Testing with F# (2015)
Chapter 4. Unit Testing
Unit testing is the art of designing your program in such a way that you can easily test each function as isolated units and such verify its correctness. Unit testing is not only a tool for verification of functionality, but also mostly a tool for designing that functionality in a testable way. What you gain is the means of finding problems early, facilitating change, documentation, and design.
In this chapter, we will dive into how to write good unit tests using F#:
· Structuring your tests
· Testing in isolation
· Finding the abstraction level
· Test doubles
· Dependency injection
· Dealing with databases
After reading this chapter, you will be able to write high-quality unit tests that will require little maintenance and stand the test of refactoring, interface changes, and maintenance.
Structuring your tests
The most basic aspect of unit testing is figuring out how to structure your tests. The most common way to structure when writing tests after code is to mimic the namespace hierarchy for your system under a test in another Visual Studio project.
We write our class as follows:
namespace Company.System.BL.Calculators
{
public class PriceCalculator
{
public double GetPrice(object order)
{
return .0;
}
}
}
Then, our test would look like the following:
namespace Company.System.Tests.BL.Calculators
{
public class PriceCalculatorTests
{
[Test]
public void GetPriceShould()
{
// ...
}
}
}
Notice the differences in namespaces and naming conventions. This is a very common way to structure tests because it scales up to very large projects and is pretty straightforward.
It is clear that code is written before the tests, as the test names and hierarchy are directly proportional to the code it was written for. If we start out writing the test first, then we must begin describing what the feature is and what we intend for it to do, as shown the following:
namespace ``PriceCalculator will calculate the price of an order``
module ``for an empty order`` =
open Company.System.BL.Calculators
open NUnit.Framework
let priceCalculator = PriceCalculator()
type Order = { OrderLines : string list}
let order = { OrderLines = []}
[<Test>]
let ``the price should be 0`` () =
let result = priceCalculator.GetPrice(order)
Assert.That(result, Is.EqualTo(0))
This code is a bit messy, and we will address that shortly, but first let's look at what it really does, line by line:
· #1: The namespace declaration is the root level of the test tree and represents the user story that is being worked on
· #3: The module declaration is the scenario for the user story
· #15: The test function is the assertion
The reason for writing tests like this becomes obvious when looking at the test output. It describes the system and what it is supposed to do, and not just what we expect of the code that has already been written, as shown in the following screenshot:
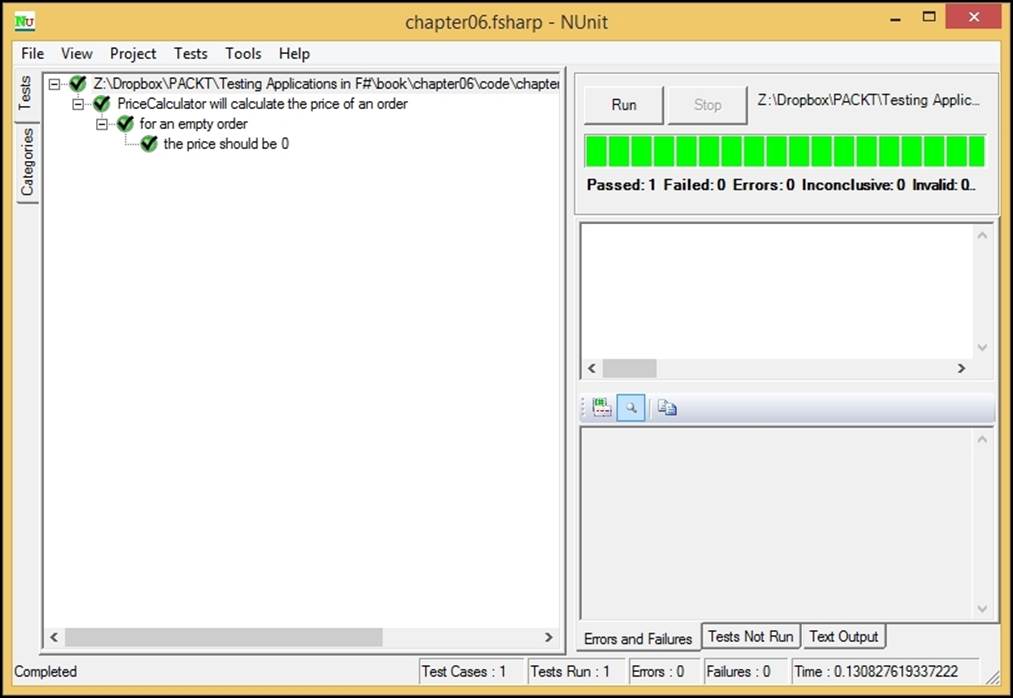
The beauty here is, of course, that you can read out the functionality of the test structure and hierarchy. The main difference between this and the old way of writing tests is that here, you document what the function is supposed to do, and previously, we only verified that the written code did what it was supposed to. This new way of writing tests, is ultimately driving the function and design of the code.
Arrange, act, assert
To bring order into our unit tests, there are certain patterns to follow. One of the most common and popular patterns is the triple A (AAA) syntax, where the A's stand for:
· Arrange
· Act
· Assert
The best way to visualize this is in code. Let's see how it works in C# code and then move on to the F# equivalent:
using NUnit.Framework;
using SUT = Company.System.BL.Calculators;
namespace Company.System.Tests.BL.Calculators.PriceCalculator
{
public class GetPrice
{
[Test]
public void ShouldReturnZeroOnEmptyOrder()
{
// Arrange
var priceCalculator = new SUT.PriceCalculator();
var order = new { };
// Act
var result = priceCalculator.GetPrice(order);
// Assert
Assert.That(result, Is.EqualTo(0), "Expecting zero price when order is empty");
}
}
}
I usually put the comments in there, to communicate to the reader that I'm using the AAA syntax, but also to make my intentions clear of where the line is drawn between arrange, act, and assert.
In the arrange segment of this code, we instantiate all the dependencies our test has, and we also set up all the state that is necessary for the test to go through. If we need to set up mocks or stubs, we do this in the arrange section.
The arrange section is simply everything we need to run the test. The act section is the reason the test exists, and should only consist of one line of code. This line of code should call into the System Under Test (SUT) in order to test what we want to verify. This act statement usually assigns the result to a result variable, but not necessarily so, as the SUT could have updated some mutated state that we'll verify. The assert section verifies that the result of running the test was successful.
Sometimes, you need some helping code to extract the result, but mostly the assert section is also only one line of code. It is crucial for the test design to assert only one thing in each test.
Now, what happens when we apply this to our F# sample?
[<Test>]
let ''the price should be 0'' () =
// arrange
let priceCalculator = PriceCalculator()
let order = { OrderLines = []}
// act
let result = priceCalculator.GetPrice(order)
// assert
Assert.That(result, Is.EqualTo(0))
It actually works very well. We will come back to this later when touching upon the framework FsUnit and how the AAA syntax applies there. It is also of great interest when doing mocking, as it provides a greater structure when writing unit tests.
Separate project versus inline tests
A hardware engineer hearing about unit testing in software for the first time might be found saying, we've been doing that for years. It is called a self-test when a hardware circuit is able to perform testing of its functions by sending itself the correct signal.
This means some of our hardware is shipping with tests. So, why are we going to such lengths in software to ship without tests?
// get the items from l1 that are not in l2
let difference l1 l2 = (set l1) - (set l2) |> Set.toList
open NUnit.Framework
[<Test>]
let ``difference between [1..10] and [1; 3; 5; 7; 9] is [2; 4; 6; 8; 10]`` () =
// arrange
let l1 = [1..10]
let l2 = [1; 3; 5; 7; 9]
// act
let result = difference l1 l2
// assert
Assert.That(result, Is.EqualTo([2; 4; 6; 8; 10]))
[<Test>]
let ``difference between [1..10] and [] is [1..10]`` () =
// arrange
let l1 = [1..10]
let l2 = []
// act
let result = difference l1 l2
// assert
Assert.That(result, Is.EqualTo([1..10]))
When looking this code, it's so painstakingly obvious that after writing a function you would add some tests for that function just underneath it.
· Your test is the closest possible to what it's testing
· Your test can test and modify private members of the SUT
· Your tests, by definition of what the system does, is part of the system itself
Turning it around, we could write the tests before the actual implementation:
namespace ``difference between a and b``
module ``when a is one-to-ten and b is even numbers`` =
open NUnit.Framework
// arrange
let a = [1..10]
let b = [2; 4; 6; 8; 10]
[<Test>]
let ``expected result is [1; 3; 5; 7; 9]`` () =
// act
let result = difference a b
// assert
CollectionAssert.AreEqual([1; 3; 5; 7; 9], result)
module ``when a is one-to-ten and b is one-to-ten`` =
open NUnit.Framework
open chapter06.fsharp._1232OS_06_06
// arrange
let a = [1..10]
let b = [1..10]
[<Test>]
let ``expected result is empty List`` () =
// act
let result = difference a b
// assert
CollectionAssert.IsEmpty(result)
The first thing you notice is that the tests have a very loose coupling to the actual implementation. Instead, the tests only state what the supposed functionality is supposed to do, and not what the already existing functionality does.
