Introduction to Regular Expressions in SAS (2014)
Chapter 4. Applications of Regular Expressions in SAS
4.1 Introduction
In this chapter, we explore some real-world applications of RegEx with SAS, demonstrating a wide variety of scenarios in which we can implement what you have learned thus far. The general categories that these examples have been placed under do not to imply that we are limited in what we can do (see Chapter 1), nor do they imply a lack of overlap between some of the examples.
Now, in order to execute some of the applications to follow, we need a good source of addresses, phone numbers, names, birthdates, and Social Security numbers. Obviously, these sources are hard to come by for experimentation (that is a lot of personal information!). Therefore, for the sake of practice, I created some code to randomly generate these more sensitive data items. The code for these random Personally Identifiable Information (PII) elements is presented below and is not repeated for the applicable applications. Access to real data sources is always preferable when developing robust code, but the following random generator does a fair job of inserting some commonly occurring variability into these elements. Feel free to experiment with it to obtain a different number of records or greater variability.
While all of the examples in this chapter are realistic, there is still room for improvement. However, we can do only so much in this book. So, at the end of each section, I assign you some homework—suggested assignments for how to improve the code already provided. These items should prove especially interesting for the advanced programmers among us.
4.1.1 Random PII Generator
The following code was developed to provide a set number of randomly generated elements for the purposes of the following examples. This process is an effort to replicate the kind of data we all see on a regular basis, PII, without encountering the usual privacy issues associated with it. As we will see in the code, every effort was made to make these elements feel real. However, it is worth noting that more advanced techniques (and more efficient techniques) were not employed because of the introductory nature of this text. If you’re interested, use this code as a baseline to develop a more sophisticated and efficient random PII generator. Doing so is a great way to support both learning and real-world development work.
Note: All occurrences of PII shown in the coming pages were generated in a random fashion. Any resemblance to actual PII is completely coincidental.
A static snapshot of randomly generated data is used below, and it is not guaranteed to be replicated. But the parameters for any data set created by this code will be the same for any data set. Also, the code uses a few different methods for creating the various data elements. I want to demonstrate the variety of methods available to us for doing any task in SAS.
Much of this code is unavoidably long due to the steps taken to create names, addresses, and other information. Unlike the example code in the previous chapter, all code going forward is more heavily commented and diagrammed to ensure that you fully understand every element.
/*First, we create datasets for First and Last names*/
data FirstNames; ❶
input Firstname $20.;
/*Common First Names (male and female) in the United States*/
datalines;
JAMES
JOHN
ROBERT
MICHAEL
WILLIAM
DAVID
RICHARD
CHARLES
JOSEPH
THOMAS
CHRISTOPHER
DANIEL
PAUL
MARK
DONALD
GEORGE
KENNETH
STEVEN
EDWARD
BRIAN
RONALD
ANTHONY
KEVIN
JASON
MATTHEW
MARY
PATRICIA
LINDA
BARBARA
ELIZABETH
JENNIFER
MARIA
SUSAN
MARGARET
DOROTHY
LISA
NANCY
KAREN
BETTY
HELEN
SANDRA
DONNA
CAROL
RUTH
SHARON
MICHELLE
LAURA
SARAH
KIMBERLY
DEBORAH
;
run;
data surnames;
input Surname $20.;
/*Common Last Names in the United States*/
datalines;
SMITH
JOHNSON
WILLIAMS
JONES
BROWN
DAVIS
MILLER
WILSON
MOORE
TAYLOR
ANDERSON
THOMAS
JACKSON
WHITE
HARRIS
MARTIN
THOMPSON
GARCIA
MARTINEZ
ROBINSON
CLARK
RODRIGUEZ
LEWIS
LEE
WALKER
;
run;
/*Next, we take a simple random sample of a fixed number of names*/
proc surveyselect data=firstnames method=srs n=25 ❷
out=firstnamesSRS;
run;
proc surveyselect data=surnames method=srs n=25
out=surnamesSRS;
run;
/*We must create an index value to perform match-merge on later*/
data firstnamesSRS;
set firstnamesSRS;
Num=_N_;
