Multiplayer Game Programming: Architecting Networked Games (2016)
Chapter 9. Scalability
Scaling up a networked game introduces a host of new challenges that don’t exist for a game of a smaller scale. This chapter takes a look at some of the issues that crop up as the scale of a game increases, and some solutions to these issues.
Object Scope and Relevancy
Recall that the discussion of the Tribes model in Chapter 1 mentioned the concept of the scope or relevancy of an object. In this context, an object is considered in scope or relevant for a particular client when that client should be informed about updates to the object in question. For a smaller game, it may be viable to have all objects always be in scope or relevant to all clients in the game. This naturally means that all updates to objects on the server will be replicated to all clients. However, such an approach is not realistic for a larger game, both in terms of bandwidth and in terms of processing time for the client. In a game with 64 players, it may not be important to know about a player several kilometers away. In this case, sending information about this far away player would be a waste of resources. It therefore makes sense that if the server deems that Client A is too far away from object J, there is no need to send any updates to Client regarding the object. An additional benefit of reducing the replication data sent to each client is that it reduces the potential for cheating, a topic that is discussed in detail in Chapter 10, “Security.”
However, object relevancy is rarely a binary proposition. For example, suppose object J is actually the avatar representing another player in the game. Suppose the game in question has a scoreboard that displays the health of every player in the game, regardless of the distance. In this scenario, the health of every player object is always relevant, even if other information regarding the player object is not. Thus it makes sense that the server will always send the health of other players, even if the rest of their object data may not be relevant. Furthermore, different objects could have different update frequencies based on their priority, which adds further complexity. In the interest of simplification, this section will consider relevancy of objects on a binary basis. But one should remain cognizant of the fact that relevancy in a commercial game rarely will be entirely binary in nature for every object in the game.
Returning to the example of the game with 64 players, the idea of deeming objects far away as out of scope is considered a spatial approach. Although simple distance checking is a very quick way to determine relevancy, typically it is not robust enough to be the sole mechanism of relevancy. To understand why this is the case, consider the example of a player in a first-person shooter. Suppose that the initial design of the game supports two different weapons: a pistol and an assault rifle. The network programmer thus decides to scope objects based on their distance—anything further than the assault rifle’s range is deemed out of scope. In testing, the amount of bandwidth consumption is right at an acceptable limit. However, if the designers later decide to add a sniper rifle with a scope, with twice the range of the assault rifle, the number of relevant objects will increase greatly.
There are other issues related to only using distance to eliminating objects. A player in the middle of a level is more likely to be in range of objects than a player on the outskirts of the level. Furthermore, considering only distances assigns equal weight to objects in front of and behind a player, which is counterintuitive. Although a distance-based approach to object scope is simple, all objects around the player are deemed relevant, even those that may be behind a wall. These issues are shown in Figure 9.1.
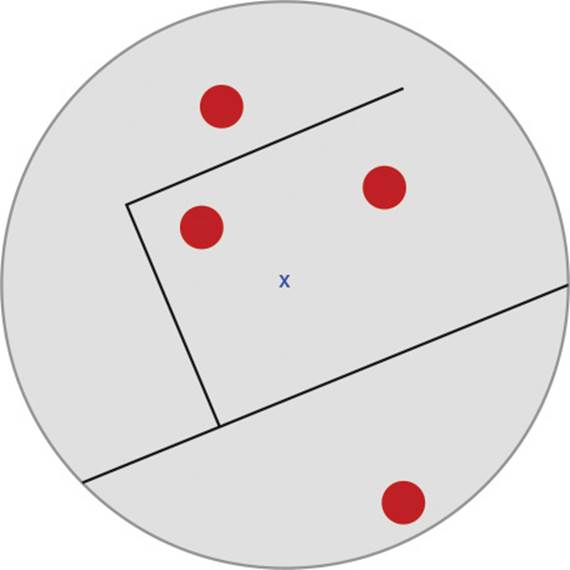
Figure 9.1 The player, designated by the X, in relation to relevant objects
The remainder of this section focuses on approaches more complex than simple distance checking. Many of these techniques are also commonly used in visibility culling, a category of rendering optimizations that try, as early as possible in the rendering process, to eliminate objects that are not visible. However, given the nature of latency in a networked game, some modifications are typically necessary to make a visibility culling approach suitable for object relevancy.