This is one way to create distance between the tests and the actual implementation.
· Tests describe the functionality, instead of retrofitting what the code does
· The SUT is forced to present a public interface for the test to call
· It's better at driving the design of the code
Should this piece of code be in the same project or another project? In my honest opinion, it doesn't matter. Having both SUT and code in the same project but separating them by other means would make some continuous integration tasks easier, but it would also bring unnecessary dependencies into production. It appears to be a give or take scenario.
FsUnit
The current state of unit testing in F# is good. You can get all the major test frameworks running with little effort, but there is still something that feels a bit off with the way tests and asserts are expressed:
open NUnit.Framework
Assert.That(result, Is.EqualTo(42))
Using FsUnit, you can achieve much higher expressiveness in writing unit tests by simply reversing the way the assert is written:
open FsUnit
result |> should equal 42
Please refer to Chapter 3, Setting Up Your Test Environment, on how to set up a testing environment with FsUnit.
The FsUnit framework is not a test runner in itself, but uses an underlying test framework to execute. The underlying framework can be of MSTest, NUnit, or xUnit. FsUnit can best be explained as having a different structure and syntax while writing tests.
While this is a more dense syntax, the need for structure still exists and AAA is more needed more than ever. Consider the following test example:
[<Measure>] type EUR
[<Measure>] type SEK
type Country = | Sweden | Germany | France
let calculateVat country (amount : float<'u>) =
match country with
| Sweden -> amount * 0.25
| Germany -> amount * 0.19
| France -> amount * 0.2
open NUnit.Framework
open FsUnit
[<Test>]
let ``Sweden should have 25% VAT`` () =
let amount = 200.<SEK>
calculateVat Sweden amount |> should equal 50<SEK>
This code will calculate the VAT in Sweden in Swedish currency. What is interesting is that when we break down the test code and see that it actually follows the AAA structure, even it doesn't explicitly tell us this is so:
[<Test>]
let ``Germany should have 19% VAT`` () =
// arrange
let amount = 200.<EUR>
// act
calculateVat Germany amount
//assert
|> should equal 38<EUR>
The only thing I did here was add the annotations for AAA. It gives us the perspective of what we're doing, what frames we're working inside, and the rules for writing good unit tests.
Assertions
We have already seen the equal assertion, which verifies that the test result is equal to the expected value. This is, by far, the most common assertion you will need:
result |> should equal 42
You can negate this assertion by using the not' statement, as follows:
result |> should not' (equal 43)
With strings, it's quite common to assert that a string starts or ends with some value, as follows:
"$12" |> should startWith "$"
"$12" |> should endWith "12"
And, you can also negate that, as follows:
"$12" |> should not' (startWith "€")
"$12" |> should not' (endWith "14")
You can verify that a result is within a boundary. This will, in turn, verify that the result is somewhere between the values of 35-45:
result |> should (equalWithin 5) 40
And, you can also negate that, as follows:
result |> should not' ((equalWithin 1) 40)
With the collection types list, array, and sequence, you can check that it contains a specific value:
[1..10] |> should contain 5
And, you can also negate it to verify that a value is missing, as follows:
[1; 1; 2; 3; 5; 8; 13] |> should not' (contain 7)
It is common to test the boundaries of a function and then its exception handling. This means you need to be able to assert exceptions, as follows:
let getPersonById id = failwith "id cannot be less than 0"
(fun () -> getPersonById -1 |> ignore) |> should throw typeof<System.Exception>
There is a be function that can be used in a lot of interesting ways. Even in situations where the equal assertion can replace some of these be structures, we can opt for a more semantic way of expressing our assertions, providing better error messages.
Let us see examples of this, as follows:
// true or false
1 = 1 |> should be True
1 = 2 |> should be False
// strings as result
"" |> should be EmptyString
null |> should be NullOrEmptyString
// null is nasty in functional programming
[] |> should not' (be Null)
// same reference
let person1 = new System.Object()
let person2 = person1
person1 |> should be (sameAs person2)
// not same reference, because copy by value
let a = System.DateTime.Now
let b = a
a |> should not' (be (sameAs b))
// greater and lesser
result |> should be (greaterThan 0)
result |> should not' (be lessThan 0)
// of type
result |> should be ofExactType<int>
// list assertions
[] |> should be Empty
[1; 2; 3] |> should not' (be Empty)
With this, you should be able to assert most of the things you're looking for. But there still might be a few edge cases out there that default FsUnit asserts won't catch.
Custom assertions
FsUnit is extensible, which makes it easy to add your own assertions on top of the chosen test runner. This has the possibility of making your tests extremely readable.
The first example will be a custom assert which verifies that a given string matches a regular expression. This will be implemented using NUnit as a framework, as follows:
open FsUnit
open NUnit.Framework.Constraints
open System.Text.RegularExpressions
// NUnit: implement a new assert
type MatchConstraint(n) =
inherit Constraint() with
override this.WriteDescriptionTo(writer : MessageWriter) : unit =
writer.WritePredicate("matches")
writer.WriteExpectedValue(sprintf "%s" n)
override this.Matches(actual : obj) =
match actual with
| :? string as input -> Regex.IsMatch(input, n)
| _ -> failwith "input must be of string type"
let match' n = MatchConstraint(n)
open NUnit.Framework
[<Test>]
let ``NUnit custom assert`` () =
"2014-10-11" |> should match' "\d{4}-\d{2}-\d{2}"
"11/10 2014" |> should not' (match' "\d{4}-\d{2}-\d{2}")
In order to create your own assert, you need to create a type that implements the NUnit.Framework.Constraints.IConstraint interface, and this is easily done by inheriting from the Constraint base class.
You need to override both the WriteDescriptionTo() and Matches() method, where the first one controls the message that will be output from the test, and the second is the actual test. In this implementation, I verify that input is a string; or the test will fail. Then, I use the Regex.IsMatch() static function to verify the match.
Next, we create an alias for the MatchConstraint() function, match', with the extra apostrophe to avoid conflict with the internal F# match expression, and then we can use it as any other assert function in FsUnit.
Doing the same for xUnit requires a completely different implementation. First, we need to add a reference to NHamcrest API. We'll find it by searching for the package in the NuGet Package Manager:
Instead, we make an implementation that uses the NHamcrest API, which is a .NET port of the Java Hamcrest library for building matchers for test expressions, shown as follows:
open System.Text.RegularExpressions
open NHamcrest
open NHamcrest.Core
// test assertion for regular expression matching
let match' pattern =
CustomMatcher<obj>(sprintf "Matches %s" pattern, fun c ->
match c with
| :? string as input -> Regex.IsMatch(input, pattern)
| _ -> false)
open Xunit
open FsUnit.Xunit
[<Fact>]
let ``Xunit custom assert`` () =
"2014-10-11" |> should match' "\d{4}-\d{2}-\d{2}"
"11/10 2014" |> should not' (match' "\d{4}-\d{2}-\d{2}")
The functionality in this implementation is the same as the NUnit version, but the implementation here is much easier. We create a function that receives an argument and return a CustomMatcher<obj> object. This will only take the output message from the test and the function to test the match.
Writing an assertion for FsUnit driven by MSTest works exactly the same way as it would in Xunit, by NHamcrest creating a CustomMatcher<obj> object.
Unquote
There is another F# assertion library that is completely different from FsUnit but with different design philosophies accomplishes the same thing, by making F# unit tests more functional. Just like FsUnit, this library provides the means of writing assertions, but relies on NUnit as a testing framework.
Instead of working with a DSL like FsUnit or API such as with the NUnit framework, the Unquote library assertions are based on F# code quotations.
Code quotations is a quite unknown feature of F# where you can turn any code into an abstract syntax tree. Namely, when the F# compiler finds a code quotation in your source file, it will not compile it, but rather expand it into a syntax tree that represents an F# expression.
The following is an example of a code quotation:
<@ 1 + 1 @>
If we execute this in F# Interactive, we'll get the following output:
val it : Quotations.Expr =
Call (None, op_Addition, [Value (1), Value (1)])
This is truly code as data, and we can use it to write code that operates on code as if it was data, which in this case, it is. It brings us closer to what a compiler does, and gives us lots of power in the metadata programming space.
We can use this to write assertions with Unquote. Start by including the Unquote NuGet package in your test project, as shown in the following screenshot:
And now, we can implement our first test using Unquote, as follows:
open NUnit.Framework
open Swensen.Unquote
[<Test>]
let ``Fibonacci sequence should start with 1, 1, 2, 3, 5`` () = test <@ fibonacci |> Seq.take 5 |> List.ofSeq = [1; 1; 2; 3; 5] @>
This works by Unquote first finding the equals operation, and then reducing each side of the equals sign until they are equal or no longer able to reduce.
