Test Scoring and Analysis Using SAS (2014)
Chapter 11. A Collection of Test Scoring, Item Analysis, and Related Programs
Introduction
This chapter contains programs (in the form of SAS macros) that perform most of the useful, test-related tasks described in this book. You can find explanations of how these programs work in the relevant chapters of this book. You will find an explanation of what each program does, how to run the program (including an example), and some sample output (if any).
You may obtain a copy of these programs from the following URL: support.sas.com/cody.
Scoring a Test (Reading Data from a Text File)
Program Name: Score_Text
Described in: Chapter 2
Purpose: To read raw test data from a text file, score the test, and create a SAS data set (temporary or permanent) to be used as input to other analysis programs. The output data set contains the student ID (ID), the answer key (Key1 to Keyn), the student responses to each item (Ans1-Ansn), the scored variables (0=incorrect, 1=correct, variable names Score1-Scoren), the raw score (Raw), and the percentage score (Percent).
Arguments:
File= the name of the text file containing the answer key and student answers.
Dsn= the name of the data set that contains the answer key, the student ID and student answers, and the scored items (0s and 1s). This can be a temporary (work) data set or a permanent SAS data set.
Length_ID= the number of characters (digits) in the student ID. The ID may contain any alphanumeric characters.
Start= the first column of the student ID.
Nitems= the number of items on the test.
Program 11.1: Score_Text
%macro Score_Text(File=, /*Name of the file containing the answer
key and the student answers */
Dsn=, /* Name of SAS data set to create */
Length_ID=, /*Number of bytes in the ID */
Start=, /*Starting column of student answers */
Nitems= /*Number of items on the test */);
data &Dsn;
infile "&File" pad end=Last;
array Ans[&Nitems] $ 1 Ans1-Ans&Nitems; ***student Answers;
array Key[&Nitems] $ 1 Key1-Key&Nitems; ***Answer Key;
array Score[&Nitems] 3 Score1-Score&Nitems; ***score array
1=right,0=wrong;
retain Key1-Key&Nitems;
if _n_= 1 then input @&Start (Key1-Key&Nitems)($upcase1.);
input @1 ID $&Length_ID..
@&start (Ans1-Ans&Nitems)($upcase1.);
do Item = 1 to &Nitems;
Score[Item] = Key[Item] eq Ans[Item];
end;
Raw=sum (of Score1-Score&Nitems);
Percent=100*Raw / &Nitems;
keep Ans1-Ans&Nitems Key1-Key&Nitems Score1-Score&Nitems ID Raw Percent;
label ID = 'Student ID'
Raw = 'Raw score'
Percent = 'Percent score';
run;
proc sort data=&Dsn;
by ID;
run;
%mend score_text;
Sample call:
%score_text(file='c:\books\test scoring\stat_test.txt',
dsn=score_stat,
length_id=9,
Start=11,
Nitems=56)
Scoring a Test (Reading Data From an Excel File)
Program Name: Score_Excel
Described in: Chapter 2
Purpose: To score a test reading data from an Excel file.
Arguments:
Dsn= the name of the data set created by the Score_Excel macro.
Folder= the name of the folder where the Excel file is stored.
Worksheet= the name of the worksheet (Sheet1 is the default).
Nitems= the number of items on the test.
Program 11.2: Score_Excel
*Macro Score_Excel
Purpose: To read test data from and Excel file and score the test;
/* This macro reads answer key and student answers stored in an
Excel Worksheet.
The first row of the worksheet contains labels as
follows:
Column A: ID
Column B to Last column: Ans1 Ans2 etc.
The second row of the worksheet contains the answer key
starting in column B.
The remaining rows contain the student ID in column A
and the student answers in columns B to the end
*/
%macro Score_Excel(Dsn=, /* Name of SAS data set to create */
Folder=, /*Name of the folder where the worksheet is
located */
File=, /*Name of the Excel worksheet containing
the answer key and the student answers */
Worksheet=Sheet1, /*worksheet name, Sheet1 is the default */
Nitems= /*Number of items on the test */);
libname readxl "&folder\&File";
data &Dsn;
set readxl."&Worksheet$"n;
retain Key1-Key&Nitems;
array Key[&Nitems] $ 1;
array Ans[&Nitems] $ 1;
array Score[&Nitems] Score1-Score&Nitems;
if _n_ = 1 then do Item = 1 to &Nitems;
Key[Item] = Ans[Item];
end;
drop Item;
do Item=1 to &Nitems;
Score[Item] = Key[Item] eq Ans[Item];
end;
Raw=sum(of Score1-Score&Nitems);
Percent=100*Raw / &Nitems;
keep Ans1-Ans&Nitems Key1-Key&Nitems Score1-Score&Nitems ID Raw Percent;
label ID = 'Student ID'
Raw = 'Raw Score'
Percent = 'Percent Score';
run;
proc sort data=&Dsn;
by ID;
run;
%mend Score_Excel;
Sample Call
To help you understand exactly how you need to structure your worksheet, the Excel worksheet shown below was created for this example. It represents a five-item test with four students. Here it is:
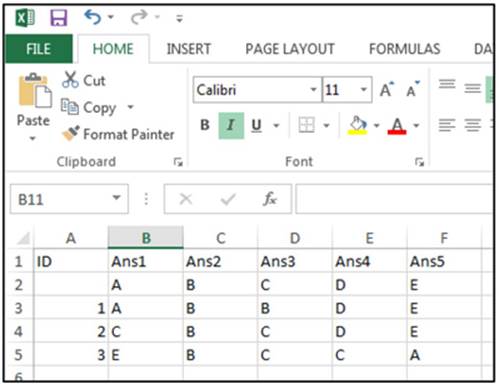
Notice that the first row contains the labels ID and Ans1 to Ans5. The second row, starting in column 2, contains the answer key. The remaining rows contain the student IDs and student answers. The name of the spreadsheet was not changed from the default name Sheet1. Here is the call. (Note: If you are using a newer version of Excel that creates files with the XLSX extension, substitute that extension on the File= parameter.)
