Introduction to Regular Expressions in SAS (2014)
Chapter 1. Introduction
1.1 Purpose of This Book
This book is meant for SAS programmers of virtually all skill levels. However, it is expected that you have at least a basic knowledge of the SAS language, including the DATA step, and how to use SAS PROCs.
This book provides all the tools you need to learn how to harness the power of regular expressions within the SAS programming language. The information provided lays the foundation for fairly advanced applications, which are discussed briefly as motivating examples later in this chapter. They are not presented to intimidate or overwhelm, but instead to encourage you to work through the coming pages with the anticipation of being able to rapidly implement what you are learning.
1.2 Layout of This Book
It is my goal in this book to provide immediately applicable information. Thus, each chapter is structured to walk through every step from theory to application with the following flow: Syntax ‣ Example. In addition to the information discussed in the coming chapters, a regular expression reference guide is included in the appendix to help with more advanced applications outside the scope of this text.
Chapter 1
In addition to providing a roadmap for the remainder of the book, this chapter provides motivational examples of how you can use this information in the real world.
Chapter 2
This chapter introduces the basic syntax and concepts for regular expressions. There is even some basic SAS code for running the examples associated with each new concept.
Chapter 3
This chapter is designed to walk through the details of implementing regular expressions within the SAS language.
Chapter 4
In this final chapter, we work through a series of in-depth examples—case studies if you will—in order to ‘put it all together.’ They don’t represent the limitations of what you can do by the end of this book, but instead provide some baseline thinking for what is possible.
Appendixes
While not comprehensive, these serve as valuable, substantial references for regular expressions, SAS documentation, and reference tables. I hope everyone can leverage the additional information to enrich current and future regular expressions capabilities.
1.3 Defining Regular Expressions
Before going any further, we need to define regular expressions.
Taking the very formal definition might not provide the desired level of clarity:
Definition 1 (formal)
regular expressions: “Regular expressions consist of constants and operator symbols that denote sets of strings and operations over these sets, respectively.”1
In the pursuit of clarity, we will operate with a slightly looser definition for regular expressions. Since practical application is our primary aim, it doesn’t make sense to adhere to an overly esoteric definition. So, for our purposes we will use the following:
Definition 2 (easier to understand—our definition)
regular expressions: character patterns used for automated searching and matching.
When programming in SAS, regular expressions are seen as strings of letters and special characters that are recognized by certain built-in SAS functions for the purpose of searching and matching. Combined with other built-in SAS functions and procedures, you can realize tremendous capabilities, some of which we explore in the next section.
Note: SAS uses the same syntax for regular expressions as the Perl programming language2. Thus, throughout SAS documentation, you find regular expressions repeatedly referred to as “Perl regular expressions.” In this book, I choose the conventions present in the SAS documentation, unless the Perl conventions are the most common to programmers. To learn more about how SAS views Perl, visit this website: http://support.sas.com/documentation/cdl/en/lefunctionsref/67239
/HTML/default/viewer.htm#p0s9ilagexmjl8n1u7e1t1jfnzlk.htm. To learn more about Perl programming, visit http://perldoc.perl.org/perlre.html. In this book, however, I primarily dispense with the references to Perl, as they can be confusing.
1.4 Motivational Examples
The information in this book is very useful for a wide array of applications. However, that will not become obvious until after you read it. So, in order to visualize how you can use this information in your work, I present some realistic examples.
As you are all probably familiar with, data is rarely provided to analysts in a form that is immediately useful. It is frequently necessary to clean, transform, and enhance source data before it can be used—especially textual data. The following examples are devoid of the coding details that are discussed later in the book, but they do demonstrate these concepts at varying levels of sophistication. The primary goal here is to simply help you to see the utility for this information, and to begin thinking about ways to leverage it.
1.4.1 Extract, Transform, and Load (ETL)
ETL is a general set of processes for extracting data from its source, modifying it to fit your end needs, and loading it into a target location that enables you to best use it (e.g., database, data store, data warehouse). We’re going to begin with a fairly basic example to get us started. Suppose we already have a SAS data set of customer addresses that contains some data quality issues. The method of recording the data is unknown to us, but visual inspection has revealed numerous occurrences of duplicative records, as in the table below. In this example, it is clearly the same individual with slightly different representations of the address and encoding for gender. But how do we fix such problems automatically for all of the records?
|
First Name |
Last Name |
DOB |
Gender |
Street |
City |
State |
Zip |
|
Robert |
Smith |
2/5/1967 |
M |
123 Fourth Street |
Fairfax, |
VA |
22030 |
|
Robert |
Smith |
2/5/1967 |
Male |
123 Fourth St. |
Fairfax |
va |
22030 |
Using regular expressions, we can algorithmically standardize abbreviations, remove punctuation, and do much more to ensure that each record is directly comparable. In this case, regular expressions enable us to perform more effective record keeping, which ultimately impacts downstream analysis and reporting.
