Seven Concurrency Models in Seven Weeks (2014)
Chapter 2. Threads and Locks
Threads-and-locks programming is like a Ford Model T. It will get you from point A to point B, but it is primitive, difficult to drive, and both unreliable and dangerous compared to newer technology.
Despite their well-known problems, threads and locks are still the default choice for writing much concurrent software, and they underpin many of the other technologies we’ll be covering. Even if you don’t plan to use them directly, you should understand how they work.
The Simplest Thing That Could Possibly Work
Threads and locks are little more than a formalization of what the underlying hardware actually does. That’s both their great strength and their great weakness.
Because they’re so simple, almost all languages support them in one form or another, and they impose very few constraints on what can be achieved through their use. But they also provide almost no help to the poor programmer, making programs very difficult to get right in the first place and even more difficult to maintain.
We’ll cover threads-and-locks programming in Java, but the principles apply to any language that supports threads. On day 1 we’ll cover the basics of multithreaded code in Java, the primary pitfalls you’ll encounter, and some rules that will help you avoid them. On day 2 we’ll go beyond these basics and investigate the facilities provided by the java.util.concurrent package. Finally, on day 3 we’ll look at some of the concurrent data structures provided by the standard library and use them to solve a realistic real-world problem.
A Word About Best Practices
We’re going to start by looking at Java’s low-level thread and lock primitives. Well-written modern code should rarely use these primitives directly, using the higher-level services we’ll talk about in days 2 and 3 instead. Understanding these higher-level services depends upon an appreciation of the underlying basics, so that’s what we’ll cover first, but be aware that you probably shouldn’t be using the Thread class directly within your production code.
Day 1: Mutual Exclusion and Memory Models
If you’ve done any concurrent programming at all, you’re probably already familiar with the concept of mutual exclusion—using locks to ensure that only one thread can access data at a time. And you’ll also be familiar with the ways in which mutual exclusion can go wrong, including race conditions and deadlocks (don’t worry if these terms mean nothing to you yet—we’ll cover them all very soon).
These are real problems, and we’ll spend plenty of time talking about them, but it turns out that there’s something even more basic you need to worry about when dealing with shared memory—the Memory Model. And if you think that race conditions and deadlocks can cause weird behavior, just wait until you see how bizarre shared memory can be.
We’re getting ahead of ourselves, though—let’s start by seeing how to create a thread.
Creating a Thread
The basic unit of concurrency in Java is the thread, which, as its name suggests, encapsulates a single thread of control. Threads communicate with each other via shared memory.
No programming book is complete without a “Hello, World!” example, so without further ado here’s a multithreaded version:
|
ThreadsLocks/HelloWorld/src/main/java/com/paulbutcher/HelloWorld.java |
|
|
|
public class HelloWorld { |
|
|
|
|
|
public static void main(String[] args) throws InterruptedException { |
|
|
Thread myThread = new Thread() { |
|
|
public void run() { |
|
|
System.out.println("Hello from new thread"); |
|
|
} |
|
|
}; |
|
|
|
|
|
myThread.start(); |
|
|
Thread.yield(); |
|
|
System.out.println("Hello from main thread"); |
|
|
myThread.join(); |
|
|
} |
|
|
} |
This code creates an instance of Thread and then starts it. From this point on, the thread’s run method executes concurrently with the remainder of main. Finally join waits for the thread to terminate (which happens when run returns).
When you run this, you might get this output:
|
|
Hello from main thread |
|
|
Hello from new thread |
Or you might get this instead:
|
|
Hello from new thread |
|
|
Hello from main thread |
Which of these you see depends on which thread gets to its println first (in my tests, I saw each approximately 50% of the time). This kind of dependence on timing is one of the things that makes multithreaded programming tough—just because you see one behavior one time you run your code doesn’t mean that you’ll see it consistently.
![]()
Joe asks:
Why the Thread.yield?
Our multithreaded “Hello, World!” includes the following line:
|
|
Thread.yield(); |
According to the Java documentation, yield is:
a hint to the scheduler that the current thread is willing to yield its current use of a processor.
Without this call, the startup overhead of the new thread would mean that the main thread would almost certainly get to its println first (although this isn’t guaranteed to be the case—and as we’ll see, in concurrent programming if something can happen, then sooner or later it will, probably at the most inconvenient moment).
Try commenting this method out and see what happens. What happens if you change it to Thread.sleep(1)?
Our First Lock
When multiple threads access shared memory, they can end up stepping on each others’ toes. We avoid this through mutual exclusion via locks, which can be held by only a single thread at a time.
Let’s create a couple of threads that interact with each other:
|
ThreadsLocks/Counting/src/main/java/com/paulbutcher/Counting.java |
|
|
|
public class Counting { |
|
|
public static void main(String[] args) throws InterruptedException { |
|
|
class Counter { |
|
|
private int count = 0; |
|
|
public void increment() { ++count; } |
|
|
public int getCount() { return count; } |
|
|
} |
|
|
final Counter counter = new Counter(); |
|
|
class CountingThread extends Thread { |
|
|
public void run() { |
|
|
for(int x = 0; x < 10000; ++x) |
|
|
counter.increment(); |
|
|
} |
|
|
} |
|
|
|
|
|
CountingThread t1 = new CountingThread(); |
|
|
CountingThread t2 = new CountingThread(); |
|
|
t1.start(); t2.start(); |
|
|
t1.join(); t2.join(); |
|
|
System.out.println(counter.getCount()); |
|
|
} |
|
|
} |
Here we have a very simple Counter class and two threads, each of which call its increment method 10,000 times. Very simple, and very broken.
Try running this code, and you’ll get a different answer each time. The last three times I ran it, I got 13850, 11867, then 12616. The reason is a race condition (behavior that depends on the relative timing of operations) in the two threads’ use of the count member of Counter.
If this surprises you, think about what the Java compiler generates for ++count. Here are the bytecodes:
|
|
getfield #2 |
|
|
iconst_1 |
|
|
iadd |
|
|
putfield #2 |
Even if you’re not familiar with JVM bytecodes, it’s clear what’s going on here: getfield #2 retrieves the value of count, iconst_1 followed by iadd adds 1 to it, and then putfield #2 writes the result back to count. This pattern is commonly known as read-modify-write.
Imagine that both threads call increment simultaneously. Thread 1 executes getfield #2, retrieving the value 42. Before it gets a chance to do anything else, thread 2 also executes getfield #2, also retrieving 42. Now we’re in trouble because both of them will increment 42 by 1, and both of them will write the result, 43, back to count. The effect is as though count had been incremented once instead of twice.
The solution is to synchronize access to count. One way to do so is to use the intrinsic lock that comes built into every Java object (you’ll sometimes hear it referred to as a mutex, monitor, or critical section) by making increment synchronized:
|
ThreadsLocks/CountingFixed/src/main/java/com/paulbutcher/Counting.java |
|
|
|
class Counter { |
|
|
private int count = 0; |
|
* |
public synchronized void increment() { ++count; } |
|
|
public int getCount() { return count; } |
|
|
} |
Now increment claims the Counter object’s lock when it’s called and releases it when it returns, so only one thread can execute its body at a time. Any other thread that calls it will block until the lock becomes free (later in this chapter we’ll see that, for simple cases like this where only one variable is involved, the java.util.concurrent.atomic package provides good alternatives to using a lock).
Sure enough, when we execute this new version, we get the result 20000 every time.
But all is not rosy—our new code still contains a subtle bug, the cause of which we’ll cover next.
Mysterious Memory
Let’s spice things up with a puzzle. What will this code output?
|
ThreadsLocks/Puzzle/src/main/java/com/paulbutcher/Puzzle.java |
|
|
Line 1 |
public class Puzzle { |
|
- |
static boolean answerReady = false; |
|
- |
static int answer = 0; |
|
- |
static Thread t1 = new Thread() { |
|
5 |
public void run() { |
|
- |
answer = 42; |
|
- |
answerReady = true; |
|
- |
} |
|
- |
}; |
|
10 |
static Thread t2 = new Thread() { |
|
- |
public void run() { |
|
- |
if (answerReady) |
|
- |
System.out.println("The meaning of life is: " + answer); |
|
- |
else |
|
15 |
System.out.println("I don't know the answer"); |
|
- |
} |
|
- |
}; |
|
- |
|
|
- |
public static void main(String[] args) throws InterruptedException { |
|
20 |
t1.start(); t2.start(); |
|
- |
t1.join(); t2.join(); |
|
- |
} |
|
- |
} |
If you’re thinking “race condition!” you’re absolutely right. We might see the answer to the meaning of life or a disappointing admission that our computer doesn’t know it, depending on the order in which the threads happen to run. But that’s not all—there’s one other result we might see:
|
|
The meaning of life is: 0 |
What?! How can answer possibly be zero if answerReady is true? It’s almost as if something switched lines 6 and 7 around underneath our feet.
Well, it turns out that it’s entirely possible for something to do exactly that. Several somethings, in fact:
· The compiler is allowed to statically optimize your code by reordering things.