run;
data surnamesSRS;
set surnamesSRS;
Num=_N_;
run;
data PII_Numbers;
n = 25; /*Determines the number of records we will create.*/
/*Arrays used for random day creation below*/❸
array x x1-x12 (1:12);
array d d1-d28 (1:28);
array a a1-a30 (1:30);
array y y1-y31 (1:31);
array z z1-z20 (1974:1994);
seed=1234567890123; /*Random Number Seed Value*/
do i= 1 to n; /*Master Loop for PhoneNumber, Date of Birth, and SSN*/
Num=i; /*Num is used as a unique index value for dataset merging
later*/
/*First, we randomly create the number segments*/❹
CountryCode = Strip(INT(10*rand('UNIFORM')));
AreaCode = Compress(INT(10*rand('UNIFORM'))||INT(10*rand('UNIFORM'))||INT(10*rand('UNIFORM')));
NextThree = Compress(INT(10*rand('UNIFORM'))||INT(10*rand('UNIFORM'))||INT(10*rand('UNIFORM')));
LastFour = Compress(INT(10*rand('UNIFORM'))||INT(10*rand('UNIFORM'))||INT(10*rand('UNIFORM'))||INT(10*rand('UNIFORM')));
/*Next, we randomly create common separator types*/
separator = rand('UNIFORM'); ❺
if separator >= .66 then do;
PhoneNumber = Compress(CountryCode||'-'||AreaCode||'-'||NextThree||'-'||LastFour);
end;
else if separator >=.33 AND separator <.66 then do;
PhoneNumber = Compress(CountryCode||' '||'('||AreaCode||')'||NextThree||'-'||LastFour);
end;
else if separator <.33 then do;
PhoneNumber = Compress('+'||CountryCode||'.'||AreaCode||'.'||NextThree||'.'||LastFour);
end;
/*Social Security Number*/ ❻
SSN=Compress(INT(10*rand('UNIFORM'))||INT(10*rand('UNIFORM'))||INT(10*rand('UNIFORM'))||'-'||
INT(10*rand('UNIFORM'))||INT(10*rand('UNIFORM'))||'-'||
INT(10*rand('UNIFORM'))||INT(10*rand('UNIFORM'))||INT(10*rand('UNIFORM'))||INT(10*rand('UNIFORM')));
/*Date Of Birth*/
call ranperk(seed, 1, of x1-x12); ❼
month=x1;
if x1=2 then do;
call ranperk(seed, 1, of d1-d28);
day=d1;
end;
else if x1 in (4,6,9,11) then do;
call ranperk(seed, 1, of a1-a30);
day=a1;
end;
else if (x1=1|x1=3|x1=5|x1=7|x1=8|x1=10|x1=12) then do;
call ranperk(seed, 1, of y1-y31);
day=y1;
end;
call ranperk(seed, 1, of z1-z20);
year=z1;
DOB=compress(month||'/'||day||'/'||year);
output; /*OUTPUT must be made explicit within a DO LOOP*/
end; /*The DATA step only runs once because there is no data.*/
keep Num SSN DOB PhoneNumber; /*The only elements we need for the next step*/
run;
/*Now we extract the addresses from a file using RegEx*/
data Addresses;
infile 'F:\Introduction to Regular Expressions with
SAS\Chapter_4_Example_Source\addresses.txt' length=linelen lrecl=500 pad;
varlen=linelen-0;
input source_text $varying500. varlen; ❽
pattern = "/^(\d+?)\t(.+)/o";
pattern_ID = prxparse(pattern);
position = PRXMATCH(pattern_ID, source_text);
if PRXMATCH(pattern_ID, source_text) then do;
Num = PRXPOSN(pattern_ID, 1, source_text) * 1;
Address = PRXPOSN(pattern_ID, 2, source_text);
end;
keep Num Address;
run;
proc print data=addresses;
run;
/*Now, we create the PII dataset with match-merge*/ ❾
data PII;
merge firstnamesSRS surnamesSRS PII_Numbers addresses;
by num;
drop num;
run;
proc print data=PII;
run;
❶ We start with an easy way to create pseudo random names, by just creating name data sets using data lines. It is not elegant or short, but it gets the job done for our purposes.
❷ Here we are sampling the name data sets, using simple random sampling and a sample size of n=25. The sample size is completely arbitrary and chosen to match the number of other random values created later in the code.
❸ The arrays are created to ensure that legitimate date values can be created for our arbitrary range of years. To avoid any complications, we are ignoring leap years (no Feb 29th in the set of possibilities) and are using an arbitrary set of 4-digit years. The seed value is an arbitrary number.
❹ Now, we construct the phone number by using the RAND function (UNIFORM option) to generate the individual digits. The INT function takes the integer portion of a value, so multiplying the random value between 0 and 1 by 10 and applying the INT function yields a single digit between 0 and 9. This method ensures that zero values are not dropped (a leading zero would otherwise not be held). Other methods can achieve the same outcome, but this is a straightforward implementation without the need for arrays. The COMPRESS function is used to remove all spaces between the connected values. However, removing this function is an easy way to make the data messier.
