Testing with F# (2015)
Chapter 2. Writing Testable Code with Functional Programming
There are three main aspects of writing code in a functional style in F# versus imperative style in a language such as C#:
· No side effects leads to fewer bugs
· Smaller isolated units are easier to test
· Expressiveness makes code right the first time
This chapter will address the following bits about functional programming:
· Purity
· Expressiveness
· Immutability
· Patterns to help you write testable code
By reading this chapter, you will learn how to write high quality code that will become easy to test. This chapter sets the groundwork for how tests will be written in the following chapters.
Purely functional
What is a computer program?
The following image shows the basic working of a computer program:
An input computed by a program returns an output. This is a very simple concept but it becomes highly relevant for functional programming.
A former colleague told me that's all there is to it: data and code that operates on data. If you want to take it further, the code itself is also data, so a computer program is really just data operating on data.
What about web programming?
The following image shows the basic working of a web server:
It's really the same thing. You have a web request that the server operates on and returns a web response.
How does this apply to functional programming?
The following image shows the basic working of functional programming:
A pure function is very much a computer program. It has an input and output, but the computation of the output adhere to certain conditions:
· The same output is always guaranteed for the same input
· The evaluation of the output cannot have side effects
This means the function cannot depend on any state outside the function scope. It also means that the function cannot affect any state outside the function scope. Actually, the computed output cannot depend on anything else other than the input arguments. All arguments sent to the function should be immutable so they don't accidentally depend on or modify a state outside the function scope.
This means any of the following cannot happen in a pure function:
· Database calls, insert, update, select, and delete
· Web service calls
· Reading or writing to the hard drive
Logging, console output, updating User Interface (UI), and user input are examples of a pure function
// reverse a string
let rec reverse = function
| "" -> ""
| s -> s.[s.Length - 1].ToString() + (reverse (s.Substring(0, s.Length - 1)))
This code reverses a string using the fact that a string is an array of characters, picking each character from the end of the string and joining it by reversing the rest of the string.
Examples of other pure functions are:
· The sin(x) function
· The fibonacci(n) function
· The List.map() function
· The md5(s) function
The pure function concept maps perfectly to mathematics. It could be visualized as a simple graph:
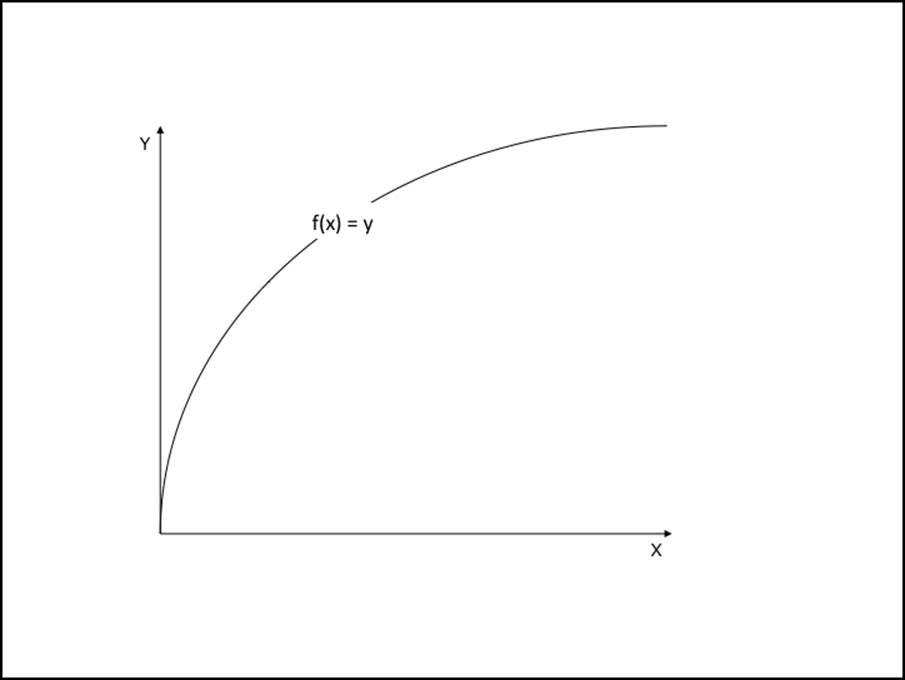
If we consider functions in our programs to work much like the math graph example, we will get a better understanding of how to create simple and straightforward programs.
This doesn't sound like any business software that you know. Do pure programs only happen in fantasy? What is the point of having pure functions?
The advantages of pure functions come in terms of quality because a function that is pure becomes easier to test. There is a universe of possible input, the function arguments for which will generate consistent output with no side effects.
Some tests for the pure reverse function mentioned earlier are as follows:
[<Test>]
let ``should reverse 'abcde' as 'edcba'`` () =
reverse "abcde" |> should equal "edcba"
[<Test>]
let ``should reverse empty string as empty string`` () =
reverse "" |> should equal ""
Most of the bugs in software development come from the mutating state and side effects because these are very hard to predict. We can avoid these bugs by writing large parts of our programs as pure functions and isolate the need for a mutating state. This would give our code a clearer focus with isolated functions and higher cohesion.
This is one way of increasing testability with functional programming.