· The JVM is allowed to dynamically optimize your code by reordering things.
· The hardware you’re running on is allowed to optimize performance by reordering things.
It goes further than just reordering. Sometimes effects don’t become visible to other threads at all. Imagine that we rewrote run as follows:
|
|
public void run() { |
|
|
while (!answerReady) |
|
|
Thread.sleep(100); |
|
|
System.out.println("The meaning of life is: " + answer); |
|
|
} |
Our program may never exit because answerReady may never appear to become true.
If your first reaction to this is that the compiler, JVM, and hardware should keep their sticky fingers out of your code, that’s understandable. Unfortunately, it’s also unachievable—much of the increased performance we’ve seen over the last few years has come from exactly these optimizations. Shared-memory parallel computers, in particular, depend on them. So we’re stuck with having to deal with the consequences.
Clearly, this can’t be a free-for-all—we need something to tell us what we can and cannot rely on. That’s where the Java memory model comes in.
Memory Visibility
The Java memory model defines when changes to memory made by one thread become visible to another thread.[6] The bottom line is that there are no guarantees unless both the reading and the writing threads use synchronization.
We’ve already seen one example of synchronization—obtaining an object’s intrinsic lock. Others include starting a thread, detecting that a thread is stopped with join, and using many of the classes in the java.util.concurrent package.
An important point that’s easily missed is that both threads need to use synchronization. It’s not enough for just the thread making changes to do so. This is the cause of a subtle bug still remaining in the code. Making increment synchronized isn’t enough—getCount needs to be synchronized as well. If it isn’t, a thread calling getCount may see a stale value (as it happens, the way that getCount is used in the code is thread-safe, because it’s called after a call to join, but it’s a ticking time bomb waiting for anyone who uses Counter).
We’ve spoken about race conditions and memory visibility, two common ways that multithreaded programs can go wrong. Now we’ll move on to the third: deadlock.
Multiple Locks
You would be forgiven if, after reading the preceding text, you thought that the only way to be safe in a multithreaded world was to make every method synchronized. Unfortunately, it’s not that easy.
Firstly, this would be dreadfully inefficient. If every method were synchronized, most threads would probably spend most of their time blocked, defeating the point of making your code concurrent in the first place. But this is the least of your worries—as soon as you have more than one lock (remember, in Java every object has its own lock), you create the opportunity for threads to become deadlocked.
We’ll demonstrate deadlock with a nice little example commonly used in academic papers on concurrency—the “dining philosophers” problem. Imagine that five philosophers are sitting around a table, with five (not ten) chopsticks arranged like this:
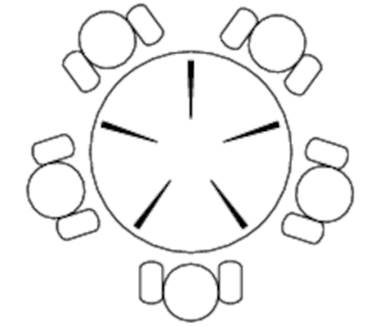
A philosopher is either thinking or hungry. If he’s hungry, he picks up the chopsticks on either side of him and eats for a while (yes, our philosophers are male—women would behave more sensibly). When he’s done, he puts them down.
Here’s how we might implement one of our philosophers:
|
ThreadsLocks/DiningPhilosophers/src/main/java/com/paulbutcher/Philosopher.java |
|
|
Line 1 |
class Philosopher extends Thread { |
|
- |
private Chopstick left, right; |
|
- |
private Random random; |
|
- |
|
|
5 |
public Philosopher(Chopstick left, Chopstick right) { |
|
- |
this.left = left; this.right = right; |
|
- |
random = new Random(); |
|
- |
} |
|
- |
|
|
10 |
public void run() { |
|
- |
try { |
|
- |
while(true) { |
|
- |
Thread.sleep(random.nextInt(1000)); // Think for a while |
|
- |
synchronized(left) { // Grab left chopstick // |
|
15 |
synchronized(right) { // Grab right chopstick // |
|
- |
Thread.sleep(random.nextInt(1000)); // Eat for a while |
|
- |
} |
|
- |
} |
|
- |
} |
|
20 |
} catch(InterruptedException e) {} |
|
- |
} |
|
- |
} |
Lines 14 and 15 demonstrate an alternative way of claiming an object’s intrinsic lock: synchronized(object).
On my machine, if I set five of these going simultaneously, they typically run very happily for hours on end (my record is over a week). Then, all of a sudden, everything grinds to a halt.
After a little thought, it’s obvious what’s going on—if all the philosophers decide to eat at the same time, they all grab their left chopstick and then find themselves stuck—each has one chopstick, and each is blocked waiting for the philosopher on his right. Deadlock.
Deadlock is a danger whenever a thread tries to hold more than one lock. Happily, there is a simple rule that guarantees you will never deadlock—always acquire locks in a fixed, global order.
Here’s one way we can achieve this:
|
ThreadsLocks/DiningPhilosophersFixed/src/main/java/com/paulbutcher/Philosopher.java |
|
|
|
class Philosopher extends Thread { |
|
* |
private Chopstick first, second; |
|
|
private Random random; |
|
|
|
|
|
public Philosopher(Chopstick left, Chopstick right) { |
|
* |
if(left.getId() < right.getId()) { |
|
* |
first = left; second = right; |
|
* |
} else { |
|
* |
first = right; second = left; |
|
* |
} |
|
|
random = new Random(); |
|
|
} |
|
|
|
|
|
public void run() { |
|
|
try { |
|
|
while(true) { |
|
|
Thread.sleep(random.nextInt(1000)); // Think for a while |
|
* |
synchronized(first) { // Grab first chopstick |
|
* |
synchronized(second) { // Grab second chopstick |
|
|
Thread.sleep(random.nextInt(1000)); // Eat for a while |
|
|
} |
|
|
} |
|
|
} |
|
|
} catch(InterruptedException e) {} |
|
|
} |
|
|
} |
![]()
Joe asks:
Can I Use an Object’s Hash to Order Locks?
One piece of advice you’ll often see is to use an object’s hash code to order lock acquisition, such as shown here:
|
|
if(System.identityHashCode(left) < System.identityHashCode(right)) { |
|
|
first = left; second = right; |
|
|
} else { |
|
|
first = right; second = left; |
|
|
} |
This technique has the advantage of working for any object, and it avoids having to add a means of ordering your objects if they don’t already define one. But hash codes aren’t guaranteed to be unique (two objects are very unlikely to have the same hash code, but it does happen). So personally speaking, I wouldn’t use this approach unless I really had no choice.
Instead of holding on to left and right chopsticks, we now hold on to first and second, using Chopstick’s id member to ensure that we always lock chopsticks in increasing ID order (we don’t actually care what IDs chopsticks have—just that they’re unique and ordered). And sure enough, now things will happily run forever without locking up.
It’s easy to see how to stick to the global ordering rule when the code to acquire locks is all in one place. It gets much harder in a large program, where a global understanding of what all the code is doing is impractical.
The Perils of Alien Methods
Large programs often make use of listeners to decouple modules. Here, for example, is a class that downloads from a URL and allows ProgressListeners to be registered:
|
ThreadsLocks/HttpDownload/src/main/java/com/paulbutcher/Downloader.java |
|
|
|
class Downloader extends Thread { |
|
|
private InputStream in; |
|
|
private OutputStream out; |
|
|
private ArrayList<ProgressListener> listeners; |
|
|
|
|
|
public Downloader(URL url, String outputFilename) throws IOException { |
|
|
in = url.openConnection().getInputStream(); |
|
|
out = new FileOutputStream(outputFilename); |
|
|
listeners = new ArrayList<ProgressListener>(); |
|
|
} |
|
|
public synchronized void addListener(ProgressListener listener) { |
|
|
listeners.add(listener); |
|
|
} |
|
|
public synchronized void removeListener(ProgressListener listener) { |
|
|
listeners.remove(listener); |
|
|
} |
|
|
private synchronized void updateProgress(int n) { |
|
|
for (ProgressListener listener: listeners) |
|
* |
listener.onProgress(n); |
|
|
} |
|
|
|
|
|
public void run() { |
|
|
int n = 0, total = 0; |
|
|
byte[] buffer = new byte[1024]; |
|
|
|
|
|
try { |
|
|
while((n = in.read(buffer)) != -1) { |
|
|
out.write(buffer, 0, n); |
|
|
total += n; |
|
|
updateProgress(total); |
|
|
} |
|
|
out.flush(); |
|
|
} catch (IOException e) { } |
|
|
} |
|
|
} |
Because addListener, removeListener, and updateProgress are all synchronized, multiple threads can call them without stepping on one another’s toes. But a trap lurks in this code that could lead to deadlock even though there’s only a single lock in use.
The problem is that updateProgress calls an alien method—a method it knows nothing about. That method could do anything, including acquiring another lock. If it does, then we’ve acquired two locks without knowing whether we’ve done so in the right order. As we’ve just seen, that can lead to deadlock.