We can easily leverage regular expressions to ensure that each record adheres to institutional standards. We can make each occurrence of Gender either “M/F” or “Male/Female,” make every instance of the Street variable use “Street” or “St.” in the address line, make each City variable include or exclude the comma, and abbreviate State as either all caps or all lowercase.
This example is quite simple, but it reveals the power of applying some basic data standardization techniques to data sets. By enforcing these standards across the entire data set, we are then able to properly identify duplicative references within the data set. In addition to making our analysis and reporting less error-prone, we can reduce data storage space and duplicative business activities associated with each record (for example, fewer customer catalogs will be mailed out, thus saving money!). For a detailed example involving ETL and how to solve this common problem of data standardization, see Section 4.2 in Chapter 4.
1.4.2 Data Manipulation
Suppose you have been given the task of creating a report on all Securities and Exchange Commission (SEC) administrative proceedings for the past ten years. However, the source data is just a bunch of .xml (XML) files, like that in Figure 1.13. To the untrained eye, this looks like a lot of gibberish; to the trained eye, it looks like a lot of work.
Figure 1.1: Sample of 2009 SEC Administrative Proceedings XML File
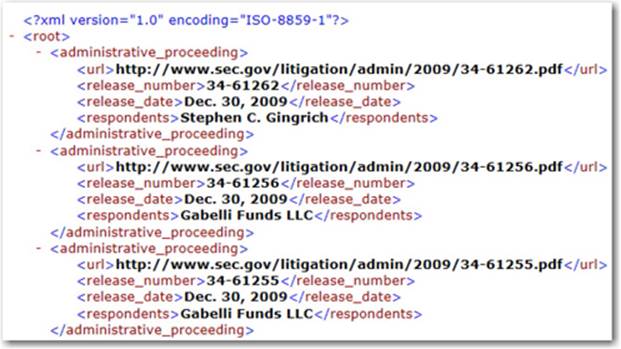
However, with the proper use of regular expressions, creating this report becomes a fairly straightforward task. Regular expressions provide a method for us to algorithmically recognize patterns in the XML file, parse the data inside each tag, and generate a data set with the correct data columns. The resulting data set would contain a row for every record, structured similarly to this data set (for files with this transactional structure):
Example Data Set Structure
|
Release_Number |
Release_Date |
Respondents |
URL |
|
34-61262 |
Dec 30, 2009 |
Stephen C. Gingrich |
http://www.sec.gov/litigation/ |
|
… |
… |
… |
… |
Note: Regular expressions cannot be used in isolation for this task due to the potential complexity of XML files. Sound logic and other Base SAS functions are required in order to process XML files in general. However, the point here is that regular expressions help us overcome some otherwise significant challenges to processing the data. If you are unfamiliar with XML or other tag-based languages (e.g., HTML), further reading on the topic is recommended. Though you don’t need to know them at a deep level in order to process them effectively, it will save a lot of heartache to have an appreciation for how they are structured. I use some tag-based languages as part of the advanced examples in this book because they are so prevalent in practice.
1.4.3 Data Enrichment
Data enrichment is the process of using the data that we have to collect additional details or information from other sources about our subject matter, thus enriching the value of that data. In addition to parsing and structuring text, we can leverage the power of regular expressions in SAS to enrich data.
So, suppose we are going to do some economic impact analysis of the main SAS campus—located in Cary, NC—on the surrounding communities. In order to do this properly, we need to perform statistical analysis using geospatial information.
The address information is easily acquired from www.sas.com. However, it is useful, if not necessary, to include additional geo-location information such as latitude and longitude for effective analysis and reporting of geospatial statistics. The process of automating this is non-trivial, containing advanced programming steps that are beyond the scope of this book. However, it is important for you to understand that the techniques described in this book lead to just such sophisticated capabilities in the future. To make these techniques more tangible, we will walk through the steps and their results.