Immutability
The default behavior of F# when using the let keyword is an immutable value. The difference between this and a variable is that the value is not possible to change. With this, there are the following benefits:
· It encourages a more declarative coding style
· It discourages side effects
· It enables parallel computation
The following is an example implementation of the String.Join function using a mutable state:
// F# implementation of String.Join
let join (separator : string) list =
// create a mutable state
let mutable result = new System.Text.StringBuilder()
let mutable hasValues = false
// iterate over the incoming list
for s in list do
hasValues <- true
result
.Append(s.ToString())
.Append(separator)
|> ignore
// if list hasValues remove last separator
if hasValues then
result.Remove(result.Length - separator.Length, separator.Length) |> ignore
// get result
result.ToString()
In this example, we used a string builder as a state where values were added together with a separator string. Once the list was iterated through, there was one trailing separator that needed to be removed before the result could be returned. This is of course true only if the sequence was nonempty.
This is how it could be written in an immutable way:
// F# implementation of String.Join
let rec join separator = function
| [] -> ""
| hd :: [] -> hd.ToString()
| hd :: tl -> hd.ToString() + separator + (join separator tl)
This implementation is quite stupid, but it is proving the point of immutability. Instead of having a state that is mutated, we used recursion to apply the same method once again with different parameters. This is much easier to test, as there are no moving parts within the function. There is nothing to debug, as there is no state that is changing.
If one were to create an expressive solution to this problem, it would rather look like this:
// F# implementation of String.Join
let join separator =
// use separator to separate two strings
let _separate s1 s2 = s1 + separator + s2
// reduce list using the separator helper function
List.reduce _separate
In this implementation, we add a few constraints by narrowing down the specification. Only a list of strings are now allowed, and the implementation will throw a System.ArgumentException exception when it encounters an empty list. This is OK if it's a part of the specification.
The problem itself is a reduce problem, so it is natural to use the higher order reduce function to solve it. All of this was, of course, a matter of exercise. You should always use the built-in String.Join function and never roll your own.
This is where you can see the functional programming excel. We moved from a 20 Lines of Code (LOC) mutable code example to a 3 LOC immutable code example.
Less code makes it easier to test, and less code may also reduce the need for testing. Each line of code brings complexity, and if we can bring down the number of lines of code by writing terser code, we also reduce the need for testing.
Immutable data structures
As we have seen, the immutable value is default in F# compared to the mutable variable in other languages. But the statement that F# makes on immutability doesn't end here. The default way of creating types in F# makes for immutable types.
An immutable type is where you set values upon creation of an instance, and each attempt to modify the state of the instance will result in a new instance. The most comprehensive example in .NET is DateTime.
This makes it possible for us to use function chaining like this:
// Now + 1 year + 1 month + 1 day
> System.DateTime.Today.AddYears(1).AddMonths(1).AddDays(1.)
In F#, we define a new type like this:
> type Customer = { FirstName : string; Surname : string; CreditCardNumber: string }
> let me = { FirstName = "Mikael"; Surname = "Lundin"; CreditCardNumber = "1234567890" }
Now if I update the credit card number, it generates an new instance.
let meNext = { me with CreditCardNumber = "2345678901" }
There are many benefits of doing this:
· If you are processing the me parameter, it will not change its state, making async operations safe.
· All data that belongs to the me parameter is accurate at the point in time when the me parameter was created. If we change me, we lose this consistency.
Fewer moving parts also make it easier to test code, as we don't have to care about the state and can focus on the input and output of functions. When dealing with systems such as trading and online ordering, immutability has become such a major player that now there are immutable databases. Take a look at Datomic and validate how an immutable database fits into immutable code.
Built-in immutable types
In order to support immutability throughout the language, there are some immutable types that come with the F# framework. These support pretty much any kind of functional computation that you would need, and with them, you can compose your own immutable type.
Most of the already defined types and data structures within the .NET framework are mutable, and you should avoid them where you can and sometimes create your own immutable versions of the functionality. It is important to find a balance here between cost versus value.
Tuple
Tuple is one of the most common data types with the F# language and is simply a way of storing two or several values in one container.
The following code is an example of a tuple:
// pattern matching
let tuple = (1, 2)
let a, b = tuple
printfn "%d + %d = %d" a b (a + b)
A tuple is immutable because once it's created, you cannot change the values without creating a new tuple.
Another important aspect of the tuple is how it maps to the out keyword of C#. Where the .NET framework supports out variables, it will be translated into a tuple in F#. The most common usage of the out keyword is the Try pattern, as follows:
// instead of bool.TryParse
// s -> bool choice
let parseBool s =
match bool.TryParse(s) with
// success, value
| true, b -> Some(b)
| false, _ -> None
The code maps the bool.TryParse functionality into the choice type, which becomes less prone to error as it forces you to handle the None case, and it only has three combinations of values instead of four, as with the tuple result.
This can be tested as follows:
[<Test>]
let ``should parse "true" as true`` () =
parseBool "true" |> should equal (Some true)
[<Test>]
let ``should parse "false" as false`` () =
parseBool "false" |> should equal (Some false)
[<Test>]
let ``cannot parse string gives none`` () =
parseBool "FileNotFound" |> should equal None
List
The list type is a very used collection type throughout F#, and it has very little in common with its mutable cousin: the System.Collections.Generic.List<T> type. Instead, it is more like a linked list with a closer resemblance to Lisp.