Static Zones
One approach to reducing the number of objects that are relevant is to break the world up into static zones. Only objects in the same static zone as the player are considered relevant. This kind of approach is often used in shared world games such as MMORPGs. For example, a town where players can meet with each other to trade goods might be one zone, whereas a forest where the players can fight monsters might be another zone. In this case, it makes no sense for players in the forest to be sent replication information about the players trading in town.
There are a couple of different ways to handle transitions over zone boundaries. One approach is to invoke a loading screen when traveling between zones. This provides enough time for the client to receive replication information regarding all of the objects in the new zone. For a more seamless transition, it may be more desirable to have objects fade in and out as their relevancy changes upon a zone transition. Assuming that the terrain for a zone never changes, the terrain could simply be stored on the client so that the zone behind a player doesn’t completely disappear upon crossing a zone boundary. However, keep in mind that storing terrain on the client may present some security issues. One solution would be to encrypt the data, a topic covered in Chapter 10, “Security.”
One drawback of static zones is they are designed around the premise that players will be roughly evenly distributed between the zones in the game. This can be very tough to guarantee in most MMORPGs. Meeting places such as towns will always have a higher concentration of players than an out-of-the-way zone for high-level characters. This problem can be exasperated by in-game events that encourage a large number of players to gather at one specific location—such as in order to fight an especially tough enemy creature. With a high concentration of players in one zone, the experience may be degraded for all the players in the zone.
Solutions to an overcrowded zone may vary by the game. In the MMORPG Asheron’s Call, if a player attempts to enter a zone with too many players, they are teleported to a neighboring zone. Although perhaps not ideal, this approach is superior to the game crashing due to too many players in one zone. Other games may actually split the zone into multiple instances, a topic discussed later in this chapter.
While viable for shared world games, static zones typically are not used for action games for two main reasons. First, most action games feature combat in a much smaller area than might be seen in an MMO game, though there are some notable exceptions, such as PlanetSide. Second, and perhaps more importantly, the pace of most action games means that the delay caused by traversing a zone boundary may be considered unacceptable.
Using the View Frustum
Recall that for a 3D game, the view frustum is a trapezoidal prism representing the area of the world that is projected into a 2D image for display. The view frustum is described in terms of an angle representing the horizontal field of view, an aspect ratio, and the distances to the near and far planes. When the projection transform is applied, objects fully enclosed by or intersecting the frustum are visible, whereas all other objects are not.
The view frustum is commonly used in visibility culling. Specifically, if an object is outside the frustum, it is not visible, so no time should be spent sending the object’s triangles to the vertex shader. One way to implement frustum culling is to represent the view frustum as the six planes comprising the sides of the frustum. Then a simplified representation of an object, such as a sphere, can be tested against the frustum planes to determine whether or not the object in question is inside or outside the frustum. A detailed discussion of the math behind frustum culling is found in (Ericson 2004).
While visibility culling based on the view frustum makes a great deal of sense, using only the frustum for object scoping in a network game presents some issues when taking into account latency. For example, if only the frustum is used, objects immediately behind the player would be considered out of scope. This may be problematic if the player quickly turns 180 degrees. It will take some time for a quick turn to be propagated to the server, and for the server to correspondingly send replication updates for objects that would suddenly scope in. One could imagine this would create some unacceptable latency, especially if the object behind the player happens to be an enemy player character. Furthermore, walls are still ignored in this approach. This issue is shown in Figure 9.2.
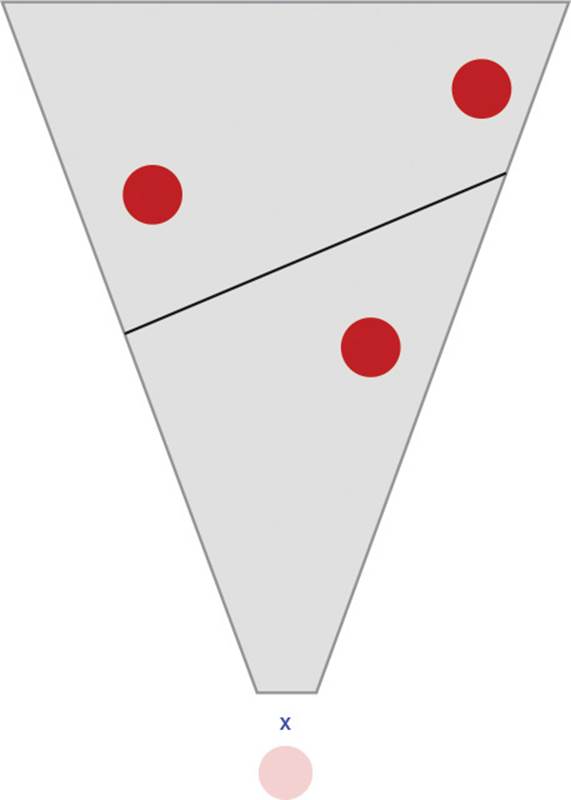
Figure 9.2 An out-of-scope object directly behind the player, X
One solution is to use both the view frustum and a distance-based system. Specifically, a distance closer than the far plane could be combined with the frustum. Then any objects that are either within the distance or within the frustum would be considered in scope, and everything else would be out of scope. This means that on a quick turn, far away objects would still go in and out of scope and walls would be ignored, but the scoping of closer objects would not change. An illustration of this approach is shown in Figure 9.3.