1. Start by extracting the address information embedded in Figure 1.2, just as in the data manipulation example, with regular expressions.
Figure 1.2: HTML Address Information
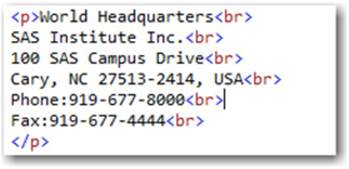
Example Data Set Structure
|
Location |
Address Line 1 |
Address Line 2 |
City |
State |
Zip |
Phone |
Fax |
|
World Headquarters |
SAS Institute Inc. |
100 SAS Campus Drive |
Cary |
NC |
27513-2414 |
919-677-8000 |
919-677-4444 |
2. Submit the address for geocoding via a web service like Google or Yahoo for free processing of the address into latitude and longitude. Type the following string into your browser to obtain the XML output, which is also sampled in Figure 1.3.http://maps.googleapis.com/maps/api/geocode/xml?address=100+SAS+Campus+Drive,+Cary,+NC&sensor=false
Figure 1.3: XML Geocoding Results
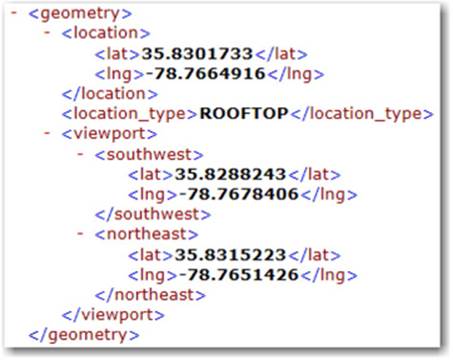
3. Use regular expressions to parse the returned XML files for the desired information—latitude and longitude in our case—and add them to the data set.
Note: We are skipping some of the details as to how our particular set of latitude and longitude points are parsed. The tools needed to perform such work are covered later in the book. This example is provided here primarily to spark your imagination about what is possible with regular expressions.
Example Data Set Structure
|
Location |
… |
Latitude |
Longitude |
|
World |
… |
35.8301733 |
-78.7664916 |
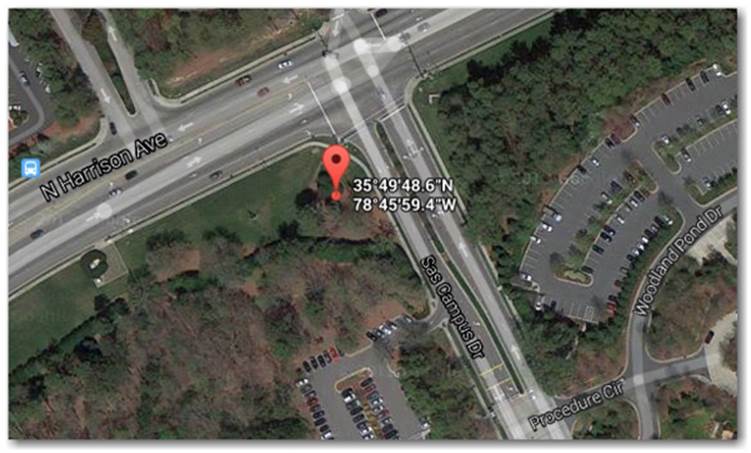
4. Verify your results by performing a reverse lookup of the latitude/longitude pair that we parsed out of the results file using https://maps.google.com/. As you can see in Figure 1.4, the expected result was achieved (SAS Campus Main Entrance in Cary, NC).
Figure 1.4: SAS Campus Using Google Maps
Now that we have an enriched data set that includes latitude and longitude, we can take the next steps for carrying out the economic impact analysis.
Hopefully, the preceding examples have proven motivating, and you are now ready to discover the power of regular expressions with SAS. And remember, the last example was quite advanced—some sophisticated SAS programming capabilities were needed to achieve the result end-to-end. However, the majority of the work leveraged regular expressions.
1 Wikipedia, http://en.wikipedia.org/wiki/Regular_expression#Formal_definition
2 For more information on the version of Perl being used, refer to the artistic license statement on the SAS support site here: http://support.sas.com/rnd/base/datastep/perl_regexp/regexp.compliance.html
3 This example file was obtained from data.gov here: http://www.sec.gov/open/datasets/administrative_proceedings_2009.xml
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.