Introduction to Regular Expressions in SAS (2014)
Chapter 3. Using Regular Expressions in SAS
3.1 Introduction
This chapter is focused on developing your understanding of built-in SAS functions and call routines, and on starting to do some real SAS coding. Here, you will learn the mechanics of how to implement the wonderful RegEx metacharacters introduced in Chapter 2. Each function or call routine introduced has associated examples to ensure that their use is clear. We also briefly discuss how each is useful.
3.1.1 Capture Buffer
Now, before we go any farther, we have to address a concept called the capture buffer. The capture buffer is a more advanced technique that I have avoided delving into thus far, but it must be understood so that you can use some functions (required for PRXPAREN and PRXPOSN, but optional for PRXCHANGE). As you should recall from Chapter 2, parentheses create logical groupings within a RegEx, but they also do something more interesting. For every set of parentheses used in a particular RegEx pattern, a slot in a memory buffer is created. This slot in memory is then referenceable just like any variable (a more experienced programmer can think of it like a pointer buffer). Each slot is created in sequential order of parentheses pair occurrence and is referenced accordingly using the $ sign.
For example, the RegEx s/(The) (cat) (is) (fat)/$4 $3 $1 $2/ creates the output “fat is The cat”. Now, imagine applying that same ability to unknown data elements instead of just to string literals. This could become a very powerful capability for standardizing or restructuring data to meet specific needs.
3.2 Built-in SAS Functions
In this section, we cover the SAS functions for performing RegEx operations. SAS functions for RegEx have the same usage limitations as other built-in functions. (See SAS documentation.) Also just like all other functions, they can only take arguments and return output in assignment statements and expressions.
Note: Each RegEx function has PRX at the beginning, which represents Perl-Regular-eXpressions.
3.2.1 PRXPARSE
Description
This function takes a RegEx pattern as input and provides a numerical RegEx pattern identifier as output. The unique pattern identifier is used by other functions and call routines to reference the pattern. This function should look familiar since we used it in our example code in Chapter 2.
Syntax
RegEx_ID = PRXPARSE (RegEx)
RegEx: The pattern to be parsed (input argument, required)
RegEx_ID: Unique numerical RegEx identifier returned by PRXPARSE (output, required)
Now, it is important to understand at this point that PRXPARSE compiles the RegEx in order to create the identifier for SAS to later reference and use. And this is what makes the RegEx //o option so important when using PRXPARSE in code. The //o option forces SAS to compile the RegEx code once, creating the RegEx identifier the first time only. When a particular RegEx is intended to be reused on every loop through the DATA step, we want to leverage this functionality in order to avoid recompiling the RegEx pattern every time it is encountered in code (i.e., on each iteration of a DATA step). If the pattern is not definitely going to be used every time through the DATA step (e.g., it’s not defined inside an IF statement), then we might not want to waste memory maintaining it. In other words, we might not always want to use the //o option—the decision is about tradeoffs. When you’re dealing with very few of these patterns or with a small amount of data, the tradeoffs don’t really apply. But when we scale up to a system using hundreds of patterns, or tens of millions of records, the tradeoffs (speed at the expense of memory usage) become very important.
Example 3.1: Defining Patterns with PRXPARSE
Let’s revisit the last bit of example code from Chapter 2 since it is already familiar. The RegEx below is defined as /Smith/o, meaning that we are looking for any occurrence of the string literal “Smith” within the data lines provided. This RegEx is the argument for PRXPARSE, which creates a pattern identifier that is assigned to the variable pattern_ID. This variable is then passed to the call routine PRXSUBSTR, which is discussed in the next section. Because you are familiar with the overall function of this code by now, this need not be a distraction.
The output of this RegEx is presented in Output 3.1. As we expected, the code found every occurrence of “Smith” regardless of what was surrounding it—including other letters.
/*RegEx Testing Framework*/
data _NULL_;
pattern = "/Smith/o"; /*<--Edit the pattern here.*/
pattern_ID = PRXPARSE(pattern);
input some_data $50.;
call prxsubstr(pattern_ID, some_data, position, length);
if position ^= 0 then
do;
match = substr(some_data, position, length);
put match:$QUOTE. "found in " some_data:$QUOTE.;
end;
datalines;
Smith, BOB A.
ROBERT Allen Smith
Smithe, Cindy
103 Pennsylvania Ave. NW, Washington, DC 20216
508 First St. NW, Washington, DC 20001
650 1st St NE, Washington, DC 20002
3000 K Street NW, Washington, DC 20007
1560 Wilson Blvd, Arlington, VA 22209
1-800-123-4567
1(800) 789-1234
;
run;
Output 3.1: Log Output of Pattern /Smith/o

3.2.2 PRXMATCH
Description
PRXMATCH returns the numerical position of the first character in the matched RegEx pattern. Additionally, it can be used in IF statements to test for a pattern match without a variable assignment, just like many other familiar SAS functions. The first argument to PRXMATCH is either the RegEx or RegEx_ID. The second is the source text variable or string literal.
Syntax
Position = PRXMATCH(RegEx_ID or RegEx, Source_Text)
RegEx_ID: Unique RegEx identifier returned by PRXPARSE (input argument, required if RegEx not used)
RegEx: The pattern to be matched (input argument, required if RegEx_ID not used)
Source_Text: The text variable or literal to be operated upon (input argument, required)
Position: Numerical position variable assignment (output, required)
As we discussed with the PRXPARSE function, RegEx patterns are compiled by SAS for use by other functions. Therefore, in addition to using the actual RegEx, PRXMATCH is able to leverage the previously compiled RegEx via the RegEx_ID argument in lieu of the RegEx itself. This allows us to compile the RegEx once via the PRXPARSE function (using the //o option), minimizing the associated computing cycles. Such small savings in computing cycles can prove significant when processing large volumes of text.