%score_excel(Folder=c:\books\test scoring,
File=Sample Test.xls,
Worksheet=Sheet1,
Dsn=test,
Nitems=5)
Printing a Roster
Program Name: Print_Roster
Described in: Chapter 2
Purpose: To print a student roster (Student ID and Score).
Arguments:
Dsn= the name of the data set created by the %Score_Text macro.
Program 11.3: Print_Roster
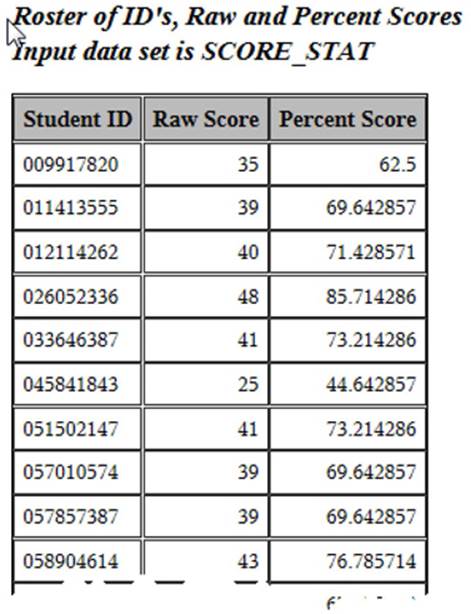
%macro print_roster(Dsn= /*Data set name */);
title "Roster of ID's, Raw and Percent Scores";
title2 "Input data set is %upcase(&Dsn)";
proc report data=&Dsn nowd headline;
columns ID Raw Percent;
define ID / "Student ID" width=10;
define Raw / "Raw Score" width=5;
define Percent / "Percent Score" width=7;
run;
%mend print_roster;
Sample Call:
%print_roster(Dsn=Score_Stat)
Sample Output:
Data Checking Program
Program Name: Data_Check
Described in: Chapter 4
Purpose: To identify data errors in student data (in a text file).
Arguments:
File= the name of the text file holding the answer key and student answers.
Length_ID= the number of characters (digits) in the student ID. The ID may contain any alphanumeric characters.
Start= the first column of the student ID.
Nitems= the number of items on the test.
Program 11.4: Data_Check
%macro data_check(File=, /*Name of the file containing the answer
key and the student answers */
Length_ID=, /*Number of bytes in the ID */
Start=, /*Starting column of student answers */
Nitems= /*Number of items on the test */);
title "Checking for Invalid ID's and Incorrect Answer Choices";
title2 "Input file is &File";
data _null_;
file print;
if _n_ = 1 then put 54*'-' /;
array ans[&Nitems] $ 1 Ans1-Ans&Nitems;
infile 'c:\books\test scoring\data_errors.txt' pad;
input @1 ID $&Length_ID..
@11 (Ans1-Ans&Nitems)($upcase1.);
if notdigit(ID) then put "Invalid ID " ID "in line " _n_;
Do Item = 1 to &Nitems;
if missing(Ans[Item]) then
put "Item #" Item "Left Blank by Student " ID;
else if Ans[Item] not in ('A','B','C','D','E') then
put "Invalid Answer for Student " ID "for Item #"
Item "entered as " Ans[Item];
end;
run;
%mend data_check;
Sample Call:
%data_check(File=c:\books\test scoring\data_errors.txt,
Length_ID=9,
Start=11,
Nitems=10)
Sample Output:

Item Analysis Program
Program Name: Item
Described in: Chapter 5
Purpose: To perform item analysis, including answer frequencies, item difficulty, point-biserial correlation, and proportion correct by quartile. Note: You need to first score the test using either of the test scoring programs described earlier.