❺ After creating the individual chunks of a phone number, we randomly assign different separator types in an effort to demonstrate the various representations that might be expected in practice.
❻ Next, we create Social Security numbers (SSNs) by applying the same techniques as with the phone numbers immediately above. However, we are not randomizing the separator. It is less often an issue, but you could do it as an extracurricular exercise.
❼ We now build the date of birth (DOB) using the arrays discussed in ❸ and the RANPERK function. This function creates random permutations of the provided arrays and provides k values from the results. Other methods could have been employed, but this is a simple approach to create random date elements within a specific range (i.e., valid dates).
❽ The DATA step for addresses uses some familiar RegEx functionality to extract addresses from a text file, along with the Num value that allows us to perform a match-merge in the next step.
❾ This final DATA step creates a single data set, PII, from the above elements.
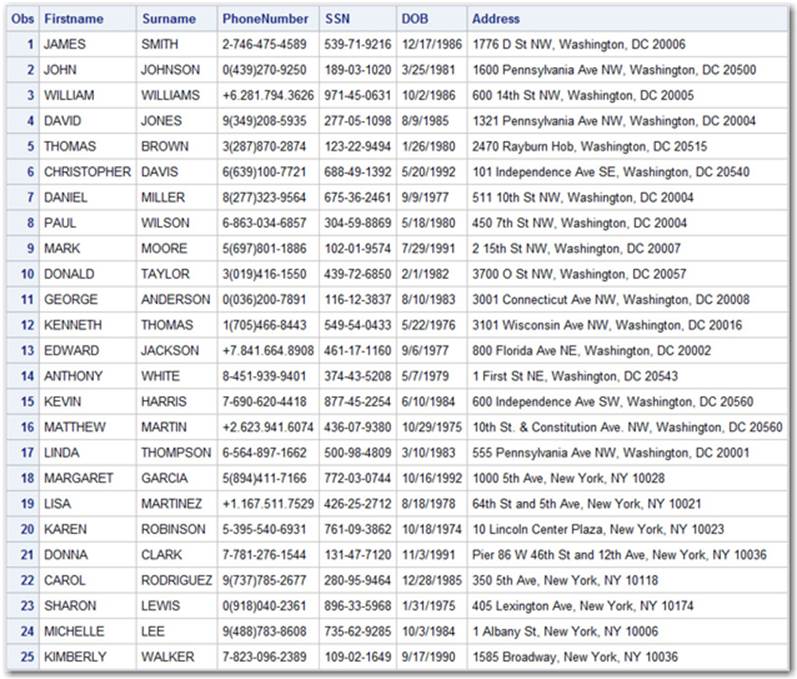
Output 4.1 displays the final data set created by our code, Rand_PII_Generator.sas. As expected, it contains 25 pseudo-random PII elements to support some of our upcoming examples.
Output 4.1: Rand_PII_Generator.sas Sample Output
4.2 Data Cleansing and Standardization
As data sets go, the randomly generated data set that we are going to work with is fairly clean. The simple fact is we can’t explore all of the ways that data can be dirty in the real world (this book would never end!). However, using some realistic data, we can test our ability to develop RegEx code to process and clean some common problems in such data sources. This exercise will prepare you to go out in the real world and tackle virtually anything you encounter because you will have all the necessary tools in your toolbox.
So, let’s start by reviewing the data elements we need in order to clean and standardize, and what things we need to check for in such sources.
Firstname
The person’s first name. This piece of data should contain character values only.
Surname
The person’s last name. This piece of data should contain character values only.
PhoneNumber
The person’s phone number. Phone numbers in different countries are written very differently, so we must be prepared to properly parse a variety of formats—especially since it is so easy for a business contact to be from or located in a different country.
SSN
The person’s Social Security number. We should see only segments of numbers separated by dashes or spaces, and we need to enforce this formatting.
DOB
The person’s date of birth. This can be represented in a few ways, but we primarily see the classic 8-digit format in the US. European dates represent the day before the month. This is where context is very important, because it is difficult to detect this format unless the obvious value thresholds are crossed.
Address
The person’s address. This data has the most natural variability and is the most interesting to parse. We primarily need to be concerned with abbreviations, punctuation, and ZIP code lengths.
Now, as I hinted at in the last chapter, data cleansing and standardization is accomplished by creating what amount to filters. These filters are a series of RegEx functions and routines applied in succession so as to yield incremental changes as each one is applied. Implemented in the correct order, we can clean up some very messy data for later use. Fortunately for us, the data set created by the PII generator is relatively tame. But only a few things need to change in order for it to become scary data. Regardless, there are a few things that we must fix in order to make use of the entire data set in its current state. For example, when we look at observation 16 from the data set (Output 4.2), we see a few issues with the address.