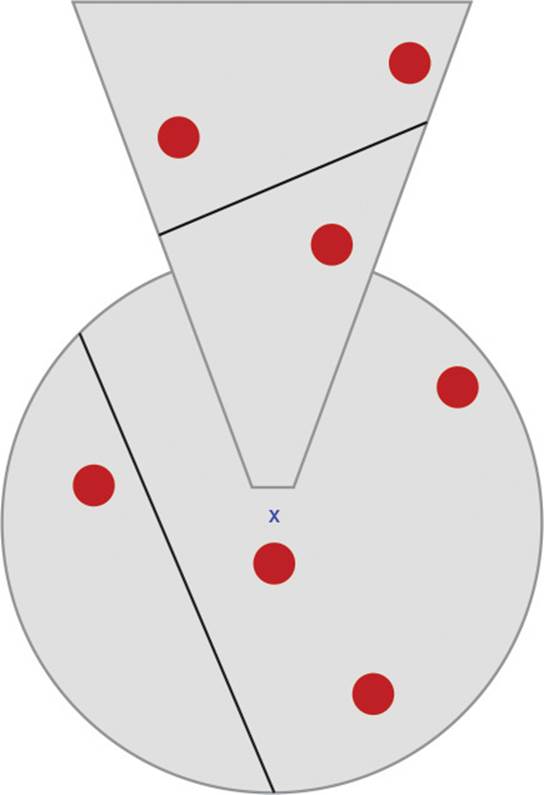
Figure 9.3 Combining a view frustum with a smaller radius to determine relevancy of objects
Other Visibility Techniques
Consider a networked racing game that features a track winding through a city. As would be apparent to anyone who has rode in a car, the amount of road that is visible can vary greatly. On a straight road with flat elevation, it is possible to see far into the distance. However, if the car is turning, the visibility is greatly reduced. Similarly, traveling uphill has lower visibility than traveling downhill. This idea of road visibility can be directly translated into the networked racing game. Specifically, if the server knows the position of a player’s car, it can know how far ahead on the track the player can see. This area will likely be much smaller than the area intersecting the view frustum, which will ideally lead to a reduction in the number of objects in scope.
This leads to the concept of a potentially visible set (PVS). Using a PVS answers the following question: From each location in the world, what is the set of regions that are potentially visible? While this may seem similar to the static zone approach, the region sizes in PVS are typically much smaller than separate zones. A static zone might be a town of several buildings, while a PVS region would be an individual room inside of a building. Furthermore, in a static zone approach, only objects within the same static zone are considered relevant. This is in contrast to PVS, where neighboring regions that are deemed potentially visible will contain relevant objects.
In a typical implementation of PVS, the world can be divided into a set of convex polygons (or if necessary, a 3D convex hull). An offline process then computes, for each convex polygon, the set of the other convex polygons that are potentially visible. At runtime, the server determines which convex polygon a player is located in. From this convex polygon, the pregenerated sets can be used to determine the set of all objects that are potentially visible. These objects can then be flagged as relevant to the player in question.
Figure 9.4 illustrates what the PVS for the hypothetical racing game might look like. Given the player’s location marked by an X, the shaded region represents the area that is potentially visible. In an actual implementation, it would be advisable to add a bit of slack in both directions. This way, objects a little bit beyond the potentially visible area would also be marked as in scope. Especially in a racing game where the cars are moving quickly, making sure to account for the latency in the server updating the scoped objects is important.