Arguments:
Dsn= the name of the data set created by the %Score_Text macro.
Nitems= the number of items on the test.
Program 11.5: Item
%macro Item(Dsn=, /*Data set name */
Nitems= /*Number of items on the test */);
proc corr data=&Dsn nosimple noprint
outp=corrout(where=(_type_='CORR'));
var Score1-Score&Nitems;
with Raw;
run;
***reshape the data set;
data corr;
set corrout;
array score[*] 3 Score1-Score&Nitems;
Do i=1 to &Nitems;
Corr = Score[i];
output;
end;
keep i Corr;
run;
***compute quartiles;
proc rank data=&Dsn groups=4 out=quart(drop=Percent ID);
ranks Quartile;
var Raw;
run;
***create item variable and reshape again;
data tab;
set quart;
length Item $ 5 Quartile Correct i 3 Choice $ 1;
array score[*] Score1-Score&Nitems;
array ans{*} $ 1 Ans1-Ans&Nitems;
array key{*} $ 1 Key1-Key&Nitems;
Quartile = Quartile+1;
Do i=1 to &Nitems;
Item=right(put(i,3.)) || " " || Key[i];
Correct=Score[i];
Choice=Ans[i];
output;
end;
keep i Item Quartile Correct Choice;
run;
proc sort data=tab;
by i;
run;
***combine correlations and quartile information;
data both;
merge corr tab;
by i;
run;
***print out a pretty table;
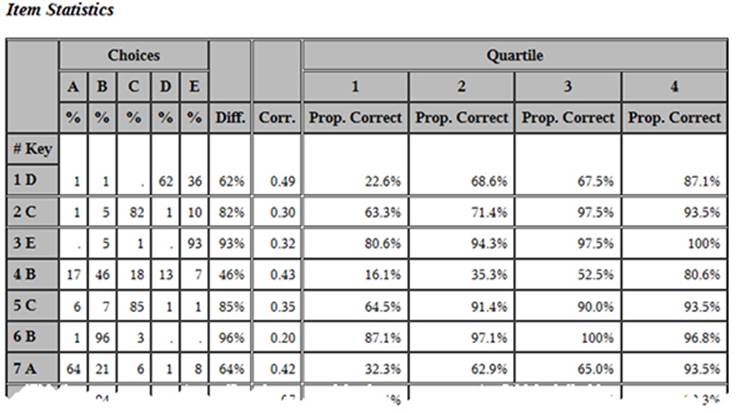
options ls=132;
title "Item Statistics";
proc tabulate format=7.2 data=both order=internal noseps;
label Quartile = 'Quartile'
Choice = 'Choices';
class Item Quartile Choice;
var Correct Corr;
table Item='# Key'*f=6.,
Choice*(pctn<Choice>)*f=3. Correct=' '*mean='Diff.'*f=Percent5.2
Corr=' '*mean='Corr.'*f=5.2
Correct=' '*Quartile*mean='Prop. Correct'*f=Percent7.2/
rts=8;
keylabel pctn='%' ;
run;
*Delete temporary data sets;
proc datasets library=work noprint;
delete corr;
delete tab;
delete both;
delete corrout;
delete quart;
quit;
%mend Item;
Sample Call:
%Item(Dsn=Score_Stat, Nitems=56)
Sample Output:
Program to Delete Items and Rescore the Test
Program Name: Print_Roster
Described in: Chapter 6
Purpose: To delete items and rescore the test.
Arguments:
Dsn= the name of the data set created by the %Score_Text macro.
Dsn_Rescore= the name of the rescored data set.
Nitems= the number of items on the original test (before deleting items).
List= the list of item numbers to delete, separated by blanks.
Program 11.6: Print_Roster
*Macro Rescore
Purpose: to rescore a test with a list of items to delete;
%macro Rescore(Dsn=, /*Name of data created by one of the scoring macros */
Dsn_Rescore=, /*Name of rescored data set */
Nitems=, /*Number of itenms on the original test */
List= /*List of items to delete, separated
by spaces */);
*Note: One of the scoring macros must be run first;
Data &Dsn_Rescore;
set &Dsn(keep=ID Score1-Score&Nitems);
array Score[&Nitems];
retain Num &Nitems;
Raw = 0;
retain Num (&Nitems);
*Determine the number of items after deletion;
if _n_ = 1 then do i = 1 to &Nitems;
if i in(&list) then Num = Num - 1;
end;
do i = 1 to &Nitems;
Raw = Raw + Score[i]*(i not in (&list));
end;
drop i Num;
Percent = 100*Raw/Num;
run;
Sample Call:
%Rescore(Dsn=Score_stat, Dsn_Rescore=temp, Nitems=56, List=1 2 3 4 5)
Scoring Multiple Test Versions (Reading Test Data and Correspondence Data from Text Files)
Program Name: Mult_Versions_txt
Described in: Chapter 6
Purpose: To score multiple test versions.