The two different methods for leveraging RegEx patterns create significant flexibility in how PRXMATCH can be used in practice. By not needing to compile the RegEx in advance, PRXMATCH allows us to embed RegEx patterns throughout our code without the extra memory allocation required to maintain them for each loop through the DATA step. This is very useful when you are using PRXMATCH in a dynamic way, such as inside nested IF statements where the RegEx is used only when certain conditions are true. Depending on the implementation, there are implications for speed as well as for memory usage.
Example 3.2: Finding Strings in Source Text with PRXMATCH
Let’s try a simple example to see how this function is used in practice. Suppose we want to find a string such as “Street” in a source text. The code below demonstrates how we print the position of each occurrence to the log. Obviously, we need to do more than just print the position in practice (such as by extracting or manipulating the matched text), but this demonstrates the basic functionality of PRXMATCH.
The PRXMATCH function is implemented in this code with the RegEx as the first argument and the datalines reference address as the second argument. The result is assigned to the variable Position. The value of Position is then written to the log using the PUT statement.
Count the character positions in the data lines. At what position do we encounter the “S” in “Street” on the lines in which they occur? Comparing the results to Output 3.2, we see that PRXMATCH is returning the position of “S” (i.e., the position for the first character in the pattern match).
data _NULL_;
input address $50.;
position = PRXMATCH('/Street/o', address);
if position ^= 0 then
do;
put position=;
end;
datalines;
103 Pennsylvania Ave NW, Washington, DC 20216
508 First Street NW, Washington, DC 20001
650 1st St NE, Washington, DC 20002
3000 K Street NW, Washington, DC 20007
;
run;
Output 3.2: Log Printout for Positions of “Street”
![]()
3.2.3 PRXCHANGE
Description
This function searches for the pattern—provided in the first argument by either RegEx_ID or RegEx—within the source text that is provided in the third argument. The pattern is matched the number of times given in the second argument, Num_Times. Upon finding each match, the function then returns the changed text as required by the RegEx. If no match is found, PRXCHANGE returns the original text unchanged.
Syntax
Output_String = PRXCHANGE(RegEx_ID or RegEx, Num_Times, Input_String)
RegEx_ID: Unique RegEx identifier returned by PRXPARSE (input argument, required if RegEx not used)
RegEx: The pattern to be matched (input argument, required if RegEx_ID not used)
Num_Times: Number of times the change is to be applied (input argument, required). -1 forces the function to make the changes as many times as the pattern occurs in the source text.
Input_String: Input text variable (input argument, required)
Output_String: Output text variable assignment (output, required)
Just like the PRXMATCH function, PRXCHANGE is able to use the actual RegEx pattern or the RegEx_ID, providing significant flexibility. The preferred use again depends on the desired application.
This function is very useful for data standardization, as you will see in more advanced examples in the next chapter. We will work through two examples below to demonstrate some more basic functionality of the PRXCHANGE function, as well as to demonstrate how to leverage the capture buffer concept introduced earlier.
Example 3.3: Standardizing Data
Data standardization is a relatively simple, yet powerful, capability provided by RegEx in SAS. PRXCHANGE enables us to scrub our data source to ensure that each occurrence of a word or phrase is exactly the same (or removed entirely). See Output 3.3 for the results. Data scrubbing becomes especially important when you are attempting to perform advanced applications such as text mining.
For instance, before doing any analysis of our data, we want to know that each occurrence of the word “street” is exactly the same. If each occurrence were not identical, we might perform a word frequency count on a document with invalid results because “street,” “Street,” “St.,” and so on would all be counted separately. Depending on the eventual use of this information, such problems could prove disastrous.
data _NULL_;
input address $50.;
text = PRXCHANGE('s/\s+([sS]t(reet)?|st\.)\s+/ St. /o',-1,address);
put text;
datalines;
103 Pennsylvania Ave NW, Washington, DC 20216
508 First St NW, Washington, DC 20001
650 1st St NE, Washington, DC 20002
3000 K Street NW, Washington, DC 20007
;
run;
Output 3.3: Log with Updated Data

Note: There are often a number of ways to achieve the same outcome. Understanding the context of an application will help you determine the best RegEx pattern to use.
Example 3.4: Using the Capture Buffer
Revisiting Example 3.3, suppose we now want to also make the addresses available to a system that accepts only comma separated values (CSV) files. This is a great opportunity to use the capture buffer. With only a couple of minor code changes, we can now process the data lines to be CSV ready.
The new line of code uses PRXCHANGE with a more complex RegEx that chunks the address into the street, city, state, and ZIP code components. And we see that the new line takes the previous output variable Text as the input argument, instead of address. Doing this allows us to make changes to the already changed text. If we were to use address, we would merely update the original data lines rather than building on the prior step.
