, which can be nicely done using theStartsWith active pattern.
After you add the extension, you should see the following behavior in F# Interactive:
> "hello \n\rworld \r!!!"
|> List.ofSeq |> parseSpans [] |> List.ofSeq;;
val it : MarkdownSpan list =
[ Literal "hello"; HardLineBreak;
Literal "world"; HardLineBreak;
Literal "!!!"]
As you can see, the Literals are separated by hard line breaks, and there are no remaining \r or \n characters or spaces, because they’re consumed when parsing the line breaks.
As explained previously, in the “Representing Markdown documents” section, Markdown documents have two levels. The first level consists of blocks (such as headings and paragraphs), and the second level consists of inline formatting (such as emphasis and links). You’ve finished writing the parser for the second level, so all that remains to be done is to parse the first level: block elements.
Parsing blocks using active patterns
When parsing Markdown spans, you needed to process input in the form of a character list. You did that by defining active patterns that work on character lists, such as StartsWith and Delimited. In this section, you need to parse Markdown blocks, which are defined in terms of lines of text (see figure 4). For example, a paragraph is a sequence of lines followed by a blank line, a code snippet is a sequence of lines that all start with four spaces, and so on.
Figure 4. In this section, we’re moving on from parsing inline formatting commands, such as emphasis or strong text, to parsing block elements. You’ll write code that splits the input into headings, paragraphs, and code blocks.

You can start by defining a few active patterns that operate on lists of lines. Using a combination of these new patterns and patterns for pattern-matching on individual lines, you’ll then be able to express most of the parsing rules.
The following listing starts by defining patterns that find lines followed by a blank line, and lines that are all prefixed with a specified string.
Listing 6. Active patterns for parsing line-based syntax


This listing demonstrates a key technique of functional programming: the use of higher-order functions to extract and reuse common functionality. Both PrefixedLines and LineSeparated split the input line list using a predicate. You capture this common functionality using a function and then use it twice in the implementation of the active patterns. To make the partitionWhile function easily discoverable, you define it in a List module so that it can be found by typing List followed by a dot.
The first of the two patterns, PrefixedLines, will be useful later for detecting code snippets. Note that the pattern is complete, meaning it can’t fail. If there are no lines starting with a given prefix, the first returned list will be empty.
You can test the behavior of the pattern interactively:
> let (PrefixedLines "..." res) = ["...1"; "...2"; "3" ]
printfn "%A" res;;
(seq ["1"; "2"], seq ["3"])
> let (PrefixedLines "..." res) = ["1"; "...2"; "...3" ]
printfn "%A" res;;
(seq [], seq ["1"; "...2"; "...3"])
The LineSeparated active pattern will be used similarly for identifying paragraphs. You can check whether it works as expected using F# Interactive as an exercise.
Now you can easily complete the parser using a combination of the three active patterns from the previous section as well as patterns for matching on the content of an individual line. The AsCharList pattern is useful when you need to match on individual lines, because it turns a string into a character list that can be passed to patterns such as StartsWith.
Listing 7 creates a parser for Markdown blocks with just a few lines. Much like parseSpans, the parseBlocks function is written as a recursive sequence expression that emits individual MarkdownBlock values as it consumes the lines of input. It takes a list of unprocessed lines as a parameter and matches it against a number of patterns.
Listing 7. Parsing Markdown blocks using active patterns