The following image shows the working of lists:
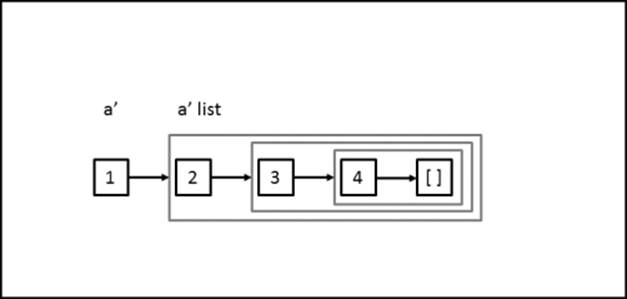
The immutable list of F# has the following properties:
· Head
· IsEmpty
· Item
· Length
· Tail
This is enough to perform most computations that require collections. Here is an example of a common way to build lists with recursion:
// not very optimized way of getting factors of n
let factors n =
let rec _factors = function
| 1 -> [1]
| k when n % k = 0 -> k :: _factors (k - 1)
| k -> _factors (k - 1)
_factors (n / 2)
One strength of the list type is the built-in language features:
// create a list
> [1..5];;
val it : int list = [1; 2; 3; 4; 5]
// pattern matching
let a :: b :: _ = [1..5];;
val b : int = 2
val a : int = 1
// generate list
> [for i in 1..5 -> i * i];;
val it : int list = [1; 4; 9; 16; 25]
Another strength of the list type is the list module and its higher order functions. I will give an example here of a few higher order functions that are very powerful to use together with the list type.
The map is a higher order function that will let you apply a function to each element in the list:
// map example
let double = (*) 2
let numbers = [1..5] |> List.map double
// val numbers : int list = [2; 4; 6; 8; 10]
The fold is a higher order function that will aggregate the list items with an accumulator value:
// fold example
let separateWithSpace = sprintf "%O %d"
let joined = [1..5] |> List.fold separateWithSpace "Joined:"
// val joined : string = "Joined: 1 2 3 4 5"
The nice thing about the fold function is that you can apply it to two lists as well. This is nice when you want to compute a value between two lists.
The following image is an example of this, using two lists of numbers. The algorithm described is called Luhn and is used to validate Swedish social security numbers. The result of this calculation should always be 0 for the Social Security Number (SSN) to be valid:
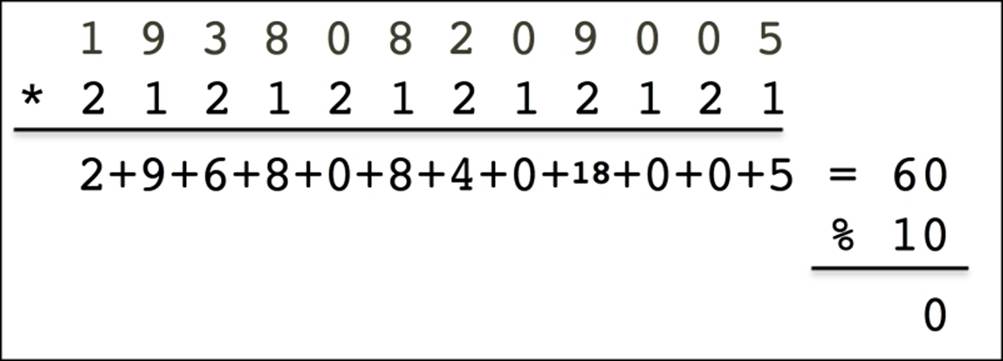
Here is a perfect situation where you want to compute a value between two lists:
// fold2 example
let multiplier = [for i in [1..12] -> (i % 2) + 1] // 2; 1; 2; 1...
let multiply acc a b = acc + (a * b)
let luhn ssn = (List.fold2 multiply 0 ssn multiplier) % 10
let result = luhn [1; 9; 3; 8; 0; 8; 2; 0; 9; 0; 0; 5]
// val result : int = 0
The partition is an excellent higher order function to use when you need to split values in a list into separate lists:
// partition example
let overSixteen = fun x -> x > 16
let youthPartition = [10..23] |> List.partition overSixteen
// val youthPartition : int list * int list =
// ([17; 18; 19; 20; 21; 22; 23], [10; 11; 12; 13; 14; 15; 16])
The reduce is a higher order function that will not use an accumulator value through the aggregation like the fold function, but uses the computation of the first two values as a seed.
The following code shows the reduce function:
// reduce example
let lesser a b = if a < b then a else b
let min = [6; 34; 2; 75; 23] |> List.reduce lesser
There are many more useful higher order functions in the List module that are free for you to explore.
Sequence
Sequence in F# is the implementation of the .NET framework's IEnumerable interface. It lets you get one element at a time without any other information about the sequence. There is no knowledge about the size of the sequence.
The F# sequence is strongly typed and quite powerful when combined with the seq computational expression. It will let us create unlimited length lists just like the yield keyword in C#:
// For multiples of three print "Fizz" instead of the number
// and for multiples of five print "Buzz"
// for multiples of both write "Fizzbuzz"
let fizzbuzz =
let rec _fizzbuzz n =
seq {
match n with
| n when n % 15 = 0 -> yield "Fizzbuzz"
| n when n % 3 = 0 -> yield "Fizz"
| n when n % 5 = 0 -> yield "Buzz"
| n -> yield n.ToString()
yield! _fizzbuzz (n + 1)
}
_fizzbuzz 1
I'm sure you recognize the classic recruitment test. This code will generate an infinite sequence of fizzbuzz output for as long as a new value is requested.