Output 4.2: PII Observation 16
![]()
In addition to having decimals immediately following the abbreviations for street and avenue, we see that the & symbol is used. Both these issues will become problematic when we attempt to parse the address into street, city, state, and zip.
Developing what needs to be fixed in any data set often can’t be done blindly. There are basic things that we can apply to any data source, such as trimming excess spaces, and so on. However, it is advisable to pull samples of data in order to understand its quality issues before you develop RegEx patterns for cleaning.
In the code below, I created a series of cleansing and standardization steps using PRXPARSE, PRXMATCH, CALL PRXCHANGE, and PRXPOSN. Notice how clean our code is by using CALL PRXCHANGE in lieu of the function version.
data CleanPII;
set PII;
ChangeAND = PRXPARSE('s/\x26/and/o'); ❶
ChangeSTR = PRXPARSE('s/\s(St\.|St)/ Street/o');
ChangeAVE = PRXPARSE('s/\s(Ave\.|Ave)/ Avenue/o');
ChangeRD = PRXPARSE('s/\s(Rd\.|Rd)/ Road/o');
ChangeDASH = PRXPARSE('s/\s*(\.|\(|\))\s*/-/o');
ChangePLUS = PRXPARSE('s/\+//o');
ChangeSPAC = PRXPARSE('s/ //o');
/*Cleaning Address*/ ❷
CALL PRXCHANGE(ChangeAND,-1,address);
CALL PRXCHANGE(ChangeSTR,-1,address);
CALL PRXCHANGE(ChangeAVE,-1,address);
CALL PRXCHANGE(ChangeRD ,-1,address);
/*Cleaning Phone Number*/
CALL PRXCHANGE(ChangeDASH,-1,PhoneNumber);
CALL PRXCHANGE(ChangePLUS,-1,PhoneNumber);
CALL PRXCHANGE(ChangeSPAC,-1,PhoneNumber);
/*Cleaning SSN*/
CALL PRXCHANGE(ChangeDASH,-1,SSN);
CALL PRXCHANGE(ChangeSPAC,-1,SSN);
/*Cleaning DOB*/
CALL PRXCHANGE(ChangeSPAC,-1,DOB);
drop ChangeAND ChangeSTR ChangeAVE ChangeRD ChangeDASH ChangePLUS
ChangeSPAC;
run;
data FinalPII;
set CleanPII;
/*Parsing the address into its discrete parts*/
Addr_Pattern = PRXPARSE('/^(\w+(\s\w+)*\s\w+),\s+(\w+\s*\w+),\s+(\w+)\s+((\d{5}\s*?-\s*?\d{4})|\d{5})/o');
if PRXMATCH(Addr_Pattern, address) then ❸
do;
Street = PRXPOSN(Addr_Pattern, 1, address);
City = PRXPOSN(Addr_Pattern, 3, address);
State = PRXPOSN(Addr_Pattern, 4, address);
Zip = PRXPOSN(Addr_Pattern, 5, address);
end;
drop Addr_Pattern address;
run;
proc print data=finalpii;
run;
❶ First, we create a series of replacement RegEx pattern identifiers using PRXPARSE. We maintain the “change” naming convention to denote that each identifier represents a RegEx pattern for changing the source.
❷ Here we apply specific RegEx_ID’s by using the CALL PRXCHANGE routine to clean each of the variables in different ways.
❸ Finally, we parse the original address data field into its constituent parts: street, city, state, and zip. The PRXPOSN function grabs each piece of the address by identifying the associated capture buffer. Notice that we have to skip buffer location 2 because the second bracket set is used for logical separation inside the first bracket set (which creates buffer location 1). Referencing buffer location 2 would provide only a subset of the street information we need.