The only solution is to avoid calling alien methods while holding a lock. One way to achieve this is to make a defensive copy of listeners before iterating through it:
|
ThreadsLocks/HttpDownloadFixed/src/main/java/com/paulbutcher/Downloader.java |
|
|
|
private void updateProgress(int n) { |
|
|
ArrayList<ProgressListener> listenersCopy; |
|
|
synchronized(this) { |
|
* |
listenersCopy = (ArrayList<ProgressListener>)listeners.clone(); |
|
|
} |
|
|
for (ProgressListener listener: listenersCopy) |
|
|
listener.onProgress(n); |
|
|
} |
This change kills several birds with one stone. Not only does it avoid calling an alien method with a lock held, it also minimizes the period during which we hold the lock. Holding locks for longer than necessary both hurts performance (by restricting the degree of achievable concurrency) and increases the danger of deadlock. This change also fixes another bug that isn’t related to concurrency—a listener can now call removeListener within its onProgress method without modifying the copy of listeners that’s mid-iteration.
Day 1 Wrap-Up
This brings us to the end of day 1. We’ve covered the basics of multithreaded code in Java, but as we’ll see in day 2, the standard library provides alternatives that are often a better choice.
What We Learned in Day 1
We covered how to create threads and use the intrinsic locks built into every Java object to enforce mutual exclusion between them. We also saw the three primary perils of threads and locks—race conditions, deadlock, and memory visibility, and we discussed some rules that help us avoid them:
· Synchronize all access to shared variables.
· Both the writing and the reading threads need to use synchronization.
· Acquire multiple locks in a fixed, global order.
· Don’t call alien methods while holding a lock.
· Hold locks for the shortest possible amount of time.
Day 1 Self-Study
Find
· Check out William Pugh’s “Java memory model” website.
· Acquaint yourself with the JSR 133 (Java memory model) FAQ.
· What guarantees does the Java memory model make regarding initialization safety? Is it always necessary to use locks to safely publish objects between threads?
· What is the double-checked locking anti-pattern? Why is it an anti-pattern?
Do
· Experiment with the original, broken “dining philosophers” example. Try modifying the length of time that philosophers think and eat and the number of philosophers. What effect does this have on how long it takes until deadlock? Imagine that you were trying to debug this and wanted to increase the likelihood of reproducing the deadlock—what would you do?
· (Hard) Create a program that demonstrates writes to memory appearing to be reordered in the absence of synchronization. This is difficult because although the Java memory model allows things to be reordered, most simple examples won’t be optimized to the point of actually demonstrating the problem.
Day 2: Beyond Intrinsic Locks
Day 1 covered Java’s Thread class and the intrinsic locks built into every Java object. For a long time this was pretty much all the support that Java provided for concurrent programming. Java 5 changed all that with the introduction of java.util.concurrent. Today we’ll look at the enhanced locking mechanisms it provides.
Intrinsic locks are convenient but limited.
· There is no way to interrupt a thread that’s blocked as a result of trying to acquire an intrinsic lock.
· There is no way to time out while trying to acquire an intrinsic lock.
· There’s exactly one way to acquire an intrinsic lock: a synchronized block.
|
|
synchronized(object) { |
|
|
use shared resources |
|
|
} |
· This means that lock acquisition and release have to take place in the same method and have to be strictly nested. Note that declaring a method as synchronized is just syntactic sugar for surrounding the method’s body with the following:
|
|
synchronized(this) { |
|
|
method body |
|
|
} |
ReentrantLock allows us to transcend these restrictions by providing explicit lock and unlock methods instead of using synchronized.
Before we go into how it improves upon intrinsic locks, here’s how ReentrantLock can be used as a straight replacement for synchronized:
|
|
Lock lock = new ReentrantLock(); |
|
|
lock.lock(); |
|
|
try { |
|
|
use shared resources |
|
|
} finally { |
|
|
lock.unlock(); |
|
|
} |
The try … finally is good practice to ensure that the lock is always released, no matter what happens in the code the lock is protecting.
Now let’s see how it lifts the restrictions of intrinsic locks.
Interruptible Locking
Because a thread that’s blocked on an intrinsic lock is not interruptible, we have no way to recover from a deadlock. We can see this with a small example that manufactures a deadlock and then tries to interrupt the threads:
|
ThreadsLocks/Uninterruptible/src/main/java/com/paulbutcher/Uninterruptible.java |
|
|
|
public class Uninterruptible { |
|
|
|
|
|
public static void main(String[] args) throws InterruptedException { |
|
|
|
|
|
final Object o1 = new Object(); final Object o2 = new Object(); |
|
|
|
|
|
Thread t1 = new Thread() { |
|
|
public void run() { |
|
|
try { |
|
|
synchronized(o1) { |
|
|
Thread.sleep(1000); |
|
|
synchronized(o2) {} |
|
|
} |
|
|
} catch (InterruptedException e) { System.out.println("t1 interrupted"); } |
|
|
} |
|
|
}; |
|
|
|
|
|
Thread t2 = new Thread() { |
|
|
public void run() { |
|
|
try { |
|
|
synchronized(o2) { |
|
|
Thread.sleep(1000); |
|
|
synchronized(o1) {} |
|
|
} |
|
|
} catch (InterruptedException e) { System.out.println("t2 interrupted"); } |
|
|
} |
|
|
}; |
|
|
|
|
|
t1.start(); t2.start(); |
|
|
Thread.sleep(2000); |
|
|
t1.interrupt(); t2.interrupt(); |
|
|
t1.join(); t2.join(); |
|
|
} |
|
|
} |
This program will deadlock forever—the only way to exit it is to kill the JVM running it.
![]()
Joe asks:
Is There Really No Way to Kill a Deadlocked Thread?
You might think that there has to be some way to kill a deadlocked thread. Sadly, you would be wrong. All the mechanisms that have been tried to achieve this have been shown to be flawed and are now deprecated.[7]
The bottom line is that there is exactly one way to exit a thread in Java, and that’s for the run method to return (possibly as a result of an InterruptedException). So if your thread is deadlocked on an intrinsic lock, you’re simply out of luck. You can’t interrupt it, and the only way that thread is ever going to exit is if you kill the JVM it’s running in.
There is a solution, however. We can reimplement our threads using ReentrantLock instead of intrinsic locks, and we can use its lockInterruptibly method:
|
ThreadsLocks/Interruptible/src/main/java/com/paulbutcher/Interruptible.java |
|
|
|
final ReentrantLock l1 = new ReentrantLock(); |
|
|
final ReentrantLock l2 = new ReentrantLock(); |
|
|
|
|
|
Thread t1 = new Thread() { |
|
|
public void run() { |
|
|
try { |
|
* |
l1.lockInterruptibly(); |
|
|
Thread.sleep(1000); |
|
* |
l2.lockInterruptibly(); |
|
|
} catch (InterruptedException e) { System.out.println("t1 interrupted"); } |
|
|
} |
|
|
}; |
This version exits cleanly when Thread.interrupt() is called. The slightly noisier syntax of this version seems a small price to pay for the ability to interrupt a deadlocked thread.
Timeouts
ReentrantLock lifts another limitation of intrinsic locks: it allows us to time out while trying to acquire a lock. This provides us with an alternative way to solve the “dining philosophers” problem from day 1.
Here’s a Philosopher that times out if it fails to get both chopsticks:
|
ThreadsLocks/DiningPhilosophersTimeout/src/main/java/com/paulbutcher/Philosopher.java |
|
|
|
class Philosopher extends Thread { |
|
|
private ReentrantLock leftChopstick, rightChopstick; |
|
|
private Random random; |
|
|
|
|
|
public Philosopher(ReentrantLock leftChopstick, ReentrantLock rightChopstick) { |
|
|
this.leftChopstick = leftChopstick; this.rightChopstick = rightChopstick; |
|
|
random = new Random(); |
|
|
} |
|
|
|
|
|
public void run() { |
|
|
try { |
|
|
while(true) { |
|
|
Thread.sleep(random.nextInt(1000)); // Think for a while |
|
|
leftChopstick.lock(); |
|
|
try { |
|
* |
if (rightChopstick.tryLock(1000, TimeUnit.MILLISECONDS)) { |
|
|
// Got the right chopstick |
|
|
try { |
|
|
Thread.sleep(random.nextInt(1000)); // Eat for a while |
|
|
} finally { rightChopstick.unlock(); } |
|
|
} else { |
|
* |
// Didn't get the right chopstick - give up and go back to thinking |
|
|
} |
|
|
} finally { leftChopstick.unlock(); } |
|
|
} |
|
|
} catch(InterruptedException e) {} |
|
|
} |
|
|
} |
Instead of using lock, this code uses tryLock, which times out if it fails to acquire the lock. This means that, even though we don’t follow the “acquire multiple locks in a fixed, global order” rule, this version will not deadlock (or at least, will not deadlock forever).