The function in listing 7 completes the Markdown parser. Writing proper tests for the function is outside of the scope of this chapter (see chapter 12 for more on testing), but you can at least test it interactively. To do that, you can use one minor but handy innovation of F# 3.0. You can write the sample document as a single string using triple quotes, which means it can freely contain quotes without escaping:
> let sample = """# Introducing F#
F# is a _functional-first_ language,
which looks like this:
let msg = "world"
printfn "hello %s!" msg
This sample prints `hello world!`
""";;
val sample : string = (...)
> let sampleDoc =
sample.Split('\r', '\n') |> List.ofSeq
|> parseBlocks |> List.ofSeq;;
val sampleDoc : list<MarkdownBlock> = [
Heading (1,[Literal "Introducing F#"]);
Paragraph
[ Literal "F# is a "; Emphasis [Literal "functional-first"];
Literal " language, which looks like this:"];
CodeBlock ["let msg = "world""; "printfn "hello %s!" msg"];
Paragraph [Literal "This sample prints "; InlineCode "hello world!"]]
To run the parser, you split the string into individual lines and then call parseBlocks. You can check that the result is an expected Markdown document consisting of a heading, a paragraph, a code block, and one more paragraph (with emphasis on the first line and inline code on the last one).
Although you can already write rich documents, there are a number of Markdown features that you can still add to the parser. Exercise 3 suggests one such addition: to solve the last part of the exercise, you’ll need to go back to the definition of the Markdown-Block type (listing 1) and add a new kind of block. Exercise 4 has you add support for another kind of block that’s supported by Markdown: a block quote.
Exercise 3
The code for parsing headings in listing 7 is slightly repetitive. The bodies of the two clauses that recognize first-level ![]() and second-level
and second-level ![]() headings are exactly the same, with the only difference being the number representing the size of the heading.
headings are exactly the same, with the only difference being the number representing the size of the heading.
You can correct that by defining an active pattern, Heading, that detects and returns the heading together with its number. Using that, you should be able to rewrite the pattern matching as follows:
| Heading(size, heading, lines) ->
yield Heading(size, parseSpans [] heading |> List.ofSeq)
yield! parseBlocks lines
This function supports only one style of headings. It handles headings written on a single line starting with the hash (#) symbol, but it doesn’t handle the alternative: a single line of text followed by a line consisting of three or more occurrences of the equals sign (=) or dash (–).
Supporting this alternative style is another interesting exercise. You’ll need to define a new active pattern to add this functionality, but the key aspect—searching for a line containing equals or dashes—can be done using List.partitionWhile. If you design the active pattern well, you can also use it to handle horizontal rules, which can be written as a line of dashes preceded by a blank line.
Exercise 4
In a Markdown document, a quote can be written by prefixing the text with the > character followed by a space. But there are a few interesting details.
If a quotation contains a longer paragraph, you don’t have to mark all the lines of the paragraph, but instead just the first line of each paragraph:
> This is a hand-written quotation
which consists of two paragraphs.
> The second paragraph is quite short.
Quotations aren’t limited to paragraphs. They may contain code snippets, headings, and other block elements:
> This is a quotation that contains F# code:
>
> printfn "Hello from quoted code!"
To implement quotations, you need to add a BlockQuote case to the MarkdownBlock type. Unlike Heading or Paragraph, which contain MarkdownSpans, the case representing quotations needs to contain MarkdownBlocks, because quotations can contain not just text, but other blocks. In the parsing code, you also need to call parseBlocks recursively to process the body of the quoted text.
The source code for this chapter comes with a number of examples that you can use to test whether your implementation of quotes works as expected.
Most of the common implementations of Markdown take a document and turn it directly into HTML, usually using regular expressions. As discussed earlier, this approach means it’s hard to generate other outputs (for example, Word documents or LaTeX), and it also means it’s difficult to postprocess the document.
By writing a parser that turns Markdown documents into an F# data type, we’ve opened a number of interesting possibilities. Code that turns the representation into HTML (or any other format) can be written with just a few lines of F#.
Turning Markdown into HTML
The .NET framework provides a number of ways to generate HTML documents. If you were using ASP.NET, you could use the ASP.NET object model to generate HTML elements. You could use the LINQ to XML library (and XDocument) to generate XHTML and guarantee that the generated code is valid XML. Finally, you can also generate HTML by hand.
In this section, you’ll use the last option to keep the code short and simple. As demonstrated in figure 5, you’ll write two functions that format blocks and spans. You’ll use imperative style, so both functions take a standard .NET TextWriter object, use it to generate HTML, and returnunit. Alternatively, you could compose and return a string, but this is an inefficient operation in .NET.
Figure 5. The functionality that turns a Markdown document into HTML is implemented using two functions. The formatBlock function emits tags corresponding to MarkdownBlock values, and formatSpan generates HTML for MarkdownSpan elements.
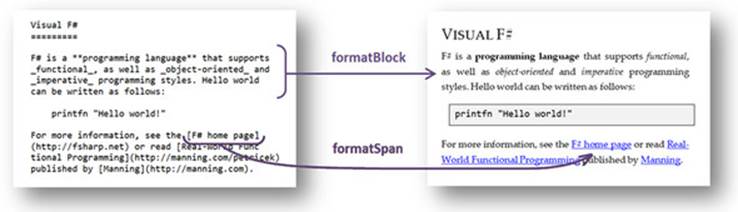
Most of the HTML-generation code in the formatBlock and formatSpan functions will generate HTML elements of the form <tag attr1="value">body</tag>, with zero or more attributes. The body in the HTML element can be generated by other code.
In your first attempt to write the code, you could call the Write method (for the opening tag), followed by code to generate the body and another call to Write for the closing tag. This works fine, but you can simplify the code slightly using the following helper function:

The first argument of the outputElement function is a TextWriter object representing the output stream. The next three arguments specify what should be written: the tag name, attributes, and a function that generates the body. It’s a perfect example of the Hole in the Middle pattern:[4]the idea is that you have some repeated code (the generation of the opening and closing tags) with a variable part in the middle. In functional languages, the pattern can be abstracted using a higher-order function that takes the body as a function and calls it where the changing part is needed.
4 See Brian Hurt’s “The ‘Hole in the middle’ pattern” article on the Enfranchised Mind blog, July 10, 2007, http://mng.bz/Lcs8. Using a more traditional OO design patterns perspective, this can be also viewed as the Strategy pattern or the Template Method pattern.
The following listing shows the remaining code needed to implement HTML generation.
Listing 8. Generating HTML from a Markdown document

This is possibly the least inspiring code sample in this chapter, because it’s so straightforward. Both functions use the function keyword to pattern-match on their argument and then implement the rendering of HTML using the output-Element helper.
When you need to render all child elements (for example, in Strong ![]() or CodeBlock
or CodeBlock ![]() ), you use the List.iter function. In this case, I prefer the iter function over a for loop, because you can nicely use partial function application. When you use (formatSpan output) as an argument, you create a function that takes a Markdown-Span, so you can pass it directly to List.iter, which calls it for all MarkdownSpan elements in the input list.
), you use the List.iter function. In this case, I prefer the iter function over a for loop, because you can nicely use partial function application. When you use (formatSpan output) as an argument, you create a function that takes a Markdown-Span, so you can pass it directly to List.iter, which calls it for all MarkdownSpan elements in the input list.
Formatting HTML efficiently
Listing 8 generates most of the HTML code by concatenating a fixed number of strings and by using the Write and WriteLine methods of TextWriter. Some of the code could be written more elegantly using the F# Printf.fprintf function, which supports standard F# format strings in a type-safe way. In my first implementation of Markdown in F#, the HTML formatting was one of the main bottlenecks. But it’s worth noting that the efficiency of the printf function has been largely improved in F# 3.1.
That said, you should always use a profiler to find out whether this is a problem for your application. In most situations, the performance of string formatting won’t be an issue.
Let’s now test the function in F# Interactive. To do that, you need to go back to the end of the “Parsing blocks using active patterns” section, where you created a sample document, sampleDoc. The following snippet shows how to render the document and store it as a string:
> let sb = System.Text.StringBuilder()
let output = new StringWriter(sb)
sampleDoc |> List.iter (formatBlock output)
sb.ToString()
;;
val it : string =
"<h1>Introducing F#</h1><p>F# is a <em>functional-first</em> language,
![]() which looks like this:</p><pre>let msg = "world"
which looks like this:</p><pre>let msg = "world"
printfn "hello %s!" msg
</pre><p>This sample prints <code>hello world!</code></p>"
To save the generated HTML as a string, you allocate a new StringBuilder and create a StringWriter that can be passed to the formatBlock function. Once again, you use List.iter and partial function application to print all blocks of the document.
The generated HTML code is correct, although not very readable because the function that generates it doesn’t add any indentation or line breaks. The only line breaks are in the <pre> tag, where they are required. Changing the implementation to produce nice and readable HTML code is a good exercise.
Processing Markdown documents
One of my key motivations for writing a custom Markdown parser was that I wanted to be able to easily write functions that transform the document in various ways. Such functions, for example, could count the number of words in the document (excluding code snippets), find allCodeBlock blocks and run a syntax highlighter on the source code, or automatically number all headings in the document. The processing you’ll implement in this section is illustrated in figure 6.
Figure 6. Document transformations that are implemented in this section. You’ll create a document that’s suitable for printing by numbering all the hyperlinks and adding a “References” section that shows the URLs of referenced web pages.