The test for this algorithm clearly shows the usage of sequences:
[<Test>]
let ``should verify the first 15 computations of the fizzbuzz sequence`` () =
fizzbuzz
|> Seq.take 15
|> Seq.reduce (sprintf "%s %s")
|> should equal "1 2 Fizz 4 Buzz Fizz 7 8 Fizz Buzz 11 Fizz 13 14 Fizzbuzz"
Creating an immutable type
When you set out to create your own types, you have great tools that will help you start out with immutable versions. The most basic type declaration is the discriminated union:
// xml representation
type Node =
| Attribute of string * string
| Element of Node list
| Value of string
A basic type is that of a record, which is in its basic setting an immutable type:
let quote =
Element
[
Attribute ("cite", "Alan Turing")
Value "Machines take me by surprise with great frequency"
]
In order to change the value of an immutable type, you need to create a new copy of it with the value changed, a true immutable type:
// <blockquote cite="Alan Turing">Machines take me by surprise with great frequency</blockquote>
Once in a while, you need to create a class, and this is when you need to be careful to create an immutable type and not a mutable one. This can be identified by the following properties:
· State can only be set upon creation
· Change of state returns a copy of the instance
· The class can only have references to other immutable types
This is an example of a good immutable class type:
type Vector = | X | Y | Z
type Point(x : int, y : int, z : int) =
// read-only properties
member __.X = x
member __.Y = y
member __.Z = z
// update
member this.Update value = function
| X -> Point(value, y, z)
| Y -> Point(x, value, z)
| Z -> Point(x, y, value)
override this.Equals (obj) =
match obj with
| :? Point as p -> p.X = this.X && p.Y = this.Y && p.Z = this.Z
| _ -> false
override this.ToString () = sprintf "{%d, %d, %d}" x y z
When updating any value, it will generate a new instance of Point instead of mutating the existing one, which makes for a good immutable class.
Writing testable code
In the previous section we have been looking at basic functional structures that helps us write better programs. Now we're ready to move on to higher level constructs that let us organize our code functionally on a more abstract way.
Active patterns
Pattern matching is one of the killer features of F# that makes it a more attractive language than C# or Visual Basic. It could have been just a nice language feature for the built-in .NET types, but actually it is highly customizable and you can define your own patterns.
Here is how you can define your own active pattern:
// active pattern for sequences
let (|Empty|NotEmpty|) sequence =
if Seq.isEmpty sequence then Empty
else NotEmpty sequence
This enables us to use the pattern directly in a match expression:
// example on usage of active pattern
// join ["1"; "2"; "3"] -> "123"
let rec join (s : seq<string>) =
match s with
| Empty -> ""
| NotEmpty s -> (Seq.head s) + join (Seq.skip 1 s)
The power of this really comes into play when using parameterized active patterns together with a complex concept, such as regular expressions:
// matching input to pattern and return matching values
let (|Matches|) (pattern : string) (input : string) =
let matches = Regex.Matches(input, pattern)
[for m in matches -> m.Value]
This pattern will match a string and run a regular expression pattern on it, returning the values of the matches. This makes for a nice combination of regular expressions and pattern matching:
// parse a serial key and concat the parts
let parseSerialKey = function
| Matches @"\w{5}" values -> System.String.Join("", values)
Here is an example of how to execute this function:
> parseSerialKey "VP9VV−VJW7Q−MHY6W−JK47R−M2KGJ";;
val it : string = "VP9VVVJW7QMHY6WJK47RM2KGJ"
This language feature makes it easier to separate out the ceremonial code to run a regular expression and the actual expression that is part of the business logic. It also makes for very readable code.
Higher order functions
We have seen examples of higher order functions for the list data structure. One easy thing to gain testability in functional programming is to write your own higher order functions and use the structure to gain higher cohesion and easier-to-test functions in isolation:
// get url content and transform it
let webGet transformer urls =
let _download url =
let webClient = new WebClient()
try
let uri = new System.Uri(url)
webClient.DownloadString(uri)
finally
webClient.Dispose()
List.map (_download >> transformer) urls
This is a higher order function that will download URLs and accept a function for what to do with the content of those URLs. This way, we can easily isolate the testing of downloading the contents of a URL, which naturally becomes an integration test, and the transformation of the result, which might or might not be a perfect unit test.
Partial application
One very simple way of dealing with dependencies in functional application is by using partial application.
Partial application will assume an unknown argument and return a function that requires one or several arguments in order to be completed. A simple way is to consider partial application when dealing with databases:
type PaymentStatus = | Unpaid | Paid | Overpaid | PartlyPaid
type Order = { id : string; paymentStatus : PaymentStatus }
// interface that describes the function to persist an order
type IPersistOrder =
abstract member Save: Order -> Order
// update payment status in database
let updatePaymentStatus order status =
(fun (dataAccess : IPersistOrder) ->
let newOrder = { order with paymentStatus = status }
dataAccess.Save(newOrder)
)
The updatePaymentStatus function has a dependency on an IPersistOrder parameter. It could easily take this dependency as another argument, but instead, we chose to make the dependency obvious to the reader by returning a function.