Livelock
Although the tryLock solution avoids infinite deadlock, that doesn’t mean it’s a good solution. Firstly, it doesn’t avoid deadlock—it simply provides a way to recover when it happens. Secondly, it’s susceptible to a phenomenon known as livelock—if all the threads time out at the same time, it’s quite possible for them to immediately deadlock again. Although the deadlock doesn’t last forever, no progress is made either.
This situation can be mitigated by having each thread use a different timeout value, for example, to minimize the chances that they will all time out simultaneously. But the bottom line is that timeouts are rarely a good solution—it’s far better to avoid deadlock in the first place.
Hand-over-Hand Locking
Imagine that we want to insert an entry into a linked list. One approach would be to have a single lock protecting the whole list, but this would mean that nobody else could access it while we held the lock. Hand-over-hand locking is an alternative in which we lock only a small portion of the list, allowing other threads unfettered access as long as they’re not looking at the particular nodes we’ve got locked. Here’s a graphical representation:
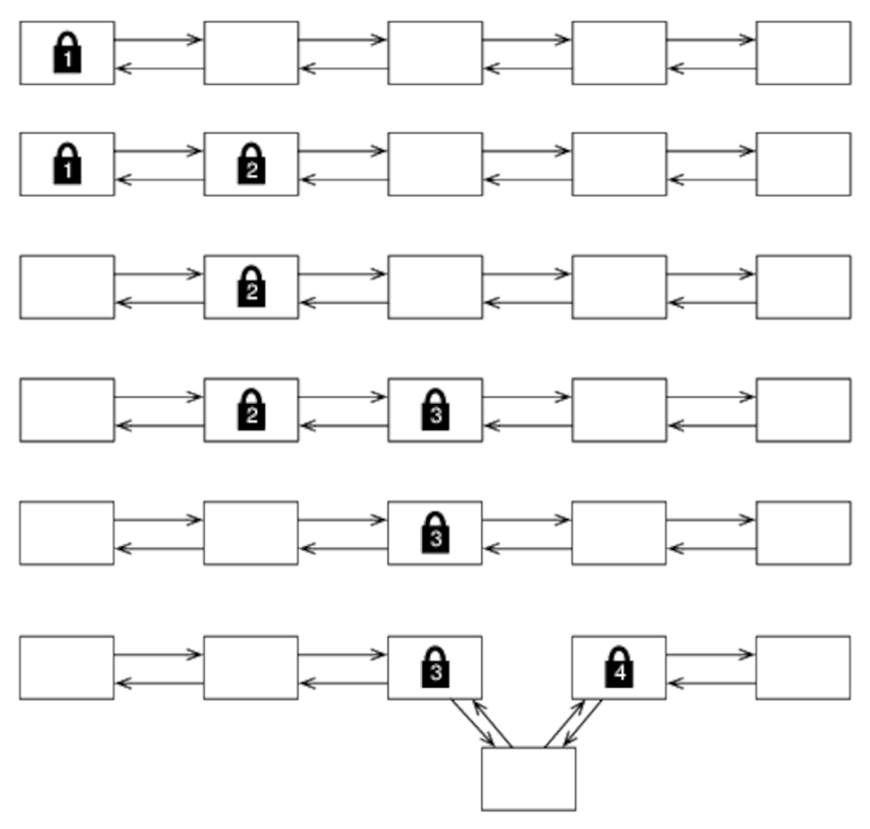
Figure 3. Hand-over-hand locking
To insert a node, we need to lock the two nodes on either side of the point we’re going to insert. We start by locking the first two nodes of the list. If this isn’t the right place to insert the new node, we unlock the first node and lock the third. If this still isn’t the right place, we unlock the second and lock the fourth. This continues until we find the appropriate place, insert the new node, and finally unlock the nodes on either side.
This sequence of locks and unlocks is impossible with intrinsic locks, but it is possible with ReentrantLock because we can call lock and unlock whenever we like. Here is a class that implements a sorted linked list using this approach:
|
ThreadsLocks/LinkedList/src/main/java/com/paulbutcher/ConcurrentSortedList.java |
|
|
Line 1 |
class ConcurrentSortedList { |
|
- |
|
|
- |
private class Node { |
|
- |
int value; |
|
5 |
Node prev; |
|
- |
Node next; |
|
- |
ReentrantLock lock = new ReentrantLock(); |
|
- |
|
|
- |
Node() {} |
|
10 |
|
|
- |
Node(int value, Node prev, Node next) { |
|
- |
this.value = value; this.prev = prev; this.next = next; |
|
- |
} |
|
- |
} |
|
15 |
|
|
- |
private final Node head; |
|
- |
private final Node tail; |
|
- |
|
|
- |
public ConcurrentSortedList() { |
|
20 |
head = new Node(); tail = new Node(); |
|
- |
head.next = tail; tail.prev = head; |
|
- |
} |
|
- |
|
|
- |
public void insert(int value) { |
|
25 |
Node current = head; |
|
- |
current.lock.lock(); |
|
- |
Node next = current.next; |
|
- |
try { |
|
- |
while (true) { |
|
30 |
next.lock.lock(); |
|
- |
try { |
|
- |
if (next == tail || next.value < value) { |
|
- |
Node node = new Node(value, current, next); |
|
- |
next.prev = node; |
|
35 |
current.next = node; |
|
- |
return; |
|
- |
} |
|
- |
} finally { current.lock.unlock(); } |
|
- |
current = next; |
|
40 |
next = current.next; |
|
- |
} |
|
- |
} finally { next.lock.unlock(); } |
|
- |
} |
|
- |
} |
The insert method ensures that the list is always sorted by searching until it finds the first entry that’s less than the new one. When it does, it inserts the new node just before.
Line 26 locks the head of the list, and line 30 locks the next node. We then check to see if we’ve found the right place to insert our new node. If not, the current node is unlocked on line 38 and we loop. If we have found the right place, lines 33–36 create the new node, insert it into the list, and return. The locks are released in the two finally blocks (lines 38 and 42).
Not only can several threads insert entries concurrently using this scheme, but other operations can also safely take place on the list. Here, for example, is a method that counts how many elements are in the list—and just for kicks it iterates backward through the list:
|
ThreadsLocks/LinkedList/src/main/java/com/paulbutcher/ConcurrentSortedList.java |
|
|
|
public int size() { |
|
|
Node current = tail; |
|
|
int count = 0; |
|
|
|
|
|
while (current.prev != head) { |
|
|
ReentrantLock lock = current.lock; |
|
|
lock.lock(); |
|
|
try { |
|
|
++count; |
|
|
current = current.prev; |
|
|
} finally { lock.unlock(); } |
|
|
} |
|
|
|
|
|
return count; |
|
|
} |
We’ll look at one further feature of ReentrantLock today—condition variables.
![]()
Joe asks:
Doesn’t This Break the “Global Ordering” Rule?
ConcurrentSortedList’s insert method acquires locks starting at the head of the list and moving toward the tail. The size method above acquires them from the tail of the list, moving toward the head. Doesn’t this violate the “Always acquire multiple locks in a fixed, global order” rule?
It doesn’t, because the size method never holds multiple locks—it never holds more than a single lock at a time.
Condition Variables
Concurrent programming often involves waiting for something to happen. Perhaps we need to wait for a queue to become nonempty before removing an element from it. Or we need to wait for space to be available in a buffer before adding something to it. This type of situation is what condition variables are designed to address.
To use a condition variable effectively, we need to follow a very specific pattern:
|
|
ReentrantLock lock = new ReentrantLock(); |
|
|
Condition condition = lock.newCondition(); |
|
|
|
|
|
lock.lock(); |
|
|
try { |
|
|
while (!condition is true) |
|
|
condition.await(); |
|
|
use shared resources |
|
|
} finally { lock.unlock(); } |
A condition variable is associated with a lock, and a thread must hold that lock before being able to wait on the condition. Once it holds the lock, it checks to see if the condition that it’s interested in is already true. If it is, then it continues with whatever it wants to do and unlocks the lock.
If, however, the condition is not true, it calls await, which atomically unlocks the lock and blocks on the condition variable. An operation is atomic if, from the point of view of another thread, it appears to be a single operation that has either happened or not—it never appears to be halfway through.
When another thread calls signal or signalAll to indicate that the condition might now be true, await unblocks and automatically reacquires the lock. An important point is that when await returns, it only indicates that the condition might be true. This is why await is called within a loop—we need to go back, recheck whether the condition is true, and potentially block on await again if necessary.