The F# representation makes document-processing tasks easy. Once you parse the document, you can recursively walk through the MarkdownBlock and MarkdownSpan types and implement any transformation or processing you need.
Implementing the tree-processing patterns
If you want to implement a single transformation, you can do that directly; but if you need multiple transformations, you won’t always want to repeat the same boilerplate code. For every processing function, you’d have to pattern-match on all MarkdownBlock and MarkdownSpan cases, call the function recursively on all child elements, and then reconstruct the original element.
Using F#, there are several ways to hide the boilerplate. The standard functional approach is to write a number of higher-order functions like map and fold that capture some processing patterns (transform a certain node to another node; aggregate some values computed from individual elements). This works well if your processing matches a supported pattern, but complex transformations require complex higher-order functions. The code still tends to be concise, but it may become more difficult to understand.
An alternative option that you’ll use here is to define active patterns that provide a more general view of the document structure. Instead of classifying elements based on their kind, you can classify elements by whether they contain children. The recursive processing then needs only a single case to handle all elements with children.
This programming idiom is used by the ExprShape module in the standard F# library. The following listing implements the same pattern for the MarkdownBlock and MarkdownSpan types.
Listing 9. Active patterns that simplify the processing of Markdown documents


This listing implements an active pattern and a function with a corresponding name for both of the types that represent a Markdown document. The idea of the idiom is that you can use the SpanNode active pattern to handle all MarkdownSpan values that contain child spans. The active pattern returns a list of children together with an opaque object that represents the shape (or the kind) of the span. In this implementation, the opaque object is just a boxed MarkdownSpan value to keep the code short, but you could define another type to make it less error-prone.
When the pattern matches, you can process the children as you wish, but you can’t perform any operation on the shape. The only thing you can do is reconstruct a span of the same shape, possibly with different child spans.
For example, when processing a HyperLink, the shape captures the fact that the span is a hyperlink and stores the linked URL. The children are MarkdownSpan elements from the body of the hyperlink. When you transform the children, you process the body of the hyperlink. To reconstruct the hyperlink, you use the Matching.SpanNode function, which builds a HyperLink using the original URL and new children. What makes this idiom elegant is that the same code will also work on other elements with children, such as Strong and Emphasis.
If you’re still slightly puzzled by the idea, don’t worry. It will all become clear when we look at an example in the next section.
Generating references from hyperlinks
When generating a printable version of a document, you need to transform the entire document in order to add numbered references to all hyperlinks. This means your recursive function for processing blocks will essentially take an original MarkdownBlock and return a newMarkdownBlock.
The processing of spans is trickier. You can’t return a new MarkdownSpan as the result, because when you find a HyperLink, you need to return multiple spans as the result. This means you need to turn a single MarkdownSpan into a list of MarkdownSpan values and then concatenate all of them to get a list of children.
In addition, you need to keep state during the processing. In particular, you need to build a list of references that contains URLs and their associated indexes. In listing 10 you do that using the ResizeArray type. The same thing could be done using an immutable list, but the solution using a mutable collection is simpler. Using an immutable list, you’d have to return the new state as part of the result instead of just returning a list of spans.
Listing 10. Generating a document with references for printing

This implementation consists of two functions that recursively process MarkdownSpan and MarkdownBlock types. The last two cases of pattern matching in both functions are similar. They implement a transformation that visits all nodes of the document but creates a copy that’s exactly the same. Thanks to the patterns and functions from the Matching module, you don’t have to explicitly handle all cases. You need just two: a case for elements with children, and a case for elements without children.
To implement a transformation that does something interesting, you need to add an additional case of the pattern matching and look for specific elements (such as HyperLink). Then you transform the element to one or more other elements, while all other elements are handled by the last two cases and copied without change.
To run the transformation on an entire document, you need to use List.map to apply generateBlockRefs on all blocks of the document:

When you run the code using F# Interactive and enter the individual values as separate commands (to make sure their value is printed), you get the following output:

Now that you’ve transformed the document to a version with numbered hyperlinks, you should also append a “References” heading followed by a list with the values from refs. The best way to do that would be to use ordered lists, but you don’t support this Markdown feature yet (the rules for parsing lists are slightly subtle). As a simple alternative, you could add a new kind of block—say, HtmlBlock—that could contain arbitrary HTML and be written directly to the output when rendering the document. In fact, Markdown supports inline HTML, so this would be a sensible extension.
Implementing HtmlBlock, or even ordered and unordered lists, makes for an interesting exercise. Exercise 5 offers a couple of suggestions that involve the processing of documents, and it should be easy to complete. If you want to check the results, your function should report that the sample document from the start of the chapter (in the “Formatting text with Markdown” section) has 45 words.
Exercise 6 is also easy when you do it for a MarkdownBlock from listing 1, but it’s interesting if you’ve completed exercise 4.
Exercise 5
The transformation that you implemented in the last example turns a document into a new document, but you can use the same programming idiom to write code that turns a document into some other value. In this exercise, your task is to implement a word counter for MarkdownDocument. You shouldn’t count words that appear in code samples (either InlineCode or CodeBlock). This essentially means you should only count words in the Literal span, but keep in mind that a Literal may contain multiple words separated by whitespace or punctuation.
Exercise 6
In this exercise, your task is to implement a document transformation that automatically adds numbers to headings. For example, take the following document:
# Paradigms
## Object-oriented
## Functional
# Conclusions
Your algorithm should add the numbers 1 and 2 to top-level headings (resulting in “1. Paradigms” and “2. Conclusions” and numbers 1.1 and 1.2 to the two subheadings (resulting in “1.1 Object-oriented” and “1.2 Functional”). To implement the processing, you only need to walk through a list of MarkdownBlock values (because MarkdownSpan can’t contain headings), but you need to find a good data structure for remembering current numbers.
If you completed exercise 4, you’ll need to decide how to handle quoted headings. Are they numbered as part of the main document, or are headings in a quotation numbered separately? Or perhaps they shouldn’t be numbered at all.
If you attempt to automatically number headings in quotations, you can also extend the patterns in the Matching module (listing 9). A Blockquote element is tricky. It contains child elements, but, in contrast with Paragraph, the child elements aren’t MarkdownSpan values, but otherMarkdownBlock values. This means you can’t handle them using Matching.BlockNode. For this reason, you’ll need to add another active pattern named Matching.BlockNested that returns an opaque shape together with children of type MarkdownBlock. For now, you need this pattern only for quotes, but later you’d also need it for lists and other complex blocks.
The Markdown format is rich, and there’s a lot of potential for extending the code in this chapter. If you want to go beyond the standard exercises, you can contribute to the more complete F# Markdown parser that inspired this chapter.[5] That implementation follows exactly the same principles as the code here. Interesting projects include turning the parser into a complete blogging system and adding different backends that convert the parsed document to other formats, such as HTML5 presentations and Word documents.
5 The implementation can be found at http://tpetricek.github.io/FSharp.Formatting/.
Summary
You can see the Markdown format as an external DSL—that is, a language or document that has its own syntax and represents a script, document, or command. In addition to writing documents, external DSLs are useful when you face repetitive programming tasks, such as describing financial contracts or writing scripts or configurations. Creating external DSLs can be a time-consuming task, so it’s typically only worth doing when they’re used often or when they allow nonprogrammers to contribute to your system (such as by specifying system behavior in a simple format).
When creating DSLs in F#, the first step is always to define an F# representation of the language (in this case, MarkdownBlock and MarkdownSpan). Then you can add parsers and processing operations, such as generating a list of references. The fact that you can use the F# representation of Markdown in a number of ways is the main benefit of the solution. If you used a parser that turns Markdown directly into HTML, it would be almost impossible to add different backends or to preprocess documents.
Recalling chapter 1, you can see all the four key issues in action in this chapter. The use of active patterns makes it possible to parse complex formats using readable code, which makes it easier to check the correctness of the implementation. At the same time, you can easily compose a few primitive active patterns to cover a large part of the Markdown format, which decreases time to market. Finally, the F# compiler produces code that’s more efficient than a standard C# parser based on regular expressions.
About the author
Tomas Petricek is a long-time F# enthusiast and author of the book Real-World Functional Programming (Manning, 2010), which explains functional programming concepts using C# 3.0 while teaching F# alongside. He is a frequent F# speaker and does F# and functional training in London, New York, and elsewhere worldwide.

Tomas has been a Microsoft MVP since 2004, writes a programming blog at http://tomasp.net, and is also a Stack Overflow addict. He contributed to the development of F# during two internships at Microsoft Research in Cambridge. Before starting a PhD at the University of Cambridge, he studied in Prague and worked as an independent .NET consultant.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.