What we can now do in our tests is replace the IPersistOrder parameter with a stub implementation, as follows:
type StubPersistOrder () =
interface IPersistOrder with
member this.Save m = m
[<Test>]
let ''should save an order with updated status'' () =
// setup
let order = { id = "12890"; paymentStatus = Unpaid}
let orderDA = new StubPersistOrder()
// test
let persistedOrder = updatePaymentStatus order Paid orderDA
// assert
persistedOrder.paymentStatus |> should equal Paid
This method of replacing dependencies with interfaces takes on an object-oriented approach. In a functional language, we could easily replace the interface with a function definition instead and achieve the same result:
type PaymentStatus = | Unpaid | Paid | Overpaid | PartlyPaid
type Order = { id : string; paymentStatus : PaymentStatus }
// update payment status in database
let updatePaymentStatus order status =
(fun (save : Order -> Order) ->
let newOrder = { order with paymentStatus = status }
save newOrder
)
The test for this can also be simplified. We no longer need an instantiation of an interface:
[<Test>]
let ``should save an order with updated status`` () =
// setup
let order = { id = "12890"; paymentStatus = Unpaid}
let nothing = (fun arg -> arg)
// test
let persistedOrder = updatePaymentStatus order Paid nothing
// assert
persistedOrder.paymentStatus |> should equal Paid
The problem with using partial application for dependency injection is that it fast becomes the same mess as you have with dependency injection in an object-oriented program. You have a dependency tree that becomes extremely deep, and you will have problems creating any kind of business object without creating a whole universe around it.
The following image is a simplification of the object dependency graph we had for one of the entities in a system that I worked on for a client:
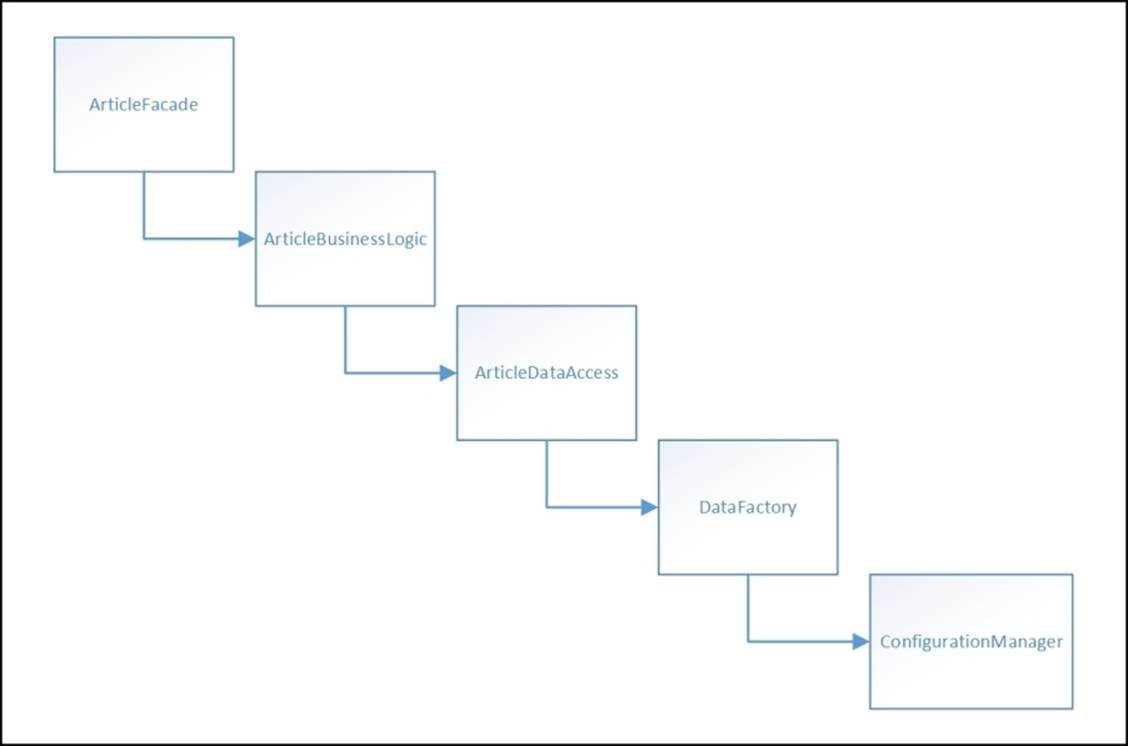
The effect is that you can't create a simple object without including all of its dependencies, and every time you need to do something, you also need to create all of these dependencies. This is where dependency injection frameworks come from to solve this kind of problem, but it really is just a band aid on top of a larger code smell.
Continuations
Let's say that I want to write a function that will get all links on a certain web page. Consider the following implementation:
// get string from url, pass result to success() or failure()
let webget_bad (url : string) success failure =
let client = new System.Net.WebClient()
try
try
// get content from web request
let content = client.DownloadString(url)
// match all href attributes in html code
let matches = Regex.Matches(content, "href=\"(.+?)\"")
// get all matching groups
[for m in matches -> m.Groups.[1].Value]
with
| ex -> failure(ex)
finally
client.Dispose()
This is very hard to test because the function itself is doing several things, such as web requests and parsing HTML attributes.
Continuation is the method of abstracting away the next step of a computation. This can be very useful when you want to create a generic function without specifying what will happen with the result.
The easiest example is that of a web client call:
// get string from url, pass result to success() or failure()
let webget (url : string) success failure =
let client = new System.Net.WebClient()
try
try
let content = client.DownloadString(url)
success(content)
with
| ex -> failure(ex)
finally
client.Dispose()
What we have here is a method with a nasty side effect of doing a web client call. This has to be wrapped not only in a try..finally clause but also in try..with for error management.