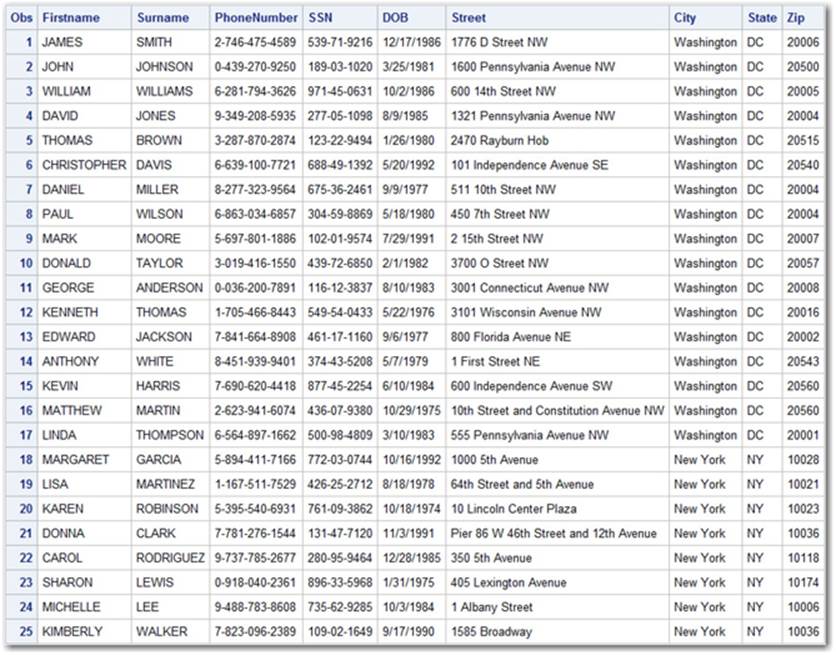
As we can see in Output 4.3, our resulting data set now has clean, standardized data in each field. Such data makes future analysis and manipulation much easier and more accurate. This exercise should serve as a nice warm-up for many other such applications.
Output 4.3: Cleaned and Standardized PII Data Set
Homework
1. Include more standard abbreviations than the few we currently have (e.g., Parkway, Court, and so on).
2. Standardize two-digit years in the date field.
3. Create a method of handling state abbreviations with decimals.
4. Use CALL PRXFREE to clean up the RegEx_IDs used in the code.
5. Enhance the data set with a Census tract lookup using the address fields.
6. Enhance the RegEx to handle multiple spaces between words, spaces before commas, and punctuation in unexpected places.
4.3 Information Extraction
Parsing large volumes of text to generate structured data sets is a common, valuable use of RegEx capabilities. For example, we might want to collect information from a technology blog or website that contains valuable customer feedback about our product. Such information could not easily or cheaply be gathered by hand for the sake of further analysis. Due to the wide variety of possible sources from which we might need to extract information, as well as the wide array of end goals for the information, there are a number of approaches to accomplishing this task. Given the proliferation of tag-based languages such as HTML and XML, we need to be prepared to effectively extract information from them.
Now, due to the semi-structured nature of tag-based languages, they are certainly easier to process than one might anticipate. All such languages have paired opening and closing tags for defining various pieces of information. We can leverage this fact to properly dissect them and extract the information we need.
With more sophisticated techniques at our disposal (like using the SAS macro facility), we could actually “learn” the embedded data elements and extract the data associated with the discovered variables. However, emphasis on these techniques is beyond the scope of this book. Therefore, we need to know the various tags that we are looking for in the XML or HTML source in advance. We will use this approach to process the XML file in our example.
Going back to the SEC administrative proceedings example from Chapter 1, let’s parse and extract the information from the associated sample file1.
Figure 4.1: SEC XML Sample
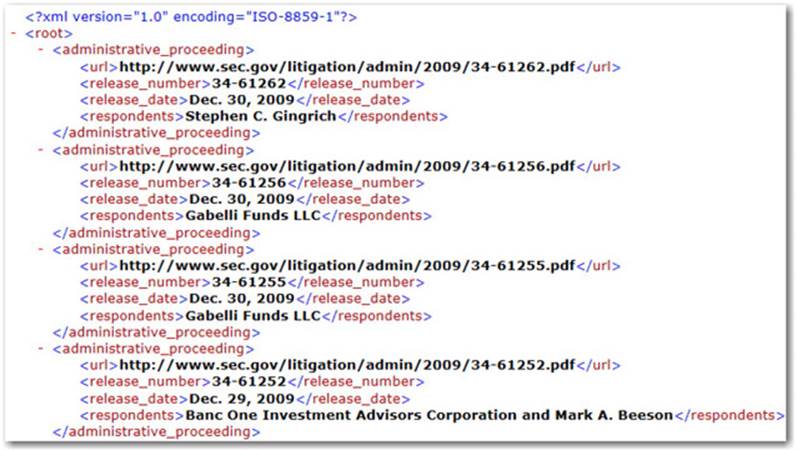
The primary concern is to effectively extract information from within the known XML tags that contain data, namely: url, release_number, release_date, and respondents. As you can see in the figure above, there are some other XML tags in the document, but they aren’t relevant to the task at hand. For instance, root and administrative_proceeding don’t contain data independent of the previously mentioned tags. They merely serve administrative functions in the context of XML for properly organizing the information for consumption by a system that reads XML directly.