Writing a test that fails and watching the output more easily explains this. The following test should fail because 9 is not a prime number:
[<Test>]
let ``prime numbers under 10 are 2, 3, 5, 7, 9`` () =
test <@ primes 10 = [2; 3; 5; 7; 9] @> // fail
The test will fail with the following message:
Test Name: prime numbers under 10 are 2, 3, 5, 7, 9
Test FullName: chapter04.prime numbers under 10 are 2, 3, 5, 7, 9
Test Outcome: Failed
Test Duration: 0:00:00.077
Result Message:
primes 10 = [2; 3; 5; 7; 9]
[2; 3; 5; 7] = [2; 3; 5; 7; 9]
false
Result StackTrace:
at Microsoft.FSharp.Core.Operators.Raise[T](Exception exn)
at chapter04.prime numbers under 10 are 2, 3, 5, 7, 9()
In the resulting message, we can see both sides of the equals sign reduced until only false remains. It's a very elegant way of breaking down a complex assertion.
Assertions
The assertions in Unquote are not as specific or extensive as the ones in FsUnit. The idea of having lots of specific assertions for different situations is to get very descriptive error messages when the tests fail. Since Unquote actually outputs the whole reduction of the statements when the test fails, the need for explicit assertions is not that high. You'll get a descript error message anyway. The absolute most common is to check for equality, as shown before. You can also verify that two expressions are not equal:
test <@ 1 + 2 = 4 - 1 @>
test <@ 1 + 2 <> 4 @>
We can check whether a value is greater or smaller than the expected value:
test <@ 42 < 1337 @>
test <@ 1337 > 42 @>
You can check for a specific exception, or just any exception:
raises<System.NullReferenceException> <@ (null : string).Length @>
raises<exn> <@ System.String.Format(null, null) @>
Here, the Unquote syntax excels compared to FsUnit, which uses a unit lambda expression to do the same thing in a quirky way.
The Unquote library also has its reduce functionality in the public API, making it possible for you to reduce and analyze an expression. Using the reduceFully syntax, we can get the reduction in a list, as shown in the following:
> <@ (1+2)/3 @> |> reduceFully |> List.map decompile;;
val it : string list = ["(1 + 2) / 3"; "3 / 3"; "1"]
If we just want the output to console output, we can run the unquote command directly:
> unquote <@ [for i in 1..5 -> i * i] = ([1..5] |> List.map (fun i -> i * i)) @>;;
Seq.toList (seq (Seq.delay (fun () -> Seq.map (fun i -> i * i) {1..5}))) = ([1..5] |> List.map (fun i -> i * i))
Seq.toList (seq seq [1; 4; 9; 16; ...]) = ([1; 2; 3; 4; 5] |> List.map (fun i -> i * i))
Seq.toList seq [1; 4; 9; 16; ...] = [1; 4; 9; 16; 25]
[1; 4; 9; 16; 25] = [1; 4; 9; 16; 25]
true
It is important to know what tools are out there, and Unquote is one of those tools that is fantastic to know about when you run into a testing problem in which you want to reduce both sides of an equals sign. Most often, this belongs to difference computations or algorithms like price calculation.
We have also seen that Unquote provides a great way of expressing tests for exceptions that is unmatched by FsUnit.
Testing in isolation
One of the most important aspects of unit testing is to test in isolation. This does not only mean to fake any external dependency, but also that the test code itself should not be tied up to some other test code.
If you're not testing in isolation, there is a potential risk that your test fails. This is not because of the system under test, but the state that has lingered from a previous test run, or external dependencies.
Writing pure functions without any state is one way of making sure your test runs in isolation. Another way is by making sure that the test creates all the needed state itself.
· Shared state, like connections, between tests is a bad ide.
· Using TestFixtureSetUp/TearDown attributes to set up a state for a set of tests is a bad ide.
· Keeping low performance resources around because they're expensive to set up is a bad ide.
The most common shared states are the following:
· The ASP.NET Model View Controller (MVC) session stat.
· Dependency injection setup
· Database connection, even though it is no longer strictly a unit test
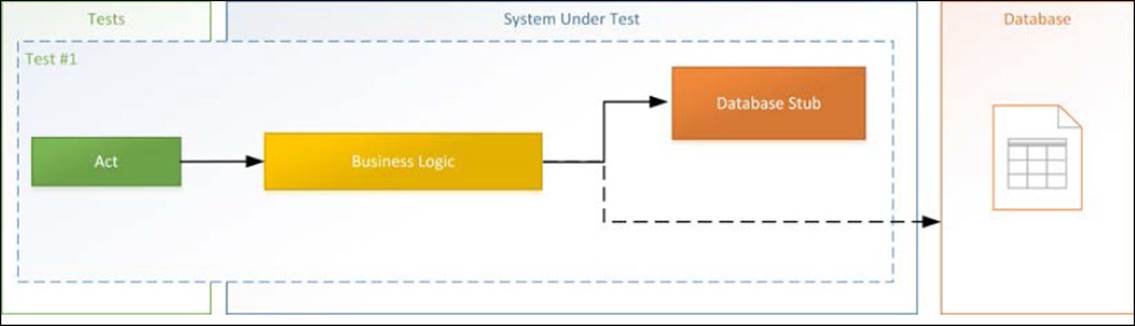
Here's how one should think about unit testing in isolation, as shown in the following screenshot:
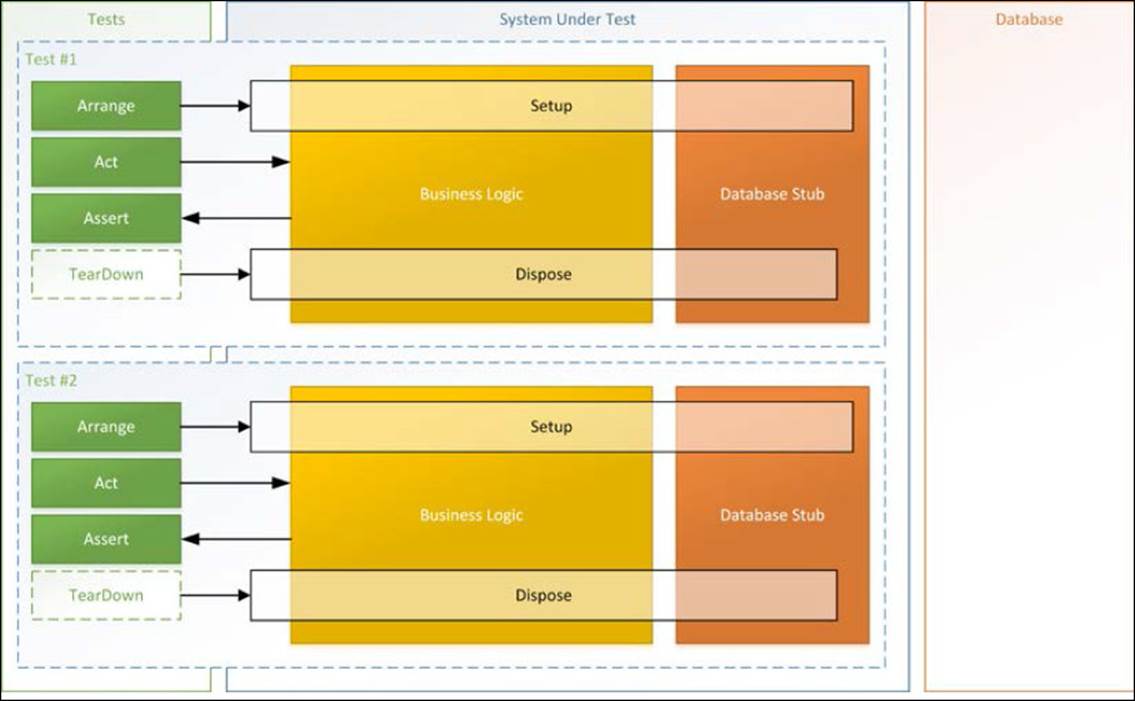
Each test is responsible for setting up the SUT and its database/web service stubs in order to perform the test and assert on the result. It is equally important that the test cleans up after itself, which in the case of unit tests most often can be handed over to the garbage collector, and doesn't need to be explicitly disposed. It is common to think that one should only isolate a test fixture from other test fixtures, but this idea of a test fixture is bad. Instead, one should strive for having each test stand for itself to as large an extent as possible, and not be dependent on outside setups. This does not mean you will have unnecessary long unit tests, provided you write SUT and tests well within that context.
The problem we often run into is that the SUT itself maintains some kind of state that is present between tests. The state can simply be a value that is set in the application domain and is present between different test runs, as follows:
let getCustomerFullNameByID id =
if cache.ContainsKey(id) then
(cache.[id] :?> Customer).FullName
else
// get from database
// NOTE: stub code
let customer = db.getCustomerByID id
cache.[id] <- customer
customer.FullName
The problem we see here is that the cache will be present from one test to another, so when the second test is running, it needs to make sure that its running with a clean cache, or the result might not be as expected.
One way to test it properly would be to separate the core logic from the cache and test them each independently. Another would be to treat it as a black box and ignore the cache completely. If the cache makes the test fail, then the functionality fails as a whole.
This depends on if we see the cache as an implementation detail of the function or a functionality by itself. Testing implementation details, or private functions, is dirty because our tests might break even if the functionality hasn't changed. And yet, there might be benefits into taking the implementation detail into account. In this case, we could use the cache functionality to easily stub out the database without the need of any mocking framework.