Success and failure are our continuations that enable us to separate out the pure functionality from the impure. This makes the code in success and failure very easy to test apart form the web client call:
// success: parse links from html
let parseLinks html =
let matches = Regex.Matches(html, "href=\"(.+?)\"")
[for m in matches -> m.Groups.[1].Value]
// failure: print exception message and return empty list
let printExceptionMessage (ex : System.Exception) =
printfn "Failed: %s" ex.Message; []
The trade-off you make using continuations is a more explicit function declaration with more arguments. This doesn't mean that you lose readability if you extract those methods and name them properly:
> webget "http://blog.mikaellundin.name" parseLinks printExceptionMessage
The following image shows the preceding command-line output:
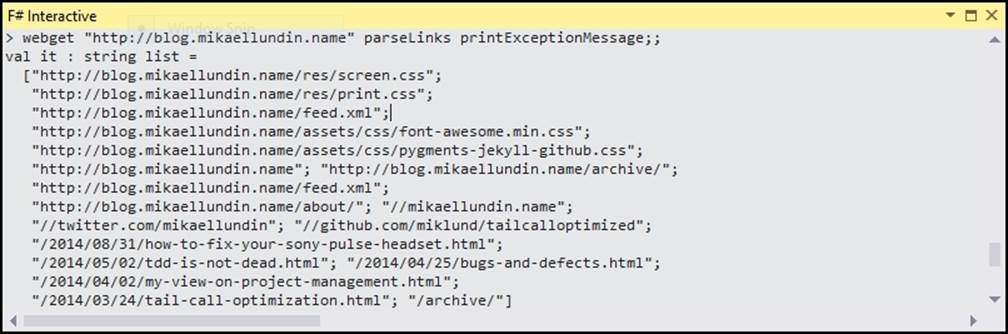
The code shows that something that is quite hard to extract into testable code in an imperative programming language, where one would inject object instances, is very easy to do with continuations in F# and achieve in very few lines of code.
Expressiveness through functional programming
There is a very important distinction between programming language paradigms. Two kinds of programming styles stand against each other:
· Imperative programming
· Declarative programming
The imperative programming style has its origin in Fortran, and the declarative programming paradigm's roots can be followed back to Lisp. The following sections will compare the two styles and explain why we prefer one over the other in testing.
Imperative programming
Imperative programming has become the standard of programming methodology with the rise of languages such as BASIC, Pascal, C, and C#. It means describing to the computer how to calculate a result, in a way that you would describe how to make a cake:
// imperative programming
let double_imperative numbers =
let doubled = System.Collections.Generic.List<int>()
for number in numbers do
let double = number * 2
doubled.Add(double)
doubled
This code example will double all the values in a list by first creating a result list and then doubling it number by number and adding it to the result. Once it goes through all the numbers, the result list will be returned.
In this code, there is a clear path of how double values are calculated, and the program describes how this is accomplished.
Declarative programming
Instead of instructing the computer how to calculate a result, you can describe what the result is. If the result is too complex, break it down into parts and describe the parts and then concatenate those parts. It leads you to a series of descriptions instead of a workflow of what should be done:
// declarative programming
let double numbers =
let double = (*) 2
Seq.map double numbers
This code example also doubles all the values in a list, but instead of describing how this is done, the code describes what this means:
· The double function means taking a value and multiplying it by 2
· Result implies by mapping double onto the numbers function
The main difference between these two methods is that imperative programming describes how and declarative programming describes what. The imperative example created a state to bake the cake, whereas the declarative example broke down the problem into describable parts.
Declarative programming is less prone to faults because there is no mutable state. It is also easier to test as you break down the problem into isolated parts that are not only individually describable but also individually testable. This way, there is a high increase in quality and testability when you use declarative programming.
Let's look at another example. You need to parse roman numerals into integers. In an imperative programming style, you would go about doing this in the following manner:
// parse a roman numeral and return its value
let parse (s : string) =
// mutable value
let mutable input = s
let mutable result = 0
let romanNumerals =
[|("M",1000); ("CM" ,900); ("D",500); ("CD",400); ("C",100 );
("XC",90); ("L",50); ("XL",40); ("X",10 ); ("IX",9); ("V",5);
("IV",4); ("I", 1)|]
while not (String.IsNullOrEmpty input) do
let mutable found = false
let mutable i = 0
// iterate over romanNumerals matching it with input string
while (not found) || i < romanNumerals.Length do
let romanNumeral, value = romanNumerals.[i]
// does input start with current romanNumeral?
if input.StartsWith(romanNumeral, StringComparison.CurrentCultureIgnoreCase) then
result <- result + value
input <- input.Substring(romanNumeral.Length)
found <- true
// iterate
i <- i + 1
// no roman numeral found at beginning of string
if (not found) then
failwith "invalid roman numeral"
result
The following is the basic usage of the parse function:
> parse "MMXIV";;
val it : int = 2014
The code starts by creating two mutable variables: one is a working copy of the incoming value and the other is a result variable. The program will then work on the input variable, matching the start of the string with roman numerals and as a numeral is found adding its value to the result and removing it from the input string. Once the string is empty, the parsing is complete and the value is in the result variable.
There are a lot of moving parts in this code, and it is hard to debug because of the different states that the variables can be in.