This gives us yet another solution to the “dining philosophers” problem:
|
ThreadsLocks/DiningPhilosophersCondition/src/main/java/com/paulbutcher/Philosopher.java |
|
|
|
class Philosopher extends Thread { |
|
|
|
|
|
private boolean eating; |
|
|
private Philosopher left; |
|
|
private Philosopher right; |
|
|
private ReentrantLock table; |
|
|
private Condition condition; |
|
|
private Random random; |
|
|
|
|
|
public Philosopher(ReentrantLock table) { |
|
|
eating = false; |
|
|
this.table = table; |
|
|
condition = table.newCondition(); |
|
|
random = new Random(); |
|
|
} |
|
|
|
|
|
public void setLeft(Philosopher left) { this.left = left; } |
|
|
public void setRight(Philosopher right) { this.right = right; } |
|
|
|
|
|
public void run() { |
|
|
try { |
|
|
while (true) { |
|
|
think(); |
|
|
eat(); |
|
|
} |
|
|
} catch (InterruptedException e) {} |
|
|
} |
|
|
|
|
|
private void think() throws InterruptedException { |
|
|
table.lock(); |
|
|
try { |
|
|
eating = false; |
|
|
left.condition.signal(); |
|
|
right.condition.signal(); |
|
|
} finally { table.unlock(); } |
|
|
Thread.sleep(1000); |
|
|
} |
|
|
|
|
|
private void eat() throws InterruptedException { |
|
|
table.lock(); |
|
|
try { |
|
|
while (left.eating || right.eating) |
|
|
condition.await(); |
|
|
eating = true; |
|
|
} finally { table.unlock(); } |
|
|
Thread.sleep(1000); |
|
|
} |
|
|
} |
This solution differs from those we’ve already seen by using only a single lock (table) and not having an explicit Chopstick class. Instead we make use of the fact that a philosopher can eat if neither of his neighbors is currently eating. In other words, a hungry philosopher is waiting for this condition:
|
|
!(left.eating || right.eating) |
When a philosopher is hungry, he first locks the table so no other philosophers can change state, and then he checks to see if his neighbors are currently eating. If they aren’t, he can start to eat and release the table. Otherwise, he calls await (which unlocks the table).
When a philosopher has finished eating and wants to start thinking, he first locks the table and sets eating to false. Then he signals both of his neighbors to let them know that they might be able to start eating and releases the table. If those neighbors are currently waiting, they’ll be woken, reacquire the lock on the table, and check again to see if they can eat.
Although this code is more complex than the other solutions we’ve seen, the payoff is that it results in significantly better concurrency. With the previous solutions, it’s often the case that only a single hungry philosopher can eat, because the others all have a single chopstick and are waiting for the other to become available. With this solution, whenever it’s theoretically possible for a philosopher to eat (when neither of his neighbors are eating), he will be able to do so.
That’s it for ReentrantLock, but there’s another alternative to intrinsic locks that we’ll cover next—atomic variables.
Atomic Variables
On day 1, we fixed our multithreaded counter by making the increment method synchronized (see the code). It turns out that java.util.concurrent.atomic provides a better option:
|
ThreadsLocks/CountingBetter/src/main/java/com/paulbutcher/Counting.java |
|
|
|
public class Counting { |
|
|
public static void main(String[] args) throws InterruptedException { |
|
|
|
|
* |
final AtomicInteger counter = new AtomicInteger(); |
|
|
|
|
|
class CountingThread extends Thread { |
|
|
public void run() { |
|
|
for(int x = 0; x < 10000; ++x) |
|
* |
counter.incrementAndGet(); |
|
|
} |
|
|
} |
|
|
|
|
|
CountingThread t1 = new CountingThread(); |
|
|
CountingThread t2 = new CountingThread(); |
|
|
|
|
|
t1.start(); t2.start(); |
|
|
t1.join(); t2.join(); |
|
|
|
|
|
System.out.println(counter.get()); |
|
|
} |
|
|
} |
AtomicInteger’s incrementAndGet method is functionally equivalent to ++count (it also supports getAndIncrement, which is equivalent to count++). Unlike ++count, however, it’s atomic.
Using an atomic variable instead of locks has a number of benefits. First, it’s not possible to forget to acquire the lock when necessary. For example, the memory-visibility problem in Counter, which arose because getCount wasn’t synchronized, cannot occur with this code. Second, because no locks are involved, it’s impossible for an operation on an atomic variable to deadlock.
Finally, atomic variables are the foundation of non-blocking, lock-free algorithms, which achieve synchronization without locks or blocking. If you think that programming with locks is tricky, then just wait until you try writing lock-free code. Happily, the classes in java.util.concurrent make use of lock-free code where possible, so you can take advantage painlessly. We’ll cover these classes in day 3, but for now this brings us to the end of day 2.
![]()
Joe asks:
What About Volatile?
Java allows us to mark a variable as volatile. Doing so guarantees that reads and writes to that variable will not be reordered. We could fix Puzzle (see the code) by making answerReady volatile.
Volatile is a very weak form of synchronization. It would not help us fix Counter, for example, because making count volatile would not ensure that count++ is atomic.
These days, with highly optimized JVMs that have very low-overhead locks, valid use cases for volatile variables are rare. If you find yourself considering volatile, you should probably use one of the java.util.concurrent.atomic classes instead.
Day 2 Wrap-Up
We’ve built upon the basics introduced in day 1 to cover the more sophisticated and flexible mechanisms provided by java.util.concurrent.locks and java.util.concurrent.atomic. Although it’s important to understand these mechanisms, you’ll rarely use locks directly in practice, as we’ll see in day 3.
What We Learned in Day 2
We saw how ReentrantLock and java.util.concurrent.atomic can overcome the limitations of intrinsic locks so that our threads can do the following:
· Be interrupted while trying to acquire a lock
· Time out while acquiring a lock
· Acquire and release locks in any order
· Use condition variables to wait for arbitrary conditions to become true
· Avoid locks entirely by using atomic variables
Day 2 Self-Study
Find
· ReentrantLock supports a fairness parameter. What does it mean for a lock to be “fair”? Why might you choose to use a fair lock? Why might you not?
· What is ReentrantReadWriteLock? How does it differ from ReentrantLock? When might you use it?
· What is a “spurious wakeup”? When can one happen and why doesn’t a well-written program care if one does?
· What is AtomicIntegerFieldUpdater? How does it differ from AtomicInteger? When might you use it?
Do
· What would happen if the loop within the “dining philosophers” implementation that uses condition variables was replaced with a simple if statement? What failure modes might you see? What would happen if the call to signal was replaced by signalAll? What problems (if any) would this cause?
· Just as intrinsic locks are more limited than ReentrantLock, they also support a more limited type of condition variable. Rewrite the dining philosophers to use an intrinsic lock plus the wait and notify or notifyAll methods. Why is it less efficient than using ReentrantLock?
· Write a version of ConcurrentSortedList that uses a single lock instead of hand-over-hand locking. Benchmark it against the other version. Does hand-over-hand locking provide any performance advantage? When might it be a good choice? When might it not?
Day 3: On the Shoulders of Giants
As well as the enhanced locks we covered in day 2, java.util.concurrent contains a collection of general-purpose, high-performance, and thoroughly debugged concurrent data structures and utilities. Today we’ll see that more often than not, these prove to be a better choice than rolling our own solution.
Thread-Creation Redux
In day 1 we saw how to start threads, but it turns out that it rarely makes sense to create threads directly. Here, for example, is a very simple server that echoes whatever it’s sent:
|
ThreadsLocks/EchoServer/src/main/java/com/paulbutcher/EchoServer.java |
|
|
|
public class EchoServer { |
|
|
|
|
|
public static void main(String[] args) throws IOException { |
|
|
|
|
|
class ConnectionHandler implements Runnable { |
|
|
InputStream in; OutputStream out; |
|
|
ConnectionHandler(Socket socket) throws IOException { |
|
|
in = socket.getInputStream(); |
|
|
out = socket.getOutputStream(); |
|
|
} |
|
|
|
|
|
public void run() { |
|
|
try { |
|
|
int n; |
|
|
byte[] buffer = new byte[1024]; |
|
|
while((n = in.read(buffer)) != -1) { |
|
|
out.write(buffer, 0, n); |
|
|
out.flush(); |
|
|
} |
|
|
} catch (IOException e) {} |
|
|
} |
|
|
} |
|
|
|
|
|
ServerSocket server = new ServerSocket(4567); |
|
|
while (true) { |
|
* |
Socket socket = server.accept(); |
|
* |
Thread handler = new Thread(new ConnectionHandler(socket)); |
|
* |
handler.start(); |
|
|
} |
|
|
} |
|
|
} |
The highlighted lines follow the common pattern of accepting an incoming connection and then immediately creating a new thread to handle it. This works fine, but it suffers from a couple of issues. First, although thread creation is cheap, it’s not free, and this design will pay that price for each connection. Second, it creates as many threads as connections—if connections are coming in faster than they can be handled, then the number of threads will increase and the server will grind to a halt and possibly even crash. This is a perfect opening for anyone who wants to subject your server to a denial-of-service attack.