In reviewing the parentheses elements in the new RegEx, we can see how the four address components are identified. On that same line, each of the four elements is placed via the buffer reference, with a comma and space immediately following. Reviewing Output 3.4, we see that the code produces the expected outcome.
data _NULL_;
input address $50.;
text = PRXCHANGE('s/\s+(Street|street|St|st|st\.)\s+/ St. /o',-1,address);
text2 = PRXCHANGE('s/(.+?),*?\s+?(\w+?),*?\s+?(\w+?)\s+?(\d+?)/$1, $2, $3,
$4/o',-1,text);
put text2;
datalines;
103 Pennsylvania Ave NW, Washington, DC 20216
508 First St NW, Washington, DC 20001
650 1st St NE, Washington, DC 20002
3000 K Street NW, Washington, DC 20007
;
run;
Output 3.4: Corrected Data in the Log

So, what else could we do to the text? A number of things remain to be performed in order to make these addresses ready for advanced applications. For instance, “Ave” and “1st” should also be standardized. Building on the example code above is the fastest way to explore the options and become more comfortable with some of these concepts.
3.2.4 PRXPOSN
Description
PRXPOSN returns the matched information from specified capture buffers. This RegEx function requires the RXSUBSTR, PRXMATCH, PRXNEXT, or PRXCHANGE functions to be running before being used so that the capture buffer can be referenced. Also, RegEx_ID is required rather than the actual RegEx. Otherwise, PRXPOSN will not work—necessitating the use of PRXPARSE. The N input argument is numeric and refers to the capture buffer (without $).
Syntax
Text = PRXPOSN(RegEx_ID, N, Source_Text)
RegEx_ID: Unique RegEx identifier returned by PRXPARSE (input argument, required)
N: Integer value of the capture buffer (input argument, required)
Source_Text: The text variable or literal to be operated upon (input argument, required)
Text: Character variable assignment of captured text (output, required)
When we know the exact number of existing capture buffer elements (i.e., N is known), then we can use PRXPOSN without an issue. However, what happens when the number of elements is different from what we expect? If there are values in the capture buffer but we make a reference that is larger than those available (maybe there are three, but we make a reference to number 5), then a missing value is returned. However, if we reference capture buffer position 0 (N=0), then the entire pattern match is returned regardless of the buffer length.
The next function, PRXPAREN, is very helpful in creating robust code when you are using the capture buffers in conjunction with PRXPOSN. It is also important to write robust RegEx patterns to ensure that you prevent issues from popping up.
Example 3.5: Extracting Data with Capture Buffers
In order to make both the capture buffer concept and this new function more clear, we’re going to walk through a concrete example. Suppose we want to process addresses for which the structure is well known and store various pieces in a SAS data set for later use. Since we know the layout of the address, the capture buffer arrangement and the application of PRXPOSN are both very straightforward.
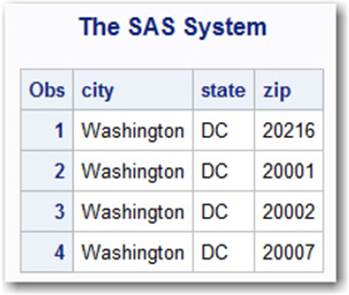
First, we create the RegEx_ID variable Text by using the PRXPARSE function. Then, we perform a logical test using the PRXMATCH function in the IF statement. Notice that this is an implicit test of a match existing (no equal sign is used). If a match of the RegEx exists within the identified text source, then we assign the various capture buffer values to variables by using PRXPOSN (city, state, and zip).
Output 3.5 displays the values of extract, the data set created in our DATA step. As expected, we extracted the city, state, and ZIP code from each datalines entry. Later, we’re going to build on this code to create a more sophisticated address extractor that includes the street information as well as the ability to include 9-digit zips.
data extract;
input address $50.;
text = PRXPARSE('/\s+(\w+),\s+(\w+)\s+(\d+)/o');
if PRXMATCH(text, address) then
do;
city = PRXPOSN(text, 1, address);
state = PRXPOSN(text, 2, address);
zip = PRXPOSN(text, 3, address);
output;
end;
keep city state zip;
datalines;
103 Pennsylvania Ave NW, Washington, DC 20216
508 First St NW, Washington, DC 20001
650 1st St NE, Washington, DC 20002
3000 K Street NW, Washington, DC 20007
3000 K Street NW, Washington, DC, 20007
;
run;
proc print data=extract;
run;
Output 3.5: PROC PRINT Results
3.2.5 PRXPAREN
Description
This function returns the numerical reference value of the largest capture buffer that contains data. It is therefore implicitly required that PRXSUBSTR, PRXMATCH, PRXNEXT, or PRXCHANGE be run prior to this function being used—just like with PRXPOSN. However, the only input argument is the RegEx_ID. Simply providing the RegEx is not an option, so this function must be used in conjunction with the PRXPARSE function.
Syntax
Paren=PRXPAREN(RegEx_ID)
RegEx_ID: Unique RegEx identifier returned by PRXPARSE (input argument, required)
Paren: Numerical reference value of the largest capture buffer (output, required)
Note: Since this function requires a RegEx_ID in lieu of the actual RegEx, it is implied that all precedents are then forced to use RegEx_ID instead of the RegEx as well—otherwise, PRXPAREN cannot be used.
What are we really trying to achieve with this function? Since it provides the length of the capture buffer by telling us the largest buffer position to contain text, we know exactly how many possible buffer values we can access. Because we know this, we can avoid errors when referencing them in code. It is worth noting that effective RegEx coding avoids many potential problems. However, it is always best practice to create fail-safe measures. Additionally, we can use this function to identify which of several options has been triggered inside the source text.