Vertical slice testing
Most often, we deal with dependencies as something we need to mock away, where as the better option would be to implement a test harness directly into the product. We know what kind of data and what kind of calls we need to make to the database, so right there, we have a public API for the database. This is often called a data access layer in a three-tier architecture (but no one ever does those anymore, right?).
As we have a public data access layer, we could easily implement an in-memory representation that can be used not only by our tests, but in development of the product, as shown in the following image:
When you're running the application in development mode, you configure it toward the in-memory version of the dependency. This provides you with the following benefits:
· You'll get a faster development environment
· Your tests will become simpler
· You have complete control of your dependency
As your development environment is doing everything in memory, it becomes blazing fast. And as you develop your application, you will appreciate adjusting that public API and getting to understand completely what you expect from that dependency. It will lead to a cleaner API, where very few side effects are allowed to seep through.
Your tests will become much simpler, as instead of mocking away the dependency, you can call the in-memory dependency and set whatever state you want.
Here's an example of what a public data access API might look like:
type IDataAccess =
abstract member GetCustomerByID : int -> Customer
abstract member FindCustomerByName : string -> Customer option
abstract member UpdateCustomerName : int -> string -> Customer
abstract member DeleteCustomerByID : int -> bool
This is surely a very simple API, but it will demonstrate the point. There is a database with a customer inside it, and we want to do some operations on that.
In this case, our in-memory implementation would look like this:
type InMemoryDataAccess() =
let data = new System.Collections.Generic.Dictionary<int, Customer>()
// expose the add method
member this.Add customer = data.Add(customer.ID, customer)
interface IDataAccess with
// throw exception if not found
member this.GetCustomerByID id =
data.[id]
member this.FindCustomerByName fullName =
data.Values |> Seq.tryFind (fun customer -> customer.FullName = fullName)
member this.UpdateCustomerName id fullName =
data.[id] <- { data.[id] with FullName = fullName }
data.[id]
member this.DeleteCustomerByID id =
data.Remove(id)
This is a simple implementation that provides the same functionality as the database would, but in memory. This makes it possible to run the tests completely in isolation without worrying about mocking away the dependencies. The dependencies are already substituted with in-memory replacements, and as seen with this example, the in-memory replacement doesn't have to be very extensive.
The only extra function except from the interface implementation is the Add() function which lets us set the state prior to the test, as this is something the interface itself doesn't provide for us.
Now, in order to sew it together with the real implementation, we need to create a configuration in order to select what version to use, as shown in the following code:
open System.Configuration
open System.Collections.Specialized
// TryGetValue extension method to NameValueCollection
type NameValueCollection with
member this.TryGetValue (key : string) =
if this.Get(key) = null then
None
else
Some (this.Get key)
let dataAccess : IDataAccess =
match ConfigurationManager.AppSettings.TryGetValue("DataAccess") with
| Some "InMemory" -> new InMemoryDataAccess() :> IDataAccess
| Some _ | None -> new DefaultDataAccess() :> IDataAccess
// usage
let fullName = (dataAccess.GetCustomerByID 1).FullName
Again, with only a few lines of code, we manage to select the appropriate IDataAccess instance and execute against it without using dependency injection or taking a penalty in code readability, as we would in C#.
The code is straightforward and easy to read, and we can execute any tests we want without touching the external dependency, or in this case, the database.
Finding the abstraction level
In order to start unit testing, you have to start writing tests; this is what they'll tell you. If you want to get good at it, just start writing tests, any and a lot of them. The rest will solve itself.
I've watched experienced developers sit around staring dumbfounded at an empty screen because they couldn't get into their mind how to get started, what to test.
The question is not unfounded. In fact, it is still debated in the Test Driven Development (TDD) community what should be tested. The ground rule is that the test should bring at least as much value as the cost of writing it, but that is a bad rule for someone new to testing, as all tests are expensive for them to write.
Public interface
Once your tests suite grows into a couple thousand tests, they will start breaking, not only when you change functionality and expect them to break, but when you add functionality or optimize the inner workings of a function.
This is what we call brittle tests. They break, even when the condition they're testing hasn't changed.
The reason for this is always because the test knows too much about the system that it's testing. It makes assumptions on what the implementation of the SUT looks like, and when those assumptions no longer are true, the test breaks.
To look at a brittle test scenario, we will use this string concatenation function as our SUT, as shown in the following code:
// implementation detail
let sb = System.Text.StringBuilder()
// concat values of a list
// BAD CODE don't do this
let concat (separator : string) (items : string list) =
// clear from any previous concatenations
sb.Clear()
// append all values to string builder
for item in items do
sb.Append(item) |> ignore
sb.Append(separator)
// remove last separator
if not items.IsEmpty then
sb.Remove(sb.Length - separator.Length, separator.Length) |> ignore
sb.ToString()
We all know that a StringBuilder class is the most efficient way of concatenating strings, but they come with a penalty of instantiation. So, we create a global StringBuilder class that is instantiated once, and then reuse it between concatenations. This is a good example of bad pre-optimization.
Let's look at some tests for this:
[<Test>]
let ``should remove last separator from result`` () =
let data = ["The"; "quick"; "brown"; "fox"; "jumps"; "over"; "the"; "lazy"; "dog"]
concat " " data |> should not' (endWith " ")
[<Test>]
let ``should clear the string builder before second concatenation`` () =
let data = ["The"; "quick"; "brown"; "fox"; "jumps"; "over"; "the"; "lazy"; "dog"]
concat " " data |> ignore
concat " " data |> ignore
sb.ToString() |> should equal "The quick brown fox jumps over the lazy dog"
Both these tests state something that is true about the SUT, but they are both bad. The first test assumes that the result is built up by adding the item and separator consecutive until the end, and then the last separator is deleted. This is an implementation detail of the function.
The second test goes into even more detail about the implementation and states how the StringBuilder class should be used in the concatenation. These tests are both operating on a bad abstraction level.
Now, what happens when running this code in production is that it crashes unexpectedly at heavy load. It turns out, by the following test, that it is not thread-safe:
> let data = ['a'..'z'] |> List.map (fun c -> c.ToString())
Array.Parallel.init 51 (fun _ -> concat "" data);;
System.AggregateException: One or more errors occurred. ---> System.ArgumentOutOfRangeException: Index was out of range. Must be non-negative and less than the size of the collection.
Parameter name: chunkLength
at System.Text.StringBuilder.ToString()
The use of the StringBuilder class is no longer justified and instead the SUT is rewritten to the following:
// no longer in use
let sb = System.Text.StringBuilder()
// concat values of a list
let concat separator = List.reduce (fun s1 s2 -> sprintf "%s%s%s" s1 separator s2)
[<Test>]
let ``should remove last separator from result`` () =
let data = ["The"; "quick"; "brown"; "fox"; "jumps"; "over"; "the"; "lazy"; "dog"]
concat " " data |> should not' (endWith " ")
[<Test>]
let ``should clear the string builder before second concatenation`` () =
let data = ["The"; "quick"; "brown"; "fox"; "jumps"; "over"; "the"; "lazy"; "dog"]
concat " " data |> ignore
concat " " data |> ignore
sb.ToString() |> should equal "The quick brown fox jumps over the lazy dog"
The first test will still turn green, but the assumption that it's testing is no longer valid. Since the SUT changed, the test itself no longer provides any value and should be deleted, but because it stays green, it will probably hang around as useless baggage to your test suite.
The second test will break because it has a direct dependency on the implementation detail of the previous SUT. Even though we really didn't change the functionality of the concat function, this test must now be removed in order to run the test suite.
So, if these two seemingly fine tests were wrong, where is the correct abstraction level for our tests?
A beginner's mistake is to implement a function and then decide what to test by looking at the function body. Instead, one should look at the function contract in order to decide what to test. This is where design by contract comes back to us, as we're talking about:
· What the functionality expects
· What the functionality guarantees
· What the functionality maintains
As long as these factors are all maintained, we can make ourselves ensured that the functionality hasn't changed as we keep maintaining the code. Then, how the functionality internally sustains this contract is not that much of an interest to our tests.
Reusing the same SUT, here are some tests that focus on defining from an outside perspective what is expected of the concat function, as follows:
[<Test>]
let ``cannot concatenate with null separator`` () =
raises<exn> <@ concat null ["a"; "b"] @>
[<Test>]
let ``should return empty string for empty list`` () =
concat " " List.Empty |> should equal ""
[<Test>]
let ``should return item from a one item list`` () =
concat " " ["a"] |> should equal "a"
[<Test>]
let ``should return concatenated result from string list with empty separator`` () =
concat System.String.Empty ["a"; "b"; "c"] |> should equal "abc"
[<Test>]
let ``should be able to form a comma separated value`` () =
concat ", " ["a"; "b"; "c"] |> should equal "a, b, c"
These tests define both what the function expects and what it guarantees, but nothing about what it maintains. The simple reason that functional code seldom maintains any state, and this is not something that we very often have to test for, in contrast to object-oriented code, where maintaining state is a central concept.