We can avoid these problems by using a thread pool:
|
ThreadsLocks/EchoServerBetter/src/main/java/com/paulbutcher/EchoServer.java |
|
|
|
int threadPoolSize = Runtime.getRuntime().availableProcessors() * 2; |
|
|
ExecutorService executor = Executors.newFixedThreadPool(threadPoolSize); |
|
|
while (true) { |
|
|
Socket socket = server.accept(); |
|
|
executor.execute(new ConnectionHandler(socket)); |
|
|
} |
This code creates a thread pool with twice as many threads as there are available processors. If more than this number of execute requests are active at a time, they will be queued until a thread becomes free. Not only does this mean that we don’t incur the overhead of thread creation for each connection, but it also ensures that our server will continue to make progress in the face of high load (not that it will service the incoming requests quickly enough to keep up, but at least some of them will be serviced).
![]()
Joe asks:
How Large Should My Thread Pool Be?
The optimum number of threads will vary according to the hardware you’re running on, whether your threads are IO or CPU bound, what else the machine is doing at the same time, and a host of other factors.
Having said that, a good rule of thumb is that for computation-intensive tasks, you probably want to have approximately the same number of threads as available cores. Larger numbers are appropriate for IO-intensive tasks.
Beyond this rule of thumb, your best bet is to create a realistic load test and break out the stopwatch.
Copy on Write
On day 1 we looked at how to call listeners safely in a concurrent program. If you recall, we modified updateProgress to make a defensive copy (see the code). It turns out that the Java standard library provides a more elegant, ready-made solution in CopyOnWriteArrayList:
|
ThreadsLocks/HttpDownloadBetter/src/main/java/com/paulbutcher/Downloader.java |
|
|
|
private CopyOnWriteArrayList<ProgressListener> listeners; |
|
|
|
|
|
public void addListener(ProgressListener listener) { |
|
|
listeners.add(listener); |
|
|
} |
|
|
public void removeListener(ProgressListener listener) { |
|
|
listeners.remove(listener); |
|
|
} |
|
|
private void updateProgress(int n) { |
|
|
for (ProgressListener listener: listeners) |
|
|
listener.onProgress(n); |
|
|
} |
As its name suggests, CopyOnWriteArrayList turns our previous defensive copy strategy on its head. Instead of making a copy before iterating through the list, it makes a copy whenever it’s changed. Any existing iterators will continue to refer to the previous copy. This isn’t an approach that would be appropriate for many use cases, but it’s perfect for this one.
First, as you can see, it results in very clear and concise code. In fact, apart from the definition of listeners, it’s identical to the naïve, non-thread-safe version we first came up with in the code. Second, it’s more efficient because we don’t have to make a copy each time updateProgress is called, but only when listeners is modified (which is likely to happen much less often).
A Complete Program
Up until now, we’ve looked at individual tools in isolation. For the remainder of today, we’ll look at solving a small but realistic problem: What’s the most commonly used word on Wikipedia?
It should be easy enough to find out—just download an XML dump and write a program to parse it and count the words.[8] Given that the dump weighs in at around 40 GiB, it’s going to take a while; perhaps we can speed it up by parallelizing things?
Let’s start by getting a baseline—how long does a simple sequential program take to count the words in the first 100,000 pages?
|
ThreadsLocks/WordCount/src/main/java/com/paulbutcher/WordCount.java |
|
|
|
public class WordCount { |
|
|
private static final HashMap<String, Integer> counts = |
|
|
new HashMap<String, Integer>(); |
|
|
|
|
|
public static void main(String[] args) throws Exception { |
|
|
Iterable<Page> pages = new Pages(100000, "enwiki.xml"); |
|
|
for(Page page: pages) { |
|
|
Iterable<String> words = new Words(page.getText()); |
|
|
for (String word: words) |
|
|
countWord(word); |
|
|
} |
|
|
} |
|
|
|
|
|
private static void countWord(String word) { |
|
|
Integer currentCount = counts.get(word); |
|
|
if (currentCount == null) |
|
|
counts.put(word, 1); |
|
|
else |
|
|
counts.put(word, currentCount + 1); |
|
|
} |
|
|
} |
On my MacBook Pro, this runs in just under 105 seconds.
So where do we start with a parallel version? Each iteration of the main loop performs two tasks—first it parses enough of the XML to produce a Page, and then it consumes that page by counting the words in its text.
There is a classic pattern that can be applied to this kind of problem—the producer-consumer pattern. Instead of a single thread that alternates between producing values and then consuming them, we create two threads, a producer and a consumer.
Here’s a Parser implemented as a producer:
|
ThreadsLocks/WordCountProducerConsumer/src/main/java/com/paulbutcher/Parser.java |
|
|
|
class Parser implements Runnable { |
|
|
private BlockingQueue<Page> queue; |
|
|
|
|
|
public Parser(BlockingQueue<Page> queue) { |
|
|
this.queue = queue; |
|
|
} |
|
|
|
|
|
public void run() { |
|
|
try { |
|
* |
Iterable<Page> pages = new Pages(100000, "enwiki.xml"); |
|
* |
for (Page page: pages) |
|
* |
queue.put(page); |
|
|
} catch (Exception e) { e.printStackTrace(); } |
|
|
} |
|
|
} |
The run method contains the outer loop of our sequential solution, but instead of counting the words in the newly parsed page, it adds it to the tail of a queue.
Here’s the corresponding consumer:
|
ThreadsLocks/WordCountProducerConsumer/src/main/java/com/paulbutcher/Counter.java |
|
|
|
class Counter implements Runnable { |
|
|
private BlockingQueue<Page> queue; |
|
|
private Map<String, Integer> counts; |
|
|
|
|
|
public Counter(BlockingQueue<Page> queue, |
|
|
Map<String, Integer> counts) { |
|
|
this.queue = queue; |
|
|
this.counts = counts; |
|
|
} |
|
|
|
|
|
public void run() { |
|
|
try { |
|
|
while(true) { |
|
* |
Page page = queue.take(); |
|
|
if (page.isPoisonPill()) |
|
|
break; |
|
|
|
|
* |
Iterable<String> words = new Words(page.getText()); |
|
* |
for (String word: words) |
|
* |
countWord(word); |
|
|
} |
|
|
} catch (Exception e) { e.printStackTrace(); } |
|
|
} |
|
|
} |
As you might expect, it contains the inner loop of our sequential solution, taking its input from the queue.
Finally, here’s a modified version of our main loop that creates these two threads:
|
ThreadsLocks/WordCountProducerConsumer/src/main/java/com/paulbutcher/WordCount.java |
|
|
|
ArrayBlockingQueue<Page> queue = new ArrayBlockingQueue<Page>(100); |
|
|
HashMap<String, Integer> counts = new HashMap<String, Integer>(); |
|
|
|
|
|
Thread counter = new Thread(new Counter(queue, counts)); |
|
|
Thread parser = new Thread(new Parser(queue)); |
|
|
|
|
|
counter.start(); |
|
|
parser.start(); |
|
|
parser.join(); |
|
|
queue.put(new PoisonPill()); |
|
|
counter.join(); |
ArrayBlockingQueue from java.util.concurrent is a concurrent queue that’s ideal for implementing the producer-consumer pattern. Not only does it provide efficient concurrent put and take methods, but these methods will block when necessary. Trying to take from an empty queue will block until the queue is nonempty, and trying to put into a full queue will block until the queue has space available.
![]()
Joe asks:
Why a Blocking Queue?
As well as blocking queues, java.util.concurrent provides ConcurrentLinkedQueue, an unbounded, wait-free, and nonblocking queue. That sounds like a very desirable set of attributes, so why isn’t it a good choice for this problem?
The issue is that the producer and consumer may not (almost certainly will not) run at the same speed. In particular, if the producer runs faster than the consumer, the queue will get larger and larger. Given that the Wikipedia dump we’re parsing is around 40 GiB, that could easily result in the queue becoming too large to fit in memory.
Using a blocking queue, by contrast, will allow the producer to get ahead of the consumer, but not too far.
One other interesting aspect of this solution is how the consumer knows when to exit:
|
ThreadsLocks/WordCountProducerConsumer/src/main/java/com/paulbutcher/Counter.java |
|
|
|
if (page.isPoisonPill()) |
|
|
break; |
As its name suggests, a poison pill is a special token that indicates that the end of the available data has been reached and that the consumer should therefore exit. It’s very similar to the way that C/C++ uses a null character to indicate the end of a string.
The good news is that this has sped things up—instead of running in 105 seconds, this version runs in 95.
That’s great, but we can do better. The beauty of the producer-consumer pattern is that it allows us not only to produce and consume values in parallel, but also to have multiple producers and/or multiple consumers.
But should we concentrate on speeding up the producer or the consumer? Where is the code spending its time? If I temporarily modify the code so that only the producer runs and I get my stopwatch out, I find that I can parse the first 100,000 pages in around 10 seconds.
This isn’t surprising if you think about it for a moment. The original, sequential version of the code ran in 105 seconds, and the producer-consumer version ran in 95. Clearly parsing takes 10 seconds, and counting the words takes 95. By parsing and counting in parallel, we can reduce the total to whichever is the longest of these—in this case, 95 seconds.