Here's an example of how to write this in a more expressive and declarative way:
// partial active pattern to match start of string
let (|StartsWith|_|) (p : string) (s : string) =
if s.StartsWith(p, StringComparison.CurrentCultureIgnoreCase) then
Some(s.Substring(p.Length))
else
None
// parse a roman numeral and return its value
let rec parse = function
| "" -> 0
| StartsWith "M" rest -> 1000 + (parse rest)
| StartsWith "CM" rest -> 900 + (parse rest)
| StartsWith "D" rest -> 500 + (parse rest)
| StartsWith "CD" rest -> 400 + (parse rest)
| StartsWith "C" rest -> 100 + (parse rest)
| StartsWith "XC" rest -> 90 + (parse rest)
| StartsWith "L" rest -> 50 + (parse rest)
| StartsWith "XL" rest -> 40 + (parse rest)
| StartsWith "X" rest -> 10 + (parse rest)
| StartsWith "IX" rest -> 9 + (parse rest)
| StartsWith "V" rest -> 5 + (parse rest)
| StartsWith "IV" rest -> 4 + (parse rest)
| StartsWith "I" rest -> 1 + (parse rest)
| _ -> failwith "invalid roman numeral"
The following is the basic usage of the function:
> parse "MMXIV";;
val it : int = 2014
This code used an F# concept called active pattern and then used pattern matching to match the beginning of the string with the different roman numerals. The value of the parsed numeral is added by parsing the rest of the string.
There are no moving parts in this example, only expressions of what each Roman numeral is worth. The functionality is easier to debug and to test.
Tail call optimization
Writing expressive code is very powerful and gives your code a lot of readability, but it can also be hurtful.
The following will create a comma-separated string out of a list of values:
// join values together to a comma separated string
let rec join = function
| [] -> ""
| hd :: [] -> hd
| hd :: tl -> hd + ", " + (join tl)
This code will expand into the following call tree.
> ["1"; "2"; "3"; "4"; "5"] |> join;;
join ["1"; "2"; "3"; "4"; "5"]
<− join ["2"; "3"; "4"; "5"]
<− join ["3"; "4"; "5"]
<− join ["4"; "5"]
<− join ["5"]
<− join []
There are two problems with this:
· It is very inefficient to perform these many function calls
· Each function call will occupy a record on the stack, leading to stack overflow for large recursion trees
We can show this by running the following tests. First, we run the join function with 30,000 items with timing on:
> #time;;
> [1..30000] |> List.map (fun n −> n.ToString()) |> join;;
Real: 00:00:06.288, CPU: 00:00:06.203, GC gen0: 140, gen1: 61, gen2: 60
val it : string = "1, 2, .... 30000"
The execution lasts for about 6 seconds. In the second test, we run the join function with 1,00,000 items:
> [1..100000] |> List.map (fun n −> n.ToString()) |> join;;
Process is terminated due to StackOverflowException.
Session termination detected. Press Enter to restart.
The result is a crash because there was not enough room on the stack for that many items.
The F# compiler has something called tail call optimization to deal with these problems. You can write expressive code and still have it running safe without the risk of the StackOverflowException exception. You only need to be aware of how to write code so it becomes optimized:
// join values together to a comma separated string
let join list =
let rec _join res = function
| [] -> res
| hd :: tl -> _join (res + ", " + hd) tl
if list = List.Empty then
""
else
(_join (List.head list) (List.tail list))
The structure of this function is somewhat different. Instead of returning the result, the result is built up into a result argument for each recursion. The fact that the recursive call is the last call of the function makes it possible for the compiler to optimize it.
I'm using an inner function join because of two reasons. First, to avoid exposing the res argument to the caller, as it should not be a part of the function definition.
The other is to simplify the match case, as the first iteration should only add the head element of the list to the result.
We can write a test to make sure that it can handle a lot of items:
[<Test>]
let ``should be able to handle 100000 items`` () =
let values = [1..100000] |> List.map (fun n -> n.ToString())
(fun () -> (join values) |> ignore) |> should not' (throw typeof<System.StackOverflowException>)
This gives us an idea of whether the function is able to handle the amount of data we're expecting to throw at it, but it really doesn't say whether it will eventually overflow the stack.
You can use a tool such as ilspy to decompile the assemblies and look at the Intermediate Language (IL) code. Let's take a look at what our first example looks like in C# after decompiling it:
public static string join(FSharpList<string> _arg1)
{
if (_arg1.TailOrNull == null)
{
return "";
}
if (_arg1.TailOrNull.TailOrNull == null)
{
return _arg1.HeadOrDefault;
}
FSharpList<string> tl = _arg1.TailOrNull;
string hd = _arg1.HeadOrDefault;
return hd + ", " + _1232OS_04_08.join(tl);
}
The last line is the culprit where the method makes a call to itself. Now, let's look at the second example with the tail recursion optimization:
public static string join(FSharpList<string> list)
{
FSharpFunc<string, FSharpFunc<FSharpList<string>, string>> _join = new _1232OS_04_09._join@7();
return FSharpFunc<string, FSharpList<string>>.InvokeFast<string>(_join, ListModule.Head<string>(list), ListModule.Tail<string>(list));
}
[Serializable]
internal class _join@7 : OptimizedClosures.FSharpFunc<string, FSharpList<string>, string>
{
internal _join@7()
{
}
public override string Invoke(string res, FSharpList<string> _arg1)
{
while (true)
{
FSharpList<string> fSharpList = _arg1;
if (fSharpList.TailOrNull == null)
{
break;
}
FSharpList<string> fSharpList2 = fSharpList;
FSharpList<string> tl = fSharpList2.TailOrNull;
string hd = fSharpList2.HeadOrDefault;
string arg_33_0 = res + ", " + hd;
_arg1 = tl;
res = arg_33_0;
}
return res;
}
}
F# is not very beautiful anymore after it got decompiled to C#, but the message here is clear. In the second example, the compiler optimized the recursive call into a while(true) loop, and this solved the whole problem with the stack overflow.