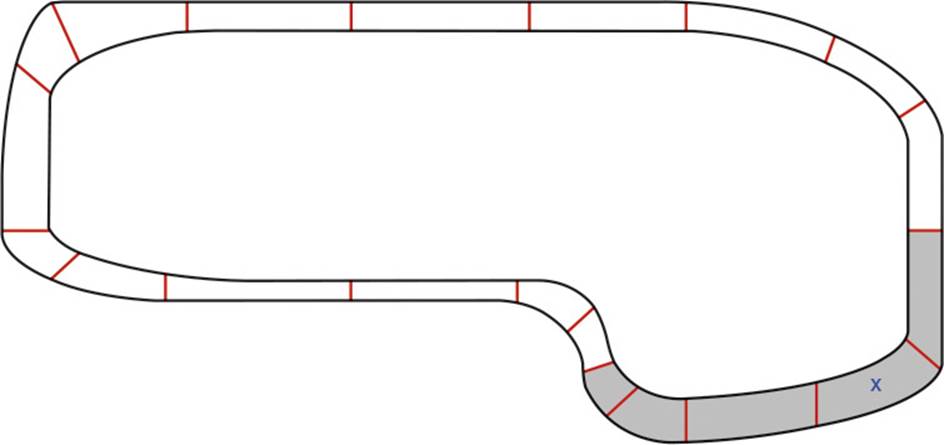
Figure 9.4 A sample PVS in a racing game
The PVS system also works well for a corridor-based first-person shooter, in the vein of Doom or Quake. For this type of game, it may also be desirable to use a related technique called portals. In a portal culling system, each room is a region and each door or window is considered a portal. The frustums created by the portals can be combined with the view frustum to greatly reduce the number of relevant objects. This system requires a greater amount of runtime processing than a PVS, but if your game is already using portals to reduce overdraw on the client, it may not be too difficult to extend the code to work for server-side object scoping.
In a similar vein, some games may merit consideration of hierarchical culling approaches such as BSP, quadtree, or octree. Each of these hierarchical culling techniques partition the objects in the world using tree data structure. An in-depth discussion of these techniques can be found in (Ericson 2004). Keep in mind that using any of these more advanced techniques for object scoping will significantly increase the amount of time it takes. This is especially true given that the scoping process must be run separately for each client connected to the server. Unless you find your game really struggling to keep up with the volume of object replication, it probably is extreme to use these hierarchical culling systems for object scoping. A well-implemented PVS system should be more than sufficient for most action-oriented games, and many games may not even require the level of detail a PVS system provides.
Relevancy When Not Visible
It is important to note that visibility may not, in all instances, directly correlate with the relevancy of a particular object. Take the example of an FPS where players can throw a grenade. If a grenade explodes in a nearby room, it is important that the grenade be replicated to all clients nearby, even if it is not visible. This is because the client expects to hear the sound of a grenade explosion, even if the grenade is not visible at the moment of explosion.
One approach to solving this issue is to treat grenades differently from other objects. For example, they could be replicated by radius rather than by visibility. Another option is to replicate the explosion effect via RPC to the clients to whom the grenade itself is not relevant. This second approach may reduce the amount of data sent to the clients that need to know about the explosion sound (and potentially the particle effect), but don’t need to replicate the actual grenade. This may mean that the grenade explosion information will be replicated to clients that can’t actually hear it, but as long as this is a special case and not abused for a large amount of objects, it should not significantly increase bandwidth usage.
If the game is very much audio-based, it may even be possible to compute sound occlusion information on the server in order to determine relevancy. However, realistically such computation is generally done on the client side—it’s unlikely a commercial game would actually need to compute audio relevancy with such a degree of accuracy on the server. A radial or RPC-based approach should be fine for most games.
Server Partitioning
Server partitioning or sharding is the concept of running multiple server processes simultaneously. Most action games inherently use this approach because each active game has a cap on the number of active players—often within the range of 8 to 16 players. The number of players supported per game is largely a game design decision, but there is also an undeniable technical benefit to such a system. The idea is that by having separate servers, the load on any one particular server should not be overwhelming.
Examples of games that use server partitioning include Call of Duty, League of Legends, and Battlefield. Since each server runs a separate game, there is no gameplay interaction between the players of two separate games. However, many of these games still have statistics, experience, levels, or other information that is written to a shared database. This means that each server process will have access to some backend database, which can be considered part of the gamer services, a concept covered in more detail in Chapter 12, “Gamer Services.”