It's all about finding and exploring the public interface of the functionality without caring so much about how it is provided. This is where test-first development excels, as we do not know the internals of the implementation before we've started writing the code.
Private functions
Object-oriented programming (OOP) is all about the class exposing a public interface toward other classes and keeping its internals private. In F#, everything is public by default, unless it's a let value binding inside a type declaration. Those are private.
If we agree that implementation details should not be tested, and private methods are implementation details, where does that takes us in F#, where everything is public by default? Should we start marking helper functions private to sort them from the publicinterface we want to expose, or are we just recreating one OOP dysfunction in a functional language?
To a consumer of your interfaces, the private functions aren't important, and to a reader of the code, it is not of interest to know what functions are private. Instead, it is much more interesting for both consumer and reader to know what functions are public.
Signature files to the rescue! We can use these to define what the public interface is for a module, and have a clear communication on what to expect from our SUT to the rest of the system. A signature file is simply an F# file with the file fsi extension, which defines what members of a namespace or module should be public.
The following is a module that defines two operations around prime numbers. It checks if a number is both a prime and a function for extracting all prime factors of a number:
module Prime =
// cache
let mutable cache = [2]
// sieve [2..10] -> [2; 3; 5; 7]
let rec sieve = function
| [] -> []
| hd :: tl -> hd :: sieve(tl |> List.filter (fun x -> x % hd > 0))
// expand [2] 10 -> [2; 3; 5; 7]
let expand input n =
let max = input |> List.max
if n <= max then
// no expansion
input
else
// expand and recalculate
input @ [max + 1..n] |> sieve
// lessThanHalfOf 10 4 -> true
let lessOrHalfOf n = (fun x -> x <= (n / 2))
// returns that n is evenly divisible to number
let evenlyDivisible n = (fun x -> n % x = 0)
// isPrime 13 -> true
let isPrime n =
// update sieve
cache <- expand cache (n / 2)
// not evenly divisible by any number in sieve
cache
|> Seq.takeWhile (lessOrHalfOf n)
|> Seq.exists (evenlyDivisible n)
|> not
// primeFactors 26 -> [2; 13]
let primeFactors n =
// update sieve
cache <- expand cache (n / 2)
// all evenly divisible by n
cache
|> Seq.takeWhile (lessOrHalfOf n)
|> Seq.filter (evenlyDivisible n)
|> Seq.toList
This code uses a mutable Sieve of Eratosthenes algorithm in order to calculate prime numbers. The sieve is maintained by expanding it whenever necessary. The first time we validate isPrime 1337, it will take 15 milliseconds to calculate the answer, but the next time it will return instantly thanks to the maintained sieve.
There are a lot of helper functions in this module that helps aid in making the actual code more readable, but for as far as the tests are concerned, the only interesting parts are the isPrime and primeFactors functions. In order to communicate this more clearly, we can add a signature file that looks as shown in the following code:
module Prime =
// isPrime 13 -> true
val isPrime : int -> bool
// primeFactors 26 -> [2; 13]
val primeFactors : int -> int list
When adding an fsi file to your project, make sure it appears before the actual implementation file, or the fsc compiler will throw an error that you're adding the same declarations twice.
By defining the signature of what should be public, all other definitions in the module become private by default. This lets us write tests that focus on the right things:
[<Test>]
let ``should evaluate 23 as a prime number`` =
Prime.isPrime 23 |> should be True
[<Test>]
let ``should evaluate prime factors of 26 as 2 and 13`` =
Prime.primeFactors 26 |> should equal [2; 13]
Encapsulation may not be so strongly advocated in functional programming as it is in object-oriented programming, but it is still highly important for the test you write that you focus on the public definition and the contract of the functions instead of the internals of the implementation. This way, you will end up with a test suite that is easily maintained for years to come.
Test doubles
The definition of a test double is a dependency you inject into your program, instead of ordinary functionality, in order to isolate the thing you want to test. We've already seen what you can do by making in-memory versions of your dependencies built in. Sometimes, we want our tests to be able to inject a specific tests dependency that is not built in, and this is where the SUT needs to be extensible enough to allow it.
Just as in C#, we use an interface or abstract class to enable extensibility and allow for dependency injection. To enable this, F# provides us with the ability to implement interfaces using object expressions. This is a great feature for testing.
As an example, lets start with defining an interface. This interface will open a Comma Separated Value (CSV) file and allow reading it line by line, as shown in the following code:
// loading and processing a csv file line by line
type ICsvReader =
// open file and return sequence of values per line
abstract member Load : string -> seq<string list>
Here is the real implementation of the interface:
// implementation of ICsvReader
type CsvReader () =
interface ICsvReader with
member this.Load filePath = seq {
use streamReader = new StreamReader(filePath)
while not streamReader.EndOfStream do
let line = streamReader.ReadLine()
yield line.Split([|','; ';'|]) |> List.ofSeq
}
This is pretty intuitive. We open up a StreamReader class and sequentially read one line at a time until we reach the EndOfStream class.
Now, we can use this for reading customers from a file. First, we define the following schema:
// schema of the data in csv file
type Customer = { ID : int; Name : string; Email : string; EnabledSubscription : bool }
// turn the csv schema into Customer records
let schema (record : string list) =
assert (record.Length = 4)
let id :: name :: email :: enabledSubscription :: [] = record
{ID = System.Int32.Parse(id);
Name = name;
Email = email;
EnabledSubscription = bool.Parse(enabledSubscription)
}
We use this to turn the CSV result from a string list into a Customer record. Next, we're ready to read the whole file into Customer records, as shown in the following code:
// load the whole csv file into list of Customer instances
let getCustomersFromCsvFile filePath (csvReader : ICsvReader) =
csvReader.Load filePath
|> Seq.map schema
|> Seq.toList
And, we can easily verify it from F# Interactive.
> getCustomersFromCsvFile @"data.txt" (new CsvReader());;
val it : Customer list =
[{ID = 1;
Name = "John Doe";
Email = "john.doe@test.com";
EnabledSubscription = true;};
{ID = 2;
Name = "Jane Doe";
Email = "jane.doe@test.com";
EnabledSubscription = false;};
{ID = 3;
Name = "Mikael Lundin";
Email = "hello@mikaellundin.name";
EnabledSubscription = false;}]
In order to unit test this, we need to exchange the CsvReader for our own implementation that doesn't read from the hard drive. This is where we can use object expressions to simplify our test implementation:
[<Test>]
let ``should convert all lines from file into Customers`` () =
// arrange
let data = [
["1"; "John Doe"; "john.doe@test.com"; "true"];
["2"; "Jane Doe"; "jane.doe@test.com"; "false"];
["3"; "Mikael Lundin"; "hello@mikaellundin.com"; "False"]
]
// interface implementation by object expression
let csvReader =
{ new ICsvReader with
member this.Load filePath = data |> List.toSeq }
// act & assert
(getCustomersFromCsvFile "" csvReader).Length |> should equal data.Length
The interesting part here is where the CsvReader is created right in the test and then injected into the getCustomersFromCsvFile file. In C#, this has only been possible with the use of mocking frameworks, but here, it is possible to do directly in the language.
This feature does not completely remove the need of mocking frameworks, as you have to implement the whole interface with object expressions, and this might not always be of interest to the test you're writing.
Dependency injection
What we're used to from object-oriented systems is that dependencies are injected into the classes where they're used. There are a couple of different kinds of injections, namely:
· Constructor injection
· Property injection
· Method injection
Constructor injection is by far the most common injection type in object-oriented programming. This is, of course, in order to make the necessary dependencies mandatory and not have to check if they're set or not.
Here is what constructor injection would look like in F#:
type CustomerRepository (csvReader : ICsvReader) =
member this.Load filePath =
csvReader.Load filePath
|> Seq.map schema
|> Seq.toList
The dependency, which here is the ICsvReader, is received in the constructor of the CustomerRepository type.
The way to test this is pretty obvious; by creating a test double for the ICsvReader, as seen before, and injecting it into the constructor:
[<Test>]
let ``should parse ID as int`` () =
// arrange
let data = ["1"; "John Doe"; "john.doe@test.com"; "true"]
// interface implementation by object expression
let csvReader =
{ new ICsvReader with
member this.Load filePath = seq { yield data }}
// act & assert
let firstCustomer = CustomerRepository(csvReader).Load("").Item(0)
firstCustomer.ID |> should equal 1
Property injection is often used when the dependency is not mandatory, in order for the class to operate. Another situation when you would use property injection is when you want to simplify the class API and provide default instances but still enable extension by using property injection.
This is what property injection looks like:
type CustomerRepository () =
let mutable csvReader = new CsvReader() :> ICsvReader
// extension property
member this.CsvReader
with get() = csvReader
and set(value) = csvReader <- value
member this.Load filePath =
csvReader.Load filePath
|> Seq.map schema
|> Seq.toList
This code is discouraged in F#, as it is mutable. In functional programming with F#, we should strive for immutability, and only use mutability for mutable problems and optimizations.