Arguments:
Dsn= the name of the data set to create.
Length_ID= the number of characters (digits) in the student ID. The ID may contain any alphanumeric characters.
Start= the first column of the student ID.
Nversions= the number of versions of the test.
Nitems= the number of items on the test.
Corr_File= the name of the text file holding the correspondence information (see Chapter 6 for details).
Program 11.7: Mult_Versions_txt
*Macro Mult_Version_Txt
Purpose: To read test and correspondence data for multiple
test versions from text files and score the test;
%macro mult_version_txt(File=, /*Name of the file containing the answer
key and the student answers */
Corr_File=, /*Name of the file with correspondence
information */
Nversions=, /* Number of versions */
Dsn=, /* Name of SAS data set to create */
Length_ID=, /*Number of bytes in the ID */
Version_Col=, /* Column for version number */
Start=, /*Starting column of student answers */
Nitems= /*Number of items on the test */);
data &Dsn;
retain Key1-Key&Nitems;
array Response[&Nitems] $ 1;
array Ans[&Nitems] $ 1;
array Key[&Nitems] $ 1;
array Score[&Nitems];
array Correspondence[&Nversions,&Nitems] _temporary_;
if _n_ = 1 then do;
*Load correspondence array;
infile "&Corr_File";
do Version = 1 to &Nversions;
do Item = 1 to &Nitems;
input Correspondence[Version,Item] @;
end;
end;
infile "&File" pad;
input @&Start (Key1-Key&Nitems)($upcase1.);
end;
infile "&File" pad;
input @1 ID $&Length_ID..
@&Version_Col Version 1.
@&start (Response1-Response&Nitems)($Upcase1.);
Raw = 0;
do Item = 1 to &Nitems;
Ans[Item] = Response[correspondence[Version,Item]];
Score[Item] = (Ans[Item] eq Key[Item]);
Raw + Score[Item];
end;
drop Item Response1-Response&Nitems;
run;
%mend mult_version_txt;
Sample Call:
%mult_version_txt(File=c:\books\test scoring\mult_versions.txt,
Corr_File=c:\books\test scoring\corresp.txt,
Nversions=3,
Dsn=Multiple1,
Length_ID=9,
Version_Col=10,
Start=11,
Nitems=5)
Scoring Multiple Test Versions (Reading Test Data from a Text File and Correspondence Data from an Excel File)
Program Name: Mult_Versions_Excel_corr
Described in: Chapter 6
Purpose: To score multiple test versions.
Arguments:
File= the name of the text file containing the answer key and student data.
Corr_File= the name of the Excel file containing the correspondence data (see Chapter 6 for the structure of this file).
Nversions= the number of test versions.
Dsn= the name of the data set to create.
Length_ID= the number of characters (digits) in the student ID. The ID may contain any alphanumeric characters.
Start= the first column of the student ID.
Nitems= the number of items on the test.
Program 11.8: Mult_Versions_Excel_corr
*Macro Mult_Version_Excel_Corr
Purpose: To read test and from a text file and correspondence
data for multiple test versions from an Excel file
and score the test;
%macro mult_version_Excel_corr
(File=, /*Name of the file containing the answer
key and the student answers */
Corr_File=, /*Name of the Excel file with
correspondence information */
Nversions=, /* Number of versions */
Dsn=, /* Name of SAS data set to create */
Length_ID=, /*Number of bytes in the ID */
Version_Col=, /* Column for version number */
Start=, /*Starting column of student answers */
Nitems= /*Number of items on the test */);
libname readxl "&Corr_File";
data &Dsn;
retain Key1-Key&Nitems;
array Response[&Nitems] $ 1;
array Ans[&Nitems] $ 1;
array Key[&Nitems] $ 1;
array Score[&Nitems];
array Q[&Nitems];
array Correspondence[&Nversions,&Nitems] _temporary_;
if _n_ = 1 then do;
*Load correspondence array;
do Version = 1 to &Nversions;
set readxl.'Sheet1$'n;
do Item = 1 to &Nitems;
Correspondence[Version,Item] = Q[Item];
end;
end;
infile "&File" pad;
input @&Start (Key1-Key&Nitems)($upcase1.);
end;
infile "&File" pad;
input @1 ID $&Length_ID..
@&Version_Col Version 1.
@&Start (Response1-Response&Nitems)($upcase1.);
Raw = 0;
do Item = 1 to &Nitems;
Ans[Item] = Response[correspondence[Version,Item]];
Score[Item] = (Ans[Item] eq Key[Item]);
Raw + Score[Item];
end;
drop Item Response1-Response&Nitems;
run;
%mend mult_version_Excel_corr;
Sample Call:
%mult_version_Excel_corr(File=c:\books\test scoring\mult_versions.txt,
Corr_File=c:\books\test scoring\correspondence.xlsx,
Nversions=3,
Dsn=Multiple2,
Length_ID=9,
Version_Col=10,
Start=11,
Nitems=5)
Scoring Multiple Test Versions (Reading Test Data and Correspondence Data from Excel Files)
Program Name: Mult_Versions_Excel_corr
Described in: Chapter 6
Purpose: To score multiple test versions.