In a server partitioning approach, it is a common occurrence that one machine is actually capable of running several server processes simultaneously. In many big-budget games, the developer provisions machines in a data center for the purpose of running several server processes. For these games, part of the game’s architecture needs to handle distribution of processes to each machine. One approach is to have a master process that decides when server processes should be created, and on which machine. When a game ends, the server process can write any persistent data before exiting. Then when players decide to start a new match, the master process can determine which machine is under the least load, and have a new server process be created on that machine. It is also possible for developers to use cloud hosting for their servers, a configuration discussed inChapter 13, “Cloud Hosting Dedicated Servers.”
Server partitioning is also used as an extension to the static zone approach used in MMOs. Specifically, each static zone, or a collection of static zones, can be run as a separate server process. For example, the popular MMORPG World of Warcraft features multiple continents. Each continent runs on a separate server process. When a player transitions from one content to another, the client displays a loading screen while their character state is transferred to the server process for the new continent. Every continent is composed of several different static zones. Unlike changing continents, crossing the boundary between two zones is seamless, because all of the zones on the continent are still running on the same server process. Figure 9.5 illustrates what this type of configuration might look like for a hypothetical MMORPG. Each hexagon represents a static zone, and the dotted lines represent travel points between the two continents.
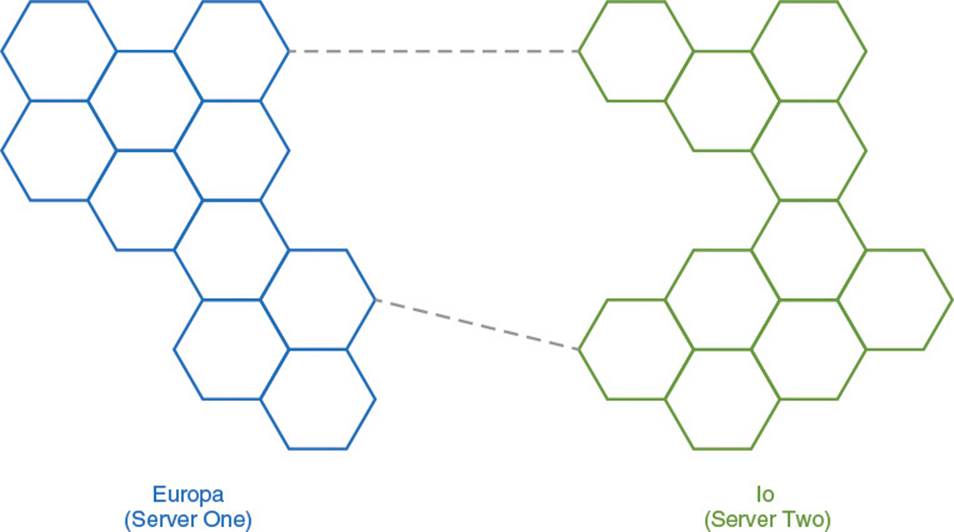
Figure 9.5 Use of server partitioning for separate continents, but not zones, in a hypothetical MMORPG
As with static zones, server partitioning only works well if the players are roughly evenly distributed between each server. If there are too many players on one server, the server can still encounter performance issues. This is not an issue in a game with a fixed player cap, but it can certainly be an issue in an MMO. Depending on the game, there are many different potential solutions to this problem. Some games simply have a server cap and force players to wait in a queue if a server becomes too full. In the case of Eve Online, the server slows down the game’s time step. This slow-motion mode, called time dilation, allows the server to keep all players connected in a situation that it otherwise would not be able to maintain.
Instancing
In instancing, one shared game supports several separate instances at once. This term is usually applied to shared world games where all the characters reside on the same server, but may not be playing in the same instance at the same time. For example, many MMORPGs use instancing for dungeon content designed for a fixed number of players. This way, groups of players can experience highly scripted content, free from the interference of other players. In most games that implement this sort of instancing, there is a portal or similar construct that transitions the players from a shared zone into an instance.
Sometimes instancing is also used as a solution for overcrowded zones. For example, Star Wars: The Old Republic sets a cap on the number of players that can be in one particular zone. If the player count becomes too high, a second instance of the zone will be forked from the original instance. This does introduce some complexity for players. If two players try to meet in one zone, they might actually end up in two different instances of the zone. In the case of The Old Republic, the solution is to allow a player to teleport into a group member’s instance, in the event it is different.