Example 3.6: Identifying Capture Buffers
Ideally, whenever we want to use the PRXPOSN function, the data that we expect to be available in the source is available. However, we know that in reality, that is not always the case. So, we have to write code that can account for a reasonable amount of variability in any data that we might need to process. We are going to explore an advanced example in the next chapter (see Section 4.2) that leverages the basic concepts outlined by this example.
Now, suppose we have a pattern with multiple possible matches embedded in it. How do we know which option allowed the pattern to create a match? In the code below, we see that it is possible to use PRXPAREN to answer this question. We have a simple pattern with three possible matches: “Dog”, “Rat”, and “Cat”. Each is encapsulated by parentheses to create a capture buffer location. However, notice that the entire group is inside yet another set of parentheses. While unnecessary for practical purposes, this was done to demonstrate how capture buffers are numbered. Also note that this is not the most efficient way to write such code. We have sacrificed efficiency here in order to clarify how the buffers work. Notice in our output that “Dog” has a capture buffer of 2 despite being the first item in the OR list. Why? Because the outer set of parentheses is encountered first by SAS, thus creating a capture buffer element at position 1.
If we were to use PRXPOSN under each IF statement with position 1 in our argument list, we would see that each of the three cases below would be provided as output (i.e., when “Dog” is true, “Dog” would be in buffer 1 as well as in buffer 2, and so on). See Output 3.6 for the results.
data _null_;
RegEx_ID=prxparse('/\b((Dog)|(Rat)|(Cat))\b/o');
position=prxmatch(RegEx_ID, 'The Cat in the Hat');
if position then paren=prxparen(RegEx_ID);
put 'I matched capture buffer ' paren;
position=prxmatch(RegEx_ID, 'The Rat in the Hat');
if position then paren=prxparen(RegEx_ID);
put 'I matched capture buffer ' paren;
position=prxmatch(RegEx_ID, 'The Dog on the Roof');
if position then paren=prxparen(RegEx_ID);
put 'I matched capture buffer ' paren;
run;
As I have indicated, our goal here is to identify which particular capture buffer is used. This allows us to build more sophisticated functionality in the future, such as conditional information capture or standardization.
Output 3.6: Log Output

3.3 Built-in SAS Call Routines
In this section, you learn about the PRX call routines available in SAS for performing many of the same RegEx tasks as the functions previously discussed, as well as some new ones. However, just like with all other call routines, PRX call routines cannot be used in expressions or assignment statements. The way they are implemented, and their ultimate functionality, is slightly different when compared to the functions. These differences are explored more thoroughly in the associated examples.
3.3.1 CALL PRXCHANGE
Description
This call routine performs the match-and-replace operation similar to that of the PRXCHANGE function. However, unlike the function version, the call routine must receive a RegEx identifier, without the option of using the associated RegEx instead. Also, there are some additional routine arguments not available in the function (result_length and truncation_value). The only required arguments are: RegEx_ID, Num_Times, and Input_string. All remaining arguments are optional.
Syntax
CALL PRXCHANGE(RegEx_ID, Num_Times, Input_string, Output_string,
result_length, trunc_value, num_changes)
RegEx_ID: Unique RegEx identifier returned by PRXPARSE (input argument, required)
Num_Times: Number of times the change is to be applied (input argument, required)
Input_string: Input text variable (input argument, required)
Output_string: Output text variable (input argument, optional). Default is Input_string.
result_length: Length of the characters put into Output_string (returned value, optional)
Trunc_value: Binary integer (0 or 1 only) value (returned value, optional). 1 means that the inserted text is longer than the text replaced. 0 means that the inserted text is either the same length or shorter than the text being replaced.
num_changes: The number of times the changes were made (returned value, optional)
Using the call routine in lieu of the function can often be cleaner from a coding perspective, especially when managing large programs. But there is a more practical reason for using this call routine instead of the function: accessing the additional functionality provided by the optional arguments. Since we have the ability to write changes directly back to the original variable, we can avoid creating new variables unnecessarily. This is especially useful when applying multiple data standardization filters to source text.
Note: Writing changes back to the existing variable makes them irreversible in the event of a mistake. So, while our ultimate use of this functionality requires the overwriting approach for sound memory management, creating new variables or data sets is ideal when you are still learning. It allows you to experiment and make mistakes without fear of making permanent changes to source data.
Example 3.7: Transforming Data
Let's look at basic usage for making changes to our source text. This is a simple example of how to use the call routine. Notice how compact this makes our code while maintaining functionality. Output 3.7 demonstrates that we have the anticipated functionality (replacing various forms of ”street” with “St.”).
data _NULL_;
input address $50.;
mypattern = PRXPARSE('s/\s+(Street|street|St|st|st\.)\s+/ St. /o');
CALL PRXCHANGE(mypattern,-1,address);
put address;
datalines;
103 Pennsylvania Ave NW, Washington, DC 20216
508 First St NW, Washington, DC 20001
650 1st St NE, Washington DC 20002
3000 K Street NW, Washington, DC 20007
;
run;
Output 3.7: Results in the SAS Log

Now that we’ve looked at a basic implementation of CALL PRXCHANGE, let’s explore the optional arguments.
Example 3.8: Redacting Sensitive Data
In this example, we focus on developing your understanding of the optional elements in CALL PRXCHANGE. As a change of pace, we’re going to develop a basic way to redact sensitive information. This is a frequent need, especially in the medical field, for protecting Personally Identifiable Information (PII)1. Now, we’re not going to eliminate all PII from the provided data because we are just demonstrating the functionality of CALL PRXCHANGE. However, this process is done more rigorously in the next chapter and on a larger scale.