data SECFilings;
infile 'F:\Introduction to Regular Expressions with SAS\Chapter_4_Example_Source\administrative_proceedings_2009.xml'
length=linelen lrecl=500 pad;
varlen=linelen-0;
input source_text $varying500. varlen; ❶
format ReleaseNumber $20. ReleaseDate $20. Respondents $500. URL $500.;
start = 1;
stop = varlen;
Pattern_ID = PRXPARSE('/\<(\w+)\>(.+?)\<\/(\w+)\>/o'); ❷
CALL PRXNEXT(pattern_ID, start, stop, source_text, position, length); ❸
DO WHILE (position > 0);
tag = PRXPOSN(pattern_ID,1,source_text);
if tag='url' then URL = PRXPOSN(pattern_ID,2,source_text);
else if tag='release_number' then ReleaseNumber =
PRXPOSN(pattern_ID,2,source_text);
else if tag='release_date' then ReleaseDate =
PRXPOSN(pattern_ID,2,source_text);
else if tag='respondents' then do;
Respondents = PRXPOSN(pattern_ID,2,source_text); ❹
put releasenumber releasedate respondents url;
output;
end;
retain URL ReleaseNumber ReleaseDate Respondents; ❺
CALL PRXNEXT(pattern_ID, start, stop, source_text, position,
length);
end;
keep ReleaseNumber ReleaseDate Respondents URL;
run;
proc print data=secfilings;
run;
❶ We begin by bringing data in from our XML file source via the INFILE statement, using the length, LRECL, and pad options. (See the SAS documentation for additional information about these options.) Next, using the INPUT statement, the data at positions 1-varlen in the Program Data Vector (PDV) are assigned to source_text. Because we set LRECL=500, we cannot capture more than 500 bytes at one time, but we can capture less. For this reason, we use the format $varying500.
❷ Using the PRXPARSE function, we create a RegEx pattern identifier, Pattern_ID. This RegEx matches on a pattern that starts with an opening XML tag, contains any number and variety of characters in the middle, and ends with a closing XML tag.
❸ Just like our example in Chapter 3, we make an initial call the CALL PRXNEXT routine to set the initial values of our outputs prior to the DO WHILE loop.
❹ Since we are trying to build a single record to contain all four data elements, we have to condition the OUTPUT statement on the last one of these elements that occurs in the XML—which happens to be respondents.
❺ The RETAIN statement must be used in order to keep all of the variable values between each occurrence of the OUTPUT statement. Otherwise, the DO loop will dump their values between each iteration.
Output 4.4: Sample of Extracted Data
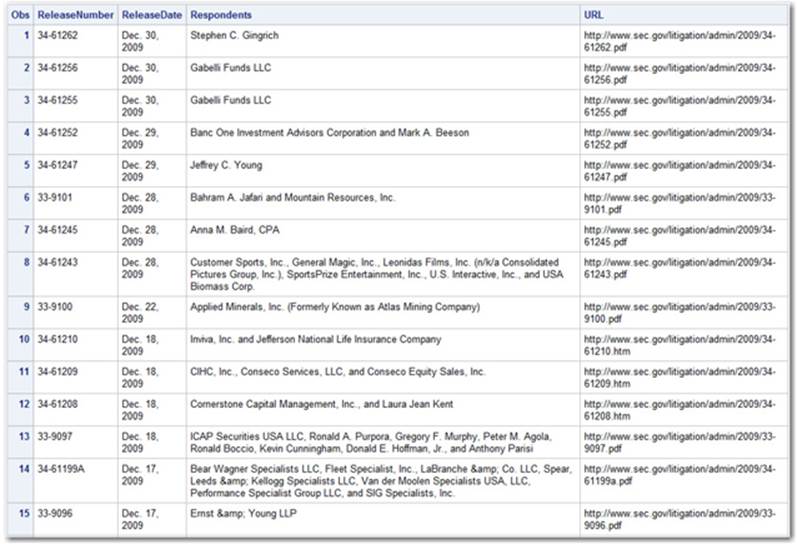
As we can see in Output 4.4, the code effectively captured the four elements out of our XML source. This approach is generalizable to many other hierarchical file types such as HTML and should be interesting to explore.
Homework
1. Rearrange the ReleaseDate field to look like a different standard SAS date format.
2. Create a variable named Count that provides the number of Respondents on each row. This will be both fun and tricky.
3. Enhance the current RegEx pattern to force a match of a closing tag with the same name. There are two occurrences in the existing output where a formatting tag called SUB is embedded in the Respondents field. Our existing code stops on the closing tag for SUB instead of on the closing tag for respondents. The fix for this is not difficult, but requires more code than you might anticipate.