So to improve performance further, we need to parallelize the counting process and have multiple consumers. The following figure shows where we’re heading:
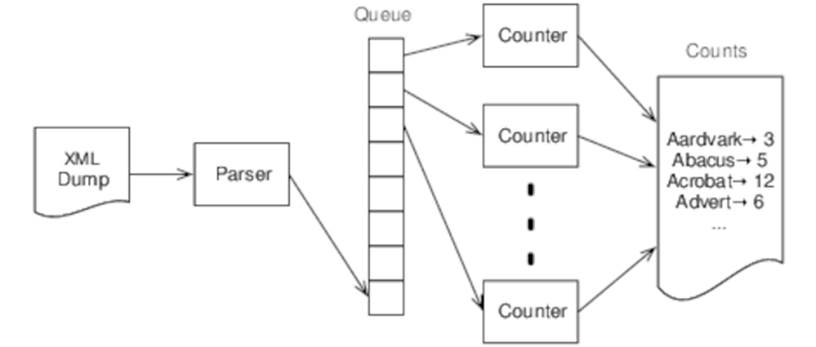
If we’re going to have multiple threads counting words simultaneously, we’re going to have to find a way to synchronize access to the counts map.
The first thing we might consider is using a synchronized map, returned by the synchronizedMap method in Collections. Unfortunately, synchronized collections don’t provide atomic read-modify-write methods, so this isn’t going to help us. If we want to use a HashMap, we’re going to have to synchronize access to it ourselves.
Here’s a modified countWord method that does exactly this:
|
ThreadsLocks/WordCountSynchronizedHashMap/src/main/java/com/paulbutcher/Counter.java |
|
|
|
private void countWord(String word) { |
|
* |
lock.lock(); |
|
|
try { |
|
|
Integer currentCount = counts.get(word); |
|
|
if (currentCount == null) |
|
|
counts.put(word, 1); |
|
|
else |
|
|
counts.put(word, currentCount + 1); |
|
* |
} finally { lock.unlock(); } |
|
|
} |
And here’s a modified main loop that runs multiple consumers:
|
ThreadsLocks/WordCountSynchronizedHashMap/src/main/java/com/paulbutcher/WordCount.java |
|
|
|
ArrayBlockingQueue<Page> queue = new ArrayBlockingQueue<Page>(100); |
|
|
HashMap<String, Integer> counts = new HashMap<String, Integer>(); |
|
|
ExecutorService executor = Executors.newCachedThreadPool(); |
|
|
for (int i = 0; i < NUM_COUNTERS; ++i) |
|
|
executor.execute(new Counter(queue, counts)); |
|
|
Thread parser = new Thread(new Parser(queue)); |
|
|
parser.start(); |
|
|
parser.join(); |
|
|
for (int i = 0; i < NUM_COUNTERS; ++i) |
|
|
queue.put(new PoisonPill()); |
|
|
executor.shutdown(); |
|
|
executor.awaitTermination(10L, TimeUnit.MINUTES); |
This is very similar to what we had before, except we’ve switched to using a thread pool, which is more convenient than managing multiple threads ourselves. And we need to make sure that we add the right number of poison pills to the queue to shut down cleanly.
This all looks great, but our hopes are about to be dashed. Here’s how long it takes to run with one and two consumers (speedup is relative to the sequential version):
|
Consumers |
Time (s) |
Speedup |
|
1 |
101 |
1.04 |
|
2 |
212 |
0.49 |
Why does adding another consumer make things slower? And not just slightly slower, but more than twice as slow?
The answer is excessive contention—too many threads are trying to access a single shared resource simultaneously. In our case, the consumers are spending so much of their time with the counts map locked that they spend more time waiting for the other to unlock it than they spend actually doing useful work, which leads to horrid performance.
Happily, we’re not beaten yet. ConcurrentHashMap in java.util.concurrent looks like exactly what we need. Not only does it provide atomic read-modify-write methods, but it’s been designed to support high levels of concurrent access (via a technique called lock striping).
Here’s a modified countWord that uses ConcurrentHashMap:
|
ThreadsLocks/WordCountConcurrentHashMap/src/main/java/com/paulbutcher/Counter.java |
|
|
|
private void countWord(String word) { |
|
|
while (true) { |
|
|
Integer currentCount = counts.get(word); |
|
|
if (currentCount == null) { |
|
|
if (counts.putIfAbsent(word, 1) == null) |
|
|
break; |
|
|
} else if (counts.replace(word, currentCount, currentCount + 1)) { |
|
|
break; |
|
|
} |
|
|
} |
|
|
} |
It’s worth spending a little time understanding exactly how this works. Instead of put, we’re now using a combination of putIfAbsent and replace. Here’s the documentation for putIfAbsent:
If the specified key is not already associated with a value, associate it with the given value. This is equivalent to
|
|
if (!map.containsKey(key)) |
|
|
return map.put(key, value); |
|
|
else |
|
|
return map.get(key); |
except that the action is performed atomically.
And for replace:
Replaces the entry for a key only if currently mapped to a given value. This is equivalent to
|
|
if (map.containsKey(key) && map.get(key).equals(oldValue)) { |
|
|
map.put(key, newValue); |
|
|
return true; |
|
|
} else return false; |
except that the action is performed atomically.
So whenever we call either of these functions, we need to check their return value to work out whether they have successfully made the change we expected. If not, we need to loop around and try again.
With this version, the stopwatch is much kinder to us:
|
Consumers |
Time (s) |
Speedup |
|
1 |
120 |
0.87 |
|
2 |
83 |
1.26 |
|
3 |
65 |
1.61 |
|
4 |
63 |
1.67 |
|
5 |
70 |
1.50 |
|
6 |
79 |
1.33 |
Success! This time, adding more consumers makes us go faster, at least until we have more than four consumers, after which things get slower again.
Having said that, although 63 seconds is certainly faster than the 105 seconds taken by the sequential version of the code, it’s not even twice as fast. My MacBook has four cores—surely we should be able to get closer to a 4x speedup?
With a little thought, it’s clear that our solution is creating far more contention for the counts map than it has to. Instead of each consumer updating a shared set of counts concurrently, each should maintain its own local set of counts. All we need to do is merge these local counts before we exit:
|
ThreadsLocks/WordCountBatchConcurrentHashMap/src/main/java/com/paulbutcher/Counter.java |
|
|
|
private void mergeCounts() { |
|
|
for (Map.Entry<String, Integer> e: localCounts.entrySet()) { |
|
|
String word = e.getKey(); |
|
|
Integer count = e.getValue(); |
|
|
while (true) { |
|
|
Integer currentCount = counts.get(word); |
|
|
if (currentCount == null) { |
|
|
if (counts.putIfAbsent(word, count) == null) |
|
|
break; |
|
|
} else if (counts.replace(word, currentCount, currentCount + count)) { |
|
|
break; |
|
|
} |
|
|
} |
|
|
} |
|
|
} |
This gets us much closer to our ideal 4x speedup:
|
Consumers |
Time (s) |
Speedup |
|
1 |
95 |
1.10 |
|
2 |
57 |
1.83 |
|
3 |
40 |
2.62 |
|
4 |
39 |
2.69 |
|
5 |
35 |
2.96 |
|
6 |
33 |
3.14 |
|
7 |
41 |
2.55 |
Not only does this version increase in performance more quickly as we add consumers, but it even continues to improve in performance beyond four consumers. This is possible because each of the cores in my MacBook supports two “hyperthreads”—availableProcessors actually returns eight, even though there are only four physical cores.
Figure 4, Word Count Performance by Number of Consumers shows a graph that shows the performance of the three different versions.
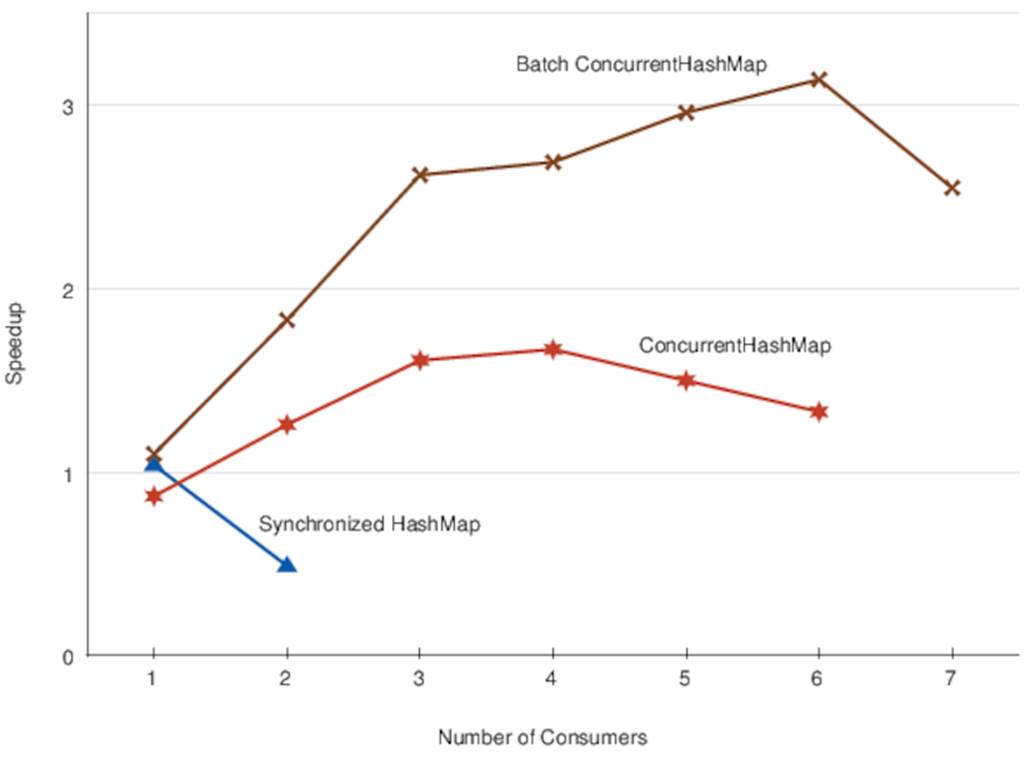
Figure 4. Word Count Performance by Number of Consumers
You’ll see this curve again and again when working with parallel programs. The performance initially increases linearly and is then followed by a period where performance continues to increase, but more slowly. Eventually performance will peak, and adding more threads will only make things slower.