In the code below, we start by creating a data set to pass into the DATA step, called example. This data set contains name, address, and phone number information in various configurations. In the DATA step, we create a RegEx_ID using PRXPARSE, and then use CALL PRXCHANGE to execute the changes prescribed by the RegEx. Notice that one RegEx_ID is commented out. The RegEx in that line behaves very differently from the initial RegEx_ID definition, which allows us to demonstrate the trunc_val and num_changes options. We use this commented RegEx_ID to create Output 3.8.2. After the DATA step, we perform a PROC PRINT to create the output shown in both Output 3.8.1 and Output 3.8.2.
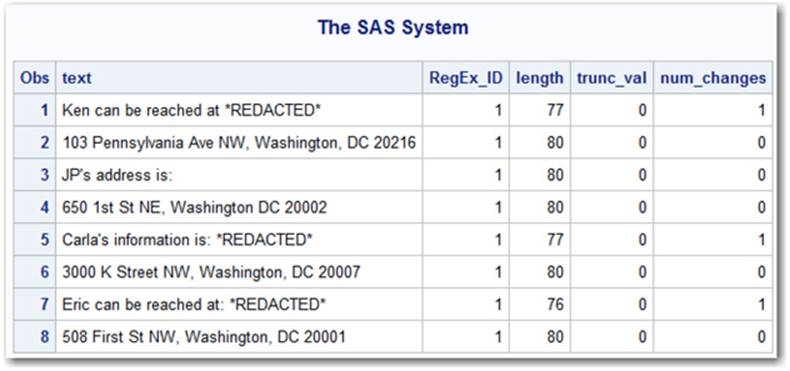
data example;
input text $80.;
datalines;
Ken can be reached at (801)443-9876
103 Pennsylvania Ave NW, Washington, DC 20216
JP's address is:
650 1st St NE, Washington DC 20002
Carla's information is: (910)998-8762
3000 K Street NW, Washington, DC 20007
Eric can be reached at: (321) 456-7890
508 First St NW, Washington, DC 20001
;
run;
data changed;
set example;
*RegEx_ID = PRXPARSE('s/\d+/***NUMBER REMOVED***/o');
RegEx_ID = PRXPARSE('s/\([1-9]\d\d\)\s?[1-9]\d\d-
\d\d\d\d/*REDACTED*/o');
Call PRXCHANGE(RegEx_ID, -1, text, text, length, trunc_val,
num_changes);
put text=;
run;
proc print data=changed;
run;
Simple Insert Results
As we can see in the results below, the phone numbers have been redacted in the original text by using the value *REDACTED*. The rest of the data set shows our optional variable values. Length is the total length of the string written to Text (we just wrote back to the old string this time). trunc_val is 0 for every row because the inserted value is no longer than the original phone numbers. In fact, lines 1, 5, and 7 shrink because the inserted content is shorter. And finally, num_changes records the number of times the phone numbers were redacted on each line (multiple phone numbers per line would have resulted in that number occurring in this column).
Output 3.8.1: SAS PROC PRINT Results
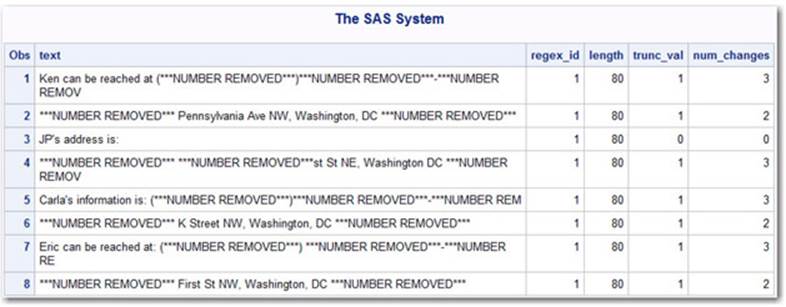
More Advanced Insert Results
The commented RegEx_ID definition creates very different output for Output 3.8.2—a longer replacement value that occurs for every group of numbers (***NUMBER REMOVED*** is inserted). The variables are all the same as in Output 3.8.1, but notice how the values change. For instance, trunc_val now equals 1 every time a redaction occurred, and num_changes is frequently greater than 1. Also, notice something else very important about this output: some lines of text are actually truncated!
Remember, the trunc_val variable being set to 1 does not mean that data loss is certainly going to occur. Instead, it means that it could occur. Think of this as a warning flag telling us, “Hey, keep a look out for a problem.” And a problem is what we would indeed have for some of these lines of text. The insertion of longer text pushes all following text to the right (beyond the 80-character length defined for the variable Text). Now, when there is a significant amount of white space to the right of our text, this doesn’t result in an issue. However, when there is valuable information to the right of our inserted text, we will likely have data loss. Regardless how small the loss of data, the integrity of our entire data set is compromised if we do not design code that avoids this problem. We discuss this concept a bit more in the next chapter.
Output 3.8.2: SAS PROC PRINT Results
3.3.2 CALL PRXPOSN
Description
This call routine takes the RegEx_ID provided by PRXPARSE and the numerical capture buffer position N as inputs. It produces the matching Position and Length as outputs.