Arguments:
File= the name of the text file containing the answer key and student data.
Corr_File= the name of the Excel file containing the correspondence data (see Chapter 6 for the structure of this file).
Nversions= the number of test versions.
Dsn= the name of the data set to create.
Length_ID= the number of characters (digits) in the student ID. The ID may contain any alphanumeric characters.
Start= the first column of the student ID.
Nitems= the number of items on the test.
Program 11.9: Mult_Versions_Excel_corr
*Macro Mult_Version_Excel
Purpose: To read test and from a text file and correspondence
data for multiple test versions from an Excel file
and score the test;
%macro mult_version_Excel
(Test_File=, /*Name of the Excel file containing
the student answers */
Corr_File=, /*Name of the Excel file with
correspondence information */
Nversions=, /* Number of versions */
Dsn=, /* Name of SAS data set to create */
Nitems= /*Number of items on the test */);
libname readxl "&Corr_File";
libname readtest "&Test_File";
data &Dsn;
retain Key1-Key&Nitems;
array R[&Nitems] $ 1;
array Ans[&Nitems] $ 1;
array Key[&Nitems] $ 1;
array Score[&Nitems];
array Q[&Nitems];
array Correspondence[&Nversions,&Nitems] _temporary_;
if _n_ = 1 then do;
*Load correspondence array;
do Version = 1 to &Nversions;
set readxl.'Sheet1$'n;
do Item = 1 to &Nitems;
Correspondence[Version,Item] = Q[Item];
end;
end;
set readtest.'Sheet1$'n(rename=(ID=Num_ID));
do Item = 1 to &Nitems;
Key[Item] = R[Item];
end;
end;
set readtest.'Sheet1$'n (firstobs=2);
Raw = 0;
do Item = 1 to &Nitems;
Ans[Item] = R[correspondence[Version,Item]];
Score[Item] = (Ans[Item] eq Key[Item]);
Raw + Score[Item];
end;
drop Item R1-R&Nitems Num_ID Q1-Q&Nitems;
run;
%mend mult_version_Excel;
Sample Call:
%mult_version_Excel
(Test_File=c:\books\test scoring\Mult_Versions.xlsx,
Corr_File=c:\books\test scoring\correspondence.xlsx,
Nversions=3,
Dsn=Multiple3,
Nitems=5)
KR-20 Calculation
Program Name: KR_20
Described in: Chapter 7
Purpose: To perform item analysis, including answer frequencies, item difficulty, point-biserial correlation, and proportion correct by quartile.
Arguments:
Dsn= the name of the data set created by the %Score_Text macro.
Nitems= the number of items on the test.
Program 11.10: KR_20
%macro KR_20(Dsn=, /*Name of the data set */
Nitems= /*Number of items on the test */);
*Note: You must run one of the the Score macros before running this macro;
proc means data=&dsn noprint;
output out=variance var=Raw_Var Item_Var1-Item_Var&Nitems;
var Raw Score1-Score&Nitems;
run;
title "Computing the Kuder-Richard Formula 20";
data _null_;
file print;
set variance;
array Item_Var[&Nitems];
do i = 1 to &Nitems;
Item_Variance + Item_Var[i];
end;
KR_20 = (&Nitems/%eval(&Nitems - 1))*(1 - Item_Variance/Raw_Var);
put (KR_20 Item_Variance Raw_Var)(= 7.3);
drop i;
run;
proc datasets library=work noprint;
delete variance;
quit;
%mend KR_20;
Sample Call:
%KR_20(Dsn=Score_Stat, Nitems=56)
Sample Output:

Program to Detect Cheating (Method One)
Program Name: Compare_Wrong
Described in: Chapter 10
Purpose: To detect cheating on a multiple-choice exam. This method utilizes the set of wrong answers from one student and counts the number of the same wrong answers in this set to all other students in the class.
Arguments:
File= the name of the text file holding the answer key and student answers.
Length_ID= the number of characters (digits) in the student ID. The ID may contain any alphanumeric characters.
Start= the first column of the student ID.
ID1= the ID of the first student.
ID2= the ID of the second student.
Nitems= the number of items on the test.