When testing, we need to first create an instance of the CustomerRepository type and then exchange the CsvReader for our test double. It requires a bit more ceremony than dealing with the following constructor injection:
[<Test>]
let ``should parse EnabledSubscription as bool`` () =
// arrange
let customerRepository = CustomerRepository()
let data = ["1"; "John Doe"; "john.doe@test.com"; "true"]
// interface implementation by object expression
let csvReader =
{ new ICsvReader with
member this.Load filePath = seq { yield data }}
// exchange internal CsvReader with our test double
customerRepository.CsvReader <- csvReader
// act & assert
let firstCustomer = customerRepository.Load("").Item(0)
firstCustomer.EnabledSubscription |> should be True
Method injection in object-oriented programming is simply done by sending the dependency directly to the method as a parameter. This is discouraged in object-oriented programming, as it often is a sign of poor design. In functional programming this is quite a common way of dealing with dependencies, by sending, however, them as an argument to the function shown as follows:
type CustomerRepository () =
member this.Load filePath (csvReader : ICsvReader) =
csvReader.Load filePath
|> Seq.map schema
|> Seq.toList
The difference here is that the ICsvReader is sent directly into the Load method:
[<Test>]
let ``should parse data row into Customer`` () =
// arrange
let data = ["1"; "John Doe"; "john.doe@test.com"; "true"]
// interface implementation by object expression
let csvReader =
{ new ICsvReader with
member this.Load filePath = seq { yield data }}
// act
let firstCustomer = (CustomerRepository().Load "" csvReader).Item(0)
// assert
firstCustomer.ID |> should equal 1
firstCustomer.Name |> should equal "John Doe"
firstCustomer.Email |> should equal "john.doe@test.com"
firstCustomer.EnabledSubscription |> should equal true
This concludes how dependency injection in object-oriented programming translates to F#, but in functional programming, there are a couple different approaches when it comes to dealing with dependencies.
Functional injection
The interface declaration is not a functional concept and doesn't really fit into functional programming, but it does lend itself well to present dependency injection in F#. Instead of using the interface to enable extensibility, we should rely on the function signature and use that as the base of the dependency.
Let's continue using the ICsvReader as an example. It really only contains one method, so instead of having an interface, we could resort to its functional signature:
string -> seq<string list>
Based on that, our implementation would look as follows:
let csvFileReader (filePath : string) = seq {
use streamReader = new System.IO.StreamReader(filePath)
while not streamReader.EndOfStream do
let line = streamReader.ReadLine()
yield line.Split([|','; ';'|]) |> List.ofSeq
}
// load the whole csv file into list of Customer instances
let getCustomers (getData : string -> seq<string list>) filePath =
getData filePath
|> Seq.map schema
|> Seq.toList
Here, we use the function signature, called csvReader, as the dependency in the getCustomersFromCsvFile file. I have written out the whole function signature here for clarity, but I could remove it all and have the F# compiler discover the type.
The usage then looks as shown in the following code:
getCustomers @"data.txt" csvFileReader
For testing, we don't have to implement an interface anymore, but can rather just supply a function that matches the function signature of the dependency:
[<Test>]
let ``should convert all lines from file into Customers`` () =
// arrange
let getData x = seq {
yield ["1"; "John Doe"; "john.doe@test.com"; "true"];
yield ["2"; "Jane Doe"; "jane.doe@test.com"; "false"];
yield ["3"; "Mikael Lundin"; "hello@mikaellundin.com"; "False"]
}
// act & assert
(getCustomers getData "").Length |> should equal 3
This greatly simplified testing with the dependency and made the test more intuitive to read. The risk of using function signatures instead of interfaces is that the SUT might become harder to read and maintain, and you would need to be better disciplined to document what is expected of the dependency.
Currying
When dealing with functional programming, there is a pattern called currying , which means we're not supplying all arguments to a function, but are instead receive a function that produces the results with the extra arguments.
Here is a basic example:
> let add a b = a + b;;
val add : a:int -> b:int -> int
> let addFive = add 5;;
val addFive : (int -> int)
First, we define a function add by adding two numbers together. Then, we send 5 into that function and call it the addFive function. The function signature changes, as we have now supplied one argument, and the new addFive function accepts the other.
This is easier to understand if we expand the function declaration and see what really happens:
> let add = (fun a -> (fun b -> a + b));;
val add : a:int -> b:int -> int
> let addFive = (fun b -> 5 + b);;
val addFive : b:int -> int
The declarations are exactly the same as before. The let expression is really just syntactic sugar around lambdas, as shown here. We can use this to our advantage.
In the following example, I create a compare function for later use when sorting a list of customers by their IDs:
type Customer = {
ID : int
Name : string
}
let compareByID (c1 : Customer) (c2 : Customer) =
-1 * c1.ID.CompareTo(c2.ID)
By using currying, we can, in our tests, verify one function parameter at a time by setting one function parameter to a static value. In this case, I will provide a static c1 and vary c2 between my tests. I will do this by a partial application on the compareByID parameter:
// using currying to set the stage
let compareWithFive customer =
compareByID customer { ID = 5; Name = "Mikael Lundin" }
Now I can use this in my tests:
[<Test>]
let ``customer 3 is more than customer 5`` () =
compareWithFive { ID = 3; Name = "John James" } |> should equal 1
[<Test>]
let ``customer 7 is less than customer 5`` () =
compareWithFive { ID = 7; Name = "Milo Miazaki" } |> should equal -1
[<Test>]
let ``customer 5 is equal to customer 5`` () =
compareWithFive { ID = 5; Name = "Mikael Lundin" } |> should equal 0
This is a very simple technique, albeit a powerful one. We can use currying in order to better communicate the intent of our testing, and by clearly testing one parameter at a time.
Higher order functions
Another technique when testing is to use a higher order function as the dependency. This higher order function would then be replaceable for the test.
In the following example, we use a getData() higher order function that in the system will read from a file on the hard drive, but in our test will return an in-memory collection:
// return value should match the function signature: unit -> seq<string list>
let csvFileReader (filePath : string) =
(fun _ -> seq {
use streamReader = new System.IO.StreamReader(filePath)
while not streamReader.EndOfStream do
let line = streamReader.ReadLine()
yield line.Split([|','; ';'|]) |> List.ofSeq
})
// getData: unit -> seq<string list>
let getCustomers getData =
getData() |> Seq.map schema |> Seq.toList
The usage of this is the beautiful part of it, because it becomes so trivial, as shown in the following:
getCustomers (csvFileReader "")
And now, we can exchange the getData signature part for reading from the database, calling a web service, or using an in-memory test double in our unit tests:
[<Test>]
let ``should convert all lines from file into Customers`` () =
// arrange
let getData = (fun _ -> seq {
yield ["1"; "John Doe"; "john.doe@test.com"; "true"];
yield ["2"; "Jane Doe"; "jane.doe@test.com"; "false"];
})
// act & assert
(getCustomers getData).Length |> should equal 2
The difference here is that we don't have to send in an empty string into the getData function, but can apply any kind of argument we wish as long as we adhere to the function signature of the getCustomers function.
Stubbing with Foq
There are two specific types of test doubles, namely stubs and mocks. A stub is a least effort implementation of an abstract class or interface. Sometimes, it is prepared with some stub data, meaning data that is necessary in order to run our tests.
A mock is also a test double, but it will record any interaction and be able to answer asserts on those interactions. You can ask the mock questions such as: was the GetUsers() method called with the ID 42 parameter? And in this way, you can verify the interactions of an isolated unit with its outside world.
There are many .NET mocking frameworks that would work well with F#, like Rhino Mocks, Moq, and NMock. Foq is, however, one framework that is specific to F# and uses its code quotations, as we've already seen with Unquote.