From a design perspective, instancing allows for content more in line with single-player or smaller multiplayer games, all while still having characters tied to a shared world. Some games even use instancing as a way to allow for a zone to evolve throughout the course of a quest line. However, the counterargument is that instancing makes the world feel less shared than it might otherwise.
From a performance standpoint, as long as the cost of spinning up an instance is properly managed, instancing can be beneficial. Instancing can guarantee that no more than X players are ever relevant at one point in time, especially if the zones can spawn separate instances. It is even possible to combine instancing with server partitioning in order to further decrease the load on specific server processes. Because entering an instance will almost always involve a loading screen for the client, there is no reason the client could not be transferred to a separate server, much how the continents in World of Warcraft run on separate server processes.
Prioritization and Frequency
For some games, the performance of the server is not the main bottleneck. Instead, the issue is the amount of data transmitted over the network to the clients. This may especially be an issue for mobile games that need to support a plethora of network conditions. Chapter 5 discussed some ways to solve this problem, such as using partial object replication. However, if testing determines that the amount of bandwidth the game is using is still too high, then there are some additional techniques to consider.
One approach is to assign a priority to different objects. Objects with a higher priority can be replicated first, and lower-priority objects are only replicated if there are no higher-priority objects left to replicate. This can be thought of as a way to ration bandwidth—there is only a limited amount of bandwidth available, so it may as well be used for the most important objects.
When using prioritization, it generally is important to still allow lower-priority objects through on occasion. Otherwise, lower-priority objects will never be updated on clients. This can be accomplished by allowing different objects to have different replication frequencies. For example, important objects might be updated a couple of times per second, but less important objects might only be updated every couple of seconds. The frequency could also be combined with base priority to compute some sort of dynamic priority—in essence, increasing the priority of a lower-priority object if it has been too long since the previous update.
This same sort of prioritization can also be applied to remote procedure calls. If certain RPCs are ultimately irrelevant to the game state, they can be dropped from transmission if there is not enough bandwidth to send them. This is similar to how packets can be sent reliably or unreliably, as discussed in Chapter 2.
Summary
Reducing the volume of data sent to any one client is important as a networked game scales up in size. One way to achieve this is to reduce the total number of objects in scope to a particular client. A simple approach is to deem objects too far away from a client as out of scope, though this one-size-fits-all approach may not work well in all scenarios. Another approach, especially popular in shared world games, is to partition the world into static zones. This way, only players in the same zone are relevant to each other.
It is also possible to leverage visibility culling techniques to reduce the number of relevant objects. While relying solely on the view frustum is not recommended, combining it with a smaller radius can work well. Other games that have clear sectioning of levels, such as corridor-based shooters or racing games might use PVS. With PVS, it is possible to determine which regions are visible from any location in the level. Still other visibility techniques such as portals may see some use on a case-by-case basis. Finally, there are instances where visibility should not be the only criteria for relevancy, such as when a grenade explodes.
Server partitioning can be used to reduce the load on any one server. This can be done both for action games with fixed player caps, and for large shared world games where zones can be placed on separate server processes. Similarly, instancing is a method that forks a shared world into areas that are more manageable from a performance or design standpoint.
There are other techniques, not related to object relevancy, that can be used to limit bandwidth usage of a networked game. One is to assign priority to different objects or RPCs so that the most important information is prioritized first. Another approach is to reduce the frequency that replication updates are sent for all but the most important objects.
Review Questions
1. What are the drawbacks of using only distances to determine object relevancy?
2. What is a static zone, and what are its potential benefits?
3. How can the view frustum be represented for the purposes of culling? What happens if only the frustum is used to determine object relevancy?
4. What is a potentially visible set, and how does this approach differ from static zones?
5. If a shared world game suffers from zone overcrowding, what are some potential solutions to this problem?
6. What are some approaches, other than reducing the number of relevant objects, to reduce the bandwidth requirements of a networked game?
Additional Readings
Ericson, Christer. Real-Time Collision Detection. San Francisco: Morgan Kaufmann, 2004.
Fannar, Hallidor. “The Server Technology of EVE Online: How to Cope With 300,000 Players on One Server.” Presented at the Game Developer’s Conference, Austin, TX, 2008.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.