Syntax
CALL PRXPOSN(RegEx_ID, N, Position, Length)
RegEx_ID: Unique RegEx identifier returned by PRXPARSE (input argument, required)
N: Integer value of the capture buffer (input argument, required)
Position: Integer value of the character position for the first character in the matched pattern (returned value, required)
Length: Integer value for the length of the matched pattern (returned value, optional)
This call routine takes in the RegEx_ID (RegEx is not allowed!) and capture buffer, and returns the exact locations where it occurs in the most recent match. The match results from PRXMATCH, PRXCHANGE, PRXSUBSTR, or CALL PRXNEXT (discussed in Section 3.3.4) must exist in order for CALL PRXPOSN to work properly. We then must use the SUBSTR function to extract the identified text.
Example 3.9: Context-specific Algorithm Development
Sometimes it’s useful to condition code behavior on specific words occurring in text. In this example, you’ll see how the functionality of CALL PRXPOSN can be used in combination with PRXPAREN, PRXMATCH, PRXPARSE, and SUBSTR to do just that.
First, we create the RegEx_ID by using PRXPARSE, which is then passed to PRXMATCH. If a result from PRXMATCH exists (i.e., a pattern match is found), then we determine which of the capture buffers in the pattern is matched via PRXPAREN. The output of PRXPAREN is used as input to the CALL PRXPOSN routine to create the Position and Length outputs. SUBSTR is then used to extract the specified text. We then print a message, depending on the buffer position. See the results in Output 3.9.
data _null_;
input text $50.;
RegEx_ID=prxparse('/((Dog)|(Rat)|(Cat))/o');
if prxmatch(RegEx_ID, text) then do;
paren=prxparen(RegEx_ID);
CALL PRXPOSN(RegEx_ID, paren, position, length);
buffer = substr(text, position, length);
put 'I matched capture buffer ' paren 'with ' buffer;
end;
if paren=2 then put 'I love dogs!';
else put 'I cannot stand a ' buffer'!';
datalines;
The Cat in the Hat
The Rat in the Hat
The Dog on the Roof
;
run;
Output 3.9: Log Output of Code Behavior
I added the additional commentary about cats, rats, and dogs to show a second way to perform conditioning on the parsed text. Obviously, you could perform more interesting things, and it should be fun to experiment with in the future. We use this concept in the next chapter to build out some interesting functionality.

3.3.3 CALL PRXSUBSTR
Description
This call routine takes RegEx_ID and Source_Text as inputs, and returns Position and Length as outputs. Using the actual RegEx is not an option.
Syntax
CALL PRXSUBSTR(RegEx_ID, Source_Text, Position, Length)
RegEx_ID: Unique RegEx identifier returned by PRXPARSE (input argument, required)
Source_Text: The text to be operated upon (input argument, required)
Position: Integer value of the character position for the first character in the matched pattern (returned value, required)
Length: Integer value for the length of the matched pattern (returned value, optional)
This call routine is used extensively in Information Extraction applications like those discussed in Chapter 4. Since only the position and length of matches are identified by CALL PRXSUBTR, it must be used in conjunction with a function like SUBSTR in order to extract the actual text.
Example 3.10: Information Extraction
In this example, we revisit the now-familiar example code from Chapter 2. It is a great example of how you can leverage the CALL PRXSUBSTR in many applications.
The code below creates a RegEx pattern to search for all occurrences of “Smith” in our source text. It then generates a RegEx_ID using PRXPARSE. The code then uses CALL PRXSUBSTR to search through source text with the provided pattern and return the position and length of matching text. As you know by now, this could have been a much more complex pattern, but the simplicity here helps to highlight the functionality that we are focused on learning. After the call routine, the code checks to see whether the position variable (Position) is 0, which is the default value indicating that it did not find a match. If a position does exist, the code proceeds to use SUBSTR to capture text from the source using the position and length obtained by CALL PRXSUBSTR. Results are then output to the log. See Output 3.10.
data _NULL_;
pattern = "/Smith/o"; /*<--Edit the pattern here.*/
pattern_ID = PRXPARSE(pattern);
input some_data $50.;
CALL PRXSUBSTR(pattern_ID, some_data, position, length);
if position ^= 0 then
do;
match = substr(some_data, position, length);
put match:$QUOTE. "found in " some_data:$QUOTE.;
end;
datalines;
Smith, BOB A.
ROBERT Allen Smith
Smithe, Cindy
103 Pennsylvania Ave. NW, Washington, DC 20216
508 First St. NW, Washington, DC 20001
650 1st St NE, Washington, DC 20002
3000 K Street NW, Washington, DC 20007
1560 Wilson Blvd, Arlington, VA 22209
1-800-123-4567
1(800) 789-1234
;
run;
As we expected, the output shows the various occurrences of “Smith” from within the provided data lines. This example brings us full circle with the above code, pulling all of the pieces together.
Output 3.10: Log Results for “Smith”

3.3.4 CALL PRXNEXT
Description
This routine searches through Source_Text, between the Start and Stop positions, for the pattern associated with RegEx_ID. It returns the Position and Length of the location.
Syntax
CALL PRXNEXT(RegEx_ID, Start, Stop, Source_Text, Position, Length)
RegEx_ID: Unique RegEx identifier returned by PRXPARSE (input argument, required)
Start: Numerical constant, variable, or expression containing the starting character position to begin the search (input argument, required)
Stop: Numerical constant, variable, or expression containing the last character position to use in the search. If the value is -1, the stop position becomes the last non-blank character position in the source. (input argument, required)
Source_Text: The text to be operated upon (input argument, required)
Position: Integer value of the character position for the first character in the matched pattern (returned value, required)
Length: Integer value for the length of the matched pattern (returned value, required)
This call routine can be used for two applications:
1. searching for a pattern within a defined range
2. searching for a pattern iteratively throughout text, including multiple occurrences per line
The first application of CALL PRXNEXT is a straightforward implementation of the routine’s parameters. However, the second usage is less apparent from its definition. Therefore, we focus on that usage of the routine in our example.