When writing expressive, declarative code, it is important to understand tail recursion. It is one of those things that will bite you, not while writing the code but in production where the data is much more diverse and hard to predict.
It is important to understand when to strive for tail call optimization and how to verify that it's actually there.
Parallel execution
The following was quoted in 2005:
|
"The free lunch is over." |
||
|
--Herb Sutter |
||
Since this happened, we have been looking for a way to do parallel execution in a simple way. Our computers aren't getting faster, but they are gaining more and more parallel execution power. This is, however, useless unless we find a way of utilizing this power.
We struggle to make our applications scale out to several CPU cores. Our tools have threads, locks, mutexes, and semaphores, and still we're not able to write concurrent programs that work well. This is because using those tools is very hard. Predicting the execution flow in a concurrent program is very hard and so is debugging a concurrent program.
The result of threading and locks leads to problems such as race conditions and deadlocks. One of the major caveats for concurrent programming is the state, and a mutable state is the beloved best friend of imperative programming. There is a major difference in parallelizing the imperative and declarative programs.
You have two reasons for your application to become concurrent:
· Your program is CPU-bound
· Your program is I/O-bound
For this purpose, F# has the async computational expression:
// download contents to url
let download url =
printfn "Start: %s" url
async {
// create client
let webClient = new WebClient()
try
let uri = System.Uri(url)
// download string
return! webClient.AsyncDownloadString(uri)
finally
printfn "Finish: %s" url
webClient.Dispose()
}
We can quite easily provide a test for this code if we are aware of the consequences of its side effects:
[<Test>]
let ``should download three urls in parallel`` () =
let baseUrl = "http://blog.mikaellundin.name"
let paths = [
"/2014/08/31/how-to-fix-your-sony-pulse-headset.html";
"/2014/05/02/tdd-is-not-dead.html";
"/2014/04/25/bugs-and-defects.html"]
// build urls
let urls = paths |> List.map (fun path -> baseUrl + path)
// test & await
let result = urls |> List.map (download) |> Async.Parallel |> Async.RunSynchronously
// assert
Assert.That((result |> (Seq.nth 0)), Is.StringContaining "Sony Pulse Headset")
Assert.That((result |> (Seq.nth 1)), Is.StringContaining "Writing code is not easy")
Assert.That((result |> (Seq.nth 2)), Is.StringContaining "Lexical Errors")
The important aspect here is that execution of individual computations don't need to end in the same order as they begin, but they will still render the same result.
This can be seen in the test output, as follows.
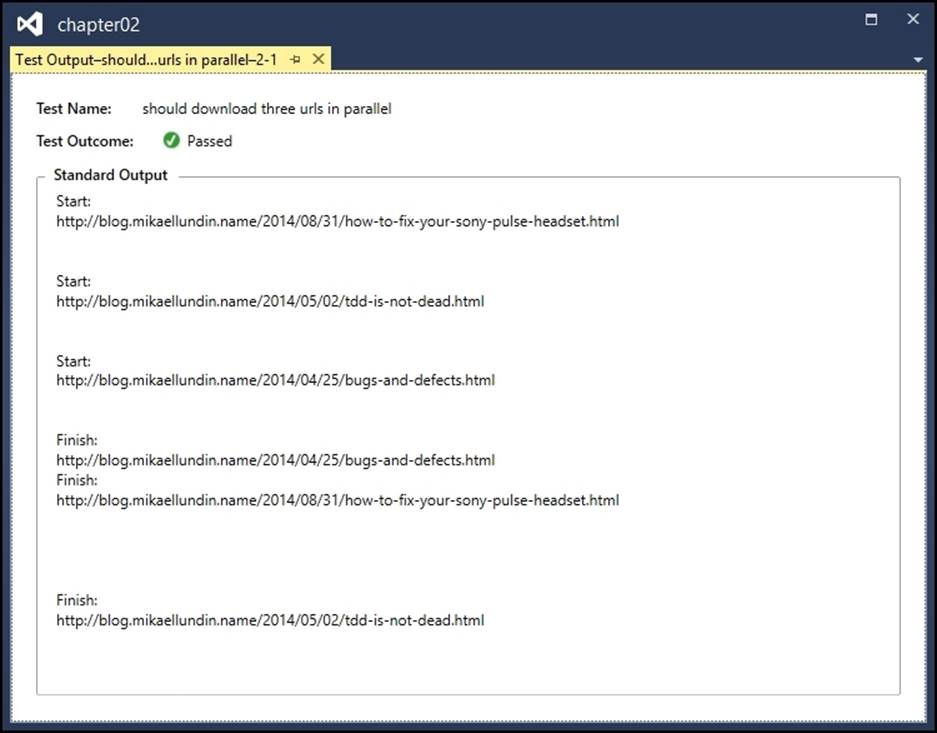
Writing code that is without side effects can help when you need to do concurrent programming because it will simplify the scenarios of having no state and needing no lock mechanisms. The declarative way of writing asynchronous code in F# makes it easier to test, as parallelization can be isolated within a function member and tested from a black box perspective.
Summary
Functional programming is very powerful as it leads to very terse programs with high-quality and low number of faults. This is because good functional code doesn't have any side effects—a place where most of the imperative object-oriented code has its bugs.
In this chapter, we've been looking at functional concepts that make it easier to write good code that doesn't cause side effects and has a low number of bugs, but also code that is easier to test.
The next chapter we'll reach into the toolset that exists for programs written in F# and what it takes to get started with functional testing.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.