It’s worth taking a moment to reflect on what we’ve just done. We’ve created a relatively sophisticated producer-consumer program, with multiple consumers coordinating with one another via a concurrent queue and a concurrent map. And we did all of this without any explicit locking because we built on top of the facilities provided in the standard library.
Day 3 Wrap-Up
This brings us to the end of day 3 and the end of our discussion of programming with threads and locks.
What We Learned in Day 3
We saw how the facilities provided by java.util.concurrent not only make it easier to create concurrent programs, but also make those programs safer and more efficient by doing the following:
· Using thread pools instead of creating threads directly
· Creating simpler and more efficient listener-management code with CopyOnWriteArrayList
· Allowing producers and consumers to communicate efficiently with ArrayBlockingQueue
· Supporting highly concurrent access to a map with ConcurrentHashMap
Day 3 Self-Study
Find
· The documentation for ForkJoinPool—how does a fork/join pool differ from a thread pool? When might you prefer one, and when the other?
· What is work-stealing and when might it be useful? How would you implement work-stealing with the facilities provided by java.util.concurrent?
· What is the difference between a CountDownLatch and a CyclicBarrier? When might you use one, and when the other?
· What is Amdahl’s law? What does it say about the maximum theoretical speedup we might be able to get for our word-counting algorithm?
Do
· Rewrite the producer-consumer code to use a separate “end of data” flag instead of a poison pill. Make sure that your solution correctly handles the cases where the producer runs faster than the consumer and vice versa. What will happen if the consumer has already tried to remove something from the queue when the “end of data” flag is set? Why do you think that the poison-pill approach is so commonly used?
· Run the different versions of the word-count program on your computer, as well as any others you can get access to. How do the performance graphs differ from one computer to another? If you could run it on a computer with 32 cores, do you think you would see anything close to a 32x speedup?
Wrap-Up
Threads-and-locks programming probably divides opinion more than any of the other techniques we’ll cover. It has a reputation for being fiendishly difficult to get right, and plenty of programmers shrink from it, avoiding multithreaded programming at all costs. Others don’t understand the fuss—a few simple rules need to be followed, and if you follow them it’s no harder than any other form of programming.
Let’s look at its strengths and weaknesses.
Strengths
The primary strength of threads and locks is the model’s broad applicability. As you might expect, given that they’re the basis upon which many of the approaches we’ll cover later are built, they can be applied to a very wide range of problems. Because they are “close to the metal”—little more than a formalization of what the underlying hardware does anyway—they can be very efficient when used correctly. This means that they can be used to tackle problems of a wide range of granularities, from fine to coarse.
In addition, they can easily be integrated into most programming languages. Language designers can add threads and locks to an existing imperative or object-oriented language with little effort.
Weaknesses
Threads and locks provide no direct support for parallelism (recall that concurrency and parallelism are related but different things—see Concurrent or Parallel?. As we’ve seen with the word-counting example, they can be used to parallelize a sequential algorithm, but this has to be constructed out of concurrent primitives, which introduces the specter of nondeterminism.
Outside of a few experimental distributed shared-memory research systems, threads and locks support only shared-memory architectures. If you need to support distributed memory (and, by extension, either geographical distribution or resilience), you will need to look elsewhere. This also means that threads and locks cannot be used to solve problems that are too large to fit on a single system.
The greatest weakness of the approach, however, is that threads-and-locks programming is hard. It may be easy for a language designer to add them to a language, but they provide us, the poor programmers, with very little help.
The Elephant in the Room
To my mind, what makes multithreaded programming difficult is not that writing it is hard, but that testing it is hard. It’s not the pitfalls that you can fall into; it’s the fact that you don’t necessarily know whether you’ve fallen into one of them.
Let’s take the memory model as an example. As we saw in Memory Visibility, all sorts of odd things can happen if two threads access a memory location without synchronization. But how do you know if you’ve got it wrong? How would you write a test to prove that you never access memory without appropriate synchronization?
Sadly, there isn’t any way to do so. You can certainly write something to stress-test your code, but passing those tests doesn’t mean that it’s correct. We know, for example, that the solution to the “dining philosophers” problem in the code is wrong and might deadlock, but I’ve seen it run for more than a week without doing so.
The fact that threading bugs tend to happen infrequently is a large part of the problem—more than once, I’ve been woken in the small hours of the morning to be told that a server has locked up after running without problem for months on end. If it happened every ten minutes, I’m sure we’d quickly find the problem, but if you need to run the server for months before the problem recurs, it’s virtually impossible to debug.
Worse than this, it’s quite possible to write programs that contain threading bugs that will never fail no matter how thoroughly or for how long we test them. Just because they access memory in a way that might result in accesses being reordered doesn’t mean that they actually will be. So we’ll be completely unaware of the problem until we upgrade the JVM or move to different hardware, when we’ll suddenly be faced with a mysterious failure that no one understands.
Maintenance
All these problems are bad enough when you’re creating code, but code rarely stands still. It’s one thing to make sure that everything’s synchronized correctly, locks are acquired in the right order, and no foreign functions are called with locks held. It’s quite another to guarantee that it will remain that way after twelve months of maintenance by ten different programmers. In the last decade, we’ve learned how to use automated testing to help us refactor with confidence, but if you can’t reliably test for threading problems, you can’t reliably refactor multithreaded code.
The upshot is that our only recourse is to think very carefully about our multithreaded code. And then when we’ve done that, think about it very carefully some more. Needless to say, this is neither easy nor scalable.
Picking Through the Wreckage
Diagnosing a threading problem can be similar to how I imagine Formula 1 engineers must feel when trying to diagnose an engine failure. The engine runs flawlessly for hours and then suddenly, with little or no warning, fails spectacularly, showering following cars with oil and lumps of crankcase.
When the car is dragged back to the workshop, the poor engineers are faced with a pile of wreckage and somehow need to figure out what caused the failure. The problem was probably something tiny—a failed oil-pump bearing or broken valve, but how can they tell what it was from the mess on the bench?
What tends to happen is that they put as much data logging in place as possible and send the driver back out with a new engine. Hopefully the data will contain something informative the next time a failure happens.
Other Languages
If you want to go deeper into threads-and-locks programming on the JVM, an excellent starting point is Java Concurrency in Practice [Goe06], which was written by the authors of the java.util.concurrent package. The details of multithreaded programming vary between languages, but the general principles we covered in this chapter are broadly applicable. The rules about using synchronization to access shared variables; acquiring locks in a fixed, global order; and avoiding alien method calls while holding a lock are applicable to any language with threads and locks.
In particular, although we spoke about only the Java memory model, reordered memory accesses in concurrent code are not unique to Java. The difference is that most languages don’t have a well-defined memory model that constrains how and when such reorderings are allowed. Java was the pioneer, the first major language to have a well-defined memory model. C and C++ only recently caught up when a memory model was added to the C11 and C++ 11 standards.
Final Thoughts
For all its challenges, multithreaded programming is going to be with us for the foreseeable future. But we’ll cover other options that you should have in your toolbox in the rest of this book.
In the next chapter we’ll look at functional programming, which avoids many of the problems with threads and locks by avoiding mutable state. Even if you never write any functional code, understanding the principles behind functional programming is valuable—as you’ll see, they underlie many of the other concurrency models we’ll cover.
Footnotes
|
[6] |
http://docs.oracle.com/javase/specs/jls/se7/html/jls-17.html#jls-17.4 |
|
[7] |
http://docs.oracle.com/javase/1.5.0/docs/guide/misc/threadPrimitiveDeprecation.html |
|
[8] |
http://dumps.wikimedia.org/enwiki/ |
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.