Program 11.11: Compare_Wrong
%macro Compare_wrong
(File=, /*Name of text file containing key and
test data */
Length_ID=, /*Number of bytes in the ID */
Start=, /*Starting column of student answers */
ID1=, /*ID of first student */
ID2=, /*ID of second student */
Nitems= /*Number of items on the test */ );
data ID_one(keep=ID Num_wrong_One Ans_One1-Ans_One&Nitems Wrong_One1-Wrong_One&Nitems)
Not_One(keep=ID Num_wrong Ans1-Ans&Nitems Wrong1-Wrong&Nitems);
/* Data set ID_One contains values for Student 1
Data set Not_one contains data on other students
Arrays with "one" in the variable names are data from
ID1.
*/
infile "&File" end=last pad;
/*First record is the answer key*/
array Ans[&Nitems] $ 1;
array Ans_One[&Nitems] $ 1;
array Key[&Nitems] $ 1;
array Wrong[&Nitems];
array Wrong_One[&Nitems];
retain Key1-Key&Nitems;
if _n_ = 1 then input @&Start (Key1-Key&Nitems)($upcase1.);
input @1 ID $&Length_ID..
@&Start (Ans1-Ans&Nitems)($upcase1.);
if ID = "&ID1" then do;
do i = 1 to &Nitems;
Wrong_One[i] = Key[i] ne Ans[i];
Ans_One[i] = Ans[i];
end;
Num_Wrong_One = sum(of Wrong_One1-Wrong_One&Nitems);
output ID_one;
return;
end;
do i = 1 to &Nitems;
Wrong[i] = Key[i] ne Ans[i];
end;
output Not_One;
run;
/*
DATA step COMPARE counts the number of same wrong answers as student
ID1.
*/
data compare;
if _n_ = 1 then set ID_One;
set Not_One;
array Ans[&Nitems] $ 1;
array Ans_One[&Nitems] $ 1;
array Wrong[&Nitems];
array Wrong_One[&Nitems];
Num_Match = 0;
do i = 1 to &Nitems;
if Wrong_One[i] = 1 then Num_Match + Ans[i] eq Ans_One[i];
end;
keep Num_Match ID;
run;
proc sgplot data=compare;
title 'Distribution of the number of matches between';
title2 "Students &ID1, &ID2, and the rest of the class";
title3 "Data file is &File";
histogram Num_Match;
run;
/*
Compute the mean and standard deviation on the number of the same
wrong answers as ID1 but eliminate both ID1 and ID2 from the
calculation
*/
proc means data=compare(where=(ID not in ("&ID1" "&ID2")))noprint;
var Num_Match;
output out=Mean_SD mean=Mean_Num_match std=SD_Num_match;
run;
data _null_;
file print;
title1 "Exam file name: &File";
title2 "Number of Items: &Nitems";
title3 "Statistics for students &ID1 and &ID2";
set compare (where=(ID = "&ID2"));
set mean_sd;
set ID_One;
Diff = Num_Match - Mean_Num_Match;
z = Diff / SD_Num_match;
Prob = 1 - probnorm(z);
put // "Student &ID1 got " Num_wrong_One "items wrong" /
"Students &ID1 and &ID2 have " Num_Match "wrong answers in common" /
"The mean number of matches is" Mean_Num_Match 6.3/
"The standard deviation is" SD_Num_match 6.3/
"The z-score is " z 6.3 " with a probability of " Prob;
run;
proc datasets library=work noprint;
delete ID_One;
delete Not_One Means;
quit;
%mend compare_wrong;
Sample Call:
%compare_wrong(File=c:\books\test scoring\stat_cheat.txt,
Length_ID=9,
Start=11,
ID1=123456789,
ID2=987654321,
Nitems=56)
Sample Output:

Program to Detect Cheating (Method Two)
Program Name: Joint_Wrong
Described in: Chapter 10
Purpose: To detect cheating on a multiple-choice exam. This method utilizes the set of wrong answers that two students both got wrong (called joint-wrongs) and counts the number of the same wrong answers in this set to all other students in the class.
Arguments:
File= the name of the text file holding the answer key and student answers.
Length_ID= the number of characters (digits) in the student ID. The ID may contain any alphanumeric characters.
Start= the first column of the student ID.
ID1= the ID of the first student.
ID2= the ID of the second student.
Nitems= the number of items on the test.
Program 11.12: Joint_Wrong
%macro Joint_Wrong
(File=, /*Name of text file containing key and
test data */
Length_ID=, /*Number of bytes in the ID */
Start=, /*Starting column of student answers */
ID1=, /*ID of first student */
ID2=, /*ID of second student */
Nitems= /*Number of items on the test */ );
data ID_one(keep=ID Num_Wrong_One Ans_One1-Ans_One&Nitems Wrong_One1-Wrong_One&Nitems)
ID_two(keep=ID Num_Wrong_Two Ans_Two1-Ans_Two&Nitems Wrong_Two1-Wrong_Two&Nitems)
Others(keep=ID Num_wrong Ans1-Ans&Nitems Wrong1-Wrong&Nitems);
/* Data set ID_One contains values for Student 1
Data set ID_Two contains values for Student 2
Data set Others contains data on other students
*/
infile "&File" end=last pad;
/*First record is the answer key*/
array Ans[&Nitems] $ 1;
array Ans_One[&Nitems] $ 1;
array Ans_Two[&Nitems] $ 1;
array Key[&Nitems] $ 1;
array Wrong[&Nitems];
array Wrong_One[&Nitems];
array Wrong_Two[&Nitems];
array Joint[&Nitems];
retain Key1-Key&Nitems;
if _n_ = 1 then input @&Start (Key1-Key&Nitems)($upcase1.);
input @1 ID $&Length_ID..