Example 3.11: Pattern Matching Multiple Times per Line
Being able to identify a pattern any number of times in a particular line of text is valuable for many practical applications. For example, performing word frequency counts clearly requires this ability in order for accurate counts to be obtained.
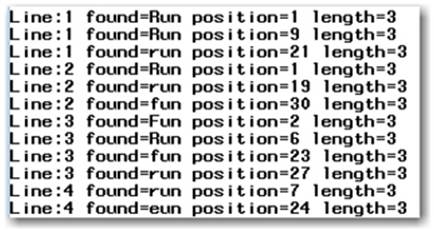
The code below shows how to use CALL PRXNEXT to identify multiple occurrences of our pattern on each row from the data-lines source. The pattern is defined to match on any string that is three word characters (\w) in length and that ends with “un”. The Start and Stop variables are initialized to character positions 1 and Length(some_data) respectively. These variables must be provided with initial values for the routine’s first use. However, subsequent calls automatically reset the start position to the character position immediately following the most recent successful match. This is a fact that we take advantage of with the DO WHILE loop below. If we were to eliminate the loop portion of code, we would merely be searching for the pattern in a defined range (use the above application #1), but having the loop allows us to achieve the desired functionality (use the above application #2). See the results in Output 3.11.
data _NULL_;
input some_data $50.;
pattern = "/\wun/o";
pattern_ID = PRXPARSE(pattern);
start = 1;
stop = length(some_data);
CALL PRXNEXT(pattern_ID, start, stop, some_data, position, length);
do while (position > 0);
found = substr(some_data, position, length);
put "Line:" _N_ found= position= length=;
CALL PRXNEXT(pattern_ID, start, stop, some_data, position, length);
end;
datalines;
Running Runners who run.
Runners who think running is fun.
"Fun Runs" are not-so-fun runs for me.
Let's run at the next reunion.
;
run;
Log Output of Pattern Match Results
Output 3.11 contains the literal string that was found, its position, and its length. As we should expect by now, the pattern that is created ignores the surrounding text—which makes the example slightly more interesting. Review the output (count the character locations in the data lines), and notice that we did indeed achieve the desire results.
Output 3.11: Log Output of Pattern Match Results
3.3.5 CALL PRXDEBUG
Description
This routine is used to perform debugging of all PRX functions and call routines, and accepts only one input.
Syntax
CALL PRXDEBUG (ON-OFF)
ON-OFF: Numerical constant, variable, or expression. If it equals 0, then debugging is turned off, but any positive value turns it on. (input argument, required)
This routine prints step-by-step output to the log, enabling a low-level understanding of any PRX program. However, be prepared—this routine can create voluminous output. It is best to use it in a targeted way at first in order to understand how a specific function or routine is working (or not working). If we were to use this routine for an entire program, we should be ready to read very large amounts of procedural output, which is an inefficient approach to diagnosing issues. It is best to perform gross-level diagnostics using PUT statements and dummy variables, thus narrowing the focus to a specific code segment before using CALL PRXDEBUG. In practice, this is the fastest approach to identifying the source of logical errors.
Example 3.12: Debugging the PRXPARSE Function
In keeping with our goal of using the CALL PRXDEBUG in a targeted way to debug code, we are going to apply it only to the PRXPARSE function in the code below. Notice that we have to turn it on and off at different points in the code in order to identify the segment to which we want our debug output limited. See the results in Output 3.12.
data _null_;
input text $50.;
CALL PRXDEBUG(1);
RegEx_ID=prxparse('/((Dog)|(Rat)|(Cat))/o');
CALL PRXDEBUG(0);
if prxmatch(RegEx_ID, text) then do;
paren=prxparen(RegEx_ID);
CALL PRXPOSN(RegEx_ID, paren, position, length);
buffer = substr(text, position, length);
put 'I matched capture buffer ' paren 'with ' buffer;
end;
if paren=2 then put 'I love dogs!';
else put 'I cannot stand a ' buffer'!';
datalines;
The Cat in the Hat
The Rat in the Hat
The Dog on the Roof
;
run;
Debugging Information Printed to the Log
Reviewing the output in Output 3.12, we see that the debugging information for just a single PRX function can be quite large, thus reinforcing my earlier point about limiting the scope of CALL PRXDEBUG.
The first line denotes compilation of a RegEx within the PRXPARSE function. The next line shows us the compiled RegEx size and starting location for the lines that follow. Specifically, the size of 26 refers to the 26 lines of compiled RegEx code (numbers on the left with a trailing semi-colon), and first refers to the first line of code execution. The numbers in parentheses to the right of each line correspond to labels for the compiled RegEx (these labels work much like our pseudo code labels in Chapter 2).
Lines 1 through 26 are the compiled steps within our RegEx, and they become easy to follow once we understand what each represents. For instance, the various OPEN and CLOSE statements correspond to our opening and closing parentheses; BRANCH corresponds to the OR tests between the inner three parenthesis pairs; and EXACT is for the string literal match of the associated word. END obviously means the end of the subroutine.
The remaining output is just the rest of our code running as normal. Should our code be malfunctioning, we would not likely see such normal output when using CALL PRXDEBUG.