You can install Foq directly to your project from the NuGet Package Manager, as shown in the following screenshot:
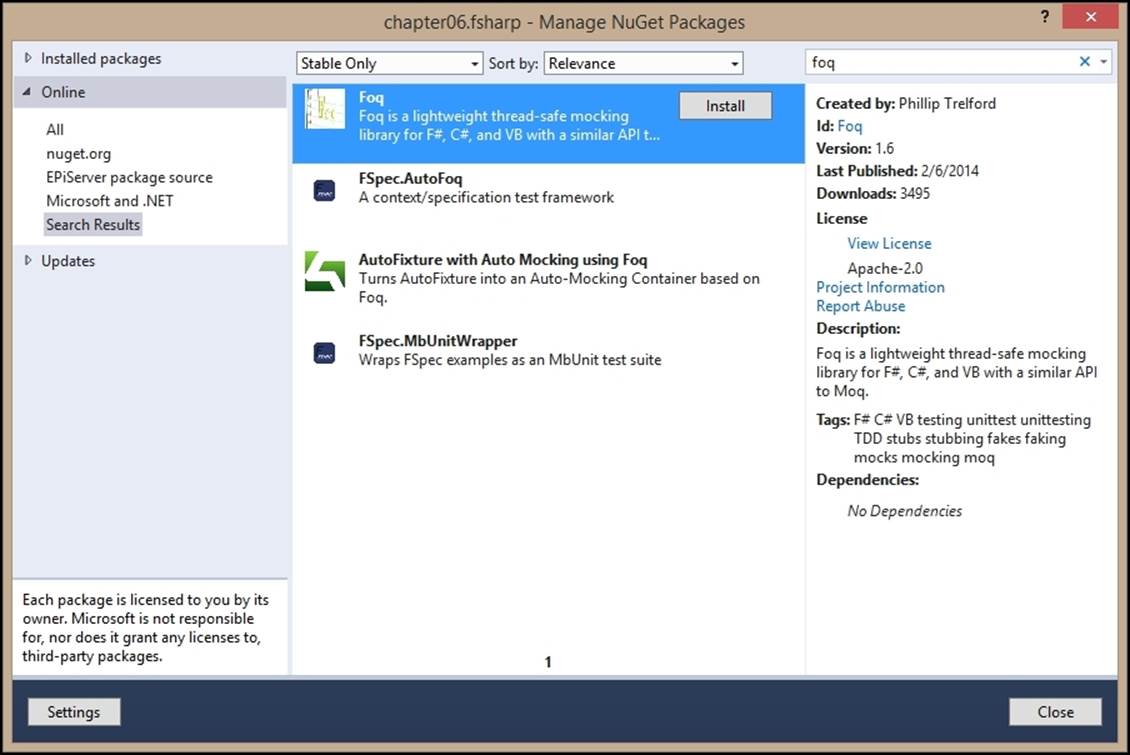
This will add Foq as a reference to your project and you can use it to start writing your first stub.
Let's say we have an interface for managing users in the database, as shown in the following code:
type IUserDataAccess =
abstract member GetUser: int -> User
abstract member GetUsers: unit -> User list
abstract member UpdateUser: User -> bool
abstract member CreateUser: User -> User
abstract member DeleteUser: int -> bool
Using this interface, we want to implement a function to generate a new password for a user. We use the following code:
// update a user with new password
let resetUserPassword (dataAccess : IUserDataAccess) user length =
// define password alphabet
let alphabet = ['a'..'z'] @ ['A'..'Z'] @ ['0'..'9'] @ ['@'; '$'; '#'; ','; '.']
// pick random character from alphabet
let random seed alphabet : char = List.nth alphabet ((System.Random(seed)).Next(alphabet.Length))
// create a string out of random characters
let password = [for i in 1..length -> random i alphabet]
|> List.fold (fun acc value -> sprintf "%s%c" acc value) ""
// create new user instance
let user = {user with Password = password}
// store user to database and return
dataAccess.UpdateUser user |> ignore
user
What is interesting for this example is that the code is dependent on the IUserDataAccess method and we're only making use of one method in the interface declaration. If we were to use interface object expression implementation to stub this out, we would have to implement the whole interface, which would get quite messy:
[<Test>]
let ``should generate a new password on user`` () =
// arrange
let dataAccess =
{ new IUserDataAccess with
member this.GetUser id = { ID = id; Password = "" }
member this.GetUsers () = []
member this.UpdateUser user = true
member this.CreateUser user = user
member this.DeleteUser id = true }
// act
let user = resetUserPassword dataAccess { ID = 1; Password = "" } 12
// assert
user.Password |> should haveLength 12
Instead of using this tedious method, we can generate a stub with Foq, like this.
[<Test>]
let ``generated password should always be unique`` () =
// arrange
let dataAccess =
Mock<IUserDataAccess>()
.Setup(fun x -> <@ x.UpdateUser(any()) @>).Returns(true)
.Create()
// act
let user1 = resetUserPassword dataAccess { ID = 1; Password = "" } 12
let user2 = resetUserPassword dataAccess { ID = 2; Password = "" } 12
// assert
user1.Password |> should not' (equal user2.Password)
The test here is failing, but the interesting thing is to look at how we managed to create a stub with Foq which would only define behavior for one member of the stubbed interface, instead of stubbing out the whole thing.
In this case, we just caught any call to the IUserDataAccess method.UpdateUser and returned true. We could actually set up different return values for different inputs, as shown in the following code:
// delete a list of users
let deleteUsers users (dataAccess : IUserDataAccess) =
users
|> List.map (fun user -> dataAccess.DeleteUser user.ID)
|> List.zip users
This function takes a list of user IDs and deletes the corresponding users from the database. It then reports for each user if the deletion was successful (true) or if it failed (false).
We can easily test this by setting up our stub to return different results depending on the input:
[<Test>]
let ``should report status on deleted users`` () =
// arrange
let users = [|{ ID = 1; Password = "pass1" };
{ ID = 2; Password = "pass1" };
{ ID = 3; Password = "pass1" }|]
let dataAccess =
Mock<IUserDataAccess>()
.Setup(fun da -> <@ da.DeleteUser(users.[0].ID) @>).Returns(true)
.Setup(fun da -> <@ da.DeleteUser(users.[1].ID) @>).Returns(false)
.Setup(fun da -> <@ da.DeleteUser(users.[2].ID) @>).Returns(true)
.Create()
// act
let result1 :: result2 :: result3 :: [] = deleteUsers (users |> List.ofArray) dataAccess
// assert
result1 |> should equal (users.[0], true)
result2 |> should equal (users.[1], false)
result3 |> should equal (users.[2], true)
Foq will record our setup, and when the request comes, it will return the result we have set up for it.
You can also use Foq to verify that your code can handle the edge cases of your integration points, for instance, when the external system throws an exception at you and expects you to catch it:
let update (dataAccess : IUserDataAccess) user =
try
dataAccess.UpdateUser user
with
// user has not been persisted before updating
| :? System.Data.MissingPrimaryKeyException -> false
The Update function will handle a MissingPrimaryKeyException exception coming from the database:
[<Test>]
let ``should return false when updating a user that doesn't exist`` () =
// arrange
let dataAccess =
Mock<IUserDataAccess>()
.Setup(fun da -> <@ da.UpdateUser(any()) @>)
.Raises<System.Data.MissingPrimaryKeyException>()
.Create()
// act
let result = update dataAccess { ID = 1; Password = "pass1" }
// assert
result |> should be False
The test shows how we can simulate this by setting up the data access stub to raise the exception, and then expecting it to be handled property in the SUT.
It doesn't get much more complicated than this when stubbing with Foq. The need for stubbing is, in itself, not as great in functional programming as it is in object-oriented, as you can most often extract a dependency by its functional signature instead of having a class for it.
Interfaces should, as a rule, be limited to providing only one service, and having large interface declarations is a code smell. Foq doesn't really come into great use until you have a large interface where you want to stub away only a few of its methods. For those other cases, you're fine just using interface implementation by object expressions.
Mocking
Even though Foq is calling itself a mocking framework, a mock is really a recorder of events on a dependency. You can use it to verify the interactions between parts in your system.
Let's say we have a situation where we want to synchronize customer data from a CRM system onto our local database. We could have interfaces as shown in the following code:
type Customer = { ID : int; Name : string }
type ICustomerService =
abstract member GetCustomers : unit -> Customer list
type ICustomerDataAccess =
abstract member GetCustomer : int -> Customer option
abstract member InsertCustomer : Customer -> unit
abstract member UpdateCustomer : Customer -> unit
We write a simple scheduled job that will synchronize data nightly:
let synchronize (service : ICustomerService) (dataAccess : ICustomerDataAccess) =
// get customers from service
let customers = service.GetCustomers()
// partition into inserts and updates
let inserts, updates =
customers |> List.partition (fun customer -> None = dataAccess.GetCustomer customer.ID)
// insert all new records
for customer in inserts do
dataAccess.InsertCustomer customer
// update all existing records
for customer in updates do
dataAccess.UpdateCustomer customer
The code itself is pretty straightforward. We extract all customers and split them into two lists, the ones that are going to be inserted, and those that are to be updated. Then, we execute the inserts and updates.
The problem is not a very functional problem, and the solution here is not a pure functional solution, making it hard to test because it doesn't return anything we can assert on.