4.4 Search and Replacement
The specific needs for search and replace functionality can vary greatly, but nowhere is this capability more necessary than for PII redaction. Redacting PII is a frequent concern in the public sector, where information sharing between government agencies or periodic public information release is often mandated. We revisit the data from our cleansing and standardization example here since it includes the kinds of information we would likely want to redact. However, in an effort to make this more realistic, the example data set that we used in Section 4.2 has been exported to a text file. We want to know how to perform this task on any data source, from the highly structured to the completely unstructured. We have already worked with structured data sources for this technique, so exploring unstructured data sources is a natural next step.
Now, before we get into how to perform the redaction, it is worth showing how the TXT file was created. Despite knowing how it is created in advance, we want to behave as though we have no knowledge of its construction in order to ensure that we are creating reasonably robust code.
You can see in the code snippet below that we simply take the resulting data set from Section 4.2 , FinalPII, as input via the SET statement. Next, we use the FILE statement to create the TXT file reference. Once the FILE statement is used, the following PUT statement automatically writes the identified variables to it.
data _NULL_;
set finalpii;
file 'F:\Introduction to Regular Expressions with SAS\Chapter_4_Example_Source\FinallPII_Output.txt';
put surname firstname ssn dob phonenumber street city state zip;
run;
Output 4.5 shows the output provided by this code. As we can see, the structure is largely removed, though not entirely gone. This allows us to more closely approximate what you might encounter in the real world (which could be PII stored in a Microsoft Word file).
Output 4.5: PII Raw Text
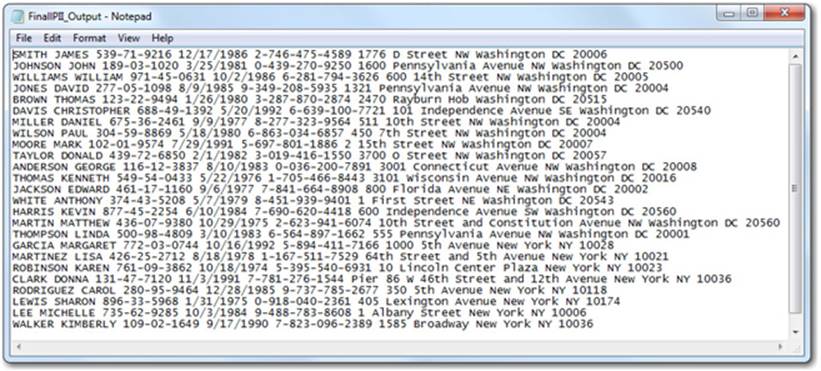
Now that we have an unstructured data source to work with, we can create the code to redact all sensitive data elements. The challenge of doing this effectively is that we can’t depend on the structure of surrounding text to inform the redaction decisions of our code. For this reason, it is important that our code takes great care to ensure that we properly detect the individual elements before redacting them.
Below is the code that performs our redaction of the PII elements SSN, DOB, PhoneNumber, Street, City, and Zip. Now, many organizations are allowed to publish small amounts of information that individuals authorize in advance, such as city or phone number. However, we’re focusing on how to redact all of them, because keeping a select few is easy. In addition to performing the redaction steps, we also output the redacted text to a new TXT file. Again, this is an effort to support a realistic use of these techniques. For instance, many organizations keep donor or member information in text files that are updated by administrative staff. There are valid reasons for sharing portions of that information either internally or with select external entities, but doing so must be undertaken with great care. Thus, it is useful for such files to be automatically scrubbed prior to being given a final review and then shared with others.
Note: While the following code is more realistic than what we developed in Chapter 3, it still needs to be improved for robust, real-world applications. The homework for this chapter has some suggestions, but there is always room for additional refinement.