Output 3.12: Debugging Information Printed to the Log
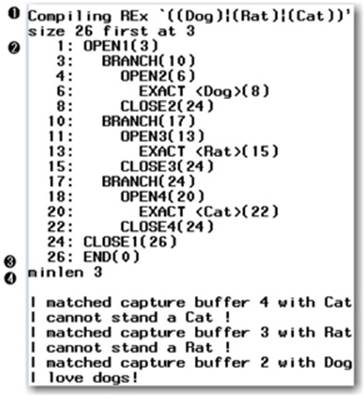
❶ The compilation process begins for the quoted RegEx contained by PRXPARSE.
❷ Notice that each OPEN and CLOSE pair have the same number (OPEN1 and CLOSE1). These numbers correspond to the numerical value of the capture buffer that was formed by that set of parentheses.
❸ Each line ends with a number enclosed in parentheses, denoting the next line to jump to from that line. However, the END tag shows a jump to 0, which takes us out of the subroutine.
❹ The minlen field defines the minimum length for the match to be 3. This information is used by subsequent functions and routines when using this compiled pattern.
Moving the placement of our debug routine call should prove to yield some interesting, and potentially rather long, output. Doing so is the best way to become more familiar with the low-level operations SAS is performing behind the scenes of our PRX code.
Significant amounts of information can be provided by the PRXDEBUG output, but a much deeper study of debug output is outside the scope of this text. For more information about debug output and its meaning, visit the SAS Support website2.
3.3.6 CALL PRXFREE
Description
This call routine releases memory resources associated with a RegEx, using its unique RegEx_ID. Subsequent references to this identifier return a missing value.
Syntax
CALL PRXFREE(RegEx_ID)
RegEx_ID: Unique RegEx identifier returned by PRXPARSE (input argument, required)
This routine is used to free up memory for a specified RegEx_ID and becomes very important for managing the memory of large programs. Remember, there is much more happening behind the scenes of the RegEx_ID construction, despite merely having a numerical identifier. (See CALL PRXDEBUG.) It can’t be stressed enough that memory management can be a significant problem for large programs if not handled properly. Although SAS still handles memory cleanup to avoid memory leaks when a session ends, it is possible to run into memory limitations within a single session. Think very strategically about which RegEx_IDs—or any other variables for that matter—are necessary for each chunk of code.
Example 3.13: Releasing Memory with CALL PRXFREE
In order to demonstrate the functionality of CALL PRXFREE, we are revisiting a new version of the example code for PRXCHANGE. However, instead of printing output as in the original example, we are going to concern ourselves only with the results related to CALL PRXFREE. (See Output 3.13.)
As we can see in the code below, the PUT statement is used to print the values of Street_RXID and AddParse_RXID to the log for each run through the DATA step (creating four writes to the log). However, using the IF statement, we run the CALL PRXFREE routine on the last record to release the memory associated with both RegEx_IDs. Then, we print the results to the log. This creates a fifth write to the log, but the values are missing this time because our routine was successful at releasing the memory allocated for them—making them unrecoverable.
data sample;
input address $50.;
datalines;
103 Pennsylvania Ave NW, Washington, DC 20216
508 First St NW, Washington, DC 20001
650 1st St NE, Washington DC 20002
3000 K Street NW, Washington, DC 20007
;
run;
data _null_;
set sample end=last;
Street_RXID = PRXPARSE('s/\s+?(S|s)\w+?\s+/ St. /o');
AddParse_RXID = PRXPARSE('s/(.+?),*?\s+?(\w+?),*?\s+?(\w+?)\s+?(\d+?)/$1,
$2, $3, $4/o');
text = PRXCHANGE(Street_RXID,-1,address);
text2 = PRXCHANGE(AddParse_RXID,-1,text);
put Street_RXID AddParse_RXID;
if last then do;
CALL PRXFREE(Street_RXID);
CALL PRXFREE(AddParse_RXID);
put Street_RXID AddParse_RXID;
end;
run;
Output 3.13: Log Printout
![]()
The missing values displayed for each of the RegEx_ID variables demonstrate that the CALL PRXFREE routine released all memory associated with both.
3.4 Summary
In this chapter, we have explored the PRX suite of functions and call routines available in SAS for implementing RegEx patterns. They collectively provide tremendous capability, enabling the advanced applications that we begin to explore in the next chapter.
As we have seen throughout the chapter, PRX functions and call routines cannot replace well-written RegEx patterns, despite providing incredible functionality. Attempting to leverage functions and call routines with poorly written RegEx patterns is like trying to drive a sports car with no fuel.
Also, while the PRX functions and call routines represent flexible, powerful capabilities to be leveraged for a wide variety of applications—basic and advanced—they often cannot stand alone. It is important to leverage them in conjunction with other elements of SAS to develop robust code; a fact that we have merely had a glimpse of in this chapter. For instance, some very advanced RegEx applications benefit from the use of MACRO programming techniques (beyond the anticipated skill level of this book).
Now, at this point, we are done. You have all the basic tools in place to make truly useful, robust SAS programs that leverage regular expressions. However, as promised from the outset, we are going to really pull everything together via a series of advanced, case-study-style examples in the next chapter.
1 National Institutes of Standards and Technology (NIST) special publication 800-122, April 2010, Guide to Protecting the Confidentiality of Personally Identifiable Information (PII), http://csrc.nist.gov/publications/nistpubs/800-122/sp800-122.pdf
2 SAS Support, debug information: https://support.sas.com/rnd/base/datastep/perl_regexp/regexp.debug.html
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.