@&Start (Ans1-Ans&Nitems)($upcase1.);
if ID = "&ID1" then do;
do i = 1 to &Nitems;
Wrong_One[i] = Key[i] ne Ans[i];
Ans_One[i] = Ans[i];
end;
Num_Wrong_One = sum(of Wrong_One1-Wrong_One&Nitems);
output ID_One others;
return;
end;
if ID = "&ID2" then do;
do i = 1 to &Nitems;
Wrong_Two[i] = Key[i] ne Ans[i];
Ans_Two[i] = Ans[i];
end;
Num_Wrong_Two = sum(of Wrong_Two1-Wrong_Two&Nitems);
output ID_Two others;
return;
end;
/*Compute wrong answers for the class not including ID1 and ID2 */
Num_Wrong = 0;
do i = 1 to &Nitems;
Wrong[i] = Key[i] ne Ans[i];
end;
Num_Wrong = sum(of Wrong1-Wrong&Nitems);
output Others;
run;
*DATA step joint compute item number for the joint-wrongs;
Data ID1ID2;
array Wrong_One[&Nitems];
array Wrong_Two[&Nitems];
array Joint[&Nitems];
set ID_One(keep=Wrong_One1-Wrong_One&Nitems);
Set ID_Two(keep=Wrong_Two1-Wrong_Two&Nitems);
Num_Wrong_Both = 0;
do i = 1 to &Nitems;
Joint[i] = Wrong_One[i] and Wrong_Two[i];
Num_Wrong_Both + Wrong_One[i] and Wrong_Two[i];
end;
drop i;
run;
*DATA step COMPARE counts the number of same wrong answers on joint-wrongs.;
data compare;
if _n_ = 1 then do;
set ID_One(keep=Ans_One1-Ans_One&Nitems);
set ID1ID2;
end;
set others;
array Ans[&Nitems] $ 1;
array Ans_One[&Nitems] $ 1;
array Joint[&Nitems];
Num_Match = 0;
do i = 1 to &Nitems;
if Joint[i] = 1 then Num_Match + Ans[i] eq Ans_One[i];
end;
keep Num_Match ID;
run;
proc sgplot data=compare;
title 'Distribution of the number of matches between';
title2 "Students &ID1, &ID2, and the rest of the class";
title3 "Data file is &File";
histogram Num_Match;
run;
/*
Compute the mean and standard deviation on the number of same
wrong answers as ID1 but eliminate both ID1 and ID2 from the
calculation
*/
proc means data=compare(where=(ID not in ("&ID1" "&ID2")))noprint;
var Num_Match;
output out=Mean_SD mean=Mean_Num_match std=SD_Num_match;
run;
options ls=132;
data _null_;
file print;
title1 "Exam file name: &File";
title2 "Number of Items: &Nitems";
title3 "Statistics for students &ID1 and &ID2";
set mean_sd;
set ID_One(Keep=Num_Wrong_One);
set ID_Two(keep=Num_Wrong_Two);
set ID1ID2(Keep=Num_Wrong_Both);
set compare(where=(ID eq "&ID2"));
Diff = Num_Wrong_Both - Mean_Num_Match;
z = Diff / SD_Num_match;
Prob = 1 - probnorm(z);
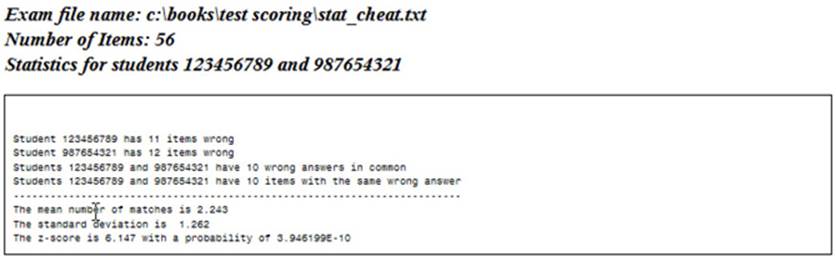
put // "Student &ID1 has " Num_Wrong_One "items wrong" /
"Student &ID2 has " Num_Wrong_Two "items wrong" /
"Students &ID1 and &ID2 have " Num_Wrong_Both "wrong answers in common" /
"Students &ID1 and &ID2 have " Num_Match "items with the same wrong answer" /
73*'-' /
"The mean number of matches is" Mean_Num_Match 6.3 /
"The standard deviation is " SD_Num_match 6.3 /
"The z-score is" z 6.3 " with a probability of " Prob;
run;
proc datasets library=work noprint;
delete ID_One ID_Two Others compare ID1ID2 Mean_SD plot;
quit;
%mend joint_wrong;
Sample Call:
%joint_wrong(File=c:\books\test scoring\stat_cheat.txt,
Length_ID=9,
Start=11,
ID1=123456789,
ID2=987654321,
Nitems=56)
Sample Output:
Program to Search for Possible Cheating
Program Name: Search
Described in: Chapter 10
Purpose: To detect cheating on a multiple-choice exam. This method utilizes the set of wrong answers that two students both got wrong (called joint-wrongs) and counts the number of the same wrong answers in this set to all other students in the class.