data _NULL_;
infile 'F:\Introduction to Regular Expressions with SAS\Chapter_4_Example_Source\FinallPII_Output.txt' length=linelen
lrecl=500 pad;
varlen=linelen-0;
input source_text $varying500. varlen;
Redact_SSN = PRXPARSE('s/\d{3}\s*-\s*\d{2}\s*-\s*\d{4}/REDACTED/o'); ❶
Redact_Phone = PRXPARSE('s/(\d\s*-)?\s*\d{3}\s*-\s*\d{3}\s*-
\s*\d{4}/REDACTED/o');
Redact_DOB = PRXPARSE('s/\d{1,2}\s*\/\s*\d{1,2}\s*\/\s*\d{4}/REDACTED/o');
Redact_Addr =
PRXPARSE('s/\s+(\w+(\s\w+)*\s\w+)\s+(\w+\s*\w+)\s+(\w+)\s+((\d{5}\s*?-
\s*?\d{4})|\d{5})/ REDACTED, $4 REDACTED/o');
CALL PRXCHANGE(Redact_Addr,-1,source_text); ❷
CALL PRXCHANGE(Redact_SSN,-1,source_text);
CALL PRXCHANGE(Redact_Phone,-1,source_text);
CALL PRXCHANGE(Redact_DOB,-1,source_text);
file 'F:\Introduction to Regular Expressions with SAS\Chapter_4_Example_Source\RedactedPII_Output.txt';
put source_text; ❸
run;
❶ We create four different RegEx_ID’s associated with the different PII elements that we want to redact from our source file—SSN, PhoneNumber, DOB, Street, City, and Zip.
❷ We use the CALL PRXCHANGE routine to apply the four different redaction patterns in sequence.
❸ Using the FILE statement, we create an output TXT file for writing our resulting text changes to. Since we overwrote the original text using the CALL PRXCHANGE routine (i.e., changes were inserted back into source_text), we need to output only the original variable, source_text, with the PUT statement.
Figure 4.2: Redacted PII Data
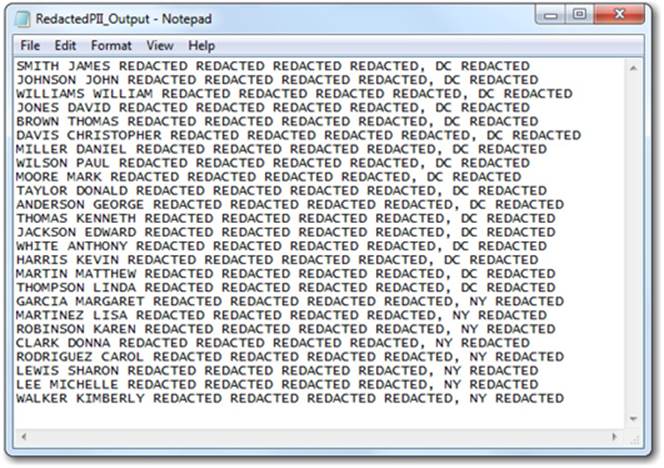
As we can see in the resulting file of redacted output (Figure 4.2), only the individual’s name and state are left. The redacting clearly worked, but in this context the resulting information might not be the most readable. How can we achieve the same goal while making the output easier to read? It’s simple. Instead of inserting REDACTED we can insert “” (i.e., nothing), which effectively deletes the text. Try it out and see what happens.
Homework
1. Update the RegEx patterns to allow City to be shown (tricky with two-word names like New York).
2. Incorporate the results of Section 4.2 , Homework item 5 so that the Census tract can be displayed.
3. Use the random PII generator in Section 4.1 to incorporate an entirely new field to then display this output in.
4. Make this code more robust by incorporating zero-width metacharacter concepts such as word boundaries (\b) to ensure that word edges are identified properly.
4.5 Summary
In this chapter, we finally put it all together with a series of examples that touch on multiple ways regular expressions can be used in SAS. Hopefully, they were each motivating, educational, and useful—and actually helped the prior chapters all make more sense.
We worked through three long-form examples—“Data Cleansing and Standardization”, “Information Extraction”, and “Search and Replacement”—that address commonly needed capabilities that should be generalizable to many contexts. These include, but are not limited to: law enforcement, retail, E-commerce, healthcare, finance, and defense.
At this point, you have all the tools and experience that you need in order to apply this information to highly complex problems in the real world. But before you do, here are some reminders.
4.5.1 Start Small
It can’t be overstated how beneficial it is to start with a simple task and build from there. By implementing RegEx capabilities on merely a small segment of a much larger problem, you are able to more carefully build each element—ultimately ensuring more rapid progress on the overall problem with less rework. This approach also enables the beginner to develop capabilities without becoming overwhelmed, which is always important for maintaining momentum on development projects.
4.5.2 Think Big
Though you might be solving a small portion of a larger problem, you always have to think about the big picture. Always take the time to understand the context surrounding any development effort; the secondary and tertiary effects of your work can never be fully anticipated. Also, thinking about the various aspects of any project can help you to anticipate the needs of your RegEx patterns.
1 The file was downloaded manually from the SEC website, in XML format. The original website source can be found here: http://www.sec.gov/litigation/admin/adminarchive/adminarc2009.shtml
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.