This is a situation where we would need to use a mock, in order to test the logic. Let's start by adding RhinoMocks to our test project, as shown in the following screenshot:
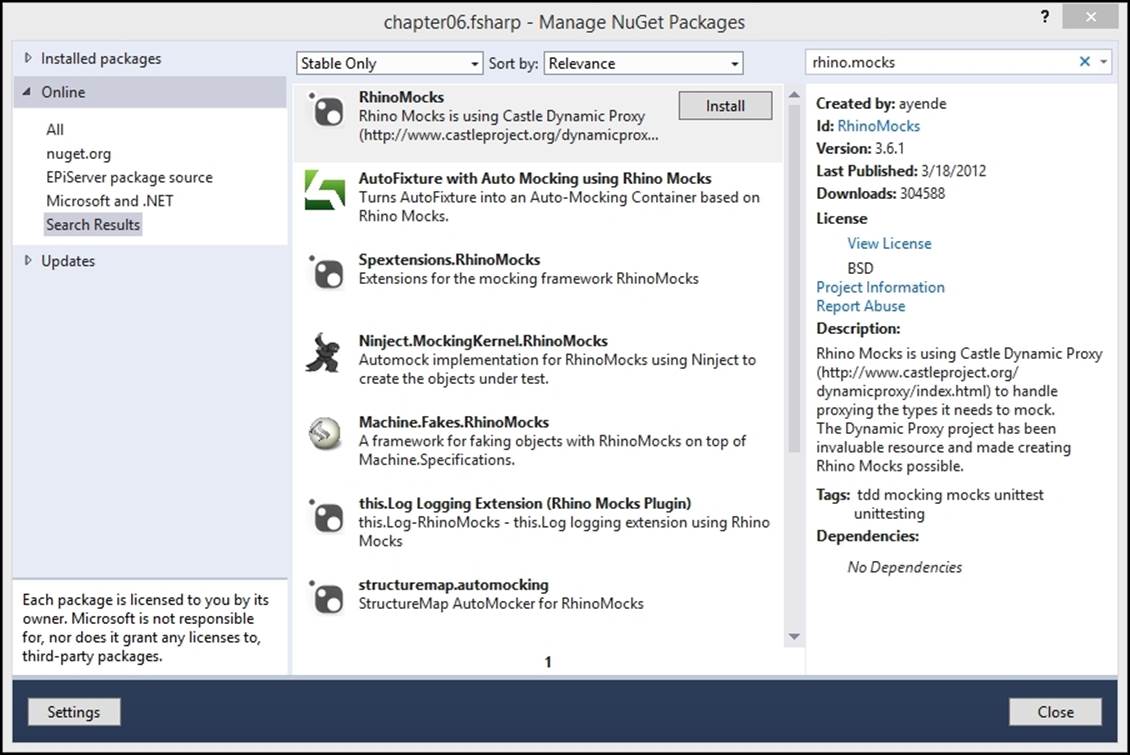
This is a great tool for recording and replaying behavior in your SUT:
open Rhino.Mocks
[<Test>]
let ``should update customers that are already in database`` () =
// arrange
let data = [|{ ID = 1; Name = "John Doe" }; { ID = 2; Name = "Jane Doe" }|]
let customerService = MockRepository.GenerateMock<ICustomerService>();
let customerDataAccess = MockRepository.GenerateMock<ICustomerDataAccess>();
// setup getting data
customerService.Expect(fun service -> service.GetCustomers()).Return(data |> Seq.toList);
// setup try getting customers from database
customerDataAccess.Expect(fun da -> da.GetCustomer 1).Return(Some data.[0])
customerDataAccess.Expect(fun da -> da.GetCustomer 2).Return(None)
// act
synchronize customerService customerDataAccess
// assert
customerDataAccess.AssertWasCalled(fun da -> da.UpdateCustomer(data.[0]))
customerService.VerifyAllExpectations()
customerDataAccess.VerifyAllExpectations()
Now, this code reads as being very verbose, but it is quite simple in its essence. First, we define some test data where #1 should already exist in the database and #2 should be new.
We put an expectation on the customerService function, when it gets a call to the GetCustomers() method, it should return our test data.
Then, we put an expectation on the customerDataAccess function to define that in #1, there should be a customer returned and in #2, there should be a None customer parameter .
We execute the SUT, and lastly, we verify that the customerDataAccess function, the UpdateCustomer() method was called with the customer that already existed. After that, we call the VerifyAllExpectations() method to make sure the expectations we've set up were followed through.
If you would like to go even further, you could use the MockRepository.GenerateStrictMock method instead, which is a mock that won't accept any other calls to the mock objects except those you've put expectations on.
For over a year, I thought this was really great stuff, until I started using it in scale. The problem with mocking is that you tend to get very brittle tests. Every time you change an implementation detail, the mocks will break, even if that change didn't affect the publicinterface. Refactoring became very hard and tedious with mock tests breaking, and when a test breaks, though nothing is wrong, it starts costing more in maintenance to justify the value it brings.
The problem is, of course, that the test knows too much about the implementation details, so much that we can't change the implementation details without breaking the test. This is the problem with mocking, just as with private members; when the test knows too much about the inner workings of the SUT, they become brittle and costly.
Knowing the dangers of mocking, you should mock in moderation. Test the public interfaces, and only put expectations on dependencies when that dependency is a part of the public interface. Know the pain to get the gain.
Dealing with databases
The most common question when it comes to unit testing is how to remove the dependency to the database. I have already touched upon a set of techniques on how to use test doubles in order to get around dependencies, but I wanted to use this section of the chapter to take a concrete example of a database and show how to get around it.
When writing code for connecting with a database, I use the convention of isolating all database code within a module and providing that module with a signature file in order to hide its internals.
This will be demonstrated by writing an e-mail queue that is used for storing e-mails in an SQL database before sending them. This is done because the page load of a web application should not have direct dependency on a Simple Mail Transfer Protocol(SMTP) server. Instead, e-mails are stored in a table and picked up by a Windows service that will do the sending.
First, you need to add references to the System.Data, Sytem.Data.Linq, and FSharp.Data.TypeProviders namespaces:
module EmailDataAccess =
// insert an e-mail to the database
val insert : Email -> unit
// get all queued e-mails from database
val getAll : unit -> Email list
// delete an e-mail from the database
val delete : int -> unit
This is the signature file of the database module that we're using to access the database. It should be noted that this is not an interface as in object-oriented programming, but just a public definition of the module.
Here is our implementation of the EmailDataAccess module:
module EmailDataAccess =
open System
open System.Data
open System.Data.Linq
open Microsoft.FSharp.Data.TypeProviders
open Microsoft.FSharp.Linq
type dbSchema = SqlDataConnection<"Data Source=.;Initial Catalog=Chapter04;Integrated Security=SSPI;">
let db = dbSchema.GetDataContext()
// Enable the logging of database activity to the console.
db.DataContext.Log <- System.Console.Out
// insert an e-mail to the database
let insert (email : Email) =
let entity = new dbSchema.ServiceTypes.Email(ToAddress = email.ToAddress,
FromAddress = email.FromAddress,
Subject = email.Subject,
Body = email.Body)
db.Email.InsertOnSubmit(entity)
db.DataContext.SubmitChanges()
// get all queued e-mails from database
let getAll () =
query {
for row in db.Email do
select {
ID = Some row.ID;
ToAddress = row.ToAddress;
FromAddress = row.FromAddress;
Subject = row.Subject;
Body = row.Body }
} |> Seq.toList
// delete an e-mail from the database
let delete id =
query {
for row in db.Email do
where (row.ID = id)
select row
} |> db.Email.DeleteAllOnSubmit
db.DataContext.SubmitChanges()
In this implementation, I make sure to hide all the ugliness of the SQL type provider and only expose the public definitions we want to make visible. This is often forgotten in functional programming, but very important in terms of maintainability.
Now, we can implement the e-mail queue, like this:
module EmailQueue =
// push e-mails on the queue
let push (daInsert : Email -> unit) email =
daInsert email
// pop e-mail from the queue
let pop (daGetAll : unit -> Email list) (daDelete : int -> unit) =
seq {
for email in daGetAll() do
daDelete email.ID.Value |> ignore
yield email
}
It has two functions, push and pop. The pop function will return a sequence of e-mail messages that will be removed from the database as they are retrieved from the sequence. This means if the execution fails in the middle, it won't delete records that haven't been processed, and it will not leave records in the queue that have already been processed. Nice and tidy.
This has no dependency at all to the previously written EmailDataAccess library. Instead, we send in the dependencies as functions. Here is a usage example:
// push the e-mail
push email EmailDataAccess.insert |> ignore
// pop the e-mail
let popped = pop EmailDataAccess.getAll EmailDataAccess.delete |> Seq.nth(0)
And this makes it trivial to exchange the dependencies and write our unit tests like this:
[<Test>]
let ``should delete record when iterating on pop sequence`` () =
// arrange
let email = {
ID = None;
ToAddress = "hello@mikaellundin.name";
FromAddress = "hello@mikaellundin.name";
Subject = "Test message";
Body = "Test body"
}
// stub implementation of EmailDataAccess
let db = System.Collections.Generic.Dictionary<int, Email>()
let insert email = db.Add (0, { email with ID = Some 0 })
let getAll () = db.Values |> Seq.cast<Email> |> Seq.toList
let delete id = ignore <| db.Remove id
// act
push insert email |> ignore
pop getAll delete |> Seq.nth(0) |> ignore
// assert
db.Count |> should equal 0
The dependencies are easy enough to stub that we don't need to use an interface implementation, stubbing, or a mocking framework. It's enough to implement some functions that match the functional signature of what we're depending on.
Summary
In this chapter we've learned how to write unit tests by using the appropriate tools to our disposal: NUnit, FsUnit, Unquote, and Foq. We have also learned about different techniques for handling external dependencies, using interfaces and functional signatures, and executing dependency injection into constructors, properties, and methods. Finally, we talked about test doubles, stubs, and mocks and the reasons for avoiding mocking, even in situations where it would seem tempting.
In the next chapter, we will learn about integration testing, when and what to integration test, and how to prepare test data for integration testing. We will test databases and web services and dive into the level of investment that needs to be done in the external system we're testing against.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.