Arguments:
File= the name of the text file holding the answer key and student answers.
Length_ID= the number of characters (digits) in the student ID. The ID may contain any alphanumeric characters.
Start= the first column of the student ID.
ID1= the ID of the first student.
Threshold= the p-value cutoff. All students with the same number of wrong answers as Student 1 that result in a p-value below the cutoff will be listed.
Nitems= the number of items on the test.
Program 11.13: Search
%macro search
(File=, /*Name of text file containing key and
test data */
Length_ID=, /*Number of bytes in the ID */
Start=, /*Starting column of student answers */
ID1=, /*ID of first student */
Threshold=.01, /*Probability threshold */
Nitems= /*Number of items on the test */ );
***This Data Step finds the item numbers incorrect in the first id;
data ID_one(keep=ID Num_wrong_One Ans_One1-Ans_One&Nitems Wrong_One1-Wrong_One&Nitems)
Not_One(keep=ID Num_wrong Ans1-Ans&Nitems Wrong1-Wrong&Nitems);
/* Data set ID_One contains values for Student 1
Data set Not_one contains data on other students
Arrays with "one" in the variable names are data from
ID1.
*/
infile "&File" end=last pad;
retain Key1-Key&&Nitems;
/*First record is the answer key*/
array Ans[&Nitems] $ 1;
array Ans_One[&Nitems] $ 1;
array Key[&Nitems] $ 1;
array Wrong[&Nitems];
array Wrong_One[&Nitems];
if _n_ = 1 then input @&Start (Key1-Key&Nitems)($upcase1.);
input @1 ID $&Length_ID..
@&Start (Ans1-Ans&Nitems)($upcase1.);
if ID = "&ID1" then do;
do i = 1 to &Nitems;
Wrong_One[i] = Key[i] ne Ans[i];
Ans_One[i] = Ans[i];
end;
Num_Wrong_One = sum(of Wrong_One1-Wrong_One&Nitems);
output ID_one;
return;
end;
do i = 1 to &Nitems;
Wrong[i] = Key[i] ne Ans[i];
end;
Num_Wrong = sum(of Wrong1-Wrong&Nitems);
drop i;
output Not_One;
run;
data compare;
array Ans[&Nitems] $ 1;
array Wrong[&Nitems];
array Wrong_One[&Nitems];
array Ans_One[&Nitems] $ 1;
set Not_One;
if _n_ = 1 then set ID_One(drop=ID);
* if ID = "&ID" then delete;
***Compute # matches on set of wrong answers;
Num_Match = 0;
do i = 1 to &Nitems;
if Wrong_One[i] = 1 then Num_Match + Ans[i] eq Ans_One[i];
end;
keep ID Num_Match Num_Wrong_One;
run;
proc means data=compare(where=(ID ne "&ID1")) noprint;
var Num_Match;
output out=means(drop=_type_ _freq_) mean=Mean_match std=Sd_match;
run;
title 'Distribution of the number of matches between';
title2 "Student &ID1 and the rest of the class";
title3 "Data file is &File";
proc sgplot data=compare;
histogram Num_Match / binwidth=1;
run;
data _null_;
file print;
title "Statistics for student &ID1";
if _n_ = 1 then set means;
set compare;
z = (Num_Match - Mean_match) / Sd_match;
Prob = 1 - probnorm(z);
if Prob < &Threshold then
put /
"ID = " ID "had " Num_Match " wrong answers compare, "
"Prob = " Prob;
run;
proc datasets library=work noprint;
delete compare ID_One means Not_One;
quit;
%mend search;
Sample Call:
%search(File=c:\books\test scoring\stat_cheat.txt,
Length_ID=9,
Start=11,
ID1=123456789,
Threshold=.01,
Nitems=56)
Sample Output:

Conclusion
The programs (macros) in this chapter should, hopefully, allow you to perform a wide variety of test scoring and item analysis activities. You may use them as is or, if you have some SAS programming skills, modify them for your own use.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.